BTreeMap: introduce marker::ValMut and reserve Mut for unique access
The mutable BTreeMap iterators (apart from `DrainFilter`) are double-ended, meaning they have to rely on a front and a back handle that each represent a reference into the tree. Reserve a type category `marker::ValMut` for them, so that we guarantee that they cannot reach operations on handles with borrow type `marker::Mut`and that these operations can assume unique access to the tree.
Including #75195, benchmarks report no genuine change:
```
benchcmp old new --threshold 5
name old ns/iter new ns/iter diff ns/iter diff % speedup
btree::map::iter_100 3,333 3,023 -310 -9.30% x 1.10
btree::map::range_unbounded_vs_iter 36,624 31,569 -5,055 -13.80% x 1.16
```
r? @Mark-Simulacrum
Functions such as `is_enclave_range` and `is_user_range` in
`sgx::os::fortanix_sgx::mem` are often used to make sure memory ranges
passed to an enclave from untrusted code or passed to other trusted code
functions are safe to use for their intended purpose. Currently, these
functions do not perform any checks to make sure the range provided
doesn't overflow when adding the range length to the base address. While
debug builds will panic if overflow occurs, release builds will simply
wrap the result, leading to false positive results for either function.
The burden is placed on application authors to know to perform overflow
checks on their own before calling these functions, which can easily
lead to security vulnerabilities if omitted. Additionally, since such
checks are performed in the Intel SGX SDK versions of these functions,
developers migrating from Intel SGX SDK code may expect these functions
to operate the same.
This commit adds explicit overflow checking to `is_enclave_range` and
`is_user_range`, returning `false` if overflow occurs in order to
prevent misuse of invalid memory ranges. It also alters the checks to
account for ranges that lie exactly at the end of the address space,
where calculating `p + len` would overflow despite the range being
valid.
Respect `-Z proc-macro-backtrace` flag for panics inside libproc_macro
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
This is very similar to the existing `Box<[T; N]>: TryFrom<Box<[T]>>`, but allows avoiding the `shrink_to_fit` if you have a vector and not a boxed slice.
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
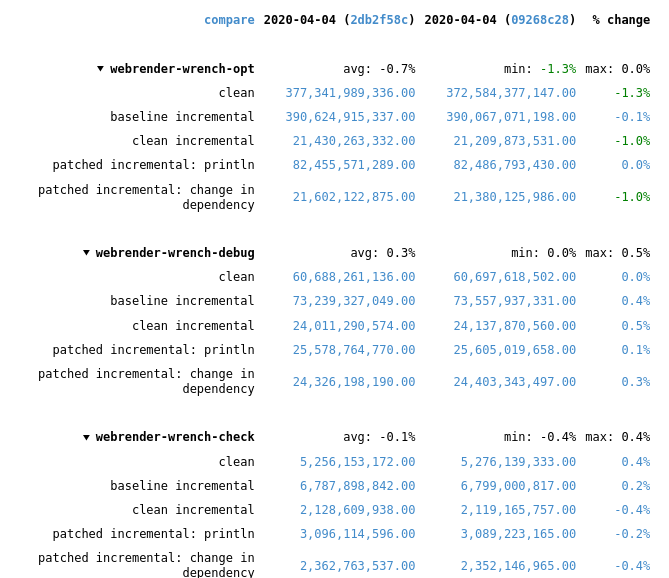
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
The InPlaceIterable debug assert checks that the write pointer
did not advance beyond the read pointer. But TrustedRandomAccess
never advances the read pointer, thus triggering the assert.
Skip the assert if the source pointer did not change during iteration.
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
The optimization meant that every extend code path had to emit llvm
IR for from_iter and extend spec_extend, which likely impacts
compile times while only improving a few edge-cases
switch to try_fold and segregate the drop handling to keep
collect::<Vec<u8>>() and similar optimizer-friendly
It comes at the cost of less accurate debug_asserts and code complexity
Fixes#76270
Previously, any panic occuring during a call to a libproc_macro method
(e.g. calling `Ident::new` with an invalid identifier) would always
cause an ICE message to be printed.
Convert many files to intra-doc links
Helps with https://github.com/rust-lang/rust/issues/75080
r? @poliorcetics
I recommend reviewing one commit at a time, but the diff is small enough you can do it all at once if you like :)
Applied `#![deny(unsafe_op_in_unsafe_fn)]` in library/std/src/wasi
partial fix for #73904
There are still more that was not applied in [mod.rs]( 38fab2ea92/library/std/src/sys/wasi/mod.rs) and that is due to its using files from `../unsupported`
like:
```
#[path = "../unsupported/cmath.rs"]
pub mod cmath;
```
Fix typos in vec try_reserve(_exact) docs
`try_reserve` and `try_reserve_exact` docs refer to calling `reserve` and `reserve_exact`.
`try_reserve_exact` example uses `try_reserve` method instead of `try_reserve_exact`.
Move to intra-doc links for library/core/src/iter/traits/iterator.rs
Helps with #75080.
@jyn514 We're almost finished with this issue. Thanks for mentoring. If you have other topics to work on just let me know, I will be around in Discord.
@rustbot modify labels: T-doc, A-intra-doc-links
Known issues:
* Link from `core` to `std` (#74481):
[`OsStr`]
[`String`]
[`VecDeque<T>`]
Rename and expose LoopState as ControlFlow
Basic PR for #75744. Addresses everything there except for documentation; lots of examples are probably a good idea.
Make all methods of `std::net::Ipv4Addr` const
Make the following methods of `std::net::Ipv4Addr` unstable const under the `const_ipv4` feature:
- `octets`
- `is_loopback`
- `is_private`
- `is_link_local`
- `is_global` (unstable)
- `is_shared` (unstable)
- `is_ietf_protocol_assignment` (unstable)
- `is_benchmarking` (unstable)
- `is_reserved` (unstable)
- `is_multicast`
- `is_broadcast`
- `is_documentation`
- `to_ipv6_compatible`
- `to_ipv6_mapped`
This would make all methods of `Ipv6Addr` const.
Of these methods, `is_global`, `is_broadcast`, `to_ipv6_compatible`, and `to_ipv6_mapped` require a change in implementation.
Part of #76205
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
Add a note for Ipv4Addr::to_ipv6_compatible
Previous discussion: #75019
> I think adding a comment saying "This isn't typically the method you want; these addresses don't typically function on modern systems. Use `to_ipv6_mapped` instead." would be a good first step, whether this method gets marked as deprecated or not.
_Originally posted by @joshtriplett in https://github.com/rust-lang/rust/pull/75150#issuecomment-680267745_
- Use intra-doc links for `std::io` in `std::fs`
- Use intra-doc links for File::read in unix/ext/fs.rs
- Remove explicit intra-doc links for `true` in `net/addr.rs`
- Use intra-doc links in alloc/src/sync.rs
- Use intra-doc links in src/ascii.rs
- Switch to intra-doc links in alloc/rc.rs
- Use intra-doc links in core/pin.rs
- Use intra-doc links in std/prelude
- Use shorter links in `std/fs.rs`
`io` is already in scope.
flt2dec: properly handle uninitialized memory
The float-to-str code currently uses uninitialized memory incorrectly (see https://github.com/rust-lang/rust/issues/76092). This PR fixes that.
Specifically, that code used `&mut [T]` as "out references", but it would be incorrect for the caller to actually pass uninitialized memory. So the PR changes this to `&mut [MaybeUninit<T>]`, and then functions return a `&[T]` to the part of the buffer that they initialized (some functions already did that, indirectly via `&Formatted`, others were adjusted to return that buffer instead of just the initialized length).
What I particularly like about this is that it moves `unsafe` to the right place: previously, the outermost caller had to use `unsafe` to assert that things are initialized; now it is the functions that do the actual initializing which have the corresponding `unsafe` block when they call `MaybeUninit::slice_get_ref` (renamed in https://github.com/rust-lang/rust/pull/76217 to `slice_assume_init_ref`).
Reviewers please be aware that I have no idea how any of this code actually works. My changes were purely mechanical and type-driven. The test suite passes so I guess I didn't screw up badly...
Cc @sfackler this is somewhat related to your RFC, and possibly some of this code could benefit from (a generalized version of) the API you describe there. But for now I think what I did is "good enough".
Fixes https://github.com/rust-lang/rust/issues/76092.
`try_reserve` and `try_reserve_exact` docs refer to calling `reserve` and `reserve_exact`.
`try_reserve_exact` example uses `try_reserve` method instead of `try_reserve_exact`.
Make all methods of `std::net::Ipv6Addr` const
Make the following methods of `std::net::Ipv6Addr` unstable const under the `const_ipv6` feature:
- `segments`
- `is_unspecified`
- `is_loopback`
- `is_global` (unstable)
- `is_unique_local`
- `is_unicast_link_local_strict`
- `is_documentation`
- `multicast_scope`
- `is_multicast`
- `to_ipv4_mapped`
- `to_ipv4`
This would make all methods of `Ipv6Addr` const.
Changed the implementation of `is_unspecified` and `is_loopback` to use a `match` instead of `==`, all other methods did not require a change.
All these methods are dependent on `segments`, the current implementation of which requires unstable `const_fn_transmute` ([PR#75085](https://github.com/rust-lang/rust/pull/75085)).
Part of #76205
Move to intra-doc links for library/core/src/panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from `core` to `std` (#74481):
[`set_hook`]
[`String`]
Add more examples to lexicographic cmp on Iterators.
Given two arrays of T1 and T2, the most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T1.
Which is only possible because of the first rule.
Insta-stabilize the methods `is_ready` and `is_pending` of `Poll`.
Possible because of the recent stabilization of const control flow.
Also adds a test for these methods in a const context.
Makes the following methods of `std::net::Ipv4Addr` unstable const under the `const_ipv4` feature:
- `is_global`
- `is_reserved`
- `is_broadcast`
- `to_ipv6_compatible`
- `to_ipv6_mapped`
This results in all methods of `Ipv4Addr` being const.
Also adds tests for these methods in a const context.
Make the following methods of `std::net::Ipv6Addr` unstable const under the `const_ipv6` feature:
- `segments`
- `is_unspecified`
- `is_loopback`
- `is_global` (unstable)
- `is_unique_local`
- `is_unicast_link_local_strict`
- `is_documentation`
- `multicast_scope`
- `is_multicast`
- `to_ipv4_mapped`
- `to_ipv4`
Changed the implementation of `is_unspecified` and `is_loopback` to use a `match` instead of `==`.
Part of #76205
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Stabilizes these methods as const under the `const_ordering` feature.
Also adds a test for these methods in a const context.
Possible because of #49146 (Allow `if` and `match` in constants).
rename get_{ref, mut} to assume_init_{ref,mut} in Maybeuninit
References #63568
Rework with comments addressed from #66174
Have replaced most of the occurrences I've found, hopefully didn't miss out anything
r? @RalfJung
(thanks @danielhenrymantilla for the initial work on this)
This reverts commit 7e2548fe69.
Now I know why it was redefined: it seems like it's potentially because
of the orphan rule. Here are the error messages:
error[E0119]: conflicting implementations of trait `std::fmt::Debug` for type `!`:
--> src/primitive_docs.rs:236:1
|
6 | impl Debug for ! {
| ^^^^^^^^^^^^^^^^
|
= note: conflicting implementation in crate `core`:
- impl std::fmt::Debug for !;
error[E0117]: only traits defined in the current crate can be implemented for arbitrary types
--> src/primitive_docs.rs:236:1
|
6 | impl Debug for ! {
| ^^^^^^^^^^^^^^^-
| | |
| | `!` is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
Make `cow_is_borrowed` methods const
Constify the following methods of `alloc::borrow::Cow`:
- `is_borrowed`
- `is_owned`
Analogous to the const methods `is_some` and `is_none` for Option, and `is_ok` and `is_err` for Result.
These methods are still unstable under `cow_is_borrowed`.
Possible because of #49146 (Allow if and match in constants).
Tracking issue: #65143
Move `#[cfg(test)]` modules into separate files to save recompiling the `std` crate
Implements an accepted proposal: https://github.com/rust-lang/compiler-team/issues/344
Some notes for reviewers:
* `mod tests` nested in `mod foo` in `mod bar`, I move `foo` to a new file, `tests` is a new file in foo: For example library/std/src/sys/sgx/abi/tls.rs
* `mod test` (not `mod tests`) also is moved.
* `mod benches` are moved.
* `mod tests` is placed before any `use` statements: The topic is discussed in https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Code.20Style.20process
* Some files in cloudabi was changed too. But I notice copyright banners in those files, should we ping cloudabi people?
* I formatted files after moving tests around. I think that may make it easier to review :p .
* Some files don't need `ignore-tidy-filelength` anymore.
Get rid of bounds check in slice::chunks_exact() and related function…
…s during construction
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
Use intra-doc links for `core/src/slice.mod.rs`
partial help in #75080
r? @jyn514
- most are using primitive types links, which cannot be used with intra links at the moment
- also `std` cannot be referenced in any link, `std::ptr::NonNull` and `std::slice` could not be referenced
Add `-Z proc-macro-backtrace` to allow showing proc-macro panics
Fixes#75050
Previously, we would unconditionally suppress the panic hook during
proc-macro execution. This commit adds a new flag
`-Z proc-macro-backtrace`, which allows running the panic hook for
easier debugging.
Constify the following methods of `std::net::Ipv4Addr`:
- `octets`
- `is_loopback`
- `is_private`
- `is_link_local`
- `is_shared`
- `is_ietf_protocol_assignment`
- `is_benchmarking`
- `is_multicast`
- `is_documentation`
Also insta-stabilizes these methods as const.
Possible because of the stabilization of const integer arithmetic and control flow.
Fixes#75050
Previously, we would unconditionally suppress the panic hook during
proc-macro execution. This commit adds a new flag
-Z proc-macro-backtrace, which allows running the panic hook for
easier debugging.
Constify the following methods of `alloc::borrow::Cow`:
- `is_borrowed`
- `is_owned`
These methods are still unstable under `cow_is_borrowed`.
Possible because of #49146 (Allow if and match in constants).
Tracking issue: #65143
Make some Ordering methods const
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Possible because of #49146 (Allow `if` and `match` in constants).
Tracking issue: #76113
Stabilize the following methods of `Result` as const:
- `is_ok`
- `is_err`
- `as_ref`
Possible because of stabilization of #49146 (Allow if and match in constants).
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
These are unsafe variants of the non-unchecked functions and don't do
any bounds checking.
For the time being these are not public and only a preparation for the
following commit. Making it public and stabilization can follow later
and be discussed in https://github.com/rust-lang/rust/issues/76014 .
`alloc::slice` uses `core::slice` functions, documentation are copied
from there and the links as well without resolution. `crate::ptr...`
cannot be resolved in `alloc::slice`, but `ptr` itself is imported in
both `alloc::slice` and `core::slice`, so we used that instead.
vars() rather than vars function
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use [xxx()] rather than the [xxx] function
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Env text representation of function intra-doc link
Suggested by @jyn514
Link join_paths in env doc for parity
Change xxx to env::xxx for lib env doc
Add link requsted by @jyn514
Fix doc build with same link
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Fix missing intra-doc link
Fix added whitespace in doc
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Add brackets for `join_paths`
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use unused link join_paths
Removed same link for join_paths
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Remove unsed link join_paths
Move to intra-doc links for library/core/src/sync/atomic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from core to std:
[`Arc`]
[`std:🧵:yield_now`]
[`std:🧵:sleep`]
[`std::sync::Mutex`]
Shorten liballoc doc intra link while readable
r? @jyn514
Do you want to reviews these sort of pull requests in the future? I might send a few of them while reading vec code.
The most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T.
Which is only possible because of the first rule.
Update compiler-builtins
Update the compiler-builtins dependency to include latest changes.
This allows for `aarch64-unknown-linux-musl` to pass all tests.
Fixes#57820 and fixes#46651
Substantial refactor to the design of LineWriter
# Preamble
This is the first in a series of pull requests designed to move forward with https://github.com/rust-lang/rust/issues/60673 (and the related [5 year old FIXME](ea7181b5f7/src/libstd/io/stdio.rs (L459-L461))), which calls for an update to `Stdout` such that it can be block-buffered rather than line-buffered under certain circumstances (such as a `tty`, or a user setting the mode with a function call). This pull request refactors the logic `LineWriter` into a `LineWriterShim`, which operates on a `BufWriter` by mutable reference, such that it is easy to invoke the line-writing logic on an existing `BufWriter` without having to construct a new `LineWriter`.
Additionally, fixes#72721
## A note on flushing
Because the word **flush** tends to be pretty overloaded in this discussion, I'm going to use the word **unbuffered** to refer to a `BufWriter` sending its data to the wrapped writer via `write`, without calling `flush` on it, and I'll be using **flushed** when referring to sending data via flush, which recursively writes the data all the way to the final sink.
For example, given a `T = BufWriter<BufWriter<File>>`, saying that `T` **unbuffers** its data means that it is sent to the inner `BufWriter`, but not necessarily to the `File`, whereas saying that `T` **flushes** its data means that causes it (via `Write::flush`) to be delivered all the way to `File`.
# Goals
Once it became clear (for reasons described below) that the best way to approach this would involve refactoring `LineWriter` to work more directly on `BufWriter`'s internals, I established the following design goals for the refactor:
- Do not duplicate logic with `BufWriter`. It's great at buffering and then unbuffering data, so use the existing logic as much as possible.
- Minimize superfluous copying of data into `BufWriter`'s buffer.
- Eliminate calls to `BufWriter::flush` and instead do the same thing as `BufWriter::write`, which is to only write to the wrapped writer (rather than flushing all the way down to the final data sink).
- Uphold the "at-most 1 write of new data" convention of `Write::write`
- Minimize or eliminate dropping errors (that is, eliminate the parts of the old design that threw away errors because `write` *must* report if any bytes were written)
- As much as possible, attempt to fully flush completed lines, and *not* flush partial lines. One of the advantages of this design is that, so long as we don't encounter lines larger than the `BufWriter`'s capacity, partial lines will never be unbuffered, while completed lines will *always* be unbuffered (with subsequent calls to `LineWriter::write` retrying failed writes before processing new data.
# Design
There are two major & related parts of the design.
First, a new internal stuct, `LineWriterShim`, is added. This struct implements all of the actual logic of line-writing in a `Write` implementation, but it only operates on an `&mut BufWriter`. This means that this shim can be constructed on-the-fly to apply line writing logic to an existing `BufWriter`. This is in fact how `LineWriter` has been updated to operate, and it is also how `Stdout` is being updated in my [development branch](https://github.com/Lucretiel/rust/tree/stdout-block-buffer) to switch which mode it wants to use at runtime.
[An example of how this looks in practice](f24f272df6/src/libstd/io/stdio.rs (L479-L484)
)
The second major part of the design that the line-buffering logic, implemented in `LineWriterShim`, has been updated to work slightly more directly on the internals of `BufWriter`. Mostly it makes us of the public interface—particularly `buffer()` and `get_mut()`—but it also controls the flushing of the buffer with `flush_buf` rather than `flush`, and it writes to the buffer infallibly with a new `write_to_buffer` method. This has several advantages:
- Data no longer has to round trip through the `BufWriter`'s buffer. If the user provides a complete line, that line is written directly to the inner writer (after ensuring the existing buffer is flushed).
- The conventional contract of `write`—that at-most 1 attempt to write new data is made—is much more cleanly upheld, because we don't have to perform fallible flushes and perform semi-complicated logic of trying to pretend errors at different stages didn't happen. Instead, after attempting to write lines directly to the buffer, we can infallibly add trailing data to the buffer without allowing any attempts to continue writing it to the `inner` writer.
- Perhaps most importantly, `LineWriter` *no longer performs a full flush on every line.* This makes its behavior much more consistent with `BufWriter`, which unbuffers data to its inner writer, without trying to flush it all the way to the final device. Previously, `LineWriter` had no choice but to use `flush` to ensure that the lines were unbuffered, but by writing directly to `inner` via `get_mut()` (when appropriate), we can use a more correct behavior.
## New(ish) line buffering logic
The logic for line writing has been cleaned up, as described above. It now follows this algorithm for `write`, with minor adjustments for `write_all` and `write_vectored`:
- Does our input data contain a newline?
- If no:
- simply use the regular `BufWriter::write` to write it; this will append it to the buffer and/or flush it as necessary based on how full the buffer is and how much input data there is.
- additionally, if the current buffer ends with `'\n'`, attempt to immediately flush it with `flush_buf` before calling `BufWriter::write` This reproduces the old `needs_flush` behavior and ensures completed lines are flushed as soon as possible. The reason we only check if the buffer *ends* with `'\n'` is discussed later.
- If yes:
- First, `flush_buf`
- Then use `bufwriter.get_mut().write()` to write the input data directly to the underlying writer, up to the last newline. Make at most one attempt at this.
- If it errors, return the error
- If it succeeds with a full write, add the remaining data (between the last newline and the end of the input) to the buffer. In order to uphold the "at-most 1 attempt to write new data" convention, no attempts are made to write this data to the inner writer (though obviously a subsequent write may immediately flush it, e.g., if it totally filled the buffer's capacity.
- If it only partially succeeds, buffer the data only up to the last newline. We do this to try to avoid writing partial lines to the inner writer where possible (that is, whenever the lines are shorter than the total buffer capacity).
While it was not my intention for this behavior to diverge from this existing `LineWriter` algorithm, this updated design emerged very naturally once `LineWriter` wasn't burdened with having to only operate via `BufWriter::flush`. There essentially two main changes to observable behavior:
- `flush` is no longer used to unbuffer lines. The are only written to the writer wrapped by `LineWriter`; this inner writer might do its own buffering. This change makes `LineWriter` consistent with the behavior of `BufWriter`. This is probably the most obvious user-visible change; it's the one I most expect to provoke issue reports, if any are provoked.
- Unless a line exceeds the capacity of the buffer, partial lines are not unbuffered (without the user manually calling flush). This is a less surprising behavior, and is enabled because `LineWriter` now has more precise control of what data is buffered and when it is unbuffered. I'd be surprised if anyone is relying on `LineWriter` unbuffering or flushing *partial* lines that are shorter than the capacity, so I'm not worried about this one.
None of these changes are inconsistent with any published documentation of `LineWriter`. Nonetheless, like all changes with user-facing behavior changes, this design will obviously have to be very carefully scrutinized.
# Alternative designs and design rationalle
The initial goal of this project was to provide a way for the `LineWriter` logic to be operable directly on a `BufWriter`, so that the updated `Stdout` doesn't need to do something convoluted like `enum { BufWriter, LineWriter }` (which ends up being ~~impossible~~ difficult to transition between states after being constructed). The design went through several iterations before arriving at the current draft.
The major first version simply involved adding methods like `write_line_buffered` to `BufWriter`; these would contain the actual logic of line-buffered writing, and would additionally have the advantages (described above) of operating directly on the internals of `BufWriter`. The idea was that `LineWriter` would simply call these methods, and the updated `Stdout` would use either `BufWriter::write` or `BufWriter::write_line_buffered`, depending on what mode it was in.
The major issue with this design is that it loses the ability to take advantage of the `io::Write` trait, which provides several useful default implementations of the various io methods, such as `write_fmt` and `write_all`, just using the core methods. For this reason, the `write_line_buffered` design was retained, but moved into a separate struct called `LineWriterShim` which operates on an `&mut LineWriter`. As part of this move, the logic was lightly retooled to not touch the innards of `BufWriter` directly, but instead to make use of the unexported helper methods like `flush_buf`.
The other design evolutions were mostly related to answering questions like "how much data should be buffered", "how should partial line writes be handled", etc. As much as possible I tried to answer these by emulating the current `LineWriter` logic (which, for example, retries partial line writes on subsequent calls to `write`) while still meeting the refactor design goals.
# Next steps
~Currently, this design fails a few `LineWriter` tests, mostly because they expect `LineWriter` to *fully* flush its content. There are also some changes to the way that `LineWriter` buffers data *after* writing completed lines, aimed at ensuring that partial lines are not unbuffered prematurely. I want to make sure I fully understand the intent behind these tests before I either update the test or update this design so that they pass.~
However, in the meantime I wanted to get this published so that feedback could start to accumulate on it. There's a lot of errata around how I arrived at this design that didn't really fit in this overlong document, so please ask questions about anything that confusing or unclear and hopefully I can explain more of the rationale that led to it.
# Test updates
This design required some tests to be updated; I've research the intent behind these tests (mostly via `git blame`) and updated them appropriately. Those changes are cataloged here.
- `test_line_buffer_fail_flush`: This test was added as a regression test for #32085, and is intended to assure that an errors from `flush` aren't propagated when preceded by a successful `write`. Because type of issue is no longer possible, because `write` calls `buffer.get_mut().write()` instead of `buffer.write(); buffer.flush();`, I'm simply removing this test entirely. Other, similar error invariants related to errors during write-retrying are handled in other test cases.
- `erroneous_flush_retried`: This test was added as a regression test for #37807, and was intended to ensure that flush-retrying (via `needs_flush`) and error-ignoring were being handled correctly (ironically, this issue was caused by the flush-error-ignoring, above). Half of that issue is not possible by design with this refactor, because we no longer make fallible i/o calls that might produce errors we have to ignore after unbuffering lines. The `should_flush` behavior is captured by checking for a trailing newline in the `LineWriter` buffer; this test now checks that behavior.
- `line_vectored`: changes here were pretty minor, mostly related to when partial lines are or aren't written. The old implementation of `write_vectored` used very complicated logic to precisely determine the location of the last newline and precisely write up to that point; this required doing several consecutive fallible writes, with all the complex error handling or ignoring issues that come with it. The updated design does at-most one write of a subset of total buffers (that is, it doesn't split in the middle of a buffer), even if that means writing partial lines. One of the major advantages of the new design is that the underlying vectored write operation on the device can be taken advantage of, even with small writes, so long as they include a newline; previously these were unconditionally buffered then written.
- `line_vectored_partial_and_errors`: Pretty similiar to `line_vectored`, above; this test is for basic error recovery in `write_vectored` for vectored writes. As previously discussed, the mocked behavior being tested for (errors ignored under certain circumstances) no occurs, so I've simplified the test while doing my best to retain its spirit.
Add InstrProfilingPlatformFuchsia.c to profiler_builtins
All other Platform files included in `llvm-project/compiler-rt` were
present, except Fuchsia.
Now that there is a functional end-to-end version of
`-Zinstrument-coverage`, I need to start building and testing
coverage-enabled Rust programs on Fuchsia, and this file is required.
r? @tmandry
FYI, @wesleywiser
Fix potential UB in align_offset doc examples
Currently it takes a pointer only to the first element in the array, this changes the code to take a pointer to the whole array.
miri can't catch this right now because it later calls `x.len()` which re-tags the pointer for the whole array.
https://github.com/rust-lang/miri/issues/1526#issuecomment-680897144
Abort when foreign exceptions are caught by catch_unwind
Prior to this PR, foreign exceptions were not caught by catch_unwind, and instead passed through invisibly. This represented a painful soundness hole in some libraries ([take_mut](https://github.com/Sgeo/take_mut/blob/master/src/lib.rs#L37)), which relied on `catch_unwind` to handle all possible exit paths from a closure.
With this PR, foreign exceptions are now caught by `catch_unwind` and will trigger an abort since catching foreign exceptions is currently UB according to the latest proposals by the FFI unwind project group.
cc @rust-lang/wg-ffi-unwind
All other Platform files included in `llvm-project/compiler-rt` were
present, except Fuchsia.
Now that there is a functional end-to-end version of
`-Zinstrument-coverage`, I need to start building and testing
coverage-enabled Rust programs on Fuchsia, and this file is required.
[AVR] Replace broken 'avr-unknown-unknown' target with 'avr-unknown-gnu-atmega328' target
The `avr-unknown-unknown` target has never worked correctly, always trying to invoke
the host linker and failing. It aimed to be a mirror of AVR-GCC's
default handling of the `avr-unknown-unknown' triple (assume bare
minimum chip features, silently skip linking runtime libraries, etc).
This behaviour is broken-by-default as it will cause a miscompiled executable
when flashed.
This patch improves the AVR builtin target specifications to instead
expose only a 'avr-unknown-gnu-atmega328' target. This target system is
`gnu`, as it uses the AVR-GCC frontend along with avr-binutils. The
target triple ABI is 'atmega328'.
In the future, it should be possible to replace the dependency on
AVR-GCC and binutils by using the in-progress AVR LLD and compiler-rt support.
Perhaps at that point it would make sense to add an
'avr-unknown-unknown-atmega328' target as a better default when
implemented.
There is no current intention to add in-tree AVR target specifications for other
AVR microcontrollers - this one can serve as a reference implementation
for other devices via `rustc --print target-spec-json
avr-unknown-gnu-atmega328p`.
There should be no users of the existing 'avr-unknown-unknown' Rust
target as a custom target specification JSON has always been
recommended, and the avr-unknown-unknown target could never pass the
linking step anyway.
Update docs for SystemTime Windows implementation
Windows now uses `GetSystemTimePreciseAsFileTime` (since #69858) on versions of Windows that support it.
Unconfuse Unpin docs a bit
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
Call into fastfail on abort in libpanic_abort on Windows x86(_64)
This partially resolves#73215 though this is only for x86 targets. This code is directly lifted from [libstd](13290e83a6/library/std/src/sys/windows/mod.rs (L315)). `__fastfail` is the preferred way to abort a process on Windows as it will hook into debugger toolchains.
Other platforms expose a `_rust_abort` symbol which wraps `std::sys::abort_internal`. This would also work on Windows, but is a slightly largely change as we'd need to make sure that the symbol is properly exposed to the linker. I'm inlining the call to the `__fastfail`, but the indirection through `rust_abort` might be a cleaner approach.
A different instruction must be used on ARM architectures. I'd like to verify this works first before tackling ARM.
I would like to propose these two simple methods for stabilization:
- Knowing that a range is exhaused isn't otherwise trivial
- Clippy would like to suggest them, but had to do extra work to disable that path <https://github.com/rust-lang/rust-clippy/issues/3807> because they're unstable
- These work on `PartialOrd`, consistently with now-stable `contains`, and are thus more general than iterator-based approaches that need `Step`
- They've been unchanged for some time, and have picked up uses in the compiler
- Stabilizing them doesn't block any future iterator-based is_empty plans, as the inherent ones are preferred in name resolution
Minor changes to Ipv4Addr
Minor changes to Ipv4Addr
* Impl IntoInner rather than AsInner for Ipv4Addr
* Add some comments
* Add test to show endiannes of Ipv4Addr display
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
Report an ambiguity if both modules and primitives are in scope for intra-doc links
Closes https://github.com/rust-lang/rust/issues/75381
- Add a new `prim@` disambiguator, since both modules and primitives are in the same namespace
- Refactor `report_ambiguity` into a closure
Additionally, I noticed that rustdoc would previously allow `[struct@char]` if `char` resolved to a primitive (not if it had a DefId). I fixed that and added a test case.
I also need to update libstd to use `prim@char` instead of `type@char`. If possible I would also like to refactor `ambiguity_error` to use `Disambiguator` instead of its own hand-rolled match - that ran into issues with `prim@` (I updated one and not the other) and it would be better for them to be in sync.
Use allow(unused_imports) instead of cfg(doc) for imports used only for intra-doc links
This prevents links from breaking when items are re-exported in a
different crate and the original isn't being documented.
Spotted in https://github.com/rust-lang/rust/pull/75832#discussion_r475275837 (thanks ollie!)
r? @ollie27
Fix typo in documentation of i32 wrapping_abs()
Hi!
I was reading through the std library docs and noticed that this section flowed a bit oddly; comparing it against https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_div and https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_neg , I noticed that those two pieces of documentation used a semicolon here.
This is my first time submitting a PR to this repo. Am I doing this right? Are tiny typo-fix PRs like this worth submitting, or are they not a good use of time?
Thank you!
Switch to intra-doc links in `std::macros`
Part of #75080.
---
* Switch to intra-doc links in `std::macros`
* Fix typo in module docs
* Link to `std::io::stderr` instead of `std::io::Stderr` to match the
link text
* Link to `std::io::stdout`
---
@rustbot modify labels: A-intra-doc-links T-doc T-rustdoc
Document that slice refers to any pointer type to a sequence
I was recently confused about the way slices are represented in memory. The necessary information was not available in the std-docs directly, but was a mix of different material from the reference and book.
This PR should clear up the definition of slices a bit more in the documentation. Especially the fact that the term slice refers to the pointer/reference type, e.g. `&[T]`, and not `[T]`.
It also documents that slice pointers are twice the size of pointers to `Sized` types, as this concept may be unfamiliar to users coming from other languages that do not have the concept of "fat pointers" (especially C/C++).
I've documented why this was important to me and my findings in [this blog post](https://codecrash.me/understanding-rust-slices).
r? @lcnr
stabilize ptr_offset_from
This stabilizes ptr::offset_from, and closes https://github.com/rust-lang/rust/issues/41079. It also removes the deprecated `wrapping_offset_from`. This function was deprecated 19 days ago and was never stable; given an FCP of 10 days and some waiting time until FCP starts, that leaves at least a month between deprecation and removal which I think is fine for a nightly-only API.
Regarding the open questions in https://github.com/rust-lang/rust/issues/41079:
* Should offset_from abort instead of panic on ZSTs? -- As far as I know, there is no precedent for such aborts. We could, however, declare this UB. Given that the size is always known statically and the check thus rather cheap, UB seems excessive.
* Should there be more methods like this with different restrictions (to allow nuw/nsw, perhaps) or that return usize (like how isize-taking offset is more conveniently done with usize-taking add these days)? -- No reason to block stabilization on that, we can always add such methods later.
Also nominating the lang team because this exposes an intrinsic.
The stabilized method is best described [by its doc-comment](56d4b2d69a/src/libcore/ptr/const_ptr.rs (L227)). The documentation forgot to mention the requirement that both pointers must "have the same provenance", aka "be derived from pointers to the same allocation", which I am adding in this PR. This is a precondition that [Miri already implements](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=a3b9d0a07a01321f5202cd99e9613480) and that, should LLVM ever obtain a `psub` operation to subtract pointers, will likely be required for that operation (following the semantics in [this paper](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf)).
New zeroed slice
Add to #63291 the methods
```rust
impl<T> Box<[T]> { pub fn new_zeroed_slice(len: usize) -> Box<[MaybeUninit<T>]> {…} }
impl<T> Rc<[T]> { pub fn new_zeroed_slice(len: usize) -> Rc<[MaybeUninit<T>]> {…} }
impl<T> Arc<[T]> { pub fn new_zeroed_slice(len: usize) -> Arc<[MaybeUninit<T>]> {…} }
```
as suggested in https://github.com/rust-lang/rust/issues/63291#issuecomment-605511675 .
Also optimize `{Rc, Arc}::new_zeroed` to use `alloc_zeroed`, otherwise they are no more efficient than using `new_uninit` and zeroing the memory manually (which was the original implementation).
Move to intra-doc links for library/core/src/alloc/{layout, global, mod}.rs
Helps with #75080. The files already contained intra-doc links, so there are only minor changes.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* [`handle_alloc_error`]: Link from `core` to `alloc` could not be resolved.
* [`slice`]: slice is a primitive type, but could not be resolved; had to use [`crate::slice`] instead.
Move to intra-doc links for /library/core/src/intrinsics.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* The following f32 and f64 primitive methods cannot be resolved:
f32/f64::powi
f32/f64::sqrt
f32/f64::sin
f32/f64::cos
f32/f64::powf
f32/f64::exp
f32/f64::exp2
f32/f64::ln
f32/f64::log2
f32/f64::log10
f32/f64::mul_add
f32/f64::abs
f32/f64::copysign
f32/f64::floor
f32/f64::ceil
f32/f64::trunc
f32/f64::round
* Links from core to std:
[`std::pointer::*`]
[`std::process::abort`]
[`from_raw_parts`]
[`Vec::append`]
* Links with anchors?
I provided a separate commit that replaced links with anchors by intra-doc links.
Here the anchor location information gets lost, so its questionable whether to
actually replace those links.
enable align_to tests in Miri
With https://github.com/rust-lang/miri/issues/1074 resolved, we can enable these tests in Miri.
I also tweaked the test sized to get reasonable execution times with decent test coverage.
clarify documentation of remove_dir errors
remove_dir will error if the path doesn't exist or isn't a directory.
It's useful to clarify that this is "remove dir or fail" not "remove dir
if it exists".
I don't think this belongs in the title. "Removes an existing, empty
directory" is strangely worded-- there's no such thing as a non-existing
directory. Better to just say explicitly it will return an error.
Use min_specialization in libcore
Getting `TrustedRandomAccess` to work is the main interesting thing here.
- `get_unchecked` is now an unstable, hidden method on `Iterator`
- The contract for `TrustedRandomAccess` is made clearer in documentation
- Fixed a bug where `Debug` would create aliasing references when using the specialized zip impl
- Added tests for the side effects of `next_back` and `nth`.
closes#68536
Move to intra-doc links for task.rs and vec.rs
Partial fix for #75080
links for [`get`], [`get_mut`] skipped due to #75643
link for [`copy_from_slice`] skipped due to #63351
`stride == 1` case can be computed more efficiently through `-p (mod
a)`. That, then translates to a nice and short sequence of LLVM
instructions:
%address = ptrtoint i8* %p to i64
%negptr = sub i64 0, %address
%offset = and i64 %negptr, %a_minus_one
And produces pretty much ideal code-gen when this function is used in
isolation.
Typical use of this function will, however, involve use of
the result to offset a pointer, i.e.
%aligned = getelementptr inbounds i8, i8* %p, i64 %offset
This still looks very good, but LLVM does not really translate that to
what would be considered ideal machine code (on any target). For example
that's the codegen we obtain for an unknown alignment:
; x86_64
dec rsi
mov rax, rdi
neg rax
and rax, rsi
add rax, rdi
In particular negating a pointer is not something that’s going to be
optimised for in the design of CISC architectures like x86_64. They
are much better at offsetting pointers. And so we’d love to utilize this
ability and produce code that's more like this:
; x86_64
lea rax, [rsi + rdi - 1]
neg rsi
and rax, rsi
To achieve this we need to give LLVM an opportunity to apply its
various peep-hole optimisations that it does during DAG selection. In
particular, the `and` instruction appears to be a major inhibitor here.
We cannot, sadly, get rid of this load-bearing operation, but we can
reorder operations such that LLVM has more to work with around this
instruction.
One such ordering is proposed in #75579 and results in LLVM IR that
looks broadly like this:
; using add enables `lea` and similar CISCisms
%offset_ptr = add i64 %address, %a_minus_one
%mask = sub i64 0, %a
%masked = and i64 %offset_ptr, %mask
; can be folded with `gepi` that may follow
%offset = sub i64 %masked, %address
…and generates the intended x86_64 machine code. One might also wonder
how the increased amount of code would impact a RISC target. Turns out
not much:
; aarch64 previous ; aarch64 new
sub x8, x1, #1 add x8, x1, x0
neg x9, x0 sub x8, x8, #1
and x8, x9, x8 neg x9, x1
add x0, x0, x8 and x0, x8, x9
(and similarly for ppc, sparc, mips, riscv, etc)
The only target that seems to do worse is… wasm32.
Onto actual measurements – the best way to evaluate snippets like these
is to use llvm-mca. Much like Aarch64 assembly would allow to suspect,
there isn’t any performance difference to be found. Both snippets
execute in same number of cycles for the CPUs I tried. On x86_64,
we get throughput improvement of >50%, however!
Remove `#[cfg(miri)]` from OnceCell tests
They were carried over from once_cell crate, but they are not entirely
correct (as miri now supports more things), and we don't run miri
tests for std, so let's just remove them.
Maybe one day we'll run miri in std, but then we can just re-install
these attributes.
Move to intra doc links for std::io
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
r? @jyn514
I had no problems with those files so I added some small links here and there.
Improve codegen for `align_offset`
In this PR the `align_offset` implementation is changed/improved to produce better code in certain scenarios such as when pointer type is has a stride of 1 or when building for low optimisation levels.
While these changes do not achieve the "ideal" codegen referenced in #75579, it gets significantly closer to it. I’m not actually sure if the codegen can actually be much better with this function returning the offset, rather than the aligned pointer.
See the descriptions for separate commits for further information.
They were carried over from once_cell crate, but they are not entirely
correct (as miri now supports more things), and we don't run miri
tests for std, so let's just remove them.
Maybe one day we'll run miri in std, but then we can just re-install
these attributes.
Switch to intra-doc links in /src/sys/unix/ext/*.rs
Partial fix for #75080
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
r? @jyn514
These two links are not resolving to either `crate::fs::File...` or `fs::File...`
```
# unix/ext/fs.rs
27: /// [`File::read`]: ../../../../std/fs/struct.File.html#method.read
130: /// [`File::write`]: ../../../../std/fs/struct.File.html#method.write
```
docs(marker/copy): provide example for `&T` being `Copy`
### Edited 2020-08-16 (most recent)
In the current documentation about the `Copy` marker trait, there is a section
with examples of structs that can implement `Copy`. Currently there is no example for
showing that shared references (`&T`) are also `Copy`.
It is worth to have a dedicated example for `&T` being `Copy`, because shared
references are an integral part of the language and it being `Copy` is not as
intuitive as other types that share this behaviour like `i32` or `bool`.
The example picks up on the previous non-`Copy` struct and shows that
structs can be `Copy`, even when they hold a shared reference to a non-`Copy` type.
-----------------------------------------
### Edited 2020-08-02, 3:28 p.m.
I've just realized that it says "in addition to the **implementors listed below**", which makes this PR kind of "wrong", because `&T` is indeed in the "implementors listed below".
Maybe we can instead show an example with `&T` in the [When can my type be Copy](https://doc.rust-lang.org/std/marker/trait.Copy.html#when-can-my-type-be-copy) section.
What I really want to achieve is that it becomes more obvious that `&T` is also `Copy`, because, I think, it is very valuable to know and it wasn't obvious for me, until I read something about it in a forum post.
What do you think? I would create another PR for that.
**Please feel free to close this PR.**
-----------------------------------
### Original post
In the current documentation about the `Copy` marker trait, there is a section
about "additional implementors", which list additional implementors of the `Copy` trait.
The fact that shared references are also `Copy` is mixed with another point,
which makes it hard to recognize and make it seem not as important.
This clarifies the fact that shared references are also `Copy`, by mentioning it as a
separate item in the list of "additional implementors".
See also X-Link mem::{swap, take, replace}
Since it's easy to end up at one of these functions when you really wanted the other one, cross link them with descriptions of why you'd want to use them.
Don't panic in Vec::shrink_to_fit
We can help the compiler see that `Vec::shrink_to_fit` will never reach the panic case in `RawVec::shrink_to_fit`, just by guarding the call only for cases where the capacity is strictly greater. A capacity less than the length is only possible through an unsafe call to `set_len`, which would break the `Vec` invariants, so `shrink_to_fit` can just ignore that.
This removes the panicking code from the examples in both #71861 and #75636.
Move to intra doc links for ascii.rs and panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
I also updated the doc to fix the wording in `AsciiExt` since it is now deprecated.
The two file are small changes so I bundled them together.
Some links could not be changed to make them work, I believe those are known issues with primitive types.
Add `as_uninit`-like methods to pointer types and unify documentation of `as_ref` methods
This adds a convenient method to retrieve a `&(mut) [MaybeUninit<T>]` from slice pointers (`*const [T]`, `*mut [T]`, `NonNull<[T]>`). See also https://github.com/rust-lang/wg-allocators/issues/66#issuecomment-671789105.
~I'll add a tracking issue as soon as it's reviewed and CI passed.~
Tracking Issue: #75402
r? @RalfJung
Reference lang items during AST lowering
Fixes#60607 and fixes#61019.
This PR introduces `QPath::LangItem` to the HIR and uses it in AST lowering instead of constructing a `hir::Path` from a slice of symbols:
- Credit for much of this work goes to @matthewjasper, I basically just [rebased their earlier work](a227c706b7 (diff-c0f791ead38d2d02916faaad0f56f41d)).
- ~~Changes to Clippy might not be correct, they compile but attempting to run tests through `./x.py` produced failures which appeared spurious, so I didn't run any clippy tests.~~
- Changes to save analysis might not be correct - tests pass but I don't have a lot of confidence in those changes being correct.
- I've used `GenericBounds::LangItemTrait` rather than changing `PolyTraitRef`, as suggested by @matthewjasper [in this comment](a227c706b7 (r40107992)) but I'd prefer that be left for a follow-up.
- I've split things into smaller commits fairly arbitrarily to make the diff easier to review, each commit should compile but might not pass tests until the final commit.
r? @oli-obk
cc @matthewjasper
Fix example in `NonNull::as_uninit_slice`
Rename feature gate to "ptr_as_uninit"
Make methods more consistent with already stable methods
Make `pointer::as_uninit_slice` return an `Option`
Fix placement for `// SAFETY` section
Add `as_uninit_ref` and `as_uninit_mut` to pointers
Fix doctest
Update tracking issue
Fix doc links
Apply suggestions from review
Make wording about counterparts consistent
Fix doc links
Improve documentation
Fix doc-tests
Fix doc links ... again
Apply suggestions from review
Apply suggestions from Review
Apply suggestion from review to all affected files
Add missing words in safety sections in `as_uninit_slice_mut`
Fix safety-comment in `NonNull::as_uninit_slice_mut`
Move to intra-doc links for /library/core/src/any.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Links from `core` to `std` (#74481):
* `[Box]: ../../std/boxed/struct.Box.html`
pin docs: add some forward references
@nagisa had some questions about pinning that were answered in the docs, which they did not realize because that discussion is below the examples. I still think it makes sense to introduce the examples before that discussion, since it give the discussion something concrete to refer to, but this PR adds some forward references so people don't think the examples conclude the docs.
@nagisa do you think this would have helped?
Code blocks in doc comments are compiled and run, so we show `Copy` works in this example.
Co-authored-by: Poliorcetics <poliorcetics@users.noreply.github.com>
Previously checking for `pmoda == 0` would get LLVM to generate branchy
code, when, for `stride = 1` the offset can be computed without such a
branch by doing effectively a `-p % a`.
For well-known (constant) alignments, with the new ordering of these
conditionals, we end up generating 2 to 3 cheap instructions on x86_64:
movq %rdi, %rax
negl %eax
andl $7, %eax
instead of 5+ as previously.
For unknown alignments the new code also generates just 3 instructions:
negq %rdi
leaq -1(%rsi), %rax
andq %rdi, %rax
At opt-level <= 1, the methods such as `wrapping_mul` are not being
inlined, causing significant bloating and slowdowns of the
implementation at these optimisation levels.
With use of these intrinsics, the codegen of this function at
-Copt_level=1 is the same as it is at -Copt_level=3.
In the current documentation about the `Copy` marker trait, there is a section
with examples of structs that can implement `Copy`. Currently there is no example for
showing that shared references (`&T`) are also `Copy`.
It is worth to have a dedicated example for `&T` being `Copy`, because shared
references are an integral part of the language and it being `Copy` is not as
intuitive as other types that share this behaviour like `i32` or `bool`.
The example picks up on the previous non-`Copy` struct and shows that
structs can be `Copy`, even when they hold a shared reference to a non-`Copy` type.
This commit adds new lang items which will be used in AST lowering once
`QPath::LangItem` is introduced.
Co-authored-by: Matthew Jasper <mjjasper1@gmail.com>
Signed-off-by: David Wood <david@davidtw.co>
Move to intra doc links in std::net
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
The links for `true` and `false` had to stay else `rustdoc` complained, it is intended ?
Doc: String isn't a collection
On forums one user was confused by this text, interpreting it as saying that `String` is a `Vec<char>` literally, rather than figuratively for the purpose of collect. I've reworded that paragraph.
Switch to intra-doc links in `core::option`
Part of #75080.
I didn't change some of the links since they link into `std` and you can't link from `core` to `std` (#74481).
Also, at least one other link can't be switched to an intra-doc link because it's not supported yet (#74489).
Add sanitizer support on FreeBSD
Restarting #47337. Everything is better now, no more weird llvm problems, well not everything:
Unfortunately, the sanitizers don't have proper support for versioned symbols (https://github.com/google/sanitizers/issues/628), so `libc`'s usage of `stat@FBSD_1.0` and so on explodes, e.g. in calling `std::fs::metadata`.
Building std (now easy thanks to cargo `-Zbuild-std`) and libc with `freebsd12/13` config via the `LIBC_CI=1` env variable is a good workaround…
```
LIBC_CI=1 RUSTFLAGS="-Z sanitizer=address" cargo +san-test -Zbuild-std run --target x86_64-unknown-freebsd --verbose
```
…*except* std won't build because there's no `st_lspare` in the ino64 version of the struct, so an std patch is required:
```diff
--- i/src/libstd/os/freebsd/fs.rs
+++ w/src/libstd/os/freebsd/fs.rs
@@ -66,8 +66,6 @@ pub trait MetadataExt {
fn st_flags(&self) -> u32;
#[stable(feature = "metadata_ext2", since = "1.8.0")]
fn st_gen(&self) -> u32;
- #[stable(feature = "metadata_ext2", since = "1.8.0")]
- fn st_lspare(&self) -> u32;
}
#[stable(feature = "metadata_ext", since = "1.1.0")]
@@ -136,7 +134,4 @@ impl MetadataExt for Metadata {
fn st_flags(&self) -> u32 {
self.as_inner().as_inner().st_flags as u32
}
- fn st_lspare(&self) -> u32 {
- self.as_inner().as_inner().st_lspare as u32
- }
}
```
I guess std could like.. detect that `libc` isn't built for the old ABI, and replace the implementation of `st_lspare` with a panic?
Revert the fundamental changes in #74762 and #75257
Before possibly going over to #75487. Also contains some added and fixed comments.
r? @Mark-Simulacrum
std/sys/unix/time: make it easier for LLVM to optimize `Instant` subtraction.
This PR is the minimal change necessary to get LLVM to optimize `if self.t.tv_nsec >= other.t.tv_nsec` to branchless instructions (at least on x86_64), inspired by @m-ou-se's own attempts at optimizing `Instant` subtraction.
I stumbled over this by looking at the total number of instructions executed by `rustc -Z self-profile`, and found that after disabling ASLR, the largest source of non-determinism remaining was from this `if` taking one branch or the other, depending on the values involved.
The reason this code is even called so many times to make a difference, is that `measureme` (the `-Z self-profile` implementation) currently uses `Instant::elapsed` for its event timestamps (of which there can be millions).
I doubt it's critical to land this, although perhaps it could slightly improve some forms of benchmarking.
Migrate unit tests of btree collections to their native breeding ground
There's one BTreeSet test case that I couldn't easily convince to come along, maybe because it truly is an integration test. But leaving it in place would mean git wouldn't see the move so I also moved it to a new file.
r? @Mark-Simulacrum
BTreeMap: purge innocent use of into_kv_mut
Replace the use of `into_kv_mut` into more precise calls. This makes more sense if you know that the single remaining use of `into_kv_mut` is in fact evil and can be trialled in court (#75200) and sent to a correction facility (#73971).
No real performance difference reported (but functions that might benefit a tiny constant bit like `BTreeMap::get_mut` aren't benchmarked):
```
benchcmp old new --threshold 5
name old ns/iter new ns/iter diff ns/iter diff % speedup
btree::map::clone_fat_100 63,073 59,256 -3,817 -6.05% x 1.06
btree::map::iter_100 3,514 3,235 -279 -7.94% x 1.09
```
Change Debug impl of SocketAddr and IpAddr to match their Display output
This has already been done for `SocketAddrV4`, `SocketAddrV6`, `IpAddrV4` and `IpAddrV6`. I don't see a point to keep the rather bad to read derived impl, especially so when pretty printing:
V4(
127.0.0.1
)
From the `Display`, one can easily and unambiguously see if it's V4 or V6. Two examples:
```
127.0.0.1:443
[2001:db8:85a3::8a2e:370:7334]:443
```
Luckily the docs explicitly state that `Debug` output is not stable and that it may be changed at any time.
Using `Display` as `Debug` is very convenient for configuration structs (e.g. for webservers) that often just have a `derive(Debug)` and are printed that way to the one starting the server.
Improve documentation on process::Child.std* fields
As a relative beginner, it took a while for me to figure out I could just steal the references to avoid partially moving the child and thus retain ability to call functions on it (and store it in structs etc).
This solves several problems
- race conditions where a file is truncated while copying from it. if we blindly trusted
the file size this would lead to an infinite loop
- proc files appearing empty to copy_file_range but not to read/write
https://github.com/coreutils/coreutils/commit/4b04a0c
- copy_file_range returning 0 for some filesystems (overlay? bind mounts?)
inside docker, again leading to an infinite loop
Constified str::from_utf8_unchecked
This would be useful for const code to use an array to construct a string using guaranteed utf8 inputs, and then create a `&str` from it.
As a relative beginner, it took a while for me to figure out I could just steal the references to avoid partially moving the child and thus retain ability to call functions on it (and store it in structs etc).
Stop BTreeMap casts from reborrowing
Down in btree/node.rs, the interface and use of `cast_unchecked` look a bit shady. It's really just there for inverting `forget_type` which does not borrow. By borrowing we can't write the same `cast_unchecked` in the same way at the Handle level.
No change in undefined behaviour or performance.
Expand function pointer docs
Be more explicit in the ABI section, and add a section on how to obtain a function pointer, which can be somewhat confusing.
Cc https://github.com/rust-lang/rust/issues/75239
Hard way to respect BTreeMap's minimum node length
Resolves#74834 the hard way (though not the hardest imaginable).
Benchmarks (which are all biased/realistic, inserting keys in ascending order) say:
```
benchcmp r0 r1 --threshold 10
name r0 ns/iter r1 ns/iter diff ns/iter diff % speedup
btree::map::clone_slim_100_and_clear 2,183 2,723 540 24.74% x 0.80
btree::map::clone_slim_100_and_drain_all 3,652 4,173 521 14.27% x 0.88
btree::map::clone_slim_100_and_drain_half 3,320 3,940 620 18.67% x 0.84
btree::map::clone_slim_100_and_into_iter 2,154 2,717 563 26.14% x 0.79
btree::map::clone_slim_100_and_pop_all 3,372 3,870 498 14.77% x 0.87
btree::map::clone_slim_100_and_remove_all 5,111 5,647 536 10.49% x 0.91
btree::map::clone_slim_100_and_remove_half 3,259 3,821 562 17.24% x 0.85
btree::map::iter_0 1,733 1,509 -224 -12.93% x 1.15
btree::map::iter_100 2,714 3,739 1,025 37.77% x 0.73
btree::map::iter_10k 3,728 4,269 541 14.51% x 0.87
btree::map::range_unbounded_unbounded 28,426 36,631 8,205 28.86% x 0.78
btree::map::range_unbounded_vs_iter 28,808 34,056 5,248 18.22% x 0.85
```
This difference is not caused by the `debug_assert`-related code in the function `splitpoint`, it's the same without.
Add `array` lang item and `[T; N]::map(f: FnMut(T) -> S)`
This introduces an `array` lang item so functions can be defined on top of `[T; N]`. This was previously not done because const-generics was not complete enough to allow for this. Now it is in a state that is usable enough to start adding functions.
The function added is a monadic (I think?) map from `[T; N] -> [S; N]`. Until transmute can function on arrays, it also allocates an extra temporary array, but this can be removed at some point.
r? @lcnr
Switch from indexing to zip, and also use `write` on `MaybeUninit`.
Add array_map feature to core/src/lib
Attempt to fix issue of no such feature
Update w/ pickfire's review
This changes a couple of names around, adds another small test of variable size,
and hides the rustdoc #![feature(..)].
Fmt doctest
Add suggestions from lcnr
Add basic test
And also run fmt which is where the other changes are from
Fix mut issues
These only appear when running tests, so resolved by adding mut
Swap order of forget
Add pub and rm guard impl
Add explicit type to guard
Add safety note
Change guard type from T to S
It should never have been T, as it guards over [MaybeUninit<S>; N]
Also add feature to test
This creates the language item for arrays, and adds the map fn which is like map in options or
iterators. It currently allocates an extra array, unfortunately.
Added fixme for transmuting
Fix typo
Add drop guard
Move to intra doc links whenever possible within std/src/lib.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
There are some things like
```rust
`//! [`Option<T>`]: option::Option`
```
that will either be fixed in the future or have open issues about them.
Fix minor things in the `f32` primitive docs
All of these were review comments in #74621 that I first fixed in that PR, but later accidentally overwrote by a force push.
Thanks @the8472 for noticing.
r? @KodrAus
Fix wasi::fs::OpenOptions to imply write when append is on
This PR fixes a bug in `OpenOptions` of `wasi` platform that it currently doesn't imply write mode when only `append` is enabled.
As explained in the [doc of OpenOptions#append](https://doc.rust-lang.org/std/fs/struct.OpenOptions.html#method.append), calling `.append(true)` should imply `.write(true)` as well.
## Reproduce
Given below simple Rust program:
```rust
use std::fs::OpenOptions;
use std::io::Write;
fn main() {
let mut file = OpenOptions::new()
.write(true)
.create(true)
.open("foo.txt")
.unwrap();
writeln!(file, "abc").unwrap();
}
```
it can successfully compiled into wasm and execute by `wasmtime` runtime:
```sh
$ rustc --target wasm32-wasi write.rs
$ ~/wasmtime/target/debug/wasmtime run --dir=. write.wasm
$ cat foo.txt
abc
```
However when I change `.write(true)` to `.append(true)`, it fails to execute by the error "Capabilities insufficient":
```sh
$ ~/wasmtime/target/debug/wasmtime run --dir=. append.wasm
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 76, kind: Other, message: "Capabilities insufficient" }', append.rs:10:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Error: failed to run main module `append.wasm`
...
```
This is because of lacking "rights" on the opened file:
```sh
$ RUST_LOG=trace ~/wasmtime/target/debug/wasmtime run --dir=. append.wasm 2>&1 | grep validate_rights
TRACE wasi_common::entry > | validate_rights failed: required rights = HandleRights { base: fd_write (0x40), inheriting: empty (0x0) }; actual rights = HandleRights { base: fd_seek|fd_fdstat_set_flags|fd_sync|fd_tell|fd_advise|fd_filestat_set_times|poll_fd_readwrite (0x88000bc), inheriting: empty (0x0) }
```
The previous `assert_eq` generated quite some code, which is especially
problematic when this call is inlined. This commit also slightly
improves the panic message from:
assertion failed: `(left == right)`
left: `3`,
right: `2`: destination and source slices have different lengths
...to:
source slice length (2) does not match destination slice length (3)
Add Ipv6Addr::to_ipv4_mapped
* add Ipv6Addr::to_ipv4_mapped
* ~~deprecate Ipv4Addr::to_ipv6_compatible & Ipv6Addr::to_ipv4~~ reference: #75150
According to [IETF RFC 4291](https://tools.ietf.org/html/rfc4291#page-10), the "IPv4-Compatible IPv6 address" is deprecated.
> 2.5.5.1. IPv4-Compatible IPv6 Address
>
> The "IPv4-Compatible IPv6 address" was defined to assist in the IPv6
> transition. The format of the "IPv4-Compatible IPv6 address" is as
> follows:
>
> | 80 bits | 16 | 32 bits |
> +--------------------------------------+--------------------------+
> |0000..............................0000|0000| IPv4 address |
> +--------------------------------------+----+---------------------+
>
> Note: The IPv4 address used in the "IPv4-Compatible IPv6 address"
> must be a globally-unique IPv4 unicast address.
>
> The "IPv4-Compatible IPv6 address" is now deprecated because the
> current IPv6 transition mechanisms no longer use these addresses.
> New or updated implementations are not required to support this
> address type.
And the current implementation of `Ipv4Addr::to_ipv6_compatible`is incorrect: it does not check whether the IPv4 address is a globally-unique IPv4 unicast address.
Please let me know if there are any issues with this pull request.
fix wrong word in documentation
Change "two" to "three", since there are three significantly different things printed below that sentence:
---
While these:
```rust
println!("{}, `{name:.*}` has 3 fractional digits", "Hello", 3, name=1234.56);
println!("{}, `{name:.*}` has 3 characters", "Hello", 3, name="1234.56");
println!("{}, `{name:>8.*}` has 3 right-aligned characters", "Hello", 3, name="1234.56");
```
print two significantly different things:
``` rust
Hello, `1234.560` has 3 fractional digits
Hello, `123` has 3 characters
Hello, ` 123` has 3 right-aligned characters
```
---
[`https://doc.rust-lang.org/std/fmt/#precision`](https://doc.rust-lang.org/std/fmt/#precision)
Requested changes to [*mut T|*const T]::set_ptr_value
This is a follow-up to PR #74774 (tracking issue #75091), acting on some change requests made after approval:
- adds `#[must_use]` attribute
- changes type of `val` pointer argument from `()` to `u8`
- adjusts documentation mentioning pointer provenance
Improve `f32` and `f64` primitive documentation
I noticed that the docs for the primitive floats were fairly short. I first only wanted to add the IEEE specification information (compare [the reference](https://doc.rust-lang.org/reference/types/numeric.html)), but then also added some more beginner-friendly docs. Let me know what you think!
Random doc team assign:
r? @rylev
Use intra-doc links in /library/core/src/cmp.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Links from `core` to `std` (#74481):
* [`Vec::sort_by_key`]
Std panicking unsafe block in unsafe fn
Partial fix of #73904.
This encloses `unsafe` operations in `unsafe fn` in `libstd/ffi/panicking.rs`.
I also made a two lines change to `libstd/thread/local.rs` to add the necessary `unsafe` block without breaking everything else.
@rustbot modify labels: F-unsafe-block-in-unsafe-fn
Unfortunately, sanitizers do not support versioned symbols[1],
so they break filesystem access via the legacy, pre-ino64 ABI.
To use sanitizers on FreeBSD >= 12, we need to build the libc
crate with LIBC_CI=1 to use the new ABI -- including the libc
used for std. But that removes the st_lspare field std was
expecting for the deprecated metadata extension.
Add a way to skip that field to allow the build to work.
[1]: https://github.com/google/sanitizers/issues/628
Move to intra-doc links in library/std/src/path.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issue: The following links are broken (they are inside trait impls, undocumented in this file, inheriting from the original doc):
- [`Hasher`]
- [`Self`] (referencing `../primitive.slice.html`)
- [`Ordering`]
remove_dir will error if the path doesn't exist or isn't a directory.
It's useful to clarify that this is "remove dir or fail" not "remove dir
if it exists".
I don't think this belongs in the title. "Removes an existing, empty
directory" is strangely worded-- there's no such thing as a non-existing
directory. Better to just say explicitly it will return an error.
Add back unwinding support for Sony PSP
This PR adds back unwinding support for the Sony PSP. The `mipsel-sony-psp` target works well with unwinding. In [rust-psp], we use the `panic_unwind` crate along with LLVM's libunwind to catch panics, run destructors, and print them to the debug screen without aborting all threads.
[rust-psp]: https://github.com/overdrivenpotato/rust-psp
Rollup of 15 pull requests
Successful merges:
- #74712 (Update E0271 explanation)
- #74842 (adjust remaining targets)
- #75151 (Consistent variable name alloc for raw_vec)
- #75162 (Fix the documentation for move about Fn traits implementations)
- #75248 (Add `as_mut_ptr` to `NonNull<[T]>`)
- #75262 (Show multi extension example for Path in doctests)
- #75266 (Add safety section to `NonNull::as_*` method docs)
- #75284 (Show relative example for Path ancestors)
- #75285 (Separate example for Path strip_prefix)
- #75287 (Show Path extension example change multi extension)
- #75288 (Use assert! for Path exists example to check bool)
- #75289 (Remove ambiguity from PathBuf pop example)
- #75290 (fix `min_const_generics` version)
- #75291 (Clean up E0750)
- #75292 (Clean up E0502)
Failed merges:
r? @ghost
Add safety section to `NonNull::as_*` method docs
This basically adds the safety section of `*mut T::as_{ref,mut}` to the
same methods on `NonNull` with minor modifications to fit the
differences.
Part of #48929.
Simplify array::IntoIter
- Initialization can use `transmute_copy` to do the bitwise copy.
- `as_slice` can use `get_unchecked` and `MaybeUninit::slice_get_ref`,
and `as_mut_slice` can do similar.
- `next` and `next_back` can use the corresponding `Range` methods.
- `Clone` doesn't need any unsafety, and we can dynamically update the
new range to get partial drops if `T::clone` panics.
r? @LukasKalbertodt
Implement `into_keys` and `into_values` for associative maps
This PR implements `into_keys` and `into_values` for HashMap and BTreeMap types. They are implemented as unstable, under `map_into_keys_values` feature.
Fixes#55214.
r? @dtolnay
This basically adds the safety section of `*mut T::as_{ref,mut}` to the
same methods on `NonNull` with minor modifications to fit the
differences.
Part of #48929.
make MaybeUninit::as_(mut_)ptr const
I think it was just an oversight that they are not const yet.
I also changed their implementation as the old one created references to uninitialized memory.^^
Prevent `__rust_begin_short_backtrace` frames from being tail-call optimised away
I've stumbled across some situations where there (unexpectedly) was no `__rust_begin_short_backtrace` frame on the stack during unwinding.
On closer examination, it appeared that the calls to that function had been tail-call optimised away.
This PR follows [@bjorn3's suggestion on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Disabling.20tail.20call.20optimisation.3F/near/205699133), by adding calls to `black_box` that hint to rustc not to perform TCO.
Fixes#47429
- Initialization can use `transmute_copy` to do the bitwise copy.
- `as_slice` can use `get_unchecked` and `MaybeUninit::slice_get_ref`,
and `as_mut_slice` can do similar.
- `next` and `next_back` can use the corresponding `Range` methods.
- `Clone` doesn't need any unsafety, and we can dynamically update the
new range to get partial drops if `T::clone` panics.
Rollup of 4 pull requests
Successful merges:
- #74774 (adds [*mut|*const] ptr::set_ptr_value)
- #75079 (Disallow linking to items with a mismatched disambiguator)
- #75203 (Make `IntoIterator` lifetime bounds of `&BTreeMap` match with `&HashMap` )
- #75227 (Fix ICE when using asm! on an unsupported architecture)
Failed merges:
r? @ghost
Make `IntoIterator` lifetime bounds of `&BTreeMap` match with `&HashMap`
This is a pretty small change on the lifetime bounds of `IntoIterator` implementations of both `&BTreeMap` and `&mut BTreeMap`. This is loosening the lifetime bounds, so more code should be accepted with this PR. This is lifetime bounds will still be implicit since we have `type Item = (&'a K, &'a V);` in the implementation. This change will make the HashMap and BTreeMap share the same signature, so we can share the same function/trait with both HashMap and BTreeMap in the code.
Fixes#74034.
r? @dtolnay hey, I was touching this file on my previous PR and wanted to fix this on the way. Would you mind taking a look at this, or redirecting it if you are busy?
adds [*mut|*const] ptr::set_ptr_value
I propose the addition of these two functions to `*mut T` and `*const T`, respectively. The motivation for this is primarily byte-wise pointer arithmetic on (potentially) fat pointers, i.e. for types with a `T: ?Sized` bound. A concrete use-case has been discussed in [this](https://internals.rust-lang.org/t/byte-wise-fat-pointer-arithmetic/12739) thread.
TL;DR: Currently, byte-wise pointer arithmetic with potentially fat pointers in not possible in either stable or nightly Rust without making assumptions about the layout of fat pointers, which is currently still an implementation detail and not formally stabilized. This PR adds one function to `*mut T` and `*const T` each, allowing to circumvent this restriction without exposing any internal implementation details.
One possible alternative would be to add specific byte-wise pointer arithmetic functions to the two pointer types in addition to the already existing count-wise functions. However, I feel this fairly niche use case does not warrant adding a whole set of new functions like `add_bytes`, `offset_bytes`, `wrapping_offset_bytes`, etc. (times two, one for each pointer type) to `libcore`.
All #[cfg(unix)] platforms follow the POSIX standard and define _SC_IOV_MAX so
that we rely purely on POSIX semantics to determine the limits on I/O vector
count.
Keep the I/O vector count limit in a `SyncOnceCell` to avoid the overhead of
repeatedly calling `sysconf` as these limits are guaranteed to not change during
the lifetime of a process by POSIX.
Both Linux and MacOS enforce limits on the vector count when performing vectored
I/O via the readv and writev system calls and return EINVAL when these limits
are exceeded. This changes the standard library to handle those limits as short
reads and writes to avoid forcing its users to query these limits using
platform specific mechanisms.
Completes support for coverage in external crates
Follow-up to #74959 :
The prior PR corrected for errors encountered when trying to generate
the coverage map on source code inlined from external crates (including
macros and generics) by avoiding adding external DefIds to the coverage
map.
This made it possible to generate a coverage report including external
crates, but the external crate coverage was incomplete (did not include
coverage for the DefIds that were eliminated.
The root issue was that the coverage map was converting Span locations
to source file and locations, using the SourceMap for the current crate,
and this would not work for spans from external crates (compliled with a
different SourceMap).
The solution was to convert the Spans to filename and location during
MIR generation instead, so precompiled external crates would already
have the correct source code locations embedded in their MIR, when
imported into another crate.
@wesleywiser FYI
r? @tmandry
Co-authored-by: Weiyi Wang <wwylele@gmail.com>
Co-authored-by: Adam Reichold <adam.reichold@t-online.de>
Co-authored-by: Josh Stone <cuviper@gmail.com>
Co-authored-by: Scott McMurray <scottmcm@users.noreply.github.com>
Co-authored-by: tmiasko <tomasz.miasko@gmail.com>
The prior PR corrected for errors encountered when trying to generate
the coverage map on source code inlined from external crates (including
macros and generics) by avoiding adding external DefIds to the coverage
map.
This made it possible to generate a coverage report including external
crates, but the external crate coverage was incomplete (did not include
coverage for the DefIds that were eliminated.
The root issue was that the coverage map was converting Span locations
to source file and locations, using the SourceMap for the current crate,
and this would not work for spans from external crates (compliled with a
different SourceMap).
The solution was to convert the Spans to filename and location during
MIR generation instead, so precompiled external crates would already
have the correct source code locations embedded in their MIR, when
imported into another crate.
add `unsigned_abs` to signed integers
Mentioned on rust-lang/rfcs#2914
This PR simply adds an `unsigned_abs` to signed integers function which returns the correct absolute value as a unsigned integer.
Move bulk of BTreeMap::insert method down to new method on handle
Adjust the boundary between the map and node layers for insertion: do more in the node layer, keep root manipulation and pointer dereferencing separate. No change in undefined behaviour or performance.
r? @Mark-Simulacrum
Stabilize `Result::as_deref` and `as_deref_mut`
FCP completed in https://github.com/rust-lang/rust/issues/50264#issuecomment-645681400.
This PR stabilizes two new APIs for `std::result::Result`:
```rust
fn as_deref(&self) -> Result<&T::Target, &E> where T: Deref;
fn as_deref_mut(&mut self) -> Result<&mut T::Target, &mut E> where T: DerefMut;
```
This PR also removes two rarely used unstable APIs from `Result`:
```rust
fn as_deref_err(&self) -> Result<&T, &E::Target> where E: Deref;
fn as_deref_mut_err(&mut self) -> Result<&mut T, &mut E::Target> where E: DerefMut;
```
Closes#50264
BTreeMap: define forget_type only when relevant
Similar to `forget_node_type` for handles.
No effect on generated code, apart maybe from the superfluous calls that might not have been optimized away.
r? @Mark-Simulacrum
BTreeMap::drain_filter should not touch the root during iteration
Although Miri doesn't point it out, I believe there is undefined behaviour using `drain_filter` when draining the 11th-last element from a tree that was larger. When this happens, the last remaining child nodes are merged, the root becomes empty and is popped from the tree. That last step establishes a mutable reference to the node elected root and writes a pointer in `node::Root`, while iteration continues to visit the same node.
This is mostly code from #74437, slightly adapted.
In the current documentation about the `Copy` marker trait, there is a section
about "additional implementors", which list additional implementors of the `Copy` trait.
The fact that shared references are also `Copy` is mixed with another point,
which makes it hard to recognize and make it seem not as important.
This clarifies the fact that shared references are also `Copy`, by mentioning it as a
separate item in the list of "additional implementors".
Fix std::fs::File::metadata permission on WASI target
Previously `std::fs::File::metadata` on wasm32-wasi would call `fd_filestat_get`
to get metadata associated with fd, but that fd is opened without
RIGHTS_FD_FILESTAT_GET right, so it will failed on correctly implemented WASI
environment.
This change instead to add the missing rights when opening an fd.
Stabilize Vec::leak as a method
Closes https://github.com/rust-lang/rust/issues/62195
The signature is changed to a method rather than an associated function:
```diff
-pub fn leak<'a>(vec: Vec<T>) -> &'a mut [T]
+pub fn leak<'a>(self) -> &'a mut [T]
```
The reason for `Box::leak` not to be a method (`Deref` to an arbitrary `T` which might have its own, different `leak` method) does not apply.
add `slice::array_chunks` to std
Now that #74113 has landed, these methods are suddenly usable. A rebirth of #72334
Tests are directly copied from `chunks_exact` and some additional tests for type inference.
r? @withoutboats as you are both part of t-libs and working on const generics. closes#60735
Previously `std::fs::File::metadata` on wasm32-wasi would call `fd_filestat_get`
to get metadata associated with fd, but that fd is opened without
RIGHTS_FD_FILESTAT_GET right, so it will failed on correctly implemented WASI
environment.
This change instead to add the missing rights when opening an fd.
Make `Option::unwrap` unstably const
This is lumped into the `const_option` feature gate (#67441), which enables a potpourri of `Option` methods.
cc @rust-lang/wg-const-eval
r? @oli-obk
Don't use "weak count" around Weak::from_raw_ptr
As `Rc/Arc::weak_count` returns 0 when having no strong counts, this
could be confusing and it's better to avoid using that completely.
Closes#73840.
`Result::unwrap` is not eligible becuase it formats the contents of the
`Err` variant. `unwrap_or`, `unwrap_or_else` and friends are not
eligible because they drop things or invoke closures.
Make `mem::size_of_val` and `mem::align_of_val` unstably const
Implements #46571 but does not stabilize it. I wanted this while working on something today.
The only reason not to immediately stabilize are concerns around [custom DSTs](https://github.com/rust-lang/rust/issues/46571#issuecomment-387669352). That proposal has made zero progress in the last two years and const eval is rich enough to support pretty much any user-defined `len` function as long as nightly features are allowed (`raw_ptr_deref`).
Currently, this raises a `const_err` lint when passed an `extern type`.
r? @oli-obk
cc @rust-lang/wg-const-eval
Remove links to rejected errata 4406 for RFC 4291
Fixes#74198.
For now I simply removed the links, the docs seems clear enough to me but I'm no expert in the domain so don't hesitate to correct me if more is needed.
cc @ghanan94.
@rustbot modify labels: T-doc, T-libs
Stabilize const_type_id feature
The tracking issue for `const_type_id` points to the ill-fated #41875. So I'm re-energizing `TypeId` shenanigans by opening this one up to see if there's anything blocking us from stabilizing the constification of type ids.
Will wait for CI before pinging teams/groups.
-----
This PR stabilizes the `const_type_id` feature, which allows `TypeId::of` (and the underlying unstable intrinsic) to be called in constant contexts.
There are some [sanity tests](https://github.com/rust-lang/rust/blob/master/src/test/ui/consts/const-typeid-of-rpass.rs) that demonstrate its usage, but I’ve included some more below.
As a simple example, you could create a constant item that contains some type ids:
```rust
use std::any::TypeId;
const TYPE_IDS: [TypeId; 2] = [
TypeId::of::<u32>(),
TypeId::of::<i32>(),
];
assert_eq!(TypeId::of::<u32>(), TYPE_IDS[0]);
```
Type ids can also now appear in associated constants. You could create a trait that associates each type with its constant type id:
```rust
trait Any where Self: 'static {
const TYPE_ID: TypeId = TypeId::of::<Self>();
}
impl<T: 'static> Any for T { }
assert_eq!(TypeId::of::<usize>(), usize::TYPE_ID);
```
`TypeId::of` is generic, which we saw above in the way the generic `Self` argument was used. This has some implications for const evaluation. It means we can make trait impls evaluate differently depending on information that wasn't directly passed through the trait system. This violates the _parametricity_ property, which requires all instances of a generic function to behave the same way with respect to its generic parameters. That's not unique to `TypeId::of`, other generic const functions based on compiler intrinsics like `mem::align_of` can also violate parametricity. In practice Rust doesn't really have type parametricity anyway since it monomorphizes generics into concrete functions, so violating it using type ids isn’t new.
As an example of how impls can behave differently, you could combine constant type ids with the `const_if_match` feature to dispatch calls based on the type id of the generic `Self`, rather than based on information about `Self` that was threaded through trait bounds. It's like a rough-and-ready form of specialization:
```rust
#![feature(const_if_match)]
trait Specialized where Self: 'static {
// An associated constant that determines the function to call
// at compile-time based on `TypeId::of::<Self>`.
const CALL: fn(&Self) = {
const USIZE: TypeId = TypeId::of::<usize>();
match TypeId::of::<Self>() {
// Use a closure for `usize` that transmutes the generic `Self` to
// a concrete `usize` and dispatches to `Self::usize`.
USIZE => |x| Self::usize(unsafe { &*(x as *const Self as *const usize) }),
// For other types, dispatch to the generic `Self::default`.
_ => Self::default,
}
};
fn call(&self) {
// Call the function we determined at compile-time
(Self::CALL)(self)
}
fn default(x: &Self);
fn usize(x: &usize);
}
// Implement our `Specialized` trait for any `Debug` type.
impl<T: fmt::Debug + 'static> Specialized for T {
fn default(x: &Self) {
println!("default: {:?}", x);
}
fn usize(x: &usize) {
println!("usize: {:?}", x);
}
}
// Will print "usize: 42"
Specialized::call(&42usize);
// Will print "default: ()"
Specialized::call(&());
```
Type ids have some edges that this stabilization exposes to more contexts. It's possible for type ids to collide (but this is a bug). Since they can change between compiler versions, it's never valid to cast a type id to its underlying value.
Fix RefUnwindSafe & UnwinsSafe impls for lazy::SyncLazy
I *think* we should implement those unconditionally with respect to `F`.
The user code can't observe the closure in any way, and we poison lazy if the closure itself panics.
But I've never fully wrapped my head around `UnwindSafe` traits, so 🤷♂️
Add str::[r]split_once
This is useful for quick&dirty parsing of key: value config pairs. Used a bunch in Cargo and rust-analyzer:
* https://github.com/rust-lang/cargo/search?q=splitn%282&unscoped_q=splitn%282
* https://github.com/rust-analyzer/rust-analyzer/search?q=split_delim&unscoped_q=split_delim
In theory, once const-generics are done, this functionality could be achieved without a dedicated method with
```rust
match s.splitn(delimier, 2).collect_array::<2>() {
Some([prefix, suffix]) => todo!(),
None => todo!(),
}
```
Even in that world, having a dedicated method seems clearer on the intention.
I am not sure about naming -- this is something I've just came up with yesterday, I don't know off the top of my head analogs in other languages.
If T-libs thinks this is a reasonable API to have, I'll open a tracking issue and add more thorough tests.
Add #[inline] to RawWaker::new
`RawWaker::new` is used when creating a new waker or cloning an existing one,
for example as in code below. The `RawWakerVTable::new` can be const evaluated,
but `RawWaker::new` itself cannot since waker pointer is not known at compile
time. Add `#[inline]` to avoid overhead of a function call.
```rust
unsafe fn clone_waker<W: Wake + Send + Sync + 'static>(waker: *const ()) -> RawWaker {
unsafe { Arc::incr_strong_count(waker as *const W) };
RawWaker::new(
waker as *const (),
&RawWakerVTable::new(clone_waker::<W>, wake::<W>, wake_by_ref::<W>, drop_waker::<W>),
)
}
```
This commit is a proof-of-concept for switching the standard library's
backtrace symbolication mechanism on most platforms from libbacktrace to
gimli. The standard library's support for `RUST_BACKTRACE=1` requires
in-process parsing of object files and DWARF debug information to
interpret it and print the filename/line number of stack frames as part
of a backtrace.
Historically this support in the standard library has come from a
library called "libbacktrace". The libbacktrace library seems to have
been extracted from gcc at some point and is written in C. We've had a
lot of issues with libbacktrace over time, unfortunately, though. The
library does not appear to be actively maintained since we've had
patches sit for months-to-years without comments. We have discovered a
good number of soundness issues with the library itself, both when
parsing valid DWARF as well as invalid DWARF. This is enough of an issue
that the libs team has previously decided that we cannot feed untrusted
inputs to libbacktrace. This also doesn't take into account the
portability of libbacktrace which has been difficult to manage and
maintain over time. While possible there are lots of exceptions and it's
the main C dependency of the standard library right now.
For years it's been the desire to switch over to a Rust-based solution
for symbolicating backtraces. It's been assumed that we'll be using the
Gimli family of crates for this purpose, which are targeted at safely
and efficiently parsing DWARF debug information. I've been working
recently to shore up the Gimli support in the `backtrace` crate. As of a
few weeks ago the `backtrace` crate, by default, uses Gimli when loaded
from crates.io. This transition has gone well enough that I figured it
was time to start talking seriously about this change to the standard
library.
This commit is a preview of what's probably the best way to integrate
the `backtrace` crate into the standard library with the Gimli feature
turned on. While today it's used as a crates.io dependency, this commit
switches the `backtrace` crate to a submodule of this repository which
will need to be updated manually. This is not done lightly, but is
thought to be the best solution. The primary reason for this is that the
`backtrace` crate needs to do some pretty nontrivial filesystem
interactions to locate debug information. Working without `std::fs` is
not an option, and while it might be possible to do some sort of
trait-based solution when prototyped it was found to be too unergonomic.
Using a submodule allows the `backtrace` crate to build as a submodule
of the `std` crate itself, enabling it to use `std::fs` and such.
Otherwise this adds new dependencies to the standard library. This step
requires extra attention because this means that these crates are now
going to be included with all Rust programs by default. It's important
to note, however, that we're already shipping libbacktrace with all Rust
programs by default and it has a bunch of C code implementing all of
this internally anyway, so we're basically already switching
already-shipping functionality to Rust from C.
* `object` - this crate is used to parse object file headers and
contents. Very low-level support is used from this crate and almost
all of it is disabled. Largely we're just using struct definitions as
well as convenience methods internally to read bytes and such.
* `addr2line` - this is the main meat of the implementation for
symbolication. This crate depends on `gimli` for DWARF parsing and
then provides interfaces needed by the `backtrace` crate to turn an
address into a filename / line number. This crate is actually pretty
small (fits in a single file almost!) and mirrors most of what
`dwarf.c` does for libbacktrace.
* `miniz_oxide` - the libbacktrace crate transparently handles
compressed debug information which is compressed with zlib. This crate
is used to decompress compressed debug sections.
* `gimli` - not actually used directly, but a dependency of `addr2line`.
* `adler32`- not used directly either, but a dependency of
`miniz_oxide`.
The goal of this change is to improve the safety of backtrace
symbolication in the standard library, especially in the face of
possibly malformed DWARF debug information. Even to this day we're still
seeing segfaults in libbacktrace which could possibly become security
vulnerabilities. This change should almost entirely eliminate this
possibility whilc also paving the way forward to adding more features
like split debug information.
Some references for those interested are:
* Original addition of libbacktrace - #12602
* OOM with libbacktrace - #24231
* Backtrace failure due to use of uninitialized value - #28447
* Possibility to feed untrusted data to libbacktrace - #21889
* Soundness fix for libbacktrace - #33729
* Crash in libbacktrace - #39468
* Support for macOS, never merged - ianlancetaylor/libbacktrace#2
* Performance issues with libbacktrace - #29293, #37477
* Update procedure is quite complicated due to how many patches we
need to carry - #50955
* Libbacktrace doesn't work on MinGW with dynamic libs - #71060
* Segfault in libbacktrace on macOS - #71397
Switching to Rust will not make us immune to all of these issues. The
crashes are expected to go away, but correctness and performance may
still have bugs arise. The gimli and `backtrace` crates, however, are
actively maintained unlike libbacktrace, so this should enable us to at
least efficiently apply fixes as situations come up.
This commit updates the src/stdarch submodule primarily to include
rust-lang/stdarch#874 which updated and revamped WebAssembly SIMD
intrinsics and renamed WebAssembly atomics intrinsics. This is all
unstable surface area of the standard library so the changes should be
ok here. The SIMD updates also enable SIMD intrinsics to be used by any
program any any time, yay!
cc #74372, a tracking issue I've opened for the stabilization of SIMD
intrinsics
This has already been done for `SocketAddrV4`, `SocketAddrV6`,
`IpAddrV4` and `IpAddrV6`. I don't see a point to keep the rather bad
to read derived impl, especially when pretty printing:
V4(
127.0.0.1
)
From the `Display`, one can easily and unambiguously see if it's V4 or
V6. Using `Display` as `Debug` is very convenient for configuration
structs (e.g. for webservers) that often just have a `derive(Debug)`
and are printed that way to the user.
{kind=link}
{kind=link}