[rustdoc] [GUI tests] Make theme switching closer to reality
Better to actually perform actions user do rather than only testing the change through local storage.
As for `browser-ui-test` update: I updated `puppeteer` version (to `0.19.4`) and fixed a bug when displaying the file if it came from an `include`.
r? `@notriddle`
Re-enable the early otherwise branch optimization
Closes#95162. Fixes#119014.
This is the first part of #121397.
An invalid enum discriminant can come from anywhere. We have to check to see if all successors contain the discriminant statement. This should have a pass to hoist instructions.
r? cjgillot
Before this fix, the call to `body()` would crash, since `has_body()`
would return true, but we would try to retrieve the body of an intrinsic
which is not allowed.
Instead, the `Instance::body()` function will now convert an Intrinsic
into an Item before retrieving its body.
This change uses the same "exact" paths as trait implementors
and type alias inlining to track items with multiple
reachable paths. This way, if you search for `vec`, you get
only the `std` exports of it, and not the one from `alloc`.
It still includes all the items in the search index so that
you can search for them by all available paths. For example,
try `core::option` and `std::option`, and notice that the
results page doesn't show duplicates, but still shows all
the items in their respective crates.
Pass list of defineable opaque types into canonical queries
This eliminates `DefiningAnchor::Bubble` for good and brings the old solver closer to the new one wrt cycles and nested obligations. At that point the difference between `DefiningAnchor::Bind([])` and `DefiningAnchor::Error` was academic. We only used the difference for some sanity checks, which actually had to be worked around in places, so I just removed `DefiningAnchor` entirely and just stored the list of opaques that may be defined.
fixes#108498
fixes https://github.com/rust-lang/rust/issues/116877
* [x] run crater
- https://github.com/rust-lang/rust/pull/122077#issuecomment-2013293931
There is already a workaround in `compiletest` to deal with custom
`CARGO_HOME` using `-Zignore-directory-in-diagnostics-source-blocks={}`.
A similar need exists when dependencies come from the local `vendor`
directory, which distro builds often use, so now we ignore that too.
Also, `issue-21763.rs` was normalizing `hashbrown-` paths, presumably
expecting a version suffix, but the vendored path doesn't include the
version. Now that matches `[\\/]hashbrown` instead.
To separate `ReifyReason::FnPtr` from `ReifyReason::VTable`, we
hyphenated the shims. Hyphens are not actually legal, but underscores
are, so use those instead.
CFI: Fix ICE in KCFI non-associated function pointers
We oddly weren't testing the more usual case of casting non-methods to function pointers. The KCFI shim insertion logic would ICE on these due to asking for an irrefutable associated item if we cast a function to a function pointer without needing a traditional shim.
r? `@compiler-errors`
Don't emit divide-by-zero panic paths in `StepBy::len`
I happened to notice today that there's actually two such calls emitted in the assembly: <https://rust.godbolt.org/z/1Wbbd3Ts6>
Since they're impossible, hopefully telling LLVM that will also help optimizations elsewhere.
Fix `ByMove` coroutine-closure shim (for 2021 precise closure capturing behavior)
This PR reworks the way that we perform the `ByMove` coroutine-closure shim to account for the fact that the upvars of the outer coroutine-closure and the inner coroutine might not line up due to edition-2021 closure capture rules changes.
Specifically, the number of upvars may differ *and/or* the inner coroutine may have additional projections applied to an upvar. This PR reworks the information we pass into the `ByMoveBody` MIR visitor to account for both of these facts.
I tried to leave comments explaining exactly what everything is doing, but let me know if you have questions.
r? oli-obk
Safe Transmute: Compute transmutability from `rustc_target::abi::Layout`
In its first step of computing transmutability, `rustc_transmutability` constructs a byte-level representation of type layout (`Tree`). Previously, this representation was computed for ADTs by inspecting the ADT definition and performing our own layout computations. This process was error-prone, verbose, and limited our ability to analyze many types (particularly default-repr types).
In this PR, we instead construct `Tree`s from `rustc_target::abi::Layout`s. This helps ensure that layout optimizations are reflected our analyses, and increases the kinds of types we can now analyze, including:
- default repr ADTs
- transparent unions
- `UnsafeCell`-containing types
Overall, this PR expands the expressvity of `rustc_transmutability` to be much closer to the transmutability analysis performed by miri. Future PRs will work to close the remaining gaps (e.g., support for `Box`, raw pointers, `NonZero*`, coroutines, etc.).
r? `@compiler-errors`
Fix argument ABI for overaligned structs on ppc64le
When passing a 16 (or higher) aligned struct by value on ppc64le, it needs to be passed as an array of `i128` rather than an array of `i64`. This will force the use of an even starting doubleword.
For the case of a 16 byte struct with alignment 16 it is important that `[1 x i128]` is used instead of `i128` -- apparently, the latter will get treated similarly to `[2 x i64]`, not exhibiting the correct ABI. Add a `force_array` flag to `Uniform` to support this.
The relevant clang code can be found here:
fe2119a7b0/clang/lib/CodeGen/Targets/PPC.cpp (L878-L884)fe2119a7b0/clang/lib/CodeGen/Targets/PPC.cpp (L780-L784)
I think the corresponding psABI wording is this:
> Fixed size aggregates and unions passed by value are mapped to as
> many doublewords of the parameter save area as the value uses in
> memory. Aggregrates and unions are aligned according to their
> alignment requirements. This may result in doublewords being
> skipped for alignment.
In particular the last sentence. Though I didn't find any wording for Clang's behavior of clamping the alignment to 16.
Fixes https://github.com/rust-lang/rust/issues/122767.
r? `@cuviper`
We oddly weren't testing the more usual case of casting non-methods to
function pointers. The KCFI shim insertion logic would ICE on these due
to asking for an irrefutable associated item if we cast a function to a
function pointer without needing a traditional shim.
Implement minimal, internal-only pattern types in the type system
rebase of https://github.com/rust-lang/rust/pull/107606
You can create pattern types with `std::pat::pattern_type!(ty is pat)`. The feature is incomplete and will panic on you if you use any pattern other than integral range patterns. The only way to create or deconstruct a pattern type is via `transmute`.
This PR's implementation differs from the MCP's text. Specifically
> This means you could implement different traits for different pattern types with the same base type. Thus, we just forbid implementing any traits for pattern types.
is violated in this PR. The reason is that we do need impls after all in order to make them usable as fields. constants of type `std::time::Nanoseconds` struct are used in patterns, so the type must be structural-eq, which it only can be if you derive several traits on it. It doesn't need to be structural-eq recursively, so we can just manually implement the relevant traits on the pattern type and use the pattern type as a private field.
Waiting on:
* [x] move all unrelated commits into their own PRs.
* [x] fix niche computation (see 2db07f94f44f078daffe5823680d07d4fded883f)
* [x] add lots more tests
* [x] T-types MCP https://github.com/rust-lang/types-team/issues/126 to finish
* [x] some commit cleanup
* [x] full self-review
* [x] remove 61bd325da19a918cc3e02bbbdce97281a389c648, it's not necessary anymore I think.
* [ ] ~~make sure we never accidentally leak pattern types to user code (add stability checks or feature gate checks and appopriate tests)~~ we don't even do this for the new float primitives
* [x] get approval that [the scope expansion to trait impls](https://rust-lang.zulipchat.com/#narrow/stream/326866-t-types.2Fnominated/topic/Pattern.20types.20types-team.23126/near/427670099) is ok
r? `@BoxyUwU`
In its first step of computing transmutability, `rustc_transmutability`
constructs a byte-level representation of type layout (`Tree`). Previously, this
representation was computed for ADTs by inspecting the ADT definition and
performing our own layout computations. This process was error-prone, verbose,
and limited our ability to analyze many types (particularly default-repr types).
In this PR, we instead construct `Tree`s from `rustc_target::abi::Layout`s. This
helps ensure that layout optimizations are reflected our analyses, and increases
the kinds of types we can now analyze, including:
- default repr ADTs
- transparent unions
- `UnsafeCell`-containing types
Overall, this PR expands the expressvity of `rustc_transmutability` to be much
closer to the transmutability analysis performed by miri. Future PRs will work
to close the remaining gaps (e.g., support for `Box`, raw pointers, `NonZero*`,
coroutines, etc.).
Do some preparation work for compiletest check-cfg
This PR does several preparation work for having always-on check-cfg in compiletest.
In particular, this PR does two main things:
- It unifies all the *always-false* cfgs under the `FALSE` cfg (as it seems to be the convention under `tests/ui`)
- It also removes some useless conditions
This is done ahead of the introduction of the always-on check-cfg in compiletest to reduce the amount of changes in that follow-up work. I also think that this is useful even without that follow-up work.
[Test] issue-122805.rs should limit to little endian target
In issue-122805.rs, codegen on big endian target is different from little endian target.
```llvm
%0 = load <8 x i16>, ptr %value, align 2
store <8 x i16> %0, ptr %_0, align 1
ret void
```
This is expected since the conversion is unnecessary on BE target for this case.
When passing a 16 (or higher) aligned struct by value on ppc64le,
it needs to be passed as an array of `i128` rather than an array
of `i64`. This will force the use of an even starting register.
For the case of a 16 byte struct with alignment 16 it is important
that `[1 x i128]` is used instead of `i128` -- apparently, the
latter will get treated similarly to `[2 x i64]`, not exhibiting
the correct ABI. Add a `force_array` flag to `Uniform` to support
this.
The relevant clang code can be found here:
fe2119a7b0/clang/lib/CodeGen/Targets/PPC.cpp (L878-L884)fe2119a7b0/clang/lib/CodeGen/Targets/PPC.cpp (L780-L784)
I think the corresponding psABI wording is this:
> Fixed size aggregates and unions passed by value are mapped to as
> many doublewords of the parameter save area as the value uses in
> memory. Aggregrates and unions are aligned according to their
> alignment requirements. This may result in doublewords being
> skipped for alignment.
In particular the last sentence.
Fixes https://github.com/rust-lang/rust/issues/122767.
compiletest: properly handle revisioned run-rustfix tests
Before this PR, if you have a revisioned `//@ run-rustfix` test like `//`@[foo]` run-rustfix`, you would run into an error saying crate name cannot contain `.` characters because the fixed test file trying to be compiled is named `<test-name>.<revision>.fixed`, from which `rustc` infers the crate name to be `<test-name>.<revision>` which is not a valid crate name.
This PR fixes the problem by constructing a synthetic crate name from `<test-name>.<revision>`, by
1. replacing all `-` with `_`, and
2. replacing all `.` with `__`
and pass that constructed crate name with `--crate-name` to rustc to compile the fixed file.
Fixes https://github.com/rust-lang/rust/issues/123596.
Use unchecked_sub in str indexing
https://github.com/rust-lang/rust/pull/108763 applied this logic to indexing for slices, but of course `str` has its own separate impl.
Found this by skimming over the codegen for https://github.com/oxidecomputer/hubris/; their dist builds enable overflow checks so the lack of `unchecked_sub` was producing an impossible-to-hit overflow check and also inhibiting some inlining.
r? scottmcm
Save/restore more items in cache with incremental compilation
Right now they don't play very well together, consider a simple example:
```
$ export RUSTFLAGS="--emit asm"
$ cargo new --lib foo
Created library `foo` package
$ cargo build -q
$ touch src/lib.rs
$ cargo build
error: could not copy
"/path/to/foo/target/debug/deps/foo-e307cc7fa7b6d64f.4qbzn9k8mosu50a5.rcgu.s"
to "/path/to/foo/target/debug/deps/foo-e307cc7fa7b6d64f.s":
No such file or directory (os error 2)
```
Touch triggers the rebuild, incremental compilation detects no changes (yay) and everything explodes while trying to copy files were they should go.
This pull request fixes it by copying and restoring more files in the incremental compilation cache
Fixes https://github.com/rust-lang/rust/issues/89149
Fixes https://github.com/rust-lang/rust/issues/88829
Related: https://internals.rust-lang.org/t/interaction-between-incremental-compilation-and-emit/20551
Add `f16` and `f128` to rustdoc's `PrimitiveType`
Fix a few places where these primitives were missing from librustdoc. This should fix the CI failures from doc links in https://github.com/rust-lang/rust/pull/122470.
Rewrite `version` test run-make as an UI test
Claiming the simple `version` test from #121876.
Reasoning: As discussed in #123297, 10 years ago, some changes to CLI flags warranted the creation of the `version` test. Since it's not actually executing the compiled binary, it has no purpose being a `run-make` test and should instead be an UI test.
This is the exact same change as it was shown on my closed PR #123297. Changes were ready, but I did a major Git mishap while trying to fix a tidy error and messed up my branch. The details of this error are explained [here](https://github.com/rust-lang/rust/pull/123297#issuecomment-2041152379).
I happened to notice today that there's actually two such calls emitted in the assembly: <https://rust.godbolt.org/z/1Wbbd3Ts6>
Since they're impossible, hopefully telling LLVM that will also help optimizations elsewhere.
Do not ICE when encountering a lifetime error involving an argument with
an immutable reference of a method that differs from the trait definition.
Fix#123414.
Simplify/cleanup `search-result-color.goml`
Greatly shorten code of `search-result-color.goml` GUI test.
I split the changes into smaller commits to allow to more easily see what changed.
r? `@notriddle`
Add missing -Zquery-dep-graph to the spike-neg incr comp tests
This ensures that the tests actually test what they are meant to test rather than exitting immediately with an error that -Zquery-dep-graph has to be passed.
This ensures that the tests actually test what they are meant to test
rather than exitting immediately with an error that -Zquery-dep-graph
has to be passed.
Rollup of 7 pull requests
Successful merges:
- #123294 (Require LLVM_CONFIG to be set in rustc_llvm/build.rs)
- #123467 (MSVC targets should use COFF as their archive format)
- #123498 (explaining `DefKind::Field`)
- #123519 (Improve cfg and check-cfg configuration)
- #123525 (CFI: Don't rewrite ty::Dynamic directly)
- #123526 (Do not ICE when calling incorrectly defined `transmute` intrinsic)
- #123528 (Hide async_gen_internals from standard library documentation)
r? `@ghost`
`@rustbot` modify labels: rollup
CFI: Don't rewrite ty::Dynamic directly
Now that we're using a type folder, the arguments in predicates are processed automatically - we don't need to descend manually.
We also want to keep projection clauses around, and this does so.
r? `@compiler-errors`
Check def id before calling `match_projection_projections`
When I "inlined" `assemble_candidates_from_predicates` into `for_each_item_bound` in #120584, I forgot to copy over the check that actually made sure the def id of the candidate was equal to the def id of the obligation. This means that we normalize goal a bit too often even if it's not productive to do so.
This PR adds that def id check back.
Fixes#123448
Now that we're using a type folder, the arguments in predicates are
processed automatically - we don't need to descend manually.
We also want to keep projection clauses around, and this does so.
CFI: Restore typeid_for_instance default behavior
Restore typeid_for_instance default behavior of performing self type erasure, since it's the most common case and what it does most of the time. Using concrete self (or not performing self type erasure) is for assigning a secondary type id, and secondary type ids are only assigned when they're unique and to methods, and also are only tested for when methods are used as function pointers.
Add aarch64-apple-visionos and aarch64-apple-visionos-sim tier 3 targets
Introduces `aarch64-apple-visionos` and `aarch64-apple-visionos-sim` as tier 3 targets. This allows native development for the Apple Vision Pro's visionOS platform.
This work has been tracked in https://github.com/rust-lang/compiler-team/issues/642. There is a corresponding `libc` change https://github.com/rust-lang/libc/pull/3568 that is not required for merge.
Ideally we would be able to incorporate [this change](https://github.com/gimli-rs/object/pull/626) to the `object` crate, but the author has stated that a release will not be cut for quite a while. Therefore, the two locations that would reference the xrOS constant from `object` are hardcoded to their MachO values of 11 and 12, accompanied by TODOs to mark the code as needing change. I am open to suggestions on what to do here to get this checked in.
# Tier 3 Target Policy
At this tier, the Rust project provides no official support for a target, so we place minimal requirements on the introduction of targets.
> A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
See [src/doc/rustc/src/platform-support/apple-visionos.md](e88379034a/src/doc/rustc/src/platform-support/apple-visionos.md)
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
> * Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
> * If possible, use only letters, numbers, dashes and underscores for the name. Periods (.) are known to cause issues in Cargo.
This naming scheme matches `$ARCH-$VENDOR-$OS-$ABI` which is matches the iOS Apple Silicon simulator (`aarch64-apple-ios-sim`) and other Apple targets.
> Tier 3 targets may have unusual requirements to build or use, but must not
create legal issues or impose onerous legal terms for the Rust project or for
Rust developers or users.
> - The target must not introduce license incompatibilities.
> - Anything added to the Rust repository must be under the standard Rust license (`MIT OR Apache-2.0`).
> - The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the `tidy` tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to besubject to any new license requirements.
> - Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, `rustc` built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> - "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are *not* limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
This contribution is fully available under the standard Rust license with no additional legal restrictions whatsoever. This PR does not introduce any new dependency less permissive than the Rust license policy.
The new targets do not depend on proprietary libraries.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
This new target mirrors the standard library for watchOS and iOS, with minor divergences.
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
Documentation is provided in [src/doc/rustc/src/platform-support/apple-visionos.md](e88379034a/src/doc/rustc/src/platform-support/apple-visionos.md)
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> * This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via `@)` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> * Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> * In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
I acknowledge these requirements and intend to ensure that they are met.
This target does not touch any existing tier 2 or tier 1 targets and should not break any other targets.
When encoutnering a case like
```rust
//@ run-rustfix
use std::collections::HashMap;
fn main() {
let vs = vec![0, 0, 1, 1, 3, 4, 5, 6, 3, 3, 3];
let mut counts = HashMap::new();
for num in vs {
let count = counts.entry(num).or_insert(0);
*count += 1;
}
let _ = counts.iter().max_by_key(|(_, v)| v);
```
produce the following suggestion
```
error: lifetime may not live long enough
--> $DIR/return-value-lifetime-error.rs:13:47
|
LL | let _ = counts.iter().max_by_key(|(_, v)| v);
| ------- ^ returning this value requires that `'1` must outlive `'2`
| | |
| | return type of closure is &'2 &i32
| has type `&'1 (&i32, &i32)`
|
help: dereference the return value
|
LL | let _ = counts.iter().max_by_key(|(_, v)| **v);
| ++
```
Fix#50195.
Port `run-make/issue-7349` to a codegen test
The test does not need to be a run-make test, it can use the codegen test infrastructure.
Also took the opportunity to rename the test to `no-redundant-item-monomorphization` so it's not just some opaque issue number.
Part of #121876.
Actually use the inferred `ClosureKind` from signature inference in coroutine-closures
A follow-up to https://github.com/rust-lang/rust/pull/123349, which fixes another subtle bug: We were not taking into account the async closure kind we infer during closure signature inference.
When I pass a closure directly to an arg like `fn(x: impl async FnOnce())`, that should have the side-effect of artificially restricting the kind of the async closure to `ClosureKind::FnOnce`. We weren't doing this -- that's a quick fix; however, it uncovers a second, more subtle bug with the way that `move`, async closures, and `FnOnce` interact.
Specifically, when we have an async closure like:
```
let x = Struct;
let c = infer_as_fnonce(async move || {
println!("{x:?}");
}
```
The outer closure captures `x` by move, but the inner coroutine still immutably borrows `x` from the outer closure. Since we've forced the closure to by `async FnOnce()`, we can't actually *do* a self borrow, since the signature of `AsyncFnOnce::call_once` doesn't have a borrowed lifetime. This means that all `async move` closures that are constrained to `FnOnce` will fail borrowck.
We can fix that by detecting this case specifically, and making the *inner* async closure `move` as well. This is always beneficial to closure analysis, since if we have an `async FnOnce()` that's `move`, there's no reason to ever borrow anything, so `move` isn't artificially restrictive.
Match ergonomics: implement "`&`pat everywhere"
Implements the eat-two-layers (feature gate `and_pat_everywhere`, all editions) ~and the eat-one-layer (feature gate `and_eat_one_layer_2024`, edition 2024 only, takes priority on that edition when both feature gates are active)~ (EDIT: will be done in later PR) semantics.
cc #123076
r? ``@Nadrieril``
``@rustbot`` label A-patterns A-edition-2024
Restore typeid_for_instance default behavior of performing self type
erasure, since it's the most common case and what it does most of the
time. Using concrete self (or not performing self type erasure) is for
assigning a secondary type id, and secondary type ids are only assigned
when they're unique and to methods, and also are only tested for when
methods are used as function pointers.
CFI: Add test for `call_once` addr taken
One of the proposed ways to reduce the non-passed argument erasure would cause this test to fail. Adding this now ensures that any attempt to reduce non-passed argument erasure won't make the same mistake.
r? `@compiler-errors`
cc `@rcvalle`
Default to light theme if JS is enabled but not working
It doesn't [fix] #123399 but it allows to reduce the problem:
* if JS is completely disabled, then `noscript.css` will be applied
* if JS failed for any reason, then the light theme will be applied (because `noscript.css` won't be applied)
r? `@notriddle`
change `NormalizesTo` to fully structurally normalize
notes in https://hackmd.io/wZ016dE4QKGIhrOnHLlThQ
need to also update the dev-guide once this PR lands. in short, the setup is now as follows:
`normalizes-to` internally implements one step normalization, applying that normalization to the `goal.predicate.term` causes the projected term to get recursively normalized. With this `normalizes-to` normalizes until the projected term is rigid, meaning that we normalize as many steps necessary, but at least 1.
To handle rigid aliases, we add another candidate only if the 1 to inf step normalization failed. With this `normalizes-to` is now full structural normalization. We can now change `AliasRelate` to simply emit `normalizes-to` goals for the rhs and lhs.
This avoids the concerns from https://github.com/rust-lang/trait-system-refactor-initiative/issues/103 and generally feels cleaner
One of the proposed ways to reduce the non-passed argument erasure would
cause this test to fail. Adding this now ensures that any attempt to
reduce non-passed argument erasure won't make the same mistake.
some smaller DefiningOpaqueTypes::No -> Yes switches
r? `@compiler-errors`
These are some easy cases, so let's get them out of the way first.
I added tests exercising the specialization code paths that I believe weren't tested so far.
follow-up to https://github.com/rust-lang/rust/pull/117348
Only inspect user-written predicates for privacy concerns
fixes#123288
Previously we looked at the elaborated predicates, which, due to adding various bounds on fields, end up requiring trivially true bounds. But these bounds can contain private types, which the privacy visitor then found and errored about.
match lowering: make false edges more precise
When lowering match expressions, we add false edges to hide details of the lowering from borrowck. Morally we pretend we're testing the patterns (and guards) one after the other in order. See the tests for examples. Problem is, the way we implement this today is too coarse for deref patterns.
In deref patterns, a pattern like `deref [1, x]` matches on a `Vec` by creating a temporary to store the output of the call to `deref()` and then uses that to continue matching. Here the pattern has a binding, which we set up after the pre-binding block. Problem is, currently the false edges tell borrowck that the pre-binding block can be reached from a previous arm as well, so the `deref()` temporary may not be initialized. This triggers an error when we try to use the binding `x`.
We could call `deref()` a second time, but this opens the door to soundness issues if the deref impl is weird. Instead in this PR I rework false edges a little bit.
What we need from false edges is a (fake) path from each candidate to the next, specifically from candidate C's pre-binding block to next candidate D's pre-binding block. Today, we link the pre-binding blocks directly. In this PR, I link them indirectly by choosing an earlier node on D's success path. Specifically, I choose the earliest block on D's success path that doesn't make a loop (if I chose e.g. the start block of the whole match (which is on the success path of all candidates), that would make a loop). This turns out to be rather straightforward to implement.
r? `@matthewjasper` if you have the bandwidth, otherwise let me know
check `FnDef` return type for WF
better version of #106807, fixes#84533 (mostly). It's not perfect given that we still ignore WF requirements involving bound regions but I wasn't able to quickly write an example, so even if theoretically exploitable, it should be far harder to trigger.
This is strictly more restrictive than checking the return type for WF as part of the builtin `FnDef: FnOnce` impl (#106807) and moving to this approach in the future will not break any code.
~~It also agrees with my theoretical view of how this should behave~~
r? types
CFI: Support function pointers for trait methods
Adds support for both CFI and KCFI for function pointers to trait methods by attaching both concrete and abstract types to functions.
KCFI does this through generation of a `ReifyShim` on any function pointer for a method that could go into a vtable, and keeping this separate from `ReifyShim`s that are *intended* for vtable us by setting a `ReifyReason` on them.
CFI does this by setting both the concrete and abstract type on every instance.
This should land after #123024 or a similar PR, as it diverges the implementation of CFI vs KCFI.
r? `@compiler-errors`
instantiate higher ranked goals outside of candidate selection
This PR modifies `evaluate` to more eagerly instantiate higher-ranked goals, preventing the `leak_check` during candidate selection from detecting placeholder errors involving that binder.
For a general background regarding higher-ranked region solving and the leak check, see https://hackmd.io/qd9Wp03cQVy06yOLnro2Kg.
> The first is something called the **leak check**. You can think of it as a "quick and dirty" approximation for the region check, which will come later. The leak check detects some kinds of errors early, essentially deciding between "this set of outlives constraints are guaranteed to result in an error eventually" or "this set of outlives constraints may be solvable".
## The ideal future
We would like to end up with the following idealized design to handle universal binders:
```rust
fn enter_forall<'tcx, T, R>(
forall: Binder<'tcx, T>,
f: impl FnOnce(T) -> R,
) -> R {
let new_universe = infcx.increment_universe_index();
let value = instantiate_binder_with_placeholders_in(new_universe, forall);
let result = f(value);
eagerly_handle_higher_ranked_region_constraints_in(new_universe);
infcx.decrement_universe_index();
assert!(!result.has_placeholders_in_or_above(new_universe));
result
}
```
That is, when universally instantiating a binder, anything using the placeholders has to happen inside of a limited scope (the closure `f`). After this closure has completed, all constraints involving placeholders are known.
We then handle any *external constraints* which name these placeholders. We destructure `TypeOutlives` constraints involving placeholders and eagerly handle any region constraints involving these placeholders. We do not return anything mentioning the placeholders created inside of this function to the caller.
Being able to eagerly handle *all* region constraints involving placeholders will be difficult due to complex `TypeOutlives` constraints, involving inference variables or alias types, and higher ranked implied bounds. The exact issues and possible solutions are out of scope of this FCP.
#### How does the leak check fit into this
The `leak_check` is an underapproximation of `eagerly_handle_higher_ranked_region_constraints_in`. It detects some kinds of errors involving placeholders from `new_universe`, but not all of them.
It only looks at region outlives constraints, ignoring `TypeOutlives`, and checks whether one of the following two conditions are met for **placeholders in or above `new_universe`**, in which case it results in an error:
- `'!p1: '!p2` a placeholder `'!p2` outlives a different placeholder `'!p1`
- `'!p1: '?2` an inference variable `'?2` outlives a placeholder `'!p1` *which it cannot name*
It does not handle all higher ranked region constraints, so we still return constraints involving placeholders from `new_universe` which are then (re)checked by `lexical_region_resolve` or MIR borrowck.
As we check higher ranked constraints in the full regionck anyways, the `leak_check` is not soundness critical. It's current only purpose is to move some higher ranked region errors earlier, enabling it to guide type inference and trait solving. Adding additional uses of the `leak_check` in the future would only strengthen inference and is therefore not breaking.
## Where do we use currently use the leak check
The `leak_check` is currently used in two places:
Coherence does not use a proper regionck, only relying on the `leak_check` called [at the end of the implicit negative overlap check](8b94152af6/compiler/rustc_trait_selection/src/traits/coherence.rs (L235-L238)). During coherence all parameters are instantiated with inference variables, so the only possible region errors are higher-ranked. We currently also sometimes make guesses when destructuring `TypeOutlives` constraints which can theoretically result in incorrect errors. This could result in overlapping impls.
We also use the `leak_check` [at the end of `fn evaluation_probe`](8b94152af6/compiler/rustc_trait_selection/src/traits/select/mod.rs (L607-L610)). This function is used during candidate assembly for `Trait` goals. Most notably we use [inside of `evaluate_candidate` during winnowing](0e4243538b/compiler/rustc_trait_selection/src/traits/select/mod.rs (L491-L502)). Conceptionally, it is as if we compute each candidate in a separate `enter_forall`.
## The current use in `fn evaluation_probe` is undesirable
Because we only instantiate a higher-ranked goal once inside of `fn evaluation_probe`, errors involving placeholders from that binder can impact selection. This results in inconsistent behavior ([playground](
*[playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=dac60ebdd517201788899ffa77364831)*)):
```rust
trait Leak<'a> {}
impl Leak<'_> for Box<u32> {}
impl Leak<'static> for Box<u16> {}
fn impls_leak<T: for<'a> Leak<'a>>() {}
trait IndirectLeak<'a> {}
impl<'a, T: Leak<'a>> IndirectLeak<'a> for T {}
fn impls_indirect_leak<T: for<'a> IndirectLeak<'a>>() {}
fn main() {
// ok
//
// The `Box<u16>` impls fails the leak check,
// meaning that we apply the `Box<u32>` impl.
impls_leak::<Box<_>>();
// error: type annotations needed
//
// While the `Box<u16>` impl would fail the leak check
// we have already instantiated the binder while applying
// the generic `IndirectLeak` impl, so during candidate
// selection of `Leak` we do not detect the placeholder error.
// Evaluation of `Box<_>: Leak<'!a>` is therefore ambiguous,
// resulting in `for<'a> Box<_>: Leak<'a>` also being ambiguous.
impls_indirect_leak::<Box<_>>();
}
```
We generally prefer `where`-bounds over implementations during candidate selection, both for [trait goals](11f32b73e0/compiler/rustc_trait_selection/src/traits/select/mod.rs (L1863-L1887)) and during [normalization](11f32b73e0/compiler/rustc_trait_selection/src/traits/project.rs (L184-L198)). However, we currently **do not** use the `leak_check` during candidate assembly in normalizing. This can result in inconsistent behavior:
```rust
trait Trait<'a> {
type Assoc;
}
impl<'a, T> Trait<'a> for T {
type Assoc = usize;
}
fn trait_bound<T: for<'a> Trait<'a>>() {}
fn projection_bound<T: for<'a> Trait<'a, Assoc = usize>>() {}
// A function with a trivial where-bound which is more
// restrictive than the impl.
fn function<T: Trait<'static, Assoc = usize>>() {
// ok
//
// Proving `for<'a> T: Trait<'a>` using the where-bound results
// in a leak check failure, so we use the more general impl,
// causing this to succeed.
trait_bound::<T>();
// error
//
// Proving the `Projection` goal `for<'a> T: Trait<'a, Assoc = usize>`
// does not use the leak check when trying the where-bound, causing us
// to prefer it over the impl, resulting in a placeholder error.
projection_bound::<T>();
// error
//
// Trying to normalize the type `for<'a> fn(<T as Trait<'a>>::Assoc)`
// only gets to `<T as Trait<'a>>::Assoc` once `'a` has been already
// instantiated, causing us to prefer the where-bound over the impl
// resulting in a placeholder error. Even if were were to also use the
// leak check during candidate selection for normalization, this
// case would still not compile.
let _higher_ranked_norm: for<'a> fn(<T as Trait<'a>>::Assoc) = |_| ();
}
```
This is also likely to be more performant. It enables more caching in the new trait solver by simply [recursively calling the canonical query][new solver] after instantiating the higher-ranked goal.
It is also unclear how to add the leak check to normalization in the new solver. To handle https://github.com/rust-lang/trait-system-refactor-initiative/issues/1 `Projection` goals are implemented via `AliasRelate`. This again means that we instantiate the binder before ever normalizing any alias. Even if we were to avoid this, we lose the ability to [cache normalization by itself, ignoring the expected `term`](5bd5d214ef/compiler/rustc_trait_selection/src/solve/normalizes_to/mod.rs (L34-L49)). We cannot replace the `term` with an inference variable before instantiating the binder, as otherwise `for<'a> T: Trait<Assoc<'a> = &'a ()>` breaks. If we only replace the term after instantiating the binder, we cannot easily evaluate the goal in a separate context, as [we'd then lose the information necessary for the leak check](11f32b73e0/compiler/rustc_next_trait_solver/src/canonicalizer.rs (L230-L232)). Adding this information to the canonical input also seems non-trivial.
## Proposed solution
I propose to instantiate the binder outside of candidate assembly, causing placeholders from higher-ranked goals to get ignored while selecting their candidate. This mostly[^1] matches the [current behavior of the new solver][new solver]. The impact of this change is therefore as follows:
```rust
trait Leak<'a> {}
impl Leak<'_> for Box<u32> {}
impl Leak<'static> for Box<u16> {}
fn impls_leak<T: for<'a> Leak<'a>>() {}
trait IndirectLeak<'a> {}
impl<'a, T: Leak<'a>> IndirectLeak<'a> for T {}
fn impls_indirect_leak<T: for<'a> IndirectLeak<'a>>() {}
fn guide_selection() {
// ok -> ambiguous
impls_leak::<Box<_>>();
// ambiguous
impls_indirect_leak::<Box<_>>();
}
trait Trait<'a> {
type Assoc;
}
impl<'a, T> Trait<'a> for T {
type Assoc = usize;
}
fn trait_bound<T: for<'a> Trait<'a>>() {}
fn projection_bound<T: for<'a> Trait<'a, Assoc = usize>>() {}
// A function which a trivial where-bound which is more
// restrictive than the impl.
fn function<T: Trait<'static, Assoc = usize>>() {
// ok -> error
trait_bound::<T>();
// error
projection_bound::<T>();
// error
let _higher_ranked_norm: for<'a> fn(<T as Trait<'a>>::Assoc) = |_| ();
}
```
This does not change the behavior if candidates have higher ranked nested goals, as in this case the `leak_check` causes the nested goal to result in an error ([playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=a74c25300b23db9022226de99d8a2fa6)):
```rust
trait LeakCheckFailure<'a> {}
impl LeakCheckFailure<'static> for () {}
trait Trait<T> {}
impl Trait<u32> for () where for<'a> (): LeakCheckFailure<'a> {}
impl Trait<u16> for () {}
fn impls_trait<T: Trait<U>, U>() {}
fn main() {
// ok
//
// It does not matter whether candidate assembly
// considers the placeholders from higher-ranked goal.
//
// Either `for<'a> (): LeakCheckFailure<'a>` has no
// applicable candidate or it has a single applicable candidate
// when then later results in an error. This allows us to
// infer `U` to `u16`.
impls_trait::<(), _>()
}
```
## Impact on existing crates
This is a **breaking change**. [A crater run](https://github.com/rust-lang/rust/pull/119820#issuecomment-1926862174) found 17 regressed crates with 7 root causes.
For a full analysis of all affected crates, see https://gist.github.com/lcnr/7c1c652f30567048ea240554a36ed95c.
---
I believe this breakage to be acceptable and would merge this change. I am confident that the new position of the leak check matches our idealized future and cannot envision any other consistent alternative. Where possible, I intend to open PRs fixing/avoiding the regressions before landing this PR.
I originally intended to remove the `coherence_leak_check` lint in the same PR. However, while I am confident in the *position* of the leak check, deciding on its exact behavior is left as future work, cc #112999. This PR therefore only moves the leak check while keeping the lint when relying on it in coherence.
[new solver]: https://github.com/rust-lang/rust/blob/master/compiler/rustc_trait_selection/src/solve/eval_ctxt/mod.rs#L479-L484
[^1]: the new solver has a separate cause of inconsistent behavior rn https://github.com/rust-lang/trait-system-refactor-initiative/issues/53#issuecomment-1914310171
r? `@nikomatsakis`
Assert that args are actually compatible with their generics, rather than just their count
Right now we just check that the number of args is right, rather than actually checking the kinds. Uplift a helper fn that I wrote from trait selection to do just that. Found a couple bugs along the way.
r? `@lcnr` or `@fmease` (or anyone really lol)
pattern analysis: fix union handling
Little known fact: rust supports union patterns. Exhaustiveness handles them soundly but reports nonsensical missing patterns. This PR fixes the reported patterns and documents what we're doing.
r? `@compiler-errors`
Rename `expose_addr` to `expose_provenance`
`expose_addr` is a bad name, an address is just a number and cannot be exposed. The operation is actually about the provenance of the pointer.
This PR thus changes the name of the method to `expose_provenance` without changing its return type. There is sufficient precedence for returning a useful value from an operation that does something else without the name indicating such, e.g. [`Option::insert`](https://doc.rust-lang.org/nightly/std/option/enum.Option.html#method.insert) and [`MaybeUninit::write`](https://doc.rust-lang.org/nightly/std/mem/union.MaybeUninit.html#method.write).
Returning the address is merely convenient, not a fundamental part of the operation. This is implied by the fact that integers do not have provenance since
```rust
let addr = ptr.addr();
ptr.expose_provenance();
let new = ptr::with_exposed_provenance(addr);
```
must behave exactly like
```rust
let addr = ptr.expose_provenance();
let new = ptr::with_exposed_provenance(addr);
```
as the result of `ptr.expose_provenance()` and `ptr.addr()` is the same integer. Therefore, this PR removes the `#[must_use]` annotation on the function and updates the documentation to reflect the important part.
~~An alternative name would be `expose_provenance`. I'm not at all opposed to that, but it makes a stronger implication than we might want that the provenance of the pointer returned by `ptr::with_exposed_provenance`[^1] is the same as that what was exposed, which is not yet specified as such IIUC. IMHO `expose` does not make that connection.~~
A previous version of this PR suggested `expose` as name, libs-api [decided on](https://github.com/rust-lang/rust/pull/122964#issuecomment-2033194319) `expose_provenance` to keep the symmetry with `with_exposed_provenance`.
CC `@RalfJung`
r? libs-api
[^1]: I'm using the new name for `from_exposed_addr` suggested by #122935 here.
Better reporting on generic argument mismatchs
This allows better reporting as per issue #116615 .
If you have a function:
```
fn foo(a: T, b: T) {}
```
and call it like so:
```
foo(1, 2.)
```
it'll give improved error reported similar to the following:
```
error[E0308]: mismatched types
--> generic-mismatch-reporting-issue-116615.rs:6:12
|
6 | foo(1, 2.);
| --- - ^^ expected integer, found floating-point number
| | |
| | expected argument `b` to be an integer because that argument needs to match the type of this parameter
| arguments to this function are incorrect
|
note: function defined here
--> generic-mismatch-reporting-issue-116615.rs:1:4
|
1 | fn foo<T>(a: T, b: T) {}
| ^^^ - ---- ----
| | | |
| | | this parameter needs to match the integer type of `a`
| | `b` needs to match the type of this parameter
| `a` and `b` all reference this parameter T
```
Open question, do we need to worry about error message translation into other languages? Not sure what the status of that is in Rust.
NB: Needs some checking over and some tests have altered that need sanity checking, but overall this is starting to get somewhere now. Will take out of draft PR status when this has been done, raising now to allow feedback at this stage, probably 90% ready.
Reproduce the bug from <https://github.com/rust-lang/rust/issues/123282>
that indicates this feature gate hits edition-dependent resolution paths.
Resolution changed in edition 2018, so test that as well.
Remove MIR unsafe check
Now that THIR unsafeck is enabled by default in stable I think we can remove MIR unsafeck entirely. This PR also removes safety information from MIR.
Rollup of 4 pull requests
Successful merges:
- #122411 ( Provide cabi_realloc on wasm32-wasip2 by default )
- #123349 (Fix capture analysis for by-move closure bodies)
- #123359 (Link against libc++abi and libunwind as well when building LLVM wrappers on AIX)
- #123388 (use a consistent style for links)
r? `@ghost`
`@rustbot` modify labels: rollup
Fix capture analysis for by-move closure bodies
The check we were doing to figure out if a coroutine was borrowing from its parent coroutine-closure was flat-out wrong -- a misunderstanding of mine of the way that `tcx.closure_captures` represents its captures.
Fixes#123251 (the miri/ui test I added should more than cover that issue)
r? `@oli-obk` -- I recognize that this PR may be underdocumented, so please ask me what I should explain further.
Rename `UninhabitedEnumBranching` to `UnreachableEnumBranching`
Per [#120268](https://github.com/rust-lang/rust/pull/120268#discussion_r1517492060), I rename `UninhabitedEnumBranching` to `UnreachableEnumBranching` .
I solved some nits to add some comments.
I adjusted the workaround restrictions. This should be useful for `a <= b` and `if let Some/Ok(v)`. For enum with few variants, `early-tailduplication` should not cause compile time overhead.
r? RalfJung
Add `Context::ext`
This change enables `Context` to carry arbitrary extension data via a single `&mut dyn Any` field.
```rust
#![feature(context_ext)]
impl Context {
fn ext(&mut self) -> &mut dyn Any;
}
impl ContextBuilder {
fn ext(self, data: &'a mut dyn Any) -> Self;
fn from(cx: &'a mut Context<'_>) -> Self;
fn waker(self, waker: &'a Waker) -> Self;
}
```
Basic usage:
```rust
struct MyExtensionData {
executor_name: String,
}
let mut ext = MyExtensionData {
executor_name: "foo".to_string(),
};
let mut cx = ContextBuilder::from_waker(&waker).ext(&mut ext).build();
if let Some(ext) = cx.ext().downcast_mut::<MyExtensionData>() {
println!("{}", ext.executor_name);
}
```
Currently, `Context` only carries a `Waker`, but there is interest in having it carry other kinds of data. Examples include [LocalWaker](https://github.com/rust-lang/rust/issues/118959), [a reactor interface](https://github.com/rust-lang/libs-team/issues/347), and [multiple arbitrary values by type](https://docs.rs/context-rs/latest/context_rs/). There is also a general practice in the ecosystem of sharing data between executors and futures via thread-locals or globals that would arguably be better shared via `Context`, if it were possible.
The `ext` field would provide a low friction (to stabilization) solution to enable experimentation. It would enable experimenting with what kinds of data we want to carry as well as with what data structures we may want to use to carry such data.
Dedicated fields for specific kinds of data could still be added directly on `Context` when we have sufficient experience or understanding about the problem they are solving, such as with `LocalWaker`. The `ext` field would be for data for which we don't have such experience or understanding, and that could be graduated to dedicated fields once proven.
Both the provider and consumer of the extension data must be aware of the concrete type behind the `Any`. This means it is not possible for the field to carry an abstract interface. However, the field can carry a concrete type which in turn carries an interface. There are different ways one can imagine an interface-carrying concrete type to work, hence the benefit of being able to experiment with such data structures.
## Passing interfaces
Interfaces can be placed in a concrete type, such as a struct, and then that type can be casted to `Any`. However, one gotcha is `Any` cannot contain non-static references. This means one cannot simply do:
```rust
struct Extensions<'a> {
interface1: &'a mut dyn Trait1,
interface2: &'a mut dyn Trait2,
}
let mut ext = Extensions {
interface1: &mut impl1,
interface2: &mut impl2,
};
let ext: &mut dyn Any = &mut ext;
```
To work around this without boxing, unsafe code can be used to create a safe projection using accessors. For example:
```rust
pub struct Extensions {
interface1: *mut dyn Trait1,
interface2: *mut dyn Trait2,
}
impl Extensions {
pub fn new<'a>(
interface1: &'a mut (dyn Trait1 + 'static),
interface2: &'a mut (dyn Trait2 + 'static),
scratch: &'a mut MaybeUninit<Self>,
) -> &'a mut Self {
scratch.write(Self {
interface1,
interface2,
})
}
pub fn interface1(&mut self) -> &mut dyn Trait1 {
unsafe { self.interface1.as_mut().unwrap() }
}
pub fn interface2(&mut self) -> &mut dyn Trait2 {
unsafe { self.interface2.as_mut().unwrap() }
}
}
let mut scratch = MaybeUninit::uninit();
let ext: &mut Extensions = Extensions::new(&mut impl1, &mut impl2, &mut scratch);
// ext can now be casted to `&mut dyn Any` and back, and used safely
let ext: &mut dyn Any = ext;
```
## Context inheritance
Sometimes when futures poll other futures they want to provide their own `Waker` which requires creating their own `Context`. Unfortunately, polling sub-futures with a fresh `Context` means any properties on the original `Context` won't get propagated along to the sub-futures. To help with this, some additional methods are added to `ContextBuilder`.
Here's how to derive a new `Context` from another, overriding only the `Waker`:
```rust
let mut cx = ContextBuilder::from(parent_cx).waker(&new_waker).build();
```
Avoid expanding to unstable internal method
Fixes#123156
Rather than expanding to `std::rt::begin_panic`, the expansion is now to `unreachable!()`. The resulting behavior is identical. A test that previously triggered the same error as #123156 has been added to ensure it does not regress.
r? compiler
rename ptr::from_exposed_addr -> ptr::with_exposed_provenance
As discussed on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/To.20expose.20or.20not.20to.20expose/near/427757066).
The old name, `from_exposed_addr`, makes little sense as it's not the address that is exposed, it's the provenance. (`ptr.expose_addr()` stays unchanged as we haven't found a better option yet. The intended interpretation is "expose the provenance and return the address".)
The new name nicely matches `ptr::without_provenance`.
Make inductive cycles always ambiguous
This makes inductive cycles always result in ambiguity rather than be treated like a stack-dependent error.
This has some interactions with specialization, and so breaks a few UI tests that I don't agree should've ever worked in the first place, and also breaks a handful of crates in a way that I don't believe is a problem.
On the bright side, it puts us in a better spot when it comes to eventually enabling coinduction everywhere.
## Results
This was cratered in https://github.com/rust-lang/rust/pull/116494#issuecomment-2008657494, which boils down to two regressions:
* `lu_packets` - This code should have never compiled in the first place. More below.
* **ALL** other regressions are due to `commit_verify@0.11.0-beta.1` (edit: and `commit_verify@0.10.x`) - This actually seems to be fixed in version `0.11.0-beta.5`, which is the *most* up to date version, but it's still prerelease on crates.io so I don't think cargo ends up picking `beta.5` when building dependent crates.
### `lu_packets`
Firstly, this crate uses specialization, so I think it's automatically worth breaking. However, I've minimized [the regression](https://crater-reports.s3.amazonaws.com/pr-116494-3/try%23d614ed876e31a5f3ad1d0fbf848fcdab3a29d1d8/gh/lcdr.lu_packets/log.txt) to:
```rust
// Upstream crate
pub trait Serialize {}
impl Serialize for &() {}
impl<S> Serialize for &[S] where for<'a> &'a S: Serialize {}
// ----------------------------------------------------------------------- //
// Downstream crate
#![feature(specialization)]
#![allow(incomplete_features, unused)]
use upstream::Serialize;
trait Replica {
fn serialize();
}
impl<T> Replica for T {
default fn serialize() {}
}
impl<T> Replica for Option<T>
where
for<'a> &'a T: Serialize,
{
fn serialize() {}
}
```
Specifically this fails when computing the specialization graph for the `downstream` crate.
The code ends up cycling on `&[?0]: Serialize` when we equate `&?0 = &[?1]` during impl matching, which ends up needing to prove `&[?1]: Serialize`, which since cycles are treated like ambiguity, ends up in a **fatal overflow**. For some reason this requires two crates, squashing them into one crate doesn't work.
Side-note: This code is subtly order dependent. When minimizing, I ended up having the code start failing on `nightly` very easily after removing and reordering impls. This seems to me all the more reason to remove this behavior altogether.
## Side-note: Item Bounds (edit: this was fixed independently in #121123)
Due to the changes in #120584 where we now consider an alias's item bounds *and* all the item bounds of the alias's nested self type aliases, I've had to add e6b64c6194 which is a hack to make sure we're not eagerly normalizing bounds that have nothing to do with the predicate we're trying to solve, and which result in.
This is fixed in a more principled way in #121123.
---
r? lcnr for an initial review
rustdoc: synthetic auto trait impls: accept unresolved region vars for now
https://github.com/rust-lang/rust/pull/123348#issuecomment-2032494255:
> Right, [in #123340] I've intentionally changed a `vid_map.get(vid).unwrap_or(r)` to a `vid_map[vid]` making rustdoc panic if `rustc::AutoTraitFinder` returns a region inference variable that cannot be resolved because that is really fishy. I can change it back with a `FIXME: investigate` […]. [O]nce I [fully] understand [the arcane] `rustc::AutoTraitFinder` [I] can fix the underlying issue if there's one.
>
> `rustc::AutoTraitFinder` can also return placeholder regions `RePlaceholder` which doesn't seem right either and which makes rustdoc ICE, too (we have a GitHub issue for that already[, namely #120606]).
Fixes#123370.
Fixes#112242.
r? ``@GuillaumeGomez``
CFI: Support non-general coroutines
Previously, we assumed all `ty::Coroutine` were general coroutines and attempted to generalize them through the `Coroutine` trait. Select appropriate traits for each kind of coroutine.
I have this marked as a draft because it currently only fixes async coroutines, and I think it make sense to try to fix gen/async gen coroutines before this is merged.
If the issue [mentioned](https://github.com/rust-lang/rust/pull/123106#issuecomment-2030794213) in the original PR is actually affecting someone, we can land this as is to remedy it.
Check that nested statics in thread locals are duplicated per thread.
follow-up to #123310
cc ``@compiler-errors`` ``@RalfJung``
fwiw: I have no idea how thread local statics make that work under LLVM, and miri fails on this example, which I would have expected to be the correct behaviour.
Since the `#[thread_local]` attribute is just an internal implementation detail, I'm just going to start hard erroring on nested mutable statics in thread locals.
Make sure to insert `Sized` bound first into clauses list
#120323 made it so that we don't insert an implicit `Sized` bound whenever we see an *explicit* `Sized` bound. However, since the code that inserts implicit sized bounds puts the bound as the *first* in the list, that means that it had the **side-effect** of possibly meaning we check `Sized` *after* checking other trait bounds.
If those trait bounds result in ambiguity or overflow or something, it may change how we winnow candidates. (**edit: SEE** #123303) This is likely the cause for the regression in https://github.com/rust-lang/rust/issues/123279#issuecomment-2028899598, since the impl...
```rust
impl<T: Job + Sized> AsJob for T { // <----- changing this to `Sized + Job` or just `Job` (which turns into `Sized + Job`) will FIX the issue.
}
```
...looks incredibly suspicious.
Fixes [after beta-backport] #123279.
Alternative is to revert #120323. I don't have a strong opinion about this, but think it may be nice to keep the diagnostic changes around.
De-LLVM the unchecked shifts [MCP#693]
This is just one part of the MCP (https://github.com/rust-lang/compiler-team/issues/693), but it's the one that IMHO removes the most noise from the standard library code.
Seems net simpler this way, since MIR already supported heterogeneous shifts anyway, and thus it's not more work for backends than before.
r? WaffleLapkin
Add `Ord::cmp` for primitives as a `BinOp` in MIR
Update: most of this OP was written months ago. See https://github.com/rust-lang/rust/pull/118310#issuecomment-2016940014 below for where we got to recently that made it ready for review.
---
There are dozens of reasonable ways to implement `Ord::cmp` for integers using comparison, bit-ops, and branches. Those differences are irrelevant at the rust level, however, so we can make things better by adding `BinOp::Cmp` at the MIR level:
1. Exactly how to implement it is left up to the backends, so LLVM can use whatever pattern its optimizer best recognizes and cranelift can use whichever pattern codegens the fastest.
2. By not inlining those details for every use of `cmp`, we drastically reduce the amount of MIR generated for `derive`d `PartialOrd`, while also making it more amenable to MIR-level optimizations.
Having extremely careful `if` ordering to μoptimize resource usage on broadwell (#63767) is great, but it really feels to me like libcore is the wrong place to put that logic. Similarly, using subtraction [tricks](https://graphics.stanford.edu/~seander/bithacks.html#CopyIntegerSign) (#105840) is arguably even nicer, but depends on the optimizer understanding it (https://github.com/llvm/llvm-project/issues/73417) to be practical. Or maybe [bitor is better than add](https://discourse.llvm.org/t/representing-in-ir/67369/2?u=scottmcm)? But maybe only on a future version that [has `or disjoint` support](https://discourse.llvm.org/t/rfc-add-or-disjoint-flag/75036?u=scottmcm)? And just because one of those forms happens to be good for LLVM, there's no guarantee that it'd be the same form that GCC or Cranelift would rather see -- especially given their very different optimizers. Not to mention that if LLVM gets a spaceship intrinsic -- [which it should](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Suboptimal.20inlining.20in.20std.20function.20.60binary_search.60/near/404250586) -- we'll need at least a rustc intrinsic to be able to call it.
As for simplifying it in Rust, we now regularly inline `{integer}::partial_cmp`, but it's quite a large amount of IR. The best way to see that is with 8811efa88b (diff-d134c32d028fbe2bf835fef2df9aca9d13332dd82284ff21ee7ebf717bfa4765R113) -- I added a new pre-codegen MIR test for a simple 3-tuple struct, and this PR change it from 36 locals and 26 basic blocks down to 24 locals and 8 basic blocks. Even better, as soon as the construct-`Some`-then-match-it-in-same-BB noise is cleaned up, this'll expose the `Cmp == 0` branches clearly in MIR, so that an InstCombine (#105808) can simplify that to just a `BinOp::Eq` and thus fix some of our generated code perf issues. (Tracking that through today's `if a < b { Less } else if a == b { Equal } else { Greater }` would be *much* harder.)
---
r? `@ghost`
But first I should check that perf is ok with this
~~...and my true nemesis, tidy.~~
Adds support for both CFI and KCFI for attaching concrete and abstract
types to functions. KCFI does this through generation of `ReifyShim` on
any function pointer that could go in a vtable, and checking the
`ReifyReason` when emitting the instance. CFI does this by attaching
both the concrete and abstract type to every instance.
TypeID codegen tests are switched to be anchored on the left rather than
the right in order to allow emission of additional type attachments.
Fixes#115953
Previously, we assumed all `ty::Coroutine` were general coroutines and
attempted to generalize them through the `Coroutine` trait. Select
appropriate traits for each kind of coroutine.
Update to new browser-ui-test version
This new version brings a lot of new internal improvements (mostly around validating the commands input).
It also improved some command names and arguments.
r? `@notriddle`
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
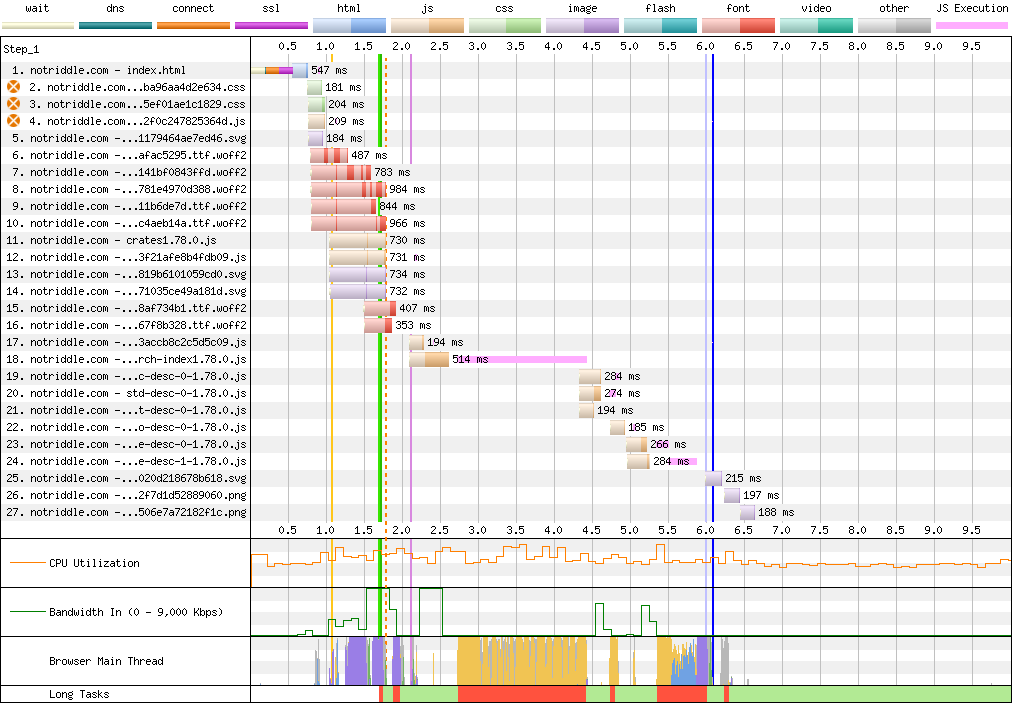
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
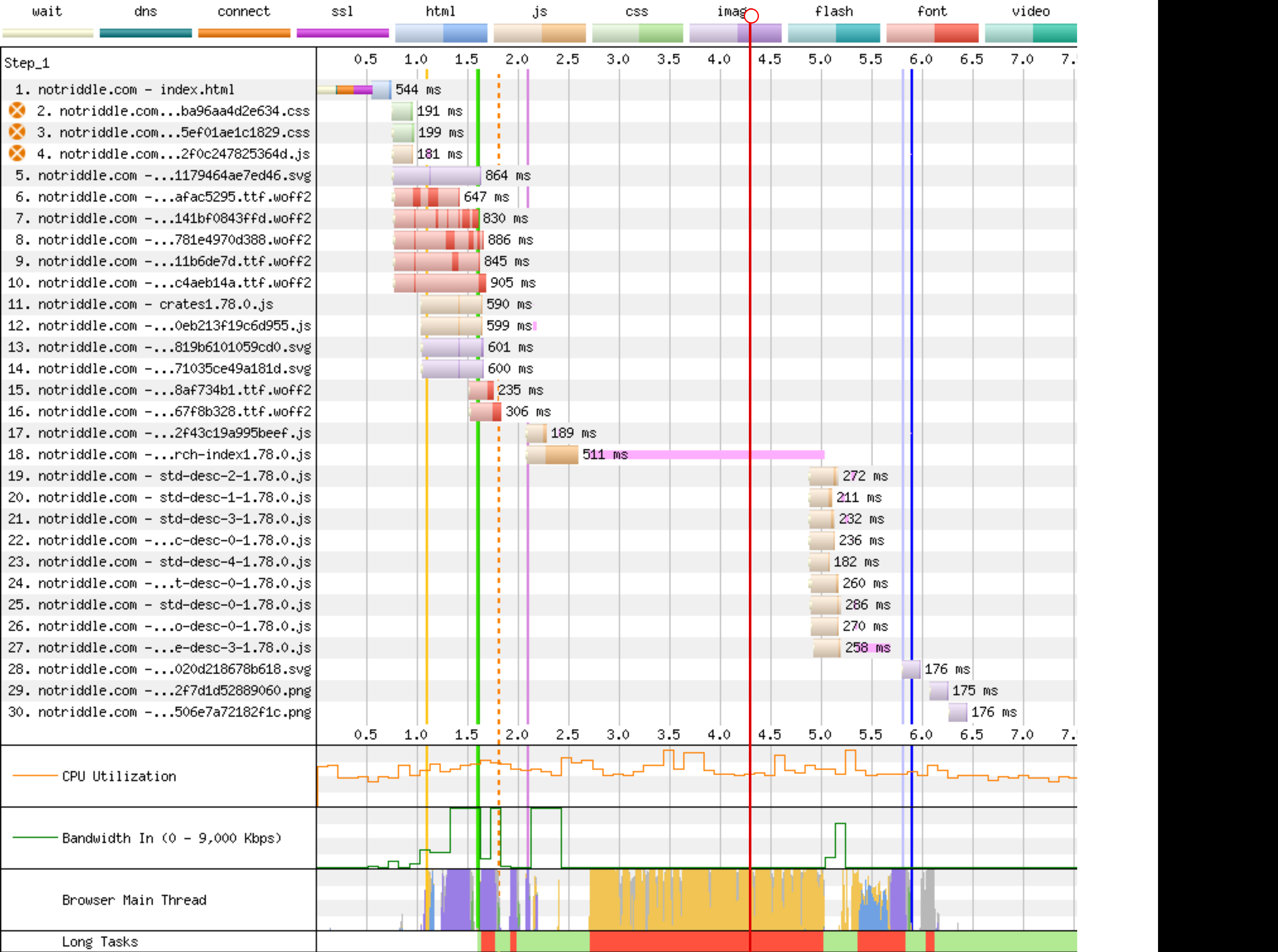
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
rustdoc: heavily simplify the synthesis of auto trait impls
`gd --numstat HEAD~2 HEAD src/librustdoc/clean/auto_trait.rs`
**+315 -705** 🟩🟥🟥🟥⬛
---
As outlined in issue #113015, there are currently 3[^1] large separate routines that “clean” `rustc_middle::ty` data types related to generics & predicates to rustdoc data types. Every single one has their own kinds of bugs. While I've patched a lot of bugs in each of the routines in the past, it's about time to unify them. This PR is only the first in a series. It completely **yanks** the custom “bounds cleaning” of mod `auto_trait` and reuses the routines found in mod `simplify`. As alluded to, `simplify` is also flawed but it's still more complete than `auto_trait`'s routines. [See also my review comment over at `tests/rustdoc/synthetic_auto/bounds.rs`](https://github.com/rust-lang/rust/pull/123340#discussion_r1546900539).
This is preparatory work for rewriting “bounds cleaning” from scratch in follow-up PRs in order to finally [fix] #113015.
Apart from that, I've eliminated all potential sources of *instability* in the rendered output.
See also #119597. I'm pretty sure this fixes#119597.
This PR does not attempt to fix [any other issues related to synthetic auto trait impls](https://github.com/rust-lang/rust/issues?q=is%3Aissue+is%3Aopen+label%3AA-synthetic-impls%20label%3AA-auto-traits).
However, it's definitely meant to be a *stepping stone* by making `auto_trait` more contributor-friendly.
---
* Replace `FxHash{Map,Set}` with `FxIndex{Map,Set}` to guarantee a stable iteration order
* Or as a perf opt, `UnordSet` (a thin wrapper around `FxHashSet`) in cases where we never iterate over the set.
* Yes, we do make use of `swap_remove` but that shouldn't matter since all the callers are deterministic. It does make the output less “predictable” but it's still better than before. Ofc, I rely on `rustc_infer` being deterministic. I hope that holds.
* Utilizing `clean::simplify` over the custom “bounds cleaning” routines wipes out the last reference to `collect_referenced_late_bound_regions` in rustdoc (`simplify` uses `bound_vars`) which was a source of instability / unpredictability (cc #116388)
* Remove the types `RegionTarget` and `RegionDeps` from `librustdoc`. They were duplicates of the identical types found in `rustc`. Just import them from `rustc`. For some reason, they were duplicated when splitting `auto_trait` in two in #49711.
* Get rid of the useless “type namespace” `AutoTraitFinder` in `librustdoc`
* The struct only held a `DocContext`, it was over-engineered
* Turn the associated functions into free ones
* Eliminates rightward drift; increases legibility
* `rustc` also contains a useless `AutoTraitFinder` struct but I plan on removing that in a follow-up PR
* Rename a bunch of methods to be way more descriptive
* Eliminate `use super::*;`
* Lead to `clean/mod.rs` accumulating a lot of unnecessary imports
* Made `auto_traits` less modular
* Eliminate a custom `TypeFolder`: We can just use the rustc helper `fold_regions` which does that for us
I plan on adding extensive documentation to `librustdoc`'s `auto_trait` in follow-up PRs.
I don't want to do that in this PR because further refactoring & bug fix PRs may alter the overall structure of `librustdoc`'s & `rustc`'s `auto_trait` modules to a great degree. I'm slowly digging into the dark details of `rustc`'s `auto_trait` module again and once I have the full picture I will be able to provide proper docs.
---
While this PR does indeed touch `rustc`'s `auto_trait` — mostly tiny refactorings — I argue this PR doesn't need any compiler reviewers next to rustdoc ones since that module falls under the purview of rustdoc — it used to be part of `librustdoc` after all (#49711).
Sorry for not having split this into more commits. If you'd like me to I can try to split it into more atomic commits retroactively. However, I don't know if that would actually make reviewing easier. I think the best way to review this might just be to place the master version of `auto_trait` on the left of your screen and the patched one on the right, not joking.
r? `@GuillaumeGomez`
[^1]: Or even 4 depending on the way you're counting.
Refactor stack overflow handling
Currently, every platform must implement a `Guard` that protects a thread from stack overflow. However, UNIX is the only platform that actually does so. Windows has a different mechanism for detecting stack overflow, while the other platforms don't detect it at all. Also, the UNIX stack overflow handling is split between `sys::pal::unix::stack_overflow`, which implements the signal handler, and `sys::pal::unix::thread`, which detects/installs guard pages.
This PR cleans this by getting rid of `Guard` and unifying UNIX stack overflow handling inside `stack_overflow` (commit 1). Therefore we can get rid of `sys_common::thread_info`, which stores `Guard` and the current `Thread` handle and move the `thread::current` TLS variable into `thread` (commit 2).
The second commit is not strictly speaking necessary. To keep the implementation clean, I've included it here, but if it causes too much noise, I can split it out without any trouble.
Don't inherit codegen attrs from parent static
Putting this up partly for discussion and partly for review. Specifically, in #121644, `@oli-obk` designed a system that creates new static items for representing nested allocations in statics. However, in that PR, oli made it so that these statics inherited the codegen attrs from the parent.
This causes problems such as colliding symbols with `#[export_name]` and ICEs with `#[no_mangle]` since these synthetic statics have no `tcx.item_name(..)`.
So the question is, is there any case where we *do* want to inherit codegen attrs from the parent? The only one that seems a bit suspicious is the thread-local attribute. And there may be some interesting interactions with the coverage attributes as well...
Fixes (after backport) #123274. Fixes#123243. cc #121644.
r? `@oli-obk` cc `@nnethercote` `@RalfJung` (reviewers on that pr)
Fix error message for `env!` when env var is not valid Unicode
Currently (without this PR) the `env!` macro emits an ```environment variable `name` not defined at compile time``` error when the environment variable is defined, but not a valid Unicode string. This PR introduces a separate more accurate error message, and a test to verify this behaviour.
For reference, before this PR, the new test would have outputted:
```
error: environment variable `NON_UNICODE_VAR` not defined at compile time
--> non_unicode_env.rs:2:13
|
2 | let _ = env!("NON_UNICODE_VAR");
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= help: use `std::env::var("NON_UNICODE_VAR")` to read the variable at run time
= note: this error originates in the macro `env` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to 1 previous error
```
whereas with this PR, the test ouputs:
```
error: environment variable `NON_UNICODE_VAR` is not a valid Unicode string
--> non_unicode_env.rs:2:13
|
2 | let _ = env!("NON_UNICODE_VAR");
| ^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this error originates in the macro `env` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to 1 previous error
```
Use the `Align` type when parsing alignment attributes
Use the `Align` type in `rustc_attr::parse_alignment`, removing the need to call `Align::from_bytes(...).unwrap()` later in the compilation process.
Rewrite `core-no-fp-fmt-parse` test in Rust
Claiming the simple "core-no-fp-fmt-parse" test from #121876. `run_make_support` was altered with `arg_path` written in #121918 by `@abhay-51,` with additional doc comment.
Preliminary GSoC contribution for the project proposal mentored by `@jieyouxu.`
match lowering: sort `Eq` candidates in the failure case too
This is a slight tweak to MIR gen of matches. Take a match like:
```rust
match (s, flag) {
("a", _) if foo() => 1,
("b", true) => 2,
("a", false) => 3,
(_, true) => 4,
_ => 5,
}
```
If we switch on `s == "a"`, the first candidate matches, and we learn almost nothing about the second candidate. So there's a choice:
1. (what we do today) stop sorting candidates, keep the "b" case grouped with everything below. This could allow us to be clever here and test on `flag == true` next.
2. (what this PR does) sort "b" into the failure case. The "b" will be alone (fewer opportunities for picking a good test), but that means the two "a" cases require a single test.
Today, we aren't clever in which tests we pick, so this is an unambiguous win. In a future where we pick tests better, idk. Grouping tests as much as possible feels like a generally good strategy.
This was proposed in https://github.com/rust-lang/rust/issues/29623 (9 years ago :D)
The original proposal allows reference patterns
with "compatible" mutability, however it's not clear
what that means so for now we require an exact match.
I don't know the type system code well, so if something
seems to not make sense it's probably because I made a
mistake
CFI: Abstract Closures and Coroutines
This will abstract coroutines in a moment, it's just abstracting closures for now to show `@rcvalle`
This uses the same principal as the methods on traits - figure out the `dyn` type representing the fn trait, instantiate it, and attach that alias set. We're essentially just computing how we would be called in a dynamic context, and attaching that.
Similar to methods on a trait object, the most common way to indirectly
call a closure or coroutine is through the vtable on the appropriate
trait. This uses the same approach as we use for trait methods, after
backing out the trait arguments from the type.
Add support for `NonNull`s in the `ambiguous_wide_ptr_comparisions` lint
This PR add support for `NonNull` pointers in the `ambiguous_wide_ptr_comparisions` lint.
Fixes https://github.com/rust-lang/rust/issues/121264
r? `@Nadrieril` (since you just reviewed #121268, feel free to reassign)
KCFI: Require -C panic=abort
While the KCFI scheme is not incompatible with unwinding, LLVM's `invoke` instruction does not currently support KCFI bundles. While it likely will in the near future, we won't be able to assume that in Rust for a while.
We encountered this problem while [turning on closure support](https://github.com/rust-lang/rust/pull/123106#issuecomment-2027436640).
r? ``@workingjubilee``
Replace regions in const canonical vars' types with `'static` in next-solver canonicalizer
We shouldn't ever have non-static regions in consts on stable (or really any regions at all, lol).
The test I committed is less minimal than, e.g., https://github.com/rust-lang/rust/issues/123155?notification_referrer_id=NT_kwDOADgQyrMxMDAzNDU4MDI0OTozNjc0MzE0#issuecomment-2025472029 -- however, I believe that it actually portrays the underlying issue here a bit better than that one.
In the linked issue, we end up emitting a normalizes-to predicate for a const placeholder because we don't actually unify `false` and `""`. In the test I committed, we emit a normalizes-to predicate as a part of actually solving a negative coherence goal.
Fixes#123155Fixes#118783
r? lcnr
This is just one part of the MCP, but it's the one that IMHO removes the most noise from the standard library code.
Seems net simpler this way, since MIR already supported heterogeneous shifts anyway, and thus it's not more work for backends than before.
CFI: Support calling methods on supertraits
Automatically adjust `Virtual` calls to supertrait functions to use the supertrait's trait object type as the receiver rather than the child trait.
cc `@compiler-errors` - this is the next usage of `trait_object_ty` I intend to have, so I thought it might be relevant while reviewing the existing one.
Remove len argument from RawVec::reserve_for_push
Removes `RawVec::reserve_for_push`'s `len` argument since it's always the same as capacity.
Also makes `Vec::insert` use `RawVec::reserve_for_push`.
Stabilize `unchecked_{add,sub,mul}`
Tracking issue: #85122
I think we might as well just stabilize these basic three. They're the ones that have `nuw`/`nsw` flags in LLVM.
Notably, this doesn't include the potentially-more-complex or -more-situational things like `unchecked_neg` or `unchecked_shr` that are under different feature flags.
To quote Ralf https://github.com/rust-lang/rust/issues/85122#issuecomment-1681669646,
> Are there any objections to stabilizing at least `unchecked_{add,sub,mul}`? For those there shouldn't be any surprises about what their safety requirements are.
*Semantially* these are [already available on stable, even in `const`, via](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=bdb1ff889b61950897f1e9f56d0c9a36) `checked_*`+`unreachable_unchecked`. So IMHO we might as well just let people write them directly, rather than try to go through a `let Some(x) = x.checked_add(y) else { unsafe { hint::unreachable_unchecked() }};` dance.
I added additional text to each method to attempt to better describe the behaviour and encourage `wrapping_*` instead.
r? rust-lang/libs-api
Add detection of [Partial]Ord methods in the `ambiguous_wide_pointer_comparisons` lint
Partially addresses https://github.com/rust-lang/rust/issues/121264 by adding diagnostics items for PartialOrd and Ord methods, detecting such diagnostics items as "binary operation" and suggesting the correct replacement.
I also took the opportunity to change the suggestion to use new methods `.cast()` on `*mut T` an d `*const T`.
While the KCFI scheme is not incompatible with unwinding, LLVM's
`invoke` instruction does not currently support KCFI bundles. While it
likely will in the near future, we won't be able to assume that in Rust
for a while.
Rollup of 4 pull requests
Successful merges:
- #123176 (Normalize the result of `Fields::ty_with_args`)
- #123186 (copy any file from stage0/lib to stage0-sysroot/lib)
- #123187 (Forward port 1.77.1 release notes)
- #123188 (compiler: fix few unused_peekable and needless_pass_by_ref_mut clippy lints)
r? `@ghost`
`@rustbot` modify labels: rollup
Normalize the result of `Fields::ty_with_args`
We were only instantiating before, which would leak an AliasTy. I added a test case that reproduce the issue seen here:
https://github.com/model-checking/kani/issues/3113
r? ``@oli-obk``
Simplify trim-paths feature by merging all debuginfo options together
This PR simplifies the trim-paths feature by merging all debuginfo options together, as described in https://github.com/rust-lang/rust/issues/111540#issuecomment-1994010274.
And also do some correctness fixes found during the review.
cc `@weihanglo`
r? `@michaelwoerister`
Match ergonomics 2024: implement mutable by-reference bindings
Implements the mutable by-reference bindings portion of match ergonomics 2024 (#123076), with the `mut ref`/`mut ref mut` syntax, under feature gate `mut_ref`.
r? `@Nadrieril`
`@rustbot` label A-patterns A-edition-2024
CFI: Fix methods as function pointer cast
Fix casting between methods and function pointers by assigning a secondary type id to methods with their concrete self so they can be used as function pointers.
This was split off from #116404.
cc `@compiler-errors` `@workingjubilee`
Eliminate `UbChecks` for non-standard libraries
The purpose of this PR is to allow other passes to treat `UbChecks` as constants in MIR for optimization after #122629.
r? RalfJung
Codegen const panic messages as function calls
This skips emitting extra arguments at every callsite (of which there
can be many). For a librustc_driver build with overflow checks enabled,
this cuts 0.7MB from the resulting shared library (see [perf]).
A sample improvement from nightly:
```
leaq str.0(%rip), %rdi
leaq .Lalloc_d6aeb8e2aa19de39a7f0e861c998af13(%rip), %rdx
movl $25, %esi
callq *_ZN4core9panicking5panic17h17cabb89c5bcc999E@GOTPCREL(%rip)
```
to this PR:
```
leaq .Lalloc_d6aeb8e2aa19de39a7f0e861c998af13(%rip), %rdi
callq *_RNvNtNtCsduqIKoij8JB_4core9panicking11panic_const23panic_const_div_by_zero@GOTPCREL(%rip)
```
[perf]: https://perf.rust-lang.org/compare.html?start=a7e4de13c1785819f4d61da41f6704ed69d5f203&end=64fbb4f0b2d621ff46d559d1e9f5ad89a8d7789b&stat=instructions:u
Rollup of 6 pull requests
Successful merges:
- #123063 (Function ABI is irrelevant for reachability)
- #123096 (Don't check match scrutinee of postfix match for unused parens)
- #123146 (Use compiletest directives instead of manually checking TARGET / tools)
- #123160 (remove `def_id_to_node_id` in ast lowering)
- #123162 (Correctly get complete intra-doc link data)
- #123164 (Bump Unicode printables to version 15.1, align to unicode_data)
r? `@ghost`
`@rustbot` modify labels: rollup