Report allocation errors as panics
OOM is now reported as a panic but with a custom payload type (`AllocErrorPanicPayload`) which holds the layout that was passed to `handle_alloc_error`.
This should be review one commit at a time:
- The first commit adds `AllocErrorPanicPayload` and changes allocation errors to always be reported as panics.
- The second commit removes `#[alloc_error_handler]` and the `alloc_error_hook` API.
ACP: https://github.com/rust-lang/libs-team/issues/192Closes#51540Closes#51245
More `IS_ZST` in `library`
I noticed that `post_inc_start` and `pre_dec_end` were doing this check in different ways
d19b64fb54/library/core/src/slice/iter/macros.rs (L76-L93)
so started making this PR, then added a few more I found since I was already making changes anyway.
I noticed that `post_inc_start` and `pre_dec_end` were doing this check in different ways
d19b64fb54/library/core/src/slice/iter/macros.rs (L76-L93)
so started making this PR, then added a few more I found since I was already making changes anyway.
Add `tidy-alphabetical` to features in `alloc` & `std`
So that people have to keep them sorted in future, rather than just sticking them on the end where they conflict more often.
Follow-up to #110269
cc `@jyn514`
binary_heap: Optimize Extend implementation.
This PR makes the `Extend` implementation for `BinaryHeap` no longer rely on specialization, so that it always use the bulk rebuild optimization that was previously only available for the `Vec` specialization.
Improve documentation for str::replace() and str::replacen()
Currently, to know what the function will return when the pattern doesn't match, the docs require the reader to understand the implementation detail and mentally evaluate or run the example code. It is not immediately clear.
This PR makes it more explicit so the reader can quickly find the information.
Rollup of 7 pull requests
Successful merges:
- #106985 (Enhanced doucmentation of binary search methods for `slice` and `VecDeque` for unsorted instances)
- #109509 (compiletest: Don't allow tests with overlapping prefix names)
- #109719 (RELEASES: Add "Only support Android NDK 25 or newer" to 1.68.0)
- #109748 (Don't ICE on `DiscriminantKind` projection in new solver)
- #109749 (Canonicalize float var as float in new solver)
- #109761 (Drop binutils on powerpc-unknown-freebsd)
- #109766 (Fix title for openharmony.md)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Enhanced doucmentation of binary search methods for `slice` and `VecDeque` for unsorted instances
Fixes#106746. Issue #106746 raises the concern that the binary search methods for slices and deques aren't explicit enough about the fact that they are only applicable to sorted slices/deques. I changed the explanation for these methods. I took the relatively harsh description of the behaviour of binary search on unsorted collections ("unspecified and meaningless") from the description of the [`partition_point`](https://doc.rust-lang.org/std/primitive.slice.html#method.partition_point) method:
> If this slice is not partitioned, the returned result is unspecified and meaningless, as this method performs a kind of binary search.
Partial stabilization of `once_cell`
This PR aims to stabilize a portion of the `once_cell` feature:
- `core::cell::OnceCell`
- `std::cell::OnceCell` (re-export of the above)
- `std::sync::OnceLock`
This will leave `LazyCell` and `LazyLock` unstabilized, which have been moved to the `lazy_cell` feature flag.
Tracking issue: https://github.com/rust-lang/rust/issues/74465 (does not fully close, but it may make sense to move to a new issue)
Future steps for separate PRs:
- ~~Add `#[inline]` to many methods~~ #105651
- Update cranelift usage of the `once_cell` crate
- Update rust-analyzer usage of the `once_cell` crate
- Update error messages discussing once_cell
## To be stabilized API summary
```rust
// core::cell (in core/cell/once.rs)
pub struct OnceCell<T> { .. }
impl<T> OnceCell<T> {
pub const fn new() -> OnceCell<T>;
pub fn get(&self) -> Option<&T>;
pub fn get_mut(&mut self) -> Option<&mut T>;
pub fn set(&self, value: T) -> Result<(), T>;
pub fn get_or_init<F>(&self, f: F) -> &T where F: FnOnce() -> T;
pub fn into_inner(self) -> Option<T>;
pub fn take(&mut self) -> Option<T>;
}
impl<T: Clone> Clone for OnceCell<T>;
impl<T: Debug> Debug for OnceCell<T>
impl<T> Default for OnceCell<T>;
impl<T> From<T> for OnceCell<T>;
impl<T: PartialEq> PartialEq for OnceCell<T>;
impl<T: Eq> Eq for OnceCell<T>;
```
```rust
// std::sync (in std/sync/once_lock.rs)
impl<T> OnceLock<T> {
pub const fn new() -> OnceLock<T>;
pub fn get(&self) -> Option<&T>;
pub fn get_mut(&mut self) -> Option<&mut T>;
pub fn set(&self, value: T) -> Result<(), T>;
pub fn get_or_init<F>(&self, f: F) -> &T where F: FnOnce() -> T;
pub fn into_inner(self) -> Option<T>;
pub fn take(&mut self) -> Option<T>;
}
impl<T: Clone> Clone for OnceLock<T>;
impl<T: Debug> Debug for OnceLock<T>;
impl<T> Default for OnceLock<T>;
impl<#[may_dangle] T> Drop for OnceLock<T>;
impl<T> From<T> for OnceLock<T>;
impl<T: PartialEq> PartialEq for OnceLock<T>
impl<T: Eq> Eq for OnceLock<T>;
impl<T: RefUnwindSafe + UnwindSafe> RefUnwindSafe for OnceLock<T>;
unsafe impl<T: Send> Send for OnceLock<T>;
unsafe impl<T: Sync + Send> Sync for OnceLock<T>;
impl<T: UnwindSafe> UnwindSafe for OnceLock<T>;
```
No longer planned as part of this PR, and moved to the `rust_cell_try` feature gate:
```rust
impl<T> OnceCell<T> {
pub fn get_or_try_init<F, E>(&self, f: F) -> Result<&T, E> where F: FnOnce() -> Result<T, E>;
}
impl<T> OnceLock<T> {
pub fn get_or_try_init<F, E>(&self, f: F) -> Result<&T, E> where F: FnOnce() -> Result<T, E>;
}
```
I am new to this process so would appreciate mentorship wherever needed.
Remove ~const from alloc
There is currently an effort underway to stop using `~const Trait`, temporarily, so as to refactor the logic underlying const traits with relative ease. This means it has to go from the standard library, as well.
I have taken the initial step of just removing these impls from alloc, as removing them from core is a much more tangled task. In addition, all of these implementations are one more-or-less logically-connected group, so reverting their deconstification as a group seems like it will also be sensible.
r? `@fee1-dead`
Change advance(_back)_by to return the remainder instead of the number of processed elements
When advance_by can't advance the iterator by the number of requested elements it now returns the amount by which it couldn't be advanced instead of the amount by which it did.
This simplifies adapters like chain, flatten or cycle because the remainder doesn't have to be calculated as the difference between requested steps and completed steps anymore.
Additionally switching from `Result<(), usize>` to `Result<(), NonZeroUsize>` reduces the size of the result and makes converting from/to a usize representing the number of remaining steps cheap.
A successful advance is now signalled by returning `0` and other values now represent the remaining number
of steps that couldn't be advanced as opposed to the amount of steps that have been advanced during a partial advance_by.
This simplifies adapters a bit, replacing some `match`/`if` with arithmetic. Whether this is beneficial overall depends
on whether `advance_by` is mostly used as a building-block for other iterator methods and adapters or whether
we also see uses by users where `Result` might be more useful.
Stabilize `nonnull_slice_from_raw_parts`
FCP is done: https://github.com/rust-lang/rust/issues/71941#issuecomment-1100910416
Note that this doesn't const-stabilize `NonNull::slice_from_raw_parts` as `slice_from_raw_parts_mut` isn't const-stabilized yet. Given #67456 and #57349, it's not likely available soon, meanwhile, stabilizing only the feature makes some sense, I think.
Closes#71941
Currently, to know what the function will return when the pattern
doesn't match, the docs require the reader to understand the
implementation detail and mentally evaluate or run the example
code. It is not immediately clear.
This PR makes it more explicit so the reader can quickly find the
information.
Implement Default for some alloc/core iterators
Add `Default` impls to the following collection iterators:
* slice::{Iter, IterMut}
* binary_heap::IntoIter
* btree::map::{Iter, IterMut, Keys, Values, Range, IntoIter, IntoKeys, IntoValues}
* btree::set::{Iter, IntoIter, Range}
* linked_list::IntoIter
* vec::IntoIter
and these adapters:
* adapters::{Chain, Cloned, Copied, Rev, Enumerate, Flatten, Fuse, Rev}
For iterators which are generic over allocators it only implements it for the global allocator because we can't conjure an allocator from nothing or would have to turn the allocator field into an `Option` just for this change.
These changes will be insta-stable.
ACP: https://github.com/rust-lang/libs-team/issues/77
Remove the assume(!is_null) from Vec::as_ptr
At a guess, this code is leftover from LLVM was worse at keeping track of the niche information here. In any case, we don't need this anymore: Removing this `assume` doesn't get rid of the `nonnull` attribute on the return type.
Introduce `Rc::into_inner`, as a parallel to `Arc::into_inner`
Unlike `Arc`, `Rc` doesn't have the same race condition to avoid, but
maintaining an equivalent API still makes it easier to work with both
`Rc` and `Arc`.
Unlike `Arc`, `Rc` doesn't have the same race condition to avoid, but
maintaining an equivalent API still makes it easier to work with both
`Rc` and `Arc`.
Rollup of 9 pull requests
Successful merges:
- #104363 (Make `unused_allocation` lint against `Box::new` too)
- #106633 (Stabilize `nonzero_min_max`)
- #106844 (allow negative numeric literals in `concat!`)
- #108071 (Implement goal caching with the new solver)
- #108542 (Force parentheses around `match` expression in binary expression)
- #108690 (Place size limits on query keys and values)
- #108708 (Prevent overflow through Arc::downgrade)
- #108739 (Prevent the `start_bx` basic block in codegen from having two `Builder`s at the same time)
- #108806 (Querify register_tools and post-expansion early lints)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Make `unused_allocation` lint against `Box::new` too
Previously it only linted against `box` syntax, which likely won't ever be stabilized, which is pretty useless. Even now I'm not sure if it's a meaningful lint, but it's at least something 🤷
This means that code like the following will be linted against:
```rust
Box::new([1, 2, 3]).len();
f(&Box::new(1)); // where f : &i32 -> ()
```
The lint works by checking if a `Box::new` (or `box`) expression has an a borrow adjustment, meaning that the code that first stores the box in a variable won't be linted against:
```rust
let boxed = Box::new([1, 2, 3]); // no lint
boxed.len();
```
Fix `vec_deque::Drain` FIXME
In my original `VecDeque` rewrite, I didn't use `VecDeque::slice_ranges` in `Drain::as_slices`, even though that's basically the exact use case for `slice_ranges`. The reason for this was that a `VecDeque` wrapped in a `Drain` actually has its length set to `drain_start`, so that there's no potential use after free if you `mem::forget` the `Drain`. I modified `slice_ranges` to accept an explicit `len` parameter instead, which it now uses to bounds check the given range. This way, `Drain::as_slices` can use `slice_ranges` internally instead of having to basically just copy paste the `slice_ranges` code. Since `slice_ranges` is just an internal helper function, this shouldn't change the user facing behavior in any way.
Remove or document uses of #[rustc_box] in library
r? `@thomcc`
Only one of these uses is tested for in the rustc-perf benchmark suite. The impact there on compile time is somewhat dramatic, but I am inclined to make this change as a simplification to the library and wait for people to complain if it explodes their compilation time. I think in the absence of data or reports from users about what code paths really matter, if we are optimizing for compilation time, it's hard to argue against using `#[rustc_box]` everywhere we currently call `Box::new`.
This adds both a test specific to #108453 as well as an exhaustive test
that goes through all possible combinations of head index, length and target capacity
for a deque with capacity 16.
Previously the bulk rebuild specialization was only available with Vec, and
for general iterators Extend only provided pre-allocation through reserve().
By using a drop guard, we can safely bulk rebuild even if the iterator may
panic. This allows benefiting from the bulk rebuild optimization without
collecting iterator elements into a Vec beforehand, which would nullify any
performance gains from bulk rebuild.
Implement more methods for `vec_deque::IntoIter`
This implements a couple `Iterator` methods on `vec_deque::IntoIter` (`(try_)fold`, `(try_)rfold` `advance_(back_)by`, `next_chunk`, `count` and `last`) to allow these to be more efficient than their default implementations, also allowing many other `Iterator` methods that use these under the hood to take advantage of these manual implementations. `vec::IntoIter` has similar implementations for many of these methods. This PR does not yet implement `TrustedRandomAccess` and friends, as I'm not very familiar with the required safety guarantees.
r? `@the8472` (since you also took over my last PR)
Use associated items of `char` instead of freestanding items in `core::char`
The associated functions and constants on `char` have been stable since 1.52 and the freestanding items have soft-deprecated since 1.62 (https://github.com/rust-lang/rust/pull/95566). This PR ~~marks them as "deprecated in future", similar to the integer and floating point modules (`core::{i32, f32}` etc)~~ replaces all uses of `core::char::*` with `char::*` to prepare for future deprecation of `core::char::*`.
simplify layout calculations in rawvec
The use of `Layout::array` was introduced in #83706 which lead to a [perf regression](https://github.com/rust-lang/rust/pull/83706#issuecomment-1048377719).
This PR basically reverts that change since rust currently only supports stride == size types, but to be on the safe side it leaves a const-assert there to make sure this gets caught if those assumptions ever change.
Stabilize feature `cstr_from_bytes_until_nul`
This PR seeks to stabilize `cstr_from_bytes_until_nul`.
Partially addresses #95027
This function has only been on nightly for about 10 months, but I think it is simple enough that there isn't harm discussing stabilization. It has also had at least a handful of mentions on both the user forum and the discord, so it seems like it's already in use or at least known.
This needs FCP still.
Comment on potential discussion points:
- eventual conversion of `CStr` to be a single thin pointer: this function will still be useful to provide a safe way to create a `CStr` after this change.
- should this return a length too, to address concerns about the `CStr` change? I don't see it as being particularly useful, and it seems less ergonomic (i.e. returning `Result<(&CStr, usize), FromBytesUntilNulError>`). I think users that also need this length without the additional `strlen` call are likely better off using a combination of other methods, but this is up for discussion
- `CString::from_vec_until_nul`: this is also useful, but it doesn't even have a nightly implementation merged yet. I propose feature gating that separately, as opposed to blocking this `CStr` implementation on that
Possible alternatives:
A user can use `from_bytes_with_nul` on a slice up to `my_slice[..my_slice.iter().find(|c| c == 0).unwrap()]`. However; that is significantly less ergonomic, and is a bit more work for the compiler to optimize compared the direct `memchr` call that this wraps.
## New stable API
```rs
// both in core::ffi
pub struct FromBytesUntilNulError(());
impl CStr {
pub const fn from_bytes_until_nul(
bytes: &[u8]
) -> Result<&CStr, FromBytesUntilNulError>
}
```
cc ```@ericseppanen``` original author, ```@Mark-Simulacrum``` original reviewer, ```@m-ou-se``` brought up some issues on the thin pointer CStr
```@rustbot``` modify labels: +T-libs-api +needs-fcp
Implement cursors for BTreeMap
See the ACP for an overview of the API: https://github.com/rust-lang/libs-team/issues/141
The implementation is split into 2 commits:
- The first changes the internal insertion functions to return a handle to the newly inserted element. The lifetimes involved are a bit hairy since we need a mutable handle to both the `BTreeMap` itself (which holds the root) and the nodes allocated in memory. I have tested that this passes the standard library testsuite under miri.
- The second commit implements the cursor API itself. This is more straightforward to follow but still involves some unsafe code to deal with simultaneous mutable borrows of the tree root and the node that is currently being iterated.
Bump bootstrap compiler to 1.68
This also changes our stage0.json to include the rustc component for the rustfmt pinned nightly toolchain, which is currently necessary due to rustfmt dynamically linking to that toolchain's librustc_driver and libstd.
r? `@pietroalbini`
Make Vec::clone_from and slice::clone_into share the same code
In the past, `Vec::clone_from` was implemented using `slice::clone_into`. The code from `clone_into` was later duplicated into `clone_from` in 8725e4c337, which is the commit that adds custom allocator support to Vec. Presumably this was done because the `slice::clone_into` method only works for vecs with the default allocator so it would have the wrong type to clone into `Vec<T, A>`.
Later on in 361398009b the code for the two methods diverged because the `Vec::clone_from` version gained a specialization to optimize the case when T is Copy. In order to reduce code duplication and make them both be able to take advantage of this specialization, this PR moves the specialization into the slice module and makes vec use it again.
Don't re-export private/unstable ArgumentV1 from `alloc`.
The `alloc::fmt::ArgumentV1` re-export was marked as `#[stable]` even though the original `core::fmt::ArgumentV1` is `#[unstable]` (and `#[doc(hidden)]`).
(It wasn't usable though:
```
error[E0658]: use of unstable library feature 'fmt_internals': internal to format_args!
--> src/main.rs:4:12
|
4 | let _: alloc::fmt::ArgumentV1 = todo!();
| ^^^^^^^^^^^^^^^^^^^^^^
|
= help: add `#![feature(fmt_internals)]` to the crate attributes to enable
```
)
Part of #99012
In the past, Vec::clone_from was implemented using slice::clone_into.
The code from clone_into was later duplicated into clone_from in
8725e4c337, which is the commit that adds custom allocator support to
Vec. Presumably this was done because the slice::clone_into only works
for vecs with the default allocator so it would have the wrong type to
clone into Vec<T, A>.
Now that the clone_into implementation is moved out into a specializable
trait anyway we might as well use that to share the code between the two
methods.
The implementation for the ToOwned::clone_into method on [T] is a copy
of the code for vec::clone_from. In 361398009b the code for
vec::clone_from gained a specialization for when T is Copy. This commit
copies that specialization over to the clone_into implementation.
Add `Arc::into_inner` for safely discarding `Arc`s without calling the destructor on the inner type.
ACP: rust-lang/libs-team#162
Reviving #79665.
I want to get this merged this time; this does not contain changes (apart from very minor changes in comments/docs).
See #79665 for further description of the PR. The only “unresolved” points that led to that PR being closed, AFAICT, were
* The desire to also implement a `Rc::into_inner` function
* however, this can very well also happen as a subsequent PR
* Possible need for further discussion on the naming “`into_inner`” (?)
* `into_inner` seems fine to me; also, this PR introduces unstable API, and names can be changed later, too
* ~~I don't know if a tracking issue for the feature flag is supposed to be opened before or after this PR gets merged (if *before*, then I can add the issue number to the `#[unstable…]` attribute)~~ There is a [tracking issue](https://github.com/rust-lang/rust/issues/106894) now.
I say “unresolved” in quotation marks because from my point of view, if reviewers agree, the PR can be merged immediately and as-is :-)
Unify stable and unstable sort implementations in same core module
This moves the stable sort implementation to the core::slice::sort module. By virtue of being in core it can't access `Vec`. The two `Vec` used by merge sort, `buf` and `runs`, are modelled as custom types that implement the very limited required `Vec` interface with the help of provided allocation and free functions. This is done to allow future re-use of functions and logic between stable and unstable sort. Such as `insert_head`.
This is in preparation of #100856 and #104116. It only moves code, it *doesn't* change any of the sort related logic. This unlocks the ability to share `insert_head`, `insert_tail`, `swap_if_less` `merge` and more.
Tagging ````@Mark-Simulacrum```` I hope this allows progress on #100856, by moving `merge_sort` here I hope future changes will be easier to review.
Implement `alloc::vec::IsZero` for `Option<$NUM>` types
Fixes#106911
Mirrors the `NonZero$NUM` implementations with an additional `assert_zero_valid`.
`None::<i32>` doesn't stricly satisfy `IsZero` but for the purpose of allocating we can produce more efficient codegen.
Don't do pointer arithmetic on pointers to deallocated memory
vec::Splice can invalidate the slice::Iter inside vec::Drain. So we replace them with dangling pointers which, unlike ones to deallocated memory, are allowed.
Fixes miri test failures.
Fixes https://github.com/rust-lang/miri/issues/2759
vec::Splice can invalidate the slice::Iter inside vec::Drain.
So we replace them with dangling pointers which, unlike ones to
deallocated memory, are allowed.
Leak amplification for peek_mut() to ensure BinaryHeap's invariant is always met
In the libs-api team's discussion around #104210, some of the team had hesitations around exposing malformed BinaryHeaps of an element type whose Ord and Drop impls are trusted, and which does not contain interior mutability.
For example in the context of this kind of code:
```rust
use std::collections::BinaryHeap;
use std::ops::Range;
use std::slice;
fn main() {
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let cut_points = BinaryHeap::from(vec![4, 2, 7]);
println!("{:?}", chop(slice, cut_points));
}
// This is a souped up slice::split_at_mut to split in arbitrary many places.
//
// usize's Ord impl is trusted, so 1 single bounds check guarantees all those
// output slices are non-overlapping and in-bounds
fn chop<T>(slice: &mut [T], mut cut_points: BinaryHeap<usize>) -> Vec<&mut [T]> {
let mut vec = Vec::with_capacity(cut_points.len() + 1);
let max = match cut_points.pop() {
Some(max) => max,
None => {
vec.push(slice);
return vec;
}
};
assert!(max <= slice.len());
let len = slice.len();
let ptr: *mut T = slice.as_mut_ptr();
let get_unchecked_mut = unsafe {
|range: Range<usize>| &mut *slice::from_raw_parts_mut(ptr.add(range.start), range.len())
};
vec.push(get_unchecked_mut(max..len));
let mut end = max;
while let Some(start) = cut_points.pop() {
vec.push(get_unchecked_mut(start..end));
end = start;
}
vec.push(get_unchecked_mut(0..end));
vec
}
```
```console
[['7', '8', '9'], ['4', '5', '6'], ['2', '3'], ['0', '1']]
```
In the current BinaryHeap API, `peek_mut()` is the only thing that makes the above function unsound.
```rust
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let mut cut_points = BinaryHeap::from(vec![4, 2, 7]);
{
let mut max = cut_points.peek_mut().unwrap();
*max = 0;
std::mem::forget(max);
}
println!("{:?}", chop(slice, cut_points));
```
```console
[['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], [], ['2', '3'], ['0', '1']]
```
Or worse:
```rust
let slice = &mut ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'];
let mut cut_points = BinaryHeap::from(vec![100, 100]);
{
let mut max = cut_points.peek_mut().unwrap();
*max = 0;
std::mem::forget(max);
}
println!("{:?}", chop(slice, cut_points));
```
```console
[['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'], [], ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '\u{1}', '\0', '?', '翾', '?', '翾', '\0', '\0', '?', '翾', '?', '翾', '?', '啿', '?', '啿', '?', '啿', '?', '啿', '?', '啿', '?', '翾', '\0', '\0', '', '啿', '\u{5}', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\0', '\u{8}', '\0', '`@',` '\0', '\u{1}', '\0', '?', '翾', '?', '翾', '?', '翾', '
thread 'main' panicked at 'index out of bounds: the len is 33 but the index is 33', library/core/src/unicode/unicode_data.rs:319:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
---
This PR makes `peek_mut()` use leak amplification (https://doc.rust-lang.org/1.66.0/nomicon/leaking.html#drain) to preserve the heap's invariant even in the situation that `PeekMut` gets leaked.
I'll also follow up in the tracking issue of unstable `drain_sorted()` (#59278) and `retain()` (#71503).
mv binary_heap.rs binary_heap/mod.rs
I confess this request is somewhat selfish, as it's made in order to ease synchronisation with my [copse](https://crates.io/crates/copse) crate (see eggyal/copse#6 for explanation). I wholly understand that such grounds may be insufficient to justify merging this request—but no harm in asking, right?
Document that `Vec::from_raw_parts[_in]` must be given a pointer from the correct allocator.
Currently, the documentation of `Vec::from_raw_parts` and `Vec::from_raw_parts_in` says nothing about what allocator the pointer must come from. This PR adds that missing information explicitly.
Loosen the bound on the Debug implementation of Weak.
Both `rc::Weak<T>` and `sync::Weak<T>` currently require `T: Debug` in their own `Debug` implementations, but they don't currently use it; they only ever print a fixed string.
A general implementation of Debug for Weak that actually attempts to upgrade and rely on the contents is unlikely in the future because it may have unbounded recursion in the presence of reference cycles, which Weak is commonly used in. (This was the justification for why the current implementation [was implemented the way it is](f0976e2cf3)).
When I brought it up [on the forum](https://internals.rust-lang.org/t/could-the-bound-on-weak-debug-be-relaxed/15504), it was suggested that, even if an implementation is specialized in the future that relies on the data stored within the Weak, it would likely rely on specialization anyway, and could therefore easily specialize on the Debug bound as well.
Update `rand` in the stdlib tests, and remove the `getrandom` feature from it.
The main goal is actually removing `getrandom`, so that eventually we can allow running the stdlib test suite on tier3 targets which don't have `getrandom` support. Currently those targets can only run the subset of stdlib tests that exist in uitests, and (generally speaking), we prefer not to test libstd functionality in uitests, which came up recently in https://github.com/rust-lang/rust/pull/104095 and https://github.com/rust-lang/rust/pull/104185. Additionally, the fact that we can't update `rand`/`getrandom` means we're stuck with the old set of tier3 targets, so can't test new ones.
~~Anyway, I haven't checked that this actually does allow use on tier3 targets (I think it does not, as some work is needed in stdlib submodules) but it moves us slightly closer to this, and seems to allow at least finally updating our `rand` dep, which definitely improves the status quo.~~ Checked and works now.
For the most part, our tests and benchmarks are fine using hard-coded seeds. A couple tests seem to fail with this (stuff manipulating the environment expecting no collisions, for example), or become pointless (all inputs to a function become equivalent). In these cases I've done a (gross) dance (ab)using `RandomState` and `Location::caller()` for some extra "entropy".
Trying to share that code seems *way* more painful than it's worth given that the duplication is a 7-line function, even if the lines are quite gross. (Keeping in mind that sharing it would require adding `rand` as a non-dev dep to std, and exposing a type from it publicly, all of which sounds truly awful, even if done behind a perma-unstable feature).
See also some previous attempts:
- https://github.com/rust-lang/rust/pull/86963 (in particular https://github.com/rust-lang/rust/pull/86963#issuecomment-885438936 which explains why this is non-trivial)
- https://github.com/rust-lang/rust/pull/89131
- https://github.com/rust-lang/rust/pull/96626#issuecomment-1114562857 (I tried in that PR at the same time, but settled for just removing the usage of `thread_rng()` from the benchmarks, since that was the main goal).
- https://github.com/rust-lang/rust/pull/104185
- Probably more. It's very tempting of a thing to "just update".
r? `@Mark-Simulacrum`
default OOM handler: use non-unwinding panic, to match std handler
The OOM handler in std will by default abort. This adjusts the default in liballoc to do the same, using the `can_unwind` flag on the panic info to indicate a non-unwinding panic.
In practice this probably makes little difference since the liballoc default will only come into play in no-std situations where people write a custom panic handler, which most likely will not implement unwinding. But still, this seems more consistent.
Cc `@rust-lang/wg-allocators,` https://github.com/rust-lang/rust/issues/66741
Revert "Implement allow-by-default `multiple_supertrait_upcastable` lint"
This is a clean revert of #105484.
I confirmed that reverting that PR fixes the regression reported in #106247. ~~I can't say I understand what this code is doing, but maybe it can be re-landed with a different implementation.~~ **Edit:** https://github.com/rust-lang/rust/issues/106247#issuecomment-1367174384 has an explanation of why #105484 ends up surfacing spurious `where_clause_object_safety` errors. The implementation of `where_clause_object_safety` assumes we only check whether a trait is object safe when somebody actually uses that trait with `dyn`. However the implementation of `multiple_supertrait_upcastable` added in the problematic PR involves checking *every* trait for whether it is object-safe.
FYI `@nbdd0121` `@compiler-errors`
Implement allow-by-default `multiple_supertrait_upcastable` lint
The lint detects when an object-safe trait has multiple supertraits.
Enabled in libcore and liballoc as they are low-level enough that many embedded programs will use them.
r? `@nikomatsakis`
Test leaking of BinaryHeap Drain iterators
Add test cases about forgetting the `BinaryHeap::Drain` iterator, and slightly fortifies some other test cases.
Consists of separate commits that I don't think are relevant on their own (but I'll happily turn these into more PRs if desired).
The lint "clippy::uninlined_format_args" recommends inline
variables in format strings. Fix two places in the docs that do
not do this. I noticed this because I copy/pasted one example in
to my project, then noticed this lint error. This fixes:
error: variables can be used directly in the `format!` string
--> src/main.rs:30:22
|
30 | let string = format!("{:.*}", decimals, magnitude);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error: variables can be used directly in the `format!` string
--> src/main.rs:39:2
|
39 | write!(&mut io::stdout(), "{}", args).unwrap();
Send `VecDeque::from_iter` via `Vec::from_iter`
Since it's O(1) to convert between them now, might as well reuse the logic.
Mostly for the various specializations it does, but might also save some monomorphization work if, say, people collect slice iterators into both `Vec`s and `VecDeque`s.
improve doc of into_boxed_slice and impl From<Vec<T>> for Box<[T]>
Improves description of `into_boxed_slice`, and adds example to `impl From<Vec<T>> for Box<[T]>`.
Fixes#98908
Since it's O(1) to convert between them now, might as well reuse the logic.
Mostly for the various specializations it does, but might also save some monomorphization work if, say, people collect slice iterators into both `Vec`s and `VecDeque`s.
Update VecDeque implementation to use head+len instead of head+tail
(See #99805)
This changes `alloc::collections::VecDeque`'s internal representation from using head and tail indices to using a head index and a length field. It has a few advantages over the current design:
* It allows the buffer to be of length 0, which means the `VecDeque::new` new longer has to allocate and could be changed to a `const fn`
* It allows the `VecDeque` to fill the buffer completely, unlike the old implementation, which always had to leave a free space
* It removes the restriction for the size to be a power of two, allowing it to properly `shrink_to_fit`, unlike the old `VecDeque`
* The above points also combine to allow the `Vec<T> -> VecDeque<T>` conversion to be very cheap and guaranteed O(1). I mention this in the `From<Vec<T>>` impl, but it's not a strong guarantee just yet, as that would likely need some form of API change proposal.
All the tests seem to pass for the new `VecDeque`, with some slight adjustments.
r? `@scottmcm`
Stop peeling the last iteration of the loop in `Vec::resize_with`
`resize_with` uses the `ExtendWith` code that peels the last iteration:
341d8b8a2c/library/alloc/src/vec/mod.rs (L2525-L2529)
But that's kinda weird for `ExtendFunc` because it does the same thing on the last iteration anyway:
341d8b8a2c/library/alloc/src/vec/mod.rs (L2494-L2502)
So this just has it use the normal `extend`-from-`TrustedLen` code instead.
r? `@ghost`
Clarify and restrict when `{Arc,Rc}::get_unchecked_mut` is allowed.
(Tracking issue for `{Arc,Rc}::get_unchecked_mut`: #63292)
(I'm using `Rc` in this comment, but it applies for `Arc` all the same).
As currently documented, `Rc::get_unchecked_mut` can lead to unsoundness when multiple `Rc`/`Weak` pointers to the same allocation exist. The current documentation only requires that other `Rc`/`Weak` pointers to the same allocation "must not be dereferenced for the duration of the returned borrow". This can lead to unsoundness in (at least) two ways: variance, and `Rc<str>`/`Rc<[u8]>` aliasing. ([playground link](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=d7e2d091c389f463d121630ab0a37320)).
This PR changes the documentation of `Rc::get_unchecked_mut` to restrict usage to when all `Rc<T>`/`Weak<T>` have the exact same `T` (including lifetimes). I believe this is sufficient to prevent unsoundness, while still allowing `get_unchecked_mut` to be called on an aliased `Rc` as long as the safety contract is upheld by the caller.
## Alternatives
* A less strict, but still sound alternative would be to say that the caller must only write values which are valid for all aliased `Rc`/`Weak` inner types. (This was [mentioned](https://github.com/rust-lang/rust/issues/63292#issuecomment-568284090) in the tracking issue). This may be too complicated to clearly express in the documentation.
* A more strict alternative would be to say that there must not be any aliased `Rc`/`Weak` pointers, i.e. it is required that get_mut would return `Some(_)`. (This was also mentioned in the tracking issue). There is at least one codebase that this would cause to become unsound ([here](be5a164d77/src/memtable.rs (L166)), where additional locking is used to ensure unique access to an aliased `Rc<T>`; I saw this because it was linked on the tracking issue).
This moves the stable sort implementation to the core::slice::sort module. By
virtue of being in core it can't access `Vec`. The two `Vec` used by merge sort,
`buf` and `runs`, are modelled as custom types that implement the very limited
required `Vec` interface with the help of provided allocation and free
functions. This is done to allow future re-use of functions and logic between
stable and unstable sort. Such as `insert_head`.
`VecDeque::resize` should re-use the buffer in the passed-in element
Today it always copies it for *every* appended element, but one of those clones is avoidable.
This adds `iter::repeat_n` (https://github.com/rust-lang/rust/issues/104434) as the primitive needed to do this. If this PR is acceptable, I'll also use this in `Vec` rather than its custom `ExtendElement` type & infrastructure that is harder to share between multiple different containers:
101e1822c3/library/alloc/src/vec/mod.rs (L2479-L2492)
Attempt to reuse `Vec<T>` backing storage for `Rc/Arc<[T]>`
If a `Vec<T>` has sufficient capacity to store the inner `RcBox<[T]>`, we can just reuse the existing allocation and shift the elements up, instead of making a new allocation.
run alloc benchmarks in Miri and fix UB
Miri since recently has a "fake monotonic clock" that works even with isolation. Its measurements are not very meaningful but it means we can run these benches and check them for UB.
And that's a good thing since there was UB here: fixes https://github.com/rust-lang/rust/issues/104096.
r? ``@thomcc``
disable btree size tests on Miri
Seems fine not to run these in Miri, they can't have UB anyway. And this lets us do layout randomization in Miri.
r? ``@thomcc``
The new implementation doesn't use weak lang items and instead changes
`#[alloc_error_handler]` to an attribute macro just like
`#[global_allocator]`.
The attribute will generate the `__rg_oom` function which is called by
the compiler-generated `__rust_alloc_error_handler`. If no `__rg_oom`
function is defined in any crate then the compiler shim will call
`__rdl_oom` in the alloc crate which will simply panic.
This also fixes link errors with `-C link-dead-code` with
`default_alloc_error_handler`: `__rg_oom` was previously defined in the
alloc crate and would attempt to reference the `oom` lang item, even if
it didn't exist. This worked as long as `__rg_oom` was excluded from
linking since it was not called.
This is a prerequisite for the stabilization of
`default_alloc_error_handler` (#102318).
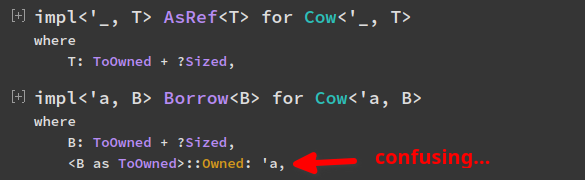
Remove redundant lifetime bound from `impl Borrow for Cow`
The lifetime bound `B::Owned: 'a` is redundant and doesn't make a difference,
because `Cow<'a, B>` comes with an implicit `B: 'a`, and associated types
will outlive lifetimes outlived by the `Self` type (and all the trait's
generic parameters, of which there are none in this case), so the implicit `B: 'a`
implies `B::Owned: 'a` anyway.
The explicit lifetime bound here does however [end up in documentation](https://doc.rust-lang.org/std/borrow/enum.Cow.html#impl-Borrow%3CB%3E),
and that's confusing in my opinion, so let's remove it ^^
_(Documentation right now, compare to `AsRef`, too:)_
Adjust argument type for mutable with_metadata_of (#75091)
The method takes two pointer arguments: one `self` supplying the pointer value, and a second pointer supplying the metadata.
The new parameter type more clearly reflects the actual requirements. The provenance of the metadata parameter is disregarded completely. Using a mutable pointer in the call site can be coerced to a const pointer while the reverse is not true.
In some cases, the current parameter type can thus lead to a very slightly confusing additional cast. [Example](cad93775eb).
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = val as *const _ as *mut T;
let ptr = uninit.as_ptr().with_metadata_of(ptr);
```
This could then instead be simplified to:
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = uninit.as_ptr().with_metadata_of(&**val);
```
Tracking issue: https://github.com/rust-lang/rust/issues/75091
``@dtolnay`` you're reviewed #95249, would you mind chiming in?
Remove incorrect comment in `Vec::drain`
r? ``@scottmcm``
Turns out this comment wasn't correct for 6 years, since #34951, which switched from using `slice::IterMut` into using `slice::Iter`.
Add `Box<[T; N]>: TryFrom<Vec<T>>`
We have `[T; N]: TryFrom<Vec<T>>` (#76310) and `Box<[T; N]>: TryFrom<Box<[T]>>`, but not this combination.
`vec.into_boxed_slice().try_into()` isn't quite a replacement for this, as that'll reallocate unnecessarily in the error case.
**Insta-stable, so needs an FCP**
(I tried to make this work with `, A`, but that's disallowed because of `#[fundamental]` https://github.com/rust-lang/rust/issues/29635#issuecomment-1247598385)
Detect and reject out-of-range integers in format string literals
Until now out-of-range integers in format string literals were silently ignored. They wrapped around to zero at usize::MAX, producing unexpected results.
When using debug builds of rustc, such integers in format string literals even cause an 'attempt to add with overflow' panic in rustc.
Fix this by producing an error diagnostic for integers in format string literals which do not fit into usize.
Fixes#102528
add Vec::push_within_capacity - fallible, does not allocate
This method can serve several purposes. It
* is fallible
* guarantees that items in Vec aren't moved
* allows loops that do `reserve` and `push` separately to avoid pulling in the allocation machinery a second time in the `push` part which should make things easier on the optimizer
* eases the path towards `ArrayVec` a bit since - compared to `push()` - there are fewer questions around how it should be implemented
I haven't named it `try_push` because that should probably occupy a middle ground that will still try to reserve and only return an error in the unlikely OOM case.
resolves#84649
Previously "bare\r" was split into ["bare"] even though the
documentation said that only LF and CRLF count as newlines.
This fix is a behavioural change, even though it brings the behaviour
into line with the documentation, and into line with that of
`std::io::BufRead::lines()`.
This is an alternative to #91051, which proposes to document rather
than fix the behaviour.
Fixes#94435.
Co-authored-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
{kind=link}