Update sysinfo to 0.30.8
Fixes a Mac specific issue when using `metrics = true` in `config.toml`.
```config.toml
# Collect information and statistics about the current build and writes it to
# disk. Enabling this or not has no impact on the resulting build output. The
# schema of the file generated by the build metrics feature is unstable, and
# this is not intended to be used during local development.
metrics = true
```
During repeated builds, as the generated `metrics.json` grew, eventually `refresh_cpu()` would be called in quick enough succession (specifically: under 200ms) that a divide by zero would occur, leading to a `NaN` which would not be serialized, then when the `metrics.json` was re-read it would fail to parse.
That error looks like this (collected from Ferrocene's CI):
```
Compiling rustdoc-tool v0.0.0 (/Users/distiller/project/src/tools/rustdoc)
Finished release [optimized] target(s) in 38.37s
thread 'main' panicked at src/utils/metrics.rs:180:21:
serde_json::from_slice::<JsonRoot>(&contents) failed with invalid type: null, expected f64 at line 1 column 9598
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:40
Exited with code exit status 1
```
Related: https://github.com/GuillaumeGomez/sysinfo/pull/1236
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
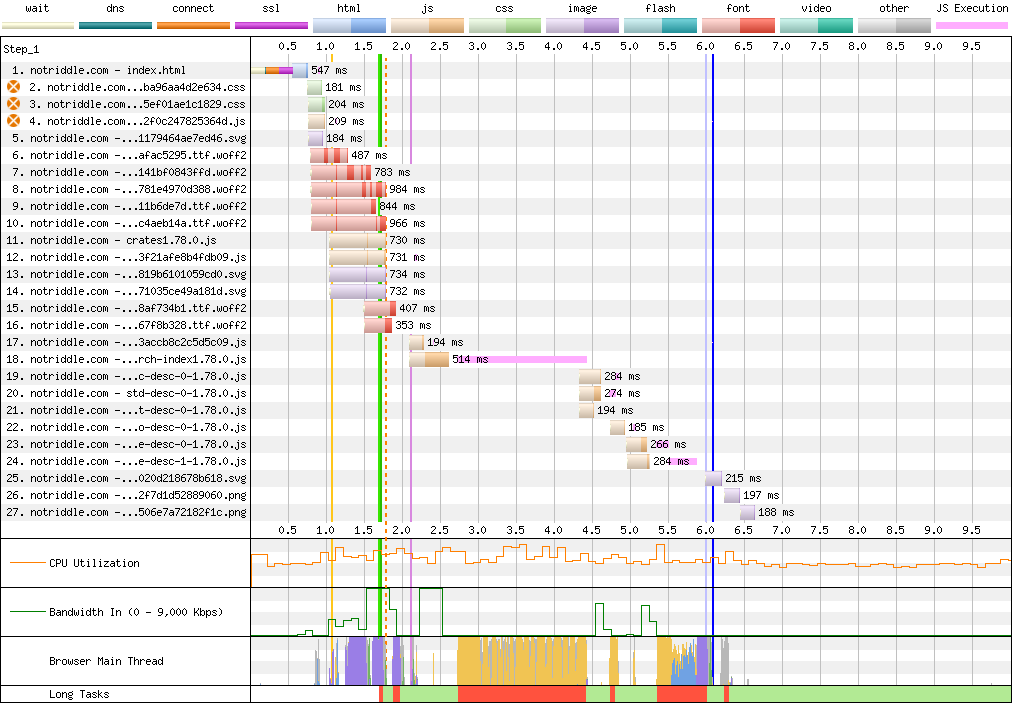
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
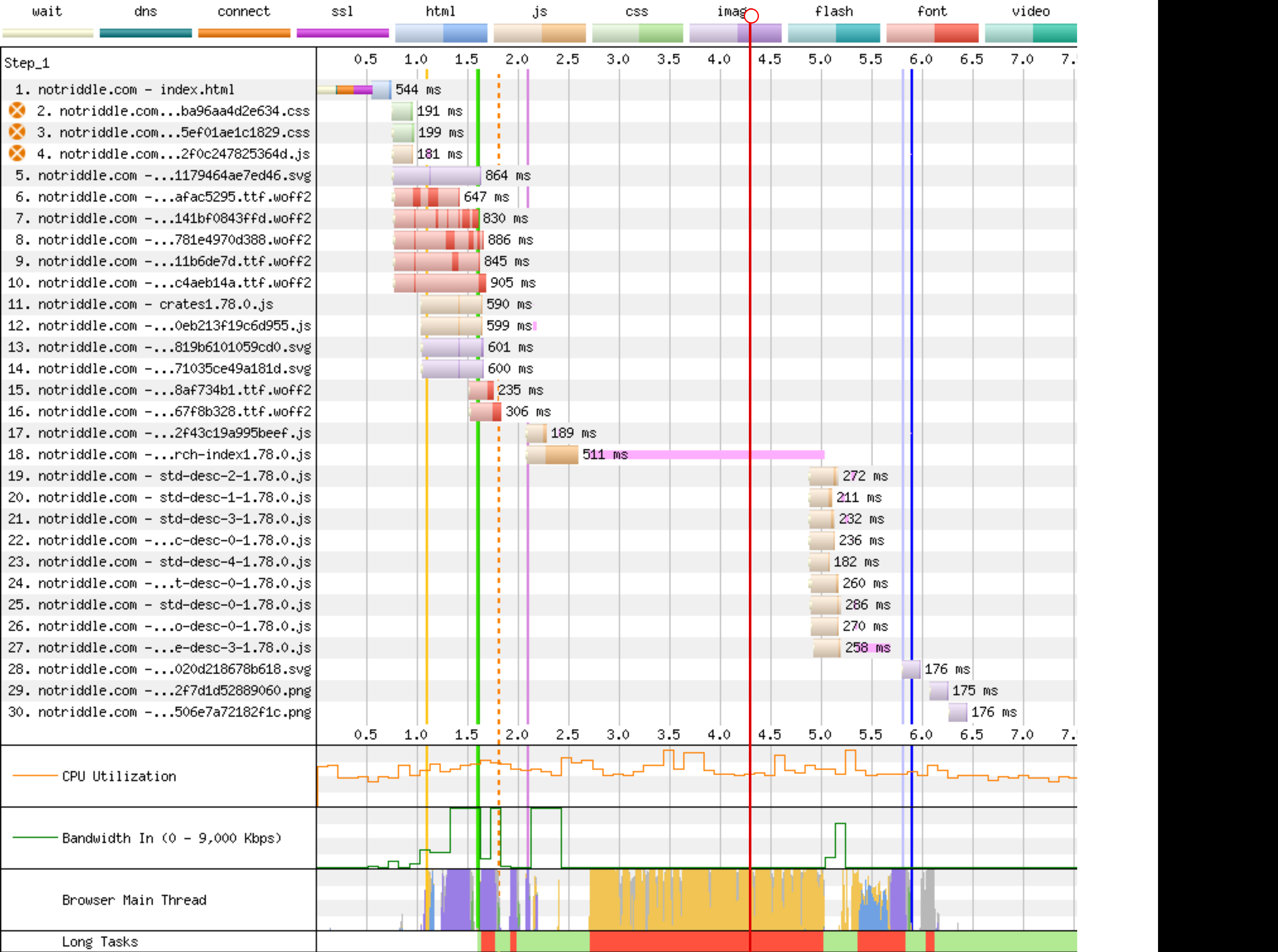
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
Use the `Align` type when parsing alignment attributes
Use the `Align` type in `rustc_attr::parse_alignment`, removing the need to call `Align::from_bytes(...).unwrap()` later in the compilation process.
Print a backtrace in const eval if interrupted
Demo:
```rust
#![feature(const_eval_limit)]
#![const_eval_limit = "0"]
const OW: u64 = {
let mut res: u64 = 0;
let mut i = 0;
while i < u64::MAX {
res = res.wrapping_add(i);
i += 1;
}
res
};
fn main() {
println!("{}", OW);
}
```
```
╭ ➜ ben@archlinux:~/rust
╰ ➤ rustc +stage1 spin.rs
^Cerror[E0080]: evaluation of constant value failed
--> spin.rs:8:33
|
8 | res = res.wrapping_add(i);
| ^ Compilation was interrupted
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
|
= note: this note originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to previous error
For more information about this error, try `rustc --explain E0080`.
```
CFI: Support complex receivers
Right now, we only support rewriting `&self` and `&mut self` into `&dyn MyTrait` and `&mut dyn MyTrait`. This expands it to handle the full gamut of receivers by calculating the receiver based on *substitution* rather than based on a rewrite. This means that, for example, `Arc<Self>` will become `Arc<dyn MyTrait>` appropriately with this change.
This approach also allows us to support associated type constraints as well, so we will correctly rewrite `&self` into `&dyn MyTrait<T=i32>`, for example.
r? ```@workingjubilee```
Previously, we only rewrote `&self` and `&mut self` receivers. By
instantiating the method from the trait definition, we can make this
work work with arbitrary legal receivers instead.
"Handle" calls to upstream monomorphizations in compiler_builtins
This is pretty cooked, but I think it works.
compiler-builtins has a long-standing problem that at link time, its rlib cannot contain any calls to `core`. And yet, in codegen we _love_ inserting calls to symbols in `core`, generally from various panic entrypoints.
I intend this PR to attack that problem as completely as possible. When we generate a function call, we now check if we are generating a function call from `compiler_builtins` and whether the callee is a function which was not lowered in the current crate, meaning we will have to link to it.
If those conditions are met, actually generating the call is asking for a linker error. So we don't. If the callee diverges, we lower to an abort with the same behavior as `core::intrinsics::abort`. If the callee does not diverge, we produce an error. This means that compiler-builtins can contain panics, but they'll SIGILL instead of panicking. I made non-diverging calls a compile error because I'm guessing that they'd mostly get into compiler-builtins by someone making a mistake while working on the crate, and compile errors are better than linker errors. We could turn such calls into aborts as well if that's preferred.
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
Bump windows-bindgen to 0.55.0
windows-bindgen is the crate used to generate std's Windows API bindings.
Not many changes for us, it's mostly just simplifying the generate code (e.g. no more `-> ()`). The one substantial change is some structs now use `i8` byte arrays instead of `u8`. However, this only impacts one test.
Test wasm32-wasip1 in CI, not wasm32-unknown-unknown
This commit changes CI to no longer test the `wasm32-unknown-unknown` target and instead test the `wasm32-wasip1` target. There was some discussion of this in a [Zulip thread], and the motivations for this PR are:
* Runtime failures on `wasm32-unknown-unknown` print nothing, meaning all you get is "something failed". In contrast `wasm32-wasip1` can print to stdout/stderr.
* The unknown-unknown target is missing lots of pieces of libstd, and while `wasm32-wasip1` is also missing some pieces (e.g. threads) it's missing fewer pieces. This means that many more tests can be run.
Overall my hope is to improve the debuggability of wasm failures on CI and ideally be a bit less of a maintenance burden.
This commit specifically removes the testing of `wasm32-unknown-unknown` and replaces it with testing of `wasm32-wasip1`. Along the way there were a number of other archiectural changes made as well, including:
* A new `target.*.runtool` option can now be specified in `config.toml` which is passed as `--runtool` to `compiletest`. This is used to reimplement execution of WebAssembly in a less-wasm-specific fashion.
* The default value for `runtool` is an ambiently located WebAssembly runtime found on the system, if any. I've implemented logic for Wasmtime.
* Existing testing support for `wasm32-unknown-unknown` and Emscripten has been removed. I'm not aware of Emscripten testing being run any time recently and otherwise `wasm32-wasip1` is in theory the focus now.
* I've added a new `//@ needs-threads` directive for `compiletest` and classified a bunch of wasm-ignored tests as needing threads. In theory these tests can run on `wasm32-wasi-preview1-threads`, for example.
* I've tried to audit all existing tests that are either `ignore-emscripten` or `ignore-wasm*`. Many now run on `wasm32-wasip1` due to being able to emit error messages, for example. Many are updated with comments as to why they can't run as well.
* The `compiletest` output matching for `wasm32-wasip1` automatically uses "match a subset" mode implemented in `compiletest`. This is because WebAssembly runtimes often add extra information on failure, such as the `unreachable` instruction in `panic!`, which isn't able to be matched against the golden output from native platforms.
* I've ported most existing `run-make` tests that use custom Node.js wrapper scripts to the new run-make-based-in-Rust infrastructure. To do this I added `wasmparser` as a dependency of `run-make-support` for the various wasm tests to use that parse wasm files. The one test that executed WebAssembly now uses `wasmtime`-the-CLI to execute the test instead. I have not ported over an exception-handling test as Wasmtime doesn't implement this yet.
* I've updated the `test` crate to print out timing information for WASI targets as it can do that (gets a previously ignored test now passing).
* The `test-various` image now builds a WASI sysroot for the WASI target and additionally downloads a fixed release of Wasmtime, currently the latest one at 18.0.2, and uses that for testing.
[Zulip thread]: https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Have.20wasm.20tests.20ever.20caused.20problems.20on.20CI.3F/near/424317944
This commit rewrites a number of `run-make` tests centered around wasm
to instead use `rmake.rs` and additionally use the `wasm32-wasip1`
target instead of `wasm32-unknown-unknown`. Testing no longer requires
Node.js and additionally uses the `wasmparser` crate from crates.io to
parse outputs and power assertions.
Misc improvements to non local defs lint implementation
This PR is a collection of small improvements I found when I [needlessly tried](https://www.github.com/rust-lang/rust/pull/120393#issuecomment-1971787475) to fix a "perf-regression" in the lint implementation.
I recommend looking at each commit individually.
Optimize `Symbol::integer` by utilizing in-place formatting
This PR optimize `Symbol::integer` by utilizing `itoa` in-place formatting instead of going through a dynamically allocated `String` and the format machinery.
<details>
For some context: I was profiling `rustc --check-cfg` with callgrind and due to the way we currently setup all the targets and we end-up calling `Symbol::integer` multiple times for all the targets. Using `itoa` reduced the number of instructions.
</details>
Introduces the `arm64ec-pc-windows-msvc` target for building Arm64EC ("Emulation Compatible") binaries for Windows.
For more information about Arm64EC see <https://learn.microsoft.com/en-us/windows/arm/arm64ec>.
Tier 3 policy:
> A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
I will be the maintainer for this target.
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
Target uses the `arm64ec` architecture to match LLVM and MSVC, and the `-pc-windows-msvc` suffix to indicate that it targets Windows via the MSVC environment.
> Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
Target name exactly specifies the type of code that will be produced.
> If possible, use only letters, numbers, dashes and underscores for the name. Periods (.) are known to cause issues in Cargo.
Done.
> Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
> The target must not introduce license incompatibilities.
Uses the same dependencies, requirements and licensing as the other `*-pc-windows-msvc` targets.
> Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
Understood.
> The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
> Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
Uses the same dependencies, requirements and licensing as the other `*-pc-windows-msvc` targets.
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
Understood, I am not a member of the Rust team.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
Both `core` and `alloc` are supported.
Support for `std` dependends on making changes to the standard library, `stdarch` and `backtrace` which cannot be done yet as the bootstrapping compiler raises a warning ("unexpected `cfg` condition value") for `target_arch = "arm64ec"`.
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
Documentation is provided in src/doc/rustc/src/platform-support/arm64ec-pc-windows-msvc.md
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via @) to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
Understood.
Leverage `anstyle-svg`, as `cargo` does now, to emit `.svg` files
instead of `.stderr` files for tests that explicitly enable color
output. This will make reviewing changes to the graphical output of
tests much more human friendly.
Introduce `run-make` V2 infrastructure, a `run_make_support` library and port over 2 tests as example
## Preface
See [issue #40713: Switch run-make tests from Makefiles to rust](https://github.com/rust-lang/rust/issues/40713) for more context.
## Basic Description of `run-make` V2
`run-make` V2 aims to eliminate the dependency on `make` and `Makefile`s for building `run-make`-style tests. Makefiles are replaced by *recipes* (`rmake.rs`). The current implementation runs `run-make` V2 tests in 3 steps:
1. We build the support library `run_make_support` which the `rmake.rs` recipes depend on as a tool lib.
2. We build the recipe `rmake.rs` and link in the support library.
3. We run the recipe to build and run the tests.
`rmake.rs` is basically a replacement for `Makefile`, and allows running arbitrary Rust code. The support library is built using cargo, and so can depend on external crates if desired.
The infrastructure implemented by this PR is very barebones, and is the minimally required infrastructure needed to build, run and pass the two example `run-make` tests ported over to the new infrastructure.
### Example `run-make` V2 test
```rs
// ignore-tidy-linelength
extern crate run_make_support;
use std::path::PathBuf;
use run_make_support::{aux_build, rustc};
fn main() {
aux_build()
.arg("--emit=metadata")
.arg("stable.rs")
.run();
let mut stable_path = PathBuf::from(env!("TMPDIR"));
stable_path.push("libstable.rmeta");
let output = rustc()
.arg("--emit=metadata")
.arg("--extern")
.arg(&format!("stable={}", &stable_path.to_string_lossy()))
.arg("main.rs")
.run();
let stderr = String::from_utf8_lossy(&output.stderr);
let version = include_str!(concat!(env!("S"), "/src/version"));
let expected_string = format!("stable since {}", version.trim());
assert!(stderr.contains(&expected_string));
}
```
## Follow Up Work
- [ ] Adjust rustc-dev-guide docs
rustc: Fix wasm64 metadata object files
It looks like LLD will detect object files being either 32 or 64-bit depending on any memory present. LLD will additionally reject 32-bit objects during a 64-bit link. Previously metadata objects did not have any memories in them which led LLD to conclude they were 32-bit objects which broke 64-bit targets for wasm.
This commit fixes this by ensuring that for 64-bit targets there's a memory object present to get LLD to detect it's a 64-bit target. Additionally this commit moves away from a hand-crafted wasm encoder to the `wasm-encoder` crate on crates.io as the complexity grows for the generated object file.
Closes#121460
{kind=link}