Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
Miri: relax fn ptr check
As discussed in https://github.com/rust-lang/unsafe-code-guidelines/issues/72#issuecomment-1025407536, the function pointer check done by Miri is currently overeager: contrary to our usual principle of only checking rather uncontroversial validity invariants, we actually check that the pointer points to a real function.
So, this relaxes the check to what the validity invariant probably will be (and what the reference already says it is): the function pointer must be non-null, and that's it.
The check that CTFE does on the final value of a constant is unchanged -- CTFE recurses through references, so it makes some sense to also recurse through function pointers. We might still want to relax this in the future, but that would be a separate change.
r? `@oli-obk`
Change `char` type in debuginfo to DW_ATE_UTF
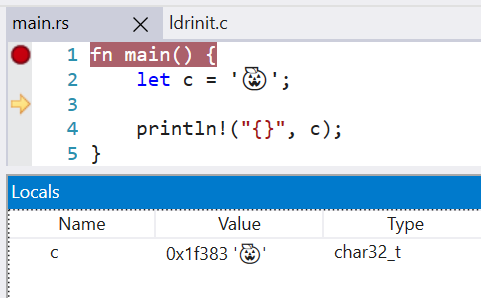
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more
appropriate encoding is DW_ATE_UTF.
Clang uses this same debug encoding for char32_t.
This fixes the display of `char` types in Windows debuggers as well as LLDB.
rustdoc-json: Better Header Type
- Make ABI an enum, instead of being stringly typed
- Replace Qualifier HashSet with 3 bools
- Merge ABI field into header, as they always occor together
r? ``@CraftSpider``
``@rustbot`` modify labels: +A-rustdoc-json +T-rustdoc
Introduce `ChunkedBitSet` and use it for some dataflow analyses.
This reduces peak memory usage significantly for some programs with very
large functions.
r? `@ghost`
This reduces peak memory usage significantly for some programs with very
large functions, such as:
- `keccak`, `unicode_normalization`, and `match-stress-enum`, from
the `rustc-perf` benchmark suite;
- `http-0.2.6` from crates.io.
The new type is used in the analyses where the bitsets can get huge
(e.g. 10s of thousands of bits): `MaybeInitializedPlaces`,
`MaybeUninitializedPlaces`, and `EverInitializedPlaces`.
Some refactoring was required in `rustc_mir_dataflow`. All existing
analysis domains are either `BitSet` or a trivial wrapper around
`BitSet`, and access in a few places is done via `Borrow<BitSet>` or
`BorrowMut<BitSet>`. Now that some of these domains are `ClusterBitSet`,
that no longer works. So this commit replaces the `Borrow`/`BorrowMut`
usage with a new trait `BitSetExt` containing the needed bitset
operations. The impls just forward these to the underlying bitset type.
This required fiddling with trait bounds in a few places.
The commit also:
- Moves `static_assert_size` from `rustc_data_structures` to
`rustc_index` so it can be used in the latter; the former now
re-exports it so existing users are unaffected.
- Factors out some common "clear excess bits in the final word"
functionality in `bit_set.rs`.
- Uses `fill` in a few places instead of loops.
Rollup of 7 pull requests
Successful merges:
- #94169 (Fix several asm! related issues)
- #94178 (tidy: fire less "ignoring file length unneccessarily" warnings)
- #94179 (solarish current_exe using libc call directly)
- #94196 (compiletest: Print process output info with less whitespace)
- #94208 (Add the let else tests found missing in the stabilization report)
- #94237 (Do not suggest wrapping an item if it has ambiguous un-imported methods)
- #94246 (ScalarMaybeUninit is explicitly hexadecimal in its formatting)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
ScalarMaybeUninit is explicitly hexadecimal in its formatting
This makes `ScalarMaybeUninit` consistent with `Scalar` after the changes in https://github.com/rust-lang/rust/pull/94189.
r? ``@oli-obk``
Do not suggest wrapping an item if it has ambiguous un-imported methods
If the method is defined for the receiver we have, but is ambiguous during probe, then it probably comes from one of several traits that just weren't `use`d. Don't suggest wrapping the receiver in `Box`/etc., even if that makes the method probe unambiguous.
Fixes#94218
Fix several asm! related issues
This is a combination of several fixes, each split into a separate commit. Splitting these into PRs is not practical since they conflict with each other.
Fixes#92378Fixes#85247
r? ``@nagisa``
change `mir::Constant` in mir dumps
this removes duplicate information and avoids printing the `stable_crate_id` in mir dumps which broke CI in #94059
r? `@oli-obk` cc `@b-naber`
Simplify rustc_serialize by dropping support for decoding into JSON
This PR currently bundles two (somewhat separate) tasks.
First, it removes the JSON Decoder trait impl, which permitted going from JSON to Rust structs. For now, we keep supporting JSON deserialization, but only to `Json` (an equivalent of serde_json::Value). The primary hard to remove user there is for custom targets -- which need some form of JSON deserialization -- but they already have a custom ad-hoc pass for moving from Json to a Rust struct.
A [comment](e7aca89598/compiler/rustc_target/src/spec/mod.rs (L1653)) there suggests that it would be impractical to move them to a Decodable-based impl, at least without backwards compatibility concerns. I suspect that if we were widely breaking compat there, it would make sense to use serde_json at this point which would produce better error messages; the types in rustc_target are relatively isolated so we would not particularly suffer from using serde_derive.
The second part of the PR (all but the first commit) is to simplify the Decoder API by removing the non-primitive `read_*` functions. These primarily add indirection (through a closure), which doesn't directly cause a performance issue (the unique closure types essentially guarantee monomorphization), but does increase the amount of work rustc and LLVM need to do. This could be split out to a separate PR, but is included here in part to help motivate the first part.
Future work might consist of:
* Specializing enum discriminant encoding to avoid leb128 for small enums (since we know the variant count, we can directly use read/write u8 in almost all cases)
* Adding new methods to support faster deserialization (e.g., access to the underlying byte stream)
* Currently these are somewhat ad-hoc supported by specializations for e.g. `Vec<u8>`, but other types which could benefit don't today.
* Removing the Decoder trait entirely in favor of a concrete type -- today, we only really have one impl of it modulo wrappers used for specialization-based dispatch.
Highly recommend review with whitespace changes off, as the removal of closures frequently causes things to be de-indented.
Better error if the user tries to do assignment ... else
If the user tries to do assignment ... else, we now issue a more comprehensible error in the parser.
closes#93995
CTFE engine: Scalar: expose size-generic to_(u)int methods
This matches the size-generic constructors `Scalar::from_(u)int`, and it would have helped in https://github.com/rust-lang/miri/pull/1978.
r? `@oli-obk`
rustc_const_eval: adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This PR handles rustc_const_eval.
{kind=link}