`rust-lang/book` recently added two mdBook preprocessors. Enable
`rustbook` to use those preprocessors for books where they are requested
by the `book.toml` by adding the preprocessors as path dependencies, and
ignoring them where they are not requested, i.e. by all the books other
than TRPL at present.
This replaces the hardcoded rustc-perf commit and ad-hoc downloading and
unpacking of its zipped source with defaulting to use the new rustc-perf
submodule.
While it would be nice to make `opt-dist` able to initialize the
submodule automatically when pointing to a Rust checkout _other_ than
the one opt-dist was built in, that would require a bigger refactor that
moved `update_submodule`, from bootstrap, into build_helper.
Regardless, I imagine it must be quite rare to use `opt-dist` with a
checkout that is neither from a rust-src tarball (which will contain the
submodule), nor the checkout opt-dist itself was built (bootstrap will
update the submodule when opt-dist is built).
Unfortunately, we can't always offer a machine-applicable suggestion when there are subpatterns from macro expansion.
Co-Authored-By: Guillaume Boisseau <Nadrieril@users.noreply.github.com>
use key-value format in stage0 file
Currently, we are working on the python removal task on bootstrap. Which means we have to extract some data from the stage0 file using shell scripts. However, parsing values from the stage0.json file is painful because shell scripts don't have a built-in way to parse json files.
This change simplifies the stage0 file format to key-value pairs, which makes it easily readable from any environment.
See the zulip thread for more details: https://rust-lang.zulipchat.com/#narrow/stream/326414-t-infra.2Fbootstrap/topic/Using.20different.20format.20in.20the.20stage0.20file
Update ena to 0.14.3
Includes https://github.com/rust-lang/ena/pull/53, which removes a trivial `Self: Sized` bound that prevents `ena` from building on the new solver.
Avoid `alloca`s in codegen for simple `mir::Aggregate` statements
The core idea here is to remove the abstraction penalty of simple newtypes in codegen.
Even something simple like constructing a
```rust
#[repr(transparent)] struct Foo(u32);
```
forces an `alloca` to be generated in nightly right now.
Certainly LLVM can optimize that away, but it would be nice if it didn't have to.
Quick example:
```rust
#[repr(transparent)]
pub struct Transparent32(u32);
#[no_mangle]
pub fn make_transparent(x: u32) -> Transparent32 {
let a = Transparent32(x);
a
}
```
on nightly we produce <https://rust.godbolt.org/z/zcvoM79ae>
```llvm
define noundef i32 `@make_transparent(i32` noundef %x) unnamed_addr #0 {
%a = alloca i32, align 4
store i32 %x, ptr %a, align 4
%0 = load i32, ptr %a, align 4, !noundef !3
ret i32 %0
}
```
but after this PR we produce
```llvm
define noundef i32 `@make_transparent(i32` noundef %x) unnamed_addr #0 {
start:
ret i32 %x
}
```
(even before the optimizer runs).
There are some test cases involving `parse` and `tokenstream` and
`mut_visit` that are located in `rustc_expand`. Because it used to be
the case that constructing a `ParseSess` required the involvement of
`rustc_expand`. However, since #64197 merged (a long time ago)
`rust_expand` no longer needs to be involved.
This commit moves the tests into `rustc_parse`. This is the optimal
place for the `parse` tests. It's not ideal for the `tokenstream` and
`mut_visit` tests -- they would be better in `rustc_ast` -- but they
still rely on parsing, which is not available in `rustc_ast`. But
`rustc_parse` is lower down in the crate graph and closer to `rustc_ast`
than `rust_expand`, so it's still an improvement for them.
The exact renaming is as follows:
- rustc_expand/src/mut_visit/tests.rs -> rustc_parse/src/parser/mut_visit/tests.rs
- rustc_expand/src/tokenstream/tests.rs -> rustc_parse/src/parser/tokenstream/tests.rs
- rustc_expand/src/tests.rs + rustc_expand/src/parse/tests.rs ->
compiler/rustc_parse/src/parser/tests.rs
The latter two test files are combined because there's no need for them
to be separate, and having a `rustc_parse::parser::parse` module would
be weird. This also means some `pub(crate)`s can be removed.
This ensures the version of time used in rustc includes this change:
https://github.com/time-rs/time/pull/671.
This fix is a necessary prerequisite for #99969,
which adds FromIterator implementations for Box<str>.
Previously, time had an Into::into that resolved to the identity impl
followed by a collect::<Result<Box<_>, _>>().
With the new FromIterator implementations for Box<str>,
the Into::into resolution is ambiguous and time fails to compile.
The fix removes the identity Into::into conversion,
allowing time to compile with the new FromIterator implementations.
This version of time also matches what cargo recently switched to
in https://github.com/rust-lang/cargo/pull/13834.
Port repr128-dwarf run-make test to rmake
This PR ports the repr128-dwarf run-make test to rmake, using the `gimli` crate instead of the `llvm-dwarfdump` command.
Note that this PR changes `rmake.rs` files to be compiled with the 2021 edition (previously no edition was passed to `rustc`, meaning they were compiled with the 2015 edition). This means that `panic!("{variable}")` will now work as expected in `rmake.rs` files (there's already a usage in the [wasm-symbols-not-exported test](aca749eefc/tests/run-make/wasm-symbols-not-exported/rmake.rs (L34)) that this will fix).
Tracking issue: #121876
Implement `PROBLEMATIC_CONSTS` generalization
You forgot that `A≈4`, `B≈8`, and `E≈3` and some more constants.
The new `PROBLEMATIC_CONSTS` was generated using this code:
```py
from functools import reduce
def generate_problems(consts: list, letter_digit: dict):
for const in consts:
problem = reduce(lambda string, rep: string.replace(*reversed(rep)), ['%X' % const, *letter_digit.items()])
indexes = [index for index, c in enumerate(problem) if c in letter_digit.keys()]
for i in range(1 << len(indexes)):
yield int(''.join(letter_digit[c] if index in indexes and (i >> indexes.index(index)) & 1 else c for index, c in enumerate(problem)), 0x10)
problems = generate_problems(
[
# Old PROBLEMATIC_CONSTS:
184594741, 2880289470, 2881141438, 2965027518, 2976579765, 3203381950, 3405691582, 3405697037,
3735927486, 3735932941, 4027431614, 4276992702,
# More of my own:
195934910, 252707358, 762133, 179681982, 173390526
],
{
'A': '4',
'B': '8',
'E': '3',
}
)
# print(list(problems)) # won't use that to print formatted
from itertools import islice
while len(cur_problems := list(islice(problems, 8))):
print(' ', end='')
print(*cur_problems, sep=', ', end='')
print(',')
```
Add support for Arm64EC to the Standard Library
Adds the final pieces so that the standard library can be built for arm64ec-pc-windows-msvc (initially added in #119199)
* Bumps `windows-sys` to 0.56.0, which adds support for Arm64EC.
* Correctly set the `isEC` parameter for LLVM's `writeArchive` function.
* Add `#![feature(asm_experimental_arch)]` to library crates where Arm64EC inline assembly is used, as it is currently unstable.
Port the 2 `rust-lld` run-make tests to `rmake`
In preparation for finalizing most of the `rust-lld` work, this PR ports the following tests to `rmake`:
- `tests/run-make/rust-lld`
- `tests/run-make/rust-lld-custom-target`
As they use `$(CGREP) -e` I added `regex` as an exported dependency to the `run_make_support` library.
Unfortunately, the most recent versions depend on `memchr` 2.6.0 but it's currently pinned at 2.5.0 in the workspace, and therefore had to settle for the older `regex-1.8.0`.
r? `@jieyouxu`
Update ar_archive_writer to 0.2.0
This adds a whole bunch of tests checking for any difference with llvm's archive writer. It also fixes two mistakes in the porting from C++ to Rust. The first one causes a divergence for Mach-O archives which may or may not be harmless. The second will definitively cause issues, but only applies to thin archives, which rustc currently doesn't create.
Rollup of 8 pull requests
Successful merges:
- #123651 (Thread local updates for idiomatic examples)
- #123699 (run-make-support: tidy up support library)
- #123779 (OpenBSD fix long socket addresses)
- #123875 (Doc: replace x with y for hexa-decimal fmt)
- #123879 (Add missing `unsafe` to some internal `std` functions)
- #123889 (reduce tidy overheads in run-make checks)
- #123898 (Generic associated consts: Check regions earlier when comparing impl with trait item def)
- #123902 (compiletest: Update rustfix to 0.8.1)
r? `@ghost`
`@rustbot` modify labels: rollup
compiletest: Update rustfix to 0.8.1
This updates the version of rustfix used in compiletest to be closer to what cargo is using. This is to help ensure `cargo fix` and compiletest are aligned. There are some unpublished changes to `rustfix`, which will update in a future PR when those are published.
Will plan to update ui_test in the near future to avoid the duplicate.
This adds a whole bunch of tests checking for any difference with llvm's
archive writer. It also fixes two mistakes in the porting from C++ to
Rust. The first one causes a divergence for Mach-O archives which may or
may not be harmless. The second will definitively cause issues, but only
applies to thin archives, which rustc currently doesn't create.
Create the rustc_sanitizers crate and move the source code for the CFI
and KCFI sanitizers to it.
Co-authored-by: David Wood <agile.lion3441@fuligin.ink>
Update sysinfo to 0.30.8
Fixes a Mac specific issue when using `metrics = true` in `config.toml`.
```config.toml
# Collect information and statistics about the current build and writes it to
# disk. Enabling this or not has no impact on the resulting build output. The
# schema of the file generated by the build metrics feature is unstable, and
# this is not intended to be used during local development.
metrics = true
```
During repeated builds, as the generated `metrics.json` grew, eventually `refresh_cpu()` would be called in quick enough succession (specifically: under 200ms) that a divide by zero would occur, leading to a `NaN` which would not be serialized, then when the `metrics.json` was re-read it would fail to parse.
That error looks like this (collected from Ferrocene's CI):
```
Compiling rustdoc-tool v0.0.0 (/Users/distiller/project/src/tools/rustdoc)
Finished release [optimized] target(s) in 38.37s
thread 'main' panicked at src/utils/metrics.rs:180:21:
serde_json::from_slice::<JsonRoot>(&contents) failed with invalid type: null, expected f64 at line 1 column 9598
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Build completed unsuccessfully in 0:00:40
Exited with code exit status 1
```
Related: https://github.com/GuillaumeGomez/sysinfo/pull/1236
rustdoc-search: shard the search result descriptions
## Preview
This makes no visual changes to rustdoc search. It's a pure perf improvement.
<details><summary>old</summary>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240317_AiDc61_2EM,240317_AiDcM0_2EN>
Waterfall diagram:
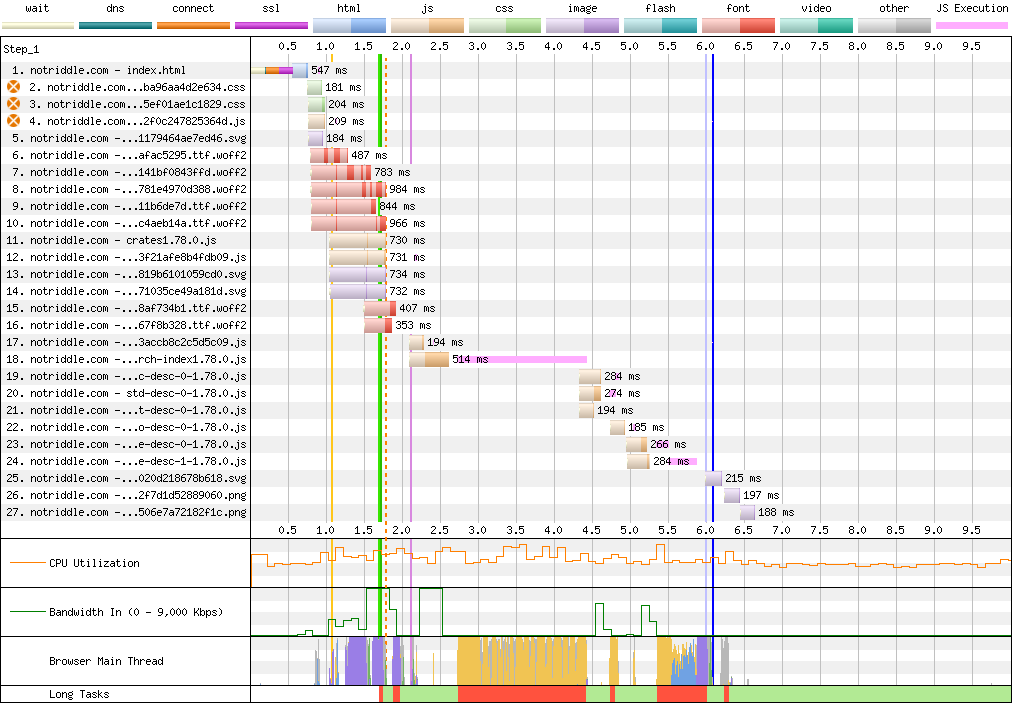
</details>
Preview: <http://notriddle.com/rustdoc-html-demo-10/doc2/std/index.html?search=vec>
WebPageTest Comparison with before branch on a sort of worst case (searching `vec`, winds up downloading most of the shards anyway): <https://www.webpagetest.org/video/compare.php?tests=240322_BiDcCH_13R,240322_AiDcJY_104>
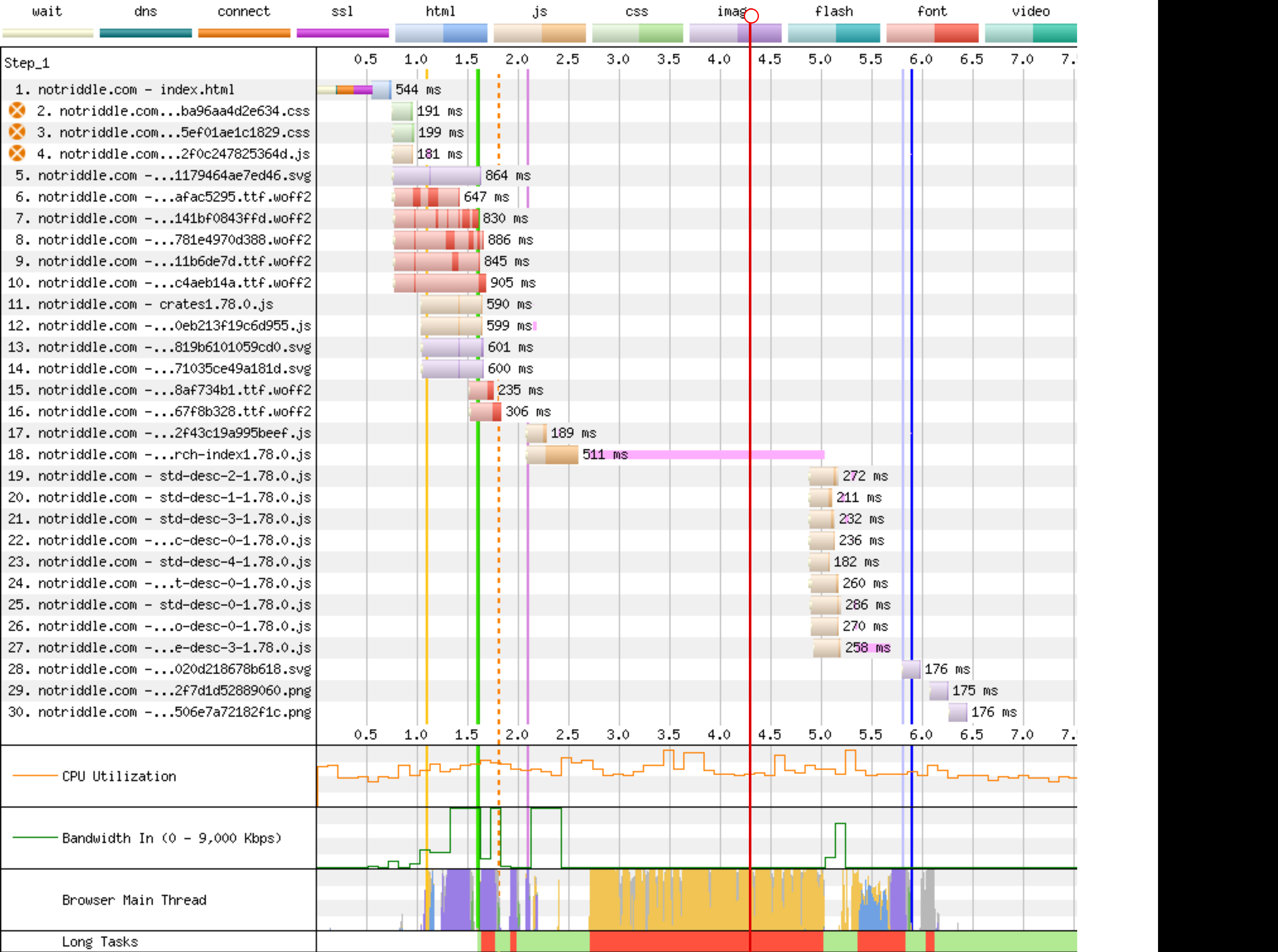
## Description
r? `@GuillaumeGomez`
The descriptions are, on almost all crates[^1], the majority of the size of the search index, even though they aren't really used for searching. This makes it relatively easy to separate them into their own files.
Additionally, this PR pulls out information about whether there's a description into a bitmap. This allows us to sort, truncate, *then* download.
This PR also bumps us to ES8. Out of the browsers we support, all of them support async functions according to caniuse.
https://caniuse.com/async-functions
[^1]:
<https://microsoft.github.io/windows-docs-rs/>, a crate with
44MiB of pure names and no descriptions for them, is an outlier
and should not be counted. But this PR should improve it, by replacing a long line of empty strings with a compressed bitmap with a single Run section. Just not very much.
## Detailed sizes
```console
$ cat test.sh
set -ex
cp ../search-index*.js search-index.js
awk 'FNR==NR {a++;next} FNR<a-3' search-index.js{,} | awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}' | sed -E "s:\\\\':':g" > search-index.json
jq -c '.t' search-index.json > t.json
jq -c '.n' search-index.json > n.json
jq -c '.q' search-index.json > q.json
jq -c '.D' search-index.json > D.json
jq -c '.e' search-index.json > e.json
jq -c '.i' search-index.json > i.json
jq -c '.f' search-index.json > f.json
jq -c '.c' search-index.json > c.json
jq -c '.p' search-index.json > p.json
jq -c '.a' search-index.json > a.json
du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
$ bash test.sh
+ cp ../search-index1.78.0.js search-index.js
+ awk 'FNR==NR {a++;next} FNR<a-3' search-index.js search-index.js
+ awk 'NR>1 {gsub(/\],\\$/,""); gsub(/^\["[^"]+",/,""); print} {next}'
+ sed -E 's:\\'\'':'\'':g'
+ jq -c .t search-index.json
+ jq -c .n search-index.json
+ jq -c .q search-index.json
+ jq -c .D search-index.json
+ jq -c .e search-index.json
+ jq -c .i search-index.json
+ jq -c .f search-index.json
+ jq -c .c search-index.json
+ jq -c .p search-index.json
+ jq -c .a search-index.json
+ du -hs t.json n.json q.json D.json e.json i.json f.json c.json p.json a.json
64K t.json
800K n.json
8.0K q.json
4.0K D.json
16K e.json
192K i.json
544K f.json
4.0K c.json
36K p.json
20K a.json
```
These are, roughly, the size of each section in the standard library (this tool actually excludes libtest, for parsing-json-with-awk reasons, but libtest is tiny so it's probably not important).
t = item type, like "struct", "free fn", or "type alias". Since one byte is used for every item, this implies that there are approximately 64 thousand items in the standard library.
n = name, and that's now the largest section of the search index with the descriptions removed from it
q = parent *module* path, stored parallel to the items within
D = the size of each description shard, stored as vlq hex numbers
e = empty description bit flags, stored as a roaring bitmap
i = parent *type* index as a link into `p`, stored as decimal json numbers; used only for associated types; might want to switch to vlq hex, since that's shorter, but that would be a separate pr
f = function signature, stored as lists of lists that index into `p`
c = deprecation flag, stored as a roaring bitmap
p = parent *type*, stored separately and linked into from `i` and `f`
a = alias, as [[key, value]] pairs
## Search performance
http://notriddle.com/rustdoc-html-demo-11/perf-shard/index.html
For example, in stm32f4:
<table><thead><tr><th>before<th>after</tr></thead>
<tbody><tr><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 617
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 198
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 282
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 426
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 673
```
</td><td>
```
Testing T -> U ... in_args = 0, returned = 0, others = 200
wall time = 716
Testing T, U ... in_args = 0, returned = 0, others = 200
wall time = 207
Testing T -> T ... in_args = 0, returned = 0, others = 200
wall time = 289
Testing crc32 ... in_args = 0, returned = 0, others = 0
wall time = 418
Testing spi::pac ... in_args = 0, returned = 0, others = 0
wall time = 687
```
</td></tr><tr><td>
```
user: 005.345 s
sys: 002.955 s
wall: 006.899 s
child_RSS_high: 583664 KiB
group_mem_high: 557876 KiB
```
</td><td>
```
user: 004.652 s
sys: 000.565 s
wall: 003.865 s
child_RSS_high: 538696 KiB
group_mem_high: 511724 KiB
```
</td></tr>
</table>
This perf tester is janky and unscientific enough that the apparent differences might just be noise. If it's not an order of magnitude, it's probably not real.
## Future possibilities
* Currently, results are not shown until the descriptions are downloaded. Theoretically, the description-less results could be shown. But actually doing that, and making sure it works properly, would require extra work (we have to be careful to avoid layout jumps).
* More than just descriptions can be sharded this way. But we have to be careful to make sure the size wins are worth the round trips. Ideally, data that’s needed only for display should be sharded while data needed for search isn’t.
* [Full text search](https://internals.rust-lang.org/t/full-text-search-for-rustdoc-and-doc-rs/20427) also needs this kind of infrastructure. A good implementation might store a compressed bloom filter in the search index, then download the full keyword in shards. But, we have to be careful not just of the amount readers have to download, but also of the amount that [publishers](https://gist.github.com/notriddle/c289e77f3ed469d1c0238d1d135d49e1) have to store.
Use the `Align` type when parsing alignment attributes
Use the `Align` type in `rustc_attr::parse_alignment`, removing the need to call `Align::from_bytes(...).unwrap()` later in the compilation process.
Print a backtrace in const eval if interrupted
Demo:
```rust
#![feature(const_eval_limit)]
#![const_eval_limit = "0"]
const OW: u64 = {
let mut res: u64 = 0;
let mut i = 0;
while i < u64::MAX {
res = res.wrapping_add(i);
i += 1;
}
res
};
fn main() {
println!("{}", OW);
}
```
```
╭ ➜ ben@archlinux:~/rust
╰ ➤ rustc +stage1 spin.rs
^Cerror[E0080]: evaluation of constant value failed
--> spin.rs:8:33
|
8 | res = res.wrapping_add(i);
| ^ Compilation was interrupted
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
note: erroneous constant used
--> spin.rs:15:20
|
15 | println!("{}", OW);
| ^^
|
= note: this note originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
error: aborting due to previous error
For more information about this error, try `rustc --explain E0080`.
```
CFI: Support complex receivers
Right now, we only support rewriting `&self` and `&mut self` into `&dyn MyTrait` and `&mut dyn MyTrait`. This expands it to handle the full gamut of receivers by calculating the receiver based on *substitution* rather than based on a rewrite. This means that, for example, `Arc<Self>` will become `Arc<dyn MyTrait>` appropriately with this change.
This approach also allows us to support associated type constraints as well, so we will correctly rewrite `&self` into `&dyn MyTrait<T=i32>`, for example.
r? ```@workingjubilee```
Previously, we only rewrote `&self` and `&mut self` receivers. By
instantiating the method from the trait definition, we can make this
work work with arbitrary legal receivers instead.
"Handle" calls to upstream monomorphizations in compiler_builtins
This is pretty cooked, but I think it works.
compiler-builtins has a long-standing problem that at link time, its rlib cannot contain any calls to `core`. And yet, in codegen we _love_ inserting calls to symbols in `core`, generally from various panic entrypoints.
I intend this PR to attack that problem as completely as possible. When we generate a function call, we now check if we are generating a function call from `compiler_builtins` and whether the callee is a function which was not lowered in the current crate, meaning we will have to link to it.
If those conditions are met, actually generating the call is asking for a linker error. So we don't. If the callee diverges, we lower to an abort with the same behavior as `core::intrinsics::abort`. If the callee does not diverge, we produce an error. This means that compiler-builtins can contain panics, but they'll SIGILL instead of panicking. I made non-diverging calls a compile error because I'm guessing that they'd mostly get into compiler-builtins by someone making a mistake while working on the crate, and compile errors are better than linker errors. We could turn such calls into aborts as well if that's preferred.
This adds a bit more data than "pure sharding" by
including information about which items have no description
at all. This way, it can sort the results, then truncate,
then finally download the description.
With the "e" bitmap: 2380KiB
Without the "e" bitmap: 2364KiB
Bump windows-bindgen to 0.55.0
windows-bindgen is the crate used to generate std's Windows API bindings.
Not many changes for us, it's mostly just simplifying the generate code (e.g. no more `-> ()`). The one substantial change is some structs now use `i8` byte arrays instead of `u8`. However, this only impacts one test.
Test wasm32-wasip1 in CI, not wasm32-unknown-unknown
This commit changes CI to no longer test the `wasm32-unknown-unknown` target and instead test the `wasm32-wasip1` target. There was some discussion of this in a [Zulip thread], and the motivations for this PR are:
* Runtime failures on `wasm32-unknown-unknown` print nothing, meaning all you get is "something failed". In contrast `wasm32-wasip1` can print to stdout/stderr.
* The unknown-unknown target is missing lots of pieces of libstd, and while `wasm32-wasip1` is also missing some pieces (e.g. threads) it's missing fewer pieces. This means that many more tests can be run.
Overall my hope is to improve the debuggability of wasm failures on CI and ideally be a bit less of a maintenance burden.
This commit specifically removes the testing of `wasm32-unknown-unknown` and replaces it with testing of `wasm32-wasip1`. Along the way there were a number of other archiectural changes made as well, including:
* A new `target.*.runtool` option can now be specified in `config.toml` which is passed as `--runtool` to `compiletest`. This is used to reimplement execution of WebAssembly in a less-wasm-specific fashion.
* The default value for `runtool` is an ambiently located WebAssembly runtime found on the system, if any. I've implemented logic for Wasmtime.
* Existing testing support for `wasm32-unknown-unknown` and Emscripten has been removed. I'm not aware of Emscripten testing being run any time recently and otherwise `wasm32-wasip1` is in theory the focus now.
* I've added a new `//@ needs-threads` directive for `compiletest` and classified a bunch of wasm-ignored tests as needing threads. In theory these tests can run on `wasm32-wasi-preview1-threads`, for example.
* I've tried to audit all existing tests that are either `ignore-emscripten` or `ignore-wasm*`. Many now run on `wasm32-wasip1` due to being able to emit error messages, for example. Many are updated with comments as to why they can't run as well.
* The `compiletest` output matching for `wasm32-wasip1` automatically uses "match a subset" mode implemented in `compiletest`. This is because WebAssembly runtimes often add extra information on failure, such as the `unreachable` instruction in `panic!`, which isn't able to be matched against the golden output from native platforms.
* I've ported most existing `run-make` tests that use custom Node.js wrapper scripts to the new run-make-based-in-Rust infrastructure. To do this I added `wasmparser` as a dependency of `run-make-support` for the various wasm tests to use that parse wasm files. The one test that executed WebAssembly now uses `wasmtime`-the-CLI to execute the test instead. I have not ported over an exception-handling test as Wasmtime doesn't implement this yet.
* I've updated the `test` crate to print out timing information for WASI targets as it can do that (gets a previously ignored test now passing).
* The `test-various` image now builds a WASI sysroot for the WASI target and additionally downloads a fixed release of Wasmtime, currently the latest one at 18.0.2, and uses that for testing.
[Zulip thread]: https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Have.20wasm.20tests.20ever.20caused.20problems.20on.20CI.3F/near/424317944
This commit rewrites a number of `run-make` tests centered around wasm
to instead use `rmake.rs` and additionally use the `wasm32-wasip1`
target instead of `wasm32-unknown-unknown`. Testing no longer requires
Node.js and additionally uses the `wasmparser` crate from crates.io to
parse outputs and power assertions.
Misc improvements to non local defs lint implementation
This PR is a collection of small improvements I found when I [needlessly tried](https://www.github.com/rust-lang/rust/pull/120393#issuecomment-1971787475) to fix a "perf-regression" in the lint implementation.
I recommend looking at each commit individually.
Optimize `Symbol::integer` by utilizing in-place formatting
This PR optimize `Symbol::integer` by utilizing `itoa` in-place formatting instead of going through a dynamically allocated `String` and the format machinery.
<details>
For some context: I was profiling `rustc --check-cfg` with callgrind and due to the way we currently setup all the targets and we end-up calling `Symbol::integer` multiple times for all the targets. Using `itoa` reduced the number of instructions.
</details>
Introduces the `arm64ec-pc-windows-msvc` target for building Arm64EC ("Emulation Compatible") binaries for Windows.
For more information about Arm64EC see <https://learn.microsoft.com/en-us/windows/arm/arm64ec>.
Tier 3 policy:
> A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
I will be the maintainer for this target.
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
Target uses the `arm64ec` architecture to match LLVM and MSVC, and the `-pc-windows-msvc` suffix to indicate that it targets Windows via the MSVC environment.
> Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
Target name exactly specifies the type of code that will be produced.
> If possible, use only letters, numbers, dashes and underscores for the name. Periods (.) are known to cause issues in Cargo.
Done.
> Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
> The target must not introduce license incompatibilities.
Uses the same dependencies, requirements and licensing as the other `*-pc-windows-msvc` targets.
> Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
Understood.
> The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
> Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
Uses the same dependencies, requirements and licensing as the other `*-pc-windows-msvc` targets.
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
Understood, I am not a member of the Rust team.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
Both `core` and `alloc` are supported.
Support for `std` dependends on making changes to the standard library, `stdarch` and `backtrace` which cannot be done yet as the bootstrapping compiler raises a warning ("unexpected `cfg` condition value") for `target_arch = "arm64ec"`.
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
Documentation is provided in src/doc/rustc/src/platform-support/arm64ec-pc-windows-msvc.md
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via @) to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
Understood.
Leverage `anstyle-svg`, as `cargo` does now, to emit `.svg` files
instead of `.stderr` files for tests that explicitly enable color
output. This will make reviewing changes to the graphical output of
tests much more human friendly.
Introduce `run-make` V2 infrastructure, a `run_make_support` library and port over 2 tests as example
## Preface
See [issue #40713: Switch run-make tests from Makefiles to rust](https://github.com/rust-lang/rust/issues/40713) for more context.
## Basic Description of `run-make` V2
`run-make` V2 aims to eliminate the dependency on `make` and `Makefile`s for building `run-make`-style tests. Makefiles are replaced by *recipes* (`rmake.rs`). The current implementation runs `run-make` V2 tests in 3 steps:
1. We build the support library `run_make_support` which the `rmake.rs` recipes depend on as a tool lib.
2. We build the recipe `rmake.rs` and link in the support library.
3. We run the recipe to build and run the tests.
`rmake.rs` is basically a replacement for `Makefile`, and allows running arbitrary Rust code. The support library is built using cargo, and so can depend on external crates if desired.
The infrastructure implemented by this PR is very barebones, and is the minimally required infrastructure needed to build, run and pass the two example `run-make` tests ported over to the new infrastructure.
### Example `run-make` V2 test
```rs
// ignore-tidy-linelength
extern crate run_make_support;
use std::path::PathBuf;
use run_make_support::{aux_build, rustc};
fn main() {
aux_build()
.arg("--emit=metadata")
.arg("stable.rs")
.run();
let mut stable_path = PathBuf::from(env!("TMPDIR"));
stable_path.push("libstable.rmeta");
let output = rustc()
.arg("--emit=metadata")
.arg("--extern")
.arg(&format!("stable={}", &stable_path.to_string_lossy()))
.arg("main.rs")
.run();
let stderr = String::from_utf8_lossy(&output.stderr);
let version = include_str!(concat!(env!("S"), "/src/version"));
let expected_string = format!("stable since {}", version.trim());
assert!(stderr.contains(&expected_string));
}
```
## Follow Up Work
- [ ] Adjust rustc-dev-guide docs
rustc: Fix wasm64 metadata object files
It looks like LLD will detect object files being either 32 or 64-bit depending on any memory present. LLD will additionally reject 32-bit objects during a 64-bit link. Previously metadata objects did not have any memories in them which led LLD to conclude they were 32-bit objects which broke 64-bit targets for wasm.
This commit fixes this by ensuring that for 64-bit targets there's a memory object present to get LLD to detect it's a 64-bit target. Additionally this commit moves away from a hand-crafted wasm encoder to the `wasm-encoder` crate on crates.io as the complexity grows for the generated object file.
Closes#121460
add platform-specific function to get the error number for HermitOS
Extending `std` to get the last error number for HermitOS.
HermitOS is a tier 3 platform and this PR changes only files, wich are related to the tier 3 platform.
Extending `std` to get the last error number for HermitOS.
HermitOS is a tier 3 platform and this PR changes only files,
wich are related to the tier 3 platform.
Split rustc_type_ir to avoid rustc_ast from depending on it
unblocks #121576
and resolves a FIXME in `rustc_ast`'s `Cargo.toml`
The new crate is tiny, but it will get bigger in #121576
It looks like LLD will detect object files being either 32 or 64-bit
depending on any memory present. LLD will additionally reject 32-bit
objects during a 64-bit link. Previously metadata objects did not have
any memories in them which led LLD to conclude they were 32-bit objects
which broke 64-bit targets for wasm.
This commit fixes this by ensuring that for 64-bit targets there's a
memory object present to get LLD to detect it's a 64-bit target.
Additionally this commit moves away from a hand-crafted wasm encoder to
the `wasm-encoder` crate on crates.io as the complexity grows for the
generated object file.
Closes#121460
Unify dylib loading between proc macros and codegen backends
As bonus this makes the errors when failing to load a proc macro more informative to match the backend loading errors. In addition it makes it slightly easier to patch rustc to work on platforms that don't support dynamic linking like wasm.
As bonus this makes the errors when failing to load a proc macro more
informative to match the backend loading errors. In addition it makes it
slightly easier to patch rustc to work on platforms that don't support
dynamic linking like wasm.
The goal of this commit is to remove warnings using LLVM tip-of-tree
`wasm-ld`. In llvm/llvm-project#78658 the `wasm-ld` LLD driver no longer
looks at archive indices and instead looks at all the objects in
archives. Previously `lib.rmeta` files were simply raw rustc metadata
bytes, not wasm objects, meaning that `wasm-ld` would emit a warning
indicating so.
WebAssembly targets previously passed `--fatal-warnings` to `wasm-ld` by
default which meant that if Rust were to update to LLVM 18 then all wasm
targets would not work. This immediate blocker was resolved in
rust-lang/rust#120278 which removed `--fatal-warnings` which enabled a
theoretical update to LLVM 18 for wasm targets. This current state is
ok-enough for now because rustc squashes all linker output by default if
it doesn't fail. This means, for example, that rustc squashes all the
linker warnings coming out of `wasm-ld` about `lib.rmeta` files with
LLVM 18. This again isn't a pressing issue because the information is
all hidden, but it runs the risk of being annoying if another linker
error were to happen and then the output would have all these unrelated
warnings that couldn't be fixed.
Thus, this PR comes into the picture. The goal of this PR is to resolve
these warnings by using the WebAssembly object file format on wasm
targets instead of using raw rustc metadata. When I first implemented
the rlib-in-objects scheme in #84449 I remember either concluding that
`wasm-ld` would either include the metadata in the output or I thought
we didn't have to do anything there at all. I think I was wrong on both
counts as `wasm-ld` does not include the metadata in the final output
unless the object is referenced and we do actually need to do something
to resolve these warnings.
This PR updates the object file format containing rustc metadata on
WebAssembly targets to be an actual WebAssembly file. This enables the
`wasm` feature of the `object` crate to be able to read the custom
section in the same manner as other platforms, but currently `object`
doesn't support writing wasm object files so a handwritten encoder is
used instead.
The only caveat I know of with this is that if `wasm-ld` does indeed
look at the object file then the metadata will be included in the final
output. I believe the only thing that could cause that at this time is
`--whole-archive` which I don't think is passed for rlibs. I would
clarify that I'm not 100% certain about this, however.
tidy: reduce allocs
this reduces allocs in tidy from (dhat output)
```
==31349== Total: 1,365,199,543 bytes in 4,774,213 blocks
==31349== At t-gmax: 10,975,708 bytes in 66,093 blocks
==31349== At t-end: 2,880,947 bytes in 12,332 blocks
==31349== Reads: 5,210,008,956 bytes
==31349== Writes: 1,280,920,127 bytes
```
to
```
==66633== Total: 791,565,538 bytes in 3,503,144 blocks
==66633== At t-gmax: 10,914,511 bytes in 65,997 blocks
==66633== At t-end: 395,531 bytes in 941 blocks
==66633== Reads: 4,249,388,949 bytes
==66633== Writes: 814,119,580 bytes
```
<del>by wrapping regex and updating `ignore` (effect probably not only from `ignore`, didn't measured)</del>
also moves one more regex into `Lazy` to reduce regex rebuilds.
yes, once_cell better, but ...
this reduces from
==31349== Total: 1,365,199,543 bytes in 4,774,213 blocks
==31349== At t-gmax: 10,975,708 bytes in 66,093 blocks
==31349== At t-end: 2,880,947 bytes in 12,332 blocks
==31349== Reads: 5,210,008,956 bytes
==31349== Writes: 1,280,920,127 bytes
to
==47796== Total: 821,467,407 bytes in 3,955,595 blocks
==47796== At t-gmax: 10,976,209 bytes in 66,100 blocks
==47796== At t-end: 2,944,016 bytes in 12,490 blocks
==47796== Reads: 4,788,959,023 bytes
==47796== Writes: 975,493,639 bytes
miropt-test-tools: remove regex usage
this removes regex usage and slightly refactors ext stripping in one case
Update mdbook to 0.4.37
This updates mdbook to 0.4.37.
Changelog: https://github.com/rust-lang/mdBook/blob/master/CHANGELOG.md#mdbook-0437
The primary change is the update to pulldown-cmark which has a large number of markdown parsing changes. There shouldn't be any significant changes to the rendering of any of the books (I have posted some PRs to fix some minor issues to the ones that were affected).
The existing regex-based HTML parsing was just too primitive to
correctly handle HTML content. Some books have legitimate `href="…"`
text which should not be validated because it is part of the text, not
actual HTML.
Actually abort in -Zpanic-abort-tests
When a test fails in panic=abort, it can be useful to have a debugger or other tooling hook into the `abort()` call for debugging. Doing this some other way would require it to hard code details of Rust's panic machinery.
There's no reason we couldn't have done this in the first place; using a single exit code for "success" or "failed" was just simpler. Now we are aware of the special exit codes for posix and windows platforms, logging a special error if an unrecognized code is used on those platforms, and falling back to just "failure" on other platforms.
This continues to account for `#[should_panic]` inside the test process itself, so there's no risk of misinterpreting a random call to `abort()` as an expected panic. Any exit code besides `TR_OK` is logged as a test failure.
As an added benefit, this would allow us to support panic=immediate_abort (but not `#[should_panic]`), without noise about unexpected exit codes when a test fails.
Fixes footnote handling in rustdoc
Fixes#100638.
You can now declare footnotes like this:
```rust
//! Reference to footnotes A[^1], B[^2] and C[^3].
//!
//! [^1]: Footnote A.
//! [^2]: Footnote B.
//! [^3]: Footnote C.
```
r? `@notriddle`
Error codes are integers, but `String` is used everywhere to represent
them. Gross!
This commit introduces `ErrCode`, an integral newtype for error codes,
replacing `String`. It also introduces a constant for every error code,
e.g. `E0123`, and removes the `error_code!` macro. The constants are
imported wherever used with `use rustc_errors::codes::*`.
With the old code, we have three different ways to specify an error code
at a use point:
```
error_code!(E0123) // macro call
struct_span_code_err!(dcx, span, E0123, "msg"); // bare ident arg to macro call
\#[diag(name, code = "E0123")] // string
struct Diag;
```
With the new code, they all use the `E0123` constant.
```
E0123 // constant
struct_span_code_err!(dcx, span, E0123, "msg"); // constant
\#[diag(name, code = E0123)] // constant
struct Diag;
```
The commit also changes the structure of the error code definitions:
- `rustc_error_codes` now just defines a higher-order macro listing the
used error codes and nothing else.
- Because that's now the only thing in the `rustc_error_codes` crate, I
moved it into the `lib.rs` file and removed the `error_codes.rs` file.
- `rustc_errors` uses that macro to define everything, e.g. the error
code constants and the `DIAGNOSTIC_TABLES`. This is in its new
`codes.rs` file.
Avoid code generation for ThinVec<Diagnostic>'s destructor in the query system
This avoids 2 instances of the destructor of `ThinVec<Diagnostic>` from being included in `execute_job`. It also outlines the cold branch in `store_side_effects` / `store_side_effects_for_anon_node`.
pat_analysis: Don't rely on contiguous `VariantId`s outside of rustc
Today's pattern_analysis uses `BitSet` and `IndexVec` on the provided enum variant ids, which only makes sense if these ids count the variants from 0. In rust-analyzer, the variant ids are global interning ids, which would make `BitSet` and `IndexVec` ridiculously wasteful. In this PR I add some shims to use `FxHashSet`/`FxHashMap` instead outside of rustc.
r? ```@compiler-errors```
Use `zip_eq` to enforce that things being zipped have equal sizes
Some `zip`s are best enforced to be equal, since size mismatches suggest deeper bugs in the compiler.
Exhaustiveness: remove the need for arena-allocation within the algorithm
After https://github.com/rust-lang/rust/pull/119688, exhaustiveness checking doesn't need access to the arena anymore. This simplifies the lifetime story and makes it compile on stable without the extra dependency.
r? `@compiler-errors`
next solver: provisional cache
this adds the cache removed in #115843. However, it should now correctly track whether a provisional result depends on an inductive or coinductive stack.
While working on this, I was using the following doc: https://hackmd.io/VsQPjW3wSTGUSlmgwrDKOA. I don't think it's too helpful to understanding this, but am somewhat hopeful that the inline comments are more useful.
There are quite a few future perf improvements here. Given that this is already very involved I don't believe it is worth it (for now). While working on this PR one of my few attempts to significantly improve perf ended up being unsound again because I was not careful enough ✨
r? `@compiler-errors`
annotate-snippets: update to 0.10
Ports `annotate-snippets` to 0.10, temporary dupes versions; other crates left that depends on 0.9 is `ui_test` and `rustfmt`.
{kind=link}