Don't leak the function that is called on drop
It probably wasn't causing problems anyway, but still, a `// this leaks, please don't pass anything that owns memory` is not sustainable.
I could implement a version which does not require `Option`, but it would require `unsafe`, at which point it's probably not worth it.
Use `Option::is_some_and` and `Result::is_ok_and` in the compiler
`.is_some_and(..)`/`.is_ok_and(..)` replace `.map_or(false, ..)` and `.map(..).unwrap_or(false)`, making the code more readable.
This PR is a sibling of https://github.com/rust-lang/rust/pull/111873#issuecomment-1561316515
Preprocess and cache dominator tree
Preprocessing dominators has a very strong effect for https://github.com/rust-lang/rust/pull/111344.
That pass checks that assignments dominate their uses repeatedly. Using the unprocessed dominator tree caused a quadratic runtime (number of bbs x depth of the dominator tree).
This PR also caches the dominator tree and the pre-processed dominators in the MIR cfg cache.
Rebase of https://github.com/rust-lang/rust/pull/107157
cc `@tmiasko`
Process current bucket instead of parent's bucket when starting loop for dominators.
The linked paper by Georgiadis suggests in §2.2.3 to process `bucket[w]` when beginning the loop, instead of `bucket[parent[w]]` when finishing it.
In the test case, we correctly computed `idom[2] = 0` and `sdom[3] = 1`, but the algorithm returned `idom[3] = 1`, instead of the correct value 0, because of the path 0-7-2-3.
This provoked LLVM ICE in https://github.com/rust-lang/rust/pull/111061#issuecomment-1546912112. LLVM checks that SSA assignments dominate uses using its own implementation of Lengauer-Tarjan, and saw case where rustc was breaking the dominance property.
r? `@Mark-Simulacrum`
Change the immediate_dominator return type to Option, and use None to
indicate that node has no immediate dominator.
Also fix the issue where the start node would be returned as its own
immediate dominator.
Introduce `DynSend` and `DynSync` auto trait for parallel compiler
part of parallel-rustc #101566
This PR introduces `DynSend / DynSync` trait and `FromDyn / IntoDyn` structure in rustc_data_structure::marker. `FromDyn` can dynamically check data structures for thread safety when switching to parallel environments (such as calling `par_for_each_in`). This happens only when `-Z threads > 1` so it doesn't affect single-threaded mode's compile efficiency.
r? `@cjgillot`
bump windows crate 0.46 -> 0.48
This drops duped version of crate(0.46), reduces `rustc_driver.dll` ~800kb and reduces exported functions number from 26k to 22k.
Also while here, added `tidy-alphabetical` sorting to lists in tidy allowed lists.
Min specialization improvements
- Don't allow specialization impls with no items, such implementations are probably not correct and only occur as mistakes in the compiler and standard library
- Fix a missing normalization call
- Adds spans for lifetime errors from overly general specializations
Closes#79457Closes#109815
Such implementations are usually mistakes and are not used in the
compiler or standard library (after this commit) so forbid them with
`min_specialization`.
Move the WorkerLocal type from the rustc-rayon fork into rustc_data_structures
This PR moves the definition of the `WorkerLocal` type from `rustc-rayon` into `rustc_data_structures`. This is enabled by the introduction of the `Registry` type which allows you to group up threads to be used by `WorkerLocal` which is basically just an array with an per thread index. The `Registry` type mirrors the one in Rayon and each Rayon worker thread is also registered with the new `Registry`. Safety for `WorkerLocal` is ensured by having it keep a reference to the registry and checking on each access that we're still on the group of threads associated with the registry used to construct it.
Accessing a `WorkerLocal` is micro-optimized due to it being hot since it's used for most arena allocations.
Performance is slightly improved for the parallel compiler:
<table><tr><td rowspan="2">Benchmark</td><td colspan="1"><b>Before</b></th><td colspan="2"><b>After</b></th></tr><tr><td align="right">Time</td><td align="right">Time</td><td align="right">%</th></tr><tr><td>🟣 <b>clap</b>:check</td><td align="right">1.9992s</td><td align="right">1.9949s</td><td align="right"> -0.21%</td></tr><tr><td>🟣 <b>hyper</b>:check</td><td align="right">0.2977s</td><td align="right">0.2970s</td><td align="right"> -0.22%</td></tr><tr><td>🟣 <b>regex</b>:check</td><td align="right">1.1335s</td><td align="right">1.1315s</td><td align="right"> -0.18%</td></tr><tr><td>🟣 <b>syn</b>:check</td><td align="right">1.8235s</td><td align="right">1.8171s</td><td align="right"> -0.35%</td></tr><tr><td>🟣 <b>syntex_syntax</b>:check</td><td align="right">6.9047s</td><td align="right">6.8930s</td><td align="right"> -0.17%</td></tr><tr><td>Total</td><td align="right">12.1586s</td><td align="right">12.1336s</td><td align="right"> -0.21%</td></tr><tr><td>Summary</td><td align="right">1.0000s</td><td align="right">0.9977s</td><td align="right"> -0.23%</td></tr></table>
cc `@SparrowLii`
Sprinkle some `#[inline]` in `rustc_data_structures::tagged_ptr`
This is based on `nm --demangle (rustc +a --print sysroot)/lib/librustc_driver-*.so | rg CopyTaggedPtr` which shows many methods that should probably be inlined. May fix the regression in https://github.com/rust-lang/rust/pull/110795.
r? ```@Nilstrieb```
Add `impl_tag!` macro to implement `Tag` for tagged pointer easily
r? `@Nilstrieb`
This should also lifts the need to think about safety from the callers (`impl_tag!` is robust (ish, see the macro issue)) and removes the possibility of making a "weird" `Tag` impl.
Encode hashes as bytes, not varint
In a few places, we store hashes as `u64` or `u128` and then apply `derive(Decodable, Encodable)` to the enclosing struct/enum. It is more efficient to encode hashes directly than try to apply some varint encoding. This PR adds two new types `Hash64` and `Hash128` which are produced by `StableHasher` and replace every use of storing a `u64` or `u128` that represents a hash.
Distribution of the byte lengths of leb128 encodings, from `x build --stage 2` with `incremental = true`
Before:
```
( 1) 373418203 (53.7%, 53.7%): 1
( 2) 196240113 (28.2%, 81.9%): 3
( 3) 108157958 (15.6%, 97.5%): 2
( 4) 17213120 ( 2.5%, 99.9%): 4
( 5) 223614 ( 0.0%,100.0%): 9
( 6) 216262 ( 0.0%,100.0%): 10
( 7) 15447 ( 0.0%,100.0%): 5
( 8) 3633 ( 0.0%,100.0%): 19
( 9) 3030 ( 0.0%,100.0%): 8
( 10) 1167 ( 0.0%,100.0%): 18
( 11) 1032 ( 0.0%,100.0%): 7
( 12) 1003 ( 0.0%,100.0%): 6
( 13) 10 ( 0.0%,100.0%): 16
( 14) 10 ( 0.0%,100.0%): 17
( 15) 5 ( 0.0%,100.0%): 12
( 16) 4 ( 0.0%,100.0%): 14
```
After:
```
( 1) 372939136 (53.7%, 53.7%): 1
( 2) 196240140 (28.3%, 82.0%): 3
( 3) 108014969 (15.6%, 97.5%): 2
( 4) 17192375 ( 2.5%,100.0%): 4
( 5) 435 ( 0.0%,100.0%): 5
( 6) 83 ( 0.0%,100.0%): 18
( 7) 79 ( 0.0%,100.0%): 10
( 8) 50 ( 0.0%,100.0%): 9
( 9) 6 ( 0.0%,100.0%): 19
```
The remaining 9 or 10 and 18 or 19 are `u64` and `u128` respectively that have the high bits set. As far as I can tell these are coming primarily from `SwitchTargets`.
Spelling compiler
This is per https://github.com/rust-lang/rust/pull/110392#issuecomment-1510193656
I'm going to delay performing a squash because I really don't expect people to be perfectly happy w/ my changes, I really am a human and I really do make mistakes.
r? Nilstrieb
I'm going to be flying this evening, but I should be able to squash / respond to reviews w/in a day or two.
I tried to be careful about dropping changes to `tests`, afaict only two files had changes that were likely related to the changes for a given commit (this is where not having eagerly squashed should have given me an advantage), but, that said, picking things apart can be error prone.
Rollup of 7 pull requests
Successful merges:
- #109981 (Set commit information environment variables when building tools)
- #110348 (Add list of supported disambiguators and suffixes for intra-doc links in the rustdoc book)
- #110409 (Don't use `serde_json` to serialize a simple JSON object)
- #110442 (Avoid including dry run steps in the build metrics)
- #110450 (rustdoc: Fix invalid handling of nested items with `--document-private-items`)
- #110461 (Use `Item::expect_*` and `ImplItem::expect_*` more)
- #110465 (Assure everyone that `has_type_flags` is fast)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Don't use `serde_json` to serialize a simple JSON object
This avoids `rustc_data_structures` depending on `serde_json` which allows it to be compiled much earlier, unlocking most of rustc.
This used to not matter, but after #110407 we're not blocked on fluent anymore, which means that it's now a blocking edge.
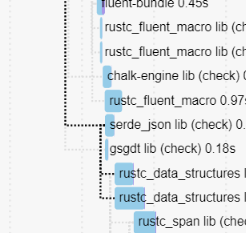
This saves a few more seconds.
cc ````@Zoxc```` who added it recently
Implement StableHasher::write_u128 via write_u64
In https://github.com/rust-lang/rust/pull/110367#issuecomment-1510114777 the cachegrind diffs indicate that nearly all the regression is from this:
```
22,892,558 ???:<rustc_data_structures::sip128::SipHasher128>::slice_write_process_buffer
-9,502,262 ???:<rustc_data_structures::sip128::SipHasher128>::short_write_process_buffer::<8>
```
Which happens because the diff for that perf run swaps a `Hash::hash` of a `u64` to a `u128`. But `slice_write_process_buffer` is a `#[cold]` function, and is for handling hashes of arbitrary-length byte arrays.
Using the much more optimizer-friendly `u64` path twice to hash a `u128` provides a nice perf boost in some benchmarks.
Tagged pointers, now with strict provenance!
This is a big refactor of tagged pointers in rustc, with three main goals:
1. Porting the code to the strict provenance
2. Cleanup the code
3. Document the code (and safety invariants) better
This PR has grown quite a bit (almost a complete rewrite at this point...), so I'm not sure what's the best way to review this, but reviewing commit-by-commit should be fine.
r? `@Nilstrieb`
Remove some suspicious cast truncations
These truncations were added a long time ago, and as best I can tell without a perf justification. And with rust-lang/rust#110410 it has become perf-neutral to not truncate anymore. We worked hard for all these bits, let's use them.
Turns out
- `owning_ref` is unsound due to `Box` aliasing stuff
- `rustc` doesn't need 99% of the `owning_ref` API
- `rustc` can use a far simpler abstraction that is `OwnedSlice`
Also, `MTRef<'a, T>` is a typedef for a reference to a `T`, but in
practice it's only used (and useful) in combination with `MTLock`, i.e.
`MTRef<'a, MTLock<T>>`. So this commit changes it to be a typedef for a
reference to an `MTLock<T>`, and renames it as `MTLockRef`. I think this
clarifies things, because I found `MTRef` quite puzzling at first.
Add `-Z time-passes-format` to allow specifying a JSON output for `-Z time-passes`
This adds back the `-Z time` option as that is useful for [my rustc benchmark tool](https://github.com/Zoxc/rcb), reverting https://github.com/rust-lang/rust/pull/102725. It now uses nanoseconds and bytes as the units so it is renamed to `time-precise`.
- only borrow the refcell once per loop
- avoid complex matches to reduce branch paths in the hot loop
- use a by-ref fast path that avoids mutations at the expense of having false negatives
Rename `MapInPlace` as `FlatMapInPlace`.
After removing the `map_in_place` method, which isn't much use because modifying every element in a collection such as a `Vec` can be done trivially with iteration.
r? ``@lqd``
Do not implement HashStable for HashSet (MCP 533)
This PR removes all occurrences of `HashSet` in query results, replacing it either with `FxIndexSet` or with `UnordSet`, and then removes the `HashStable` implementation of `HashSet`. This is part of implementing [MCP 533](https://github.com/rust-lang/compiler-team/issues/533), that is, removing the `HashStable` implementations of all collection types with unstable iteration order.
The changes are mostly mechanical. The only place where additional sorting is happening is in Miri's override implementation of the `exported_symbols` query.
After removing the `map_in_place` method, which isn't much use because
modifying every element in a collection such as a `Vec` can be done
trivially with iteration.
Use a lock-free datastructure for source_span
follow up to the perf regression in https://github.com/rust-lang/rust/pull/105462
The main regression is likely the CStore, but let's evaluate the perf impact of this on its own
Better debug logs for borrowck constraint graph
It's really cumbersome to work with `RegionVar`s when trying to debug borrowck code or when trying to understand how the borrowchecker works. This PR collects some region information (behind `cfg(debug_assertions)`) for created `RegionVar`s (NLL region vars, this PR doesn't touch canonicalization) and prints the nodes and edges of the strongly connected constraints graph using representatives that use that region information (either lifetime names, locations in MIR or spans).
Bump bootstrap compiler to 1.68
This also changes our stage0.json to include the rustc component for the rustfmt pinned nightly toolchain, which is currently necessary due to rustfmt dynamically linking to that toolchain's librustc_driver and libstd.
r? `@pietroalbini`
Use stable metric for const eval limit instead of current terminator-based logic
This patch adds a `MirPass` that inserts a new MIR instruction `ConstEvalCounter` to any loops and function calls in the CFG. This instruction is used during Const Eval to count against the `const_eval_limit`, and emit the `StepLimitReached` error, replacing the current logic which uses Terminators only.
The new method of counting loops and function calls should be more stable across compiler versions (i.e., not cause crates that compiled successfully before, to no longer compile when changes to the MIR generation/optimization are made).
Also see: #103877
Consistently use dominates instead of is_dominated_by
There is a number of APIs that answer dominance queries. Previously they were named either "dominates" or "is_dominated_by". Consistently use the "dominates" form.
No functional changes.
Use UnordMap and UnordSet for id collections (DefIdMap, LocalDefIdMap, etc)
This PR changes the `rustc_data_structures::define_id_collections!` macro to use `UnordMap` and `UnordSet` instead of `FxHashMap` and `FxHashSet`. This should account for a large portion of hash-maps being used in places where they can cause trouble.
The changes required are moderate but non-zero:
- In some places the collections are extracted into sorted vecs.
- There are a few instances where for-loops have been changed to extends.
~~Let's see what the performance impact is. With a bit more refactoring, we might be able to get rid of some of the additional sorting -- but the change set is already big enough. Unless there's a performance impact, I'd like to do further changes in subsequent PRs.~~
Performance does not seem to be negatively affected ([perf-run here](https://github.com/rust-lang/rust/pull/106977#issuecomment-1396776699)).
Part of [MCP 533](https://github.com/rust-lang/compiler-team/issues/533).
r? `@ghost`
There is a number of APIs that answer dominance queries. Previously they
were named either "dominates" or "is_dominated_by". Consistently use the
"dominates" form.
No functional changes.
Switching them to `Break(())` and `Continue(())` instead.
libs-api would like to remove these constants, so stop using them in compiler to make the removal PR later smaller.
Convert all the crates that have had their diagnostic migration
completed (except save_analysis because that will be deleted soon and
apfloat because of the licensing problem).
HIR debug output is currently very verbose, especially when used with
the alternate (`#`) flag. This commit reduces the amount of noisy
newlines by forcing a few small key types to stay on one line, which
makes the output easier to read and scroll by.
```
$ rustc +after hello_world.rs -Zunpretty=hir-tree | wc -l
582
$ rustc +before hello_world.rs -Zunpretty=hir-tree | wc -l
932
```
Remove the `..` from the body, only a few invocations used it and it's
inconsistent with rust syntax.
Use `;` instead of `,` between consts. As the Rust syntax gods inteded.
Put all cached values into a central struct instead of just the stable hash
cc `@nnethercote`
this allows re-use of the type for Predicate without duplicating all the logic for the non-hash cached fields
Add StableOrd trait as proposed in MCP 533.
The `StableOrd` trait can be used to mark types as having a stable sort order across compilation sessions. Collections that sort their items in a stable way can safely implement HashStable by hashing items in sort order.
See https://github.com/rust-lang/compiler-team/issues/533 for more information.
Rollup of 9 pull requests
Successful merges:
- #104199 (Keep track of the start of the argument block of a closure)
- #105050 (Remove useless borrows and derefs)
- #105153 (Create a hacky fail-fast mode that stops tests at the first failure)
- #105164 (Restore `use` suggestion for `dyn` method call requiring `Sized`)
- #105193 (Disable coverage instrumentation for naked functions)
- #105200 (Remove useless filter in unused extern crate check.)
- #105201 (Do not call fn_sig on non-functions.)
- #105208 (Add AmbiguityError for inconsistent resolution for an import)
- #105214 (update Miri)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Remove useless borrows and derefs
They are nothing more than noise.
<sub>These are not all of them, but my clippy started crashing (stack overflow), so rip :(</sub>
The StableOrd trait can be used to mark types as having a stable
sort order across compilation sessions. Collections that sort their
items in a stable way can safely implement HashStable by
hashing items in sort order.
Use liballoc's specialised in-place vec collection
liballoc already specialises in-place vector collection, so manually
reimplementing it in `IdFunctor::try_map_id` was superfluous.
Use Set instead of Vec in transitive_relation
Helps with #103195. It doesn't fix the underlying quadraticness but it makes it _a lot_ faster to an extent where even doubling the amount of nested references still takes less than two seconds (50s on nightly).
I want to see whether this causes regressions (because the vec was usually quite small) or improvements (as lookup for bigger sets is now much faster) in real code.
Remove "execute" bit from lock file permissions
Previously, flock would set the "execute" bit on Rust lock files. That makes no sense.
This patch clears the "execute" bit on Rust lock files.
See issue #102531.
Remove `-Ztime`
Because it has a lot of overlap with `-Ztime-passes` but is generally less useful. Plus some related cleanups.
Best reviewed one commit at a time.
r? `@davidtwco`
`print_time_passes_entry` unconditionally prints data about a pass. The
most commonly used call site, in `VerboseTimingGuard::drop`, guards it
with a `should_print_passes` test. But there are a couple of other call
sites that don't do that test.
This commit moves the `should_print_passes` test within
`print_time_passes_entry` so that all passes are treated equally.
The compiler currently has `-Ztime` and `-Ztime-passes`. I've used
`-Ztime-passes` for years but only recently learned about `-Ztime`.
What's the difference? Let's look at the `-Zhelp` output:
```
-Z time=val -- measure time of rustc processes (default: no)
-Z time-passes=val -- measure time of each rustc pass (default: no)
```
The `-Ztime-passes` description is clear, but the `-Ztime` one is less so.
Sounds like it measures the time for the entire process?
No. The real difference is that `-Ztime-passes` prints out info about passes,
and `-Ztime` does the same, but only for a subset of those passes. More
specifically, there is a distinction in the profiling code between a "verbose
generic activity" and an "extra verbose generic activity". `-Ztime-passes`
prints both kinds, while `-Ztime` only prints the first one. (It took me
a close reading of the source code to determine this difference.)
In practice this distinction has low value. Perhaps in the past the "extra
verbose" output was more voluminous, but now that we only print stats for a
pass if it exceeds 5ms or alters the RSS, `-Ztime-passes` is less spammy. Also,
a lot of the "extra verbose" cases are for individual lint passes, and you need
to also use `-Zno-interleave-lints` to see those anyway.
Therefore, this commit removes `-Ztime` and the associated machinery. One thing
to note is that the existing "extra verbose" activities all have an extra
string argument, so the commit adds the ability to accept an extra argument to
the "verbose" activities.
Make cycle errors recoverable
In particular, this allows rustdoc to recover from cycle errors when normalizing associated types for documentation.
In the past, ```@jackh726``` has said we need to be careful about overflow errors: https://github.com/rust-lang/rust/pull/91430#issuecomment-983997013
> Off the top of my head, we definitely should be careful about treating overflow errors the same as
"not implemented for some reason" errors. Otherwise, you could end up with behavior that is
different depending on recursion depth. But, that might be context-dependent.
But cycle errors should be safe to unconditionally report; they don't depend on the recursion depth, they will always be an error whenever they're encountered.
Helps with https://github.com/rust-lang/rust/issues/81091.
r? ```@lcnr``` cc ```@matthewjasper```
In particular, this allows rustdoc to recover from cycle errors when normalizing associated types for documentation.
In the past, `@jackh726` has said we need to be careful about overflow errors:
> Off the top of my head, we definitely should be careful about treating overflow errors the same as
"not implemented for some reason" errors. Otherwise, you could end up with behavior that is
different depending on recursion depth. But, that might be context-dependent.
But cycle errors should be safe to unconditionally report; they don't depend on the recursion depth, they will always be an error whenever they're encountered.
On later stages, the feature is already stable.
Result of running:
rg -l "feature.let_else" compiler/ src/librustdoc/ library/ | xargs sed -s -i "s#\\[feature.let_else#\\[cfg_attr\\(bootstrap, feature\\(let_else\\)#"
Replace `rustc_data_structures::thin_vec::ThinVec` with `thin_vec::ThinVec`
`rustc_data_structures::thin_vec::ThinVec` looks like this:
```
pub struct ThinVec<T>(Option<Box<Vec<T>>>);
```
It's just a zero word if the vector is empty, but requires two
allocations if it is non-empty. So it's only usable in cases where the
vector is empty most of the time.
This commit removes it in favour of `thin_vec::ThinVec`, which is also
word-sized, but stores the length and capacity in the same allocation as
the elements. It's good in a wider variety of situation, e.g. in enum
variants where the vector is usually/always non-empty.
The commit also:
- Sorts some `Cargo.toml` dependency lists, to make additions easier.
- Sorts some `use` item lists, to make additions easier.
- Changes `clean_trait_ref_with_bindings` to take a
`ThinVec<TypeBinding>` rather than a `&[TypeBinding]`, because this
avoid some unnecessary allocations.
r? `@spastorino`
Fix a bunch of typo
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
`rustc_data_structures::thin_vec::ThinVec` looks like this:
```
pub struct ThinVec<T>(Option<Box<Vec<T>>>);
```
It's just a zero word if the vector is empty, but requires two
allocations if it is non-empty. So it's only usable in cases where the
vector is empty most of the time.
This commit removes it in favour of `thin_vec::ThinVec`, which is also
word-sized, but stores the length and capacity in the same allocation as
the elements. It's good in a wider variety of situation, e.g. in enum
variants where the vector is usually/always non-empty.
The commit also:
- Sorts some `Cargo.toml` dependency lists, to make additions easier.
- Sorts some `use` item lists, to make additions easier.
- Changes `clean_trait_ref_with_bindings` to take a
`ThinVec<TypeBinding>` rather than a `&[TypeBinding]`, because this
avoid some unnecessary allocations.
In some places we use `Vec<Attribute>` and some places we use
`ThinVec<Attribute>` (a.k.a. `AttrVec`). This results in various points
where we have to convert between `Vec` and `ThinVec`.
This commit changes the places that use `Vec<Attribute>` to use
`AttrVec`. A lot of this is mechanical and boring, but there are
some interesting parts:
- It adds a few new methods to `ThinVec`.
- It implements `MapInPlace` for `ThinVec`, and introduces a macro to
avoid the repetition of this trait for `Vec`, `SmallVec`, and
`ThinVec`.
Overall, it makes the code a little nicer, and has little effect on
performance. But it is a precursor to removing
`rustc_data_structures::thin_vec::ThinVec` and replacing it with
`thin_vec::ThinVec`, which is implemented more efficiently.
Upgrade indexmap and thorin-dwp to use hashbrown 0.12
This removes the last dependencies on hashbrown 0.11.
This also upgrades to hashbrown 0.12.3 to fix a double-free (#99372).
Stop keeping metadata in memory before writing it to disk
Fixes#96358
I created this PR according with the instruction given in the issue except for the following points:
- While the issue says "Write metadata into the temporary file in `encode_and_write_metadata` even if `!need_metadata_file`", I could not do that. That is because though I tried to do that and run `x.py test`, I got a lot of test failures as follows.
<details>
<summary>List of failed tests</summary>
<pre>
<code>
failures:
[ui] src/test/ui/json-multiple.rs
[ui] src/test/ui/json-options.rs
[ui] src/test/ui/rmeta/rmeta-rpass.rs
[ui] src/test/ui/save-analysis/emit-notifications.rs
[ui] src/test/ui/svh/changing-crates.rs
[ui] src/test/ui/svh/svh-change-lit.rs
[ui] src/test/ui/svh/svh-change-significant-cfg.rs
[ui] src/test/ui/svh/svh-change-trait-bound.rs
[ui] src/test/ui/svh/svh-change-type-arg.rs
[ui] src/test/ui/svh/svh-change-type-ret.rs
[ui] src/test/ui/svh/svh-change-type-static.rs
[ui] src/test/ui/svh/svh-use-trait.rs
test result: FAILED. 12915 passed; 12 failed; 100 ignored; 0 measured; 0 filtered out; finished in 71.41s
Some tests failed in compiletest suite=ui mode=ui host=x86_64-unknown-linux-gnu target=x86_64-unknown-linux-gnu
Build completed unsuccessfully in 0:01:58
</code>
</pre>
</details>
- I could not resolve the extra tasks about `create_rmeta_file` and `create_compressed_metadata_file` for my lack of ability.
Fix RSS reporting on macOS
> NOTE: This is a duplicate of #98164, which I closed because I borked my rustc fork
Currently, `rustc_data_structures::profiling::get_resident_set_size()` always returns `None` on macOS. This is because
macOS does not implement procfs used in the unix version of the function:
```rust
...
else if #[cfg(unix)] {
pub fn get_resident_set_size() -> Option<usize> {
let field = 1;
let contents = fs::read("/proc/self/statm").ok()?;
let contents = String::from_utf8(contents).ok()?;
let s = contents.split_whitespace().nth(field)?;
let npages = s.parse::<usize>().ok()?;
Some(npages * 4096)
}
...
```
The proposed solution uses libproc, and more specifically `proc_pidinfo`, which has been available on macOS since 10.5 if the function signature inside libproc.h is to be believed:
```c
int proc_pidinfo(int pid, int flavor, uint64_t arg, void *buffer, int buffersize) __OSX_AVAILABLE_STARTING(__MAC_10_5, __IPHONE_2_0);
```
Rename rustc_serialize::opaque::Encoder as MemEncoder.
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
(This was previously merged as commit 5 in #94732 and then was reverted
in #97905 because of a perf regression caused by commit 4 in #94732.)
r? ```@bjorn3```
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
(This was previously merged as commit 5 in #94732 and then was reverted
in #97905 because of a perf regression caused by commit 4 in #94732.)
This avoids the name clash with `rustc_serialize::Encoder` (a trait),
and allows lots qualifiers to be removed and imports to be simplified
(e.g. fewer `as` imports).
There are two impls of the `Encoder` trait: `opaque::Encoder` and
`opaque::FileEncoder`. The former encodes into memory and is infallible, the
latter writes to file and is fallible.
Currently, standard `Result`/`?`/`unwrap` error handling is used, but this is a
bit verbose and has non-trivial cost, which is annoying given how rare failures
are (especially in the infallible `opaque::Encoder` case).
This commit changes how `Encoder` fallibility is handled. All the `emit_*`
methods are now infallible. `opaque::Encoder` requires no great changes for
this. `opaque::FileEncoder` now implements a delayed error handling strategy.
If a failure occurs, it records this via the `res` field, and all subsequent
encoding operations are skipped if `res` indicates an error has occurred. Once
encoding is complete, the new `finish` method is called, which returns a
`Result`. In other words, there is now a single `Result`-producing method
instead of many of them.
This has very little effect on how any file errors are reported if
`opaque::FileEncoder` has any failures.
Much of this commit is boring mechanical changes, removing `Result` return
values and `?` or `unwrap` from expressions. The more interesting parts are as
follows.
- serialize.rs: The `Encoder` trait gains an `Ok` associated type. The
`into_inner` method is changed into `finish`, which returns
`Result<Vec<u8>, !>`.
- opaque.rs: The `FileEncoder` adopts the delayed error handling
strategy. Its `Ok` type is a `usize`, returning the number of bytes
written, replacing previous uses of `FileEncoder::position`.
- Various methods that take an encoder now consume it, rather than being
passed a mutable reference, e.g. `serialize_query_result_cache`.
Because it really has two halves:
- A read-only part that checks if further work is needed.
- The further work part, which is much less hot.
This makes things a bit clearer and nicer.
It creates the src pointer first, which is then invalidated by a
unique borrow of the destination pointer. Swap the borrows around
to fix this. Found with miri.
Some tests took too long and owning_ref is fundamentally flawed,
so don't run these tests or run them with a shorter N. This makes
miri with `-Zmiri-strict-provenance` usable to find UB.
Begin fixing all the broken doctests in `compiler/`
Begins to fix#95994.
All of them pass now but 24 of them I've marked with `ignore HELP (<explanation>)` (asking for help) as I'm unsure how to get them to work / if we should leave them as they are.
There are also a few that I marked `ignore` that could maybe be made to work but seem less important.
Each `ignore` has a rough "reason" for ignoring after it parentheses, with
- `(pseudo-rust)` meaning "mostly rust-like but contains foreign syntax"
- `(illustrative)` a somewhat catchall for either a fragment of rust that doesn't stand on its own (like a lone type), or abbreviated rust with ellipses and undeclared types that would get too cluttered if made compile-worthy.
- `(not-rust)` stuff that isn't rust but benefits from the syntax highlighting, like MIR.
- `(internal)` uses `rustc_*` code which would be difficult to make work with the testing setup.
Those reason notes are a bit inconsistently applied and messy though. If that's important I can go through them again and try a more principled approach. When I run `rg '```ignore \(' .` on the repo, there look to be lots of different conventions other people have used for this sort of thing. I could try unifying them all if that would be helpful.
I'm not sure if there was a better existing way to do this but I wrote my own script to help me run all the doctests and wade through the output. If that would be useful to anyone else, I put it here: https://github.com/Elliot-Roberts/rust_doctest_fixing_tool
Fixing #95444 by only displaying passes that take more than 5 millise…
As discussed in #95444, I have added the code to test and only display prints that are greater than 5 milliseconds.
r? `@jyn514`
Add a dedicated length-prefixing method to `Hasher`
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
Fixes#94026
r? rust-lang/libs
---
The core of this change is the following two new methods on `Hasher`:
```rust
pub trait Hasher {
/// Writes a length prefix into this hasher, as part of being prefix-free.
///
/// If you're implementing [`Hash`] for a custom collection, call this before
/// writing its contents to this `Hasher`. That way
/// `(collection![1, 2, 3], collection![4, 5])` and
/// `(collection![1, 2], collection![3, 4, 5])` will provide different
/// sequences of values to the `Hasher`
///
/// The `impl<T> Hash for [T]` includes a call to this method, so if you're
/// hashing a slice (or array or vector) via its `Hash::hash` method,
/// you should **not** call this yourself.
///
/// This method is only for providing domain separation. If you want to
/// hash a `usize` that represents part of the *data*, then it's important
/// that you pass it to [`Hasher::write_usize`] instead of to this method.
///
/// # Examples
///
/// ```
/// #![feature(hasher_prefixfree_extras)]
/// # // Stubs to make the `impl` below pass the compiler
/// # struct MyCollection<T>(Option<T>);
/// # impl<T> MyCollection<T> {
/// # fn len(&self) -> usize { todo!() }
/// # }
/// # impl<'a, T> IntoIterator for &'a MyCollection<T> {
/// # type Item = T;
/// # type IntoIter = std::iter::Empty<T>;
/// # fn into_iter(self) -> Self::IntoIter { todo!() }
/// # }
///
/// use std:#️⃣:{Hash, Hasher};
/// impl<T: Hash> Hash for MyCollection<T> {
/// fn hash<H: Hasher>(&self, state: &mut H) {
/// state.write_length_prefix(self.len());
/// for elt in self {
/// elt.hash(state);
/// }
/// }
/// }
/// ```
///
/// # Note to Implementers
///
/// If you've decided that your `Hasher` is willing to be susceptible to
/// Hash-DoS attacks, then you might consider skipping hashing some or all
/// of the `len` provided in the name of increased performance.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_length_prefix(&mut self, len: usize) {
self.write_usize(len);
}
/// Writes a single `str` into this hasher.
///
/// If you're implementing [`Hash`], you generally do not need to call this,
/// as the `impl Hash for str` does, so you can just use that.
///
/// This includes the domain separator for prefix-freedom, so you should
/// **not** call `Self::write_length_prefix` before calling this.
///
/// # Note to Implementers
///
/// The default implementation of this method includes a call to
/// [`Self::write_length_prefix`], so if your implementation of `Hasher`
/// doesn't care about prefix-freedom and you've thus overridden
/// that method to do nothing, there's no need to override this one.
///
/// This method is available to be overridden separately from the others
/// as `str` being UTF-8 means that it never contains `0xFF` bytes, which
/// can be used to provide prefix-freedom cheaper than hashing a length.
///
/// For example, if your `Hasher` works byte-by-byte (perhaps by accumulating
/// them into a buffer), then you can hash the bytes of the `str` followed
/// by a single `0xFF` byte.
///
/// If your `Hasher` works in chunks, you can also do this by being careful
/// about how you pad partial chunks. If the chunks are padded with `0x00`
/// bytes then just hashing an extra `0xFF` byte doesn't necessarily
/// provide prefix-freedom, as `"ab"` and `"ab\u{0}"` would likely hash
/// the same sequence of chunks. But if you pad with `0xFF` bytes instead,
/// ensuring at least one padding byte, then it can often provide
/// prefix-freedom cheaper than hashing the length would.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_str(&mut self, s: &str) {
self.write_length_prefix(s.len());
self.write(s.as_bytes());
}
}
```
With updates to the `Hash` implementations for slices and containers to call `write_length_prefix` instead of `write_usize`.
`write_str` defaults to using `write_length_prefix` since, as was pointed out in the issue, the `write_u8(0xFF)` approach is insufficient for hashers that work in chunks, as those would hash `"a\u{0}"` and `"a"` to the same thing. But since `SipHash` works byte-wise (there's an internal buffer to accumulate bytes until a full chunk is available) it overrides `write_str` to continue to use the add-non-UTF-8-byte approach.
---
Compatibility:
Because the default implementation of `write_length_prefix` calls `write_usize`, the changed hash implementation for slices will do the same thing the old one did on existing `Hasher`s.
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
95444: Adding passes that include memory increase
Fix95444: Change the substraction with the abs_diff() method
Fix95444: Change the substraction with abs_diff() method
rustc_metadata: Do not encode unnecessary module children
This should remove the syntax context shift and the special case for `ExternCrate` in decoder in https://github.com/rust-lang/rust/pull/95880.
This PR also shifts some work from decoding to encoding, which is typically useful for performance (but probably not much in this case).
r? `@cjgillot`
Allow self-profiler to only record potentially costly arguments when argument recording is turned on
As discussed [on zulip](https://rust-lang.zulipchat.com/#narrow/stream/247081-t-compiler.2Fperformance/topic/Identifying.20proc-macro.20slowdowns/near/277304909) with `@wesleywiser,` I'd like to record proc-macro expansions in the self-profiler, with some detailed data (per-expansion spans for example, to follow #95473).
At the same time, I'd also like to avoid doing expensive things when tracking a generic activity's arguments, if they were not specifically opted into the event filter mask, to allow the self-profiler to be used in hotter contexts.
This PR tries to offer:
- a way to ensure a closure to record arguments will only be called in that situation, so that potentially costly arguments can still be recorded when needed. With the additional requirement that, if possible, it would offer a way to record non-owned data without adding many `generic_activity_with_arg_{...}`-style methods. This lead to the `generic_activity_with_arg_recorder` single entry-point, and the closure parameter would offer the new methods, able to be executed in a context where costly argument could be created without disturbing the profiled piece of code.
- some facilities/patterns allowing to record more rustc specific data in this situation, without making `rustc_data_structures` where the self-profiler is defined, depend on other rustc crates (causing circular dependencies): in particular, spans. They are quite tricky to turn into strings (if the default `Debug` impl output does not match the context one needs them for), and since I'd also like to avoid the allocation there when arg recording is turned off today, that has turned into another flexibility requirement for the API in this PR (separating the span-specific recording into an extension trait). **edit**: I've removed this from the PR so that it's easier to review, and opened https://github.com/rust-lang/rust/pull/95739.
- allow for extensibility in the future: other ways to record arguments, or additional data attached to them could be added in the future (e.g. recording the argument's name as well as its data).
Some areas where I'd love feedback:
- the API and names: the `EventArgRecorder` and its method for example. As well as the verbosity that comes from the increased flexibility.
- if I should convert the existing `generic_activity_with_arg{s}` to just forward to `generic_activity_with_arg_recorder` + `recorder.record_arg` (or remove them altogether ? Probably not): I've used the new API in the simple case I could find of allocating for an arg that may not be recorded, and the rest don't seem costly.
- [x] whether this API should panic if no arguments were recorded by the user-provided closure (like this PR currently does: it seems like an error to use an API dedicated to record arguments but not call the methods to then do so) or if this should just record a generic activity without arguments ?
- whether the `record_arg` function should be `#[inline(always)]`, like the `generic_activity_*` functions ?
As mentioned, r? `@wesleywiser` following our recent discussion.
make unaligned_references lint deny-by-default
This lint has been warn-by-default for a year now (since https://github.com/rust-lang/rust/pull/82525), so I think it is time to crank it up a bit. Code that triggers the lint causes UB (without `unsafe`) when executed, so we really don't want people to write code like this.
Cached stable hash cleanups
r? `@nnethercote`
Add a sanity assertion in debug mode to check that the cached hashes are actually the ones we get if we compute the hash each time.
Add a new data structure that bundles all the hash-caching work to make it easier to re-use it for different interned data structures
Enforce well formedness for type alias impl trait's hidden type
fixes#84657
This was not an issue with return-position-impl-trait because the generic bounds of the function are the same as those of the opaque type, and the hidden type must already be well formed within the function.
With type-alias-impl-trait the hidden type could be defined in a function that has *more* lifetime bounds than the type alias. This is fine, but the hidden type must still be well formed without those additional bounds.
This allows profiling costly arguments to be recorded only when `-Zself-profile-events=args` is on: using a closure that takes an `EventArgRecorder` and call its `record_arg` or `record_args` methods.
{kind=link}