The manual implementation has the same bounds, so I don't think there's
any reason for a manual implementation. The names used in the derive
implementation are even nicer (`first`/`second`) than the manual
implementation (`t`/`u`), and include the `done_first` field too.
This would attempt to print the Debug representation of the lock that
the guard has locked, which will try to lock again, fail, and just print
"<locked>" unhelpfully.
After this change, this just prints the contents of the mutex, like the
other smart pointers (and MutexGuard) do.
Add IEEE 754 compliant fmt/parse of -0, infinity, NaN
This pull request improves the Rust float formatting/parsing libraries to comply with IEEE 754's formatting expectations around certain special values, namely signed zero, the infinities, and NaN. It also adds IEEE 754 compliance tests that, while less stringent in certain places than many of the existing flt2dec/dec2flt capability tests, are intended to serve as the beginning of a roadmap to future compliance with the standard. Some relevant documentation is also adjusted with clarifying remarks.
This PR follows from discussion in https://github.com/rust-lang/rfcs/issues/1074, and closes#24623.
The most controversial change here is likely to be that -0 is now printed as -0. Allow me to explain: While there appears to be community support for an opt-in toggle of printing floats as if they exist in the naively expected domain of numbers, i.e. not the extended reals (where floats live), IEEE 754-2019 is clear that a float converted to a string should be capable of being transformed into the original floating point bit-pattern when it satisfies certain conditions (namely, when it is an actual numeric value i.e. not a NaN and the original and destination float width are the same). -0 is given special attention here as a value that should have its sign preserved. In addition, the vast majority of other programming languages not only output `-0` but output `-0.0` here.
While IEEE 754 offers a broad leeway in how to handle producing what it calls a "decimal character sequence", it is clear that the operations a language provides should be capable of round tripping, and it is confusing to advertise the f32 and f64 types as binary32 and binary64 yet have the most basic way of producing a string and then reading it back into a floating point number be non-conformant with the standard. Further, existing documentation suggested that e.g. -0 would be printed with -0 regardless of the presence of the `+` fmt character, but it prints "+0" instead if given such (which was what led to the opening of #24623).
There are other parsing and formatting issues for floating point numbers which prevent Rust from complying with the standard, as well as other well-documented challenges on the arithmetic level, but I hope that this can be the beginning of motion towards solving those challenges.
Document that the SocketAddr memory representation is not stable
Intended to help out with #78802. Work has been put into finding and fixing code that assumes the memory layout of `SocketAddrV4` and `SocketAddrV6`. But it turns out there are cases where new code continues to make the same assumption ([example](96927dc2b7 (diff-917db3d8ca6f862ebf42726b23c72a12b35e584e497ebdb24e474348d7c6ffb6R610-R621))).
The memory layout of a type in `std` is never part of the public API. Unless explicitly stated I guess. But since that is invalidly relied upon by a considerable amount of code for these particular types, it might make sense to explicitly document this. This can be temporary. Once #78802 lands it does not make sense to rely on the layout any longer, and this documentation can also be removed.
This adds support for CMSG handling on macOS and fixes it on OpenBSD
and other BSDs.
When traversing the CMSG list, the previous code had an exception for
Android where the next element after the last pointer could point to
the first pointer instead of NULL. This is actually not specific to
Android: the `libc::CMSG_NXTHDR` implementation for Linux and
emscripten have a special case to return NULL when the length of the
previous element is zero; most other implementations simply return the
previous element plus a zero offset in this case.
This MR additionally adds `SocketAncillary::is_empty` because clippy
is right that it should be added.
Proper Unix terminology is "exit status" (vs "wait status"). "exit
code" is imprecise on Unix and therefore unclear. (As far as I can
tell, "exit code" is correct terminology on Windows.)
This new wording is unfortunately inconsistent with the identifier
names in the Rust stdlib.
It is the identifier names that are wrong, as discussed at length in eg
https://doc.rust-lang.org/nightly/std/process/struct.ExitStatus.htmlhttps://doc.rust-lang.org/nightly/std/os/unix/process/trait.ExitStatusExt.html
Unfortunately for API stability reasons it would be a lot of work, and
a lot of disruption, to change the names in the stdlib (eg to rename
`std::process::ExitStatus` to `std::process::ChildStatus` or
something), but we should fix the message output. Many (probably
most) readers of these messages about exit statuses will be users and
system administrators, not programmers, who won't even know that Rust
has this wrong terminology.
So I think the right thing is to fix the documentation (as I have
already done) and, now, the terminology in the implementation.
This is a user-visible change to the behaviour of all Rust programs
which run Unix subprocesses. Hopefully no-one is matching against the
exit status string, except perhaps in tests.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Add internal io::Error::new_const to avoid allocations.
This makes it possible to have a io::Error containing a message with zero allocations, and uses that everywhere to avoid the *three* allocations involved in `io::Error::new(kind, "message")`.
The function signature isn't perfect, because it needs a reference to the `&str`. So for now, this is just a `pub(crate)` function. Later, we'll be able to use `fn new_const<MSG: &'static str>(kind: ErrorKind)` to make that a bit better. (Then we'll also be able to use some ZST trickery if that would result in more efficient code.)
See https://github.com/rust-lang/rust/issues/83352
"semantic equivalence" is too strong a phrasing here, which is why
actually explaining what kind of circumstances might produce a -0
was chosen instead.
Move `std::sys::unix::platform` to `std::sys::unix::ext`
This moves the operating system dependent alias `platform` (`std::os::{linux, android, ...}`) from `std::sys::unix` to `std::sys::unix::ext` (a.k.a. `std::os::unix`), removing the need for compatibility code in `unix_ext` when documenting on another platform.
This is also a step in making it possible to properly move `std::sys::unix::ext` to `std::os::unix`, as ideally `std::sys` should not depend on the rest of `std`.
Deprecate std::os::haiku::raw, which accidentally wasn't deprecated
In early 2016, all `std::os::*::raw` modules [were deprecated](aa23c98450) in accordance with [RFC 1415](https://github.com/rust-lang/rfcs/blob/master/text/1415-trim-std-os.md). However, at this same time support for Haiku was being added to libstd, landing shortly after the aforementioned commit, and due to some crossed wires a `std::os::haiku::raw` module was added and was not marked as deprecated.
I have been in correspondence with the author of the Haiku patch, ````@nielx,```` who has confirmed that this was simply an oversight and that the definitions from the libc crate should be preferred instead.
Clarify docs for Read::read's return value
Right now the docs for `Read::read`'s return value are phrased in a way that makes it easy for the reader to assume that the return value is never larger than the passed buffer. This PR clarifies that this is a requirement for implementations of the trait, but that callers have to expect a buggy yet safe implementation failing to do so, especially if unchecked accesses to the buffer are done afterwards.
I fell into this trap recently, and when I noticed, I looked at the docs again and had the feeling that I might not have been the first one to miss this.
The same issue of trusting the return value of `read` was also present in std itself for about 2.5 years and only fixed recently, see #80895.
I hope that clarifying the docs might help others to avoid this issue.
Reuse `std::sys::unsupported::pipe` on `hermit`
Pipes are not supported on `hermit` and `hermit/pipe.rs` is identical to `unsupported/pipe.rs`. This PR reduces duplication between the two by doing the following on `hermit`:
```rust
#[path = "../unsupported/pipe.rs"]
pub mod pipe;
```
Add more links between hash and btree collections
- Link from `core::hash` to `HashMap` and `HashSet`
- Link from HashMap and HashSet to the module-level documentation on
when to use the collection
- Link from several collections to Wikipedia articles on the general
concept
See also https://github.com/rust-lang/rust/pull/81989#issuecomment-783920840.
Deprecate `intrinsics::drop_in_place` and `collections::Bound`, which accidentally weren't deprecated
Fixes#82080.
I've taken the liberty of updating the `since` values to 1.52, since an unobservable deprecation isn't much of a deprecation (even the detailed release notes never bothered to mention these deprecations).
As mentioned in the issue I'm *pretty* sure that using a type alias for `Bound` is semantically equivalent to the re-export; [the reference implies](https://doc.rust-lang.org/reference/items/type-aliases.html) that type aliases only observably differ from types when used on unit structs or tuple structs, whereas `Bound` is an enum.
Deprecate RustcEncodable and RustcDecodable.
We can't remove the `RustcEncodable` and `RustcDecodable` derive macros from the prelude, but we can deprecate them.
Added `try_exists()` method to `std::path::Path`
This method is similar to the existing `exists()` method, except it
doesn't silently ignore the errors, leading to less error-prone code.
This change intentionally does NOT touch the documentation of `exists()`
nor recommend people to use this method while it's unstable.
Such changes are reserved for stabilization to prevent confusing people.
Apart from that it avoids conflicts with #80979.
`@joshtriplett` requested this PR in [internals discussion](https://internals.rust-lang.org/t/the-api-of-path-exists-encourages-broken-code/13817/25?u=kixunil)
"spotlight" is not a very specific or self-explaining name.
Additionally, the dialog that it triggers is called "Notable traits".
So, "notable trait" is a better name.
* Rename `#[doc(spotlight)]` to `#[doc(notable_trait)]`
* Rename `#![feature(doc_spotlight)]` to `#![feature(doc_notable_trait)]`
* Update documentation
* Improve documentation
use RWlock when accessing os::env (take 2)
This reverts commit acdca316c3 (#82877) i.e. redoes #81850 since the invalid unlock attempts in the child process have been fixed in #82949
r? `@joshtriplett`
Demonstrate best practice for feeding stdin of a child processes
Documentation change.
It's possible to create a deadlock with stdin/stdout I/O on a single thread:
* the child process may fill its stdout buffer, and have to wait for the parent process to read it,
* but the parent process may be waiting until its stdin write finishes before reading the stdout.
Therefore, the parent process should use separate threads for writing and reading.
These examples are not deadlocking in practice, because they use short strings, but I think it's better to demonstrate code that works even for long writes. The problem is non-obvious and tricky to debug (it seems that even libstd has a similar issue: #45572).
This also demonstrates how to use stdio with threads: it's not obvious that `.take()` can be used to avoid fighting with the borrow checker.
I've checked that the modified examples run fine.
std: Fix a bug on the wasm32-wasi target opening files
This commit fixes an issue pointed out in #82758 where LTO changed the
behavior of a program. It turns out that LTO was not at fault here, it
simply uncovered an existing bug. The bindings to
`__wasilibc_find_relpath` assumed that the relative portion of the path
returned was always contained within thee input `buf` we passed in. This
isn't actually the case, however, and sometimes the relative portion of
the path may reference a sub-portion of the input string itself.
The fix here is to use the relative path pointer coming out of
`__wasilibc_find_relpath` as the source of truth. The `buf` used for
local storage is discarded in this function and the relative path is
copied out unconditionally. We might be able to get away with some
`Cow`-like business or such to avoid the extra allocation, but for now
this is probably the easiest patch to fix the original issue.
Implement Extend and FromIterator for OsString
Add the following trait impls:
- `impl Extend<OsString> for OsString`
- `impl<'a> Extend<&'a OsStr> for OsString`
- `impl FromIterator<OsString> for OsString`
- `impl<'a> FromIterator<&'a OsStr> for OsString`
Because `OsString` is a platform string with no particular semantics, concatenating them together seems acceptable.
I came across a use case for these trait impls in https://github.com/artichoke/artichoke/pull/1089:
Artichoke is a Ruby interpreter. Its CLI accepts multiple `-e` switches for executing inline Ruby code, like:
```console
$ cargo -q run --bin artichoke -- -e '2.times {' -e 'puts "foo: #{__LINE__}"' -e '}'
foo: 2
foo: 2
```
I use `clap` for command line argument parsing, which collects these `-e` commands into a `Vec<OsString>`. To pass these commands to the interpreter for `Eval`, I need to join them together. Combining these impls with `Iterator::intersperse` https://github.com/rust-lang/rust/issues/79524 would enable me to build a single bit of Ruby code.
Currently, I'm doing something like:
```rust
let mut commands = commands.into_iter();
let mut buf = if let Some(command) = commands.next() {
command
} else {
return Ok(Ok(()));
};
for command in commands {
buf.push("\n");
buf.push(command);
}
```
If there's interest, I'd also like to add impls for `Cow<'a, OsStr>`, which would avoid allocating the `"\n"` `OsString` in the concatenate + intersperse use case.
Fix io::copy specialization using copy_file_range when writer was opened with O_APPEND
fixes#82410
While `sendfile()` returns `EINVAL` when the output was opened with O_APPEND, `copy_file_range()` does not and returns `EBADF` instead, which – unlike other `EBADF` causes – is not fatal for this operation since a regular `write()` will likely succeed.
We now treat `EBADF` as a non-fatal error for `copy_file_range` and fall back to a read-write copy as we already did for several other errors.
Do not attempt to unlock envlock in child process after a fork.
This implements the first two points from https://github.com/rust-lang/rust/issues/64718#issuecomment-793030479
This is a breaking change for cases where the environment is accessed in a Command::pre_exec closure. Except for single-threaded programs these uses were not correct anyway since they aren't async-signal safe.
Note that we had a ui test that explicitly tried `env::set_var` in `pre_exec`. As expected it failed with these changes when I tested locally.
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Fixes to ExitStatus and its docs
* On Unix, properly display every possible wait status (and don't panic on weird values)
* In the documentation, be clear and consistent about "exit status" vs "wait status".
Stabilize `unsafe_op_in_unsafe_fn` lint
This makes it possible to override the level of the `unsafe_op_in_unsafe_fn`, as proposed in https://github.com/rust-lang/rust/issues/71668#issuecomment-729770896.
Tracking issue: #71668
r? ```@nikomatsakis``` cc ```@SimonSapin``` ```@RalfJung```
# Stabilization report
This is a stabilization report for `#![feature(unsafe_block_in_unsafe_fn)]`.
## Summary
Currently, the body of unsafe functions is an unsafe block, i.e. you can perform unsafe operations inside.
The `unsafe_op_in_unsafe_fn` lint, stabilized here, can be used to change this behavior, so performing unsafe operations in unsafe functions requires an unsafe block.
For now, the lint is allow-by-default, which means that this PR does not change anything without overriding the lint level.
For more information, see [RFC 2585](https://github.com/rust-lang/rfcs/blob/master/text/2585-unsafe-block-in-unsafe-fn.md)
### Example
```rust
// An `unsafe fn` for demonstration purposes.
// Calling this is an unsafe operation.
unsafe fn unsf() {}
// #[allow(unsafe_op_in_unsafe_fn)] by default,
// the behavior of `unsafe fn` is unchanged
unsafe fn allowed() {
// Here, no `unsafe` block is needed to
// perform unsafe operations...
unsf();
// ...and any `unsafe` block is considered
// unused and is warned on by the compiler.
unsafe {
unsf();
}
}
#[warn(unsafe_op_in_unsafe_fn)]
unsafe fn warned() {
// Removing this `unsafe` block will
// cause the compiler to emit a warning.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
#[deny(unsafe_op_in_unsafe_fn)]
unsafe fn denied() {
// Removing this `unsafe` block will
// cause a compilation error.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
```
This is a breaking change for cases where the environment is
accessed in a Command::pre_exec closure. Except for
single-threaded programs these uses were not correct
anyway since they aren't async-signal safe.
It's possible to create a deadlock with stdin/stdout I/O on a single thread:
* the child process may fill its stdout buffer, and have to wait for the parent process to read it,
* but the parent process may be waiting until its stdin write finishes before reading the stdout.
Therefore, the parent process should use separate threads for writing and reading.
Bump libc dependency of std to 0.2.88.
This PR bumps the `libc` dependency of `std` to 0.2.88. This will fix `TcpListener::accept` for Android on x86 platforms (31a2777d8f).
This will really finally fix https://github.com/rust-lang/rust/issues/82400 for the main branch :)
r? ``@JohnTitor``
Revert switch of env locking to rwlock, to fix deadlock in process spawning
This reverts commit 354f19cf24, reversing changes made to 0cfba2fd09.
PR https://github.com/rust-lang/rust/pull/81850 switched the environment lock from a mutex to an rwlock. However, process spawning (when not able to use `posix_spawn`) locks the environment before forking, and unlocks it after forking (in both the parent and the child). With a mutex, this works (although probably not correct even with a mutex). With an rwlock, on at least some targets, unlocking in the child does not work correctly, resulting in a deadlock.
This has manifested as CI hangs on i686 Linux; that target doesn't use `posix_spawn` in the CI environment due to the age of the installed C library (currently glibc 2.23). (Switching to `posix_spawn` would just mask this issue, though, which would still arise in any case that can't use `posix_spawn`.)
Some additional cleanup of environment handling around process spawning may help, but for now, revert the PR and go back to a standard mutex.
Fixes#82221
Add note about the `#[doc(no-inline)]` usage
This is required to correctly build the documentation (including all submodules, that are only available in certain targets).
See the linked issue and #82861 for reference.
Generalize Write impl for Vec<u8> to Vec<u8, A>
As discussed in the [issue tracker for the wg-allocators working group][1], updating this impl for allocator support was most likely just forgotten previously. This PR fixes this.
r? `````@TimDiekmann`````
[1]: https://github.com/rust-lang/wg-allocators/issues/86
As discussed in the issue tracker for the wg-allocators working group[1], updating this implementation for allocator support was most likely just forgotten in the original PR.
[1]: https://github.com/rust-lang/wg-allocators/issues/86
This commit fixes an issue pointed out in #82758 where LTO changed the
behavior of a program. It turns out that LTO was not at fault here, it
simply uncovered an existing bug. The bindings to
`__wasilibc_find_relpath` assumed that the relative portion of the path
returned was always contained within thee input `buf` we passed in. This
isn't actually the case, however, and sometimes the relative portion of
the path may reference a sub-portion of the input string itself.
The fix here is to use the relative path pointer coming out of
`__wasilibc_find_relpath` as the source of truth. The `buf` used for
local storage is discarded in this function and the relative path is
copied out unconditionally. We might be able to get away with some
`Cow`-like business or such to avoid the extra allocation, but for now
this is probably the easiest patch to fix the original issue.
Add assert_matches macro.
This adds `assert_matches!(expression, pattern)`.
Unlike the other asserts, this one ~~consumes the expression~~ may consume the expression, to be able to match the pattern. (It could add a `&` implicitly, but that's noticable in the pattern, and will make a consuming guard impossible.)
See https://github.com/rust-lang/rust/issues/62633#issuecomment-790737853
This re-uses the same `left: .. right: ..` output as the `assert_eq` and `assert_ne` macros, but with the pattern as the right part:
assert_eq:
```
assertion failed: `(left == right)`
left: `Some("asdf")`,
right: `None`
```
assert_matches:
```
assertion failed: `(left matches right)`
left: `Ok("asdf")`,
right: `Err(_)`
```
cc ```@cuviper```
Add {BTreeMap,HashMap}::try_insert
`{BTreeMap,HashMap}::insert(key, new_val)` returns `Some(old_val)` if the key was already in the map. It's often useful to assert no duplicate values are inserted.
We experimented with `map.insert(key, val).unwrap_none()` (https://github.com/rust-lang/rust/issues/62633), but decided that that's not the kind of method we'd like to have on `Option`s.
`insert` always succeeds because it replaces the old value if it exists. One could argue that `insert()` is never the right method for panicking on duplicates, since already handles that case by replacing the value, only allowing you to panic after that already happened.
This PR adds a `try_insert` method that instead returns a `Result::Err` when the key already exists. This error contains both the `OccupiedEntry` and the value that was supposed to be inserted. This means that unwrapping that result gives more context:
```rust
map.insert(10, "world").unwrap_none();
// thread 'main' panicked at 'called `Option::unwrap_none()` on a `Some` value: "hello"', src/main.rs:8:29
```
```rust
map.try_insert(10, "world").unwrap();
// thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value:
// OccupiedError { key: 10, old_value: "hello", new_value: "world" }', src/main.rs:6:33
```
It also allows handling the failure in any other way, as you have full access to the `OccupiedEntry` and the value.
`try_insert` returns a reference to the value in case of success, making it an alternative to `.entry(key).or_insert(value)`.
r? ```@Amanieu```
Fixes https://github.com/rust-lang/rfcs/issues/3092
Avoid unnecessary Vec construction in BufReader
As mentioned in #80460, creating a `Vec` and calling `Vec::into_boxed_slice()` emits unnecessary calls to `realloc()` and `free()`. Updated the code to use `Box::new_uninit_slice()` to create a boxed slice directly. I think this also makes it more explicit that the initial contents of the buffer are uninitialized.
r? ``@m-ou-se``
Improved IO Bytes Size Hint
After trying to implement better `size_hint()` return values for `File` in [this PR](https://github.com/rust-lang/rust/pull/81044) and changing to implementing it for `BufReader` in [this PR](https://github.com/rust-lang/rust/pull/81052), I have arrived at this implementation that provides tighter bounds for the `Bytes` iterator of various readers including `BufReader`, `Empty`, and `Chain`.
Unfortunately, for `BufReader`, the size_hint only improves after calling `fill_buffer` due to it using the contents of the buffer for the hint. Nevertheless, the the tighter bounds should result in better pre-allocation of space to handle the contents of the `Bytes` iterator.
Closes#81052
Implement NOOP_METHOD_CALL lint
Implements the beginnings of https://github.com/rust-lang/lang-team/issues/67 - a lint for detecting noop method calls (e.g, calling `<&T as Clone>::clone()` when `T: !Clone`).
This PR does not fully realize the vision and has a few limitations that need to be addressed either before merging or in subsequent PRs:
* [ ] No UFCS support
* [ ] The warning message is pretty plain
* [ ] Doesn't work for `ToOwned`
The implementation uses [`Instance::resolve`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/instance/struct.Instance.html#method.resolve) which is normally later in the compiler. It seems that there are some invariants that this function relies on that we try our best to respect. For instance, it expects substitutions to have happened, which haven't yet performed, but we check first for `needs_subst` to ensure we're dealing with a monomorphic type.
Thank you to ```@davidtwco,``` ```@Aaron1011,``` and ```@wesleywiser``` for helping me at various points through out this PR ❤️.
If different unices have different bit patterns for WIFSTOPPED and
WIFCONTINUED then simply being glibc is probably not good enough for
this rather ad-hoc test to work. Do it on Linux only.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
unix: Non-mutable bufs in send_vectored_with_ancillary_to
This is the same PR as [#79753](https://github.com/rust-lang/rust/pull/79753). It was closed because of inactivity. Therefore, I create a new one. ````@lukaslihotzki````
Add is_enclave_range/is_user_range overflow checks
Fixes#76343.
This adds overflow checking to `is_enclave_range` and `is_user_range` in `sgx::os::fortanix_sgx::mem` in order to mitigate possible security issues with enclave code. It also accounts for an edge case where the memory range provided ends exactly at the end of the address space, where calculating `p + len` would overflow back to zero despite the range potentially being valid.
Convert primitives in the standard library to intra-doc links
Blocked on https://github.com/rust-lang/rust/pull/80181. I forgot that this needs to wait for the beta bump so the standard library can be documented with `doc --stage 0`.
Notably I didn't convert `core::slice` because it's like 50 links and I got scared 😨
Clarify that SyncOnceCell::set blocks.
Reading the discussion of this feature, I gained the mistaken impression that neither `set` nor `get` blocked, and thus calling `get` immediately after `set` was not guaranteed to succeed. It turns out that `set` *does* block, guaranteeing that the cell contains a value once `set` returns. This change updates the documentation to state that explicitly.
Happy to adjust the wording as desired.
Reading the discussion of this feature, I gained the mistaken impression that neither `set` nor `get` blocked, and thus calling `get` immediately after `set` was not guaranteed to succeed. It turns out that `set` *does* block, guaranteeing that the cell contains a value once `set` returns. This change updates the documentation to state that explicitly.
Remove the x86_64-rumprun-netbsd target
Herein we remove the target from the compiler and the code from libstd intended to support the now-defunct rumprun project.
Closes#81514
clarify RW lock's priority gotcha
In particular, the following program works on Linux, but deadlocks on
mac:
```rust
use std::{
sync::{Arc, RwLock},
thread,
time::Duration,
};
fn main() {
let lock = Arc::new(RwLock::new(()));
let r1 = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _rg = lock.read();
eprintln!("r1/1");
sleep(1000);
let _rg = lock.read();
eprintln!("r1/2");
sleep(5000);
}
});
sleep(100);
let w = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _wg = lock.write();
eprintln!("w");
}
});
sleep(100);
let r2 = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _rg = lock.read();
eprintln!("r2");
sleep(2000);
}
});
r1.join().unwrap();
r2.join().unwrap();
w.join().unwrap();
}
fn sleep(ms: u64) {
std:🧵:sleep(Duration::from_millis(ms))
}
```
Context: I was completely mystified by a my CI deadlocking on mac ([here](https://github.com/matklad/xshell/pull/7)), until ``@azdavis`` debugged the issue. See a stand-alone reproduciton here: https://github.com/matklad/xshell/pull/15
Add missing "see its documentation for more" stdio
StdoutLock and StderrLock does not have example, it would be better
to leave "see its documentation for more" like iter docs.
In particular, the following program works on Linux, but deadlocks on
mac:
use std::{
sync::{Arc, RwLock},
thread,
time::Duration,
};
fn main() {
let lock = Arc::new(RwLock::new(()));
let r1 = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _rg = lock.read();
eprintln!("r1/1");
sleep(1000);
let _rg = lock.read();
eprintln!("r1/2");
sleep(5000);
}
});
sleep(100);
let w = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _wg = lock.write();
eprintln!("w");
}
});
sleep(100);
let r2 = thread::spawn({
let lock = Arc::clone(&lock);
move || {
let _rg = lock.read();
eprintln!("r2");
sleep(2000);
}
});
r1.join().unwrap();
r2.join().unwrap();
w.join().unwrap();
}
fn sleep(ms: u64) {
std:🧵:sleep(Duration::from_millis(ms))
}
Use libc::accept4 on Android instead of raw syscall.
This PR replaces the use of a raw `accept4` syscall with `libc::accept4`. This was originally added (by me) because `std` couldn't update to the latest `libc` with `accept4` support for android. By now, libc is already on 0.2.85, so the workaround can be removed.
`@rustbot` label +O-android +T-libs-impl
Add a `size()` function to WASI's `MetadataExt`.
WASI's `filestat` type includes a size field, so expose it in
`MetadataExt` via a `size()` function, similar to the corresponding Unix
function.
r? ``````@alexcrichton``````
Enable API documentation for `std::os::wasi`.
This adds API documentation support for `std::os::wasi` modeled after
how `std::os::unix` works, so that WASI can be documented [here] along
with the other platforms.
[here]: https://doc.rust-lang.org/stable/std/os/index.html
Two changes of particular interest:
- This changes the `AsRawFd` for `io::Stdin` for WASI to return
`libc::STDIN_FILENO` instead of `sys::stdio::Stdin.as_raw_fd()` (and
similar for `Stdout` and `Stderr`), which matches how the `unix`
version works. `STDIN_FILENO` etc. may not always be explicitly
reserved at the WASI level, but as long as we have Rust's `std` and
`libc`, I think it's reasonable to guarantee that we'll always use
`libc::STDIN_FILENO` for stdin.
- This duplicates the `osstr2str` utility function, rather than
trying to share it across all the configurations that need it.
r? ```@alexcrichton```
library: Normalize safety-for-unsafe-block comments
Almost all safety comments are of the form `// SAFETY:`,
so normalize the rest and fix a few of them that should
have been a `/// # Safety` section instead.
Furthermore, make `tidy` only allow the uppercase form. While
currently `tidy` only checks `core`, it is a good idea to prevent
`core` from drifting to non-uppercase comments, so that later
we can start checking `alloc` etc. too.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Update outdated comment in unix Command.
The big comment in the `Command` struct has been incorrect for some time (at least since #46789 which removed `envp`). Rather than try to remove the allocations, this PR just updates the comment to reflect reality. There is an explanation for the reasoning at https://github.com/rust-lang/rust/pull/31409#issuecomment-182122895, discussing the potential of being able to call `Command::exec` after `libc::fork`. That can still be done in the future, but I think for now it would be good to just correct the comment.
Add an impl of Error on `Arc<impl Error>`.
`Display` already exists so this should be a non-controversial change (famous last words).
Would have to be insta-stable.
rust_2015 and rust_2018 are just re-exports of v1.
rust_2021 is a module that for now just re-exports everything from v1,
such that we can add more things later.
Almost all safety comments are of the form `// SAFETY:`,
so normalize the rest and fix a few of them that should
have been a `/// # Safety` section instead.
Furthermore, make `tidy` only allow the uppercase form. While
currently `tidy` only checks `core`, it is a good idea to prevent
`core` from drifting to non-uppercase comments, so that later
we can start checking `alloc` etc. too.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
This adds API documentation support for `std::os::wasi` modeled after
how `std::os::unix` works, so that WASI can be documented [here] along
with the other platforms.
[here]: https://doc.rust-lang.org/stable/std/os/index.html
Two changes of particular interest:
- This changes the `AsRawFd` for `io::Stdin` for WASI to return
`libc::STDIN_FILENO` instead of `sys::stdio::Stdin.as_raw_fd()` (and
similar for `Stdout` and `Stderr`), which matches how the `unix`
version works. `STDIN_FILENO` etc. may not always be explicitly
reserved at the WASI level, but as long as we have Rust's `std` and
`libc`, I think it's reasonable to guarantee that we'll always use
`libc::STDIN_FILENO` for stdin.
- This duplicates the `osstr2str` utility function, rather than
trying to share it across all the configurations that need it.
Update the bootstrap compiler
This updates the bootstrap compiler, notably leaving out a change to enable semicolon in macro expressions lint, because stdarch still depends on the old behavior.
- Link from `core::hash` to `HashMap` and `HashSet`
- Link from HashMap and HashSet to the module-level documentation on
when to use the collection
- Link from several collections to Wikipedia articles on the general
concept
add diagnostic items for OsString/PathBuf/Owned as well as to_vec on slice
This is adding diagnostic items to be used by rust-lang/rust-clippy#6730, but my understanding is the clippy-side change does need to be done over there since I am adding a new clippy feature.
Add diagnostic items to the following types:
OsString (os_string_type)
PathBuf (path_buf_type)
Owned (to_owned_trait)
As well as the to_vec method on slice/[T]
Make WASI's `hard_link` behavior match other platforms.
Following #78026, `std::fs::hard_link` on most platforms does not follow
symlinks. Change the WASI implementation to also not follow symlinks.
r? ```@alexcrichton```
The use of `ExitStatus` as the Rust type name for a Unix *wait
status*, not an *exit status*, is very confusing, but sadly probably
too late to change.
This area is confusing enough in Unix already (and many programmers
are already confuxed). We can at least document it.
I chose *not* to mention the way shells like to exit with signal
numbers, thus turning signal numbers into exit statuses. This is only
relevant for Rust programs using `std::process` if they run shells.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Currently, on Nightly, this panics:
```
use std::process::ExitStatus;
use std::os::unix::process::ExitStatusExt;
fn main() {
let st = ExitStatus::from_raw(0x007f);
println!("st = {}", st);
}
```
This is because the impl of Display assumes that if .code() is None,
.signal() must be Some. That was a false assumption, although it was
true with buggy code before
5b1316f781
unix ExitStatus: Do not treat WIFSTOPPED as WIFSIGNALED
This is not likely to have affected many people in practice, because
`Command` will never produce such a wait status (`ExitStatus`).
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Provide NonZero_c_* integers
I'm pretty sure I am going want this for #73125 and it seems like an
omission that would be in any case good to remedy.
<strike>Because the raw C types are in `std`, not `core`, to achieve this we
must export the relevant macros from `core` so that `std` can use
them. That's done with a new `num_internals` perma-unstable feature.
The macros need to take more parameters for the module to get the
types from and feature attributes to use.
I have eyeballed the docs output for core, to check that my changes to
these macros have made no difference to the core docs output.</strike>
Implement RFC 2580: Pointer metadata & VTable
RFC: https://github.com/rust-lang/rfcs/pull/2580
~~Before merging this PR:~~
* [x] Wait for the end of the RFC’s [FCP to merge](https://github.com/rust-lang/rfcs/pull/2580#issuecomment-759145278).
* [x] Open a tracking issue: https://github.com/rust-lang/rust/issues/81513
* [x] Update `#[unstable]` attributes in the PR with the tracking issue number
----
This PR extends the language with a new lang item for the `Pointee` trait which is special-cased in trait resolution to implement it for all types. Even in generic contexts, parameters can be assumed to implement it without a corresponding bound.
For this I mostly imitated what the compiler was already doing for the `DiscriminantKind` trait. I’m very unfamiliar with compiler internals, so careful review is appreciated.
This PR also extends the standard library with new unstable APIs in `core::ptr` and `std::ptr`:
```rust
pub trait Pointee {
/// One of `()`, `usize`, or `DynMetadata<dyn SomeTrait>`
type Metadata: Copy + Send + Sync + Ord + Hash + Unpin;
}
pub trait Thin = Pointee<Metadata = ()>;
pub const fn metadata<T: ?Sized>(ptr: *const T) -> <T as Pointee>::Metadata {}
pub const fn from_raw_parts<T: ?Sized>(*const (), <T as Pointee>::Metadata) -> *const T {}
pub const fn from_raw_parts_mut<T: ?Sized>(*mut (),<T as Pointee>::Metadata) -> *mut T {}
impl<T: ?Sized> NonNull<T> {
pub const fn from_raw_parts(NonNull<()>, <T as Pointee>::Metadata) -> NonNull<T> {}
/// Convenience for `(ptr.cast(), metadata(ptr))`
pub const fn to_raw_parts(self) -> (NonNull<()>, <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *const T {
pub const fn to_raw_parts(self) -> (*const (), <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *mut T {
pub const fn to_raw_parts(self) -> (*mut (), <T as Pointee>::Metadata) {}
}
/// `<dyn SomeTrait as Pointee>::Metadata == DynMetadata<dyn SomeTrait>`
pub struct DynMetadata<Dyn: ?Sized> {
// Private pointer to vtable
}
impl<Dyn: ?Sized> DynMetadata<Dyn> {
pub fn size_of(self) -> usize {}
pub fn align_of(self) -> usize {}
pub fn layout(self) -> crate::alloc::Layout {}
}
unsafe impl<Dyn: ?Sized> Send for DynMetadata<Dyn> {}
unsafe impl<Dyn: ?Sized> Sync for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Debug for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Unpin for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Copy for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Clone for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Eq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialEq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Ord for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialOrd for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Hash for DynMetadata<Dyn> {}
```
API differences from the RFC, in areas noted as unresolved questions in the RFC:
* Module-level functions instead of associated `from_raw_parts` functions on `*const T` and `*mut T`, following the precedent of `null`, `slice_from_raw_parts`, etc.
* Added `to_raw_parts`
I'm pretty sure I am going want this for #73125 and it seems like an
omission that would be in any case good to remedy.
It's a shame we don't have competent token pasting and case mangling
for use in macro_rules!.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
This file contained a lot of repetitive code. This was about to get
considerably worse, with introduction of a slew of new aliases.
No functional change. I've eyeballed the docs and they don't seem to
have changed either.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Quotes the arg and not quotes the arg have different effect on Windows when the program called
are msys2/cygwin program.
Refer to https://github.com/msys2/MSYS2-packages/issues/2176
Signed-off-by: Yonggang Luo <luoyonggang@gmail.com>
Add diagnostic items to the following types:
OsString (os_string_type)
PathBuf (path_buf_type)
Owned (to_owned_trait)
As well as the to_vec method on slice/[T]
Add the following trait impls:
- `impl Extend<OsString> for OsString`
- `impl<'a> Extend<&'a OsStr> for OsString`
- `impl FromIterator<OsString> for OsString`
- `impl<'a> FromIterator<&'a OsStr> for OsString`
Because `OsString` is a platform string with no particular semantics,
concatenating them together seems acceptable.
use RWlock when accessing os::env
Multiple threads modifying the current process environment is fairly uncommon. Optimize for the more common read case.
r? ````@m-ou-se````
Upgrade wasm32 image to Ubuntu 20.04
This switches the wasm32 image, which is used to test
wasm32-unknown-emscripten, to Ubuntu 20.04. While at it, enable
most of the excluded tests, as they seem to work fine with some
minor fixes.
This method is similar to the existing `exists()` method, except it
doesn't silently ignore the errors, leading to less error-prone code.
This change intentionally does NOT touch the documentation of `exists()`
nor recommend people to use this method while it's unstable.
Such changes are reserved for stabilization to prevent confusing people.
Apart from that it avoids conflicts with #80979.
This switches the wasm32 image, which is used to test
wasm32-unknown-emscripten to Ubuntu 20.04. While at it, enable
most of the excluded tests, as they seem to work fine with some
minor fixes.
Expose correct symlink API on WASI
As described in https://github.com/rust-lang/rust/issues/68574, the currently exposed API for symlinks is, in fact, a thin wrapper around the corresponding syscall, and not suitable for public usage.
The reason is that the 2nd param in the call is expected to be a handle of a "preopened directory" (a WASI concept for exposing dirs), and the only way to retrieve such handle right now is by tinkering with a private `__wasilibc_find_relpath` API, which is an implementation detail and definitely not something we want users to call directly.
Making matters worse, the semantics of this param aren't obvious from its name (`fd`), and easy to misinterpret, resulting in people trying to pass a handle of the target file itself (as in https://github.com/vitiral/path_abs/pull/50), which doesn't work as expected.
I did a [codesearch among open-source repos](https://sourcegraph.com/search?q=std%3A%3Aos%3A%3Awasi%3A%3Afs%3A%3Asymlink&patternType=literal), and the usage above is so far the only usage of this API at all, but we should fix it before more people start using it incorrectly.
While this is technically a breaking API change, I believe it's a justified one, as 1) it's OS-specific and 2) there was strictly no way to correctly use the previous form of the API, and if someone does use it, they're likely doing it wrong like in the example above.
The new API does not lead to the same confusion, as it mirrors `std::os::unix::fs::symlink` and `std::os::windows::fs::symlink_{file,dir}` variants by accepting source/target paths.
Fixes#68574.
r? ``@alexcrichton``
Stabilize poison API of Once, rename poisoned()
This stabilizes:
* `OnceState`
* `OnceState::is_poisoned()` (previously named `poisoned()`)
* `Once::call_once_force()`
`poisoned()` was renamed because the new name is more clear as a few
people agreed and nobody objected.
Closes#33577
Notes:
* I'm not entirely sure it's supposed to be 1.51, LMK if I did it wrong
* I failed to run tests locally, so we will have to leave it to bors or someone else can try
OsStr eq_ignore_ascii_case takes arg by value
Per a comment on #70516 this changes `eq_ignore_ascii_case` to take the generic parameter `S: AsRef<OsStr>` by value instead of by reference.
This is technically a breaking change to an unstable method. I think the only way it would break is if you called this method with an explicit type parameter, ie `my_os_str.eq_ignore_ascii_case::<str>("foo")` becomes `my_os_str.eq_ignore_ascii_case::<&str>("foo")`.
Besides that, I believe it is overall more flexible since it can now take an owned `OsString` for example.
If this change should be made in some other PR (like #80193) then please just close this.
This stabilizes:
* `OnceState`
* `OnceState::is_poisoned()` (previously named `poisoned()`)
* `Once::call_once_force()`
`poisoned()` was renamed because the new name is more clear as a few
people agreed and nobody objected.
Closes#33577
Per a comment on #70516 this changes `eq_ignore_ascii_case` to take the generic parameter `S: AsRef<OsStr>` by value instead of by reference.
This is technically a breaking change to an unstable method. I think the only way it would break is if you called this method with an explicit type parameter, ie `my_os_str.eq_ignore_ascii_case::<str>("foo")` becomes `my_os_str.eq_ignore_ascii_case::<&str>("foo")`.
Besides that, I believe it is overall more flexible since it can now take an owned `OsString` for example.
If this change should be made in some other PR (like #80193) then please just close this.
Add doc aliases for "delete"
This patch adds doc aliases for "delete". The added aliases are supposed to reference usages `delete` in other programming languages.
- `HashMap::remove`, `BTreeMap::remove` -> `Map#delete` and `delete` keyword in JavaScript.
- `HashSet::remove`, `BTreeSet::remove` -> `Set#delete` in JavaScript.
- `mem::drop` -> `delete` keyword in C++.
- `fs::remove_file`, `fs::remove_dir`, `fs::remove_dir_all`-> `File#delete` in Java, `File#delete` and `Dir#delete` in Ruby.
Before this change, searching for "delete" in documentation returned no results.
sys: use `process::abort()` instead of `arch::wasm32::unreachable()`
Rationale:
- `abort()` lowers to `wasm32::unreachable()` anyway.
- `abort()` isn't `unsafe`.
- `abort()` matches the comment better.
- `abort()` avoids confusion by future readers (e.g. https://github.com/rust-lang/rust/pull/81527): the naming of wasm's `unreachable` instruction is a bit unfortunate because it is not related to the `unreachable()` intrinsic (intended to trigger UB).
Codegen is likely to be different since `unreachable()` is `inline` while `abort()` is `cold`. Since it doesn't look like we are expecting here to trigger this case, the latter seems better anyway.
Add AArch64 big-endian and ILP32 targets
This PR adds 3 new AArch64 targets:
- `aarch64_be-unknown-linux-gnu`
- `aarch64-unknown-linux-gnu_ilp32`
- `aarch64_be-unknown-linux-gnu_ilp32`
It also fixes some ABI issues on big-endian ARM and AArch64.
Fix calling convention for CRT startup
My PR #81478 used the wrong calling convention for a set of
functions that are called by the CRT. These functions need to use
`extern "C"`.
This would only affect x86, which is the only target (that I know of)
that has multiple calling conventions.
```@bors``` r? ```@m-ou-se```
Let io::copy reuse BufWriter buffers
This optimization will allow users to implicitly set the buffer size for io::copy by wrapping the writer into a `BufWriter` if the default block size is insufficient, which should fix#49921
Due to min_specialization limitations this approach only works with `BufWriter` but not for `BufReader<R>` since `R` is unconstrained and thus the necessary specialization on `R: Read` is not always applicable. Once specialization becomes more powerful this optimization could be extended to look at the reader and writer side and use whichever buffer is larger.
Implement Rust 2021 panic
This implements the Rust 2021 versions of `panic!()`. See https://github.com/rust-lang/rust/issues/80162 and https://github.com/rust-lang/rfcs/pull/3007.
It does so by replacing `{std, core}::panic!()` by a bulitin macro that expands to either `$crate::panic::panic_2015!(..)` or `$crate::panic::panic_2021!(..)` depending on the edition of the caller.
This does not yet make std's panic an alias for core's panic on Rust 2021 as the RFC proposes. That will be a separate change: c5273bdfb2 That change is blocked on figuring out what to do with https://github.com/rust-lang/rust/issues/80846 first.
My PR #81478 used the wrong calling convention for a set of
functions that are called by the CRT. These functions need to use
`extern "C"`.
This would only affect x86, which is the only target (that I know of)
that has multiple calling conventions.
This patch adds doc aliases for "delete". The added aliases are
supposed to reference usages `delete` in other programming
languages.
- `HashMap::remove`, `BTreeMap::remove` -> `Map#delete` and `delete`
keyword in JavaScript.
- `HashSet::remove`, `BTreeSet::remove` -> `Set#delete` in JavaScript.
- `mem::drop` -> `delete` keyword in C++.
- `fs::remove_file`, `fs::remove_dir`, `fs::remove_dir_all`
-> `File#delete` in Java, `File#delete` and `Dir#delete` in Ruby.
Before this change, searching for "delete" in documentation
returned no results.
Resolve DLL imports at CRT startup, not on demand
On Windows, libstd uses GetProcAddress to locate some DLL imports, so
that libstd can run on older versions of Windows. If a given DLL import
is not present, then libstd uses other behavior (such as fallback
implementations).
This commit uses a feature of the Windows CRT to do these DLL imports
during module initialization, before main() (or DllMain()) is called.
This is the ideal time to resolve imports, because the module is
effectively single-threaded at that point; no other threads can
touch the data or code of the module that is being initialized.
This avoids several problems. First, it makes the cost of performing
the DLL import lookups deterministic. Right now, the DLL imports are
done on demand, which means that application threads _might_ have to
do the DLL import during some time-sensitive operation. This is a
small source of unpredictability. Since threads can race, it's even
possible to have more than one thread running the same redundant
DLL lookup.
This commit also removes using the heap to allocate strings, during
the DLL lookups.
Stabilize raw ref macros
This stabilizes `raw_ref_macros` (https://github.com/rust-lang/rust/issues/73394), which is possible now that https://github.com/rust-lang/rust/issues/74355 is fixed.
However, as I already said in https://github.com/rust-lang/rust/issues/73394#issuecomment-751342185, I am not particularly happy with the current names of the macros. So I propose we also change them, which means I am proposing to stabilize the following in `core::ptr`:
```rust
pub macro const_addr_of($e:expr) {
&raw const $e
}
pub macro mut_addr_of($e:expr) {
&raw mut $e
}
```
The macro name change means we need another round of FCP. Cc `````@rust-lang/libs`````
Fixes#73394
Add `core::stream::Stream`
[[Tracking issue: #79024](https://github.com/rust-lang/rust/issues/79024)]
This patch adds the `core::stream` submodule and implements `core::stream::Stream` in accordance with [RFC2996](https://github.com/rust-lang/rfcs/pull/2996). The RFC hasn't been merged yet, but as requested by the libs team in https://github.com/rust-lang/rfcs/pull/2996#issuecomment-725696389 I'm filing this PR to get the ball rolling.
## Documentatation
The docs in this PR have been adapted from [`std::iter`](https://doc.rust-lang.org/std/iter/index.html), [`async_std::stream`](https://docs.rs/async-std/1.7.0/async_std/stream/index.html), and [`futures::stream::Stream`](https://docs.rs/futures/0.3.8/futures/stream/trait.Stream.html). Once this PR lands my plan is to follow this up with PRs to add helper methods such as `stream::repeat` which can be used to document more of the concepts that are currently missing. That will allow us to cover concepts such as "infinite streams" and "laziness" in more depth.
## Feature gate
The feature gate for `Stream` is `stream_trait`. This matches the `#[lang = "future_trait"]` attribute name. The intention is that only the APIs defined in RFC2996 will use this feature gate, with future additions such as `stream::repeat` using their own feature gates. This is so we can ensure a smooth path towards stabilizing the `Stream` trait without needing to stabilize all the APIs in `core::stream` at once. But also don't start expanding the API until _after_ stabilization, as was the case with `std::future`.
__edit:__ the feature gate has been changed to `async_stream` to match the feature gate proposed in the RFC.
## Conclusion
This PR introduces `core::stream::{Stream, Next}` and re-exports it from `std` as `std::stream::{Stream, Next}`. Landing `Stream` in the stdlib has been a mult-year process; and it's incredibly exciting for this to finally happen!
---
r? `````@KodrAus`````
cc/ `````@rust-lang/wg-async-foundations````` `````@rust-lang/libs`````
As described in https://github.com/rust-lang/rust/issues/68574, the currently exposed API for symlinks is, in fact, a thin wrapper around the corresponding syscall, and not suitable for public usage.
The reason is that the 2nd param in the call is expected to be a handle of a "preopened directory" (a WASI concept for exposing dirs), and the only way to retrieve such handle right now is by tinkering with a private `__wasilibc_find_relpath` API, which is an implementation detail and definitely not something we want users to call directly.
Making matters worse, the semantics of this param aren't obvious from its name (`fd`), and easy to misinterpret, resulting in people trying to pass a handle of the target file itself (as in https://github.com/vitiral/path_abs/pull/50), which doesn't work as expected.
I did a codesearch among open-source repos, and the usage above is so far the only usage of this API at all, but we should fix it before more people start using it incorrectly.
While this is technically a breaking API change, I believe it's a justified one, as 1) it's OS-specific and 2) there was strictly no way to correctly use the previous form of the API, and if someone does use it, they're likely doing it wrong like in the example above.
The new API does not lead to the same confusion, as it mirrors `std::os::unix::fs::symlink` and `std::os::windows::fs::symlink_{file,dir}` variants by accepting source/target paths.
Fixes#68574.
Rationale:
- `abort()` lowers to `wasm32::unreachable()` anyway.
- `abort()` isn't `unsafe`.
- `abort()` matches the comment better.
- `abort()` avoids confusion by future readers (e.g.
https://github.com/rust-lang/rust/pull/81527): the naming of wasm's
`unreachable' instruction is a bit unfortunate because it is not
related to the `unreachable()` intrinsic (intended to trigger UB).
Codegen is likely to be different since `unreachable()` is `inline`
while `abort()` is `cold`. Since it doesn't look like we are expecting
here to trigger this case, the latter seems better anyway.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
On Windows, libstd uses GetProcAddress to locate some DLL imports, so
that libstd can run on older versions of Windows. If a given DLL import
is not present, then libstd uses other behavior (such as fallback
implementations).
This commit uses a feature of the Windows CRT to do these DLL imports
during module initialization, before main() (or DllMain()) is called.
This is the ideal time to resolve imports, because the module is
effectively single-threaded at that point; no other threads can
touch the data or code of the module that is being initialized.
This avoids several problems. First, it makes the cost of performing
the DLL import lookups deterministic. Right now, the DLL imports are
done on demand, which means that application threads _might_ have to
do the DLL import during some time-sensitive operation. This is a
small source of unpredictability. Since threads can race, it's even
possible to have more than one thread running the same redundant
DLL lookup.
This commit also removes using the heap to allocate strings, during
the DLL lookups.
Stabilize `Seek::stream_position` (feature `seek_convenience`)
Tracking issue: #59359
Unresolved questions from tracking issue:
- "Override `stream_len` for `File`?" → we can do that in the future, this does not block stabilization.
- "Rename to `len` and `position`?" → as noted in the tracking issue, both of these shorter names have problems (`len` is usually a cheap getter, `position` clashes with `Cursor`). I do think the current names are perfectly fine.
- "Rename `stream_position` to `tell`?" → as mentioned in [the comment bringing this up](https://github.com/rust-lang/rust/issues/59359#issuecomment-559541545), `stream_position` is more descriptive. I don't think `tell` would be a good name.
What remains to decide, is whether or not adding these methods is worth it.
Trying to shrink_to greater than capacity should be no-op
Per the discussion in https://github.com/rust-lang/rust/issues/56431, `shrink_to` shouldn't panic if you try to make a vector shrink to a capacity greater than its current capacity.
Make std::future a re-export of core::future
After 1a764a7ef5, there are no `std::future`-specific items (except for `cfg(bootstrap)` items removed in 93eed402ad). So, instead of defining `std` own module, we can re-export the `core::future` directly.
Implement Error for &(impl Error)
Opening this up just to see what it breaks. It's unfortunate that `&(impl Error)` doesn't actually implement `Error`. If this direct approach doesn't work out then I'll try something different, like an `Error::by_ref` method.
**EDIT:** This is a super low-priority experiment so feel free to cancel it for more important crater runs! 🙂
-----
# Stabilization Report
## Why?
We've been working for the last few years to try "fix" the `Error` trait, which is probably one of the most fundamental in the whole standard library. One of its issues is that we commonly expect you to work with abstract errors through `dyn Trait`, but references and smart pointers over `dyn Trait` don't actually implement the `Error` trait. If you have a `&dyn Error` or a `Box<dyn Error>` you simply can't pass it to a method that wants a `impl Error`.
## What does this do?
This stabilizes the following trait impl:
```rust
impl<'a, T: Error + ?Sized + 'static> Error for &'a T;
```
This means that `&dyn Error` will now satisfy a `impl Error` bound.
It doesn't do anything with `Box<dyn Error>` directly. We discussed how we could do `Box<dyn Error>` in the thread here (and elsewhere in the past), but it seems like we need something like lattice-based specialization or a sprinkling of snowflake compiler magic to make that work. Having said that, with this new impl you _can_ now get a `impl Error` from a `Box<dyn Error>` by dereferencing it.
## What breaks?
A crater run revealed a few crates broke with something like the following:
```rust
// where e: &'short &'long dyn Error
err.source()
```
previously we'd auto-deref that `&'short &'long dyn Error` to return a `Option<&'long dyn Error>` from `source`, but now will call directly on `&'short impl Error`, so will return a `Option<&'short dyn Error>`. The fix is to manually deref:
```rust
// where e: &'short &'long dyn Error
(*err).source()
```
In the recent Libs meeting we considered this acceptable breakage.
Remove delay-binding for Win XP and Vista
The minimum supported Windows version is now Windows 7. Windows XP
and Windows Vista are no longer supported; both are already broken, and
require extra steps to use.
This commit removes the delayed-binding support for Windows API
functions that are present on all supported Windows targets. This has
several benefits: Removes needless complexity. Removes a load and
dynamic call on hot paths in mutex acquire / release. This may have
performance benefits.
* "Drop official support for Windows XP"
https://github.com/rust-lang/compiler-team/issues/378
* "Firefox has ended support for Windows XP and Vista"
https://support.mozilla.org/en-US/kb/end-support-windows-xp-and-vista
Inline methods of Path and OsString
These methods are not generic, and therefore aren't candidates for cross-crate inlining without an `#[inline]` attribute.
Document why not use concat! in dbg! macro
Original title: Reduce code generated by `dbg!` macro
The expanded code before/after: <https://rust.godbolt.org/z/hE3j95>.
---
We cannot use `concat!` since `file!` could contains `{` or the expression is a block (`{ .. }`).
Using it will generated malformed format strings.
So let's document this reason why we don't use `concat!` macro at all.
The minimum supported Windows version is now Windows 7. Windows XP
and Windows Vista are no longer supported; both are already broken, and
require extra steps to use.
This commit removes the delayed-binding support for Windows API
functions that are present on all supported Windows targets. This has
several benefits: Removes needless complexity. Removes a load and
dynamic call on hot paths in mutex acquire / release. This may have
performance benefits.
* "Drop official support for Windows XP"
https://github.com/rust-lang/compiler-team/issues/378
* "Firefox has ended support for Windows XP and Vista"
https://support.mozilla.org/en-US/kb/end-support-windows-xp-and-vista
std: Update wasi-libc commit of the wasm32-wasi target
This brings in an implementation of `current_dir` and `set_current_dir`
(emulation in `wasi-libc`) as well as an updated version of finding
relative paths. This also additionally updates clang to the latest
release to build wasi-libc with.
BufWriter: Provide into_raw_parts
If something goes wrong, one might want to unpeel the layers of nested
Writers to perform recovery actions on the underlying writer, or reuse
its resources.
`into_inner` can be used for this when the inner writer is still
working. But when the inner writer is broken, and returning errors,
`into_inner` simply gives you the error from flush, and the same
`Bufwriter` back again.
Here I provide the necessary function, which I have chosen to call
`into_raw_parts`.
I had to do something with `panicked`. Returning it to the caller as
a boolean seemed rather bare. Throwing the buffered data away in this
situation also seems unfriendly: maybe the programmer knows something
about the underlying writer and can recover somehow.
So I went for a custom Error. This may be overkill, but it does have
the nice property that a caller who actually wants to look at the
buffered data, rather than simply extracting the inner writer, will be
told by the type system if they forget to handle the panicked case.
If a caller doesn't need the buffer, it can just be discarded. That
WriterPanicked is a newtype around Vec<u8> means that hopefully the
layouts of the Ok and Err variants can be very similar, with just a
boolean discriminant. So this custom error type should compile down
to nearly no code.
*If this general idea is felt appropriate, I will open a tracking issue, etc.*
Don't use posix_spawn_file_actions_addchdir_np on macOS.
There is a bug on macOS where using `posix_spawn_file_actions_addchdir_np` with a relative executable path will cause `posix_spawnp` to return ENOENT, even though it successfully spawned the process in the given directory.
`posix_spawn_file_actions_addchdir_np` was introduced in macOS 10.15 first released in Oct 2019. I have tested macOS 10.15.7 and 11.0.1.
Example offending program:
```rust
use std::fs;
use std::os::unix::fs::PermissionsExt;
use std::process::*;
fn main() {
fs::create_dir_all("bar").unwrap();
fs::create_dir_all("foo").unwrap();
fs::write("foo/foo.sh", "#!/bin/sh\necho hello ${PWD}\n").unwrap();
let perms = fs::Permissions::from_mode(0o755);
fs::set_permissions("foo/foo.sh", perms).unwrap();
let c = Command::new("../foo/foo.sh").current_dir("bar").spawn();
eprintln!("{:?}", c);
}
```
This prints:
```
Err(Os { code: 2, kind: NotFound, message: "No such file or directory" })
hello /Users/eric/Temp/bar
```
I wanted to open this PR to get some feedback on possible solutions. Alternatives:
* Do nothing.
* Document the bug.
* Try to detect if the executable is a relative path on macOS, and avoid using `posix_spawn_file_actions_addchdir_np` only in that case.
I looked at the [XNU source code](https://opensource.apple.com/source/xnu/xnu-6153.141.1/bsd/kern/kern_exec.c.auto.html), but I didn't see anything obvious that would explain the behavior. The actual chdir succeeds, it is something else further down that fails, but I couldn't see where.
EDIT: I forgot to mention, relative exe paths with `current_dir` in general are discouraged (see #37868). I don't know if #37868 is fixable, since normalizing it would change the semantics for some platforms. Another option is to convert the executable to an absolute path with something like joining the cwd with the new cwd and the executable, but I'm uncertain about that.
Clarify what the effects of a 'logic error' are
This clarifies what a 'logic error' is (which is a term used to describe what happens if you put things in a hash table or btree and then use something like a refcell to break the internal ordering). This tries to be as vague as possible, as we don't really want to promise what happens, except "bad things, but not UB". This was discussed in #80657
This brings in an implementation of `current_dir` and `set_current_dir`
(emulation in `wasi-libc`) as well as an updated version of finding
relative paths. This also additionally updates clang to the latest
release to build wasi-libc with.
Deprecate atomic::spin_loop_hint in favour of hint::spin_loop
For https://github.com/rust-lang/rust/issues/55002
We wanted to leave `atomic::spin_loop_hint` alone when stabilizing `hint::spin_loop` so folks had some time to migrate. This now deprecates `atomic_spin_loop_hint`.
Fix handling of malicious Readers in read_to_end
A malicious `Read` impl could return overly large values from `read`, which would result in the guard's drop impl setting the buffer's length to greater than its capacity! ~~To fix this, the drop impl now uses the safe `truncate` function instead of `set_len` which ensures that this will not happen. The result of calling the function will be nonsensical, but that's fine given the contract violation of the `Read` impl.~~
~~The `Guard` type is also used by `append_to_string` which does not pass untrusted values into the length field, so I've copied the guard type into each function and only modified the one used by `read_to_end`. We could just keep a single one and modify it, but it seems a bit cleaner to keep the guard code close to the functions and related specifically to them.~~
To fix this, we now assert that the returned length is not larger than the buffer passed to the method.
For reference, this bug has been present for ~2.5 years since 1.20: ecbb896b9e.
Closes#80894.
Add a `std::io::read_to_string` function
I recognize that you're usually supposed to open an issue first, but the
implementation is very small so it's okay if this is closed and it was 'wasted
work' :)
-----
The equivalent of `std::fs::read_to_string`, but generalized to all
`Read` impls.
As the documentation on `std::io::read_to_string` says, the advantage of
this function is that it means you don't have to create a variable first
and it provides more type safety since you can only get the buffer out
if there were no errors. If you use `Read::read_to_string`, you have to
remember to check whether the read succeeded because otherwise your
buffer will be empty.
It's friendlier to newcomers and better in most cases to use an explicit
return value instead of an out parameter.
Add missing methods to unix ExitStatusExt
These are the methods corresponding to the remaining exit status examination macros from `wait.h`. `WCOREDUMP` isn't in SuS but is it is very standard. I have not done portability testing to see if this builds everywhere, so I may need to Do Something if it doesn't.
There is also a bugfix and doc improvement to `.signal()`, and an `.into_raw()` accessor.
This would fix#73128 and fix#73129. Please let me know if you like this direction, and if so I will open the tracking issue and so on.
If this MR goes well, I may tackle #73125 next - I have an idea for how to do it.
This is not particularly pretty but the current situation is a mess
and I don't think I'm making it significantly worse.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
As discussed in #79982.
I think the "new interfaces", ie the new trait and impl, must be
insta-stable. This seems OK because we are, in fact, adding a new
restriction to the stable API.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
We need to be clear that this never returns WSTOPSIG. That is, if
WIFSTOPPED, the return value is None.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
A unix wait status can contain, at least, exit statuses, termination
signals, and stop signals.
WTERMSIG is only valid if WIFSIGNALED.
https://pubs.opengroup.org/onlinepubs/9699919799/functions/wait.html
It will not be easy to experience this bug with `Command`, because
that doesn't pass WUNTRACED. But you could make an ExitStatus
containing, say, a WIFSTOPPED, from a call to one of the libc wait
functions.
(In the WIFSTOPPED case, there is WSTOPSIG. But a stop signal is
encoded differently to a termination signal, so WTERMSIG and WSTOPSIG
are by no means the same.)
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
use Once instead of Mutex to manage capture resolution
For #78299
This allows us to return borrows of the captured backtrace frames that are tied to a borrow of the Backtrace itself, instead of to some short-lived Mutex guard.
We could alternatively share `&Mutex<Capture>`s and lock on-demand, but then we could potentially forget to call `resolve()` before working with the capture. It also makes it semantically clearer what synchronization is needed on the capture.
cc `@seanchen1991` `@rust-lang/project-error-handling`
Fix safety comment
The size assertion in the comment was inverted compared to the code. After fixing that the implication that `(new_size >= old_size) => new_size != 0` still doesn't hold so explain why `old_size != 0` at this point.
Rustdoc: Fix macros 2.0 and built-in derives being shown at the wrong path
Fixes#74355
- ~~waiting on author + draft PR since my code ought to be cleaned up _w.r.t._ the way I avoid the `.unwrap()`s:~~
- ~~dummy items may avoid the first `?`,~~
- ~~but within the module traversal some tests did fail (hence the second `?`), meaning the crate did not possess the exact path of the containing module (`extern` / `impl` blocks maybe? I'll look into that).~~
r? `@jyn514`
Optimize away some path lookups in the generic `fs::copy` implementation
This also eliminates a use of a `Path` convenience function, in support
of #80741, refactoring `std::path` to focus on pure data structures and
algorithms.
Stabilize slice::strip_prefix and slice::strip_suffix
These two methods are useful. The corresponding methods on `str` are already stable.
I believe that stablising these now would not get in the way of, in the future, extending these to take a richer pattern API a la `str`'s patterns.
Tracking PR: #73413. I also have an outstanding PR to improve the docs for these two functions and the corresponding ones on `str`: #75078
I have tried to follow the [instructions in the dev guide](https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr). The part to do with `compiler/rustc_feature` did not seem applicable. I assume that's because these are just library features, so there is no corresponding machinery in rustc.
The size assertion in the comment was inverted compared to the code. After fixing that the implication that `(new_size >= old_size) => new_size != 0` still doesn't hold so explain why `old_size != 0` at this point.
This also eliminates a use of a `Path` convenience function, in support
of #80741, refactoring `std::path` to focus on pure data structures and
algorithms.
The heading style for `std::prelude` is to be consistent with the
headings for `std` and `core`: `# The Rust Standard Library` and
`# The Rust Core Library`, respectively.
This allows us to return borrows of the captured backtrace frames
that are tied to a borrow of the Backtrace itself, instead of to
some short-lived Mutex guard.
It also makes it semantically clearer what synchronization is needed
on the capture.
slightly more typed interface to panic implementation
The panic payload is currently being passed around as a `usize`. However, it actually is a pointer, and the involved types are available on all ends of this API, so I propose we use the proper pointer type to avoid some casts. Avoiding int-to-ptr casts also makes this code work with `miri -Zmiri-track-raw-pointers`.
Fix intra-doc links for non-path primitives
This does *not* currently work for associated items that are
auto-implemented by the compiler (e.g. `never::eq`), because they aren't
present in the source code. I plan to fix this in a follow-up PR.
Fixes https://github.com/rust-lang/rust/issues/63351 using the approach mentioned in https://github.com/rust-lang/rust/issues/63351#issuecomment-683352130.
r? `@Manishearth`
cc `@petrochenkov` - this makes `rustc_resolve::Res` public, is that ok? I'd just add an identical type alias in rustdoc if not, which seems a waste.
We hope later to extend `core::str::Pattern` to slices too, perhaps as
part of stabilising that. We want to minimise the amount of type
inference breakage when we do that, so we don't want to stabilise
strip_prefix and strip_suffix taking a simple `&[T]`.
@KodrAus suggested the approach of introducing a new perma-unstable
trait, which reduces this future inference break risk.
I found it necessary to make two impls of this trait, as the unsize
coercion don't apply when hunting for trait implementations.
Since SlicePattern's only method returns a reference, and the whole
trait is just a wrapper for slices, I made the trait type be the
non-reference type [T] or [T;N] rather than the reference. Otherwise
the trait would have a lifetime parameter.
I marked both the no-op conversion functions `#[inline]`. I'm not
sure if that is necessary but it seemed at the very least harmless.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Stabilize `core::slice::fill`
Tracking issue https://github.com/rust-lang/rust/issues/70758
Stabilizes the `core::slice::fill` API in Rust 1.50, adding a `memset` doc alias so people coming from C/C++ looking for this operation can find it in the docs. This API hasn't seen any changes since we changed the signature in https://github.com/rust-lang/rust/pull/71165/, and it seems like the right time to propose stabilization. Thanks!
r? `@m-ou-se`
This caught several bugs where people expected `slice` to link to the
primitive, but it linked to the module instead.
This also uses `cfg_attr(bootstrap)` since the ambiguity only occurs
when compiling with stage 1.
Add array search aliases
Missed this in https://github.com/rust-lang/rust/pull/80068. This one will really fix https://github.com/rust-lang/rust/issues/46075.
The last alias especially I'm a little unsure about - maybe fuzzy search should be fixed in rustdoc instead? Happy to make that change although I'd have to figure out how.
r? ``@m-ou-se`` although cc ``@GuillaumeGomez`` for the search issue.
Fix failing build of std on armv5te-unknown-linux-uclibceabi due to missing cmsg_len_zero
I'm getting the following error when trying to build `std` on `armv5te-unknown-linux-uclibceabi`:
```
error[E0425]: cannot find value `cmsg_len_zero` in this scope
--> /home/operutka/.rustup/toolchains/nightly-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/sys/unix/ext/net/ancillary.rs:376:47
|
376 | let data_len = (*cmsg).cmsg_len - cmsg_len_zero;
| ^^^^^^^^^^^^^ not found in this scope
```
Obviously, this branch:
```rust
cfg_if::cfg_if! {
if #[cfg(any(target_os = "android", all(target_os = "linux", target_env = "gnu")))] {
let cmsg_len_zero = libc::CMSG_LEN(0) as libc::size_t;
} else if #[cfg(any(
target_os = "dragonfly",
target_os = "emscripten",
target_os = "freebsd",
all(target_os = "linux", target_env = "musl",),
target_os = "netbsd",
target_os = "openbsd",
))] {
let cmsg_len_zero = libc::CMSG_LEN(0) as libc::socklen_t;
}
}
```
does not cover the case `all(target_os = "linux", target_env = "uclibc")`.
Mark `-1` as an available niche for file descriptors
Based on discussion from <https://internals.rust-lang.org/t/can-the-standard-library-shrink-option-file/12768>, the file descriptor `-1` is chosen based on the POSIX API designs that use it as a sentinel to report errors. A bigger niche could've been chosen, particularly on Linux, but would not necessarily be portable.
This PR also adds a test case to ensure that the -1 niche (which is kind of hacky and has no obvious test case) works correctly. It requires the "upper" bound, which is actually -1, to be expressed in two's complement.
The equivalent of `std::fs::read_to_string`, but generalized to all
`Read` impls.
As the documentation on `std::io::read_to_string` says, the advantage of
this function is that it means you don't have to create a variable first
and it provides more type safety since you can only get the buffer out
if there were no errors. If you use `Read::read_to_string`, you have to
remember to check whether the read succeeded because otherwise your
buffer will be empty.
It's friendlier to newcomers and better in most cases to use an explicit
return value instead of an out parameter.
Move {f32,f64}::clamp to core.
`clamp` was recently stabilized (tracking issue: https://github.com/rust-lang/rust/issues/44095). But although `Ord::clamp` was added in `core` (because `Ord` is in `core`), the versions for the `f32` and `f64` primitives were added in `std` (together with `floor`, `sin`, etc.), not in `core` (together with `min`, `max`, `from_bits`, etc.).
This change moves them to `core`, such that `clamp` on floats is available in `no_std` programs as well.
Stabilize all stable methods of `Ipv4Addr`, `Ipv6Addr` and `IpAddr` as const
This PR stabilizes all currently stable methods of `Ipv4Addr`, `Ipv6Addr` and `IpAddr` as const.
Tracking issue: #76205
`Ipv4Addr` (`const_ipv4`):
- `octets`
- `is_loopback`
- `is_private`
- `is_link_local`
- `is_multicast`
- `is_broadcast`
- `is_docmentation`
- `to_ipv6_compatible`
- `to_ipv6_mapped`
`Ipv6Addr` (`const_ipv6`):
- `segments`
- `is_unspecified`
- `is_loopback`
- `is_multicast`
- `to_ipv4`
`IpAddr` (`const_ip`):
- `is_unspecified`
- `is_loopback`
- `is_multicast`
## Motivation
The ip methods seem like prime candidates to be made const: their behavior is defined by an external spec, and based solely on the byte contents of an address. These methods have been made unstable const in the beginning of September, after the necessary const integer arithmetic was stabilized.
There is currently a PR open (#78802) to change the internal representation of `IpAddr{4,6}` from `libc` types to a byte array. This does not have any impact on the constness of the methods.
## Implementation
Most of the stabilizations are straightforward, with the exception of `Ipv6Addr::segments`, which uses the unstable feature `const_fn_transmute`. The code could be rewritten to equivalent stable code, but this leads to worse code generation (#75085).
This is why `segments` gets marked with `#[rustc_allow_const_fn_unstable(const_fn_transmute)]`, like the already const-stable `Ipv6Addr::new`, the justification being that a const-stable alternative implementation exists https://github.com/rust-lang/rust/pull/76206#issuecomment-685044184.
## Future posibilities
This PR const-stabilizes all currently stable ip methods, however there are also a number of unstable methods under the `ip` feature (#27709). These methods are already unstable const. There is a PR open (#76098) to stabilize those methods, which could include const-stabilization. However, stabilizing those methods as const is dependent on `Ipv4Addr::octets` and `Ipv6Addr::segments` (covered by this PR).
Add the "async" and "promise" doc aliases to `core::future::Future`
Adds the "async" and "promise" doc aliases to `core::future::Future`. This enables people who search for "async" or "promise" to find `Future`, which is Rust's core primitive for async programming. Thanks!
Stabilize or_insert_with_key
Stabilizes the `or_insert_with_key` feature from https://github.com/rust-lang/rust/issues/71024. This allows inserting key-derived values when a `HashMap`/`BTreeMap` entry is vacant.
The difference between this and `.or_insert_with(|| ... )` is that this provides a reference to the key to the closure after it is moved with `.entry(key_being_moved)`, avoiding the need to copy or clone the key.
Edit formatting in Rust Prelude docs
Use consistent punctuation and capitalization in the list of things re-exported in the prelude.
Also adds a (possibly missing) word.
Refactor and fix `parse_prefix` on Windows
This PR is an extension of #78692 as well as a general refactor of `parse_prefix`:
**Fixes**:
There are two errors in the current implementation of `parse_prefix`:
Firstly, in the current implementation only `\` is recognized as a separator character in device namespace prefixes. This behavior is only correct for verbatim paths; `"\\.\C:/foo"` should be parsed as `"C:"` instead of `"C:/foo"`.
Secondly, the current implementation only handles single separator characters. In non-verbatim paths a series of separator characters should be recognized as a single boundary, e.g. the UNC path `"\\localhost\\\\\\C$\foo"` should be parsed as `"\\localhost\\\\\\C$"` and then `UNC(server: "localhost", share: "C$")`, but currently it is not parsed at all, because it starts being parsed as `\\localhost\` and then has an invalid empty share location.
Paths like `"\\.\C:/foo"` and `"\\localhost\\\\\\C$\foo"` are valid on Windows, they are equivalent to just `"C:\foo"`.
**Refactoring**:
All uses of `&[u8]` within `parse_prefix` are extracted to helper functions and`&OsStr` is used instead. This reduces the number of places unsafe is used:
- `get_first_two_components` is adapted to the more general `parse_next_component` and used in more places
- code for parsing drive prefixes is extracted to `parse_drive`
Add fast futex-based thread parker for Windows.
This adds a fast futex-based thread parker for Windows. It either uses WaitOnAddress+WakeByAddressSingle or NT Keyed Events (NtWaitForKeyedEvent+NtReleaseKeyedEvent), depending on which is available. Together, this makes this thread parker work for Windows XP and up. Before this change, park()/unpark() did not work on Windows XP: it needs condition variables, which only exist since Windows Vista.
---
Unfortunately, NT Keyed Events are an undocumented Windows API. However:
- This API is relatively simple with obvious behaviour, and there are several (unofficial) articles documenting the details. [1]
- parking_lot has been using this API for years (on Windows versions before Windows 8). [2] Many big projects extensively use parking_lot, such as servo and the Rust compiler itself.
- It is the underlying API used by Windows SRW locks and Windows critical sections. [3] [4]
- The source code of the implementations of Wine, ReactOs, and Windows XP are available and match the expected behaviour.
- The main risk with an undocumented API is that it might change in the future. But since we only use it for older versions of Windows, that's not a problem.
- Even if these functions do not block or wake as we expect (which is unlikely, see all previous points), this implementation would still be memory safe. The NT Keyed Events API is only used to sleep/block in the right place.
[1]\: http://www.locklessinc.com/articles/keyed_events/
[2]\: https://github.com/Amanieu/parking_lot/commit/43abbc964e
[3]\: https://docs.microsoft.com/en-us/archive/msdn-magazine/2012/november/windows-with-c-the-evolution-of-synchronization-in-windows-and-c
[4]\: Windows Internals, Part 1, ISBN 9780735671300
---
The choice of fallback API is inspired by parking_lot(_core), but the implementation of this thread parker is different. While parking_lot has no use for a fast path (park() directly returning if unpark() was already called), this implementation has a fast path that returns without even checking which waiting/waking API to use, as the same atomic variable with compatible states is used in all cases.
doc(array,vec): add notes about side effects when empty-initializing
Copying some context from a conversation in the Rust discord:
* Both `vec![T; 0]` and `[T; 0]` are syntactically valid, and produce empty containers of their respective types
* Both *also* have side effects:
```rust
fn side_effect() -> String {
println!("side effect!");
"foo".into()
}
fn main() {
println!("before!");
let x = vec![side_effect(); 0];
let y = [side_effect(); 0];
println!("{:?}, {:?}", x, y);
}
```
produces:
```
before!
side effect!
side effect!
[], []
```
This PR just adds two small notes to each's documentation, warning users that side effects can occur.
I've also submitted a clippy proposal: https://github.com/rust-lang/rust-clippy/issues/6439
Link loop/for keyword
Even though the reference already have all of these, I am just adding related keywords in the see also to let others easily click on the related keyword.
Windows TLS: ManuallyDrop instead of mem::forget
The Windows TLS implementation still used `mem::forget` instead of `ManuallyDrop`, leading to the usual problem of "using" the `Box` when it should not be used any more.
Dogfood `str_split_once()`
Part of https://github.com/rust-lang/rust/issues/74773.
Beyond increased clarity, this fixes some instances of a common confusion with how `splitn(2)` behaves: the first element will always be `Some()`, regardless of the delimiter, and even if the value is empty.
Given this code:
```rust
fn main() {
let val = "...";
let mut iter = val.splitn(2, '=');
println!("Input: {:?}, first: {:?}, second: {:?}", val, iter.next(), iter.next());
}
```
We get:
```
Input: "no_delimiter", first: Some("no_delimiter"), second: None
Input: "k=v", first: Some("k"), second: Some("v")
Input: "=", first: Some(""), second: Some("")
```
Using `str_split_once()` makes more clear what happens when the delimiter is not found.
Make the kernel_copy tests more robust/concurrent.
These tests write to the same filenames in /tmp and in some cases these files don't get cleaned up properly. This caused issues for us when different users run the tests on the same system, e.g.:
```
---- sys::unix::kernel_copy::tests::bench_file_to_file_copy stdout ----
thread 'sys::unix::kernel_copy::tests::bench_file_to_file_copy' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 13, kind: PermissionDenied, message: "Permission denied" }', library/std/src/sys/unix/kernel_copy/tests.rs:71:10
---- sys::unix::kernel_copy::tests::bench_file_to_socket_copy stdout ----
thread 'sys::unix::kernel_copy::tests::bench_file_to_socket_copy' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 13, kind: PermissionDenied, message: "Permission denied" }', library/std/src/sys/unix/kernel_copy/tests.rs💯10
```
Use `std::sys_common::io__test::tmpdir()` to solve this.
CC ``@the8472.``
Improve documentation for `std::{f32,f64}::mul_add`
Makes it more clear that performance improvement is not guaranteed when using FMA, even when the target architecture supports it natively.
Enforce no-move rule of ReentrantMutex using Pin and fix UB in stdio
A `sys_common::ReentrantMutex` may not be moved after initializing it with `.init()`. This was not enforced, but only stated as a requirement in the comments on the unsafe functions. This change enforces this no-moving rule using `Pin`, by changing `&self` to a `Pin` in the `init()` and `lock()` functions.
This uncovered a bug I introduced in #77154: stdio.rs (the only user of ReentrantMutex) called `init()` on its ReentrantMutexes while constructing them in the intializer of `SyncOnceCell::get_or_init`, which would move them afterwards. Interestingly, the ReentrantMutex unit tests already had the same bug, so this invalid usage has been tested on all (CI-tested) platforms for a long time. Apparently this doesn't break badly on any of the major platforms, but it does break the rules.\*
To be able to keep using SyncOnceCell, this adds a `SyncOnceCell::get_or_init_pin` function, which makes it possible to work with pinned values inside a (pinned) SyncOnceCell. Whether this function should be public or not and what its exact behaviour and interface should be if it would be public is something I'd like to leave for a separate issue or PR. In this PR, this function is internal-only and marked with `pub(crate)`.
\* Note: That bug is now included in 1.48, while this patch can only make it to ~~1.49~~ 1.50. We should consider the implications of 1.48 shipping with a wrong usage of `pthread_mutex_t` / `CRITICAL_SECTION` / .. which technically invokes UB according to their specification. The risk is very low, considering the objects are not 'used' (locked) before the move, and the ReentrantMutex unit tests have verified this works fine in practice.
Edit: This has been backported and included in 1.48. And soon 1.49 too.
---
In future changes, I want to push this usage of Pin further inside `sys` instead of only `sys_common`, and apply it to all 'unmovable' objects there (`Mutex`, `Condvar`, `RwLock`). Also, while `sys_common`'s mutexes and condvars are already taken care of by #77147 and #77648, its `RwLock` should still be made movable or get pinned.
Based on discussion from https://internals.rust-lang.org/t/can-the-standard-library-shrink-option-file/12768,
the file descriptor -1 is chosen based on the POSIX API designs that use it as a sentinel to report errors.
A bigger niche could've been chosen, particularly on Linux, but would not necessarily be portable.
This PR also adds a test case to ensure that the -1 niche
(which is kind of hacky and has no obvious test case) works correctly.
It requires the "upper" bound, which is actually -1, to be expressed in two's complement.
implement better availability probing for copy_file_range
Followup to https://github.com/rust-lang/rust/pull/75428#discussion_r469616547
Previously syscall detection was overly pessimistic. Any attempt to copy to an immutable file (EPERM) would disable copy_file_range support for the whole process.
The change tries to copy_file_range on invalid file descriptors which will never run into the immutable file case and thus we can clearly distinguish syscall availability.
ext/ucred: Support PID in peer creds on macOS
This is a follow-up to https://github.com/rust-lang/rust/pull/75148 (RFC: https://github.com/rust-lang/rust/issues/42839).
The original PR used `getpeereid` on macOS and the BSDs, since they don't (generally) support the `SO_PEERCRED` mechanism that Linux supplies.
This PR splits the macOS/iOS implementation of `peer_cred()` from that of the BSDs, since macOS supplies the `LOCAL_PEERPID` sockopt as a source of the missing PID. It also adds a `cfg`-gated tests that ensures that platforms with support for PIDs in `UCred` have the expected data.
Use is_write_vectored to optimize the write_vectored implementation for BufWriter
In case when the underlying writer does not have an efficient implementation `write_vectored`, the present implementation of
`write_vectored` for `BufWriter` may still forward vectored writes directly to the writer depending on the total length of the data. This misses the advantage of buffering, as the actually written slice may be small.
Provide an alternative code path for the non-vectored case, where the slices passed to `BufWriter` are coalesced in the buffer before being flushed to the underlying writer with plain `write` calls. The buffer is only bypassed if an individual slice's length is at least as large as the buffer.
Remove a FIXME comment referring to #72919 as the issue has been closed with an explanation provided.
The code in io::stdio before this change misused the ReentrantMutexes,
by calling init() on them and moving them afterwards. Now that
ReentrantMutex requires Pin for init(), this mistake is no longer easy
to make.
Fix incorrect io::Take's limit resulting from io::copy specialization
The specialization introduced in #75272 fails to update `io::Take` wrappers after performing the copy syscalls which bypass those wrappers. The buffer flushing before the copy does update them correctly, but the bytes copied after the initial flush weren't subtracted.
The fix is to subtract the bytes copied from each `Take` in the chain of wrappers, even when an error occurs during the syscall loop. To do so the `CopyResult` enum now has to carry the bytes copied so far in the error case.
Provide IntoInnerError::into_parts
Hi. This is an updated version of the IntoInnerError bits of my previous portmanteau MR #78689. Thanks to `@jyn514` and `@m-ou-se` for helpful comments there.
I have made this insta-stable since it seems like it will probably be uncontroversial, but that is definitely something that someone from the libs API team should be aware of and explicitly consider.
I included a tangentially-related commit providing documentation of the buffer full behaviiour of `&mut [u8] as Write`; the behaviour I am documenting is relied on by the doctest for `into_parts`.
In particular, IntoIneerError only currently provides .error() which
returns a reference, not an owned value. This is not helpful and
means that a caller of BufWriter::into_inner cannot acquire an owned
io::Error which seems quite wrong.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
If something goes wrong, one might want to unpeel the layers of nested
Writers to perform recovery actions on the underlying writer, or reuse
its resources.
`into_inner` can be used for this when the inner writer is still
working. But when the inner writer is broken, and returning errors,
`into_inner` simply gives you the error from flush, and the same
`Bufwriter` back again.
Here I provide the necessary function, which I have chosen to call
`into_raw_parts`.
I had to do something with `panicked`. Returning it to the caller as
a boolean seemed rather bare. Throwing the buffered data away in this
situation also seems unfriendly: maybe the programmer knows something
about the underlying writer and can recover somehow.
So I went for a custom Error. This may be overkill, but it does have
the nice property that a caller who actually wants to look at the
buffered data, rather than simply extracting the inner writer, will be
told by the type system if they forget to handle the panicked case.
If a caller doesn't need the buffer, it can just be discarded. That
WriterPanicked is a newtype around Vec<u8> means that hopefully the
layouts of the Ok and Err variants can be very similar, with just a
boolean discriminant. So this custom error type should compile down
to nearly no code.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Use more std:: instead of core:: in docs for consistency
``@rustbot`` label T-doc
Some cleanup work to use `std::` instead of `core::` in docs as much as possible. This helps with terminology and consistency, especially for newcomers from other languages that have often heard of `std` to describe the standard library but not of `core`.
Edit: I also added more intra doc links when I saw the opportunity.
These tests write to the same filenames in /tmp and in some cases these
files don't get cleaned up properly. This caused issues for us when
different users run the tests on the same system, e.g.:
```
---- sys::unix::kernel_copy::tests::bench_file_to_file_copy stdout ----
thread 'sys::unix::kernel_copy::tests::bench_file_to_file_copy' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 13, kind: PermissionDenied, message: "Permission denied" }', library/std/src/sys/unix/kernel_copy/tests.rs:71:10
---- sys::unix::kernel_copy::tests::bench_file_to_socket_copy stdout ----
thread 'sys::unix::kernel_copy::tests::bench_file_to_socket_copy' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 13, kind: PermissionDenied, message: "Permission denied" }', library/std/src/sys/unix/kernel_copy/tests.rs💯10
```
Use `std::sys_common::io__test::tmpdir()` to solve this.
unix: Extend UnixStream and UnixDatagram to send and receive file descriptors
Add the functions `recv_vectored_fds` and `send_vectored_fds` to `UnixDatagram` and `UnixStream`. With this functions `UnixDatagram` and `UnixStream` can send and receive file descriptors, by using `recvmsg` and `sendmsg` system call.
std::io: Use sendfile for UnixStream
`UnixStream` was forgotten in #75272 .
Benchmark yields the following results.
Before:
`running 1 test
test sys::unix::kernel_copy::tests::bench_file_to_uds_copy ... bench: 54,399 ns/iter (+/- 6,817) = 2409 MB/s`
After:
`running 1 test
test sys::unix::kernel_copy::tests::bench_file_to_uds_copy ... bench: 18,627 ns/iter (+/- 6,007) = 7036 MB/s`
Rename `optin_builtin_traits` to `auto_traits`
They were originally called "opt-in, built-in traits" (OIBITs), but
people realized that the name was too confusing and a mouthful, and so
they were renamed to just "auto traits". The feature flag's name wasn't
updated, though, so that's what this PR does.
There are some other spots in the compiler that still refer to OIBITs,
but I don't think changing those now is worth it since they are internal
and not particularly relevant to this PR.
Also see <https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/opt-in.2C.20built-in.20traits.20(auto.20traits).20feature.20name>.
r? `@oli-obk` (feel free to re-assign if you're not the right reviewer for this)
Fix typo in `keyword` docs for traits
This PR fixes a small typo in the `keyword_docs.rs` file, describing the differences between the 2015 and 2018 editions of traits.
They were originally called "opt-in, built-in traits" (OIBITs), but
people realized that the name was too confusing and a mouthful, and so
they were renamed to just "auto traits". The feature flag's name wasn't
updated, though, so that's what this PR does.
There are some other spots in the compiler that still refer to OIBITs,
but I don't think changing those now is worth it since they are internal
and not particularly relevant to this PR.
Also see <https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/opt-in.2C.20built-in.20traits.20(auto.20traits).20feature.20name>.
Drop support for all cloudabi targets
`cloudabi` is a tier-3 target, and [it is no longer being maintained upstream][no].
This PR drops supports for cloudabi targets. Those targets are:
* aarch64-unknown-cloudabi
* armv7-unknown-cloudabi
* i686-unknown-cloudabi
* x86_64-unknown-cloudabi
Since this drops supports for a target, I'd like somebody to tag `relnotes` label to this PR.
Some other issues:
* The tidy exception for `cloudabi` crate is still remained because
* `parking_lot v0.9.0` and `parking_lot v0.10.2` depends on `cloudabi v0.0.3`.
* `parking_lot v0.11.0` depends on `cloudabi v0.1.0`.
[no]: https://github.com/NuxiNL/cloudabi#note-this-project-is-unmaintained
Stabilize `IpAddr::is_ipv4` and `is_ipv6` as const
Insta-stabilize the methods `is_ipv4` and `is_ipv6` of `std::net::IpAddr` as const, in the same way as [PR#76198](https://github.com/rust-lang/rust/pull/76198).
Possible because of the recent stabilization of const control flow.
Part of #76225 and #76205.
Insta-stabilize the methods `is_ipv4` and `is_ipv6` of `IpAddr`.
Possible because of the recent stabilization of const control flow.
Also adds a test for these methods in a const context.
Do what write does and optimize for the most likely case:
slices are much smaller than the buffer. If a slice does not fit
completely in the remaining capacity of the buffer, it is left out
rather than buffered partially. Special treatment is only left for
oversized slices that are written directly to the underlying writer.
Now that BufWriter always claims to support vectored writes,
look through it at the wrapped writer to decide whether to
use vectored writes for LineWriter.
If the underlying writer does not support efficient vectored output,
do it differently: always try to coalesce the slices in the buffer
until one comes that does not fit entirely. Flush the buffer before
the first slice if needed.
Stabilize clamp
Tracking issue: https://github.com/rust-lang/rust/issues/44095
Clamp has been merged and unstable for about a year and a half now. How do we feel about stabilizing this?
std: Update the bactrace crate submodule
This commit updates the `library/backtrace` submodule which primarily
pulls in support for split-debuginfo on macOS, avoiding the need for
`dsymutil` to get run to get line numbers and filenames in backtraces.
rustc_expand: Mark inner `#![test]` attributes as soft-unstable
Custom inner attributes are feature gated (https://github.com/rust-lang/rust/issues/54726) except for attributes having name `test` literally, which are not gated for historical reasons.
`#![test]` is an inner proc macro attribute, so it has all the issues described in https://github.com/rust-lang/rust/issues/54726 too.
This PR gates it with the `soft_unstable` lint.
This commit updates the `library/backtrace` submodule which primarily
pulls in support for split-debuginfo on macOS, avoiding the need for
`dsymutil` to get run to get line numbers and filenames in backtraces.
unix/weak: pass arguments to syscall at the given type
Given that we know the type the argument should have, it seems a bit strange not to use that information.
r? `@m-ou-se` `@cuviper`
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
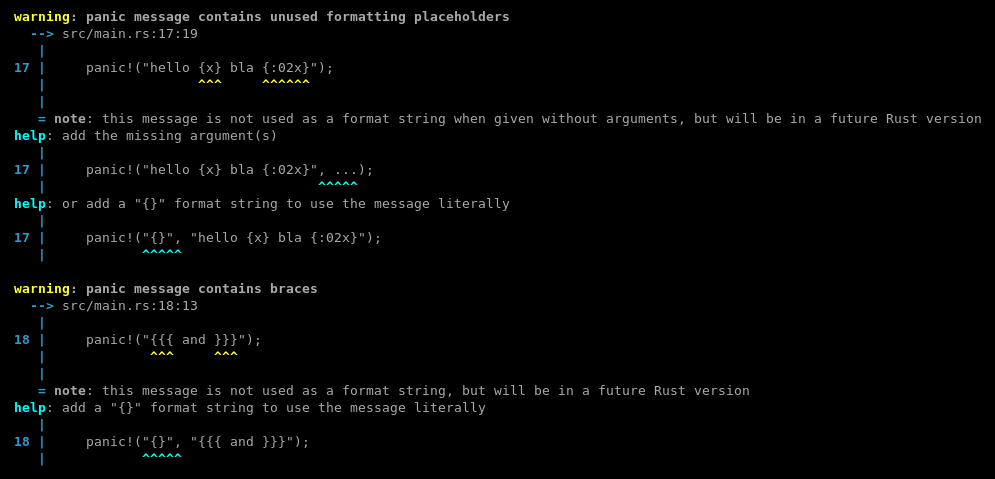
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
Fix typo in `std::io::Write` docs
These referred to a “`Write`er”—extra *e*. Presumably a copy-paste
holdover from “`Read`er”.
Test Plan:
Running ``git grep '`\?[Ww]rite`\?er'`` no longer finds any results.
wchargin-branch: io-write-docs
Tighten the bounds on atomic Ordering in std::sys::unix::weak::Weak
This moves reading this from multiple SeqCst reads to Relaxed read + Acquire fence if we are actually going to use the data.
Would love to avoid the Acquire fence, but doing so would need Ordering::Consume, which neither Rust, nor LLVM supports (a shame, since this fence is hardly free on ARM, which is what I was hoping to improve).
r? ``@Amanieu`` (Sorry for always picking you, but I know a lot of people wouldn't feel comfortable reviewing atomic ordering changes)
linux: try to use libc getrandom to allow interposition
We'll try to use a weak `getrandom` symbol first, because that allows
things like `LD_PRELOAD` interposition. For example, perf measurements
might want to disable randomness to get reproducible results. If the
weak symbol is not found, we fall back to a raw `SYS_getrandom` call.
Updated the list of white-listed target features for x86
This PR both adds in-source documentation on what to look out for when adding a new (X86) feature set and [adds all that are detectable at run-time in Rust stable as of 1.27.0](https://github.com/rust-lang/stdarch/blob/master/crates/std_detect/src/detect/arch/x86.rs).
This should only enable the use of the corresponding LLVM intrinsics.
Actual intrinsics need to be added separately in rust-lang/stdarch.
It also re-orders the run-time-detect test statements to be more consistent
with the actual list of intrinsics whitelisted and removes underscores not present
in the actual names (which might be mistaken as being part of the name)
The reference for LLVM's feature names used is [this file](https://github.com/llvm/llvm-project/blob/master/llvm/include/llvm/Support/X86TargetParser.def).
This PR was motivated as the compiler end's part for allowing #67329 to be adressed over on rust-lang/stdarch
These referred to a “`Write`er”—extra *e*. Presumably a copy-paste
holdover from “`Read`er”.
Test Plan:
Running ``git grep '`\?[Ww]rite`\?er'`` no longer finds any results.
wchargin-branch: io-write-docs
Rollup of 9 pull requests
Successful merges:
- #77939 (Ensure that the source code display is working with DOS backline)
- #78138 (Upgrade dlmalloc to version 0.2)
- #78967 (Make codegen tests compatible with extra inlining)
- #79027 (Limit storage duration of inlined always live locals)
- #79077 (document that __rust_alloc is also magic to our LLVM fork)
- #79088 (clarify `span_label` documentation)
- #79097 (Code block invalid html tag lint)
- #79105 (std: Fix test `symlink_hard_link` on Windows)
- #79107 (build-manifest: strip newline from rustc version)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
std: Fix test `symlink_hard_link` on Windows
The test was introduced in https://github.com/rust-lang/rust/pull/78026 and fails depending on Windows version and admin rights.
Other similar tests check for symlink creation permissions before doing anything, this PR performs the same check for `symlink_hard_link` as well.
Upgrade dlmalloc to version 0.2
In preparation of adding dynamic memory management support for SGXv2-enabled platforms, the dlmalloc crate has been refactored. More specifically, support has been added to implement platform specification outside of the dlmalloc crate. (see https://github.com/alexcrichton/dlmalloc-rs/pull/15)
This PR upgrades dlmalloc to version 0.2 for the `wasm` and `sgx` targets.
As the dlmalloc changes have received a positive review, but have not been merged yet, this PR contains a commit to prevent tidy from aborting CI prematurely.
cc: `@jethrogb`
Make the libstd build script smaller
Of all sysroot crates currently only compiler_builtins, miniz_oxide and std require a build script. compiler_builtins uses to conditionally enable certain features and possibly compile a C version ([source](63ccaf11f0/build.rs)), miniz_oxide only uses it to detect if liballoc is supported as the MSRV is 1.34.0 instead of the 1.36.0 which stabilized liballoc ([source](28514ec09f/miniz_oxide/build.rs)). std now only uses it to enable `freebsd12` when the `RUST_STD_FREEBSD_12_ABI` env var is set, to determine if `restricted-std` should be set, to set the `STD_ENV_ARCH` env var identical to `CARGO_CFG_TARGET_ARCH`, and to unconditionally enable `backtrace_in_libstd`.
If all build scripts were to be removed, it would be possible for rustc to completely compile it's own sysroot. It currently requires a rustc version that already has an available libstd to compile the build scripts. If rustc can completely compile it's own sysroot, rustbuild could be simplified to not forcefully use the bootstrap compiler for build scripts.
`@rustbot` modify labels: +T-compiler +libs-impl
We'll try to use a weak `getrandom` symbol first, because that allows
things like `LD_PRELOAD` interposition. For example, perf measurements
might want to disable randomness to get reproducible results. If the
weak symbol is not found, we fall back to a raw `SYS_getrandom` call.
Simplify output capturing
This is a sequence of incremental improvements to the unstable/internal `set_panic` and `set_print` mechanism used by the `test` crate:
1. Remove the `LocalOutput` trait and use `Arc<Mutex<dyn Write>>` instead of `Box<dyn LocalOutput>`. In practice, all implementations of `LocalOutput` were just `Arc<Mutex<..>>`. This simplifies some logic and removes all custom `Sink` implementations such as `library/test/src/helpers/sink.rs`. Also removes a layer of indirection, as the outermost `Box` is now gone. It also means that locking now happens per `write_fmt`, not per individual `write` within. (So `"{} {}\n"` now results in one `lock()`, not four or more.)
2. Since in all cases the `dyn Write`s were just `Vec<u8>`s, replace the type with `Arc<Mutex<Vec<u8>>>`. This simplifies things more, as error handling and flushing can be removed now. This also removes the hack needed in the default panic handler to make this work with `::realstd`, as (unlike `Write`) `Vec<u8>` is from `alloc`, not `std`.
3. Replace the `RefCell`s by regular `Cell`s. The `RefCell`s were mostly used as `mem::replace(&mut *cell.borrow_mut(), something)`, which is just `Cell::replace`. This removes an unecessary bookkeeping and makes the code a bit easier to read.
4. Merge `set_panic` and `set_print` into a single `set_output_capture`. Neither the test crate nor rustc (the only users of this feature) have a use for using these separately. Merging them simplifies things even more. This uses a new function name and feature name, to make it clearer this is internal and not supposed to be used by other crates.
Might be easier to review per commit.
Rename/Deprecate LayoutErr in favor of LayoutError
Implements rust-lang/wg-allocators#73.
This patch renames LayoutErr to LayoutError, and uses a type alias to support users using the old name.
The new name will be instantly stable in release 1.49 (current nightly), the type alias will become deprecated in release 1.51 (so that when the current nightly is 1.51, 1.49 will be stable).
This is the only error type in `std` that ends in `Err` rather than `Error`, if this PR lands all stdlib error types will end in `Error` 🥰
Fix an intrinsic invocation on threaded wasm
This looks like it was forgotten to get updated in #74482 and wasm with
threads isn't built on CI so we didn't catch this by accident.
specialize io::copy to use copy_file_range, splice or sendfile
Fixes#74426.
Also covers #60689 but only as an optimization instead of an official API.
The specialization only covers std-owned structs so it should avoid the problems with #71091
Currently linux-only but it should be generalizable to other unix systems that have sendfile/sosplice and similar.
There is a bit of optimization potential around the syscall count. Right now it may end up doing more syscalls than the naive copy loop when doing short (<8KiB) copies between file descriptors.
The test case executes the following:
```
[pid 103776] statx(3, "", AT_STATX_SYNC_AS_STAT|AT_EMPTY_PATH, STATX_ALL, {stx_mask=STATX_ALL|STATX_MNT_ID, stx_attributes=0, stx_mode=S_IFREG|0644, stx_size=17, ...}) = 0
[pid 103776] write(4, "wxyz", 4) = 4
[pid 103776] write(4, "iklmn", 5) = 5
[pid 103776] copy_file_range(3, NULL, 4, NULL, 5, 0) = 5
```
0-1 `stat` calls to identify the source file type. 0 if the type can be inferred from the struct from which the FD was extracted
𝖬 `write` to drain the `BufReader`/`BufWriter` wrappers. only happen when buffers are present. 𝖬 ≾ number of wrappers present. If there is a write buffer it may absorb the read buffer contents first so only result in a single write. Vectored writes would also be an option but that would require more invasive changes to `BufWriter`.
𝖭 `copy_file_range`/`splice`/`sendfile` until file size, EOF or the byte limit from `Take` is reached. This should generally be *much* more efficient than the read-write loop and also have other benefits such as DMA offload or extent sharing.
## Benchmarks
```
OLD
test io::tests::bench_file_to_file_copy ... bench: 21,002 ns/iter (+/- 750) = 6240 MB/s [ext4]
test io::tests::bench_file_to_file_copy ... bench: 35,704 ns/iter (+/- 1,108) = 3671 MB/s [btrfs]
test io::tests::bench_file_to_socket_copy ... bench: 57,002 ns/iter (+/- 4,205) = 2299 MB/s
test io::tests::bench_socket_pipe_socket_copy ... bench: 142,640 ns/iter (+/- 77,851) = 918 MB/s
NEW
test io::tests::bench_file_to_file_copy ... bench: 14,745 ns/iter (+/- 519) = 8889 MB/s [ext4]
test io::tests::bench_file_to_file_copy ... bench: 6,128 ns/iter (+/- 227) = 21389 MB/s [btrfs]
test io::tests::bench_file_to_socket_copy ... bench: 13,767 ns/iter (+/- 3,767) = 9520 MB/s
test io::tests::bench_socket_pipe_socket_copy ... bench: 26,471 ns/iter (+/- 6,412) = 4951 MB/s
```
Previously EOVERFLOW handling was only applied for io::copy specialization
but not for fs::copy sharing the same code.
Additionally we lower the chunk size to 1GB since we have a user report
that older kernels may return EINVAL when passing 0x8000_0000
but smaller values succeed.
Android builds use feature level 14, the libc wrapper for splice is gated
on feature level 21+ so we have to invoke the syscall directly.
Additionally the emulator doesn't seem to support it so we also have to
add ENOSYS checks.
Update thread and futex APIs to work with Emscripten
This updates the thread and futex APIs in `std` to match the APIs exposed by
Emscripten. This allows threads to run on `wasm32-unknown-emscripten` and the
thread parker to compile without errors related to the missing `futex` module.
To make use of this, Rust code must be compiled with `-C target-feature=atomics`
and Emscripten must link with `-pthread`.
I have confirmed this works well locally when building multithreaded crates.
Attempting to enable `std` thread tests currently fails for seemingly obscure
reasons and Emscripten is currently disabled in CI, so further work is needed to
have proper test coverage here.
This updates the thread and futex APIs in `std` to match the APIs exposed by
Emscripten. This allows threads to run on `wasm32-unknown-emscripten` and the
thread parker to compile without errors related to the missing `futex` module.
To make use of this, Rust code must be compiled with `-C target-feature=atomics`
and Emscripten must link with `-pthread`.
I have confirmed this works well locally when building multithreaded crates.
Attempting to enable `std` thread tests currently fails for seemingly obscure
reasons and Emscripten is currently disabled in CI, so further work is needed to
have proper test coverage here.
Duration::zero() -> Duration::ZERO
In review for #72790, whether or not a constant or a function should be favored for `#![feature(duration_zero)]` was seen as an open question. In https://github.com/rust-lang/rust/issues/73544#issuecomment-691701670 an invitation was opened to either stabilize the methods or propose a switch to the constant value, supplemented with reasoning. Followup comments suggested community preference leans towards the const ZERO, which would be reason enough.
ZERO also "makes sense" beside existing associated consts for Duration. It is ever so slightly awkward to have a series of constants specifying 1 of various units but leave 0 as a method, especially when they are side-by-side in code. It seems unintuitive for the one non-dynamic value (that isn't from Default) to be not-a-const, which could hurt discoverability of the associated constants overall. Elsewhere in `std`, methods for obtaining a constant value were even deprecated, as seen with [std::u32::min_value](https://doc.rust-lang.org/std/primitive.u32.html#method.min_value).
Most importantly, ZERO costs less to use. A match supports a const pattern, but const fn can only be used if evaluated through a const context such as an inline `const { const_fn() }` or a `const NAME: T = const_fn()` declaration elsewhere. Likewise, while https://github.com/rust-lang/rust/issues/73544#issuecomment-691949373 notes `Duration::zero()` can optimize to a constant value, "can" is not "will". Only const contexts have a strong promise of such. Even without that in mind, the comment in question still leans in favor of the constant for simplicity. As it costs less for a developer to use, may cost less to optimize, and seems to have more of a community consensus for it, the associated const seems best.
r? ```@LukasKalbertodt```
The discussion seems to have resolved that this lint is a bit "noisy" in
that applying it in all places would result in a reduction in
readability.
A few of the trivial functions (like `Path::new`) are fine to leave
outside of closures.
The general rule seems to be that anything that is obviously an
allocation (`Box`, `Vec`, `vec![]`) should be in a closure, even if it
is a 0-sized allocation.
It was only ever used with Vec<u8> anyway. This simplifies some things.
- It no longer needs to be flushed, because that's a no-op anyway for
a Vec<u8>.
- Writing to a Vec<u8> never fails.
- No #[cfg(test)] code is needed anymore to use `realstd` instead of
`std`, because Vec comes from alloc, not std (like Write).
{kind=link}