Add alignment to the NPO guarantee
This PR [changes](https://github.com/rust-lang/rust/pull/114845#discussion_r1294363357) "same size" to "same size and alignment" in the option module's null pointer optimization docs in <https://doc.rust-lang.org/std/option/#representation>.
As far as I know, this has been true for a long time in the actual rustc implementation, but it's not in the text of those docs, so I figured I'd bring this up to FCP it.
I also see no particular reason that we'd ever *want* to have higher alignment on these. In many of the cases it's impossible, as the minimum alignment is already the size of the type, but even if we *could* do things like on 32-bit we could say that `NonZeroU64` is 4-align but `Option<NonZeroU64>` is 8-align, I just don't see any value in doing that, so feel completely fine closing this door for the few things on which the NPO is already guaranteed. These are basically all primitives, and should end up with the same size & alignment as those primitives.
(There's no layout guarantee for something like `Option<[u8; 3]>`, where it'd be at least plausible to consider raising the alignment from 1 to 4 on, say, some hypothetical target that doesn't have efficient unaligned 4-byte load/stores. And even if we ever did start to offer some kind of guarantee around such a type, I doubt we'd put it under the "null pointer" optimization header.)
Screenshots for the new examples:

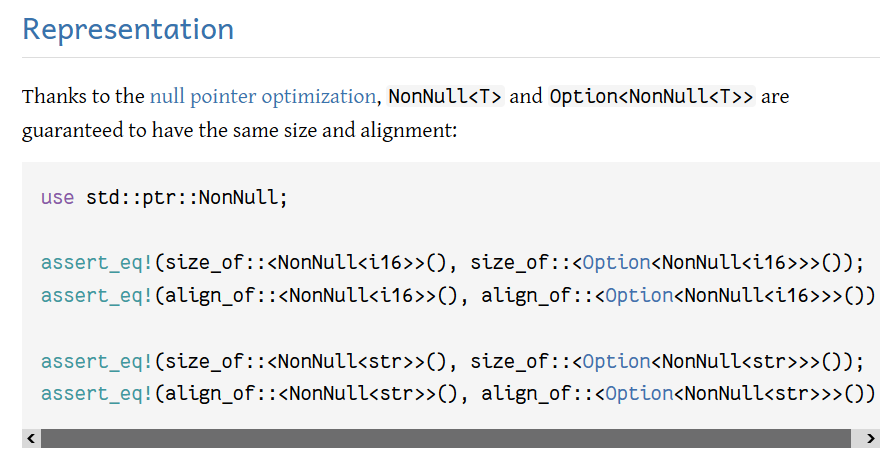
Implement Step for ascii::Char
This allows iterating over ranges of `ascii::Char`, similarly to ranges of `char`.
Note that `ascii::Char` is still unstable, tracked in #110998.
docs: improve std::fs::read doc
#### What does this PR do
1. Rephrase a confusing sentence in the document of `std::fs::read()`
-----
Closes#114432
cc `@Dexus0` `@saethlin`
Currently, `CStr::from_ptr` contains its own implementation of `strlen`
that uses `const_eval_select` to either call libc's `strlen` or use a
naive Rust implementation. Refactor that into its own function so we can
use it elsewhere in the module.
Add note that Vec::as_mut_ptr() does not materialize a reference to the internal buffer
See discussion on https://github.com/thomcc/rust-typed-arena/issues/62 and [t-opsem](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/is.20this.20typed_arena.20code.20sound.20under.20stacked.2Ftree.20borrows.3F)
This method already does the correct thing here, but it is worth guaranteeing that it does so it can be used more freely in unsafe code without having to worry about potential Stacked/Tree Borrows violations. This moves one more unsafe usage pattern from the "very likely sound but technically not fully defined" box into "definitely sound", and currently our surface area of the latter is woefully small.
I'm not sure how best to word this, opening this PR as a way to start discussion.
Fix implementation of `Duration::checked_div`
I ran across this while running some sanity checks on `time`. Quickcheck immediately found a bug, and as I'd modified the code from `std` I knew there was a bug here as well.
tl;dr this code fails ([playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=1189a3efcdfc192c27d6d87815359353))
```rust
use std::time::Duration;
fn main() {
assert_eq!(
Duration::new(1, 1).checked_div(7),
Some(Duration::new(0, 142_857_143)),
);
}
```
The existing code determines that 1/7 = 0 (seconds), 1/7 = 0 (nanoseconds), 1 billion / 7 = 142,857,142 (extra nanoseconds). The billion comes from multiplying the remainder of the seconds (1) by the number of nanoseconds in a second. However, **this wrongly ignores any remaining nanoseconds**. This PR takes that into consideration, adds a test, and also changes the roundabout way of calculating the remainder into directly computing it.
Note: This is _not_ a rounding error. This result divides evenly.
`@rustbot` label +A-time +C-bug +S-waiting-on-reviewer +T-libs
Document that SystemTime does not count leap seconds
Fixes#77994
This may not be entirely uncontroversial. I know that `@Ekleog` is going to disagree. However, in support of this docs change:
This documents the current behaviour. The alternative would be to plan to *change* the behaviour.
There are many programs which need to get a POSIX time (a `time_t`). Right now, `duration_since(UNIX_EPOCH)` is the only facility in std that does that. So, that is what programs use. Changing the behaviour would break[1] all of those programs. We would need to define a new API that can be used to get a POSIX time, and get everyone to use it. This seems highly unpalatable.
And, even if we wanted to do that, time with leap seconds is a lot less easy to work with. We would need to arrange to have a leap seconds table available to `std` somehow, and make sure that it was kept up to date. Currently we don't offer to do that for timezone data, which has similar needs. There are other complications. So it seems it would be awkwarrd to *implement* a facility that provides time including leap seconds, and the resulting value would be hard for applications to work with.
Therefore, I think it's clear that we don't want to plan to ever change `SystemTime`. We should plan to keep it the way it is. Providing TAI (for example) should be left to external crates, or additional APIs we may add in the future.
For more discussion see #77994 and in particular `@fanf2's` https://github.com/rust-lang/rust/issues/77994#issuecomment-1409448174
[1] Of course, by "break" we really only mean *future* breakage in the case where there is, in fact, ever another leap second. There may well not be: they are in the process of being abolished (although this is of course being contested). But if we decide that `SystemTime::now().duraton_since(UNIX_EPOCH)` counts leap seconds, it would start to return `Durations`s that are 27s different to the current answers. That's clearly unacceptable. And we can hardly change `UNIX_EPOCH` by 27s.
wasi: round up the size for `aligned_alloc`
C11 `aligned_alloc` requires that the size be a multiple of the
alignment. This is enforced in the wasi-libc emmalloc implementation,
which always returns NULL if the size is not a multiple.
(The default `MALLOC_IMPL=dlmalloc` does not currently check this.)
Correct and expand documentation of `handle_alloc_error` and `set_alloc_error_hook`.
The primary goal of this change is to remove the false claim that `handle_alloc_error` always aborts; instead, code should be prepared for `handle_alloc_error` to possibly unwind, and be sound under that condition.
I saw other opportunities for improvement, so I have added all the following information:
* `handle_alloc_error` may panic instead of aborting. (Fixes#114898)
* What happens if a hook returns rather than diverging.
* A hook may panic. (This was already demonstrated in an example, but not stated in prose.)
* A hook must be sound to call — it cannot assume that it is only called by the runtime, since its function pointer can be retrieved by safe code.
I've checked these statements against the source code of `alloc` and `std`, but there may be nuances I haven't caught, so a careful review is welcome.
Go into more detail about panicking in drop.
This patch was sitting around in my drafts. I don't recall the motivation, but I think it was someone expressing confusion over “will likely abort” (since, in fact, a panicking drop _not_ caused by dropping while panicking will predictably _not_ abort).
I hope that the new text will leave people well-informed about why not to panic and when it is reasonable to panic.
C11 `aligned_alloc` requires that the size be a multiple of the
alignment. This is enforced in the wasi-libc emmalloc implementation,
which always returns NULL if the size is not a multiple.
(The default `MALLOC_IMPL=dlmalloc` does not currently check this.)
Make `rustc_on_unimplemented` std-agnostic for `alloc::rc`
See https://github.com/rust-lang/rust/issues/112923
Just a few lines related to `alloc:rc` for `Send` and `Sync`.
That seems to be all of the `... = "std::..."` issues found, but there a few notes with `std::` inside them still.
r? `@WaffleLapkin`
Add a new helper to avoid calling io::Error::kind
On `cfg(unix)`, `Error::kind` emits an enormous jump table that LLVM seems unable to optimize out. I don't really understand why, but see for yourself: https://godbolt.org/z/17hY496KG
This change lets us check for `ErrorKind::Interrupted` without going through a big match. I've checked the codegen locally, and it has the desired effect on the codegen for `BufReader::read_exact`.
This implements the ability to add arbitrary attributes to a command on Windows targets using a new `raw_attribute` method on the [`CommandExt`](https://doc.rust-lang.org/stable/std/os/windows/process/trait.CommandExt.html) trait. Setting these attributes provides extended configuration options for Windows processes.
Co-authored-by: Tyler Ruckinger <t.ruckinger@gmail.com>
kmc-solid: Import `std::sync::PoisonError` in `std::sys::solid::os`
Follow-up to #114968. Fixes a missing import in [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets.
```
error[E0433]: failed to resolve: use of undeclared type `PoisonError`
C:\Users\xxxxx\.rustup\toolchains\nightly-2023-08-23-x86_64-pc-windows-gnu\lib\rustlib\src\rust\library\std\src\sys\solid\os.rs(85,36)
|
85 | ENV_LOCK.read().unwrap_or_else(PoisonError::into_inner)
| ^^^^^^^^^^^ use of undeclared type `PoisonError`
|
```
Add support for `ptr::write`s for the `invalid_reference_casting` lint
This PR adds support for `ptr::write` and others for the `invalid_reference_casting` lint.
Detecting instances where instead of using the deref (`*`) operator to assign someone uses `ptr::write`, `ptr::write_unaligned` or `ptr::write_volatile`.
```rust
let data_len = 5u64;
std::ptr::write(
std::mem::transmute::<*const u64, *mut u64>(&data_len),
new_data_len,
);
```
r? ``@est31``
I tried working with `UdpSocket` and ran into `EINVAL` errors with no
clear indication of what causes the error. Also, it was uncharacteristically
hard to figure this module out, compared to other Rust `std` modules.
1. `send` and `send_to` return a `usize`
This one is just clarity. Usually, returned `usize`s indicate that the
buffer might have only been sent partially. This is not the case with
UDP. Since that `usize` must always be `buffer.len()`, I have documented
that.
2. `bind` limits `connect` and `send_to`
When you bind to a limited address space like localhost, you can only
`connect` to addresses in that same address space. Error kind:
`AddrNotAvailable`.
3. `connect`ing to localhost locks you to localhost
On Linux, if you first `connect` to localhost, subsequent `connect`s to
non-localhost addresses fail. Error kind: `InvalidInput`.
Co-authored-by: Jubilee <46493976+workingjubilee@users.noreply.github.com>
Xous passes slice pointers around in order to manipulate memory.
This is feature-gated behind `slice_ptr_len`. Xous is currently
the only target to use this feature, so gate it behind an OS flag.
Signed-off-by: Sean Cross <sean@xobs.io>
Add an implementation of thread local storage. This uses a container
that is pointed to by the otherwise-unsed `$tp` register. This container
is allocated on-demand, so threads that use no TLS will not allocate
this extra memory.
Signed-off-by: Sean Cross <sean@xobs.io>
Add support for determining the current time. This connects to the
ticktimer server in order to get the system uptime.
Signed-off-by: Sean Cross <sean@xobs.io>
Add support for stdout. This enables basic console printing via
`println!()`. Output is written to the log server.
Signed-off-by: Sean Cross <sean@xobs.io>
Xous has a concept of `services` that provide various features.
Processes may connect to these services by name or by address. Most
services require a name server in order to connect.
Add a file with the most common services, and provide a way to connect
to a service by querying the name server.
Signed-off-by: Sean Cross <sean@xobs.io>
Basic alloc support on Xous is supported by the `dlmalloc` crate. This
necessitates bumping the dlmalloc version to 0.2.4.
Signed-off-by: Sean Cross <sean@xobs.io>
Add the basics to get the operating system running, including how to
exit the operating system.
Since Xous has no libc, there is no default entrypoint. Add a `_start`
entrypoint to the system-specific os module.
Signed-off-by: Sean Cross <sean@xobs.io>
Xous has no C FFI. Instead, all FFI is done via syscalls that are
specified in Rust. Add these FFI calls to libstd, as well as some of the
currently-supported syscalls.
This enables Rust programs to interact with the Xous operating system
while avoiding adding an extra dependency to libstd.
Signed-off-by: Sean Cross <sean@xobs.io>
Add `suggestion` for some `#[deprecated]` items
Consider code:
```rust
fn main() {
let _ = ["a", "b"].connect(" ");
}
```
Currently it shows deprecated warning:
```rust
warning: use of deprecated method `std::slice::<impl [T]>::connect`: renamed to join
--> src/main.rs:2:24
|
2 | let _ = ["a", "b"].connect(" ");
| ^^^^^^^
|
= note: `#[warn(deprecated)]` on by default
```
This PR adds `suggestion` for `connect` and some other deprecated items, so the warning will be changed to this:
```rust
warning: use of deprecated method `std::slice::<impl [T]>::connect`: renamed to join
--> src/main.rs:2:24
|
2 | let _ = ["a", "b"].connect(" ");
| ^^^^^^^
|
= note: `#[warn(deprecated)]` on by default
help: replace the use of the deprecated method
|
2 | let _ = ["a", "b"].join(" ");
| ^^^^
```
custom_mir: change Call() terminator syntax to something more readable
I find our current syntax very hard to read -- I cannot even remember the order of arguments, and having the "next block" *before* the actual function call is very counter-intuitive IMO. So I suggest we use `Call(ret_val = function(v), next_block)` instead.
r? `@JakobDegen`
Fix UB in `std::sys::os::getenv()`
Fixes#114949.
Reduced the loops to 1k iterations (100k was taking way too long), Miri no longer shows any UB.
`@rustbot` label +A-process +C-bug +I-unsound +O-unix
rustdoc: Add lint `redundant_explicit_links`
Closes#87799.
- Lint warns by default
- Reworks link parser to cache original link's display text
r? `@jyn514`
Usage zero as language id for `FormatMessageW()`
This switches the language selection from using system language (note that this might be different than application language, typically stored as thread ui language) to use `FormatMessageW` default search strategy, which is `neutral` first, then `thread ui lang`, then `user language`, then `system language`, then `English`. (See https://learn.microsoft.com/en-us/windows/win32/api/winbase/nf-winbase-formatmessagew)
This allows the Rust program to take more control of `std::io::Error`'s message field, by setting up thread ui language themselves before hand (which many programs already do).
Inline strlen_rt in CStr::from_ptr
This enables LLVM to optimize this function as if it was strlen (LLVM knows what it does, and can avoid calling it in certain situations) without having to enable std-aware LTO. This is essentially doing what https://github.com/rust-lang/rust/pull/90007 did, except updated for this function being `const`.
Pretty sure it's safe to roll-up, considering last time I did make this change it didn't affect performance (`CStr::from_ptr` isn't really used all that often in Rust code that is checked by rust-perf).
Increase clarity about Hash - Eq consistency in HashMap and HashSet docs
As discussed [here](https://users.rust-lang.org/t/what-hapens-if-hash-and-partialeq-dont-match-when-using-hashmap/98052/13) the description of logic errors in `HashMap` and `HashSet` does not explicitly apply to
```text
k1 == k2 -> hash(k1) == hash(k2)
```
but this is likely what is intended.
This PR is a small doc change to correct this.
r? rust-lang/libs
Add the following facts:
* `handle_alloc_error` may panic instead of aborting.
* What happens if a hook returns rather than diverging.
* A hook may panic. (This was already demonstrated in an example,
but not stated in prose.)
* A hook must be sound to call — it cannot assume that it is only
called by the runtime, since its function pointer can be retrieved by
safe code.
Add `modulo` and `mod` as doc aliases for `rem_euclid`.
When I was learning Rust I looked for “a modulo function” and couldn’t find one, so thought I had to write my own; it wasn't at all obvious that a function with “rem” in the name was the function I wanted. Hopefully this will save the next learner from that.
However, it does have the disadvantage that the top results in rustdoc for “mod” are now these aliases instead of the Rust keyword, which probably isn't ideal.
Add doc aliases for trigonometry and other f32,f64 methods.
These are common alternate names, usually a less-abbreviated form, for the operation; e.g. `arctan` instead of `atan`. Prompted by <https://users.rust-lang.org/t/64-bit-trigonometry/98599>
When I was learning Rust I looked for “a modulo function” and couldn’t
find one, so thought I had to write my own; it wasn't at all obvious
that a function with “rem” in the name was the function I wanted.
Hopefully this will save the next learner from that.
However, it does have the disadvantage that the top results in rustdoc
for “mod” are now these aliases instead of the Rust keyword, which
probably isn't ideal.
Synchronize with all calls to `unpark` in id-based thread parker
[The documentation for `thread::park`](https://doc.rust-lang.org/nightly/std/thread/fn.park.html#memory-ordering) guarantees that "park synchronizes-with all prior unpark operations". In the id-based thread parking implementation, this is not implemented correctly, as the state variable is reset with a simple store, so there will not be a *synchronizes-with* edge if an `unpark` happens just before the reset. This PR corrects this, replacing the load-check-reset sequence with a single `compare_exchange`.
Partially revert #107200
`Ok(0)` is indeed something the caller may interpret as an error, but
that's the *correct* thing to return if the writer can't accept any more
bytes.
avoid transmuting Box when we can just cast raw pointers instead
Always better to avoid a transmute, in particular when the layout assumptions it is making are not clearly documented. :)
Rollup of 5 pull requests
Successful merges:
- #113115 (we are migrating to askama)
- #114784 (Improve `invalid_reference_casting` lint)
- #114822 (Improve code readability by moving fmt args directly into the string)
- #114878 (rustc book: make more pleasant to search)
- #114899 (Add missing Clone/Debug impls to SMIR Trait related tys)
r? `@ghost`
`@rustbot` modify labels: rollup
Optimizing the rest of bool's Ord implementation
After coming across issue #66780, I realized that the other functions provided by Ord (`min`, `max`, and `clamp`) were similarly inefficient for bool. This change provides implementations for them in terms of boolean operators, resulting in much simpler assembly and faster code.
Fixes issue #114653
[Comparison on Godbolt](https://rust.godbolt.org/z/5nb5P8e8j)
`max` assembly before:
```assembly
example::max:
mov eax, edi
mov ecx, eax
neg cl
mov edx, esi
not dl
cmp dl, cl
cmove eax, esi
ret
```
`max` assembly after:
```assembly
example::max:
mov eax, edi
or eax, esi
ret
```
`clamp` assembly before:
```assembly
example:🗜️
mov eax, esi
sub al, dl
inc al
cmp al, 2
jae .LBB1_1
mov eax, edi
sub al, sil
movzx ecx, dil
sub dil, dl
cmp dil, 1
movzx edx, dl
cmovne edx, ecx
cmp al, -1
movzx eax, sil
cmovne eax, edx
ret
.LBB1_1:
; identical assert! code
```
`clamp` assembly after:
```assembly
example:🗜️
test edx, edx
jne .LBB1_2
test sil, sil
jne .LBB1_3
.LBB1_2:
or dil, sil
and dil, dl
mov eax, edi
ret
.LBB1_3:
; identical assert! code
```
Cleaner assert_eq! & assert_ne! panic messages
This PR finishes refactoring of the assert messages per #94005. The panic message format change #112849 used to be part of this PR, but has been factored out and just merged. It might be better to keep both changes in the same release once FCP vote completes.
Modify panic message for `assert_eq!`, `assert_ne!`, the currently unstable `assert_matches!`, as well as the corresponding `debug_assert_*` macros.
```rust
assert_eq!(1 + 1, 3);
assert_eq!(1 + 1, 3, "my custom message value={}!", 42);
```
#### Old messages
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion failed: `(left == right)`
left: `2`,
right: `3`
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion failed: `(left == right)`
left: `2`,
right: `3`: my custom message value=42!
```
#### New messages
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion `left == right` failed
left: 2
right: 3
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion `left == right` failed: my custom message value=42!
left: 2
right: 3
```
History of fixing #94005
* #94016 was a lengthy PR that was abandoned
* #111030 was similar, but it stringified left and right arguments, and thus caused compile time performance issues, thus closed
* #112849 factored out the two-line formatting of all panic messages
Fixes#94005
r? `@m-ou-se`
Modify panic message for `assert_eq!`, `assert_ne!`, the currently unstable `assert_matches!`, as well as the corresponding `debug_assert_*` macros.
```rust
assert_eq!(1 + 1, 3);
assert_eq!(1 + 1, 3, "my custom message value={}!", 42);
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion failed: `(left == right)`
left: `2`,
right: `3`
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion failed: `(left == right)`
left: `2`,
right: `3`: my custom message value=42!
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion `left == right` failed
left: 2
right: 3
```
```plain
thread 'main' panicked at $DIR/main.rs:6:5:
assertion `left == right` failed: my custom message value=42!
left: 2
right: 3
```
This PR is a simpler subset of the #111030, but it does NOT stringify the original left and right source code assert expressions, thus should be faster to compile.
Improve docs for impl Default for ExitStatus
This addresses a review comment in #106425 (which is on the way to being merged I think).
Some of the other followup work is more complicated so I'm going to do individual MRs.
~~Note this branch is on top of #106425~~
Rollup of 10 pull requests
Successful merges:
- #114711 (Infer `Lld::No` linker hint when the linker stem is a generic compiler driver)
- #114772 (Add `{Local}ModDefId` to more strongly type DefIds`)
- #114800 (std: add some missing repr(transparent))
- #114820 (Add test for unknown_lints from another file.)
- #114825 (Upgrade std to gimli 0.28.0)
- #114827 (Only consider object candidates for object-safe dyn types in new solver)
- #114828 (Probe when assembling upcast candidates so they don't step on eachother's toes in new solver)
- #114829 (Separate `consider_unsize_to_dyn_candidate` from other unsize candidates)
- #114830 (Clean up some bad UI testing annotations)
- #114831 (Check projection args before substitution in new solver)
r? `@ghost`
`@rustbot` modify labels: rollup
Don't panic in ceil_char_boundary
Implementing the alternative mentioned in this comment: https://github.com/rust-lang/rust/issues/93743#issuecomment-1579935853
Since `floor_char_boundary` will always work (rounding down to the length of the string is possible), it feels best for `ceil_char_boundary` to not panic either. However, the semantics of "rounding up" past the length of the string aren't very great, which is why the method originally panicked in these cases.
Taking into account how people are using this method, it feels best to simply return the end of the string in these cases, so that the result is still a valid char boundary.
std: add some missing repr(transparent)
For some types we don't want to stably guarantee this, so hide the `repr` from rustdoc. This nice approach was suggested by `@thomcc.`
add a csky-unknown-linux-gnuabiv2 target
This is the rustc side changes to support csky based Linux target(`csky-unknown-linux-gnuabiv2`).
Tier 3 policy:
> A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
I pledge to do my best maintaining it.
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
This `csky` section is the arch name and the `unknown-linux` section is the same as other linux target, and `gnuabiv2` is from the cross-compile toolchain of `gcc`
> Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
I think the explanation in platform support doc is enough to make this aspect clear.
> Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
It's using open source tools only.
> The target must not introduce license incompatibilities.
No new license
> Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
Understood.
> The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
There are no new dependencies/features required.
> Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
As previously said it's using open source tools only.
> "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
There are no such terms present/
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
I'm not the reviewer here.
> This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
I'm not the reviewer here.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
It supports for std
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
I have added the documentation, and I think it's clear.
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via `@)` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
Understood.
> Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
Understood.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
I believe I didn't break any other target.
> In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
I think there are no such problems in this PR.
core/any: remove Provider trait, rename Demand to Request
This touches on two WIP features:
* `error_generic_member_access`
* tracking issue: https://github.com/rust-lang/rust/issues/99301
* RFC (WIP): https://github.com/rust-lang/rfcs/pull/2895
* `provide_any`
* tracking issue: https://github.com/rust-lang/rust/issues/96024
* RFC: https://github.com/rust-lang/rfcs/pull/3192
The changes in this PR are intended to address libs meeting feedback summarized by `@Amanieu` in https://github.com/rust-lang/rust/issues/96024#issuecomment-1554773172
The specific items this PR addresses so far are:
> We feel that the names "demand" and "request" are somewhat synonymous and would like only one of those to be used for better consistency.
I went with `Request` here since it sounds nicer, but I'm mildly concerned that at first glance it could be confused with the use of the word in networking context.
> The Provider trait should be deleted and its functionality should be merged into Error. We are happy to only provide an API that is only usable with Error. If there is demand for other uses then this can be provided through an external crate.
The net impact this PR has is that examples which previously looked like
```
core::any::request_ref::<String>(&err).unwramp()
```
now look like
```
(&err as &dyn core::error::Error).request_value::<String>().unwrap()
```
These are methods that based on the type hint when called return an `Option<T>` of that type. I'll admit I don't fully understand how that's done, but it involves `core::any::tags::Type` and `core::any::TaggedOption`, neither of which are exposed in the public API, to construct a `Request` which is then passed to the `Error.provide` method.
Something that I'm curious about is whether or not they are essential to the use of `Request` types (prior to this PR referred to as `Demand`) and if so does the fact that they are kept private imply that `Request`s are only meant to be constructed privately within the standard library? That's what it looks like to me.
These methods ultimately call into code that looks like:
```
/// Request a specific value by tag from the `Error`.
fn request_by_type_tag<'a, I>(err: &'a (impl Error + ?Sized)) -> Option<I::Reified>
where
I: tags::Type<'a>,
{
let mut tagged = core::any::TaggedOption::<'a, I>(None);
err.provide(tagged.as_request());
tagged.0
}
```
As far as the `Request` API is concerned, one suggestion I would like to make is that the previous example should look more like this:
```
/// Request a specific value by tag from the `Error`.
fn request_by_type_tag<'a, I>(err: &'a (impl Error + ?Sized)) -> Option<I::Reified>
where
I: tags::Type<'a>,
{
let tagged_request = core::any::Request<I>::new_tagged();
err.provide(tagged_request);
tagged.0
}
```
This makes it possible for anyone to construct a `Request` for use in their own projects without exposing an implementation detail like `TaggedOption` in the API surface.
Otherwise noteworthy is that I had to add `pub(crate)` on both `core::any::TaggedOption` and `core::any::tags` since `Request`s now need to be constructed in the `core::error` module. I considered moving `TaggedOption` into the `core::error` module but again I figured it's an implementation detail of `Request` and belongs closer to that.
At the time I am opening this PR, I have not yet looked into the following bit of feedback:
> We took a look at the generated code and found that LLVM is unable to optimize multiple .provide_* calls into a switch table because each call fetches the type id from Erased::type_id separately each time and the compiler doesn't know that these calls all return the same value. This should be fixed.
This is what I'll focus on next while waiting for feedback on the progress so far. I suspect that learning more about the type IDs will help me understand the need for `TaggedOption` a little better.
* remove `impl Provider for Error`
* rename `Demand` to `Request`
* update docstrings to focus on the conceptual API provided by `Request`
* move `core::any::{request_ref, request_value}` functions into `core::error`
* move `core::any::tag`, `core::any::Request`, an `core::any::TaggedOption` into `core::error`
* replace `provide_any` feature name w/ `error_generic_member_access`
* move `core::error::request_{ref,value} tests into core::tests::error module
* update unit and doc tests
Allow using external builds of the compiler-rt profile lib
This changes the bootstrap config `target.*.profiler` from a plain bool
to also allow a string, which will be used as a path to the pre-built
profiling runtime for that target. Then `profiler_builtins/build.rs`
reads that in a `LLVM_PROFILER_RT_LIB` environment variable.
Add `Iterator::map_windows`
Tracking issue: #87155.
This is inherited from the old PR #82413.
Unlike #82413, this PR implements the `MapWindows` to be lazy: only when pulling from the outer iterator, `.next()` of the inner iterator will be called.
## Implementaion Steps
- [x] Implement `MapWindows` to keep the iterators' [*Laziness*](https://doc.rust-lang.org/std/iter/index.html#laziness) contract.
- [x] Fix the known bug of memory access error.
- [ ] Full specialization of iterator-related traits for `MapWindows`.
- [x] `Iterator::size_hint`,
- [x] ~`Iterator::count`~,
- [x] `ExactSizeIterator` (when `I: ExactSizeIterator`),
- [x] ~`TrustedLen` (when `I: TrustedLen`)~,
- [x] `FusedIterator`,
- [x] ~`Iterator::advance_by`~,
- [x] ~`Iterator::nth`~,
- [ ] ...
- [ ] More tests and docs.
## Unresolved Questions:
- [ ] Is there any more iterator-related traits should be specialized?
- [ ] Is the double-space buffer worth?
- [ ] Should there be `rmap_windows` or something else?
- [ ] Taking GAT for consideration, should the mapper function be `FnMut(&[I::Item; N]) -> R` or something like `FnMut(ArrayView<'_, I::Item, N>) -> R`? Where `ArrayView` is mentioned in https://github.com/rust-lang/generic-associated-types-initiative/issues/2.
- It can save memory, only the same size as the array window is needed,
- It is more efficient, which requires less data copies,
- It is possibly compatible with the GATified version of `LendingIterator::windows`.
- But it prevents the array pattern matching like `iter.map_windows(|_arr: [_; N]| ())`, unless we extend the array pattern to allow matching the `ArrayView`.
Tell LLVM that the negation in `<*const T>::sub` cannot overflow
Today it's just `sub` <https://rust.godbolt.org/z/8EzEPnMr5>; with this PR it's `sub nsw`.
reduce deps for windows-msvc targets for backtrace
(eventually) mirrors https://github.com/rust-lang/backtrace-rs/pull/543
Some dependencies of backtrace don't used on windows-msvc targets, so exclude them:
miniz_oxide (+ adler)
addr2line (+ gimli)
object (+ memchr)
This saves about 30kb of std.dll + 17.5mb of rlibs
Fix documentation of impl From<Vec<T>> for Rc<[T]>
The example in the documentation of `impl From<Vec<T>> for <Rc<[T]>` is irrelevant (likely was copied from `impl From<Box<T>> for <Rc<T>`). I suggest taking corresponding example from the documentation of `Arc` and replacing `Arc` with `Rc`.
[library/std] Replace condv while loop with `cvar.wait_while`.
`wait_while` takes care of spurious wake-ups in centralized place, reducing chances for mistakes and potential future optimizations (who knows, maybe in future there will be no spurious wake-ups? :)
Inline trivial (noop) flush calls
At work I noticed that `writer.flush()?` didn't get optimized away in cases where the flush is obviously a no-op, which I had expected (well, desired).
I went through and added `#[inline]` to a bunch of cases that were obviously noops, or delegated to ones that were obviously noops. I omitted platforms I don't have access to (some tier3). I didn't do this very scientifically, in cases where it was non-obvious I left `#[inline]` off.
This is inherited from the old PR.
This method returns an iterator over mapped windows of the starting
iterator. Adding the more straight-forward `Iterator::windows` is not
easily possible right now as the items are stored in the iterator type,
meaning the `next` call would return references to `self`. This is not
allowed by the current `Iterator` trait design. This might change once
GATs have landed.
The idea has been brought up by @m-ou-se here:
https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/Iterator.3A.3A.7Bpairwise.2C.20windows.7D/near/224587771
Co-authored-by: Lukas Kalbertodt <lukas.kalbertodt@gmail.com>
test_get_dbpath_for_term(): handle non-utf8 paths (fix FIXME)
Removes a FIXME for #9639
Part of #44366 which is E-help-wanted
The remaining two FIXMEs for #9639 are considerably more complicated, so I will create separate PRs for them.
Rollup of 6 pull requests
Successful merges:
- #113939 (open pidfd in child process and send to the parent via SOCK_SEQPACKET+CMSG)
- #114548 (Migrate a trait selection error to use diagnostic translation)
- #114606 (fix: not insert missing lifetime for `ConstParamTy`)
- #114634 (Mention riscv64-linux-android support in Android documentation)
- #114638 (Remove old RPITIT tests (revisions were removed))
- #114641 (Rename copying `ascii::Char` methods from `as_` to `to_`)
r? `@ghost`
`@rustbot` modify labels: rollup
Rename copying `ascii::Char` methods from `as_` to `to_`
Tracking issue: #110998.
The [API guidelines][naming] describe `as_` as used for borrowed -> borrowed operations, and `to_` for
owned -> owned operations on `Copy` types.
[naming]: https://rust-lang.github.io/api-guidelines/naming.html
open pidfd in child process and send to the parent via SOCK_SEQPACKET+CMSG
This avoids using `clone3` when a pidfd is requested while still getting it in a 100% race-free manner by passing it up from the child process.
This should solve most concerns in #82971
Make ExitStatus implement Default
And, necessarily, make it inhabited even on platforms without processes.
I noticed while preparing https://github.com/rust-lang/rfcs/pull/3362 that there was no way for anyone to construct an `ExitStatus`.
This would be insta-stable so needs an FCP.
The `debug_assert_matches` macro was marked with the `#[macro_export]` attribute,
despite being a declarative macro/macro 2.0, for which the exporting rules are similar
to items. In fact, `#[macro_export]` on a decl macro has no effect on its visibility.
Add a new `compare_bytes` intrinsic instead of calling `memcmp` directly
As discussed in #113435, this lets the backends be the place that can have the "don't call the function if n == 0" logic, if it's needed for the target. (I didn't actually *add* those checks, though, since as I understood it we didn't actually need them on known targets?)
Doing this also let me make it `const` (unstable), which I don't think `extern "C" fn memcmp` can be.
cc `@RalfJung` `@Amanieu`
Optimize `Iterator` implementation for `&mut impl Iterator + Sized`
This adds a specialization trait to forward `fold`, `try_fold`,... to the inner iterator where possible
unix/kernel_copy.rs: copy_file_range_candidate allows empty output files
This is for https://github.com/rust-lang/rust/issues/114341
The `meta.len() > 0` condition here is intended for inputs only, ie. when input is in the `/proc` filesystem as documented.
That inaccurately included empty output files which are then shunted to the sendfile() routine leading to higher than nescessary IO util in some cases, specifically with CoW filesystems like btrfs.
Simply, determine what is input or output given the passed boolean.
This is for https://github.com/rust-lang/rust/issues/114341
The `meta.len() > 0` condition here is intended for inputs only,
ie. when input is in the `/proc` filesystem as documented.
That inaccurately included empty output files which are then shunted to
the sendfile() routine leading to higher than nescessary IO util in some
cases, specifically with CoW filesystems like btrfs.
Further, `NoneObtained` is not relevant in this context, so remove it.
Simply, determine what is input or output given the passed enum Unit.
Add `internal_features` lint
Implements https://github.com/rust-lang/compiler-team/issues/596
Also requires some more test blessing for codegen tests etc
`@jyn514` had the idea of just `allow`ing the lint by default in the test suite. I'm not sure whether this is a good idea, but it's definitely one worth considering. Additional input encouraged.
Expand, rename and improve `incorrect_fn_null_checks` lint
This PR,
- firstly, expand the lint by now linting on references
- secondly, it renames the lint `incorrect_fn_null_checks` -> `useless_ptr_null_checks`
- and thirdly it improves the lint by catching `ptr::from_mut`, `ptr::from_ref`, as well as `<*mut _>::cast` and `<*const _>::cast_mut`
Fixes https://github.com/rust-lang/rust/issues/113601
cc ```@est31```
It lints against features that are inteded to be internal to the
compiler and standard library. Implements MCP #596.
We allow `internal_features` in the standard library and compiler as those
use many features and this _is_ the standard library from the "internal to the compiler and
standard library" after all.
Marking some features as internal wasn't exactly the most scientific approach, I just marked some
mostly obvious features. While there is a categorization in the macro,
it's not very well upheld (should probably be fixed in another PR).
We always pass `-Ainternal_features` in the testsuite
About 400 UI tests and several other tests use internal features.
Instead of throwing the attribute on each one, just always allow them.
There's nothing wrong with testing internal features^^
Clarify documentation for `CStr`
* Better differentiate summaries for `from_bytes_until_nul` and `from_bytes_with_nul`
* Add some links where they may be helpful
Improve `invalid_reference_casting` lint
This PR is a follow-up to https://github.com/rust-lang/rust/pull/111567 and https://github.com/rust-lang/rust/pull/113422.
This PR does multiple things:
- First it adds support for deferred de-reference, the goal is to support code like this, where the casting and de-reference are not done on the same expression
```rust
let myself = self as *const Self as *mut Self;
*myself = Self::Ready(value);
```
- Second it does not lint anymore on SB/TB UB code by only checking assignments (`=`, `+=`, ...) and creation of mutable references `&mut *`
- Thirdly it greatly improves the diagnostics in particular for cast from `&mut` to `&mut` or assignments
- ~~And lastly it renames the lint from `cast_ref_to_mut` to `invalid_reference_casting` which is more consistent with the ["rules"](https://github.com/rust-lang/rust-clippy/issues/2845) and also more consistent with what the lint checks~~ *https://github.com/rust-lang/rust/pull/113422*
This PR is best reviewed commit by commit.
r? compiler
`wait_while` takes care of spurious wake-ups in centralized place,
reducing chances for mistakes and potential future optimizations
(who knows, maybe in future there will be no spurious wake-ups? :)
WASI threads, implementation of wasm32-wasi-preview1-threads target
This PR adds a target proposed in https://github.com/rust-lang/compiler-team/issues/574 by `@abrown` and implementation of `std:🧵:spawn` for the target `wasm32-wasi-preview1-threads`
### Tier 3 Target Policy
As tier 3 targets, the new targets are required to adhere to [the tier 3 target policy](https://doc.rust-lang.org/nightly/rustc/target-tier-policy.html#tier-3-target-policy) requirements. This section quotes each requirement in entirety and describes how they are met.
> - A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
See [src/doc/rustc/src/platform-support/wasm32-wasi-preview1-threads.md](https://github.com/rust-lang/rust/pull/112922/files#diff-a48ee9d94f13e12be24eadd08eb47b479c153c340eeea4ef22276d876dfd4f3e).
> - Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
> - Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
If possible, use only letters, numbers, dashes and underscores for the name. Periods (.) are known to cause issues in Cargo.
The target is using the same name for $ARCH=wasm32 and $OS=wasi as existing Rust targets. The suffix `preview1` introduced to accurately set expectations because eventually this target will be deprecated and follows [MCP 607](https://github.com/rust-lang/compiler-team/issues/607). The suffix `threads` indicates that it’s an extension that enables threads to the existing target and it follows [MCP 574](https://github.com/rust-lang/compiler-team/issues/574) which describes the rationale behind introducing a separate target.
> - Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
> - The target must not introduce license incompatibilities.
> - Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
> - The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
> - Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> - "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
This PR does not introduce any new dependency.
The new target doesn’t support building host tools.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
The full standard library is available for this target as it’s an extension to an existing target that has already supported it.
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
Only manual test running is supported at the moment with some tweaks in the test runner codebase. For build and running tests see [src/doc/rustc/src/platform-support/wasm32-wasi-preview1-threads.md](https://github.com/rust-lang/rust/pull/112922/files#diff-a48ee9d94f13e12be24eadd08eb47b479c153c340eeea4ef22276d876dfd4f3e).
> - Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> - This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
> - Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via `@)` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> - Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
> - Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> - In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
I acknowledge these requirements and intend to ensure they are met.
Change default panic handler message format.
This changes the default panic hook's message format from:
```
thread '{thread}' panicked at '{message}', {location}
```
to
```
thread '{thread}' panicked at {location}:
{message}
```
This puts the message on its own line without surrounding quotes, making it easiser to read. For example:
Before:
```
thread 'main' panicked at 'env variable `IMPORTANT_PATH` should be set by `wrapper_script.sh`', src/main.rs:4:6
```
After:
```
thread 'main' panicked at src/main.rs:4:6:
env variable `IMPORTANT_PATH` should be set by `wrapper_script.sh`
```
---
See this PR by `@nyurik,` which does that for only multi-line messages (specifically because of `assert_eq`): https://github.com/rust-lang/rust/pull/111071
This is the change that does that for *all* panic messages.
Re-export core::ffi::FromBytesUntilNulError in std::ffi
Like the other CStr and CString error types, make a re-export for std::ffi::FromBytesUntilNulError.
This seems to have slipped through the cracks in the cstr_from_bytes_until_nul implementation and core_c_str migration.
Tracking Issue: #95027
Make `Debug` representations of `[Lazy, Once]*[Cell, Lock]` consistent with `Mutex` and `RwLock`
`Mutex` prints `<locked>` as a field value when its inner value cannot be accessed, but the lazy types print a fixed string like "`OnceCell(Uninit)`". This could cause confusion if the inner type is a unit type named `Uninit` and does not respect the pretty-printing flag. With this change, the format message is now "`OnceCell(<uninit>)`", consistent with `Mutex`.
Improve test case for experimental API remove_matches
## Add Test Cases for `remove_matches` Function
### Motivation
After reading the discussion in [this GitHub thread](https://github.com/rust-lang/rust/pull/71780), I'm trying to redesign the current API to use less memory when working with `String` and to make it simpler. I've discovered that some test cases are very helpful in ensuring that the new API behaves as intended. I'm still in the process of redesigning the current API, and these test cases have proven to be very useful.
### Testing
The current test has been tested with the command `./x test --stage 0 library/alloc`.
### Overview
This pull request adds several new test cases for the `remove_matches` function to make sure it works correctly in different situations. The `remove_matches` function is used to get rid of all instances of a specific pattern from a given text. These test cases thoroughly check how the function behaves in various scenarios.
### Test Cases
1. **Single Pattern Occurrence** (`test_single_pattern_occurrence`):
- Description: Tests the removal of a single pattern occurrence from the text.
- Input: Text: "abc", Pattern: 'b'
- Expected Output: "ac"
2. **Repeat Test Single Pattern Occurrence** (`repeat_test_single_pattern_occurrence`):
- Description: Repeats the previous test case to ensure consecutive removal of the same pattern.
- Input: Text: "ac", Pattern: 'b'
- Expected Output: "ac"
3. **Single Character Pattern** (`test_single_character_pattern`):
- Description: Tests the removal of a single character pattern.
- Input: Text: "abcb", Pattern: 'b'
- Expected Output: "ac"
4. **Pattern with Special Characters** (`test_pattern_with_special_characters`):
- Description: Tests the removal of a pattern containing special characters.
- Input: Text: "ศไทย中华Việt Nam; foobarศ", Pattern: 'ศ'
- Expected Output: "ไทย中华Việt Nam; foobar"
5. **Pattern Empty Text and Pattern** (`test_pattern_empty_text_and_pattern`):
- Description: Tests the removal of an empty pattern from an empty text.
- Input: Text: "", Pattern: ""
- Expected Output: ""
6. **Pattern Empty Text** (`test_pattern_empty_text`):
- Description: Tests the removal of a pattern from an empty text.
- Input: Text: "", Pattern: "something"
- Expected Output: ""
7. **Empty Pattern** (`test_empty_pattern`):
- Description: Tests the behavior of removing an empty pattern from the text.
- Input: Text: "Testing with empty pattern.", Pattern: ""
- Expected Output: "Testing with empty pattern."
8. **Multiple Consecutive Patterns 1** (`test_multiple_consecutive_patterns_1`):
- Description: Tests the removal of multiple consecutive occurrences of a pattern.
- Input: Text: "aaaaa", Pattern: 'a'
- Expected Output: ""
9. **Multiple Consecutive Patterns 2** (`test_multiple_consecutive_patterns_2`):
- Description: Tests the removal of a longer pattern that occurs consecutively.
- Input: Text: "Hello **world****today!**", Pattern: "**"
- Expected Output: "Hello worldtoday!"
10. **Case Insensitive Pattern** (`test_case_insensitive_pattern`):
- Description: Tests the removal of a case-insensitive pattern from the text.
- Input: Text: "CASE ** SeNsItIvE ** PaTtErN.", Pattern: "sEnSiTiVe"
- Expected Output: "CASE ** SeNsItIvE ** PaTtErN."
Use `LazyLock` to lazily resolve backtraces
By using TAIT to name the initializing closure, `LazyLock` can be used to replace the current `LazilyResolvedCapture`.
Stabilize const-weak-new
This is a fairly uncontroversial library stabilization, so I'm going ahead and proposing it to ride the trains to stable.
This stabilizes the following APIs, which are defined to be non-allocating constructors.
```rust
// alloc::rc
impl<T> Weak<T> {
pub const fn new() -> Weak<T>;
}
// alloc::sync
impl<T> Weak<T> {
pub const fn new() -> Weak<T>;
}
```
Closes#95091
``@rustbot`` modify labels: +needs-fcp
Bump its stabilization version several times along
the way to accommodate changes in release processes.
Co-authored-by: Mara Bos <m-ou.se@m-ou.se>
Co-authored-by: Trevor Gross <t.gross35@gmail.com>