Rename Machine memory hooks to suggest when they run
Some of the other memory hooks start with `before_` or `after_` to indicate that they run before or after a certain operation. These don't, so I was a bit confused as to when they are supposed to run.
`memory_read` can be read two ways in English, "memory was read" or "this is a memory read" so without the prefix this was especially ambiguous.
Erase regions better in `promote_candidate`
Use `tcx.erase_regions` instead of manually walking through the substs.... this also makes the code slightly simpler 🙈Fixes#100360Fixes#89851
Use `TraitEngine` in more places that don't specifically need `FulfillmentContext::new_in_snapshot`
Not sure if this change is worthwhile, but couldn't hurt re: chalkification
r? types
Improve size assertions.
- For any file with four or more size assertions, move them into a
separate module (as is already done for `hir.rs`).
- Add some more for AST nodes and THIR nodes.
- Put the `hir.rs` ones in alphabetical order.
r? `@lqd`
- For any file with four or more size assertions, move them into a
separate module (as is already done for `hir.rs`).
- Add some more for AST nodes and THIR nodes.
- Put the `hir.rs` ones in alphabetical order.
Deeply deny fn and raw ptrs in const generics
I think this is right -- just because we wrap a fn ptr in a wrapper type does not mean we should allow it in a const parameter.
We now reject both of these in the same way:
```
#![feature(adt_const_params)]
#[derive(Eq, PartialEq)]
struct Wrapper();
fn foo<const W: Wrapper>() {}
fn foo2<const F: fn()>() {}
```
This does regress one test (`src/test/ui/consts/refs_check_const_eq-issue-88384.stderr`), but I'm not sure it should've passed in the first place.
cc: ``@b-naber`` who introduced that test^
fixes#99641
interpret, ptr_offset_from: refactor and test too-far-apart check
We didn't have any tests for the "too far apart" message, and indeed that check mostly relied on the in-bounds check and was otherwise probably not entirely correct... so I rewrote that check, and it is before the in-bounds check so we can test it separately.
interpret: rename Tag/PointerTag to Prov/Provenance
We were pretty inconsistent with calling this the "tag" vs the "provenance" of the pointer; I think we should consistently call it "provenance".
r? `@oli-obk`
Let's avoid using two different terms for the same thing -- let's just call it "provenance" everywhere.
In Miri, provenance consists of an AllocId and an SbTag (Stacked Borrows tag), which made this even more confusing.
interpret: make some large types not Copy
Also remove some unused trait impls (mostly HashStable).
This didn't find any unnecessary copies that I managed to avoid, but it might still be better to require explicit clone for these types? Not sure.
r? `@oli-obk`
Use constant eval to do strict mem::uninit/zeroed validity checks
I'm not sure about the code organisation here, I just dumped the check in rustc_const_eval at the root. Not hard to move it elsewhere, in any case.
Also, this means cranelift codegen intrinsics lose the strict checks, since they don't seem to depend on rustc_const_eval, and I didn't see a point in keeping around two copies.
I also left comments in the is_zero_valid methods about "uhhh help how do i do this", those apply to both methods equally.
Also rustc_codegen_ssa now depends on rustc_const_eval... is this okay?
Pinging `@RalfJung` since you were the one who mentioned this to me, so I'm assuming you're interested.
Haven't had a chance to run full tests on this since it's really warm, and it's 1AM, I'll check out any failures/comments in the morning :)
interpret/visitor: support visiting with a PlaceTy
Finally we can visit a `PlaceTy` in a way that will only do `force_allocation` when needed ti visit a field. :)
r? `@oli-obk`
interpret: get rid of MemPlaceMeta::Poison
This is achieved by refactoring the projection code (`{mplace,place,operand}_{downcast,field,index,...}`) so that we no longer need to call `assert_mem_place` in the operand handling.
Pull Derefer before ElaborateDrops
_Follow up work to #97025#96549#96116#95887 #95649_
This moves `Derefer` before `ElaborateDrops` and creates a new `Rvalue` called `VirtualRef` that allows us to bypass many constraints for `DerefTemp`.
r? `@oli-obk`
interpret: refactor projection handling code
Moves our projection handling code into a common file, and avoids the use of a
general mplace-based fallback function by have more specialized implementations.
mplace_index (and the other slice-related functions) could be more efficient by
copy-pasting the body of operand_index. Or we could do some trait magic to share
the code between them. But for now this is probably fine.
This is the common part of https://github.com/rust-lang/rust/pull/99013 and https://github.com/rust-lang/rust/pull/99097. I am seeing some strange perf results so this probably should be its own change so we know which diff caused which perf changes...
r? `@oli-obk`
Moves our projection handling code into a common file, and avoids the use of a
general mplace-based fallback function by have more specialized implementations.
mplace_index (and the other slice-related functions) could be more efficient by
copy-pasting the body of operand_index. Or we could do some trait magic to share
the code between them. But for now this is probably fine.
Implement `SourceMap::is_span_accessible`
This patch adds `SourceMap::is_span_accessible` and replaces `span_to_snippet(span).is_ok()` and `span_to_snippet(span).is_err()` with it. This removes a `&str` to `String` conversion.
don't allow ZST in ScalarInt
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So I propose we stop using ScalarInt to represent ZST (which are clearly not integers). Instead, we can add new ZST variants to those types that did not have other variants which could be used for this purpose.
Based on https://github.com/rust-lang/rust/pull/98831. Only the commits starting from "don't allow ZST in ScalarInt" are new.
r? `@oli-obk`
There are several indications that we should not ZST as a ScalarInt:
- We had two ways to have ZST valtrees, either an empty `Branch` or a `Leaf` with a ZST in it.
`ValTree::zst()` used the former, but the latter could possibly arise as well.
- Likewise, the interpreter had `Immediate::Uninit` and `Immediate::Scalar(Scalar::ZST)`.
- LLVM codegen already had to special-case ZST ScalarInt.
So instead add new ZST variants to those types that did not have other variants
which could be used for this purpose.
Clarify MIR semantics of storage statements
Seems worthwhile to start closing out some of the less controversial open questions about MIR semantics. Hopefully this is fairly non-controversial - it's what we implement already, and I see no reason to do anything more restrictive. cc ``@tmiasko`` who commented on this when it was discussed in the original PR that added these docs.
interpret: use AllocRange in UninitByteAccess
also use nice new format string syntax in `interpret/error.rs`, and use the `#` flag to add `0x` prefixes where applicable.
r? ``@oli-obk``
Make MIR basic blocks field public
This makes it possible to mutably borrow different fields of the MIR
body without resorting to methods like `basic_blocks_local_decls_mut_and_var_debug_info`.
To preserve validity of control flow graph caches in the presence of
modifications, a new struct `BasicBlocks` wraps together basic blocks
and control flow graph caches.
The `BasicBlocks` dereferences to `IndexVec<BasicBlock, BasicBlockData>`.
On the other hand a mutable access requires explicit `as_mut()` call.
This makes it possible to mutably borrow different fields of the MIR
body without resorting to methods like `basic_blocks_local_decls_mut_and_var_debug_info`.
To preserve validity of control flow graph caches in the presence of
modifications, a new struct `BasicBlocks` wraps together basic blocks
and control flow graph caches.
The `BasicBlocks` dereferences to `IndexVec<BasicBlock, BasicBlockData>`.
On the other hand a mutable access requires explicit `as_mut()` call.
interpret: remove support for unsized_locals
I added support for unsized_locals in https://github.com/rust-lang/rust/pull/59780 but the current implementation is a crude hack and IMO definitely not the right way to have unsized locals in MIR. It also [causes problems](https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/Missing.20Layout.20Check.20in.20.60interpret.2Foperand.2Ers.60.3F). and what codegen does is unsound and has been for years since clearly nobody cares (so I hope nobody actually relies on that implementation and I'll be happy if Miri ensures they do not). I think if we want to have unsized locals in Miri/MIR we should add them properly, either by having a `StorageLive` that takes metadata or by having an `alloca` that returns a pointer (making the ptr indirection explicit) or something like that.
So, this PR removes the `LocalValue::Unallocated` hack. It adds `Immediate::Uninit`, for several reasons:
- This lets us still do fairly little work in `push_stack_frame`, in particular we do not actually have to create any allocations.
- If/when I remove `ScalarMaybeUninit`, we will need something like this to have an "optimized" representation of uninitialized locals. Without this we'd have to put uninitialized integers into the heap!
- const-prop needs some way to indicate "I don't know the value of this local'; it used to use `LocalValue::Unallocated` for that, now it can use `Immediate::Uninit`.
There is still a fundamental difference between `LocalValue::Unallocated` and `Immediate::Uninit`: the latter is considered a regular local that you can read from and write to, it just has a more optimized representation when compared with an actual `Allocation` that is fully uninit. In contrast, `LocalValue::Unallocated` had this really odd behavior where you would write to it but not read from it. (This is in fact what caused the problems mentioned above.)
While at it I also did two drive-by cleanups/improvements:
- In `pop_stack_frame`, do the return value copying and local deallocation while the frame is still on the stack. This leads to better error locations being reported. The old errors were [sometimes rather confusing](https://rust-lang.zulipchat.com/#narrow/stream/269128-miri/topic/Cron.20Job.20Failure.202022-06-24/near/287445522).
- Deduplicate `copy_op` and `copy_op_transmute`.
r? `@oli-obk`
Operand::Uninit is an *allocated* operand that is fully uninitialized.
This lets us lazily allocate the actual backing store of *all* locals (no matter their ABI).
I also reordered things in pop_stack_frame at the same time.
I should probably have made that a separate commit...
Change enum->int casts to not go through MIR casts.
follow-up to https://github.com/rust-lang/rust/pull/96814
this simplifies all backends and even gives LLVM more information about the return value of `Rvalue::Discriminant`, enabling optimizations in more cases.
fix interpreter validity check on Box
Follow-up to https://github.com/rust-lang/rust/pull/98554: avoid walking over parts of the value twice.
And then move all that logic into the general visitor so not each visitor implementation has to deal with it...
Interpret: AllocRange Debug impl, and use it more consistently
The two commits are pretty independent but it did not seem worth having two PRs for them.
r? ``@oli-obk``
interpret: don't rely on ScalarPair for overflowed arithmetic
This is for https://github.com/rust-lang/rust/pull/97861.
Cc `@eddyb`
I would like to avoid making this depend on `dest.layout.abi` to avoid a branch that we are not usually covering both sides of. Though OTOH this seems like fairly straight-forward code. But let's benchmark this option first to see how bad that extra `force_allocation` really is.
CTFE interning: don't walk allocations that don't need it
The interning of const allocations visits the mplace looking for references to intern. Walking big aggregates like big static arrays can be costly, so we only do it if the allocation we're interning contains references or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied to cases where there are no references/relocations either.
---
While initially looking at this in the context of #93215, I've been testing with smaller allocations than the 16GB one in that issue, and with different init/uninit patterns (esp. via padding).
In that example, by default, `eval_to_allocation_raw` is the heaviest query followed by `incr_comp_serialize_result_cache`. So I'll show numbers when incremental compilation is disabled, to focus on the const allocations themselves at 95% of the compilation time, at bigger array sizes on these minimal examples like `static ARRAY: [u64; LEN] = [0; LEN];`.
That is a close construction to parts of the `ctfe-stress-test-5` benchmark, which has const allocations in the megabytes, while most crates usually have way smaller ones. This PR will have the most impact in these situations, as the walk during the interning starts to dominate the runtime.
Unicode crates (some of which are present in our benchmarks) like `ucd`, `encoding_rs`, etc come to mind as having bigger than usual allocations as well, because of big tables of code points (in the hundreds of KB, so still an order of magnitude or 2 less than the stress test).
In a check build, for a single static array shown above, from 100 to 10^9 u64s (for lengths in powers of ten), the constant factors are lowered:
(log scales for easier comparisons)
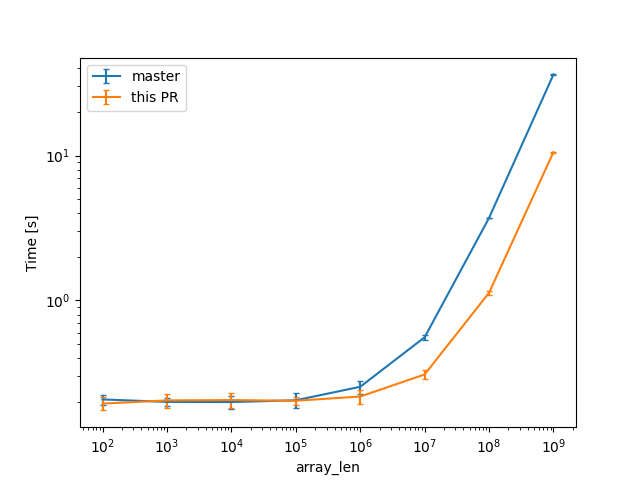
(linear scale for absolute diff at higher Ns)
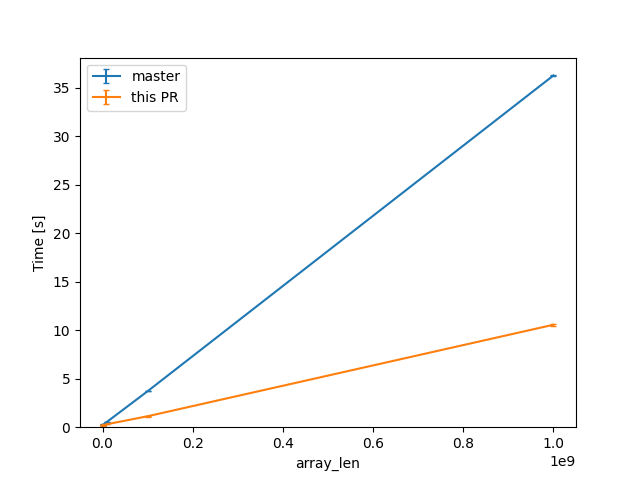
For one of the alternatives of that issue
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[u128; COLS]; ROWS] = [[0; COLS]; ROWS];
```
we can see a similar reduction of around 3x (from 38s to 12s or so).
For the same size, the slowest case IIRC is when there are uninitialized bytes e.g. via padding
```rust
const ROWS: usize = 100_000;
const COLS: usize = 10_000;
static TWODARRAY: [[(u64, u8); COLS]; ROWS] = [[(0, 0); COLS]; ROWS];
```
then interning/walking does not dominate anymore (but means there is likely still some interesting work left to do here).
Compile times in this case rise up quite a bit, and avoiding interning walks has less impact: around 23%, from 730s on master to 568s with this PR.
Enable MIR inlining
Continuation of https://github.com/rust-lang/rust/pull/82280 by `@wesleywiser.`
#82280 has shown nice compile time wins could be obtained by enabling MIR inlining.
Most of the issues in https://github.com/rust-lang/rust/issues/81567 are now fixed,
except the interaction with polymorphization which is worked around specifically.
I believe we can proceed with enabling MIR inlining in the near future
(preferably just after beta branching, in case we discover new issues).
Steps before merging:
- [x] figure out the interaction with polymorphization;
- [x] figure out how miri should deal with extern types;
- [x] silence the extra arithmetic overflow warnings;
- [x] remove the codegen fulfilment ICE;
- [x] remove the type normalization ICEs while compiling nalgebra;
- [ ] tweak the inlining threshold.
interpret: make a comment less scary
This slipped past my review: "has no meaning" could be read as "is undefined behavior". That is certainly not what we mean so be more clear.
cleanup mir visitor for `rustc::pass_by_value`
by changing `& $($mutability)?` to `$(& $mutability)?`
I also did some formatting changes because I started doing them for the visit methods I changed and then couldn't get myself to stop xx, I hope that's still fairly easy to review.
Const eval no longer runs MIR optimizations so unless this is getting
run as part of a MIR optimization like const-prop, there can be unused
type parameters even if polymorphization is enabled.
interpret: add From<&MplaceTy> for PlaceTy
We have a similar instance for `&MPlaceTy` to `OpTy`. Also add the same for `&mut`.
This avoids having to write `&(*place).into()`, which we have a few times here and at least twice in Miri (and it comes up again in my current patch).
r? ```@oli-obk```
interpret: do not prune requires_caller_location stack frames quite so early
https://github.com/rust-lang/rust/pull/87000 made the interpreter skip `caller_location` frames for its stacktraces and `cur_span`. However, those functions are used for much more than just panic reporting, and e.g. when Miri reports UB somewhere, it probably wants to point inside `caller_location` frames. (And if it did not, it would want to have its own logic to decide that, not be forced into it by the core interpreter engine.) This fixes some rare ICEs in Miri that say "we should never pop more than one frame at once".
So let's remove all `caller_location` logic from the core interpreter, and instead move it to CTFE error reporting. This does not change user-visible behavior. That's the first commit.
We might additionally want to change CTFE error reporting to treat panics differently from other errors: only prune `caller_location` frames for panics. The second commit does that. But honestly I am not sure if this is an improvement.
r? ``@oli-obk``
Checking the size/alignment of an mplace may be costly, so we only do it
on the types where the walk we want to avoid could be expensive: the larger types
like arrays and slices, rather than on all aggregates being interned.
Reorganizes the previous commits to have a single exit-point to avoid doing the
potentially costly walk. Also moves the relocations tests before the interior
mutability test: only references are important when checking for `UnsafeCell`s
and we're checking if there are any to decide to avoid the walk anyways.
The interning of const allocations visits the mplace looking for references
to intern. Walking big aggregates like big static arrays can be costly,
so we only do it if the allocation we're interning contains references
or interior mutability.
Walking ZSTs was avoided before, and this optimization is now applied
to cases where there are no references/relocations either.
We now have an infallible function that also tells us which kind of allocation we are talking about.
Also we do longer have to distinguish between data and function allocations for liveness.
Remove dereferencing of Box from codegen
Through #94043, #94414, #94873, and #95328, I've been fixing issues caused by Box being treated like a pointer when it is not a pointer. However, these PRs just introduced special cases for Box. This PR removes those special cases and instead transforms a deref of Box into a deref of the pointer it contains.
Hopefully, this is the end of the Box<T, A> ICEs.
The current code is a basis for `is_const_fn_raw`, and `impl_constness`
is no longer a valid name, which is previously used for determining the
constness of impls, and not items in general.
And likewise for the `Const::val` method.
Because its type is called `ConstKind`. Also `val` is a confusing name
because `ConstKind` is an enum with seven variants, one of which is
called `Value`. Also, this gives consistency with `TyS` and `PredicateS`
which have `kind` fields.
The commit also renames a few `Const` variables from `val` to `c`, to
avoid confusion with the `ConstKind::Value` variant.
Remove unnecessary `to_string` and `String::new`
73fa217bc1 changed the type of the `suggestion` argument to `impl ToString`. This patch removes unnecessary `to_string` and `String::new`.
cc: `````@davidtwco`````
interpret: unify offset_from check with offset check
`offset` does the check with a single `check_ptr_access` call while `offset_from` used two calls. Make them both just one one call.
I originally intended to actually factor this into a common function, but I am no longer sure if that makes a lot of sense... the two functions start with pretty different precondition (e.g. `offset` *knows* that the 2nd pointer has the same provenance).
I also reworded the UB messages a little. Saying it "cannot" do something is not how we usually phrase UB (as far as I know). Instead it's not *allowed* to do that.
r? ``````@oli-obk``````
use precise spans for recursive const evaluation
This fixes https://github.com/rust-lang/rust/issues/73283 by using a `TyCtxtAt` with a more precise span when the interpreter recursively calls itself. Hopefully such calls are sufficiently rare that this does not cost us too much performance.
(In theory, cycles can also arise through layout computation, as layout can depend on consts -- but layout computation happens all the time so we'd have to do something to not make this terrible for performance.)
This commit makes type folding more like the way chalk does it.
Currently, `TypeFoldable` has `fold_with` and `super_fold_with` methods.
- `fold_with` is the standard entry point, and defaults to calling
`super_fold_with`.
- `super_fold_with` does the actual work of traversing a type.
- For a few types of interest (`Ty`, `Region`, etc.) `fold_with` instead
calls into a `TypeFolder`, which can then call back into
`super_fold_with`.
With the new approach, `TypeFoldable` has `fold_with` and
`TypeSuperFoldable` has `super_fold_with`.
- `fold_with` is still the standard entry point, *and* it does the
actual work of traversing a type, for all types except types of
interest.
- `super_fold_with` is only implemented for the types of interest.
Benefits of the new model.
- I find it easier to understand. The distinction between types of
interest and other types is clearer, and `super_fold_with` doesn't
exist for most types.
- With the current model is easy to get confused and implement a
`super_fold_with` method that should be left defaulted. (Some of the
precursor commits fixed such cases.)
- With the current model it's easy to call `super_fold_with` within
`TypeFolder` impls where `fold_with` should be called. The new
approach makes this mistake impossible, and this commit fixes a number
of such cases.
- It's potentially faster, because it avoids the `fold_with` ->
`super_fold_with` call in all cases except types of interest. A lot of
the time the compile would inline those away, but not necessarily
always.
Rollup of 5 pull requests
Successful merges:
- #97312 (Compute lifetimes in scope at diagnostic time)
- #97495 (Add E0788 for improper #[no_coverage] usage)
- #97579 (Avoid creating `SmallVec`s in `global_llvm_features`)
- #97767 (interpret: do not claim UB until we looked more into variadic functions)
- #97787 (E0432: rust 2018 -> rust 2018 or later in --explain message)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
interpret: better control over whether we read data with provenance
The resolution in https://github.com/rust-lang/unsafe-code-guidelines/issues/286 seems to be that when we load data at integer type, we implicitly strip provenance. So let's implement that in Miri at least for scalar loads. This makes use of the fact that `Scalar` layouts distinguish pointer-sized integers and pointers -- so I was expecting some wild bugs where layouts set this incorrectly, but so far that does not seem to happen.
This does not entirely implement the solution to https://github.com/rust-lang/unsafe-code-guidelines/issues/286; we still do the wrong thing for integers in larger types: we will `copy_op` them and then do validation, and validation will complain about the provenance. To fix that we need mutating validation; validation needs to strip the provenance rather than complaining about it. This is a larger undertaking (but will also help resolve https://github.com/rust-lang/miri/issues/845 since we can reset padding to `Uninit`).
The reason this is useful is that we can now implement `addr` as a `transmute` from a pointer to an integer, and actually get the desired behavior of stripping provenance without exposing it!
take back half-baked noaliasing check in Assignment
Doing an aliasing check in `copy_op` does not make a ton of sense. We have to eventually do something in the `Assignment` statement handling instead.
rename PointerAddress → PointerExposeAddress
`PointerAddress` sounds a bit too much like `ptr.addr()`, but this corresponds to `ptr.expose_addr()`.
r? `@tmiasko`
Ensure we never consider the null pointer dereferencable
This replaces the checks that are being removed in https://github.com/rust-lang/rust/pull/97188. Those checks were too early and hence incorrect.
Miri call ABI check: ensure type size+align stay the same
We should almost certainly not accept calls where caller and callee disagree on the size or alignment of the type.
The checks we do *almost* imply that, except that `ScalarPair` types can have `repr(align)` and thus differ in size/align even when they are pairs of the same primitive type.
r? ``@oli-obk``
Add validation layer for Derefer
_Follow up work to #96549#96116#95857 #95649_
This adds validation for Derefer making sure it is always the first projection.
r? rust-lang/mir-opt
Replace `#[default_method_body_is_const]` with `#[const_trait]`
pulled out of #96077
related issues: #67792 and #92158
cc `@fee1-dead`
This is groundwork to only allowing `impl const Trait` for traits that are marked with `#[const_trait]`. This is necessary to prevent adding a new default method from becoming a breaking change (as it could be a non-const fn).
Move various checks to typeck so them failing causes the typeck result to get tainted
Fixes#69487fixes#79047
cc `@RalfJung` this gets rid of the `Transmute` invalid program error variant
Implement proper stability check for const impl Trait, fall back to unstable const when undeclared
Continuation of #93960
`@jhpratt` it looks to me like the test was simply not testing for the failure you were looking for? Your checks actually do the right thing for const traits?
Remove unneeded null pointer asserts in ptr2int casts
This removes an assert that a pointer with address 0 has no provenance. This change is needed to support permissive provenance work in Miri, and seems justified by `ptr.with_addr(0)` working and a discussion on Zulip regarding LLVM semantics.
r? `@RalfJung`
interpret/validity: separately control checking numbers for being init and non-ptr
This lets Miri control this in a more fine-grained way.
r? `@oli-obk`
Rather than deferring to const eval for checking if a trait is const, we
now check up-front. This allows the error to be emitted earlier, notably
at the same time as other stability checks.
Also included in this commit is a change of the default const stability
level to UNstable. Previously, an item that was `const` but did not
explicitly state it was unstable was implicitly stable.
interpret/validity: reject references to uninhabited types
According to https://doc.rust-lang.org/reference/behavior-considered-undefined.html, this is definitely UB. And we can check this without actually looking up anything in memory, we just need the reference value and its type, making this a great candidate for a validity invariant IMO and my favorite resolution of https://github.com/rust-lang/unsafe-code-guidelines/issues/77.
With this PR, Miri with `-Zmiri-check-number-validity` implements all my preferred options for what the validity invariants of our types could be. :)
CTFE has been doing recursive checking anyway, so this is backwards compatible but might change the error output. I will submit a PR with the new Miri tests soon.
r? `@oli-obk`
Add a query for checking whether a function is an intrinsic.
work towards #93145
This will reduce churn when we add more ways to declare intrinsics
r? `@scottmcm`
Add EarlyBinder
Chalk has no concept of `Param` (e0ade19d13/chalk-ir/src/lib.rs (L579)) or `ReEarlyBound` (e0ade19d13/chalk-ir/src/lib.rs (L1308)). Everything is just "bound" - the equivalent of rustc's late-bound. It's not completely clear yet whether to move everything to the same time of binder in rustc or add `Param` and `ReEarlyBound` in Chalk.
Either way, tracking when we have or haven't already substituted out these in rustc can be helpful.
As a first step, I'm just adding a `EarlyBinder` newtype that is required to call `subst`. I also add a couple "transparent" `bound_*` wrappers around a couple query that are often immediately substituted.
r? `@nikomatsakis`
Initial work on Miri permissive-exposed-provenance
Rustc portion of the changes for portions of a permissive ptr-to-int model for Miri. The main changes here are changing `ptr_get_alloc` and `get_alloc_id` to return an Option, and also making ptr-to-int casts have an expose side effect.
{kind=link}
{kind=link}