Give `impl Trait` in a `const fn` its own feature gate
...previously it was gated under `#![feature(const_fn)]`.
I think we actually want to do this in all const-contexts? If so, this should be `#![feature(const_impl_trait)]` instead. I don't think there's any way to make use of `impl Trait` within a `const` initializer.
cc #77463
r? `@oli-obk`
Eliminate bounds checking in slice::Windows
This is how `<core::slice::Windows as Iterator>::next` looks right now:
```rust
fn next(&mut self) -> Option<&'a [T]> {
if self.size > self.v.len() {
None
} else {
let ret = Some(&self.v[..self.size]);
self.v = &self.v[1..];
ret
}
}
```
The line with `self.v = &self.v[1..];` relies on assumption that `self.v` is definitely not empty at this point. Else branch is taken when `self.size <= self.v.len()`, so `self.v` can be empty if `self.size` is zero. In practice, since `Windows` is never created directly but rather trough `[T]::windows` which panics when `size` is zero, `self.size` is never zero. However, the compiler doesn't know about this check, so it keeps the code which checks bounds and panics.
Using `NonZeroUsize` lets the compiler know about this invariant and reliably eliminate bounds checking without `unsafe` on `-O2`. Here is assembly of `Windows<'a, u32>::next` before and after this change ([goldbolt](https://godbolt.org/z/xrefzx)):
<details>
<summary>Before</summary>
```
example::next:
push rax
mov rcx, qword ptr [rdi + 8]
mov rdx, qword ptr [rdi + 16]
cmp rdx, rcx
jbe .LBB0_2
xor eax, eax
pop rcx
ret
.LBB0_2:
test rcx, rcx
je .LBB0_5
mov rax, qword ptr [rdi]
mov rsi, rax
add rsi, 4
add rcx, -1
mov qword ptr [rdi], rsi
mov qword ptr [rdi + 8], rcx
pop rcx
ret
.LBB0_5:
lea rdx, [rip + .L__unnamed_1]
mov edi, 1
xor esi, esi
call qword ptr [rip + core::slice::slice_index_order_fail@GOTPCREL]
ud2
.L__unnamed_2:
.ascii "./example.rs"
.L__unnamed_1:
.quad .L__unnamed_2
.asciz "\f\000\000\000\000\000\000\000\016\000\000\000\027\000\000"
```
</details>
<details>
<summary>After</summary>
```
example::next:
mov rcx, qword ptr [rdi + 8]
mov rdx, qword ptr [rdi + 16]
cmp rdx, rcx
jbe .LBB0_2
xor eax, eax
ret
.LBB0_2:
mov rax, qword ptr [rdi]
lea rsi, [rax + 4]
add rcx, -1
mov qword ptr [rdi], rsi
mov qword ptr [rdi + 8], rcx
ret
```
</details>
Note the lack of call to `core::slice::slice_index_order_fail` in second snippet.
#### Possible reasons _not_ to merge this PR:
* this changes the error message on panic in `[T]::windows`. However, AFAIK this messages are not covered by backwards compatibility policy.
Implement advance_by, advance_back_by for iter::Chain
Part of #77404.
This PR does two things:
- implement `Chain::advance[_back]_by` in terms of `advance[_back]_by` on `self.a` and `advance[_back]_by` on `self.b`
- change `Chain::nth[_back]` to use `advance[_back]_by` on `self.a` and `nth[_back]` on `self.b`
This ensures that `Chain::nth` can take advantage of an efficient `nth` implementation on the second iterator, in case it doesn't implement `advance_by`.
cc `@scottmcm` in case you want to review this
Use more intra-doc-links in `core::fmt`
This is a follow-up to #75819, which encountered some broken links due to #75176, so this PR contains the links that are blocked on #75176.
r? @jyn514
Allows getting the slices directly, rather than just through an iterator as in `array_chunks(_mut)`. The constructors for those iterators are then written in terms of these methods, so the iterator constructors no longer have any `unsafe` of their own.
Hint the maximum length permitted by invariant of slices
One of the safety invariants of references, and in particular of references to slices, is that they may not cover more than `isize::MAX` bytes. The unsafe `from_raw_parts` constructors of slices explicitly requires the caller to guarantee this fact. Violating it would also be UB with regards to the semantics of generated llvm code.
This effectively bounds the length of a (non-ZST) slice from above by a compile time constant. But when the length is loaded from a function argument it appears llvm is not aware of this requirement. The additional value range assertions allow some further elision of code branches, including overflow checks, especially in the presence of artithmetic on the indices.
This may have a performance impact, adding more code to a common method but allowing more optimization. I'm not quite sure, is the Rust side of const-prop strong enough to elide the irrelevant match branches?
Fixes: #67186
Uses assume to check the length against a constant upper bound. The
inlined result then informs the optimizer of the sound value range.
This was tried with unreachable_unchecked before which introduces a
branch. This has the advantage of not being executed in sound code but
complicates basic blocks. It resulted in ~2% increased compile time in
some worst cases.
Add a codegen test for the assumption, testing the issue from #67186
Implement as_ne_bytes() for integers and floats
This is related to issue #64464.
I am pretty sure that these functions are actually const-ify-able, and technically as_bits() can also be implemented for floats, but I might need some comments on both.
Use less divisions in display u128/i128
This PR is an absolute mess, and I need to test if it improves the speed of fmt::Display for u128/i128, but I think it's correct.
It hopefully is more efficient by cutting u128 into at most 2 u64s, and also chunks by 1e16 instead of just 1e4.
Also I specialized the implementations for uints to always be non-false because it bothered me that it was checked at all
Do not merge until I benchmark it and also clean up the god awful mess of spaghetti.
Based on prior work in #44583
cc: `@Dylan-DPC`
Due to work on `itoa` and suggestion in original issue:
r? `@dtolnay`
Stabilize slice_ptr_range.
This has been unstable for almost a year now. Time to stabilize?
Closes#65807.
@rustbot modify labels: +T-libs +A-raw-pointers +A-slice +needs-fcp
This commit entroduces `core::str::SplitInclusive::as_str` method similar to
`core::str::Split::as_str`, but under different gate -
"str_split_inclusive_as_str" (this is done so because `SplitInclusive` is
itself unstable).
This commit introduses 2 methods under "str_split_as_str" gate with common
signature of `&Split<'a, _> -> &'a str'`. Both of them work like
`Chars::as_str` - return unyield part of the inner string.
Refactor memchr to allow optimization
Closes#75659
The implementation already uses naive search if the slice if short enough, but the case is complicated enough to not be optimized away. This PR refactors memchr so that it exists early when the slice is short enough.
Codegen-wise, as shown in #75659, memchr was not inlined previously so the only way I could find to test this is to check if there is no memchr call. Let me know if there is a more robust solution here.
Add Iterator::advance_by and DoubleEndedIterator::advance_back_by
This PR adds the iterator method
```rust
fn advance_by(&mut self, n: usize) -> Result<(), usize>
```
that advances the iterator by `n` elements, returning `Ok(())` if this succeeds or `Err(len)` if the length of the iterator was less than `n`.
Currently `Iterator::nth` is the method to override for efficiently advancing an iterator by multiple elements at once. `advance_by` is superior for this purpose because
- it's simpler to implement: instead of advancing the iterator and producing the next element you only need to advance the iterator
- it composes better: iterators like `Chain` and `FlatMap` can implement `advance_by` in terms of `advance_by` on their inner iterators, but they cannot implement `nth` in terms of `nth` on their inner iterators (see #60395)
- the default implementation of `nth` can trivially be implemented in terms of `advance_by` and `next`, which this PR also does
This PR also adds `DoubleEndedIterator::advance_back_by` for all the same reasons.
I'll make a tracking issue if it's decided this is worth merging. Also let me know if anything can be improved, this went through several iterations so there might very well still be room for improvement (especially in the doc comments). I've written overrides of these methods for most iterators that already override `nth`/`nth_back`, but those still need tests so I'll add them in a later PR.
cc @cuviper @scottmcm @Amanieu
Split core/str/mod.rs to smaller files
Note for reviewer:
* I split to multiple commits for easier reviewing, but I could git squash them all to one if requested.
* Recommend pulling this change locally and using advanced git diff viewer or this command:
```bash
git show --reverse --color-moved=dimmed-zebra --color-moved-ws=ignore-all-space master..
```
---
I split `core/str/mod.rs` to these modules:
* `converts`: Contains helper functions to convert from bytes to str.
* `error`: For error structs like Utf8Error.
* `iter`: For iterators of many str methods.
* `traits`: For indexing operations and build in traits on str.
* `validations`: For functions validating utf8 --- This name is awkward, maybe utf8.rs is better.
Add zero padding
Add benchmarks for fmt u128
This tests both when there is the max amount of work(all characters used)
And least amount of work(1 character used)
Add doc alias for iterator fold
fold is known in python and javascript as reduce,
not sure about inject but it was written in doc there.
This was my first confusion when coming into rust, I somehow cannot find where is reduce, sometimes I still forget that it is known as `fold`.
Remove `#[rustc_allow_const_fn_ptr]` and add `#![feature(const_fn_fn_ptr_basics)]`
`rustc_allow_const_fn_ptr` was a hack to work around the lack of an escape hatch for the "min `const fn`" checks in const-stable functions. Now that we have co-opted `allow_internal_unstable` for this purpose, we no longer need a bespoke attribute.
Now this functionality is gated under `const_fn_fn_ptr_basics` (how concise!), and `#[allow_internal_unstable(const_fn_fn_ptr_basics)]` replaces `#[rustc_allow_const_fn_ptr]`. `const_fn_fn_ptr_basics` allows function pointer types to appear in the arguments and locals of a `const fn` as well as function pointer casts to be performed inside a `const fn`. Both of these were allowed in constants and statics already. Notably, this does **not** allow users to invoke function pointers in a const context. Presumably, we will use a nicer name for that (`const_fn_ptr`?).
r? @oli-obk
UI to unit test for those using Cell/RefCell/UnsafeCell
Helps with #76268.
I'm working on all files using `Cell` and moving them to unit tests when possible.
r? @matklad
This was a hack to work around the lack of an escape hatch for the "min
`const fn`" checks in const-stable functions. Now that we have co-opted
`allow_internal_unstable` for this purpose, we no longer need the
bespoke attribute.
Add `#![feature(const_fn_floating_point_arithmetic)]`
cc #76618
This is a template for splitting up `const_fn` into granular feature gates. I think this will make it easier, both for us and for users, to track stabilization of each individual feature. We don't *have* to do this, however. We could also keep stabilizing things out from under `const_fn`.
cc @rust-lang/wg-const-eval
r? @oli-obk
Explicitly document the size guarantees that Option makes.
Triggered by a discussion on wg-unsafe-code-guidelines about which layouts of `Option<T>` one can guarantee are optimised to a single pointer.
CC @RalfJung
It's possible for method resolution to pick this method over a lower
priority stable method, causing compilation errors. Since this method
is permanently unstable, give it a name that is very unlikely to be used
in user code.
Make [].as_[mut_]ptr_range() (unstably) const.
Gated behind `const_ptr_offset`, as suggested by https://github.com/rust-lang/rust/issues/65807#issuecomment-697229404
This also marks `[].as_mut_ptr()` as const, because it's used by `as_mut_ptr_range`. I gated it behind the same feature, because I figured it's not worth adding a separate tracking issue for const `as_mut_ptr`.
Use `Self` in docs when possible
Fixes#76542.
I used `rg '\s*//[!/]\s+fn [\w_]+\(&?self, ' .` in `library/` to find instances, I found some with that and some by manually checking.
@rustbot modify labels: C-enhancement T-doc
add array::from_ref
mirrors the methods in `std::slice` with the same name.
I guess this method previously didn't exist as there was close to no reason to create an array of size `1`.
This will change due to const generics in the near future.
revert const_type_id stabilization
This reverts #72488, which is currently on beta and scheduled to stabilize in `1.47.0`, based on https://github.com/rust-lang/rust/pull/75923#issuecomment-696676511
It turns out we might not be quite ready to stabilize `TypeId` in const contexts before having a chance to rework its internals. Since `TypeId` is a bit of an oddity we want to be careful about how those internals are currently being relied on while making changes. That will be easier to do without having to also consider compile-time contexts.
r? `@eddyb`
Add #[track_caller] to more panicking Cell functions
Continuation of #74526
Adds the #[track_caller] attribute to almost all panicking Cell
functions. The ones that borrow two Cells in their function
body are spared, because the panic location helps pinpoint
which of the two borrows failed. You'd need to have
full debuginfo and backtraces enabled together with column
info in order to be able to discern the cases.
Column info in debuginfo is only available on non-Windows platforms.
Add cfg(target_has_atomic_equal_alignment) and use it for Atomic::from_mut.
Fixes some platform-specific problems with #74532 by using the actual alignment of the types instead of hardcoding a few `target_arch`s.
r? @RalfJung
Continuation of #74526
Adds the #[track_caller] attribute to almost all panicking Cell
functions. The ones that borrow two Cells in their function
body are spared, because the panic location helps pinpoint
which of the two borrows failed. You'd need to have
full debuginfo and backtraces enabled together with column
info in order to be able to discern the cases.
Column info is only available on non-Windows platforms.
Make some methods of `Pin` unstable const
Make the following methods unstable const under the `const_pin` feature:
- `new`
- `new_unchecked`
- `into_inner`
- `into_inner_unchecked`
- `get_ref`
- `into_ref`
- `get_mut`
- `get_unchecked_mut`
Of these, `into_inner` and `into_inner_unchecked` require the unstable `const_precise_live_drops`.
Also adds tests for these methods in a const context.
Tracking issue: #76654
r? @ecstatic-morse
Don't recommend ManuallyDrop to customize drop order
See
https://internals.rust-lang.org/t/need-for-controlling-drop-order-of-fields/12914/21
for the discussion.
TL;DR: ManuallyDrop is unsafe and footguny, but you can just ask the compiler to do all the work for you by re-ordering declarations.
Specifically, the original example from the docs is much better written as
```rust
struct Peach;
struct Banana;
struct Melon;
struct FruitBox {
melon: Melon,
// XXX: mind the relative drop order of the fields below
peach: Peach,
banana: Banana,
}
```
Revert adding Atomic::from_mut.
This reverts #74532, which made too many assumptions about platforms, breaking some things.
Will need to be added later with a better way of gating on proper alignment, without hardcoding cfg(target_arch)s.
---
To be merged if fixing from_mut (#76965) takes too long.
r? @ghost
Add non-`unsafe` `.get_mut()` for `Unsafecell`
- Tracking issue: https://github.com/rust-lang/rust/issues/76943
As discussed in: https://internals.rust-lang.org/t/add-non-unsafe-get-mut-for-unsafecell/12407
- ### [Rendered documentation](https://modest-dubinsky-1f9f47.netlify.app/core/cell/struct.unsafecell)
This PR tries to move the sound `&mut UnsafeCell<T> -> &mut T` projection that all the "downstream" constructions were already relying on, up to the root abstraction, where it rightfully belongs, and officially blessing it.
- this **helps reduce the amount of `unsafe` snippets out there** (_c.f._, the second commit of this PR: 09503fd1b3)
The fact that this getter is now expose for `UnsafeCell<T>` itself, will also help convey the idea that **`UnsafeCell` is not magical _w.r.t._ `&mut` accesses**, contrary to what some people incorrectly think.
- Even the standard library itself at some point had such a confusion, _c.f._ this comment where there is a mention of multi-threaded (and thus _shared_) access despite dealing with exclusive references over unique ownership: 59fb88d061/library/core/src/cell.rs (L498-L499)
r? @RalfJung
Use intra-doc links in core/src/iter when possible
Helps with #75080.
I also updated lots of links to use `fn()` instead of `fn` when possible.
@rustbot modify labels: T-doc A-intra-doc-links
r? @jyn514
Stabilize some Option methods as const
Stabilize the following methods of `Option` as const:
- `is_some`
- `is_none`
- `as_ref`
These methods are currently const under the unstable feature `const_option` (tracking issue: #67441).
I believe these methods to be eligible for stabilization because of the stabilization of #49146 (Allow if and match in constants) and the trivial implementations, see also: [PR#75463](https://github.com/rust-lang/rust/pull/75463).
Related: #76225
Remove MMX from Rust
Follow-up to https://github.com/rust-lang/stdarch/pull/890
This removes most of MMX from Rust (tests pass with small changes), keeping stable `is_x86_feature_detected!("mmx")` working.
Stabilize the following methods of `Option` as const:
- `is_some`
- `is_none`
- `as_ref`
Possible because of stabilization of #49146 (Allow if and match in constants).
Rollup of 15 pull requests
Successful merges:
- #76732 (Add docs for `BasicBlock`)
- #76832 (Let backends define custom targets)
- #76866 (Remove unused feature gates from library/ crates)
- #76875 (Move to intra-doc links in library/alloc/src/collections/binary_heap.rs)
- #76876 (Move to intra-doc links in collections/btree/map.rs and collections/linked_list.rs)
- #76877 (Move to intra-doc links in collections/vec_deque.rs and collections/vec_deque/drain.rs)
- #76878 (Move the version number to a plaintext file)
- #76883 (README.md: Remove prompts from code blocks)
- #76887 (Add missing examples on HashSet iter types)
- #76890 (use matches!() macro for simple if let conditions)
- #76891 (don't take `TyCtxt` by reference)
- #76910 (transmute: use diagnostic item)
- #76924 (Add tracking issue for feature(unix_socket_peek))
- #76926 (BTreeMap: code readability tweaks)
- #76940 (Don't allow implementing trait directly on type-alias-impl-trait)
Failed merges:
r? `@ghost`
transmute: use diagnostic item
closes#66075, we now have no remaining uses of `match_def_path` in the compiler while some uses still remain in `clippy`.
cc @RalfJung
Remove unused feature gates from library/ crates
Removes some unused feature gates from library crates. It's likely not a complete list as I only tested a subset for which it's more likely that it is unused.
Stabilize some Result methods as const
Stabilize the following methods of Result as const:
- `is_ok`
- `is_err`
- `as_ref`
A test is also included, analogous to the test for `const_option`.
These methods are currently const under the unstable feature `const_result` (tracking issue: #67520).
I believe these methods to be eligible for stabilization because of the stabilization of #49146 (Allow if and match in constants) and the trivial implementations, see also: [PR#75463](https://github.com/rust-lang/rust/pull/75463) and [PR#76135](https://github.com/rust-lang/rust/pull/76135).
Note: these methods are the only methods currently under the `const_result` feature, thus this PR results in the removal of the feature.
Related: #76225
This made too many assumptions about platforms, breaking some things.
Will need to be added later with a better way of gating on proper
alignment, without hardcoding cfg(target_arch)s.
Add associated constant `BITS` to all integer types
Recently I've regularly come across this snippet (in a few different crates, including `core` and `std`):
```rust
std::mem::size_of<usize>() * 8
```
I think it's time for a `usize::BITS`.
do not inline black_box when building for Miri
We cannot do the assembly trick in Miri, but let's at least make sure MIR inlining does not circumvent the black_box.
Also use black_box instead of local optimization barriers in a few const tests.
Add array_windows fn
This mimicks the functionality added by array_chunks, and implements a const-generic form of
`windows`. It makes egregious use of `unsafe`, but by necessity because the array must be
re-interpreted as a slice of arrays, and unlike array_chunks this cannot be done by casting the
original array once, since each time the index is advanced it needs to move one element, not
`N`.
I'm planning on adding more tests, but this should be good enough as a premise for the functionality.
Notably: should there be more functions overwritten for the iterator implementation/in general?
~~I've marked the issue as #74985 as there is no corresponding exact issue for `array_windows`, but it's based of off `array_chunks`.~~
Edit: See Issue #75027 created by @lcnr for tracking issue
~~Do not merge until I add more tests, please.~~
r? @lcnr
Updated issue to #75027
Update to rm oob access
And hopefully fix docs as well
Fixed naming conflict in test
Fix test which used 1-indexing
Nth starts from 0, woops
Fix a bunch of off by 1 errors
See https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=757b311987e3fae1ca47122969acda5a
Add even more off by 1 errors
And also write `next` and `next_back` in terms of `nth` and `nth_back`.
Run fmt
Fix forgetting to change fn name in test
add nth_back test & document unsafe
Remove as_ref().unwrap()
Documented occurrences of unsafe, noting what invariants are maintained
Fix liballoc test suite for Miri
Mostly, fix the regression introduced by https://github.com/rust-lang/rust/pull/75207 that caused slices (i.e., references) to be created to invalid memory or memory that has aliasing pointers that we want to keep valid. @dylni this changes the type of `check_range` to only require the length, not the full reference to the slice, which indeed is all the information this function requires.
Also reduce the size of a test introduced in https://github.com/rust-lang/rust/pull/70793 to make it not take 3 minutes in Miri.
This makes https://github.com/RalfJung/miri-test-libstd work again.
Make all methods of `Duration` unstably const
Make the following methods of `Duration` unstable const under `duration_const_2`:
- `from_secs_f64`
- `from_secs_f32`
- `mul_f64`
- `mul_f32`
- `div_f64`
- `div_f32`
This results in all methods of `Duration` being (unstable) const.
Moved the tests to `library` as part of #76268.
Possible because of #72449, which made the relevant `f32` and `f64` methods const.
Tracking issue: #72440
r? @ecstatic-morse
Make some Ordering methods const
Resubmission of [PR#75463](https://github.com/rust-lang/rust/pull/75463) as per [PR#76172](https://github.com/rust-lang/rust/pull/76172).
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Insta-stabilizes these methods as const under the `const_ordering` feature, as their implementation is a trivial match and the recent stabilization of #49146 (Allow `if` and `match` in constants).
Note: the `const_ordering` feature has never actually been used as these methods have not been `#[rustc_const_unstable]`.
Tracking issue: #76113
Note when a a move/borrow error is caused by a deref coercion
Fixes#73268
When a deref coercion occurs, we may end up with a move error if the
base value has been partially moved out of. However, we do not indicate
anywhere that a deref coercion is occuring, resulting in an error
message with a confusing span.
This PR adds an explicit note to move errors when a deref coercion is
involved. We mention the name of the type that the deref-coercion
resolved to, as well as the `Deref::Target` associated type being used.
Split `core::slice` to smaller mods
Unfortunately the `#[lang = "slice"]` is too big (3003 lines), I cannot split it further.
Note for reviewer:
* I split to multiple commits for easier reviewing, but I could git squash them all to one if requested.
* Recommend pulling this change locally and using advanced git diff viewer or this command:
```
git show --reverse --color-moved=dimmed-zebra master..
```
---
I split core/slice/mod.rs to these modules:
* `ascii`: For operations on `[u8]`.
* `cmp`: For comparison operations on `[T]`, like PartialEq and SliceContains impl.
* `index`: For indexing operations like Index/IndexMut and SliceIndex.
* `iter`: For Iterator definitions and implementation on `[T]`.
- `macros`: For iterator! and forward_iterator! macros.
* `raw`: For free function to create `&[T]` or `&mut [T]` from pointer + length or a reference.
The heapsort wrapper in mod.rs is removed in favor of reexport from `sort::heapsort`.
Remove internal and unstable MaybeUninit::UNINIT.
Looks like it is no longer necessary, as `uninit_array()` can be used instead in the few cases where it was needed.
(I wanted to just add `#[doc(hidden)]` to remove clutter from the documentation, but looks like it can just be removed entirely.)
Make the following methods unstable const under the `const_pin` feature:
- `new`
- `new_unchecked`
- `into_inner`
- `into_inner_unchecked`
- `get_ref`
- `into_ref`
Also adds tests for these methods in a const context.
Tracking issue: #76654
Make the following methods of `Duration` unstable const under `duration_const_2`:
- `from_secs_f64`
- `from_secs_f32`
- `mul_f64`
- `mul_f32`
- `div_f64`
- `div_f32`
This results in all methods of `Duration` being (unstable) const.
Also adds tests for these methods in a const context, moved the test to `library` as part of #76268.
Possible because of #72449, which made the relevant `f32` and `f64` methods const.
Tracking issue: #72440
Add MaybeUninit::assume_init_drop.
`ManuallyDrop`'s documentation tells the user to use `MaybeUninit` instead when handling uninitialized data. However, the main functionality of `ManuallyDrop` (`drop`) is not available directly on `MaybeUninit`. Adding it makes it easier to switch from one to the other.
I re-used the `maybe_uninit_extra` feature and tracking issue number (#63567), since it seems very related. (And to avoid creating too many features tracking issues for `MaybeUninit`.)
Add saturating methods for `Duration`
In some project, I needed a `saturating_add` method for `Duration`. I implemented it myself but i thought it would be a nice addition to the standard library as it matches closely with the integers types.
3 new methods have been introduced and are gated by the new `duration_saturating_ops` unstable feature:
* `Duration::saturating_add`
* `Duration::saturating_sub`
* `Duration::saturating_mul`
If have left the tracking issue to `none` for now as I want first to understand if those methods would be acceptable at all. If agreed, I'll update the PR with the tracking issue.
Further more, to match the behavior of integers types, I introduced 2 associated constants:
* `Duration::MIN`: this one is somehow a duplicate from `Duration::zero()` method, but at the time this method was added, `MIN` was rejected as it was considered a different semantic (see https://github.com/rust-lang/rust/pull/72790#issuecomment-636511743).
* `Duration::MAX`
Both have been gated by the already existing unstable feature `duration_constants`, I can introduce a new unstable feature if needed or just re-use the `duration_saturating_ops`.
We might have to decide whether:
* `MIN` should be replaced by `ZERO`?
* associated constants over methods?
Add `slice::array_chunks_mut`
This follows `array_chunks` from #74373 with a mutable version, `array_chunks_mut`. The implementation is identical apart from mutability. The new tests are adaptations of the `chunks_exact_mut` tests, plus an inference test like the one for `array_chunks`.
I reused the unstable feature `array_chunks` and tracking issue #74985, but I can separate that if desired.
r? `@withoutboats`
cc `@lcnr`
Stabilize core::future::{pending,ready}
This PR stabilizes `core::future::{pending,ready}`, tracking issue https://github.com/rust-lang/rust/issues/70921.
## Motivation
These functions have been on nightly for three months now, and have lived as part of the futures ecosystem for several years. In that time these functions have undergone several iterations, with [the `async-std` impls](https://docs.rs/async-std/1.6.2/async_std/future/index.html) probably diverging the most (using `async fn`, which in hindsight was a mistake).
It seems the space around these functions has been _thoroughly_ explored over the last couple of years, and the ecosystem has settled on the current shape of the functions. It seems highly unlikely we'd want to make any further changes to these functions, so I propose we stabilize.
## Implementation notes
This stabilization PR was fairly straightforward; this feature has already thoroughly been reviewed by the libs team already in https://github.com/rust-lang/rust/pull/70834. So all this PR does is remove the feature gate.
Fixes#73268
When a deref coercion occurs, we may end up with a move error if the
base value has been partially moved out of. However, we do not indicate
anywhere that a deref coercion is occuring, resulting in an error
message with a confusing span.
This PR adds an explicit note to move errors when a deref coercion is
involved. We mention the name of the type that the deref-coercion
resolved to, as well as the `Deref::Target` associated type being used.
Use intra-doc links in `core::ptr`
Part of #75080.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
---
@rustbot modify labels: A-intra-doc-links T-doc
`write` is ambiguous because there's also a macro called `write`.
Also removed unnecessary and potentially confusing link to a function in
its own docs.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
ManuallyDrop's documentation tells the user to use MaybeUninit instead
when handling uninitialized data. However, the main functionality of
ManuallyDrop (drop) was not available directly on MaybeUninit. Adding it
makes it easier to switch from one to the other.
Remove unneeded `#[cfg(not(test))]` from libcore
This fixes rust-analyzer inside these modules (currently it does not analyze them, assuming they're configured out).
Use ops::ControlFlow in rustc_data_structures::graph::iterate
Since I only know about this because you mentioned it,
r? @ecstatic-morse
If we're not supposed to use new `core` things in compiler for a while then feel free to close, but it felt reasonable to merge the two types since they're the same, and it might be convenient for people to use `?` in their traversal code.
(This doesn't do the type parameter swap; NoraCodes has signed up to do that one.)
Indent a note to make folding work nicer
Sublime Text folds code based on indentation. It maybe an unnecessary change, but does it look nicer after that ?
Move various ui const tests to `library`
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
r? @matklad
Try to improve the documentation of `filter()` and `filter_map()`.
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Use Arc::clone and Rc::clone in documentation
This PR replaces uses of `x.clone()` by `Rc::clone(&x)` (or `Arc::clone(&x)`) to better match the documentation for those types.
@rustbot modify labels: T-doc
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
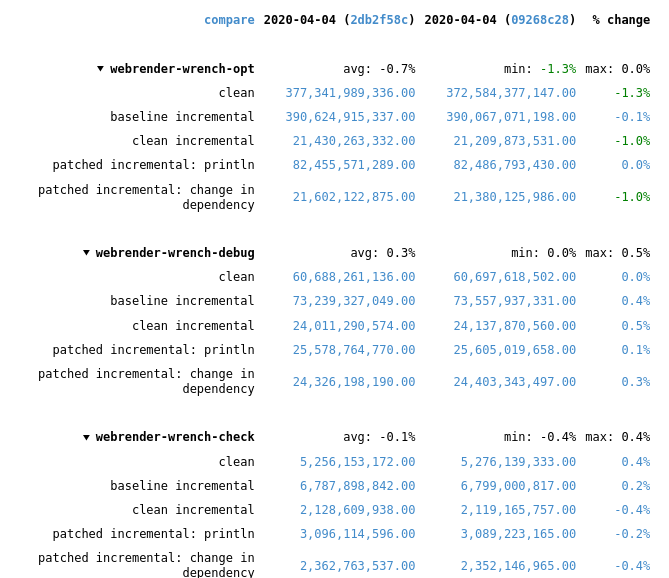
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
Convert many files to intra-doc links
Helps with https://github.com/rust-lang/rust/issues/75080
r? @poliorcetics
I recommend reviewing one commit at a time, but the diff is small enough you can do it all at once if you like :)
Move to intra-doc links for library/core/src/iter/traits/iterator.rs
Helps with #75080.
@jyn514 We're almost finished with this issue. Thanks for mentoring. If you have other topics to work on just let me know, I will be around in Discord.
@rustbot modify labels: T-doc, A-intra-doc-links
Known issues:
* Link from `core` to `std` (#74481):
[`OsStr`]
[`String`]
[`VecDeque<T>`]
Rename and expose LoopState as ControlFlow
Basic PR for #75744. Addresses everything there except for documentation; lots of examples are probably a good idea.
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
- Use intra-doc links for `std::io` in `std::fs`
- Use intra-doc links for File::read in unix/ext/fs.rs
- Remove explicit intra-doc links for `true` in `net/addr.rs`
- Use intra-doc links in alloc/src/sync.rs
- Use intra-doc links in src/ascii.rs
- Switch to intra-doc links in alloc/rc.rs
- Use intra-doc links in core/pin.rs
- Use intra-doc links in std/prelude
- Use shorter links in `std/fs.rs`
`io` is already in scope.
flt2dec: properly handle uninitialized memory
The float-to-str code currently uses uninitialized memory incorrectly (see https://github.com/rust-lang/rust/issues/76092). This PR fixes that.
Specifically, that code used `&mut [T]` as "out references", but it would be incorrect for the caller to actually pass uninitialized memory. So the PR changes this to `&mut [MaybeUninit<T>]`, and then functions return a `&[T]` to the part of the buffer that they initialized (some functions already did that, indirectly via `&Formatted`, others were adjusted to return that buffer instead of just the initialized length).
What I particularly like about this is that it moves `unsafe` to the right place: previously, the outermost caller had to use `unsafe` to assert that things are initialized; now it is the functions that do the actual initializing which have the corresponding `unsafe` block when they call `MaybeUninit::slice_get_ref` (renamed in https://github.com/rust-lang/rust/pull/76217 to `slice_assume_init_ref`).
Reviewers please be aware that I have no idea how any of this code actually works. My changes were purely mechanical and type-driven. The test suite passes so I guess I didn't screw up badly...
Cc @sfackler this is somewhat related to your RFC, and possibly some of this code could benefit from (a generalized version of) the API you describe there. But for now I think what I did is "good enough".
Fixes https://github.com/rust-lang/rust/issues/76092.
Move to intra-doc links for library/core/src/panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from `core` to `std` (#74481):
[`set_hook`]
[`String`]
Add more examples to lexicographic cmp on Iterators.
Given two arrays of T1 and T2, the most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T1.
Which is only possible because of the first rule.
Insta-stabilize the methods `is_ready` and `is_pending` of `Poll`.
Possible because of the recent stabilization of const control flow.
Also adds a test for these methods in a const context.
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Stabilizes these methods as const under the `const_ordering` feature.
Also adds a test for these methods in a const context.
Possible because of #49146 (Allow `if` and `match` in constants).
rename get_{ref, mut} to assume_init_{ref,mut} in Maybeuninit
References #63568
Rework with comments addressed from #66174
Have replaced most of the occurrences I've found, hopefully didn't miss out anything
r? @RalfJung
(thanks @danielhenrymantilla for the initial work on this)
Get rid of bounds check in slice::chunks_exact() and related function…
…s during construction
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
Use intra-doc links for `core/src/slice.mod.rs`
partial help in #75080
r? @jyn514
- most are using primitive types links, which cannot be used with intra links at the moment
- also `std` cannot be referenced in any link, `std::ptr::NonNull` and `std::slice` could not be referenced
Make some Ordering methods const
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Possible because of #49146 (Allow `if` and `match` in constants).
Tracking issue: #76113
Stabilize the following methods of `Result` as const:
- `is_ok`
- `is_err`
- `as_ref`
Possible because of stabilization of #49146 (Allow if and match in constants).
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
These are unsafe variants of the non-unchecked functions and don't do
any bounds checking.
For the time being these are not public and only a preparation for the
following commit. Making it public and stabilization can follow later
and be discussed in https://github.com/rust-lang/rust/issues/76014 .
`alloc::slice` uses `core::slice` functions, documentation are copied
from there and the links as well without resolution. `crate::ptr...`
cannot be resolved in `alloc::slice`, but `ptr` itself is imported in
both `alloc::slice` and `core::slice`, so we used that instead.
Move to intra-doc links for library/core/src/sync/atomic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from core to std:
[`Arc`]
[`std:🧵:yield_now`]
[`std:🧵:sleep`]
[`std::sync::Mutex`]
The most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T.
Which is only possible because of the first rule.
Fix potential UB in align_offset doc examples
Currently it takes a pointer only to the first element in the array, this changes the code to take a pointer to the whole array.
miri can't catch this right now because it later calls `x.len()` which re-tags the pointer for the whole array.
https://github.com/rust-lang/miri/issues/1526#issuecomment-680897144
Unconfuse Unpin docs a bit
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
I would like to propose these two simple methods for stabilization:
- Knowing that a range is exhaused isn't otherwise trivial
- Clippy would like to suggest them, but had to do extra work to disable that path <https://github.com/rust-lang/rust-clippy/issues/3807> because they're unstable
- These work on `PartialOrd`, consistently with now-stable `contains`, and are thus more general than iterator-based approaches that need `Step`
- They've been unchanged for some time, and have picked up uses in the compiler
- Stabilizing them doesn't block any future iterator-based is_empty plans, as the inherent ones are preferred in name resolution
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
Report an ambiguity if both modules and primitives are in scope for intra-doc links
Closes https://github.com/rust-lang/rust/issues/75381
- Add a new `prim@` disambiguator, since both modules and primitives are in the same namespace
- Refactor `report_ambiguity` into a closure
Additionally, I noticed that rustdoc would previously allow `[struct@char]` if `char` resolved to a primitive (not if it had a DefId). I fixed that and added a test case.
I also need to update libstd to use `prim@char` instead of `type@char`. If possible I would also like to refactor `ambiguity_error` to use `Disambiguator` instead of its own hand-rolled match - that ran into issues with `prim@` (I updated one and not the other) and it would be better for them to be in sync.
Use allow(unused_imports) instead of cfg(doc) for imports used only for intra-doc links
This prevents links from breaking when items are re-exported in a
different crate and the original isn't being documented.
Spotted in https://github.com/rust-lang/rust/pull/75832#discussion_r475275837 (thanks ollie!)
r? @ollie27
Fix typo in documentation of i32 wrapping_abs()
Hi!
I was reading through the std library docs and noticed that this section flowed a bit oddly; comparing it against https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_div and https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_neg , I noticed that those two pieces of documentation used a semicolon here.
This is my first time submitting a PR to this repo. Am I doing this right? Are tiny typo-fix PRs like this worth submitting, or are they not a good use of time?
Thank you!
stabilize ptr_offset_from
This stabilizes ptr::offset_from, and closes https://github.com/rust-lang/rust/issues/41079. It also removes the deprecated `wrapping_offset_from`. This function was deprecated 19 days ago and was never stable; given an FCP of 10 days and some waiting time until FCP starts, that leaves at least a month between deprecation and removal which I think is fine for a nightly-only API.
Regarding the open questions in https://github.com/rust-lang/rust/issues/41079:
* Should offset_from abort instead of panic on ZSTs? -- As far as I know, there is no precedent for such aborts. We could, however, declare this UB. Given that the size is always known statically and the check thus rather cheap, UB seems excessive.
* Should there be more methods like this with different restrictions (to allow nuw/nsw, perhaps) or that return usize (like how isize-taking offset is more conveniently done with usize-taking add these days)? -- No reason to block stabilization on that, we can always add such methods later.
Also nominating the lang team because this exposes an intrinsic.
The stabilized method is best described [by its doc-comment](56d4b2d69a/src/libcore/ptr/const_ptr.rs (L227)). The documentation forgot to mention the requirement that both pointers must "have the same provenance", aka "be derived from pointers to the same allocation", which I am adding in this PR. This is a precondition that [Miri already implements](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=a3b9d0a07a01321f5202cd99e9613480) and that, should LLVM ever obtain a `psub` operation to subtract pointers, will likely be required for that operation (following the semantics in [this paper](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf)).
Move to intra-doc links for library/core/src/alloc/{layout, global, mod}.rs
Helps with #75080. The files already contained intra-doc links, so there are only minor changes.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* [`handle_alloc_error`]: Link from `core` to `alloc` could not be resolved.
* [`slice`]: slice is a primitive type, but could not be resolved; had to use [`crate::slice`] instead.
Move to intra-doc links for /library/core/src/intrinsics.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* The following f32 and f64 primitive methods cannot be resolved:
f32/f64::powi
f32/f64::sqrt
f32/f64::sin
f32/f64::cos
f32/f64::powf
f32/f64::exp
f32/f64::exp2
f32/f64::ln
f32/f64::log2
f32/f64::log10
f32/f64::mul_add
f32/f64::abs
f32/f64::copysign
f32/f64::floor
f32/f64::ceil
f32/f64::trunc
f32/f64::round
* Links from core to std:
[`std::pointer::*`]
[`std::process::abort`]
[`from_raw_parts`]
[`Vec::append`]
* Links with anchors?
I provided a separate commit that replaced links with anchors by intra-doc links.
Here the anchor location information gets lost, so its questionable whether to
actually replace those links.
enable align_to tests in Miri
With https://github.com/rust-lang/miri/issues/1074 resolved, we can enable these tests in Miri.
I also tweaked the test sized to get reasonable execution times with decent test coverage.
Use min_specialization in libcore
Getting `TrustedRandomAccess` to work is the main interesting thing here.
- `get_unchecked` is now an unstable, hidden method on `Iterator`
- The contract for `TrustedRandomAccess` is made clearer in documentation
- Fixed a bug where `Debug` would create aliasing references when using the specialized zip impl
- Added tests for the side effects of `next_back` and `nth`.
closes#68536
`stride == 1` case can be computed more efficiently through `-p (mod
a)`. That, then translates to a nice and short sequence of LLVM
instructions:
%address = ptrtoint i8* %p to i64
%negptr = sub i64 0, %address
%offset = and i64 %negptr, %a_minus_one
And produces pretty much ideal code-gen when this function is used in
isolation.
Typical use of this function will, however, involve use of
the result to offset a pointer, i.e.
%aligned = getelementptr inbounds i8, i8* %p, i64 %offset
This still looks very good, but LLVM does not really translate that to
what would be considered ideal machine code (on any target). For example
that's the codegen we obtain for an unknown alignment:
; x86_64
dec rsi
mov rax, rdi
neg rax
and rax, rsi
add rax, rdi
In particular negating a pointer is not something that’s going to be
optimised for in the design of CISC architectures like x86_64. They
are much better at offsetting pointers. And so we’d love to utilize this
ability and produce code that's more like this:
; x86_64
lea rax, [rsi + rdi - 1]
neg rsi
and rax, rsi
To achieve this we need to give LLVM an opportunity to apply its
various peep-hole optimisations that it does during DAG selection. In
particular, the `and` instruction appears to be a major inhibitor here.
We cannot, sadly, get rid of this load-bearing operation, but we can
reorder operations such that LLVM has more to work with around this
instruction.
One such ordering is proposed in #75579 and results in LLVM IR that
looks broadly like this:
; using add enables `lea` and similar CISCisms
%offset_ptr = add i64 %address, %a_minus_one
%mask = sub i64 0, %a
%masked = and i64 %offset_ptr, %mask
; can be folded with `gepi` that may follow
%offset = sub i64 %masked, %address
…and generates the intended x86_64 machine code. One might also wonder
how the increased amount of code would impact a RISC target. Turns out
not much:
; aarch64 previous ; aarch64 new
sub x8, x1, #1 add x8, x1, x0
neg x9, x0 sub x8, x8, #1
and x8, x9, x8 neg x9, x1
add x0, x0, x8 and x0, x8, x9
(and similarly for ppc, sparc, mips, riscv, etc)
The only target that seems to do worse is… wasm32.
Onto actual measurements – the best way to evaluate snippets like these
is to use llvm-mca. Much like Aarch64 assembly would allow to suspect,
there isn’t any performance difference to be found. Both snippets
execute in same number of cycles for the CPUs I tried. On x86_64,
we get throughput improvement of >50%, however!
Improve codegen for `align_offset`
In this PR the `align_offset` implementation is changed/improved to produce better code in certain scenarios such as when pointer type is has a stride of 1 or when building for low optimisation levels.
While these changes do not achieve the "ideal" codegen referenced in #75579, it gets significantly closer to it. I’m not actually sure if the codegen can actually be much better with this function returning the offset, rather than the aligned pointer.
See the descriptions for separate commits for further information.
docs(marker/copy): provide example for `&T` being `Copy`
### Edited 2020-08-16 (most recent)
In the current documentation about the `Copy` marker trait, there is a section
with examples of structs that can implement `Copy`. Currently there is no example for
showing that shared references (`&T`) are also `Copy`.
It is worth to have a dedicated example for `&T` being `Copy`, because shared
references are an integral part of the language and it being `Copy` is not as
intuitive as other types that share this behaviour like `i32` or `bool`.
The example picks up on the previous non-`Copy` struct and shows that
structs can be `Copy`, even when they hold a shared reference to a non-`Copy` type.
-----------------------------------------
### Edited 2020-08-02, 3:28 p.m.
I've just realized that it says "in addition to the **implementors listed below**", which makes this PR kind of "wrong", because `&T` is indeed in the "implementors listed below".
Maybe we can instead show an example with `&T` in the [When can my type be Copy](https://doc.rust-lang.org/std/marker/trait.Copy.html#when-can-my-type-be-copy) section.
What I really want to achieve is that it becomes more obvious that `&T` is also `Copy`, because, I think, it is very valuable to know and it wasn't obvious for me, until I read something about it in a forum post.
What do you think? I would create another PR for that.
**Please feel free to close this PR.**
-----------------------------------
### Original post
In the current documentation about the `Copy` marker trait, there is a section
about "additional implementors", which list additional implementors of the `Copy` trait.
The fact that shared references are also `Copy` is mixed with another point,
which makes it hard to recognize and make it seem not as important.
This clarifies the fact that shared references are also `Copy`, by mentioning it as a
separate item in the list of "additional implementors".
See also X-Link mem::{swap, take, replace}
Since it's easy to end up at one of these functions when you really wanted the other one, cross link them with descriptions of why you'd want to use them.
Add `as_uninit`-like methods to pointer types and unify documentation of `as_ref` methods
This adds a convenient method to retrieve a `&(mut) [MaybeUninit<T>]` from slice pointers (`*const [T]`, `*mut [T]`, `NonNull<[T]>`). See also https://github.com/rust-lang/wg-allocators/issues/66#issuecomment-671789105.
~I'll add a tracking issue as soon as it's reviewed and CI passed.~
Tracking Issue: #75402
r? @RalfJung
Reference lang items during AST lowering
Fixes#60607 and fixes#61019.
This PR introduces `QPath::LangItem` to the HIR and uses it in AST lowering instead of constructing a `hir::Path` from a slice of symbols:
- Credit for much of this work goes to @matthewjasper, I basically just [rebased their earlier work](a227c706b7 (diff-c0f791ead38d2d02916faaad0f56f41d)).
- ~~Changes to Clippy might not be correct, they compile but attempting to run tests through `./x.py` produced failures which appeared spurious, so I didn't run any clippy tests.~~
- Changes to save analysis might not be correct - tests pass but I don't have a lot of confidence in those changes being correct.
- I've used `GenericBounds::LangItemTrait` rather than changing `PolyTraitRef`, as suggested by @matthewjasper [in this comment](a227c706b7 (r40107992)) but I'd prefer that be left for a follow-up.
- I've split things into smaller commits fairly arbitrarily to make the diff easier to review, each commit should compile but might not pass tests until the final commit.
r? @oli-obk
cc @matthewjasper
Fix example in `NonNull::as_uninit_slice`
Rename feature gate to "ptr_as_uninit"
Make methods more consistent with already stable methods
Make `pointer::as_uninit_slice` return an `Option`
Fix placement for `// SAFETY` section
Add `as_uninit_ref` and `as_uninit_mut` to pointers
Fix doctest
Update tracking issue
Fix doc links
Apply suggestions from review
Make wording about counterparts consistent
Fix doc links
Improve documentation
Fix doc-tests
Fix doc links ... again
Apply suggestions from review
Apply suggestions from Review
Apply suggestion from review to all affected files
Add missing words in safety sections in `as_uninit_slice_mut`
Fix safety-comment in `NonNull::as_uninit_slice_mut`
Move to intra-doc links for /library/core/src/any.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Links from `core` to `std` (#74481):
* `[Box]: ../../std/boxed/struct.Box.html`
pin docs: add some forward references
@nagisa had some questions about pinning that were answered in the docs, which they did not realize because that discussion is below the examples. I still think it makes sense to introduce the examples before that discussion, since it give the discussion something concrete to refer to, but this PR adds some forward references so people don't think the examples conclude the docs.
@nagisa do you think this would have helped?
Code blocks in doc comments are compiled and run, so we show `Copy` works in this example.
Co-authored-by: Poliorcetics <poliorcetics@users.noreply.github.com>
Previously checking for `pmoda == 0` would get LLVM to generate branchy
code, when, for `stride = 1` the offset can be computed without such a
branch by doing effectively a `-p % a`.
For well-known (constant) alignments, with the new ordering of these
conditionals, we end up generating 2 to 3 cheap instructions on x86_64:
movq %rdi, %rax
negl %eax
andl $7, %eax
instead of 5+ as previously.
For unknown alignments the new code also generates just 3 instructions:
negq %rdi
leaq -1(%rsi), %rax
andq %rdi, %rax
At opt-level <= 1, the methods such as `wrapping_mul` are not being
inlined, causing significant bloating and slowdowns of the
implementation at these optimisation levels.
With use of these intrinsics, the codegen of this function at
-Copt_level=1 is the same as it is at -Copt_level=3.
In the current documentation about the `Copy` marker trait, there is a section
with examples of structs that can implement `Copy`. Currently there is no example for
showing that shared references (`&T`) are also `Copy`.
It is worth to have a dedicated example for `&T` being `Copy`, because shared
references are an integral part of the language and it being `Copy` is not as
intuitive as other types that share this behaviour like `i32` or `bool`.
The example picks up on the previous non-`Copy` struct and shows that
structs can be `Copy`, even when they hold a shared reference to a non-`Copy` type.
This commit adds new lang items which will be used in AST lowering once
`QPath::LangItem` is introduced.
Co-authored-by: Matthew Jasper <mjjasper1@gmail.com>
Signed-off-by: David Wood <david@davidtw.co>
Doc: String isn't a collection
On forums one user was confused by this text, interpreting it as saying that `String` is a `Vec<char>` literally, rather than figuratively for the purpose of collect. I've reworded that paragraph.
Switch to intra-doc links in `core::option`
Part of #75080.
I didn't change some of the links since they link into `std` and you can't link from `core` to `std` (#74481).
Also, at least one other link can't be switched to an intra-doc link because it's not supported yet (#74489).
Constified str::from_utf8_unchecked
This would be useful for const code to use an array to construct a string using guaranteed utf8 inputs, and then create a `&str` from it.
Switch from indexing to zip, and also use `write` on `MaybeUninit`.
Add array_map feature to core/src/lib
Attempt to fix issue of no such feature
Update w/ pickfire's review
This changes a couple of names around, adds another small test of variable size,
and hides the rustdoc #![feature(..)].
Fmt doctest
Add suggestions from lcnr
Add basic test
And also run fmt which is where the other changes are from
Fix mut issues
These only appear when running tests, so resolved by adding mut
Swap order of forget
Add pub and rm guard impl
Add explicit type to guard
Add safety note
Change guard type from T to S
It should never have been T, as it guards over [MaybeUninit<S>; N]
Also add feature to test
This creates the language item for arrays, and adds the map fn which is like map in options or
iterators. It currently allocates an extra array, unfortunately.
Added fixme for transmuting
Fix typo
Add drop guard
The previous `assert_eq` generated quite some code, which is especially
problematic when this call is inlined. This commit also slightly
improves the panic message from:
assertion failed: `(left == right)`
left: `3`,
right: `2`: destination and source slices have different lengths
...to:
source slice length (2) does not match destination slice length (3)
Use intra-doc links in /library/core/src/cmp.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Links from `core` to `std` (#74481):
* [`Vec::sort_by_key`]
Rollup of 15 pull requests
Successful merges:
- #74712 (Update E0271 explanation)
- #74842 (adjust remaining targets)
- #75151 (Consistent variable name alloc for raw_vec)
- #75162 (Fix the documentation for move about Fn traits implementations)
- #75248 (Add `as_mut_ptr` to `NonNull<[T]>`)
- #75262 (Show multi extension example for Path in doctests)
- #75266 (Add safety section to `NonNull::as_*` method docs)
- #75284 (Show relative example for Path ancestors)
- #75285 (Separate example for Path strip_prefix)
- #75287 (Show Path extension example change multi extension)
- #75288 (Use assert! for Path exists example to check bool)
- #75289 (Remove ambiguity from PathBuf pop example)
- #75290 (fix `min_const_generics` version)
- #75291 (Clean up E0750)
- #75292 (Clean up E0502)
Failed merges:
r? @ghost
Add safety section to `NonNull::as_*` method docs
This basically adds the safety section of `*mut T::as_{ref,mut}` to the
same methods on `NonNull` with minor modifications to fit the
differences.
Part of #48929.
Simplify array::IntoIter
- Initialization can use `transmute_copy` to do the bitwise copy.
- `as_slice` can use `get_unchecked` and `MaybeUninit::slice_get_ref`,
and `as_mut_slice` can do similar.
- `next` and `next_back` can use the corresponding `Range` methods.
- `Clone` doesn't need any unsafety, and we can dynamically update the
new range to get partial drops if `T::clone` panics.
r? @LukasKalbertodt
This basically adds the safety section of `*mut T::as_{ref,mut}` to the
same methods on `NonNull` with minor modifications to fit the
differences.
Part of #48929.
- Initialization can use `transmute_copy` to do the bitwise copy.
- `as_slice` can use `get_unchecked` and `MaybeUninit::slice_get_ref`,
and `as_mut_slice` can do similar.
- `next` and `next_back` can use the corresponding `Range` methods.
- `Clone` doesn't need any unsafety, and we can dynamically update the
new range to get partial drops if `T::clone` panics.
Rollup of 4 pull requests
Successful merges:
- #74774 (adds [*mut|*const] ptr::set_ptr_value)
- #75079 (Disallow linking to items with a mismatched disambiguator)
- #75203 (Make `IntoIterator` lifetime bounds of `&BTreeMap` match with `&HashMap` )
- #75227 (Fix ICE when using asm! on an unsupported architecture)
Failed merges:
r? @ghost
adds [*mut|*const] ptr::set_ptr_value
I propose the addition of these two functions to `*mut T` and `*const T`, respectively. The motivation for this is primarily byte-wise pointer arithmetic on (potentially) fat pointers, i.e. for types with a `T: ?Sized` bound. A concrete use-case has been discussed in [this](https://internals.rust-lang.org/t/byte-wise-fat-pointer-arithmetic/12739) thread.
TL;DR: Currently, byte-wise pointer arithmetic with potentially fat pointers in not possible in either stable or nightly Rust without making assumptions about the layout of fat pointers, which is currently still an implementation detail and not formally stabilized. This PR adds one function to `*mut T` and `*const T` each, allowing to circumvent this restriction without exposing any internal implementation details.
One possible alternative would be to add specific byte-wise pointer arithmetic functions to the two pointer types in addition to the already existing count-wise functions. However, I feel this fairly niche use case does not warrant adding a whole set of new functions like `add_bytes`, `offset_bytes`, `wrapping_offset_bytes`, etc. (times two, one for each pointer type) to `libcore`.
Completes support for coverage in external crates
Follow-up to #74959 :
The prior PR corrected for errors encountered when trying to generate
the coverage map on source code inlined from external crates (including
macros and generics) by avoiding adding external DefIds to the coverage
map.
This made it possible to generate a coverage report including external
crates, but the external crate coverage was incomplete (did not include
coverage for the DefIds that were eliminated.
The root issue was that the coverage map was converting Span locations
to source file and locations, using the SourceMap for the current crate,
and this would not work for spans from external crates (compliled with a
different SourceMap).
The solution was to convert the Spans to filename and location during
MIR generation instead, so precompiled external crates would already
have the correct source code locations embedded in their MIR, when
imported into another crate.
@wesleywiser FYI
r? @tmandry
The prior PR corrected for errors encountered when trying to generate
the coverage map on source code inlined from external crates (including
macros and generics) by avoiding adding external DefIds to the coverage
map.
This made it possible to generate a coverage report including external
crates, but the external crate coverage was incomplete (did not include
coverage for the DefIds that were eliminated.
The root issue was that the coverage map was converting Span locations
to source file and locations, using the SourceMap for the current crate,
and this would not work for spans from external crates (compliled with a
different SourceMap).
The solution was to convert the Spans to filename and location during
MIR generation instead, so precompiled external crates would already
have the correct source code locations embedded in their MIR, when
imported into another crate.
add `unsigned_abs` to signed integers
Mentioned on rust-lang/rfcs#2914
This PR simply adds an `unsigned_abs` to signed integers function which returns the correct absolute value as a unsigned integer.
Stabilize `Result::as_deref` and `as_deref_mut`
FCP completed in https://github.com/rust-lang/rust/issues/50264#issuecomment-645681400.
This PR stabilizes two new APIs for `std::result::Result`:
```rust
fn as_deref(&self) -> Result<&T::Target, &E> where T: Deref;
fn as_deref_mut(&mut self) -> Result<&mut T::Target, &mut E> where T: DerefMut;
```
This PR also removes two rarely used unstable APIs from `Result`:
```rust
fn as_deref_err(&self) -> Result<&T, &E::Target> where E: Deref;
fn as_deref_mut_err(&mut self) -> Result<&mut T, &mut E::Target> where E: DerefMut;
```
Closes#50264
In the current documentation about the `Copy` marker trait, there is a section
about "additional implementors", which list additional implementors of the `Copy` trait.
The fact that shared references are also `Copy` is mixed with another point,
which makes it hard to recognize and make it seem not as important.
This clarifies the fact that shared references are also `Copy`, by mentioning it as a
separate item in the list of "additional implementors".
add `slice::array_chunks` to std
Now that #74113 has landed, these methods are suddenly usable. A rebirth of #72334
Tests are directly copied from `chunks_exact` and some additional tests for type inference.
r? @withoutboats as you are both part of t-libs and working on const generics. closes#60735
Make `Option::unwrap` unstably const
This is lumped into the `const_option` feature gate (#67441), which enables a potpourri of `Option` methods.
cc @rust-lang/wg-const-eval
r? @oli-obk
`Result::unwrap` is not eligible becuase it formats the contents of the
`Err` variant. `unwrap_or`, `unwrap_or_else` and friends are not
eligible because they drop things or invoke closures.
Make `mem::size_of_val` and `mem::align_of_val` unstably const
Implements #46571 but does not stabilize it. I wanted this while working on something today.
The only reason not to immediately stabilize are concerns around [custom DSTs](https://github.com/rust-lang/rust/issues/46571#issuecomment-387669352). That proposal has made zero progress in the last two years and const eval is rich enough to support pretty much any user-defined `len` function as long as nightly features are allowed (`raw_ptr_deref`).
Currently, this raises a `const_err` lint when passed an `extern type`.
r? @oli-obk
cc @rust-lang/wg-const-eval
Stabilize const_type_id feature
The tracking issue for `const_type_id` points to the ill-fated #41875. So I'm re-energizing `TypeId` shenanigans by opening this one up to see if there's anything blocking us from stabilizing the constification of type ids.
Will wait for CI before pinging teams/groups.
-----
This PR stabilizes the `const_type_id` feature, which allows `TypeId::of` (and the underlying unstable intrinsic) to be called in constant contexts.
There are some [sanity tests](https://github.com/rust-lang/rust/blob/master/src/test/ui/consts/const-typeid-of-rpass.rs) that demonstrate its usage, but I’ve included some more below.
As a simple example, you could create a constant item that contains some type ids:
```rust
use std::any::TypeId;
const TYPE_IDS: [TypeId; 2] = [
TypeId::of::<u32>(),
TypeId::of::<i32>(),
];
assert_eq!(TypeId::of::<u32>(), TYPE_IDS[0]);
```
Type ids can also now appear in associated constants. You could create a trait that associates each type with its constant type id:
```rust
trait Any where Self: 'static {
const TYPE_ID: TypeId = TypeId::of::<Self>();
}
impl<T: 'static> Any for T { }
assert_eq!(TypeId::of::<usize>(), usize::TYPE_ID);
```
`TypeId::of` is generic, which we saw above in the way the generic `Self` argument was used. This has some implications for const evaluation. It means we can make trait impls evaluate differently depending on information that wasn't directly passed through the trait system. This violates the _parametricity_ property, which requires all instances of a generic function to behave the same way with respect to its generic parameters. That's not unique to `TypeId::of`, other generic const functions based on compiler intrinsics like `mem::align_of` can also violate parametricity. In practice Rust doesn't really have type parametricity anyway since it monomorphizes generics into concrete functions, so violating it using type ids isn’t new.
As an example of how impls can behave differently, you could combine constant type ids with the `const_if_match` feature to dispatch calls based on the type id of the generic `Self`, rather than based on information about `Self` that was threaded through trait bounds. It's like a rough-and-ready form of specialization:
```rust
#![feature(const_if_match)]
trait Specialized where Self: 'static {
// An associated constant that determines the function to call
// at compile-time based on `TypeId::of::<Self>`.
const CALL: fn(&Self) = {
const USIZE: TypeId = TypeId::of::<usize>();
match TypeId::of::<Self>() {
// Use a closure for `usize` that transmutes the generic `Self` to
// a concrete `usize` and dispatches to `Self::usize`.
USIZE => |x| Self::usize(unsafe { &*(x as *const Self as *const usize) }),
// For other types, dispatch to the generic `Self::default`.
_ => Self::default,
}
};
fn call(&self) {
// Call the function we determined at compile-time
(Self::CALL)(self)
}
fn default(x: &Self);
fn usize(x: &usize);
}
// Implement our `Specialized` trait for any `Debug` type.
impl<T: fmt::Debug + 'static> Specialized for T {
fn default(x: &Self) {
println!("default: {:?}", x);
}
fn usize(x: &usize) {
println!("usize: {:?}", x);
}
}
// Will print "usize: 42"
Specialized::call(&42usize);
// Will print "default: ()"
Specialized::call(&());
```
Type ids have some edges that this stabilization exposes to more contexts. It's possible for type ids to collide (but this is a bug). Since they can change between compiler versions, it's never valid to cast a type id to its underlying value.
{kind=link}
{kind=link}