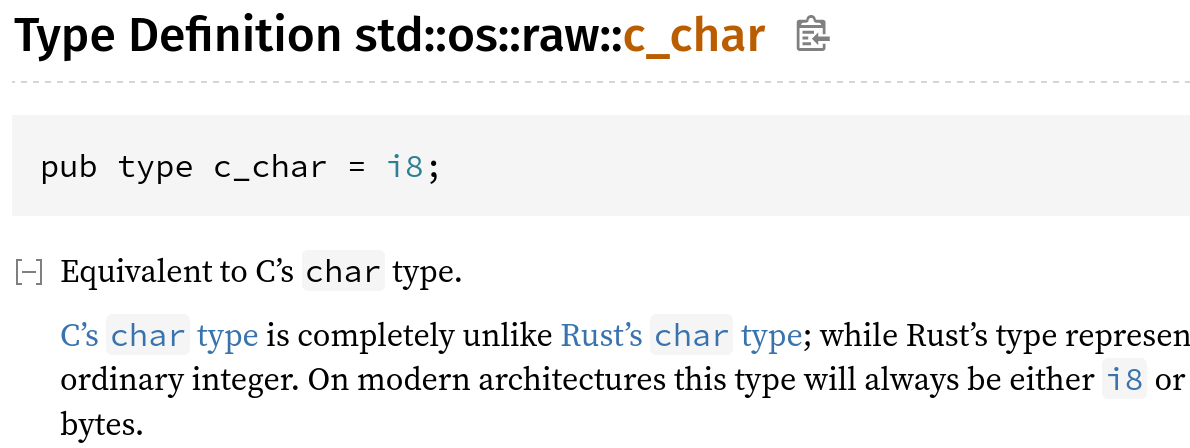
Define c_char using cfg_if rather than repeating 40-line cfg
Libstd has a 40-line cfg that defines the targets on which `c_char` is unsigned, and then repeats the same cfg with `not(…)` for the targets on which `c_char` is signed.
This PR replaces it with a `cfg_if!` in which an `else` takes care of the signed case.
I confirmed that `x.py doc library/std` inlines the type alias because c_char_definition is not a publicly accessible path:
Make available the remaining float intrinsics that require runtime support
from a platform's libm, and thus cannot be included in a no-deps libcore,
by exposing them through a sealed trait, `std::simd::StdFloat`.
We might use the trait approach a bit more in the future, or maybe not.
Ideally, this trait doesn't stick around, even if so.
If we don't need to intermesh it with std, it can be used as a crate,
but currently that is somewhat uncertain.
The creation of libc::sockaddr_un is a safe operation, no need for it to
be unsafe.
This also uses the more performant copy_nonoverlapping instead of an
iterator.
Replace iterator-based construction of collections by `Into<T>`
Just a few quality of life improvements in the doc examples. I also removed some `Vec`s in favor of arrays.
Add a `try_clone()` function to `OwnedFd`.
As suggested in #88564. This adds a `try_clone()` to `OwnedFd` by
refactoring the code out of the existing `File`/`Socket` code.
r? ``@joshtriplett``
Fix STD compilation for the ESP-IDF target (regression from CVE-2022-21658)
Commit 54e22eb7db broke the compilation of STD for the ESP-IDF embedded "unix-like" Tier 3 target, because the fix for [CVE-2022-21658](https://blog.rust-lang.org/2022/01/20/Rust-1.58.1.html) uses [libc flags](https://github.com/esp-rs/esp-idf-svc/runs/4892221554?check_suite_focus=true) which are not supported on the ESP-IDF platform.
This PR simply redirects the ESP-IDF compilation to the "classic" implementation, similar to REDOX. This should be safe because:
* Neither of the two filesystems supported by ESP-IDF (spiffs and fatfs) support [symlinks](https://github.com/natevw/fatfs/blob/master/README.md) in the first place
* There is no notion of fs permissions at all, as the ESP-IDF is an embedded platform that does not have the notion of users, groups, etc.
* Similarly, ESP-IDF has just one "process" - the firmware itself - which contains the user code and the "OS" fused together and running with all permissions
impl Not for !
The lack of this impl caused trouble for me in some degenerate cases of macro-generated code of the form `if !$cond {...}`, even without `feature(never_type)` on a stable compiler. Namely if `$cond` contains a `return` or `break` or similar diverging expression, which would otherwise be perfectly legal in boolean position, the code previously failed to compile with:
```console
error[E0600]: cannot apply unary operator `!` to type `!`
--> library/core/tests/ops.rs:239:8
|
239 | if !return () {}
| ^^^^^^^^^^ cannot apply unary operator `!`
```
Stabilize arc_new_cyclic
This stabilizes feature `arc_new_cyclic` as the implementation has been merged for one year and there is no unresolved questions. The FCP is not started yet.
Closes#75861 .
``@rustbot`` label +T-libs-api
Print a helpful message if unwinding aborts when it reaches a nounwind function
This is implemented by routing `TerminatorKind::Abort` back through the panic handler, but with a special flag in the `PanicInfo` which indicates that the panic handler should *not* attempt to unwind the stack and should instead abort immediately.
This is useful for the planned change in https://github.com/rust-lang/lang-team/issues/97 which would make `Drop` impls `nounwind` by default.
### Code
```rust
#![feature(c_unwind)]
fn panic() {
panic!()
}
extern "C" fn nounwind() {
panic();
}
fn main() {
nounwind();
}
```
### Before
```
$ ./test
thread 'main' panicked at 'explicit panic', test.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Illegal instruction (core dumped)
```
### After
```
$ ./test
thread 'main' panicked at 'explicit panic', test.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at 'panic in a function that cannot unwind', test.rs:7:1
stack backtrace:
0: 0x556f8f86ec9b - <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt::hdccefe11a6ac4396
1: 0x556f8f88ac6c - core::fmt::write::he152b28c41466ebb
2: 0x556f8f85d6e2 - std::io::Write::write_fmt::h0c261480ab86f3d3
3: 0x556f8f8654fa - std::panicking::default_hook::{{closure}}::h5d7346f3ff7f6c1b
4: 0x556f8f86512b - std::panicking::default_hook::hd85803a1376cac7f
5: 0x556f8f865a91 - std::panicking::rust_panic_with_hook::h4dc1c5a3036257ac
6: 0x556f8f86f079 - std::panicking::begin_panic_handler::{{closure}}::hdda1d83c7a9d34d2
7: 0x556f8f86edc4 - std::sys_common::backtrace::__rust_end_short_backtrace::h5b70ed0cce71e95f
8: 0x556f8f865592 - rust_begin_unwind
9: 0x556f8f85a764 - core::panicking::panic_no_unwind::h2606ab3d78c87899
10: 0x556f8f85b910 - test::nounwind::hade6c7ee65050347
11: 0x556f8f85b936 - test::main::hdc6e02cb36343525
12: 0x556f8f85b7e3 - core::ops::function::FnOnce::call_once::h4d02663acfc7597f
13: 0x556f8f85b739 - std::sys_common::backtrace::__rust_begin_short_backtrace::h071d40135adb0101
14: 0x556f8f85c149 - std::rt::lang_start::{{closure}}::h70dbfbf38b685e93
15: 0x556f8f85c791 - std::rt::lang_start_internal::h798f1c0268d525aa
16: 0x556f8f85c131 - std::rt::lang_start::h476a7ee0a0bb663f
17: 0x556f8f85b963 - main
18: 0x7f64c0822b25 - __libc_start_main
19: 0x556f8f85ae8e - _start
20: 0x0 - <unknown>
thread panicked while panicking. aborting.
Aborted (core dumped)
```
add support for the l4-bender linker on the x86_64-unknown-l4re-uclibc tier 3 target
This PR contains the work by ```@humenda``` to update support for the `x86_64-unknown-l4re-uclibc` tier 3 target (published at [humenda/rust](https://github.com/humenda/rust)), rebased and adapted to current rust in follow up commits by myself. The publishing of the rebased changes is authorized and preferred by the original author. As the goal was to distort the original work as little as possible, individual commits introduce changes that are incompatible to the newer code base that the changes were rebased on. These incompatibilities have been remedied in follow up commits, so that the PR as a whole should result in a clean update of the target.
If you prefer another strategy to mainline these changes while preserving attribution, please let me know.
delete `Stdin::split` forwarder
Part of #87096. Delete the `Stdin::split` forwarder because it's seen as too niche to expose at this level.
`@rustbot` label T-libs-api A-io
Improve `Arc` and `Rc` documentation
This makes two changes (I can split the PR if necessary, but the changes are pretty small):
1. A bunch of trait implementations claimed to be zero cost; however, they use the `Arc<T>: From<Box<T>>` impl which is definitely not free, especially for large dynamically sized `T`.
2. The code in deferred initialization examples unnecessarily used excessive amounts of `unsafe`. This has been reduced.
- Fix style errors.
- L4-bender does not yet support dynamic linking.
- Stack unwinding is not yet supported for x86_64-unknown-l4re-uclibc.
For now, just abort on panics.
- Use GNU-style linker options where possible. As suggested by review:
- Use standard GNU-style ld syntax for relro flags.
- Use standard GNU-style optimization flags and logic.
- Use standard GNU-style ld syntax for --subsystem.
- Don't read environment variables in L4Bender linker. Thanks to
CARGO_ENCODED_RUSTFLAGS introduced in #9601, l4-bender's arguments can
now be passed from the L4Re build system without resorting to custom
parsing of environment variables.
readdir() is preferred over readdir_r() on Linux and many other
platforms because it more gracefully supports long file names. Both
glibc and musl (and presumably all other Linux libc implementations)
guarantee that readdir() is thread-safe as long as a single DIR* is not
accessed concurrently, which is enough to make a readdir()-based
implementation of ReadDir safe. This implementation is already used for
some other OSes including Fuchsia, Redox, and Solaris.
See #40021 for more details. Fixes#86649. Fixes#34668.
Help optimize out backtraces when disabled
The comment in `rust_backtrace_env` says:
> // If the `backtrace` feature of this crate isn't enabled quickly return
> // `None` so this can be constant propagated all over the place to turn
> // optimize away callers.
but this optimization has regressed, because the only caller of this function had an alternative path that unconditionally (and pointlessly) asked for a full backtrace, so the disabled state couldn't propagate.
I've added a getter for the full format that respects the feature flag, so that the caller will now be able to really optimize out the disabled backtrace path. I've also made `rust_backtrace_env` trivially inlineable when backtraces are disabled.
Add MaybeUninit::(slice_)as_bytes(_mut)
This adds methods to convert between `MaybeUninit<T>` and a slice of `MaybeUninit<u8>`. This is safe since `MaybeUninit<u8>` can correctly handle padding bytes in any `T`.
These methods are added:
```rust
impl<T> MaybeUninit<T> {
pub fn as_bytes(&self) -> &[MaybeUninit<u8>];
pub fn as_bytes_mut(&mut self) -> &mut [MaybeUninit<u8>];
pub fn slice_as_bytes(this: &[MaybeUninit<T>]) -> &[MaybeUninit<u8>];
pub fn slice_as_bytes_mut(this: &mut [MaybeUninit<T>]) -> &mut [MaybeUninit<u8>];
}
```
Change PhantomData type for `BuildHasherDefault` (and more)
Changes `PhantomData<H>` to `PhantomData<fn() -> H>` for `BuildHasherDefault`. This preserves the covariance of `H`, while it lifts the currently inferred unnecessary bounds like [`H: Send` for `BuildHasherDefault<H>: Send`](https://doc.rust-lang.org/1.57.0/std/hash/struct.BuildHasherDefault.html#impl-Send), etc.
_Edit:_ Also does a similar change for `iter::Empty` and `future::Pending`.
Little improves in CString `new` when creating from slice
Old code already contain optimization for cases with `&str` and `&[u8]` args. This commit adds a specialization for `&mut[u8]` too.
Also, I added usage of old slice in search for zero bytes instead of new buffer because it produce better code for constant inputs on Windows LTO builds. For other platforms, this wouldn't cause any difference because it calls `libc` anyway.
Inlined `_new` method into spec trait to reduce amount of code generated to `CString::new` callers.
doc: guarantee call order for sort_by_cached_key
`slice::sort_by_cached_key` takes a caching function `f: impl FnMut(&T) -> K`, which means that the order that calls to the caching function are made is user-visible. This adds a clause to the documentation to promise the current behavior, which is that `f` is called on all elements of the slice from left to right, unless the slice has len < 2 in which case `f` is not called.
For example, this can be used to ensure that the following code is a correct way to involve the index of the element in the sort key:
```rust
let mut index = 0;
slice.sort_by_cached_key(|x| (my_key(index, x), index += 1).0);
```
Fix stdarch submodule pointing to commit outside tree
PR #93016 was merged with the stdarch submodule pointing to a commit in
a PR branch and not in master. This was due to a circular dependency
between the rust and stdarch changes which would cause the other to fail
to build.
cc #75109
PR #93016 was merged with the stdarch submodule pointing to a commit in
a PR branch and not in master. This was due to a circular dependency
between the rust and stdarch changes which would cause the other to fail
to build.
cc #75109
add `rustc_diagnostic_item` attribute to `AtomicBool` type
I wanted to use this in clippy and found that it didn't work. So hopefully this addition will fix it.
Use `carrying_{mul|add}` in `num::bignum`
Now that we have (unstable) methods for this, we don't need the bespoke trait methods for it in the `bignum` implementation.
cc #85532
Add `log2` and `log10` to `NonZeroU*`
This version is nice in that it doesn't need to worry about zeros, and thus doesn't have any error cases.
cc `int_log` tracking issue #70887
(I didn't add them to `NonZeroI*` despite it being on `i*` since allowing negatives bring back the error cases again.)
Remove deprecated LLVM-style inline assembly
The `llvm_asm!` was deprecated back in #87590 1.56.0, with intention to remove
it once `asm!` was stabilized, which already happened in #91728 1.59.0. Now it
is time to remove `llvm_asm!` to avoid continued maintenance cost.
Closes#70173.
Closes#92794.
Closes#87612.
Closes#82065.
cc `@rust-lang/wg-inline-asm`
r? `@Amanieu`
fix const_ptr_offset_from tracking issue
The old tracking issue #41079 was for exposing those functions at all, and got closed when they were stabilized. We had nothing tracking their `const`ness so I opened a new tracking issue: https://github.com/rust-lang/rust/issues/92980.
Copy an example to PartialOrd as well
In https://github.com/rust-lang/rust/pull/88202 I added an example for deriving PartialOrd on enums, but only later did I realize that I actually put the example on Ord.
This copies the example to PartialOrd as well, which is where I intended for it to be.
We could also delete the example on Ord, but I see there's already some highly similar examples shared between Ord and PartialOrd, so I figured we could leave it.
I also changed some type annotations in an example from `x : T` to the more common style (in Rust) of `x: T`.
Clarify explicitly that BTree{Map,Set} are ordered.
One of the main reasons one would want to use a BTree{Map,Set} rather than a Hash{Map,Set} is because they maintain their keys in sorted order; but this was never explicitly stated in the top-level docs (it was only indirectly alluded to there, and stated explicitly in the docs for `iter`, `values`, etc.)
This PR states the ordering guarantee more prominently.
Add diagnostic items for macros
For use in Clippy, it adds diagnostic items to all the stable public macros
Clippy has lints that look for almost all of these (currently by name or path), but there are a few that aren't currently part of any lint, I could remove those if it's preferred to add them as needed rather than ahead of time
Yield means something else in the context of generators, which are
sufficiently close to iterators that it's better to avoid the
terminology collision here.
Implement `panic::update_hook`
Add a new function `panic::update_hook` to allow creating panic hooks that forward the call to the previously set panic hook, without race conditions. It works by taking a closure that transforms the old panic hook into a new one, while ensuring that during the execution of the closure no other thread can modify the panic hook. This is a small function so I hope it can be discussed here without a formal RFC, however if you prefer I can write one.
Consider the following example:
```rust
let prev = panic::take_hook();
panic::set_hook(Box::new(move |info| {
println!("panic handler A");
prev(info);
}));
```
This is a common pattern in libraries that need to do something in case of panic: log panic to a file, record code coverage, send panic message to a monitoring service, print custom message with link to github to open a new issue, etc. However it is impossible to avoid race conditions with the current API, because two threads can execute in this order:
* Thread A calls `panic::take_hook()`
* Thread B calls `panic::take_hook()`
* Thread A calls `panic::set_hook()`
* Thread B calls `panic::set_hook()`
And the result is that the original panic hook has been lost, as well as the panic hook set by thread A. The resulting panic hook will be the one set by thread B, which forwards to the default panic hook. This is not considered a big issue because the panic handler setup is usually run during initialization code, probably before spawning any other threads.
Using the new `panic::update_hook` function, this race condition is impossible, and the result will be either `A, B, original` or `B, A, original`.
```rust
panic::update_hook(|prev| {
Box::new(move |info| {
println!("panic handler A");
prev(info);
})
});
```
I found one real world use case here: 988cf403e7/src/detection.rs (L32) the workaround is to detect the race condition and panic in that case.
The pattern of `take_hook` + `set_hook` is very common, you can see some examples in this pull request, so I think it's natural to have a function that combines them both. Also using `update_hook` instead of `take_hook` + `set_hook` reduces the number of calls to `HOOK_LOCK.write()` from 2 to 1, but I don't expect this to make any difference in performance.
### Unresolved questions:
* `panic::update_hook` takes a closure, if that closure panics the error message is "panicked while processing panic" which is not nice. This is a consequence of holding the `HOOK_LOCK` while executing the closure. Could be avoided using `catch_unwind`?
* Reimplement `panic::set_hook` as `panic::update_hook(|_prev| hook)`?
Remove `&mut` from `io::read_to_string` signature
``@m-ou-se`` [realized][1] that because `Read` is implemented for `&mut impl
Read`, there's no need to take `&mut` in `io::read_to_string`.
Removing the `&mut` from the signature allows users to remove the `&mut`
from their calls (and thus pass an owned reader) if they don't use the
reader later.
r? `@m-ou-se`
[1]: https://github.com/rust-lang/rust/issues/80218#issuecomment-874322129
Inline std::os::unix::ffi::OsStringExt methods
Those methods essentially do nothing at assembly level. On Unix systems, `OsString` is represented as a `Vec` without performing any transformations.
Simplification of BigNum::bit_length
As indicated in the comment, the BigNum::bit_length function could be
optimized by using CLZ, which is often a single instruction instead a
loop.
I think the code is also simpler now without the loop.
I added some additional tests for Big8x3 and Big32x40 to ensure that
there were no regressions.
Extend const_convert to rest of blanket core::convert impls
This adds constness to all the blanket impls in `core::convert` under the existing `const_convert` feature, tracked by #88674.
Existing impls under that feature:
```rust
impl<T> const From<T> for T;
impl<T, U> const Into<U> for T where U: ~const From<T>;
impl<T> const ops::Try for Option<T>;
impl<T> const ops::FromResidual for Option<T>;
impl<T, E> const ops::Try for Result<T, E>;
impl<T, E, F> const ops::FromResidual<Result<convert::Infallible, E>> for Result<T, F> where F: ~const From<E>;
```
Additional impls:
```rust
impl<T: ?Sized, U: ?Sized> const AsRef<U> for &T where T: ~const AsRef<U>;
impl<T: ?Sized, U: ?Sized> const AsRef<U> for &mut T where T: ~const AsRef<U>;
impl<T: ?Sized, U: ?Sized> const AsMut<U> for &mut T where T: ~const AsMut<U>;
impl<T, U> const TryInto<U> for T where U: ~const TryFrom<T>;
impl<T, U> const TryFrom<U> for T where U: ~const Into<T>;
```
Partially stabilize `maybe_uninit_extra`
This covers:
```rust
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
```
It does not cover the const-ness of `write` under `const_maybe_uninit_write` nor the const-ness of `assume_init_read` (this commit adds `const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
`@m-ou-se` [realized][1] that because `Read` is implemented for `&mut impl
Read`, there's no need to take `&mut` in `io::read_to_string`.
Removing the `&mut` from the signature allows users to remove the `&mut`
from their calls (and thus pass an owned reader) if they don't use the
reader later.
[1]: https://github.com/rust-lang/rust/issues/80218#issuecomment-874322129
Add `std::error::Report` type
This is a continuation of https://github.com/rust-lang/rust/pull/90174, split into a separate PR since I cannot push to ```````@seanchen1991``````` 's fork
Simpilfy thread::JoinInner.
`JoinInner`'s `native` field was an `Option`, but that's unnecessary.
Also, thanks to `Arc::get_mut`, there's no unsafety needed in `JoinInner::join()`.
`WSADuplicateSocketW` returns 0 on success, which differs from
handle-oriented functions which return 0 on error. Use `sys::net::cvt`
to handle its return value, which handles the socket convention of
returning 0 on success, rather than `sys::cvt`, which handles the
handle-oriented convention of returning 0 on failure.
Eliminate "boxed" wording in `std::error::Error` documentation
In commit 29403ee, documentation for the methods on `std::any::Any` was
modified so that they referred to the concrete value behind the trait
object as the "inner" value. This is a more accurate wording than
"boxed": while putting trait objects inside boxes is arguably the most
common use, they can also be placed behind other pointer types like
`&mut` or `std::sync::Arc`.
This commit does the same documentation changes for `std::error::Error`.
Improve documentation for File::options to give a more likely example
`File::options().read(true).open(...)` is equivalent to just
`File::open`. Change the example to set the `append` flag instead, and
then change the filename to something more likely to be written in
append mode.
This covers:
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
It does not cover the const-ness of `write` under
`const_maybe_uninit_write` nor the const-ness of
`assume_init_read` (this commit adds
`const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Replace usages of vec![].into_iter with [].into_iter
`[].into_iter` is idiomatic over `vec![].into_iter` because its simpler and faster (unless the vec is optimized away in which case it would be the same)
So we should change all the implementation, documentation and tests to use it.
I skipped:
* `src/tools` - Those are copied in from upstream
* `src/test/ui` - Hard to tell if `vec![].into_iter` was used intentionally or not here and not much benefit to changing it.
* any case where `vec![].into_iter` was used because we specifically needed a `Vec::IntoIter<T>`
* any case where it looked like we were intentionally using `vec![].into_iter` to test it.
`File::options().read(true).open(...)` is equivalent to just
`File::open`. Change the example to set the `append` flag instead, and
then change the filename to something more likely to be written in
append mode.
In commit 29403ee, documentation for the methods on `std::any::Any` was
modified so that they referred to the concrete value behind the trait
object as the "inner" value. This is a more accurate wording than
"boxed": while putting trait objects inside boxes is arguably the most
common use, they can also be placed behind other pointer types like
`&mut` or `std::sync::Arc`.
This commit does the same documentation changes for `std::error::Error`.
As indicated in the comment, the BigNum::bit_length function could be
optimized by using CLZ, which is often a single instruction instead a
loop.
I think the code is also simpler now without the loop.
I added some additional tests for Big8x3 and Big32x40 to ensure that
there were no regressions.
Mak DefId to AccessLevel map in resolve for export
hir_id to accesslevel in resolve and applied in privacy
using local def id
removing tracing probes
making function not recursive and adding comments
Move most of Exported/Public res to rustc_resolve
moving public/export res to resolve
fix missing stability attributes in core, std and alloc
move code to access_levels.rs
return for some kinds instead of going through them
Export correctness, macro changes, comments
add comment for import binding
add comment for import binding
renmae to access level visitor, remove comments, move fn as closure, remove new_key
fmt
fix rebase
fix rebase
fmt
fmt
fix: move macro def to rustc_resolve
fix: reachable AccessLevel for enum variants
fmt
fix: missing stability attributes for other architectures
allow unreachable pub in rustfmt
fix: missing impl access level + renaming export to reexport
Missing impl access level was found thanks to a test in clippy
Make `Atomic*::from_mut` return `&mut Atomic*`
```rust
impl Atomic* {
pub fn from_mut(v: &mut bool) -> &mut Self;
// ^^^^---- previously was just a &
}
```
This PR makes `from_mut` atomic methods tracked in #76314 return unique references to atomic types, instead of shared ones. This makes `from_mut` and `get_mut` inverses of each other, allowing to undo either of them by the other.
r? `@RalfJung`
(as Ralf was [concerned](https://github.com/rust-lang/rust/issues/76314#issuecomment-955062593) about this)
Implemented const casts of raw pointers
This adds `as_mut()` method for `*const T` and `as_const()` for `*mut T`
which are intended to make casting of consts safer. This was discussed
in the [internals discussion][discussion].
Given that this is a simple change and multiple people agreed to it including `@RalfJung` I decided to go ahead and open the PR.
[discussion]: https://internals.rust-lang.org/t/casting-constness-can-be-risky-heres-a-simple-fix/15933
Add some missing `#[must_use]` to some `f{32,64}` operations
This PR adds `#[must_use]` to the following methods:
- `f32::recip`
- `f32::max`
- `f32::min`
- `f32::maximum`
- `f32::minimum`
and their equivalents in `f64`.
These methods all produce a new value without modifying the original and so are pointless to call without using the result.
Add note about non_exhaustive to variant_count
Since `variant_count` isn't returning something opaque, I thought it makes sense to explicitly call out that its return value may change for some enums.
cc #73662
Previously suggested in https://github.com/rust-lang/rfcs/issues/2854.
It makes sense to have this since `char` implements `From<u8>`. Likewise
`u32`, `u64`, and `u128` (since #79502) implement `From<char>`.
Rollup of 7 pull requests
Successful merges:
- #92092 (Drop guards in slice sorting derive src pointers from &mut T, which is invalidated by interior mutation in comparison)
- #92388 (Fix a minor mistake in `String::try_reserve_exact` examples)
- #92442 (Add negative `impl` for `Ord`, `PartialOrd` on `LocalDefId`)
- #92483 (Stabilize `result_cloned` and `result_copied`)
- #92574 (Add RISC-V detection macro and more architecture instructions)
- #92575 (ast: Always keep a `NodeId` in `ast::Crate`)
- #92583 (⬆️ rust-analyzer)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add RISC-V detection macro and more architecture instructions
This pull request includes:
- Update `stdarch` dependency to include ratified RISC-V supervisor and hypervisor instruction intrinsics which is useful in Rust kernel development
- Add macro `is_riscv_feature_detected!`
- Modify impl of `core::hint::spin_loop` to comply with latest version of `core::arch`
After this update, users may now develop RISC-V kernels and user applications more freely.
r? `@Amanieu`
Fix a minor mistake in `String::try_reserve_exact` examples
The examples of `String::try_reserve_exact` didn't actually use `try_reserve_exact`, which was probably a minor mistake, and this PR fixed it.
Drop guards in slice sorting derive src pointers from &mut T, which is invalidated by interior mutation in comparison
I tried to run https://github.com/rust-lang/miri-test-libstd on `alloc` with `-Zmiri-track-raw-pointers`, and got a failure on the test `slice::panic_safe`. The test failure has nothing to do with panic safety, it's from how the test tests for panic safety.
I minimized the test failure into this very silly program:
```rust
use std::cell::Cell;
use std::cmp::Ordering;
#[derive(Clone)]
struct Evil(Cell<usize>);
fn main() {
let mut input = vec![Evil(Cell::new(0)); 3];
// Hits the bug pattern via CopyOnDrop in core
input.sort_unstable_by(|a, _b| {
a.0.set(0);
Ordering::Less
});
// Hits the bug pattern via InsertionHole in alloc
input.sort_by(|_a, b| {
b.0.set(0);
Ordering::Less
});
}
```
To fix this, I'm just removing the mutability/uniqueness where it wasn't required.
Rollup of 7 pull requests
Successful merges:
- #91587 (core::ops::unsize: improve docs for DispatchFromDyn)
- #91907 (Allow `_` as the length of array types and repeat expressions)
- #92515 (RustWrapper: adapt for an LLVM API change)
- #92516 (Do not use deprecated -Zsymbol-mangling-version in bootstrap)
- #92530 (Move `contains` method of Option and Result lower in docs)
- #92546 (Update books)
- #92551 (rename StackPopClean::None to Root)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Move `contains` method of Option and Result lower in docs
Follow-up to #92444 trying to get the `Option` and `Result` rustdocs in better shape.
This addresses the request in https://github.com/rust-lang/rust/issues/62358#issuecomment-645676285. The `contains` methods are previously too high up in the docs on both `Option` and `Result` — stuff like `ok` and `map` and `and_then` should all be featured higher than `contains`. All of those are more ubiquitously useful than `contains`.
intra-doc: Make `Receiver::into_iter` into a clickable link
The documentation on `std::sync::mpsc::Iter` and `std::sync::mpsc::TryIter` provides links to the corresponding `Receiver` methods, unlike `std::sync::mpsc::IntoIter` does.
This was left out in c59b188aae
Related to #29377
Modifications to `std::io::Stdin` on Windows so that there is no longer a 4-byte buffer minimum in read().
This is an attempted fix of issue #91722, where a too-small buffer was passed to the read function of stdio on Windows. This caused an error to be returned when `read_to_end` or `read_to_string` were called. Both delegate to `std::io::default_read_to_end`, which creates a buffer that is of length >0, and forwards it to `std::io::Stdin::read()`. The latter method returns an error if the length of the buffer is less than 4, as there might not be enough space to allocate a UTF-16 character. This creates a problem when the buffer length is in `0 < N < 4`, causing the bug.
The current modification creates an internal buffer, much like the one used for the write functions
I'd also like to acknowledge the help of ``@agausmann`` and ``@hkratz`` in detecting and isolating the bug, and for suggestions that made the fix possible.
Couple disclaimers:
- Firstly, I didn't know where to put code to replicate the bug found in the issue. It would probably be wise to add that case to the testing suite, but I'm afraid that I don't know _where_ that test should be added.
- Secondly, the code is fairly fundamental to IO operations, so my fears are that this may cause some undesired side effects ~or performance loss in benchmarks.~ The testing suite runs on my computer, and it does fix the issue noted in #91722.
- Thirdly, I left the "surrogate" field in the Stdin struct, but from a cursory glance, it seems to be serving the same purpose for other functions. Perhaps merging the two would be appropriate.
Finally, this is my first pull request to the rust language, and as such some things may be weird/unidiomatic/plain out bad. If there are any obvious improvements I could do to the code, or any other suggestions, I would appreciate them.
Edit: Closes#91722
It now panic!()s on its own, rather than resume_unwind'ing the panic
payload from the thread. Using resume_unwind skips the panic_handler,
meaning that the main thread would never have a panic handler run, which
can get confusing.
- Do not `#[doc(hidden)]` the `#[derive]` macro attribute
- Add a link to the reference section to `derive`'s inherent docs
- Do the same for `#[test]` and `#[global_allocator]`
- Fix `GlobalAlloc` link (why is it on `core` and not `alloc`?)
- Try `no_inline`-ing the `std` reexports from `core`
- Revert "Try `no_inline`-ing the `std` reexports from `core`"
- Address PR review
- Also document the unstable macros
The documentation on `std::sync::mpsc::Iter` and `std::sync::mpsc::TryIter` provides links to the corresponding `Receiver` methods, unlike `std::sync::mpsc::IntoIter` does.
This was left out in c59b188aae
Related to #29377
Consolidate Result's and Option's methods into fewer impl blocks
`Result`'s and `Option`'s methods have historically been separated up into `impl` blocks based on their trait bounds, with the bounds specified on type parameters of the impl block. I find this unhelpful because closely related methods, like `unwrap_or` and `unwrap_or_default`, end up disproportionately far apart in source code and rustdocs:
<pre>
impl<T> Option<T> {
pub fn unwrap_or(self, default: T) -> T {
...
}
<img alt="one eternity later" src="https://user-images.githubusercontent.com/1940490/147780325-ad4e01a4-c971-436e-bdf4-e755f2d35f15.jpg" width="750">
}
impl<T: Default> Option<T> {
pub fn unwrap_or_default(self) -> T {
...
}
}
</pre>
I'd prefer for method to be in as few impl blocks as possible, with the most logical grouping within each impl block. Any bounds needed can be written as `where` clauses on the method instead:
```rust
impl<T> Option<T> {
pub fn unwrap_or(self, default: T) -> T {
...
}
pub fn unwrap_or_default(self) -> T
where
T: Default,
{
...
}
}
```
*Warning: the end-to-end diff of this PR is computed confusingly by git / rendered confusingly by GitHub; it's practically impossible to review that way. I've broken the PR into commits that move small groups of methods for which git behaves better — these each should be easily individually reviewable.*
Track caller of slice split and swap
Improves error location for `slice.split_at*()` and `slice.swap()`.
These are generic inline functions, so the `#[track_caller]` on them is free — only changes a value of an argument already passed to panicking code.
Rollup of 7 pull requests
Successful merges:
- #84083 (Clarify the guarantees that ThreadId does and doesn't make.)
- #91593 (Remove unnecessary bounds for some Hash{Map,Set} methods)
- #92297 (Reduce compile time of rustbuild)
- #92332 (Add test for where clause order)
- #92438 (Enforce formatting for rustc_codegen_cranelift)
- #92463 (Remove pronunciation guide from Vec<T>)
- #92468 (Emit an error for `--cfg=)`)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Remove unnecessary bounds for some Hash{Map,Set} methods
This PR moves `HashMap::{into_keys,into_values,retain}` and `HashSet::retain` from `impl` blocks with `K: Eq + Hash, S: BuildHasher` into the blocks without them. It doesn't seem to me there is any reason these methods need to be bounded by that. This change brings `HashMap::{into_keys,into_values}` on par with `HashMap::{keys,values,values_mut}` which are not bounded either.
Clarify the guarantees that ThreadId does and doesn't make.
The existing documentation does not spell out whether `ThreadId`s are unique during the lifetime of a thread or of a process. I had to examine the source code to realise (pleasingly!) that they're unique for the lifetime of a process. That seems worth documenting clearly, as it's a strong guarantee.
Examining the way `ThreadId`s are created also made me realise that the `as_u64` method on `ThreadId` could be a trap for the unwary on those platforms where the platform's notion of a thread identifier is also a 64 bit integer (particularly if they happen to use a similar identifier scheme to `ThreadId`). I therefore think it's worth being even clearer that there's no relationship between the two.
Remove CommandEnv::apply
It's not being used and uses unsound set_var and remove_var functions. This is an internal function that isn't exported (even with `process_internals` feature), so this shouldn't break anything.
Also see #92365. Note that this isn't the only use of those methods in standard library, so that particular pull request will need more changes than just this to work (in particular, `test_capture_env_at_spawn` is using `set_var` and `remove_var`).
Implement split_at_spare_mut without Deref to a slice so that the spare slice is valid
~I'm not sure I understand what's going on here correctly. And I'm pretty sure this safety comment needs to be changed. I'm just referring to the same thing that `as_mut_ptr_range` does.~ (Thanks `@RalfJung` for the guidance and clearing things up)
I tried to run https://github.com/rust-lang/miri-test-libstd on alloc with -Zmiri-track-raw-pointers, and got a failure on the test `vec::test_extend_from_within`.
I minimized the test failure into this program:
```rust
#![feature(vec_split_at_spare)]
fn main() {
Vec::<i32>::with_capacity(1).split_at_spare_mut();
}
```
The problem is that the existing implementation is actually getting a pointer range where both pointers are derived from the initialized region of the Vec's allocation, but we need the second one to be valid for the region between len and capacity. (thanks Ralf for clearing this up)
Add try_reserve and try_reserve_exact for OsString
Add `try_reserve` and `try_reserve_exact` for OsString.
Part of https://github.com/rust-lang/rust/issues/91789
I will squash the commits after PR is ready to merge.
Signed-off-by: Xuanwo <github@xuanwo.io>
It appears `find_max_slow` comes from the BinaryHeap docs, where the
try_reserve example is a slow implementation of find_max. It has no
relevance to this code in OsString though.
The crate name is already set in Cargo.toml. The comment says there is
some logic in the compiler that reads #![crate_name] and not
--crate-name, but I can't find it. Removing it seems to work fine.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}