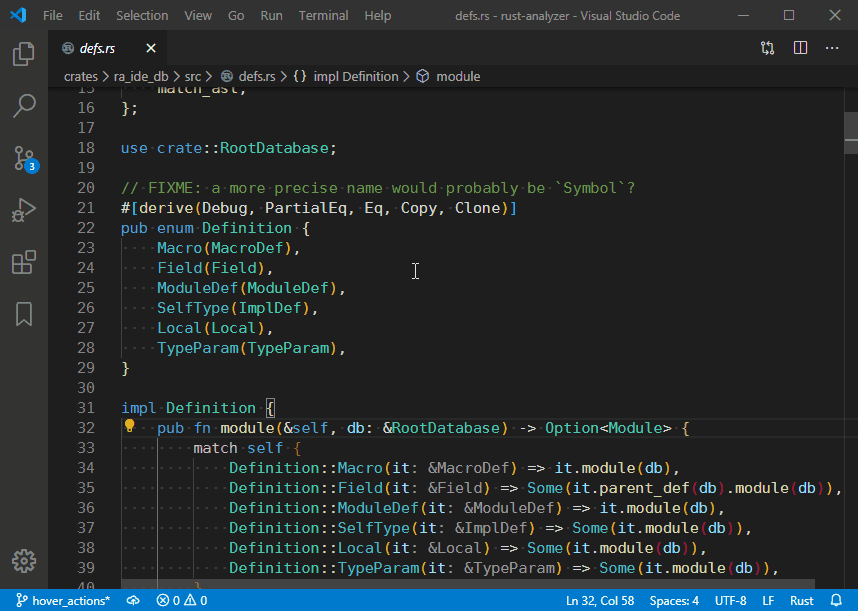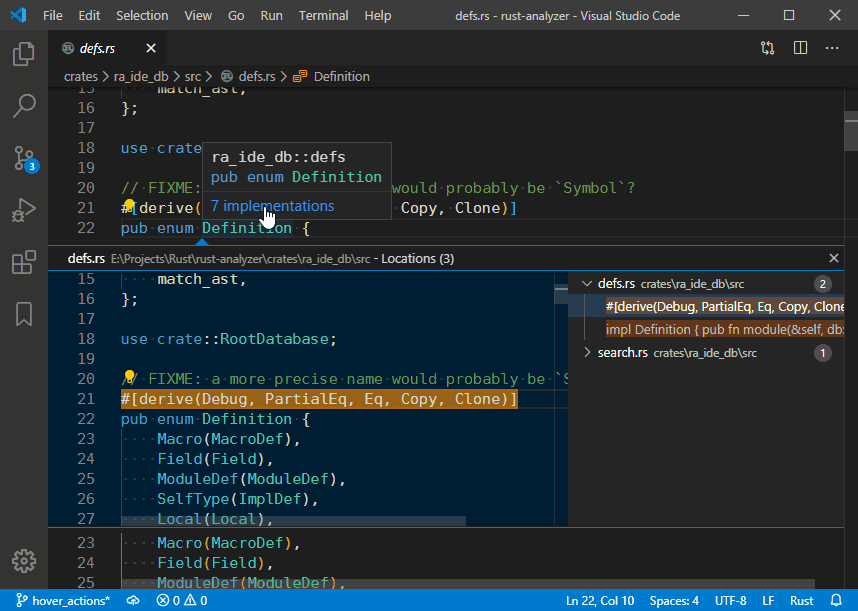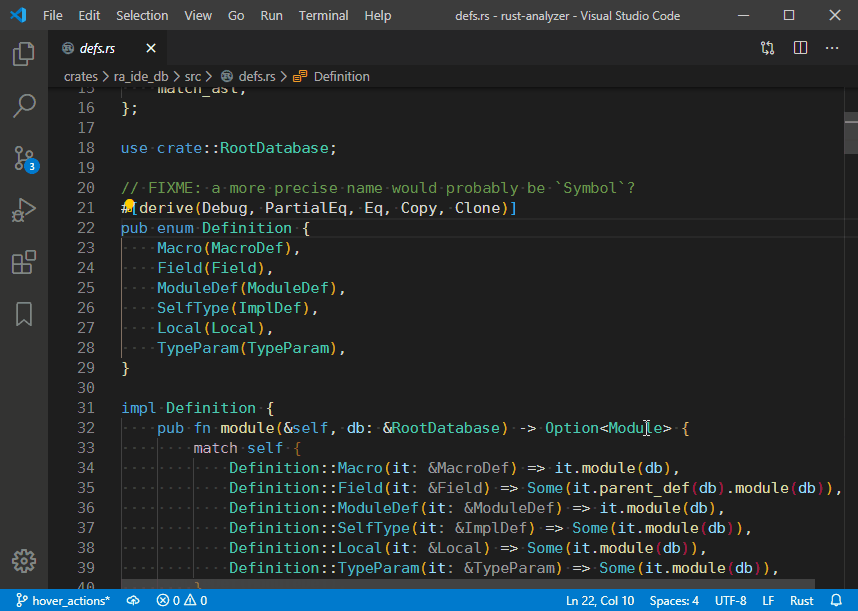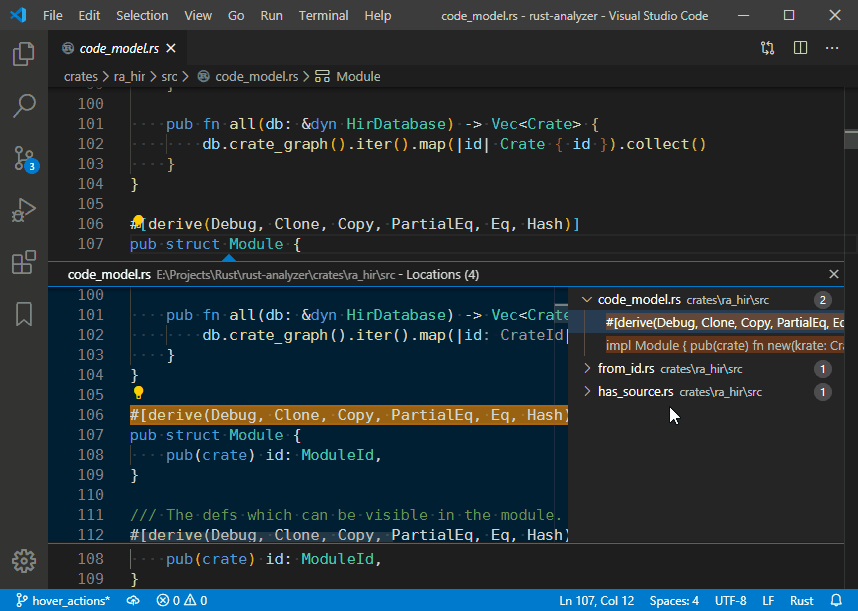
Some features of rust-analyzer requires support for custom commands on
the client side. Specifically, hover & code lens need this.
Stock LSP doesn't have a way for the server to know which client-side
commands are available. For that reason, we historically were just
sending the commands, not worrying whether the client supports then or
not.
That's not really great though, so in this PR we add infrastructure for
the client to explicitly opt-into custom commands, via `extensions`
field of the ClientCapabilities.
To preserve backwards compatability, if the client doesn't set the
field, we assume that it does support all custom commands. In the
future, we'll start treating that case as if the client doesn't support
commands.
So, if you maintain a rust-analyzer client and implement
`rust-analyzer/runSingle` and such, please also advertise this via a
capability.
9693: feat: Add the Hover Range capability which enables showing the type of an expression r=matklad a=alexfertel
Closes https://github.com/rust-analyzer/rust-analyzer/issues/389
This PR extends the `textDocument/hover` method to allow getting the type of an expression. It looks like this:

Edit: One thing I noticed is that when hovering a selection that includes a macro it doesn't work, so maybe this would need a follow-up issue discussing what problem that may have.
(PS: What a great project! I am learning a lot! 🚀)
Co-authored-by: Alexander Gonzalez <alexfertel97@gmail.com>
Co-authored-by: Alexander González <alexfertel97@gmail.com>
9558: Do not erase Cargo diagnostics from the closed documents r=matklad a=SomeoneToIgnore
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/6850
The LSP specification at https://microsoft.github.io/language-server-protocol/specifications/specification-3-14/#textDocument_publishDiagnostics states that
> Diagnostics notification are sent from the server to the client to signal results of validation runs.
>
> Diagnostics are “owned” by the server so it is the server’s responsibility to clear them if necessary. The following rule is used for VS Code servers that generate diagnostics:
>
> * if a language is single file only (for example HTML) then diagnostics are cleared by the server when the file is closed.
> * if a language has a project system (for example C#) diagnostics are not cleared when a file closes. When a project is opened all diagnostics for all files are recomputed (or read from a cache).
>
> When a file changes it is the server’s responsibility to re-compute diagnostics and push them to the client. If the computed set is empty it has to push the empty array to clear former diagnostics. Newly pushed diagnostics always replace previously pushed diagnostics. There is no merging that happens on the client side.
So for projects we should not clear any diagnostics from cargo/json projects.
Our "standalone file" mode is in a way a project too, with sysroot attached and a potential support for dynamic standalone files.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
9634: minor update to excludeDirs doc r=lnicola a=dae
I saw reference to globs in #7755, but it doesn't look like they're
actually supported, and I had to dig through the source to discover
that the folders are relative to the workspace root. Further digging
was required to get VS Code from hanging for long periods trying to
watch giant Bazel folders that had already been excluded from Rust
Analyzer. Hopefully this tweak will save others the confusion :-)
Co-authored-by: Damien Elmes <gpg@ankiweb.net>
Co-authored-by: Damien Elmes <dae@users.noreply.github.com>
I saw reference to globs in #7755, but it doesn't look like they're
actually supported, and I had to dig through the source to discover
that the folders are relative to the workspace root. Further digging
was required to get VS Code from hanging for long periods trying to
watch giant Bazel folders that had already been excluded from Rust
Analyzer. Hopefully this tweak will save others the confusion :-)
Note that, while we don't currently have a fuzzy-matching score, it
makes sense to special-case postfix templates -- it's very annoying when
`.not()` gets sorted before `.not`. We might want to move this infra to
fuzzy matching, once we have that!
Before this PR, SourceChange used a bool and CompletionItem used an enum
to signify if edit is a snippet. It makes sense to use the same pattern
in both cases. `bool` feels simpler, as there's only one consumer of
this API, and all producers are encapsulated anyway (we check the
capability at the production site).
One source completion can produce up to two lsp completions.
Additionally, `preselct` and `sort_text` are global properties of the
whole set of completions, so the right granularity here is to convert
many completions.
As a side-benefit, we no loger allocate intermediate vec.
Moving tests to `rust-analyzer` crate allows removing walkdir dependency
from `xtask`. It does seem more reasonable to keep tidy tests outside of
the "build system" and closer to other integration tests.
* Keep codegen adjacent to the relevant crates.
* Remove codgen deps from xtask, speeding-up from-source installation.
This regresses the release process a bit, as it now needs to run the
tests (and, by extension, compile the code).
9269: Recreate status page r=lnicola a=Milo123459
I'm working on redesigning the status page.
Co-authored-by: Milo <50248166+Milo123459@users.noreply.github.com>
9380: feat: Implement goto_declaration support r=matklad a=Veykril
This is just a simple implementation that falls back to `goto_definition` for everything but modules where it goes to the actual module declaration if possible.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9348: output to log file if RA_LOG_FILE is defined in environment r=rezural a=rezural
This adds a check for RA_LOG_FILE, and logs to that if defined. It currently overrides flags.log_file. If this is undesirable, I will add a check.
Co-authored-by: rezural <rezural@protonmail.com>
9264: feat: Make documentation on hover configurable r=Veykril a=Veykril
This also implements deprecation support for config options as this renames `hoverActions_linksInHover` to `hover_linksInHover`.
Fixes#9232
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9258: minor: Give `ImportPrefix` variants better config names r=matklad a=Veykril
I feel like `crate` and `self` work better than `by_crate` and `by_self`. The only reason for the current names were that `Self` doesn't work for the variant name on the rust side so I forgot about setting proper config names on serde layer.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
9260: tree-wide: make rustdoc links spiky so they are clickable r=matklad a=lf-
Rustdoc was complaining about these while I was running with --document-private-items and I figure they should be fixed.
Co-authored-by: Jade <software@lfcode.ca>
8866: Update salsa r=matklad a=jonas-schievink
This updates salsa to include https://github.com/salsa-rs/salsa/pull/265, and removes all cancellation-related code from rust-analyzer
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
The current logic used to transfer global_excludes into vfs exclusions
only transfers global_excludes that are the parent of an item in
dirs.include.
This commit additionally adds an item from global_exclude to the vfs
exclusions if the global_exclude is a child of an included item.
8767: implement range formatting r=matklad a=euclio
Fixes#7580.
This PR implements the `textDocument/rangeFormatting` request using `rustfmt`'s `--file-lines` option.
Still needs some tests. What I want to know is how I should handle the instability of the `--file-lines` option. It's still unstable in rustfmt, so it's only available on nightly, and needs a special flag to enable. Is there a way for `rust-analyzer` to detect if it's using nightly rustfmt, or for users to opt-in?
Co-authored-by: Andy Russell <arussell123@gmail.com>
8942: Add `library` semantic token modifier to items from other crates r=arzg a=arzg
Closes#5772.
A lot of code here is pretty repetitive; please let me know if you have any ideas how to improve it, or whether it’s fine as-is.
Side-note: How can I add tests for this? I don’t see a way for the test Rust code in `test_highlighting` to reference other crates to observe the new behaviour.
Co-authored-by: Aramis Razzaghipour <aramisnoah@gmail.com>
8873: Implement import-granularity guessing r=matklad a=Veykril
This renames our `MergeBehavior` to `ImportGranularity` as rustfmt has it as the purpose of them are basically the same. `ImportGranularity::Preserve` currently has no specific purpose for us as we don't have an organize imports assist yet, so it currently acts the same as `ImportGranularity::Item`.
We now try to guess the import style on a per file basis and fall back to the user granularity setting if the file has no specific style yet or where it is ambiguous. This can be turned off by setting `import.enforceGranularity` to `true`.
Closes https://github.com/rust-analyzer/rust-analyzer/issues/8870
Co-authored-by: Lukas Tobias Wirth <lukastw97@gmail.com>
The new extension allows filtering of workspace symbool lookup
results by search scope or search kind.
Filtering can be configured in 3 different ways:
- The '#' or '*' markers can be added inline with the symbol lookup
query.
The '#' marker means symbols should be looked up in the current
workspace and any dependencies. If not specified, only current
workspace is considered.
The '*' marker means all kinds of symbols should be looked up
(types, functions, etc). If not specified, only type symbols are
returned.
- Each LSP request can take an optional search_scope or search_kind
argument query parameter.
- Finally there are 2 global config options that can be set for all
requests served by the active RA instance.
Add support for setting the global config options to the VSCode
extension.
The extension does not use the per-request way, but it's useful for
other IDEs.
The latest version of VSCode filters out the inline markers, so
currently the only reasonable way to use the new functionality is
via the global config.
8795: Allow semantic tokens for strings to be disabled r=matklad a=djrenren
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/7111
Pretty straightforward change, but open to any suggestions if there's a more recommended testing strategy than what I went with.
Co-authored-by: John Renner <john@jrenner.net>
8674: fix for #8664: Emit folding ranges for multi-line where clauses r=matklad a=m5tfi
#8664
I added a test that assert folding multi-line where clauses while leaving single lined one. Please, let me know if the code needs further improvements.
Co-authored-by: m5tfi <72708423+m5tfi@users.noreply.github.com>
According to the spec we should return ServerNotInitialized if the server is waiting for an initialize request and something else comes in.
Upgrading to lsp-server 0.5.1 will do this and retry until the initialize request comes in.
Fixes#8581
8540: Prevent being able to rename items that are not part of the workspace r=Veykril a=Veykril
This change causes renames that happen on items coming from crates outside the workspace to fail. I believe this should be the right approach, but usage of cargo's workspace might not be entirely correct for preventing these kinds of refactoring from touching things they shouldn't. I'm not entirely sure?
cc #6623, this is one of the bigger footguns when it comes to refactoring, especially in combination with import aliases people tend to rename items coming from a crates dependency which this prevents.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8354: Distinguishing between different operators in semantic highlighting r=matklad a=chetankhilosiya
Co-authored-by: Chetan Khilosiya <chetan.khilosiya@gmail.com>
Conceptually, using a *message* here is wrong, because this is a
"status", rather than "point in time" thing. But statuses are an LSP
extension, while messages are stable. As a compromise, send message only
for more critical `metadata` failures, and only once per state change.
8410: Use CompletionTextEdit::InsertAndReplace if supported by the client r=Veykril a=Veykril
Fixes#8404, Fixes#3130
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8375: feat: show errors from `cargo metadata` and initial `cargo check` in the status bar r=matklad a=matklad
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
We have a CLI for benchmarking, but no one actually uses it it seems.
Let's try switching to "internal" benchmarks, implemented as rust tests.
They should be easier to "script" to automate tracking of perf
regressions.
8132: Add `'` to trigger_characters, allowing more direct lifetime completions r=Veykril a=Veykril
Fixes having to type a character after `'` to complete lifetimes and labels
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
8021: Enable searching for builtin types r=matklad a=Veykril
Not too sure how useful this is for reference search overall, but for completeness sake it should be there
Also enables document highlighting for them.
8022: some clippy::performance fixes r=matklad a=matthiaskrgr
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unnecessary resizing
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Co-authored-by: Matthias Krüger <matthias.krueger@famsik.de>
use vec![] instead of Vec::new() + push()
avoid redundant clones
use chars instead of &str for single char patterns in ends_with() and starts_with()
allocate some Vecs with capacity to avoid unneccessary resizing
7873: Consider unresolved qualifiers during flyimport r=matklad a=SomeoneToIgnore
Closes https://github.com/rust-analyzer/rust-analyzer/issues/7679
Takes unresolved qualifiers into account, providing better completions (or none, if the path is resolved or do not match).
Does not handle cases when both path qualifier and some trait has to be imported: there are many extra issues with those (such as overlapping imports, for instance) that will require large diffs to address.
Also does not do a fuzzy search on qualifier, that requires some adjustments in `import_map` for better queries and changes to the default replace range which also seems relatively big to include here.
7933: Improve compilation speed r=matklad a=matklad
bors r+
🤖
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
7891: Improve handling of rustc_private r=matklad a=DJMcNab
This PR changes how `rust-analyzer` handles `rustc_private`. In particular, packages now must opt-in to using `rustc_private` in `Cargo.toml`, by adding:
```toml
[package.metadata.rust-analyzer]
rustc_private=true
```
This means that depending on crates which also use `rustc_private` will be significantly improved, since their dependencies on the `rustc_private` crates will be resolved properly.
A similar approach could be used in #6714 to allow annotating that your package uses the `test` crate, although I have not yet handled that in this PR.
Additionally, we now only index the crates which are transitive dependencies of `rustc_driver` in the `rustcSource` directory. This should not cause any change in behaviour when using `rustcSource: "discover"`, as the source used then will only be a partial clone. However, if `rustcSource` pointing at a local checkout of rustc, this should significantly improve the memory usage and lower indexing time. This is because we avoids indexing all crates in `src/tools/`, which includes `rust-analyzer` itself.
Furthermore, we also prefer named dependencies over dependencies from `rustcSource`. This ensures that feature resolution for crates which are depended on by both `rustc` and your crate uses the correct set for analysing your crate.
See also [introductory zulip stream](https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Fwg-rls-2.2E0/topic/Fixed.20crate.20graphs.20and.20optional.20builtin.20crates/near/229086673)
I have tested this in [priroda](https://github.com/oli-obk/priroda/), and it provides a significant improvement to the development experience (once I give `miri` the required data in `Cargo.toml`)
Todo:
- [ ] Documentation
This is ready to review, and I will add documentation if this would be accepted (or if I get time to do so anyway)
Co-authored-by: Daniel McNab <36049421+DJMcNab@users.noreply.github.com>
7335: added region folding r=matklad a=LucianoBestia
Regions of code that you'd like to be folded can be wrapped with `// #region` and `// #endregion` line comments.
This is called "Region Folding". It is originally available for many languages in VSCode. But Rust-analyzer has its own folding function and this is missing.
With this Pull Request I am suggesting a simple solution.
The regions are a special kind of comments, so I added a bit of code in the comment folding function.
The regex to match are: `^\s*//\s*#?region\b` and `^\s*//\s*#?endregion\b`.
The number of space characters is not important. There is an optional # character. The line can end with a name of the region.
Example:
```rust
// 1. some normal comment
// region: test
// 2. some normal comment
calling_function(x,y);
// endregion: test
```
I added a test for this new functionality in `folding_ranges.rs`.
Please, take a look and comment.
I found that these exact regexes are already present in the file `language-configuration.json`, but I don't find a way to read this configuration. So my regex is hardcoded in the code.
7691: Suggest name in extract variable r=matklad a=cpud36
Generate better default name in extract variable assist as was mentioned in issue #1587
# Currently supported
(in order of declining precedence)
1. Expr is argument to a function; use corresponding parameter name
2. Expr is result of a function or method call; use this function/method's name
3. Use expr type name (if possible)
4. Fallback to `var_name` otherwise
# Showcase


# Questions
* Should we more aggressively strip known types? E.g. we already strip `&T -> T`; should we strip `Option<T> -> T`, `Result<T, E> -> T`, and others?
* Integers and floats use `var_name` by default. Should we introduce a name, like `i`, `f` etc?
* Can we return a list and suggest a name when renaming(like IntelliJ does)?
* Should we add counters to remove duplicate variables? E.g. `type`, `type1`, type2`, etc.
Co-authored-by: Luciano Bestia <LucianoBestia@gmail.com>
Co-authored-by: Luciano <31509965+LucianoBestia@users.noreply.github.com>
Co-authored-by: Vladyslav Katasonov <cpud47@gmail.com>
Reading through the code for diagnostics and observing debug logs, I noticed
that diagnostics are transmitted after every change for every opened file,
even if they haven't changed (especially visible for files with no diagnostics).
This change avoids marking files as "changed" if diagnostics are the same to what
was already sent before. This will only work if diagnostics are always produced in
the same order, but from my limited testing it seems this is the case.
7690: Extract `fn load_workspace(…)` from `fn load_cargo(…)` r=matklad a=regexident
Unfortunately in https://github.com/rust-analyzer/rust-analyzer/pull/7595 I forgot to `pub use` (rather than just `use`) the newly introduced `LoadCargoConfig`.
So this PR fixes this now.
It also:
- splits up `fn load_cargo` into a "workspace loading" and a "project loading" phase
- adds a `progress: &dyn Fn(String)` to allow third-parties to provide CLI progress updates, too
The motivation behind both of these is the fact that rust-analyzer currently does not support caching.
As such any third-party making use of `ra_ap_…` needs to providing a caching layer itself.
Unlike for rust-analyzer itself however a common use-pattern of third-parties is to analyze a specific target (`--lib`/`--bin <BIN>`/…) from a specific package (`--package`). The targets/packages of a crate can be obtained via `ProjectWorkspace::load(…)`, which currently is performed inside of `fn load_cargo`, effectively making the returned `ProjectWorkspace` inaccessible to the outer caller. With this information one can then provide early error handling via CLI (in case of ambiguities or invalid arguments, etc), instead of `fn load_cargo` failing with a possibly obscure error message. It also allows for annotating the persisted caches with its specific associated package/target selector and short-circuit quickly if a matching cache is found on disk, significantly cutting load times.
Before:
```rust
pub struct LoadCargoConfig {
pub cargo_config: &CargoConfig,
pub load_out_dirs_from_check: bool,
pub with_proc_macro: bool,
}
pub fn load_cargo(
root: &Path,
config: &LoadCargoConfig
) -> Result<(AnalysisHost, vfs::Vfs)> {
// ...
}
```
After:
```rust
pub fn load_workspace(
root: &Path,
config: &CargoConfig,
progress: &dyn Fn(String),
) -> Result<ProjectWorkspace> {
// ...
}
pub struct LoadCargoConfig {
pub load_out_dirs_from_check: bool,
pub with_proc_macro: bool,
}
pub fn load_cargo(
ws: ProjectWorkspace,
config: &LoadCargoConfig,
progress: &dyn Fn(String),
) -> Result<(AnalysisHost, vfs::Vfs)> {
// ...
}
```
Co-authored-by: Vincent Esche <regexident@gmail.com>
7657: utf8 r=matklad a=matklad
- Prepare for utf-8 offsets
- reduce code duplication in tests
- Make utf8 default, implement utf16 in terms of it
- Make it easy to add additional context for offset conversion
- Implement utf8 offsets
closes#7453
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
7661: Start LSP 3.17 support r=kjeremy a=kjeremy
Companion to https://github.com/gluon-lang/lsp-types/pull/199 which <strike>has not been merged yet</strike> has been merged.
This doesn't opt into any 3.17 functionality yet.
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
7643: Automatically detect the rustc-src directory (fixes#3517) r=matklad a=bnjbvr
If the configured rustcSource was not set, then try to automatically
detect a source for the sysroot rustc directory.
I wasn't sure how to do it in the case of the project.json file, though.
7663: Tolerate spaces in nix binary patching r=matklad a=CertainLach
If path to original file contains space (I.e on code insiders, where
default data directory is ~/Code - Insiders/), then there is syntax
error evaluating src arg.
Instead pass path as str, and coerce to path back in nix expression
Co-authored-by: Benjamin Bouvier <public@benj.me>
Co-authored-by: Yaroslav Bolyukin <iam@lach.pw>
In some situations we reloaded the workspace in the tests after having reported
to be ready. There's two fixes here:
1. Add a version to the VFS config and include that version in progress reports,
so that we don't think we're done prematurely;
2. Delay status transitions until after changes are applied. Otherwise the last
change during loading can potentially trigger a workspace reload, if it contains
interesting changes.
I've noticed that there are various suggestions that rust-analyzer seems
to filter out, even if they make sense.
Here's an example of where it seems like there should be a suggestion,
but there isn't:

It turns out that this specific suggestion is not considered
`MachineApplicable`, which are the only suggestions that rust-analyzer
accepts. However if you read the documentation for `MachineApplicable`,
b3897e3d13/compiler/rustc_lint_defs/src/lib.rs (L27-L29)
then you realize that these are specifically only those suggestions that
rust-analyzer could even automatically apply (in some distant future,
behind some setting or so). Other suggestions that may have some
semantic impact do not use `MachineApplicable`. So all other suggestions
are still intended to be suggested to the user, just not automatically
applied without the user being consulted.
b3897e3d13/compiler/rustc_lint_defs/src/lib.rs (L22-L24)
So with that in mind, rust-analyzer should almost definitely not filter
out `MaybeIncorrect` (which honestly is named horribly, it just means
that it's a semantic change, not just a syntactical one).
Then there's `HasPlaceholders` which basically is just another semantic
one, but with placeholders. The user will have to make some adjustments,
but the suggestion still is perfectly valid. rust-analyzer could
probably detect those placeholders and put proper "tab through" markers
there for the IDE, but that's not necessary for now.
Then the last one is `Unspecified` which is so unknown that I don't even
know how to judge it, meaning that the suggestion should probably also
just be suggested to the user and then they can decide.
So with all that in mind, I'm proposing to get rid of the check for
Applicability entirely.
7457: Add no-buffering file logging and wait for a debugger option. r=vsrs a=vsrs
Adds two command line flags: `--no-buffering` and `--wait-dbg`.
Not sure if someone else needs this, but personally I found both flags extremely useful trying to figure out why RA does not work with Visual Studio. Or better to say why Visual Studio does not work with RA.
Co-authored-by: vsrs <vit@conrlab.com>
7353: Add LifetimeParam and ConstParam to CompletionItemKind r=matklad a=Veykril
Adds `LifetimeParam` and `ConstParam` to `CompletionItemKind` and maps them both to `TypeParam` in the protocol conversion as there are no equivalents, so nothing really changes there.
`ConstParam` could be mapped to `Const` I guess but I'm split on whether that would be better?
Additions were solely inspired by (the single) test output for const params.
Also sorts the variants of `CompletionItemKind` and its to_proto match.
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
I've noticed a bunch of "main loop too long" warnings in console when
typing in Cargo.toml. Profiling showed that the culprit is `rustc
--print cfg` call.
I moved it to the background project loading phase, where it belongs.
This highlighted a problem: we generally use single `cfg`, while it
really should be per crate.
7220: same level folder rename for will_rename_files r=kjeremy a=ShuiRuTian
use tricky way to support folder rename.
Another step after #7009 and for #4471
Co-authored-by: ShuiRuTian <158983297@qq.com>
Co-authored-by: Song Gao <158983297@qq.com>
7218: Fix typos r=Veykril a=regexident
Apart from the very last commit on this PR (which fixes a public type's name) all changes are non-breaking.
Co-authored-by: Vincent Esche <regexident@gmail.com>
After we started reporting progress when running cargo check during
loading, it is possible to crash the client with two identical progress
tokens.
This points to a deeper issue: we might be running several cargo checks
concurrently, which doesn't make sense.
This commit linearizes all workspace fetches, making sure no updates are
lost.
As an additional touch, it also normalizes progress & result reporting,
to make sure they stand in sync.
This leaks a lot of LSP details into ide layer, which we want to avoid:
c9cec381bc/docs/dev (lsp-independence)
Additionally, all what this infra does is providing a toggle for
auto-import completion, but we already have one!
Rather than eagerly converting JSON, we losslessly keep it as is, and
change the shape of user-submitted data at the last moment.
This also allows us to remove a bunch of wrong Defaults
7068: Add VSCode command to view the hir of a function body r=theotherphil a=theotherphil
Will fix https://github.com/rust-analyzer/rust-analyzer/issues/7061. Very rough initial version just to work out where I needed to wire everything up.
@matklad would you be happy merging a hir visualiser of some kind? If so, do you have any thoughts on what you'd like it show, and how?
I've spent very little time on this thus far, so I'm fine with throwing away the contents of this PR, but I want to avoid taking the time to make this more polished/interactive/useful only to discover that no-one else has any interest in this functionality.
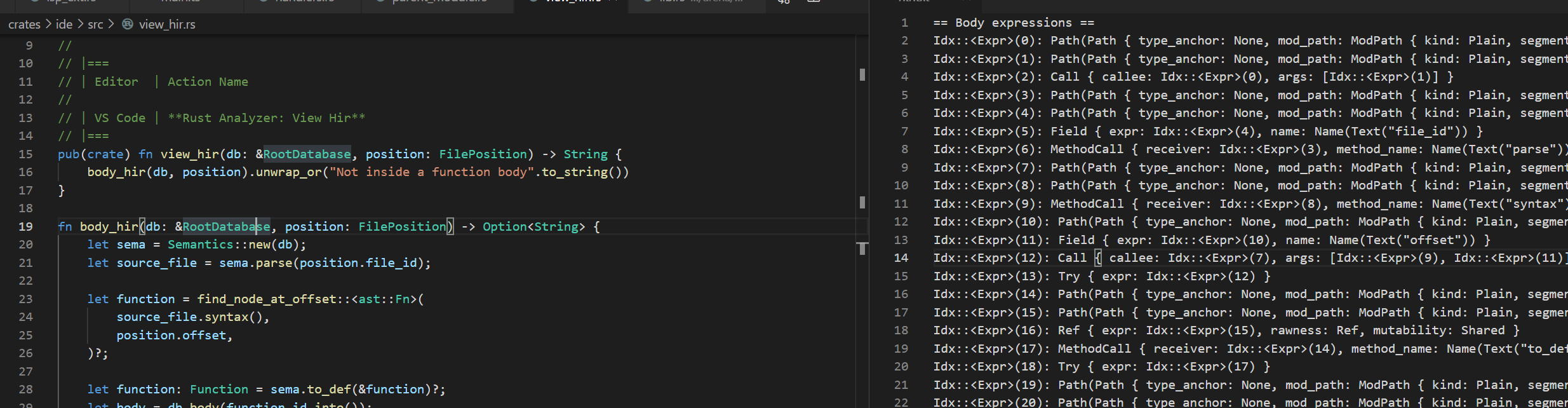
Co-authored-by: Phil Ellison <phil.j.ellison@gmail.com>
7115: Migrate HasSource::source to return Option r=matklad a=nick96
I've made a start on fixing #6913 based on the provided work plan, migrating `HasSource::source` to return an `Option`. The simple cases are migrated but there are a few that I'm unsure exactly how they should be handled:
- Logging the processing of functions in `AnalysisStatsCmd::run`: In verbose mode it includes the path to the module containing the function and the syntax range. I've handled this with an if-let but would it be better to blow up here with `expect`? I'm not 100% on the code paths but if we're processing a function definition then the source should exist.
I've handled `source()` in all code paths as `None` being a valid return value but are there some cases where we should just blow up? Also, all I've done is bubble up the returned `None`s, there may be some places where we can recover and still provide something.
Co-authored-by: Nick Spain <nicholas.spain@stileeducation.com>
Co-authored-by: Nick Spain <nicholas.spain96@gmail.com>
In an attempt to fix#6052 and #4249 this attempts to detect
if rustfmt is a rustup proxy which isn't installed, and reports
the error message to the user for them to fix.
In theory this ought to be memoised but for now it'll do as-is.
Future work might be to ask the user if they would like us to
trigger the installation (if possible).
Signed-off-by: Daniel Silverstone <dsilvers@digital-scurf.org>
Assist vs UnresolvedAssist split doesn't really pull its weight. This
is especially bad if we want to include `Assist` as a field of
diagnostics, where we'd have to make the thing generic.
7030: Support labels in reference search r=matklad a=Veykril
Implements general navigation for labels, goto def, rename and gives labels their own semantic highlighting class.
Fixes#6966
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
Avoid mutation of snapshot's config -- that's spooky action at a
distance. Instead, copy it over to a local variable.
This points out a minor architecture problem, which we won't fix right
away.
Various `ide`-level config structs, like `AssistConfig`, are geared
towards one-shot use when calling a specific methods. On the other
hand, the large `Config` struct in `rust-analyzer` is a long-term
config store.
The fact that `Config` stores `AssistConfig` is accidental -- a better
design would probably be to just store `ConfigData` inside `Config`
and create various `Config`s on the fly out of it.
6993: Clean up descriptions for settings r=matklad a=rherrmann
Use two consecutive newlines (`\n\n`) to actually continue text on a
new line.
Use proper markup to reference related settings.
Consistently format references to files, command line arguments, etc.
as `code`. Format mentions of UI elements in _italic_.
Fix typos, add missing full-stops, add missing default values.
Co-authored-by: Rüdiger Herrmann <ruediger.herrmann@gmx.de>
Use two consecutive newlines (`\n\n`) to actually continue text on a
new line.
Use proper markup to reference related settings.
Consistently format references to files, editor commands, command line
arguments, files, etc. as `code`.
Fix typos, add missing full-stops, add missing default values.
Curiously, LSP uses different enums for those, and unsurprising and
annoyingly, there are things which exist in one but not in the other.
Let's not repeat the mistake and unify the two things
6785: Fix "no value set for FileTextQuery(FileId(..))" r=jonas-schievink a=jonas-schievink
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/6622
Let's hope I got it right this time, but I feel like I slowly begin to understand the main loop logic.
bors r+
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
6761: Make config.rs a single source of truth for configuration. r=matklad a=matklad
Configuration is editor-independent. For this reason, we pick
JSON-schema as the repr of the source of truth. We do specify it using
rust-macros and some quick&dirty hackery though.
The idea for syncing truth with package.json is to just do that
manually, but there's a test to check that they are actually synced.
I'll add something like `rust-analyzer --config-schema` in a follow-up
commit.
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
Configuration is editor-independent. For this reason, we pick
JSON-schema as the repr of the source of truth. We do specify it using
rust-macros and some quick&dirty hackery though.
The idea for syncing truth with package.json is to just do that
manually, but there's a test to check that they are actually synced.
There's CLI to print config's json schema:
$ rust-analyzer --print-config-schema
We go with a CLI rather than LSP request/response to make it easier to
incorporate the thing into extension's static config. This is roughtly
how we put the thing in package.json.
6650: Make completion and assists module independent r=matklad a=SomeoneToIgnore
A follow-up of https://github.com/rust-analyzer/rust-analyzer/pull/6553#discussion_r524402907
Move the common code for both assists and completion modules into a separate crate.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
6553: Auto imports in completion r=matklad a=SomeoneToIgnore

Closes https://github.com/rust-analyzer/rust-analyzer/issues/1062 but does not handle the completion order, since it's a separate task for https://github.com/rust-analyzer/rust-analyzer/issues/4922 , https://github.com/rust-analyzer/rust-analyzer/issues/4922 and maybe something else.
2 quirks in the current implementation:
* traits are not auto imported during method completion
If I understand the current situation right, we cannot search for traits by a **part** of a method name, we need a full name with correct case to get a trait for it.
* VSCode (?) autocompletion is not as rigid as in Intellij Rust as you can notice on the animation.
Intellij is able to refresh the completions on every new symbol added, yet VS Code does not query the completions on every symbol for me.
With a few debug prints placed in RA, I've observed the following behaviour: after the first set of completion suggestions is received, next symbol input does not trigger a server request, if the completions contain this symbol.
When more symbols added, the existing completion suggestions are filtered out until none are left and only then, on the next symbol it queries for completions.
It seems like the only alternative to get an updated set of results is to manually retrigger it with Esc and Ctrl + Space.
Despite the eerie latter bullet, the completion seems to work pretty fine and fast nontheless, but if you have any ideas on how to make it more smooth, I'll gladly try it out.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
6524: Add support for loading rustc private crates r=matklad a=xldenis
This PR presents a solution to the problem of making`rustc_private` crates visible to `rust-analyzer`.
Currently developers add dependencies to those crates behind a `cfg(NOT_A_TARGET)` target to prevent `cargo` from building them.
This solution is unsatisfactory since it requires modifying `Cargo.toml` and causes problems for collaboration or CI.
The proposed solution suggested by @matklad is to allow users to give RA a path where the `rustc` sources could be found and then load that like a normal workspace.
This PR implements this solution by adding a `rustcSource` configuration item and adding the cargo metadata to the crate graph if it is provided.
------
I have no idea how this should be tested, or if this code is generally tested at all. I've locally run the extension with these changes and it correctly loads the relevant crates on a `rustc_private` project of mine.
Co-authored-by: Xavier Denis <xldenis@gmail.com>
Historically, we intentinally violated JSON-RPC spec here by hard
crashing. The idea was to poke both the clients and servers to fix
stuff.
However, this is confusing for server implementors, and falls down in
one important place -- protocol extension are not always backwards
compatible, which causes crashes simply due to version mismatch. We
had once such case with our own extension, and one for semantic
tokens.
So let's be less adventerous and just err on the err side!
6331: correct hover text for items with doc attribute with raw strings r=matklad a=JoshMcguigan
Fixes#6300 by improving the handling of raw string literals in attribute style doc comments.
This still has a bug where it could consume too many `"` at the start or end of the comment text, just as the original code had. Not sure if we want to fix that as part of this PR or not? If so, I think I'd prefer to add a unit test for either the `as_simple_key_value` function (I'm not exactly sure where this would belong / how to set this up) or create a `fn(&SmolStr) -> &SmolStr` to unit test by factoring out the `trim` operations from `as_simple_key_value`. Thoughts on this?
6342: Shorter dependency chain r=matklad a=popzxc
Continuing implementing suggestions from the `Completion refactoring` zulip thread.
This PR does the following:
- Removes dependency of `completions` on `assists` by moving required functionality into `ide_db`.
- Moves completely `call_info` crate into `ide_db` as it looks like it fits perfect there.
- Adds a bunch of new tests and docs.
- Adds the re-export of `base_db` to the `ide_db` and removes direct dependency on `base_db` from other crates.
The last point is controversial, I guess, but I noticed that in places where `ide_db` is used, `base_db` is also *always* used. Thus I think the dependency on the `base_db` is implied by the fact of `ide_db` interfaces, and thus it makes sense to just provide `base_db` out of the box.
Co-authored-by: Josh Mcguigan <joshmcg88@gmail.com>
Co-authored-by: Igor Aleksanov <popzxc@yandex.ru>
6251: Semantic Highlight: Add Callable modifier for variables r=matklad a=GrayJack
This PR added the `HighlightModifier::Callable` variant and assigned it to variables and parameters that are fn pointers, closures and implements FnOnce trait.
This allows to colorize these variables/parameters when used in call expression.
6310: Rewrite algo::diff to support insertion and deletion r=matklad a=Veykril
This in turn also makes `algo::diff` generate finer diffs(maybe even minimal diffs?) as insertions and deletions aren't always represented as as replacements of parent nodes now.
Required for #6287 to go on.
Co-authored-by: GrayJack <gr41.j4ck@gmail.com>
Co-authored-by: Lukas Wirth <lukastw97@gmail.com>
6324: Improve #[cfg] diagnostics r=jonas-schievink a=jonas-schievink
Unfortunately I ran into https://github.com/rust-analyzer/rust-analyzer/issues/4058 while testing this on https://github.com/nrf-rs/nrf-hal/, so I didn't see much of it in action yet, but it does seem to work.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
Declaration names sounds like a name of declaration -- something you
can use for analysis. It empathically isn't, and is just a label
displayed in various UI. It's important not to confuse the two, least
we accidentally mix semantics with UI (I believe, there's already a
case of this in the FamousDefs at least).
5917: Add a command to open docs for the symbol under the cursor r=matklad a=zacps
#### Todo
- [ ] Decide if there should be a default keybind or context menu entry
- [x] Figure out how to get the documentation path for methods and other non-top-level defs
- [x] Design the protocol extension. In future we'll probably want parameters for local/remote documentation URLs, so that should maybe be done in this PR?
- [x] Code organisation
- [x] Tests
Co-authored-by: Zac Pullar-Strecker <zacmps@gmail.com>
Return an error with a meaningful message for requests to
`textDocument/rename` if the operation cannot be performed.
Pass errors raised by rename handling code to the LSP runtime.
As a consequence, the VS Code client shows and logs the request
as if a server-side programming error occured.
Resolves https://github.com/rust-analyzer/rust-analyzer/issues/3981
Percentage is a UI concern, the physical fact here is fraction. It's
sad that percentage bleeds into the protocol level, we even duplicated
this bad API ourselves!
6124: Better normalized crate name usage r=jonas-schievink a=SomeoneToIgnore
Closes https://github.com/rust-analyzer/rust-analyzer/issues/5343
Closes https://github.com/rust-analyzer/rust-analyzer/issues/5932
Uses normalized name for code snippets (to be able to test the fix), hover messages and documentation rewrite links (are there any tests for those?).
Also renamed the field to better resemble the semantics.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
This removes all markdown when the client does not support the markdown MarkupKind
Otherwise the output on the editor will have some markdown boilerplate, making it less readable
This seems like a better factoring logically; ideally, clients shouldn't touch
`set_` methods of the database directly. Additionally, I think this
should remove the unfortunate duplication in fixture code.
6018: Correct project_root path for ProjectJson. r=jonas-schievink a=woody77
It was already the folder containing the rust-project.json file, not the file itself. This also removes the Option-ness of it, since it's now an infallible operation to set the member value.
Co-authored-by: Aaron Wood <aaronwood@google.com>
6036: Don't re-read open files from disk when reloading a workspace r=kjeremy a=lnicola
Fixes#5742Fixes#4263
or so I hope.
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
6017: Don't return any TextEdit if formatting is unchanged r=jonas-schievink a=cuviper
I found that `textDocument/formatting` was always returning a full
`TextEdit` replacement, even when there are no changes, which caused Vim
(w/ vim-lsp) to always indicate a modified buffer after formatting. We
can easily compare whether there were changes and return `null` if not,
so the client knows there's nothing to do.
Co-authored-by: Josh Stone <cuviper@gmail.com>
I found that `textDocument/formatting` was always returning a full
`TextEdit` replacement, even when there are no changes, which caused Vim
(w/ vim-lsp) to always indicate a modified buffer after formatting. We
can easily compare whether there were changes and return `null` if not,
so the client knows there's nothing to do.
5643: Add new consuming modifier, apply consuming and mutable to methods r=matklad a=Nashenas88
This adds a new `consuming` semantic modifier for syntax highlighters.
This also emits `mutable` and `consuming` in two cases:
- When a method takes `&mut self`, then it now has `function.mutable` emitted.
- When a method takes `self`, and the type of `Self` is not `Copy`, then `function.consuming` is emitted.
CC @flodiebold
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
5682: Add an option to disable diagnostics r=matklad a=popzxc
As far as I know, currently it's not possible to disable a selected type of diagnostics provided by `rust-analyzer`.
This causes an inconvenient situation with a false-positive warnings: you either have to disable all the diagnostics, or you have to ignore these warnings.
There are some open issues related to this problem, e.g.: https://github.com/rust-analyzer/rust-analyzer/issues/5412, https://github.com/rust-analyzer/rust-analyzer/issues/5502
This PR attempts to make it possible to selectively disable some diagnostics on per-project basis.
Co-authored-by: Igor Aleksanov <popzxc@yandex.ru>
5687: Fix document symbols order r=matklad a=magurotuna
Resolves#5655
And adds tests for `handle_document_symbol`, both with `hierarchical_symbols` enabled and with it disabled.
Previously document symbols were displayed in reverse order in sublime text with its LSP plugin, but this patch fixes it like this:
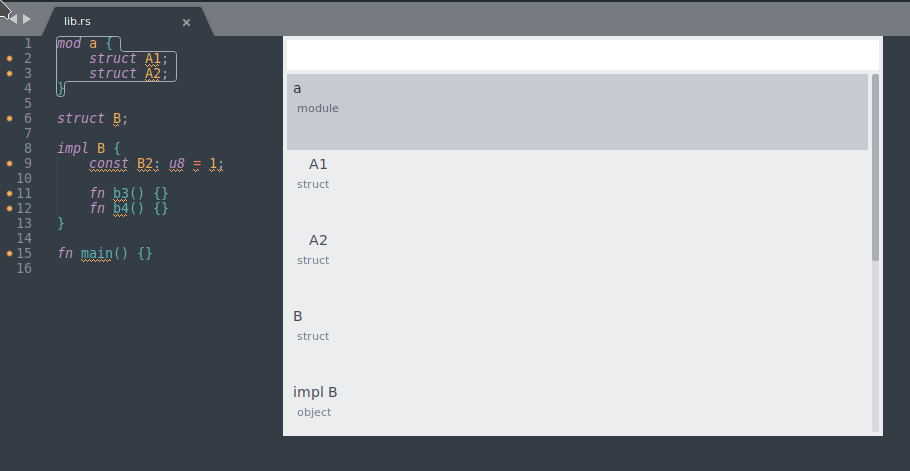
Co-authored-by: Yusuke Tanaka <yusuktan@maguro.dev>
The idea here is that, on CI, we only want to cache crates.io
dependencies, and not local crates. This keeps the size of the cache
low, and also improves performance, as network and moving files on
disk (on Windows) can be slow.
5692: Add support for extern crate r=jonas-schievink a=Nashenas88
This adds syntax highlighting, hover and goto def functionality for extern crate.
Fixes#5690
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
5693: Fix no inlay hints / unresolved tokens until manual edit to refresh r=jonas-schievink a=Veetaha
Fixes https://github.com/rust-analyzer/rust-analyzer/issues/5349
Now we return ContentModified during the workspace loading. This signifies the language
client to retry the operation (i.e. the client will
continue polling the server while it returns ContentModified).
I believe that there might be cases of overly big projects where the backoff
logic we have setup in `sendRequestWithRetry` (which we use for inlay hints)
might bail too early (currently the largest retry standby time is 10 seconds).
However, I've tried on one of my project with 500+ dependencies and it is still enough.
Here are the examples before/after the change (the gifs are quite lengthy because they show testing rather large cargo workspace).
<details>
<summary>Before</summary>
Here you can see that the client receives empty array of inlay hints and does nothing more.
Same applies to semantic tokens. The client receives unresolved tokens and does nothing more.
The user needs to do a manual edit to refresh the editor.

</details>
<details>
<summary>After</summary>
Here the server returns ContentModified, so the client periodically retries the requests and eventually receives the wellformed response.
</details>
Co-authored-by: Veetaha <veetaha2@gmail.com>
5414: Fix test code lens r=jonas-schievink a=avrong
Closes#5217
The implementation is quite similar to #4821. Maybe we should somehow deal with duplicated code.
Also, both of these requests introduce some unclear behavior. I'm not sure how to process this, therefore asking for advice. Examples are below.
<img width="286" alt="image" src="https://user-images.githubusercontent.com/6342851/87713209-83595f80-c7b2-11ea-8c0f-a12e7571e7df.png">
Co-authored-by: Aleksei Trifonov <avrong@avrong.me>
No we return ContentModified during the workspace loading. This signifies the language
client to retry the operation (i.e. the client will
continue polling the server while it returns ContentModified).
I believe that there might be cases of overly big projects where the backoff
logic we have setup in `sendRequestWithRetry` (which we use for inlay hints)
might bail too early (currently the largest retry standby time is 10 seconds).
However, I've tried on one of my project with 500+ dependencies and it is still enough.
5526: Handle semantic token deltas r=kjeremy a=kjeremy
This basically takes the naive approach where we always compute the tokens but save space sending over the wire which apparently solves some GC problems with vscode.
This is waiting for https://github.com/gluon-lang/lsp-types/pull/174 to be merged. I am also unsure of the best way to stash the tokens into `DocumentData` in a safe manner.
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
`current_dir` and relative paths to executables works differently on
unix and windows (unix behavior does not make sense), see:
17e30e83a1/src/lib.rs (L295-L324)
The original motivation to set cwd was to make rustfmt read the
correct rustfmt.toml, but that was future proofing, rather than a bug
fix.
So, let's just remove this and see if breaks or fixes more use-cases.
If support for per-file config is needed, we could use `--config-path`
flag.
5596: Add checkOnSave.noDefaultFeatures and correct, how we handle some cargo flags. r=clemenswasser a=clemenswasser
This PR adds the `rust-analyzer.checkOnSave.noDefaultFeatures` option
and fixes the handling of `cargo.allFeatures`, `cargo.noDefaultFeatures` and `cargo.features`.
Fixes: #5550
Co-authored-by: Clemens Wasser <clemens.wasser@gmail.com>
5563: Check all targets for package-level tasks r=matklad a=SomeoneToIgnore
When invoking "Select Runnable" with the caret on a runnable with a specific target (test, bench, binary), append the corresponding argument for the `cargo check -p` module runnable.
Co-authored-by: Kirill Bulatov <mail4score@gmail.com>
5520: Add DocumentData to represent in-memory document with LSP info r=matklad a=kjeremy
At the moment this only holds document version information but in the near-future it will hold other things like semantic token delta info.
Co-authored-by: kjeremy <kjeremy@gmail.com>
The methods `edits_for_file` and `find_matches_in_file` are replaced with just `edits` and `matches`. This simplifies the API a bit, but more importantly it makes it possible in a subsequent commit for SSR to decide to not search all files.
5481: Track document versions in the server r=kjeremy a=kjeremy
This also pushes diagnostics for the correct file version on close so that when it is reopened stale diagnostics are not shown.
Closes#5452
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
5467: Allow null or empty values for configuration r=matklad a=kjeremy
Allow the client to respond to `workspace/configuration` with `null` values. This is allowed per the spec if the client doesn't know about the configuration we've requested.
This also protects against `null` or `{}` during initialize. I'm not sure if we want to interpret `{}` as "don't change anything" but I think that's a reasonable approach to take.
This should help with LSP clients working out of the box.
Fixes#5464
Co-authored-by: kjeremy <kjeremy@gmail.com>
5327: Mark fixes from check as preferred r=matklad a=kjeremy
This allows us to run the auto fix command from vscode to automatically fix diagnostics in the file.
They are also distinguished in the UI.
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
5350: Filter assists r=matklad a=kjeremy
Uses the `CodeActionContext::only` field to compute only those assists the client cares about.
It works but I don't really like the implementation.
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Jeremy Kolb <kjeremy@gmail.com>
5244: Add a command to compute memory usage statistics r=matklad a=jonas-schievink
This allows inspecting memory usage on a live rust-analyzer instance after it has been used interactively.
This will only work with `--features jemalloc`, so maybe it should print something more useful when that's not available? Right now it will just print 0 Bytes for every query.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5209: Fixes to memory usage stats r=matklad a=jonas-schievink
This brings the unaccounted memory down from 287mb to 250mb, and displays memory used by VFS and "other" allocations.
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
5192: Implement rust-analyzer feature configuration to tests. r=matklad a=daxpedda
Fixes#3198.
I'm unsure if it is desired this way, maybe we want to make a seperate configuration?
Co-authored-by: daxpedda <daxpedda@gmail.com>
5101: Add expect -- a light-weight alternative to insta r=matklad a=matklad
This PR implements a small snapshot-testing library. Snapshot updating is done by setting an env var, or by using editor feature (which runs a test with env-var set).
Here's workflow for updating a failing test:
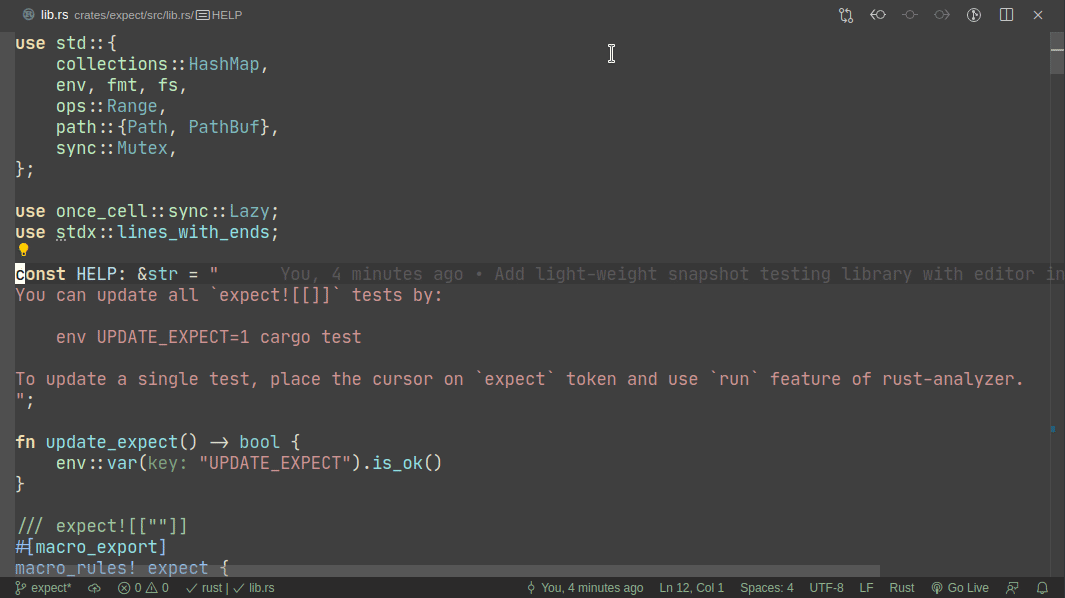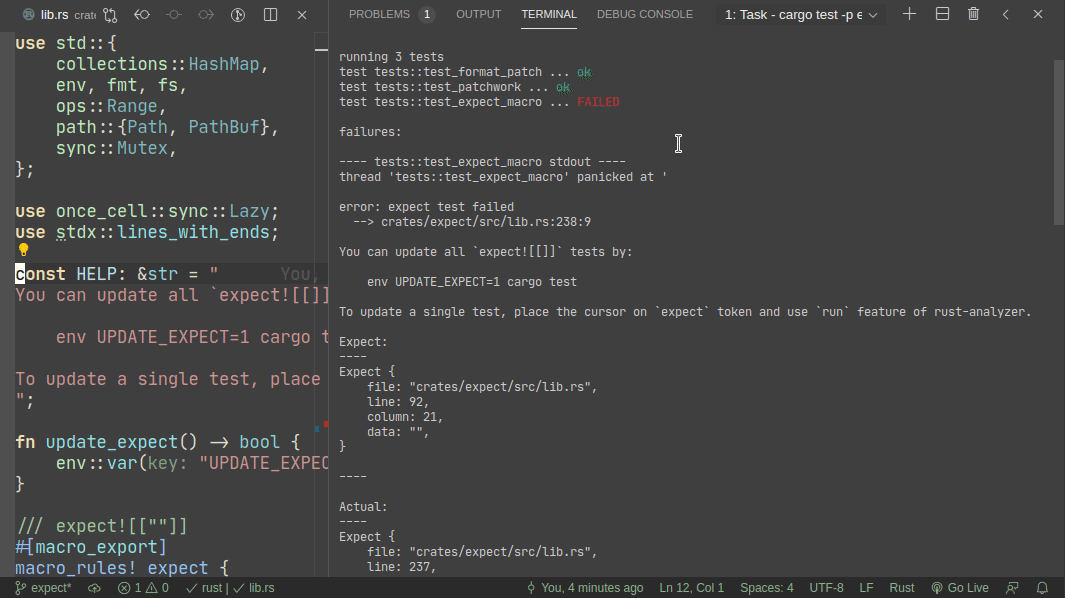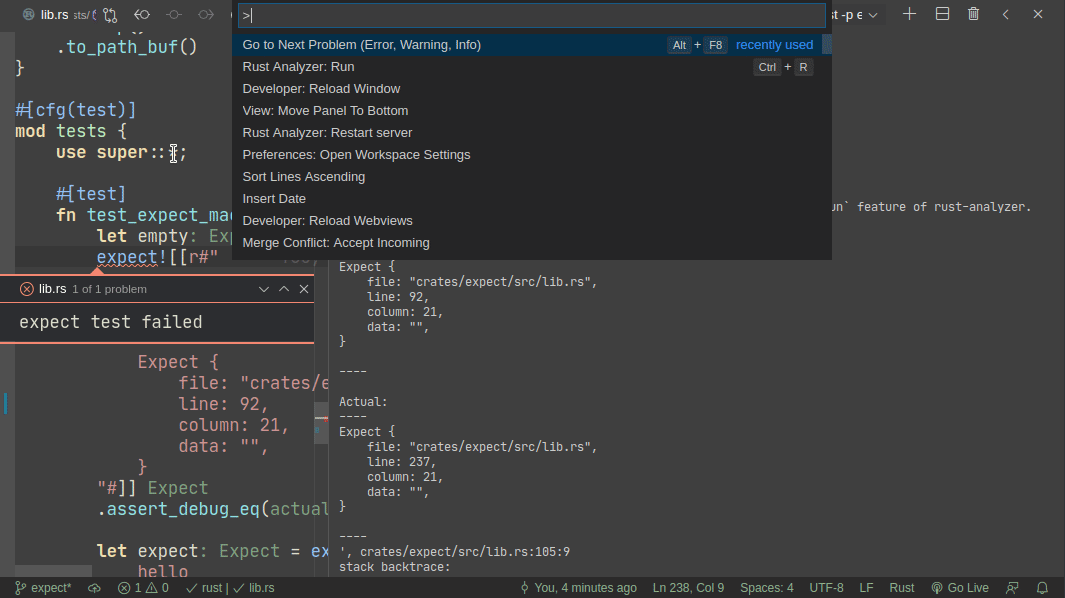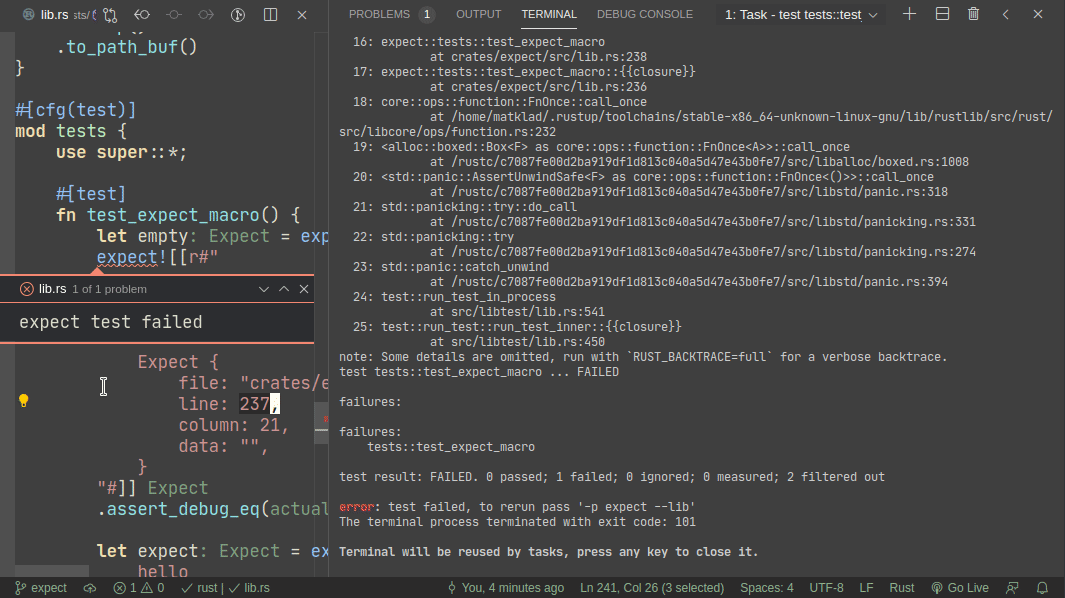
Here's workflow for adding a new test:
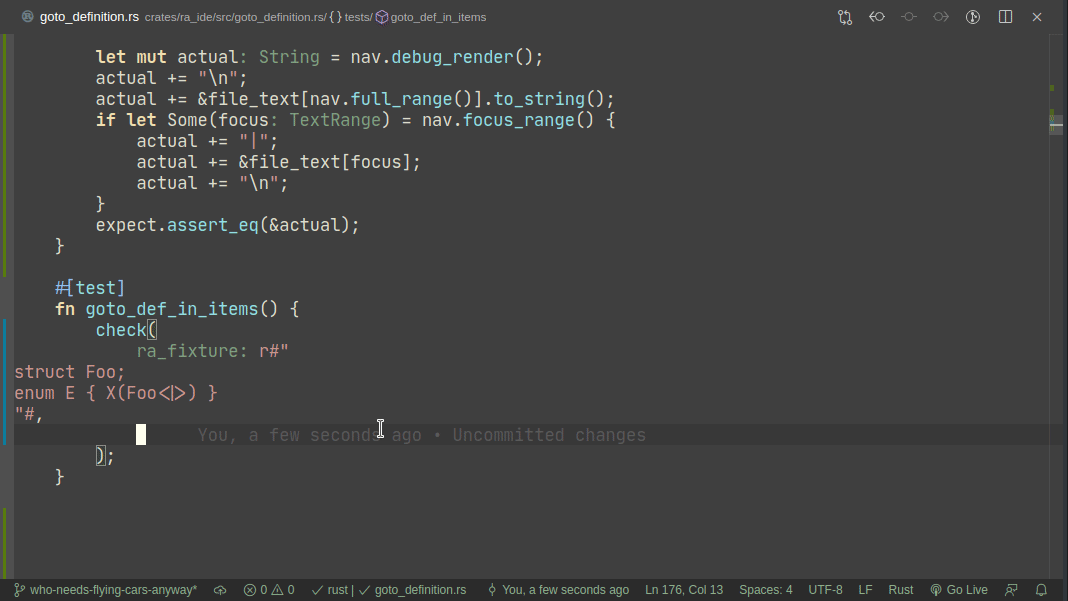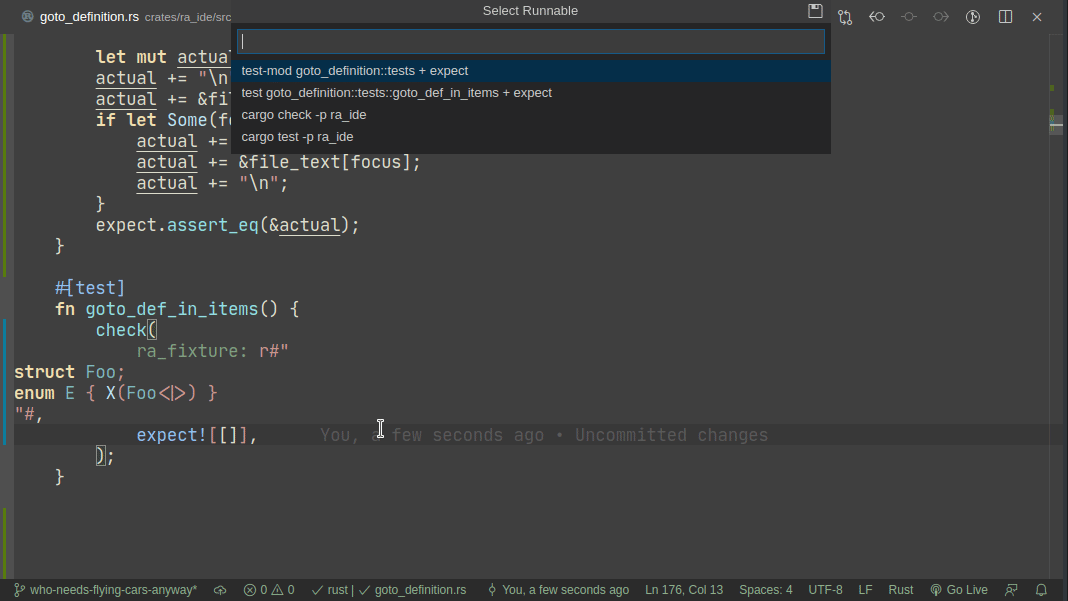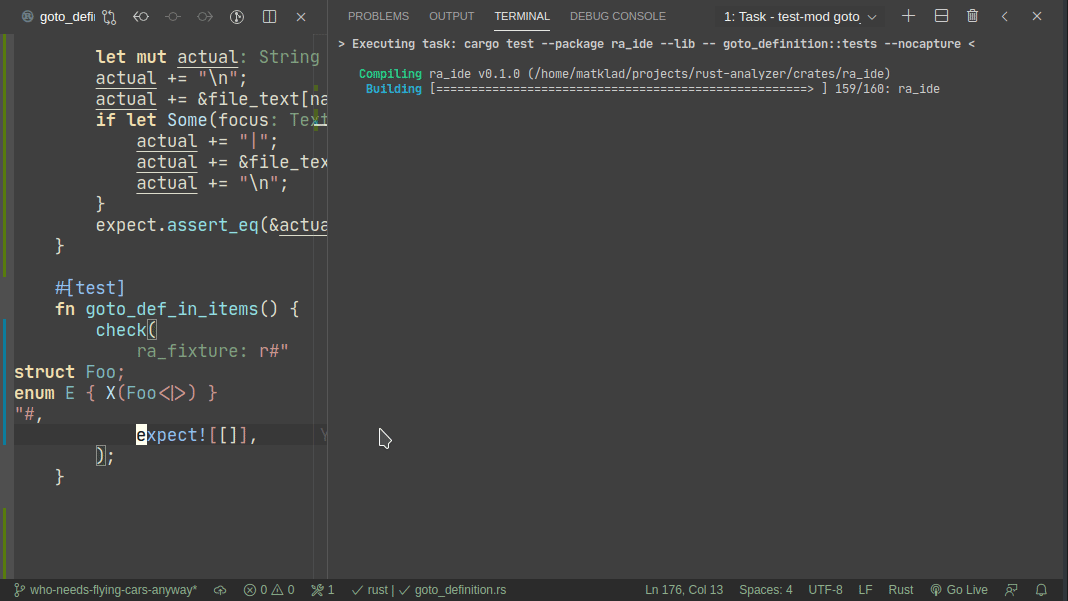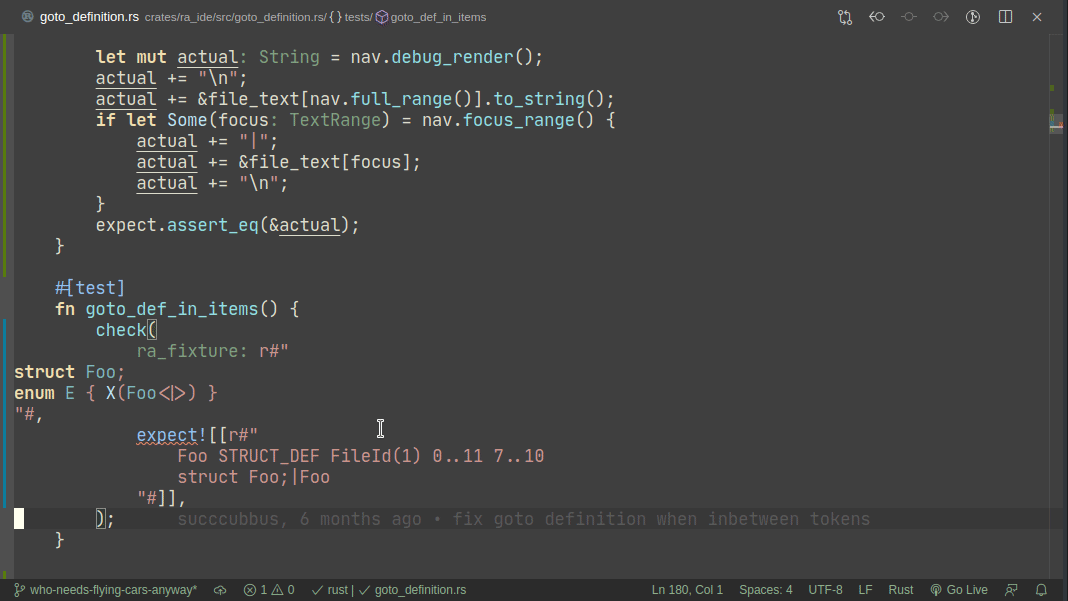
Note that colorized diffs are not implemented in this PR, but should be easy to add (we already use them in test_utils).
Main differences from insta (which is essential for rust-analyzer development, thanks @mitsuhiko!):
* self-updating tests, no need for a separate tool
* fewer features (only inline snapshots, no redactions)
* fewer deps (no yaml, no persistence)
* tighter integration with editor
* first-class snapshot object, which can be used to write test functions (as opposed to testing macros)
* trivial to tweak for rust-analyzer needs, by virtue of being a workspace member.
I think eventually we should converge to a single snapshot testing library, but I am not sure that `expect` is exactly right, so I suggest rolling with both insta and expect for some time (if folks agree that expect might be better in the first place!).
# Editor Integration Implementation
The thing I am most excited about is the ability to update a specific snapshot from the editor. I want this to be available to other snapshot-testing libraries (cc @mitsuhiko, @aaronabramov), so I want to document how this works.
The ideal UI here would be a code action (💡). Unfortunately, it seems like it is impossible to implement without some kind of persistence (if you save test failures into some kind of a database, like insta does, than you can read the database from the editor plugin). Note that it is possible to highlight error by outputing error message in rustc's format. Unfortunately, one can't use the same trick to implement a quick fix.
For this reason, expect makes use of another rust-analyzer feature -- ability to run a single test at the cursor position. This does need some expect-specific code in rust-analyzer unfortunately. Specifically, if rust-analyzer notices that the cursor is on `expect!` macro, it adds a special flag to runnable's JSON. However, given #5017 it is possible to approximate this well-enough without rust-analyzer integration. Specifically, an extension can register a special runner which checks (using regexes) if rust-anlyzer runnable covers text with specific macro invocation and do special magic in that case.
closes#3835
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
5120: Add a simple SSR subcommand to the rust-analyzer command line binary r=davidlattimore a=davidlattimore
Is adding the dependency on ra_ide_db OK? It's needed for the call to `db.local_roots()`
Co-authored-by: David Lattimore <dml@google.com>
There are two reasons why we don't want a generic ra_progress crate
just yet:
*First*, it introduces a common interface between separate components,
and that is usually undesirable (b/c components start to fit the
interface, rather than doing what makes most sense for each particular
component).
*Second*, it introduces a separate async channel for progress, which
makes it harder to correlate progress reports with the work done. Ie,
when we see 100% progress, it's not blindly obvious that the work has
actually finished, we might have some pending messages still.
5015: Account for updated module ids when determining whether a resolution is changed r=matklad a=Nashenas88
Fixes#4943
5027: Make Debug less verbose for VfsPath and use Display in analysis-stats r=matklad a=lnicola
5028: Remove namedExports config r=matklad a=lnicola
Fixes a warning:
```
(!) Plugin commonjs: The namedExports option from "@rollup/plugin-commonjs" is deprecated. Named exports are now handled automatically.
```
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
4940: Add support for marking doctest items as distinct from normal code r=ltentrup a=Nashenas88
This adds `HighlightTag::Generic | HighlightModifier::Injected` as the default highlight for all elements within a doctest. Please feel free to suggest that a new tag be created or a different one used.

Fixes#4929Fixes#4939
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
Co-authored-by: Paul Daniel Faria <nashenas88@users.noreply.github.com>
4937: Allow overriding rust-analyzer display version r=matklad a=oxalica
The build script invokes `git` for version information which is displayed when rust-analyzer is called with `--version`. But in build environment without `git` or when the source code is not a git repo, there's no way to manually specify the version information.
This patch respects environment variable ~`REV`~ `RUST_ANALYZER_REV` in compile time for overriding.
Related: https://github.com/NixOS/nixpkgs/pull/90976
Co-authored-by: oxalica <oxalicc@pm.me>
4903: Add highlighting support for doc comments r=matklad a=Nashenas88
The language server protocol includes a semantic modifier for documentation. This change exports that modifier for doc comments so users can choose to highlight them differently compared to regular comments.
Example:
<img width="375" alt="Screen Shot 2020-06-16 at 10 34 14 AM" src="https://user-images.githubusercontent.com/1673130/84788271-f6599580-afbc-11ea-96e5-7a0215da620b.png">
CC @woody77
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
4934: Remove special casing for library symbols r=matklad a=matklad
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
We might as well handle them internally, via queries.
I am not sure, but it looks like the current LibraryData setup might
even predate salsa? It's not really needed and creates a bunch of
complexity.
4927: Better encapsulate reverse-mapping of files to cargo targets r=matklad a=matklad
We need to find a better way to do it...
CrateGraph by itself is fine, CargoWorkspace as well, but the mapping
between the two seems arbitrary...
bors r+
🤖
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
4913: Remove debugging code for incremental sync r=matklad a=lnicola
4915: Inspect markdown code fences to determine whether to apply syntax highlighting r=matklad a=ltentrup
Fixes#4904
4916: Warnings as hint or info r=matklad a=GabbeV
Fixes#4229
This PR is my second attempt at providing a solution to the above issue. My last PR(#4721) had to be rolled back(#4862) due to it overriding behavior many users expected. This PR solves a broader problem while trying to minimize surprises for the users.
### Problem description
The underlying problem this PR tries to solve is the mismatch between [Rustc lint levels](https://doc.rust-lang.org/rustc/lints/levels.html) and [LSP diagnostic severity](https://microsoft.github.io/language-server-protocol/specification#diagnostic). Rustc currently doesn't have a lint level less severe than warning forcing the user to disable warnings if they think they get to noisy. LSP however provides two severitys below warning, information and hint. This allows editors like VSCode to provide more fine grained control over how prominently to show different diagnostics.
Info severity shows a blue squiggly underline in code and can be filtered separately from errors and warnings in the problems panel.


Hint severity doesn't show up in the problems panel at all and only show three dots under the affected code or just faded text if the diagnostic also has the unnecessary tag.
### Solution
The solution provided by this PR allows the user to configure lists of of warnings to report as info severity and hint severity respectively. I purposefully only convert warnings and not errors as i believe it's a good idea to have the editor show the same severity as the compiler as much as possible.

### Open questions
#### Discoverability
How do we teach this to new and existing users? Should a section be added to the user manual? If so where and what should it say?
#### Defaults
Other languages such as TypeScript report unused code as hint by default. Should rust-analyzer similarly report some problems as hint/info by default?
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
Co-authored-by: Leander Tentrup <leander.tentrup@gmail.com>
Co-authored-by: Gabriel Valfridsson <gabriel.valfridsson@gmail.com>
Anchoring to the SourceRoot wont' work if the path is absolute:
#[path = "/tmp/foo.rs"]
mod foo;
Anchoring to a file will.
However, we *should* anchor, instead of just producing an abs path.
I can imagine a situation where, for example, rust-analyzer processes
crates from different machines (or, for example, from in-memory git
branch), where the same absolute path in different crates might refer
to different files in the end!
4784: Change management of test cfg to better support json projects r=Nashenas88 a=Nashenas88
This helps support json projects where they can decide whether to add the `test` cfg or not. One alternative is to add support for marking json project crates as a sysroot crate, and adding logic to remove the `test` cfg in those cases. In my opinion, that option gives less flexibility to json projects and leads to more functionality that needs to be maintained.
Fixes#4508
cc @woody77
Co-authored-by: Paul Daniel Faria <Nashenas88@users.noreply.github.com>
Co-authored-by: Paul Daniel Faria <nashenas88@users.noreply.github.com>
4729: Hover actions r=matklad a=vsrs
This PR adds a `hoverActions` LSP extension and a `Go to Implementations` action as an example:
4748: Add an `ImportMap` and use it to resolve item paths in `find_path` r=matklad a=jonas-schievink
Removes the "go faster" queries I added in https://github.com/rust-analyzer/rust-analyzer/pull/4501 and https://github.com/rust-analyzer/rust-analyzer/pull/4506. I've checked this PR on the rustc code base and the assists are still fast.
This should fix https://github.com/rust-analyzer/rust-analyzer/issues/4515.
Note that this does introduce a change in behavior: We now always refer to items defined in external crates using paths through the external crate. Previously we could also use a local path (if for example the extern crate was reexported locally), as seen in the changed test. If that is undesired I can fix that, but the test didn't say why the previous behavior would be preferable.
Co-authored-by: vsrs <vit@conrlab.com>
Co-authored-by: Jonas Schievink <jonasschievink@gmail.com>
Co-authored-by: Jonas Schievink <jonas.schievink@ferrous-systems.com>
4740: Remove unneeded "./" prefix affecting error messages r=kjeremy a=dtolnay
I noticed this in the error in the commit message of https://github.com/rust-analyzer/rust-analyzer/pull/4739.
Before:
```console
error[E0599]: no method named `initialize_finish` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/./src/bin/main.rs:99:16
|
99 | connection.initialize_finish(initialize_id, initialize_result)?;
| ^^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
```
After:
```console
error[E0599]: no method named `initialize_finish` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/src/bin/main.rs:99:16
|
99 | connection.initialize_finish(initialize_id, initialize_result)?;
| ^^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
```
```diff
- --> crates/rust-analyzer/./src/bin/main.rs:99:16
+ --> crates/rust-analyzer/src/bin/main.rs:99:16
```
Co-authored-by: David Tolnay <dtolnay@gmail.com>
Before:
error[E0599]: no method named `initialize_finish` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/./src/bin/main.rs:99:16
|
99 | connection.initialize_finish(initialize_id, initialize_result)?;
| ^^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
After:
error[E0599]: no method named `initialize_finish` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/src/bin/main.rs:99:16
|
99 | connection.initialize_finish(initialize_id, initialize_result)?;
| ^^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
My codebase already depended on lsp-server and introducing a dependency
on rust-analyzer failed at first because it assumes some functions that
were first present in lsp-server 0.3.2.
Without this change:
error[E0599]: no method named `initialize_start` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/./src/bin/main.rs:83:57
|
83 | let (initialize_id, initialize_params) = connection.initialize_start()?;
| ^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
error[E0599]: no method named `initialize_finish` found for struct `lsp_server::Connection` in the current scope
--> crates/rust-analyzer/./src/bin/main.rs:99:16
|
99 | connection.initialize_finish(initialize_id, initialize_result)?;
| ^^^^^^^^^^^^^^^^^ method not found in `lsp_server::Connection`
Eventually, we should support "just open random rust file" use case,
we don't really do this now, so let's avoid spending time on it until
we fix it properly.
As per matklad, we now pass the responsibility for finding the binary to the frontend.
Also, added caching for finding the binary path to reduce
the amount of filesystem interactions.
The line separator is moved below the function signature to split
regions between the docs. This is very similar to how IntelliJ
displays tooltips. Adding an additional separator between the module
name and function signature currently has rendering issues.
Fixes#4594
Alternative to #4615
4602: Add boolean literal semantic token type to package.json r=matklad a=lnicola
Closes#4583.
CC @GrayJack
4603: Add self keyword semantic token type r=matklad a=lnicola
Not sure if this is warranted a new token type or just a modifier.
---
CC #4583, @GrayJack
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
4571: KISS SourceChange r=matklad a=matklad
The idea behind requiring the label is a noble one, but we are not
really using it consistently anyway, and it should be easy to retrofit
later, should we need it.
bors r+
Co-authored-by: Aleksey Kladov <aleksey.kladov@gmail.com>
The idea behind requiring the label is a noble one, but we are not
really using it consistently anyway, and it should be easy to retrofit
later, should we need it.
4516: LSP: Two stage initialization r=kjeremy a=kjeremy
Fills in server information.
Derives CodeAction capabilities from the client. If code action literals
are unsupported we fall back to the "simple support" which just sends back
commands (this is already supported in our config). The difference being
that we did not adjust our server capabilities so that if the client was
checking for `CodeActionProvider: "true"` in the response that would have failed.
Part of #144Fixes#4130 (the specific case called out in that issue)
Co-authored-by: kjeremy <kjeremy@gmail.com>
This also changes our handiling of snippet edits on the client side.
`editor.insertSnippet` unfortunately forces indentation, which we
really don't want to have to deal with. So, let's just implement our
manual hacky way of dealing with a simple subset of snippets we
actually use in rust-analyzer
Fills in server information.
Derives CodeAction capabilities from the client. If code action literals
are unsupported we fall back to the "simple support" which just sends back
commands (this is already supported in our config). The difference being
that we did not adjust our server capabilities so that if the client was
checking for `CodeActionProvider: "true"` in the response that would have failed.
4448: Generate configuration for launch.json r=vsrs a=vsrs
This PR adds two new commands: `"rust-analyzer.debug"` and `"rust-analyzer.newDebugConfig"`. The former is a supplement to the existing `"rust-analyzer.run"` command and works the same way: asks for a runnable and starts new debug session. The latter allows adding a new configuration to **launch.json** (or to update an existing one).
If the new option `"rust-analyzer.debug.useLaunchJson"` is set to true then `"rust-analyzer.debug"` and Debug Lens will first look for existing debug configuration in **launch.json**. That is, it has become possible to specify startup arguments, env variables, etc.
`"rust-analyzer.debug.useLaunchJson"` is false by default, but it might be worth making true the default value. Personally I prefer true, but I'm not sure if it is good for all value.
----
I think that this PR also solves https://github.com/rust-analyzer/rust-analyzer/issues/3441.
Both methods to update launch.json mentioned in the issue do not work:
1. Menu. It is only possible to add a launch.json configuration template via a debug adapter. And anyway it's only a template and it is impossible to specify arguments from an extension.
2. DebugConfigurationProvider. The exact opposite situation: it is possible to specify all debug session settings, but it is impossible to export these settings to launch.json.
Separate `"rust-analyzer.newDebugConfig"` command looks better for me.
----
Fixes#4450Fixes#3441
Co-authored-by: vsrs <vit@conrlab.com>
Co-authored-by: vsrs <62505555+vsrs@users.noreply.github.com>
4397: Textmate cooperation r=matklad a=georgewfraser
This PR tweaks the fallback TextMate scopes to make them more consistent with the existing grammar and other languages, and edits the builtin TextMate grammar to align with semantic coloring. Before is on the left, after is on the right:
<img width="855" alt="Screen Shot 2020-05-10 at 1 45 51 PM" src="https://user-images.githubusercontent.com/1369240/81512320-a8be7e80-92d4-11ea-8940-2c03f6769015.png">
**Use keyword.other for regular keywords instead of keyword**. This is a really peculiar quirk of TextMate conventions, but virtually *all* TextMate grammars use `keyword.other` (colored blue in VSCode Dark+) for regular keywords and `keyword.control` (colored purple in VSCode Dark+) for control keywords. The TextMate scope `keyword` is colored like control keywords, not regular keywords. It may seem strange that the `keyword` scope is not the right fallback for the `keyword` semantic token, but TextMate has a long and weird history. Note how keywords change from purple back to blue (what they were before semantic coloring was added):
**(1) Use punctuation.section.embedded for format specifiers**. This aligns with how Typescript colors formatting directives:
<img width="238" alt="Screen Shot 2020-05-09 at 10 54 01 AM" src="https://user-images.githubusercontent.com/1369240/81481258-93b5f280-91e3-11ea-99c2-c6d258c5bcad.png">
**(2) Consistently use `entity.name.type.*` scopes for type names**. Avoid using `entity.name.*` which gets colored like a keyword.
**(3) Use Property instead of Member for fields**. Property and Member are very similar, but if you look at the TextMate fallback scopes, it's clear that Member is intended for function-like-things (methods?) and Property is intended for variable-like-things.
**(4) Color `for` as a regular keyword when it's part of `impl Trait for Struct`**.
**(5) Use `variable.other.constant` for constants instead of `entity.name.constant`**. In the latest VSCode insiders, variable.other.constant has a subtly different color that differentiates constants from ordinary variables. It looks close to the green of types but it's not the same---it's a new color recently added to take advantage of semantic coloring.
I also made some minor changes that make the TextMate scopes better match the semantic scopes. The effect of this for the user is you observe less of a change when semantic coloring "activates". You can see the changes I made relative to the built-in TextMate grammar here:
a91d15c80c..97428b6d52 (diff-6966c729b862f79f79bf7258eb3e0885)
Co-authored-by: George Fraser <george@fivetran.com>
4394: Simplify r=matklad a=Veetaha
4414: Highlighting improvements r=matklad a=matthewjasper
- `static mut`s are highlighted as `mutable`.
- The name of the macro declared by `macro_rules!` is now highlighted.
Co-authored-by: veetaha <veetaha2@gmail.com>
Co-authored-by: Matthew Jasper <mjjasper1@gmail.com>
This starts the transition to a new method of documenting the cfgs that are
enabled for a given crate in the json file. This is changing from a list
of atoms and a dict of key:value pairs, to a list of strings that is
equivalent to that returned by `rustc --print cfg ..`, and parsed in the
same manner by rust-analyzer.
This is the first of two changes, which adds the new field that contains
the list of strings. Next change will complete the transition and remove
the previous fields.
4166: Defining a default target to support cross-compilation targets r=matklad a=FuriouZz
Related to #4163
Co-authored-by: Christophe MASSOLIN <christophe.massolin@gmail.com>
4207: Add unwrap block assist #4156 r=matklad a=bnjjj
close issue #4156
4253: Remove `workspaceLoaded` setting r=matklad a=eminence
The `workspaceLoaded` notification setting was originally designed to
control the display of a popup message that said:
"workspace loaded, {} rust packages"
This popup was removed and replaced by a much sleeker message in the
VSCode status bar that provides a real-time status while loading:
rust-analyzer: {}/{} packages
This was done as part of #3587
The change in this PR simply renames this setting from `workspaceLoaded` to
`progress` to better describe what it actually controls. At the moment,
the only type of progress message that is controlled by this setting is
the initial load messages, but in theory other messages could also be
controlled by this setting.
Reviewer notes:
* If we didn't like the idea of causing minor breaking to user's config, we could keep the setting name as `workspaceLoaded`
* I think we can now close both #2719 and #3176 since the notification dialog in question no longer exists (actually I think you can close those issues even if you reject this PR 😄 )
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Co-authored-by: Andrew Chin <achin@eminence32.net>
The `workspaceLoaded` notification setting was originally designed to
control the display of a popup message that said:
"workspace loaded, {} rust packages"
This popup was removed and replaced by a much sleeker message in the
VSCode status bar that provides a real-time status while loading:
rust-analyzer: {}/{} packages
This was done as part of #3587
The new status-bar indicator is unobtrusive and shouldn't need to be
disabled. So this setting is removed.
4161: lsp-types 0.74 r=kjeremy a=kjeremy
* Fixes a bunch of param types to take partial progress into account.
* Will allow us to support insert/replace text in completions
Co-authored-by: kjeremy <kjeremy@gmail.com>
4113: Support returning non-hierarchical symbols r=matklad a=kjeremy
If `hierarchicalDocumentSymbolSupport` is not true in the client capabilites
then it does not support the `DocumentSymbol[]` return type from the
`textDocument/documentSymbol` request and we must fall back to `SymbolInformation[]`.
This is one of the few requests that use the client capabilities to
differentiate between return types and could cause problems for clients.
See https://github.com/microsoft/language-server-protocol/pull/538#issuecomment-442510767 for more context.
Found while looking at #144
4136: add support for cfg feature attributes on expression #4063 r=matklad a=bnjjj
close issue #4063
4141: Fix typo r=matklad a=Veetaha
4142: Remove unnecessary async from vscode language client creation r=matklad a=Veetaha
Co-authored-by: kjeremy <kjeremy@gmail.com>
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
Co-authored-by: veetaha <veetaha2@gmail.com>
4133: main: eagerly prime goto-definition caches r=matklad a=BurntSushi
This commit eagerly primes the caches used by goto-definition by
submitting a "phantom" goto-definition request. This is perhaps a bit
circuitous, but it does actually get the job done. The result of this
change is that once RA is finished its initial loading of a project,
goto-definition requests are instant. There don't appear to be any more
surprise latency spikes.
This _partially_ addresses #1650 in that it front-loads the latency of the
first goto-definition request, which in turn makes it more predictable and
less surprising. In particular, this addresses the use case where one opens
the text editor, starts reading code for a while, and only later issues the
first goto-definition request. Before this PR, that first goto-definition request
is guaranteed to have high latency in any reasonably sized project. But
after this PR, there's a good chance that it will now be instant.
What this _doesn't_ address is that initial loading time. In fact, it makes it
longer by adding a phantom goto-definition request to the initial startup
sequence. However, I observed that while this did make initial loading
slower, it was overall a somewhat small (but not insignificant) fraction
of initial loading time.
-----
At least, the above is what I _want_ to do. The actual change in this PR is just a proof-of-concept. I came up with after an evening of printf-debugging. Once I found the spot where this cache priming should go, I was unsure of how to generate a phantom input. So I just took an input I knew worked from my printf-debugging and hacked it in. Obviously, what I'd like to do is make this more general such that it will always work.
I don't know whether this is the "right" approach or not. My guess is that there is perhaps a cleaner solution that more directly primes whatever cache is being lazily populated rather than fudging the issue with a phantom goto-definition request.
I created this as a draft PR because I'd really like help making this general. I think whether y'all want to accept this patch is perhaps a separate question. IMO, it seems like a good idea, but to be honest, I'm happy to maintain this patch on my own since it's so trivial. But I would like to generalize it so that it will work in any project.
My thinking is that all I really need to do is find a file and a token somewhere in the loaded project, and then use that as input. But I don't quite know how to connect all the data structures to do that. Any help would be appreciated!
cc @matklad since I've been a worm in your ear about this problem. :-)
Co-authored-by: Andrew Gallant <jamslam@gmail.com>
This commit makes RA more aggressive about eagerly priming the caches.
In particular, this fixes an issue where even after RA was done priming
its caches, an initial goto-definition request would have very high
latency. This fixes that issue by requesting syntax highlighting for
everything. It is presumed that this is a tad wasteful, but not overly
so.
This commit also tweaks the logic that determines when the cache is
primed. Namely, instead of just priming it when the state is loaded
initially, we attempt to prime it whenever some state changes. This
fixes an issue where if a modification notification is seen before cache
priming is done, it would stop the cache priming early.
4125: Avoid lossy OsString conversions r=matklad a=lnicola
This is a bit invasive, and perhaps for not much benefit since non-UTF-8 environment variables don't work anyway.
Co-authored-by: Laurențiu Nicola <lnicola@dend.ro>
If `hierarchicalDocumentSymbolSupport` is not true in the client capabilites
then it does not support the `DocumentSymbol[]` return type from the
`textDocument/documentSymbol` request and we must fall back to `SymbolInformation[]`.
This is one of the few requests that use the client capabilities to
differentiate between return types and could cause problems for clients.
See https://github.com/microsoft/language-server-protocol/pull/538#issuecomment-442510767 for more context.
Found while looking at #144
4101: Panic proc macro srv if read request failed r=matklad a=edwin0cheng
This PR fixed a bug when the rust-analyzer is killed suddenly, the `rust-analyzer proc-macro` will become stale.
Co-authored-by: Edwin Cheng <edwin0cheng@gmail.com>
I might be reading this wrong, but it looks like we are setting it to
essentially arbitrary string at the moment, as there are no defined
order on the items in the *set* of completions.
3954: Improve autocompletion by looking on the type and name r=matklad a=bnjjj
This tweet (https://twitter.com/tjholowaychuk/status/1248918374731714560) gaves me the idea to implement that in rust-analyzer.
Basically for this first example I made some examples when we are in a function call definition. I look on the parameter list to prioritize autocompletions for the same types and if it's the same type + the same name then it's displayed first in the completion list.
So here is a draft, first step to open a discussion and know what you think about the implementation. It works (cf tests) but maybe I can make a better implementation at some places. Be careful the code needs some refactoring to be better and concise.
PS: It was lot of fun writing this haha
Co-authored-by: Benjamin Coenen <5719034+bnjjj@users.noreply.github.com>
In general, there should be no reason to call `.to_string_lossy`.
If you want to display the path, use `.display()`.
If you want to pass the path to an OS API (like std::process::Command)
than use `PathBuf` or `OsString`.
4092: feat: run ignored tests r=matklad a=hdevalke
I started making some exercices on https://exercism.io/ and a lot of test have the `#[ignore]` attribute.
The `Run Test|Debug` code lens show up, but running the test results in:
```
running 1 test
test test_one_piece ... ignored
test result: ok. 0 passed; 0 failed; 1 ignored; 0 measured; 5 filtered out
```
This pull request adds the `--ignored` flag if needed.
Co-authored-by: Hannes De Valkeneer <hannes@de-valkeneer.be>
This is a quick way to implement unresolved reference diagnostics.
For example, adding to VS Code config
"editor.tokenColorCustomizationsExperimental": {
"unresolvedReference": "#FF0000"
},
will highlight all unresolved refs in red.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
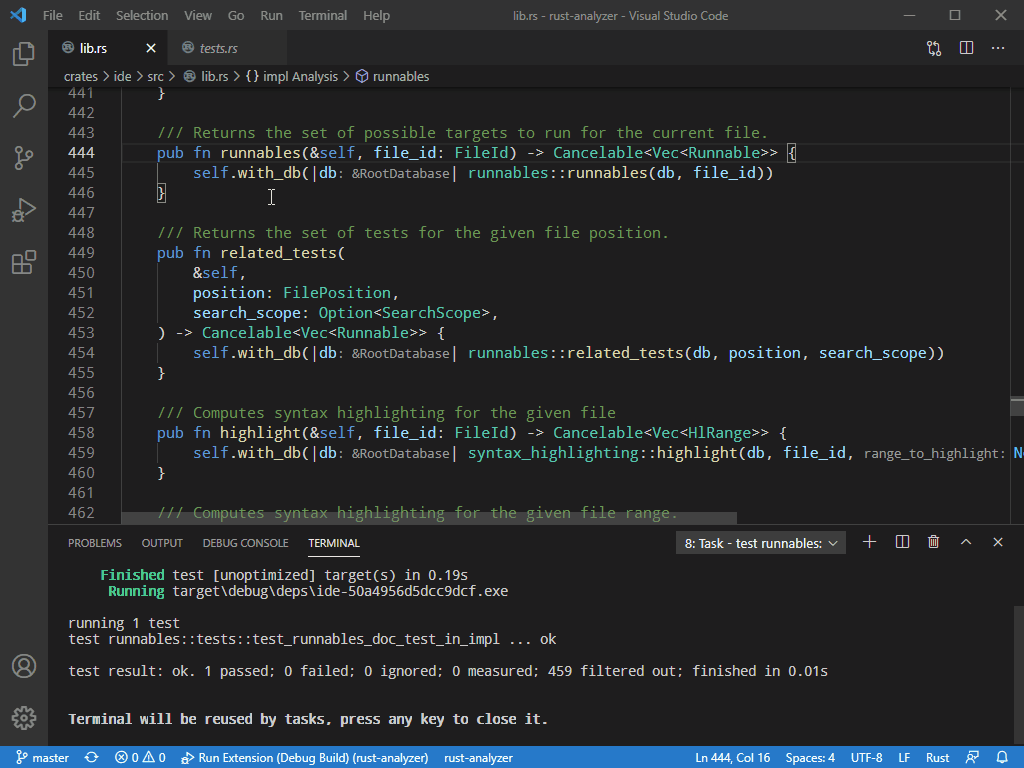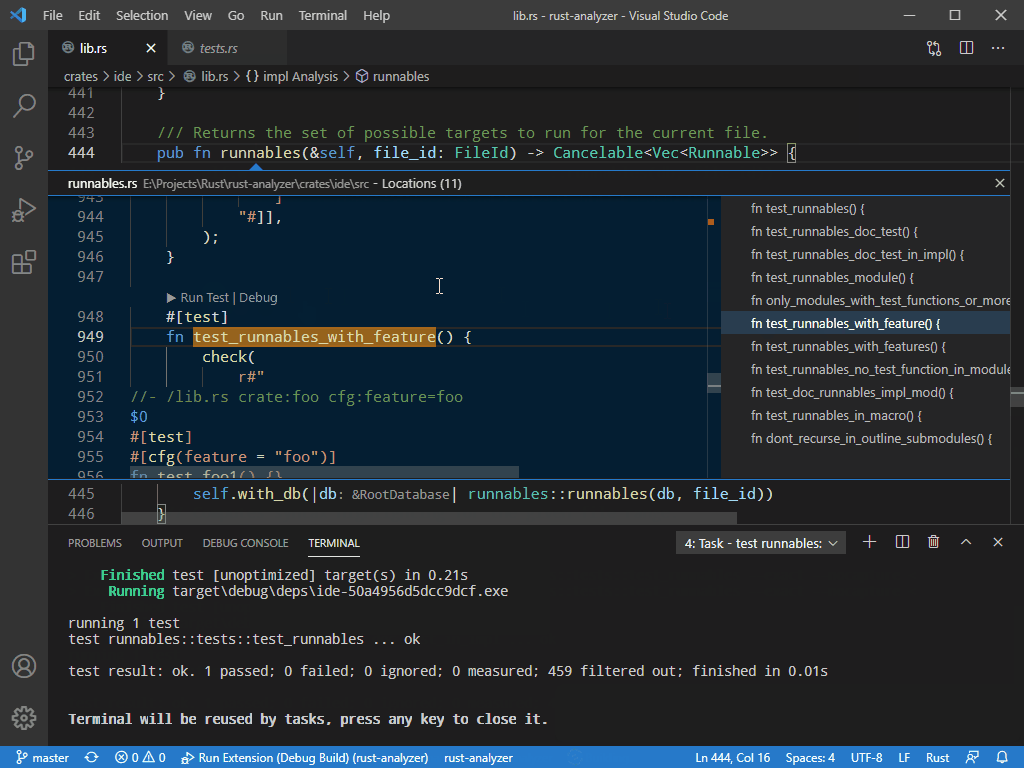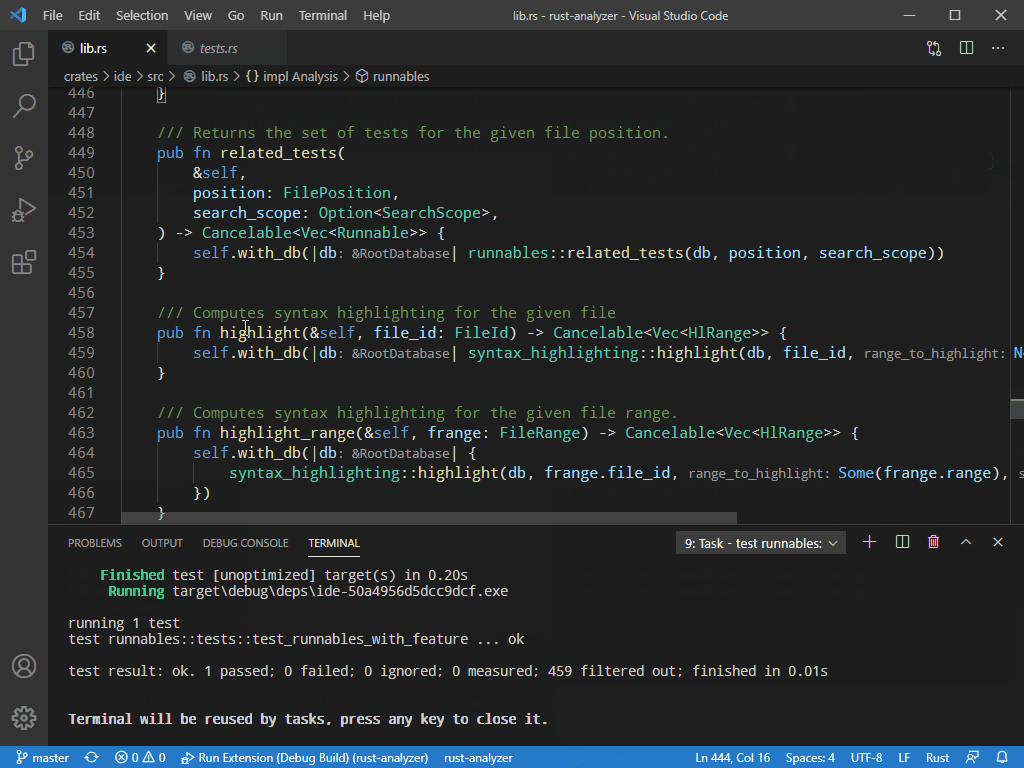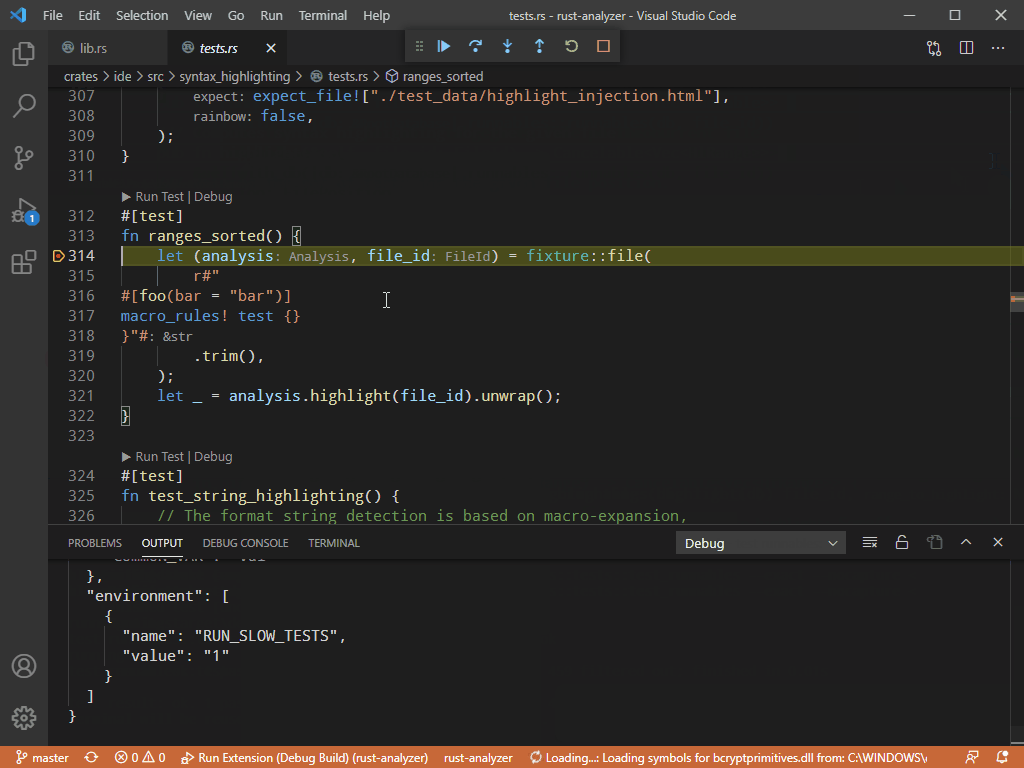{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
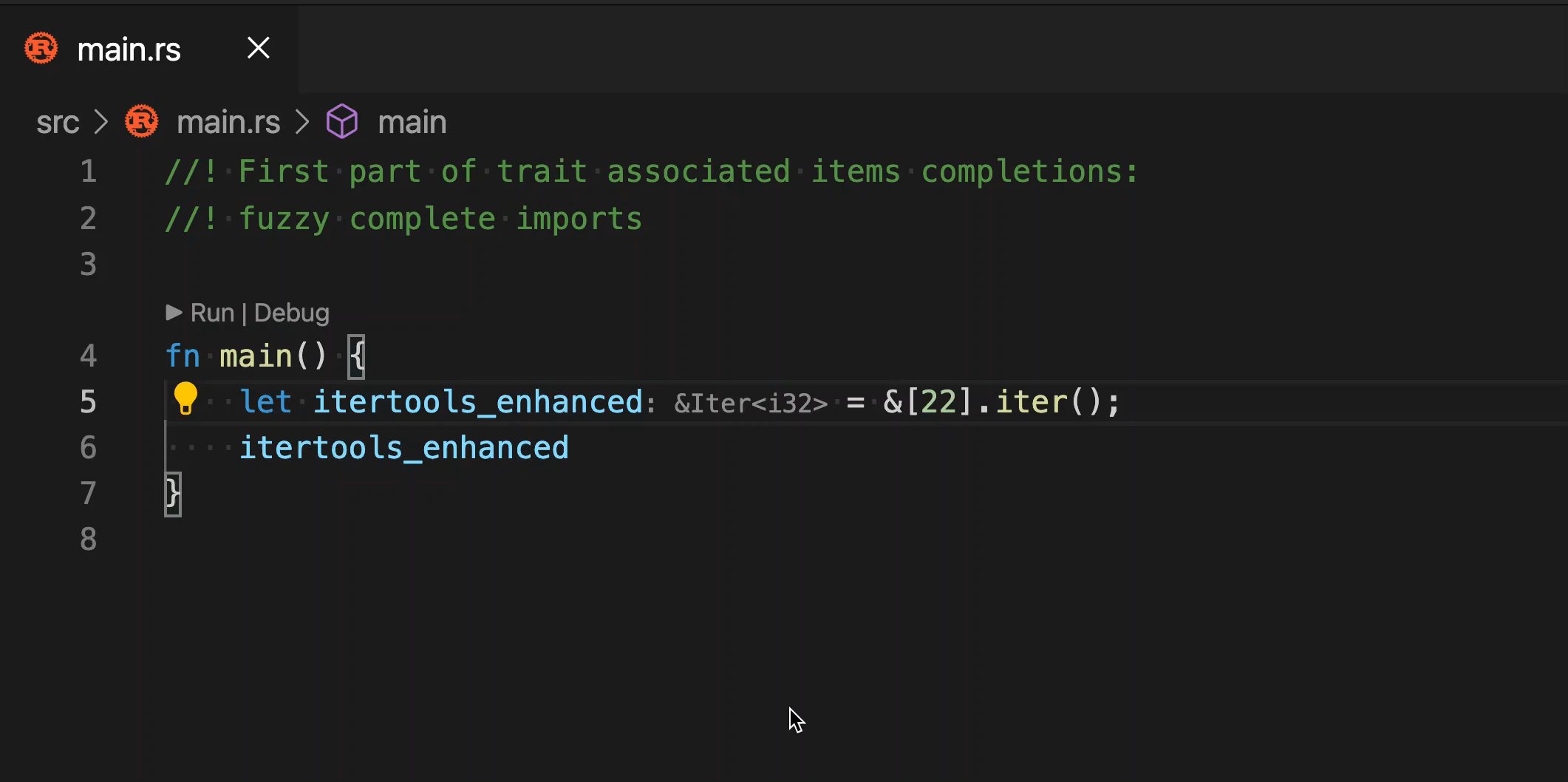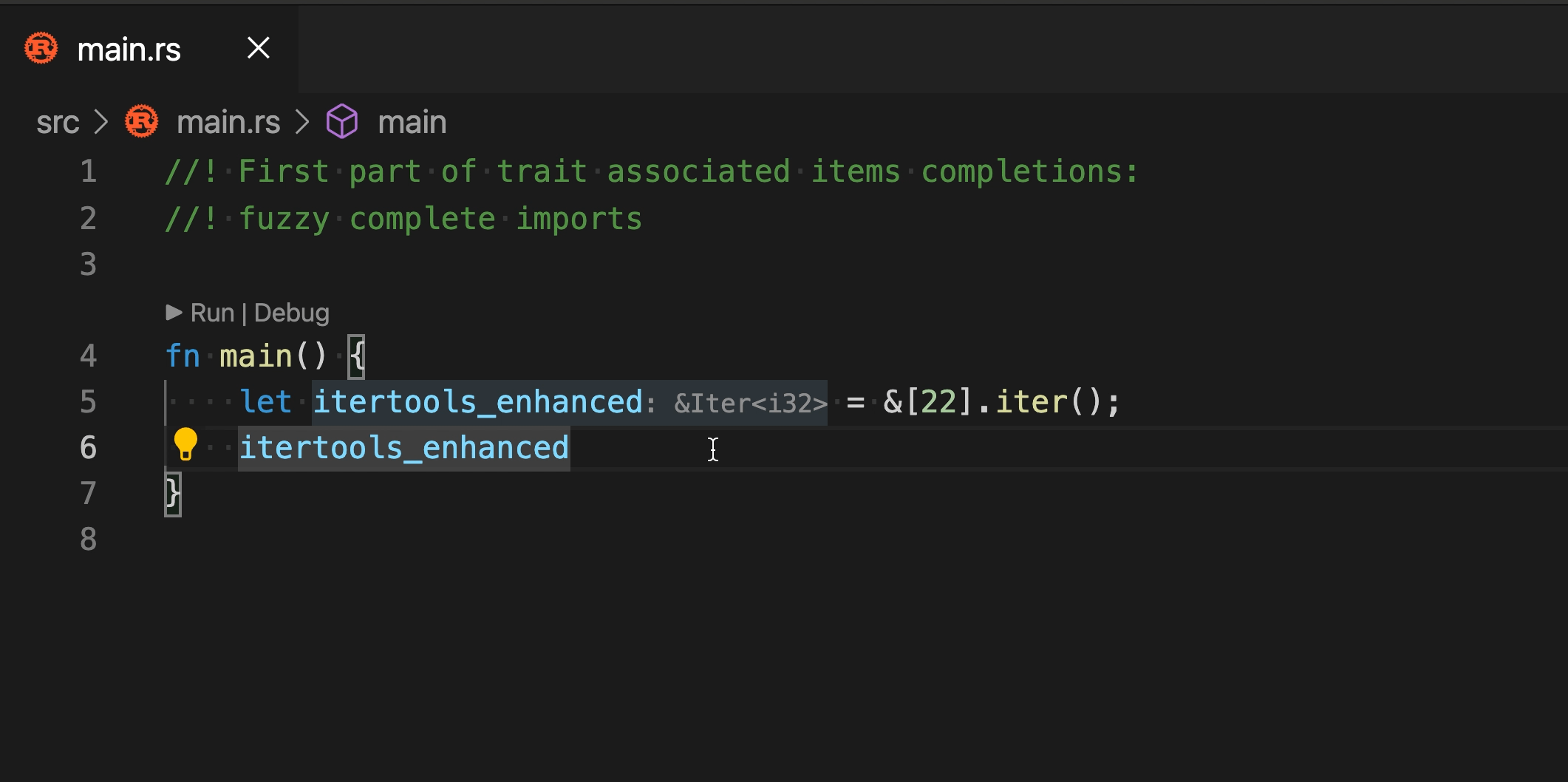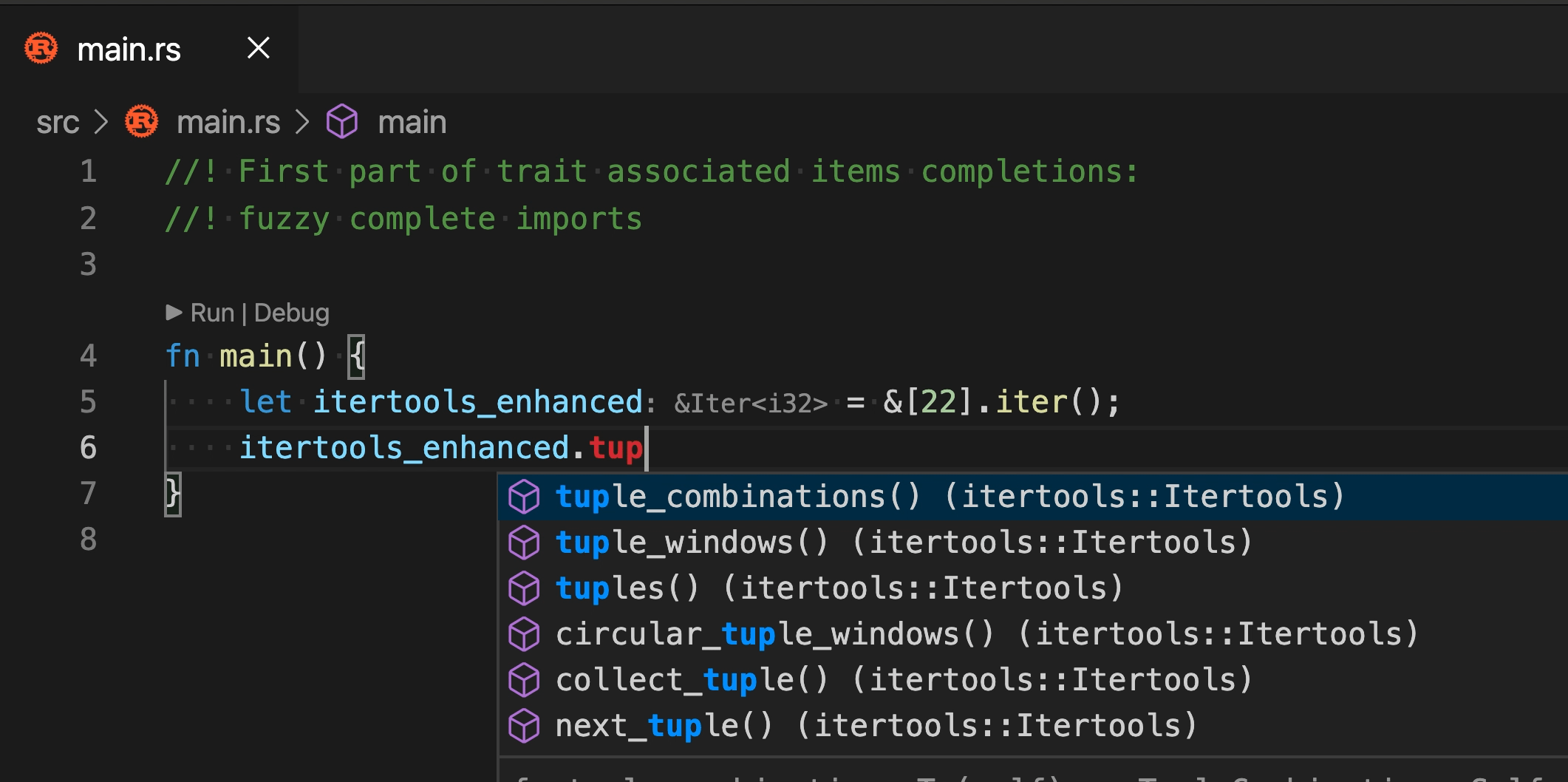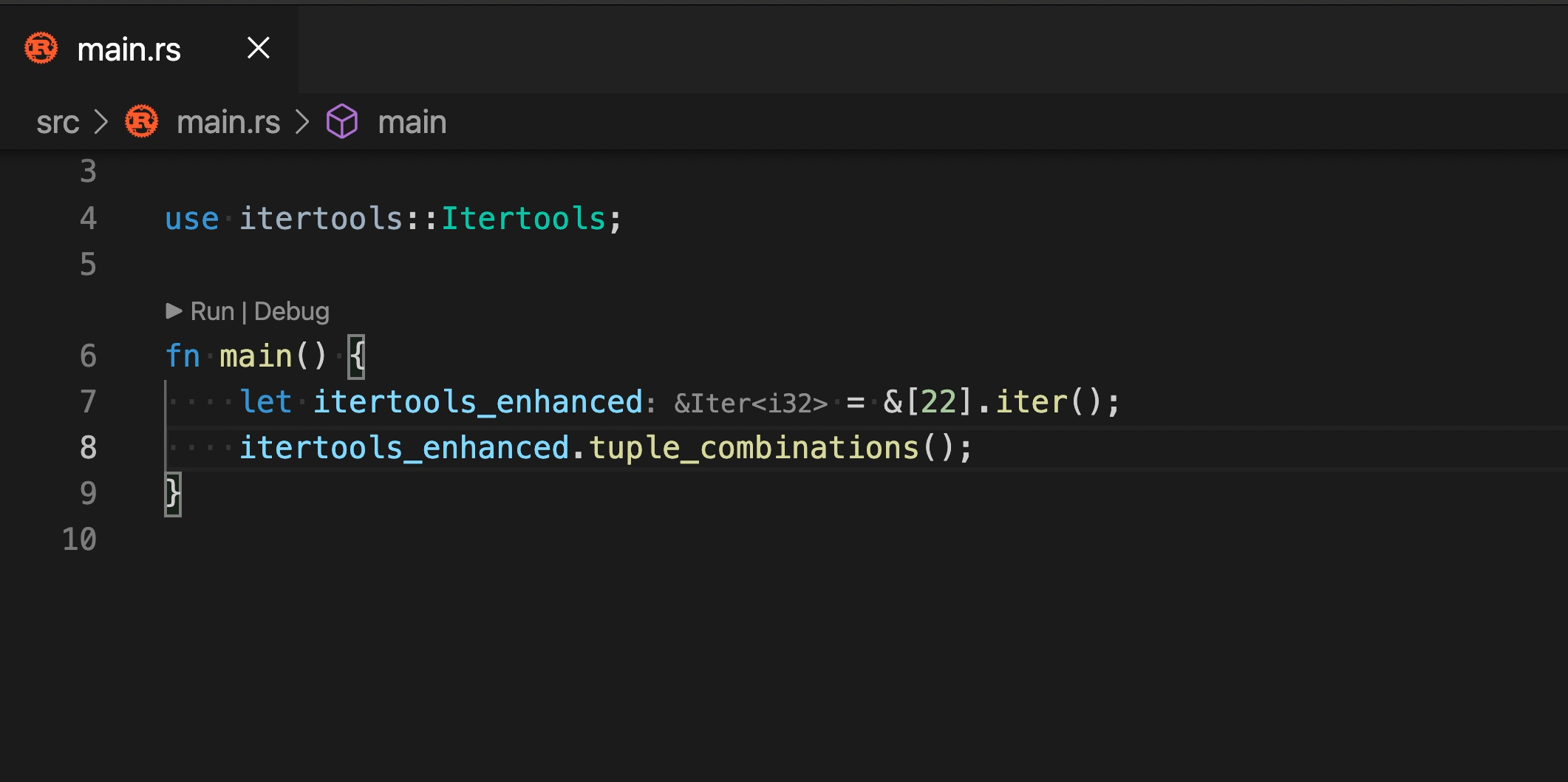{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
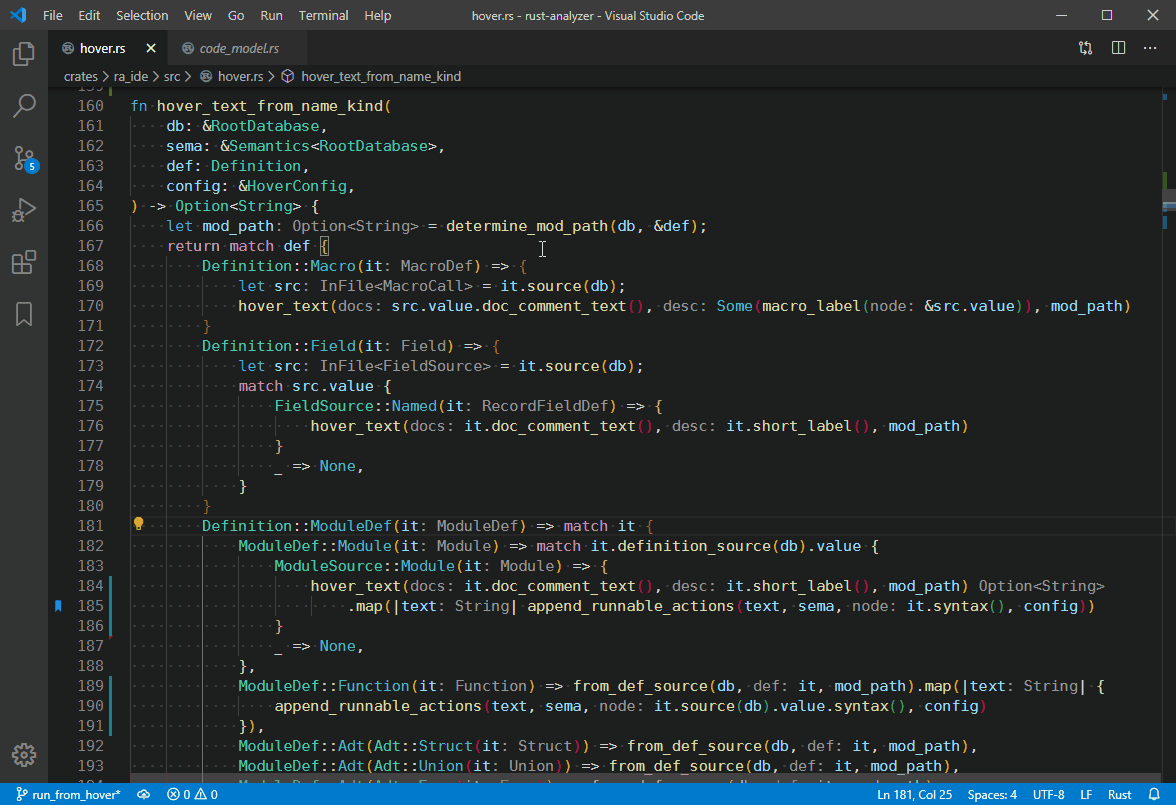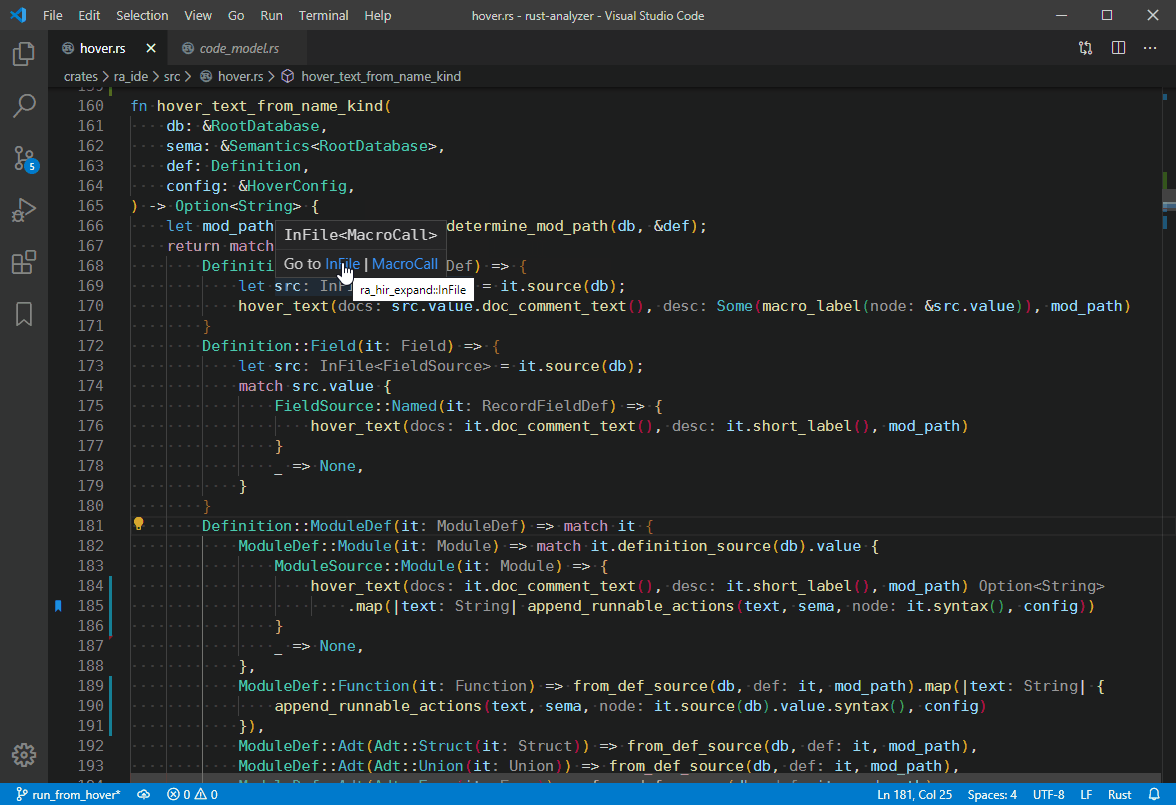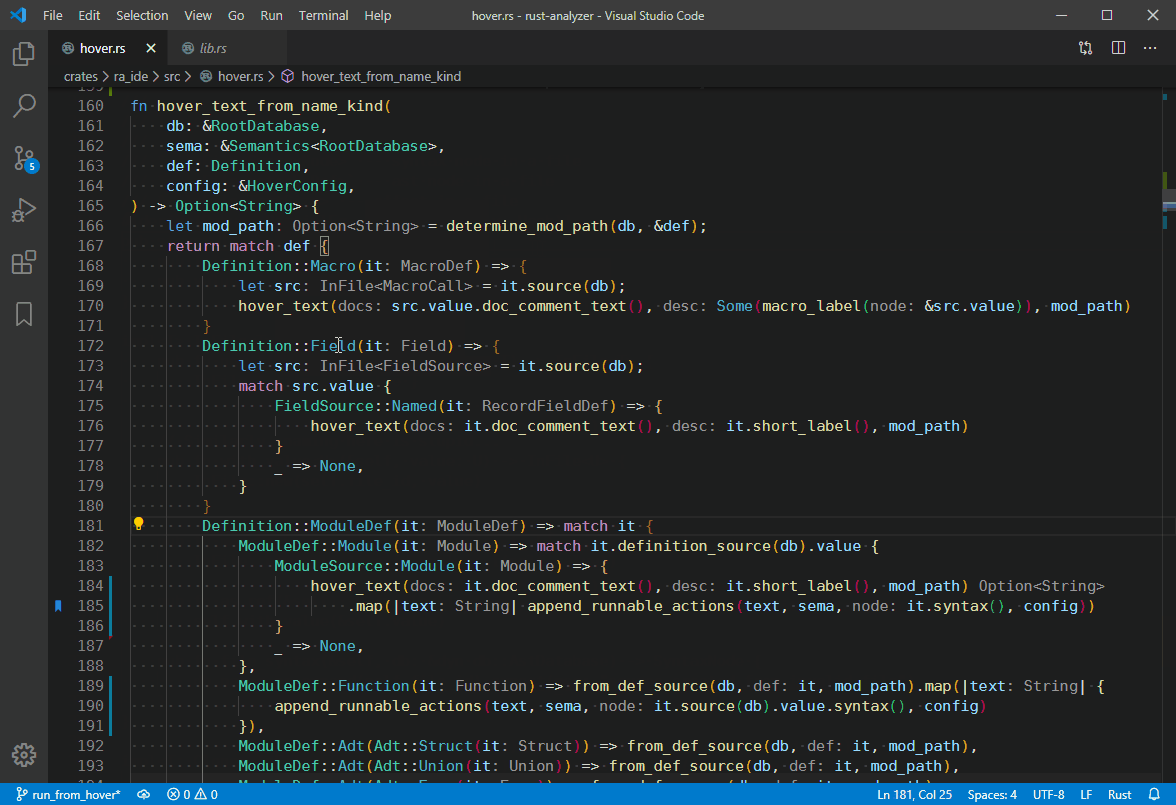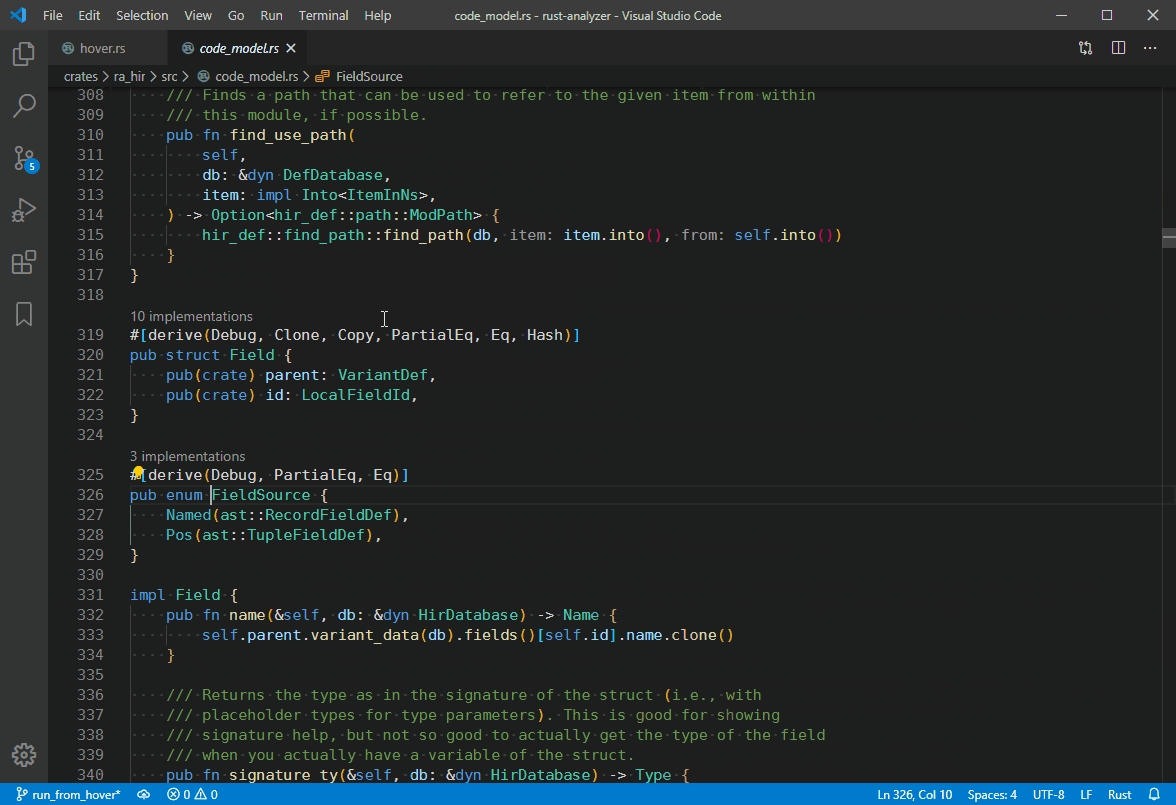{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}