Currently, we parse macros at the end of a block
(e.g. `fn foo() { my_macro!() }`) as expressions, rather than
statements. This means that a macro invoked in this position
cannot expand to items or semicolon-terminated expressions.
In the future, we might want to start parsing these kinds of macros
as statements. This would make expansion more 'token-based'
(i.e. macro expansion behaves (almost) as if you just textually
replaced the macro invocation with its output). However,
this is a breaking change (see PR #78991), so it will require
further discussion.
Since the current behavior will not be changing any time soon,
we need to address the interaction with the
`SEMICOLON_IN_EXPRESSIONS_FROM_MACROS` lint. Since we are parsing
the result of macro expansion as an expression, we will emit a lint
if there's a trailing semicolon in the macro output. However, this
results in a somewhat confusing message for users, since it visually
looks like there should be no problem with having a semicolon
at the end of a block
(e.g. `fn foo() { my_macro!() }` => `fn foo() { produced_expr; }`)
To help reduce confusion, this commit adds a note explaining
that the macro is being interpreted as an expression. Additionally,
we suggest adding a semicolon after the macro *invocation* - this
will cause us to parse the macro call as a statement. We do *not*
use a structured suggestion for this, since the user may actually
want to remove the semicolon from the macro definition (allowing
the block to evaluate to the expression produced by the macro).
These attributes are currently discarded.
This may change in the future (see #63221), but for now,
placing inert attributes on a macro invocation does nothing,
so we should warn users about it.
Technically, it's possible for there to be attribute macro
on the same macro invocation (or at a higher scope), which
inspects the inert attribute. For example:
```rust
#[look_for_inline_attr]
#[inline]
my_macro!()
#[look_for_nested_inline]
mod foo { #[inline] my_macro!() }
```
However, this would be a very strange thing to do.
Anyone running into this can manually suppress the warning.
When we need to emit a lint at a macro invocation, we currently use the
`NodeId` of its parent definition (e.g. the enclosing function). This
means that any `#[allow]` / `#[deny]` attributes placed 'closer' to the
macro (e.g. on an enclosing block or statement) will have no effect.
This commit computes a better `lint_node_id` in `InvocationCollector`.
When we visit/flat_map an AST node, we assign it a `NodeId` (earlier
than we normally would), and store than `NodeId` in current
`ExpansionData`. When we collect a macro invocation, the current
`lint_node_id` gets cloned along with our `ExpansionData`, allowing it
to be used if we need to emit a lint later on.
This improves the handling of `#[allow]` / `#[deny]` for
`SEMICOLON_IN_EXPRESSIONS_FROM_MACROS` and some `asm!`-related lints.
The 'legacy derive helpers' lint retains its current behavior
(I've inlined the now-removed `lint_node_id` function), since
there isn't an `ExpansionData` readily available.
expand: Support helper attributes for built-in derive macros
This is needed for https://github.com/rust-lang/rust/pull/86735 (derive macro `Default` should have a helper attribute `default`).
With this PR we can specify helper attributes for built-in derives using syntax `#[rustc_builtin_macro(MacroName, attributes(attr1, attr2, ...))]` which mirrors equivalent syntax for proc macros `#[proc_macro_derive(MacroName, attributes(attr1, attr2, ...))]`.
Otherwise expansion infra was already ready for this.
The attribute parsing code is shared between proc macro derives and built-in macros (`fn parse_macro_name_and_helper_attrs`).
Rollup of 6 pull requests
Successful merges:
- #87085 (Search result colors)
- #87090 (Make BTreeSet::split_off name elements like other set methods do)
- #87098 (Unignore some pretty printing tests)
- #87099 (Upgrade `cc` crate to 1.0.69)
- #87101 (Suggest a path separator if a stray colon is found in a match arm)
- #87102 (Add GUI test for "go to first" feature)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
- The `Rustc::expn_id` field kept redundant information
- `SyntaxContext` is no longer thrown away before `save_proc_macro_span` because it's thrown away during metadata encoding anyway
Currently, we only point at the span of the macro argument. When the
macro call is itself generated by another macro, this can make it
difficult or impossible to determine which macro is responsible for
producing the error.
Remove unused feature gates
The first commit removes a usage of a feature gate, but I don't expect it to be controversial as the feature gate was only used to workaround a limitation of rust in the past. (closures never being `Clone`)
The second commit uses `#[allow_internal_unstable]` to avoid leaking the `trusted_step` feature gate usage from inside the index newtype macro. It didn't work for the `min_specialization` feature gate though.
The third commit removes (almost) all feature gates from the compiler that weren't used anyway.
As described in issue #85708, we currently do not properly decode
`SyntaxContext::root()` and `ExpnId::root()` from foreign crates. As a
result, when we decode a span from a foreign crate with
`SyntaxContext::root()`, we end up up considering it to have the edition
of the *current* crate, instead of the foreign crate where it was
originally created.
A full fix for this issue will be a fairly significant undertaking.
Fortunately, it's possible to implement a partial fix, which gives us
the correct edition-dependent behavior for `:pat` matchers when the
macro is loaded from another crate. Since we have the edition of the
macro's defining crate available, we can 'recover' from seeing a
`SyntaxContext::root()` and use the edition of the macro's defining
crate.
Any solution to issue #85708 must reproduce the behavior of this
targeted fix - properly preserving a foreign `SyntaxContext::root()`
means (among other things) preserving its edition, which by definition
is the edition of the foreign crate itself. Therefore, this fix moves us
closer to the correct overall solution, and does not expose any new
incorrect behavior to macros.
Fix `--remap-path-prefix` not correctly remapping `rust-src` component paths and unify handling of path mapping with virtualized paths
This PR fixes#73167 ("Binaries end up containing path to the rust-src component despite `--remap-path-prefix`") by preventing real local filesystem paths from reaching compilation output if the path is supposed to be remapped.
`RealFileName::Named` introduced in #72767 is now renamed as `LocalPath`, because this variant wraps a (most likely) valid local filesystem path.
`RealFileName::Devirtualized` is renamed as `Remapped` to be used for remapped path from a real path via `--remap-path-prefix` argument, as well as real path inferred from a virtualized (during compiler bootstrapping) `/rustc/...` path. The `local_path` field is now an `Option<PathBuf>`, as it will be set to `None` before serialisation, so it never reaches any build output. Attempting to serialise a non-`None` `local_path` will cause an assertion faliure.
When a path is remapped, a `RealFileName::Remapped` variant is created. The original path is preserved in `local_path` field and the remapped path is saved in `virtual_name` field. Previously, the `local_path` is directly modified which goes against its purpose of "suitable for reading from the file system on the local host".
`rustc_span::SourceFile`'s fields `unmapped_path` (introduced by #44940) and `name_was_remapped` (introduced by #41508 when `--remap-path-prefix` feature originally added) are removed, as these two pieces of information can be inferred from the `name` field: if it's anything other than a `FileName::Real(_)`, or if it is a `FileName::Real(RealFileName::LocalPath(_))`, then clearly `name_was_remapped` would've been false and `unmapped_path` would've been `None`. If it is a `FileName::Real(RealFileName::Remapped{local_path, virtual_name})`, then `name_was_remapped` would've been true and `unmapped_path` would've been `Some(local_path)`.
cc `@eddyb` who implemented `/rustc/...` path devirtualisation
This PR implements span quoting, allowing proc-macros to produce spans
pointing *into their own crate*. This is used by the unstable
`proc_macro::quote!` macro, allowing us to get error messages like this:
```
error[E0412]: cannot find type `MissingType` in this scope
--> $DIR/auxiliary/span-from-proc-macro.rs:37:20
|
LL | pub fn error_from_attribute(_args: TokenStream, _input: TokenStream) -> TokenStream {
| ----------------------------------------------------------------------------------- in this expansion of procedural macro `#[error_from_attribute]`
...
LL | field: MissingType
| ^^^^^^^^^^^ not found in this scope
|
::: $DIR/span-from-proc-macro.rs:8:1
|
LL | #[error_from_attribute]
| ----------------------- in this macro invocation
```
Here, `MissingType` occurs inside the implementation of the proc-macro
`#[error_from_attribute]`. Previosuly, this would always result in a
span pointing at `#[error_from_attribute]`
This will make many proc-macro-related error message much more useful -
when a proc-macro generates code containing an error, users will get an
error message pointing directly at that code (within the macro
definition), instead of always getting a span pointing at the macro
invocation site.
This is implemented as follows:
* When a proc-macro crate is being *compiled*, it causes the `quote!`
macro to get run. This saves all of the sapns in the input to `quote!`
into the metadata of *the proc-macro-crate* (which we are currently
compiling). The `quote!` macro then expands to a call to
`proc_macro::Span::recover_proc_macro_span(id)`, where `id` is an
opaque identifier for the span in the crate metadata.
* When the same proc-macro crate is *run* (e.g. it is loaded from disk
and invoked by some consumer crate), the call to
`proc_macro::Span::recover_proc_macro_span` causes us to load the span
from the proc-macro crate's metadata. The proc-macro then produces a
`TokenStream` containing a `Span` pointing into the proc-macro crate
itself.
The recursive nature of 'quote!' can be difficult to understand at
first. The file `src/test/ui/proc-macro/quote-debug.stdout` shows
the output of the `quote!` macro, which should make this eaier to
understand.
This PR also supports custom quoting spans in custom quote macros (e.g.
the `quote` crate). All span quoting goes through the
`proc_macro::quote_span` method, which can be called by a custom quote
macro to perform span quoting. An example of this usage is provided in
`src/test/ui/proc-macro/auxiliary/custom-quote.rs`
Custom quoting currently has a few limitations:
In order to quote a span, we need to generate a call to
`proc_macro::Span::recover_proc_macro_span`. However, proc-macros
support renaming the `proc_macro` crate, so we can't simply hardcode
this path. Previously, the `quote_span` method used the path
`crate::Span` - however, this only works when it is called by the
builtin `quote!` macro in the same crate. To support being called from
arbitrary crates, we need access to the name of the `proc_macro` crate
to generate a path. This PR adds an additional argument to `quote_span`
to specify the name of the `proc_macro` crate. Howver, this feels kind
of hacky, and we may want to change this before stabilizing anything
quote-related.
Additionally, using `quote_span` currently requires enabling the
`proc_macro_internals` feature. The builtin `quote!` macro
has an `#[allow_internal_unstable]` attribute, but this won't work for
custom quote implementations. This will likely require some additional
tricks to apply `allow_internal_unstable` to the span of
`proc_macro::Span::recover_proc_macro_span`.
Unify rustc and rustdoc parsing of `cfg()`
This extracts a new `parse_cfg` function that's used between both.
- Treat `#[doc(cfg(x), cfg(y))]` the same as `#[doc(cfg(x)]
#[doc(cfg(y))]`. Previously it would be completely ignored.
- Treat `#[doc(inline, cfg(x))]` the same as `#[doc(inline)]
#[doc(cfg(x))]`. Previously, the cfg would be ignored.
- Pass the cfg predicate through to rustc_expand to be validated
Technically this is a breaking change, but doc_cfg is still nightly so I don't think it matters.
Fixes https://github.com/rust-lang/rust/issues/84437.
r? `````````@petrochenkov`````````
This extracts a new `parse_cfg` function that's used between both.
- Treat `#[doc(cfg(x), cfg(y))]` the same as `#[doc(cfg(x)]
#[doc(cfg(y))]`. Previously it would be completely ignored.
- Treat `#[doc(inline, cfg(x))]` the same as `#[doc(inline)]
#[doc(cfg(x))]`. Previously, the cfg would be ignored.
- Pass the cfg predicate through to rustc_expand to be validated
Co-authored-by: Vadim Petrochenkov <vadim.petrochenkov@gmail.com>
Implement RFC 1260 with feature_name `imported_main`.
This is the second extraction part of #84062 plus additional adjustments.
This (mostly) implements RFC 1260.
However there's still one test case failure in the extern crate case. Maybe `LocalDefId` doesn't work here? I'm not sure.
cc https://github.com/rust-lang/rust/issues/28937
r? `@petrochenkov`
This PR modifies the macro expansion infrastructure to handle attributes
in a fully token-based manner. As a result:
* Derives macros no longer lose spans when their input is modified
by eager cfg-expansion. This is accomplished by performing eager
cfg-expansion on the token stream that we pass to the derive
proc-macro
* Inner attributes now preserve spans in all cases, including when we
have multiple inner attributes in a row.
This is accomplished through the following changes:
* New structs `AttrAnnotatedTokenStream` and `AttrAnnotatedTokenTree` are introduced.
These are very similar to a normal `TokenTree`, but they also track
the position of attributes and attribute targets within the stream.
They are built when we collect tokens during parsing.
An `AttrAnnotatedTokenStream` is converted to a regular `TokenStream` when
we invoke a macro.
* Token capturing and `LazyTokenStream` are modified to work with
`AttrAnnotatedTokenStream`. A new `ReplaceRange` type is introduced, which
is created during the parsing of a nested AST node to make the 'outer'
AST node aware of the attributes and attribute target stored deeper in the token stream.
* When we need to perform eager cfg-expansion (either due to `#[derive]` or `#[cfg_eval]`),
we tokenize and reparse our target, capturing additional information about the locations of
`#[cfg]` and `#[cfg_attr]` attributes at any depth within the target.
This is a performance optimization, allowing us to perform less work
in the typical case where captured tokens never have eager cfg-expansion run.
expand: Do not ICE when a legacy AST-based macro attribute produces and empty expression
Fixes https://github.com/rust-lang/rust/issues/80251
The reported error is the same as for `let _ = #[cfg(FALSE)] EXPR;`
Found with https://github.com/est31/warnalyzer.
Dubious changes:
- Is anyone else using rustc_apfloat? I feel weird completely deleting
x87 support.
- Maybe some of the dead code in rustc_data_structures, in case someone
wants to use it in the future?
- Don't change rustc_serialize
I plan to scrap most of the json module in the near future (see
https://github.com/rust-lang/compiler-team/issues/418) and fixing the
tests needed more work than I expected.
TODO: check if any of the comments on the deleted code should be kept.
Add function core::iter::zip
This makes it a little easier to `zip` iterators:
```rust
for (x, y) in zip(xs, ys) {}
// vs.
for (x, y) in xs.into_iter().zip(ys) {}
```
You can `zip(&mut xs, &ys)` for the conventional `iter_mut()` and
`iter()`, respectively. This can also support arbitrary nesting, where
it's easier to see the item layout than with arbitrary `zip` chains:
```rust
for ((x, y), z) in zip(zip(xs, ys), zs) {}
for (x, (y, z)) in zip(xs, zip(ys, zs)) {}
// vs.
for ((x, y), z) in xs.into_iter().zip(ys).zip(xz) {}
for (x, (y, z)) in xs.into_iter().zip((ys.into_iter().zip(xz)) {}
```
It may also format more nicely, especially when the first iterator is a
longer chain of methods -- for example:
```rust
iter::zip(
trait_ref.substs.types().skip(1),
impl_trait_ref.substs.types().skip(1),
)
// vs.
trait_ref
.substs
.types()
.skip(1)
.zip(impl_trait_ref.substs.types().skip(1))
```
This replaces the tuple-pair `IntoIterator` in #78204.
There is prior art for the utility of this in [`itertools::zip`].
[`itertools::zip`]: https://docs.rs/itertools/0.10.0/itertools/fn.zip.html
With this PR, we now lint for all cases where we perform some kind of
proc-macro back-compat hack.
The `js-sys` had an internal fix made to properly handle
`None`-delimited groups, so we need to manually check the version in the
filename. As a result, we no longer apply the back-compat hack to cases
where the version number is missing file the file path. This should not
affect any users of the `crates.io` crate.
Unlike the other cases of this lint, there's no simple way to detect if
an old version of the relevant crate (`syn`) is in use. The `actix-web`
crate only depends on `pin-project` v1.0.0, so checking the version of
`actix-web` does not guarantee that a new enough version of
`pin-project` (and therefore `syn`) is in use.
Instead, we rely on the fact that virtually all of the regressed crates
are pinned to a pre-1.0 version of `pin-project`. When this is the case,
bumping the `actix-web` dependency will pull in the *latest* version of
`pin-project`, which has an explicit dependency on a newer v dependency
on a newer version of `syn`.
The lint message tells users to update `actix-web`, since that's what
they're most likely to have control over. We could potentially tell them
to run `cargo update -p syn`, but I think it's more straightforward to
suggest an explicit change to the `Cargo.toml`
The `actori-web` fork had its last commit over a year ago, and appears
to just be a renamed fork of `actix-web`. Therefore, I've removed the
`actori-web` check entirely - any crates that actually get broken can
simply update `syn` themselves.
Extend `proc_macro_back_compat` lint to `procedural-masquerade`
We now lint on *any* use of `procedural-masquerade` crate. While this
crate still exists, its main reverse dependency (`cssparser`) no longer
depends on it. Any crates still depending off should stop doing so, as
it only exists to support very old Rust versions.
If a crate actually needs to support old versions of rustc via
`procedural-masquerade`, then they'll just need to accept the warning
until we remove it entirely (at the same time as the back-compat hack).
The latest version of `procedural-masquerade` does work with the
latest rustc, but trying to check for the version seems like more
trouble than it's worth.
While working on this, I realized that the `proc-macro-hack` check was
never actually doing anything. The corresponding enum variant in
`proc-macro-hack` is named `Value` or `Nested` - it has never been
called `Input`. Due to a strange Crater issue, the Crater run that
tested adding this did *not* end up testing it - some of the crates that
would have failed did not actually have their tests checked, making it
seem as though the `proc-macro-hack` check was working.
The Crater issue is being discussed at
https://rust-lang.zulipchat.com/#narrow/stream/242791-t-infra/topic/Nearly.20identical.20Crater.20runs.20processed.20a.20crate.20differently/near/230406661
Despite the `proc-macro-hack` check not actually doing anything, we
haven't gotten any reports from users about their build being broken.
I went ahead and removed it entirely, since it's clear that no one is
being affected by the `proc-macro-hack` regression in practice.
StructField -> FieldDef ("field definition")
Field -> ExprField ("expression field", not "field expression")
FieldPat -> PatField ("pattern field", not "field pattern")
Also rename visiting and other methods working on them.
We now lint on *any* use of `procedural-masquerade` crate. While this
crate still exists, its main reverse dependency (`cssparser`) no longer
depends on it. Any crates still depending off should stop doing so, as
it only exists to support very old Rust versions.
If a crate actually needs to support old versions of rustc via
`procedural-masquerade`, then they'll just need to accept the warning
until we remove it entirely (at the same time as the back-compat hack).
The latest version of `procedural-masquerade` does not work with the
latest rustc, but trying to check for the version seems like more
trouble than it's worth.
While working on this, I realized that the `proc-macro-hack` check was
never actually doing anything. The corresponding enum variant in
`proc-macro-hack` is named `Value` or `Nested` - it has never been
called `Input`. Due to a strange Crater issue, the Crater run that
tested adding this did *not* end up testing it - some of the crates that
would have failed did not actually have their tests checked, making it
seem as though the `proc-macro-hack` check was working.
The Crater issue is being discussed at
https://rust-lang.zulipchat.com/#narrow/stream/242791-t-infra/topic/Nearly.20identical.20Crater.20runs.20processed.20a.20crate.20differently/near/230406661
Despite the `proc-macro-hack` check not actually doing anything, we
haven't gotten any reports from users about their build being broken.
I went ahead and removed it entirely, since it's clear that no one is
being affected by the `proc-macro-hack` regression in practice.
Now that future-incompat-report support has landed in nightly Cargo, we
can start to make progress towards removing the various proc-macro
back-compat hacks that have accumulated in the compiler.
This PR introduces a new lint `proc_macro_back_compat`, which results in
a future-incompat-report entry being generated. All proc-macro
back-compat warnings will be grouped under this lint. Note that this
lint will never actually become a hard error - instead, we will remove
the special cases for various macros, which will cause older versions of
those crates to emit some other error.
I've added code to fire this lint for the `time-macros-impl` case. This
is the easiest case out of all of our current back-compat hacks - the
crate was renamed to `time-macros`, so seeing a filename with
`time-macros-impl` guarantees that an older version of the parent `time`
crate is in use.
When Cargo's future-incompat-report feature gets stabilized, affected
users will start to see future-incompat warnings when they build their
crates.
expand: Do not allocate `Lrc` for `allow_internal_unstable` list unless necessary
This allocation is done for any macro defined in the current crate, or used from a different crate.
EDIT: This also removes an `Lrc` increment from each *use* of such macro, which may be more significant.
Noticed when reviewing https://github.com/rust-lang/rust/pull/82367.
This probably doesn't matter, but let's do a perf run.
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
expand: Refactor module loading
This is an accompanying PR to https://github.com/rust-lang/rust/pull/82399, but they can be landed independently.
See individual commits for more details.
Anyone should be able to review this equally well because all people actually familiar with this code left the project.
Inherit `#[stable(..)]` annotations in enum variants and fields from its item
Lint changes for #65515. The stdlib will have to be updated once this lands in beta and that version is promoted in master.
This ownership kind is only constructed in the case of path attributes like `#[path = ".."]` without a file name segment, which always represent some kind of directories and will produce and error on attempt to parse them as a module file.
When token-based attribute handling is implemeneted in #80689,
we will need to access tokens from `HasAttrs` (to perform
cfg-stripping), and we will to access attributes from `HasTokens` (to
construct a `PreexpTokenStream`).
This PR merges the `HasAttrs` and `HasTokens` traits into a new
`AstLike` trait. The previous `HasAttrs` impls from `Vec<Attribute>` and `AttrVec`
are removed - they aren't attribute targets, so the impls never really
made sense.
Crate root is sufficiently different from `mod` items, at least at syntactic level.
Also remove customization point for "`mod` item or crate root" from AST visitors.
Along the way, we also implement a handful of diagnostics improvements
and fixes, particularly with respect to the special handling of `||` in
place of `|` and when there are leading verts in function params, which
don't allow top-level or-patterns anyway.
Fixes#81543
After we expand a macro, we try to parse the resulting tokens as a AST
node. This commit makes several improvements to how we handle spans when
an error occurs:
* Only ovewrite the original `Span` if it's a dummy span. This preserves
a more-specific span if one is available.
* Use `self.prev_token` instead of `self.token` when emitting an error
message after encountering EOF, since an EOF token always has a dummy
span
* Make `SourceMap::next_point` leave dummy spans unused. A dummy span
does not have a logical 'next point', since it's a zero-length span.
Re-using the span span preserves its 'dummy-ness' for other checks
cc #79813
This PR adds an allow-by-default future-compatibility lint
`SEMICOLON_IN_EXPRESSIONS_FROM_MACROS`. It fires when a trailing semicolon in a
macro body is ignored due to the macro being used in expression
position:
```rust
macro_rules! foo {
() => {
true; // WARN
}
}
fn main() {
let val = match true {
true => false,
_ => foo!()
};
}
```
The lint takes its level from the macro call site, and
can be allowed for a particular macro by adding
`#[allow(semicolon_in_expressions_from_macros)]`.
The lint is set to warn for all internal rustc crates (when being built
by a stage1 compiler). After the next beta bump, we can enable
the lint for the bootstrap compiler as well.
Make `-Z time-passes` less noisy
- Add the module name to `pre_AST_expansion_passes` and don't make it a
verbose event (since it normally doesn't take very long, and it's
emitted many times)
- Don't make the following rustdoc events verbose; they're emitted many times.
+ build_extern_trait_impl
+ build_local_trait_impl
+ build_primitive_trait_impl
+ get_auto_trait_impls
+ get_blanket_trait_impls
- Remove the `get_auto_trait_and_blanket_synthetic_impls` rustdoc event; it's wholly
covered by get_{auto,blanket}_trait_impls and not very useful.
I found this while working on https://github.com/rust-lang/rust/pull/81275 but it's independent of those changes.
- Add the module name to `pre_AST_expansion_passes` and don't make it a
verbose event (since it normally doesn't take very long, and it's
emitted many times)
- Don't make the following rustdoc events verbose; they're emitted many times.
+ build_extern_trait_impl
+ build_local_trait_impl
+ build_primitive_trait_impl
+ get_auto_trait_impls
+ get_blanket_trait_impls
- Remove `get_auto_trait_and_blanket_synthetic_impls`; it's wholly
covered by get_{auto,blanket}_trait_impls and not very useful.
Fixes#81007
Previously, we would fail to collect tokens in the proper place when
only builtin attributes were present. As a result, we would end up with
attribute tokens in the collected `TokenStream`, leading to duplication
when we attempted to prepend the attributes from the AST node.
We now explicitly track when token collection must be performed due to
nomterminal parsing.
Allow #[rustc_builtin_macro = "name"]
This adds the option of specifying the name of a builtin macro in the `#[rustc_builtin_macro]` attribute: `#[rustc_builtin_macro = "name"]`.
This makes it possible to have both `std::panic!` and `core::panic!` as a builtin macro, by using different builtin macro names for each. This is needed to implement the edition-specific behaviour of the panic macros of RFC 3007.
Also removes `SyntaxExtension::is_derive_copy`, as the macro name (e.g. `sym::Copy`) is now tracked and provides that information directly.
r? ``@petrochenkov``
This makes it possible to have both std::panic and core::panic as a
builtin macro, by using different builtin macro names for each.
Also removes SyntaxExtension::is_derive_copy, as the macro name (e.g.
sym::Copy) is now tracked and provides that information directly.
Fix some clippy lints
Happy to revert these if you think they're less readable, but personally I like them better now (especially the `else { if { ... } }` to `else if { ... }` change).
We now collect tokens for the underlying node wrapped by `StmtKind`
instead of storing tokens directly in `Stmt`.
`LazyTokenStream` now supports capturing a trailing semicolon after it
is initially constructed. This allows us to avoid refactoring statement
parsing to wrap the parsing of the semicolon in `parse_tokens`.
Attributes on item statements
(e.g. `fn foo() { #[bar] struct MyStruct; }`) are now treated as
item attributes, not statement attributes, which is consistent with how
we handle attributes on other kinds of statements. The feature-gating
code is adjusted so that proc-macro attributes are still allowed on item
statements on stable.
Two built-in macros (`#[global_allocator]` and `#[test]`) needed to be
adjusted to support being passed `Annotatable::Stmt`.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
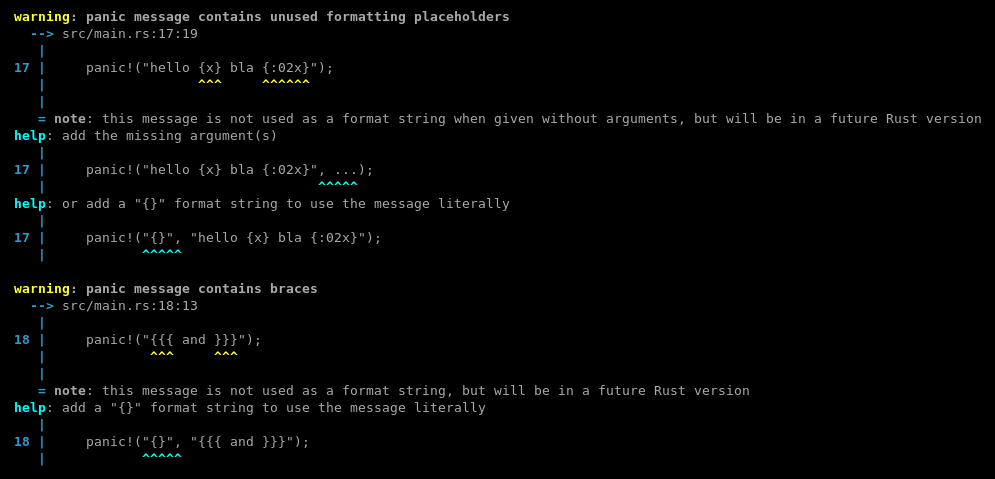
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
Implement destructuring assignment for structs and slices
This is the second step towards implementing destructuring assignment (RFC: rust-lang/rfcs#2909, tracking issue: #71126). This PR is the second part of #71156, which was split up to allow for easier review.
Note that the first PR (#78748) is not merged yet, so it is included as the first commit in this one. I thought this would allow the review to start earlier because I have some time this weekend to respond to reviews. If ``@petrochenkov`` prefers to wait until the first PR is merged, I totally understand, of course.
This PR implements destructuring assignment for (tuple) structs and slices. In order to do this, the following *parser change* was necessary: struct expressions are not required to have a base expression, i.e. `Struct { a: 1, .. }` becomes legal (in order to act like a struct pattern).
Unfortunately, this PR slightly regresses the diagnostics implemented in #77283. However, it is only a missing help message in `src/test/ui/issues/issue-77218.rs`. Other instances of this diagnostic are not affected. Since I don't exactly understand how this help message works and how to fix it yet, I was hoping it's OK to regress this temporarily and fix it in a follow-up PR.
Thanks to ``@varkor`` who helped with the implementation, particularly around the struct rest changes.
r? ``@petrochenkov``
Do not collect tokens for doc comments
Doc comment is a single token and AST has all the information to re-create it precisely.
Doc comments are also responsible for majority of calls to `collect_tokens` (with `num_calls == 1` and `num_calls == 0`, cc https://github.com/rust-lang/rust/pull/78736).
(I also moved token collection into `fn parse_attribute` to deduplicate code a bit.)
r? `@Aaron1011`
rustc_ast: Do not panic by default when visiting macro calls
Panicking by default made sense when we didn't have HIR or MIR and everything worked on AST, but now all AST visitors run early and majority of them have to deal with macro calls, often by ignoring them.
The second commit renames `visit_mac` to `visit_mac_call`, the corresponding structures were renamed earlier in https://github.com/rust-lang/rust/pull/69589.
Improve errors about #[deprecated] attribute
This change:
1. Turns `#[deprecated]` on a trait impl block into an error, which fixes#78625;
2. Changes these and other errors about `#[deprecated]` to use the span of the attribute instead of the item; and
3. Turns this error into a lint, to make sure it can be capped with `--cap-lints` and doesn't break any existing dependencies.
Can be reviewed per commit.
---
Example:
```rust
struct X;
#[deprecated = "a"]
impl Default for X {
#[deprecated = "b"]
fn default() -> Self {
X
}
}
```
Before:
```
error: This deprecation annotation is useless
--> src/main.rs:6:5
|
6 | / fn default() -> Self {
7 | | X
8 | | }
| |_____^
```
After:
```
error: this `#[deprecated]' annotation has no effect
--> src/main.rs:3:1
|
3 | #[deprecated = "a"]
| ^^^^^^^^^^^^^^^^^^^ help: try removing the deprecation attribute
|
= note: `#[deny(useless_deprecated)]` on by default
error: this `#[deprecated]' annotation has no effect
--> src/main.rs:5:5
|
5 | #[deprecated = "b"]
| ^^^^^^^^^^^^^^^^^^^ help: try removing the deprecation attribute
```
Treat trailing semicolon as a statement in macro call
See #61733 (comment)
We now preserve the trailing semicolon in a macro invocation, even if
the macro expands to nothing. As a result, the following code no longer
compiles:
```rust
macro_rules! empty {
() => { }
}
fn foo() -> bool { //~ ERROR mismatched
{ true } //~ ERROR mismatched
empty!();
}
```
Previously, `{ true }` would be considered the trailing expression, even
though there's a semicolon in `empty!();`
This makes macro expansion more token-based.
See https://github.com/rust-lang/rust/issues/61733#issuecomment-716188981
We now preserve the trailing semicolon in a macro invocation, even if
the macro expands to nothing. As a result, the following code no longer
compiles:
```rust
macro_rules! empty {
() => { }
}
fn foo() -> bool { //~ ERROR mismatched
{ true } //~ ERROR mismatched
empty!();
}
```
Previously, `{ true }` would be considered the trailing expression, even
though there's a semicolon in `empty!();`
This makes macro expansion more token-based.
expand: Tweak a comment in implementation of `macro_rules`
The answer to the removed FIXME is that we don't apply mark to the span `sp` just because that span is no longer used. We could apply it, but that would just be unnecessary extra work.
The comments in code tell why the span is unused, it's a span of `$var` literally, which is lost for `tt` variables because their tokens are outputted directly, but kept for other variables which are outputted as [groups](https://doc.rust-lang.org/nightly/proc_macro/struct.Group.html) and `sp` is kept as the group's span.
Closes https://github.com/rust-lang/rust/issues/2887
Split out statement attributes changes from #78306
This is the same as PR https://github.com/rust-lang/rust/pull/78306, but `unused_doc_comments` is modified to explicitly ignore statement items (which preserves the current behavior).
This shouldn't have any user-visible effects, so it can be landed without lang team discussion.
---------
When the 'early' and 'late' visitors visit an attribute target, they
activate any lint attributes (e.g. `#[allow]`) that apply to it.
This can affect warnings emitted on sibiling attributes. For example,
the following code does not produce an `unused_attributes` for
`#[inline]`, since the sibiling `#[allow(unused_attributes)]` suppressed
the warning.
```rust
trait Foo {
#[allow(unused_attributes)] #[inline] fn first();
#[inline] #[allow(unused_attributes)] fn second();
}
```
However, we do not do this for statements - instead, the lint attributes
only become active when we visit the struct nested inside `StmtKind`
(e.g. `Item`).
Currently, this is difficult to observe due to another issue - the
`HasAttrs` impl for `StmtKind` ignores attributes for `StmtKind::Item`.
As a result, the `unused_doc_comments` lint will never see attributes on
item statements.
This commit makes two interrelated fixes to the handling of inert
(non-proc-macro) attributes on statements:
* The `HasAttr` impl for `StmtKind` now returns attributes for
`StmtKind::Item`, treating it just like every other `StmtKind`
variant. The only place relying on the old behavior was macro
which has been updated to explicitly ignore attributes on item
statements. This allows the `unused_doc_comments` lint to fire for
item statements.
* The `early` and `late` lint visitors now activate lint attributes when
invoking the callback for `Stmt`. This ensures that a lint
attribute (e.g. `#[allow(unused_doc_comments)]`) can be applied to
sibiling attributes on an item statement.
For now, the `unused_doc_comments` lint is explicitly disabled on item
statements, which preserves the current behavior. The exact locatiosn
where this lint should fire are being discussed in PR #78306
When the 'early' and 'late' visitors visit an attribute target, they
activate any lint attributes (e.g. `#[allow]`) that apply to it.
This can affect warnings emitted on sibiling attributes. For example,
the following code does not produce an `unused_attributes` for
`#[inline]`, since the sibiling `#[allow(unused_attributes)]` suppressed
the warning.
```rust
trait Foo {
#[allow(unused_attributes)] #[inline] fn first();
#[inline] #[allow(unused_attributes)] fn second();
}
```
However, we do not do this for statements - instead, the lint attributes
only become active when we visit the struct nested inside `StmtKind`
(e.g. `Item`).
Currently, this is difficult to observe due to another issue - the
`HasAttrs` impl for `StmtKind` ignores attributes for `StmtKind::Item`.
As a result, the `unused_doc_comments` lint will never see attributes on
item statements.
This commit makes two interrelated fixes to the handling of inert
(non-proc-macro) attributes on statements:
* The `HasAttr` impl for `StmtKind` now returns attributes for
`StmtKind::Item`, treating it just like every other `StmtKind`
variant. The only place relying on the old behavior was macro
which has been updated to explicitly ignore attributes on item
statements. This allows the `unused_doc_comments` lint to fire for
item statements.
* The `early` and `late` lint visitors now activate lint attributes when
invoking the callback for `Stmt`. This ensures that a lint
attribute (e.g. `#[allow(unused_doc_comments)]`) can be applied to
sibiling attributes on an item statement.
For now, the `unused_doc_comments` lint is explicitly disabled on item
statements, which preserves the current behavior. The exact locatiosn
where this lint should fire are being discussed in PR #78306
This allows us to avoid synthesizing tokens in `prepend_attr`, since we
have the original tokens available.
We still need to synthesize tokens when expanding `cfg_attr`,
but this is an unavoidable consequence of the syntax of `cfg_attr` -
the user does not supply the `#` and `[]` tokens that a `cfg_attr`
expands to.
This approach lives exclusively in the parser, so struct expr bodies
that are syntactically correct on their own but are otherwise incorrect
will still emit confusing errors, like in the following case:
```rust
fn foo() -> Foo {
bar: Vec::new()
}
```
```
error[E0425]: cannot find value `bar` in this scope
--> src/file.rs:5:5
|
5 | bar: Vec::new()
| ^^^ expecting a type here because of type ascription
error[E0214]: parenthesized type parameters may only be used with a `Fn` trait
--> src/file.rs:5:15
|
5 | bar: Vec::new()
| ^^^^^ only `Fn` traits may use parentheses
error[E0107]: wrong number of type arguments: expected 1, found 0
--> src/file.rs:5:10
|
5 | bar: Vec::new()
| ^^^^^^^^^^ expected 1 type argument
```
If that field had a trailing comma, that would be a parse error and it
would trigger the new, more targetted, error:
```
error: struct literal body without path
--> file.rs:4:17
|
4 | fn foo() -> Foo {
| _________________^
5 | | bar: Vec::new(),
6 | | }
| |_^
|
help: you might have forgotten to add the struct literal inside the block
|
4 | fn foo() -> Foo { Path {
5 | bar: Vec::new(),
6 | } }
|
```
Partially address last part of #34255.
Detect overflow in proc_macro_server subspan
* Detect overflow in proc_macro_server subspan
* Add tests for overflow in Vec::drain
* Add tests for overflow in String / VecDeque operations using ranges
We currently only attach tokens when parsing a `:stmt` matcher for a
`macro_rules!` macro. Proc-macro attributes on statements are still
unstable, and need additional work.
remove public visibility previously needed for rustfmt
`submod_path_from_attr` in rustc_expand::module was previously public because it was also consumed by rustfmt. However, we've done a bit of refactoring in rustfmt and no longer need to use this function.
This changes the visibility to the parent mod as was originally going to be done before the rustfmt dependency was realized (c189565edc (diff-cd1b379893bae95f7991d5a3f3c6d337R201))
Proc-macro API currently exposes jointness in `Punct` tokens. That is,
`+` in `+one` is **non** joint.
Our lexer produces jointness info for all tokens, so we need to censor
it *somewhere*
Previously we did this in a lexer, but it makes more sense to do this
in a proc-macro server.
Run cfg-stripping on generic parameters before invoking derive macros
Fixes#75930
This changes the tokens seen by a proc-macro. However, ising a `#[cfg]` attribute
on a generic paramter is unusual, and combining it with a proc-macro
derive is probably even more unusual. I don't expect this to cause any
breakage.
{kind=link}