mirror of
https://github.com/rust-lang/rust.git
synced 2025-04-17 06:26:55 +00:00
Rollup merge of #122614 - notriddle:notriddle/search-desc, r=GuillaumeGomez
rustdoc-search: shard the search result descriptions ## Preview This makes no visual changes to rustdoc search. It's a pure perf improvement. <details><summary>old</summary> Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec> WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN> Waterfall diagram: 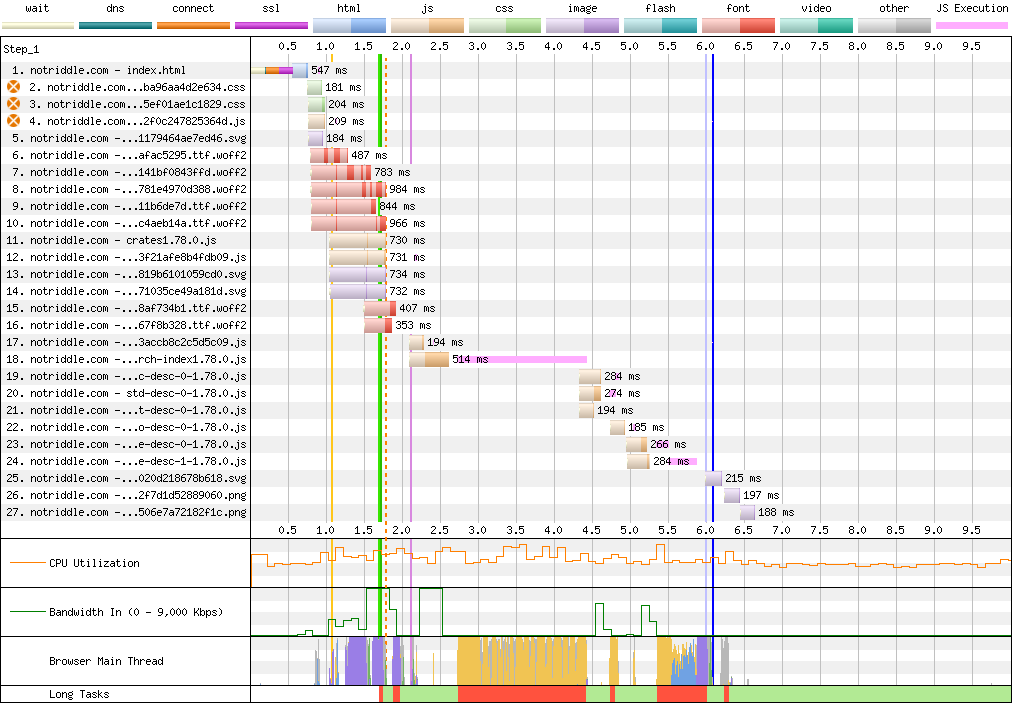 </details> Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec> WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104> 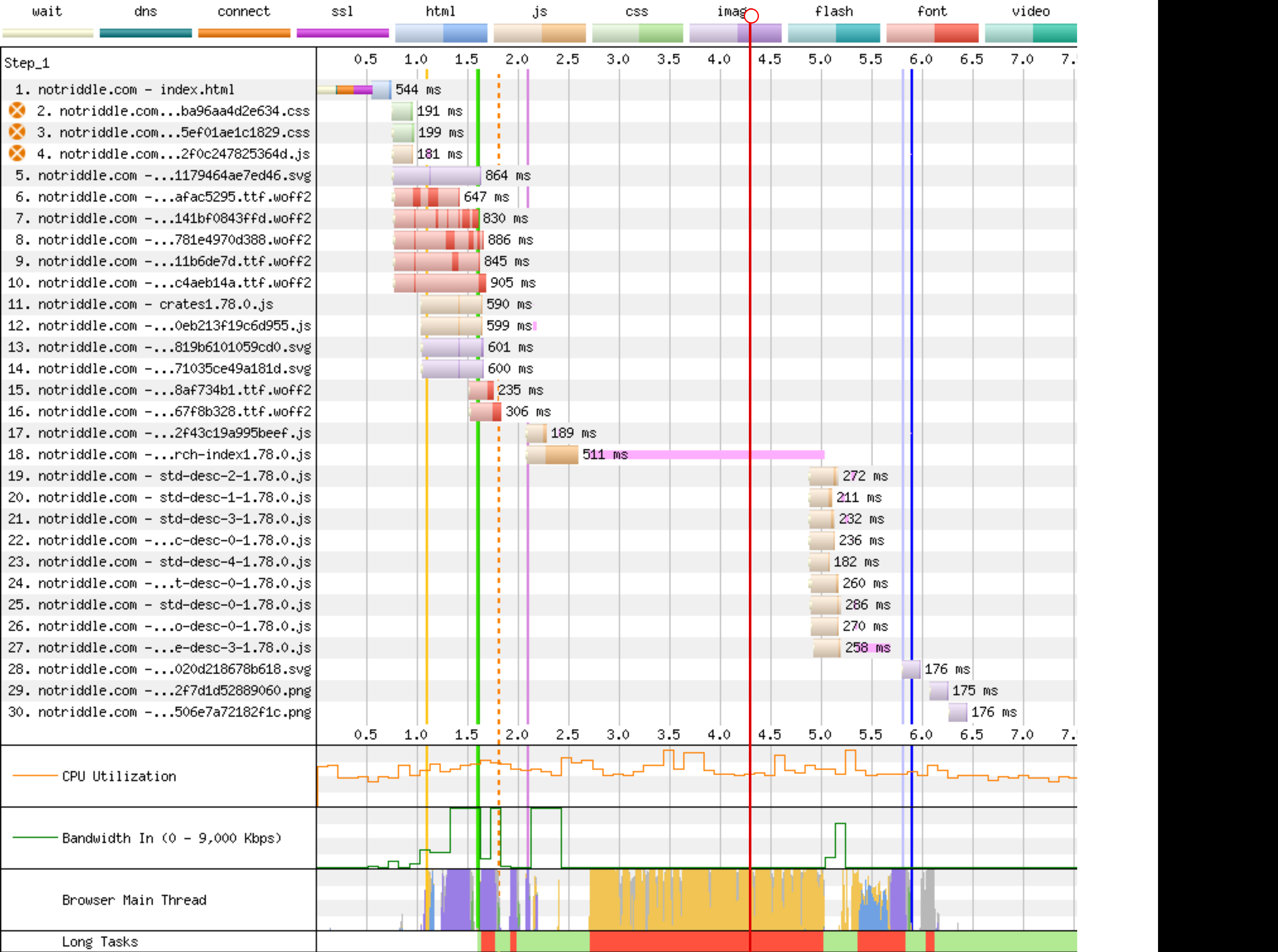 ## Description r? `@GuillaumeGomez` The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files. Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download. This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse. https://caniuse.com/async-functions [^1]: <https://microsoft.github.io/windows-docs-rs/>, a crate with 44MiB of pure names and no descriptions for them, is an outlier and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much. ## Detailed sizes ```console $ cat test.sh set -ex cp ../search-index*.js search-index.js awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json jq -c '.t' search-index.json > t.json jq -c '.n' search-index.json > n.json jq -c '.q' search-index.json > q.json jq -c '.D' search-index.json > D.json jq -c '.e' search-index.json > e.json jq -c '.i' search-index.json > i.json jq -c '.f' search-index.json > f.json jq -c '.c' search-index.json > c.json jq -c '.p' search-index.json > p.json jq -c '.a' search-index.json > a.json du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json $ bash test.sh + cp ../search-index1.78.0.js search-index.js + awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js + awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' + sed -E 's:\\'\'':'\'':g' + jq -c .t search-index.json + jq -c .n search-index.json + jq -c .q search-index.json + jq -c .D search-index.json + jq -c .e search-index.json + jq -c .i search-index.json + jq -c .f search-index.json + jq -c .c search-index.json + jq -c .p search-index.json + jq -c .a search-index.json + du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json 64K t.json 800K n.json 8.0K q.json 4.0K D.json 16K e.json 192K i.json 544K f.json 4.0K c.json 36K p.json 20K a.json ``` These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important). t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library. n = name, and that's now the largest section of the search index with the descriptions removed from it q = parent *module* path, stored parallel to the items within D = the size of each description shard, stored as vlq hex numbers e = empty description bit flags, stored as a roaring bitmap i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr f = function signature, stored as lists of lists that index into `p` c = deprecation flag, stored as a roaring bitmap p = parent *type*, stored separately and linked into from `i` and `f` a = alias, as [[key, value]] pairs ## Search performance http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html For example, in stm32f4: <table><thead><tr><th>before<th>after</tr></thead> <tbody><tr><td> ``` Testing T -> U ... in_args = 0, returned = 0, others = 200 wall time = 617 Testing T, U ... in_args = 0, returned = 0, others = 200 wall time = 198 Testing T -> T ... in_args = 0, returned = 0, others = 200 wall time = 282 Testing crc32 ... in_args = 0, returned = 0, others = 0 wall time = 426 Testing spi::pac ... in_args = 0, returned = 0, others = 0 wall time = 673 ``` </td><td> ``` Testing T -> U ... in_args = 0, returned = 0, others = 200 wall time = 716 Testing T, U ... in_args = 0, returned = 0, others = 200 wall time = 207 Testing T -> T ... in_args = 0, returned = 0, others = 200 wall time = 289 Testing crc32 ... in_args = 0, returned = 0, others = 0 wall time = 418 Testing spi::pac ... in_args = 0, returned = 0, others = 0 wall time = 687 ``` </td></tr><tr><td> ``` user: 005.345 s sys: 002.955 s wall: 006.899 s child_RSS_high: 583664 KiB group_mem_high: 557876 KiB ``` </td><td> ``` user: 004.652 s sys: 000.565 s wall: 003.865 s child_RSS_high: 538696 KiB group_mem_high: 511724 KiB ``` </td></tr> </table> This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real. ## Future possibilities * Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps). * More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t. * [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
This commit is contained in:
commit
3aab05eecb
@ -4783,6 +4783,8 @@ version = "0.0.0"
|
||||
dependencies = [
|
||||
"arrayvec",
|
||||
"askama",
|
||||
"base64",
|
||||
"byteorder",
|
||||
"expect-test",
|
||||
"indexmap",
|
||||
"itertools 0.12.1",
|
||||
|
||||
@ -60,7 +60,7 @@ ENV SCRIPT python3 ../x.py --stage 2 test src/tools/expand-yaml-anchors && \
|
||||
/scripts/validate-error-codes.sh && \
|
||||
reuse --include-submodules lint && \
|
||||
# Runs checks to ensure that there are no ES5 issues in our JS code.
|
||||
es-check es6 ../src/librustdoc/html/static/js/*.js && \
|
||||
es-check es8 ../src/librustdoc/html/static/js/*.js && \
|
||||
eslint -c ../src/librustdoc/html/static/.eslintrc.js ../src/librustdoc/html/static/js/*.js && \
|
||||
eslint -c ../src/tools/rustdoc-js/.eslintrc.js ../src/tools/rustdoc-js/tester.js && \
|
||||
eslint -c ../src/tools/rustdoc-gui/.eslintrc.js ../src/tools/rustdoc-gui/tester.js
|
||||
|
||||
@ -9,6 +9,8 @@ path = "lib.rs"
|
||||
[dependencies]
|
||||
arrayvec = { version = "0.7", default-features = false }
|
||||
askama = { version = "0.12", default-features = false, features = ["config"] }
|
||||
base64 = "0.21.7"
|
||||
byteorder = "1.5"
|
||||
itertools = "0.12"
|
||||
indexmap = "2"
|
||||
minifier = "0.3.0"
|
||||
|
||||
@ -184,40 +184,15 @@ pub(crate) enum RenderTypeId {
|
||||
|
||||
impl RenderTypeId {
|
||||
pub fn write_to_string(&self, string: &mut String) {
|
||||
// (sign, value)
|
||||
let (sign, id): (bool, u32) = match &self {
|
||||
let id: i32 = match &self {
|
||||
// 0 is a sentinel, everything else is one-indexed
|
||||
// concrete type
|
||||
RenderTypeId::Index(idx) if *idx >= 0 => (false, (idx + 1isize).try_into().unwrap()),
|
||||
RenderTypeId::Index(idx) if *idx >= 0 => (idx + 1isize).try_into().unwrap(),
|
||||
// generic type parameter
|
||||
RenderTypeId::Index(idx) => (true, (-*idx).try_into().unwrap()),
|
||||
RenderTypeId::Index(idx) => (*idx).try_into().unwrap(),
|
||||
_ => panic!("must convert render types to indexes before serializing"),
|
||||
};
|
||||
// zig-zag encoding
|
||||
let value: u32 = (id << 1) | (if sign { 1 } else { 0 });
|
||||
// Self-terminating hex use capital letters for everything but the
|
||||
// least significant digit, which is lowercase. For example, decimal 17
|
||||
// would be `` Aa `` if zig-zag encoding weren't used.
|
||||
//
|
||||
// Zig-zag encoding, however, stores the sign bit as the last bit.
|
||||
// This means, in the last hexit, 1 is actually `c`, -1 is `b`
|
||||
// (`a` is the imaginary -0), and, because all the bits are shifted
|
||||
// by one, `` A` `` is actually 8 and `` Aa `` is -8.
|
||||
//
|
||||
// https://rust-lang.github.io/rustc-dev-guide/rustdoc-internals/search.html
|
||||
// describes the encoding in more detail.
|
||||
let mut shift: u32 = 28;
|
||||
let mut mask: u32 = 0xF0_00_00_00;
|
||||
while shift < 32 {
|
||||
let hexit = (value & mask) >> shift;
|
||||
if hexit != 0 || shift == 0 {
|
||||
let hex =
|
||||
char::try_from(if shift == 0 { '`' } else { '@' } as u32 + hexit).unwrap();
|
||||
string.push(hex);
|
||||
}
|
||||
shift = shift.wrapping_sub(4);
|
||||
mask = mask >> 4;
|
||||
}
|
||||
search_index::encode::write_vlqhex_to_string(id, string);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
pub(crate) mod encode;
|
||||
|
||||
use std::collections::hash_map::Entry;
|
||||
use std::collections::{BTreeMap, VecDeque};
|
||||
|
||||
@ -17,12 +19,46 @@ use crate::html::format::join_with_double_colon;
|
||||
use crate::html::markdown::short_markdown_summary;
|
||||
use crate::html::render::{self, IndexItem, IndexItemFunctionType, RenderType, RenderTypeId};
|
||||
|
||||
use encode::{bitmap_to_string, write_vlqhex_to_string};
|
||||
|
||||
/// The serialized search description sharded version
|
||||
///
|
||||
/// The `index` is a JSON-encoded list of names and other information.
|
||||
///
|
||||
/// The desc has newlined descriptions, split up by size into 128KiB shards.
|
||||
/// For example, `(4, "foo\nbar\nbaz\nquux")`.
|
||||
///
|
||||
/// There is no single, optimal size for these shards, because it depends on
|
||||
/// configuration values that we can't predict or control, such as the version
|
||||
/// of HTTP used (HTTP/1.1 would work better with larger files, while HTTP/2
|
||||
/// and 3 are more agnostic), transport compression (gzip, zstd, etc), whether
|
||||
/// the search query is going to produce a large number of results or a small
|
||||
/// number, the bandwidth delay product of the network...
|
||||
///
|
||||
/// Gzipping some standard library descriptions to guess what transport
|
||||
/// compression will do, the compressed file sizes can be as small as 4.9KiB
|
||||
/// or as large as 18KiB (ignoring the final 1.9KiB shard of leftovers).
|
||||
/// A "reasonable" range for files is for them to be bigger than 1KiB,
|
||||
/// since that's about the amount of data that can be transferred in a
|
||||
/// single TCP packet, and 64KiB, the maximum amount of data that
|
||||
/// TCP can transfer in a single round trip without extensions.
|
||||
///
|
||||
/// [1]: https://en.wikipedia.org/wiki/Maximum_transmission_unit#MTUs_for_common_media
|
||||
/// [2]: https://en.wikipedia.org/wiki/Sliding_window_protocol#Basic_concept
|
||||
/// [3]: https://learn.microsoft.com/en-us/troubleshoot/windows-server/networking/description-tcp-features
|
||||
pub(crate) struct SerializedSearchIndex {
|
||||
pub(crate) index: String,
|
||||
pub(crate) desc: Vec<(usize, String)>,
|
||||
}
|
||||
|
||||
const DESC_INDEX_SHARD_LEN: usize = 128 * 1024;
|
||||
|
||||
/// Builds the search index from the collected metadata
|
||||
pub(crate) fn build_index<'tcx>(
|
||||
krate: &clean::Crate,
|
||||
cache: &mut Cache,
|
||||
tcx: TyCtxt<'tcx>,
|
||||
) -> String {
|
||||
) -> SerializedSearchIndex {
|
||||
let mut itemid_to_pathid = FxHashMap::default();
|
||||
let mut primitives = FxHashMap::default();
|
||||
let mut associated_types = FxHashMap::default();
|
||||
@ -319,7 +355,6 @@ pub(crate) fn build_index<'tcx>(
|
||||
.collect::<Vec<_>>();
|
||||
|
||||
struct CrateData<'a> {
|
||||
doc: String,
|
||||
items: Vec<&'a IndexItem>,
|
||||
paths: Vec<(ItemType, Vec<Symbol>)>,
|
||||
// The String is alias name and the vec is the list of the elements with this alias.
|
||||
@ -328,6 +363,11 @@ pub(crate) fn build_index<'tcx>(
|
||||
aliases: &'a BTreeMap<String, Vec<usize>>,
|
||||
// Used when a type has more than one impl with an associated item with the same name.
|
||||
associated_item_disambiguators: &'a Vec<(usize, String)>,
|
||||
// A list of shard lengths encoded as vlqhex. See the comment in write_vlqhex_to_string
|
||||
// for information on the format.
|
||||
desc_index: String,
|
||||
// A list of items with no description. This is eventually turned into a bitmap.
|
||||
empty_desc: Vec<u32>,
|
||||
}
|
||||
|
||||
struct Paths {
|
||||
@ -409,7 +449,6 @@ pub(crate) fn build_index<'tcx>(
|
||||
let mut names = Vec::with_capacity(self.items.len());
|
||||
let mut types = String::with_capacity(self.items.len());
|
||||
let mut full_paths = Vec::with_capacity(self.items.len());
|
||||
let mut descriptions = Vec::with_capacity(self.items.len());
|
||||
let mut parents = Vec::with_capacity(self.items.len());
|
||||
let mut functions = String::with_capacity(self.items.len());
|
||||
let mut deprecated = Vec::with_capacity(self.items.len());
|
||||
@ -432,7 +471,6 @@ pub(crate) fn build_index<'tcx>(
|
||||
parents.push(item.parent_idx.map(|x| x + 1).unwrap_or(0));
|
||||
|
||||
names.push(item.name.as_str());
|
||||
descriptions.push(&item.desc);
|
||||
|
||||
if !item.path.is_empty() {
|
||||
full_paths.push((index, &item.path));
|
||||
@ -444,7 +482,8 @@ pub(crate) fn build_index<'tcx>(
|
||||
}
|
||||
|
||||
if item.deprecation.is_some() {
|
||||
deprecated.push(index);
|
||||
// bitmasks always use 1-indexing for items, with 0 as the crate itself
|
||||
deprecated.push(u32::try_from(index + 1).unwrap());
|
||||
}
|
||||
}
|
||||
|
||||
@ -455,17 +494,16 @@ pub(crate) fn build_index<'tcx>(
|
||||
let has_aliases = !self.aliases.is_empty();
|
||||
let mut crate_data =
|
||||
serializer.serialize_struct("CrateData", if has_aliases { 9 } else { 8 })?;
|
||||
crate_data.serialize_field("doc", &self.doc)?;
|
||||
crate_data.serialize_field("t", &types)?;
|
||||
crate_data.serialize_field("n", &names)?;
|
||||
// Serialize as an array of item indices and full paths
|
||||
crate_data.serialize_field("q", &full_paths)?;
|
||||
crate_data.serialize_field("d", &descriptions)?;
|
||||
crate_data.serialize_field("i", &parents)?;
|
||||
crate_data.serialize_field("f", &functions)?;
|
||||
crate_data.serialize_field("c", &deprecated)?;
|
||||
crate_data.serialize_field("D", &self.desc_index)?;
|
||||
crate_data.serialize_field("p", &paths)?;
|
||||
crate_data.serialize_field("b", &self.associated_item_disambiguators)?;
|
||||
crate_data.serialize_field("c", &bitmap_to_string(&deprecated))?;
|
||||
crate_data.serialize_field("e", &bitmap_to_string(&self.empty_desc))?;
|
||||
if has_aliases {
|
||||
crate_data.serialize_field("a", &self.aliases)?;
|
||||
}
|
||||
@ -473,16 +511,58 @@ pub(crate) fn build_index<'tcx>(
|
||||
}
|
||||
}
|
||||
|
||||
// Collect the index into a string
|
||||
format!(
|
||||
let (empty_desc, desc) = {
|
||||
let mut empty_desc = Vec::new();
|
||||
let mut result = Vec::new();
|
||||
let mut set = String::new();
|
||||
let mut len: usize = 0;
|
||||
let mut item_index: u32 = 0;
|
||||
for desc in std::iter::once(&crate_doc).chain(crate_items.iter().map(|item| &item.desc)) {
|
||||
if desc == "" {
|
||||
empty_desc.push(item_index);
|
||||
item_index += 1;
|
||||
continue;
|
||||
}
|
||||
if set.len() >= DESC_INDEX_SHARD_LEN {
|
||||
result.push((len, std::mem::replace(&mut set, String::new())));
|
||||
len = 0;
|
||||
} else if len != 0 {
|
||||
set.push('\n');
|
||||
}
|
||||
set.push_str(&desc);
|
||||
len += 1;
|
||||
item_index += 1;
|
||||
}
|
||||
result.push((len, std::mem::replace(&mut set, String::new())));
|
||||
(empty_desc, result)
|
||||
};
|
||||
|
||||
let desc_index = {
|
||||
let mut desc_index = String::with_capacity(desc.len() * 4);
|
||||
for &(len, _) in desc.iter() {
|
||||
write_vlqhex_to_string(len.try_into().unwrap(), &mut desc_index);
|
||||
}
|
||||
desc_index
|
||||
};
|
||||
|
||||
assert_eq!(
|
||||
crate_items.len() + 1,
|
||||
desc.iter().map(|(len, _)| *len).sum::<usize>() + empty_desc.len()
|
||||
);
|
||||
|
||||
// The index, which is actually used to search, is JSON
|
||||
// It uses `JSON.parse(..)` to actually load, since JSON
|
||||
// parses faster than the full JavaScript syntax.
|
||||
let index = format!(
|
||||
r#"["{}",{}]"#,
|
||||
krate.name(tcx),
|
||||
serde_json::to_string(&CrateData {
|
||||
doc: crate_doc,
|
||||
items: crate_items,
|
||||
paths: crate_paths,
|
||||
aliases: &aliases,
|
||||
associated_item_disambiguators: &associated_item_disambiguators,
|
||||
desc_index,
|
||||
empty_desc,
|
||||
})
|
||||
.expect("failed serde conversion")
|
||||
// All these `replace` calls are because we have to go through JS string for JSON content.
|
||||
@ -490,7 +570,8 @@ pub(crate) fn build_index<'tcx>(
|
||||
.replace('\'', r"\'")
|
||||
// We need to escape double quotes for the JSON.
|
||||
.replace("\\\"", "\\\\\"")
|
||||
)
|
||||
);
|
||||
SerializedSearchIndex { index, desc }
|
||||
}
|
||||
|
||||
pub(crate) fn get_function_type_for_search<'tcx>(
|
||||
|
||||
243
src/librustdoc/html/render/search_index/encode.rs
Normal file
243
src/librustdoc/html/render/search_index/encode.rs
Normal file
@ -0,0 +1,243 @@
|
||||
use base64::prelude::*;
|
||||
|
||||
pub(crate) fn write_vlqhex_to_string(n: i32, string: &mut String) {
|
||||
let (sign, magnitude): (bool, u32) =
|
||||
if n >= 0 { (false, n.try_into().unwrap()) } else { (true, (-n).try_into().unwrap()) };
|
||||
// zig-zag encoding
|
||||
let value: u32 = (magnitude << 1) | (if sign { 1 } else { 0 });
|
||||
// Self-terminating hex use capital letters for everything but the
|
||||
// least significant digit, which is lowercase. For example, decimal 17
|
||||
// would be `` Aa `` if zig-zag encoding weren't used.
|
||||
//
|
||||
// Zig-zag encoding, however, stores the sign bit as the last bit.
|
||||
// This means, in the last hexit, 1 is actually `c`, -1 is `b`
|
||||
// (`a` is the imaginary -0), and, because all the bits are shifted
|
||||
// by one, `` A` `` is actually 8 and `` Aa `` is -8.
|
||||
//
|
||||
// https://rust-lang.github.io/rustc-dev-guide/rustdoc-internals/search.html
|
||||
// describes the encoding in more detail.
|
||||
let mut shift: u32 = 28;
|
||||
let mut mask: u32 = 0xF0_00_00_00;
|
||||
// first skip leading zeroes
|
||||
while shift < 32 {
|
||||
let hexit = (value & mask) >> shift;
|
||||
if hexit != 0 || shift == 0 {
|
||||
break;
|
||||
}
|
||||
shift = shift.wrapping_sub(4);
|
||||
mask = mask >> 4;
|
||||
}
|
||||
// now write the rest
|
||||
while shift < 32 {
|
||||
let hexit = (value & mask) >> shift;
|
||||
let hex = char::try_from(if shift == 0 { '`' } else { '@' } as u32 + hexit).unwrap();
|
||||
string.push(hex);
|
||||
shift = shift.wrapping_sub(4);
|
||||
mask = mask >> 4;
|
||||
}
|
||||
}
|
||||
|
||||
// Used during bitmap encoding
|
||||
enum Container {
|
||||
/// number of ones, bits
|
||||
Bits(Box<[u64; 1024]>),
|
||||
/// list of entries
|
||||
Array(Vec<u16>),
|
||||
/// list of (start, len-1)
|
||||
Run(Vec<(u16, u16)>),
|
||||
}
|
||||
impl Container {
|
||||
fn popcount(&self) -> u32 {
|
||||
match self {
|
||||
Container::Bits(bits) => bits.iter().copied().map(|x| x.count_ones()).sum(),
|
||||
Container::Array(array) => {
|
||||
array.len().try_into().expect("array can't be bigger than 2**32")
|
||||
}
|
||||
Container::Run(runs) => {
|
||||
runs.iter().copied().map(|(_, lenm1)| u32::from(lenm1) + 1).sum()
|
||||
}
|
||||
}
|
||||
}
|
||||
fn push(&mut self, value: u16) {
|
||||
match self {
|
||||
Container::Bits(bits) => bits[value as usize >> 6] |= 1 << (value & 0x3F),
|
||||
Container::Array(array) => {
|
||||
array.push(value);
|
||||
if array.len() >= 4096 {
|
||||
let array = std::mem::replace(array, Vec::new());
|
||||
*self = Container::Bits(Box::new([0; 1024]));
|
||||
for value in array {
|
||||
self.push(value);
|
||||
}
|
||||
}
|
||||
}
|
||||
Container::Run(runs) => {
|
||||
if let Some(r) = runs.last_mut()
|
||||
&& r.0 + r.1 + 1 == value
|
||||
{
|
||||
r.1 += 1;
|
||||
} else {
|
||||
runs.push((value, 0));
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
fn try_make_run(&mut self) -> bool {
|
||||
match self {
|
||||
Container::Bits(bits) => {
|
||||
let mut r: u64 = 0;
|
||||
for (i, chunk) in bits.iter().copied().enumerate() {
|
||||
let next_chunk =
|
||||
i.checked_add(1).and_then(|i| bits.get(i)).copied().unwrap_or(0);
|
||||
r += !chunk & u64::from((chunk << 1).count_ones());
|
||||
r += !next_chunk & u64::from((chunk >> 63).count_ones());
|
||||
}
|
||||
if (2 + 4 * r) >= 8192 {
|
||||
return false;
|
||||
}
|
||||
let bits = std::mem::replace(bits, Box::new([0; 1024]));
|
||||
*self = Container::Run(Vec::new());
|
||||
for (i, bits) in bits.iter().copied().enumerate() {
|
||||
if bits == 0 {
|
||||
continue;
|
||||
}
|
||||
for j in 0..64 {
|
||||
let value = (u16::try_from(i).unwrap() << 6) | j;
|
||||
if bits & (1 << j) != 0 {
|
||||
self.push(value);
|
||||
}
|
||||
}
|
||||
}
|
||||
true
|
||||
}
|
||||
Container::Array(array) if array.len() <= 5 => false,
|
||||
Container::Array(array) => {
|
||||
let mut r = 0;
|
||||
let mut prev = None;
|
||||
for value in array.iter().copied() {
|
||||
if value.checked_sub(1) != prev {
|
||||
r += 1;
|
||||
}
|
||||
prev = Some(value);
|
||||
}
|
||||
if 2 + 4 * r >= 2 * array.len() + 2 {
|
||||
return false;
|
||||
}
|
||||
let array = std::mem::replace(array, Vec::new());
|
||||
*self = Container::Run(Vec::new());
|
||||
for value in array {
|
||||
self.push(value);
|
||||
}
|
||||
true
|
||||
}
|
||||
Container::Run(_) => true,
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
// checked against roaring-rs in
|
||||
// https://gitlab.com/notriddle/roaring-test
|
||||
pub(crate) fn write_bitmap_to_bytes(
|
||||
domain: &[u32],
|
||||
mut out: impl std::io::Write,
|
||||
) -> std::io::Result<()> {
|
||||
// https://arxiv.org/pdf/1603.06549.pdf
|
||||
let mut keys = Vec::<u16>::new();
|
||||
let mut containers = Vec::<Container>::new();
|
||||
let mut key: u16;
|
||||
let mut domain_iter = domain.into_iter().copied().peekable();
|
||||
let mut has_run = false;
|
||||
while let Some(entry) = domain_iter.next() {
|
||||
key = (entry >> 16).try_into().expect("shifted off the top 16 bits, so it should fit");
|
||||
let value: u16 = (entry & 0x00_00_FF_FF).try_into().expect("AND 16 bits, so it should fit");
|
||||
let mut container = Container::Array(vec![value]);
|
||||
while let Some(entry) = domain_iter.peek().copied() {
|
||||
let entry_key: u16 =
|
||||
(entry >> 16).try_into().expect("shifted off the top 16 bits, so it should fit");
|
||||
if entry_key != key {
|
||||
break;
|
||||
}
|
||||
domain_iter.next().expect("peeking just succeeded");
|
||||
container
|
||||
.push((entry & 0x00_00_FF_FF).try_into().expect("AND 16 bits, so it should fit"));
|
||||
}
|
||||
keys.push(key);
|
||||
has_run = container.try_make_run() || has_run;
|
||||
containers.push(container);
|
||||
}
|
||||
// https://github.com/RoaringBitmap/RoaringFormatSpec
|
||||
use byteorder::{WriteBytesExt, LE};
|
||||
const SERIAL_COOKIE_NO_RUNCONTAINER: u32 = 12346;
|
||||
const SERIAL_COOKIE: u32 = 12347;
|
||||
const NO_OFFSET_THRESHOLD: u32 = 4;
|
||||
let size: u32 = containers.len().try_into().unwrap();
|
||||
let start_offset = if has_run {
|
||||
out.write_u32::<LE>(SERIAL_COOKIE | ((size - 1) << 16))?;
|
||||
for set in containers.chunks(8) {
|
||||
let mut b = 0;
|
||||
for (i, container) in set.iter().enumerate() {
|
||||
if matches!(container, &Container::Run(..)) {
|
||||
b |= 1 << i;
|
||||
}
|
||||
}
|
||||
out.write_u8(b)?;
|
||||
}
|
||||
if size < NO_OFFSET_THRESHOLD {
|
||||
4 + 4 * size + ((size + 7) / 8)
|
||||
} else {
|
||||
4 + 8 * size + ((size + 7) / 8)
|
||||
}
|
||||
} else {
|
||||
out.write_u32::<LE>(SERIAL_COOKIE_NO_RUNCONTAINER)?;
|
||||
out.write_u32::<LE>(containers.len().try_into().unwrap())?;
|
||||
4 + 4 + 4 * size + 4 * size
|
||||
};
|
||||
for (&key, container) in keys.iter().zip(&containers) {
|
||||
// descriptive header
|
||||
let key: u32 = key.into();
|
||||
let count: u32 = container.popcount() - 1;
|
||||
out.write_u32::<LE>((count << 16) | key)?;
|
||||
}
|
||||
if !has_run || size >= NO_OFFSET_THRESHOLD {
|
||||
// offset header
|
||||
let mut starting_offset = start_offset;
|
||||
for container in &containers {
|
||||
out.write_u32::<LE>(starting_offset)?;
|
||||
starting_offset += match container {
|
||||
Container::Bits(_) => 8192u32,
|
||||
Container::Array(array) => u32::try_from(array.len()).unwrap() * 2,
|
||||
Container::Run(runs) => 2 + u32::try_from(runs.len()).unwrap() * 4,
|
||||
};
|
||||
}
|
||||
}
|
||||
for container in &containers {
|
||||
match container {
|
||||
Container::Bits(bits) => {
|
||||
for chunk in bits.iter() {
|
||||
out.write_u64::<LE>(*chunk)?;
|
||||
}
|
||||
}
|
||||
Container::Array(array) => {
|
||||
for value in array.iter() {
|
||||
out.write_u16::<LE>(*value)?;
|
||||
}
|
||||
}
|
||||
Container::Run(runs) => {
|
||||
out.write_u16::<LE>((runs.len()).try_into().unwrap())?;
|
||||
for (start, lenm1) in runs.iter().copied() {
|
||||
out.write_u16::<LE>(start)?;
|
||||
out.write_u16::<LE>(lenm1)?;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
Ok(())
|
||||
}
|
||||
|
||||
pub(crate) fn bitmap_to_string(domain: &[u32]) -> String {
|
||||
let mut buf = Vec::new();
|
||||
let mut strbuf = String::new();
|
||||
write_bitmap_to_bytes(&domain, &mut buf).unwrap();
|
||||
BASE64_STANDARD.encode_string(&buf, &mut strbuf);
|
||||
strbuf
|
||||
}
|
||||
@ -24,6 +24,7 @@ use crate::formats::cache::Cache;
|
||||
use crate::formats::item_type::ItemType;
|
||||
use crate::formats::Impl;
|
||||
use crate::html::format::Buffer;
|
||||
use crate::html::render::search_index::SerializedSearchIndex;
|
||||
use crate::html::render::{AssocItemLink, ImplRenderingParameters};
|
||||
use crate::html::{layout, static_files};
|
||||
use crate::visit::DocVisitor;
|
||||
@ -46,7 +47,7 @@ use crate::{try_err, try_none};
|
||||
pub(super) fn write_shared(
|
||||
cx: &mut Context<'_>,
|
||||
krate: &Crate,
|
||||
search_index: String,
|
||||
search_index: SerializedSearchIndex,
|
||||
options: &RenderOptions,
|
||||
) -> Result<(), Error> {
|
||||
// Write out the shared files. Note that these are shared among all rustdoc
|
||||
@ -312,7 +313,7 @@ pub(super) fn write_shared(
|
||||
let dst = cx.dst.join(&format!("search-index{}.js", cx.shared.resource_suffix));
|
||||
let (mut all_indexes, mut krates) =
|
||||
try_err!(collect_json(&dst, krate.name(cx.tcx()).as_str()), &dst);
|
||||
all_indexes.push(search_index);
|
||||
all_indexes.push(search_index.index);
|
||||
krates.push(krate.name(cx.tcx()).to_string());
|
||||
krates.sort();
|
||||
|
||||
@ -335,6 +336,32 @@ else if (window.initSearch) window.initSearch(searchIndex);
|
||||
Ok(v.into_bytes())
|
||||
})?;
|
||||
|
||||
let search_desc_dir = cx.dst.join(format!("search.desc/{krate}", krate = krate.name(cx.tcx())));
|
||||
if Path::new(&search_desc_dir).exists() {
|
||||
try_err!(std::fs::remove_dir_all(&search_desc_dir), &search_desc_dir);
|
||||
}
|
||||
try_err!(std::fs::create_dir_all(&search_desc_dir), &search_desc_dir);
|
||||
let kratename = krate.name(cx.tcx()).to_string();
|
||||
for (i, (_, data)) in search_index.desc.into_iter().enumerate() {
|
||||
let output_filename = static_files::suffix_path(
|
||||
&format!("{kratename}-desc-{i}-.js"),
|
||||
&cx.shared.resource_suffix,
|
||||
);
|
||||
let path = search_desc_dir.join(output_filename);
|
||||
try_err!(
|
||||
std::fs::write(
|
||||
&path,
|
||||
&format!(
|
||||
r##"searchState.loadedDescShard({kratename}, {i}, {data})"##,
|
||||
kratename = serde_json::to_string(&kratename).unwrap(),
|
||||
data = serde_json::to_string(&data).unwrap(),
|
||||
)
|
||||
.into_bytes()
|
||||
),
|
||||
&path
|
||||
);
|
||||
}
|
||||
|
||||
write_invocation_specific("crates.js", &|| {
|
||||
let krates = krates.iter().map(|k| format!("\"{k}\"")).join(",");
|
||||
Ok(format!("window.ALL_CRATES = [{krates}];").into_bytes())
|
||||
|
||||
@ -5,7 +5,7 @@ module.exports = {
|
||||
},
|
||||
"extends": "eslint:recommended",
|
||||
"parserOptions": {
|
||||
"ecmaVersion": 2015,
|
||||
"ecmaVersion": 8,
|
||||
"sourceType": "module"
|
||||
},
|
||||
"rules": {
|
||||
|
||||
@ -329,6 +329,30 @@ function preLoadCss(cssUrl) {
|
||||
search.innerHTML = "<h3 class=\"search-loading\">" + searchState.loadingText + "</h3>";
|
||||
searchState.showResults(search);
|
||||
},
|
||||
descShards: new Map(),
|
||||
loadDesc: async function({descShard, descIndex}) {
|
||||
if (descShard.promise === null) {
|
||||
descShard.promise = new Promise((resolve, reject) => {
|
||||
// The `resolve` callback is stored in the `descShard`
|
||||
// object, which is itself stored in `this.descShards` map.
|
||||
// It is called in `loadedDescShard` by the
|
||||
// search.desc script.
|
||||
descShard.resolve = resolve;
|
||||
const ds = descShard;
|
||||
const fname = `${ds.crate}-desc-${ds.shard}-`;
|
||||
const url = resourcePath(
|
||||
`search.desc/${descShard.crate}/${fname}`,
|
||||
".js",
|
||||
);
|
||||
loadScript(url, reject);
|
||||
});
|
||||
}
|
||||
const list = await descShard.promise;
|
||||
return list[descIndex];
|
||||
},
|
||||
loadedDescShard: function(crate, shard, data) {
|
||||
this.descShards.get(crate)[shard].resolve(data.split("\n"));
|
||||
},
|
||||
};
|
||||
|
||||
const toggleAllDocsId = "toggle-all-docs";
|
||||
@ -381,7 +405,7 @@ function preLoadCss(cssUrl) {
|
||||
window.location.replace("#" + item.id);
|
||||
}, 0);
|
||||
}
|
||||
}
|
||||
},
|
||||
);
|
||||
}
|
||||
}
|
||||
@ -585,7 +609,7 @@ function preLoadCss(cssUrl) {
|
||||
const script = document
|
||||
.querySelector("script[data-ignore-extern-crates]");
|
||||
const ignoreExternCrates = new Set(
|
||||
(script ? script.getAttribute("data-ignore-extern-crates") : "").split(",")
|
||||
(script ? script.getAttribute("data-ignore-extern-crates") : "").split(","),
|
||||
);
|
||||
for (const lib of libs) {
|
||||
if (lib === window.currentCrate || ignoreExternCrates.has(lib)) {
|
||||
@ -1098,7 +1122,7 @@ function preLoadCss(cssUrl) {
|
||||
} else {
|
||||
wrapper.style.setProperty(
|
||||
"--popover-arrow-offset",
|
||||
(wrapperPos.right - pos.right + 4) + "px"
|
||||
(wrapperPos.right - pos.right + 4) + "px",
|
||||
);
|
||||
}
|
||||
wrapper.style.visibility = "";
|
||||
@ -1680,7 +1704,7 @@ href="https://doc.rust-lang.org/${channel}/rustdoc/read-documentation/search.htm
|
||||
pendingSidebarResizingFrame = false;
|
||||
document.documentElement.style.setProperty(
|
||||
"--resizing-sidebar-width",
|
||||
desiredSidebarSize + "px"
|
||||
desiredSidebarSize + "px",
|
||||
);
|
||||
}, 100);
|
||||
}
|
||||
|
||||
@ -206,14 +206,14 @@ const editDistanceState = {
|
||||
// insertion
|
||||
this.current[j - 1] + 1,
|
||||
// substitution
|
||||
this.prev[j - 1] + substitutionCost
|
||||
this.prev[j - 1] + substitutionCost,
|
||||
);
|
||||
|
||||
if ((i > 1) && (j > 1) && (a[aIdx] === b[bIdx - 1]) && (a[aIdx - 1] === b[bIdx])) {
|
||||
// transposition
|
||||
this.current[j] = Math.min(
|
||||
this.current[j],
|
||||
this.prevPrev[j - 2] + 1
|
||||
this.prevPrev[j - 2] + 1,
|
||||
);
|
||||
}
|
||||
}
|
||||
@ -242,6 +242,14 @@ function initSearch(rawSearchIndex) {
|
||||
* @type {Array<Row>}
|
||||
*/
|
||||
let searchIndex;
|
||||
/**
|
||||
* @type {Map<String, RoaringBitmap>}
|
||||
*/
|
||||
let searchIndexDeprecated;
|
||||
/**
|
||||
* @type {Map<String, RoaringBitmap>}
|
||||
*/
|
||||
let searchIndexEmptyDesc;
|
||||
/**
|
||||
* @type {Uint32Array}
|
||||
*/
|
||||
@ -426,7 +434,7 @@ function initSearch(rawSearchIndex) {
|
||||
return c === "," || c === "=";
|
||||
}
|
||||
|
||||
/**
|
||||
/**
|
||||
* Returns `true` if the given `c` character is a path separator. For example
|
||||
* `:` in `a::b` or a whitespace in `a b`.
|
||||
*
|
||||
@ -856,8 +864,8 @@ function initSearch(rawSearchIndex) {
|
||||
parserState,
|
||||
parserState.userQuery.slice(start, end),
|
||||
generics,
|
||||
isInGenerics
|
||||
)
|
||||
isInGenerics,
|
||||
),
|
||||
);
|
||||
}
|
||||
}
|
||||
@ -1295,7 +1303,7 @@ function initSearch(rawSearchIndex) {
|
||||
*
|
||||
* @return {ResultsTable}
|
||||
*/
|
||||
function execQuery(parsedQuery, filterCrates, currentCrate) {
|
||||
async function execQuery(parsedQuery, filterCrates, currentCrate) {
|
||||
const results_others = new Map(), results_in_args = new Map(),
|
||||
results_returned = new Map();
|
||||
|
||||
@ -1342,9 +1350,9 @@ function initSearch(rawSearchIndex) {
|
||||
* @param {Results} results
|
||||
* @param {boolean} isType
|
||||
* @param {string} preferredCrate
|
||||
* @returns {[ResultObject]}
|
||||
* @returns {Promise<[ResultObject]>}
|
||||
*/
|
||||
function sortResults(results, isType, preferredCrate) {
|
||||
async function sortResults(results, isType, preferredCrate) {
|
||||
const userQuery = parsedQuery.userQuery;
|
||||
const result_list = [];
|
||||
for (const result of results.values()) {
|
||||
@ -1394,8 +1402,8 @@ function initSearch(rawSearchIndex) {
|
||||
}
|
||||
|
||||
// sort deprecated items later
|
||||
a = aaa.item.deprecated;
|
||||
b = bbb.item.deprecated;
|
||||
a = searchIndexDeprecated.get(aaa.item.crate).contains(aaa.item.bitIndex);
|
||||
b = searchIndexDeprecated.get(bbb.item.crate).contains(bbb.item.bitIndex);
|
||||
if (a !== b) {
|
||||
return a - b;
|
||||
}
|
||||
@ -1422,8 +1430,8 @@ function initSearch(rawSearchIndex) {
|
||||
}
|
||||
|
||||
// sort by description (no description goes later)
|
||||
a = (aaa.item.desc === "");
|
||||
b = (bbb.item.desc === "");
|
||||
a = searchIndexEmptyDesc.get(aaa.item.crate).contains(aaa.item.bitIndex);
|
||||
b = searchIndexEmptyDesc.get(bbb.item.crate).contains(bbb.item.bitIndex);
|
||||
if (a !== b) {
|
||||
return a - b;
|
||||
}
|
||||
@ -1446,7 +1454,16 @@ function initSearch(rawSearchIndex) {
|
||||
return 0;
|
||||
});
|
||||
|
||||
return transformResults(result_list);
|
||||
const transformed = transformResults(result_list);
|
||||
const descs = await Promise.all(transformed.map(result => {
|
||||
return searchIndexEmptyDesc.get(result.crate).contains(result.bitIndex) ?
|
||||
"" :
|
||||
searchState.loadDesc(result);
|
||||
}));
|
||||
for (const [i, result] of transformed.entries()) {
|
||||
result.desc = descs[i];
|
||||
}
|
||||
return transformed;
|
||||
}
|
||||
|
||||
/**
|
||||
@ -1477,7 +1494,7 @@ function initSearch(rawSearchIndex) {
|
||||
whereClause,
|
||||
mgensIn,
|
||||
solutionCb,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
) {
|
||||
if (unboxingDepth >= UNBOXING_LIMIT) {
|
||||
return false;
|
||||
@ -1524,7 +1541,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
)) {
|
||||
continue;
|
||||
}
|
||||
@ -1541,7 +1558,7 @@ function initSearch(rawSearchIndex) {
|
||||
whereClause,
|
||||
mgensScratch,
|
||||
solutionCb,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
)) {
|
||||
return true;
|
||||
}
|
||||
@ -1551,7 +1568,7 @@ function initSearch(rawSearchIndex) {
|
||||
whereClause,
|
||||
mgens ? new Map(mgens) : null,
|
||||
solutionCb,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
)) {
|
||||
return true;
|
||||
}
|
||||
@ -1625,7 +1642,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgensScratch,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
if (!solution) {
|
||||
return false;
|
||||
@ -1638,7 +1655,7 @@ function initSearch(rawSearchIndex) {
|
||||
whereClause,
|
||||
simplifiedMgens,
|
||||
solutionCb,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
if (passesUnification) {
|
||||
return true;
|
||||
@ -1646,7 +1663,7 @@ function initSearch(rawSearchIndex) {
|
||||
}
|
||||
return false;
|
||||
},
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
if (passesUnification) {
|
||||
return true;
|
||||
@ -1663,7 +1680,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
)) {
|
||||
continue;
|
||||
}
|
||||
@ -1689,7 +1706,7 @@ function initSearch(rawSearchIndex) {
|
||||
whereClause,
|
||||
mgensScratch,
|
||||
solutionCb,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
);
|
||||
if (passesUnification) {
|
||||
return true;
|
||||
@ -1820,7 +1837,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgensIn,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
) {
|
||||
if (fnType.bindings.size < queryElem.bindings.size) {
|
||||
return false;
|
||||
@ -1849,7 +1866,7 @@ function initSearch(rawSearchIndex) {
|
||||
// possible solutions
|
||||
return false;
|
||||
},
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
return newSolutions;
|
||||
});
|
||||
@ -1887,7 +1904,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
) {
|
||||
if (unboxingDepth >= UNBOXING_LIMIT) {
|
||||
return false;
|
||||
@ -1914,7 +1931,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgensTmp,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
} else if (fnType.generics.length > 0 || fnType.bindings.size > 0) {
|
||||
const simplifiedGenerics = [
|
||||
@ -1926,7 +1943,7 @@ function initSearch(rawSearchIndex) {
|
||||
queryElem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
}
|
||||
return false;
|
||||
@ -1975,7 +1992,7 @@ function initSearch(rawSearchIndex) {
|
||||
elem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth + 1
|
||||
unboxingDepth + 1,
|
||||
);
|
||||
}
|
||||
if (row.id > 0 && elem.id > 0 && elem.pathWithoutLast.length === 0 &&
|
||||
@ -1989,7 +2006,7 @@ function initSearch(rawSearchIndex) {
|
||||
elem,
|
||||
whereClause,
|
||||
mgens,
|
||||
unboxingDepth
|
||||
unboxingDepth,
|
||||
);
|
||||
}
|
||||
}
|
||||
@ -2007,7 +2024,7 @@ function initSearch(rawSearchIndex) {
|
||||
return 0;
|
||||
}
|
||||
const maxPathEditDistance = Math.floor(
|
||||
contains.reduce((acc, next) => acc + next.length, 0) / 3
|
||||
contains.reduce((acc, next) => acc + next.length, 0) / 3,
|
||||
);
|
||||
let ret_dist = maxPathEditDistance + 1;
|
||||
const path = ty.path.split("::");
|
||||
@ -2066,12 +2083,13 @@ function initSearch(rawSearchIndex) {
|
||||
crate: item.crate,
|
||||
name: item.name,
|
||||
path: item.path,
|
||||
desc: item.desc,
|
||||
descShard: item.descShard,
|
||||
descIndex: item.descIndex,
|
||||
ty: item.ty,
|
||||
parent: item.parent,
|
||||
type: item.type,
|
||||
is_alias: true,
|
||||
deprecated: item.deprecated,
|
||||
bitIndex: item.bitIndex,
|
||||
implDisambiguator: item.implDisambiguator,
|
||||
};
|
||||
}
|
||||
@ -2192,7 +2210,7 @@ function initSearch(rawSearchIndex) {
|
||||
results_others,
|
||||
results_in_args,
|
||||
results_returned,
|
||||
maxEditDistance
|
||||
maxEditDistance,
|
||||
) {
|
||||
if (!row || (filterCrates !== null && row.crate !== filterCrates)) {
|
||||
return;
|
||||
@ -2204,7 +2222,7 @@ function initSearch(rawSearchIndex) {
|
||||
// atoms in the function not present in the query
|
||||
const tfpDist = compareTypeFingerprints(
|
||||
fullId,
|
||||
parsedQuery.typeFingerprint
|
||||
parsedQuery.typeFingerprint,
|
||||
);
|
||||
if (tfpDist !== null) {
|
||||
const in_args = row.type && row.type.inputs
|
||||
@ -2276,7 +2294,7 @@ function initSearch(rawSearchIndex) {
|
||||
|
||||
const tfpDist = compareTypeFingerprints(
|
||||
row.id,
|
||||
parsedQuery.typeFingerprint
|
||||
parsedQuery.typeFingerprint,
|
||||
);
|
||||
if (tfpDist === null) {
|
||||
return;
|
||||
@ -2298,10 +2316,10 @@ function initSearch(rawSearchIndex) {
|
||||
row.type.where_clause,
|
||||
mgens,
|
||||
null,
|
||||
0 // unboxing depth
|
||||
0, // unboxing depth
|
||||
);
|
||||
},
|
||||
0 // unboxing depth
|
||||
0, // unboxing depth
|
||||
)) {
|
||||
return;
|
||||
}
|
||||
@ -2419,7 +2437,7 @@ function initSearch(rawSearchIndex) {
|
||||
}
|
||||
|
||||
return [typeNameIdMap.get(name).id, constraints];
|
||||
})
|
||||
}),
|
||||
);
|
||||
}
|
||||
|
||||
@ -2446,7 +2464,7 @@ function initSearch(rawSearchIndex) {
|
||||
results_others,
|
||||
results_in_args,
|
||||
results_returned,
|
||||
maxEditDistance
|
||||
maxEditDistance,
|
||||
);
|
||||
}
|
||||
}
|
||||
@ -2477,10 +2495,15 @@ function initSearch(rawSearchIndex) {
|
||||
innerRunQuery();
|
||||
}
|
||||
|
||||
const ret = createQueryResults(
|
||||
const [sorted_in_args, sorted_returned, sorted_others] = await Promise.all([
|
||||
sortResults(results_in_args, true, currentCrate),
|
||||
sortResults(results_returned, true, currentCrate),
|
||||
sortResults(results_others, false, currentCrate),
|
||||
]);
|
||||
const ret = createQueryResults(
|
||||
sorted_in_args,
|
||||
sorted_returned,
|
||||
sorted_others,
|
||||
parsedQuery);
|
||||
handleAliases(ret, parsedQuery.original.replace(/"/g, ""), filterCrates, currentCrate);
|
||||
if (parsedQuery.error !== null && ret.others.length !== 0) {
|
||||
@ -2581,14 +2604,14 @@ function initSearch(rawSearchIndex) {
|
||||
* @param {ParsedQuery} query
|
||||
* @param {boolean} display - True if this is the active tab
|
||||
*/
|
||||
function addTab(array, query, display) {
|
||||
async function addTab(array, query, display) {
|
||||
const extraClass = display ? " active" : "";
|
||||
|
||||
const output = document.createElement("div");
|
||||
if (array.length > 0) {
|
||||
output.className = "search-results " + extraClass;
|
||||
|
||||
array.forEach(item => {
|
||||
for (const item of array) {
|
||||
const name = item.name;
|
||||
const type = itemTypes[item.ty];
|
||||
const longType = longItemTypes[item.ty];
|
||||
@ -2624,7 +2647,7 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
|
||||
link.appendChild(description);
|
||||
output.appendChild(link);
|
||||
});
|
||||
}
|
||||
} else if (query.error === null) {
|
||||
output.className = "search-failed" + extraClass;
|
||||
output.innerHTML = "No results :(<br/>" +
|
||||
@ -2666,7 +2689,7 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
* @param {boolean} go_to_first
|
||||
* @param {string} filterCrates
|
||||
*/
|
||||
function showResults(results, go_to_first, filterCrates) {
|
||||
async function showResults(results, go_to_first, filterCrates) {
|
||||
const search = searchState.outputElement();
|
||||
if (go_to_first || (results.others.length === 1
|
||||
&& getSettingValue("go-to-only-result") === "true")
|
||||
@ -2699,9 +2722,11 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
|
||||
currentResults = results.query.userQuery;
|
||||
|
||||
const ret_others = addTab(results.others, results.query, true);
|
||||
const ret_in_args = addTab(results.in_args, results.query, false);
|
||||
const ret_returned = addTab(results.returned, results.query, false);
|
||||
const [ret_others, ret_in_args, ret_returned] = await Promise.all([
|
||||
addTab(results.others, results.query, true),
|
||||
addTab(results.in_args, results.query, false),
|
||||
addTab(results.returned, results.query, false),
|
||||
]);
|
||||
|
||||
// Navigate to the relevant tab if the current tab is empty, like in case users search
|
||||
// for "-> String". If they had selected another tab previously, they have to click on
|
||||
@ -2822,7 +2847,7 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
* and display the results.
|
||||
* @param {boolean} [forced]
|
||||
*/
|
||||
function search(forced) {
|
||||
async function search(forced) {
|
||||
const query = parseQuery(searchState.input.value.trim());
|
||||
let filterCrates = getFilterCrates();
|
||||
|
||||
@ -2850,8 +2875,8 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
// recent search query is added to the browser history.
|
||||
updateSearchHistory(buildUrl(query.original, filterCrates));
|
||||
|
||||
showResults(
|
||||
execQuery(query, filterCrates, window.currentCrate),
|
||||
await showResults(
|
||||
await execQuery(query, filterCrates, window.currentCrate),
|
||||
params.go_to_first,
|
||||
filterCrates);
|
||||
}
|
||||
@ -2920,7 +2945,7 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
pathIndex = type[PATH_INDEX_DATA];
|
||||
generics = buildItemSearchTypeAll(
|
||||
type[GENERICS_DATA],
|
||||
lowercasePaths
|
||||
lowercasePaths,
|
||||
);
|
||||
if (type.length > BINDINGS_DATA && type[BINDINGS_DATA].length > 0) {
|
||||
bindings = new Map(type[BINDINGS_DATA].map(binding => {
|
||||
@ -3030,101 +3055,49 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
* The raw function search type format is generated using serde in
|
||||
* librustdoc/html/render/mod.rs: IndexItemFunctionType::write_to_string
|
||||
*
|
||||
* @param {{
|
||||
* string: string,
|
||||
* offset: number,
|
||||
* backrefQueue: FunctionSearchType[]
|
||||
* }} itemFunctionDecoder
|
||||
* @param {Array<{name: string, ty: number}>} lowercasePaths
|
||||
* @param {Map<string, integer>}
|
||||
*
|
||||
* @return {null|FunctionSearchType}
|
||||
*/
|
||||
function buildFunctionSearchType(itemFunctionDecoder, lowercasePaths) {
|
||||
const c = itemFunctionDecoder.string.charCodeAt(itemFunctionDecoder.offset);
|
||||
itemFunctionDecoder.offset += 1;
|
||||
const [zero, ua, la, ob, cb] = ["0", "@", "`", "{", "}"].map(c => c.charCodeAt(0));
|
||||
// `` ` `` is used as a sentinel because it's fewer bytes than `null`, and decodes to zero
|
||||
// `0` is a backref
|
||||
if (c === la) {
|
||||
return null;
|
||||
}
|
||||
// sixteen characters after "0" are backref
|
||||
if (c >= zero && c < ua) {
|
||||
return itemFunctionDecoder.backrefQueue[c - zero];
|
||||
}
|
||||
if (c !== ob) {
|
||||
throw ["Unexpected ", c, " in function: expected ", "{", "; this is a bug"];
|
||||
}
|
||||
// call after consuming `{`
|
||||
function decodeList() {
|
||||
let c = itemFunctionDecoder.string.charCodeAt(itemFunctionDecoder.offset);
|
||||
const ret = [];
|
||||
while (c !== cb) {
|
||||
ret.push(decode());
|
||||
c = itemFunctionDecoder.string.charCodeAt(itemFunctionDecoder.offset);
|
||||
function buildFunctionSearchTypeCallback(lowercasePaths) {
|
||||
return functionSearchType => {
|
||||
if (functionSearchType === 0) {
|
||||
return null;
|
||||
}
|
||||
itemFunctionDecoder.offset += 1; // eat cb
|
||||
return ret;
|
||||
}
|
||||
// consumes and returns a list or integer
|
||||
function decode() {
|
||||
let n = 0;
|
||||
let c = itemFunctionDecoder.string.charCodeAt(itemFunctionDecoder.offset);
|
||||
if (c === ob) {
|
||||
itemFunctionDecoder.offset += 1;
|
||||
return decodeList();
|
||||
}
|
||||
while (c < la) {
|
||||
n = (n << 4) | (c & 0xF);
|
||||
itemFunctionDecoder.offset += 1;
|
||||
c = itemFunctionDecoder.string.charCodeAt(itemFunctionDecoder.offset);
|
||||
}
|
||||
// last character >= la
|
||||
n = (n << 4) | (c & 0xF);
|
||||
const [sign, value] = [n & 1, n >> 1];
|
||||
itemFunctionDecoder.offset += 1;
|
||||
return sign ? -value : value;
|
||||
}
|
||||
const functionSearchType = decodeList();
|
||||
const INPUTS_DATA = 0;
|
||||
const OUTPUT_DATA = 1;
|
||||
let inputs, output;
|
||||
if (typeof functionSearchType[INPUTS_DATA] === "number") {
|
||||
inputs = [buildItemSearchType(functionSearchType[INPUTS_DATA], lowercasePaths)];
|
||||
} else {
|
||||
inputs = buildItemSearchTypeAll(
|
||||
functionSearchType[INPUTS_DATA],
|
||||
lowercasePaths
|
||||
);
|
||||
}
|
||||
if (functionSearchType.length > 1) {
|
||||
if (typeof functionSearchType[OUTPUT_DATA] === "number") {
|
||||
output = [buildItemSearchType(functionSearchType[OUTPUT_DATA], lowercasePaths)];
|
||||
const INPUTS_DATA = 0;
|
||||
const OUTPUT_DATA = 1;
|
||||
let inputs, output;
|
||||
if (typeof functionSearchType[INPUTS_DATA] === "number") {
|
||||
inputs = [buildItemSearchType(functionSearchType[INPUTS_DATA], lowercasePaths)];
|
||||
} else {
|
||||
output = buildItemSearchTypeAll(
|
||||
functionSearchType[OUTPUT_DATA],
|
||||
lowercasePaths
|
||||
inputs = buildItemSearchTypeAll(
|
||||
functionSearchType[INPUTS_DATA],
|
||||
lowercasePaths,
|
||||
);
|
||||
}
|
||||
} else {
|
||||
output = [];
|
||||
}
|
||||
const where_clause = [];
|
||||
const l = functionSearchType.length;
|
||||
for (let i = 2; i < l; ++i) {
|
||||
where_clause.push(typeof functionSearchType[i] === "number"
|
||||
? [buildItemSearchType(functionSearchType[i], lowercasePaths)]
|
||||
: buildItemSearchTypeAll(functionSearchType[i], lowercasePaths));
|
||||
}
|
||||
const ret = {
|
||||
inputs, output, where_clause,
|
||||
if (functionSearchType.length > 1) {
|
||||
if (typeof functionSearchType[OUTPUT_DATA] === "number") {
|
||||
output = [buildItemSearchType(functionSearchType[OUTPUT_DATA], lowercasePaths)];
|
||||
} else {
|
||||
output = buildItemSearchTypeAll(
|
||||
functionSearchType[OUTPUT_DATA],
|
||||
lowercasePaths,
|
||||
);
|
||||
}
|
||||
} else {
|
||||
output = [];
|
||||
}
|
||||
const where_clause = [];
|
||||
const l = functionSearchType.length;
|
||||
for (let i = 2; i < l; ++i) {
|
||||
where_clause.push(typeof functionSearchType[i] === "number"
|
||||
? [buildItemSearchType(functionSearchType[i], lowercasePaths)]
|
||||
: buildItemSearchTypeAll(functionSearchType[i], lowercasePaths));
|
||||
}
|
||||
return {
|
||||
inputs, output, where_clause,
|
||||
};
|
||||
};
|
||||
itemFunctionDecoder.backrefQueue.unshift(ret);
|
||||
if (itemFunctionDecoder.backrefQueue.length > 16) {
|
||||
itemFunctionDecoder.backrefQueue.pop();
|
||||
}
|
||||
return ret;
|
||||
}
|
||||
|
||||
/**
|
||||
@ -3245,6 +3218,185 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
return functionTypeFingerprint[(fullId * 4) + 3];
|
||||
}
|
||||
|
||||
class VlqHexDecoder {
|
||||
constructor(string, cons) {
|
||||
this.string = string;
|
||||
this.cons = cons;
|
||||
this.offset = 0;
|
||||
this.backrefQueue = [];
|
||||
}
|
||||
// call after consuming `{`
|
||||
decodeList() {
|
||||
const cb = "}".charCodeAt(0);
|
||||
let c = this.string.charCodeAt(this.offset);
|
||||
const ret = [];
|
||||
while (c !== cb) {
|
||||
ret.push(this.decode());
|
||||
c = this.string.charCodeAt(this.offset);
|
||||
}
|
||||
this.offset += 1; // eat cb
|
||||
return ret;
|
||||
}
|
||||
// consumes and returns a list or integer
|
||||
decode() {
|
||||
const [ob, la] = ["{", "`"].map(c => c.charCodeAt(0));
|
||||
let n = 0;
|
||||
let c = this.string.charCodeAt(this.offset);
|
||||
if (c === ob) {
|
||||
this.offset += 1;
|
||||
return this.decodeList();
|
||||
}
|
||||
while (c < la) {
|
||||
n = (n << 4) | (c & 0xF);
|
||||
this.offset += 1;
|
||||
c = this.string.charCodeAt(this.offset);
|
||||
}
|
||||
// last character >= la
|
||||
n = (n << 4) | (c & 0xF);
|
||||
const [sign, value] = [n & 1, n >> 1];
|
||||
this.offset += 1;
|
||||
return sign ? -value : value;
|
||||
}
|
||||
next() {
|
||||
const c = this.string.charCodeAt(this.offset);
|
||||
const [zero, ua, la] = ["0", "@", "`"].map(c => c.charCodeAt(0));
|
||||
// sixteen characters after "0" are backref
|
||||
if (c >= zero && c < ua) {
|
||||
this.offset += 1;
|
||||
return this.backrefQueue[c - zero];
|
||||
}
|
||||
// special exception: 0 doesn't use backref encoding
|
||||
// it's already one character, and it's always nullish
|
||||
if (c === la) {
|
||||
this.offset += 1;
|
||||
return this.cons(0);
|
||||
}
|
||||
const result = this.cons(this.decode());
|
||||
this.backrefQueue.unshift(result);
|
||||
if (this.backrefQueue.length > 16) {
|
||||
this.backrefQueue.pop();
|
||||
}
|
||||
return result;
|
||||
}
|
||||
}
|
||||
class RoaringBitmap {
|
||||
constructor(str) {
|
||||
const strdecoded = atob(str);
|
||||
const u8array = new Uint8Array(strdecoded.length);
|
||||
for (let j = 0; j < strdecoded.length; ++j) {
|
||||
u8array[j] = strdecoded.charCodeAt(j);
|
||||
}
|
||||
const has_runs = u8array[0] === 0x3b;
|
||||
const size = has_runs ?
|
||||
((u8array[2] | (u8array[3] << 8)) + 1) :
|
||||
((u8array[4] | (u8array[5] << 8) | (u8array[6] << 16) | (u8array[7] << 24)));
|
||||
let i = has_runs ? 4 : 8;
|
||||
let is_run;
|
||||
if (has_runs) {
|
||||
const is_run_len = Math.floor((size + 7) / 8);
|
||||
is_run = u8array.slice(i, i + is_run_len);
|
||||
i += is_run_len;
|
||||
} else {
|
||||
is_run = new Uint8Array();
|
||||
}
|
||||
this.keys = [];
|
||||
this.cardinalities = [];
|
||||
for (let j = 0; j < size; ++j) {
|
||||
this.keys.push(u8array[i] | (u8array[i + 1] << 8));
|
||||
i += 2;
|
||||
this.cardinalities.push((u8array[i] | (u8array[i + 1] << 8)) + 1);
|
||||
i += 2;
|
||||
}
|
||||
this.containers = [];
|
||||
let offsets = null;
|
||||
if (!has_runs || this.keys.length >= 4) {
|
||||
offsets = [];
|
||||
for (let j = 0; j < size; ++j) {
|
||||
offsets.push(u8array[i] | (u8array[i + 1] << 8) | (u8array[i + 2] << 16) |
|
||||
(u8array[i + 3] << 24));
|
||||
i += 4;
|
||||
}
|
||||
}
|
||||
for (let j = 0; j < size; ++j) {
|
||||
if (offsets && offsets[j] !== i) {
|
||||
console.log(this.containers);
|
||||
throw new Error(`corrupt bitmap ${j}: ${i} / ${offsets[j]}`);
|
||||
}
|
||||
if (is_run[j >> 3] & (1 << (j & 0x7))) {
|
||||
const runcount = (u8array[i] | (u8array[i + 1] << 8));
|
||||
i += 2;
|
||||
this.containers.push(new RoaringBitmapRun(
|
||||
runcount,
|
||||
u8array.slice(i, i + (runcount * 4)),
|
||||
));
|
||||
i += runcount * 4;
|
||||
} else if (this.cardinalities[j] >= 4096) {
|
||||
this.containers.push(new RoaringBitmapBits(u8array.slice(i, i + 8192)));
|
||||
i += 8192;
|
||||
} else {
|
||||
const end = this.cardinalities[j] * 2;
|
||||
this.containers.push(new RoaringBitmapArray(
|
||||
this.cardinalities[j],
|
||||
u8array.slice(i, i + end),
|
||||
));
|
||||
i += end;
|
||||
}
|
||||
}
|
||||
}
|
||||
contains(keyvalue) {
|
||||
const key = keyvalue >> 16;
|
||||
const value = keyvalue & 0xFFFF;
|
||||
for (let i = 0; i < this.keys.length; ++i) {
|
||||
if (this.keys[i] === key) {
|
||||
return this.containers[i].contains(value);
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
|
||||
class RoaringBitmapRun {
|
||||
constructor(runcount, array) {
|
||||
this.runcount = runcount;
|
||||
this.array = array;
|
||||
}
|
||||
contains(value) {
|
||||
const l = this.runcount * 4;
|
||||
for (let i = 0; i < l; i += 4) {
|
||||
const start = this.array[i] | (this.array[i + 1] << 8);
|
||||
const lenm1 = this.array[i + 2] | (this.array[i + 3] << 8);
|
||||
if (value >= start && value <= (start + lenm1)) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
class RoaringBitmapArray {
|
||||
constructor(cardinality, array) {
|
||||
this.cardinality = cardinality;
|
||||
this.array = array;
|
||||
}
|
||||
contains(value) {
|
||||
const l = this.cardinality * 2;
|
||||
for (let i = 0; i < l; i += 2) {
|
||||
const start = this.array[i] | (this.array[i + 1] << 8);
|
||||
if (value === start) {
|
||||
return true;
|
||||
}
|
||||
}
|
||||
return false;
|
||||
}
|
||||
}
|
||||
class RoaringBitmapBits {
|
||||
constructor(array) {
|
||||
this.array = array;
|
||||
}
|
||||
contains(value) {
|
||||
return !!(this.array[value >> 3] & (1 << (value & 7)));
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Convert raw search index into in-memory search index.
|
||||
*
|
||||
@ -3252,6 +3404,8 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
*/
|
||||
function buildIndex(rawSearchIndex) {
|
||||
searchIndex = [];
|
||||
searchIndexDeprecated = new Map();
|
||||
searchIndexEmptyDesc = new Map();
|
||||
const charA = "A".charCodeAt(0);
|
||||
let currentIndex = 0;
|
||||
let id = 0;
|
||||
@ -3271,26 +3425,48 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
id = 0;
|
||||
|
||||
for (const [crate, crateCorpus] of rawSearchIndex) {
|
||||
// a string representing the lengths of each description shard
|
||||
// a string representing the list of function types
|
||||
const itemDescShardDecoder = new VlqHexDecoder(crateCorpus.D, noop => noop);
|
||||
let descShard = {
|
||||
crate,
|
||||
shard: 0,
|
||||
start: 0,
|
||||
len: itemDescShardDecoder.next(),
|
||||
promise: null,
|
||||
resolve: null,
|
||||
};
|
||||
const descShardList = [ descShard ];
|
||||
|
||||
// Deprecated items and items with no description
|
||||
searchIndexDeprecated.set(crate, new RoaringBitmap(crateCorpus.c));
|
||||
searchIndexEmptyDesc.set(crate, new RoaringBitmap(crateCorpus.e));
|
||||
let descIndex = 0;
|
||||
|
||||
// This object should have exactly the same set of fields as the "row"
|
||||
// object defined below. Your JavaScript runtime will thank you.
|
||||
// https://mathiasbynens.be/notes/shapes-ics
|
||||
const crateRow = {
|
||||
crate: crate,
|
||||
crate,
|
||||
ty: 3, // == ExternCrate
|
||||
name: crate,
|
||||
path: "",
|
||||
desc: crateCorpus.doc,
|
||||
descShard,
|
||||
descIndex,
|
||||
parent: undefined,
|
||||
type: null,
|
||||
id: id,
|
||||
id,
|
||||
word: crate,
|
||||
normalizedName: crate.indexOf("_") === -1 ? crate : crate.replace(/_/g, ""),
|
||||
deprecated: null,
|
||||
bitIndex: 0,
|
||||
implDisambiguator: null,
|
||||
};
|
||||
id += 1;
|
||||
searchIndex.push(crateRow);
|
||||
currentIndex += 1;
|
||||
if (!searchIndexEmptyDesc.get(crate).contains(0)) {
|
||||
descIndex += 1;
|
||||
}
|
||||
|
||||
// a String of one character item type codes
|
||||
const itemTypes = crateCorpus.t;
|
||||
@ -3302,19 +3478,9 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
// i.e. if indices 4 and 11 are present, but 5-10 and 12-13 are not present,
|
||||
// 5-10 will fall back to the path for 4 and 12-13 will fall back to the path for 11
|
||||
const itemPaths = new Map(crateCorpus.q);
|
||||
// an array of (String) descriptions
|
||||
const itemDescs = crateCorpus.d;
|
||||
// an array of (Number) the parent path index + 1 to `paths`, or 0 if none
|
||||
const itemParentIdxs = crateCorpus.i;
|
||||
// a string representing the list of function types
|
||||
const itemFunctionDecoder = {
|
||||
string: crateCorpus.f,
|
||||
offset: 0,
|
||||
backrefQueue: [],
|
||||
};
|
||||
// an array of (Number) indices for the deprecated items
|
||||
const deprecatedItems = new Set(crateCorpus.c);
|
||||
// an array of (Number) indices for the deprecated items
|
||||
// a map Number, string for impl disambiguators
|
||||
const implDisambiguator = new Map(crateCorpus.b);
|
||||
// an array of [(Number) item type,
|
||||
// (String) name]
|
||||
@ -3326,6 +3492,12 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
// an array of [{name: String, ty: Number}]
|
||||
const lowercasePaths = [];
|
||||
|
||||
// a string representing the list of function types
|
||||
const itemFunctionDecoder = new VlqHexDecoder(
|
||||
crateCorpus.f,
|
||||
buildFunctionSearchTypeCallback(lowercasePaths),
|
||||
);
|
||||
|
||||
// convert `rawPaths` entries into object form
|
||||
// generate normalizedPaths for function search mode
|
||||
let len = paths.length;
|
||||
@ -3354,12 +3526,26 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
lastPath = "";
|
||||
len = itemTypes.length;
|
||||
for (let i = 0; i < len; ++i) {
|
||||
const bitIndex = i + 1;
|
||||
if (descIndex >= descShard.len &&
|
||||
!searchIndexEmptyDesc.get(crate).contains(bitIndex)) {
|
||||
descShard = {
|
||||
crate,
|
||||
shard: descShard.shard + 1,
|
||||
start: descShard.start + descShard.len,
|
||||
len: itemDescShardDecoder.next(),
|
||||
promise: null,
|
||||
resolve: null,
|
||||
};
|
||||
descIndex = 0;
|
||||
descShardList.push(descShard);
|
||||
}
|
||||
let word = "";
|
||||
if (typeof itemNames[i] === "string") {
|
||||
word = itemNames[i].toLowerCase();
|
||||
}
|
||||
const path = itemPaths.has(i) ? itemPaths.get(i) : lastPath;
|
||||
const type = buildFunctionSearchType(itemFunctionDecoder, lowercasePaths);
|
||||
const type = itemFunctionDecoder.next();
|
||||
if (type !== null) {
|
||||
if (type) {
|
||||
const fp = functionTypeFingerprint.subarray(id * 4, (id + 1) * 4);
|
||||
@ -3380,22 +3566,26 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
// This object should have exactly the same set of fields as the "crateRow"
|
||||
// object defined above.
|
||||
const row = {
|
||||
crate: crate,
|
||||
crate,
|
||||
ty: itemTypes.charCodeAt(i) - charA,
|
||||
name: itemNames[i],
|
||||
path: path,
|
||||
desc: itemDescs[i],
|
||||
path,
|
||||
descShard,
|
||||
descIndex,
|
||||
parent: itemParentIdxs[i] > 0 ? paths[itemParentIdxs[i] - 1] : undefined,
|
||||
type,
|
||||
id: id,
|
||||
id,
|
||||
word,
|
||||
normalizedName: word.indexOf("_") === -1 ? word : word.replace(/_/g, ""),
|
||||
deprecated: deprecatedItems.has(i),
|
||||
bitIndex,
|
||||
implDisambiguator: implDisambiguator.has(i) ? implDisambiguator.get(i) : null,
|
||||
};
|
||||
id += 1;
|
||||
searchIndex.push(row);
|
||||
lastPath = row.path;
|
||||
if (!searchIndexEmptyDesc.get(crate).contains(bitIndex)) {
|
||||
descIndex += 1;
|
||||
}
|
||||
}
|
||||
|
||||
if (aliases) {
|
||||
@ -3419,6 +3609,7 @@ ${item.displayPath}<span class="${type}">${name}</span>\
|
||||
}
|
||||
}
|
||||
currentIndex += itemTypes.length;
|
||||
searchState.descShards.set(crate, descShardList);
|
||||
}
|
||||
// Drop the (rather large) hash table used for reusing function items
|
||||
TYPES_POOL = new Map();
|
||||
|
||||
@ -211,14 +211,14 @@ function updateSidebarWidth() {
|
||||
if (desktopSidebarWidth && desktopSidebarWidth !== "null") {
|
||||
document.documentElement.style.setProperty(
|
||||
"--desktop-sidebar-width",
|
||||
desktopSidebarWidth + "px"
|
||||
desktopSidebarWidth + "px",
|
||||
);
|
||||
}
|
||||
const srcSidebarWidth = getSettingValue("src-sidebar-width");
|
||||
if (srcSidebarWidth && srcSidebarWidth !== "null") {
|
||||
document.documentElement.style.setProperty(
|
||||
"--src-sidebar-width",
|
||||
srcSidebarWidth + "px"
|
||||
srcSidebarWidth + "px",
|
||||
);
|
||||
}
|
||||
}
|
||||
|
||||
@ -6,7 +6,7 @@ module.exports = {
|
||||
},
|
||||
"extends": "eslint:recommended",
|
||||
"parserOptions": {
|
||||
"ecmaVersion": 2015,
|
||||
"ecmaVersion": 8,
|
||||
"sourceType": "module"
|
||||
},
|
||||
"rules": {
|
||||
|
||||
@ -1,3 +1,4 @@
|
||||
/* global globalThis */
|
||||
const fs = require("fs");
|
||||
const path = require("path");
|
||||
|
||||
@ -133,7 +134,7 @@ function valueCheck(fullPath, expected, result, error_text, queryName) {
|
||||
expected_value,
|
||||
result.get(key),
|
||||
error_text,
|
||||
queryName
|
||||
queryName,
|
||||
);
|
||||
} else {
|
||||
error_text.push(`${queryName}==> EXPECTED has extra key in map from field ` +
|
||||
@ -212,11 +213,11 @@ function runParser(query, expected, parseQuery, queryName) {
|
||||
return error_text;
|
||||
}
|
||||
|
||||
function runSearch(query, expected, doSearch, loadedFile, queryName) {
|
||||
async function runSearch(query, expected, doSearch, loadedFile, queryName) {
|
||||
const ignore_order = loadedFile.ignore_order;
|
||||
const exact_check = loadedFile.exact_check;
|
||||
|
||||
const results = doSearch(query, loadedFile.FILTER_CRATE);
|
||||
const results = await doSearch(query, loadedFile.FILTER_CRATE);
|
||||
const error_text = [];
|
||||
|
||||
for (const key in expected) {
|
||||
@ -238,7 +239,7 @@ function runSearch(query, expected, doSearch, loadedFile, queryName) {
|
||||
}
|
||||
|
||||
let prev_pos = -1;
|
||||
entry.forEach((elem, index) => {
|
||||
for (const [index, elem] of entry.entries()) {
|
||||
const entry_pos = lookForEntry(elem, results[key]);
|
||||
if (entry_pos === -1) {
|
||||
error_text.push(queryName + "==> Result not found in '" + key + "': '" +
|
||||
@ -260,13 +261,13 @@ function runSearch(query, expected, doSearch, loadedFile, queryName) {
|
||||
} else {
|
||||
prev_pos = entry_pos;
|
||||
}
|
||||
});
|
||||
}
|
||||
}
|
||||
return error_text;
|
||||
}
|
||||
|
||||
function runCorrections(query, corrections, getCorrections, loadedFile) {
|
||||
const qc = getCorrections(query, loadedFile.FILTER_CRATE);
|
||||
async function runCorrections(query, corrections, getCorrections, loadedFile) {
|
||||
const qc = await getCorrections(query, loadedFile.FILTER_CRATE);
|
||||
const error_text = [];
|
||||
|
||||
if (corrections === null) {
|
||||
@ -299,18 +300,27 @@ function checkResult(error_text, loadedFile, displaySuccess) {
|
||||
return 1;
|
||||
}
|
||||
|
||||
function runCheckInner(callback, loadedFile, entry, getCorrections, extra) {
|
||||
async function runCheckInner(callback, loadedFile, entry, getCorrections, extra) {
|
||||
if (typeof entry.query !== "string") {
|
||||
console.log("FAILED");
|
||||
console.log("==> Missing `query` field");
|
||||
return false;
|
||||
}
|
||||
let error_text = callback(entry.query, entry, extra ? "[ query `" + entry.query + "`]" : "");
|
||||
let error_text = await callback(
|
||||
entry.query,
|
||||
entry,
|
||||
extra ? "[ query `" + entry.query + "`]" : "",
|
||||
);
|
||||
if (checkResult(error_text, loadedFile, false) !== 0) {
|
||||
return false;
|
||||
}
|
||||
if (entry.correction !== undefined) {
|
||||
error_text = runCorrections(entry.query, entry.correction, getCorrections, loadedFile);
|
||||
error_text = await runCorrections(
|
||||
entry.query,
|
||||
entry.correction,
|
||||
getCorrections,
|
||||
loadedFile,
|
||||
);
|
||||
if (checkResult(error_text, loadedFile, false) !== 0) {
|
||||
return false;
|
||||
}
|
||||
@ -318,16 +328,16 @@ function runCheckInner(callback, loadedFile, entry, getCorrections, extra) {
|
||||
return true;
|
||||
}
|
||||
|
||||
function runCheck(loadedFile, key, getCorrections, callback) {
|
||||
async function runCheck(loadedFile, key, getCorrections, callback) {
|
||||
const expected = loadedFile[key];
|
||||
|
||||
if (Array.isArray(expected)) {
|
||||
for (const entry of expected) {
|
||||
if (!runCheckInner(callback, loadedFile, entry, getCorrections, true)) {
|
||||
if (!await runCheckInner(callback, loadedFile, entry, getCorrections, true)) {
|
||||
return 1;
|
||||
}
|
||||
}
|
||||
} else if (!runCheckInner(callback, loadedFile, expected, getCorrections, false)) {
|
||||
} else if (!await runCheckInner(callback, loadedFile, expected, getCorrections, false)) {
|
||||
return 1;
|
||||
}
|
||||
console.log("OK");
|
||||
@ -338,7 +348,7 @@ function hasCheck(content, checkName) {
|
||||
return content.startsWith(`const ${checkName}`) || content.includes(`\nconst ${checkName}`);
|
||||
}
|
||||
|
||||
function runChecks(testFile, doSearch, parseQuery, getCorrections) {
|
||||
async function runChecks(testFile, doSearch, parseQuery, getCorrections) {
|
||||
let checkExpected = false;
|
||||
let checkParsed = false;
|
||||
let testFileContent = readFile(testFile);
|
||||
@ -367,12 +377,12 @@ function runChecks(testFile, doSearch, parseQuery, getCorrections) {
|
||||
let res = 0;
|
||||
|
||||
if (checkExpected) {
|
||||
res += runCheck(loadedFile, "EXPECTED", getCorrections, (query, expected, text) => {
|
||||
res += await runCheck(loadedFile, "EXPECTED", getCorrections, (query, expected, text) => {
|
||||
return runSearch(query, expected, doSearch, loadedFile, text);
|
||||
});
|
||||
}
|
||||
if (checkParsed) {
|
||||
res += runCheck(loadedFile, "PARSED", getCorrections, (query, expected, text) => {
|
||||
res += await runCheck(loadedFile, "PARSED", getCorrections, (query, expected, text) => {
|
||||
return runParser(query, expected, parseQuery, text);
|
||||
});
|
||||
}
|
||||
@ -393,6 +403,35 @@ function loadSearchJS(doc_folder, resource_suffix) {
|
||||
const searchIndexJs = path.join(doc_folder, "search-index" + resource_suffix + ".js");
|
||||
const searchIndex = require(searchIndexJs);
|
||||
|
||||
globalThis.searchState = {
|
||||
descShards: new Map(),
|
||||
loadDesc: async function({descShard, descIndex}) {
|
||||
if (descShard.promise === null) {
|
||||
descShard.promise = new Promise((resolve, reject) => {
|
||||
descShard.resolve = resolve;
|
||||
const ds = descShard;
|
||||
const fname = `${ds.crate}-desc-${ds.shard}-${resource_suffix}.js`;
|
||||
fs.readFile(
|
||||
`${doc_folder}/search.desc/${descShard.crate}/${fname}`,
|
||||
(err, data) => {
|
||||
if (err) {
|
||||
reject(err);
|
||||
} else {
|
||||
eval(data.toString("utf8"));
|
||||
}
|
||||
},
|
||||
);
|
||||
});
|
||||
}
|
||||
const list = await descShard.promise;
|
||||
return list[descIndex];
|
||||
},
|
||||
loadedDescShard: function(crate, shard, data) {
|
||||
//console.log(this.descShards);
|
||||
this.descShards.get(crate)[shard].resolve(data.split("\n"));
|
||||
},
|
||||
};
|
||||
|
||||
const staticFiles = path.join(doc_folder, "static.files");
|
||||
const searchJs = fs.readdirSync(staticFiles).find(f => f.match(/search.*\.js$/));
|
||||
const searchModule = require(path.join(staticFiles, searchJs));
|
||||
@ -474,7 +513,7 @@ function parseOptions(args) {
|
||||
return null;
|
||||
}
|
||||
|
||||
function main(argv) {
|
||||
async function main(argv) {
|
||||
const opts = parseOptions(argv.slice(2));
|
||||
if (opts === null) {
|
||||
return 1;
|
||||
@ -482,7 +521,7 @@ function main(argv) {
|
||||
|
||||
const parseAndSearch = loadSearchJS(
|
||||
opts["doc_folder"],
|
||||
opts["resource_suffix"]
|
||||
opts["resource_suffix"],
|
||||
);
|
||||
let errors = 0;
|
||||
|
||||
@ -494,21 +533,29 @@ function main(argv) {
|
||||
};
|
||||
|
||||
if (opts["test_file"].length !== 0) {
|
||||
opts["test_file"].forEach(file => {
|
||||
for (const file of opts["test_file"]) {
|
||||
process.stdout.write(`Testing ${file} ... `);
|
||||
errors += runChecks(file, doSearch, parseAndSearch.parseQuery, getCorrections);
|
||||
});
|
||||
errors += await runChecks(file, doSearch, parseAndSearch.parseQuery, getCorrections);
|
||||
}
|
||||
} else if (opts["test_folder"].length !== 0) {
|
||||
fs.readdirSync(opts["test_folder"]).forEach(file => {
|
||||
for (const file of fs.readdirSync(opts["test_folder"])) {
|
||||
if (!file.endsWith(".js")) {
|
||||
return;
|
||||
continue;
|
||||
}
|
||||
process.stdout.write(`Testing ${file} ... `);
|
||||
errors += runChecks(path.join(opts["test_folder"], file), doSearch,
|
||||
errors += await runChecks(path.join(opts["test_folder"], file), doSearch,
|
||||
parseAndSearch.parseQuery, getCorrections);
|
||||
});
|
||||
}
|
||||
}
|
||||
return errors > 0 ? 1 : 0;
|
||||
}
|
||||
|
||||
process.exit(main(process.argv));
|
||||
main(process.argv).catch(e => {
|
||||
console.log(e);
|
||||
process.exit(1);
|
||||
}).then(x => process.exit(x));
|
||||
|
||||
process.on("beforeExit", () => {
|
||||
console.log("process did not complete");
|
||||
process.exit(1);
|
||||
});
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
#![crate_name = "foo"]
|
||||
|
||||
// @hasraw 'search-index.js' 'Foo short link.'
|
||||
// @hasraw 'search.desc/foo/foo-desc-0-.js' 'Foo short link.'
|
||||
// @!hasraw - 'www.example.com'
|
||||
// @!hasraw - 'More Foo.'
|
||||
|
||||
|
||||
Loading…
Reference in New Issue
Block a user