Remove internal and unstable MaybeUninit::UNINIT.
Looks like it is no longer necessary, as `uninit_array()` can be used instead in the few cases where it was needed.
(I wanted to just add `#[doc(hidden)]` to remove clutter from the documentation, but looks like it can just be removed entirely.)
Make the following methods unstable const under the `const_pin` feature:
- `new`
- `new_unchecked`
- `into_inner`
- `into_inner_unchecked`
- `get_ref`
- `into_ref`
Also adds tests for these methods in a const context.
Tracking issue: #76654
Make the following methods of `Duration` unstable const under `duration_const_2`:
- `from_secs_f64`
- `from_secs_f32`
- `mul_f64`
- `mul_f32`
- `div_f64`
- `div_f32`
This results in all methods of `Duration` being (unstable) const.
Also adds tests for these methods in a const context, moved the test to `library` as part of #76268.
Possible because of #72449, which made the relevant `f32` and `f64` methods const.
Tracking issue: #72440
Add MaybeUninit::assume_init_drop.
`ManuallyDrop`'s documentation tells the user to use `MaybeUninit` instead when handling uninitialized data. However, the main functionality of `ManuallyDrop` (`drop`) is not available directly on `MaybeUninit`. Adding it makes it easier to switch from one to the other.
I re-used the `maybe_uninit_extra` feature and tracking issue number (#63567), since it seems very related. (And to avoid creating too many features tracking issues for `MaybeUninit`.)
Add saturating methods for `Duration`
In some project, I needed a `saturating_add` method for `Duration`. I implemented it myself but i thought it would be a nice addition to the standard library as it matches closely with the integers types.
3 new methods have been introduced and are gated by the new `duration_saturating_ops` unstable feature:
* `Duration::saturating_add`
* `Duration::saturating_sub`
* `Duration::saturating_mul`
If have left the tracking issue to `none` for now as I want first to understand if those methods would be acceptable at all. If agreed, I'll update the PR with the tracking issue.
Further more, to match the behavior of integers types, I introduced 2 associated constants:
* `Duration::MIN`: this one is somehow a duplicate from `Duration::zero()` method, but at the time this method was added, `MIN` was rejected as it was considered a different semantic (see https://github.com/rust-lang/rust/pull/72790#issuecomment-636511743).
* `Duration::MAX`
Both have been gated by the already existing unstable feature `duration_constants`, I can introduce a new unstable feature if needed or just re-use the `duration_saturating_ops`.
We might have to decide whether:
* `MIN` should be replaced by `ZERO`?
* associated constants over methods?
Add `slice::array_chunks_mut`
This follows `array_chunks` from #74373 with a mutable version, `array_chunks_mut`. The implementation is identical apart from mutability. The new tests are adaptations of the `chunks_exact_mut` tests, plus an inference test like the one for `array_chunks`.
I reused the unstable feature `array_chunks` and tracking issue #74985, but I can separate that if desired.
r? `@withoutboats`
cc `@lcnr`
Stabilize core::future::{pending,ready}
This PR stabilizes `core::future::{pending,ready}`, tracking issue https://github.com/rust-lang/rust/issues/70921.
## Motivation
These functions have been on nightly for three months now, and have lived as part of the futures ecosystem for several years. In that time these functions have undergone several iterations, with [the `async-std` impls](https://docs.rs/async-std/1.6.2/async_std/future/index.html) probably diverging the most (using `async fn`, which in hindsight was a mistake).
It seems the space around these functions has been _thoroughly_ explored over the last couple of years, and the ecosystem has settled on the current shape of the functions. It seems highly unlikely we'd want to make any further changes to these functions, so I propose we stabilize.
## Implementation notes
This stabilization PR was fairly straightforward; this feature has already thoroughly been reviewed by the libs team already in https://github.com/rust-lang/rust/pull/70834. So all this PR does is remove the feature gate.
Fixes#73268
When a deref coercion occurs, we may end up with a move error if the
base value has been partially moved out of. However, we do not indicate
anywhere that a deref coercion is occuring, resulting in an error
message with a confusing span.
This PR adds an explicit note to move errors when a deref coercion is
involved. We mention the name of the type that the deref-coercion
resolved to, as well as the `Deref::Target` associated type being used.
Use intra-doc links in `core::ptr`
Part of #75080.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
---
@rustbot modify labels: A-intra-doc-links T-doc
`write` is ambiguous because there's also a macro called `write`.
Also removed unnecessary and potentially confusing link to a function in
its own docs.
The only link that I did not change is a link to a function on the
`pointer` primitive because intra-doc links for the `pointer` primitive
don't work yet (see #63351).
ManuallyDrop's documentation tells the user to use MaybeUninit instead
when handling uninitialized data. However, the main functionality of
ManuallyDrop (drop) was not available directly on MaybeUninit. Adding it
makes it easier to switch from one to the other.
Remove unneeded `#[cfg(not(test))]` from libcore
This fixes rust-analyzer inside these modules (currently it does not analyze them, assuming they're configured out).
Use ops::ControlFlow in rustc_data_structures::graph::iterate
Since I only know about this because you mentioned it,
r? @ecstatic-morse
If we're not supposed to use new `core` things in compiler for a while then feel free to close, but it felt reasonable to merge the two types since they're the same, and it might be convenient for people to use `?` in their traversal code.
(This doesn't do the type parameter swap; NoraCodes has signed up to do that one.)
Indent a note to make folding work nicer
Sublime Text folds code based on indentation. It maybe an unnecessary change, but does it look nicer after that ?
Move various ui const tests to `library`
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
r? @matklad
Try to improve the documentation of `filter()` and `filter_map()`.
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Use Arc::clone and Rc::clone in documentation
This PR replaces uses of `x.clone()` by `Rc::clone(&x)` (or `Arc::clone(&x)`) to better match the documentation for those types.
@rustbot modify labels: T-doc
I believe the documentation is currently a little misleading.
For example, in the docs for `filter()`:
> If the closure returns `false`, it will try again, and call the closure on
> the next element, seeing if it passes the test.
This kind of implies that if the closure returns true then we *don't* "try
again" and no further elements are considered. In actuality that's not the
case, every element is tried regardless of what happened with the previous
element.
This change tries to clarify that by removing the uses of "try again"
altogether.
Move:
- `src\test\ui\consts\const-nonzero.rs` to `library\core`
- `src\test\ui\consts\ascii.rs` to `library\core`
- `src\test\ui\consts\cow-is-borrowed` to `library\alloc`
Part of #76268
specialize some collection and iterator operations to run in-place
This is a rebase and update of #66383 which was closed due inactivity.
Recent rustc changes made the compile time regressions disappear, at least for webrender-wrench. Running a stage2 compile and the rustc-perf suite takes hours on the hardware I have at the moment, so I can't do much more than that.
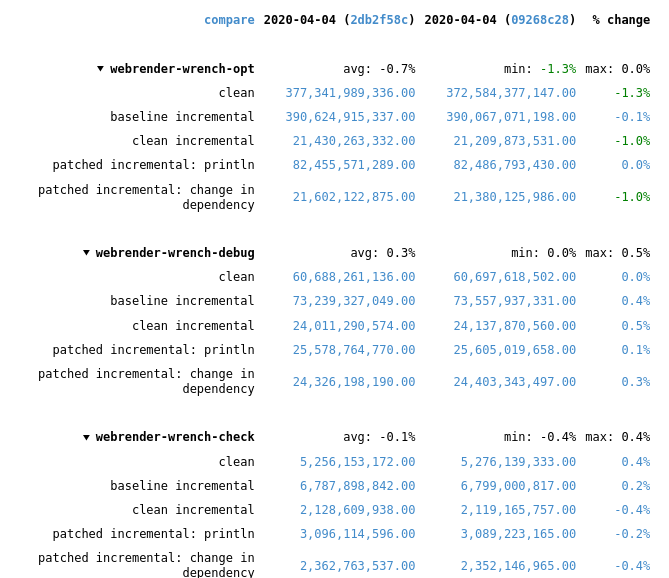
In the best case of the `vec::bench_in_place_recycle` synthetic microbenchmark these optimizations can provide a 15x speedup over the regular implementation which allocates a new vec for every benchmark iteration. [Benchmark results](https://gist.github.com/the8472/6d999b2d08a2bedf3b93f12112f96e2f). In real code the speedups are tiny, but it also depends on the allocator used, a system allocator that uses a process-wide mutex will benefit more than one with thread-local pools.
## What was changed
* `SpecExtend` which covered `from_iter` and `extend` specializations was split into separate traits
* `extend` and `from_iter` now reuse the `append_elements` if passed iterators are from slices.
* A preexisting `vec.into_iter().collect::<Vec<_>>()` optimization that passed through the original vec has been generalized further to also cover cases where the original has been partially drained.
* A chain of *Vec<T> / BinaryHeap<T> / Box<[T]>* `IntoIter`s through various iterator adapters collected into *Vec<U>* and *BinaryHeap<U>* will be performed in place as long as `T` and `U` have the same alignment and size and aren't ZSTs.
* To enable above specialization the unsafe, unstable `SourceIter` and `InPlaceIterable` traits have been added. The first allows reaching through the iterator pipeline to grab a pointer to the source memory. The latter is a marker that promises that the read pointer will advance as fast or faster than the write pointer and thus in-place operation is possible in the first place.
* `vec::IntoIter` implements `TrustedRandomAccess` for `T: Copy` to allow in-place collection when there is a `Zip` adapter in the iterator. TRA had to be made an unstable public trait to support this.
## In-place collectible adapters
* `Map`
* `MapWhile`
* `Filter`
* `FilterMap`
* `Fuse`
* `Skip`
* `SkipWhile`
* `Take`
* `TakeWhile`
* `Enumerate`
* `Zip` (left hand side only, `Copy` types only)
* `Peek`
* `Scan`
* `Inspect`
## Concerns
`vec.into_iter().filter(|_| false).collect()` will no longer return a vec with 0 capacity, instead it will return its original allocation. This avoids the cost of doing any allocation or deallocation but could lead to large allocations living longer than expected.
If that's not acceptable some resizing policy at the end of the attempted in-place collect would be necessary, which in the worst case could result in one more memcopy than the non-specialized case.
## Possible followup work
* split liballoc/vec.rs to remove `ignore-tidy-filelength`
* try to get trivial chains such as `vec.into_iter().skip(1).collect::<Vec<)>>()` to compile to a `memmove` (currently compiles to a pile of SIMD, see #69187 )
* improve up the traits so they can be reused by other crates, e.g. itertools. I think currently they're only good enough for internal use
* allow iterators sourced from a `HashSet` to be in-place collected into a `Vec`
rustdoc: do not use plain summary for trait impls
Fixes#38386.
Fixes#48332.
Fixes#49430.
Fixes#62741.
Fixes#73474.
Unfortunately this is not quite ready to go because the newly-working links trigger a bunch of linkcheck failures. The failures are tough to fix because the links are resolved relative to the implementor, which could be anywhere in the module hierarchy.
(In the current docs, these links end up rendering as uninterpreted markdown syntax, so I don't think these failures are any worse than the status quo. It might be acceptable to just add them to the linkchecker whitelist.)
Ideally this could be fixed with intra-doc links ~~but it isn't working for me: I am currently investigating if it's possible to solve it this way.~~ Opened #73829.
EDIT: This is now ready!
Convert many files to intra-doc links
Helps with https://github.com/rust-lang/rust/issues/75080
r? @poliorcetics
I recommend reviewing one commit at a time, but the diff is small enough you can do it all at once if you like :)
Move to intra-doc links for library/core/src/iter/traits/iterator.rs
Helps with #75080.
@jyn514 We're almost finished with this issue. Thanks for mentoring. If you have other topics to work on just let me know, I will be around in Discord.
@rustbot modify labels: T-doc, A-intra-doc-links
Known issues:
* Link from `core` to `std` (#74481):
[`OsStr`]
[`String`]
[`VecDeque<T>`]
Rename and expose LoopState as ControlFlow
Basic PR for #75744. Addresses everything there except for documentation; lots of examples are probably a good idea.
Add `[T; N]::as_[mut_]slice`
Part of me trying to populate arrays with a couple of basic useful methods, like slices already have. The ability to add methods to arrays were added in #75212. Tracking issue: #76118
This adds:
```rust
impl<T, const N: usize> [T; N] {
pub fn as_slice(&self) -> &[T];
pub fn as_mut_slice(&mut self) -> &mut [T];
}
```
These methods are like the ones on `std::array::FixedSizeArray` and in the crate `arraytools`.
- Use intra-doc links for `std::io` in `std::fs`
- Use intra-doc links for File::read in unix/ext/fs.rs
- Remove explicit intra-doc links for `true` in `net/addr.rs`
- Use intra-doc links in alloc/src/sync.rs
- Use intra-doc links in src/ascii.rs
- Switch to intra-doc links in alloc/rc.rs
- Use intra-doc links in core/pin.rs
- Use intra-doc links in std/prelude
- Use shorter links in `std/fs.rs`
`io` is already in scope.
flt2dec: properly handle uninitialized memory
The float-to-str code currently uses uninitialized memory incorrectly (see https://github.com/rust-lang/rust/issues/76092). This PR fixes that.
Specifically, that code used `&mut [T]` as "out references", but it would be incorrect for the caller to actually pass uninitialized memory. So the PR changes this to `&mut [MaybeUninit<T>]`, and then functions return a `&[T]` to the part of the buffer that they initialized (some functions already did that, indirectly via `&Formatted`, others were adjusted to return that buffer instead of just the initialized length).
What I particularly like about this is that it moves `unsafe` to the right place: previously, the outermost caller had to use `unsafe` to assert that things are initialized; now it is the functions that do the actual initializing which have the corresponding `unsafe` block when they call `MaybeUninit::slice_get_ref` (renamed in https://github.com/rust-lang/rust/pull/76217 to `slice_assume_init_ref`).
Reviewers please be aware that I have no idea how any of this code actually works. My changes were purely mechanical and type-driven. The test suite passes so I guess I didn't screw up badly...
Cc @sfackler this is somewhat related to your RFC, and possibly some of this code could benefit from (a generalized version of) the API you describe there. But for now I think what I did is "good enough".
Fixes https://github.com/rust-lang/rust/issues/76092.
Move to intra-doc links for library/core/src/panic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from `core` to `std` (#74481):
[`set_hook`]
[`String`]
Add more examples to lexicographic cmp on Iterators.
Given two arrays of T1 and T2, the most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T1.
Which is only possible because of the first rule.
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Stabilizes these methods as const under the `const_ordering` feature.
Also adds a test for these methods in a const context.
Possible because of #49146 (Allow `if` and `match` in constants).
rename get_{ref, mut} to assume_init_{ref,mut} in Maybeuninit
References #63568
Rework with comments addressed from #66174
Have replaced most of the occurrences I've found, hopefully didn't miss out anything
r? @RalfJung
(thanks @danielhenrymantilla for the initial work on this)
Get rid of bounds check in slice::chunks_exact() and related function…
…s during construction
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
Use intra-doc links for `core/src/slice.mod.rs`
partial help in #75080
r? @jyn514
- most are using primitive types links, which cannot be used with intra links at the moment
- also `std` cannot be referenced in any link, `std::ptr::NonNull` and `std::slice` could not be referenced
Make some Ordering methods const
Constify the following methods of `core::cmp::Ordering`:
- `reverse`
- `then`
Possible because of #49146 (Allow `if` and `match` in constants).
Tracking issue: #76113
Stabilize the following methods of `Result` as const:
- `is_ok`
- `is_err`
- `as_ref`
Possible because of stabilization of #49146 (Allow if and match in constants).
LLVM can't figure out in
let rem = self.len() % chunk_size;
let len = self.len() - rem;
let (fst, snd) = self.split_at(len);
and
let rem = self.len() % chunk_size;
let (fst, snd) = self.split_at(rem);
that the index passed to split_at() is smaller than the slice length and
adds a bounds check plus panic for it.
Apart from removing the overhead of the bounds check this also allows
LLVM to optimize code around the ChunksExact iterator better.
These are unsafe variants of the non-unchecked functions and don't do
any bounds checking.
For the time being these are not public and only a preparation for the
following commit. Making it public and stabilization can follow later
and be discussed in https://github.com/rust-lang/rust/issues/76014 .
`alloc::slice` uses `core::slice` functions, documentation are copied
from there and the links as well without resolution. `crate::ptr...`
cannot be resolved in `alloc::slice`, but `ptr` itself is imported in
both `alloc::slice` and `core::slice`, so we used that instead.
Move to intra-doc links for library/core/src/sync/atomic.rs
Helps with #75080.
@rustbot modify labels: T-doc, A-intra-doc-links, T-rustdoc
Known issues:
* Link from core to std:
[`Arc`]
[`std:🧵:yield_now`]
[`std:🧵:sleep`]
[`std::sync::Mutex`]
The most important rule of lexicographical comparison is that two arrays
of equal length will be compared until the first difference occured.
The examples provided only focuses on the second rule that says that the
shorter array will be filled with some T2 that is less than every T.
Which is only possible because of the first rule.
Fix potential UB in align_offset doc examples
Currently it takes a pointer only to the first element in the array, this changes the code to take a pointer to the whole array.
miri can't catch this right now because it later calls `x.len()` which re-tags the pointer for the whole array.
https://github.com/rust-lang/miri/issues/1526#issuecomment-680897144
Unconfuse Unpin docs a bit
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
I would like to propose these two simple methods for stabilization:
- Knowing that a range is exhaused isn't otherwise trivial
- Clippy would like to suggest them, but had to do extra work to disable that path <https://github.com/rust-lang/rust-clippy/issues/3807> because they're unstable
- These work on `PartialOrd`, consistently with now-stable `contains`, and are thus more general than iterator-based approaches that need `Step`
- They've been unchanged for some time, and have picked up uses in the compiler
- Stabilizing them doesn't block any future iterator-based is_empty plans, as the inherent ones are preferred in name resolution
* Don't say that Unpin is used to prevent moves, because it is used
to *allow* moves
* Be more precise about kindedness of things, it is
`Pin<Pointer<Data>>`, rather than just `Pin<Pointer>`.
Report an ambiguity if both modules and primitives are in scope for intra-doc links
Closes https://github.com/rust-lang/rust/issues/75381
- Add a new `prim@` disambiguator, since both modules and primitives are in the same namespace
- Refactor `report_ambiguity` into a closure
Additionally, I noticed that rustdoc would previously allow `[struct@char]` if `char` resolved to a primitive (not if it had a DefId). I fixed that and added a test case.
I also need to update libstd to use `prim@char` instead of `type@char`. If possible I would also like to refactor `ambiguity_error` to use `Disambiguator` instead of its own hand-rolled match - that ran into issues with `prim@` (I updated one and not the other) and it would be better for them to be in sync.
Use allow(unused_imports) instead of cfg(doc) for imports used only for intra-doc links
This prevents links from breaking when items are re-exported in a
different crate and the original isn't being documented.
Spotted in https://github.com/rust-lang/rust/pull/75832#discussion_r475275837 (thanks ollie!)
r? @ollie27
Fix typo in documentation of i32 wrapping_abs()
Hi!
I was reading through the std library docs and noticed that this section flowed a bit oddly; comparing it against https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_div and https://doc.rust-lang.org/std/primitive.i32.html#method.wrapping_neg , I noticed that those two pieces of documentation used a semicolon here.
This is my first time submitting a PR to this repo. Am I doing this right? Are tiny typo-fix PRs like this worth submitting, or are they not a good use of time?
Thank you!
stabilize ptr_offset_from
This stabilizes ptr::offset_from, and closes https://github.com/rust-lang/rust/issues/41079. It also removes the deprecated `wrapping_offset_from`. This function was deprecated 19 days ago and was never stable; given an FCP of 10 days and some waiting time until FCP starts, that leaves at least a month between deprecation and removal which I think is fine for a nightly-only API.
Regarding the open questions in https://github.com/rust-lang/rust/issues/41079:
* Should offset_from abort instead of panic on ZSTs? -- As far as I know, there is no precedent for such aborts. We could, however, declare this UB. Given that the size is always known statically and the check thus rather cheap, UB seems excessive.
* Should there be more methods like this with different restrictions (to allow nuw/nsw, perhaps) or that return usize (like how isize-taking offset is more conveniently done with usize-taking add these days)? -- No reason to block stabilization on that, we can always add such methods later.
Also nominating the lang team because this exposes an intrinsic.
The stabilized method is best described [by its doc-comment](56d4b2d69a/src/libcore/ptr/const_ptr.rs (L227)). The documentation forgot to mention the requirement that both pointers must "have the same provenance", aka "be derived from pointers to the same allocation", which I am adding in this PR. This is a precondition that [Miri already implements](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=a3b9d0a07a01321f5202cd99e9613480) and that, should LLVM ever obtain a `psub` operation to subtract pointers, will likely be required for that operation (following the semantics in [this paper](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf)).
{kind=link}
{kind=link}