This expands the existing `#[must_use]` check in `unused_attributes`
to lint against pretty much everything `#[must_use]` doesn't support.
Fixes#93906.
Avoid query cache sharding code in single-threaded mode
In non-parallel compilers, this is just adding needless overhead at compilation time (since there is only one shard statically anyway). This amounts to roughly ~10 seconds reduction in bootstrap time, with overall neutral (some wins, some losses) performance results.
Parallel compiler performance should be largely unaffected by this PR; sharding is kept there.
It is currently hard coded to llvm if enabled and cranelift otherwise.
This made some sense when cranelift was the only alternative codegen
backend. Since the introduction of the gcc backend this doesn't make
much sense anymore. Before this PR bootstrapping rustc using a backend
other than llvm or cranelift required changing the source of
rustc_interface. With this PR it becomes a matter of putting the right
backend as first enabled backend in config.toml.
rustc_trait_selection: adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This PR handles rustc_trait_selection.
No branch protection metadata unless enabled
Even if we emit metadata disabling branch protection, this metadata may
conflict with other modules (e.g. during LTO) that have different branch
protection metadata set.
This is an unstable flag and feature, so ideally the flag not being
specified should act as if the feature wasn't implemented in the first
place.
Additionally this PR also ensures we emit an error if
`-Zbranch-protection` is set on targets other than the supported
aarch64. For now the error is being output from codegen, but ideally it
should be moved to earlier in the pipeline before stabilization.
Beyond `&`/`&mut`/`Box`, this covers `char`, discriminants, `NonZero*`, etc.
All such types currently cause a Miri error if left uninitialized,
and an `invalid_value` lint in cases like `mem::uninitialized::<char>()`
Note that this _does not_ change whether or not it is UB for `u64` (or
other integer types with no invalid values) to be undef.
Restrict query recursion in `needs_significant_drop`
Overly aggressive use of the query system to improve caching lead to query cycles and consequently ICEs. This patch fixes this by restricting the use of the query system as a cache to those cases where it is definitely correct.
Closes#92725 .
This is essentially a revert of #90845 for the significant drop case only. The general `needs_drop` still does the same thing. The hope is that this is enough to preserve the performance improvements of that PR while fixing the ICE. Should get a perf run to verify that this is the case.
cc `@cjgillot`
Initiate the inner usage of `let_chains`
The intention here is create a strong and robust foundation for a possible future stabilization so please, do not let the lack of any external tool support prevent the merge of this PR. Besides, `let_chains` is useful by itself.
cc #53667
Rollup of 5 pull requests
Successful merges:
- #93400 (Do not suggest using a const parameter when there are bounds on an unused type parameter)
- #93982 (Provide extra note if synthetic type args are specified)
- #94087 (Remove unused `unsound_ignore_borrow_on_drop`)
- #94235 (chalk: Fix wrong debrujin index in opaque type handling.)
- #94306 (Avoid exhausting stack space in dominator compression)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Avoid exhausting stack space in dominator compression
Doesn't add a test case -- I ended up running into this while playing with the generated example from #43578, which we could do with a run-make test (to avoid checking a large code snippet into tree), but I suspect we don't want to wait for it to compile (locally it takes ~14s -- not terrible, but doesn't seem worth it to me). In practice stack space exhaustion is difficult to test for, too, since if we set the bound too low a different call structure above us (e.g., a nearer ensure_sufficient_stack call) would let the test pass even with the old impl, most likely.
Locally it seems like this manages to perform approximately equivalently to the recursion, but will run perf to confirm.
chalk: Fix wrong debrujin index in opaque type handling.
A folder in opaque type lowering was substituting all opaque type references with a variable with debrujin index 0 ignoring how many binders deep we are.
This caused an ICE with `Not enough bound vars: ^0 not found in []` ([full logs](https://gist.github.com/Dirbaio/2b9374ff4fce37afb9d665dc9f0000df)) with the following code.
```rust
fn main() -> () {}
async fn foo(x: u32) -> u32 {
x
}
```
With the fix, it no longer ICEs. It still doesn't typecheck due to generator issues. I've added a "known-bug" test so that at least it doesn't regress back to ICEing.
r? ``@jackh726``
fix a message
implement a rustfix-applicable suggestion
implement `suggest_floating_point_literal`
add `ObligationCauseCode::BinOp`
remove duplicate code
fix function names in uitests
use `Diagnostic` instead of `DiagnosticBuilder`
Populate liveness facts when calling `get_body_with_borrowck_facts` without `-Z polonius`
For a new feature of [Flowistry](https://github.com/willcrichton/flowistry), a static-analysis tool, we need to obtain a `mir::Body`'s liveness facts using `get_body_with_borrowck_facts` (added in #86977). We'd like to do this without passing `-Z polonius` as a compiler arg to avoid borrow checking the entire crate.
Support for doing this was added in #88983, but the Polonius input facts used for liveness analysis are empty. This happens because the liveness input facts are populated in `liveness::generate` depending only on the value of `AllFacts::enabled` (which is toggled via compiler args).
This PR propagates the [`use_polonius`](8b09ba6a5d/compiler/rustc_borrowck/src/nll.rs (L168)) flag to `liveness::generate` to support populating liveness facts without requiring the `-Z polonius` flag.
This fix is somewhat patchy - if it'd be better to add more widely-accessible state (like `AllFacts::enabled`) I'd be open to ideas!
Rollup of 4 pull requests
Successful merges:
- #93850 (Don't ICE when an extern static is too big for the current architecture)
- #94154 (Wire up unstable rustc --check-cfg to rustdoc)
- #94353 (Fix debug_assert in unused lint pass)
- #94366 (Add missing item to release notes)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Fix debug_assert in unused lint pass
This fixes a debug assertion in the unused lint pass. As a side effect, this also improves the span generated for tuples in the `unused_must_use` lint.
found in #94329
A reproducer for this would be
```rust
fn main() { (1, (3,)); }
```
Not sure, if I should add a regression test for a `debug_assert`.
Don't ICE when an extern static is too big for the current architecture
Fixes#93760
Emit an error instead of ICEing when an `extern` static's size overflows the allowed maximum for the target.
Changes the error message in the existing `delay_span_bug` call to the true layout error, first for debugging purposes, but opted to leave in to potentially assist future developers as it was being reached in unexpected ways already.
Print `ParamTy` and `ParamConst` instead of displaying them
Display for `ParamTy` and `ParamConst` is implemented in terms of print.
Using print avoids creating a new `FmtPrinter` just to display the
parameter name.
r? `@Mark-Simulacrum`
Miri fn ptr check: don't use conservative null check
In https://github.com/rust-lang/rust/pull/94270 I used the wrong NULL check for function pointers: `memory.ptr_may_be_null` is conservative even on machines that support ptr-to-int casts, leading to false errors in Miri.
This fixes that problem, and also replaces that foot-fun of a method with `scalar_may_be_null` which is never unnecessarily conservative.
r? `@oli-obk`
Remove an unnecessary restriction in `dest_prop`
I had asked about this [on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/Do.20unions.20have.20active.20fields.3F) but didn't receive a response, so putting up this PR that makes the change I think we can. If it turns out that this is wrong, hopefully I'll find out here. Reposting my Zulip comment:
> Not sure what channel to put this into, so using this as a fallback. The dest prop MIR opt has this comment:
>
> ```rust
> //! Subtle case: If `dest` is a, or projects through a union, then we have to make sure that there
> //! remains an assignment to it, since that sets the "active field" of the union. But if `src` is
> //! a ZST, it might not be initialized, so there might not be any use of it before the assignment,
> //! and performing the optimization would simply delete the assignment, leaving `dest`
> //! uninitialized.
> ```
>
> In particular, the claim seems to be that we can't take
> ```
> x = ();
> y.field = x;
> ```
> where `y` is a union having `field: ()` as one of its variants, and optimize the entire thing away (assuming `x` is unused otherwise). As far as I know though, Rust unions don't have active fields. Is this comment correct and am I missing something? Is there a worry about this interacting poorly with FFI code/C unions/LTO or something?
This PR just removes that comment and the associated code. Also it fixes one unrelated comment that did not match the code it was commenting on.
r? rust-lang/mir-opt
don't special case `DefKind::Ctor` in encoding
considering that we still use `DefKind::Ctor` for these in `Res`, this seems weird and definitely felt like a bug when encountering it while working on #89862.
r? `@cjgillot`
Remove in band lifetimes
As discussed in t-lang backlog bonanza, the `in_band_lifetimes` FCP closed in favor for the feature not being stabilized. This PR removes `#![feature(in_band_lifetimes)]` in its entirety.
Let me know if this PR is too hasty, and if we should instead do something intermediate for deprecate the feature first.
r? `@scottmcm` (or feel free to reassign, just saw your last comment on #44524)
Closes#44524
This fixes a debug assertion in the unused lint pass. As a side effect,
this also improves the span generated for tuples in the
`unused_must_use` lint.
debuginfo: Simplify TypeMap used during LLVM debuginfo generation.
This PR simplifies the TypeMap that is used in `rustc_codegen_llvm::debuginfo::metadata`. It was unnecessarily complicated because it was originally implemented when types were not yet normalized before codegen. So it did it's own normalization and kept track of multiple unnormalized types being mapped to a single unique id.
This PR is based on https://github.com/rust-lang/rust/pull/93503, which is not merged yet.
The PR also removes the arena used for allocating string ids and instead uses `InlinableString` from the [inlinable_string](https://crates.io/crates/inlinable_string) crate. That might not be the best choice, since that crate does not seem to be very actively maintained. The [flexible-string](https://crates.io/crates/flexible-string) crate would be an alternative.
r? `@ghost`
Consider mutations as borrows in generator drop tracking
This is needed to match MIR more conservative approximation of any borrowed value being live across a suspend point (See #94067). This change considers an expression such as `x.y = z` to be a borrow of `x` and therefore keeps `x` live across suspend points.
r? `@nikomatsakis`
Use undef for (some) partially-uninit constants
There needs to be some limit to avoid perf regressions on large arrays
with undef in each element (see comment in the code).
Fixes: #84565
Original PR: #83698
Depends on LLVM 14: #93577
Convert `newtype_index` to a proc macro
The `macro_rules!` implementation was becomng excessively complicated,
and difficult to modify. The new proc macro implementation should make
it much easier to add new features (e.g. skipping certain `#[derive]`s)
rustc_errors: let `DiagnosticBuilder::emit` return a "guarantee of emission".
That is, `DiagnosticBuilder` is now generic over the return type of `.emit()`, so we'll now have:
* `DiagnosticBuilder<ErrorReported>` for error (incl. fatal/bug) diagnostics
* can only be created via a `const L: Level`-generic constructor, that limits allowed variants via a `where` clause, so not even `rustc_errors` can accidentally bypass this limitation
* asserts `diagnostic.is_error()` on emission, just in case the construction restriction was bypassed (e.g. by replacing the whole `Diagnostic` inside `DiagnosticBuilder`)
* `.emit()` returns `ErrorReported`, as a "proof" token that `.emit()` was called
(though note that this isn't a real guarantee until after completing the work on
#69426)
* `DiagnosticBuilder<()>` for everything else (warnings, notes, etc.)
* can also be obtained from other `DiagnosticBuilder`s by calling `.forget_guarantee()`
This PR is a companion to other ongoing work, namely:
* #69426
and it's ongoing implementation:
#93222
the API changes in this PR are needed to get statically-checked "only errors produce `ErrorReported` from `.emit()`", but doesn't itself provide any really strong guarantees without those other `ErrorReported` changes
* #93244
would make the choices of API changes (esp. naming) in this PR fit better overall
In order to be able to let `.emit()` return anything trustable, several changes had to be made:
* `Diagnostic`'s `level` field is now private to `rustc_errors`, to disallow arbitrary "downgrade"s from "some kind of error" to "warning" (or anything else that doesn't cause compilation to fail)
* it's still possible to replace the whole `Diagnostic` inside the `DiagnosticBuilder`, sadly, that's harder to fix, but it's unlikely enough that we can paper over it with asserts on `.emit()`
* `.cancel()` now consumes `DiagnosticBuilder`, preventing `.emit()` calls on a cancelled diagnostic
* it's also now done internally, through `DiagnosticBuilder`-private state, instead of having a `Level::Cancelled` variant that can be read (or worse, written) by the user
* this removes a hazard of calling `.cancel()` on an error then continuing to attach details to it, and even expect to be able to `.emit()` it
* warnings were switched to *only* `can_emit_warnings` on emission (instead of pre-cancelling early)
* `struct_dummy` was removed (as it relied on a pre-`Cancelled` `Diagnostic`)
* since `.emit()` doesn't consume the `DiagnosticBuilder` <sub>(I tried and gave up, it's much more work than this PR)</sub>,
we have to make `.emit()` idempotent wrt the guarantees it returns
* thankfully, `err.emit(); err.emit();` can return `ErrorReported` both times, as the second `.emit()` call has no side-effects *only* because the first one did do the appropriate emission
* `&mut Diagnostic` is now used in a lot of function signatures, which used to take `&mut DiagnosticBuilder` (in the interest of not having to make those functions generic)
* the APIs were already mostly identical, allowing for low-effort porting to this new setup
* only some of the suggestion methods needed some rework, to have the extra `DiagnosticBuilder` functionality on the `Diagnostic` methods themselves (that change is also present in #93259)
* `.emit()`/`.cancel()` aren't available, but IMO calling them from an "error decorator/annotator" function isn't a good practice, and can lead to strange behavior (from the caller's perspective)
* `.downgrade_to_delayed_bug()` was added, letting you convert any `.is_error()` diagnostic into a `delay_span_bug` one (which works because in both cases the guarantees available are the same)
This PR should ideally be reviewed commit-by-commit, since there is a lot of fallout in each.
r? `@estebank` cc `@Manishearth` `@nikomatsakis` `@mark-i-m`
As an example:
#[test]
#[ignore = "not yet implemented"]
fn test_ignored() {
...
}
Will now render as:
running 2 tests
test tests::test_ignored ... ignored, not yet implemented
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
These links never worked, but the lint was suppressed due to the fact
that the span was pointing into the macro. With the new macro
implementation, the span now points directly to the doc comment in the
macro invocation, so it's no longer suppressed.
The `macro_rules!` implementation was becomng excessively complicated,
and difficult to modify. The new proc macro implementation should make
it much easier to add new features (e.g. skipping certain `#[derive]`s)
Avoid emitting full macro body into JSON errors
While investigating https://github.com/rust-lang/rust/issues/94322, it was noted that currently the JSON diagnostics for macro backtraces include the full def_site span -- the whole macro body.
It seems like this shouldn't be necessary, so this PR adjusts the span to just be the "guessed head", typically the macro name. It doesn't look like we keep enough information to synthesize a nicer span here at this time.
Atop #92123, this reduces output for the src/test/ui/suggestions/missing-lifetime-specifier.rs test from 660 KB to 156 KB locally.
properly handle fat pointers to uninhabitable types
Calculate the pointee metadata size by using `tcx.struct_tail_erasing_lifetimes` instead of duplicating the logic in `fat_pointer_kind`. Open to alternatively suggestions on how to fix this.
Fixes#94149
r? ````@michaelwoerister```` since you touched this code last, I think!
Improve `--check-cfg` implementation
This pull-request is a mix of improvements regarding the `--check-cfg` implementation:
- Simpler internal representation (usage of `Option` instead of separate bool)
- Add --check-cfg to the unstable book (based on the RFC)
- Improved diagnostics:
* List possible values when the value is unexpected
* Suggest if possible a name or value that is similar
- Add more tests (well known names, mix of combinations, ...)
r? ```@petrochenkov```
better ObligationCause for normalization errors in `can_type_implement_copy`
Some logic is needed so we can point to the field when given totally nonsense types like `struct Foo(<u32 as Iterator>::Item);`
Fixes#93687
Overly aggressive use of the query system to improve caching lead to query cycles and consequently
ICEs. This patch fixes this by restricting the use of the query system as a cache to those cases
where it is definitely correct.
Always format to internal String in FmtPrinter
This avoids monomorphizing for different parameters, decreasing generic code
instantiated downstream from rustc_middle -- locally seeing 7% unoptimized LLVM IR
line wins on rustc_borrowck, for example.
We likely can't/shouldn't get rid of the Result-ness on most functions, though some
further cleanup avoiding fmt::Error where we now know it won't occur may be possible,
though somewhat painful -- fmt::Write is a pretty annoying API to work with in practice
when you're trying to use it infallibly.
Partially move cg_ssa towards using a single builder
Not all codegen backends can handle hopping between blocks well. For example Cranelift requires blocks to be terminated before switching to building a new block. Rust-gpu requires a `RefCell` to allow hopping between blocks and cg_gcc currently has a buggy implementation of hopping between blocks. This PR reduces the amount of cases where cg_ssa switches between blocks before they are finished and mostly fixes the block hopping in cg_gcc. (~~only `scalar_to_backend` doesn't handle it correctly yet in cg_gcc~~ fixed that one.)
`@antoyo` please review the cg_gcc changes.
Miri: relax fn ptr check
As discussed in https://github.com/rust-lang/unsafe-code-guidelines/issues/72#issuecomment-1025407536, the function pointer check done by Miri is currently overeager: contrary to our usual principle of only checking rather uncontroversial validity invariants, we actually check that the pointer points to a real function.
So, this relaxes the check to what the validity invariant probably will be (and what the reference already says it is): the function pointer must be non-null, and that's it.
The check that CTFE does on the final value of a constant is unchanged -- CTFE recurses through references, so it makes some sense to also recurse through function pointers. We might still want to relax this in the future, but that would be a separate change.
r? `@oli-obk`
Change `char` type in debuginfo to DW_ATE_UTF
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more appropriate encoding is `DW_ATE_UTF`.
Clang also uses the DW_ATE_UTF for `char32_t` in C++.
This fixes the display of the `char` type in the Windows debuggers. Without this change, the variable did not show in the locals window.
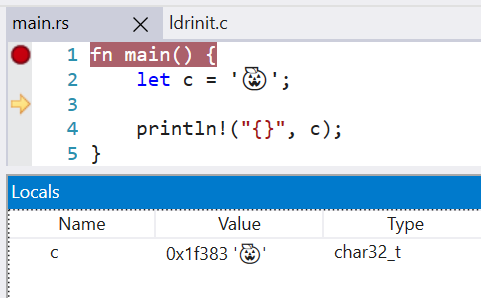
LLDB 13 is also able to display the char value, when before it failed with `need to add support for DW_TAG_base_type 'char' encoded with DW_ATE = 0x8, bit_size = 32`
r? `@wesleywiser`
`scan_escape` currently has a fast path (for when the first char isn't
'\\') and a slow path.
This commit changes `scan_escape` so it only handles the slow path, i.e.
the actual escaping code. The fast path is inlined into the two call
sites.
This change makes the code faster, because there is no function call
overhead on the fast path. (`scan_escape` is a big function and doesn't
get inlined.)
This change also improves readability, because it removes a bunch of
mode checks on the the fast paths.
Rust previously encoded the `char` type as DW_ATE_unsigned_char. The more
appropriate encoding is DW_ATE_UTF.
Clang uses this same debug encoding for char32_t.
This fixes the display of `char` types in Windows debuggers as well as LLDB.
rustdoc-json: Better Header Type
- Make ABI an enum, instead of being stringly typed
- Replace Qualifier HashSet with 3 bools
- Merge ABI field into header, as they always occor together
r? ``@CraftSpider``
``@rustbot`` modify labels: +A-rustdoc-json +T-rustdoc
Display for `ParamTy` and `ParamConst` is implemented in terms of print.
Using print avoids creating a new `FmtPrinter` just to display the
parameter name.
Introduce `ChunkedBitSet` and use it for some dataflow analyses.
This reduces peak memory usage significantly for some programs with very
large functions.
r? `@ghost`
This reduces peak memory usage significantly for some programs with very
large functions, such as:
- `keccak`, `unicode_normalization`, and `match-stress-enum`, from
the `rustc-perf` benchmark suite;
- `http-0.2.6` from crates.io.
The new type is used in the analyses where the bitsets can get huge
(e.g. 10s of thousands of bits): `MaybeInitializedPlaces`,
`MaybeUninitializedPlaces`, and `EverInitializedPlaces`.
Some refactoring was required in `rustc_mir_dataflow`. All existing
analysis domains are either `BitSet` or a trivial wrapper around
`BitSet`, and access in a few places is done via `Borrow<BitSet>` or
`BorrowMut<BitSet>`. Now that some of these domains are `ClusterBitSet`,
that no longer works. So this commit replaces the `Borrow`/`BorrowMut`
usage with a new trait `BitSetExt` containing the needed bitset
operations. The impls just forward these to the underlying bitset type.
This required fiddling with trait bounds in a few places.
The commit also:
- Moves `static_assert_size` from `rustc_data_structures` to
`rustc_index` so it can be used in the latter; the former now
re-exports it so existing users are unaffected.
- Factors out some common "clear excess bits in the final word"
functionality in `bit_set.rs`.
- Uses `fill` in a few places instead of loops.
Rollup of 7 pull requests
Successful merges:
- #94169 (Fix several asm! related issues)
- #94178 (tidy: fire less "ignoring file length unneccessarily" warnings)
- #94179 (solarish current_exe using libc call directly)
- #94196 (compiletest: Print process output info with less whitespace)
- #94208 (Add the let else tests found missing in the stabilization report)
- #94237 (Do not suggest wrapping an item if it has ambiguous un-imported methods)
- #94246 (ScalarMaybeUninit is explicitly hexadecimal in its formatting)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
ScalarMaybeUninit is explicitly hexadecimal in its formatting
This makes `ScalarMaybeUninit` consistent with `Scalar` after the changes in https://github.com/rust-lang/rust/pull/94189.
r? ``@oli-obk``
Do not suggest wrapping an item if it has ambiguous un-imported methods
If the method is defined for the receiver we have, but is ambiguous during probe, then it probably comes from one of several traits that just weren't `use`d. Don't suggest wrapping the receiver in `Box`/etc., even if that makes the method probe unambiguous.
Fixes#94218
Fix several asm! related issues
This is a combination of several fixes, each split into a separate commit. Splitting these into PRs is not practical since they conflict with each other.
Fixes#92378Fixes#85247
r? ``@nagisa``
change `mir::Constant` in mir dumps
this removes duplicate information and avoids printing the `stable_crate_id` in mir dumps which broke CI in #94059
r? `@oli-obk` cc `@b-naber`
Simplify rustc_serialize by dropping support for decoding into JSON
This PR currently bundles two (somewhat separate) tasks.
First, it removes the JSON Decoder trait impl, which permitted going from JSON to Rust structs. For now, we keep supporting JSON deserialization, but only to `Json` (an equivalent of serde_json::Value). The primary hard to remove user there is for custom targets -- which need some form of JSON deserialization -- but they already have a custom ad-hoc pass for moving from Json to a Rust struct.
A [comment](e7aca89598/compiler/rustc_target/src/spec/mod.rs (L1653)) there suggests that it would be impractical to move them to a Decodable-based impl, at least without backwards compatibility concerns. I suspect that if we were widely breaking compat there, it would make sense to use serde_json at this point which would produce better error messages; the types in rustc_target are relatively isolated so we would not particularly suffer from using serde_derive.
The second part of the PR (all but the first commit) is to simplify the Decoder API by removing the non-primitive `read_*` functions. These primarily add indirection (through a closure), which doesn't directly cause a performance issue (the unique closure types essentially guarantee monomorphization), but does increase the amount of work rustc and LLVM need to do. This could be split out to a separate PR, but is included here in part to help motivate the first part.
Future work might consist of:
* Specializing enum discriminant encoding to avoid leb128 for small enums (since we know the variant count, we can directly use read/write u8 in almost all cases)
* Adding new methods to support faster deserialization (e.g., access to the underlying byte stream)
* Currently these are somewhat ad-hoc supported by specializations for e.g. `Vec<u8>`, but other types which could benefit don't today.
* Removing the Decoder trait entirely in favor of a concrete type -- today, we only really have one impl of it modulo wrappers used for specialization-based dispatch.
Highly recommend review with whitespace changes off, as the removal of closures frequently causes things to be de-indented.
Better error if the user tries to do assignment ... else
If the user tries to do assignment ... else, we now issue a more comprehensible error in the parser.
closes#93995
CTFE engine: Scalar: expose size-generic to_(u)int methods
This matches the size-generic constructors `Scalar::from_(u)int`, and it would have helped in https://github.com/rust-lang/miri/pull/1978.
r? `@oli-obk`
rustc_const_eval: adopt let else in more places
Continuation of #89933, #91018, #91481, #93046, #93590, #94011.
I have extended my clippy lint to also recognize tuple passing and match statements. The diff caused by fixing it is way above 1 thousand lines. Thus, I split it up into multiple pull requests to make reviewing easier. This PR handles rustc_const_eval.
The previous approach of checking for the reserve-r9 target feature
didn't actually work because LLVM only sets this feature very late when
initializing the per-function subtarget.
safely `transmute<&List<Ty<'tcx>>, &List<GenericArg<'tcx>>>`
This PR has 3 relevant steps which are is split in distinct commits.
The first commit now interns `List<Ty<'tcx>>` and `List<GenericArg<'tcx>>` together, potentially reusing memory while allowing free conversions between these two using `List<Ty<'tcx>>::as_substs()` and `SubstsRef<'tcx>::try_as_type_list()`.
Using this, we then use `&'tcx List<Ty<'tcx>>` instead of a `SubstsRef<'tcx>` for tuple fields, simplifying a bunch of code.
Finally, as tuple fields and other generic arguments now use a different `TypeFoldable<'tcx>` impl, we optimize the impl for `List<Ty<'tcx>>` improving perf by slightly less than 1% in tuple heavy benchmarks.
Revert #93800, fixing CI time regression
This reverts commit a240ccd81c (merge commit of #93800), reversing
changes made to 393fdc1048.
This PR was likely responsible for a relatively large regression in
dist-x86_64-msvc-alt builder times, from approximately 1.7 to 2.8 hours,
bringing that builder into the pool of the slowest builders we currently have.
This seems to be limited to the alt builder due to needing parallel-compiler
enabled, likely leading to slow LLVM compilation for some reason. See some
investigation in [this Zulip stream](https://rust-lang.zulipchat.com/#narrow/stream/242791-t-infra/topic/msvc.28.3F.29.20builders.20running.20much.20slower).
cc `@lcnr` `@oli-obk` `@b-naber` (per original PRs review/author)
We can re-apply this PR once the regression is fixed, but it is sufficiently large that I don't think keeping this on master is viable in the meantime unless there's a very strong case to be made for it. Alternatively, we can disable that builder (it's not critical since it's an alt build), but that obviously carries its own costs.
The previous implementation was written before types were properly
normalized for code generation and had to assume a more complicated
relationship between types and their debuginfo -- generating separate
identifiers for debuginfo nodes that were based on normalized types.
Since types are now already normalized, we can use them as identifiers
for debuginfo nodes.
Normalize obligation and expected trait_refs in confirm_poly_trait_refs
Consolidate normalization the obligation and expected trait refs in `confirm_poly_trait_refs`. Also, _always_ normalize these trait refs -- we were already normalizing the obligation trait ref when confirming closure and generator candidates, but this does it for fn pointer confirmation as well.
This presumably does more work in the case that the obligation's trait ref is already normalized, but we can see from the perf runs in #94070, it actually (paradoxically, perhaps) improves performance when paired with logic that normalizes projections in fulfillment loop.
This reverts commit a240ccd81c, reversing
changes made to 393fdc1048.
This PR was likely responsible for a relatively large regression in
dist-x86_64-msvc-alt builder times, from approximately 1.7 to 2.8 hours,
bringing that builder into the pool of the slowest builders we currently have.
This seems to be limited to the alt builder due to needing parallel-compiler
enabled, likely leading to slow LLVM compilation for some reason.
{kind=link}