Implement `PROBLEMATIC_CONSTS` generalization
You forgot that `A≈4`, `B≈8`, and `E≈3` and some more constants.
The new `PROBLEMATIC_CONSTS` was generated using this code:
```py
from functools import reduce
def generate_problems(consts: list, letter_digit: dict):
for const in consts:
problem = reduce(lambda string, rep: string.replace(*reversed(rep)), ['%X' % const, *letter_digit.items()])
indexes = [index for index, c in enumerate(problem) if c in letter_digit.keys()]
for i in range(1 << len(indexes)):
yield int(''.join(letter_digit[c] if index in indexes and (i >> indexes.index(index)) & 1 else c for index, c in enumerate(problem)), 0x10)
problems = generate_problems(
[
# Old PROBLEMATIC_CONSTS:
184594741, 2880289470, 2881141438, 2965027518, 2976579765, 3203381950, 3405691582, 3405697037,
3735927486, 3735932941, 4027431614, 4276992702,
# More of my own:
195934910, 252707358, 762133, 179681982, 173390526
],
{
'A': '4',
'B': '8',
'E': '3',
}
)
# print(list(problems)) # won't use that to print formatted
from itertools import islice
while len(cur_problems := list(islice(problems, 8))):
print(' ', end='')
print(*cur_problems, sep=', ', end='')
print(',')
```
Add support for Arm64EC to the Standard Library
Adds the final pieces so that the standard library can be built for arm64ec-pc-windows-msvc (initially added in #119199)
* Bumps `windows-sys` to 0.56.0, which adds support for Arm64EC.
* Correctly set the `isEC` parameter for LLVM's `writeArchive` function.
* Add `#![feature(asm_experimental_arch)]` to library crates where Arm64EC inline assembly is used, as it is currently unstable.
Port the 2 `rust-lld` run-make tests to `rmake`
In preparation for finalizing most of the `rust-lld` work, this PR ports the following tests to `rmake`:
- `tests/run-make/rust-lld`
- `tests/run-make/rust-lld-custom-target`
As they use `$(CGREP) -e` I added `regex` as an exported dependency to the `run_make_support` library.
Unfortunately, the most recent versions depend on `memchr` 2.6.0 but it's currently pinned at 2.5.0 in the workspace, and therefore had to settle for the older `regex-1.8.0`.
r? `@jieyouxu`
Update ar_archive_writer to 0.2.0
This adds a whole bunch of tests checking for any difference with llvm's archive writer. It also fixes two mistakes in the porting from C++ to Rust. The first one causes a divergence for Mach-O archives which may or may not be harmless. The second will definitively cause issues, but only applies to thin archives, which rustc currently doesn't create.
Rollup of 8 pull requests
Successful merges:
- #123651 (Thread local updates for idiomatic examples)
- #123699 (run-make-support: tidy up support library)
- #123779 (OpenBSD fix long socket addresses)
- #123875 (Doc: replace x with y for hexa-decimal fmt)
- #123879 (Add missing `unsafe` to some internal `std` functions)
- #123889 (reduce tidy overheads in run-make checks)
- #123898 (Generic associated consts: Check regions earlier when comparing impl with trait item def)
- #123902 (compiletest: Update rustfix to 0.8.1)
r? `@ghost`
`@rustbot` modify labels: rollup
compiletest: Update rustfix to 0.8.1
This updates the version of rustfix used in compiletest to be closer to what cargo is using. This is to help ensure `cargo fix` and compiletest are aligned. There are some unpublished changes to `rustfix`, which will update in a future PR when those are published.
Will plan to update ui_test in the near future to avoid the duplicate.
This adds a whole bunch of tests checking for any difference with llvm's
archive writer. It also fixes two mistakes in the porting from C++ to
Rust. The first one causes a divergence for Mach-O archives which may or
may not be harmless. The second will definitively cause issues, but only
applies to thin archives, which rustc currently doesn't create.
Create the rustc_sanitizers crate and move the source code for the CFI
and KCFI sanitizers to it.
Co-authored-by: David Wood <agile.lion3441@fuligin.ink>
Update sysinfo to 0.30.8
Fixes a Mac specific issue when using `metrics = true` in `config.toml`.
```config.toml
# Collect information and statistics about the current build and writes it to
# disk. Enabling this or not has no impact on the resulting build output. The
# schema of the file generated by the build metrics feature is unstable, and
# this is not intended to be used during local development.
metrics = true
```
During repeated builds, as the generated `metrics.json` grew, eventually `refresh_cpu()` would be called in quick enough succession (specifically: under 200ms) that a divide by zero would occur, leading to a `NaN` which would not be serialized, then when the `metrics.json` was re-read it would fail to parse.
That error looks like this (collected from Ferrocene's CI):
```
Compiling rustdoc-tool v0.0.0 (/Users/distiller/project/src/tools/rustdoc)
Finished release [optimized] target(s) in 38.37s
thread 'main' panicked at src/utils/metrics.rs:180:21:
serde_json::from_slice::<JsonRoot>(&contents) failed with invalid type: null, expected f64 at line 1 column 9598
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:40
Exited with code exit status 1
```
Related: https://github.com/GuillaumeGomez/sysinfo/pull/1236
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
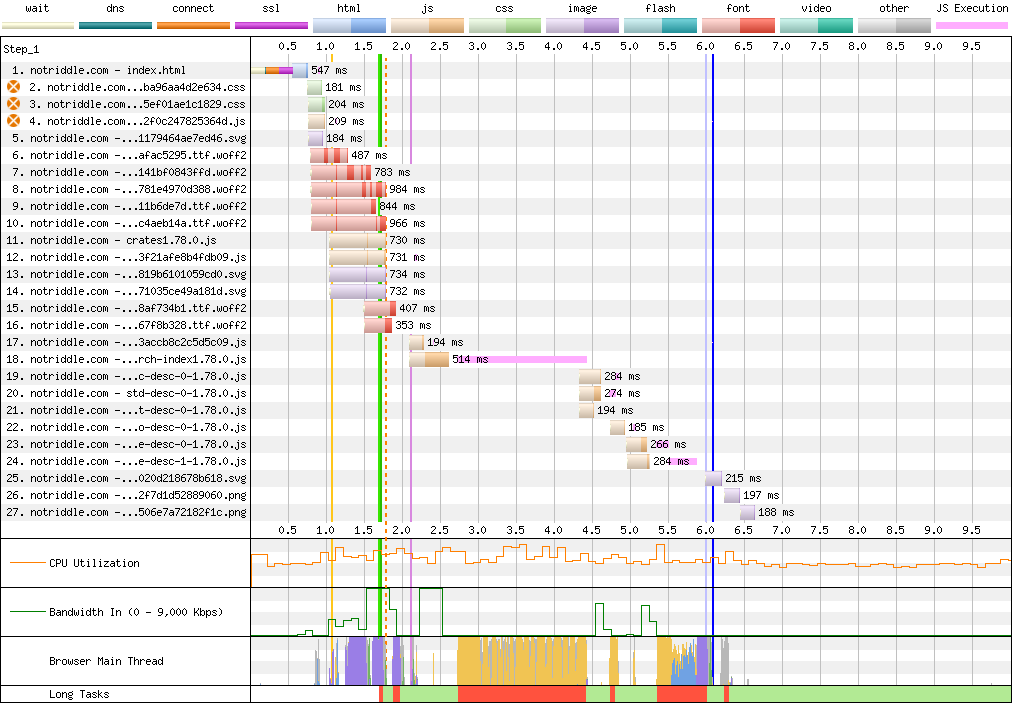
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
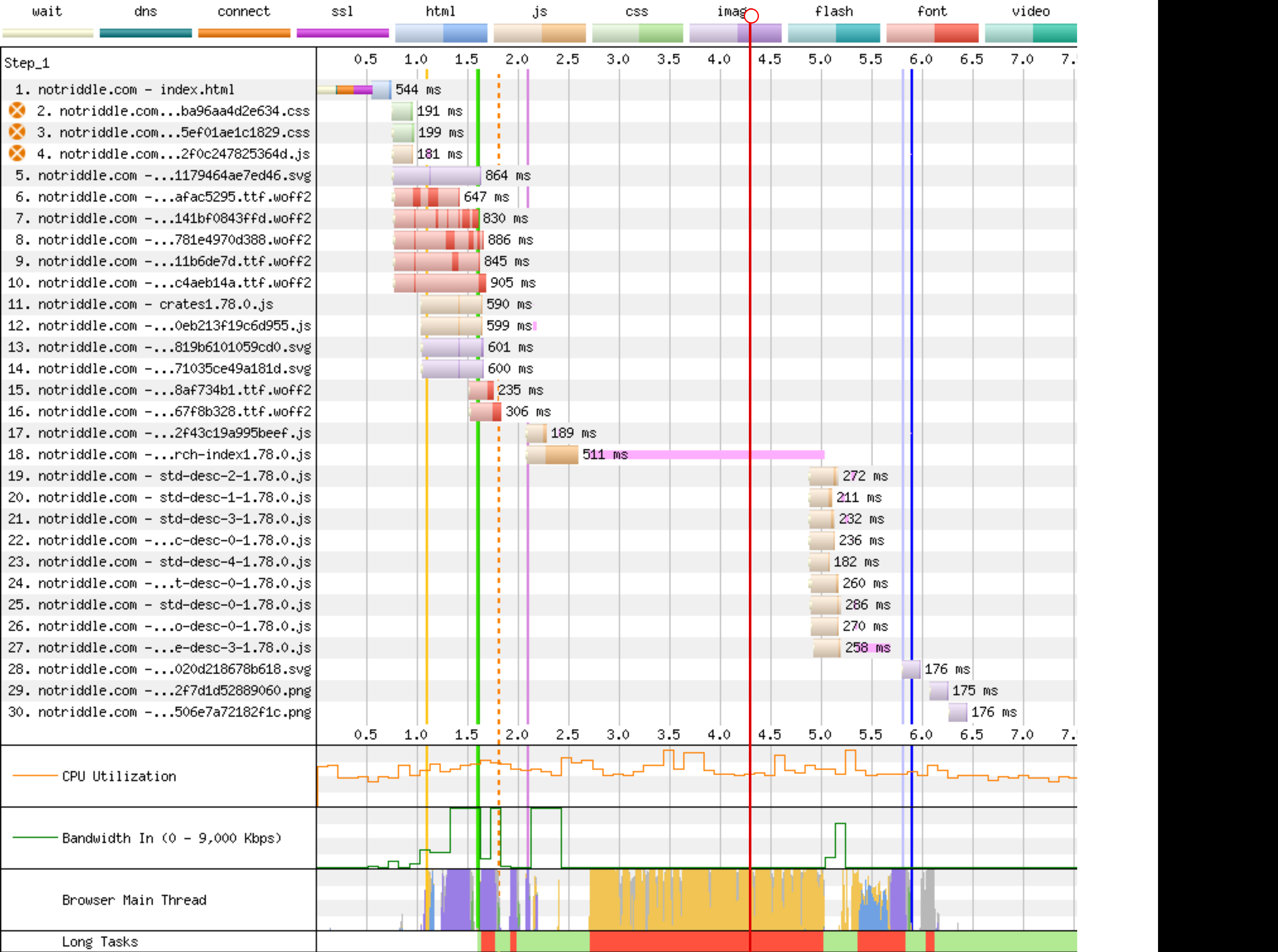
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
Use the `Align` type when parsing alignment attributes
Use the `Align` type in `rustc_attr::parse_alignment`, removing the need to call `Align::from_bytes(...).unwrap()` later in the compilation process.
Print a backtrace in const eval if interrupted
Demo:
```rust
#![feature(const_eval_limit)]
#![const_eval_limit = "0"]
const OW: u64 = {
let mut res: u64 = 0;
let mut i = 0;
while i < u64::MAX {
res = res.wrapping_add(i);
i += 1;
}
res
};
fn main() {
println!("{}", OW);
}
```
```
╭ ➜ ben@archlinux:~/rust
╰ ➤ rustc +stage1 spin.rs
^Cerror[E0080]: evaluation of constant value failed
--> spin.rs:8:33
|
8 | res = res.wrapping_add(i);
| ^ Compilation was interrupted
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
|
= note: this note originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to previous error
For more information about this error, try `rustc --explain E0080`.
```
CFI: Support complex receivers
Right now, we only support rewriting `&self` and `&mut self` into `&dyn MyTrait` and `&mut dyn MyTrait`. This expands it to handle the full gamut of receivers by calculating the receiver based on *substitution* rather than based on a rewrite. This means that, for example, `Arc<Self>` will become `Arc<dyn MyTrait>` appropriately with this change.
This approach also allows us to support associated type constraints as well, so we will correctly rewrite `&self` into `&dyn MyTrait<T=i32>`, for example.
r? ```@workingjubilee```
Previously, we only rewrote `&self` and `&mut self` receivers. By
instantiating the method from the trait definition, we can make this
work work with arbitrary legal receivers instead.
"Handle" calls to upstream monomorphizations in compiler_builtins
This is pretty cooked, but I think it works.
compiler-builtins has a long-standing problem that at link time, its rlib cannot contain any calls to `core`. And yet, in codegen we _love_ inserting calls to symbols in `core`, generally from various panic entrypoints.
I intend this PR to attack that problem as completely as possible. When we generate a function call, we now check if we are generating a function call from `compiler_builtins` and whether the callee is a function which was not lowered in the current crate, meaning we will have to link to it.
If those conditions are met, actually generating the call is asking for a linker error. So we don't. If the callee diverges, we lower to an abort with the same behavior as `core::intrinsics::abort`. If the callee does not diverge, we produce an error. This means that compiler-builtins can contain panics, but they'll SIGILL instead of panicking. I made non-diverging calls a compile error because I'm guessing that they'd mostly get into compiler-builtins by someone making a mistake while working on the crate, and compile errors are better than linker errors. We could turn such calls into aborts as well if that's preferred.
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB