"spotlight" is not a very specific or self-explaining name.
Additionally, the dialog that it triggers is called "Notable traits".
So, "notable trait" is a better name.
* Rename `#[doc(spotlight)]` to `#[doc(notable_trait)]`
* Rename `#![feature(doc_spotlight)]` to `#![feature(doc_notable_trait)]`
* Update documentation
* Improve documentation
Add `reverse` search alias for Iterator::rev()
When searching for "reverse" in rustdoc you can't find the rev method on Iterator so here is a search alias for that.
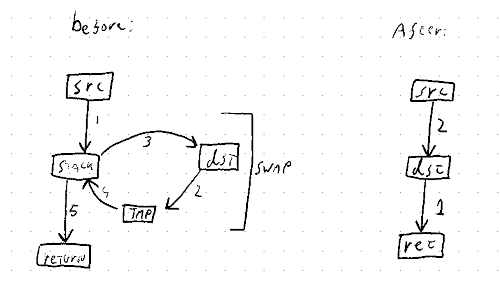
Don't implement mem::replace with mem::swap.
`swap` is a complicated operation, so this changes the implementation of `replace` to use `read` and `write` instead.
See https://github.com/rust-lang/rust/pull/83019.
I wrote there:
> Implementing the simpler operation (replace) with the much more complicated operation (swap) doesn't make a whole lot of sense. `replace` is just read+write, and the primitive for moving out of a `&mut`. `swap` is for doing that to *two* `&mut` at the same time, which is both more niche and more complicated (as shown by `swap_nonoverlapping_bytes`).
This could be especially interesting for `Option<VeryLargeStruct>::take()`, since swapping such a large structure with `swap_nonoverlapping_bytes` is going to be much less efficient than `ptr::write()`'ing a `None`.
But also for small values where `swap` just reads/writes using temporary variable, this makes a `replace` or `take` operation simpler:
convert slice doc link to intra-doc links
Continuing where #80189 stopped, with `core::slice`.
I had an issue with two dead links in my doc when implementing `Deref<Target = [T]>` for one of my type. This means that [`binary_search_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.binary_search_by_key) was available, but not [`sort_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.sort_by_key) even though it was linked in it's doc (same issue with [`as_ptr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_ptr) and [`as_mut_pbr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_mut_ptr)). It becomes available if I implement `DerefMut`, as it needs an `&mut self`.
<details>
<summary>Code that will have dead links in its doc</summary>
```rust
pub struct A;
pub struct B;
impl std::ops::Deref for B{
type Target = [A];
fn deref(&self) -> &Self::Target {
&A
}
}
```
</details>
I removed the link to `sort_by_key` from `binary_search_by_key` doc as I didn't find a nice way to have a live link:
- `binary_search_by_key` is in `core`
- `sort_by_key` is in `alloc`
- intra-doc link `slice::sort_by_key` doesn't work, as `alloc` is not available when `core` is being build (the warning can't be ignored: ```error[E0710]: an unknown tool name found in scoped lint: `rustdoc::broken_intra_doc_links` ```)
- keeping the link as an anchor `#method.sort_by_key` meant a dead link
- an absolute link would work but doesn't feel right...
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Add Option::get_or_default
Tracking issue: #82901
The original issue is #55042, which was closed, but for an invalid reason (see discussion there). Opening this to reconsider (I hope that's okay). It seems like the only gap for `Option` being "entry-like".
I ran into a need for this method where I had a `Vec<Option<MyData>>` and wanted to do `vec[n].get_or_default().my_data_method()`. Using an `Option` as an inner component of a data structure is probably where the need for this will normally arise.
Stabilize `unsafe_op_in_unsafe_fn` lint
This makes it possible to override the level of the `unsafe_op_in_unsafe_fn`, as proposed in https://github.com/rust-lang/rust/issues/71668#issuecomment-729770896.
Tracking issue: #71668
r? ```@nikomatsakis``` cc ```@SimonSapin``` ```@RalfJung```
# Stabilization report
This is a stabilization report for `#![feature(unsafe_block_in_unsafe_fn)]`.
## Summary
Currently, the body of unsafe functions is an unsafe block, i.e. you can perform unsafe operations inside.
The `unsafe_op_in_unsafe_fn` lint, stabilized here, can be used to change this behavior, so performing unsafe operations in unsafe functions requires an unsafe block.
For now, the lint is allow-by-default, which means that this PR does not change anything without overriding the lint level.
For more information, see [RFC 2585](https://github.com/rust-lang/rfcs/blob/master/text/2585-unsafe-block-in-unsafe-fn.md)
### Example
```rust
// An `unsafe fn` for demonstration purposes.
// Calling this is an unsafe operation.
unsafe fn unsf() {}
// #[allow(unsafe_op_in_unsafe_fn)] by default,
// the behavior of `unsafe fn` is unchanged
unsafe fn allowed() {
// Here, no `unsafe` block is needed to
// perform unsafe operations...
unsf();
// ...and any `unsafe` block is considered
// unused and is warned on by the compiler.
unsafe {
unsf();
}
}
#[warn(unsafe_op_in_unsafe_fn)]
unsafe fn warned() {
// Removing this `unsafe` block will
// cause the compiler to emit a warning.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
#[deny(unsafe_op_in_unsafe_fn)]
unsafe fn denied() {
// Removing this `unsafe` block will
// cause a compilation error.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
```
Added #[repr(transparent)] to core::cmp::Reverse
I found casting from an `&T` to an `&Reverse<T>` potentially useful, but found that `Reverse` was not `#[repr(transparent)]`, so after asking about it [on Reddit](https://www.reddit.com/r/rust/comments/le60uv/make_stdcmpreverse_reprtransparent_and_add_a/), I decided to go ahead and make a pull request which simply adds the attribute to the struct.
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
improve offset_from docs
`@thomcc` pointed out that the current docs leave it kind of unclear how one can satisfy the "no wrapping around `isize` or the address space" requirement of `offset_from`, so make the docs clearer about that.
FWIW, I don't think I entirely agree with that second paragraph about large objects (that I left mostly unchanged here). LLVM, to my knowledge, fundamentally assumes that all allocations fit into an `isize::MAX`. So in that sense creating a larger allocation is simply UB. I would expect a guarantee that Rust heap allocation methods will never return allocations larger than `isize::MAX` (or rather, Rust heap allocation methods should require that the `Layout` is no larger than `isize::MAX`). However, I cannot find any such requirement documented currently. Large allocations are not mentioned at all in the allocator docs, which is quite surprising -- even if we say that such allocations are not insta-UB (which I think is incompatible with LLVM), they are still extremely footgunny since `ptr::offset`/`ptr::add` do not support offsetting by more than `isize::MAX` bytes.
Furthermore, the allocator docs don't even say anything about allocations wrapping around the address space. But that is certainly something allocators must ensure never happens; we cannot expect clients to defend against this.
Cc `@rust-lang/wg-allocators`
Improve transmute docs with further clarifications
Closes#82493.
Please let me know if any of the new wording sounds off, English is not my mother tongue.
Prevent specialized ZipImpl from calling `__iterator_get_unchecked` twice with the same index
Fixes#82291
It's open for review, but conflicts with #82289, wait before merging. The conflict involves only the new test, so it should be rather trivial to fix.
Make some Option, Result methods unstably const
The following methods are now unstably const:
- Option::transpose
- Option::flatten
- Result::flatten
While some methods for could likely be made `const` in the future, nearly all of them require something to be dropped at compile-time, which isn't currently supported. The functions listed above should have a trivial path to stabilization.
Improve slice.binary_search_by()'s best-case performance to O(1)
This PR aimed to improve the [slice.binary_search_by()](https://doc.rust-lang.org/std/primitive.slice.html#method.binary_search_by)'s best-case performance to O(1).
# Noticed
I don't know why the docs of `binary_search_by` said `"If there are multiple matches, then any one of the matches could be returned."`, but the implementation isn't the same thing. Actually, it returns the **last one** if multiple matches found.
Then we got two options:
## If returns the last one is the correct or desired result
Then I can rectify the docs and revert my changes.
## If the docs are correct or desired result
Then my changes can be merged after fully reviewed.
However, if my PR gets merged, another issue raised: this could be a **breaking change** since if multiple matches found, the returning order no longer the last one instead of it could be any one.
For example:
```rust
let mut s = vec![0, 1, 1, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55];
let num = 1;
let idx = s.binary_search(&num);
s.insert(idx, 2);
// Old implementations
assert_eq!(s, [0, 1, 1, 1, 1, 2, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
// New implementations
assert_eq!(s, [0, 1, 1, 1, 2, 1, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
```
# Benchmarking
**Old implementations**
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 4)
test slice::binary_search_l1_with_dups ... bench: 59 ns/iter (+/- 3)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 5)
test slice::binary_search_l2_with_dups ... bench: 77 ns/iter (+/- 17)
test slice::binary_search_l3 ... bench: 183 ns/iter (+/- 23)
test slice::binary_search_l3_with_dups ... bench: 185 ns/iter (+/- 19)
```
**New implementations (1)**
Implemented by this PR.
```rust
if cmp == Equal {
return Ok(mid);
} else if cmp == Less {
base = mid
}
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 58 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 4)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 6)
test slice::binary_search_l3 ... bench: 200 ns/iter (+/- 30)
test slice::binary_search_l3_with_dups ... bench: 157 ns/iter (+/- 6)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 8)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 2)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l3 ... bench: 198 ns/iter (+/- 21)
test slice::binary_search_l3_with_dups ... bench: 158 ns/iter (+/- 11)
```
**New implementations (2)**
Suggested by `@nbdd0121` in [comment](https://github.com/rust-lang/rust/pull/74024#issuecomment-665430239).
```rust
base = if cmp == Greater { base } else { mid };
if cmp == Equal { break }
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 7)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 5)
test slice::binary_search_l2 ... bench: 75 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 56 ns/iter (+/- 3)
test slice::binary_search_l3 ... bench: 195 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 7)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 38 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 11)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 4)
test slice::binary_search_l3 ... bench: 194 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 18)
```
I run some benchmarking testings against on two implementations. The new implementation has a lot of improvement in duplicates cases, while in `binary_search_l3` case, it's a little bit slower than the old one.
Add diagnostic item to `Default` trait
This PR adds diagnostic item to `Default` trait to be used by rust-lang/rust-clippy#6562 issue.
Also fixes the obsolete path to the `symbols.rs` file in the comment.
Add assert_matches macro.
This adds `assert_matches!(expression, pattern)`.
Unlike the other asserts, this one ~~consumes the expression~~ may consume the expression, to be able to match the pattern. (It could add a `&` implicitly, but that's noticable in the pattern, and will make a consuming guard impossible.)
See https://github.com/rust-lang/rust/issues/62633#issuecomment-790737853
This re-uses the same `left: .. right: ..` output as the `assert_eq` and `assert_ne` macros, but with the pattern as the right part:
assert_eq:
```
assertion failed: `(left == right)`
left: `Some("asdf")`,
right: `None`
```
assert_matches:
```
assertion failed: `(left matches right)`
left: `Ok("asdf")`,
right: `Err(_)`
```
cc ```@cuviper```
Add suggestion `.collect()` for iterators in iterators
Closes#81584
```
error[E0515]: cannot return value referencing function parameter `y`
--> main3.rs:4:38
|
4 | ... .map(|y| y.iter().map(|x| x + 1))
| -^^^^^^^^^^^^^^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `y` is borrowed here
| help: Maybe use `.collect()` to allocate the iterator
```
Added the suggestion: `help: Maybe use `.collect()` to allocate the iterator`
Implement NOOP_METHOD_CALL lint
Implements the beginnings of https://github.com/rust-lang/lang-team/issues/67 - a lint for detecting noop method calls (e.g, calling `<&T as Clone>::clone()` when `T: !Clone`).
This PR does not fully realize the vision and has a few limitations that need to be addressed either before merging or in subsequent PRs:
* [ ] No UFCS support
* [ ] The warning message is pretty plain
* [ ] Doesn't work for `ToOwned`
The implementation uses [`Instance::resolve`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_middle/ty/instance/struct.Instance.html#method.resolve) which is normally later in the compiler. It seems that there are some invariants that this function relies on that we try our best to respect. For instance, it expects substitutions to have happened, which haven't yet performed, but we check first for `needs_subst` to ensure we're dealing with a monomorphic type.
Thank you to ```@davidtwco,``` ```@Aaron1011,``` and ```@wesleywiser``` for helping me at various points through out this PR ❤️.
enable atomic_min/max tests in Miri
Thanks to `@henryboisdequin` and `@GregBowyer,` Miri now supports these intrinsics. :)
Also includes the necessary Miri update.
Turn may_have_side_effect into an associated constant
The `may_have_side_effect` is an implementation detail of `TrustedRandomAccess`
trait. It describes if obtaining an iterator element may have side effects. It
is currently implemented as an associated function.
Turn `may_have_side_effect` into an associated constant. This makes the
value immediately available to the optimizer.
Convert primitives in the standard library to intra-doc links
Blocked on https://github.com/rust-lang/rust/pull/80181. I forgot that this needs to wait for the beta bump so the standard library can be documented with `doc --stage 0`.
Notably I didn't convert `core::slice` because it's like 50 links and I got scared 😨
- Rename `broken_intra_doc_links` to `rustdoc::broken_intra_doc_links`
- Ensure that the old lint names still work and give deprecation errors
- Register lints even when running doctests
Otherwise, all `rustdoc::` lints would be ignored.
- Register all existing lints as removed
This unfortunately doesn't work with `register_renamed` because tool
lints have not yet been registered when rustc is running. For similar
reasons, `check_backwards_compat` doesn't work either. Call
`register_removed` directly instead.
- Fix fallout
+ Rustdoc lints for compiler/
+ Rustdoc lints for library/
Note that this does *not* suggest `rustdoc::broken_intra_doc_links` for
`rustdoc::intra_doc_link_resolution_failure`, since there was no time
when the latter was valid.
Change twice used large const table to static
This table is used twice in core::num::dec2flt::algorithm::power_of_ten. According to the semantics of const, a separate huge definition of the table is inlined at both places.
5233edcf1c/library/core/src/num/dec2flt/algorithm.rs (L16-L22)
Theoretically this gets cleaned up by optimization passes, but in practice I am experiencing a miscompile from LTO on this code. Making the table a static, which would only be defined a single time and not require attention from LTO, eliminates the miscompile and seems semantically more appropriate anyway. A separate bug report on the LTO bug is forthcoming.
Original addition of `const` is from #27307.
The panic when the right operand is `0` is expected, but the
overflow-related panic (which occurs only for `MIN % -1`) is somewhat
surprising for two reasons: a return value of `0` would be reasonable
in this case, and, for most arithmetic operations, overflow results in
panic only when `debug_assertions` is enabled. As a result, it's
helpful to document this behavior.
The panic on division by zero is expected, but the panic on overflow
is somewhat surprising (since most arithmetic operations panic on
overflow only when `debug_assertions` is enabled). As a result, it's
helpful to document this behavior.
This commit fixes the statement of the inequality that the Euclidean
remainder satisfies. (The remainder is guaranteed to be less than
abs(rhs), not rhs.) It also rewords the documentation to make it a
little easier to read.
This table is used twice in core::num::dec2flt::algorithm::power_of_ten.
According to the semantics of const, a separate huge definition of the
table is inlined at both places.
fn power_of_ten(e: i16) -> Fp {
assert!(e >= table::MIN_E);
let i = e - table::MIN_E;
let sig = table::POWERS.0[i as usize];
let exp = table::POWERS.1[i as usize];
Fp { f: sig, e: exp }
}
Theoretically this gets cleaned up by optimization passes, but in
practice I am experiencing a miscompile from LTO on this code. Making
the table a static, which would only be defined a single time and not
require attention from LTO, eliminates the miscompile and seems
semantically more appropriate anyway. A separate bug report on the LTO
bug is forthcoming.
Specialize slice::fill with Copy type and u8/i8/bool
I don't expect rustperf could measure any perf improvements with this changes
since `slice::fill` is newly added.
Godbolt link for this change: <https://rust.godbolt.org/z/r3fzee>.
r? `@matthewjasper` since this patch added new specialization.
This commit adds `as_str` methods to `SplitWhitespace` and `SplitAsciiWhitespace`
str iterators. The methods return the remainder, similar to `as_str` methods on
`Chars` and other split iterators.
This commit also makes fields of some iterators `pub(crate)`.
[librustdoc] Only split lang string on `,`, ` `, and `\t`
Split markdown lang strings into tokens on `,`.
The previous behavior was to split lang strings into tokens on any
character that wasn't a `_`, `_`, or alphanumeric.
This is a potentially breaking change, so please scrutinize! See discussion in #78344.
I noticed some test cases that made me wonder if there might have been some reason for the original behavior:
```
t("{.no_run .example}", false, true, Ignore::None, true, false, false, false, v(), None);
t("{.sh .should_panic}", true, false, Ignore::None, false, false, false, false, v(), None);
t("{.example .rust}", false, false, Ignore::None, true, false, false, false, v(), None);
t("{.test_harness .rust}", false, false, Ignore::None, true, true, false, false, v(), None);
```
It seemed pretty peculiar to specifically test lang strings in braces, with all the tokens prefixed by `.`.
I did some digging, and it looks like the test cases were added way back in [this commit from 2014](https://github.com/rust-lang/rust/commit/3fef7a74ca9a) by `@skade.`
It looks like they were added just to make sure that the splitting was permissive, and aren't testing that those strings in particular are accepted.
Closes https://github.com/rust-lang/rust/issues/78344.
Make char and u8 methods const
char methods `len_utf8`, `len_utf16`, `to_ascii_lowercase`, `eq_ignore_ascii_case` can be made const.
`u8` methods `to_ascii_lowercase`, `to_ascii_uppercase` are required to be const as well.
`u8::eq_ignore_ascii_case` was additionally made const.
Rebase of https://github.com/rust-lang/rust/pull/79549 originally authored by ``@YenForYang.`` Changes from that PR:
- Squashed all commits from #79549.
- rebased to latest upstream master.
- Removed const attributes for `char::escape_unicode` and `char::escape_default`.
- Updated `since` attributes for `const` stabilization to 1.52.0.
cc ``@m-ou-se.``
Make ptr::write const
~~The code in this PR as of right now is not much more than an experiment.~~
~~This should, if I am not mistaken, in theory compile and pass the tests once the bootstraping compiler is updated. Thus the PR is blocked on that which should happen some time after the February the 9th. Also we might want to wait for #79989 to avoid regressing performance due to using `mem::forget` over `intrinsics::forget`~~.
Convert core/num/mod.rs to intra-doc links
Helps with #75080.
This can't convert the associated constants `MAX` and `MIN` until #74489 is merged.
r? `@poliorcetics`
rust_2015 and rust_2018 are just re-exports of v1.
rust_2021 is a module that for now just re-exports everything from v1,
such that we can add more things later.
Expand FlattenCompat folds
The former `chain`+`chain`+`fold` implementation looked nice from a
functional-programming perspective, but it introduced unnecessary layers
of abstraction on every `flat_map`/`flatten` fold. It's straightforward
to just fold each part in turn, and this makes it look like a simplified
version of the existing `try_fold` implementation.
For the `iter::bench_flat_map*` benchmarks, I get a large improvement in
`bench_flat_map_chain_sum`, from 1,598,473 ns/iter to 499,889 ns/iter,
and the rest are unchanged.
`escape_unicode`, `escape_default`, `len_utf8`, `len_utf16`, to_ascii_lowercase`, `eq_ignore_ascii_case`
`u8` methods `to_ascii_lowercase`, `to_ascii_uppercase` also must be made const
u8 methods made const
Update methods.rs
Update mod.rs
Update methods.rs
Fix `since` in rustc_const_stable to next stable
Fix `since` in rustc_const_stable to next stable
Update methods.rs
Update mod.rs
Update the bootstrap compiler
This updates the bootstrap compiler, notably leaving out a change to enable semicolon in macro expressions lint, because stdarch still depends on the old behavior.
- Link from `core::hash` to `HashMap` and `HashSet`
- Link from HashMap and HashSet to the module-level documentation on
when to use the collection
- Link from several collections to Wikipedia articles on the general
concept
Slight perf improvement on char::to_ascii_lowercase
`char::to_ascii_lowercase()` was checking if it was ascii and then if it was in the right range. Instead propose to check once (I think removing a compare and a shift in the process: [godbolt](https://godbolt.org/z/e5Tora) ).
before:
```
test char::methods::bench_to_ascii_lowercase ... bench: 11,196 ns/iter (+/- 632)
test char::methods::bench_to_ascii_uppercase ... bench: 11,656 ns/iter (+/- 671)
```
after:
```
test char::methods::bench_to_ascii_lowercase ... bench: 9,612 ns/iter (+/- 979)
test char::methods::bench_to_ascii_uppercase ... bench: 8,241 ns/iter (+/- 701)
```
(calling u8::to_ascii_lowercase and letting that flip the 5th bit is also an option, but it's more instructions. I'm thinking for things around ascii and char we want to be as efficient as possible.)
Improve design of `assert_len`
It was discussed in the [tracking issue](https://github.com/rust-lang/rust/issues/76393#issuecomment-761765448) that `assert_len`'s name and usage are confusing. This PR improves them based on a suggestion by ``@scottmcm`` in that issue.
I also improved the documentation to make it clearer when you might want to use this method.
Old example:
```rust
let range = range.assert_len(slice.len());
```
New example:
```rust
let range = range.ensure_subset_of(..slice.len());
```
Fixes#81157
improve UnsafeCell docs
Sometimes [questions like this come up](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-lang.2Fwg-unsafe-code-guidelines/topic/UnsafeCells.20as.20raw.20pointers) because the UnsafeCell docs say "it's the only legal way to obtain aliasable data that is considered mutable". That is not entirely correct, since raw pointers also provide that option. So I propose we focus the docs on the interaction of `UnsafeCell` and *shared references* specifically, which is really where they are needed.
Add internal `collect_into_array[_unchecked]` to remove duplicate code
Unlike the similar PRs #69985, #75644 and #79659, this PR only adds private functions and does not propose any new public API. The change is just for the purpose of avoiding duplicate code.
Many array methods already contained the same kind of code and there are still many array related methods to come (e.g. `Iterator::{chunks, map_windows, next_n, ...}`, `[T; N]::{cloned, copied, ...}`, ...) which all basically need this functionality. Writing custom `unsafe` code for each of those doesn't seem like a good idea. I added two functions in this PR (and not just the `unsafe` version) because I already know that I need the `Option`-returning version for `Iterator::map_windows`.
This is closely related to https://github.com/rust-lang/rust/issues/81615. I think that all options listed in that issue can be implemented using the function added in this PR. The only instance where `collect_array_into` might not be general enough is when the caller want to handle incomplete arrays manually. Currently, if `iter` yields fewer than `N` items, `None` is returned and the already yielded items are dropped. But as this is just a private function, it can be made more general in future PRs.
And while this was not the goal, this seems to lead to better assembly for `array::map`: https://rust.godbolt.org/z/75qKTa (CC ``@JulianKnodt)``
Let me know what you think :)
CC ``@matklad`` ``@bstrie``
Improve assert_eq! and assert_ne!
This PR improves `assert_eq!` and `assert_ne!` by moving the panicking code in an external function.
It does not change the fast path, but the move of the formatting in the cold path (the panic) may have a positive effect on in instruction cache use and with inlining.
Moreover, the use of trait objects instead of generic may improve compile times for `assert_eq!`-heavy code.
Godbolt link: ~~https://rust.godbolt.org/z/TYa9MT~~ \
Updated: https://rust.godbolt.org/z/bzE84x
simplify eat_digits
Simplify eat_digits by checking values in iterator, plus decrease function size, by returning unchecked slices.
https://godbolt.org/z/cxjav4
Add tests for Atomic*::fetch_{min,max}
This ensures that all atomic operations except for fences are tested. This has been useful to test my work on using atomic instructions for atomic operations in cg_clif instead of a global lock.
Ensure valid TraitRefs are created for GATs
This fixes `ProjectionTy::trait_ref` to use the correct substs. Places that need all of the substs have been updated to not use `trait_ref`.
r? ````@jackh726````
Implement RFC 2580: Pointer metadata & VTable
RFC: https://github.com/rust-lang/rfcs/pull/2580
~~Before merging this PR:~~
* [x] Wait for the end of the RFC’s [FCP to merge](https://github.com/rust-lang/rfcs/pull/2580#issuecomment-759145278).
* [x] Open a tracking issue: https://github.com/rust-lang/rust/issues/81513
* [x] Update `#[unstable]` attributes in the PR with the tracking issue number
----
This PR extends the language with a new lang item for the `Pointee` trait which is special-cased in trait resolution to implement it for all types. Even in generic contexts, parameters can be assumed to implement it without a corresponding bound.
For this I mostly imitated what the compiler was already doing for the `DiscriminantKind` trait. I’m very unfamiliar with compiler internals, so careful review is appreciated.
This PR also extends the standard library with new unstable APIs in `core::ptr` and `std::ptr`:
```rust
pub trait Pointee {
/// One of `()`, `usize`, or `DynMetadata<dyn SomeTrait>`
type Metadata: Copy + Send + Sync + Ord + Hash + Unpin;
}
pub trait Thin = Pointee<Metadata = ()>;
pub const fn metadata<T: ?Sized>(ptr: *const T) -> <T as Pointee>::Metadata {}
pub const fn from_raw_parts<T: ?Sized>(*const (), <T as Pointee>::Metadata) -> *const T {}
pub const fn from_raw_parts_mut<T: ?Sized>(*mut (),<T as Pointee>::Metadata) -> *mut T {}
impl<T: ?Sized> NonNull<T> {
pub const fn from_raw_parts(NonNull<()>, <T as Pointee>::Metadata) -> NonNull<T> {}
/// Convenience for `(ptr.cast(), metadata(ptr))`
pub const fn to_raw_parts(self) -> (NonNull<()>, <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *const T {
pub const fn to_raw_parts(self) -> (*const (), <T as Pointee>::Metadata) {}
}
impl<T: ?Sized> *mut T {
pub const fn to_raw_parts(self) -> (*mut (), <T as Pointee>::Metadata) {}
}
/// `<dyn SomeTrait as Pointee>::Metadata == DynMetadata<dyn SomeTrait>`
pub struct DynMetadata<Dyn: ?Sized> {
// Private pointer to vtable
}
impl<Dyn: ?Sized> DynMetadata<Dyn> {
pub fn size_of(self) -> usize {}
pub fn align_of(self) -> usize {}
pub fn layout(self) -> crate::alloc::Layout {}
}
unsafe impl<Dyn: ?Sized> Send for DynMetadata<Dyn> {}
unsafe impl<Dyn: ?Sized> Sync for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Debug for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Unpin for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Copy for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Clone for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Eq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialEq for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Ord for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> PartialOrd for DynMetadata<Dyn> {}
impl<Dyn: ?Sized> Hash for DynMetadata<Dyn> {}
```
API differences from the RFC, in areas noted as unresolved questions in the RFC:
* Module-level functions instead of associated `from_raw_parts` functions on `*const T` and `*mut T`, following the precedent of `null`, `slice_from_raw_parts`, etc.
* Added `to_raw_parts`
Add a `Result::into_ok_or_err` method to extract a `T` from `Result<T, T>`
When updating code to handle the semi-recent deprecation of `compare_and_swap` in favor of `compare_exchange`, which returns `Result<T, T>`, I wanted this. I've also wanted it with code using `slice::binary_search` before.
The name (and perhaps the documentation) is the hardest part here, but this name seems consistent with the other Result methods, and equivalently memorable.
Document that `assert!` format arguments are evaluated lazily
It can be useful to do some computation in `assert!` format arguments, in order to get better error messages. For example:
```rust
assert!(
some_condition,
"The state is invalid. Details: {}",
expensive_call_to_get_debugging_info(),
);
```
It seems like `assert!` only evaluates the format arguments if the assertion fails, which is useful but doesn't appear to be documented anywhere. This PR documents the behavior and adds some tests.
To digit simplification
I found out the other day that all the ascii digits have the first four bits as one would hope them to. (Eg. char `2` ends `0b0010`). There are two bits to indicate it's in the digit range ( `0b0011_0000`). If it is a true digit then all the higher bits aside from these two will be 0 (as ascii is the lowest part of the unicode u32 spectrum). So XORing with `0b11_0000` should mean we either get the number 0-9 or alternativly we get a larger number in the u32 space. If we get something that's not 0-9 then it will be discarded as it will be greater than the radix.
The code seems so fast though that there's quite a lot of noise in the benchmarks so it's not that easy to prove conclusively that it's faster as well as less instructions.
The non-fast path I was toying with as well wondering if we could do this as then we'd only have one return and less instructions still:
```
match self {
'a'..='z' => self as u32 - 'a' as u32 + 10,
'A'..='Z' => self as u32 - 'A' as u32 + 10,
_ => { radix = 10; self as u32 ^ ASCII_DIGIT_MASK},
}
```
Here's the [godbolt](https://godbolt.org/z/883c9n).
( H/T to ``@byteshadow`` for pointing out xor was what I needed)
It can be useful to do some computation in `assert!` format arguments, in order to get better error messages. For example:
```rust
assert!(
some_condition,
"The state is invalid. Details: {}",
expensive_call_to_get_debugging_info(),
);
```
It seems like `assert!` only evaluates the format arguments if the assertion fails, which is useful but doesn't appear to be documented anywhere. This PR documents the behavior and adds some tests.
The former `chain`+`chain`+`fold` implementation looked nice from a
functional-programming perspective, but it introduced unnecessary layers
of abstraction on every `flat_map`/`flatten` fold. It's straightforward
to just fold each part in turn, and this makes it look like a simplified
version of the existing `try_fold` implementation.
For the `iter::bench_flat_map*` benchmarks, I get a large improvement in
`bench_flat_map_chain_sum`, from 1,598,473 ns/iter to 499,889 ns/iter,
and the rest are unchanged.
This does not suggest adding such a function to the public API. This is
just for the purpose of avoiding duplicate code. Many array methods
already contained the same kind of code and there are still many array
related methods to come (e.g. `Iterator::{chunks, map_windows, next_n,
...}`) which all basically need this functionality. Writing custom
`unsafe` code for each of those seems not like a good idea.
The `may_have_side_effect` is an implementation detail of `TrustedRandomAccess`
trait. It describes if obtaining an iterator element may have side effects. It
is currently implemented as an associated function.
Turn `may_have_side_effect` into an associated constant. This makes the
value immediately available to the optimizer.
The use of module-level functions instead of associated functions
on `<*const T>` or `<*mut T>` follows the precedent of
`ptr::slice_from_raw_parts` and `ptr::slice_from_raw_parts_mut`.
Increment `self.index` before calling `Iterator::self.a.__iterator_ge…
…`t_unchecked` in `Zip` `TrustedRandomAccess` specialization
Otherwise if `Iterator::self.a.__iterator_get_unchecked` panics the
index would not have been incremented yet and another call to
`Iterator::next` would read from the same index again, which is not
allowed according to the API contract of `TrustedRandomAccess` for
`!Clone`.
Fixes https://github.com/rust-lang/rust/issues/81740
Only split doctest lang strings on `,`, ` `, and `\t`. Additionally, to
preserve backwards compatibility with pandoc-style langstrings, strip a
surrounding `{}`, and remove leading `.`s from each token.
Prior to this change, doctest lang strings were split on all
non-alphanumeric characters except `-` or `_`, which limited future
extensions to doctest lang string tokens, for example using `=` for
key-value tokens.
This is a breaking change, although it is not expected to be disruptive,
because lang strings using separators other than `,` and ` ` are not
very common
Bump stabilization version for const int methods
These methods missed the beta cutoff. See #80962 for details.
`@rustbot` modify labels to +A-const-fn, +A-intrinsics
r? `@m-ou-se`
Expand the docs for ops::ControlFlow a bit
Since I was writing some examples for an RFC anyway.
And I almost made the mistake of reordering the variants, so added a note and a test about that.
Stabilize remaining integer methods as `const fn`
This pull request stabilizes the following methods as `const fn`:
- `i*::checked_div`
- `i*::checked_div_euclid`
- `i*::checked_rem`
- `i*::checked_rem_euclid`
- `i*::div_euclid`
- `i*::overflowing_div`
- `i*::overflowing_div_euclid`
- `i*::overflowing_rem`
- `i*::overflowing_rem_euclid`
- `i*::rem_euclid`
- `i*::wrapping_div`
- `i*::wrapping_div_euclid`
- `i*::wrapping_rem`
- `i*::wrapping_rem_euclid`
- `u*::checked_div`
- `u*::checked_div_euclid`
- `u*::checked_rem`
- `u*::checked_rem_euclid`
- `u*::div_euclid`
- `u*::overflowing_div`
- `u*::overflowing_div_euclid`
- `u*::overflowing_rem`
- `u*::overflowing_rem_euclid`
- `u*::rem_euclid`
- `u*::wrapping_div`
- `u*::wrapping_div_euclid`
- `u*::wrapping_rem`
- `u*::wrapping_rem_euclid`
These can all be implemented on the current stable (1.49). There are two unstable details: const likely/unlikely and unchecked division/remainder. Both of these are for optimizations, and are in no way required to make the methods function; there is no exposure of these details publicly. Per comments below, it seems best practice is to stabilize the intrinsics. As such, `intrinsics::unchecked_div` and `intrinsics::unchecked_rem` have been stabilized as `const` as part of this pull request as well. The methods themselves remain unstable.
I believe part of the reason these were not stabilized previously was the behavior around division by 0 and modulo 0. After testing on nightly, the diagnostic for something like `const _: i8 = 5i8 % 0i8;` is similar to that of `const _: i8 = 5i8.rem_euclid(0i8);` (assuming the appropriate feature flag is enabled). As such, I believe these methods are ready to be stabilized as `const fn`.
This pull request represents the final methods mentioned in #53718. As such, this PR closes#53718.
`@rustbot` modify labels to +A-const-fn, +T-libs
expand/resolve: Turn `#[derive]` into a regular macro attribute
This PR turns `#[derive]` into a regular attribute macro declared in libcore and defined in `rustc_builtin_macros`, like it was previously done with other "active" attributes in https://github.com/rust-lang/rust/pull/62086, https://github.com/rust-lang/rust/pull/62735 and other PRs.
This PR is also a continuation of #65252, #69870 and other PRs linked from them, which layed the ground for converting `#[derive]` specifically.
`#[derive]` still asks `rustc_resolve` to resolve paths inside `derive(...)`, and `rustc_expand` gets those resolution results through some backdoor (which I'll try to address later), but otherwise `#[derive]` is treated as any other macro attributes, which simplifies the resolution-expansion infra pretty significantly.
The change has several observable effects on language and library.
Some of the language changes are **feature-gated** by [`feature(macro_attributes_in_derive_output)`](https://github.com/rust-lang/rust/issues/81119).
#### Library
- `derive` is now available through standard library as `{core,std}::prelude::v1::derive`.
#### Language
- `derive` now goes through name resolution, so it can now be renamed - `use derive as my_derive; #[my_derive(Debug)] struct S;`.
- `derive` now goes through name resolution, so this resolution can fail in corner cases. Crater found one such regression, where import `use foo as derive` goes into a cycle with `#[derive(Something)]`.
- **[feature-gated]** `#[derive]` is now expanded as any other attributes in left-to-right order. This allows to remove the restriction on other macro attributes following `#[derive]` (https://github.com/rust-lang/reference/issues/566). The following macro attributes become a part of the derive's input (this is not a change, non-macro attributes following `#[derive]` were treated in the same way previously).
- `#[derive]` is now expanded as any other attributes in left-to-right order. This means two derive attributes `#[derive(Foo)] #[derive(Bar)]` are now expanded separately rather than together. It doesn't generally make difference, except for esoteric cases. For example `#[derive(Foo)]` can now produce an import bringing `Bar` into scope, but previously both `Foo` and `Bar` were required to be resolved before expanding any of them.
- **[feature-gated]** `#[derive()]` (with empty list in parentheses) actually becomes useful. For historical reasons `#[derive]` *fully configures* its input, eagerly evaluating `cfg` everywhere in its target, for example on fields.
Expansion infra doesn't do that for other attributes, but now when macro attributes attributes are allowed to be written after `#[derive]`, it means that derive can *fully configure* items for them.
```rust
#[derive()]
#[my_attr]
struct S {
#[cfg(FALSE)] // this field in removed by `#[derive()]` and not observed by `#[my_attr]`
field: u8
}
```
- `#[derive]` on some non-item targets is now prohibited. This was accidentally allowed as noop in the past, but was warned about since early 2018 (#50092), despite that crater found a few such cases in unmaintained crates.
- Derive helper attributes used before their introduction are now reported with a deprecation lint. This change is long overdue (since macro modularization, https://github.com/rust-lang/rust/issues/52226#issuecomment-422605033), but it was hard to do without fixing expansion order for derives. The deprecation is tracked by #79202.
```rust
#[trait_helper] // warning: derive helper attribute is used before it is introduced
#[derive(Trait)]
struct S {}
```
Crater analysis: https://github.com/rust-lang/rust/pull/79078#issuecomment-731436821
Add a note about the correctness and the effect on unsafe code to the `ExactSizeIterator` docs
As it is a safe trait it does not provide any guarantee that the
returned length is correct and as such unsafe code must not rely on it.
That's why `TrustedLen` exists.
Fixes https://github.com/rust-lang/rust/issues/81739
Update LayoutError/LayoutErr stability attributes
`LayoutError` ended up not making it into 1.49.0, updating the stability attributes to reflect that.
I also pushed `LayoutErr` deprecation back a release to allow 2 releases before the deprecation comes into effect.
This change should be backported to beta.
Add lint for `panic!(123)` which is not accepted in Rust 2021.
This extends the `panic_fmt` lint to warn for all cases where the first argument cannot be interpreted as a format string, as will happen in Rust 2021.
It suggests to add `"{}",` to format the message as a string. In the case of `std::panic!()`, it also suggests the recently stabilized
`std::panic::panic_any()` function as an alternative.
It renames the lint to `non_fmt_panic` to match the lint naming guidelines.

This is part of #80162.
r? ```@estebank```
As it is a safe trait it does not provide any guarantee that the
returned length is correct and as such unsafe code must not rely on it.
That's why `TrustedLen` exists.
Fixes https://github.com/rust-lang/rust/issues/81739
Otherwise if `Iterator::self.a.__iterator_get_unchecked` panics the
index would not have been incremented yet and another call to
`Iterator::next` would read from the same index again, which is not
allowed according to the API contract of `TrustedRandomAccess` for
`!Clone`.
Fixes https://github.com/rust-lang/rust/issues/81740
Add some links to the cell docs.
This adds a few links to the cell module docs to make it a little easier to navigate to the types and functions it references.
Fix bug with assert!() calling the wrong edition of panic!().
The span of `panic!` produced by the `assert` macro did not carry the right edition. This changes `assert` to call the right version.
Also adds tests for the 2021 edition of panic and assert, that would've caught this.
Add doc aliases for "delete"
This patch adds doc aliases for "delete". The added aliases are supposed to reference usages `delete` in other programming languages.
- `HashMap::remove`, `BTreeMap::remove` -> `Map#delete` and `delete` keyword in JavaScript.
- `HashSet::remove`, `BTreeSet::remove` -> `Set#delete` in JavaScript.
- `mem::drop` -> `delete` keyword in C++.
- `fs::remove_file`, `fs::remove_dir`, `fs::remove_dir_all`-> `File#delete` in Java, `File#delete` and `Dir#delete` in Ruby.
Before this change, searching for "delete" in documentation returned no results.
Implement Rust 2021 panic
This implements the Rust 2021 versions of `panic!()`. See https://github.com/rust-lang/rust/issues/80162 and https://github.com/rust-lang/rfcs/pull/3007.
It does so by replacing `{std, core}::panic!()` by a bulitin macro that expands to either `$crate::panic::panic_2015!(..)` or `$crate::panic::panic_2021!(..)` depending on the edition of the caller.
This does not yet make std's panic an alias for core's panic on Rust 2021 as the RFC proposes. That will be a separate change: c5273bdfb2 That change is blocked on figuring out what to do with https://github.com/rust-lang/rust/issues/80846 first.
This patch adds doc aliases for "delete". The added aliases are
supposed to reference usages `delete` in other programming
languages.
- `HashMap::remove`, `BTreeMap::remove` -> `Map#delete` and `delete`
keyword in JavaScript.
- `HashSet::remove`, `BTreeSet::remove` -> `Set#delete` in JavaScript.
- `mem::drop` -> `delete` keyword in C++.
- `fs::remove_file`, `fs::remove_dir`, `fs::remove_dir_all`
-> `File#delete` in Java, `File#delete` and `Dir#delete` in Ruby.
Before this change, searching for "delete" in documentation
returned no results.
Optimize decimal formatting of 128-bit integers
## Description
This PR optimizes the `udivmod_1e19` function, which is used for formatting 128-bit integers, based on the algorithm provided in \[1\]. This optimization improves performance of formatting 128-bit integers, especially on 64-bit architectures. It also slightly reduces the output binary size.
## Assembler comparison
https://godbolt.org/z/YrG5zY
## Performance
#### previous results
```
test fmt::write_u128_max ... bench: 552 ns/iter (+/- 4)
test fmt::write_u128_min ... bench: 125 ns/iter (+/- 2)
```
#### new results
```
test fmt::write_u128_max ... bench: 205 ns/iter (+/- 13)
test fmt::write_u128_min ... bench: 129 ns/iter (+/- 5)
```
## Reference
\[1\] T. Granlund and P. Montgomery, “Division by Invariant Integers Using Multiplication” in Proc. of the SIGPLAN94 Conference on Programming Language Design and Implementation, 1994, pp. 61–72
Remove requirement that forces symmetric and transitive PartialEq impls to exist
### Counterexample of symmetry:
If you [have](https://docs.rs/proc-macro2/1.0.24/proc_macro2/struct.Ident.html#impl-PartialEq%3CT%3E) an impl like:
```rust
impl<T> PartialEq<T> for Ident
where
T: ?Sized + AsRef<str>
```
then Rust will not even allow the symmetric impl to exist.
```console
error[E0210]: type parameter `T` must be covered by another type when it appears before the first local type (`Ident`)
--> src/main.rs:9:6
|
9 | impl<T> PartialEq<Ident> for T where T: ?Sized + AsRef<str> {
| ^ type parameter `T` must be covered by another type when it appears before the first local type (`Ident`)
|
= note: implementing a foreign trait is only possible if at least one of the types for which it is implemented is local, and no uncovered type parameters appear before that first local type
= note: in this case, 'before' refers to the following order: `impl<..> ForeignTrait<T1, ..., Tn> for T0`, where `T0` is the first and `Tn` is the last
```
<br>
### Counterexample of transitivity:
Consider these two existing impls from `regex` and `clap`:
```rust
// regex
/// An inline representation of `Option<char>`.
pub struct Char(u32);
impl PartialEq<char> for Char {
fn eq(&self, other: &char) -> bool {
self.0 == *other as u32
}
}
```
```rust
// clap
pub(crate) enum KeyType {
Short(char),
Long(OsString),
Position(u64),
}
impl PartialEq<char> for KeyType {
fn eq(&self, rhs: &char) -> bool {
match self {
KeyType::Short(c) => c == rhs,
_ => false,
}
}
}
```
It's nice to be able to add `PartialEq<proc_macro::Punct> for char` in libproc_macro (https://github.com/rust-lang/rust/pull/80595), but it makes no sense to force an `impl PartialEq<Punct> for Char` and `impl PartialEq<Punct> for KeyType` in `regex` and `clap` in code that otherwise has nothing to do with proc macros.
<br>
`@rust-lang/libs`
Stabilize `core::slice::fill_with`
_Tracking issue: https://github.com/rust-lang/rust/issues/79221_
This stabilizes the `slice_fill_with` feature for Rust 1.51, following the stabilization of `slice_fill` in 1.50. This was requested by libs team members in https://github.com/rust-lang/rust/pull/79213.
This PR also adds the "memset" alias for `slice::fill_with`, mirroring the alias set on the `slice::fill` sibling API. This will ensure someone looking for "memset" will find both variants.
r? `@Amanieu`
Stabilize by-value `[T; N]` iterator `core::array::IntoIter`
Tracking issue: https://github.com/rust-lang/rust/issues/65798
This is unblocked now that `min_const_generics` has been stabilized in https://github.com/rust-lang/rust/pull/79135.
This PR does *not* include the corresponding `IntoIterator` impl, which is https://github.com/rust-lang/rust/pull/65819. Instead, an iterator can be constructed through the `new` method.
`new` would become unnecessary when `IntoIterator` is implemented and might be deprecated then, although it will stay stable.
Implement missing `AsMut<str>` for `str`
Allows `&mut str` to be taken by a Generic which requires `T` such that `T: AsMut<str>`. Motivating example:
```rust
impl<'i, T> From<T> for StructImmut<'i> where
T: AsRef<str> + 'i,
{
fn from(asref: T) -> Self {
let string: &str = asref.as_ref();
// ...
}
}
impl<'i, T> From<T> for StructMut<'i> where
T: AsMut<str> + 'i,
{
fn from(mut asmut: T) -> Self {
let string: &mut str = asmut.as_mut();
// ...
}
}
```
The Immutable form of this structure can be constructed by `StructImmut::from(s)` where `s` may be a `&String` or a `&str`, because `AsRef<str>` is implemented for `str`. However, the mutable form of the structure can be constructed in the same way **only** with a `&mut String`, and **not** with a `&mut str`.
This change does have some precedent, because as can be seen in [the Implementors](https://doc.rust-lang.org/std/convert/trait.AsMut.html#implementors), `AsMut<[T]>` is implemented for `[T]` as well as for `Vec<T>`, but `AsMut<str>` is implemented only for `String`. This would complete the symmetry.
As a trait implementation, this should be immediately stable.
Slight simplification of chars().count()
Slight simplification: No need to call len(), we can just count the number of non continuation bytes.
I can't see any reason not to do this, can you?
Stabilize `unsigned_abs`
Resolves#74913.
This PR stabilizes the `i*::unsigned_abs()` method, which returns the absolute value of an integer _as its unsigned equivalent_. This has the advantage that it does not overflow on `i*::MIN`.
I have gone ahead and used this in a couple locations throughout the repository.
Stabilize raw ref macros
This stabilizes `raw_ref_macros` (https://github.com/rust-lang/rust/issues/73394), which is possible now that https://github.com/rust-lang/rust/issues/74355 is fixed.
However, as I already said in https://github.com/rust-lang/rust/issues/73394#issuecomment-751342185, I am not particularly happy with the current names of the macros. So I propose we also change them, which means I am proposing to stabilize the following in `core::ptr`:
```rust
pub macro const_addr_of($e:expr) {
&raw const $e
}
pub macro mut_addr_of($e:expr) {
&raw mut $e
}
```
The macro name change means we need another round of FCP. Cc `````@rust-lang/libs`````
Fixes#73394
Add `core::stream::Stream`
[[Tracking issue: #79024](https://github.com/rust-lang/rust/issues/79024)]
This patch adds the `core::stream` submodule and implements `core::stream::Stream` in accordance with [RFC2996](https://github.com/rust-lang/rfcs/pull/2996). The RFC hasn't been merged yet, but as requested by the libs team in https://github.com/rust-lang/rfcs/pull/2996#issuecomment-725696389 I'm filing this PR to get the ball rolling.
## Documentatation
The docs in this PR have been adapted from [`std::iter`](https://doc.rust-lang.org/std/iter/index.html), [`async_std::stream`](https://docs.rs/async-std/1.7.0/async_std/stream/index.html), and [`futures::stream::Stream`](https://docs.rs/futures/0.3.8/futures/stream/trait.Stream.html). Once this PR lands my plan is to follow this up with PRs to add helper methods such as `stream::repeat` which can be used to document more of the concepts that are currently missing. That will allow us to cover concepts such as "infinite streams" and "laziness" in more depth.
## Feature gate
The feature gate for `Stream` is `stream_trait`. This matches the `#[lang = "future_trait"]` attribute name. The intention is that only the APIs defined in RFC2996 will use this feature gate, with future additions such as `stream::repeat` using their own feature gates. This is so we can ensure a smooth path towards stabilizing the `Stream` trait without needing to stabilize all the APIs in `core::stream` at once. But also don't start expanding the API until _after_ stabilization, as was the case with `std::future`.
__edit:__ the feature gate has been changed to `async_stream` to match the feature gate proposed in the RFC.
## Conclusion
This PR introduces `core::stream::{Stream, Next}` and re-exports it from `std` as `std::stream::{Stream, Next}`. Landing `Stream` in the stdlib has been a mult-year process; and it's incredibly exciting for this to finally happen!
---
r? `````@KodrAus`````
cc/ `````@rust-lang/wg-async-foundations````` `````@rust-lang/libs`````
Make more traits of the From/Into family diagnostic items
Following traits are now diagnostic items:
- `From` (unchanged)
- `Into`
- `TryFrom`
- `TryInto`
This also adds symbols for those items:
- `into_trait`
- `try_from_trait`
- `try_into_trait`
Related: https://github.com/rust-lang/rust-clippy/pull/6620#discussion_r562482587
Add `unwrap_unchecked()` methods for `Option` and `Result`
In particular:
- `unwrap_unchecked()` for `Option`.
- `unwrap_unchecked()` and `unwrap_err_unchecked()` for `Result`.
These complement other `*_unchecked()` methods in `core` etc.
Currently there are a couple of places it may be used inside rustc (`LinkedList`, `BTree`). It is also easy to find other repositories with similar functionality.
Fixes#48278.
Prevent query cycles in the MIR inliner
r? `@eddyb` `@wesleywiser`
cc `@rust-lang/wg-mir-opt`
The general design is that we have a new query that is run on the `validated_mir` instead of on the `optimized_mir`. That query is forced before going into the optimization pipeline, so as to not try to read from a stolen MIR.
The query should not be cached cross crate, as you should never call it for items from other crates. By its very design calls into other crates can never cause query cycles.
This is a pessimistic approach to inlining, since we strictly have more calls in the `validated_mir` than we have in `optimized_mir`, but that's not a problem imo.
More clear documentation for NonNull<T>
Rephrase and hopefully clarify the discussion of covariance in `NonNull<T>` documentation.
I'm very much not an expert so someone should definitely double check the correctness of what I'm saying. At the same time, the new language makes more sense to me, so hopefully it also is more logical to others whose knowledge of covariance basically begins and ends with the [Rustonomicon chapter](https://doc.rust-lang.org/nomicon/subtyping.html).
Related to #48929.
This is a temporary change only, as we wait to resolve dynamic dispatch issues. The `Stream::next` method and corresponding documentation are expected to be fully restored once we have a path to proceed.
Ref: https://github.com/rust-lang/rfcs/pull/2996#issuecomment-757386206
update docs
Change branching in `iter.skip()`
Optimize branching in `Skip`, which was brought up in #80416.
This assumes that if `next` is called, it's likely that there will be more calls to `next`, and the branch for skip will only be hit once thus it's unlikely to take that path. Even w/o the `unlikely` intrinsic, it compiles more efficiently, I believe because the path where `next` is called is always taken.
It should be noted there are very few places in the compiler where `Skip` is used, so probably won't have a noticeable perf impact.
[New impl](https://godbolt.org/z/85rdj4)
[Old impl](https://godbolt.org/z/Wc74rh)
[Some additional asm examples](https://godbolt.org/z/feKzoz) although they really don't have a ton of difference between them.
Following traits are now diagnostic items:
- `From` (unchanged)
- `Into`
- `TryFrom`
- `TryInto`
This also adds symbols for those items:
- `into_trait`
- `try_from_trait`
- `try_into_trait`
Expand docs on Iterator::intersperse
Unstable feature in #79524. This expands on the docs to bring them more in line with how other methods of `Iterator` are demonstrated.
Stability oddity with const intrinsics
cc `@RalfJung`
In https://github.com/rust-lang/rust/pull/80699#discussion_r551495670 `@usbalbin` realized we accepted some intrinsics as `const` without a `#[rustc_const_(un)stable]` attribute. I did some digging, and that example works because intrinsics inherit their stability from their parents... including `#[rustc_const_(un)stable]` attributes. While we may want to fix that (not sure, wasn't there just a MCPed PR that caused this on purpose?), we definitely want tests for it, thus this PR adding tests and some fun tracing statements.
Add NonZeroUn::is_power_of_two
This saves instructions on both new and old machines <https://rust.godbolt.org/z/4fjTMz>
- On the default x64 target (with no fancy instructions available) it saves a few instructions by not needing to also check for zero.
- On newer targets (with BMI1) it uses `BLSR` for super-short assembly.
This can be used for things like checks against alignments stored in `NonZeroUsize`.
Add `as_rchunks` (and friends) to slices
`@est31` mentioned (https://github.com/rust-lang/rust/issues/76354#issuecomment-717027175) that, for completeness, there needed to be an `as_chunks`-like method that chunks from the end (with the remainder at the beginning) like `rchunks` does.
So here's a PR for `as_rchunks: &[T] -> (&[T], &[[T; N]])` and `as_rchunks_mut: &mut [T] -> (&mut [T], &mut [[T; N]])`.
But as I was doing this and copy-pasting `from_raw_parts` calls, I thought that I should extract that into an unsafe method. It started out a private helper, but it seemed like `as_chunks_unchecked` could be reasonable as a "real" method, so I added docs and made it public. Let me know if you think it doesn't pull its weight.
Rollup of 17 pull requests
Successful merges:
- #78455 (Introduce {Ref, RefMut}::try_map for optional projections in RefCell)
- #80144 (Remove giant badge in README)
- #80614 (Explain why borrows can't be held across yield point in async blocks)
- #80670 (TrustedRandomAaccess specialization composes incorrectly for nested iter::Zips)
- #80681 (Clarify what the effects of a 'logic error' are)
- #80764 (Re-stabilize Weak::as_ptr and friends for unsized T)
- #80901 (Make `x.py --color always` apply to logging too)
- #80902 (Add a regression test for #76281)
- #80941 (Do not suggest invalid code in pattern with loop)
- #80968 (Stabilize the poll_map feature)
- #80971 (Put all feature gate tests under `feature-gates/`)
- #81021 (Remove doctree::Import)
- #81040 (doctest: Reset errors before dropping the parse session)
- #81060 (Add a regression test for #50041)
- #81065 (codegen_cranelift: Fix redundant semicolon warn)
- #81069 (Add sample code for Rc::new_cyclic)
- #81081 (Add test for #34792)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
TrustedRandomAaccess specialization composes incorrectly for nested iter::Zips
I found this while working on improvements for TRA.
After partially consuming a Zip adapter and then wrapping it into another Zip where the adapters use their `TrustedRandomAccess` specializations leads to the outer adapter returning elements which should have already been consumed.
If the optimizer gets tripped up by the addition this might affect performance for chained `zip()` iterators even when the inner one is not partially advanced but it would require more extensive fixes to `TrustedRandomAccess` to communicate those offsets earlier.
Included test fails on nightly, [playground link](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2018&gist=24fa1edf8a104ff31f5a24830593b01f)
implement ptr::write without dedicated intrinsic
This makes `ptr::write` more consistent with `ptr::write_unaligned`, `ptr::read`, `ptr::read_unaligned`, all of which are implemented in terms of `copy_nonoverlapping`.
This means we can also remove `move_val_init` implementations in codegen and Miri, and its special handling in the borrow checker.
Also see [this Zulip discussion](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/ptr.3A.3Aread.20vs.20ptr.3A.3Awrite).
Fix formatting specifiers doc links
d36e3e23a8 seems to have inadvertently changed many of these links to point to `core::fmt` instead of `std::fmt`. The information about formatting specifiers is only documented in [`std::fmt`](https://doc.rust-lang.org/std/fmt/); [`core::fmt`](https://doc.rust-lang.org/core/fmt/) is empty. 3baf6a4a74 seems to have already fixed a couple of these links to point back to `std::fmt`.
Deprecate atomic::spin_loop_hint in favour of hint::spin_loop
For https://github.com/rust-lang/rust/issues/55002
We wanted to leave `atomic::spin_loop_hint` alone when stabilizing `hint::spin_loop` so folks had some time to migrate. This now deprecates `atomic_spin_loop_hint`.
Add Iterator::intersperse_with
This is a follow-up to #79479, tracking in #79524, as discussed https://github.com/rust-lang/rust/pull/79479#issuecomment-752671731.
~~Note that I had to manually implement `Clone` and `Debug` because `derive` insists on placing a `Clone`-bound on the struct-definition, which is too narrow. There is a long-standing issue # for this somewhere around here :-)~~
Also, note that I refactored the guts of `Intersperse` into private functions and re-used them in `IntersperseWith`, so I also went light on duplicating all the tests.
If this is suitable to be merged, the tracking issue should be updated, since it only mentions `intersperse`.
Happy New Year!
r? ``@m-ou-se``
Add as_ref and as_mut methods for Bound
Add as_ref and as_mut method for std::ops::range::Bound, patterned off
of the methods of the same name on Option.
I'm not quite sure what the process is for introducing new feature gates (this is my first contribution) so I've left these ungated, but happy to do whatever is necessary to gate them.
These tests invoke the various op traits using all accepted types they
are implemented for as well as for references to those types.
This fixes#49660 and ensures the following implementations exist:
* `Add`, `Sub`, `Mul`, `Div`, `Rem`
* `T op T`, `T op &T`, `&T op T` and `&T op &T`
* for all integer and floating point types
* `AddAssign`, `SubAssign`, `MulAssign`, `DivAssign`, `RemAssign`
* `&mut T op T` and `&mut T op &T`
* for all integer and floating point types
* `Neg`
* `op T` and `op &T`
* for all signed integer and floating point types
* `Not`
* `op T` and `op &T`
* for `bool`
* `BitAnd`, `BitOr`, `BitXor`
* `T op T`, `T op &T`, `&T op T` and `&T op &T`
* for all integer types and bool
* `BitAndAssign`, `BitOrAssign`, `BitXorAssign`
* `&mut T op T` and `&mut T op &T`
* for all integer types and bool
* `Shl`, `Shr`
* `L op R`, `L op &R`, `&L op R` and `&L op &R`
* for all pairs of integer types
* `ShlAssign`, `ShrAssign`
* `&mut L op R`, `&mut L op &R`
* for all pairs of integer types
Rework diagnostics for wrong number of generic args (fixes#66228 and #71924)
This PR reworks the `wrong number of {} arguments` message, so that it provides more details and contextual hints.
Stabilize split_inclusive
### Contents of this MR
This stabilises:
* `slice::split_inclusive`
* `slice::split_inclusive_mut`
* `str::split_inclusive`
Closes#72360.
### A possible concern
The proliferation of `split_*` methods is not particularly pretty. The existence of `split_inclusive` seems to invite the addition of `rsplit_inclusive`, `splitn_inclusive`, etc. We could instead have a more general API, along these kinds of lines maybe:
```
pub fn split_generic('a,P,H>(&'a self, pat: P, how: H) -> ...
where P: Pattern
where H: SplitHow;
pub fn split_generic_mut('a,P,H>(&'a mut self, pat: P, how: H) -> ...
where P: Pattern
where H: SplitHow;
trait SplitHow {
fn reverse(&self) -> bool;
fn inclusive -> bool;
fn limit(&self) -> Option<usize>;
}
pub struct SplitFwd;
...
pub struct SplitRevInclN(pub usize);
```
But maybe that is worse.
### Let us defer that? ###
This seems like a can of worms. I think we can defer opening it now; if and when we have something more general, these two methods can become convenience aliases. But I thought I would mention it so the lang API team can consider it and have an opinion.
Add `MaybeUninit` method `array_assume_init`
When initialising an array element-by-element, the conversion to the initialised array is done through `mem::transmute`, which is both ugly and does not work with const generics (see #61956). This PR proposes the associated method `array_assume_init`, matching the style of `slice_assume_init_*`:
```rust
unsafe fn array_assume_init<T, const N: usize>(array: [MaybeUninit<T>; N]) -> [T; N];
```
Example:
```rust
let mut array: [MaybeUninit<i32>; 3] = MaybeUninit::uninit_array();
array[0].write(0);
array[1].write(1);
array[2].write(2);
// SAFETY: Now safe as we initialised all elements
let array: [i32; 3] = unsafe {
MaybeUninit::array_assume_init(array)
};
```
Things I'm unsure about:
* Should this be a method of array instead?
* Should the function be const?
std/core docs: fix wrong link in PartialEq
PartialEq doc was attempting to link to ``[`Eq`]`` but instead we got a link to `` `eq` ``. Disambiguate with `trait@Eq`.
You can see the bad link [here](https://doc.rust-lang.org/std/cmp/trait.PartialEq.html) (Second sentence, "floating point types implement PartialEq but not Eq").
These methods work very similarly to `Option`'s methods `as_ref` and
`as_mut`. They are useful in several situation, particularly when
calling other array methods (like `map`) on the result. Unfortunately,
we can't easily call them `as_ref` and `as_mut` as that would shadow
those methods on slices, thus being a breaking change (that is likely
to affect a lot of code).
In particular:
- `unwrap_unchecked()` for `Option`.
- `unwrap_unchecked()` and `unwrap_err_unchecked()` for `Result`.
These complement other `*_unchecked()` methods in `core` etc.
Currently there are a couple of places it may be used inside rustc
(`LinkedList`, `BTree`). It is also easy to find other repositories
with similar functionality.
Fixes#48278.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Implement From<char> for u64 and u128.
With this PR you can write
```
let u = u64::from('👤');
let u = u128::from('👤');
```
Previously, you could already write `as` conversions ([Playground link](https://play.rust-lang.org/?version=stable&mode=debug&edition=2018&gist=cee18febe28e69024357d099f07ca081)):
```
// Lossless conversions
dbg!('👤' as u32); // Prints 128100
dbg!('👤' as u64); // Prints 128100
dbg!('👤' as u128); // Prints 128100
// truncates, thus no `From` impls.
dbg!('👤' as u8); // Prints 100
dbg!('👤' as u16); // Prints 62564
// These `From` impls already exist.
dbg!(u32::from('👤')); // Prints 128100
dbg!(u64::from(u32::from('👤'))); // Prints 128100
```
The idea is from ``@gendx`` who opened [this Internals thread](https://internals.rust-lang.org/t/implement-from-char-for-u64/13454), and ``@withoutboats`` responded that someone should open a PR for it.
Some people mentioned `From<char>` impls for `f32` and `f64`, but that doesn't seem correct to me, so I didn't include them here.
I don't know what the feature should be named. Must it be registered somewhere, like unstable features?
r? ``@withoutboats``
I split the example into two: one that fails to compile, and one that
works. I also made them identical except for the addition of `by_ref`
so we don't confuse readers with random differences.
Stabilize slice::strip_prefix and slice::strip_suffix
These two methods are useful. The corresponding methods on `str` are already stable.
I believe that stablising these now would not get in the way of, in the future, extending these to take a richer pattern API a la `str`'s patterns.
Tracking PR: #73413. I also have an outstanding PR to improve the docs for these two functions and the corresponding ones on `str`: #75078
I have tried to follow the [instructions in the dev guide](https://rustc-dev-guide.rust-lang.org/stabilization_guide.html#stabilization-pr). The part to do with `compiler/rustc_feature` did not seem applicable. I assume that's because these are just library features, so there is no corresponding machinery in rustc.
Change:
```
`parse` can parse any type that...
```
to:
```
`parse` can parse into any type that...
```
Word `into` added to be more precise and in coherence with other parts of the doc.
Add more code spans to docs in intrinsics.rs
I have added some more code spans in core/src/intrinsics.rs, changing some `=` to `==`, etc. I also changed the wording in some sections.
After partially consuming a Zip adapter and then wrapping it into
another Zip where the adapters use their TrustedRandomAccess specializations
leads to the outer adapter returning elements which should have already been
consumed.
remove allow(incomplete_features) from std
cc https://github.com/rust-lang/rust/pull/80349#issuecomment-753357123
> Now I am somewhat concerned that the standard library uses some of these features...
I think it is theoretically ok to use incomplete features in the standard library or the compiler if we know that there is an already working subset and we explicitly document what we have to be careful about. Though at that point it is probably better to try and split the incomplete feature into two separate ones, similar to `min_specialization`.
Will be interesting once `feature(const_evaluatable_checked)` works well enough to imo be used in the compiler but not yet well enough to be removed from `INCOMPLETE_FEATURES`.
r? `@RalfJung`
Add docs note about `Any::type_id` on smart pointers
Fixes#79868.
There's an issue I've run into a couple times while using values of type `Box<dyn Any>` - essentially, calling `value.type_id()` doesn't dereference to the trait object, but uses the implementation of `Any` for `Box<dyn Any>`, giving us the `TypeId` of the container instead of the object inside it.
I couldn't find any notes about this in the documentation and - while it could be inferred from existing knowledge of Rust and the blanket implemenation of `Any` - I think it'd be nice to have a note about it in the documentation for the `any` module.
Anyways, here's a first draft of a section about it. I'm happy to revise wording :)
The return of the GroupBy and GroupByMut iterators on slice
According to https://github.com/rust-lang/rfcs/pull/2477#issuecomment-742034372, I am opening this PR again, this time I implemented it in safe Rust only, it is therefore much easier to read and is completely safe.
This PR proposes to add two new methods to the slice, the `group_by` and `group_by_mut`. These two methods provide a way to iterate over non-overlapping sub-slices of a base slice that are separated by the predicate given by the user (e.g. `Partial::eq`, `|a, b| a.abs() < b.abs()`).
```rust
let slice = &[1, 1, 1, 3, 3, 2, 2, 2];
let mut iter = slice.group_by(|a, b| a == b);
assert_eq!(iter.next(), Some(&[1, 1, 1][..]));
assert_eq!(iter.next(), Some(&[3, 3][..]));
assert_eq!(iter.next(), Some(&[2, 2, 2][..]));
assert_eq!(iter.next(), None);
```
[An RFC](https://github.com/rust-lang/rfcs/pull/2477) was open 2 years ago but wasn't necessary.
Remove all doc_comment!{} hacks by using #[doc = expr] where needed.
This replaces about 200 cases of
`````rust
doc_comment! {
concat!("The smallest value that can be represented by this integer type.
# Examples
Basic usage:
```
", $Feature, "assert_eq!(", stringify!($SelfT), "::MIN, ", stringify!($Min), ");",
$EndFeature, "
```"),
#[stable(feature = "assoc_int_consts", since = "1.43.0")]
pub const MIN: Self = !0 ^ ((!0 as $UnsignedT) >> 1) as Self;
}
`````
by
```rust
/// The smallest value that can be represented by this integer type.
///
/// # Examples
///
/// Basic usage:
///
/// ```
#[doc = concat!("assert_eq!(", stringify!($SelfT), "::MIN, ", stringify!($Min), ");")]
/// ```
#[stable(feature = "assoc_int_consts", since = "1.43.0")]
pub const MIN: Self = !0 ^ ((!0 as $UnsignedT) >> 1) as Self;
```
---
**Note:** For a usable diff, make sure to enable 'ignore whitspace': https://github.com/rust-lang/rust/pull/79150/files?diff=unified&w=1
Rollup of 9 pull requests
Successful merges:
- #78934 (refactor: removing library/alloc/src/vec/mod.rs ignore-tidy-filelength)
- #79479 (Add `Iterator::intersperse`)
- #80128 (Edit rustc_ast::ast::FieldPat docs)
- #80424 (Don't give an error when creating a file for the first time)
- #80458 (Some Promotion Refactoring)
- #80488 (Do not create dangling &T in Weak<T>::drop)
- #80491 (Miri: make size/align_of_val work for dangling raw ptrs)
- #80495 (Rename kw::Invalid -> kw::Empty)
- #80513 (Add regression test for #80062)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add "chr" as doc alias to char::from_u32
Many programming languages provide a function called `chr` - Perl, Python, PHP, Visual Basic, SQL. This change makes `char::from_u32` easier to discover in the documentation.
`ord` is not added as its name conflicts with `Ord` trait, and it's not exactly clear what it could point to (`<u32 as From<char>>::from`?). I don't think it's exactly necessary, as `char::from_u32` documentation page says you can do reverse conversion with `as` operator anyway.
Add "length" as doc alias to len methods
Currently when searching for `length` there are no results: https://doc.rust-lang.org/std/?search=length. This makes `len` methods appear when searching for `length`.
Add `impl Div<NonZeroU{0}> for u{0}` which cannot panic
Dividing an unsigned int by a `NonZeroUxx` requires a user to write (for example, in [this SO question](https://stackoverflow.com/questions/64855738/how-to-inform-the-optimizer-that-nonzerou32get-will-never-return-zero)):
```
pub fn safe_div(x: u32, y: std::num::NonZeroU32) -> u32 {
x / y.get()
}
```
which generates a panicking-checked-div [assembly](https://godbolt.org/#g:!((g:!((g:!((h:codeEditor,i:(fontScale:14,j:1,lang:rust,selection:(endColumn:2,endLineNumber:6,positionColumn:2,positionLineNumber:6,selectionStartColumn:2,selectionStartLineNumber:6,startColumn:2,startLineNumber:6),source:%27pub+fn+div(x:+u32,+y:+u32)+-%3E+u32+%7B%0A++++x+/+y%0A%7D%0Apub+fn+safe_div(x:+u32,+y:+std::num::NonZeroU32)+-%3E+u32+%7B%0A++++x+/+y.get()+//+an+unchecked+division+expected%0A%7D%27),l:%275%27,n:%270%27,o:%27Rust+source+%231%27,t:%270%27)),k:50,l:%274%27,n:%270%27,o:%27%27,s:0,t:%270%27),(g:!((h:compiler,i:(compiler:r1470,filters:(b:%270%27,binary:%271%27,commentOnly:%270%27,demangle:%270%27,directives:%270%27,execute:%271%27,intel:%270%27,libraryCode:%271%27,trim:%271%27),fontScale:14,j:1,lang:rust,libs:!(),options:%27-O%27,selection:(endColumn:1,endLineNumber:1,positionColumn:1,positionLineNumber:1,selectionStartColumn:1,selectionStartLineNumber:1,startColumn:1,startLineNumber:1),source:1),l:%275%27,n:%270%27,o:%27rustc+1.47.0+(Editor+%231,+Compiler+%231)+Rust%27,t:%270%27)),k:50,l:%274%27,n:%270%27,o:%27%27,s:0,t:%270%27)),l:%272%27,n:%270%27,o:%27%27,t:%270%27)),version:4).
Avoiding the `panic` currently requires `unsafe` code.
This PR adds an `impl Div<NonZeroU{0}> for u{0}` (and `impl Rem<NonZeroU{0}> for u{0}`) which calls the `unchecked_div` (and `unchecked_rem`) intrinsic without any additional checks,
making the following code compile:
```
pub fn safe_div(x: u32, y: std::num::NonZeroU32) -> u32 {
x / y
}
pub fn safe_rem(x: u32, y: std::num::NonZeroU32) -> u32 {
x % y
}
```
The doc is set to match the regular div impl [docs](https://doc.rust-lang.org/beta/src/core/ops/arith.rs.html#460).
I've marked these as stable because (as I understand it) trait impls are automatically stable. I'm happy to change it to unstable if needed.
Following `@dtolnay` template from a similar issue:
this adds the following **stable** impls, which rely on dividing unsigned integers by nonzero integers being well defined and previously would have involved unsafe code to encode that knowledge:
```
impl Div<NonZeroU8> for u8 {
type Output = u8;
}
impl Rem<NonZeroU8> for u8 {
type Output = u8;
}
```
and equivalent for u16, u32, u64, u128, usize, but **not** for i8, i16, i32, i64, i128, isize (since -1/MIN is undefined).
r? `@dtolnay`
We hope later to extend `core::str::Pattern` to slices too, perhaps as
part of stabilising that. We want to minimise the amount of type
inference breakage when we do that, so we don't want to stabilise
strip_prefix and strip_suffix taking a simple `&[T]`.
@KodrAus suggested the approach of introducing a new perma-unstable
trait, which reduces this future inference break risk.
I found it necessary to make two impls of this trait, as the unsize
coercion don't apply when hunting for trait implementations.
Since SlicePattern's only method returns a reference, and the whole
trait is just a wrapper for slices, I made the trait type be the
non-reference type [T] or [T;N] rather than the reference. Otherwise
the trait would have a lifetime parameter.
I marked both the no-op conversion functions `#[inline]`. I'm not
sure if that is necessary but it seemed at the very least harmless.
Signed-off-by: Ian Jackson <ijackson@chiark.greenend.org.uk>
Stabilize `core::slice::fill`
Tracking issue https://github.com/rust-lang/rust/issues/70758
Stabilizes the `core::slice::fill` API in Rust 1.50, adding a `memset` doc alias so people coming from C/C++ looking for this operation can find it in the docs. This API hasn't seen any changes since we changed the signature in https://github.com/rust-lang/rust/pull/71165/, and it seems like the right time to propose stabilization. Thanks!
r? `@m-ou-se`
Deprecate atomic compare_and_swap method
Finish implementing [RFC 1443](https://github.com/rust-lang/rfcs/blob/master/text/1443-extended-compare-and-swap.md) (https://github.com/rust-lang/rfcs/pull/1443).
It was decided to deprecate `compare_and_swap` [back in Rust 1.12 already](https://github.com/rust-lang/rust/issues/31767#issuecomment-215903038). I can't find any info about that decision being reverted. My understanding is just that it has been forgotten. If there has been a decision on keeping `compare_and_swap` then it's hard to find, and even if this PR does not go through it can act as a place where people can find out about the decision being reverted.
Atomic operations are hard to understand, very hard. And it does not help that there are multiple similar methods to do compare and swap with. They are so similar that for a reader it might be hard to understand the difference. This PR aims to make that simpler by finally deprecating `compare_and_swap` which is essentially just a more limited version of `compare_exchange`. The documentation is also updated (according to the RFC text) to explain the differences a bit better.
Even if we decide to not deprecate `compare_and_swap`. I still think the documentation for the atomic operations should be improved to better describe their differences and similarities. And the documentation can be written nicer than the PR currently proposes, but I wanted to start somewhere. Most of it is just copied from the RFC.
The documentation for `compare_exchange` and `compare_exchange_weak` indeed describe how they work! The problem is that they are more complex and harder to understand than `compare_and_swap`. So for someone who does not fully grasp this they might fall back to using `compare_and_swap`. Making the documentation outline the similarities and differences might build a bridge for people so they can cross over to the more powerful and sometimes more efficient operations.
The conversions I do to avoid the `std` internal deprecation errors are very straight forward `compare_and_swap -> compare_exchange` changes where the orderings are just using the mapping in the new documentation. Only in one place did I use `compare_exchange_weak`. This can probably be improved further. But the goal here was not for those operations to be perfect. Just to not get worse and to allow the deprecation to happen.
Added [T; N]::zip()
This is my first PR to rust so I hope I have done everything right, or at least close :)
---
This is PR adds the array method `[T; N]::zip()` which, in my mind, is a natural extension to #75212.
My implementation of `zip()` is mostly just a modified copy-paste of `map()`. Should I keep the comments? Also am I right in assuming there should be no way for the `for`-loop to panic, thus no need for the dropguard seen in the `map()`-function?
The doc comment is in a similar way a slightly modified copy paste of [`Iterator::zip()`](https://doc.rust-lang.org/beta/std/iter/trait.Iterator.html#method.zip)
`@jplatte` mentioned in [#75490](https://github.com/rust-lang/rust/pull/75490#issuecomment-677790758) `zip_with()`,
> zip and zip_with seem like they would be useful :)
is this something I should add (assuming there is interest for this PR at all :))
Fix memory leak in test "mem::uninit_write_slice_cloned_no_drop"
This fixes#80116. I replaced the `Rc` based method I was using with a type that panics when dropped.
Move {f32,f64}::clamp to core.
`clamp` was recently stabilized (tracking issue: https://github.com/rust-lang/rust/issues/44095). But although `Ord::clamp` was added in `core` (because `Ord` is in `core`), the versions for the `f32` and `f64` primitives were added in `std` (together with `floor`, `sin`, etc.), not in `core` (together with `min`, `max`, `from_bits`, etc.).
This change moves them to `core`, such that `clamp` on floats is available in `no_std` programs as well.
Integer types have a `count_ones` method that end up calling
`intrinsics::ctpop`.
On some architectures, that intrinsic is translated as a corresponding
CPU instruction know as "popcount" or "popcnt".
This PR makes it so that searching for those names in rustdoc shows those methods.
CC https://blog.rust-lang.org/2020/11/19/Rust-1.48.html#adding-search-aliases
MaybeUninit::copy/clone_from_slice
This PR adds 2 new methods to MaybeUninit under the feature of `maybe_uninit_write_slice`: `copy_from_slice` and `clone_from_slice`.
These are useful for initializing uninitialized buffers (such as the one returned by `Vec::spare_capacity_mut` for example) with initialized data.
The methods behave similarly to the methods on slices, but the destination is uninitialized and they return the destination slice as an initialized slice.
std::iter: document iteration over `&T` and `&mut T`
A colleague of mine is new to Rust, and mentioned that it was “slightly
confusing” to figure out what `&mut` does in iterating over `&mut foo`:
```rust
for value in &mut self.my_vec {
// ...
}
```
My colleague had read the `std::iter` docs and not found the answer
there. There is a brief section at the top about “the three forms of
iteration”, which mentions `iter_mut`, but it doesn’t cover the purpose
of `&mut coll` for a collection `coll`. This patch adds an explanatory
section to the docs. I opted to create a new section so that it can
appear after the note that `impl<I: Iterator> IntoIterator for I`, and
it’s nice for the existing “three forms of iteration” to appear near the
top.
Test Plan:
Ran `./x.py doc library/core`, and the result looked good, including
links. Manually copy-pasted the two doctests into the playground and ran
them.
wchargin-branch: doc-iter-by-reference
Add some core::cmp::Ordering helpers
...to allow easier equal-to-or-greater-than and less-than-or-equal-to
comparisons.
Prior to Rust 1.42 a greater-than-or-equal-to comparison might be written
either as a match block, or a traditional conditional check like this:
```rust
if cmp == Ordering::Equal || cmp == Ordering::Greater {
// Do something
}
```
Which requires two instances of `cmp`. Don't forget that while `cmp` here
is very short, it could be something much longer in real use cases.
From Rust 1.42 a nicer alternative is possible:
```rust
if matches!(cmp, Ordering::Equal | Ordering::Greater) {
// Do something
}
```
The commit adds another alternative which may be even better in some cases:
```rust
if cmp.is_equal_or_greater() {
// Do something
}
```
The earlier examples could be cleaner than they are if the variants of
`Ordering` are imported such that `Equal`, `Greater` and `Less` can be
referred to directly, but not everyone will want to do that.
The new solution can shorten lines, help avoid logic mistakes, and avoids
having to import `Ordering` / `Ordering::*`.
...to allow easier greater-than-or-equal-to and less-than-or-equal-to
comparisons, and variant checking without needing to import the enum,
similar to `Option::is_none()` / `Option::is_some()`, in situations where
you are dealing with an `Ordering` value. (Simple `PartialOrd` / `Ord`
based evaluation may not be suitable for all situations).
Prior to Rust 1.42 a greater-than-or-equal-to comparison might be written
either as a match block, or a traditional conditional check like this:
```rust
if cmp == Ordering::Equal || cmp == Ordering::Greater {
// Do something
}
```
Which requires two instances of `cmp`. Don't forget that while `cmp` here
is very short, it could be something much longer in real use cases.
From Rust 1.42 a nicer alternative is possible:
```rust
if matches!(cmp, Ordering::Equal | Ordering::Greater) {
// Do something
}
```
The commit adds another alternative which may be even better in some cases:
```rust
if cmp.is_ge() {
// Do something
}
```
The earlier examples could be cleaner than they are if the variants of
`Ordering` are imported such that `Equal`, `Greater` and `Less` can be
referred to directly, but not everyone will want to do that.
The new solution can shorten lines, help avoid logic mistakes, and avoids
having to import `Ordering` / `Ordering::*`.
Constier maybe uninit
I was playing around trying to make `[T; N]::zip()` in #79451 be `const fn`. One of the things I bumped into was `MaybeUninit::assume_init`. Is there any reason for the intrinsic `assert_inhabited<T>()` and therefore `MaybeUninit::assume_init` not being `const`?
---
I have as best as I could tried to follow the instruction in [library/core/src/intrinsics.rs](https://github.com/rust-lang/rust/blob/master/library/core/src/intrinsics.rs#L11). I have no idea what I am doing but it seems to compile after some slight changes after the copy paste. Is this anywhere near how this should be done?
Also any ideas for name of the feature gate? I guess `const_maybe_assume_init` is quite misleading since I have added some more methods. Should I add test? If so what should be tested?
Rollup of 12 pull requests
Successful merges:
- #79732 (minor stylistic clippy cleanups)
- #79750 (Fix trimming of lint docs)
- #79777 (Remove `first_merge` from liveness debug logs)
- #79795 (Privatize some of libcore unicode_internals)
- #79803 (Update xsv to prevent random CI failures)
- #79810 (Account for gaps in def path table during decoding)
- #79818 (Fixes to Rust coverage)
- #79824 (Strip prefix instead of replacing it with empty string)
- #79826 (Simplify visit_{foreign,trait}_item)
- #79844 (Move RWUTable to a separate module)
- #79861 (Update LLVM submodule)
- #79862 (Remove tab-lock and replace it with ctrl+up/down arrows to switch between search result tabs)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Privatize some of libcore unicode_internals
My understanding is that these API are perma unstable, so it doesn't
make sense to pollute docs & IDE completion[1] with them.
[1]: https://github.com/rust-analyzer/rust-analyzer/issues/6738
Use more std:: instead of core:: in docs for consistency
``@rustbot`` label T-doc
Some cleanup work to use `std::` instead of `core::` in docs as much as possible. This helps with terminology and consistency, especially for newcomers from other languages that have often heard of `std` to describe the standard library but not of `core`.
Edit: I also added more intra doc links when I saw the opportunity.
Avoid panic_bounds_check in fmt::write.
Writing any fmt::Arguments would trigger the inclusion of usize formatting and padding code in the resulting binary, because indexing used in fmt::write would generate code using panic_bounds_check, which prints the index and length.
These bounds checks are not necessary, as fmt::Arguments never contains any out-of-bounds indexes.
This change replaces them with unsafe get_unchecked, to reduce the amount of generated code, which is especially important for embedded targets.
---
Demonstration of the size of and the symbols in a 'hello world' no_std binary:
<details>
<summary>Source code</summary>
```rust
#![feature(lang_items)]
#![feature(start)]
#![no_std]
use core::fmt;
use core::fmt::Write;
#[link(name = "c")]
extern "C" {
#[allow(improper_ctypes)]
fn write(fd: i32, s: &str) -> isize;
fn exit(code: i32) -> !;
}
struct Stdout;
impl fmt::Write for Stdout {
fn write_str(&mut self, s: &str) -> fmt::Result {
unsafe { write(1, s) };
Ok(())
}
}
#[start]
fn main(_argc: isize, _argv: *const *const u8) -> isize {
let _ = writeln!(Stdout, "Hello World");
0
}
#[lang = "eh_personality"]
fn eh_personality() {}
#[panic_handler]
fn panic(_: &core::panic::PanicInfo) -> ! {
unsafe { exit(1) };
}
```
</details>
Before:
```
text data bss dec hex filename
6059 736 8 6803 1a93 before
```
```
0000000000001e00 T <T as core::any::Any>::type_id
0000000000003dd0 D core::fmt::num::DEC_DIGITS_LUT
0000000000001ce0 T core::fmt::num:👿:<impl core::fmt::Display for u64>::fmt
0000000000001ce0 T core::fmt::num:👿:<impl core::fmt::Display for usize>::fmt
0000000000001370 T core::fmt::write
0000000000001b30 t core::fmt::Formatter::pad_integral::write_prefix
0000000000001660 T core::fmt::Formatter::pad_integral
0000000000001350 T core::ops::function::FnOnce::call_once
0000000000001b80 t core::ptr::drop_in_place
0000000000001120 t core::ptr::drop_in_place
0000000000001c50 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001c90 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001b90 T core::panicking::panic_bounds_check
0000000000001c10 T core::panicking::panic_fmt
0000000000001130 t <&mut W as core::fmt::Write>::write_char
0000000000001200 t <&mut W as core::fmt::Write>::write_fmt
0000000000001250 t <&mut W as core::fmt::Write>::write_str
```
After:
```
text data bss dec hex filename
3068 600 8 3676 e5c after
```
```
0000000000001360 T core::fmt::write
0000000000001340 T core::ops::function::FnOnce::call_once
0000000000001120 t core::ptr::drop_in_place
0000000000001620 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001660 t core::iter::adapters::zip::Zip<A,B>::new
0000000000001130 t <&mut W as core::fmt::Write>::write_char
0000000000001200 t <&mut W as core::fmt::Write>::write_fmt
0000000000001250 t <&mut W as core::fmt::Write>::write_str
```
Part of #68490.
Care has been taken to leave the old consts where appropriate, for testing backcompat regressions, module shadowing, etc. The intrinsics docs were accidentally referring to some methods on f64 as std::f64, which I changed due to being contrary with how we normally disambiguate the shadow module from the primitive. In one other place I changed std::u8 to std::ops since it was just testing path handling in macros.
For places which have legitimate uses of the old consts, deprecated attributes have been optimistically inserted. Although currently unnecessary, they exist to emphasize to any future deprecation effort the necessity of these specific symbols and prevent them from being accidentally removed.
Rename `optin_builtin_traits` to `auto_traits`
They were originally called "opt-in, built-in traits" (OIBITs), but
people realized that the name was too confusing and a mouthful, and so
they were renamed to just "auto traits". The feature flag's name wasn't
updated, though, so that's what this PR does.
There are some other spots in the compiler that still refer to OIBITs,
but I don't think changing those now is worth it since they are internal
and not particularly relevant to this PR.
Also see <https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/opt-in.2C.20built-in.20traits.20(auto.20traits).20feature.20name>.
r? `@oli-obk` (feel free to re-assign if you're not the right reviewer for this)
Proposal to add Peekable::peek_mut
A "peekable" iterator has a `peek()`-method which provides an immutable reference to the next item. We currently do not have a method to modify that item, which we could easily add via a `peek_mut()`. See the test for a use-case (alike to my original use case), where a "pristine" iterator is passed on after modifying its state via `peek_mut()`.
If there is interest in this, I can expand on the tests and docs.
Document unsafety in core::slice::memchr
Contributes to #66219
Note sure if that's good enough, especially for the `align_to` call.
The docs only mention transmuting and I don't think that everything related to reference lifetimes and state validity mentioned in the [nomicon](https://doc.rust-lang.org/nomicon/transmutes.html) are relevant here.
They were originally called "opt-in, built-in traits" (OIBITs), but
people realized that the name was too confusing and a mouthful, and so
they were renamed to just "auto traits". The feature flag's name wasn't
updated, though, so that's what this PR does.
There are some other spots in the compiler that still refer to OIBITs,
but I don't think changing those now is worth it since they are internal
and not particularly relevant to this PR.
Also see <https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/opt-in.2C.20built-in.20traits.20(auto.20traits).20feature.20name>.
Qualify `panic!` as `core::panic!` in non-built-in `core` macros
Fixes#78333.
-----
Otherwise code like this
#![no_implicit_prelude]
fn main() {
::std::todo!();
::std::unimplemented!();
}
will fail to compile, which is unfortunate and presumably unintended.
This changes many invocations of `panic!` in a `macro_rules!` definition
to invocations of `$crate::panic!`, which makes the invocations hygienic.
Note that this does not make the built-in macro `assert!` hygienic.
A colleague of mine is new to Rust, and mentioned that it was “slightly
confusing” to figure out what `&mut` does in iterating over `&mut foo`:
```rust
for value in &mut self.my_vec {
// ...
}
```
My colleague had read the `std::iter` docs and not found the answer
there. There is a brief section at the top about “the three forms of
iteration”, which mentions `iter_mut`, but it doesn’t cover the purpose
of `&mut coll` for a collection `coll`. This patch adds an explanatory
section to the docs. I opted to create a new section so that it can
appear after the note that `impl<I: Iterator> IntoIterator for I`, and
it’s nice for the existing “three forms of iteration” to appear near the
top.
Implementation note: I haven’t linkified the references to `HashSet` and
`HashMap`, since those are in `std` and these docs are in `core`;
linkifying them gave an “unresolved link” rustdoc error.
Test Plan:
Ran `./x.py doc library/core`, and the result looked good. Manually
copy-pasted the two doctests into the playground and ran them.
wchargin-branch: doc-iter-by-reference
wchargin-source: 0f35369a8a735868621166608797744e97536792
Otherwise code like this
#![no_implicit_prelude]
fn main() {
::std::todo!();
::std::unimplemented!();
}
will fail to compile, which is unfortunate and presumably unintended.
This changes many invocations of `panic!` in a `macro_rules!` definition
to invocations of `$crate::panic!`, which makes the invocations hygienic.
Note that this does not make the built-in macro `assert!` hygienic.
Impl Default for PhantomPinned
`PhantomPinned` is just a marker type, with an obvious default value (the only value). So I can't think of a reason not to do this. Sure, it's used in exotic situations with unsafe code. But the people writing that code can decide for themselves if they can derive `Default`, and in many situations the derived impl will make sense:
```rust
#[derive(Default)]
struct NeedsPin {
marker: PhantomPinned,
buf: [u8; 1024],
ptr_to_data: Option<*const u8>,
}
```
Also stabilize constctlz for const ctlz_nonzero.
The public methods stabilized const by this commit are:
* `{i*,u*}::checked_pow`
* `{i*,u*}::saturating_pow`
* `{i*,u*}::wrapping_pow`
* `{i*,u*}::overflowing_pow`
* `{i*,u*}::pow`
* `u*::next_power_of_two`
* `u*::checked_next_power_of_two`
* `u*::wrapping_next_power_of_two` (the method itself is still unstable)
Stabilize refcell_take
Tracking Issue: #71395
``@KodrAus`` nominated this for FCP, so here's a PR!
I've never made a stabilization PR, so please mention if there's anything I can improve, thanks.
Stabilize alloc::Layout const functions
Stabilizes #67521. In particular the following stable methods are stabilized as `const fn`:
* `size`
* `align`
* `from_size_align`
Stabilizing `size` and `align` should not be controversial as they are simple (usize and NonZeroUsize) fields and I don't think there's any reason to make them not const compatible in the future. That being true, the other methods are trivially `const`. The only other issue being returning a `Result` from a `const fn` but this has been made more usable by recent stabilizations.
Split each iterator adapter and source into individual modules
This PR creates individual modules for each iterator adapter and iterator source.
This is done to enhance the readability of corresponding modules (`adapters/mod.rs` and `sources.rs`) which were hard to navigate and read because of lots of repeated lines (e.g.: `adapters/mod.rs` was 3k lines long). This is also in line with some adapters which already had their own modules (`Flatten`, `FlatMap`, `Chain`, `Zip`, `Fuse`).
This PR also makes `Take`s adapter fields private (I have no idea why they were `pub(super)` before).
r? ``@LukasKalbertodt``
Add f{32,64}::is_subnormal
The docs recommend that you use dedicated methods instead of calling `classify` directly, although there isn't actually a way of checking if a number is subnormal without calling classify. There are dedicated methods for all other forms, excluding `is_zero` (which is just `== 0.0` anyway).
Stabilize clamp
Tracking issue: https://github.com/rust-lang/rust/issues/44095
Clamp has been merged and unstable for about a year and a half now. How do we feel about stabilizing this?
More consistently use spaces after commas in lists in docs
This PR changes instances of lists that didn't use spaces after commas, like `vec![1,2,3]`, to `vec![1, 2, 3]` to be more consistent with idiomatic Rust style (the way these were looks strange to me, especially because there are often lists that *do* use spaces after the commas later in the same code block 😬).
I noticed one of these in an example in the stdlib docs and went looking for more, but as far as I can see, I'm only changing those spots in user-facing documentation or rustc output, and the changes make no semantic difference.
clarify rules for ZST Boxes
LLVM's rules around `getelementptr inbounds` with offset 0 are a bit annoying, and as a consequence we have no choice but say that a `Box<()>` pointing to previously allocated memory that has since been freed is UB. Clarify the docs to reflect this.
This is based on conversations on the LLVM mailing list.
* Here's my initial mail: https://lists.llvm.org/pipermail/llvm-dev/2019-February/130452.html
* The first email of the March part of that thread: https://lists.llvm.org/pipermail/llvm-dev/2019-March/130831.html
* First email of the April part: https://lists.llvm.org/pipermail/llvm-dev/2019-April/131693.html
The conclusion for me at least was that `getelementptr inbounds` with offset 0 is *not* the identity function, but can sometimes return `poison` even when the input is a regular pointer -- specifically, it returns `poison` when this pointer points into something that LLVM "knows has been deallocated", i.e., a former LLVM-managed allocation. It is however the identity function on pointers obtained by casting integers.
Note that there [are formal proposals](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf) for LLVM semantics where `getelementptr inbounds` with offset 0 isn't quite the identity function but never returns `poison` (it affects the provenance of the pointer but in a way that doesn't matter if this pointer is never used for memory accesses), and indeed this is likely necessary to consistently describe LLVM semantics. But with the informal LLVM LangRef that we have right now, and with LLVM devs insisting otherwise, it seems unwise to rely on this.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
Make as{_mut,}_slice on array::IntoIter public
The functions are useful in cases where you want to move data out of the IntoIter in bulk, by transmute_copy'ing the slice and then forgetting the IntoIter.
In the compiler, this is useful for providing a sped up IntoIter implementation. One can alternatively provide a separate allocate_array function but one can avoid duplicating some logic by passing everything through the generic iterator using interface.
As per suggestion in https://github.com/rust-lang/rust/pull/78569/files#r526506964
Clarify availability of atomic operations
This was noticed while we were updating the embedded rust book: https://github.com/rust-embedded/book/pull/273/files
These targets do natively have atomic load/stores, but do not support CAS operations.
This macro is used in expression position (a match arm), and only
compiles because of #33953
Regardless of what happens with that issue, this makes the
usage of the macro less confusing at the call site.
add trailing_zeros and leading_zeros to non zero types
as a way towards being able to use the optimized intrinsics ctlz_nonzero and cttz_nonzero from stable.
have not crated any tracking issue if this is not a solution that is wanted
Rename/Deprecate LayoutErr in favor of LayoutError
Implements rust-lang/wg-allocators#73.
This patch renames LayoutErr to LayoutError, and uses a type alias to support users using the old name.
The new name will be instantly stable in release 1.49 (current nightly), the type alias will become deprecated in release 1.51 (so that when the current nightly is 1.51, 1.49 will be stable).
This is the only error type in `std` that ends in `Err` rather than `Error`, if this PR lands all stdlib error types will end in `Error` 🥰
Test structural matching for all range types
As of #70166 all range types (`core::ops::Range` etc.) can be structurally matched upon, and by extension used in const generics. In reference to the fact that this is a publicly observable property of these types, and thus falls under the Rust stability guarantees of the standard library, a regression test was added in #70283.
This regression test was implemented by me by testing for the ability to use the range types within const generics, but that is not the actual property the std guarantees now (const generics is still unstable). This PR addresses that situation by adding extra tests for the range types that directly test whether they can be structurally matched upon.
Note: also adds the otherwise unrelated test `test_range_to_inclusive` for completeness with the other range unit tests
Duration::zero() -> Duration::ZERO
In review for #72790, whether or not a constant or a function should be favored for `#![feature(duration_zero)]` was seen as an open question. In https://github.com/rust-lang/rust/issues/73544#issuecomment-691701670 an invitation was opened to either stabilize the methods or propose a switch to the constant value, supplemented with reasoning. Followup comments suggested community preference leans towards the const ZERO, which would be reason enough.
ZERO also "makes sense" beside existing associated consts for Duration. It is ever so slightly awkward to have a series of constants specifying 1 of various units but leave 0 as a method, especially when they are side-by-side in code. It seems unintuitive for the one non-dynamic value (that isn't from Default) to be not-a-const, which could hurt discoverability of the associated constants overall. Elsewhere in `std`, methods for obtaining a constant value were even deprecated, as seen with [std::u32::min_value](https://doc.rust-lang.org/std/primitive.u32.html#method.min_value).
Most importantly, ZERO costs less to use. A match supports a const pattern, but const fn can only be used if evaluated through a const context such as an inline `const { const_fn() }` or a `const NAME: T = const_fn()` declaration elsewhere. Likewise, while https://github.com/rust-lang/rust/issues/73544#issuecomment-691949373 notes `Duration::zero()` can optimize to a constant value, "can" is not "will". Only const contexts have a strong promise of such. Even without that in mind, the comment in question still leans in favor of the constant for simplicity. As it costs less for a developer to use, may cost less to optimize, and seems to have more of a community consensus for it, the associated const seems best.
r? ```@LukasKalbertodt```
Refactor IntErrorKind to avoid "underflow" terminology
This PR is a continuation of #76455
# Changes
- `Overflow` renamed to `PosOverflow` and `Underflow` renamed to `NegOverflow` after discussion in #76455
- Changed some of the parsing code to return `InvalidDigit` rather than `Empty` for strings "+" and "-". https://users.rust-lang.org/t/misleading-error-in-str-parse-for-int-types/49178
- Carry the problem `char` with the `InvalidDigit` variant.
- Necessary changes were made to the compiler as it depends on `int_error_matching`.
- Redid tests to match on specific errors.
r? ```@KodrAus```
Stabilize `Poll::is_ready` and `is_pending` as const
Insta-stabilize the methods `is_ready` and `is_pending` of `std::task::Poll` as const, in the same way as [PR#76198](https://github.com/rust-lang/rust/pull/76198).
Possible because of the recent stabilization of const control flow.
Part of #76225.
Partially fix#55002, deprecate in another release
Co-authored-by: Ashley Mannix <kodraus@hey.com>
Update stable version for stabilize_spin_loop
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use better example for spinlock
As suggested by KodrAus
Remove renamed_spin_loop already available in master
Fix spin loop example
`crate::` -> `core::`
It looks weird to have `crate::` in the link text and we use the actual
crate name everywhere else.
If anyone is curious, I used this Vim command to update all the links:
%s/\(\s\)\[`crate::\(.*\)`\]/\1[`core::\2`](crate::\2)/g
Add fetch_update methods to AtomicBool and AtomicPtr
These methods were stabilized for the integer atomics in #71843, but the methods were not added for the non-integer atomics `AtomicBool` and `AtomicPtr`.
Point out that total_cmp is no strict superset of partial comparison
Partial comparison and total_cmp are not equal. This helps
preventing the mistake of creating float wrappers that
base their Ord impl on total_cmp and their PartialOrd impl on
the PartialOrd impl of the float type. PartialOrd and Ord
[are required to agree with each other](https://doc.rust-lang.org/std/cmp/trait.Ord.html#how-can-i-implement-ord).
Trivial fixes to bitwise operator documentation
Added fixes to documentation of `BitAnd`, `BitOr`, `BitXor` and
`BitAndAssign`, where the documentation for implementation on
`Vector<bool>` was using logical operators in place of the bitwise
operators.
r? @steveklabnik
Closes#78619
Clarify handling of final line ending in str::lines()
I found the description as it stands a bit confusing. I've added a bit more explanation to make it clear that a trailing line ending does not produce a final empty line.
These methods were stabilized for the integer atomics in #71843, but the methods
were not added for the non-integer atomics `AtomicBool` and `AtomicPtr`.
Partial comparison and total_cmp are not equal. This helps
preventing the mistake of creating float wrappers that
base their Ord impl on total_cmp and their PartialOrd impl on
the PartialOrd impl of the float type. PartialOrd and Ord
are required to agree with each other.
fix various aliasing issues in the standard library
This fixes various cases where the standard library either used raw pointers after they were already invalidated by using the original reference again, or created raw pointers for one element of a slice and used it to access neighboring elements.
Fix doc links to std::fmt
`std::format` and `core::write` macros' docs linked to `core::fmt` for format string reference, even though only `std::fmt` has format string documentation (and the link titles were `std::fmt`)
Added fixes to documentation of `BitAnd`, `BitOr`, `BitXor` and
`BitAndAssign`, where the documentation for implementation on
`Vector<bool>` was using logical operators in place of the bitwise
operators.
r? @steveklabnik
cc #78619
I found the description as it stands a bit confusing. I've added a bit more explanation to make it clear that a trailing line ending does not produce a final empty line.
std::format and core::write macros' docs linked to core::fmt for format string reference, even though only std::fmt has format string documentation and the link titles were std::fmt.
Improve documentation for slice strip_* functions
Prompted by the stabilisation tracking issue #73413 I looked at the docs for `strip_prefix` and `strip_suffix` for both `str` and `slice`, and I felt they could be slightly improved.
Thanks for your attention.
Separate unsized locals
Closes#71694
Takes over again #72029 and #74971
cc @RalfJung @oli-obk @pnkfelix @eddyb as they've participated in previous reviews of this PR.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}