We currently do a match on the comparison of every field in a struct or
enum variant. But the last field has a degenerate match like this:
```
match ::core::cmp::Ord::cmp(&self.y, &other.y) {
::core::cmp::Ordering::Equal =>
::core::cmp::Ordering::Equal,
cmp => cmp,
},
```
This commit changes it to this:
```
::core::cmp::Ord::cmp(&self.y, &other.y),
```
This is fairly straightforward thanks to the existing `cs_fold1`
function.
The commit also removes the `cs_fold` function which is no longer used.
(Note: there is some repetition now in `cs_cmp` and `cs_partial_cmp`. I
will remove that in a follow-up PR.)
incr.comp.: Make split-dwarf commandline options [TRACKED].
This commandline options have an influence on the contents of object files (and .dwo files), so they need to be `[TRACKED]`.
r? `@davidtwco`
interpret: don't rely on ScalarPair for overflowed arithmetic
This is for https://github.com/rust-lang/rust/pull/97861.
Cc `@eddyb`
I would like to avoid making this depend on `dest.layout.abi` to avoid a branch that we are not usually covering both sides of. Though OTOH this seems like fairly straight-forward code. But let's benchmark this option first to see how bad that extra `force_allocation` really is.
It's common to see repeated assertions like this in derived `clone` and
`eq` methods:
```
let _: ::core::clone::AssertParamIsClone<u32>;
let _: ::core::clone::AssertParamIsClone<u32>;
```
This commit avoids them.
All derive ops currently use match-destructuring to access fields. This
is reasonable for enums, but sub-optimal for structs. E.g.:
```
fn eq(&self, other: &Point) -> bool {
match *other {
Self { x: ref __self_1_0, y: ref __self_1_1 } =>
match *self {
Self { x: ref __self_0_0, y: ref __self_0_1 } =>
(*__self_0_0) == (*__self_1_0) &&
(*__self_0_1) == (*__self_1_1),
},
}
}
```
This commit changes derive ops on structs to use field access instead, e.g.:
```
fn eq(&self, other: &Point) -> bool {
self.x == other.x && self.y == other.y
}
```
This is faster to compile, results in smaller binaries, and is simpler to
generate. Unfortunately, we have to keep the old pattern generating code around
for `repr(packed)` structs because something like `&self.x` (which doesn't show
up in `PartialEq` ops, but does show up in `Debug` and `Hash` ops) isn't
allowed. But this commit at least changes those cases to use let-destructuring
instead of match-destructuring, e.g.:
```
fn hash<__H: ::core:#️⃣:Hasher>(&self, state: &mut __H) -> () {
{
let Self(ref __self_0_0) = *self;
{ ::core:#️⃣:Hash::hash(&(*__self_0_0), state) }
}
}
```
There are some unnecessary blocks remaining in the generated code, but I
will fix them in a follow-up PR.
Fix bug in `rustdoc -Whelp`
Previously, this printed the debugging options, not the lint options,
and only handled `-Whelp`, not `-A/-D/-F`.
This also fixes a few other misc issues:
- Fix `// check-stdout` for UI tests; previously it only worked for run-fail and compile-fail tests
- Add lint headers for tool lints, not just builtin lints
https://github.com/rust-lang/rust/pull/98533#issuecomment-1172004197
r? ```@GuillaumeGomez```
get rid of `tcx` in deadlock handler when parallel compilation
This is a very obscure and hard-to-trace problem that affects thread scheduling. If we copy `tcx` to the deadlock handler thread, it will perform unpredictable behavior and cause very weird problems when executing `try_collect_active_jobs`(For example, the deadlock handler thread suddenly preempts the content of the blocked worker thread and executes the unknown judgment branch, like #94654).
Fortunately we can avoid this behavior by precomputing `query_map`. This change fixes the following ui tests failure on my environment when set `parallel-compiler = true`:
```
[ui] src/test\ui\async-await\no-const-async.rs
[ui] src/test\ui\infinite\infinite-struct.rs
[ui] src/test\ui\infinite\infinite-tag-type-recursion.rs
[ui] src/test\ui\issues\issue-3008-1.rs
[ui] src/test\ui\issues\issue-3008-2.rs
[ui] src/test\ui\issues\issue-32326.rs
[ui] src/test\ui\issues\issue-57271.rs
[ui] src/test\ui\issues\issue-72554.rs
[ui] src/test\ui\parser\fn-header-semantic-fail.rs
[ui] src/test\ui\union\union-nonrepresentable.rs
```
Updates #75760Fixes#94654
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
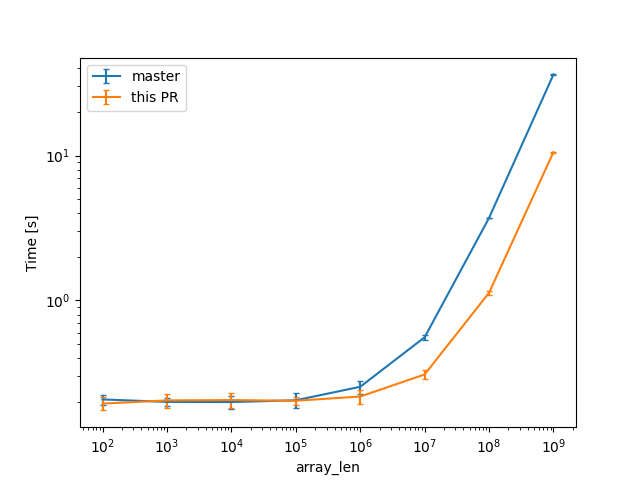
(linear scale for absolute diff at higher Ns)
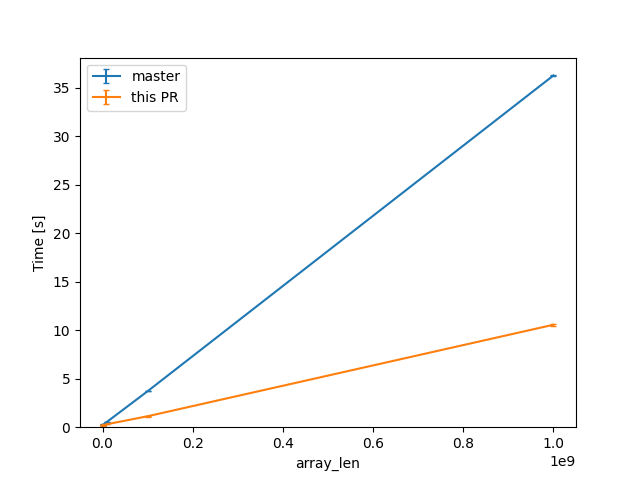
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
Fix FFI-unwind unsoundness with mixed panic mode
UB maybe introduced when an FFI exception happens in a `C-unwind` foreign function and it propagates through a crate compiled with `-C panic=unwind` into a crate compiled with `-C panic=abort` (#96926).
To prevent this unsoundness from happening, we will disallow a crate compiled with `-C panic=unwind` to be linked into `panic-abort` *if* it contains a call to `C-unwind` foreign function or function pointer. If no such call exists, then we continue to allow such mixed panic mode linking because it's sound (and stable). In fact we still need the ability to do mixed panic mode linking for std, because we only compile std once with `-C panic=unwind` and link it regardless panic strategy.
For libraries that wish to remain compile-once-and-linkable-to-both-panic-runtimes, a `ffi_unwind_calls` lint is added (gated under `c_unwind` feature gate) to flag any FFI unwind calls that will cause the linkable panic runtime be restricted.
In summary:
```rust
#![warn(ffi_unwind_calls)]
mod foo {
#[no_mangle]
pub extern "C-unwind" fn foo() {}
}
extern "C-unwind" {
fn foo();
}
fn main() {
// Call to Rust function is fine regardless ABI.
foo::foo();
// Call to foreign function, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
unsafe { foo(); }
//~^ WARNING call to foreign function with FFI-unwind ABI
let ptr: extern "C-unwind" fn() = foo::foo;
// Call to function pointer, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
ptr();
//~^ WARNING call to function pointer with FFI-unwind ABI
}
```
Fix#96926
`@rustbot` label: T-compiler F-c_unwind
Enable MIR inlining
Continuation of https://github.com/rust-lang/rust/pull/82280 by `@wesleywiser.`
#82280 has shown nice compile time wins could be obtained by enabling MIR inlining.
Most of the issues in https://github.com/rust-lang/rust/issues/81567 are now fixed,
except the interaction with polymorphization which is worked around specifically.
I believe we can proceed with enabling MIR inlining in the near future
(preferably just after beta branching, in case we discover new issues).
Steps before merging:
- [x] figure out the interaction with polymorphization;
- [x] figure out how miri should deal with extern types;
- [x] silence the extra arithmetic overflow warnings;
- [x] remove the codegen fulfilment ICE;
- [x] remove the type normalization ICEs while compiling nalgebra;
- [ ] tweak the inlining threshold.
Previously, this printed the debugging options, not the lint options,
and only handled `-Whelp`, not `-A/-D/-F`.
This also fixes a few other misc issues:
- Fix `// check-stdout` for UI tests; previously it only worked for run-fail and compile-fail tests
- Add lint headers for tool lints, not just builtin lints
- Remove duplicate run-make test
interpret: make a comment less scary
This slipped past my review: "has no meaning" could be read as "is undefined behavior". That is certainly not what we mean so be more clear.
cleanup mir visitor for `rustc::pass_by_value`
by changing `& $($mutability)?` to `$(& $mutability)?`
I also did some formatting changes because I started doing them for the visit methods I changed and then couldn't get myself to stop xx, I hope that's still fairly easy to review.
Improve some inference diagnostics
- Properly point out point location where "type must be known at this point", or else omit the note if it's not associated with a useful span.
- Fix up some type ambiguity diagnostics, errors shouldn't say "cannot infer type for reference `&'a ()`" when the given type has no inference variables.
Shorten def_span for more items.
The `def_span` query only returns the signature span for functions.
Struct/enum/union definitions can also have a very long body.
This PR shortens the associated span.
Rollup of 6 pull requests
Successful merges:
- #97488 (Suggest blanket impl to the local traits)
- #98585 (Make `ThinBox<T>` covariant in `T`)
- #98644 (fix ICE with -Wrust-2021-incompatible-closure-captures)
- #98739 (fix grammar in useless doc comment lint)
- #98741 (Many small deriving cleanups)
- #98756 (Use const instead of function and make it private)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Suggest blanket impl to the local traits
This PR will add additional suggestion regarding the blanket implementation when it is possible, by generation a new help message + suggestion.
Closes https://github.com/rust-lang/rust/issues/96076
Signed-off-by: Vincenzo Palazzo <vincenzopalazzodev@gmail.com>
Rewrite dead-code pass to avoid fetching HIR.
This allows to get a more uniform handling of spans, and to simplify the grouping of diagnostics for variants and fields.
The existing derive code allows for various possibilities that aren't
needed in practice, which complicates the code. There are only a few
auto-derived traits and new ones are unlikely, so this commit simplifies
things.
- `PtrTy` has been eliminated. The `Raw` variant was never used, and the
lifetime for the `Borrowed` variant was always `None`. That left just
the mutability field, which has been inlined as necessary.
- `MethodDef::explicit_self` was a confusing `Option<Option<PtrTy>>`.
Indicating either `&self` or nothing. It's now a `bool`.
- `borrowed_self` is renamed as `self_ref`.
- `Ty::Ptr` is renamed to `Ty::Ref`.
The `&[ast::Variant]` field isn't used.
The `Vec<Ident>` field is only used for its length, but that's always
the same as the length of the `&[Ident]` and so isn't necessary.
This created unexpected diagnostics while compiling alga:
cannot satisfy `<Self as Module>::Ring == _`
Turns out that we don't need this diagnostic as we disable inlining when
it would trigger an ICE.
Const eval no longer runs MIR optimizations so unless this is getting
run as part of a MIR optimization like const-prop, there can be unused
type parameters even if polymorphization is enabled.
interpret: add From<&MplaceTy> for PlaceTy
We have a similar instance for `&MPlaceTy` to `OpTy`. Also add the same for `&mut`.
This avoids having to write `&(*place).into()`, which we have a few times here and at least twice in Miri (and it comes up again in my current patch).
r? ```@oli-obk```
For diagnostic information of Boolean, remind it as use the type: 'bool'
Fixes#98492.
It helps programmers coming from other languages
modified: compiler/rustc_resolve/src/late/diagnostics.rs
In NLL, when we are promoting a bound out from a closure,
if we have a requirement that `T: 'a` where `'a` is in a
higher universe, we were previously ignoring that, which is
totally wrong. We should be promoting those constraints to `'static`,
since universes are not expressible across closure boundaries.
Added llvm lifetime annotations to function call argument temporaries.
The goal of this change is to ensure that llvm will do stack slot
optimization on these temporaries. This ensures that in code like:
```rust
const A: [u8; 1024] = [0; 1024];
fn copy_const() {
f(A);
f(A);
}
```
we only use 1024 bytes of stack space, instead of 2048 bytes.
I am new to developing for the rust compiler, and as such not entirely sure, but I believe this should be sufficient to close#98156.
Also, this does not contain a test case to ensure this keeps working, primarily because I am not sure how to go about testing this. I would love some suggestions as to how that could be approached.
Accept `DiagnosticMessage` in `LintDiagnosticBuilder::build` so that
lints can be built with translatable diagnostic messages.
Signed-off-by: David Wood <david.wood@huawei.com>
move MIR syntax into a dedicated file and ping some people whenever it changes
Adding or changing MIR operations/statements/whatever should be under significant scrutiny wrt their wider impact, specified semantics, and so on. So let's start by putting all that into a dedicated file and pinging some people whenever that file changes.
This PR only moves definitions around, and then fiddles with imports until it all works again.
Make TAIT behave exactly like RPIT
fixes https://github.com/rust-lang/rust/issues/96552
This makes type-alias-impl-trait behave like return-position-impl-trait. Unfortunately it also causes some cases to stop compiling due to "needing type annotations" and makes panicking cause fallback for the hidden type to `()`.
All of these are addressable, but we should probably address them for RPIT and TAIT together
r? ``@lcnr``
Avoid some `&str` to `String` conversions with `MultiSpan::push_span_label`
This patch removes some`&str` to `String` conversions with `MultiSpan::push_span_label`.
emit Retag for compound types with reference fields
I want to add an option to Miri to do retagging inside reference fields. But that means we first have to even emit `Retag` for types that *contain* references (rather than being of reference types). :)
Stacked Borrows originally did that, but we stopped doing it when hitting bunch of issues in the standard library. However I have since realized that we actually do emit `noalias` for newtypes references, which means for soundness we should recurse into fields. Also it'd probably be bad news if newtypes lose out on optimizations (and they don't, for anything else). I want to add an option for that to Miri so that we can start experimenting with those semantics.
r? ``@oli-obk``
Clean up arg mismatch diagnostic, generalize tuple wrap suggestion
This is based on top of #97542, so just look at the last commit which contains the relevant changes.
1. Remove `final_arg_types` which was one of the last places we were using raw (`usize`) indices instead of typed indices in the arg mismatch suggestion code.
2. Improve the tuple wrap suggestion, now we suggest things like `call(a, b, c, d)` -> `call(a, (b, c), d)` 😺
3. Folded in fix#98645
Erase regions in New Abstract Consts
When an abstract const is constructed, we previously included lifetimes in the set of substitutes, so it was not able to unify two abstract consts if their lifetimes did not match but the values did, despite the values not depending on the lifetimes. This caused code that should have compiled to not compile.
Fixes#98452
r? ```@lcnr```
Some borrowck diagnostic fixes
1. Remove some redundant `.as_ref` suggestion logic from borrowck, this has the consequence of also not suggesting `.as_ref` after `Option` methods, but (correctly) before.
2. Fix a bug where we were replacing a binding's name with a type. Instead, make it a note.
This is somewhat incomplete. See `src/test/ui/borrowck/suggest-as-ref-on-mut-closure.rs` for more improvements.
interpret: do not prune requires_caller_location stack frames quite so early
https://github.com/rust-lang/rust/pull/87000 made the interpreter skip `caller_location` frames for its stacktraces and `cur_span`. However, those functions are used for much more than just panic reporting, and e.g. when Miri reports UB somewhere, it probably wants to point inside `caller_location` frames. (And if it did not, it would want to have its own logic to decide that, not be forced into it by the core interpreter engine.) This fixes some rare ICEs in Miri that say "we should never pop more than one frame at once".
So let's remove all `caller_location` logic from the core interpreter, and instead move it to CTFE error reporting. This does not change user-visible behavior. That's the first commit.
We might additionally want to change CTFE error reporting to treat panics differently from other errors: only prune `caller_location` frames for panics. The second commit does that. But honestly I am not sure if this is an improvement.
r? ``@oli-obk``
Fix trait object reborrow suggestion
Fixes#93596
Slightly generalizes the logic we use to suggest fix first implemented in #95609, specifically when we have a `Sized` obligation that comes from a struct's unsized tail.
Account for `-Z simulate-remapped-rust-src-base` when resolving remapped paths
Discovered in #97682, `-Z simulate-remapped-rust-src-base` only partially simulated the behavior of `remap-debuginfo = true`. While the flag successfully simulates the remapping when stdlib's `rmeta` file is loaded, the simulated prefix was not accounted for when the remapped path's local path was being discovered. This caused the flag to not fully simulate the behavior of `remap-debuginfo = true`, leading to inconsistent behaviors.
This PR fixes https://github.com/rust-lang/rust/issues/97682 by also accounting for the simulated path.
Use typed indices in argument mismatch algorithm
I kinda went overboard with the renames, but in general, "arg" is renamed to "expected", and "input" is renamed to "provided", and we use new typed indices to make sure we're indexing into the right sized array.
Other drive-by changes:
1. Factor this logic into a new function, so we don't need to `break 'label` to escape it.
1. Factored out dependence on `final_arg_types`, which is never populated for arguments greater than the number of expected args. Instead, we just grab the final coerced expression type from `in_progress_typeck_results`.
1. Adjust the criteria we use to print (provided) type names, before we didn't suggest anything that had infer vars, but now we suggest thing that have infer vars but aren't `_`.
~Also, sorry in advance, I kinda want to backport this but I know I have folded in a lot of unnecessary drive-by changes that might discourage that. I would be open to brainstorming how to get some of these changes on beta at least.~ edit: Minimized the ICE-fixing changes to #97557
cc `@jackh726` as author of #92364, and `@estebank` as reviewer of the PR.
fixes#97484
Simplify memory ordering intrinsics
This changes the names of the atomic intrinsics to always fully include their memory ordering arguments.
```diff
- atomic_cxchg
+ atomic_cxchg_seqcst_seqcst
- atomic_cxchg_acqrel
+ atomic_cxchg_acqrel_release
- atomic_cxchg_acqrel_failrelaxed
+ atomic_cxchg_acqrel_relaxed
// And so on.
```
- `seqcst` is no longer implied
- The failure ordering on chxchg is no longer implied in some cases, but now always explicitly part of the name.
- `release` is no longer shortened to just `rel`. That was especially confusing, since `relaxed` also starts with `rel`.
- `acquire` is no longer shortened to just `acq`, such that the names now all match the `std::sync::atomic::Ordering` variants exactly.
- This now allows for more combinations on the compare exchange operations, such as `atomic_cxchg_acquire_release`, which is necessary for #68464.
- This PR only exposes the new possibilities through unstable intrinsics, but not yet through the stable API. That's for [a separate PR](https://github.com/rust-lang/rust/pull/98383) that requires an FCP.
Suffixes for operations with a single memory order:
| Order | Before | After |
|---------|--------------|------------|
| Relaxed | `_relaxed` | `_relaxed` |
| Acquire | `_acq` | `_acquire` |
| Release | `_rel` | `_release` |
| AcqRel | `_acqrel` | `_acqrel` |
| SeqCst | (none) | `_seqcst` |
Suffixes for compare-and-exchange operations with two memory orderings:
| Success | Failure | Before | After |
|---------|---------|--------------------------|--------------------|
| Relaxed | Relaxed | `_relaxed` | `_relaxed_relaxed` |
| Relaxed | Acquire | ❌ | `_relaxed_acquire` |
| Relaxed | SeqCst | ❌ | `_relaxed_seqcst` |
| Acquire | Relaxed | `_acq_failrelaxed` | `_acquire_relaxed` |
| Acquire | Acquire | `_acq` | `_acquire_acquire` |
| Acquire | SeqCst | ❌ | `_acquire_seqcst` |
| Release | Relaxed | `_rel` | `_release_relaxed` |
| Release | Acquire | ❌ | `_release_acquire` |
| Release | SeqCst | ❌ | `_release_seqcst` |
| AcqRel | Relaxed | `_acqrel_failrelaxed` | `_acqrel_relaxed` |
| AcqRel | Acquire | `_acqrel` | `_acqrel_acquire` |
| AcqRel | SeqCst | ❌ | `_acqrel_seqcst` |
| SeqCst | Relaxed | `_failrelaxed` | `_seqcst_relaxed` |
| SeqCst | Acquire | `_failacq` | `_seqcst_acquire` |
| SeqCst | SeqCst | (none) | `_seqcst_seqcst` |
Currently, `search_for_structural_match_violation` constructs an `infcx`
from a `tcx` and then only uses the `tcx` within the `infcx`. This is
wasteful because `infcx` is a big type.
This commit changes it to use the `tcx` directly. When compiling
`pest-2.1.3`, this changes the memcpy stats reported by DHAT for a `check full`
build from this:
```
433,008,916 bytes (100%, 99,787.93/Minstr) in 2,148,668 blocks (100%, 495.17/Minstr), avg size 201.52 bytes
```
to this:
```
101,422,347 bytes (99.98%, 25,243.59/Minstr) in 1,318,407 blocks (99.96%, 328.15/Minstr), avg size 76.93 bytes
```
This translates to a 4.3% reduction in instruction counts.
Checking the size/alignment of an mplace may be costly, so we only do it
on the types where the walk we want to avoid could be expensive: the larger types
like arrays and slices, rather than on all aggregates being interned.
Reorganizes the previous commits to have a single exit-point to avoid doing the
potentially costly walk. Also moves the relocations tests before the interior
mutability test: only references are important when checking for `UnsafeCell`s
and we're checking if there are any to decide to avoid the walk anyways.
The interning of const allocations visits the mplace looking for references
to intern. Walking big aggregates like big static arrays can be costly,
so we only do it if the allocation we're interning contains references
or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied
to cases where there are no references/relocations either.
translation: lint fix + more migration
- Unfortunately, the diagnostic lints are very broken and trigger much more often than they should. This PR corrects the conditional which checks if the function call being made is to a diagnostic function so that it returns in every intended case.
- The `rustc_lint_diagnostics` attribute is used by the diagnostic translation/struct migration lints to identify calls where non-translatable diagnostics or diagnostics outwith impls are being created. Any function used in creating a diagnostic should be annotated with this attribute so this PR adds the attribute to many more functions.
- Port the diagnostics from the `rustc_privacy` crate and enable the lints for that crate.
r? ``@compiler-errors``
Fix RSS reporting on macOS
> NOTE: This is a duplicate of #98164, which I closed because I borked my rustc fork
Currently, `rustc_data_structures::profiling::get_resident_set_size()` always returns `None` on macOS. This is because
macOS does not implement procfs used in the unix version of the function:
```rust
...
else if #[cfg(unix)] {
pub fn get_resident_set_size() -> Option<usize> {
let field = 1;
let contents = fs::read("/proc/self/statm").ok()?;
let contents = String::from_utf8(contents).ok()?;
let s = contents.split_whitespace().nth(field)?;
let npages = s.parse::<usize>().ok()?;
Some(npages * 4096)
}
...
```
The proposed solution uses libproc, and more specifically `proc_pidinfo`, which has been available on macOS since 10.5 if the function signature inside libproc.h is to be believed:
```c
int proc_pidinfo(int pid, int flavor, uint64_t arg, void *buffer, int buffersize) __OSX_AVAILABLE_STARTING(__MAC_10_5, __IPHONE_2_0);
```
[RFC 2011] Optimize non-consuming operators
Tracking issue: https://github.com/rust-lang/rust/issues/44838
Fifth step of https://github.com/rust-lang/rust/pull/96496
The most non-invasive approach that will probably have very little to no performance impact.
## Current behaviour
Captures are handled "on-the-fly", i.e., they are performed in the same place expressions are located.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !(
{ ***try capture `a` and then return `a`*** } > 1 && { ***try capture `b` and then return `b`*** } < 100
) {
panic!( ... );
}
```
As such, some overhead is likely to occur (Specially with very large chains of conditions).
## New behaviour for non-consuming operators
When an operator is known to not take `self`, then it is possible to capture variables **AFTER** the condition.
```rust
// `let a = 1; let b = 2; assert!(a > 1 && b < 100);`
if !( a > 1 && b < 100 ) {
{ ***try capture `a`*** }
{ ***try capture `b`*** }
panic!( ... );
}
```
So the possible impact on the runtime execution time will be diminished.
r? ````@oli-obk````
Remove `MAX_SUGGESTION_HIGHLIGHT_LINES`
After #97798 the `MAX_SUGGESTION_HIGHLIGHT_LINES` constant doesn't really make sense since we always show full suggestions. This PR removes last usages of the constant and the constant itself.
r? ``@flip1995`` (this mostly does changes in clippy)
Only keep a single query for well-formed checking
There are currently 3 queries to perform wf checks on different item-likes. This complexity is not required.
This PR replaces the query by:
- one query per item;
- one query to invoke it for a whole module.
This allows to remove HIR `ParItemLikeVisitor`.
interpret: refactor allocation info query
We now have an infallible function that also tells us which kind of allocation we are talking about.
Also we do longer have to distinguish between data and function allocations for liveness.
This will help us to avoid "catching" `InterpError`s in Miri.
r? `@oli-obk`
Fix rustdoc argument error
Fixes#88756.
It's a take over of #88831. I cherry-picked the commits, fixed the merge conflict and the failing test.
cc `@inashivb` `@jyn514`
r? `@notriddle`
catch unwind in parallel mode during wfcheck
Update #75760
When performing wfcheck, from the test results, the parallel mode will stop all checks when an `item`'s check failed, (e.g. the first ui test failure raised from [here](https://github.com/rust-lang/rust/blob/master/compiler/rustc_trait_selection/src/traits/error_reporting/mod.rs#L249))while the serial mode will output each `item`'s check result via `catch_unwind`. This leads to inconsistencies in the final output of the two mode.
In my local environment, this modification prevents the following ui tests from failing when set `parallel-compiler = true` in `config.toml`:
```
[ui] src/test\ui\associated-types\defaults-cyclic-fail-1.rs
[ui] src/test\ui\associated-types\defaults-cyclic-fail-2.rs
[ui] src/test\ui\associated-types\hr-associated-type-bound-2.rs
[ui] src/test\ui\associated-types\impl-wf-cycle-1.rs
[ui] src/test\ui\associated-types\impl-wf-cycle-2.rs
[ui] src/test\ui\issues\issue-20413.rs
[ui] src/test\ui\parallel_test\defaults-cyclic-fail-para.rs
```
The `rustc_lint_diagnostics` attribute is used by the diagnostic
translation/struct migration lints to identify calls where
non-translatable diagnostics or diagnostics outwith impls are being
created. Any function used in creating a diagnostic should be annotated
with this attribute so this commit adds the attribute to many more
functions.
Signed-off-by: David Wood <david.wood@huawei.com>
Unfortunately, the diagnostic lints are very broken and trigger much
more often than they should. Correct the conditional which checks if the
function call being made is to a diagnostic function so that it returns
in every intended case.
Signed-off-by: David Wood <david.wood@huawei.com>
Check ADT field is well-formed before checking it is sized
Fixes#96810.
There is one diagnostics regression, in [`src/test/ui/generic-associated-types/bugs/issue-80626.stderr`](https://github.com/rust-lang/rust/pull/97780/files#diff-53795946378e78a0af23a10277c628ff79091c18090fdc385801ee70c1ba6963). I am not super concerned about it, since it's GAT related.
We _could_ fix it, possibly by using the `FieldSized` obligation cause code instead of `BuiltinDerivedObligation`. But that would require changing `Sized` trait confirmation and the `adt_sized_constraint` query.
We now have an infallible function that also tells us which kind of allocation we are talking about.
Also we do longer have to distinguish between data and function allocations for liveness.
This greatly reduces round-trips to fetch relevant extra information about the
token in proc macro code, and avoids RPC messages to create Group tokens.
This greatly reduces round-trips to fetch relevant extra information about the
token in proc macro code, and avoids RPC messages to create Punct tokens.
rustc_target: Add convenience functions for adding linker arguments
They ensure that lld and non-lld linker flavors get the same set of arguments.
The second commit also adds some tests checking for linker argument inconsistencies, and tweaks some arguments to fix those inconsistencies.
Currently the generated code for methods like `eq`, `ne`, and `partial_cmp`
includes stuff like this:
```
let __self_vi = ::core::intrinsics::discriminant_value(&*self);
let __arg_1_vi = ::core::intrinsics::discriminant_value(&*other);
if true && __self_vi == __arg_1_vi {
...
}
```
This commit removes the unnecessary `true &&`, and makes the generating
code a little easier to read in the process. It also fixes some errors
in comments.
proc_macro/bridge: cache static spans in proc_macro's client thread-local state
This is the second part of https://github.com/rust-lang/rust/pull/86822, split off as requested in https://github.com/rust-lang/rust/pull/86822#pullrequestreview-1008655452. This patch removes the RPC calls required for the very common operations of `Span::call_site()`, `Span::def_site()` and `Span::mixed_site()`.
Some notes:
This part is one of the ones I don't love as a final solution from a design standpoint, because I don't like how the spans are serialized immediately at macro invocation. I think a more elegant solution might've been to reserve special IDs for `call_site`, `def_site`, and `mixed_site` at compile time (either starting at 1 or from `u32::MAX`) and making reading a Span handle automatically map these IDs to the relevant values, rather than doing extra serialization.
This would also have an advantage for potential future work to allow `proc_macro` to operate more independently from the compiler (e.g. to reduce the necessity of `proc-macro2`), as methods like `Span::call_site()` could be made to function without access to the compiler backend.
That was unfortunately tricky to do at the time, as this was the first part I wrote of the patches. After the later part (#98188, #98189), the other uses of `InternedStore` are removed meaning that a custom serialization strategy for `Span` is easier to implement.
If we want to go that path, we'll still need the majority of the work to split the bridge object and introduce the `Context` trait for free methods, and it will be easier to do after `Span` is the only user of `InternedStore` (after #98189).
macros: use typed identifiers in diag and subdiag derive
Using typed identifiers instead of strings with the Fluent identifiers in the diagnostic and subdiagnostic derives - this enables the diagnostic derive to benefit from the compile-time validation that comes with typed identifiers, namely that use of a non-existent Fluent identifier will not compile.
r? `````@oli-obk`````
make const_err show up in future breakage reports
As tracked in https://github.com/rust-lang/rust/issues/71800, const_err should become a hard error Any Day Now (TM). I'd love to move forward with that sooner rather than later; it has been deny-by-default for many years and a future incompat lint since https://github.com/rust-lang/rust/pull/80394 (landed more than a year ago). Some CTFE errors are already hard errors since https://github.com/rust-lang/rust/pull/86194. But before we truly make it a hard error in all cases, we now have one more intermediate step we can take -- to make it show up in future breakage reports.
Cc `````@rust-lang/wg-const-eval`````
This is useful for debugging drop-tracking; previously, you had to recompile
rustc from source and manually add a call to `write_graph_to_file`. This
makes the option more discoverable and configurable at runtime.
I also took the liberty of making the labels for the CFG nodes much easier to read:
previously, they looked like `id(2), local_id: 48`, now they look like
```
expr from_config (hir_id=HirId { owner: DefId(0:10 ~ default_struct_update[79f9]::foo), local_id: 2})
```
Work around llvm 12's memory ordering restrictions.
Older llvm has the pre-C++17 restriction on success and failure memory ordering, requiring the former to be at least as strong as the latter. So, for llvm 12, this upgrades the success ordering to a stronger one if necessary.
See https://github.com/rust-lang/rust/issues/68464
Suggest defining variable as mutable on `&mut _` type mismatch in pats
Suggest writing `mut a` where `&mut a` was written but a non-ref type provided.
Since we still don't have "apply either one of the suggestions but not both" kind of thing, the interaction with the suggestion of removing `&[mut]` or moving it to the type is weird, and idk how to make it better..
r? ``@compiler-errors``
Reverse folder hierarchy
#91318 introduced a trait for infallible folders distinct from the fallible version. For some reason (completely unfathomable to me now that I look at it with fresh eyes), the infallible trait was a supertrait of the fallible one: that is, all fallible folders were required to also be infallible. Moreover the `Error` associated type was defined on the infallible trait! It's so absurd that it has me questioning whether I was entirely sane.
This trait reverses the hierarchy, so that the fallible trait is a supertrait of the infallible one: all infallible folders are required to also be fallible (which is a trivial blanket implementation). This of course makes much more sense! It also enables the `Error` associated type to sit on the fallible trait, where it sensibly belongs.
There is one downside however: folders expose a `tcx` accessor method. Since the blanket fallible implementation for infallible folders only has access to a generic `F: TypeFolder`, we need that trait to expose such an accessor to which we can delegate. Alternatively it's possible to extract that accessor into a separate `HasTcx` trait (or similar) that would then be a supertrait of both the fallible and infallible folder traits: this would ensure that there's only one unambiguous `tcx` method, at the cost of a little additional boilerplate. If desired, I can submit that as a separate PR.
r? ````@jackh726````
Previously, the expand_expr method would expand bool literals as a
`Literal` token containing a `LitKind::Bool`, rather than as an `Ident`.
This is not a valid token, and the `LitKind::Bool` case needs to be
handled seperately.
Tests were added to more deeply compare the streams in the expand-expr
test suite to catch mistakes like this in the future.
Now that typed identifiers are used in both derives, constructors for
the `DiagnosticMessage` and `SubdiagnosticMessage` types are not
required.
Signed-off-by: David Wood <david.wood@huawei.com>
As in the diagnostic derive, using typed identifiers in the
subdiagnostic derive improves the diagnostics of using the subdiagnostic
derive as Fluent messages will be confirmed to exist at compile-time.
Signed-off-by: David Wood <david.wood@huawei.com>
Using typed identifiers instead of strings with the Fluent identifier
enables the diagnostic derive to benefit from the compile-time
validation that comes with typed identifiers - use of a non-existent
Fluent identifier will not compile.
Signed-off-by: David Wood <david.wood@huawei.com>
Fixup missing renames from `#[main]` to `#[rustc_main]`
In #84217 `#[main]` was removed and replaced with `#[rustc_main]`. In some places the rename was forgotten, which makes the current code confusing, because at first glance it seems that `#[main]` is still around. Perform the renames also in these places.
I noticed this (after first being confused by it) when working on #97802.
r? `@petrochenkov`
(since you reviewed the other PR)
Improve suggestion for calling fn-like expr on type mismatch
1.) Suggest calling values of with RPIT types (and probably TAIT) when we expect `Ty` and have `impl Fn() -> Ty`
2.) Suggest calling closures even when they're not assigned to a local variable first
3.) Drive-by fix of a pretty-printing bug (`impl Fn()-> Ty` => `impl Fn() -> Ty`)
r? ```@estebank```
rustc_target: Remove some redundant target properties
`is_like_emscripten` is equivalent to `os == "emscripten"`, so it's removed.
`is_like_fuchsia` is equivalent to `os == "fuchsia"`, so it's removed.
`is_like_osx` also falls into the same category and is equivalent to `vendor == "apple"`, but it's commonly used so I kept it as is for now.
`is_like_(solaris,windows,wasm)` are combinations of different operating systems or architectures (see compiler/rustc_target/src/spec/tests/tests_impl.rs) so they are also kept as is.
I think `is_like_wasm` (and maybe `is_like_osx`) are sufficiently closed sets, so we can remove these fields as well and replace them with methods like `fn is_like_wasm() { arch == "wasm32" || arch == "wasm64" }`.
On other hand, `is_like_solaris` and `is_like_windows` are sufficiently open and I can imagine custom targets introducing other values for `os`.
This is kind of a gray area.
Remove (transitive) reliance on sorting by DefId in pretty-printer
This moves us a step closer to removing the `PartialOrd/`Ord` impls
for `DefId`. See #90317
Add macro support in jump to definition feature
Fixes#91174.
To do so, I check if the span comes from an expansion, and if so, I infer the original macro `DefId` or `Span` depending if it's a defined in the current crate or not.
There is one limitation due to macro expansion though:
```rust
macro_rules! yolo { () => {}}
fn foo() {
yolo!();
}
```
In `foo`, `yolo!` won't be linked because after expansion, it is replaced by nothing (which seems logical). So I can't get an item from the `Visitor` from which I could tell if its `Span` comes from an expansion.
I added a test for this specific limitation alongside others.
Demo: https://rustdoc.crud.net/imperio/macro-jump-to-def/src/foo/check-source-code-urls-to-def-std.rs.html
As for the empty macro issue that cannot create a jump to definition, you can see it [here](https://rustdoc.crud.net/imperio/macro-jump-to-def/src/foo/check-source-code-urls-to-def-std.rs.html#35).
r? ```@jyn514```
fix universes in the NLL type tests
In the NLL code, we were not accommodating universes in the
`type_test` logic.
Fixes#98095.
r? `@compiler-errors`
This breaks some tests, however, so the purpose of this branch is more explanatory and perhaps to do a crater run.
This commit adds new methods that combine sequences of existing
formatting methods.
- `Formatter::debug_{tuple,struct}_field[12345]_finish`, equivalent to a
`Formatter::debug_{tuple,struct}` + N x `Debug{Tuple,Struct}::field` +
`Debug{Tuple,Struct}::finish` call sequence.
- `Formatter::debug_{tuple,struct}_fields_finish` is similar, but can
handle any number of fields by using arrays.
These new methods are all marked as `doc(hidden)` and unstable. They are
intended for the compiler's own use.
Special-casing up to 5 fields gives significantly better performance
results than always using arrays (as was tried in #95637).
The commit also changes the `Debug` deriving code to use these new methods. For
example, where the old `Debug` code for a struct with two fields would be like
this:
```
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
match *self {
Self {
f1: ref __self_0_0,
f2: ref __self_0_1,
} => {
let debug_trait_builder = &mut ::core::fmt::Formatter::debug_struct(f, "S2");
let _ = ::core::fmt::DebugStruct::field(debug_trait_builder, "f1", &&(*__self_0_0));
let _ = ::core::fmt::DebugStruct::field(debug_trait_builder, "f2", &&(*__self_0_1));
::core::fmt::DebugStruct::finish(debug_trait_builder)
}
}
}
```
the new code is like this:
```
fn fmt(&self, f: &mut ::core::fmt::Formatter) -> ::core::fmt::Result {
match *self {
Self {
f1: ref __self_0_0,
f2: ref __self_0_1,
} => ::core::fmt::Formatter::debug_struct_field2_finish(
f,
"S2",
"f1",
&&(*__self_0_0),
"f2",
&&(*__self_0_1),
),
}
}
```
This shrinks the code produced for `Debug` instances
considerably, reducing compile times and binary sizes.
Co-authored-by: Scott McMurray <scottmcm@users.noreply.github.com>
implement `iter_projections` function on `PlaceRef`
this makes the api more flexible. the original function now calls the PlaceRef
version to avoid duplicating the code.
Update no_default_libraries handling for emscripten target
```@sbc100``` says:
> `-sDEFAULT_LIBRARY_FUNCS_TO_INCLUDE=[]` is almost certainly wrong/out-of-date. This setting defaults to the empty list anyway these days so its redundant. Also we now support `-nodefaultlibs` so you can use that, as with other toolchains.
https://github.com/rust-lang/rust/issues/98303#issuecomment-1162163684
Migrate two diagnostics from the `rustc_builtin_macros` crate
Migrate two diagnostics to use the struct derive and be translatable.
r? ```@davidtwco```
Provide a `PathSegment.res` in more cases
I find that in many cases, the `res` associated with a `PathSegment` is `Res::Err` even though the path was fully resolved. A few diagnostics use this `res` and their error messages suffer because of the lack of resolved segment.
This fixes it a bit, but it's obviously not complete and I'm not exactly sure if it's correct.
Greatly improve error reporting for futures and generators in `note_obligation_cause_code`
Most futures don't go through this code path, because they're caught by
`maybe_note_obligation_cause_for_async_await`. But all generators do,
and `maybe_note` is imperfect and doesn't catch all futures. Improve the error message for those it misses.
At some point, we may want to consider unifying this with the code for `maybe_note_async_await`,
so that `async_await` notes all parent constraints, and `note_obligation` can point to yield points.
But both functions are quite complicated, and it's not clear to me how to combine them;
this seems like a good incremental improvement.
Helps with https://github.com/rust-lang/rust/issues/97332.
r? ``@estebank`` cc ``@eholk`` ``@compiler-errors``
In fc357039f9 `#[main]` was removed and replaced with `#[rustc_main]`.
In some place the rename was forgotten, which makes the current code
confusing, because at first glance it seems that `#[main]` is still
around. Perform the renames also in these places.
Older llvm has the pre-C++17 restriction on success and failure memory
ordering, requiring the former to be at least as strong as the latter.
So, for llvm 12, this upgrades the success ordering to a stronger one if
necessary.
Create elided lifetime parameters for function-like types
Split from https://github.com/rust-lang/rust/pull/97720
This PR refactor lifetime generic parameters in bare function types and parenthesized traits to introduce the additional required lifetimes as fresh parameters in a `for<>` bound.
This PR does the same to lifetimes appearing in closure signatures, and as-if introducing `for<>` bounds on closures (without the associated change in semantics).
r? `@petrochenkov`
The goal of this change is to ensure that llvm will do stack slot
optimization on these temporaries. This ensures that in code like:
```rust
const A: [u8; 1024] = [0; 1024];
fn copy_const() {
f(A);
f(A);
}
```
we only use 1024 bytes of stack space, instead of 2048 bytes.
Point at return expression for RPIT-related error
Certainly this needs some diagnostic refining, but I wanted to show that it was possible first and foremost. Not sure if this is the right approach. Open to feedback.
Fixes#80583
use `def_ident_span` , `body_owner_def_id` instead of `in_progress_typeck_results`, `guess_head_span`
use `body_id.owner` directly
add description to label
This comment is out dated and misleading, the arm is about TAITs
r? ```@oli-obk```
```@oli-obk``` unsure if you want to add a different comment of some sort.
```@bors``` rollup=always
Remove the unused-`#[doc(hidden)]` logic from the `unused_attributes` lint
Fixes#96890.
It was found out that `#[doc(hidden)]` on trait impl items does indeed have an effect on the generated documentation (see the linked issue). In my opinion and the one of [others](https://rust-lang.zulipchat.com/#narrow/stream/266220-rustdoc/topic/Validy.20checks.20for.20.60.23.5Bdoc.28hidden.29.5D.60/near/281846219), rustdoc's output is actually a bit flawed in that regard but that should be tracked in a new issue I suppose (I will open an issue for that in the near future).
The check was introduced in #96008 which is marked to be part of version `1.62` (current `beta`). As far as I understand, this means that **this PR needs to be backported** to `beta` to fix#96890 on time. Correct me if I am wrong.
CC `@dtolnay` (in case you would like to agree or disagree with my decision to fully remove this check)
`@rustbot` label A-lint T-compiler T-rustdoc
r? `@rust-lang/compiler`
lub: don't bail out due to empty binders
allows for the following to compile. The equivalent code using `struct Wrapper<'upper>(fn(&'upper ());` already compiles on stable.
```rust
let _: fn(&'upper ()) = match v {
true => lt_in_fn::<'a>(),
false => lt_in_fn::<'b>(),
};
```
see https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=7034a677190110941223cafac6632f70 for a complete example
r? ```@rust-lang/types```
#91318 introduced a trait for infallible folders distinct from the fallible version. For some reason (completely unfathomable to me now that I look at it with fresh eyes), the infallible trait was a supertrait of the fallible one: that is, all fallible folders were required to also be infallible. Moreover the `Error` associated type was defined on the infallible trait! It's so absurd that it has me questioning whether I was entirely sane.
This trait reverses the hierarchy, so that the fallible trait is a supertrait of the infallible one: all infallible folders are required to also be fallible (which is a trivial blanket implementation). This of course makes much more sense! It also enables the `Error` associated type to sit on the fallible trait, where it sensibly belongs.
There is one downside however: folders expose a `tcx` accessor method. Since the blanket fallible implementation for infallible folders only has access to a generic `F: TypeFolder`, we need that trait to expose such an accessor to which we can delegate. Alternatively it's possible to extract that accessor into a separate `HasTcx` trait (or similar) that would then be a supertrait of both the fallible and infallible folder traits: this would ensure that there's only one unambiguous `tcx` method, at the cost of a little additional boilerplate. If desired, I can submit that as a separate PR.
r? @jackh726
Remove the source archive functionality of ArchiveWriter
We now build archives through strictly additive means rather than taking an existing archive and potentially substracting parts. This is simpler and makes it easier to swap out the archive writer in https://github.com/rust-lang/rust/pull/97485.
`try_fold_unevaluated` for infallible folders
#97447 added folding of unevaluated constants, but did not include an override of the default (fallible) operation in the blanket impl of `FallibleTypeFolder` for infallible folders. Here we provide that missing override.
r? ```@nnethercote```
Fix erroneous span for borrowck error
I am not confident that this is the correct fix, but it does the job. Open to suggestions for a real fix instead.
Fixes#97997
The issue is that we pass a [dummy location](https://doc.rust-lang.org/nightly/nightly-rustc/src/rustc_middle/mir/visit.rs.html#302) when type-checking the ["required consts"](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/mir/struct.Body.html#structfield.required_consts) that are needed by the MIR body during borrowck. This means that when we fail to evaluate the constant, we use the span of `bb0[0]`, instead of the actual span of the constant.
There are quite a few other places that use `START_BLOCK.start_location()`, `Location::START`, etc. when calling for a random/unspecified `Location` value. This is because, unlike (for example) `Span`, we don't have a dummy/miscellaneous value to use instead. I would appreciate guidance (either in this PR, or a follow-up) on what needs to be done to clean this up in general.
Add proper tracing spans to rustc_trait_selection::traits::error_reporting
While I was trying to figure out #97704 I did some of this to make the logs more legible, so I figured I'd do the whole module and open a PR with it. afaict this is an ongoing process in the compiler from the log->tracing transition? but lmk if there was a reason for the more verbose forms of logging as they are.
Also, for some of the functions with only one log in them, I put the function name as a message for that log instead of `#[instrument]`-ing the whole function with a span? but maybe the latter would actually be preferable, I'm not actually sure.
Remove dereferencing of Box from codegen
Through #94043, #94414, #94873, and #95328, I've been fixing issues caused by Box being treated like a pointer when it is not a pointer. However, these PRs just introduced special cases for Box. This PR removes those special cases and instead transforms a deref of Box into a deref of the pointer it contains.
Hopefully, this is the end of the Box<T, A> ICEs.
Mention formatting macros when encountering `ArgumentV1` method in const
Also open to just closing this if it's overkill. There are a lot of other distracting error messages around, so maybe it's not worth fixing just this one.
Fixes#93665
Don't omit comma when suggesting wildcard arm after macro expr
* Also adds `Span::eq_ctxt` to consolidate the various usages of `span.ctxt() == other.ctxt()`
* Also fixes an unhygenic usage of spans which caused the suggestion to render weirdly when we had one arm match in a macro
* Also always suggests a comma (i.e. even after a block) if we're rendering a wildcard arm in a single-line match (looks prettier 🌹)
Fixes#94866
Drop magic value 3 from code
Magic value 3 is used to create state for a yield point. It is in fact
the number of reserved variants.
Lift RESERVED_VARIANTS out to module scope and use it instead.
#97447 added folding of unevaluated constants, but did not include an override of the default (fallible) operation in the blanket impl of `FallibleTypeFolder` for infallible folders. Here we provide that missing override.
r? @nnethercote
Include ForeignItem when visiting types for WF check
Addresses Issue 95665 by including `hir::Node::ForeignItem` as a valid
type to visit in `diagnostic_hir_wf_check`.
Fixes#95665
Magic value 3 is used to create state for a yield point. It is in fact
the number of reserved variants.
Lift RESERVED_VARIANTS out to module scope and use it instead.
Fix pretty printing of empty bound lists in where-clause
Repro:
```rust
macro_rules! assert_item_stringify {
($item:item $expected:literal) => {
assert_eq!(stringify!($item), $expected);
};
}
fn main() {
assert_item_stringify! {
fn f<'a, T>() where 'a:, T: {}
"fn f<'a, T>() where 'a:, T: {}"
}
}
```
Previously this assertion would fail because rustc renders the where-clause as `where 'a, T` which is invalid syntax.
This PR makes the above assertion pass.
This bug also affects `-Zunpretty=expanded`. The intention is for that to emit syntactically valid code, but the buggy output is not valid Rust syntax.
```console
$ rustc <(echo "fn f<'a, T>() where 'a:, T: {}") -Zunpretty=expanded
#![feature(prelude_import)]
#![no_std]
#[prelude_import]
use ::std::prelude::rust_2015::*;
#[macro_use]
extern crate std;
fn f<'a, T>() where 'a, T {}
```
```console
$ rustc <(echo "fn f<'a, T>() where 'a:, T: {}") -Zunpretty=expanded | rustc -
error: expected `:`, found `,`
--> <anon>:7:23
|
7 | fn f<'a, T>() where 'a, T {}
| ^ expected `:`
```
Make missing argument placeholder more obvious that it's a placeholder
Use `/* ty */` instead of `{ty}`, since people might be misled into thinking that this is valid syntax, and not just a diagnostic placeholder.
Fixes#96880
Both functions do some modifying of streams using `make_mut`:
- `push` sometimes glues the first token of the next stream to the last
token of the first stream.
- `build` appends tokens to the first stream.
By doing all of this in the one place, things are simpler. The first
stream can be modified in both ways (if necessary) in the one place, and
any next stream with the first token removed doesn't need to be stored.
Fix `SourceScope` for `if let` bindings.
Fixes#97799.
I'm not sure how to test this properly, is there any way to observe the difference in behavior apart from `ui` tests? I'm worried that they would be overlooked in the case of a regression.
It's a weird function: it lets you modify the token stream in the middle
of iteration. There is only one call site, and it is only used for the
rare `ProceduralMasquerade` legacy case.
Make debug_triple depend on target json file content rather than file path
This ensures that changes to target json files will force a recompilation. And more importantly that moving the files doesn't force a recompilation.
This should fix https://github.com/Rust-for-Linux/linux/issues/792 (cc ``@ojeda)``
Stabilize `Path::try_exists()` and improve doc
This stabilizes the `Path::try_exists()` method which returns
`Result<bool, io::Error>` instead of `bool` allowing handling of errors
unrelated to the file not existing. (e.g permission errors)
Along with the stabilization it also:
* Warns that the `exists()` method is error-prone and suggests to use
the newly stabilized one.
* Suggests it instead of `metadata()` to handle errors.
* Mentions TOCTOU bugs to avoid false assumption that `try_exists()` is
completely safe fixed version of `exists()`.
* Renames the feature of still-unstable `std::fs::try_exists()` to
`fs_try_exists` to avoid name conflict.
The tracking issue #83186 remains open to track `fs_try_exists`.
{kind=link}
{kind=link}
{kind=link}
{kind=link}