Make `FatalErrorMarker` lower priority than other panics
This makes `FatalErrorMarker` lower priority than other panics in a parallel sections. If any other panics occur, they will be unwound instead of `FatalErrorMarker`. This ensures `rustc` will exit with the correct error code on ICEs.
This fixes https://github.com/rust-lang/rust/issues/116659.
enable parallel rustc front end in nightly builds
Refers to the [MCP](https://github.com/rust-lang/compiler-team/issues/681), this pr does:
1. Enable the parallel front end in nightly builds, and keep the default number of threads as 1. Then users can use the parallel rustc front end via -Z threads=n option.
2. Set it up to serial front end for beta/stable builds via bootstrap.
3. Switch over the alt builders from parallel rustc to serial, so we have artifacts without parallel to test against the artifacts with parallel.
r? `@oli-obk`
cc `@cjgillot` `@nnethercote` `@bjorn3` `@Kobzol`
- Sort dependencies and features sections.
- Add `tidy` markers to the sorted sections so they stay sorted.
- Remove empty `[lib`] sections.
- Remove "See more keys..." comments.
Excluded files:
- rustc_codegen_{cranelift,gcc}, because they're external.
- rustc_lexer, because it has external use.
- stable_mir, because it has external use.
Avoid a `track_errors` by bubbling up most errors from `check_well_formed`
I believe `track_errors` is mostly papering over issues that a sufficiently convoluted query graph can hit. I made this change, while the actual change I want to do is to stop bailing out early on errors, and instead use this new `ErrorGuaranteed` to invoke `check_well_formed` for individual items before doing all the `typeck` logic on them.
This works towards resolving https://github.com/rust-lang/rust/issues/97477 and various other ICEs, as well as allowing us to use parallel rustc more (which is currently rather limited/bottlenecked due to the very sequential nature in which we do `rustc_hir_analysis::check_crate`)
cc `@SparrowLii` `@Zoxc` for the new `try_par_for_each_in` function
Remove `IdFunctor` trait.
It's defined in `rustc_data_structures` but is only used in
`rustc_type_ir`. The code is shorter and easier to read if we remove
this layer of abstraction and just do the things directly where they are
needed.
r? `@BoxyUwU`
It's defined in `rustc_data_structures` but is only used in
`rustc_type_ir`. The code is shorter and easier to read if we remove
this layer of abstraction and just do the things directly where they are
needed.
Extract parallel operations in `rustc_data_structures::sync` into a new `parallel` submodule
This extracts parallel operations in `rustc_data_structures::sync` into a new `parallel` submodule. This cuts down on the size of the large `cfg_if!` in `sync` and makes it easier to compare between serial and parallel variants.
Add optimized lock methods for `Sharded` and refactor `Lock`
This adds methods to `Sharded` which pick a shard and also locks it. These branch on parallelism just once instead of twice, improving performance.
Benchmark for `cfg(parallel_compiler)` and 1 thread:
<table><tr><td rowspan="2">Benchmark</td><td colspan="1"><b>Before</b></th><td colspan="2"><b>After</b></th></tr><tr><td align="right">Time</td><td align="right">Time</td><td align="right">%</th></tr><tr><td>🟣 <b>clap</b>:check</td><td align="right">1.6461s</td><td align="right">1.6345s</td><td align="right"> -0.70%</td></tr><tr><td>🟣 <b>hyper</b>:check</td><td align="right">0.2414s</td><td align="right">0.2394s</td><td align="right"> -0.83%</td></tr><tr><td>🟣 <b>regex</b>:check</td><td align="right">0.9205s</td><td align="right">0.9143s</td><td align="right"> -0.67%</td></tr><tr><td>🟣 <b>syn</b>:check</td><td align="right">1.4981s</td><td align="right">1.4869s</td><td align="right"> -0.75%</td></tr><tr><td>🟣 <b>syntex_syntax</b>:check</td><td align="right">5.7629s</td><td align="right">5.7256s</td><td align="right"> -0.65%</td></tr><tr><td>Total</td><td align="right">10.0690s</td><td align="right">10.0008s</td><td align="right"> -0.68%</td></tr><tr><td>Summary</td><td align="right">1.0000s</td><td align="right">0.9928s</td><td align="right"> -0.72%</td></tr></table>
cc `@SparrowLii`
Remove conditional use of `Sharded` from query state
`Sharded` is already a zero cost abstraction, so it shouldn't affect the performance of the single thread compiler if LLVM does its job.
r? `@cjgillot`
elaborate a bit on the (lack of) safety in 'Mmap::map'
Sadly none of the callers of this function even consider it worth mentioning in their unsafe block that what they are doing is completely unsound.
Fix races conditions with `SyntaxContext` decoding
This changes `SyntaxContext` decoding to work with concurrent decoding. The `remapped_ctxts` field now only stores `SyntaxContext` which have completed decoding, while the new `decoding` and `local_in_progress` keeps track of `SyntaxContext`s which are in process of being decoding and on which threads.
This fixes 2 issues with the current implementation. It can return an `SyntaxContext` which contains dummy data if another thread starts decoding before the first one has completely finished. Multiple threads could also allocate multiple `SyntaxContext`s for the same `raw_id`.
[rustc_data_structures][base_n][perf] Remove unnecessary utf8 check.
Since all output characters taken from `BASE_64` are valid UTF8 chars there is no need to waste cycles on validation.
Even though it's obviously a perf win, I've also used a [benchmark](https://gist.github.com/ttsugriy/e1e63c07927d8f31e71695a9c617bbf3) on M1 MacBook Air with following results:
```
Running benches/base_n_benchmark.rs (target/release/deps/base_n_benchmark-825fe5895b5c2693)
push_str/old time: [14.670 µs 14.852 µs 15.074 µs]
Found 11 outliers among 100 measurements (11.00%)
4 (4.00%) high mild
7 (7.00%) high severe
push_str/new time: [12.573 µs 12.674 µs 12.801 µs]
Found 11 outliers among 100 measurements (11.00%)
7 (7.00%) high mild
4 (4.00%) high severe
```
It lints against features that are inteded to be internal to the
compiler and standard library. Implements MCP #596.
We allow `internal_features` in the standard library and compiler as those
use many features and this _is_ the standard library from the "internal to the compiler and
standard library" after all.
Marking some features as internal wasn't exactly the most scientific approach, I just marked some
mostly obvious features. While there is a categorization in the macro,
it's not very well upheld (should probably be fixed in another PR).
We always pass `-Ainternal_features` in the testsuite
About 400 UI tests and several other tests use internal features.
Instead of throwing the attribute on each one, just always allow them.
There's nothing wrong with testing internal features^^
Since all output characters taken from `BASE_64` are valid UTF8 chars
there is no need to waste cycles on validation.
Even though it's obviously a perf win, I've also used a [benchmark](https://gist.github.com/ttsugriy/e1e63c07927d8f31e71695a9c617bbf3)
on M1 MacBook Air with following results:
```
Running benches/base_n_benchmark.rs (target/release/deps/base_n_benchmark-825fe5895b5c2693)
push_str/old time: [14.670 µs 14.852 µs 15.074 µs]
Performance has regressed.
Found 11 outliers among 100 measurements (11.00%)
4 (4.00%) high mild
7 (7.00%) high severe
push_str/new time: [12.573 µs 12.674 µs 12.801 µs]
Performance has regressed.
Found 11 outliers among 100 measurements (11.00%)
7 (7.00%) high mild
4 (4.00%) high severe
```
[rustc_data_structures][perf] Simplify base_n::push_str.
This minor change removes the need to reverse resulting digits. Since reverse is O(|digit_num|) but bounded by 128, it's unlikely to be a noticeable in practice. At the same time, this code is also a 1 line shorter, so combined with tiny perf win, why not?
I ran https://gist.github.com/ttsugriy/ed14860ef597ab315d4129d5f8adb191 on M1 macbook air and got a small improvement
```
Running benches/base_n_benchmark.rs (target/release/deps/base_n_benchmark-825fe5895b5c2693)
push_str/old time: [14.180 µs 14.313 µs 14.462 µs]
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
4 (4.00%) high mild
1 (1.00%) high severe
push_str/new time: [13.741 µs 13.839 µs 13.973 µs]
Performance has improved.
Found 8 outliers among 100 measurements (8.00%)
3 (3.00%) high mild
5 (5.00%) high severe
```
[rustc_data_structures] Simplify SortedMap::insert.
It looks like current usage of `swap` is aimed at achieving what `std::mem::replace` does but more concisely and idiomatically.
This minor change removes the need to reverse resulting digits.
Since reverse is O(|digit_num|) but bounded by 128, it's unlikely
to be a noticeable in practice. At the same time, this code is
also a 1 line shorter, so combined with tiny perf win, why not?
I ran https://gist.github.com/ttsugriy/ed14860ef597ab315d4129d5f8adb191
on M1 macbook air and got a small improvement
```
Running benches/base_n_benchmark.rs (target/release/deps/base_n_benchmark-825fe5895b5c2693)
push_str/old time: [14.180 µs 14.313 µs 14.462 µs]
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
4 (4.00%) high mild
1 (1.00%) high severe
push_str/new time: [13.741 µs 13.839 µs 13.973 µs]
Performance has improved.
Found 8 outliers among 100 measurements (8.00%)
3 (3.00%) high mild
5 (5.00%) high severe
```
It no longer has any uses. If it's needed in the future, it can be
easily reinstated. Or a crate such as `smallstr` can be used, much like
we use `smallvec`.
Removed unnecessary &String -> &str, now that &String implements StableOrd as well
Applied a few nits suggested by lcnr to PR #110040 (nits can be found [here](https://github.com/rust-lang/rust/pull/110040#pullrequestreview-1469452191).)
Making a new PR because the old one was already merged, and given that this just applies changes that were already suggested, reviewing it should be fairly open-and-shut.
Don't leak the function that is called on drop
It probably wasn't causing problems anyway, but still, a `// this leaks, please don't pass anything that owns memory` is not sustainable.
I could implement a version which does not require `Option`, but it would require `unsafe`, at which point it's probably not worth it.
Use `Option::is_some_and` and `Result::is_ok_and` in the compiler
`.is_some_and(..)`/`.is_ok_and(..)` replace `.map_or(false, ..)` and `.map(..).unwrap_or(false)`, making the code more readable.
This PR is a sibling of https://github.com/rust-lang/rust/pull/111873#issuecomment-1561316515
Preprocess and cache dominator tree
Preprocessing dominators has a very strong effect for https://github.com/rust-lang/rust/pull/111344.
That pass checks that assignments dominate their uses repeatedly. Using the unprocessed dominator tree caused a quadratic runtime (number of bbs x depth of the dominator tree).
This PR also caches the dominator tree and the pre-processed dominators in the MIR cfg cache.
Rebase of https://github.com/rust-lang/rust/pull/107157
cc `@tmiasko`
Process current bucket instead of parent's bucket when starting loop for dominators.
The linked paper by Georgiadis suggests in §2.2.3 to process `bucket[w]` when beginning the loop, instead of `bucket[parent[w]]` when finishing it.
In the test case, we correctly computed `idom[2] = 0` and `sdom[3] = 1`, but the algorithm returned `idom[3] = 1`, instead of the correct value 0, because of the path 0-7-2-3.
This provoked LLVM ICE in https://github.com/rust-lang/rust/pull/111061#issuecomment-1546912112. LLVM checks that SSA assignments dominate uses using its own implementation of Lengauer-Tarjan, and saw case where rustc was breaking the dominance property.
r? `@Mark-Simulacrum`
Change the immediate_dominator return type to Option, and use None to
indicate that node has no immediate dominator.
Also fix the issue where the start node would be returned as its own
immediate dominator.
Introduce `DynSend` and `DynSync` auto trait for parallel compiler
part of parallel-rustc #101566
This PR introduces `DynSend / DynSync` trait and `FromDyn / IntoDyn` structure in rustc_data_structure::marker. `FromDyn` can dynamically check data structures for thread safety when switching to parallel environments (such as calling `par_for_each_in`). This happens only when `-Z threads > 1` so it doesn't affect single-threaded mode's compile efficiency.
r? `@cjgillot`
bump windows crate 0.46 -> 0.48
This drops duped version of crate(0.46), reduces `rustc_driver.dll` ~800kb and reduces exported functions number from 26k to 22k.
Also while here, added `tidy-alphabetical` sorting to lists in tidy allowed lists.
Min specialization improvements
- Don't allow specialization impls with no items, such implementations are probably not correct and only occur as mistakes in the compiler and standard library
- Fix a missing normalization call
- Adds spans for lifetime errors from overly general specializations
Closes#79457Closes#109815
Such implementations are usually mistakes and are not used in the
compiler or standard library (after this commit) so forbid them with
`min_specialization`.
Move the WorkerLocal type from the rustc-rayon fork into rustc_data_structures
This PR moves the definition of the `WorkerLocal` type from `rustc-rayon` into `rustc_data_structures`. This is enabled by the introduction of the `Registry` type which allows you to group up threads to be used by `WorkerLocal` which is basically just an array with an per thread index. The `Registry` type mirrors the one in Rayon and each Rayon worker thread is also registered with the new `Registry`. Safety for `WorkerLocal` is ensured by having it keep a reference to the registry and checking on each access that we're still on the group of threads associated with the registry used to construct it.
Accessing a `WorkerLocal` is micro-optimized due to it being hot since it's used for most arena allocations.
Performance is slightly improved for the parallel compiler:
<table><tr><td rowspan="2">Benchmark</td><td colspan="1"><b>Before</b></th><td colspan="2"><b>After</b></th></tr><tr><td align="right">Time</td><td align="right">Time</td><td align="right">%</th></tr><tr><td>🟣 <b>clap</b>:check</td><td align="right">1.9992s</td><td align="right">1.9949s</td><td align="right"> -0.21%</td></tr><tr><td>🟣 <b>hyper</b>:check</td><td align="right">0.2977s</td><td align="right">0.2970s</td><td align="right"> -0.22%</td></tr><tr><td>🟣 <b>regex</b>:check</td><td align="right">1.1335s</td><td align="right">1.1315s</td><td align="right"> -0.18%</td></tr><tr><td>🟣 <b>syn</b>:check</td><td align="right">1.8235s</td><td align="right">1.8171s</td><td align="right"> -0.35%</td></tr><tr><td>🟣 <b>syntex_syntax</b>:check</td><td align="right">6.9047s</td><td align="right">6.8930s</td><td align="right"> -0.17%</td></tr><tr><td>Total</td><td align="right">12.1586s</td><td align="right">12.1336s</td><td align="right"> -0.21%</td></tr><tr><td>Summary</td><td align="right">1.0000s</td><td align="right">0.9977s</td><td align="right"> -0.23%</td></tr></table>
cc `@SparrowLii`
Sprinkle some `#[inline]` in `rustc_data_structures::tagged_ptr`
This is based on `nm --demangle (rustc +a --print sysroot)/lib/librustc_driver-*.so | rg CopyTaggedPtr` which shows many methods that should probably be inlined. May fix the regression in https://github.com/rust-lang/rust/pull/110795.
r? ```@Nilstrieb```
Add `impl_tag!` macro to implement `Tag` for tagged pointer easily
r? `@Nilstrieb`
This should also lifts the need to think about safety from the callers (`impl_tag!` is robust (ish, see the macro issue)) and removes the possibility of making a "weird" `Tag` impl.
Encode hashes as bytes, not varint
In a few places, we store hashes as `u64` or `u128` and then apply `derive(Decodable, Encodable)` to the enclosing struct/enum. It is more efficient to encode hashes directly than try to apply some varint encoding. This PR adds two new types `Hash64` and `Hash128` which are produced by `StableHasher` and replace every use of storing a `u64` or `u128` that represents a hash.
Distribution of the byte lengths of leb128 encodings, from `x build --stage 2` with `incremental = true`
Before:
```
( 1) 373418203 (53.7%, 53.7%): 1
( 2) 196240113 (28.2%, 81.9%): 3
( 3) 108157958 (15.6%, 97.5%): 2
( 4) 17213120 ( 2.5%, 99.9%): 4
( 5) 223614 ( 0.0%,100.0%): 9
( 6) 216262 ( 0.0%,100.0%): 10
( 7) 15447 ( 0.0%,100.0%): 5
( 8) 3633 ( 0.0%,100.0%): 19
( 9) 3030 ( 0.0%,100.0%): 8
( 10) 1167 ( 0.0%,100.0%): 18
( 11) 1032 ( 0.0%,100.0%): 7
( 12) 1003 ( 0.0%,100.0%): 6
( 13) 10 ( 0.0%,100.0%): 16
( 14) 10 ( 0.0%,100.0%): 17
( 15) 5 ( 0.0%,100.0%): 12
( 16) 4 ( 0.0%,100.0%): 14
```
After:
```
( 1) 372939136 (53.7%, 53.7%): 1
( 2) 196240140 (28.3%, 82.0%): 3
( 3) 108014969 (15.6%, 97.5%): 2
( 4) 17192375 ( 2.5%,100.0%): 4
( 5) 435 ( 0.0%,100.0%): 5
( 6) 83 ( 0.0%,100.0%): 18
( 7) 79 ( 0.0%,100.0%): 10
( 8) 50 ( 0.0%,100.0%): 9
( 9) 6 ( 0.0%,100.0%): 19
```
The remaining 9 or 10 and 18 or 19 are `u64` and `u128` respectively that have the high bits set. As far as I can tell these are coming primarily from `SwitchTargets`.
Spelling compiler
This is per https://github.com/rust-lang/rust/pull/110392#issuecomment-1510193656
I'm going to delay performing a squash because I really don't expect people to be perfectly happy w/ my changes, I really am a human and I really do make mistakes.
r? Nilstrieb
I'm going to be flying this evening, but I should be able to squash / respond to reviews w/in a day or two.
I tried to be careful about dropping changes to `tests`, afaict only two files had changes that were likely related to the changes for a given commit (this is where not having eagerly squashed should have given me an advantage), but, that said, picking things apart can be error prone.
Rollup of 7 pull requests
Successful merges:
- #109981 (Set commit information environment variables when building tools)
- #110348 (Add list of supported disambiguators and suffixes for intra-doc links in the rustdoc book)
- #110409 (Don't use `serde_json` to serialize a simple JSON object)
- #110442 (Avoid including dry run steps in the build metrics)
- #110450 (rustdoc: Fix invalid handling of nested items with `--document-private-items`)
- #110461 (Use `Item::expect_*` and `ImplItem::expect_*` more)
- #110465 (Assure everyone that `has_type_flags` is fast)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Don't use `serde_json` to serialize a simple JSON object
This avoids `rustc_data_structures` depending on `serde_json` which allows it to be compiled much earlier, unlocking most of rustc.
This used to not matter, but after #110407 we're not blocked on fluent anymore, which means that it's now a blocking edge.
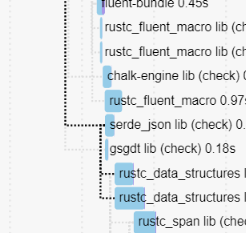
This saves a few more seconds.
cc ````@Zoxc```` who added it recently
Implement StableHasher::write_u128 via write_u64
In https://github.com/rust-lang/rust/pull/110367#issuecomment-1510114777 the cachegrind diffs indicate that nearly all the regression is from this:
```
22,892,558 ???:<rustc_data_structures::sip128::SipHasher128>::slice_write_process_buffer
-9,502,262 ???:<rustc_data_structures::sip128::SipHasher128>::short_write_process_buffer::<8>
```
Which happens because the diff for that perf run swaps a `Hash::hash` of a `u64` to a `u128`. But `slice_write_process_buffer` is a `#[cold]` function, and is for handling hashes of arbitrary-length byte arrays.
Using the much more optimizer-friendly `u64` path twice to hash a `u128` provides a nice perf boost in some benchmarks.
Tagged pointers, now with strict provenance!
This is a big refactor of tagged pointers in rustc, with three main goals:
1. Porting the code to the strict provenance
2. Cleanup the code
3. Document the code (and safety invariants) better
This PR has grown quite a bit (almost a complete rewrite at this point...), so I'm not sure what's the best way to review this, but reviewing commit-by-commit should be fine.
r? `@Nilstrieb`
Remove some suspicious cast truncations
These truncations were added a long time ago, and as best I can tell without a perf justification. And with rust-lang/rust#110410 it has become perf-neutral to not truncate anymore. We worked hard for all these bits, let's use them.
Turns out
- `owning_ref` is unsound due to `Box` aliasing stuff
- `rustc` doesn't need 99% of the `owning_ref` API
- `rustc` can use a far simpler abstraction that is `OwnedSlice`
{kind=link}