Support #[global_allocator] without the allocator shim
This makes it possible to use liballoc/libstd in combination with `--emit obj` if you use `#[global_allocator]`. This is what rust-for-linux uses right now and systemd may use in the future. Currently they have to depend on the exact implementation of the allocator shim to create one themself as `--emit obj` doesn't create an allocator shim.
Note that currently the allocator shim also defines the oom error handler, which is normally required too. Once `#![feature(default_alloc_error_handler)]` becomes the only option, this can be avoided. In addition when using only fallible allocator methods and either `--cfg no_global_oom_handling` for liballoc (like rust-for-linux) or `--gc-sections` no references to the oom error handler will exist.
To avoid this feature being insta-stable, you will have to define `__rust_no_alloc_shim_is_unstable` to avoid linker errors.
(Labeling this with both T-compiler and T-lang as it originally involved both an implementation detail and had an insta-stable user facing change. As noted above, the `__rust_no_alloc_shim_is_unstable` symbol requirement should prevent unintended dependence on this unstable feature.)
Mark internal functions and traits unsafe to reflect preconditions
No semantics are changed in this PR; I only mark some functions and and a trait `unsafe` which already had implicit preconditions. Although it seems somewhat redundant for `numfmt::Part::Copy` to contain a `&[u8]` instead of a `&str`, given that all of its current consumers ultimately expect valid UTF-8. Is the type also intended to work for byte-slice formatting in the future?
Fix duplicate `arcinner_layout_for_value_layout` calls when using the uninit `Arc` constructors
What this fixes is the duplicate calls to `arcinner_layout_for_value_layout` seen here: https://godbolt.org/z/jr5Gxozhj
The issue was discovered alongside #111603 but is otherwise unrelated to the duplicate `alloca`s, which remain unsolved. Everything I tried to solve said main issue has failed.
As for the duplicate layout calculations, I also tried slapping `#[inline]` and `#[inline(always)]` on everything in sight but the only thing that worked in the end is to dedup the calls by hand.
Specialize ToString implementation for fmt::Arguments
Generates far fewer instructions by formatting into a String with `fmt::format` directly instead of going through the `fmt::Display` impl. This change is insta-stable.
Change Vec examples to not assert exact capacity except where it is guaranteed
It was [brought up on discord](https://discord.com/channels/273534239310479360/818964227783262209/1107633959329878077) that the `Vec::into_boxed_slice` example contradicted the `Vec::with_capacity` docs in that the returned `Vec` might have _more_ capacity than requested.
So, to reduce confusion change all the `assert_eq!(vec.capacity(), _)` to `assert!(vec.capacity() >= _)`, except in 4 examples that have guaranteed capacities: `Vec::from_raw_parts`, `Vec::from_raw_parts_in`, `Vec::<()>::with_capacity`,`Vec::<(), _>::with_capacity_in`.
You will need to add the following as replacement for the old __rust_*
definitions when not using the alloc shim.
#[no_mangle]
static __rust_no_alloc_shim_is_unstable: u8 = 0;
enable `rust_2018_idioms` lint group for doctests
With this change, `rust_2018_idioms` lint group will be enabled for compiler/libstd doctests.
Resolves#106086Resolves#99144
Signed-off-by: ozkanonur <work@onurozkan.dev>
Make sure that some stdlib method signatures aren't accidental refinements
In the process of implementing https://rust-lang.github.io/rfcs/3245-refined-impls.html, I found a bunch of stdlib implementations that accidentally "refined" their method signatures by dropping (unnecessary) bounds.
This isn't currently a problem, but may become one if/when method signature refining is stabilized in the future. Shouldn't hurt to make these signatures a bit more accurate anyways.
NOTE (just to be clear lol): This does not affect behavior at all, since we don't actually take advantage of refined implementations yet!
Spelling library
Split per https://github.com/rust-lang/rust/pull/110392
I can squash once people are happy w/ the changes. It's really uncommon for large sets of changes to be perfectly acceptable w/o at least some changes.
I probably won't have time to respond until tomorrow or the next day
Updating Wake example to use new 'pin!' macro
Closes: https://github.com/rust-lang/rust/issues/109965
I have already had this reviewed and approved here: https://github.com/rust-lang/rust/pull/110026 . But because I had some git issues and chose the "nuke it" option as my solution it didn't get merged. I nuked it too quickly. I am sorry for trouble of reviewing twice.
Report allocation errors as panics
OOM is now reported as a panic but with a custom payload type (`AllocErrorPanicPayload`) which holds the layout that was passed to `handle_alloc_error`.
This should be review one commit at a time:
- The first commit adds `AllocErrorPanicPayload` and changes allocation errors to always be reported as panics.
- The second commit removes `#[alloc_error_handler]` and the `alloc_error_hook` API.
ACP: https://github.com/rust-lang/libs-team/issues/192Closes#51540Closes#51245
More `IS_ZST` in `library`
I noticed that `post_inc_start` and `pre_dec_end` were doing this check in different ways
d19b64fb54/library/core/src/slice/iter/macros.rs (L76-L93)
so started making this PR, then added a few more I found since I was already making changes anyway.
I noticed that `post_inc_start` and `pre_dec_end` were doing this check in different ways
d19b64fb54/library/core/src/slice/iter/macros.rs (L76-L93)
so started making this PR, then added a few more I found since I was already making changes anyway.
Add `tidy-alphabetical` to features in `alloc` & `std`
So that people have to keep them sorted in future, rather than just sticking them on the end where they conflict more often.
Follow-up to #110269
cc `@jyn514`
binary_heap: Optimize Extend implementation.
This PR makes the `Extend` implementation for `BinaryHeap` no longer rely on specialization, so that it always use the bulk rebuild optimization that was previously only available for the `Vec` specialization.
Improve documentation for str::replace() and str::replacen()
Currently, to know what the function will return when the pattern doesn't match, the docs require the reader to understand the implementation detail and mentally evaluate or run the example code. It is not immediately clear.
This PR makes it more explicit so the reader can quickly find the information.
Enhanced doucmentation of binary search methods for `slice` and `VecDeque` for unsorted instances
Fixes#106746. Issue #106746 raises the concern that the binary search methods for slices and deques aren't explicit enough about the fact that they are only applicable to sorted slices/deques. I changed the explanation for these methods. I took the relatively harsh description of the behaviour of binary search on unsorted collections ("unspecified and meaningless") from the description of the [`partition_point`](https://doc.rust-lang.org/std/primitive.slice.html#method.partition_point) method:
> If this slice is not partitioned, the returned result is unspecified and meaningless, as this method performs a kind of binary search.
Remove ~const from alloc
There is currently an effort underway to stop using `~const Trait`, temporarily, so as to refactor the logic underlying const traits with relative ease. This means it has to go from the standard library, as well.
I have taken the initial step of just removing these impls from alloc, as removing them from core is a much more tangled task. In addition, all of these implementations are one more-or-less logically-connected group, so reverting their deconstification as a group seems like it will also be sensible.
r? `@fee1-dead`
Change advance(_back)_by to return the remainder instead of the number of processed elements
When advance_by can't advance the iterator by the number of requested elements it now returns the amount by which it couldn't be advanced instead of the amount by which it did.
This simplifies adapters like chain, flatten or cycle because the remainder doesn't have to be calculated as the difference between requested steps and completed steps anymore.
Additionally switching from `Result<(), usize>` to `Result<(), NonZeroUsize>` reduces the size of the result and makes converting from/to a usize representing the number of remaining steps cheap.
A successful advance is now signalled by returning `0` and other values now represent the remaining number
of steps that couldn't be advanced as opposed to the amount of steps that have been advanced during a partial advance_by.
This simplifies adapters a bit, replacing some `match`/`if` with arithmetic. Whether this is beneficial overall depends
on whether `advance_by` is mostly used as a building-block for other iterator methods and adapters or whether
we also see uses by users where `Result` might be more useful.
Stabilize `nonnull_slice_from_raw_parts`
FCP is done: https://github.com/rust-lang/rust/issues/71941#issuecomment-1100910416
Note that this doesn't const-stabilize `NonNull::slice_from_raw_parts` as `slice_from_raw_parts_mut` isn't const-stabilized yet. Given #67456 and #57349, it's not likely available soon, meanwhile, stabilizing only the feature makes some sense, I think.
Closes#71941
Currently, to know what the function will return when the pattern
doesn't match, the docs require the reader to understand the
implementation detail and mentally evaluate or run the example
code. It is not immediately clear.
This PR makes it more explicit so the reader can quickly find the
information.
Implement Default for some alloc/core iterators
Add `Default` impls to the following collection iterators:
* slice::{Iter, IterMut}
* binary_heap::IntoIter
* btree::map::{Iter, IterMut, Keys, Values, Range, IntoIter, IntoKeys, IntoValues}
* btree::set::{Iter, IntoIter, Range}
* linked_list::IntoIter
* vec::IntoIter
and these adapters:
* adapters::{Chain, Cloned, Copied, Rev, Enumerate, Flatten, Fuse, Rev}
For iterators which are generic over allocators it only implements it for the global allocator because we can't conjure an allocator from nothing or would have to turn the allocator field into an `Option` just for this change.
These changes will be insta-stable.
ACP: https://github.com/rust-lang/libs-team/issues/77
Remove the assume(!is_null) from Vec::as_ptr
At a guess, this code is leftover from LLVM was worse at keeping track of the niche information here. In any case, we don't need this anymore: Removing this `assume` doesn't get rid of the `nonnull` attribute on the return type.
Introduce `Rc::into_inner`, as a parallel to `Arc::into_inner`
Unlike `Arc`, `Rc` doesn't have the same race condition to avoid, but
maintaining an equivalent API still makes it easier to work with both
`Rc` and `Arc`.
Unlike `Arc`, `Rc` doesn't have the same race condition to avoid, but
maintaining an equivalent API still makes it easier to work with both
`Rc` and `Arc`.
Rollup of 9 pull requests
Successful merges:
- #104363 (Make `unused_allocation` lint against `Box::new` too)
- #106633 (Stabilize `nonzero_min_max`)
- #106844 (allow negative numeric literals in `concat!`)
- #108071 (Implement goal caching with the new solver)
- #108542 (Force parentheses around `match` expression in binary expression)
- #108690 (Place size limits on query keys and values)
- #108708 (Prevent overflow through Arc::downgrade)
- #108739 (Prevent the `start_bx` basic block in codegen from having two `Builder`s at the same time)
- #108806 (Querify register_tools and post-expansion early lints)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Make `unused_allocation` lint against `Box::new` too
Previously it only linted against `box` syntax, which likely won't ever be stabilized, which is pretty useless. Even now I'm not sure if it's a meaningful lint, but it's at least something 🤷
This means that code like the following will be linted against:
```rust
Box::new([1, 2, 3]).len();
f(&Box::new(1)); // where f : &i32 -> ()
```
The lint works by checking if a `Box::new` (or `box`) expression has an a borrow adjustment, meaning that the code that first stores the box in a variable won't be linted against:
```rust
let boxed = Box::new([1, 2, 3]); // no lint
boxed.len();
```
Fix `vec_deque::Drain` FIXME
In my original `VecDeque` rewrite, I didn't use `VecDeque::slice_ranges` in `Drain::as_slices`, even though that's basically the exact use case for `slice_ranges`. The reason for this was that a `VecDeque` wrapped in a `Drain` actually has its length set to `drain_start`, so that there's no potential use after free if you `mem::forget` the `Drain`. I modified `slice_ranges` to accept an explicit `len` parameter instead, which it now uses to bounds check the given range. This way, `Drain::as_slices` can use `slice_ranges` internally instead of having to basically just copy paste the `slice_ranges` code. Since `slice_ranges` is just an internal helper function, this shouldn't change the user facing behavior in any way.
Remove or document uses of #[rustc_box] in library
r? `@thomcc`
Only one of these uses is tested for in the rustc-perf benchmark suite. The impact there on compile time is somewhat dramatic, but I am inclined to make this change as a simplification to the library and wait for people to complain if it explodes their compilation time. I think in the absence of data or reports from users about what code paths really matter, if we are optimizing for compilation time, it's hard to argue against using `#[rustc_box]` everywhere we currently call `Box::new`.
This adds both a test specific to #108453 as well as an exhaustive test
that goes through all possible combinations of head index, length and target capacity
for a deque with capacity 16.
Previously the bulk rebuild specialization was only available with Vec, and
for general iterators Extend only provided pre-allocation through reserve().
By using a drop guard, we can safely bulk rebuild even if the iterator may
panic. This allows benefiting from the bulk rebuild optimization without
collecting iterator elements into a Vec beforehand, which would nullify any
performance gains from bulk rebuild.
Implement more methods for `vec_deque::IntoIter`
This implements a couple `Iterator` methods on `vec_deque::IntoIter` (`(try_)fold`, `(try_)rfold` `advance_(back_)by`, `next_chunk`, `count` and `last`) to allow these to be more efficient than their default implementations, also allowing many other `Iterator` methods that use these under the hood to take advantage of these manual implementations. `vec::IntoIter` has similar implementations for many of these methods. This PR does not yet implement `TrustedRandomAccess` and friends, as I'm not very familiar with the required safety guarantees.
r? `@the8472` (since you also took over my last PR)
Use associated items of `char` instead of freestanding items in `core::char`
The associated functions and constants on `char` have been stable since 1.52 and the freestanding items have soft-deprecated since 1.62 (https://github.com/rust-lang/rust/pull/95566). This PR ~~marks them as "deprecated in future", similar to the integer and floating point modules (`core::{i32, f32}` etc)~~ replaces all uses of `core::char::*` with `char::*` to prepare for future deprecation of `core::char::*`.
simplify layout calculations in rawvec
The use of `Layout::array` was introduced in #83706 which lead to a [perf regression](https://github.com/rust-lang/rust/pull/83706#issuecomment-1048377719).
This PR basically reverts that change since rust currently only supports stride == size types, but to be on the safe side it leaves a const-assert there to make sure this gets caught if those assumptions ever change.
Stabilize feature `cstr_from_bytes_until_nul`
This PR seeks to stabilize `cstr_from_bytes_until_nul`.
Partially addresses #95027
This function has only been on nightly for about 10 months, but I think it is simple enough that there isn't harm discussing stabilization. It has also had at least a handful of mentions on both the user forum and the discord, so it seems like it's already in use or at least known.
This needs FCP still.
Comment on potential discussion points:
- eventual conversion of `CStr` to be a single thin pointer: this function will still be useful to provide a safe way to create a `CStr` after this change.
- should this return a length too, to address concerns about the `CStr` change? I don't see it as being particularly useful, and it seems less ergonomic (i.e. returning `Result<(&CStr, usize), FromBytesUntilNulError>`). I think users that also need this length without the additional `strlen` call are likely better off using a combination of other methods, but this is up for discussion
- `CString::from_vec_until_nul`: this is also useful, but it doesn't even have a nightly implementation merged yet. I propose feature gating that separately, as opposed to blocking this `CStr` implementation on that
Possible alternatives:
A user can use `from_bytes_with_nul` on a slice up to `my_slice[..my_slice.iter().find(|c| c == 0).unwrap()]`. However; that is significantly less ergonomic, and is a bit more work for the compiler to optimize compared the direct `memchr` call that this wraps.
## New stable API
```rs
// both in core::ffi
pub struct FromBytesUntilNulError(());
impl CStr {
pub const fn from_bytes_until_nul(
bytes: &[u8]
) -> Result<&CStr, FromBytesUntilNulError>
}
```
cc ```@ericseppanen``` original author, ```@Mark-Simulacrum``` original reviewer, ```@m-ou-se``` brought up some issues on the thin pointer CStr
```@rustbot``` modify labels: +T-libs-api +needs-fcp
Implement cursors for BTreeMap
See the ACP for an overview of the API: https://github.com/rust-lang/libs-team/issues/141
The implementation is split into 2 commits:
- The first changes the internal insertion functions to return a handle to the newly inserted element. The lifetimes involved are a bit hairy since we need a mutable handle to both the `BTreeMap` itself (which holds the root) and the nodes allocated in memory. I have tested that this passes the standard library testsuite under miri.
- The second commit implements the cursor API itself. This is more straightforward to follow but still involves some unsafe code to deal with simultaneous mutable borrows of the tree root and the node that is currently being iterated.
Bump bootstrap compiler to 1.68
This also changes our stage0.json to include the rustc component for the rustfmt pinned nightly toolchain, which is currently necessary due to rustfmt dynamically linking to that toolchain's librustc_driver and libstd.
r? `@pietroalbini`
Make Vec::clone_from and slice::clone_into share the same code
In the past, `Vec::clone_from` was implemented using `slice::clone_into`. The code from `clone_into` was later duplicated into `clone_from` in 8725e4c337, which is the commit that adds custom allocator support to Vec. Presumably this was done because the `slice::clone_into` method only works for vecs with the default allocator so it would have the wrong type to clone into `Vec<T, A>`.
Later on in 361398009b the code for the two methods diverged because the `Vec::clone_from` version gained a specialization to optimize the case when T is Copy. In order to reduce code duplication and make them both be able to take advantage of this specialization, this PR moves the specialization into the slice module and makes vec use it again.
Don't re-export private/unstable ArgumentV1 from `alloc`.
The `alloc::fmt::ArgumentV1` re-export was marked as `#[stable]` even though the original `core::fmt::ArgumentV1` is `#[unstable]` (and `#[doc(hidden)]`).
(It wasn't usable though:
```
error[E0658]: use of unstable library feature 'fmt_internals': internal to format_args!
--> src/main.rs:4:12
|
4 | let _: alloc::fmt::ArgumentV1 = todo!();
| ^^^^^^^^^^^^^^^^^^^^^^
|
= help: add `#![feature(fmt_internals)]` to the crate attributes to enable
```
)
Part of #99012
In the past, Vec::clone_from was implemented using slice::clone_into.
The code from clone_into was later duplicated into clone_from in
8725e4c337, which is the commit that adds custom allocator support to
Vec. Presumably this was done because the slice::clone_into only works
for vecs with the default allocator so it would have the wrong type to
clone into Vec<T, A>.
Now that the clone_into implementation is moved out into a specializable
trait anyway we might as well use that to share the code between the two
methods.
The implementation for the ToOwned::clone_into method on [T] is a copy
of the code for vec::clone_from. In 361398009b the code for
vec::clone_from gained a specialization for when T is Copy. This commit
copies that specialization over to the clone_into implementation.
Add `Arc::into_inner` for safely discarding `Arc`s without calling the destructor on the inner type.
ACP: rust-lang/libs-team#162
Reviving #79665.
I want to get this merged this time; this does not contain changes (apart from very minor changes in comments/docs).
See #79665 for further description of the PR. The only “unresolved” points that led to that PR being closed, AFAICT, were
* The desire to also implement a `Rc::into_inner` function
* however, this can very well also happen as a subsequent PR
* Possible need for further discussion on the naming “`into_inner`” (?)
* `into_inner` seems fine to me; also, this PR introduces unstable API, and names can be changed later, too
* ~~I don't know if a tracking issue for the feature flag is supposed to be opened before or after this PR gets merged (if *before*, then I can add the issue number to the `#[unstable…]` attribute)~~ There is a [tracking issue](https://github.com/rust-lang/rust/issues/106894) now.
I say “unresolved” in quotation marks because from my point of view, if reviewers agree, the PR can be merged immediately and as-is :-)
Unify stable and unstable sort implementations in same core module
This moves the stable sort implementation to the core::slice::sort module. By virtue of being in core it can't access `Vec`. The two `Vec` used by merge sort, `buf` and `runs`, are modelled as custom types that implement the very limited required `Vec` interface with the help of provided allocation and free functions. This is done to allow future re-use of functions and logic between stable and unstable sort. Such as `insert_head`.
This is in preparation of #100856 and #104116. It only moves code, it *doesn't* change any of the sort related logic. This unlocks the ability to share `insert_head`, `insert_tail`, `swap_if_less` `merge` and more.
Tagging ````@Mark-Simulacrum```` I hope this allows progress on #100856, by moving `merge_sort` here I hope future changes will be easier to review.
Implement `alloc::vec::IsZero` for `Option<$NUM>` types
Fixes#106911
Mirrors the `NonZero$NUM` implementations with an additional `assert_zero_valid`.
`None::<i32>` doesn't stricly satisfy `IsZero` but for the purpose of allocating we can produce more efficient codegen.
Don't do pointer arithmetic on pointers to deallocated memory
vec::Splice can invalidate the slice::Iter inside vec::Drain. So we replace them with dangling pointers which, unlike ones to deallocated memory, are allowed.
Fixes miri test failures.
Fixes https://github.com/rust-lang/miri/issues/2759
vec::Splice can invalidate the slice::Iter inside vec::Drain.
So we replace them with dangling pointers which, unlike ones to
deallocated memory, are allowed.
Leak amplification for peek_mut() to ensure BinaryHeap's invariant is always met
In the libs-api team's discussion around #104210, some of the team had hesitations around exposing malformed BinaryHeaps of an element type whose Ord and Drop impls are trusted, and which does not contain interior mutability.
For example in the context of this kind of code:
```rust
use std::collections::BinaryHeap;
use std::ops::Range;
use std::slice;
fn main() {
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let cut_points = BinaryHeap::from(vec![4, 2, 7]);
println!("{:?}", chop(slice, cut_points));
}
// This is a souped up slice::split_at_mut to split in arbitrary many places.
//
// usize's Ord impl is trusted, so 1 single bounds check guarantees all those
// output slices are non-overlapping and in-bounds
fn chop<T>(slice: &mut [T], mut cut_points: BinaryHeap<usize>) -> Vec<&mut [T]> {
let mut vec = Vec::with_capacity(cut_points.len() + 1);
let max = match cut_points.pop() {
Some(max) => max,
None => {
vec.push(slice);
return vec;
}
};
assert!(max <= slice.len());
let len = slice.len();
let ptr: *mut T = slice.as_mut_ptr();
let get_unchecked_mut = unsafe {
|range: Range<usize>| &mut *slice::from_raw_parts_mut(ptr.add(range.start), range.len())
};
vec.push(get_unchecked_mut(max..len));
let mut end = max;
while let Some(start) = cut_points.pop() {
vec.push(get_unchecked_mut(start..end));
end = start;
}
vec.push(get_unchecked_mut(0..end));
vec
}
```
```console
[['7', '8', '9'], ['4', '5', '6'], ['2', '3'], ['0', '1']]
```
In the current BinaryHeap API, `peek_mut()` is the only thing that makes the above function unsound.
```rust
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let mut cut_points = BinaryHeap::from(vec![4, 2, 7]);
{
let mut max = cut_points.peek_mut().unwrap();
*max = 0;
std::mem::forget(max);
}
println!("{:?}", chop(slice, cut_points));
```
```console
[['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], [], ['2', '3'], ['0', '1']]
```
Or worse:
```rust
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let mut cut_points = BinaryHeap::from(vec![100, 100]);
{
let mut max = cut_points.peek_mut().unwrap();
*max = 0;
std::mem::forget(max);
}
println!("{:?}", chop(slice, cut_points));
```
```console
[['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], [], ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '\u{1}', '\0', '?', '翾', '?', '翾', '\0', '\0', '?', '翾', '?', '翾', '?', '啿', '?', '啿', '?', '啿', '?', '啿', '?', '啿', '?', '翾', '\0', '\0', '', '啿', '\u{5}', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\u{8}', '\0', '`@',` '\0', '\u{1}', '\0', '?', '翾', '?', '翾', '?', '翾', '
thread 'main' panicked at 'index out of bounds: the len is 33 but the index is 33', library/core/src/unicode/unicode_data.rs:319:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
---
This PR makes `peek_mut()` use leak amplification (https://doc.rust-lang.org/1.66.0/nomicon/leaking.html#drain) to preserve the heap's invariant even in the situation that `PeekMut` gets leaked.
I'll also follow up in the tracking issue of unstable `drain_sorted()` (#59278) and `retain()` (#71503).
mv binary_heap.rs binary_heap/mod.rs
I confess this request is somewhat selfish, as it's made in order to ease synchronisation with my [copse](https://crates.io/crates/copse) crate (see eggyal/copse#6 for explanation). I wholly understand that such grounds may be insufficient to justify merging this request—but no harm in asking, right?
Document that `Vec::from_raw_parts[_in]` must be given a pointer from the correct allocator.
Currently, the documentation of `Vec::from_raw_parts` and `Vec::from_raw_parts_in` says nothing about what allocator the pointer must come from. This PR adds that missing information explicitly.
Loosen the bound on the Debug implementation of Weak.
Both `rc::Weak<T>` and `sync::Weak<T>` currently require `T: Debug` in their own `Debug` implementations, but they don't currently use it; they only ever print a fixed string.
A general implementation of Debug for Weak that actually attempts to upgrade and rely on the contents is unlikely in the future because it may have unbounded recursion in the presence of reference cycles, which Weak is commonly used in. (This was the justification for why the current implementation [was implemented the way it is](f0976e2cf3)).
When I brought it up [on the forum](https://internals.rust-lang.org/t/could-the-bound-on-weak-debug-be-relaxed/15504), it was suggested that, even if an implementation is specialized in the future that relies on the data stored within the Weak, it would likely rely on specialization anyway, and could therefore easily specialize on the Debug bound as well.
Update `rand` in the stdlib tests, and remove the `getrandom` feature from it.
The main goal is actually removing `getrandom`, so that eventually we can allow running the stdlib test suite on tier3 targets which don't have `getrandom` support. Currently those targets can only run the subset of stdlib tests that exist in uitests, and (generally speaking), we prefer not to test libstd functionality in uitests, which came up recently in https://github.com/rust-lang/rust/pull/104095 and https://github.com/rust-lang/rust/pull/104185. Additionally, the fact that we can't update `rand`/`getrandom` means we're stuck with the old set of tier3 targets, so can't test new ones.
~~Anyway, I haven't checked that this actually does allow use on tier3 targets (I think it does not, as some work is needed in stdlib submodules) but it moves us slightly closer to this, and seems to allow at least finally updating our `rand` dep, which definitely improves the status quo.~~ Checked and works now.
For the most part, our tests and benchmarks are fine using hard-coded seeds. A couple tests seem to fail with this (stuff manipulating the environment expecting no collisions, for example), or become pointless (all inputs to a function become equivalent). In these cases I've done a (gross) dance (ab)using `RandomState` and `Location::caller()` for some extra "entropy".
Trying to share that code seems *way* more painful than it's worth given that the duplication is a 7-line function, even if the lines are quite gross. (Keeping in mind that sharing it would require adding `rand` as a non-dev dep to std, and exposing a type from it publicly, all of which sounds truly awful, even if done behind a perma-unstable feature).
See also some previous attempts:
- https://github.com/rust-lang/rust/pull/86963 (in particular https://github.com/rust-lang/rust/pull/86963#issuecomment-885438936 which explains why this is non-trivial)
- https://github.com/rust-lang/rust/pull/89131
- https://github.com/rust-lang/rust/pull/96626#issuecomment-1114562857 (I tried in that PR at the same time, but settled for just removing the usage of `thread_rng()` from the benchmarks, since that was the main goal).
- https://github.com/rust-lang/rust/pull/104185
- Probably more. It's very tempting of a thing to "just update".
r? `@Mark-Simulacrum`
default OOM handler: use non-unwinding panic, to match std handler
The OOM handler in std will by default abort. This adjusts the default in liballoc to do the same, using the `can_unwind` flag on the panic info to indicate a non-unwinding panic.
In practice this probably makes little difference since the liballoc default will only come into play in no-std situations where people write a custom panic handler, which most likely will not implement unwinding. But still, this seems more consistent.
Cc `@rust-lang/wg-allocators,` https://github.com/rust-lang/rust/issues/66741
Revert "Implement allow-by-default `multiple_supertrait_upcastable` lint"
This is a clean revert of #105484.
I confirmed that reverting that PR fixes the regression reported in #106247. ~~I can't say I understand what this code is doing, but maybe it can be re-landed with a different implementation.~~ **Edit:** https://github.com/rust-lang/rust/issues/106247#issuecomment-1367174384 has an explanation of why #105484 ends up surfacing spurious `where_clause_object_safety` errors. The implementation of `where_clause_object_safety` assumes we only check whether a trait is object safe when somebody actually uses that trait with `dyn`. However the implementation of `multiple_supertrait_upcastable` added in the problematic PR involves checking *every* trait for whether it is object-safe.
FYI `@nbdd0121` `@compiler-errors`
Implement allow-by-default `multiple_supertrait_upcastable` lint
The lint detects when an object-safe trait has multiple supertraits.
Enabled in libcore and liballoc as they are low-level enough that many embedded programs will use them.
r? `@nikomatsakis`
Test leaking of BinaryHeap Drain iterators
Add test cases about forgetting the `BinaryHeap::Drain` iterator, and slightly fortifies some other test cases.
Consists of separate commits that I don't think are relevant on their own (but I'll happily turn these into more PRs if desired).
The lint "clippy::uninlined_format_args" recommends inline
variables in format strings. Fix two places in the docs that do
not do this. I noticed this because I copy/pasted one example in
to my project, then noticed this lint error. This fixes:
error: variables can be used directly in the `format!` string
--> src/main.rs:30:22
|
30 | let string = format!("{:.*}", decimals, magnitude);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error: variables can be used directly in the `format!` string
--> src/main.rs:39:2
|
39 | write!(&mut io::stdout(), "{}", args).unwrap();
Send `VecDeque::from_iter` via `Vec::from_iter`
Since it's O(1) to convert between them now, might as well reuse the logic.
Mostly for the various specializations it does, but might also save some monomorphization work if, say, people collect slice iterators into both `Vec`s and `VecDeque`s.
improve doc of into_boxed_slice and impl From<Vec<T>> for Box<[T]>
Improves description of `into_boxed_slice`, and adds example to `impl From<Vec<T>> for Box<[T]>`.
Fixes#98908
Since it's O(1) to convert between them now, might as well reuse the logic.
Mostly for the various specializations it does, but might also save some monomorphization work if, say, people collect slice iterators into both `Vec`s and `VecDeque`s.
Update VecDeque implementation to use head+len instead of head+tail
(See #99805)
This changes `alloc::collections::VecDeque`'s internal representation from using head and tail indices to using a head index and a length field. It has a few advantages over the current design:
* It allows the buffer to be of length 0, which means the `VecDeque::new` new longer has to allocate and could be changed to a `const fn`
* It allows the `VecDeque` to fill the buffer completely, unlike the old implementation, which always had to leave a free space
* It removes the restriction for the size to be a power of two, allowing it to properly `shrink_to_fit`, unlike the old `VecDeque`
* The above points also combine to allow the `Vec<T> -> VecDeque<T>` conversion to be very cheap and guaranteed O(1). I mention this in the `From<Vec<T>>` impl, but it's not a strong guarantee just yet, as that would likely need some form of API change proposal.
All the tests seem to pass for the new `VecDeque`, with some slight adjustments.
r? `@scottmcm`
Clarify and restrict when `{Arc,Rc}::get_unchecked_mut` is allowed.
(Tracking issue for `{Arc,Rc}::get_unchecked_mut`: #63292)
(I'm using `Rc` in this comment, but it applies for `Arc` all the same).
As currently documented, `Rc::get_unchecked_mut` can lead to unsoundness when multiple `Rc`/`Weak` pointers to the same allocation exist. The current documentation only requires that other `Rc`/`Weak` pointers to the same allocation "must not be dereferenced for the duration of the returned borrow". This can lead to unsoundness in (at least) two ways: variance, and `Rc<str>`/`Rc<[u8]>` aliasing. ([playground link](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=d7e2d091c389f463d121630ab0a37320)).
This PR changes the documentation of `Rc::get_unchecked_mut` to restrict usage to when all `Rc<T>`/`Weak<T>` have the exact same `T` (including lifetimes). I believe this is sufficient to prevent unsoundness, while still allowing `get_unchecked_mut` to be called on an aliased `Rc` as long as the safety contract is upheld by the caller.
## Alternatives
* A less strict, but still sound alternative would be to say that the caller must only write values which are valid for all aliased `Rc`/`Weak` inner types. (This was [mentioned](https://github.com/rust-lang/rust/issues/63292#issuecomment-568284090) in the tracking issue). This may be too complicated to clearly express in the documentation.
* A more strict alternative would be to say that there must not be any aliased `Rc`/`Weak` pointers, i.e. it is required that get_mut would return `Some(_)`. (This was also mentioned in the tracking issue). There is at least one codebase that this would cause to become unsound ([here](be5a164d77/src/memtable.rs (L166)), where additional locking is used to ensure unique access to an aliased `Rc<T>`; I saw this because it was linked on the tracking issue).
This moves the stable sort implementation to the core::slice::sort module. By
virtue of being in core it can't access `Vec`. The two `Vec` used by merge sort,
`buf` and `runs`, are modelled as custom types that implement the very limited
required `Vec` interface with the help of provided allocation and free
functions. This is done to allow future re-use of functions and logic between
stable and unstable sort. Such as `insert_head`.
`VecDeque::resize` should re-use the buffer in the passed-in element
Today it always copies it for *every* appended element, but one of those clones is avoidable.
This adds `iter::repeat_n` (https://github.com/rust-lang/rust/issues/104434) as the primitive needed to do this. If this PR is acceptable, I'll also use this in `Vec` rather than its custom `ExtendElement` type & infrastructure that is harder to share between multiple different containers:
101e1822c3/library/alloc/src/vec/mod.rs (L2479-L2492)
Attempt to reuse `Vec<T>` backing storage for `Rc/Arc<[T]>`
If a `Vec<T>` has sufficient capacity to store the inner `RcBox<[T]>`, we can just reuse the existing allocation and shift the elements up, instead of making a new allocation.
run alloc benchmarks in Miri and fix UB
Miri since recently has a "fake monotonic clock" that works even with isolation. Its measurements are not very meaningful but it means we can run these benches and check them for UB.
And that's a good thing since there was UB here: fixes https://github.com/rust-lang/rust/issues/104096.
r? ``@thomcc``
disable btree size tests on Miri
Seems fine not to run these in Miri, they can't have UB anyway. And this lets us do layout randomization in Miri.
r? ``@thomcc``
The new implementation doesn't use weak lang items and instead changes
`#[alloc_error_handler]` to an attribute macro just like
`#[global_allocator]`.
The attribute will generate the `__rg_oom` function which is called by
the compiler-generated `__rust_alloc_error_handler`. If no `__rg_oom`
function is defined in any crate then the compiler shim will call
`__rdl_oom` in the alloc crate which will simply panic.
This also fixes link errors with `-C link-dead-code` with
`default_alloc_error_handler`: `__rg_oom` was previously defined in the
alloc crate and would attempt to reference the `oom` lang item, even if
it didn't exist. This worked as long as `__rg_oom` was excluded from
linking since it was not called.
This is a prerequisite for the stabilization of
`default_alloc_error_handler` (#102318).
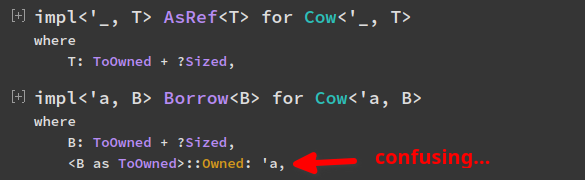
Remove redundant lifetime bound from `impl Borrow for Cow`
The lifetime bound `B::Owned: 'a` is redundant and doesn't make a difference,
because `Cow<'a, B>` comes with an implicit `B: 'a`, and associated types
will outlive lifetimes outlived by the `Self` type (and all the trait's
generic parameters, of which there are none in this case), so the implicit `B: 'a`
implies `B::Owned: 'a` anyway.
The explicit lifetime bound here does however [end up in documentation](https://doc.rust-lang.org/std/borrow/enum.Cow.html#impl-Borrow%3CB%3E),
and that's confusing in my opinion, so let's remove it ^^
_(Documentation right now, compare to `AsRef`, too:)_
Adjust argument type for mutable with_metadata_of (#75091)
The method takes two pointer arguments: one `self` supplying the pointer value, and a second pointer supplying the metadata.
The new parameter type more clearly reflects the actual requirements. The provenance of the metadata parameter is disregarded completely. Using a mutable pointer in the call site can be coerced to a const pointer while the reverse is not true.
In some cases, the current parameter type can thus lead to a very slightly confusing additional cast. [Example](cad93775eb).
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = val as *const _ as *mut T;
let ptr = uninit.as_ptr().with_metadata_of(ptr);
```
This could then instead be simplified to:
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = uninit.as_ptr().with_metadata_of(&**val);
```
Tracking issue: https://github.com/rust-lang/rust/issues/75091
``@dtolnay`` you're reviewed #95249, would you mind chiming in?
Remove incorrect comment in `Vec::drain`
r? ``@scottmcm``
Turns out this comment wasn't correct for 6 years, since #34951, which switched from using `slice::IterMut` into using `slice::Iter`.
Add `Box<[T; N]>: TryFrom<Vec<T>>`
We have `[T; N]: TryFrom<Vec<T>>` (#76310) and `Box<[T; N]>: TryFrom<Box<[T]>>`, but not this combination.
`vec.into_boxed_slice().try_into()` isn't quite a replacement for this, as that'll reallocate unnecessarily in the error case.
**Insta-stable, so needs an FCP**
(I tried to make this work with `, A`, but that's disallowed because of `#[fundamental]` https://github.com/rust-lang/rust/issues/29635#issuecomment-1247598385)
Detect and reject out-of-range integers in format string literals
Until now out-of-range integers in format string literals were silently ignored. They wrapped around to zero at usize::MAX, producing unexpected results.
When using debug builds of rustc, such integers in format string literals even cause an 'attempt to add with overflow' panic in rustc.
Fix this by producing an error diagnostic for integers in format string literals which do not fit into usize.
Fixes#102528
add Vec::push_within_capacity - fallible, does not allocate
This method can serve several purposes. It
* is fallible
* guarantees that items in Vec aren't moved
* allows loops that do `reserve` and `push` separately to avoid pulling in the allocation machinery a second time in the `push` part which should make things easier on the optimizer
* eases the path towards `ArrayVec` a bit since - compared to `push()` - there are fewer questions around how it should be implemented
I haven't named it `try_push` because that should probably occupy a middle ground that will still try to reserve and only return an error in the unlikely OOM case.
resolves#84649
Fix in-place collection leak when remaining element destructor panic
Fixes#101628
cc `@the8472`
I went for the drop guard route, placing it immediately before the `forget_allocation_drop_remaining` call and after the comment, as to signal they are closely related.
I also updated the test to check for the leak, though the only change really needed was removing the leak clean up for miri since now that's no longer leaked.
docs: be less harsh in wording for Vec::from_raw_parts
In particular, be clear that it is sound to specify memory not
originating from a previous `Vec` allocation. That is already suggested
in other parts of the documentation about zero-alloc conversions to Box<[T]>.
Incorporate a constraint from `slice::from_raw_parts` that was missing
but needs to be fulfilled, since a `Vec` can be converted into a slice.
Fixes https://github.com/rust-lang/rust/issues/98780.
Document the conditional existence of `alloc::sync` and `alloc::task`.
`alloc` declares
```rust
#[cfg(target_has_atomic = "ptr")]
pub mod sync;
```
but there is no public documentation of this condition. This PR fixes that, so that users of `alloc` can understand how to make their code compile everywhere `alloc` does, if they are writing a library with impls for `Arc`.
The wording is copied from `std::sync::atomic::AtomicPtr`, with additional advice on how to `#[cfg]` for it.
I feel quite uncertain about whether the paragraph I added to `Arc`'s documentation should actually be there, as it is a distraction for anyone using `std`. On the other hand, maybe more reminders that no_std exists would benefit the ecosystem.
Note: `target_has_atomic` is [stabilized](https://github.com/rust-lang/rust/issues/32976) but [not yet documented in the reference](https://github.com/rust-lang/reference/pull/1171).
Make `feature(const_btree_len)` implied by `feature(const_btree_new)`
...this should fix code that used the old feature that was changed in #102197
cc ```@davidtwco``` it seems like tidy doesn't check `implied_by`, should it?
Until now out-of-range integers in format string literals
were silently ignored. They wrapped around to zero at
usize::MAX, producing unexpected results.
When using debug builds of rustc, such integers in format string
literals even cause an 'attempt to add with overflow' panic in
rustc.
Fix this by producing an error diagnostic for integers in format
string literals which do not fit into usize.
Fixes#102528
Stabilize const `BTree{Map,Set}::new`
The FCP was completed in #71835.
Since `len` and `is_empty` are not const stable yet, this also creates a new feature for them since they previously used the same `const_btree_new` feature.
Make ZST checks in core/alloc more readable
There's a bunch of these checks because of special handing for ZSTs in various unsafe implementations of stuff.
This lets them be `T::IS_ZST` instead of `mem::size_of::<T>() == 0` every time, making them both more readable and more terse.
*Not* proposed for stabilization. Would be `pub(crate)` except `alloc` wants to use it too.
(And while it doesn't matter now, if we ever get something like #85836 making it a const can help codegen be simpler.)
Since `len` and `is_empty` are not const stable yet, this also
creates a new feature for them since they previously used the same
`const_btree_new` feature.
There's a bunch of these checks because of special handing for ZSTs in various unsafe implementations of stuff.
This lets them be `T::IS_ZST` instead of `mem::size_of::<T>() == 0` every time, making them both more readable and more terse.
*Not* proposed for stabilization at this time. Would be `pub(crate)` except `alloc` wants to use it too.
(And while it doesn't matter now, if we ever get something like 85836 making it a const can help codegen be simpler.)
Make `from_waker`, `waker` and `from_raw` unstably `const`
Make
- `Context::from_waker`
- `Context::waker`
- `Waker::from_raw`
`const`.
Also added a small test.
We have `[T; N]: TryFrom<Vec<T>>` and `Box<[T; N]>: TryFrom<Box<[T]>>`, but not the combination.
`vec.into_boxed_slice().try_into()` isn't quite a replacement for this, as that'll reallocate unnecessarily in the error case.
**Insta-stable, so needs an FCP**
On later stages, the feature is already stable.
Result of running:
rg -l "feature.let_else" compiler/ src/librustdoc/ library/ | xargs sed -s -i "s#\\[feature.let_else#\\[cfg_attr\\(bootstrap, feature\\(let_else\\)#"
Implement internal `IsZero` for Wrapping and Saturating for `Vec` optimizations
This implements the `IsZero` trait for the `Wrapping` and `Saturating` types so that users of these types can get the improved performance from the specialization of creating a `Vec` from a single element repeated when it has a zero bit pattern (example `vec![0_i32; 500]`, or after this PR `vec![Wrapping(0_i32); 500]`)
CC #60978
Fix a bunch of typo
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
Add `vec::Drain{,Filter}::keep_rest`
This PR adds `keep_rest` methods to `vec::Drain` and `vec::DrainFilter` under `drain_keep_rest` feature gate:
```rust
// mod alloc::vec
impl<T, A: Allocator> Drain<'_, T, A> {
pub fn keep_rest(self);
}
impl<T, F, A: Allocator> DrainFilter<'_, T, F, A>
where
F: FnMut(&mut T) -> bool,
{
pub fn keep_rest(self);
}
```
Both these methods cancel draining of elements that were not yet yielded from the iterators. While this needs more testing & documentation, I want at least start the discussion. This may be a potential way out of the "should `DrainFilter` exhaust itself on drop?" argument.
Make use of `[wrapping_]byte_{add,sub}`
These new methods trivially replace old `.cast().wrapping_offset().cast()` & similar code.
Note that [`arith_offset`](https://doc.rust-lang.org/std/intrinsics/fn.arith_offset.html) and `wrapping_offset` are the same thing.
r? ``@scottmcm``
_split off from #100746_
Box::from(slice): Clarify that contents are copied
A colleague mentioned that they interpreted the old text
as saying that only the pointer and the length are copied.
Add a clause so it is more clear that the pointed to contents
are also copied.
In Rust for Linux we are using these to make `alloc` a bit
more modular.
A `run-make-fulldeps` test is added for each of them, so that
enabling each of them independently is kept in a compilable state.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
BTree: evaluate static type-related check at compile time
`assert`s like the ones replaced here would only go off when you run the right test cases, if the code were ever incorrectly changed such that rhey would trigger. But [inspired on a nice forum question](https://users.rust-lang.org/t/compile-time-const-generic-parameter-check/69202), they can be checked at compile time.
Extra documentation for new formatting feature
Documentation of this feature was added in #90473 and released in Rust 1.58. However, high traffic macros did not receive new examples. Namely `println!()` and `format!()`.
The doc comments included in Rust are super important to the community- especially newcomers. I have met several other newbies like myself who are unaware of this recent (well about 7 months old now) update to the language allowing for convenient intra-string identifiers.
Bringing small examples of this feature to the doc comments of `println!()` and `format!()` would be helpful to everyone learning the language.
[Blog Post Announcing Feature](https://blog.rust-lang.org/2022/01/13/Rust-1.58.0.html)
[Feature PR](https://github.com/rust-lang/rust/pull/90473) - includes several instances of documentation of the feature- minus the macros in question for this PR
*This is my first time contributing to a project this large. Feedback would mean the world to me 😄*
---
*Recreated; I violated the [No-Merge Policy](https://rustc-dev-guide.rust-lang.org/git.html#no-merge-policy)*
Move Error trait into core
This PR moves the error trait from the standard library into a new unstable `error` module within the core library. The goal of this PR is to help unify error reporting across the std and no_std ecosystems, as well as open the door to integrating the error trait into the panic reporting system when reporting panics whose source is an errors (such as via `expect`).
This PR is a rewrite of https://github.com/rust-lang/rust/pull/90328 using new compiler features that have been added to support error in core.
Add guarantee that Vec::default() does not alloc
Currently `Vec::new()` is guaranteed to not allocate until elements are pushed onto the `Vec`, but such a guarantee is missing for `Vec`'s implementation of `Default::default`.
This adds such a guarantee for `Vec::default()` to the API reference.
See also [this discussion on URLO](https://users.rust-lang.org/t/guarantee-that-vec-default-does-not-allocate/79903).
Use pointer `is_aligned*` methods
This PR replaces some manual alignment checks with calls to `pointer::{is_aligned, is_aligned_to}` and removes a useless pointer cast.
r? `@scottmcm`
_split off from #100746_
Guarantee `try_reserve` preserves the contents on error
Update doc comments to make the guarantee explicit. However, some
implementations does not have the statement though.
* `HashMap`, `HashSet`: require guarantees on hashbrown side.
* `PathBuf`: simply redirecting to `OsString`.
Fixes#99606.
Currently `Vec::new()` is guaranteed to not allocate until elements are
pushed onto the `Vec`, but such a guarantee is missing for `Vec`'s
implementation of `Default::default`. This adds such a guarantee for
`Vec::default()` to the API reference.
Std module docs improvements
My primary goal is to create a cleaner separation between primitive types and primitive type helper modules (fixes#92777). I also changed a few header lines in other top-level std modules (seen at https://doc.rust-lang.org/std/) for consistency.
Some conventions used/established:
* "The \`Box\<T>` type for heap allocation." - if a module mainly provides a single type, name it and summarize its purpose in the module header
* "Utilities for the _ primitive type." - this wording is used for the header of helper modules
* Documentation for primitive types themselves are removed from helper modules
* provided-by-core functionality of primitive types is documented in the primitive type instead of the helper module (such as the "Iteration" section in the slice docs)
I wonder if some content in `std::ptr` should be in `pointer` but I did not address this.
Replace most uses of `pointer::offset` with `add` and `sub`
As PR title says, it replaces `pointer::offset` in compiler and standard library with `pointer::add` and `pointer::sub`. This generally makes code cleaner, easier to grasp and removes (or, well, hides) integer casts.
This is generally trivially correct, `.offset(-constant)` is just `.sub(constant)`, `.offset(usized as isize)` is just `.add(usized)`, etc. However in some cases we need to be careful with signs of things.
r? ````@scottmcm````
_split off from #100746_
Make some docs nicer wrt pointer offsets
This PR replaces `pointer::offset` with `pointer::add` and similarly `.cast().wrapping_add().cast()` with `.wrapping_byte_add()` **in docs**.
r? ``````@scottmcm``````
_split off from #100746_
Expose `Utf8Lossy` as `Utf8Chunks`
This PR changes the feature for `Utf8Lossy` from `str_internals` to `utf8_lossy` and improves the API. This is done to eventually expose the API as stable.
Proposal: rust-lang/libs-team#54
Tracking Issue: #99543
Update doc comments to make the guarantee explicit. However, some
implementations does not have the statement though.
* `HashMap`, `HashSet`: require guarantees on hashbrown side.
* `PathBuf`: simply redirecting to `OsString`.
Fixes#99606.
Optimized vec::IntoIter::next_chunk impl
```
x86_64v1, default
test vec::bench_next_chunk ... bench: 696 ns/iter (+/- 22)
x86_64v1, pr
test vec::bench_next_chunk ... bench: 309 ns/iter (+/- 4)
znver2, default
test vec::bench_next_chunk ... bench: 17,272 ns/iter (+/- 117)
znver2, pr
test vec::bench_next_chunk ... bench: 211 ns/iter (+/- 3)
```
On znver2 the default impl seems to be slow due to different inlining decisions. It goes through `core::array::iter_next_chunk`
which has a deep call tree.
codegen: use new {re,de,}allocator annotations in llvm
This obviates the patch that teaches LLVM internals about
_rust_{re,de}alloc functions by putting annotations directly in the IR
for the optimizer.
The sole test change is required to anchor FileCheck to the body of the
`box_uninitialized` method, so it doesn't see the `allocalign` on
`__rust_alloc` and get mad about the string `alloca` showing up. Since I
was there anyway, I added some checks on the attributes to prove the
right attributes got set.
r? `@nikic`
```
test vec::bench_next_chunk ... bench: 696 ns/iter (+/- 22)
x86_64v1, pr
test vec::bench_next_chunk ... bench: 309 ns/iter (+/- 4)
znver2, default
test vec::bench_next_chunk ... bench: 17,272 ns/iter (+/- 117)
znver2, pr
test vec::bench_next_chunk ... bench: 211 ns/iter (+/- 3)
```
The znver2 default impl seems to be slow due to inlining decisions. It goes through `core::array::iter_next_chunk`
which has a deeper call tree.
This obviates the patch that teaches LLVM internals about
_rust_{re,de}alloc functions by putting annotations directly in the IR
for the optimizer.
The sole test change is required to anchor FileCheck to the body of the
`box_uninitialized` method, so it doesn't see the `allocalign` on
`__rust_alloc` and get mad about the string `alloca` showing up. Since I
was there anyway, I added some checks on the attributes to prove the
right attributes got set.
While we're here, we also emit allocator attributes on
__rust_alloc_zeroed. This should allow LLVM to perform more
optimizations for zeroed blocks, and probably fixes#90032. [This
comment](https://github.com/rust-lang/rust/issues/24194#issuecomment-308791157)
mentions "weird UB-like behaviour with bitvec iterators in
rustc_data_structures" so we may need to back this change out if things
go wrong.
The new test cases require LLVM 15, so we copy them into LLVM
14-supporting versions, which we can delete when we drop LLVM 14.
correct the output of a `capacity` method example
The output of this example in std::alloc is different from which shown in the comment. I have tested it on both Linux and Windows.
* Implement IsZero trait for tuples up to 8 IsZero elements;
* Implement IsZero for u8/i8, leading to implementation of it for arrays of them too;
* Add more codegen tests for this optimization.
* Lower size of array for IsZero trait because it fails to inline checks
The lifetime bound `B::Owned: 'a` is redundant and doesn't make a difference,
because `Cow<'a, B>` comes with an implicit `B: 'a`, and associated types
will outlive lifetimes outlived by the `Self` type (and all the trait's
generic parameters, of which there are none in this case), so the implicit `B: 'a`
implies `B::Owned: 'a` anyway.
The explicit lifetime bound here does however end up in documentation,
and that's confusing in my opinion, so let's remove it ^^
A colleague mentioned that they interpreted the old text
as saying that only the pointer and the length are copied.
Add a clause so it is more clear that the pointed to contents
are also copied.
add missing null ptr check in alloc example
`alloc` can return null on OOM, if I understood correctly. So we should never just deref a pointer we get from `alloc`.
Borrow Vec<T, A> as [T]
Hello all,
When `Vec` was parametrized with `A`, the `Borrow` impls were omitted and currently `Vec<T, A>` can't be borrowed as `[T]`. This PR fixes that.
This was probably missed, because the `Borrow` impls are in a different file - `src/alloc/slice.rs`.
We briefly discussed this here: https://github.com/rust-lang/wg-allocators/issues/96 and I was told to go ahead and make a PR :)
I tested this by building the toolchain and building my code that needed the `Borrow` impl against it, but let me know if I should add any tests to this PR.
Stabilize `core::ffi::CStr`, `alloc::ffi::CString`, and friends
Stabilize the `core_c_str` and `alloc_c_string` feature gates.
Change `std::ffi` to re-export these types rather than creating type
aliases, since they now have matching stability.
Stabilize the `core_c_str` and `alloc_c_string` feature gates.
Change `std::ffi` to re-export these types rather than creating type
aliases, since they now have matching stability.
Stabilize `core::ffi:c_*` and rexport in `std::ffi`
This only stabilizes the base types, not the non-zero variants, since
those have their own separate tracking issue and have not gone through
FCP to stabilize.
This only stabilizes the base types, not the non-zero variants, since
those have their own separate tracking issue and have not gone through
FCP to stabilize.
In particular, be clear that it is sound to specify memory not
originating from a previous `Vec` allocation. That is already suggested
in other parts of the documentation about zero-alloc conversions to Box<[T]>.
Incorporate a constraint from `slice::from_raw_parts` that was missing
but needs to be fulfilled, since a `Vec` can be converted into a slice.
Optimize `Vec::insert` for the case where `index == len`.
By skipping the call to `copy` with a zero length. This makes it closer
to `push`.
I did this recently for `SmallVec`
(https://github.com/servo/rust-smallvec/pull/282) and it was a big perf win in
one case. Although I don't have a specific use case in mind, it seems
worth doing it for `Vec` as well.
Things to note:
- In the `index < len` case, the number of conditions checked is
unchanged.
- In the `index == len` case, the number of conditions checked increases
by one, but the more expensive zero-length copy is avoided.
- In the `index > len` case the code now reserves space for the extra
element before panicking. This seems like an unimportant change.
r? `@cuviper`
Make `ThinBox<T>` covariant in `T`
Just like `Box<T>`, we want `ThinBox<T>` to be covariant in `T`, but the
projection in `WithHeader<<T as Pointee>::Metadata>` was making it
invariant. This is now hidden as `WithOpaqueHeader`, which we type-cast
whenever the real `WithHeader<H>` type is needed.
Fixes the problem noted in <https://github.com/rust-lang/rust/issues/92791#issuecomment-1104636249>.
By skipping the call to `copy` with a zero length. This makes it closer
to `push`.
I did this recently for `SmallVec`
(https://github.com/servo/rust-smallvec/pull/282) and it was a big perf win in
one case. Although I don't have a specific use case in mind, it seems
worth doing it for `Vec` as well.
Things to note:
- In the `index < len` case, the number of conditions checked is
unchanged.
- In the `index == len` case, the number of conditions checked increases
by one, but the more expensive zero-length copy is avoided.
- In the `index > len` case the code now reserves space for the extra
element before panicking. This seems like an unimportant change.
Rust 1.62.0 introduced a couple new `unused_imports` warnings
in `no_global_oom_handling` builds, making a total of 5 warnings:
```txt
warning: unused import: `Unsize`
--> library/alloc/src/boxed/thin.rs:6:33
|
6 | use core::marker::{PhantomData, Unsize};
| ^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: unused import: `from_fn`
--> library/alloc/src/string.rs:51:18
|
51 | use core::iter::{from_fn, FusedIterator};
| ^^^^^^^
warning: unused import: `core::ops::Deref`
--> library/alloc/src/vec/into_iter.rs:12:5
|
12 | use core::ops::Deref;
| ^^^^^^^^^^^^^^^^
warning: associated function `shrink` is never used
--> library/alloc/src/raw_vec.rs:424:8
|
424 | fn shrink(&mut self, cap: usize) -> Result<(), TryReserveError> {
| ^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: associated function `forget_remaining_elements` is never used
--> library/alloc/src/vec/into_iter.rs:126:19
|
126 | pub(crate) fn forget_remaining_elements(&mut self) {
| ^^^^^^^^^^^^^^^^^^^^^^^^^
```
This patch cleans them so that projects compiling `alloc` without
infallible allocations do not see the warnings. It also enables
the use of `-Dwarnings`.
The couple `dead_code` ones may be reverted when some fallible
allocation support starts using them.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Just like `Box<T>`, we want `ThinBox<T>` to be covariant in `T`, but the
projection in `WithHeader<<T as Pointee>::Metadata>` was making it
invariant. This is now hidden as `WithOpaqueHeader`, which we type-cast
whenever the real `WithHeader<H>` type is needed.
Fix `panic` message for `BTreeSet`'s `range` API and document `panic` cases
Currently, the `panic` cases for [`BTreeSet`'s `range` API](https://doc.rust-lang.org/std/collections/struct.BTreeSet.html#method.range) are undocumented and produce a slightly wrong `panic` message (says `BTreeMap` instead of `BTreeSet`).
Panic case 1 code:
```rust
use std::collections::BTreeSet;
use std::ops::Bound::Excluded;
fn main() {
let mut set = BTreeSet::new();
set.insert(3);
set.insert(5);
set.insert(8);
for &elem in set.range((Excluded(&3), Excluded(&3))) {
println!("{elem}");
}
}
```
Panic case 1 message:
```
thread 'main' panicked at 'range start and end are equal and excluded in BTreeMap', /rustc/fe5b13d681f25ee6474be29d748c65adcd91f69e/library/alloc/src/collections/btree/search.rs:105:17
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
Panic case 2 code:
```rust
use std::collections::BTreeSet;
use std::ops::Bound::Included;
fn main() {
let mut set = BTreeSet::new();
set.insert(3);
set.insert(5);
set.insert(8);
for &elem in set.range((Included(&8), Included(&3))) {
println!("{elem}");
}
}
```
Panic case 2:
```
thread 'main' panicked at 'range start is greater than range end in BTreeMap', /rustc/fe5b13d681f25ee6474be29d748c65adcd91f69e/library/alloc/src/collections/btree/search.rs:110:17
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
This PR fixes the output messages to say `BTreeSet`, adds the relevant unit tests, and updates the documentation for the API.
clarify Arc::clone overflow check comment
I had to read this twice to realize that this is explaining that the code is technically unsound, so move that into a dedicated paragraph and make the wording a bit more explicit.
Fix documentation for `with_capacity` and `reserve` families of methods
Fixes#95614
Documentation for the following methods
- `with_capacity`
- `with_capacity_in`
- `with_capacity_and_hasher`
- `reserve`
- `reserve_exact`
- `try_reserve`
- `try_reserve_exact`
was inconsistent and often not entirely correct where they existed on the following types
- `Vec`
- `VecDeque`
- `String`
- `OsString`
- `PathBuf`
- `BinaryHeap`
- `HashSet`
- `HashMap`
- `BufWriter`
- `LineWriter`
since the allocator is allowed to allocate more than the requested capacity in all such cases, and will frequently "allocate" much more in the case of zero-sized types (I also checked `BufReader`, but there the docs appear to be accurate as it appears to actually allocate the exact capacity).
Some effort was made to make the documentation more consistent between types as well.
Documentation for the following methods
with_capacity
with_capacity_in
with_capacity_and_hasher
reserve
reserve_exact
try_reserve
try_reserve_exact
was inconsistent and often not entirely correct where they existed on the following types
Vec
VecDeque
String
OsString
PathBuf
BinaryHeap
HashSet
HashMap
BufWriter
LineWriter
since the allocator is allowed to allocate more than the requested capacity in all such cases, and will frequently "allocate" much more in the case of zero-sized types (I also checked BufReader, but there the docs appear to be accurate as it appears to actually allocate the exact capacity).
Some effort was made to make the documentation more consistent between types as well.
Fix with_capacity* methods for Vec
Fix *reserve* methods for Vec
Fix docs for *reserve* methods of VecDeque
Fix docs for String::with_capacity
Fix docs for *reserve* methods of String
Fix docs for OsString::with_capacity
Fix docs for *reserve* methods on OsString
Fix docs for with_capacity* methods on HashSet
Fix docs for *reserve methods of HashSet
Fix docs for with_capacity* methods of HashMap
Fix docs for *reserve methods on HashMap
Fix expect messages about OOM in doctests
Fix docs for BinaryHeap::with_capacity
Fix docs for *reserve* methods of BinaryHeap
Fix typos
Fix docs for with_capacity on BufWriter and LineWriter
Fix consistent use of `hasher` between `HashMap` and `HashSet`
Fix warning in doc test
Add test for capacity of vec with ZST
Fix doc test error
Add VecDeque::extend from TrustedLen specialization
Continuation of #95904
Inspired by how [`VecDeque::copy_slice` works](c08b235a5c/library/alloc/src/collections/vec_deque/mod.rs (L437-L454)).
## Benchmarks
Before
```
test vec_deque::bench_extend_chained_bytes ... bench: 1,026 ns/iter (+/- 17)
test vec_deque::bench_extend_chained_trustedlen ... bench: 1,024 ns/iter (+/- 40)
test vec_deque::bench_extend_trustedlen ... bench: 637 ns/iter (+/- 693)
```
After
```
test vec_deque::bench_extend_chained_bytes ... bench: 828 ns/iter (+/- 24)
test vec_deque::bench_extend_chained_trustedlen ... bench: 25 ns/iter (+/- 1)
test vec_deque::bench_extend_trustedlen ... bench: 21 ns/iter (+/- 0)
```
## Why do it this way
https://rust.godbolt.org/z/15qY1fMYh
The Compiler Explorer example shows how "just" removing the capacity check, like the [`Vec` `TrustedLen` specialization](c08b235a5c/library/alloc/src/vec/spec_extend.rs (L22-L58)) does, wouldn't have been enough for `VecDeque`. `wrap_add` would still have greatly limited what LLVM could do while optimizing.
---
r? `@the8472`
btree: avoid forcing the allocator to be a reference
The previous code forces the actual allocator used to be some `&A`. This generalizes the code to allow any `A: Copy`. If people truly want to use a reference, they can use `&A` themselves.
Fixes https://github.com/rust-lang/rust/issues/98176
Entry and_modify doc
This PR modifies the documentation for [HashMap](https://doc.rust-lang.org/std/collections/struct.HashMap.html#) and [BTreeMap](https://doc.rust-lang.org/std/collections/struct.BTreeMap.html#) by introducing examples for `and_modify`. `and_modify` is a function that tends to give more idiomatic rust code when dealing with these data structures -- yet it lacked examples and was hidden away. This PR adds that and addresses #98122.
I've made some choices which I tried to explain in my commits. This is my first time contributing to rust, so hopefully, I made the right choices.
Updated the btree's documentation to include two references to
add_modify.
The first is when the `Entry` API is mentioned at the beginning. With
the same reasoning as HashMap's documentation, I thought it would best
to keep `attack`, but show the `mana` example.
The second is with the `entry` function that is used for the `Entry`
API. The code example was a perfect use for `add_modify`, which is why
it was changed to reflect that.
Remove migrate borrowck mode
Closes#58781Closes#43234
# Stabilization proposal
This PR proposes the stabilization of `#![feature(nll)]` and the removal of `-Z borrowck`. Current borrow checking behavior of item bodies is currently done by first infering regions *lexically* and reporting any errors during HIR type checking. If there *are* any errors, then MIR borrowck (NLL) never occurs. If there *aren't* any errors, then MIR borrowck happens and any errors there would be reported. This PR removes the lexical region check of item bodies entirely and only uses MIR borrowck. Because MIR borrowck could never *not* be run for a compiled program, this should not break any programs. It does, however, change diagnostics significantly and allows a slightly larger set of programs to compile.
Tracking issue: #43234
RFC: https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md
Version: 1.63 (2022-06-30 => beta, 2022-08-11 => stable).
## Motivation
Over time, the Rust borrow checker has become "smarter" and thus allowed more programs to compile. There have been three different implementations: AST borrowck, MIR borrowck, and polonius (well, in progress). Additionally, there is the "lexical region resolver", which (roughly) solves the constraints generated through HIR typeck. It is not a full borrow checker, but does emit some errors.
The AST borrowck was the original implementation of the borrow checker and was part of the initially stabilized Rust 1.0. In mid 2017, work began to implement the current MIR borrow checker and that effort ompleted by the end of 2017, for the most part. During 2018, efforts were made to migrate away from the AST borrow checker to the MIR borrow checker - eventually culminating into "migrate" mode - where HIR typeck with lexical region resolving following by MIR borrow checking - being active by default in the 2018 edition.
In early 2019, migrate mode was turned on by default in the 2015 edition as well, but with MIR borrowck errors emitted as warnings. By late 2019, these warnings were upgraded to full errors. This was followed by the complete removal of the AST borrow checker.
In the period since, various errors emitted by the MIR borrow checker have been improved to the point that they are mostly the same or better than those emitted by the lexical region resolver.
While there do remain some degradations in errors (tracked under the [NLL-diagnostics tag](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-diagnostics), those are sufficiently small and rare enough that increased flexibility of MIR borrow check-only is now a worthwhile tradeoff.
## What is stabilized
As said previously, this does not fundamentally change the landscape of accepted programs. However, there are a [few](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-fixed-by-NLL) cases where programs can compile under `feature(nll)`, but not otherwise.
There are two notable patterns that are "fixed" by this stabilization. First, the `scoped_threads` feature, which is a continutation of a pre-1.0 API, can sometimes emit a [weird lifetime error](https://github.com/rust-lang/rust/issues/95527) without NLL. Second, actually seen in the standard library. In the `Extend` impl for `HashMap`, there is an implied bound of `K: 'a` that is available with NLL on but not without - this is utilized in the impl.
As mentioned before, there are a large number of diagnostic differences. Most of them are better, but some are worse. None are serious or happen often enough to need to block this PR. The biggest change is the loss of error code for a number of lifetime errors in favor of more general "lifetime may not live long enough" error. While this may *seem* bad, the former error codes were just attempts to somewhat-arbitrarily bin together lifetime errors of the same type; however, on paper, they end up being roughly the same with roughly the same kinds of solutions.
## What isn't stabilized
This PR does not completely remove the lexical region resolver. In the future, it may be possible to remove that (while still keeping HIR typeck) or to remove it together with HIR typeck.
## Tests
Many test outputs get updated by this PR. However, there are number of tests specifically geared towards NLL under `src/test/ui/nll`
## History
* On 2017-07-14, [tracking issue opened](https://github.com/rust-lang/rust/issues/43234)
* On 2017-07-20, [initial empty MIR pass added](https://github.com/rust-lang/rust/pull/43271)
* On 2017-08-29, [RFC opened](https://github.com/rust-lang/rfcs/pull/2094)
* On 2017-11-16, [Integrate MIR type-checker with NLL](https://github.com/rust-lang/rust/pull/45825)
* On 2017-12-20, [NLL feature complete](https://github.com/rust-lang/rust/pull/46862)
* On 2018-07-07, [Don't run AST borrowck on mir mode](https://github.com/rust-lang/rust/pull/52083)
* On 2018-07-27, [Add migrate mode](https://github.com/rust-lang/rust/pull/52681)
* On 2019-04-22, [Enable migrate mode on 2015 edition](https://github.com/rust-lang/rust/pull/59114)
* On 2019-08-26, [Don't downgrade errors on 2015 edition](https://github.com/rust-lang/rust/pull/64221)
* On 2019-08-27, [Remove AST borrowck](https://github.com/rust-lang/rust/pull/64790)
Avoid zero-sized allocs in ThinBox if T and H are both ZSTs.
This was surprisingly tricky, and took longer to get right than expected. `ThinBox` is a surprisingly subtle piece of code. That said, in the end, a lot of this was due to overthinking[^overthink] -- ultimately the fix ended up fairly clean and simple.
[^overthink]: Honestly, for a while I was convinced this couldn't be done without allocations or runtime branches in these cases, but that's obviously untrue.
Anyway, as a result of spending all that time debugging, I've extended the tests quite a bit, and also added more debug assertions. Many of these helped for subtle bugs I made in the middle (for example, the alloc/drop tracking is because I ended up double-dropping the value in the case where both were ZSTs), they're arguably a bit of overkill at this point, although I imagine they could help in the future too.
Anyway, these tests cover a wide range of size/align cases, nd fully pass under miri[^1]. They also do some smoke-check asserting that the value has the correct alignment, although in practice it's totally within the compiler's rights to delete these assertions since we'd have already done UB if they get hit. They have more boilerplate than they really need, but it's not *too* bad on a per-test basis.
A notable absence from testing is atypical header types, but at the moment it's impossible to manually implement `Pointee`. It would be really nice to have testing here, since it's not 100% obvious to me that the aligned read/write we use for `H` are correct in the face of arbitrary combinations of `size_of::<H>()`, `align_of::<H>()`, and `align_of::<T>()`. (That said, I spent a while thinking through it and am *pretty* sure it's fine -- I'd just feel... better if we could test some cases for non-ZST headers which have unequal and align).
[^1]: Or at least, they pass under miri if I copy the code and tests into a new crate and run miri on it (after making it less stdlibified).
Fixes#96485.
I'd request review ``@yaahc,`` but I believe you're taking some time away from reviews, so I'll request from the previous PR's reviewer (I think that the context helps, even if the actual change didn't end up being bad here).
r? ``@joshtriplett``
Improve documentation for constructors of pinned `Box`es
Adds a cross-references between `Box::pin` and `Box::into_pin` (and other related methods, i.e. the equivalent `From` implementation, and the unstable `pin_in` method), in particular now that `into_pin` [was stabilized](https://github.com/rust-lang/rust/pull/97397). The main goal is to further improve visibility of the fact that `Box<T> -> Pin<Box<T>>` conversion exits in the first place, and that `Box::pin(x)` is – essentially – just a convenience function for `Box::into_pin(Box::new(x))`
The motivating context why I think this is important is even experienced Rust users overlooking the existence this kind of conversion, [e.g. in this thread on IRLO](https://internals.rust-lang.org/t/pre-rfc-function-variants/16732/7?u=steffahn); and also the fact that that discussion brought up that there would be a bunch of Box-construction methods "missing" such as e.g. methods with fallible allocation a la "`Box::try_pin`", and similar; while those are in fact *not* necessary, because you can use `Box::into_pin(Box::try_new(x)?)` instead.
I have *not* included explicit mention of methods (e.g. `try_new`) in the docs of stable methods (e.g. `into_pin`). (Referring to unstable API in stable API docs would be bad style IMO.) Stable examples I have in mind with the statement "constructing a (pinned) Box in a different way than with `Box::new`" are things like cloning a `Box`, or `Box::from_raw`. If/when `try_new` would get stabilized, it would become a very good concrete example use-case of `Box::into_pin` IMO.
Add #[rustc_box] and use it inside alloc
This commit adds an alternative content boxing syntax, and uses it inside alloc.
```Rust
#![feature(box_syntax)]
fn foo() {
let foo = box bar;
}
```
is equivalent to
```Rust
#![feature(rustc_attrs)]
fn foo() {
let foo = #[rustc_box] Box::new(bar);
}
```
The usage inside the very performance relevant code in
liballoc is the only remaining relevant usage of box syntax
in the compiler (outside of tests, which are comparatively easy to port).
box syntax was originally designed to be used by all Rust
developers. This introduces a replacement syntax more tailored
to only being used inside the Rust compiler, and with it,
lays the groundwork for eventually removing box syntax.
[Earlier work](https://github.com/rust-lang/rust/pull/87781#issuecomment-894714878) by `@nbdd0121` to lower `Box::new` to `box` during THIR -> MIR building ran into borrow checker problems, requiring the lowering to be adjusted in a way that led to [performance regressions](https://github.com/rust-lang/rust/pull/87781#issuecomment-894872367). The proposed change in this PR lowers `#[rustc_box] Box::new` -> `box` in the AST -> HIR lowering step, which is way earlier in the compiler, and thus should cause less issues both performance wise as well as regarding type inference/borrow checking/etc. Hopefully, future work can move the lowering further back in the compiler, as long as there are no performance regressions.
Tweak insert docs
For `{Hash, BTree}Map::insert`, I always have to take a few extra seconds to think about the slight weirdness about the fact that if we "did not" insert (which "sounds" false), we return true, and if we "did" insert, (which "sounds" true), we return false.
This tweaks the doc comments for the `insert` methods of those types (as well as what looks like a rustc internal data structure that I found just by searching the codebase for "If the set did") to first use the "Returns whether _something_" pattern used in e.g. `remove`, where we say that `remove` "returns whether the value was present".
alloc: remove repeated word in comment
Linux's `checkpatch.pl` reports:
```txt
#42544: FILE: rust/alloc/vec/mod.rs:2692:
WARNING: Possible repeated word: 'to'
+ // - Elements are :Copy so it's OK to to copy them, without doing
```
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Put a bound on collection misbehavior
As currently written, when a logic error occurs in a collection's trait parameters, this allows *completely arbitrary* misbehavior, so long as it does not cause undefined behavior in std. However, because the extent of misbehavior is not specified, it is allowed for *any* code in std to start misbehaving in arbitrary ways which are not formally UB; consider the theoretical example of a global which gets set on an observed logic error. Because the misbehavior is only bound by not resulting in UB from safe APIs and the crate-level encapsulation boundary of all of std, this makes writing user unsafe code that utilizes std theoretically impossible, as it now relies on undocumented QOI (quality of implementation) that unrelated parts of std cannot be caused to misbehave by a misuse of std::collections APIs.
In practice, this is a nonconcern, because std has reasonable QOI and an implementation that takes advantage of this freedom is essentially a malicious implementation and only compliant by the most langauage-lawyer reading of the documentation.
To close this hole, we just add a small clause to the existing logic error paragraph that ensures that any misbehavior is limited to the collection which observed the logic error, making it more plausible to prove the soundness of user unsafe code.
This is not meant to be formal; a formal refinement would likely need to mention that values derived from the collection can also misbehave after a logic error is observed, as well as define what it means to "observe" a logic error in the first place. This fix errs on the side of informality in order to close the hole without complicating a normal reading which can assume a reasonable nonmalicious QOI.
See also [discussion on IRLO][1].
[1]: https://internals.rust-lang.org/t/using-std-collections-and-unsafe-anything-can-happen/16640
r? rust-lang/libs-api ```@rustbot``` label +T-libs-api -T-libs
This technically adds a new guarantee to the documentation, though I argue as written it's one already implicitly provided.
Clarify the guarantees of Vec::as_ptr and Vec::as_mut_ptr when there's no allocation
Currently the documentation says they return a pointer to the vector's buffer, which has the implied precondition that the vector allocated some memory. However `Vec`'s documentation also specifies that it won't always allocate, so it's unclear whether the pointer returned is valid in that case. Of course you won't be able to read/write actual bytes to/from it since the capacity is 0, but there's an exception: zero sized read/writes. They are still valid as long as the pointer is not null and the memory it points to wasn't deallocated, but `Vec::as_ptr` and `Vec::as_mut_ptr` don't specify that's not the case. This PR thus specifies they are actually valid for zero sized reads since `Vec` is implemented to hold a dangling pointer in those cases, which is neither null nor was deallocated.
Linux's `checkpatch.pl` reports:
```txt
#42544: FILE: rust/alloc/vec/mod.rs:2692:
WARNING: Possible repeated word: 'to'
+ // - Elements are :Copy so it's OK to to copy them, without doing
```
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Document the current aliasing rules for `Box<T>`.
Currently, `Box<T>` gets `noalias`, meaning it has the same rules as `&mut T`. This is sparsely documented, even though it can have quite a big impact on unsafe code using box. Therefore, these rules are documented here, with a big warning that they are not normative and subject to change, since we have not yet committed to an aliasing model and the state of `Box<T>` is especially uncertain.
If you have any suggestions and improvements, make sure to leave them here. This is mostly intended to inform people about what is currently going on (to prevent misunderstandings such as [Jon Gjengset's Box aliasing](https://www.youtube.com/watch?v=EY7Wi9fV5bk)).
This is supposed to _only document current UB_ and not add any new guarantees or rules.
refactor: VecDeques Iter fields to private
Made the fields of VecDeque's Iter private by creating a Iter::new(...) function to create a new instance of Iter and migrating usage to use Iter::new(...).
improve format impl for literals
The basic idea of this change can be seen here https://godbolt.org/z/MT37cWoe1.
Updates the format impl to have a fast path for string literals and the default path for regular format args.
This change will allow `format!("string literal")` to be used interchangably with `"string literal".to_owned()`.
This would be relevant in the case of `f!"string literal"` being legal (https://github.com/rust-lang/rfcs/pull/3267) in which case it would be the easiest way to create owned strings from literals, while also being just as efficient as any other impl
Use Box::new() instead of box syntax in library tests
The tests inside `library/*` have no reason to use `box` syntax as they have 0 performance relevance. Therefore, we can safely remove them (instead of having to use alternatives like the one in #97293).
Finish bumping stage0
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This now brings us to cfg-clean, with the exception of check-cfg-features in bootstrap;
I'd prefer to leave that for a separate PR at this time since it's likely to be more tricky.
cc https://github.com/rust-lang/rust/pull/97147#issuecomment-1132845061
r? `@pietroalbini`
Remove impossible panic note from `Vec::append`
Neither the number of elements in a vector can overflow a `usize`, nor
can the amount of elements in two vectors.
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
Currently, `Box<T>` gets `noalias`, meaning it has
the same rules as `&mut T`. This is
sparsely documented, even though it can have quite
a big impact on unsafe code using box. Therefore,
these rules are documented here, with a big warning
that they are not normative and subject to change,
since we have not yet committed to an aliasing model
and the state of `Box<T>` is especially uncertain.
improve case conversion happy path
Someone shared the source code for [Go's string case conversion](19156a5474/src/strings/strings.go (L558-L616)).
It features a hot path for ascii-only strings (although I assume for reasons specific to go, they've opted for a read safe hot loop).
I've borrowed these ideas and also kept our existing code to provide a fast path + seamless utf-8 correct path fallback.
(Naive) Benchmarks can be found here https://github.com/conradludgate/case-conv
For the cases where non-ascii is found near the start, the performance of this algorithm does fall back to original speeds and has not had any measurable speed loss
As currently written, when a logic error occurs in a collection's trait
parameters, this allows *completely arbitrary* misbehavior, so long as
it does not cause undefined behavior in std. However, because the extent
of misbehavior is not specified, it is allowed for *any* code in std to
start misbehaving in arbitrary ways which are not formally UB; consider
the theoretical example of a global which gets set on an observed logic
error. Because the misbehavior is only bound by not resulting in UB from
safe APIs and the crate-level encapsulation boundary of all of std, this
makes writing user unsafe code that utilizes std theoretically
impossible, as it now relies on undocumented QOI that unrelated parts of
std cannot be caused to misbehave by a misuse of std::collections APIs.
In practice, this is a nonconcern, because std has reasonable QOI and an
implementation that takes advantage of this freedom is essentially a
malicious implementation and only compliant by the most langauage-lawyer
reading of the documentation.
To close this hole, we just add a small clause to the existing logic
error paragraph that ensures that any misbehavior is limited to the
collection which observed the logic error, making it more plausible to
prove the soundness of user unsafe code.
This is not meant to be formal; a formal refinement would likely need to
mention that values derived from the collection can also misbehave after a
logic error is observed, as well as define what it means to "observe" a
logic error in the first place. This fix errs on the side of informality
in order to close the hole without complicating a normal reading which
can assume a reasonable nonmalicious QOI.
See also [discussion on IRLO][1].
[1]: https://internals.rust-lang.org/t/using-std-collections-and-unsafe-anything-can-happen/16640
Clarify slice and Vec iteration order
While already being inferable from the doc examples, it wasn't fully specified. This is the only logical way to do a slice iterator, so I think this should be uncontroversial. It also improves the `Vec::into_iter` example to better show the order and that the iterator returns owned values.
Improve codegen of String::retain method
This pull-request improve the codegen of the `String::retain` method.
Using `unwrap_unchecked` helps the optimizer to not generate a panicking path that will never be taken for valid UTF-8 like string.
Using `encode_utf8` saves us from an expensive call to `memcpy`, as the optimizer is unable to realize that `ch_len <= 4` and so can generate much better assembly code.
https://rust.godbolt.org/z/z73ohenfc
Remove libstd's calls to `C-unwind` foreign functions
Remove all libstd and its dependencies' usage of `extern "C-unwind"`.
This is a prerequiste of a WIP PR which will forbid libraries calling `extern "C-unwind"` functions to be compiled in `-Cpanic=unwind` and linked against `panic_abort` (this restriction is necessary to address soundness bug #96926).
Cargo will ensure all crates are compiled with the same `-Cpanic` but the std is only compiled `-Cpanic=unwind` but needs the ability to be linked into `-Cpanic=abort`.
Currently there are two places where `C-unwind` is used in libstd:
* `__rust_start_panic` is used for interfacing to the panic runtime. This could be `extern "Rust"`
* `_{rdl,rg}_oom`: a shim `__rust_alloc_error_handler` will be generated by codegen to call into one of these; they can also be `extern "Rust"` (in fact, the generated shim is used as `extern "Rust"`, so I am not even sure why these are not, probably because they used to `extern "C"` and was changed to `extern "C-unwind"` when we allow alloc error hooks to unwind, but they really should just be using Rust ABI).
For dependencies, there is only one `extern "C-unwind"` function call, in `unwind` crate. This can be expressed as a re-export.
More dicussions can be seen in the Zulip thread: https://rust-lang.zulipchat.com/#narrow/stream/210922-project-ffi-unwind/topic/soundness.20in.20mixed.20panic.20mode
`@rustbot` label: T-libs F-c_unwind
Use default alloc_error_handler for hermit
Hermit now properly separates kernel from userspace.
Applications for hermit can now use Rust's default `alloc_error_handler` instead of calling the kernel's `__rg_oom`.
CC: ``@stlankes``
Add `sub_ptr` on pointers (the `usize` version of `offset_from`)
We have `add`/`sub` which are the `usize` versions of `offset`, this adds the `usize` equivalent of `offset_from`. Like how `.add(d)` replaced a whole bunch of `.offset(d as isize)`, you can see from the changes here that it's fairly common that code actually knows the order between the pointers and *wants* a `usize`, not an `isize`.
As a bonus, this can do `sub nuw`+`udiv exact`, rather than `sub`+`sdiv exact`, which can be optimized slightly better because it doesn't have to worry about negatives. That's why the slice iterators weren't using `offset_from`, though I haven't updated that code in this PR because slices are so perf-critical that I'll do it as its own change.
This is an intrinsic, like `offset_from`, so that it can eventually be allowed in CTFE. It also allows checking the extra safety condition -- see the test confirming that CTFE catches it if you pass the pointers in the wrong order.
Like we have `add`/`sub` which are the `usize` version of `offset`, this adds the `usize` equivalent of `offset_from`. Like how `.add(d)` replaced a whole bunch of `.offset(d as isize)`, you can see from the changes here that it's fairly common that code actually knows the order between the pointers and *wants* a `usize`, not an `isize`.
As a bonus, this can do `sub nuw`+`udiv exact`, rather than `sub`+`sdiv exact`, which can be optimized slightly better because it doesn't have to worry about negatives. That's why the slice iterators weren't using `offset_from`, though I haven't updated that code in this PR because slices are so perf-critical that I'll do it as its own change.
This is an intrinsic, like `offset_from`, so that it can eventually be allowed in CTFE. It also allows checking the extra safety condition -- see the test confirming that CTFE catches it if you pass the pointers in the wrong order.
Implement a lint to warn about unused macro rules
This implements a new lint to warn about unused macro rules (arms/matchers), similar to the `unused_macros` lint added by #41907 that warns about entire macros.
```rust
macro_rules! unused_empty {
(hello) => { println!("Hello, world!") };
() => { println!("empty") }; //~ ERROR: 1st rule of macro `unused_empty` is never used
}
fn main() {
unused_empty!(hello);
}
```
Builds upon #96149 and #96156.
Fixes#73576
Warn on unused `#[doc(hidden)]` attributes on trait impl items
[Zulip conversation](https://rust-lang.zulipchat.com/#narrow/stream/266220-rustdoc/topic/.E2.9C.94.20Validy.20checks.20for.20.60.23.5Bdoc.28hidden.29.5D.60).
Whether an associated item in a trait impl is shown or hidden in the documentation entirely depends on the corresponding item in the trait declaration. Rustdoc completely ignores `#[doc(hidden)]` attributes on impl items. No error or warning is emitted:
```rust
pub trait Tr { fn f(); }
pub struct Ty;
impl Tr for Ty { #[doc(hidden)] fn f() {} }
// ^^^^^^^^^^^^^^ ignored by rustdoc and currently
// no error or warning issued
```
This may lead users to the wrong belief that the attribute has an effect. In fact, several such cases are found in the standard library (I've removed all of them in this PR).
There does not seem to exist any incentive to allow this in the future either: Impl'ing a trait for a type means the type *fully* conforms to its API. Users can add `#[doc(hidden)]` to the whole impl if they want to hide the implementation or add the attribute to the corresponding associated item in the trait declaration to hide the specific item. Hiding an implementation of an associated item does not make much sense: The associated item can still be found on the trait page.
This PR emits the warn-by-default lint `unused_attribute` for this case with a future-incompat warning.
`@rustbot` label T-compiler T-rustdoc A-lint
Remove `#[rustc_deprecated]`
This removes `#[rustc_deprecated]` and introduces diagnostics to help users to the right direction (that being `#[deprecated]`). All uses of `#[rustc_deprecated]` have been converted. CI is expected to fail initially; this requires #95958, which includes converting `stdarch`.
I plan on following up in a short while (maybe a bootstrap cycle?) removing the diagnostics, as they're only intended to be short-term.
Add a dedicated length-prefixing method to `Hasher`
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
Fixes#94026
r? rust-lang/libs
---
The core of this change is the following two new methods on `Hasher`:
```rust
pub trait Hasher {
/// Writes a length prefix into this hasher, as part of being prefix-free.
///
/// If you're implementing [`Hash`] for a custom collection, call this before
/// writing its contents to this `Hasher`. That way
/// `(collection![1, 2, 3], collection![4, 5])` and
/// `(collection![1, 2], collection![3, 4, 5])` will provide different
/// sequences of values to the `Hasher`
///
/// The `impl<T> Hash for [T]` includes a call to this method, so if you're
/// hashing a slice (or array or vector) via its `Hash::hash` method,
/// you should **not** call this yourself.
///
/// This method is only for providing domain separation. If you want to
/// hash a `usize` that represents part of the *data*, then it's important
/// that you pass it to [`Hasher::write_usize`] instead of to this method.
///
/// # Examples
///
/// ```
/// #![feature(hasher_prefixfree_extras)]
/// # // Stubs to make the `impl` below pass the compiler
/// # struct MyCollection<T>(Option<T>);
/// # impl<T> MyCollection<T> {
/// # fn len(&self) -> usize { todo!() }
/// # }
/// # impl<'a, T> IntoIterator for &'a MyCollection<T> {
/// # type Item = T;
/// # type IntoIter = std::iter::Empty<T>;
/// # fn into_iter(self) -> Self::IntoIter { todo!() }
/// # }
///
/// use std:#️⃣:{Hash, Hasher};
/// impl<T: Hash> Hash for MyCollection<T> {
/// fn hash<H: Hasher>(&self, state: &mut H) {
/// state.write_length_prefix(self.len());
/// for elt in self {
/// elt.hash(state);
/// }
/// }
/// }
/// ```
///
/// # Note to Implementers
///
/// If you've decided that your `Hasher` is willing to be susceptible to
/// Hash-DoS attacks, then you might consider skipping hashing some or all
/// of the `len` provided in the name of increased performance.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_length_prefix(&mut self, len: usize) {
self.write_usize(len);
}
/// Writes a single `str` into this hasher.
///
/// If you're implementing [`Hash`], you generally do not need to call this,
/// as the `impl Hash for str` does, so you can just use that.
///
/// This includes the domain separator for prefix-freedom, so you should
/// **not** call `Self::write_length_prefix` before calling this.
///
/// # Note to Implementers
///
/// The default implementation of this method includes a call to
/// [`Self::write_length_prefix`], so if your implementation of `Hasher`
/// doesn't care about prefix-freedom and you've thus overridden
/// that method to do nothing, there's no need to override this one.
///
/// This method is available to be overridden separately from the others
/// as `str` being UTF-8 means that it never contains `0xFF` bytes, which
/// can be used to provide prefix-freedom cheaper than hashing a length.
///
/// For example, if your `Hasher` works byte-by-byte (perhaps by accumulating
/// them into a buffer), then you can hash the bytes of the `str` followed
/// by a single `0xFF` byte.
///
/// If your `Hasher` works in chunks, you can also do this by being careful
/// about how you pad partial chunks. If the chunks are padded with `0x00`
/// bytes then just hashing an extra `0xFF` byte doesn't necessarily
/// provide prefix-freedom, as `"ab"` and `"ab\u{0}"` would likely hash
/// the same sequence of chunks. But if you pad with `0xFF` bytes instead,
/// ensuring at least one padding byte, then it can often provide
/// prefix-freedom cheaper than hashing the length would.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_str(&mut self, s: &str) {
self.write_length_prefix(s.len());
self.write(s.as_bytes());
}
}
```
With updates to the `Hash` implementations for slices and containers to call `write_length_prefix` instead of `write_usize`.
`write_str` defaults to using `write_length_prefix` since, as was pointed out in the issue, the `write_u8(0xFF)` approach is insufficient for hashers that work in chunks, as those would hash `"a\u{0}"` and `"a"` to the same thing. But since `SipHash` works byte-wise (there's an internal buffer to accumulate bytes until a full chunk is available) it overrides `write_str` to continue to use the add-non-UTF-8-byte approach.
---
Compatibility:
Because the default implementation of `write_length_prefix` calls `write_usize`, the changed hash implementation for slices will do the same thing the old one did on existing `Hasher`s.
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
Tweak the vec-calloc runtime check to only apply to shortish-arrays
r? `@Mark-Simulacrum`
`@nbdd0121` pointed out in https://github.com/rust-lang/rust/pull/95362#issuecomment-1114085395 that LLVM currently doesn't constant-fold the `IsZero` check for long arrays, so that seems like a reasonable justification for limiting it.
It appears that it's based on length, not byte size, (https://godbolt.org/z/4s48Y81dP), so that's what I used in the PR. Maybe it's a ["the number of inlining shall be three"](https://youtu.be/s4wnuiCwTGU?t=320) sort of situation.
Certainly there's more that could be done here -- that generated code that checks long arrays byte-by-byte is highly suboptimal, for example -- but this is an easy, low-risk tweak.
std::fmt: Various fixes and improvements to documentation
This PR contains the following changes:
- **Added argument index comments to examples for specifying precision**
The examples for specifying the precision have comments explaining which
argument the specifier is referring to. However, for implicit positional
arguments, the examples simply refer to "next arg". To simplify following the
comments, "next arg" was supplemented with the actual resulting argument index.
- **Fixed documentation for specifying precision via `.*`**
The documentation stated that in case of the syntax `{<arg>:<spec>.*}`, "the
`<arg>` part refers to the value to print, and the precision must come in the
input preceding `<arg>`". This is not correct: the <arg> part does indeed refer
to the value to print, but the precision does not come in the input preciding
arg, but in the next implicit input (as if specified with {}).
Fixes#96413.
- **Fix the grammar documentation**
According to the grammar documented, the format specifier `{: }` should not be
legal because of the whitespace it contains. However, in reality, this is
perfectly fine because the actual implementation allows spaces before the
closing brace. Fixes#71088.
Also, the exact meaning of most of the terminal symbols was not specified, for
example the meaning of `identifier`.
- **Removed reference to Formatter::buf and other private fields**
Formatter::buf is not a public field and therefore isn't very helpful in user-
facing documentation. Also, the other public fields of Formatter were removed
during stabilization of std::fmt (4af3494bb0) and can only be accessed via
getters.
- **Improved list of formatting macros**
Two improvements:
1. write! can not only receive a `io::Write`, but also a `fmt::Write` as first argument.
2. The description texts now contain links to the actual macros for easier
navigation.
Clarify docs for `from_raw_parts` on `Vec` and `String`
Closes#95427
Original safety explanation for `from_raw_parts` was unclear on safety for consuming a C string. This clarifies when doing so is safe.
Classify BinaryHeap & LinkedList unit tests as such
All but one of these so-called integration test case are unit tests, just like btree's were (#75531). In addition, reunite the unit tests of linked_list that were split off during #23104 because they needed to remain unit tests (they were later moved to the separate file they are in during #63207). The two sets could remain separate files, but I opted to merge them back together, more or less in the order they used to be, apart from one duplicate name `test_split_off` and one duplicate tiny function `list_from`.
Using unwrap_unchecked helps the optimizer to not generate panicking
path, that will never be taken for valid UTF-8 like string.
Using encode_utf8 saves us a call to a memcpy, as the optimizer is
unable to realize that ch_len <= 4 and so can generate much better
assembly code.
https://rust.godbolt.org/z/z73ohenfc
Two improvements:
1. write! can not only receive a `io::Write`, but also a `fmt::Write` as first argument.
2. The description texts now contain links to the actual macros for easier
navigation.
Formatter::buf is not a public field and therefore isn't very helpful in user-
facing documentation. Also, the other public fields of Formatter were made
private during stabilization of std::fmt (4af3494bb0) and can now only be read
via accessor methods.
According to the grammar documented, the format specifier `{: }` should not be
legal because of the whitespace it contains. However, in reality, this is
perfectly fine because the actual implementation allows spaces before the
closing brace. Fixes#71088.
Also, the exact meaning of most of the terminal symbols was not specified, for
example the meaning of `identifier`.
The examples for specifying the precision have comments explaining which
argument the specifier is referring to. However, for implicit positional
arguments, the examples simply talk about "next arg". To make it easier for
readers to follow the comments, "next arg" was supplemented with the actual
resulting argument index.
The documentation stated that in case of the syntax `{<arg>:<spec>.*}`, "the
`<arg>` part refers to the value to print, and the precision must come in the
input preceding `<arg>`". This is not correct: the <arg> part does indeed refer
to the value to print, but the precision does not come in the input preciding
arg, but in the next implicit input (as if specified with {}).
Fixes#96413.
Implement str to [u8] conversion for refcounted containers
This seems motivated to complete the APIs for shared containers since we already have similar allocation-free conversions for strings like `From<Box<[u8]>> for Box<str>`.
Insta-stable since it's a new trait impl?
Clarify that `Cow::into_owned` returns owned data
Two sections of the `Cow::into_owned` docs imply that `into_owned` returns a `Cow`. Clarify that it returns the underlying owned object, either cloned or extracted from the `Cow`.
Fix some confusing wording and improve slice-search-related docs
This adds more links between `contains` and `binary_search` because I do think they have some relevant connections. If your (big) slice happens to be sorted and you know it, surely you should be using `[3; 100].binary_search(&5).is_ok()` over `[3; 100].contains(&5)`?
This also fixes the confusing "searches this sorted X" wording which just sounds really weird because it doesn't know whether it's actually sorted. It should be but it may not be. The new wording should make it clearer that you will probably want to sort it and in the same sentence it also mentions the related function `contains`.
Similarly, this mentions `binary_search` on `contains`' docs.
This also fixes some other minor stuff and inconsistencies.
[test] Add test cases for untested functions for VecDeque
Added test cases of the following functions
- get
- get_mut
- swap
- reserve_exact
- try_reserve_exact
- try_reserve
- contains
- rotate_left
- rotate_right
- binary_search
- binary_search_by
- binary_search_by_key
`alloc`: make `vec!` unavailable under `no_global_oom_handling`
`alloc`: make `vec!` unavailable under `no_global_oom_handling`
The `vec!` macro has 3 rules, but two are not usable under
`no_global_oom_handling` builds of the standard library
(even with a zero size):
```rust
let _ = vec![42]; // Error: requires `exchange_malloc` lang_item.
let _ = vec![42; 0]; // Error: cannot find function `from_elem`.
```
Thus those two rules should not be available to begin with.
The remaining one, with an empty matcher, is just a shorthand for
`new()` and may not make as much sense to have alone, since the
idea behind `vec!` is to enable `Vec`s to be defined with the same
syntax as array expressions. Furthermore, the documentation can be
confusing since it shows the other rules.
Thus perhaps it is better and simpler to disable `vec!` entirely
under `no_global_oom_handling` environments, and let users call
`new()` instead:
```rust
let _: Vec<i32> = vec![];
let _: Vec<i32> = Vec::new();
```
Notwithstanding this, a `try_vec!` macro would be useful, such as
the one introduced in https://github.com/rust-lang/rust/pull/95051.
If the shorthand for `new()` is deemed worth keeping on its own,
then it may be interesting to have a separate `vec!` macro with
a single rule and different, simpler documentation.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Speed up Vec::clear().
Currently it just calls `truncate(0)`. `truncate()` is (a) not marked as
`#[inline]`, and (b) more general than needed for `clear()`.
This commit changes `clear()` to do the work itself. This modest change
was first proposed in rust-lang#74172, where the reviewer rejected it because
there was insufficient evidence that `Vec::clear()`'s performance
mattered enough to justify the change. Recent changes within rustc have
made `Vec::clear()` hot within `macro_parser.rs`, so the change is now
clearly worthwhile.
Although it doesn't show wins on CI perf runs, this seems to be because they
use PGO. But not all platforms currently use PGO. Also, local builds don't use
PGO, and `truncate` sometimes shows up in an over-represented fashion in local
profiles. So local profiling will be made easier by this change.
Note that this will also benefit `String::clear()`, because it just
calls `Vec::clear()`.
Finally, the commit removes the `vec-clear.rs` codegen test. It was
added in #52908. From before then until now, `Vec::clear()` just called
`Vec::truncate()` with a zero length. The body of Vec::truncate() has
changed a lot since then. Now that `Vec::clear()` is doing actual work
itself, and not just calling `Vec::truncate()`, it's not surprising that
its generated code includes a load and an icmp. I think it's reasonable
to remove this test.
r? `@m-ou-se`
The `vec!` macro has 3 rules, but two are not usable under
`no_global_oom_handling` builds of the standard library
(even with a zero size):
```rust
let _ = vec![42]; // Error: requires `exchange_malloc` lang_item.
let _ = vec![42; 0]; // Error: cannot find function `from_elem`.
```
Thus those two rules should not be available to begin with.
The remaining one, with an empty matcher, is just a shorthand for
`new()` and may not make as much sense to have alone, since the
idea behind `vec!` is to enable `Vec`s to be defined with the same
syntax as array expressions. Furthermore, the documentation can be
confusing since it shows the other rules.
Thus perhaps it is better and simpler to disable `vec!` entirely
under `no_global_oom_handling` environments, and let users call
`new()` instead:
```rust
let _: Vec<i32> = vec![];
let _: Vec<i32> = Vec::new();
```
Notwithstanding this, a `try_vec!` macro would be useful, such as
the one introduced in https://github.com/rust-lang/rust/pull/95051.
If the shorthand for `new()` is deemed worth keeping on its own,
then it may be interesting to have a separate `vec!` macro with
a single rule and different, simpler documentation.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Optimize RcInnerPtr::inc_strong()/inc_weak() instruction count
Inspired by this internals thread: https://internals.rust-lang.org/t/rc-optimization-on-64-bit-targets/16362
[The generated assembly is a bit smaller](https://rust.godbolt.org/z/TeTnf6144) and is a more efficient usage of the CPU's instruction cache. `unlikely` doesn't impact any of the small artificial tests I've done, but I've included it in case it might help more complex scenarios when this is inlined.
Currently it just calls `truncate(0)`. `truncate()` is (a) not marked as
`#[inline]`, and (b) more general than needed for `clear()`.
This commit changes `clear()` to do the work itself. This modest change
was first proposed in rust-lang#74172, where the reviewer rejected it because
there was insufficient evidence that `Vec::clear()`'s performance
mattered enough to justify the change. Recent changes within rustc have
made `Vec::clear()` hot within `macro_parser.rs`, so the change is now
clearly worthwhile.
Although it doesn't show wins on CI perf runs, this seems to be because they
use PGO. But not all platforms currently use PGO. Also, local builds don't use
PGO, and `truncate` sometimes shows up in an over-represented fashion in local
profiles. So local profiling will be made easier by this change.
Note that this will also benefit `String::clear()`, because it just
calls `Vec::clear()`.
Finally, the commit removes the `vec-clear.rs` codegen test. It was
added in #52908. From before then until now, `Vec::clear()` just called
`Vec::truncate()` with a zero length. The body of Vec::truncate() has
changed a lot since then. Now that `Vec::clear()` is doing actual work
itself, and not just calling `Vec::truncate()`, it's not surprising that
its generated code includes a load and an icmp. I think it's reasonable
to remove this test.
Update binary_search example to instead redirect to partition_point
Inspired by discussion in the tracking issue for `Result::into_ok_or_err`: https://github.com/rust-lang/rust/issues/82223#issuecomment-1067098167
People are surprised by us not providing a `Result<T, T> -> T` conversion, and the main culprit for this confusion seems to be the `binary_search` API. We should instead redirect people to the equivalent API that implicitly does that `Result<T, T> -> T` conversion internally which should obviate the need for the `into_ok_or_err` function and give us time to work towards a more general solution that applies to all enums rather than just `Result` such as making or_patterns usable for situations like this via postfix `match`.
I choose to duplicate the example rather than simply moving it from `binary_search` to partition point because most of the confusion seems to arise when people are looking at `binary_search`. It makes sense to me to have the example presented immediately rather than requiring people to click through to even realize there is an example. If I had to put it in only one place I'd leave it in `binary_search` and remove it from `partition_point` but it seems pretty obviously relevant to `partition_point` so I figured the best option would be to duplicate it.
**This Commit**
Adds some clarity around indexing into Strings and the constraints
driving various decisions there.
**Why?**
The [`String` documentation][0] mentions how `String`s can't be indexed
but `Range` has an implementation for `SliceIndex<str>`. This can be
confusing. There are also several statements to explain the lack of
`String` indexing:
- the inability to index into a `String` is an implication of UTF-8
encoding
- indexing into a `String` could not be constant-time with UTF-8
encoding
- indexing into a `String` does not have an obvious return type
This last statement made sense but the first two seemed contradictory to
the documentation around [`SliceIndex<str>`][1] which mention:
- one can index into a `String` with a `Range` (also called substring
slicing but it uses the same syntax and the method name is `index`)
- `Range` indexing into a `String` is constant-time
To resolve this seeming contradiction the documentation is reworked to
more clearly explain what factors drive the decision to disallow
indexing into a `String` with a single number.
[0]: https://doc.rust-lang.org/stable/std/string/struct.String.html#utf-8
[1]: https://doc.rust-lang.org/stable/std/slice/trait.SliceIndex.html#impl-SliceIndex%3Cstr%3E
Relevant commit messages from squashed history in order:
Add initial version of ThinBox
update test to actually capture failure
swap to middle ptr impl based on matthieu-m's design
Fix stack overflow in debug impl
The previous version would take a `&ThinBox<T>` and deref it once, which
resulted in a no-op and the same type, which it would then print causing
an endless recursion. I've switched to calling `deref` by name to let
method resolution handle deref the correct number of times.
I've also updated the Drop impl for good measure since it seemed like it
could be falling prey to the same bug, and I'll be adding some tests to
verify that the drop is happening correctly.
add test to verify drop is behaving
add doc examples and remove unnecessary Pointee bounds
ThinBox: use NonNull
ThinBox: tests for size
Apply suggestions from code review
Co-authored-by: Alphyr <47725341+a1phyr@users.noreply.github.com>
use handle_alloc_error and fix drop signature
update niche and size tests
add cfg for allocating APIs
check null before calculating offset
add test for zst and trial usage
prevent optimizer induced ub in drop and cleanup metadata gathering
account for arbitrary size and alignment metadata
Thank you nika and thomcc!
Update library/alloc/src/boxed/thin.rs
Co-authored-by: Josh Triplett <josh@joshtriplett.org>
Update library/alloc/src/boxed/thin.rs
Co-authored-by: Josh Triplett <josh@joshtriplett.org>
Bump bootstrap compiler to 1.61.0 beta
This PR bumps the bootstrap compiler to the 1.61.0 beta. The first commit changes the stage0 compiler, the second commit applies the "mechanical" changes and the third and fourth commits apply changes explained in the relevant comments.
r? `@Mark-Simulacrum`
Fix double drop of allocator in IntoIter impl of Vec
Fixes#95269
The `drop` impl of `IntoIter` reconstructs a `RawVec` from `buf`, `cap` and `alloc`, when that `RawVec` is dropped it also drops the allocator. To avoid dropping the allocator twice we wrap it in `ManuallyDrop` in the `InttoIter` struct.
Note this is my first contribution to the standard library, so I might be missing some details or a better way to solve this.
allow arbitrary inherent impls for builtin types in core
Part of https://github.com/rust-lang/compiler-team/issues/487. Slightly adjusted after some talks with `@m-ou-se` about the requirements of `t-libs-api`.
This adds a crate attribute `#![rustc_coherence_is_core]` which allows arbitrary impls for builtin types in core.
For other library crates impls for builtin types should be avoided if possible. We do have to allow the existing stable impls however. To prevent us from accidentally adding more of these in the future, there is a second attribute `#[rustc_allow_incoherent_impl]` which has to be added to **all impl items**. This only supports impls for builtin types but can easily be extended to additional types in a future PR.
This implementation does not check for overlaps in these impls. Perfectly checking that requires us to check the coherence of these incoherent impls in every crate, as two distinct dependencies may add overlapping methods. It should be easy enough to detect if it goes wrong and the attribute is only intended for use inside of std.
The first two commits are mostly unrelated cleanups.
Refactor set_ptr_value as with_metadata_of
Replaces `set_ptr_value` (#75091) with methods of reversed argument order:
```rust
impl<T: ?Sized> *mut T {
pub fn with_metadata_of<U: ?Sized>(self, val: *mut U) -> *mut U;
}
impl<T: ?Sized> *const T {
pub fn with_metadata_of<U: ?Sized>(self, val: *const U) -> *const U;
}
```
By reversing the arguments we achieve several clarifications:
- The function closely resembles `cast` with an argument to
initialize the metadata. This is easier to teach and answers a long
outstanding question that had restricted cast to `Sized` pointee
targets. See multiples reviews of
<https://github.com/rust-lang/rust/pull/47631>
- The 'object identity', in the form of provenance, is now preserved
from the receiver argument to the result. This helps explain the method as
a builder-style, instead of some kind of setter that would modify
something in-place. Ensuring that the result has the identity of the
`self` argument is also beneficial for an intuition of effects.
- An outstanding concern, 'Correct argument type', is avoided by not
committing to any specific argument type. This is consistent with cast
which does not require its receiver to be a 'raw address'.
Hopefully the usage examples in `sync/rc.rs` serve as sufficient examples of the style to convince the reader of the readability improvements of this style, when compared to the previous order of arguments.
I want to take the opportunity to motivate inclusion of this method _separate_ from metadata API, separate from `feature(ptr_metadata)`. It does _not_ involve the `Pointee` trait in any form. This may be regarded as a very, very light form that does not commit to any details of the pointee trait, or its associated metadata. There are several use cases for which this is already sufficient and no further inspection of metadata is necessary.
- Storing the coercion of `*mut T` into `*mut dyn Trait` as a way to dynamically cast some an arbitrary instance of the same type to a dyn trait instance. In particular, one can have a field of type `Option<*mut dyn io::Seek>` to memorize if a particular writer is seekable. Then a method `fn(self: &T) -> Option<&dyn Seek>` can be provided, which does _not_ involve the static trait bound `T: Seek`. This makes it possible to create an API that is capable of utilizing seekable streams and non-seekable streams (instead of a possible less efficient manner such as more buffering) through the same entry-point.
- Enabling more generic forms of unsizing for no-`std` smart pointers. Using the stable APIs only few concrete cases are available. One can unsize arrays to `[T]` by `ptr::slice_from_raw_parts` but unsizing a custom smart pointer to, e.g., `dyn Iterator`, `dyn Future`, `dyn Debug`, can't easily be done generically. Exposing `with_metadata_of` would allow smart pointers to offer their own `unsafe` escape hatch with similar parameters where the caller provides the unsized metadata. This is particularly interesting for embedded where `dyn`-trait usage can drastically reduce code size.
Allow comparing `Vec`s with different allocators using `==`
See https://stackoverflow.com/q/71021633/7884305.
I did not changed the `PartialOrd` impl too because it was not generic already (didn't support `Vec<T> <=> Vec<U> where T: PartialOrd<U>`).
Does it needs tests?
I don't think this will hurt type inference much because the default allocator is usually not inferred (`new()` specifies it directly, and even with other allocators, you pass the allocator to `new_in()` so the compiler usually knows the type).
I think this requires FCP since the impls are already stable.
Fix typo in `String::try_reserve_exact` docs
Copying the pattern from `Vec::try_reserve_exact` and `String::try_reserve`,
it looks like this doc comment is intending to refer to the currently-being-documented
function.
Copying the pattern from `Vec::try_reserve_exact` and `String::try_reserve`,
it looks like this doc comment is intending to refer to the currently-being-documented
function.
Hermit now properly separates kernel from userspace.
Applications for hermit can now use Rust's default alloc_error_handler instead of calling the kernel's __rg_oom.
add module-level documentation for vec's in-place iteration
As requested in the last libs team meeting and during previous reviews.
Feel free to point out any gaps you encounter, after all non-obvious things may with hindsight seem obvious to me.
r? `@yaahc`
CC `@steffahn`
By reversing the arguments we achieve several clarifications:
- The function closely resembles `cast` but with an argument to
initialized the metadata. This is easier to teach and answers an long
outstanding question that had restricted cast to `Sized` targets
initially. See multiples reviews of
<https://github.com/rust-lang/rust/pull/47631>
- The 'object identity', in the form or provenance, is now preserved
from the call receiver to the result. This helps explain the method as
a builder-style, instead of some kind of setter that would modify
something in-place. Ensuring that the result has the identity of the
`self` argument is also beneficial for an intuition of effects.
- An outstanding concern, 'Correct argument type', is avoided by not
committing to any specific argument type. This is consistent with cast
which does not require its receiver to be a raw address.
BTreeMap::entry: Avoid allocating if no insertion
This PR allows the `VacantEntry` to borrow from an empty tree with no root, and to lazily allocate a new root node when the user calls `.insert(value)`.
Made the fields of VecDeque's Iter private by creating a Iter::new(...) function to create a new instance of Iter and migrating usage to use Iter::new(...).
Improve doc wording for retain on some collections
I found the documentation wording on the various retain methods on many collections to be unusual.
I tried to invert the relation by switching `such that` with `for which` .
Use modern formatting for format! macros
This updates the standard library's documentation to use the new format_args syntax.
The documentation is worthwhile to update as it should be more idiomatic
(particularly for features like this, which are nice for users to get acquainted
with). The general codebase is likely more hassle than benefit to update: it'll
hurt git blame, and generally updates can be done by folks updating the code if
(and when) that makes things more readable with the new format.
A few places in the compiler and library code are updated (mostly just due to
already having been done when this commit was first authored).
`eprintln!("{}", e)` becomes `eprintln!("{e}")`, but `eprintln!("{}", e.kind())` remains untouched.
This updates the standard library's documentation to use the new syntax. The
documentation is worthwhile to update as it should be more idiomatic
(particularly for features like this, which are nice for users to get acquainted
with). The general codebase is likely more hassle than benefit to update: it'll
hurt git blame, and generally updates can be done by folks updating the code if
(and when) that makes things more readable with the new format.
A few places in the compiler and library code are updated (mostly just due to
already having been done when this commit was first authored).
fix typo in btree/vec doc: Self -> self
this pr fixes#92345
the documentation refers to the object the method is called for, not the type, so it should be using the lower case self.
Fix a layout possible miscalculation in `alloc::RawVec`
A layout miscalculation could happen in `RawVec` when used with a type whose size isn't a multiple of its alignment. I don't know if such type can exist in Rust, but the Layout API provides ways to manipulate such types. Anyway, it is better to calculate memory size in a consistent way.
Add documentation to more `From::from` implementations.
For users looking at documentation through IDE popups, this gives them relevant information rather than the generic trait documentation wording “Performs the conversion”. For users reading the documentation for a specific type for any reason, this informs them when the conversion may allocate or copy significant memory versus when it is always a move or cheap copy.
Notes on specific cases:
* The new documentation for `From<T> for T` explains that it is not a conversion at all.
* Also documented `impl<T, U> Into<U> for T where U: From<T>`, the other central blanket implementation of conversion.
* The new documentation for construction of maps and sets from arrays of keys mentions the handling of duplicates. Future work could be to do this for *all* code paths that convert an iterable to a map or set.
* I did not add documentation to conversions of a specific error type to a more general error type.
* I did not add documentation to unstable code.
This change was prepared by searching for the text "From<... for" and so may have missed some cases that for whatever reason did not match. I also looked for `Into` impls but did not find any worth documenting by the above criteria.
Replace iterator-based construction of collections by `Into<T>`
Just a few quality of life improvements in the doc examples. I also removed some `Vec`s in favor of arrays.
Stabilize arc_new_cyclic
This stabilizes feature `arc_new_cyclic` as the implementation has been merged for one year and there is no unresolved questions. The FCP is not started yet.
Closes#75861 .
``@rustbot`` label +T-libs-api
Improve `Arc` and `Rc` documentation
This makes two changes (I can split the PR if necessary, but the changes are pretty small):
1. A bunch of trait implementations claimed to be zero cost; however, they use the `Arc<T>: From<Box<T>>` impl which is definitely not free, especially for large dynamically sized `T`.
2. The code in deferred initialization examples unnecessarily used excessive amounts of `unsafe`. This has been reduced.
doc: guarantee call order for sort_by_cached_key
`slice::sort_by_cached_key` takes a caching function `f: impl FnMut(&T) -> K`, which means that the order that calls to the caching function are made is user-visible. This adds a clause to the documentation to promise the current behavior, which is that `f` is called on all elements of the slice from left to right, unless the slice has len < 2 in which case `f` is not called.
For example, this can be used to ensure that the following code is a correct way to involve the index of the element in the sort key:
```rust
let mut index = 0;
slice.sort_by_cached_key(|x| (my_key(index, x), index += 1).0);
```
Clarify explicitly that BTree{Map,Set} are ordered.
One of the main reasons one would want to use a BTree{Map,Set} rather than a Hash{Map,Set} is because they maintain their keys in sorted order; but this was never explicitly stated in the top-level docs (it was only indirectly alluded to there, and stated explicitly in the docs for `iter`, `values`, etc.)
This PR states the ordering guarantee more prominently.
Add diagnostic items for macros
For use in Clippy, it adds diagnostic items to all the stable public macros
Clippy has lints that look for almost all of these (currently by name or path), but there are a few that aren't currently part of any lint, I could remove those if it's preferred to add them as needed rather than ahead of time
Yield means something else in the context of generators, which are
sufficiently close to iterators that it's better to avoid the
terminology collision here.
Partially stabilize `maybe_uninit_extra`
This covers:
```rust
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
```
It does not cover the const-ness of `write` under `const_maybe_uninit_write` nor the const-ness of `assume_init_read` (this commit adds `const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
This covers:
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
It does not cover the const-ness of `write` under
`const_maybe_uninit_write` nor the const-ness of
`assume_init_read` (this commit adds
`const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Replace usages of vec![].into_iter with [].into_iter
`[].into_iter` is idiomatic over `vec![].into_iter` because its simpler and faster (unless the vec is optimized away in which case it would be the same)
So we should change all the implementation, documentation and tests to use it.
I skipped:
* `src/tools` - Those are copied in from upstream
* `src/test/ui` - Hard to tell if `vec![].into_iter` was used intentionally or not here and not much benefit to changing it.
* any case where `vec![].into_iter` was used because we specifically needed a `Vec::IntoIter<T>`
* any case where it looked like we were intentionally using `vec![].into_iter` to test it.
Mak DefId to AccessLevel map in resolve for export
hir_id to accesslevel in resolve and applied in privacy
using local def id
removing tracing probes
making function not recursive and adding comments
Move most of Exported/Public res to rustc_resolve
moving public/export res to resolve
fix missing stability attributes in core, std and alloc
move code to access_levels.rs
return for some kinds instead of going through them
Export correctness, macro changes, comments
add comment for import binding
add comment for import binding
renmae to access level visitor, remove comments, move fn as closure, remove new_key
fmt
fix rebase
fix rebase
fmt
fmt
fix: move macro def to rustc_resolve
fix: reachable AccessLevel for enum variants
fmt
fix: missing stability attributes for other architectures
allow unreachable pub in rustfmt
fix: missing impl access level + renaming export to reexport
Missing impl access level was found thanks to a test in clippy
Fix a minor mistake in `String::try_reserve_exact` examples
The examples of `String::try_reserve_exact` didn't actually use `try_reserve_exact`, which was probably a minor mistake, and this PR fixed it.
Drop guards in slice sorting derive src pointers from &mut T, which is invalidated by interior mutation in comparison
I tried to run https://github.com/rust-lang/miri-test-libstd on `alloc` with `-Zmiri-track-raw-pointers`, and got a failure on the test `slice::panic_safe`. The test failure has nothing to do with panic safety, it's from how the test tests for panic safety.
I minimized the test failure into this very silly program:
```rust
use std::cell::Cell;
use std::cmp::Ordering;
#[derive(Clone)]
struct Evil(Cell<usize>);
fn main() {
let mut input = vec![Evil(Cell::new(0)); 3];
// Hits the bug pattern via CopyOnDrop in core
input.sort_unstable_by(|a, _b| {
a.0.set(0);
Ordering::Less
});
// Hits the bug pattern via InsertionHole in alloc
input.sort_by(|_a, b| {
b.0.set(0);
Ordering::Less
});
}
```
To fix this, I'm just removing the mutability/uniqueness where it wasn't required.
Implement split_at_spare_mut without Deref to a slice so that the spare slice is valid
~I'm not sure I understand what's going on here correctly. And I'm pretty sure this safety comment needs to be changed. I'm just referring to the same thing that `as_mut_ptr_range` does.~ (Thanks `@RalfJung` for the guidance and clearing things up)
I tried to run https://github.com/rust-lang/miri-test-libstd on alloc with -Zmiri-track-raw-pointers, and got a failure on the test `vec::test_extend_from_within`.
I minimized the test failure into this program:
```rust
#![feature(vec_split_at_spare)]
fn main() {
Vec::<i32>::with_capacity(1).split_at_spare_mut();
}
```
The problem is that the existing implementation is actually getting a pointer range where both pointers are derived from the initialized region of the Vec's allocation, but we need the second one to be valid for the region between len and capacity. (thanks Ralf for clearing this up)
RawVec: don't recompute capacity after allocating.
Currently it sets the capacity to `ptr.len() / mem::size_of::<T>()`
after any buffer allocation/reallocation. This would be useful if
allocators ever returned a `NonNull<[u8]>` with a size larger than
requested. But this never happens, so it's not useful.
Removing this slightly reduces the size of generated LLVM IR, and
slightly speeds up the hot path of `RawVec` growth.
r? `@ghost`
Currently it sets the capacity to `ptr.len() / mem::size_of::<T>()`
after any buffer allocation/reallocation. This would be useful if
allocators ever returned a `NonNull<[u8]>` with a size larger than
requested. But this never happens, so it's not useful.
Removing this slightly reduces the size of generated LLVM IR, and
slightly speeds up the hot path of `RawVec` growth.
The previous implementation used slice::as_mut_ptr_range to derive the
pointer for the spare capacity slice. This is invalid, because that
pointer is derived from the initialized region, so it does not have
provenance over the uninitialized region.
Update example code for Vec::splice to change the length
The current example for `Vec::splice` illustrates the replacement of a section of length 2 with a new section of length 2. This isn't a particularly interesting case for splice, and makes it look a bit like a shorthand for the kind of manipulations that could be done with a mutable slice.
In order to provide a stronger example, this updates the example to use different lengths for the source and destination regions, and uses a slice from the middle of the vector to illustrate that this does not necessarily have to be at the beginning or the end.
Resolves#92067
The src pointers in CopyOnDrop and InsertionHole used to be *mut T, and
were derived via automatic conversion from &mut T. According to Stacked
Borrows 2.1, this means that those pointers become invalidated by
interior mutation in the comparison function.
But there's no need for mutability in this code path. Thus, we can
change the drop guards to use *const and derive those from &T.
add BinaryHeap::try_reserve and BinaryHeap::try_reserve_exact
`try_reserve` of many collections were stablized in https://github.com/rust-lang/rust/pull/87993 in 1.57.0. Add `try_reserve` for the rest collections such as `BinaryHeap` should be not controversial.
Use spare_capacity_mut instead of invalid unchecked indexing when joining str
This is a fix for https://github.com/rust-lang/rust/issues/91574
I think in general I'd prefer to see this code implemented with raw pointers or `MaybeUninit::write_slice`, but there's existing code in here based on copying from slice to slice, so converting everything from `&[T]` to `&[MaybeUninit<T>]` is less disruptive.
BTree: improve public descriptions and comments
BTreeSet has always used the term "value" next to and meaning the same thing as "elements" (in the mathematical sense but also used for key-value pairs in BTreeMap), while in the BTreeMap sense these "values" are known as "keys" and definitely not "values". Today I had enough of that.
r? `@Mark-Simulacrum`
Btree: assert more API compatibility
Introducing a member such as `BTreeSet::min()` would silently break compatibility if no code calls the existing `BTreeSet::min(set)`. `BTreeSet` is the only btree class silently bringing in stable members, apart from many occurrences of `#[derive(Debug)]` on iterators.
r? `@Mark-Simulacrum`
Rollup of 11 pull requests
Successful merges:
- #91668 (Remove the match on `ErrorKind::Other`)
- #91678 (Add tests fixed by #90023)
- #91679 (Move core/stream/stream/mod.rs to core/stream/stream.rs)
- #91681 (fix typo in `intrinsics::raw_eq` docs)
- #91686 (Fix `Vec::reserve_exact` documentation)
- #91697 (Delete Utf8Lossy::from_str)
- #91706 (Add unstable book entries for parts of asm that are not being stabilized)
- #91709 (Replace iterator-based set construction by *Set::From<[T; N]>)
- #91716 (Improve x.py logging and defaults a bit more)
- #91747 (Add pierwill to .mailmap)
- #91755 (Fix since attribute for const_linked_list_new feature)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Replace iterator-based set construction by *Set::From<[T; N]>
This uses the array-based construction for `BtreeSet`s and `HashSet`s instead of first creating an iterator. I could also replace the `let mut a = Set::new(); a.insert(...);` fragments if desired.
Fix `Vec::reserve_exact` documentation
The documentation previously said the new capacity cannot overflow `usize`, but in fact it cannot exceed `isize::MAX`.
Update documentation to use `from()` to initialize `HashMap`s and `BTreeMap`s
As of Rust 1.56, `HashMap` and `BTreeMap` both have associated `from()` functions. I think using these in the documentation cleans things up a bit. It allows us to remove some of the `mut`s and avoids the Initialize-Then-Modify anti-pattern.
replace vec::Drain drop loops with drop_in_place
The `Drain::drop` implementation came up in https://github.com/rust-lang/rust/pull/82185#issuecomment-789584796 as potentially interfering with other optimization work due its widespread use somewhere in `println!`
`@rustbot` label T-libs-impl
Suggest try_reserve in try_reserve_exact
During developing #91529 , I found that `try_reserve_exact` suggests `reserve` for further insertions. I think it's a mistake by copy&paste, `try_reserve` is better here.
Implement VecDeque::retain_mut
Part of https://github.com/rust-lang/rust/issues/90829.
In https://github.com/rust-lang/rust/pull/90772, someone suggested that `retain_mut` should also be implemented on `VecDeque`. I think that it follows the same logic (coherency). So first: is it ok? Second: should I create a new feature for it or can we put it into the same one?
r? `@joshtriplett`
For users looking at documentation through IDE popups, this gives them
relevant information rather than the generic trait documentation wording
“Performs the conversion”. For users reading the documentation for a
specific type for any reason, this informs them when the conversion may
allocate or copy significant memory versus when it is always a move or
cheap copy.
Notes on specific cases:
* The new documentation for `From<T> for T` explains that it is not a
conversion at all.
* Also documented `impl<T, U> Into<U> for T where U: From<T>`, the other
central blanket implementation of conversion.
* I did not add documentation to conversions of a specific error type to
a more general error type.
* I did not add documentation to unstable code.
This change was prepared by searching for the text "From<... for" and so
may have missed some cases that for whatever reason did not match. I
also looked for `Into` impls but did not find any worth documenting by
the above criteria.
Rollup of 10 pull requests
Successful merges:
- #88906 (Implement write() method for Box<MaybeUninit<T>>)
- #90269 (Make `Option::expect` unstably const)
- #90854 (Type can be unsized and uninhabited)
- #91170 (rustdoc: preload fonts)
- #91273 (Fix ICE #91268 by checking that the snippet ends with a `)`)
- #91381 (Android: -ldl must appear after -lgcc when linking)
- #91453 (Document Windows TLS drop behaviour)
- #91462 (Use try_normalize_erasing_regions in needs_drop)
- #91474 (suppress warning about set_errno being unused on DragonFly)
- #91483 (Sync rustfmt subtree)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Implement write() method for Box<MaybeUninit<T>>
This adds method similar to `MaybeUninit::write` main difference being
it returns owned `Box`. This can be used to elide copy from stack
safely, however it's not currently tested that the optimization actually
occurs.
Analogous methods are not provided for `Rc` and `Arc` as those need to
handle the possibility of sharing. Some version of them may be added in
the future.
This was discussed in #63291 which this change extends.
Remove unnecessary check in VecDeque::grow
All callers already check that the buffer is full before calling
`grow()`. This is where it makes the most sense, since `grow()` is
`inline(never)` and we don't want to pay for a function call just for
that check.
It could also be argued that it would be correct to call `grow()` even
if the buffer wasn't full yet.
This change breaks no code since `grow()` is not `pub`.
This adds method similar to `MaybeUninit::write` main difference being
it returns owned `Box`. This can be used to elide copy from stack
safely, however it's not currently tested that the optimization actually
occurs.
Analogous methods are not provided for `Rc` and `Arc` as those need to
handle the possibility of sharing. Some version of them may be added in
the future.
This was discussed in #63291 which this change extends.
Introduce `RawVec::reserve_for_push`.
If `Vec::push`'s capacity check fails it calls `RawVec::reserve`, which
then also does a capacity check.
This commit introduces `reserve_for_push` which skips the redundant
capacity check, for some slight compile time speed-ups.
I tried lots of minor variations on this, e.g. different inlining
attributes. This was the best one I could find.
r? `@ghost`
All callers already check that the buffer is full before calling
`grow()`. This is where it makes the most sense, since `grow()` is
`inline(never)` and we don't want to pay for a function call just for
that check.
It could also be argued that it would be correct to call `grow()` even
if the buffer wasn't full yet.
This change breaks no code since `grow()` is not `pub`.
If `Vec::push`'s capacity check fails it calls `RawVec::reserve`, which
then also does a capacity check.
This commit introduces `reserve_for_push` which skips the redundant
capacity check, for some slight compile time speed-ups.
I tried lots of minor variations on this, e.g. different inlining
attributes. This was the best one I could find.
Eliminate an unreachable codepath from String::from_utf8_lossy
`Utf8Lossy`'s `Iterator` implementation ensures that only the **final** chunk has an empty slice for `broken`:
dd549dcab4/library/core/src/str/lossy.rs (L46-L47)
Thus the only way the **first** chunk could have an empty `broken` is if it is the **final** chunk, i.e. there is only one chunk total. And the only way that there could be one chunk total with an empty `broken` is if the whole input is valid utf8 and non-empty.
That condition has already been handled by an early return, so at the point that the first `REPLACEMENT` is being pushed, it's impossible for `first_broken` to be empty.
Utf8Lossy's Iterator implementation ensures that only the final chunk
has an empty slice for broken. Thus the only way the first chunk could
have an empty broken is if it is the final chunk, i.e. there is only one
chunk total. And the only way that there could be one chunk total is if
the whole input is valid utf8 and non-empty. That condition has already
been handled by an early return, so at the point that the first
REPLACEMENT is being pushed, it's impossible for first_broken to be
empty.
Mark `Arc::from_inner` / `Rc::from_inner` as unsafe
While it's an internal function, it is easy to create invalid Arc/Rcs to
a dangling pointer with it.
Fixes https://github.com/rust-lang/rust/issues/89740
Add Vec::retain_mut
This is to continue the discussion started in #83218.
Original comment was:
> Take 2 of #34265, since I needed this today.
The reason I think why we should add `retain_mut` is for coherency and for discoverability. For example we have `chunks` and `chunks_mut` or `get` and `get_mut` or `iter` and `iter_mut`, etc. When looking for mutable `retain`, I would expect `retain_mut` to exist. It took me a while to find out about `drain_filter`. So even if it provides an API close to `drain_filter`, just for the discoverability, I think it's worth it.
cc ``````@m-ou-se`````` ``````@jonas-schievink`````` ``````@Mark-Simulacrum``````
Optimize BinaryHeap::extend from Vec
This improves the performance of extending `BinaryHeap`s from vectors directly. Future work may involve extending this optimization to other, similar, cases where the length of the added elements is well-known, but this is not yet done in this PR.
Make RawVec private to alloc
RawVec was previously exposed for compiler-internal use (libarena specifically) in 1acbb0a935
Since it is unstable, doc-hidden and has no associated tracking issue it was never meant for public use. And since
it is no longer used outside alloc itself it can be made private again.
Also remove some functions that are dead due to lack of internal users.
Better document `Box` and `alloc::alloc::box_free` connection
The internal `alloc::alloc::box_free` function requires that its signature matches the `owned_box` struct's declaration, but previously that connection was only documented on the `box_free` function.
This PR makes the documentation two-way to help anyone making theoretical changes to `Box` to see the connection, since changes are more likely to originate from `Box`.
RawVec was previously exposed for compiler-internal use (libarena specifically) in 1acbb0a935
Since it is unstable, doc-hidden and has no associated tracking issue it was never meant for public use. And since
it is no longer used outside alloc itself it can be made private again.
Also remove some functions that are dead due to lack of internal users.
{kind=link}