Do not fetch HIR to compute variances.
Everything can be done using higher-level queries. This simplifies the code, and should allow better incremental caching.
interpret: remove support for unsized_locals
I added support for unsized_locals in https://github.com/rust-lang/rust/pull/59780 but the current implementation is a crude hack and IMO definitely not the right way to have unsized locals in MIR. It also [causes problems](https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/Missing.20Layout.20Check.20in.20.60interpret.2Foperand.2Ers.60.3F). and what codegen does is unsound and has been for years since clearly nobody cares (so I hope nobody actually relies on that implementation and I'll be happy if Miri ensures they do not). I think if we want to have unsized locals in Miri/MIR we should add them properly, either by having a `StorageLive` that takes metadata or by having an `alloca` that returns a pointer (making the ptr indirection explicit) or something like that.
So, this PR removes the `LocalValue::Unallocated` hack. It adds `Immediate::Uninit`, for several reasons:
- This lets us still do fairly little work in `push_stack_frame`, in particular we do not actually have to create any allocations.
- If/when I remove `ScalarMaybeUninit`, we will need something like this to have an "optimized" representation of uninitialized locals. Without this we'd have to put uninitialized integers into the heap!
- const-prop needs some way to indicate "I don't know the value of this local'; it used to use `LocalValue::Unallocated` for that, now it can use `Immediate::Uninit`.
There is still a fundamental difference between `LocalValue::Unallocated` and `Immediate::Uninit`: the latter is considered a regular local that you can read from and write to, it just has a more optimized representation when compared with an actual `Allocation` that is fully uninit. In contrast, `LocalValue::Unallocated` had this really odd behavior where you would write to it but not read from it. (This is in fact what caused the problems mentioned above.)
While at it I also did two drive-by cleanups/improvements:
- In `pop_stack_frame`, do the return value copying and local deallocation while the frame is still on the stack. This leads to better error locations being reported. The old errors were [sometimes rather confusing](https://rust-lang.zulipchat.com/#narrow/stream/269128-miri/topic/Cron.20Job.20Failure.202022-06-24/near/287445522).
- Deduplicate `copy_op` and `copy_op_transmute`.
r? `@oli-obk`
Allow arithmetic and certain bitwise ops on AtomicPtr
This is mainly to support migrating from `AtomicUsize`, for the strict provenance experiment.
This is a pretty dubious set of APIs, but it should be sufficient to allow code that's using `AtomicUsize` to manipulate a tagged pointer atomically. It's under a new feature gate, `#![feature(strict_provenance_atomic_ptr)]`, but I'm not sure if it needs its own tracking issue. I'm happy to make one, but it's not clear that it's needed.
I'm unsure if it needs changes in the various non-LLVM backends. Because we just cast things to integers anyway (and were already doing so), I doubt it.
API change proposal: https://github.com/rust-lang/libs-team/issues/60Fixes#95492
Operand::Uninit is an *allocated* operand that is fully uninitialized.
This lets us lazily allocate the actual backing store of *all* locals (no matter their ABI).
I also reordered things in pop_stack_frame at the same time.
I should probably have made that a separate commit...
There was a problem with storing a `Box<T>` in a struct, where
the current rules would invalidate the value. this makes it store
a raw pointer instead, circumventing the aliasing problems.
Rename the `--output-width` flag to `--diagnostic-width` as this appears
to be the preferred name within the compiler team.
Signed-off-by: David Wood <david.wood@huawei.com>
Rename the `--terminal-width` flag to `--output-width` as the behaviour
doesn't just apply to terminals (and so is slightly less accurate).
Signed-off-by: David Wood <david.wood@huawei.com>
Formerly `-Zterminal-width`, `--terminal-width` allows the user or build
tool to inform rustc of the width of the terminal so that diagnostics
can be truncated.
Signed-off-by: David Wood <david.wood@huawei.com>
Compiling with `-Csplit-debuginfo=packed` was leaving behind `.dwo`
files because either the metadata or allocator module contained a DWARF
object which was not being removed by the
`maybe_remove_temps_from_module` closure.
Cache DWARF objects alongside object files in work products when those
exist so that DWARF object files are available for thorin in packed mode
in incremental scenarios.
Signed-off-by: David Wood <david.wood@huawei.com>
fix typo in note about multiple inaccessible type aliases
Mainly intended as a small typo fix ("aliass" -> "aliases") for the case where a type cannot be found in scope but there are multiple inaccessible type aliases that match the missing type.
In general this change would use the correct plural form in this scenario for base words that end with 's'.
macros: `LintDiagnostic` derive
- Move `LintDiagnosticBuilder` into `rustc_errors` so that a diagnostic derive can refer to it.
- Introduce a `DecorateLint` trait, which is equivalent to `SessionDiagnostic` or `AddToDiagnostic` but for lints. Necessary without making more changes to the lint infrastructure as `DecorateLint` takes a `LintDiagnosticBuilder` and re-uses all of the existing logic for determining what type of diagnostic a lint should be emitted as (e.g. error/warning).
- Various refactorings of the diagnostic derive machinery (extracting `build_field_mapping` helper and moving `sess` field out of the `DiagnosticDeriveBuilder`).
- Introduce a `LintDiagnostic` derive macro that works almost exactly like the `SessionDiagnostic` derive macro except that it derives a `DecorateLint` implementation instead. A new derive is necessary for this because `SessionDiagnostic` is intended for when the generated code creates the diagnostic. `AddToDiagnostic` could have been used but it would have required more changes to the lint machinery.
~~At time of opening this pull request, ignore all of the commits from #98624, it's just the last few commits that are new.~~
r? `@oli-obk`
Mainly intended as a small typo fix ("aliass" -> "aliases") for
the case where a type cannot be found in scope, and there are
multiple inaccessible type aliases that match the missing type.
In general this change would use the correct plural form in
this scenario for words that end with 's'.
Edit `rustc_mir_dataflow::framework::lattice::FlatSet` docs
Cosmetic improvements. Adds a paragraph break, and
ellipses to signify arbitrary size of a flat set.
Fix repr(align) enum handling
`enum`, for better or worse, supports `repr(align)`. That has already caused a bug in https://github.com/rust-lang/rust/issues/92464, which was "fixed" in https://github.com/rust-lang/rust/pull/92932, but it turns out that that fix is wrong and caused https://github.com/rust-lang/rust/issues/96185.
So this reverts #92932 (which fixes#96185), and attempts another strategy for fixing #92464: special-case enums when doing a cast, re-using the code to load the discriminant rather than assuming that the enum has scalar layout. This works fine for the interpreter.
However, #92464 contained another testcase that was previously not in the test suite -- and after adding it, it ICEs again. This is not surprising; codegen needs the same patch that I did in the interpreter. Probably this has to happen [around here](d32ce37a17/compiler/rustc_codegen_ssa/src/mir/rvalue.rs (L276)). Unfortunately I don't know how to do that -- the interpreter can load a discriminant from an operand, but codegen can only do that from a place. `@oli-obk` `@eddyb` `@bjorn3` any idea?
`SessionDiagnostic` isn't suitable for use on lints as whether or not it
creates an error or a warning is decided at compile-time by the macro,
whereas lints decide this at runtime based on the location of the lint
being reported (as it will depend on the user's `allow`/`deny`
attributes, etc). Re-using most of the machinery for
`SessionDiagnostic`, this macro introduces a `LintDiagnostic` derive
which implements a `DecorateLint` trait, taking a
`LintDiagnosticBuilder` and adding to the lint according to the
diagnostic struct.
`sess` field of `SessionDiagnosticDeriveBuilder` is never actually used
in the builder's member functions, so it doesn't need to be a field.
Signed-off-by: David Wood <david.wood@huawei.com>
Move the logic for building a field mapping (which is used by the
building of format strings in `suggestion` annotations) into a helper
function.
Signed-off-by: David Wood <david.wood@huawei.com>
lints: mostly translatable diagnostics
As lints are created slightly differently than other diagnostics, intended to try make them translatable first and then look into the applicability of diagnostic structs but ended up just making most of the diagnostics in the crate translatable (which will still be useful if I do make a lot of them structs later anyway).
r? ``@compiler-errors``
Change enum->int casts to not go through MIR casts.
follow-up to https://github.com/rust-lang/rust/pull/96814
this simplifies all backends and even gives LLVM more information about the return value of `Rvalue::Discriminant`, enabling optimizations in more cases.
clean up the borrowing in rustc_hir_pretty
A whole lot of the `&`s and `ref`s were redundant. I hope doing this in one big commit is fine, because all of the changes are pretty self-contained.
`@rustbot` label: +C-cleanup
fix interpreter validity check on Box
Follow-up to https://github.com/rust-lang/rust/pull/98554: avoid walking over parts of the value twice.
And then move all that logic into the general visitor so not each visitor implementation has to deal with it...
Interpret: AllocRange Debug impl, and use it more consistently
The two commits are pretty independent but it did not seem worth having two PRs for them.
r? ``@oli-obk``
more `need_type_info` improvements
this now deals with macros in suggestions and the source cost computation does what I want for `channel` 🎉
r? ``@estebank``
Add method to mutate MIR body without invalidating CFG caches.
In addition to adding this method, a handful of passes are updated to use it. There's still quite a few passes that could in principle make use of this as well, but do not at the moment because they use `VisitorMut` or `MirPatch`, which needs additional support for this.
The method name is slightly unwieldy, but I don't expect anyone to be writing it a lot, and at least it says what it does. If anyone has a suggestion for a better name though, would be happy to rename.
r? rust-lang/mir-opt
We currently do a match on the comparison of every field in a struct or
enum variant. But the last field has a degenerate match like this:
```
match ::core::cmp::Ord::cmp(&self.y, &other.y) {
::core::cmp::Ordering::Equal =>
::core::cmp::Ordering::Equal,
cmp => cmp,
},
```
This commit changes it to this:
```
::core::cmp::Ord::cmp(&self.y, &other.y),
```
This is fairly straightforward thanks to the existing `cs_fold1`
function.
The commit also removes the `cs_fold` function which is no longer used.
(Note: there is some repetition now in `cs_cmp` and `cs_partial_cmp`. I
will remove that in a follow-up PR.)
incr.comp.: Make split-dwarf commandline options [TRACKED].
This commandline options have an influence on the contents of object files (and .dwo files), so they need to be `[TRACKED]`.
r? `@davidtwco`
interpret: don't rely on ScalarPair for overflowed arithmetic
This is for https://github.com/rust-lang/rust/pull/97861.
Cc `@eddyb`
I would like to avoid making this depend on `dest.layout.abi` to avoid a branch that we are not usually covering both sides of. Though OTOH this seems like fairly straight-forward code. But let's benchmark this option first to see how bad that extra `force_allocation` really is.
It's common to see repeated assertions like this in derived `clone` and
`eq` methods:
```
let _: ::core::clone::AssertParamIsClone<u32>;
let _: ::core::clone::AssertParamIsClone<u32>;
```
This commit avoids them.
All derive ops currently use match-destructuring to access fields. This
is reasonable for enums, but sub-optimal for structs. E.g.:
```
fn eq(&self, other: &Point) -> bool {
match *other {
Self { x: ref __self_1_0, y: ref __self_1_1 } =>
match *self {
Self { x: ref __self_0_0, y: ref __self_0_1 } =>
(*__self_0_0) == (*__self_1_0) &&
(*__self_0_1) == (*__self_1_1),
},
}
}
```
This commit changes derive ops on structs to use field access instead, e.g.:
```
fn eq(&self, other: &Point) -> bool {
self.x == other.x && self.y == other.y
}
```
This is faster to compile, results in smaller binaries, and is simpler to
generate. Unfortunately, we have to keep the old pattern generating code around
for `repr(packed)` structs because something like `&self.x` (which doesn't show
up in `PartialEq` ops, but does show up in `Debug` and `Hash` ops) isn't
allowed. But this commit at least changes those cases to use let-destructuring
instead of match-destructuring, e.g.:
```
fn hash<__H: ::core:#️⃣:Hasher>(&self, state: &mut __H) -> () {
{
let Self(ref __self_0_0) = *self;
{ ::core:#️⃣:Hash::hash(&(*__self_0_0), state) }
}
}
```
There are some unnecessary blocks remaining in the generated code, but I
will fix them in a follow-up PR.
Fix bug in `rustdoc -Whelp`
Previously, this printed the debugging options, not the lint options,
and only handled `-Whelp`, not `-A/-D/-F`.
This also fixes a few other misc issues:
- Fix `// check-stdout` for UI tests; previously it only worked for run-fail and compile-fail tests
- Add lint headers for tool lints, not just builtin lints
https://github.com/rust-lang/rust/pull/98533#issuecomment-1172004197
r? ```@GuillaumeGomez```
get rid of `tcx` in deadlock handler when parallel compilation
This is a very obscure and hard-to-trace problem that affects thread scheduling. If we copy `tcx` to the deadlock handler thread, it will perform unpredictable behavior and cause very weird problems when executing `try_collect_active_jobs`(For example, the deadlock handler thread suddenly preempts the content of the blocked worker thread and executes the unknown judgment branch, like #94654).
Fortunately we can avoid this behavior by precomputing `query_map`. This change fixes the following ui tests failure on my environment when set `parallel-compiler = true`:
```
[ui] src/test\ui\async-await\no-const-async.rs
[ui] src/test\ui\infinite\infinite-struct.rs
[ui] src/test\ui\infinite\infinite-tag-type-recursion.rs
[ui] src/test\ui\issues\issue-3008-1.rs
[ui] src/test\ui\issues\issue-3008-2.rs
[ui] src/test\ui\issues\issue-32326.rs
[ui] src/test\ui\issues\issue-57271.rs
[ui] src/test\ui\issues\issue-72554.rs
[ui] src/test\ui\parser\fn-header-semantic-fail.rs
[ui] src/test\ui\union\union-nonrepresentable.rs
```
Updates #75760Fixes#94654
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
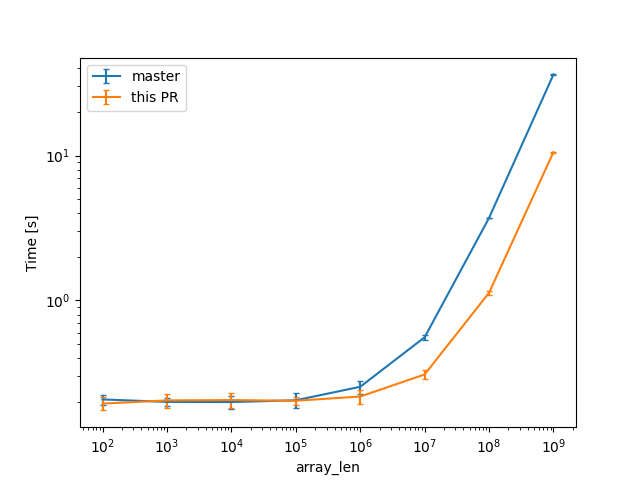
(linear scale for absolute diff at higher Ns)
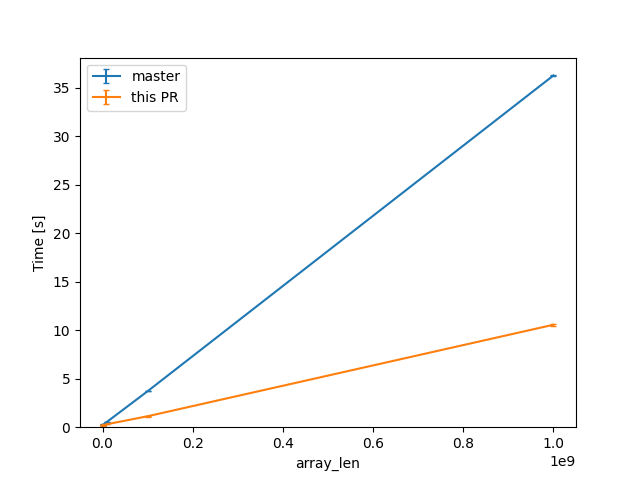
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
Fix FFI-unwind unsoundness with mixed panic mode
UB maybe introduced when an FFI exception happens in a `C-unwind` foreign function and it propagates through a crate compiled with `-C panic=unwind` into a crate compiled with `-C panic=abort` (#96926).
To prevent this unsoundness from happening, we will disallow a crate compiled with `-C panic=unwind` to be linked into `panic-abort` *if* it contains a call to `C-unwind` foreign function or function pointer. If no such call exists, then we continue to allow such mixed panic mode linking because it's sound (and stable). In fact we still need the ability to do mixed panic mode linking for std, because we only compile std once with `-C panic=unwind` and link it regardless panic strategy.
For libraries that wish to remain compile-once-and-linkable-to-both-panic-runtimes, a `ffi_unwind_calls` lint is added (gated under `c_unwind` feature gate) to flag any FFI unwind calls that will cause the linkable panic runtime be restricted.
In summary:
```rust
#![warn(ffi_unwind_calls)]
mod foo {
#[no_mangle]
pub extern "C-unwind" fn foo() {}
}
extern "C-unwind" {
fn foo();
}
fn main() {
// Call to Rust function is fine regardless ABI.
foo::foo();
// Call to foreign function, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
unsafe { foo(); }
//~^ WARNING call to foreign function with FFI-unwind ABI
let ptr: extern "C-unwind" fn() = foo::foo;
// Call to function pointer, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
ptr();
//~^ WARNING call to function pointer with FFI-unwind ABI
}
```
Fix#96926
`@rustbot` label: T-compiler F-c_unwind
Enable MIR inlining
Continuation of https://github.com/rust-lang/rust/pull/82280 by `@wesleywiser.`
#82280 has shown nice compile time wins could be obtained by enabling MIR inlining.
Most of the issues in https://github.com/rust-lang/rust/issues/81567 are now fixed,
except the interaction with polymorphization which is worked around specifically.
I believe we can proceed with enabling MIR inlining in the near future
(preferably just after beta branching, in case we discover new issues).
Steps before merging:
- [x] figure out the interaction with polymorphization;
- [x] figure out how miri should deal with extern types;
- [x] silence the extra arithmetic overflow warnings;
- [x] remove the codegen fulfilment ICE;
- [x] remove the type normalization ICEs while compiling nalgebra;
- [ ] tweak the inlining threshold.
Previously, this printed the debugging options, not the lint options,
and only handled `-Whelp`, not `-A/-D/-F`.
This also fixes a few other misc issues:
- Fix `// check-stdout` for UI tests; previously it only worked for run-fail and compile-fail tests
- Add lint headers for tool lints, not just builtin lints
- Remove duplicate run-make test
interpret: make a comment less scary
This slipped past my review: "has no meaning" could be read as "is undefined behavior". That is certainly not what we mean so be more clear.
cleanup mir visitor for `rustc::pass_by_value`
by changing `& $($mutability)?` to `$(& $mutability)?`
I also did some formatting changes because I started doing them for the visit methods I changed and then couldn't get myself to stop xx, I hope that's still fairly easy to review.
Improve some inference diagnostics
- Properly point out point location where "type must be known at this point", or else omit the note if it's not associated with a useful span.
- Fix up some type ambiguity diagnostics, errors shouldn't say "cannot infer type for reference `&'a ()`" when the given type has no inference variables.
Shorten def_span for more items.
The `def_span` query only returns the signature span for functions.
Struct/enum/union definitions can also have a very long body.
This PR shortens the associated span.
Rollup of 6 pull requests
Successful merges:
- #97488 (Suggest blanket impl to the local traits)
- #98585 (Make `ThinBox<T>` covariant in `T`)
- #98644 (fix ICE with -Wrust-2021-incompatible-closure-captures)
- #98739 (fix grammar in useless doc comment lint)
- #98741 (Many small deriving cleanups)
- #98756 (Use const instead of function and make it private)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Suggest blanket impl to the local traits
This PR will add additional suggestion regarding the blanket implementation when it is possible, by generation a new help message + suggestion.
Closes https://github.com/rust-lang/rust/issues/96076
Signed-off-by: Vincenzo Palazzo <vincenzopalazzodev@gmail.com>
Rewrite dead-code pass to avoid fetching HIR.
This allows to get a more uniform handling of spans, and to simplify the grouping of diagnostics for variants and fields.
The existing derive code allows for various possibilities that aren't
needed in practice, which complicates the code. There are only a few
auto-derived traits and new ones are unlikely, so this commit simplifies
things.
- `PtrTy` has been eliminated. The `Raw` variant was never used, and the
lifetime for the `Borrowed` variant was always `None`. That left just
the mutability field, which has been inlined as necessary.
- `MethodDef::explicit_self` was a confusing `Option<Option<PtrTy>>`.
Indicating either `&self` or nothing. It's now a `bool`.
- `borrowed_self` is renamed as `self_ref`.
- `Ty::Ptr` is renamed to `Ty::Ref`.
The `&[ast::Variant]` field isn't used.
The `Vec<Ident>` field is only used for its length, but that's always
the same as the length of the `&[Ident]` and so isn't necessary.
This created unexpected diagnostics while compiling alga:
cannot satisfy `<Self as Module>::Ring == _`
Turns out that we don't need this diagnostic as we disable inlining when
it would trigger an ICE.
Const eval no longer runs MIR optimizations so unless this is getting
run as part of a MIR optimization like const-prop, there can be unused
type parameters even if polymorphization is enabled.
interpret: add From<&MplaceTy> for PlaceTy
We have a similar instance for `&MPlaceTy` to `OpTy`. Also add the same for `&mut`.
This avoids having to write `&(*place).into()`, which we have a few times here and at least twice in Miri (and it comes up again in my current patch).
r? ```@oli-obk```
For diagnostic information of Boolean, remind it as use the type: 'bool'
Fixes#98492.
It helps programmers coming from other languages
modified: compiler/rustc_resolve/src/late/diagnostics.rs
In NLL, when we are promoting a bound out from a closure,
if we have a requirement that `T: 'a` where `'a` is in a
higher universe, we were previously ignoring that, which is
totally wrong. We should be promoting those constraints to `'static`,
since universes are not expressible across closure boundaries.
Added llvm lifetime annotations to function call argument temporaries.
The goal of this change is to ensure that llvm will do stack slot
optimization on these temporaries. This ensures that in code like:
```rust
const A: [u8; 1024] = [0; 1024];
fn copy_const() {
f(A);
f(A);
}
```
we only use 1024 bytes of stack space, instead of 2048 bytes.
I am new to developing for the rust compiler, and as such not entirely sure, but I believe this should be sufficient to close#98156.
Also, this does not contain a test case to ensure this keeps working, primarily because I am not sure how to go about testing this. I would love some suggestions as to how that could be approached.
Accept `DiagnosticMessage` in `LintDiagnosticBuilder::build` so that
lints can be built with translatable diagnostic messages.
Signed-off-by: David Wood <david.wood@huawei.com>
move MIR syntax into a dedicated file and ping some people whenever it changes
Adding or changing MIR operations/statements/whatever should be under significant scrutiny wrt their wider impact, specified semantics, and so on. So let's start by putting all that into a dedicated file and pinging some people whenever that file changes.
This PR only moves definitions around, and then fiddles with imports until it all works again.
Make TAIT behave exactly like RPIT
fixes https://github.com/rust-lang/rust/issues/96552
This makes type-alias-impl-trait behave like return-position-impl-trait. Unfortunately it also causes some cases to stop compiling due to "needing type annotations" and makes panicking cause fallback for the hidden type to `()`.
All of these are addressable, but we should probably address them for RPIT and TAIT together
r? ``@lcnr``
Avoid some `&str` to `String` conversions with `MultiSpan::push_span_label`
This patch removes some`&str` to `String` conversions with `MultiSpan::push_span_label`.
emit Retag for compound types with reference fields
I want to add an option to Miri to do retagging inside reference fields. But that means we first have to even emit `Retag` for types that *contain* references (rather than being of reference types). :)
Stacked Borrows originally did that, but we stopped doing it when hitting bunch of issues in the standard library. However I have since realized that we actually do emit `noalias` for newtypes references, which means for soundness we should recurse into fields. Also it'd probably be bad news if newtypes lose out on optimizations (and they don't, for anything else). I want to add an option for that to Miri so that we can start experimenting with those semantics.
r? ``@oli-obk``
Clean up arg mismatch diagnostic, generalize tuple wrap suggestion
This is based on top of #97542, so just look at the last commit which contains the relevant changes.
1. Remove `final_arg_types` which was one of the last places we were using raw (`usize`) indices instead of typed indices in the arg mismatch suggestion code.
2. Improve the tuple wrap suggestion, now we suggest things like `call(a, b, c, d)` -> `call(a, (b, c), d)` 😺
3. Folded in fix#98645
Erase regions in New Abstract Consts
When an abstract const is constructed, we previously included lifetimes in the set of substitutes, so it was not able to unify two abstract consts if their lifetimes did not match but the values did, despite the values not depending on the lifetimes. This caused code that should have compiled to not compile.
Fixes#98452
r? ```@lcnr```
Some borrowck diagnostic fixes
1. Remove some redundant `.as_ref` suggestion logic from borrowck, this has the consequence of also not suggesting `.as_ref` after `Option` methods, but (correctly) before.
2. Fix a bug where we were replacing a binding's name with a type. Instead, make it a note.
This is somewhat incomplete. See `src/test/ui/borrowck/suggest-as-ref-on-mut-closure.rs` for more improvements.
interpret: do not prune requires_caller_location stack frames quite so early
https://github.com/rust-lang/rust/pull/87000 made the interpreter skip `caller_location` frames for its stacktraces and `cur_span`. However, those functions are used for much more than just panic reporting, and e.g. when Miri reports UB somewhere, it probably wants to point inside `caller_location` frames. (And if it did not, it would want to have its own logic to decide that, not be forced into it by the core interpreter engine.) This fixes some rare ICEs in Miri that say "we should never pop more than one frame at once".
So let's remove all `caller_location` logic from the core interpreter, and instead move it to CTFE error reporting. This does not change user-visible behavior. That's the first commit.
We might additionally want to change CTFE error reporting to treat panics differently from other errors: only prune `caller_location` frames for panics. The second commit does that. But honestly I am not sure if this is an improvement.
r? ``@oli-obk``
Fix trait object reborrow suggestion
Fixes#93596
Slightly generalizes the logic we use to suggest fix first implemented in #95609, specifically when we have a `Sized` obligation that comes from a struct's unsized tail.
Account for `-Z simulate-remapped-rust-src-base` when resolving remapped paths
Discovered in #97682, `-Z simulate-remapped-rust-src-base` only partially simulated the behavior of `remap-debuginfo = true`. While the flag successfully simulates the remapping when stdlib's `rmeta` file is loaded, the simulated prefix was not accounted for when the remapped path's local path was being discovered. This caused the flag to not fully simulate the behavior of `remap-debuginfo = true`, leading to inconsistent behaviors.
This PR fixes https://github.com/rust-lang/rust/issues/97682 by also accounting for the simulated path.
Use typed indices in argument mismatch algorithm
I kinda went overboard with the renames, but in general, "arg" is renamed to "expected", and "input" is renamed to "provided", and we use new typed indices to make sure we're indexing into the right sized array.
Other drive-by changes:
1. Factor this logic into a new function, so we don't need to `break 'label` to escape it.
1. Factored out dependence on `final_arg_types`, which is never populated for arguments greater than the number of expected args. Instead, we just grab the final coerced expression type from `in_progress_typeck_results`.
1. Adjust the criteria we use to print (provided) type names, before we didn't suggest anything that had infer vars, but now we suggest thing that have infer vars but aren't `_`.
~Also, sorry in advance, I kinda want to backport this but I know I have folded in a lot of unnecessary drive-by changes that might discourage that. I would be open to brainstorming how to get some of these changes on beta at least.~ edit: Minimized the ICE-fixing changes to #97557
cc `@jackh726` as author of #92364, and `@estebank` as reviewer of the PR.
fixes#97484
Simplify memory ordering intrinsics
This changes the names of the atomic intrinsics to always fully include their memory ordering arguments.
```diff
- atomic_cxchg
+ atomic_cxchg_seqcst_seqcst
- atomic_cxchg_acqrel
+ atomic_cxchg_acqrel_release
- atomic_cxchg_acqrel_failrelaxed
+ atomic_cxchg_acqrel_relaxed
// And so on.
```
- `seqcst` is no longer implied
- The failure ordering on chxchg is no longer implied in some cases, but now always explicitly part of the name.
- `release` is no longer shortened to just `rel`. That was especially confusing, since `relaxed` also starts with `rel`.
- `acquire` is no longer shortened to just `acq`, such that the names now all match the `std::sync::atomic::Ordering` variants exactly.
- This now allows for more combinations on the compare exchange operations, such as `atomic_cxchg_acquire_release`, which is necessary for #68464.
- This PR only exposes the new possibilities through unstable intrinsics, but not yet through the stable API. That's for [a separate PR](https://github.com/rust-lang/rust/pull/98383) that requires an FCP.
Suffixes for operations with a single memory order:
| Order | Before | After |
|---------|--------------|------------|
| Relaxed | `_relaxed` | `_relaxed` |
| Acquire | `_acq` | `_acquire` |
| Release | `_rel` | `_release` |
| AcqRel | `_acqrel` | `_acqrel` |
| SeqCst | (none) | `_seqcst` |
Suffixes for compare-and-exchange operations with two memory orderings:
| Success | Failure | Before | After |
|---------|---------|--------------------------|--------------------|
| Relaxed | Relaxed | `_relaxed` | `_relaxed_relaxed` |
| Relaxed | Acquire | ❌ | `_relaxed_acquire` |
| Relaxed | SeqCst | ❌ | `_relaxed_seqcst` |
| Acquire | Relaxed | `_acq_failrelaxed` | `_acquire_relaxed` |
| Acquire | Acquire | `_acq` | `_acquire_acquire` |
| Acquire | SeqCst | ❌ | `_acquire_seqcst` |
| Release | Relaxed | `_rel` | `_release_relaxed` |
| Release | Acquire | ❌ | `_release_acquire` |
| Release | SeqCst | ❌ | `_release_seqcst` |
| AcqRel | Relaxed | `_acqrel_failrelaxed` | `_acqrel_relaxed` |
| AcqRel | Acquire | `_acqrel` | `_acqrel_acquire` |
| AcqRel | SeqCst | ❌ | `_acqrel_seqcst` |
| SeqCst | Relaxed | `_failrelaxed` | `_seqcst_relaxed` |
| SeqCst | Acquire | `_failacq` | `_seqcst_acquire` |
| SeqCst | SeqCst | (none) | `_seqcst_seqcst` |
Currently, `search_for_structural_match_violation` constructs an `infcx`
from a `tcx` and then only uses the `tcx` within the `infcx`. This is
wasteful because `infcx` is a big type.
This commit changes it to use the `tcx` directly. When compiling
`pest-2.1.3`, this changes the memcpy stats reported by DHAT for a `check full`
build from this:
```
433,008,916 bytes (100%, 99,787.93/Minstr) in 2,148,668 blocks (100%, 495.17/Minstr), avg size 201.52 bytes
```
to this:
```
101,422,347 bytes (99.98%, 25,243.59/Minstr) in 1,318,407 blocks (99.96%, 328.15/Minstr), avg size 76.93 bytes
```
This translates to a 4.3% reduction in instruction counts.
Checking the size/alignment of an mplace may be costly, so we only do it
on the types where the walk we want to avoid could be expensive: the larger types
like arrays and slices, rather than on all aggregates being interned.
Reorganizes the previous commits to have a single exit-point to avoid doing the
potentially costly walk. Also moves the relocations tests before the interior
mutability test: only references are important when checking for `UnsafeCell`s
and we're checking if there are any to decide to avoid the walk anyways.
The interning of const allocations visits the mplace looking for references
to intern. Walking big aggregates like big static arrays can be costly,
so we only do it if the allocation we're interning contains references
or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied
to cases where there are no references/relocations either.
translation: lint fix + more migration
- Unfortunately, the diagnostic lints are very broken and trigger much more often than they should. This PR corrects the conditional which checks if the function call being made is to a diagnostic function so that it returns in every intended case.
- The `rustc_lint_diagnostics` attribute is used by the diagnostic translation/struct migration lints to identify calls where non-translatable diagnostics or diagnostics outwith impls are being created. Any function used in creating a diagnostic should be annotated with this attribute so this PR adds the attribute to many more functions.
- Port the diagnostics from the `rustc_privacy` crate and enable the lints for that crate.
r? ``@compiler-errors``
Fix RSS reporting on macOS
> NOTE: This is a duplicate of #98164, which I closed because I borked my rustc fork
Currently, `rustc_data_structures::profiling::get_resident_set_size()` always returns `None` on macOS. This is because
macOS does not implement procfs used in the unix version of the function:
```rust
...
else if #[cfg(unix)] {
pub fn get_resident_set_size() -> Option<usize> {
let field = 1;
let contents = fs::read("/proc/self/statm").ok()?;
let contents = String::from_utf8(contents).ok()?;
let s = contents.split_whitespace().nth(field)?;
let npages = s.parse::<usize>().ok()?;
Some(npages * 4096)
}
...
```
The proposed solution uses libproc, and more specifically `proc_pidinfo`, which has been available on macOS since 10.5 if the function signature inside libproc.h is to be believed:
```c
int proc_pidinfo(int pid, int flavor, uint64_t arg, void *buffer, int buffersize) __OSX_AVAILABLE_STARTING(__MAC_10_5, __IPHONE_2_0);
```
[RFC 2011] Optimize non-consuming operators
Tracking issue: https://github.com/rust-lang/rust/issues/44838
Fifth step of https://github.com/rust-lang/rust/pull/96496
The most non-invasive approach that will probably have very little to no performance impact.
## Current behaviour
Captures are handled "on-the-fly", i.e., they are performed in the same place expressions are located.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !(
{ ***try capture `a` and then return `a`*** } > 1 && { ***try capture `b` and then return `b`*** } < 100
) {
panic!( ... );
}
```
As such, some overhead is likely to occur (Specially with very large chains of conditions).
## New behaviour for non-consuming operators
When an operator is known to not take `self`, then it is possible to capture variables **AFTER** the condition.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !( a > 1 && b < 100 ) {
{ ***try capture `a`*** }
{ ***try capture `b`*** }
panic!( ... );
}
```
So the possible impact on the runtime execution time will be diminished.
r? ````@oli-obk````
Remove `MAX_SUGGESTION_HIGHLIGHT_LINES`
After #97798 the `MAX_SUGGESTION_HIGHLIGHT_LINES` constant doesn't really make sense since we always show full suggestions. This PR removes last usages of the constant and the constant itself.
r? ``@flip1995`` (this mostly does changes in clippy)
Only keep a single query for well-formed checking
There are currently 3 queries to perform wf checks on different item-likes. This complexity is not required.
This PR replaces the query by:
- one query per item;
- one query to invoke it for a whole module.
This allows to remove HIR `ParItemLikeVisitor`.
{kind=link}
{kind=link}
{kind=link}