To decide if internal items should be inlined in a doc page,
check if the crate is itself internal, rather than if it has
the rustc_private feature flag. The standard library uses
internal items, but is not itself internal and should not show
internal items on its docs pages.
Correctly handle inlining of doc hidden foreign items
Fixes#123435.
In case a foreign item has doc(hidden) attribute, we simply merged its attributes with the re-export's, making it being removed once in the `strip_hidden` pass.
The solution was to use the same as for local reexported items: merge attributes, but not some of them (like `doc(hidden)`).
I originally checked if we could simply update `Item::is_doc_hidden` method to use `self.inline_stmt_id.is_some_and(|def_id| tcx.is_doc_hidden(def_id))` but unfortunately, it added (local) items that shouldn't be inlined. At least it unifies local and foreign items inlining, which I think is the best course of action here.
r? `@notriddle`
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
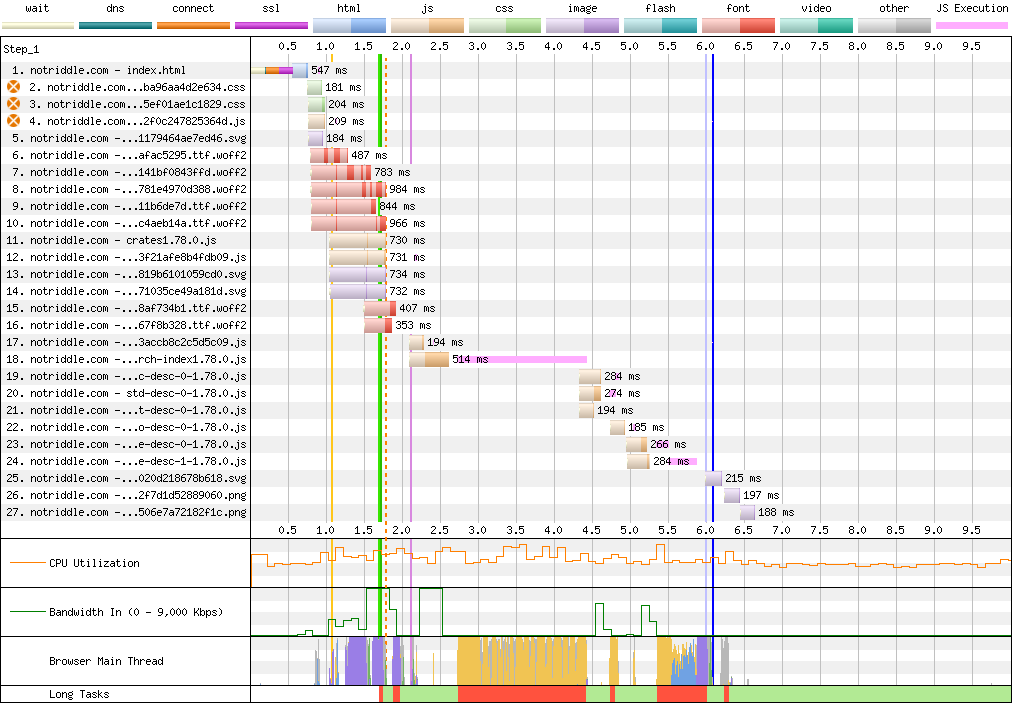
</details>
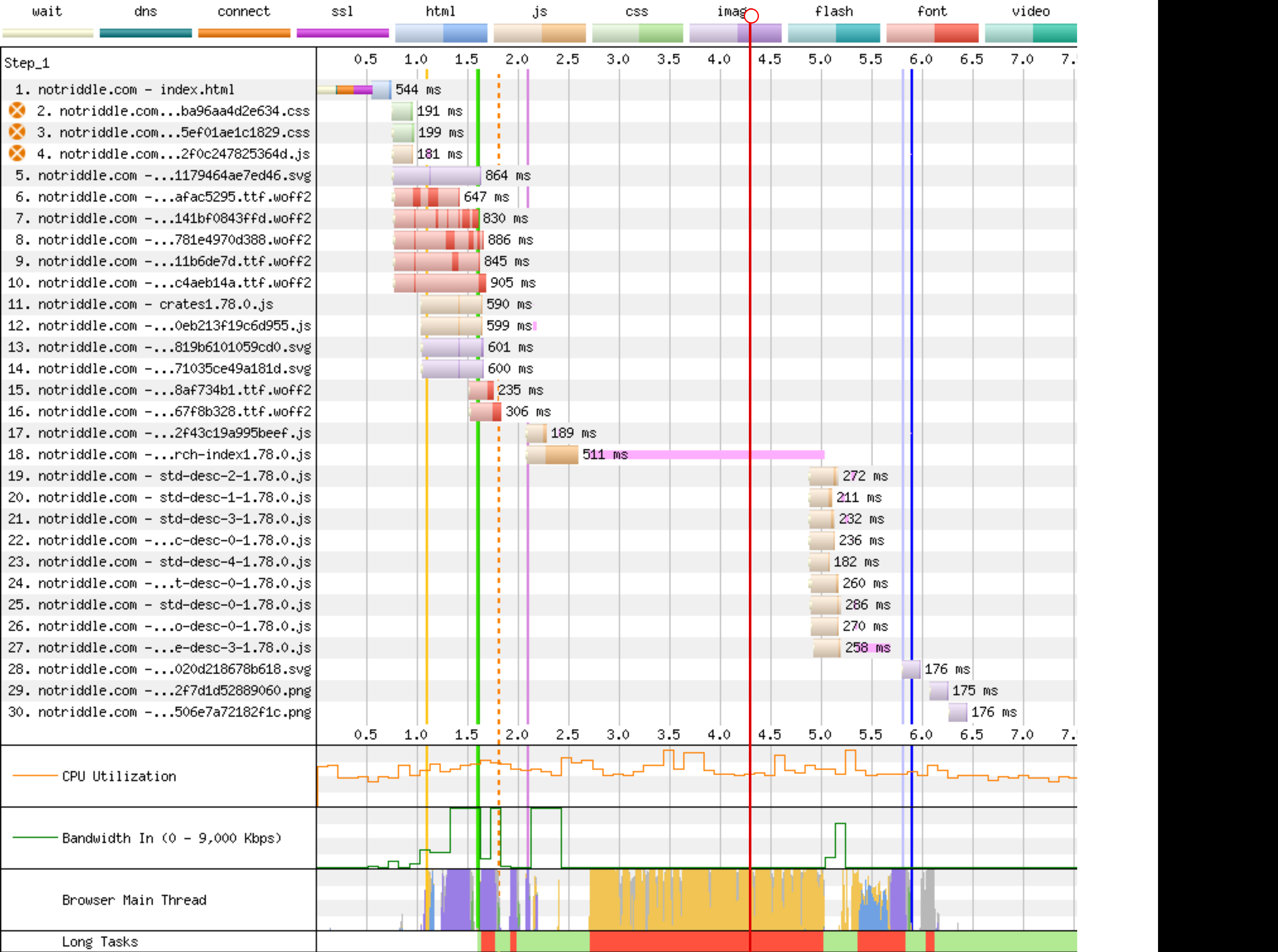
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
The descriptions are, on almost all crates[^1], the majority
of the size of the search index, even though they aren't really
used for searching. This makes it relatively easy to separate
them into their own files.
This commit also bumps us to ES8. Out of the browsers we support,
all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted.
rustdoc: fix up old test
`tests/rustdoc/line-breaks.rs` had several issues:
1. It used `//`@count`` instead of `// `@count`` (notice the space!) which gets treated as a `ui_test` directive instead of a `htmldocck` one. `compiletest` didn't flag it as an error because it's allowlisted ([#121561](https://github.com/rust-lang/rust/pull/121561)) presumably precisely because of this test. And before the compiletest→ui_test migration, these directives must've been ignored, too, because …
2. … the checks themselves no longer work either: The count of `<br>`s is actually 0 in all 3 cases because – well – we no longer generate any `<br>`s inside `<pre>`s.
Since I don't know how to ``@count`` `\n`s instead of `<br>`s, I've turned them into ``@matches`.` Btw, I don't know if this test is still desirable or if we have other tests that cover this (I haven't checked).
r? rustdoc
Expose the Freeze trait again (unstably) and forbid implementing it manually
non-emoji version of https://github.com/rust-lang/rust/pull/121501
cc #60715
This trait is useful for generic constants (associated consts of generic traits). See the test (`tests/ui/associated-consts/freeze.rs`) added in this PR for a usage example. The builtin `Freeze` trait is the only way to do it, users cannot work around this issue.
It's also a useful trait for building some very specific abstrations, as shown by the usage by the `zerocopy` crate: https://github.com/google/zerocopy/issues/941
cc ```@RalfJung```
T-lang signed off on reexposing this unstably: https://github.com/rust-lang/rust/pull/121501#issuecomment-1969827742
[rustdoc] Prevent inclusion of whitespace character after macro_rules ident
Discovered this bug randomly when looking at:
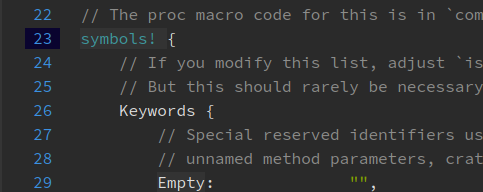
We were too eagerly trying to merge tokens that shouldn't be merged together (for example if you have a code comment followed by a code comment, we merge them in one attribute to reduce the DOM size).
r? ``@notriddle``
Fix link generation for foreign macro in jump to definition feature
The crate name is already added to the link so it shouldn't be added a second time for local foreign macros.
r? ``@notriddle``
rustdoc: fix and refactor HTML rendering a bit
* refactoring: get rid of a bunch of manual `f.alternate()` branches
* not sure why this wasn't done so already, is this perf-sensitive?
* fix an ICE in debug builds of rustdoc
* rustdoc used to crash on empty outlives-bounds: `where 'a:`
* properly escape const generic defaults
* actually print empty trait and outlives-bounds (doesn't work for cross-crate reexports yet, will fix that at some other point) since they can have semantic significance
* outlives-bounds: forces lifetime params to be early-bound instead of late-bound which is technically speaking part of the public API
* trait-bounds: can affect the well-formedness, consider
* makeshift “const-evaluatable” bounds under `generic_const_exprs`
* bounds to force wf-checking in light of #100041 (quite artificial I know, I couldn't figure out something better), see https://github.com/rust-lang/rust/pull/121160#discussion_r1491563816
Add extra indent spaces for rust-playground link
Fixes#120998
Seems add `rustfmt` for this is somehow too heavy,
only adding indent spaces at the starting of each line of code seems good enough.