I would like to propose cmp::{min_by, min_by_key, max_by, max_by_key}
for stabilization.
These are relatively simple and seemingly uncontroversial functions and
have been unchanged in unstable for a while now.
Use `#[inline(always)]` on trivial UnsafeCell methods
UnsafeCell is the standard building block for shared mutable data
structures. UnsafeCell should add zero overhead compared to using raw
pointers directly.
Some reports suggest that debug builds, or even builds at opt-level 1,
may not always be inlining its methods. Mark the methods as
`#[inline(always)]`, since once inlined the methods should result in no
actual code other than field accesses.
Bump bootstrap to 1.52 beta
This includes the standard bump, but also a workaround for new cargo behavior around clearing out the doc directory when the rustdoc version changes.
core: disable `ptr::swap_nonoverlapping_one`'s block optimization on SPIR-V.
SPIR-V primarily supports what it calls the "Logical addressing model" (and AFAIK for graphical shaders it's the only option), and what that implies is that there is no "memory" to uniformly address at some byte/word level, and that you can't really talk about values having a "raw representation" in terms of sequences of bytes. Therefore, the "block"-wise swapping optimization employed by `ptr::swap_nonoverlapping_one` (where a "block" is 32 bytes, currently), is fundamentally incompatible with SPIR-V "memory".
As such, [Rust-GPU](https://github.com/EmbarkStudios/rust-gpu/)'s `rustc_codegen_spirv` backend cannot currently allow the use of `ptr::swap_nonoverlapping_one` - but that comes at a great price, since it's the building block of `mem::{swap,replace}`, and those in turn are used by e.g. `Option::take` and `Range`'s `Iterator` implementation (the latter blocking the use of `for i in 0..n` loops).
There's 4 options I can see in terms of supporting `ptr::swap_nonoverlapping_one` in `rustc_codegen_spirv`:
* legalize the block-wise swap loop back into swapping whole values, for SPIR-V
* this is made borderline impossible by the fact that the size of the state "on the stack" is a block, and has to be expanded back to the appropriate size of the value being swapped, so in practice this would have to effectively pattern-match on the exact shape of the block-wise swapping algorithm, as a roundabout way of "patching `core::ptr` on the fly"
* (**this PR**) disable the block-wise swap optimization altogether when `#[cfg(target_arch = "spirv")`
* I've tested it and it does in fact allow compiling `for i in 0..n` loops, which was my primary motivation
* main downside IMO is the fact that `core` now acknowledges an out-of-tree backend
* as a counterpoint, any attempt to compile Rust to SPIR-V would run into this problem, one way or another
* only enable the block-wise swap optimization on targets where it's been empirically proven to be an improvement
* would avoid any surprises in terms of potentially-broken/inefficient codegen, in general
* however, it may be universally applicable (thanks to caches), even if the optimal block size could differ
* move low-level swapping into an intrinsic, where the backend can choose any optimization approach it wants
* this also has an impact on MIR optimizations (cc ``@rust-lang/wg-mir-opt)`` - which currently cannot hope to make sense of e.g. `Option::take` despite it being effectively `_0 = *_1;` `*_1 = None;` `return;`
* long-term this is my preferred approach, and I can start working on it if that's desired, but I wanted to confirm that this swapping optimization is the final blocker for [Rust-GPU](https://github.com/EmbarkStudios/rust-gpu/) supporting e.g. range `for` loops
r? ``@nagisa`` cc ``@rust-lang/libs``
UnsafeCell is the standard building block for shared mutable data
structures. UnsafeCell should add zero overhead compared to using raw
pointers directly.
Some reports suggest that debug builds, or even builds at opt-level 1,
may not always be inlining its methods. Mark the methods as
`#[inline(always)]`, since once inlined the methods should result in no
actual code other than field accesses.
Rename `#[doc(spotlight)]` to `#[doc(notable_trait)]`
Fixes#80936.
"spotlight" is not a very specific or self-explaining name.
Additionally, the dialog that it triggers is called "Notable traits".
So, "notable trait" is a better name.
* Rename `#[doc(spotlight)]` to `#[doc(notable_trait)]`
* Rename `#![feature(doc_spotlight)]` to `#![feature(doc_notable_trait)]`
* Update documentation
* Improve documentation
r? `@Manishearth`
Improve pointer arithmetic docs
* Add slightly more detailed definition of "allocated object" to the module docs, and link it from everywhere.
* Clarify the "remains attached" wording a bit (at least I hope this is clearer).
* Remove the sentence about using integer arithmetic; this seems to confuse people even if it is technically correct.
As usual, the edit needs to be done in a dozen places to remain consistent, I hope I got them all.
Instruct LLVM that binary_search returns a valid index
This allows removing bound checks when the return value of `binary_search` is used to index into the slice it was call on. I also added a codegen test for this, not sure if it's the right thing to do (I didn't find anything on the dev guide), but it felt so.
Add function core::iter::zip
This makes it a little easier to `zip` iterators:
```rust
for (x, y) in zip(xs, ys) {}
// vs.
for (x, y) in xs.into_iter().zip(ys) {}
```
You can `zip(&mut xs, &ys)` for the conventional `iter_mut()` and
`iter()`, respectively. This can also support arbitrary nesting, where
it's easier to see the item layout than with arbitrary `zip` chains:
```rust
for ((x, y), z) in zip(zip(xs, ys), zs) {}
for (x, (y, z)) in zip(xs, zip(ys, zs)) {}
// vs.
for ((x, y), z) in xs.into_iter().zip(ys).zip(xz) {}
for (x, (y, z)) in xs.into_iter().zip((ys.into_iter().zip(xz)) {}
```
It may also format more nicely, especially when the first iterator is a
longer chain of methods -- for example:
```rust
iter::zip(
trait_ref.substs.types().skip(1),
impl_trait_ref.substs.types().skip(1),
)
// vs.
trait_ref
.substs
.types()
.skip(1)
.zip(impl_trait_ref.substs.types().skip(1))
```
This replaces the tuple-pair `IntoIterator` in #78204.
There is prior art for the utility of this in [`itertools::zip`].
[`itertools::zip`]: https://docs.rs/itertools/0.10.0/itertools/fn.zip.html
update array missing `IntoIterator` msg
fixes#82602
r? ```@estebank``` do you know whether we can use the expr span in `rustc_on_unimplemented`? The label isn't too great rn
make unaligned_references future-incompat lint warn-by-default
and also remove the safe_packed_borrows lint that it replaces.
`std::ptr::addr_of!` has hit beta now and will hit stable in a month, so I propose we start fixing https://github.com/rust-lang/rust/issues/27060 for real: creating a reference to a field of a packed struct needs to eventually become a hard error; this PR makes it a warn-by-default future-incompat lint. (The lint already existed, this just raises its default level.) At the same time I removed the corresponding code from unsafety checking; really there's no reason an `unsafe` block should make any difference here.
For references to packed fields outside `unsafe` blocks, this means `unaligned_refereces` replaces the previous `safe_packed_borrows` warning with a link to https://github.com/rust-lang/rust/issues/82523 (and no more talk about unsafe blocks making any difference). So behavior barely changes, the warning is just worded differently. For references to packed fields inside `unsafe` blocks, this PR shows a new future-incompat warning.
Closes https://github.com/rust-lang/rust/issues/46043 because that lint no longer exists.
Generalize and inline slice::fill specializations
This makes the memset specialization applicable to more types. And since the code now lives in a generic method it is also eligible for cross-crate inlining which should fix#83235
Add IEEE 754 compliant fmt/parse of -0, infinity, NaN
This pull request improves the Rust float formatting/parsing libraries to comply with IEEE 754's formatting expectations around certain special values, namely signed zero, the infinities, and NaN. It also adds IEEE 754 compliance tests that, while less stringent in certain places than many of the existing flt2dec/dec2flt capability tests, are intended to serve as the beginning of a roadmap to future compliance with the standard. Some relevant documentation is also adjusted with clarifying remarks.
This PR follows from discussion in https://github.com/rust-lang/rfcs/issues/1074, and closes#24623.
The most controversial change here is likely to be that -0 is now printed as -0. Allow me to explain: While there appears to be community support for an opt-in toggle of printing floats as if they exist in the naively expected domain of numbers, i.e. not the extended reals (where floats live), IEEE 754-2019 is clear that a float converted to a string should be capable of being transformed into the original floating point bit-pattern when it satisfies certain conditions (namely, when it is an actual numeric value i.e. not a NaN and the original and destination float width are the same). -0 is given special attention here as a value that should have its sign preserved. In addition, the vast majority of other programming languages not only output `-0` but output `-0.0` here.
While IEEE 754 offers a broad leeway in how to handle producing what it calls a "decimal character sequence", it is clear that the operations a language provides should be capable of round tripping, and it is confusing to advertise the f32 and f64 types as binary32 and binary64 yet have the most basic way of producing a string and then reading it back into a floating point number be non-conformant with the standard. Further, existing documentation suggested that e.g. -0 would be printed with -0 regardless of the presence of the `+` fmt character, but it prints "+0" instead if given such (which was what led to the opening of #24623).
There are other parsing and formatting issues for floating point numbers which prevent Rust from complying with the standard, as well as other well-documented challenges on the arithmetic level, but I hope that this can be the beginning of motion towards solving those challenges.
This makes it a little easier to `zip` iterators:
```rust
for (x, y) in zip(xs, ys) {}
// vs.
for (x, y) in xs.into_iter().zip(ys) {}
```
You can `zip(&mut xs, &ys)` for the conventional `iter_mut()` and
`iter()`, respectively. This can also support arbitrary nesting, where
it's easier to see the item layout than with arbitrary `zip` chains:
```rust
for ((x, y), z) in zip(zip(xs, ys), zs) {}
for (x, (y, z)) in zip(xs, zip(ys, zs)) {}
// vs.
for ((x, y), z) in xs.into_iter().zip(ys).zip(xz) {}
for (x, (y, z)) in xs.into_iter().zip((ys.into_iter().zip(xz)) {}
```
It may also format more nicely, especially when the first iterator is a
longer chain of methods -- for example:
```rust
iter::zip(
trait_ref.substs.types().skip(1),
impl_trait_ref.substs.types().skip(1),
)
// vs.
trait_ref
.substs
.types()
.skip(1)
.zip(impl_trait_ref.substs.types().skip(1))
```
This replaces the tuple-pair `IntoIterator` in rust-lang/rust#78204.
There is prior art for the utility of this in [`itertools::zip`].
[`itertools::zip`]: https://docs.rs/itertools/0.10.0/itertools/fn.zip.html
Fixes#83046
The program
fn main() {
println!("{:?}", '"');
println!("{:?}", "'");
}
would previously print
'\"'
"\'"
With this patch it now prints:
'"'
"'"
Add Result::into_err where the Ok variant is the never type
Equivalent of #66045 but for the inverse situation where `T: Into<!>` rather than `E: Into<!>`.
I'm using the same feature gate name. I can't see why one of these methods would be OK to stabilize but not the other.
Tracking issue: #61695
Remove Option::{unwrap_none, expect_none}.
This removes `Option::unwrap_none` and `Option::expect_none` since we're not going to stabilize them, see https://github.com/rust-lang/rust/issues/62633.
Closes#62633
stabilize debug_non_exhaustive
tracking issue: https://github.com/rust-lang/rust/issues/67364
but it is still an open question whether the other `Debug*` struct's should have a similar method. I would guess that would best be put underneath a new feature gate, as this one seems uncontroversial enough to stabilize as is
Add `debug-refcell` feature to libcore
See https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Attaching.20backtraces.20to.20RefCell/near/226273614
for some background discussion
This PR adds a new off-by-default feature `debug-refcell` to libcore.
When enabled, this feature stores additional debugging information in
`RefCell`. This information is included in the panic message when
`borrow()` or `borrow_mut()` panics, to make it easier to track down the
source of the issue.
Currently, we store the caller location for the earliest active borrow.
This has a number of advantages:
* There is only a constant amount of overhead per `RefCell`
* We don't need any heap memory, so it can easily be implemented in core
* Since we are storing the *earliest* active borrow, we don't need any
extra logic in the `Drop` implementation for `Ref` and `RefMut`
Limitations:
* We only store the caller location, not a full `Backtrace`. Until
we get support for `Backtrace` in libcore, this is the best tha we can
do.
* The captured location is only displayed when `borrow()` or
`borrow_mut()` panics. If a crate calls `try_borrow().unwrap()`
or `try_borrow_mut().unwrap()`, this extra information will be lost.
To make testing easier, I've enabled the `debug-refcell` feature by
default. I'm not sure how to write a test for this feature - we would
need to rebuild core from the test framework, and create a separate
sysroot.
Since this feature will be off-by-default, users will need to use
`xargo` or `cargo -Z build-std` to enable this feature. For users using
a prebuilt standard library, this feature will be disabled with zero
overhead.
I've created a simple test program:
```rust
use std::cell::RefCell;
fn main() {
let _ = std::panic::catch_unwind(|| {
let val = RefCell::new(true);
let _first = val.borrow();
let _second = val.borrow();
let _third = val.borrow_mut();
});
let _ = std::panic::catch_unwind(|| {
let val = RefCell::new(true);
let first = val.borrow_mut();
drop(first);
let _second = val.borrow_mut();
let _thid = val.borrow();
});
}
```
which produces the following output:
```
thread 'main' panicked at 'already borrowed: BorrowMutError at refcell_test.rs:6:26', refcell_test.rs:8:26
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at 'already mutably borrowed: BorrowError at refcell_test.rs:16:27', refcell_test.rs:18:25
```
This commit removes the previous mechanism of differentiating
between "Debug" and "Display" formattings for the sign of -0 so as
to comply with the IEEE 754 standard's requirements on external
character sequences preserving various attributes of a floating
point representation.
In addition, numerous tests are fixed.
See https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Attaching.20backtraces.20to.20RefCell/near/226273614
for some background discussion
This PR adds a new off-by-default feature `debug-refcell` to libcore.
When enabled, this feature stores additional debugging information in
`RefCell`. This information is included in the panic message when
`borrow()` or `borrow_mut()` panics, to make it easier to track down the
source of the issue.
Currently, we store the caller location for the earliest active borrow.
This has a number of advantages:
* There is only a constant amount of overhead per `RefCell`
* We don't need any heap memory, so it can easily be implemented in core
* Since we are storing the *earliest* active borrow, we don't need any
extra logic in the `Drop` implementation for `Ref` and `RefMut`
Limitations:
* We only store the caller location, not a full `Backtrace`. Until
we get support for `Backtrace` in libcore, this is the best tha we can
do.
* The captured location is only displayed when `borrow()` or
`borrow_mut()` panics. If a crate calls `try_borrow().unwrap()`
or `try_borrow_mut().unwrap()`, this extra information will be lost.
To make testing easier, I've enabled the `debug-refcell` feature by
default. I'm not sure how to write a test for this feature - we would
need to rebuild core from the test framework, and create a separate
sysroot.
Since this feature will be off-by-default, users will need to use
`xargo` or `cargo -Z build-std` to enable this feature. For users using
a prebuilt standard library, this feature will be disabled with zero
overhead.
I've created a simple test program:
```rust
use std::cell::RefCell;
fn main() {
let _ = std::panic::catch_unwind(|| {
let val = RefCell::new(true);
let _first = val.borrow();
let _second = val.borrow();
let _third = val.borrow_mut();
});
let _ = std::panic::catch_unwind(|| {
let val = RefCell::new(true);
let first = val.borrow_mut();
drop(first);
let _second = val.borrow_mut();
let _thid = val.borrow();
});
}
```
which produces the following output:
```
thread 'main' panicked at 'already borrowed: BorrowMutError { location: Location { file: "refcell_test.rs", line: 6, col: 26 } }', refcell_test.rs:8:26
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at 'already mutably borrowed: BorrowError { location: Location { file: "refcell_test.rs", line: 16, col: 27 } }', refcell_test.rs:18:25
```
Clarify non-exact length in the Iterator::take documentation
There's an example which demonstrates incomplete length case, but it'd be best to explain it right from the start.
Document panicking cases for integer division and remainder
This PR documents the cases when integer division and remainder operations panic. These operations panic in two cases: division by zero and overflow.
It's surprising that these operations always panic on overflow, unlike most other arithmetic operations, which panic on overflow only when `debug_assertions` is enabled. The panic on overflow for the remainder is also surprising because a return value of `0` would be reasonable in this case. ("Overflow" occurs only for `MIN % -1`.) Since the panics on overflow are somewhat surprising, they should be documented.
I guess it's worth asking: is panic on overflow (even when `debug_assertions` is disabled) the intended behavior? If not, what's the best way forward?
Add license metadata for std dependencies
These five crates are in the dependency tree of `std` but lack license metadata:
- `alloc`
- `core`
- `panic_abort`
- `panic_unwind`
- `unwind`
Querying the dependency tree of `std` is a useful thing to be able to do, since these crates will typically be linked into Rust binaries. Tools show the license fields missing, as seen in https://github.com/rust-lang/rust/issues/67014#issuecomment-782704534. This PR adds the license field for the five crates, based on the license of the `std` package and this repo as a whole. I also added the `repository` and `descriptions` fields, since those seem useful. For `description`, I copied text from top-level comments for the respective modules - except for `unwind` which has none.
I also note that https://github.com/rust-lang/rust/pull/73530 attempted to add license metadata for all crates in this repo, but was rejected because there was question about some of them. I hope that this smaller change, focusing only on the runtime dependencies, will be easier to review.
cc `@Mark-Simulacrum` `@Lokathor`
Fix inequality in docs for div_euclid
This commit fixes the statement of the inequality that the Euclidean remainder satisfies. (The remainder is guaranteed to be less than abs(rhs), not rhs.) It also rewords the documentation to make it a little easier to read.
(You might wonder why I've written `abs(rhs)` instead of `rhs.abs()`. Two reasons: first, the `rem_euclid` docs use `abs(rhs)` instead of `rhs.abs()`, and second, the absolute value here is the mathematical absolute value, not the the `.abs()` operation which may overflow.)
Implement TrustedLen and TrustedRandomAccess for Range<integer>, array::IntoIter, VecDequeue's iterators
This should make some `FromIterator` and `.zip()` specializations applicable in a few more cases.
``@rustbot`` label libs-impl
Make NonNull::as_ref (and friends) return refs with unbound lifetimes
# Rationale:
1. The documentation for all of these functions claims that this is what the functions already do, as they all come with this comment:
> You must enforce Rust's aliasing rules, *since the returned lifetime 'a is arbitrarily chosen* and does not necessarily reflect the actual lifetime of the data...
So I think it's just a bug that they weren't this way already. Note that had it not been for this part, I wouldn't be making this PR, so if we decide we won't take this change, I'll follow it up with a docs PR to fix this.
2. This is how the equivalent raw pointer functions behave.
They also take `self` and not `&self`/`&mut self`, but that can't be changed compatibly at this point. This is the next best thing.
3. Without this fix, often code that uses these methods will find it has to expand the lifetime of the result.
(I can't speak for others but even in unsafe-heavy code, needing to do this unexpectedly is a huge red flag -- if Rust thinks something should have a specific lifetime, I assume it's for a reason)
### Can this cause existing code to be unsound?
I'm confident this can't cause new unsoundness since the reference exists for at most its lifetime, but you get a borrow checker error if you do something that would require/allow the reference to exist past its lifetime.
Additionally, the aliasing rules of a reference only applies while the reference exists.
This *must* be the case, as it is required by the rules used by safe code. (That said, the documentation in this file sort of contradicts it, but I think it's just ambiguity between the lifetime `'a` in `&'a T` and lifetime of the `&'a T` reference itself...)
We are increasing the lifetime of these references, but they should already have hard bounds on that lifetime, or they'd have borrow checker errors.
(CC ``@RalfJung`` because I have gone and done the mistake where I say something definitive about aliasing in Rust which is honestly outside the group of things I should make definitive comments about).
# Caveats
1. This is insta-stable (except for on the unstable functions ofc). I don't think there's any other alternative.
2. I don't believe this is a breaking change in practice. In theory someone could be assigning `NonNull::as_ref` to a function pointer of type `fn(&NonNull<T>) -> &T`. Now they'd need to use a slightly different function pointer type which is (probably) incompatible. This seems pathological, but I guess crater could be used if there are concerns.
3. This has no tests. The old version didn't either that I saw. I could add some stuff that fails to compile without it, if that would be useful.
4. Sometimes the NLL borrow checker gives up and decides lifetimes live till the end of the scope, as opposed to the range where they're used. If this change can cause this to happen more, then my soundness rationale is wrong, and it's likely breaking.
In practice this seems super unlikely.
Anyway. That was a lot of typing.
Fixes https://github.com/rust-lang/rust/issues/80183
Add `as_str` method for split whitespace str iterators
This PR adds `as_str` methods to `SplitWhitespace` and `SplitAsciiWhitespace`
str iterators. The methods return the remainder, similar to `as_str` methods on
`Chars` and other split iterators. This PR is a continuation of https://github.com/rust-lang/rust/pull/75265, which added `as_str` for all other str split iterators.
The feature gate for new methods is `#![feature(str_split_whitespace_as_str)]`.
`SplitWhitespace` and `SplitAsciiWhitespace` use iterators under the hood, so to implement `as_str` it's required to either
1. Make fields of some iterators `pub(crate)`
2. Add getter methods (like `into_inner`, `inner`, `inner_mut`...) to some (all) iterators
3. Completely rewrite `SplitWhitespace` and `SplitAsciiWhitespace`
This PR uses the 1. approach since it's easier to implement and requires fewer changes (and no changes to the public API). If you think that's not the right way, please, tell me.
r? `@m-ou-se`
Fix typo/inaccuracy in the documentation of Iterator::skip_while
One of the examples used to say “this leads to a possibly confusing situation, where the type of the closure is a double reference” while _actually_ referring to the type of the closure _argument_.
This PR just changes a single word in documentation.
`````@rustbot````` modify labels: A-iterators, T-doc, T-lang
One of the examples used to say “this leads to a possibly confusing situation,
where the type of the closure is a double reference” while _actually_ referring to
the type of the closure _argument_.
Add more links between hash and btree collections
- Link from `core::hash` to `HashMap` and `HashSet`
- Link from HashMap and HashSet to the module-level documentation on
when to use the collection
- Link from several collections to Wikipedia articles on the general
concept
See also https://github.com/rust-lang/rust/pull/81989#issuecomment-783920840.
Deprecate `intrinsics::drop_in_place` and `collections::Bound`, which accidentally weren't deprecated
Fixes#82080.
I've taken the liberty of updating the `since` values to 1.52, since an unobservable deprecation isn't much of a deprecation (even the detailed release notes never bothered to mention these deprecations).
As mentioned in the issue I'm *pretty* sure that using a type alias for `Bound` is semantically equivalent to the re-export; [the reference implies](https://doc.rust-lang.org/reference/items/type-aliases.html) that type aliases only observably differ from types when used on unit structs or tuple structs, whereas `Bound` is an enum.
Add a check for ASCII characters in to_upper and to_lower
This extra check has better performance. See discussion here:
https://internals.rust-lang.org/t/to-upper-speed/13896
Thanks to `@gilescope` for helping discover and test this.
Deprecate RustcEncodable and RustcDecodable.
We can't remove the `RustcEncodable` and `RustcDecodable` derive macros from the prelude, but we can deprecate them.
"spotlight" is not a very specific or self-explaining name.
Additionally, the dialog that it triggers is called "Notable traits".
So, "notable trait" is a better name.
* Rename `#[doc(spotlight)]` to `#[doc(notable_trait)]`
* Rename `#![feature(doc_spotlight)]` to `#![feature(doc_notable_trait)]`
* Update documentation
* Improve documentation
Add `reverse` search alias for Iterator::rev()
When searching for "reverse" in rustdoc you can't find the rev method on Iterator so here is a search alias for that.
Don't implement mem::replace with mem::swap.
`swap` is a complicated operation, so this changes the implementation of `replace` to use `read` and `write` instead.
See https://github.com/rust-lang/rust/pull/83019.
I wrote there:
> Implementing the simpler operation (replace) with the much more complicated operation (swap) doesn't make a whole lot of sense. `replace` is just read+write, and the primitive for moving out of a `&mut`. `swap` is for doing that to *two* `&mut` at the same time, which is both more niche and more complicated (as shown by `swap_nonoverlapping_bytes`).
This could be especially interesting for `Option<VeryLargeStruct>::take()`, since swapping such a large structure with `swap_nonoverlapping_bytes` is going to be much less efficient than `ptr::write()`'ing a `None`.
But also for small values where `swap` just reads/writes using temporary variable, this makes a `replace` or `take` operation simpler:
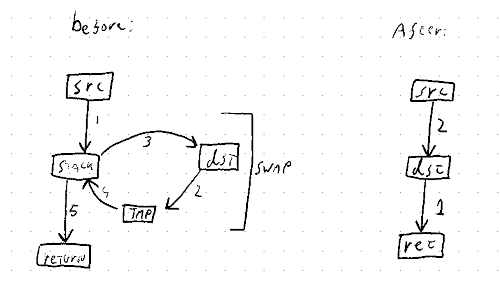
convert slice doc link to intra-doc links
Continuing where #80189 stopped, with `core::slice`.
I had an issue with two dead links in my doc when implementing `Deref<Target = [T]>` for one of my type. This means that [`binary_search_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.binary_search_by_key) was available, but not [`sort_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.sort_by_key) even though it was linked in it's doc (same issue with [`as_ptr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_ptr) and [`as_mut_pbr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_mut_ptr)). It becomes available if I implement `DerefMut`, as it needs an `&mut self`.
<details>
<summary>Code that will have dead links in its doc</summary>
```rust
pub struct A;
pub struct B;
impl std::ops::Deref for B{
type Target = [A];
fn deref(&self) -> &Self::Target {
&A
}
}
```
</details>
I removed the link to `sort_by_key` from `binary_search_by_key` doc as I didn't find a nice way to have a live link:
- `binary_search_by_key` is in `core`
- `sort_by_key` is in `alloc`
- intra-doc link `slice::sort_by_key` doesn't work, as `alloc` is not available when `core` is being build (the warning can't be ignored: ```error[E0710]: an unknown tool name found in scoped lint: `rustdoc::broken_intra_doc_links` ```)
- keeping the link as an anchor `#method.sort_by_key` meant a dead link
- an absolute link would work but doesn't feel right...
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Add Option::get_or_default
Tracking issue: #82901
The original issue is #55042, which was closed, but for an invalid reason (see discussion there). Opening this to reconsider (I hope that's okay). It seems like the only gap for `Option` being "entry-like".
I ran into a need for this method where I had a `Vec<Option<MyData>>` and wanted to do `vec[n].get_or_default().my_data_method()`. Using an `Option` as an inner component of a data structure is probably where the need for this will normally arise.
Stabilize `unsafe_op_in_unsafe_fn` lint
This makes it possible to override the level of the `unsafe_op_in_unsafe_fn`, as proposed in https://github.com/rust-lang/rust/issues/71668#issuecomment-729770896.
Tracking issue: #71668
r? ```@nikomatsakis``` cc ```@SimonSapin``` ```@RalfJung```
# Stabilization report
This is a stabilization report for `#![feature(unsafe_block_in_unsafe_fn)]`.
## Summary
Currently, the body of unsafe functions is an unsafe block, i.e. you can perform unsafe operations inside.
The `unsafe_op_in_unsafe_fn` lint, stabilized here, can be used to change this behavior, so performing unsafe operations in unsafe functions requires an unsafe block.
For now, the lint is allow-by-default, which means that this PR does not change anything without overriding the lint level.
For more information, see [RFC 2585](https://github.com/rust-lang/rfcs/blob/master/text/2585-unsafe-block-in-unsafe-fn.md)
### Example
```rust
// An `unsafe fn` for demonstration purposes.
// Calling this is an unsafe operation.
unsafe fn unsf() {}
// #[allow(unsafe_op_in_unsafe_fn)] by default,
// the behavior of `unsafe fn` is unchanged
unsafe fn allowed() {
// Here, no `unsafe` block is needed to
// perform unsafe operations...
unsf();
// ...and any `unsafe` block is considered
// unused and is warned on by the compiler.
unsafe {
unsf();
}
}
#[warn(unsafe_op_in_unsafe_fn)]
unsafe fn warned() {
// Removing this `unsafe` block will
// cause the compiler to emit a warning.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
#[deny(unsafe_op_in_unsafe_fn)]
unsafe fn denied() {
// Removing this `unsafe` block will
// cause a compilation error.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
```
Added #[repr(transparent)] to core::cmp::Reverse
I found casting from an `&T` to an `&Reverse<T>` potentially useful, but found that `Reverse` was not `#[repr(transparent)]`, so after asking about it [on Reddit](https://www.reddit.com/r/rust/comments/le60uv/make_stdcmpreverse_reprtransparent_and_add_a/), I decided to go ahead and make a pull request which simply adds the attribute to the struct.
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
improve offset_from docs
`@thomcc` pointed out that the current docs leave it kind of unclear how one can satisfy the "no wrapping around `isize` or the address space" requirement of `offset_from`, so make the docs clearer about that.
FWIW, I don't think I entirely agree with that second paragraph about large objects (that I left mostly unchanged here). LLVM, to my knowledge, fundamentally assumes that all allocations fit into an `isize::MAX`. So in that sense creating a larger allocation is simply UB. I would expect a guarantee that Rust heap allocation methods will never return allocations larger than `isize::MAX` (or rather, Rust heap allocation methods should require that the `Layout` is no larger than `isize::MAX`). However, I cannot find any such requirement documented currently. Large allocations are not mentioned at all in the allocator docs, which is quite surprising -- even if we say that such allocations are not insta-UB (which I think is incompatible with LLVM), they are still extremely footgunny since `ptr::offset`/`ptr::add` do not support offsetting by more than `isize::MAX` bytes.
Furthermore, the allocator docs don't even say anything about allocations wrapping around the address space. But that is certainly something allocators must ensure never happens; we cannot expect clients to defend against this.
Cc `@rust-lang/wg-allocators`
Improve transmute docs with further clarifications
Closes#82493.
Please let me know if any of the new wording sounds off, English is not my mother tongue.
Prevent specialized ZipImpl from calling `__iterator_get_unchecked` twice with the same index
Fixes#82291
It's open for review, but conflicts with #82289, wait before merging. The conflict involves only the new test, so it should be rather trivial to fix.
Make some Option, Result methods unstably const
The following methods are now unstably const:
- Option::transpose
- Option::flatten
- Result::flatten
While some methods for could likely be made `const` in the future, nearly all of them require something to be dropped at compile-time, which isn't currently supported. The functions listed above should have a trivial path to stabilization.
{kind=link}