[mir-opt] Allow debuginfo to be generated for a constant or a Place
Prior to this commit, debuginfo was always generated by mapping a name
to a Place. This has the side-effect that `SimplifyLocals` cannot remove
locals that are only used for debuginfo because their other uses have
been const-propagated.
To allow these locals to be removed, we now allow debuginfo to point to
a constant value. The `ConstProp` pass detects when debuginfo points to
a local with a known constant value and replaces it with the value. This
allows the later `SimplifyLocals` pass to remove the local.
Move intrinsics lowering pass from the optimization phase (where it
would not run if -Zmir-opt-level=0), to the drop lowering phase where it
runs unconditionally.
The implementation of those intrinsics in code generation and
interpreter is unnecessary. Remove it.
rustc_codegen_ssa: use bitcasts instead of type punning for scalar transmutes.
This specifically helps with `f32` <-> `u32` (`from_bits`, `to_bits`) in Rust-GPU (`rustc_codegen_spirv`), where (AFAIK) we don't yet have enough infrastructure to turn type punning memory accesses into SSA bitcasts.
(There may be more instances, but the one I've seen myself is `f32::signum` from `num-traits` inspecting e.g. the sign bit)
Sadly I've had to make an exception for `transmute`s between pointers and non-pointers, as LLVM disallows using `bitcast` for them.
r? `@nagisa` cc `@khyperia`
Prior to this commit, debuginfo was always generated by mapping a name
to a Place. This has the side-effect that `SimplifyLocals` cannot remove
locals that are only used for debuginfo because their other uses have
been const-propagated.
To allow these locals to be removed, we now allow debuginfo to point to
a constant value. The `ConstProp` pass detects when debuginfo points to
a local with a known constant value and replaces it with the value. This
allows the later `SimplifyLocals` pass to remove the local.
Fixes multiple issue with counters, with simplification
Includes a change to the implicit else span in ast_lowering, so coverage
of the implicit else no longer spans the `then` block.
Adds coverage for unused closures and async function bodies.
Fixes: #78542
Adding unreachable regions for known MIR missing from coverage map
Cleaned up PR commits, and removed link-dead-code requirement and tests
Coverage no longer depends on Issue #76038 (`-C link-dead-code` is
no longer needed or enforced, so MSVC can use the same tests as
Linux and MacOS now)
Restrict adding unreachable regions to covered files
Improved the code that adds coverage for uncalled functions (with MIR
but not-codegenned) to avoid generating coverage in files not already
included in the files with covered functions.
Resolved last known issue requiring --emit llvm-ir workaround
Fixed bugs in how unreachable code spans were added.
Warn if `dsymutil` returns an error code
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
I tried to think of ways to test this change, but so far I haven't found a good way, as you'd likely need to inject some nonsensical args into `dsymutil` to induce failure, which feels too artificial to me. Also, https://github.com/rust-lang/rust/issues/79361 suggests Rust is on the verge of disabling `dsymutil` by default, so perhaps it's okay for this change to be untested. In any case, I'm happy to add a test if someone sees a good approach.
Fixes https://github.com/rust-lang/rust/issues/78770
Stop adding '*' at the end of slice and str typenames for MSVC case
When computing debug info for MSVC debuggers, Rust compiler emits C++ style type names for compatibility with .natvis visualizers. All Ref types are treated as equivalences of C++ pointers in this process, and, as a result, their type names end with a '\*'. Since Slice and Str are treated as Ref by the compiler, their type names also end with a '\*'. This causes the .natvis engine for WinDbg fails to display data of Slice and Str objects. We addressed this problem simply by removing the '*' at the end of type names for Slice and Str types.
Debug info in WinDbg before the fix:

Debug info in WinDbg after the fix:
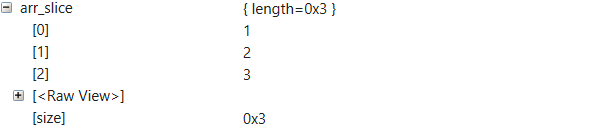
This change has also been tested with debuggers for Visual Studio, VS Code C++ and VS Code LLDB to make sure that it does not affect the behavior of other kinds of debugger.
This checks the error code returned by `dsymutil` and warns if it failed. It
also provides the stdout and stderr logs from `dsymutil`, similar to the native
linker step.
Fixes https://github.com/rust-lang/rust/issues/78770
Properly handle attributes on statements
We now collect tokens for the underlying node wrapped by `StmtKind`
nstead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
Add support for Arm64 Catalyst on ARM Macs
This is an iteration on https://github.com/rust-lang/rust/pull/63467 which was merged a while ago. In the aforementioned PR, I added support for the `X86_64-apple-ios-macabi` target triple, which is Catalyst, iOS apps running on macOS.
Very soon, Apple will launch ARM64 based Macs which will introduce `aarch64_apple_darwin.rs`, macOS apps using the Darwin ABI running on ARM. This PR adds support for Catalyst apps on ARM Macs: iOS apps compiled for the darwin ABI.
I don't have access to a Apple Developer Transition Kit (DTK), so I can't really test if the generated binaries work correctly. I'm vaguely hopeful that somebody with access to a DTK could give this a spin.
Updated the list of white-listed target features for x86
This PR both adds in-source documentation on what to look out for when adding a new (X86) feature set and [adds all that are detectable at run-time in Rust stable as of 1.27.0](https://github.com/rust-lang/stdarch/blob/master/crates/std_detect/src/detect/arch/x86.rs).
This should only enable the use of the corresponding LLVM intrinsics.
Actual intrinsics need to be added separately in rust-lang/stdarch.
It also re-orders the run-time-detect test statements to be more consistent
with the actual list of intrinsics whitelisted and removes underscores not present
in the actual names (which might be mistaken as being part of the name)
The reference for LLVM's feature names used is [this file](https://github.com/llvm/llvm-project/blob/master/llvm/include/llvm/Support/X86TargetParser.def).
This PR was motivated as the compiler end's part for allowing #67329 to be adressed over on rust-lang/stdarch
rustc_target: Further cleanup use of target options
Follow up to https://github.com/rust-lang/rust/pull/77729.
Implements items 2 and 4 from the list in https://github.com/rust-lang/rust/pull/77729#issue-500228243.
The first commit collapses uses of `target.options.foo` into `target.foo`.
The second commit renames some target options to avoid tautology:
`target.target_endian` -> `target.endian`
`target.target_c_int_width` -> `target.c_int_width`
`target.target_os` -> `target.os`
`target.target_env` -> `target.env`
`target.target_vendor` -> `target.vendor`
`target.target_family` -> `target.os_family`
`target.target_mcount` -> `target.mcount`
r? `@Mark-Simulacrum`
Monomorphize a type argument of size-of operation during codegen
This wasn't necessary until MIR inliner started to consider drop glue as
a candidate for inlining; introducing for the first time a generic use
of size-of operation.
No test at this point since this only happens with a custom inlining
threshold.
inliner: Use substs_for_mir_body
Changes from 68965 extended the kind of instances that are being
inlined. For some of those, the `instance_mir` returns a MIR body that
is already expressed in terms of the types found in substitution array,
and doesn't need further substitution.
Use `substs_for_mir_body` to take that into account.
Resolves#78529.
Resolves#78560.
with an eye on merging `TargetOptions` into `Target`.
`TargetOptions` as a separate structure is mostly an implementation detail of `Target` construction, all its fields logically belong to `Target` and available from `Target` through `Deref` impls.
This wasn't necessary until MIR inliner started to consider drop glue as
a candidate for inlining; introducing for the first time a generic use
of size-of operation.
No test at this point since this only happens with a custom inlining
threshold.
Implementing the Graph traits for the BasicCoverageBlock
graph.
optimized replacement of counters with expressions plus new BCB graphviz
* Avoid adding coverage to unreachable blocks.
* Special case for Goto at the end of the body. Make it non-reportable.
Improved debugging and formatting options (from env)
Don't automatically add counters to BCBs without CoverageSpans. They may
still get counters but only if there are dependencies from
other BCBs that have spans, I think.
Make CodeRegions optional for Counters too. It is
possible to inject counters (`llvm.instrprof.increment` intrinsic calls
without corresponding code regions in the coverage map. An expression
can still uses these counter values.
Refactored instrument_coverage.rs -> instrument_coverage/mod.rs, and
then broke up the mod into multiple files.
Compiling with coverage, with the expression optimization, works on
the json5format crate and its dependencies.
Refactored debug features from mod.rs to debug.rs
Changes from 68965 extended the kind of instances that are being
inlined. For some of those, the `instance_mir` returns a MIR body that
is already expressed in terms of the types found in substitution array,
and doesn't need further substitution.
Use `substs_for_mir_body` to take that into account.
foreign_modules query hash table lookups
When compiling a large monolithic crate we're seeing huge times in the `foreign_modules` query due to repeated iteration over foreign modules (in order to find a module by its id). This implements hash table lookups so that which massively reduces time spent in that query in this particular case. We'll need to see if the overhead of creating the hash table has a negative impact on performance in more normal compilation scenarios.
I'm working with `@wesleywiser` on this.
Add compiler support for LLVM's x86_64 ERMSB feature
This change is needed for compiler-builtins to check for this feature
when implementing memcpy/memset. See:
https://github.com/rust-lang/compiler-builtins/pull/365
Without this change, the following code compiles, but does nothing:
```rust
#[cfg(target_feature = "ermsb")]
pub unsafe fn ermsb_memcpy() { ... }
```
The change just does compile-time detection. I think that runtime
detection will have to come in a follow-up CL to std-detect.
Like all the CPU feature flags, this just references #44839
Signed-off-by: Joe Richey <joerichey@google.com>
rustc_mir: track inlined callees in SourceScopeData.
We now record which MIR scopes are the roots of *other* (inlined) functions's scope trees, which allows us to generate the correct debuginfo in codegen, similar to what LLVM inlining generates.
This PR makes the `ui` test `backtrace-debuginfo` pass, if the MIR inliner is turned on by default.
Also, `#[track_caller]` is now correct in the face of MIR inlining (cc `@anp).`
Fixes#76997.
r? `@rust-lang/wg-mir-opt`
This change is needed for compiler-builtins to check for this feature
when implementing memcpy/memset. See:
https://github.com/rust-lang/compiler-builtins/pull/365
The change just does compile-time detection. I think that runtime
detection will have to come in a follow-up CL to std-detect.
Like all the CPU feature flags, this just references #44839
Signed-off-by: Joe Richey <joerichey@google.com>
Updated the added documentation in llvm_util.rs to note which copies of LLVM need to be inspected.
Removed avx512bf16 and avx512vp2intersect because they are unsupported before LLVM 9 with the build with external LLVM 8 being supported
Re-introduced detection testing previously removed for un-requestable features tsc and mmx
This PR both adds in-source documentation on what to look out for
when adding a new (X86) feature set and adds all that are detectable at run-time in Rust stable
as of 1.27.0.
This should only enable the use of the corresponding LLVM intrinsics.
Actual intrinsics need to be added separately in rust-lang/stdarch.
It also re-orders the run-time-detect test statements to be more consistent
with the actual list of intrinsics whitelisted and removes underscores not present
in the actual names (which might be mistaken as being part of the name)
Addresses Issue #78286
Libraries compiled with coverage and linked with out enabling coverage
would fail when attempting to add the library's coverage statements to
the codegen coverage context (None).
Now, if coverage statements are encountered while compiling / linking
with `-Z instrument-coverage` disabled, codegen will *not* attempt to
add code regions to a coverage map, and it will not inject the LLVM
instrprof_increment intrinsic calls.
Prevent miscompilation in trivial loop {}
Ideally, we would want to handle a broader set of cases to fully fix the
underlying bug here. That is currently relatively expensive at compile and
runtime, so we don't do that for now.
Performance results indicate this is not a major regression, if at all, so it should be safe to land.
cc #28728
Ideally, we would want to handle a broader set of cases to fully fix the
underlying bug here. That is currently relatively expensive at compile and
runtime, so we don't do that for now.
The wrapper type led to tons of target.target
across the compiler. Its ptr_width field isn't
required any more, as target_pointer_width
is already present in parsed form.
Preparation for a subsequent change that replaces
rustc_target::config::Config with its wrapped Target.
On its own, this commit breaks the build. I don't like making
build-breaking commits, but in this instance I believe that it
makes review easier, as the "real" changes of this PR can be
seen much more easily.
Result of running:
find compiler/ -type f -exec sed -i -e 's/target\.target\([)\.,; ]\)/target\1/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target\.target$/target/g' {} \;
find compiler/ -type f -exec sed -i -e 's/target.ptr_width/target.pointer_width/g' {} \;
./x.py fmt
Rename target_pointer_width to pointer_width because it is already
member of the Target struct.
The compiler supports only three valid values for target_pointer_width:
16, 32, 64. Thus it can safely be turned into an int.
This means less allocations and clones as well as easier handling of the type.
Remove unused code
Rustc has a builtin lint for detecting unused code inside a crate, but when an item is marked `pub`, the code, even if unused inside the entire workspace, is never marked as such. Therefore, I've built [warnalyzer](https://github.com/est31/warnalyzer) to detect unused items in a cross-crate setting.
Closes https://github.com/est31/warnalyzer/issues/2
Codegen backend interface refactor
This moves several things away from the codegen backend to rustc_interface. There are a few behavioral changes where previously the incremental cache (incorrectly) wouldn't get finalized, but now it does. See the individual commit messages.
Sometimes, a backend may need to emit warnings, errors, or otherwise
need to know the span of the current item in a basic block. So, add a
set_span method to give the backend that information.
This is a combination of 18 commits.
Commit #2:
Additional examples and some small improvements.
Commit #3:
fixed mir-opt non-mir extensions and spanview title elements
Corrected a fairly recent assumption in runtest.rs that all MIR dump
files end in .mir. (It was appending .mir to the graphviz .dot and
spanview .html file names when generating blessed output files. That
also left outdated files in the baseline alongside the files with the
incorrect names, which I've now removed.)
Updated spanview HTML title elements to match their content, replacing a
hardcoded and incorrect name that was left in accidentally when
originally submitted.
Commit #4:
added more test examples
also improved Makefiles with support for non-zero exit status and to
force validation of tests unless a specific test overrides it with a
specific comment.
Commit #5:
Fixed rare issues after testing on real-world crate
Commit #6:
Addressed PR feedback, and removed temporary -Zexperimental-coverage
-Zinstrument-coverage once again supports the latest capabilities of
LLVM instrprof coverage instrumentation.
Also fixed a bug in spanview.
Commit #7:
Fix closure handling, add tests for closures and inner items
And cleaned up other tests for consistency, and to make it more clear
where spans start/end by breaking up lines.
Commit #8:
renamed "typical" test results "expected"
Now that the `llvm-cov show` tests are improved to normally expect
matching actuals, and to allow individual tests to override that
expectation.
Commit #9:
test coverage of inline generic struct function
Commit #10:
Addressed review feedback
* Removed unnecessary Unreachable filter.
* Replaced a match wildcard with remining variants.
* Added more comments to help clarify the role of successors() in the
CFG traversal
Commit #11:
refactoring based on feedback
* refactored `fn coverage_spans()`.
* changed the way I expand an empty coverage span to improve performance
* fixed a typo that I had accidently left in, in visit.rs
Commit #12:
Optimized use of SourceMap and SourceFile
Commit #13:
Fixed a regression, and synched with upstream
Some generated test file names changed due to some new change upstream.
Commit #14:
Stripping out crate disambiguators from demangled names
These can vary depending on the test platform.
Commit #15:
Ignore llvm-cov show diff on test with generics, expand IO error message
Tests with generics produce llvm-cov show results with demangled names
that can include an unstable "crate disambiguator" (hex value). The
value changes when run in the Rust CI Windows environment. I added a sed
filter to strip them out (in a prior commit), but sed also appears to
fail in the same environment. Until I can figure out a workaround, I'm
just going to ignore this specific test result. I added a FIXME to
follow up later, but it's not that critical.
I also saw an error with Windows GNU, but the IO error did not
specify a path for the directory or file that triggered the error. I
updated the error messages to provide more info for next, time but also
noticed some other tests with similar steps did not fail. Looks
spurious.
Commit #16:
Modify rust-demangler to strip disambiguators by default
Commit #17:
Remove std::process::exit from coverage tests
Due to Issue #77553, programs that call std::process::exit() do not
generate coverage results on Windows MSVC.
Commit #18:
fix: test file paths exceeding Windows max path len
Move target feature whitelist from cg_llvm to cg_ssa
These target features have to be supported or at least emulated by alternative codegen backends anyway as they are used by common crates. By moving this list to cg_ssa, other codegen backends don't have to copy
this code.
These target features have to be supported or at least emulated by
alternative codegen backends anyway as they are used by common crates.
By moving this list to cg_ssa, other codegen backends don't have to copy
this code.
Related: https://github.com/rust-lang/rust/issues/66741
Guarded with `#![feature(default_alloc_error_handler)]` a default
`alloc_error_handler` is called, if a custom allocator is used and no
other custom `#[alloc_error_handler]` is defined.
The panic message does not contain the size anymore, because it would
pull in the fmt machinery, which would blow up the code size
significantly.
Defer Apple SDKROOT detection to link time.
This defers the detection of the SDKROOT for Apple iOS/tvOS targets to link time, instead of when the `Target` is defined. This allows commands that don't need to link to work (like `rustdoc` or `rustc --print=target-list`). This also makes `--print=target-list` a bit faster.
This also removes the note in the platform support documentation about these targets being missing. When I wrote it, I misunderstood how the SDKROOT stuff worked.
Notes:
* This means that JSON spec targets can't explicitly override these flags. I think that is probably fine, as I believe the value is generally required, and can be set with the SDKROOT environment variable.
* This changes `x86_64-apple-tvos` to use `appletvsimulator`. I think the original code was wrong (it was using `iphonesimulator`). Also, `x86_64-apple-tvos` seems broken in general, and I cannot build it locally. The `data_layout` does not appear to be correct (it is a copy of the arm64 layout instead of the x86_64 layout). I have not tried building Apple's LLVM to see if that helps, but I suspect it is just wrong (I'm uncertain since I don't know how the tvOS simulator works with its bitcode-only requirements).
* I'm tempted to remove the use of `Result` for built-in target definitions, since I don't think they should be fallible. This was added in https://github.com/rust-lang/rust/pull/34980, but that only relates to JSON definitions. I think the built-in targets shouldn't fail. I can do this now, or not.
Fixes#36156Fixes#76584
Late link args order
MSYS2 changed how winpthreads is built and as the result it now depends on more mingw-w64 libraries.
This PR affects only MinGW targets since nobody else is using `late_link_args_{dynamic,static}`. Now the order is similar to how it used to be before https://github.com/rust-lang/rust/pull/67502.
Remove TrustedLen requirement from BuilderMethods::switch
The main use case of TrustedLen is allowing APIs to specialize on it,
but no use of it uses that specialization. Instead, only the .len()
function provided by ExactSizeIterator is used, which is already
required to be accurate.
Thus, the TrustedLen requirement on BuilderMethods::switch is redundant.
Ignore ZST offsets when deciding whether to use Scalar/ScalarPair layout
This is important because Scalar/ScalarPair layout previously would not be used if any ZST had nonzero offset.
For example, before this change, only `((), u128)` would be laid out like `u128`, not `(u128, ())`.
Fixes#63244
The main use case of TrustedLen is allowing APIs to specialize on it,
but no use of it uses that specialization. Instead, only the .len()
function provided by ExactSizeIterator is used, which is already
required to be accurate.
Thus, the TrustedLen requirement on BuilderMethods::switch is redundant.
Remove DeclareMethods
Most of the `DeclareMethods` API was only used internally by rustc_codegen_llvm. As such, it makes no sense to require other backends to implement them.
(`get_declared_value` and `declare_cfn` were used, in one place, specific to the `main` symbol, which I've replaced with a more specialized function to allow more flexibility in implementation - the intent is that `declare_c_main` can go away once we do something more clever, e.g. @eddyb has ideas around having a MIR shim or somesuch we can explore in a follow-up PR)
Rollup of 15 pull requests
Successful merges:
- #76722 (Test and fix Send and Sync traits of BTreeMap artefacts)
- #76766 (Extract some intrinsics out of rustc_codegen_llvm)
- #76800 (Don't generate bootstrap usage unless it's needed)
- #76809 (simplfy condition in ItemLowerer::with_trait_impl_ref())
- #76815 (Fix wording in mir doc)
- #76818 (Don't compile regex at every function call.)
- #76821 (Remove redundant nightly features)
- #76823 (black_box: silence unused_mut warning when building with cfg(miri))
- #76825 (use `array_windows` instead of `windows` in the compiler)
- #76827 (fix array_windows docs)
- #76828 (use strip_prefix over starts_with and manual slicing based on pattern length (clippy::manual_strip))
- #76840 (Move to intra doc links in core/src/future)
- #76845 (Use intra docs links in core::{ascii, option, str, pattern, hash::map})
- #76853 (Use intra-doc links in library/core/src/task/wake.rs)
- #76871 (support panic=abort in Miri)
Failed merges:
r? `@ghost`
Remove redundant nightly features
Removes a bunch of redundant/outdated nightly features. The first commit removes a `core_intrinsics` use for which a stable wrapper has been provided since. The second commit replaces the `const_generics` feature with `min_const_generics` which might get stabilized this year. The third commit is the result of a trial/error run of removing every single feature and then adding it back if compile failed. A bunch of unused features are the result that the third commit removes.
As a side effect, we now represent most promoteds as `ConstValue::Scalar` again. This is useful because all implict promoteds are just references anyway and most explicit promoteds are numeric arguments to `asm!` or SIMD instructions.
A significant amount of intrinsics do not actually need backend-specific
behaviors to be implemented, instead relying on methods already in
rustc_codegen_ssa. So, extract those methods out to rustc_codegen_ssa,
so that each backend doesn't need to reimplement the same code.
diagnostics: shorten paths of unique symbols
This is a step towards implementing a fix for #50310, and continuation of the discussion in [Pre-RFC: Nicer Types In Diagnostics - compiler - Rust Internals](https://internals.rust-lang.org/t/pre-rfc-nicer-types-in-diagnostics/11139). Impressed upon me from previous discussion in #21934 that an RFC for this is not needed, and I should just come up with code.
The recent improvements to `use` suggestions that I've contributed have given rise to this implementation. Contrary to previous suggestions, it's rather simple logic, and I believe it only reduces the amount of cognitive load that a developer would need when reading type errors.
-----
If a symbol name can only be imported from one place, and as long as it was not glob-imported anywhere in the current crate, we can trim its printed path to the last component.
This has wide implications on error messages with types, for example, shortening `std::vec::Vec` to just `Vec`, as long as there is no other `Vec` importable from anywhere.
If a symbol name can only be imported from one place for a type, and
as long as it was not glob-imported anywhere in the current crate, we
can trim its printed path and print only the name.
This has wide implications on error messages with types, for example,
shortening `std::vec::Vec` to just `Vec`, as long as there is no other
`Vec` importable anywhere.
This adds a new '-Z trim-diagnostic-paths=false' option to control this
feature.
On the good path, with no diagnosis printed, we should try to avoid
issuing this query, so we need to prevent trimmed_def_paths query on
several cases.
This change also relies on a previous commit that differentiates
between `Debug` and `Display` on various rustc types, where the latter
is trimmed and presented to the user and the former is not.
Eliminate some other bound checks when index comes from an enum
#36962 introduced an assumption for the upper limit of the enum's value. This PR adds an assumption to the lower value as well.
I've modified the original codegen test to show that derived (in that case, adding 1) values also don't generate bounds checks.
However, this test is actually carefully crafted to not hit a bug: if the enum's variants are modified to 1 and 2 instead of 2 and 3, the test fails by adding a bounds check. I suppose this is an LLVM issue and #75525, while not exactly in this context should be tracking it.
I'm not at all confident if this patch can be accepted, or even if it _should_ be accepted in this state. But I'm curious about what others think :)
~Improves~ Should improve #13926 but does not close it because it's not exactly predictable, where bounds checks may pop up against the assumptions.
Make to_immediate/from_immediate configurable by backends
`librustc_codegen_ssa` has the concept of an immediate vs. memory type, and `librustc_codegen_llvm` uses this distinction to implement `bool`s being `i8` in memory, and `i1` in immediate contexts. However, some of that implementation leaked into `codegen_ssa` when converting to/from immediate values. So, move those methods into builder traits, so that behavior can be configured by backends.
This is useful if a backend is able to keep bools as bools, or, needs to do more trickery than just bools to bytes.
(Note that there's already a large amount of things abstracted with "immediate types" - this is just bringing this particular thing in line to be abstracted as well)
---
Pinging @eddyb since that's who I was talking about this change with when they suggested I submit a PR.
Fix `-Z instrument-coverage` on MSVC
Found that `-C link-dead-code` (which was enabled automatically
under `-Z instrument-coverage`) was causing the linking error that
resulted in segmentation faults in coverage instrumented binaries. Link
dead code is now disabled under MSVC, allowing `-Z instrument-coverage`
to be enabled under MSVC for the first time.
More details are included in Issue #76038 .
Note this PR makes it possible to support `Z instrument-coverage` but
does not enable instrument coverage for MSVC in existing tests. It will be
enabled in another PR to follow this one (both PRs coming from original
PR #75828).
r? @tmandry
FYI: @wesleywiser
Found that -C link-dead-code (which was enabled automatically
under -Z instrument-coverage) was causing the linking error that
resulted in segmentation faults in coverage instrumented binaries. Link
dead code is now disabled under MSVC, allowing `-Z instrument-coverage`
to be enabled under MSVC for the first time.
More details are included in Issue #76038.
(This PR was broken out from PR #75828)
This commit removes the obsolete printer and replaces all uses of it
with `FmtPrinter`. Of the replaced uses, all but one use was in `debug!`
logging, two cases were notable:
- `MonoItem::to_string` is used in `-Z print-mono-items` and therefore
affects the output of all codegen-units tests.
- `DefPathBasedNames` was used in `librustc_codegen_llvm/type_of.rs`
with `LLVMStructCreateNamed` and that'll now get different values, but
this should result in no functional change.
Signed-off-by: David Wood <david@davidtw.co>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}