Consider mutations as borrows in generator drop tracking
This is needed to match MIR more conservative approximation of any borrowed value being live across a suspend point (See #94067). This change considers an expression such as `x.y = z` to be a borrow of `x` and therefore keeps `x` live across suspend points.
r? `@nikomatsakis`
Convert `newtype_index` to a proc macro
The `macro_rules!` implementation was becomng excessively complicated,
and difficult to modify. The new proc macro implementation should make
it much easier to add new features (e.g. skipping certain `#[derive]`s)
rustc_errors: let `DiagnosticBuilder::emit` return a "guarantee of emission".
That is, `DiagnosticBuilder` is now generic over the return type of `.emit()`, so we'll now have:
* `DiagnosticBuilder<ErrorReported>` for error (incl. fatal/bug) diagnostics
* can only be created via a `const L: Level`-generic constructor, that limits allowed variants via a `where` clause, so not even `rustc_errors` can accidentally bypass this limitation
* asserts `diagnostic.is_error()` on emission, just in case the construction restriction was bypassed (e.g. by replacing the whole `Diagnostic` inside `DiagnosticBuilder`)
* `.emit()` returns `ErrorReported`, as a "proof" token that `.emit()` was called
(though note that this isn't a real guarantee until after completing the work on
#69426)
* `DiagnosticBuilder<()>` for everything else (warnings, notes, etc.)
* can also be obtained from other `DiagnosticBuilder`s by calling `.forget_guarantee()`
This PR is a companion to other ongoing work, namely:
* #69426
and it's ongoing implementation:
#93222
the API changes in this PR are needed to get statically-checked "only errors produce `ErrorReported` from `.emit()`", but doesn't itself provide any really strong guarantees without those other `ErrorReported` changes
* #93244
would make the choices of API changes (esp. naming) in this PR fit better overall
In order to be able to let `.emit()` return anything trustable, several changes had to be made:
* `Diagnostic`'s `level` field is now private to `rustc_errors`, to disallow arbitrary "downgrade"s from "some kind of error" to "warning" (or anything else that doesn't cause compilation to fail)
* it's still possible to replace the whole `Diagnostic` inside the `DiagnosticBuilder`, sadly, that's harder to fix, but it's unlikely enough that we can paper over it with asserts on `.emit()`
* `.cancel()` now consumes `DiagnosticBuilder`, preventing `.emit()` calls on a cancelled diagnostic
* it's also now done internally, through `DiagnosticBuilder`-private state, instead of having a `Level::Cancelled` variant that can be read (or worse, written) by the user
* this removes a hazard of calling `.cancel()` on an error then continuing to attach details to it, and even expect to be able to `.emit()` it
* warnings were switched to *only* `can_emit_warnings` on emission (instead of pre-cancelling early)
* `struct_dummy` was removed (as it relied on a pre-`Cancelled` `Diagnostic`)
* since `.emit()` doesn't consume the `DiagnosticBuilder` <sub>(I tried and gave up, it's much more work than this PR)</sub>,
we have to make `.emit()` idempotent wrt the guarantees it returns
* thankfully, `err.emit(); err.emit();` can return `ErrorReported` both times, as the second `.emit()` call has no side-effects *only* because the first one did do the appropriate emission
* `&mut Diagnostic` is now used in a lot of function signatures, which used to take `&mut DiagnosticBuilder` (in the interest of not having to make those functions generic)
* the APIs were already mostly identical, allowing for low-effort porting to this new setup
* only some of the suggestion methods needed some rework, to have the extra `DiagnosticBuilder` functionality on the `Diagnostic` methods themselves (that change is also present in #93259)
* `.emit()`/`.cancel()` aren't available, but IMO calling them from an "error decorator/annotator" function isn't a good practice, and can lead to strange behavior (from the caller's perspective)
* `.downgrade_to_delayed_bug()` was added, letting you convert any `.is_error()` diagnostic into a `delay_span_bug` one (which works because in both cases the guarantees available are the same)
This PR should ideally be reviewed commit-by-commit, since there is a lot of fallout in each.
r? `@estebank` cc `@Manishearth` `@nikomatsakis` `@mark-i-m`
As an example:
#[test]
#[ignore = "not yet implemented"]
fn test_ignored() {
...
}
Will now render as:
running 2 tests
test tests::test_ignored ... ignored, not yet implemented
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
These links never worked, but the lint was suppressed due to the fact
that the span was pointing into the macro. With the new macro
implementation, the span now points directly to the doc comment in the
macro invocation, so it's no longer suppressed.
The `macro_rules!` implementation was becomng excessively complicated,
and difficult to modify. The new proc macro implementation should make
it much easier to add new features (e.g. skipping certain `#[derive]`s)
Avoid emitting full macro body into JSON errors
While investigating https://github.com/rust-lang/rust/issues/94322, it was noted that currently the JSON diagnostics for macro backtraces include the full def_site span -- the whole macro body.
It seems like this shouldn't be necessary, so this PR adjusts the span to just be the "guessed head", typically the macro name. It doesn't look like we keep enough information to synthesize a nicer span here at this time.
Atop #92123, this reduces output for the src/test/ui/suggestions/missing-lifetime-specifier.rs test from 660 KB to 156 KB locally.
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes#94149
r? ````@michaelwoerister```` since you touched this code last, I think!
Stop manually SIMDing in `swap_nonoverlapping`
Like I previously did for `reverse` (#90821), this leaves it to LLVM to pick how to vectorize it, since it can know better the chunk size to use, compared to the "32 bytes always" approach we currently have.
A variety of codegen tests are included to confirm that the various cases are still being vectorized.
It does still need logic to type-erase in some cases, though, as while LLVM is now smart enough to vectorize over slices of things like `[u8; 4]`, it fails to do so over slices of `[u8; 3]`.
As a bonus, this change also means one no longer gets the spurious `memcpy`(s?) at the end up swapping a slice of `__m256`s: <https://rust.godbolt.org/z/joofr4v8Y>
<details>
<summary>ASM for this example</summary>
## Before (from godbolt)
note the `push`/`pop`s and `memcpy`
```x86
swap_m256_slice:
push r15
push r14
push r13
push r12
push rbx
sub rsp, 32
cmp rsi, rcx
jne .LBB0_6
mov r14, rsi
shl r14, 5
je .LBB0_6
mov r15, rdx
mov rbx, rdi
xor eax, eax
.LBB0_3:
mov rcx, rax
vmovaps ymm0, ymmword ptr [rbx + rax]
vmovaps ymm1, ymmword ptr [r15 + rax]
vmovaps ymmword ptr [rbx + rax], ymm1
vmovaps ymmword ptr [r15 + rax], ymm0
add rax, 32
add rcx, 64
cmp rcx, r14
jbe .LBB0_3
sub r14, rax
jbe .LBB0_6
add rbx, rax
add r15, rax
mov r12, rsp
mov r13, qword ptr [rip + memcpy@GOTPCREL]
mov rdi, r12
mov rsi, rbx
mov rdx, r14
vzeroupper
call r13
mov rdi, rbx
mov rsi, r15
mov rdx, r14
call r13
mov rdi, r15
mov rsi, r12
mov rdx, r14
call r13
.LBB0_6:
add rsp, 32
pop rbx
pop r12
pop r13
pop r14
pop r15
vzeroupper
ret
```
## After (from my machine)
Note no `rsp` manipulation, sorry for different ASM syntax
```x86
swap_m256_slice:
cmpq %r9, %rdx
jne .LBB1_6
testq %rdx, %rdx
je .LBB1_6
cmpq $1, %rdx
jne .LBB1_7
xorl %r10d, %r10d
jmp .LBB1_4
.LBB1_7:
movq %rdx, %r9
andq $-2, %r9
movl $32, %eax
xorl %r10d, %r10d
.p2align 4, 0x90
.LBB1_8:
vmovaps -32(%rcx,%rax), %ymm0
vmovaps -32(%r8,%rax), %ymm1
vmovaps %ymm1, -32(%rcx,%rax)
vmovaps %ymm0, -32(%r8,%rax)
vmovaps (%rcx,%rax), %ymm0
vmovaps (%r8,%rax), %ymm1
vmovaps %ymm1, (%rcx,%rax)
vmovaps %ymm0, (%r8,%rax)
addq $2, %r10
addq $64, %rax
cmpq %r10, %r9
jne .LBB1_8
.LBB1_4:
testb $1, %dl
je .LBB1_6
shlq $5, %r10
vmovaps (%rcx,%r10), %ymm0
vmovaps (%r8,%r10), %ymm1
vmovaps %ymm1, (%rcx,%r10)
vmovaps %ymm0, (%r8,%r10)
.LBB1_6:
vzeroupper
retq
```
</details>
This does all its copying operations as either the original type or as `MaybeUninit`s, so as far as I know there should be no potential abstract machine issues with reading padding bytes as integers.
<details>
<summary>Perf is essentially unchanged</summary>
Though perhaps with more target features this would help more, if it could pick bigger chunks
## Before
```
running 10 tests
test slice::swap_with_slice_4x_usize_30 ... bench: 894 ns/iter (+/- 11)
test slice::swap_with_slice_4x_usize_3000 ... bench: 99,476 ns/iter (+/- 2,784)
test slice::swap_with_slice_5x_usize_30 ... bench: 1,257 ns/iter (+/- 7)
test slice::swap_with_slice_5x_usize_3000 ... bench: 139,922 ns/iter (+/- 959)
test slice::swap_with_slice_rgb_30 ... bench: 328 ns/iter (+/- 27)
test slice::swap_with_slice_rgb_3000 ... bench: 16,215 ns/iter (+/- 176)
test slice::swap_with_slice_u8_30 ... bench: 312 ns/iter (+/- 9)
test slice::swap_with_slice_u8_3000 ... bench: 5,401 ns/iter (+/- 123)
test slice::swap_with_slice_usize_30 ... bench: 368 ns/iter (+/- 3)
test slice::swap_with_slice_usize_3000 ... bench: 28,472 ns/iter (+/- 3,913)
```
## After
```
running 10 tests
test slice::swap_with_slice_4x_usize_30 ... bench: 868 ns/iter (+/- 36)
test slice::swap_with_slice_4x_usize_3000 ... bench: 99,642 ns/iter (+/- 1,507)
test slice::swap_with_slice_5x_usize_30 ... bench: 1,194 ns/iter (+/- 11)
test slice::swap_with_slice_5x_usize_3000 ... bench: 139,761 ns/iter (+/- 5,018)
test slice::swap_with_slice_rgb_30 ... bench: 324 ns/iter (+/- 6)
test slice::swap_with_slice_rgb_3000 ... bench: 15,962 ns/iter (+/- 287)
test slice::swap_with_slice_u8_30 ... bench: 281 ns/iter (+/- 5)
test slice::swap_with_slice_u8_3000 ... bench: 5,324 ns/iter (+/- 40)
test slice::swap_with_slice_usize_30 ... bench: 275 ns/iter (+/- 5)
test slice::swap_with_slice_usize_3000 ... bench: 28,277 ns/iter (+/- 277)
```
</detail>
Improve `--check-cfg` implementation
This pull-request is a mix of improvements regarding the `--check-cfg` implementation:
- Simpler internal representation (usage of `Option` instead of separate bool)
- Add --check-cfg to the unstable book (based on the RFC)
- Improved diagnostics:
* List possible values when the value is unexpected
* Suggest if possible a name or value that is similar
- Add more tests (well known names, mix of combinations, ...)
r? ```@petrochenkov```
better ObligationCause for normalization errors in `can_type_implement_copy`
Some logic is needed so we can point to the field when given totally nonsense types like `struct Foo(<u32 as Iterator>::Item);`
Fixes#93687
Always format to internal String in FmtPrinter
This avoids monomorphizing for different parameters, decreasing generic code
instantiated downstream from rustc_middle -- locally seeing 7% unoptimized LLVM IR
line wins on rustc_borrowck, for example.
We likely can't/shouldn't get rid of the Result-ness on most functions, though some
further cleanup avoiding fmt::Error where we now know it won't occur may be possible,
though somewhat painful -- fmt::Write is a pretty annoying API to work with in practice
when you're trying to use it infallibly.
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
remove feature gate in control_flow examples
Stabilization was done in https://github.com/rust-lang/rust/pull/91091, but the two examples weren't updated accordingly.
Probably too late to put it into stable, but it should be in the next release :)
Miri: relax fn ptr check
As discussed in https://github.com/rust-lang/unsafe-code-guidelines/issues/72#issuecomment-1025407536, the function pointer check done by Miri is currently overeager: contrary to our usual principle of only checking rather uncontroversial validity invariants, we actually check that the pointer points to a real function.
So, this relaxes the check to what the validity invariant probably will be (and what the reference already says it is): the function pointer must be non-null, and that's it.
The check that CTFE does on the final value of a constant is unchanged -- CTFE recurses through references, so it makes some sense to also recurse through function pointers. We might still want to relax this in the future, but that would be a separate change.
r? `@oli-obk`
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
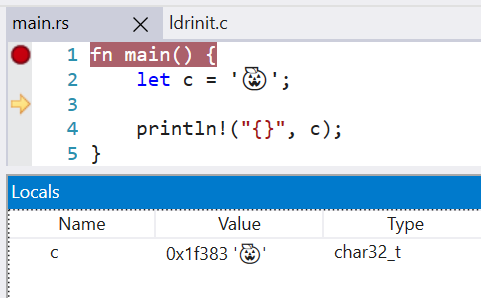
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
`scan_escape` currently has a fast path (for when the first char isn't
'\\') and a slow path.
This commit changes `scan_escape` so it only handles the slow path, i.e.
the actual escaping code. The fast path is inlined into the two call
sites.
This change makes the code faster, because there is no function call
overhead on the fast path. (`scan_escape` is a big function and doesn't
get inlined.)
This change also improves readability, because it removes a bunch of
mode checks on the the fast paths.
{kind=link}