Update docs so that deprecated method points to relevant method
The docs for the deprecated 'park_timeout_ms' method suggests that the user 'use park_timeout' method instead (at https://doc.rust-lang.org/std/thread/index.html).
Making a similar change so that the docs for the deprecated `sleep_ms` method suggest that the user `use sleep` method instead.
Add a niche to `Duration`, unix `SystemTime`, and non-apple `Instant`
As the nanoseconds fields is always between `0` and `(NANOS_PER_SEC - 1)` inclusive, use the `rustc_layout_scalar_valid_range` attributes to create a niche in the nanosecond field of `Duration` and `Timespec` (which is used to implement unix `SystemTime` and non-apple unix `Instant`; windows `Instant` is implemented with `Duration` and therefore will also benefit). This change has the benefit of making `Option<T>` the same size as `T` for the previously mentioned types. Also shrinks the nanoseconds field of `Timespec` to a `u32` as nanoseconds do not need the extra range of an `i64`, shrinking `Timespec` by 4 bytes on 32-bit platforms.
r? ```@joshtriplett```
Make `std::os::fd` public.
`std::os::fd` defines types like `OwnedFd` and `RawFd` and is common
between Unix and non-Unix platforms that share a basic file-descriptor
concept. Rust currently uses this internally to simplify its own code,
but it would be useful for external users in the same way, so make it
public.
This means that `OwnedFd` etc. will all appear in three places, for
example on unix platforms:
- `std::os::fd::OwnedFd`
- `std::os::unix::io::OwnedFd`
- `std::os::unix::prelude::OwnedFd`
r? `````@joshtriplett`````
Suggest unwrapping `???<T>` if a method cannot be found on it but is present on `T`.
This suggests various ways to get inside wrapper types if the method cannot be found on the wrapper type, but is present on the wrappee.
For this PR, those wrapper types include `Localkey`, `MaybeUninit`, `RefCell`, `RwLock` and `Mutex`.
Stabilize bench_black_box
This PR stabilize `feature(bench_black_box)`.
```rust
pub fn black_box<T>(dummy: T) -> T;
```
The FCP was completed in https://github.com/rust-lang/rust/issues/64102.
`@rustbot` label +T-libs-api -T-libs
Stabilize `#![feature(mixed_integer_ops)]`
Tracked and FCP completed in #87840.
````@rustbot```` label +T-libs-api +S-waiting-on-review +relnotes
r? rust-lang/t-libs-api
Recover error strings on Unix from_lossy_utf8
Some language settings can result in unreliable UTF-8 being produced.
This can result in failing to emit the error string, panicking instead.
from_lossy_utf8 allows us to assume these strings usually will be fine.
This fixes rust-lang#99535.
make Condvar, Mutex, RwLock const constructors work with the `unsupported` impl
applying this patch locally to the `rust-src` component fixes#98378
however, the solution seems wrong to me because PR #97791 didn't add any `rustc_const_stable` attribute to underlying implementations like `std::sys::unix::futex`, so I must be missing something about how const-stability is checked ... maybe the `restricted_std` feature (gate?) has an effect?
fixes#98378fixes#98293 (probably)
Refactor some `std` code that works with pointer offstes
This PR replaces `pointer::offset` in standard library with `pointer::add` and `pointer::sub`, [re]moving some casts and using `.addr()` while we are at it.
This is a more complicated refactor than all other sibling PRs, so take a closer look when reviewing, please 😃 (though I've checked this multiple times and it looks fine).
r? ````@scottmcm````
_split off from #100746, continuation of #100822_
Update doc after renaming `fn is_zero`
`fn is_zero` has been renamed to `fn count_is_zero` in 1b1bf24636.
This patch updates the documentation accordingly.
Remove `RtlGenRandom` (take two)
First try to use the system preferred RNG but if that fails (e.g. due to a broken system configuration) then fallback to manually opening an algorithm handle.
This mirrors the implementations on Unix platforms, and also mirrors the
existing `AsRawFd` impls.
This is similar to #100892, but is for the `*Lock` types.
Remove use of `io::ErrorKind::Other` in std
The documentation states that this `ErrorKind` is not used by the standard library. Instead, `io::ErrorKind::Uncategorized` should be used.
The two instances are in the unstable API [linux_pidfd](https://github.com/rust-lang/rust/issues/82971).
Clarify Path::extension() semantics in docs abstract
State up-front and center what shape the returned extension will have, without making the user read through the description and examples.
This is a doc-only change. There are no changes to the API contract and the clarification is in line with what was already stated/promised in the existing doc text - just clarified, summarized, and served bright and early.
Rationale: Various frameworks and libraries for different platforms have their different conventions as to whether an "extension" is ".ext" or just "ext" and anyone that's had to deal with this ambiguity in the past is always double- or triple-checking to make sure the function call returns an extension that matches the expected semantics. Offer the answer to this important question right off the bat instead of making them dig to find it.
```@rustbot``` label +A-docs
std: use `sync::RwLock` for internal statics
Since `sync::RwLock` is now `const`-constructible, it can be used for internal statics, removing the need for `sys_common::StaticRwLock`. This adds some extra allocations on platforms which need to box their locks (currently SGX and some UNIX), but these will become unnecessary with the lock improvements tracked in #93740.
First try to use the system preferred RNG but if that fails (e.g. due to a broken system configuration) then fallback to manually opening an algorithm handle.
State up-front and center what shape the returned extension will have, without
making the user read through the description and examples.
Rationale: Various frameworks and libraries for different platforms have their
different conventions as to whether an "extension" is ".ext" or just "ext" and
anyone that's had to deal with this ambiguity in the past is always double- or
triple-checking to make sure the function call returns an extension that matches
the expected semantics. Offer the answer to this important question right off
the bat instead of making them dig to find it.
Make `from_waker`, `waker` and `from_raw` unstably `const`
Make
- `Context::from_waker`
- `Context::waker`
- `Waker::from_raw`
`const`.
Also added a small test.
This documents the very surprising behaviour that `set_readonly(false)` will make a file *world writable* on Unix. I would go so far as to say that this function should be deprecated on Unix, or maybe even entirely. But documenting the bad behaviour is a good first step.
array docs - advertise how to get array from slice
On my first Rust project, I spent more time than I care to admit figuring out how to efficiently get an array from a slice. Update the array documentation to explain this a bit more clearly.
(As a side note, it's a bit unfortunate that get-array-from-slice is only available via trait since that means it can't be used from const functions yet.)
On later stages, the feature is already stable.
Result of running:
rg -l "feature.let_else" compiler/ src/librustdoc/ library/ | xargs sed -s -i "s#\\[feature.let_else#\\[cfg_attr\\(bootstrap, feature\\(let_else\\)#"
Check if TCS is a null pointer on SGX
The `EENTER` instruction only checks if the TCS is aligned, not if it zero. Saying the address returned is a `NonNull<u8>` (for which `Tcs` is a type alias) is unsound. As well-behaved runners will not put the TCS at address zero, so the definition of `Tcs` is correct. However, `std` should check the address before casting it to a `NonNull`.
ping `@jethrogb` `@raoulstrackx`
`@rustbot` label I-unsound
Optimize thread parking on NetBSD
As the futex syscall is not present in the latest stable release, NetBSD cannot use the efficient thread parker and locks Linux uses. Currently, it therefore relies on a pthread-based parker, consisting of a mutex and semaphore which protect a state variable. NetBSD however has more efficient syscalls available: [`_lwp_park`](https://man.netbsd.org/_lwp_park.2) and [`_lwp_unpark`](https://man.netbsd.org/_lwp_unpark.2). These already provide the exact semantics of `thread::park` and `Thread::unpark`, but work with thread ids. In `std`, this ID is here stored in an atomic state variable, which is also used to optimize cases were the parking token is already available at the time `thread::park` is called.
r? `@m-ou-se`
On my first Rust project, I spent more time than I care to admit
figuring out how to efficiently get an array from a slice. Update the
array documentation to explain this a bit more clearly.
(As a side note, it's a bit unfortunate that get-array-from-slice is
only available via trait since that means it can't be used from const
functions yet.)
This improves the documentation to say *why* it was deprecated. The reason was because it reads `HOME` on Windows which is meaningless there. Note that the PR that deprecated it stated that returning an empty string if `HOME` is set to an empty string was a problem, however I can find no evidence that this is the case. `cd` handles it fine whereas if `HOME` is unset it gives an explicit `HOME not set` error.
* Original deprecation reason: https://internals.rust-lang.org/t/deprecate-or-break-fix-std-env-home-dir/7315
* Original deprecation PR: https://github.com/rust-lang/rust/pull/51656
See #71684
Rollup of 5 pull requests
Successful merges:
- #101366 (Restore old behaviour on broken UNC paths)
- #101492 (Suggest adding array lengths to references to arrays if possible)
- #101529 (Fix the example code and doctest for Formatter::sign_plus)
- #101573 (update `ParamKindOrd`)
- #101612 (Fix code generation of `Rvalue::Repeat` with 128 bit values)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Restore old behaviour on broken UNC paths
This fixes#101358 by restoring the behaviour from previous stable Rust versions. I'm not convinced this is ultimately right but I think it's less wrong and maybe this should be backported to beta?
r? libs
Open a BCrypt algorithm handle
Fixes#101474, supplants #101456.
Replaces use of a pseduo handle with manually opening a algorithm handle.
Most interesting thing here is the atomics.
r? `@thomcc`
Printing to stdio/stderr that have been opened with non-blocking
(O_NONBLOCK in linux) can result in an error, which is not handled
by std::io module causing a panic.
Signed-off-by: Usama Arif <usama.arif@bytedance.com>
Don't duplicate file descriptors into stdio fds
Ensures that file descriptors are never duplicated into the stdio fds even if a stdio fd has been closed.
Make `ReentrantMutex` movable and `const`
As `MovableMutex` is now `const`, it can be used to simplify the implementation and interface of the internal reentrant mutex type. Consequently, the standard error stream does not need to be wrapped in `OnceLock` and `OnceLock::get_or_init_pin()` can be removed.
Forbid mixing `System` with direct sytem allocator calls
e.g. [on windows](dec689432f/library/std/src/sys/windows/alloc.rs (L129-L178)), trying to mix `System::alloc` and `HeapFree` will not work because of the extra work done to serve higher alignments.
Fix `std::collections::HashSet::drain` documentation
Hi!
`std::collections::HashSet::drain` contains small typo in the docstring.
I didn't read too much about the model of contributing to Rust, so merge this PR or close and fix the typo the right way :)
Thanks for Rust!
Windows RNG: Use `BCRYPT_RNG_ALG_HANDLE` by default
This only changes a small amount of actual code, the rest is documentation outlining the history of this module as I feel it will be relevant to any future issues that might crop up.
The code change is to use the `BCRYPT_RNG_ALG_HANDLE` [pseudo-handle](https://docs.microsoft.com/en-us/windows/win32/seccng/cng-algorithm-pseudo-handles) by default, which simply uses the default RNG. Previously we used `BCRYPT_USE_SYSTEM_PREFERRED_RNG` which has to load the system configuration and then find and load that RNG. I suspect this was the cause of failures on some systems (e.g. due to corrupted config). However, this is admittedly speculation as I can't reproduce the issue myself (and it does seem quite rare even in the wild). Still, removing a possible point of failure is likely worthwhile in any case.
r? libs
Support `#[unix_sigpipe = "inherit|sig_dfl"]` on `fn main()` to prevent ignoring `SIGPIPE`
When enabled, programs don't have to explicitly handle `ErrorKind::BrokenPipe` any longer. Currently, the program
```rust
fn main() { loop { println!("hello world"); } }
```
will print an error if used with a short-lived pipe, e.g.
% ./main | head -n 1
hello world
thread 'main' panicked at 'failed printing to stdout: Broken pipe (os error 32)', library/std/src/io/stdio.rs:1016:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
by enabling `#[unix_sigpipe = "sig_dfl"]` like this
```rust
#![feature(unix_sigpipe)]
#[unix_sigpipe = "sig_dfl"]
fn main() { loop { println!("hello world"); } }
```
there is no error, because `SIGPIPE` will not be ignored and thus the program will be killed appropriately:
% ./main | head -n 1
hello world
The current libstd behaviour of ignoring `SIGPIPE` before `fn main()` can be explicitly requested by using `#[unix_sigpipe = "sig_ign"]`.
With `#[unix_sigpipe = "inherit"]`, no change at all is made to `SIGPIPE`, which typically means the behaviour will be the same as `#[unix_sigpipe = "sig_dfl"]`.
See https://github.com/rust-lang/rust/issues/62569 and referenced issues for discussions regarding the `SIGPIPE` problem itself
See the [this](https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/Proposal.3A.20First.20step.20towards.20solving.20the.20SIGPIPE.20problem) Zulip topic for more discussions, including about this PR.
Tracking issue: https://github.com/rust-lang/rust/issues/97889
Uplift the `let_underscore` lints from clippy into rustc.
This PR resolves#97241.
This PR adds three lints from clippy--`let_underscore_drop`, `let_underscore_lock`, and `let_underscore_must_use`, which are meant to capture likely-incorrect uses of `let _ = ...` bindings (in particular, doing this on a type with a non-trivial `Drop` causes the `Drop` to occur immediately, instead of at the end of the scope. For a type like `MutexGuard`, this effectively releases the lock immediately, which is almost certainly the wrong behavior)
In porting the lints from clippy I had to copy over a bunch of utility functions from `clippy_util` that these lints also relied upon. Is that the right approach?
Note that I've set the `must_use` and `drop` lints to Allow by default and set `lock` to Deny by default (this matches the same settings that clippy has). In talking with `@estebank` he informed me to do a Crater run (I am not sure what type of Crater run to request here--I think it's just "check only"?)
On the linked issue, there's some discussion about using `must_use` and `Drop` together as a heuristic for when to warn--I did not implement this yet.
r? `@estebank`
Fix a bunch of typo
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
This PR will fix some typos detected by [typos].
I only picked the ones I was sure were spelling errors to fix, mostly in
the comments.
[typos]: https://github.com/crate-ci/typos
Fix UB from misalignment and provenance widening in `std::sys::windows`
This fixes two types of UB:
1. Reading past the end of a reference in types like `&c::REPARSE_DATA_BUFFER` (see https://github.com/rust-lang/unsafe-code-guidelines/issues/256). This is fixed by using `addr_of!`. I think there are probably a couple more cases where we do this for other structures, and will look into it in a bit.
2. Failing to ensure that a `[u8; N]` on the stack is sufficiently aligned to convert to a `REPARSE_DATA_BUFFER`. ~~This was done by introducing a new `AlignedAs` struct that allows aligning one type to the alignment of another type. I expect there are other places where we have this issue too, or I wouldn't introduce this type, but will get to them after this lands.~~
~~Worth noting, it *is* implemented in a way that can cause problems depending on how we fix#81996, but this would be caught by the test I added (and presumably if we decide to fix that in a way that would break this code, we'd also introduce a `#[repr(simple)]` or `#[repr(linear)]` as a replacement for this usage of `#[repr(C)]`).~~
Edit: None of that is still in the code, I just went with a `Align8` since that's all we'll need for almost everything we want to call.
These are more or less "potential UB" since it's likely at the moment everything works fine, although the alignment not causing issues might just be down to luck (and x86 being forgiving).
~~NB: I've only ensured this check builds, but will run tests soon.~~ All tests pass, including stage2 compiler tests.
r? ``@ChrisDenton``
Use getentropy when possible on all Apple platforms
As the current code comments say, `SecRandomCopyBytes` is very heavyweight (regardless of purpose) compared to just asking the kernel directly for bytes from its own CSPRNG. We were not previously making an attempt to use the more efficient `getentropy` call on other Apple targets, instead solely using it on macOS. As the function is available on newer versions of Apple's different OSes, this changes the random filling to always attempt it first everywhere, only falling back to the less ideal alternatives after. This also cleans up the multiple Apple `imp` blocks into one.
It also should give a perf improvement, even if its likely unnoticeably small.
Refed XCode header for `getentropy` in the SDK:
```h
int getentropy(void* buffer, size_t size) __OSX_AVAILABLE(10.12) __IOS_AVAILABLE(10.0) __TVOS_AVAILABLE(10.0) __WATCHOS_AVAILABLE(3.0);
```
r? ``@thomcc``
Reinstate preloading of some dll imports
I've now come around to the conclusion that there is a justification for pre-loading the synchronization functions `WaitOnAddress` and `WakeByAddressSingle`. I've found this to have a particularly impact in testing frameworks that may have short lived processes which immediately spawn lots of threads.
Also, because pre-main initializers imply a single-threaded environment, we can switch back to using relaxed atomics which might be a minor perf improvement on some platforms (though I doubt it's particularly notable).
r? ``@Mark-Simulacrum`` and sorry for the churn here.
For convenience I'll summarise previous issues with preloading and the solutions that are included in this PR (if any):
**Issue:** User pre-main initializers may be run before std's
**Solution:** The std now uses initializers that are guaranteed to run earlier than the old initializers. A note is also added that users should not copy std's behaviour if they want to ensure they run their initializers after std.
**Issue:** Miri does not understand pre-main initializers.
**Solution:** For miri only, run the function loading lazily instead.
**Issue:** We should ideally use `LoadLibrary` to get "api-ms-win-core-synch-l1-2-0". Only "ntdll" and "kernel32" are guaranteed to always be loaded.
**Solution:** None. We can't use `LoadLibrary` pre-main. However, in the past `GetModuleHandle` has always worked in practice so this should hopefully not be a problem.
If/when Windows 7 support is dropped, we can finally remove all this for good and just use normal imports.
Avoid zeroing large stack buffers in stdio on Windows
Does what it says on the tin, using `[MaybeUninit<u16>; N]` instead of `[0u16; N]`. These buffers seem to be around 8kb, which is big enough that this is likely to be a very nice perf boost to stdio-heavy windows code.
r? ``@ChrisDenton``
*(Note: this PR also has a commit that adds windows to CI, but as it mentions I'll revert that after it comes out green -- I can only do a check build on the machine I'm typing this on)*
Revert let_chains stabilization
This is the revert against master, the beta revert was already done in #100538.
Bumps the stage0 compiler which already has it reverted.
Rollup of 7 pull requests
Successful merges:
- #100898 (Do not report too many expr field candidates)
- #101056 (Add the syntax of references to their documentation summary.)
- #101106 (Rustdoc-Json: Retain Stripped Modules when they are imported, not when they have items)
- #101131 (CTFE: exposing pointers and calling extern fn is just impossible)
- #101141 (Simplify `get_trait_ref` fn used for `virtual_function_elimination`)
- #101146 (Various changes to logging of borrowck-related code)
- #101156 (Remove `Sync` requirement from lint pass objects)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add the syntax of references to their documentation summary.
Without this change, in <https://doc.rust-lang.org/1.63.0/std/#primitives>, `reference` is the only entry in that list which does not contain the syntax by which the type is named in source code. With this change, it contains them, in roughly the same way as the `pointer` entry does.
`std::os::fd` defines types like `OwnedFd` and `RawFd` and is common
between Unix and non-Unix platforms that share a basic file-descriptor
concept. Rust currently uses this internally to simplify its own code,
but it would be useful for external users in the same way, so make it
public.
This means that `OwnedFd` etc. will all appear in three places, for
example on unix platforms:
- `std::os::fd::OwnedFd`
- `std::os::unix::io::OwnedFd`
- `std::os::unix::prelude::OwnedFd`
Make use of `[wrapping_]byte_{add,sub}`
These new methods trivially replace old `.cast().wrapping_offset().cast()` & similar code.
Note that [`arith_offset`](https://doc.rust-lang.org/std/intrinsics/fn.arith_offset.html) and `wrapping_offset` are the same thing.
r? ``@scottmcm``
_split off from #100746_
Stabilize `std::io::read_to_string`
Closes#80218. 🎉
This PR stabilizes the `std::io::read_to_string` function, with the following public API:
```rust
pub fn read_to_string<R: Read>(reader: R) -> Result<String>;
```
It's analogous to `std::fs::read_to_string` for files, but it works on anything that implements `io::Read`, including `io::stdin()`.
See the tracking issue (#80218) or documentation for details.
Add a `File::create_new` constructor
We have `File::create` for creating a file or opening an existing file,
but the secure way to guarantee creating a new file requires a longhand
invocation via `OpenOptions`.
Add `File::create_new` to handle this case, to make it easier for people
to do secure file creation.
Use posix_spawn for absolute paths on macOS
Currently, on macOS, Rust never uses the fast posix_spawn path if a
directory change is requested, due to a bug in Apple's libc. However, the
bug is only triggered if the program is a relative path.
This PR makes it so that the fast path continues to work if the program
is an absolute path or a lone filename.
This was an alternative proposed in https://github.com/rust-lang/rust/pull/80537#issue-776674009, and it makes a measurable performance difference in some of my code that spawns thousands of processes.
Support parsing IP addresses from a byte string
Fixes#94821
The goal is to be able to parse addresses from a byte string without requiring to do any utf8 validation. Since internally the parser already works on byte strings, this should be possible and I personally already needed this in the past too.
~~I used the proposed approach from the issue by implementing `TryFrom<&'a [u8]>` for all 6 address types (3 ip address types and 3 socket address types). I believe implementing stable traits for stable types is insta-stable so this will probably need an FCP?~~
Switched to an unstable inherent method approach called `parse_ascii` as requested.
cc ``````@jyn514``````
Currently, on macOS, Rust never uses the fast posix_spawn path if a
directory change is requested due to a bug in Apple's libc. However, the
bug is only triggered if the program is a relative path.
This PR makes it so that the fast path continues to work if the program
is an absolute path or a lone filename.
This was an alternative proposed in
https://github.com/rust-lang/rust/pull/80537#issue-776674009, and it
makes a measurable performance difference in some of my code that spawns
thousands of processes.
Add next_up and next_down for f32/f64 - take 2
This is a revival of https://github.com/rust-lang/rust/pull/88728 which staled due to inactivity of the original author. I've address the last review comment.
---
This is a pull request implementing the features described at https://github.com/rust-lang/rfcs/pull/3173.
`@rustbot` label +T-libs-api -T-libs
r? `@scottmcm`
cc `@orlp`
This makes it possible to instruct libstd to never touch the signal
handler for `SIGPIPE`, which makes programs pipeable by default (e.g.
with `./your-program | head -n 1`) without `ErrorKind::BrokenPipe`
errors.
std: use realstd fast key when building tests
Under `cfg(test)`, the `std` crate is not the actual standard library, just any old crate we are testing. It imports the real standard library as `realstd`, and then does some careful `cfg` magic so that the crate built for testing uses the `realstd` global state rather than having its own copy of that.
However, this was not done for all global state hidden in std: the 'fast' version of thread-local keys, at least on some platforms, also involves some global state. Specifically its macOS version has this [`static REGISTERED`](bc63d5a26a/library/std/src/sys/unix/thread_local_dtor.rs (L62)) that would get duplicated. So this PR imports the 'fast' key type from `realstd` rather than using the local copy, to ensure its internal state (and that of the functions it calls) does not get duplicated.
I also noticed that the `__OsLocalKeyInner` is unused under `cfg(target_thread_local)`, so I removed it for that configuration. There was a comment saying macOS picks between `__OsLocalKeyInner` and `__FastLocalKeyInner` at runtime, but I think that comment is outdated -- I found no trace of such a runtime switching mechanism, and the library still check-builds on apple targets with this PR. (I don't have a Mac so I cannot actually run it.)
Some papercuts on error::Error
Renames the chain method, since I chain could mean anything and doesn't refer to a chain of sources (cc #58520) (and adds a comment explaining why sources is not a provided method on Error). Renames arguments to the request method from `req` to `demand` since the type is `Demand` rather than Request or Requisition.
r? ``@yaahc``
Add mention of `BufReader` in `Read::bytes` docs
There is a general paragraph about `BufRead` in the `Read` trait's docs, however using `bytes` without `BufRead` *always* has a large impact, due to reads of size 1.
`@rustbot` label +A-docs
Add standard C error function aliases to last_os_error
This aids the discoverability of `io::Error::last_os_error()` by linking to commonly used error number functions from C/C++.
I've seen a few people not realize this exists, so hopefully this helps draw attention to the API to encourage using it over integer error codes.
std::io: migrate ReadBuf to BorrowBuf/BorrowCursor
This PR replaces `ReadBuf` (used by the `Read::read_buf` family of methods) with `BorrowBuf` and `BorrowCursor`.
The general idea is to split `ReadBuf` because its API is large and confusing. `BorrowBuf` represents a borrowed buffer which is mostly read-only and (other than for construction) deals only with filled vs unfilled segments. a `BorrowCursor` is a mostly write-only view of the unfilled part of a `BorrowBuf` which distinguishes between initialized and uninitialized segments. For `Read::read_buf`, the caller would create a `BorrowBuf`, then pass a `BorrowCursor` to `read_buf`.
In addition to the major API split, I've made the following smaller changes:
* Removed some methods entirely from the API (mostly the functionality can be replicated with two calls rather than a single one)
* Unified naming, e.g., by replacing initialized with init and assume_init with set_init
* Added an easy way to get the number of bytes written to a cursor (`written` method)
As well as simplifying the API (IMO), this approach has the following advantages:
* Since we pass the cursor by value, we remove the 'unsoundness footgun' where a malicious `read_buf` could swap out the `ReadBuf`.
* Since `read_buf` cannot write into the filled part of the buffer, we prevent the filled part shrinking or changing which could cause underflow for the caller or unexpected behaviour.
## Outline
```rust
pub struct BorrowBuf<'a>
impl Debug for BorrowBuf<'_>
impl<'a> From<&'a mut [u8]> for BorrowBuf<'a>
impl<'a> From<&'a mut [MaybeUninit<u8>]> for BorrowBuf<'a>
impl<'a> BorrowBuf<'a> {
pub fn capacity(&self) -> usize
pub fn len(&self) -> usize
pub fn init_len(&self) -> usize
pub fn filled(&self) -> &[u8]
pub fn unfilled<'this>(&'this mut self) -> BorrowCursor<'this, 'a>
pub fn clear(&mut self) -> &mut Self
pub unsafe fn set_init(&mut self, n: usize) -> &mut Self
}
pub struct BorrowCursor<'buf, 'data>
impl<'buf, 'data> BorrowCursor<'buf, 'data> {
pub fn clone<'this>(&'this mut self) -> BorrowCursor<'this, 'data>
pub fn capacity(&self) -> usize
pub fn written(&self) -> usize
pub fn init_ref(&self) -> &[u8]
pub fn init_mut(&mut self) -> &mut [u8]
pub fn uninit_mut(&mut self) -> &mut [MaybeUninit<u8>]
pub unsafe fn as_mut(&mut self) -> &mut [MaybeUninit<u8>]
pub unsafe fn advance(&mut self, n: usize) -> &mut Self
pub fn ensure_init(&mut self) -> &mut Self
pub unsafe fn set_init(&mut self, n: usize) -> &mut Self
pub fn append(&mut self, buf: &[u8])
}
```
## TODO
* ~~Migrate non-unix libs and tests~~
* ~~Naming~~
* ~~`BorrowBuf` or `BorrowedBuf` or `SliceBuf`? (We might want an owned equivalent for the async IO traits)~~
* ~~Should we rename the `readbuf` module? We might keep the name indicate it includes both the buf and cursor variations and someday the owned version too. Or we could change it. It is not publicly exposed, so it is not that important~~.
* ~~`read_buf` method: we read into the cursor now, so the `_buf` suffix is a bit weird.~~
* ~~Documentation~~
* Tests are incomplete (I adjusted existing tests, but did not add new ones).
cc https://github.com/rust-lang/rust/issues/78485, https://github.com/rust-lang/rust/issues/94741
supersedes: https://github.com/rust-lang/rust/pull/95770, https://github.com/rust-lang/rust/pull/93359fixes#93305
Move EH personality functions to std
These were previously in the panic_unwind crate with dummy stubs in the
panic_abort crate. However it turns out that this is insufficient: we
still need a proper personality function even with -C panic=abort to
handle the following cases:
1) `extern "C-unwind"` still needs to catch foreign exceptions with -C
panic=abort to turn them into aborts. This requires landing pads and a
personality function.
2) ARM EHABI uses the personality function when creating backtraces.
The dummy personality function in panic_abort was causing backtrace
generation to get stuck in a loop since the personality function is
responsible for advancing the unwind state to the next frame.
Fixes#41004
Without this change, in <https://doc.rust-lang.org/1.63.0/std/#primitives>,
`reference` is the only entry in that list which does not contain the
syntax by which the type is named in source code. With this change, it
contains them, in roughly the same way as the `pointer` entry does.
Extra documentation for new formatting feature
Documentation of this feature was added in #90473 and released in Rust 1.58. However, high traffic macros did not receive new examples. Namely `println!()` and `format!()`.
The doc comments included in Rust are super important to the community- especially newcomers. I have met several other newbies like myself who are unaware of this recent (well about 7 months old now) update to the language allowing for convenient intra-string identifiers.
Bringing small examples of this feature to the doc comments of `println!()` and `format!()` would be helpful to everyone learning the language.
[Blog Post Announcing Feature](https://blog.rust-lang.org/2022/01/13/Rust-1.58.0.html)
[Feature PR](https://github.com/rust-lang/rust/pull/90473) - includes several instances of documentation of the feature- minus the macros in question for this PR
*This is my first time contributing to a project this large. Feedback would mean the world to me 😄*
---
*Recreated; I violated the [No-Merge Policy](https://rustc-dev-guide.rust-lang.org/git.html#no-merge-policy)*
Optimize `Wtf8Buf::into_string` for the case where it contains UTF-8.
Add a `is_known_utf8` flag to `Wtf8Buf`, which tracks whether the
string is known to contain UTF-8. This is efficiently computed in many
common situations, such as when a `Wtf8Buf` is constructed from a `String`
or `&str`, or with `Wtf8Buf::from_wide` which is already doing UTF-16
decoding and already checking for surrogates.
This makes `OsString::into_string` O(1) rather than O(N) on Windows in
common cases.
And, it eliminates the need to scan through the string for surrogates in
`Args::next` and `Vars::next`, because the strings are already being
translated with `Wtf8Buf::from_wide`.
Many things on Windows construct `OsString`s with `Wtf8Buf::from_wide`,
such as `DirEntry::file_name` and `fs::read_link`, so with this patch,
users of those functions can subsequently call `.into_string()` without
paying for an extra scan through the string for surrogates.
r? `@ghost`
Move Error trait into core
This PR moves the error trait from the standard library into a new unstable `error` module within the core library. The goal of this PR is to help unify error reporting across the std and no_std ecosystems, as well as open the door to integrating the error trait into the panic reporting system when reporting panics whose source is an errors (such as via `expect`).
This PR is a rewrite of https://github.com/rust-lang/rust/pull/90328 using new compiler features that have been added to support error in core.
These were previously in the panic_unwind crate with dummy stubs in the
panic_abort crate. However it turns out that this is insufficient: we
still need a proper personality function even with -C panic=abort to
handle the following cases:
1) `extern "C-unwind"` still needs to catch foreign exceptions with -C
panic=abort to turn them into aborts. This requires landing pads and a
personality function.
2) ARM EHABI uses the personality function when creating backtraces.
The dummy personality function in panic_abort was causing backtrace
generation to get stuck in a loop since the personality function is
responsible for advancing the unwind state to the next frame.
Align android `sigaddset` impl with the reference impl from Bionic
In https://github.com/rust-lang/rust/pull/100737 I noticed we were treating the sigset_t as an array of bytes, while referencing code from android (ad8dcd6023/libc/include/android/legacy_signal_inlines.h) which treats it as an array of unsigned long.
That said, the behavior difference is so subtle here that it's not hard to see why nobody noticed. This fixes the implementation to be equivalent to the one in bionic.
Use pointer `is_aligned*` methods
This PR replaces some manual alignment checks with calls to `pointer::{is_aligned, is_aligned_to}` and removes a useless pointer cast.
r? `@scottmcm`
_split off from #100746_
Guarantee `try_reserve` preserves the contents on error
Update doc comments to make the guarantee explicit. However, some
implementations does not have the statement though.
* `HashMap`, `HashSet`: require guarantees on hashbrown side.
* `PathBuf`: simply redirecting to `OsString`.
Fixes#99606.
Rework Ipv6Addr::is_global to check for global reachability rather than global scope - rebase
Rebasing of pull request #86634 off of master to try and get the feature "ip" stabilized.
I also found a test failure in the rebase that is_global was considering the benchmark space to be globally reachable.
This is related to my other rebasing pull request #99947
Std module docs improvements
My primary goal is to create a cleaner separation between primitive types and primitive type helper modules (fixes#92777). I also changed a few header lines in other top-level std modules (seen at https://doc.rust-lang.org/std/) for consistency.
Some conventions used/established:
* "The \`Box\<T>` type for heap allocation." - if a module mainly provides a single type, name it and summarize its purpose in the module header
* "Utilities for the _ primitive type." - this wording is used for the header of helper modules
* Documentation for primitive types themselves are removed from helper modules
* provided-by-core functionality of primitive types is documented in the primitive type instead of the helper module (such as the "Iteration" section in the slice docs)
I wonder if some content in `std::ptr` should be in `pointer` but I did not address this.
Replace most uses of `pointer::offset` with `add` and `sub`
As PR title says, it replaces `pointer::offset` in compiler and standard library with `pointer::add` and `pointer::sub`. This generally makes code cleaner, easier to grasp and removes (or, well, hides) integer casts.
This is generally trivially correct, `.offset(-constant)` is just `.sub(constant)`, `.offset(usized as isize)` is just `.add(usized)`, etc. However in some cases we need to be careful with signs of things.
r? ````@scottmcm````
_split off from #100746_
add miri-test-libstd support to libstd
- The first commit mirrors what we already have in liballoc.
- The second commit adds some regression tests that only really make sense to be run in Miri, since they rely on Miri's extra checks to detect anything.
- The third commit makes the MPSC tests work in reasonable time in Miri by reducing iteration counts.
- The fourth commit silences some warnings due to code being disabled with `cfg(miri)`
Windows: Load synch functions together
Attempt to load all the required sync functions and fail if any one of them fails.
This fixes a FIXME by going back to optional loading of `WakeByAddressSingle`.
Also reintroduces a macro for optional loading of functions but keeps it separate from the fallback macro rather than having that do two different jobs.
r? `@thomcc`
Expose `Utf8Lossy` as `Utf8Chunks`
This PR changes the feature for `Utf8Lossy` from `str_internals` to `utf8_lossy` and improves the API. This is done to eventually expose the API as stable.
Proposal: rust-lang/libs-team#54
Tracking Issue: #99543
Avoid zeroing a 1kb stack buffer on every call to `std::sys::windows::fill_utf16_buf`
I've also tried to be slightly more careful about integer overflows, although in practice this is likely still not handled ideally.
r? `@ChrisDenton`
Attempt to load all the required sync functions and fail if any one of them fails.
This reintroduces a macro for optional loading of functions but keeps it separate from the fallback macro rather than having that do two different jobs.
Fix HorizonOS regression in FileTimes
The changes in #98246 caused a regression for multiple Newlib-based systems. This is just a fix including HorizonOS to the list of targets which require a workaround.
``@AzureMarker`` ``@ian-h-chamberlain``
r? ``@nagisa``
promote debug_assert to assert when possible and useful
This PR fixed a very old issue https://github.com/rust-lang/rust/issues/94705 to clarify and improve the POSIX error checking, and some of the checks are skipped because can have no benefit, but I'm sure that this can open some interesting discussion.
Fixes https://github.com/rust-lang/rust/issues/94705
cc: `@tavianator`
cc: `@cuviper`
linux: Use `pthread_setname_np` instead of `prctl`
This function is available on Linux since glibc 2.12, musl 1.1.16, and
uClibc 1.0.20. The main advantage over `prctl` is that it properly
represents the pointer argument, rather than a multi-purpose `long`,
so we're better representing strict provenance (#95496).
Replace pointer casting in hashmap_random_keys with safe code
The old code was unnecessarily unsafe and relied on the layout of tuples always being the same as an array of the same size (which might be bad with `-Z randomize-layout`)?
The replacement has [identical codegen](https://rust.godbolt.org/z/qxsvdb8nx), so it seems like a reasonable change.
Stabilize backtrace
This PR stabilizes the std::backtrace module. As of #99431, the std::Error::backtrace item has been removed, and so the rest of the backtrace feature is set to be stabilized.
Previous discussion can be found in #72981, #3156.
Stabilized API summary:
```rust
pub mod std {
pub mod backtrace {
pub struct Backtrace { }
pub enum BacktraceStatus {
Unsupported,
Disabled,
Captured,
}
impl fmt::Debug for Backtrace {}
impl Backtrace {
pub fn capture() -> Backtrace;
pub fn force_capture() -> Backtrace;
pub const fn disabled() -> Backtrace;
pub fn status(&self) -> BacktraceStatus;
}
impl fmt::Display for Backtrace {}
}
}
```
`@yaahc`
Update doc comments to make the guarantee explicit. However, some
implementations does not have the statement though.
* `HashMap`, `HashSet`: require guarantees on hashbrown side.
* `PathBuf`: simply redirecting to `OsString`.
Fixes#99606.
This function is available on Linux since glibc 2.12, musl 1.1.16, and
uClibc 1.0.20. The main advantage over `prctl` is that it properly
represents the pointer argument, rather than a multi-purpose `long`,
so we're better representing strict provenance (#95496).
Remove Windows function preloading
After `@Mark-Simulacrum` asked me to provide guidance for when optionally imported functions should be preloaded, I realised my justifications were now quite weak. I think the strongest argument that can be made is that it avoids some degree of nondeterminism when calling these functions (in as far as system API calls can be said to be deterministic). However, I don't think that's particularly convincing unless there's a real world use case where it matters. Further discussion with `@thomcc` has strengthened my feeling that preloading isn't really needed.
Note that `WaitOnAddress` needed some adjustment to work without preloading. I opted not to use a macro for this special case as it seemed silly to do so for just one thing (and I don't like macros tbh).
Fix futex module imports on wasm+atomics
The futex modules were rearranged a bit in #98707, which meant that wasm+atomics would no longer compile on nightly. I don’t believe any other targets were impacted by this.
Remove synchronization from Windows `hashmap_random_keys`
Unfortunately using synchronization when generating hashmap keys can prevent it being used in `DllMain`.
~~Fixes #99341~~
Rollup of 8 pull requests
Successful merges:
- #99156 (`codegen_fulfill_obligation` expect erased regions)
- #99293 (only run --all-targets in stage0 for Std)
- #99779 (Fix item info pos and height)
- #99994 (Remove `guess_head_span`)
- #100011 (Use Parser's `restrictions` instead of `let_expr_allowed`)
- #100017 (kmc-solid: Update `Socket::connect_timeout` to be in line with #78802)
- #100037 (Update rustc man page to match `rustc --help`)
- #100042 (Update books)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
kmc-solid: Update `Socket::connect_timeout` to be in line with #78802
Fixes the build failure of the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets after #78802.
```
error[E0308]: mismatched types
--> library\std\src\sys\solid\net.rs:234:45
|
234 | cvt(netc::connect(self.0.raw(), addrp, len))
| ------------- ^^^^^ expected *-ptr, found union `SocketAddrCRepr`
| |
| arguments to this function are incorrect
|
= note: expected raw pointer `*const sockets::sockaddr`
found union `SocketAddrCRepr`
note: function defined here
--> library\std\src\sys\solid\abi\sockets.rs:173:12
|
173 | pub fn connect(s: c_int, name: *const sockaddr, namelen: socklen_t) -> c_int;
| ^^^^^^^
```
Support setting file accessed/modified timestamps
Add `struct FileTimes` to contain the relevant file timestamps, since
most platforms require setting all of them at once. (This also allows
for future platform-specific extensions such as setting creation time.)
Add `File::set_file_time` to set the timestamps for a `File`.
Implement the `sys` backends for UNIX, macOS (which needs to fall back
to `futimes` before macOS 10.13 because it lacks `futimens`), Windows,
and WASI.
Implement network primitives with ideal Rust layout, not C system layout
This PR is the result of this internals forum thread: https://internals.rust-lang.org/t/why-are-socketaddrv4-socketaddrv6-based-on-low-level-sockaddr-in-6/13321.
Instead of basing `std:::net::{Ipv4Addr, Ipv6Addr, SocketAddrV4, SocketAddrV6}` on system (C) structs, they are encoded in a more optimal and idiomatic Rust way.
This changes the public API of std by introducing structural equality impls for all four types here, which means that `match ipv4addr { SOME_CONSTANT => ... }` will now compile, whereas previously this was an error. No other intentional changes are introduced to public API.
It's possible to observe the current layout of these types (e.g., by pointer casting); most but not all libraries which were found by Crater to do this have had updates issued and affected versions yanked. See report below.
### Benefits of this change
- It will become possible to move these fundamental network types from `std` into `core` ([RFC](https://github.com/rust-lang/rfcs/pull/2832)).
- Some methods that can't be made `const fn`s today can be made `const fn`s with this change.
- `SocketAddrV4` only occupies 6 bytes instead of 16 bytes.
- These simple primitives become easier to read and uses less `unsafe`.
- Makes these types support structural equality, which means you can now (for instance) match an `Ipv4Addr` against a constant
### ~Remaining~ Previous problems
This change obviously changes the memory layout of the types. And it turns out some libraries invalidly assumes the memory layout and does very dangerous pointer casts to convert them. These libraries will have undefined behaviour and perform invalid memory access until patched.
- [x] - `mio` - Issue: https://github.com/tokio-rs/mio/issues/1386.
- [x] `0.7` branch https://github.com/tokio-rs/mio/pull/1388
- [x] `0.7.6` published https://github.com/tokio-rs/mio/pull/1398
- [x] Yank all `0.7` versions older than `0.7.6`
- [x] Report `<0.7.6` to RustSec Advisory Database https://rustsec.org/advisories/RUSTSEC-2020-0081.html
- [x] - `socket2` - Issue: https://github.com/rust-lang/socket2-rs/issues/119.
- [x] `0.3.x` branch https://github.com/rust-lang/socket2-rs/pull/120
- [x] `0.3.16` published
- [x] `master` branch https://github.com/rust-lang/socket2-rs/pull/122
- [x] Yank all `0.3` versions older than `0.3.16`
- [x] Report `<0.3.16` to RustSec Advisory Database https://rustsec.org/advisories/RUSTSEC-2020-0079.html
- [x] - `net2` - Issue: https://github.com/deprecrated/net2-rs/issues/105
- [x] https://github.com/deprecrated/net2-rs/pull/106
- [x] `0.2.36` published
- [x] Yank all `0.2` versions older than `0.2.36`
- [x] Report `<0.2.36` to RustSec Advisory Database https://rustsec.org/advisories/RUSTSEC-2020-0078.html
- [x] - `miow` - Issue: https://github.com/yoshuawuyts/miow/issues/38
- [x] `0.3.x` - https://github.com/yoshuawuyts/miow/pull/39
- [x] `0.3.6` published
- [x] `0.2.x` - https://github.com/yoshuawuyts/miow/pull/40
- [x] `0.2.2` published
- [x] Yanked all `0.2` versions older than `0.2.2`
- [x] Yanked all `0.3` versions older than `0.3.6`
- [x] Report `<0.2.2` and `<0.3.6` to RustSec Advisory Database https://rustsec.org/advisories/RUSTSEC-2020-0080.html
- [x] - `quinn master` (aka what became 0.7) - https://github.com/quinn-rs/quinn/issues/968https://github.com/quinn-rs/quinn/pull/987
- [x] - `quinn 0.6` - https://github.com/quinn-rs/quinn/pull/1045
- [x] - `quinn 0.5` - https://github.com/quinn-rs/quinn/pull/1046
- [x] - Release `0.7.0`, `0.6.2` and `0.5.4`
- [x] - `nb-connect` - https://github.com/smol-rs/nb-connect/issues/1
- [x] - Release `1.0.3`
- [x] - Yank all versions older than `1.0.3`
- [x] - `shadowsocks-rust` - https://github.com/shadowsocks/shadowsocks-rust/issues/462
- [ ] - `rio` - https://github.com/spacejam/rio/issues/44
- [ ] - `seaslug` - https://github.com/spacejam/seaslug/issues/1
#### Fixed crate versions
All crates I have found that assumed the memory layout have been fixed and published. The crates and versions that will continue working even as/if this PR is merged is (please upgrade these to help unblock this PR):
* `net2 0.2.36`
* `socket2 0.3.16`
* `miow 0.2.2`
* `miow 0.3.6`
* `mio 0.7.6`
* `mio 0.6.23` - Never had the invalid assumption itself, but has now been bumped to only allow fixed dependencies (`net2` + `miow`)
* `nb-connect 1.0.3`
* `quinn 0.5.4`
* `quinn 0.6.2`
### Release notes draft
This release changes the memory layout of `Ipv4Addr`, `Ipv6Addr`, `SocketAddrV4` and `SocketAddrV6`. The standard library no longer implements these as the corresponding `libc` structs (`sockaddr_in`, `sockaddr_in6` etc.). This internal representation was never exposed, but some crates relied on it anyway by unsafely transmuting. This change will cause those crates to make invalid memory accesses. Notably `net2 <0.2.36`, `socket2 <0.3.16`, `mio <0.7.6`, `miow <0.3.6` and a few other crates are affected. All known affected crates have been patched and have had fixed versions published over a year ago. If any affected crate is still in your dependency tree, you need to upgrade them before using this version of Rust.
Rewrite Windows `compat_fn` macro
This allows using most delay loaded functions before the init code initializes them. It also only preloads a select few functions, rather than all functions.
This is optimized for the common case where a function is used after already being loaded (or failed to load). The only change in codegen at the call site is to use an atomic load instead of a plain load, which should have negligible or no impact.
I've split the old `compat_fn` macro in two so as not to mix two different use cases. If/when Windows 7 support is dropped `compat_fn_optional` can be removed entirely.
r? rust-lang/libs
Remove some redundant checks from BufReader
The implementation of BufReader contains a lot of redundant checks. While any one of these checks is not particularly expensive to execute, especially when taken together they dramatically inhibit LLVM's ability to make subsequent optimizations by confusing data flow increasing the code size of anything that uses BufReader.
In particular, these changes have a ~2x increase on the benchmark that this adds a `black_box` to. I'm adding that `black_box` here just in case LLVM gets clever enough to remove the reads entirely. Right now it can't, but these optimizations are really setting it up to do so.
We get this optimization by factoring all the actual buffer management and bounds-checking logic into a new module inside `bufreader` with a new `Buffer` type. This makes it much easier to ensure that we have correctly encapsulated the management of the region of the buffer that we have read bytes into, and it lets us provide a new faster way to do small reads. `Buffer::consume_with` lets a caller do a read from the buffer with a single bounds check, instead of the double-check that's required to use `buffer` + `consume`.
Unfortunately I'm not aware of a lot of open-source usage of `BufReader` in perf-critical environments. Some time ago I tweaked this code because I saw `BufReader` in a profile at work, and I contributed some benchmarks to the `bincode` crate which exercise `BufReader::buffer`. These changes appear to help those benchmarks at little, but all these sorts of benchmarks are kind of fragile so I'm wary of quoting anything specific.
Stabilize Windows `FileTypeExt` with `is_symlink_dir` and `is_symlink_file`
These calls allow detecting whether a symlink is a file or a directory,
a distinction Windows maintains, and one important to software that
wants to do further operations on the symlink (e.g. removing it).
This allows using most delay loaded functions before the init code initializes them. It also only preloads a select few functions, rather than all functions.
Co-Authored-By: Mark Rousskov <mark.simulacrum@gmail.com>
kmc-solid: Use `libc::abort` to abort a program
This PR updates the target-specific abort subroutine for the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets.
The current implementation uses a `hlt` instruction, which is the most direct way to notify a connected debugger but is not the most flexible way. This PR changes it to call the `abort` libc function, making it possible for a system designer to override its behavior as they see fit.
The implementation of BufReader contains a lot of redundant checks.
While any one of these checks is not particularly expensive to execute,
especially when taken together they dramatically inhibit LLVM's ability
to make subsequent optimizations.
Add cgroupv1 support to available_parallelism
Fixes#97549
My dev machine uses cgroup v2 so I was only able to test that code path. So the v1 code path is written only based on documentation. I could use some help testing that it works on a machine with cgroups v1:
```
$ x.py build --stage 1
# quota.rs
fn main() {
println!("{:?}", std:🧵:available_parallelism());
}
# assuming stage1 is linked in rustup
$ rust +stage1 quota.rs
# spawn a new cgroup scope for the current user
$ sudo systemd-run -p CPUQuota="300%" --uid=$(id -u) -tdS
# should print Ok(3)
$ ./quota
```
If it doesn't work as expected an strace, the contents of `/proc/self/cgroups` and the structure of `/sys/fs/cgroups` would help.
Some language settings can result in unreliable UTF-8 being produced.
This can result in failing to emit the error string, panicking instead.
from_lossy_utf8 allows us to assume these strings usually will be fine.
Fix the stable version of `AsFd for Arc<T>` and `Box<T>`
These merged in #97437 for 1.64.0, apart from the main `io_safety`
feature that stabilized in 1.63.0.
std: use futex-based locks on Fuchsia
This switches `Condvar` and `RwLock` to the futex-based implementation currently used on Linux and some BSDs. Additionally, `Mutex` now has its own, priority-inheriting implementation based on the mutex in Fuchsia's `libsync`. It differs from the original in that it panics instead of aborting when reentrant locking is detected.
````@rustbot```` ping fuchsia
r? ````@m-ou-se````
stdlib support for Apple WatchOS
This is a follow-up to https://github.com/rust-lang/rust/pull/95243 (Add Apple WatchOS compiler targets) that adds stdlib support for Apple WatchOS.
`@deg4uss3r`
`@nagisa`
Windows: Use `FindFirstFileW` for getting the metadata of locked system files
Fixes#96980
Usually opening a file handle with access set to metadata only will always succeed, even if the file is locked. However some special system files, such as `C:\hiberfil.sys`, are locked by the system in a way that denies even that. So as a fallback we try reading the cached metadata from the directory.
Note that the test is a bit iffy. I don't know if `hiberfil.sys` actually exists in the CI.
r? rust-lang/libs
* Reduce duplicate impls; show only the `fn (T)` and include a sentence
saying that there exists up to twelve of them.
* Show `Copy` and `Clone`.
* Show auto traits like `Send` and `Sync`, and blanket impls like `Any`.
Implement `fmt::Write` for `OsString`
This allows to format into an `OsString` without unnecessary
allocations. E.g.
```
let mut temp_filename = path.into_os_string();
write!(&mut temp_filename, ".tmp.{}", process::id());
```
Stabilize `core::ffi::CStr`, `alloc::ffi::CString`, and friends
Stabilize the `core_c_str` and `alloc_c_string` feature gates.
Change `std::ffi` to re-export these types rather than creating type
aliases, since they now have matching stability.
Stabilize the `core_c_str` and `alloc_c_string` feature gates.
Change `std::ffi` to re-export these types rather than creating type
aliases, since they now have matching stability.
Add `struct FileTimes` to contain the relevant file timestamps, since
most platforms require setting all of them at once. (This also allows
for future platform-specific extensions such as setting creation time.)
Add `File::set_file_time` to set the timestamps for a `File`.
Implement the `sys` backends for UNIX, macOS (which needs to fall back
to `futimes` before macOS 10.13 because it lacks `futimens`), Windows,
and WASI.
Stabilize `core::ffi:c_*` and rexport in `std::ffi`
This only stabilizes the base types, not the non-zero variants, since
those have their own separate tracking issue and have not gone through
FCP to stabilize.
This only stabilizes the base types, not the non-zero variants, since
those have their own separate tracking issue and have not gone through
FCP to stabilize.
We have `File::create` for creating a file or opening an existing file,
but the secure way to guarantee creating a new file requires a longhand
invocation via `OpenOptions`.
Add `File::create_new` to handle this case, to make it easier for people
to do secure file creation.
Inline Windows `OsStrExt::encode_wide`
User crates currently produce much more code than necessary because the optimizer fails to make assumptions about this method.
Implement ExitCodeExt for Windows
Fixes#97914
### Motivation:
On Windows it is common for applications to return `HRESULT` (`i32`) or `DWORD` (`u32`) values. These stem from COM based components ([HRESULTS](https://docs.microsoft.com/en-us/windows/win32/api/objbase/nf-objbase-coinitialize)), Win32 errors ([GetLastError](https://docs.microsoft.com/en-us/windows/win32/api/errhandlingapi/nf-errhandlingapi-getlasterror)), GUI applications ([WM_QUIT](https://docs.microsoft.com/en-us/windows/win32/winmsg/wm-quit)) and more. The newly stabilized `ExitCode` provides an excellent fit for propagating these values, because `std::process::exit` does not run deconstructors which can result in errors. However, `ExitCode` currently only implements `From<u8> for ExitCode`, which disallows the full range of `i32`/`u32` values. This pull requests attempts to address that shortcoming by providing windows specific extensions that accept a `u32` value (which covers all possible `HRESULTS` and Win32 errors) analog to [ExitStatusExt::from_raw](https://doc.rust-lang.org/std/os/windows/process/trait.ExitStatusExt.html#tymethod.from_raw).
This was also intended by the original Stabilization https://github.com/rust-lang/rust/pull/93840#issue-1129209143= as pointed out by ``@eggyal`` in https://github.com/rust-lang/rust/issues/97914#issuecomment-1151076755:
> Issues around platform specific representations: We resolved this issue by changing the return type of report from i32 to the opaque type ExitCode. __That way we can change the underlying representation without affecting the API, letting us offer full support for platform specific exit code APIs in the future.__
[Emphasis added]
### API
```rust
/// Windows-specific extensions to [`process::ExitCode`].
///
/// This trait is sealed: it cannot be implemented outside the standard library.
/// This is so that future additional methods are not breaking changes.
#[stable(feature = "windows_process_exit_code_from", since = "1.63.0")]
pub trait ExitCodeExt: Sealed {
/// Creates a new `ExitCode` from the raw underlying `u32` return value of
/// a process.
#[stable(feature = "windows_process_exit_code_from", since = "1.63.0")]
fn from_raw(raw: u32) -> Self;
}
#[stable(feature = "windows_process_exit_code_from", since = "1.63.0")]
impl ExitCodeExt for process::ExitCode {
fn from_raw(raw: u32) -> Self {
process::ExitCode::from_inner(From::from(raw))
}
}
```
### Misc
I apologize in advance if I misplaced any attributes regarding stabilzation, as far as I learned traits are insta-stable so I chose to make them stable. If this is an error, please let me know and I'll correct it. I also added some additional machinery to make it work, analog to [ExitStatus](https://doc.rust-lang.org/std/process/struct.ExitStatus.html#).
EDIT: Proposal: https://github.com/rust-lang/libs-team/issues/48
Usually opening a file handle with access set to metadata only will always succeed, even if the file is locked. However some special system files, such as `C:\hiberfil.sys`, are locked by the system in a way that denies even that. So as a fallback we try reading the cached metadata from the directory.
Implement `FusedIterator` for `std::net::[Into]Incoming`
They never return `None`, so they trivially fulfill the contract.
What should I put for the stability attribute of `Incoming`?
`impl<T: AsRawFd> AsRawFd for {Arc,Box}<T>`
This allows implementing traits that require a raw FD on Arc and Box.
Previously, you'd have to add the function to the trait itself:
```rust
trait MyTrait {
fn as_raw_fd(&self) -> RawFd;
}
impl<T: MyTrait> MyTrait for Arc<T> {
fn as_raw_fd(&self) -> RawFd {
(**self).as_raw_fd()
}
}
```
In particular, this leads to lots of "multiple applicable items in scope" errors because you have to disambiguate `MyTrait::as_raw_fd` from `AsRawFd::as_raw_fd` at each call site. In generic contexts, when passing the type to a function that takes `impl AsRawFd` it's also sometimes required to use `T: MyTrait + AsRawFd`, which wouldn't be necessary if I could write `MyTrait: AsRawFd`.
After this PR, the code can be simpler:
```rust
trait MyTrait: AsRawFd {}
impl<T: MyTrait> MyTrait for Arc<T> {}
```
Fix FFI-unwind unsoundness with mixed panic mode
UB maybe introduced when an FFI exception happens in a `C-unwind` foreign function and it propagates through a crate compiled with `-C panic=unwind` into a crate compiled with `-C panic=abort` (#96926).
To prevent this unsoundness from happening, we will disallow a crate compiled with `-C panic=unwind` to be linked into `panic-abort` *if* it contains a call to `C-unwind` foreign function or function pointer. If no such call exists, then we continue to allow such mixed panic mode linking because it's sound (and stable). In fact we still need the ability to do mixed panic mode linking for std, because we only compile std once with `-C panic=unwind` and link it regardless panic strategy.
For libraries that wish to remain compile-once-and-linkable-to-both-panic-runtimes, a `ffi_unwind_calls` lint is added (gated under `c_unwind` feature gate) to flag any FFI unwind calls that will cause the linkable panic runtime be restricted.
In summary:
```rust
#![warn(ffi_unwind_calls)]
mod foo {
#[no_mangle]
pub extern "C-unwind" fn foo() {}
}
extern "C-unwind" {
fn foo();
}
fn main() {
// Call to Rust function is fine regardless ABI.
foo::foo();
// Call to foreign function, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
unsafe { foo(); }
//~^ WARNING call to foreign function with FFI-unwind ABI
let ptr: extern "C-unwind" fn() = foo::foo;
// Call to function pointer, will cause the crate to be unlinkable to panic-abort if compiled with `-Cpanic=unwind`.
ptr();
//~^ WARNING call to function pointer with FFI-unwind ABI
}
```
Fix#96926
`@rustbot` label: T-compiler F-c_unwind
fix data race in thread::scope
Puts the `ScopeData` into an `Arc` so it sticks around as long as we need it.
This means one extra `Arc::clone` per spawned scoped thread, which I hope is fine.
Fixes https://github.com/rust-lang/rust/issues/98498
r? `````@m-ou-se`````
[core] add `Exclusive` to sync
(discussed here: https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/Adding.20.60SyncWrapper.60.20to.20std)
`Exclusive` is a wrapper that exclusively allows mutable access to the inner value if you have exclusive access to the wrapper. It acts like a compile time mutex, and hold an unconditional `Sync` implementation.
## Justification for inclusion into std
- This wrapper unblocks actual problems:
- The example that I hit was a vector of `futures::future::BoxFuture`'s causing a central struct in a script to be non-`Sync`. To work around it, you either write really difficult code, or wrap the futures in a needless mutex.
- Easy to maintain: this struct is as simple as a wrapper can get, and its `Sync` implementation has very clear reasoning
- Fills a gap: `&/&mut` are to `RwLock` as `Exclusive` is to `Mutex`
## Public Api
```rust
// core::sync
#[derive(Default)]
struct Exclusive<T: ?Sized> { ... }
impl<T: ?Sized> Sync for Exclusive {}
impl<T> Exclusive<T> {
pub const fn new(t: T) -> Self;
pub const fn into_inner(self) -> T;
}
impl<T: ?Sized> Exclusive<T> {
pub const fn get_mut(&mut self) -> &mut T;
pub const fn get_pin_mut(Pin<&mut self>) -> Pin<&mut T>;
pub const fn from_mut(&mut T) -> &mut Exclusive<T>;
pub const fn from_pin_mut(Pin<&mut T>) -> Pin<&mut Exclusive<T>>;
}
impl<T: Future> Future for Exclusive { ... }
impl<T> From<T> for Exclusive<T> { ... }
impl<T: ?Sized> Debug for Exclusive { ... }
```
## Naming
This is a big bikeshed, but I felt that `Exclusive` captured its general purpose quite well.
## Stability and location
As this is so simple, it can be in `core`. I feel that it can be stabilized quite soon after it is merged, if the libs teams feels its reasonable to add. Also, I don't really know how unstable feature work in std/core's codebases, so I might need help fixing them
## Tips for review
The docs probably are the thing that needs to be reviewed! I tried my best, but I'm sure people have more experience than me writing docs for `Core`
### Implementation:
The API is mostly pulled from https://docs.rs/sync_wrapper/latest/sync_wrapper/struct.SyncWrapper.html (which is apache 2.0 licenesed), and the implementation is trivial:
- its an unsafe justification for pinning
- its an unsafe justification for the `Sync` impl (mostly reasoned about by ````@danielhenrymantilla```` here: https://github.com/Actyx/sync_wrapper/pull/2)
- and forwarding impls, starting with derivable ones and `Future`
Remove feature `const_option` from std
This is part of the effort to reduce the number of unstable features used by std. This one is easy as it's only used in one place.
attempt to optimise vectored write
benchmarked:
old:
```
test io::cursor::tests::bench_write_vec ... bench: 68 ns/iter (+/- 2)
test io::cursor::tests::bench_write_vec_vectored ... bench: 913 ns/iter (+/- 31)
```
new:
```
test io::cursor::tests::bench_write_vec ... bench: 64 ns/iter (+/- 0)
test io::cursor::tests::bench_write_vec_vectored ... bench: 747 ns/iter (+/- 27)
```
More unsafe than I wanted (and less gains) in the end, but it still does the job
These calls allow detecting whether a symlink is a file or a directory,
a distinction Windows maintains, and one important to software that
wants to do further operations on the symlink (e.g. removing it).
Update `std::alloc::System` doc example code style
`return` on the last line of a block is unidiomatic so I don't think the example should be using that here
std: use an event-flag-based thread parker on SOLID
`Mutex` and `Condvar` are being replaced by more efficient implementations, which need thread parking themselves (see #93740). Therefore, the generic `Parker` needs to be replaced on all platforms where the new lock implementation will be used, which, after #96393, are SOLID, SGX and Hermit (more PRs coming soon).
SOLID, conforming to the [μITRON specification](http://www.ertl.jp/ITRON/SPEC/FILE/mitron-400e.pdf), has event flags, which are a thread parking primitive very similar to `Parker`. However, they do not make any atomic ordering guarantees (even though those can probably be assumed) and necessitate a system call even when the thread token is already available. Hence, this `Parker`, like the Windows parker, uses an extra atomic state variable.
I future-proofed the code by wrapping the event flag in a `WaitFlag` structure, as both SGX and Hermit can share the Parker implementation, they just have slightly different primitives (SGX uses signals and Hermit has a thread blocking API).
`````@kawadakk````` I assume you are the target maintainer? Could you test this for me?
Mitigate MMIO stale data vulnerability
Intel publicly disclosed the MMIO stale data vulnerability on June 14. To mitigate this vulnerability, compiler changes are required for the `x86_64-fortanix-unknown-sgx` target.
cc: ````@jethrogb````
Windows: Iterative `remove_dir_all`
This will allow better strategies for use of memory and File handles. However, fully taking advantage of that is left to future work.
Note to reviewer: It's probably best to view the `remove_dir_all_recursive` as a new function. The diff is not very helpful (imho).
Make RwLockReadGuard covariant
Hi, first time contributor here, if anything is not as expected, please let me know.
`RwLockReadGoard`'s type constructor is invariant. Since it behaves like a smart pointer to an immutable reference, there is no reason that it should not be covariant. Take e.g.
```
fn test_read_guard_covariance() {
fn do_stuff<'a>(_: RwLockReadGuard<'_, &'a i32>, _: &'a i32) {}
let j: i32 = 5;
let lock = RwLock::new(&j);
{
let i = 6;
do_stuff(lock.read().unwrap(), &i);
}
drop(lock);
}
```
where the compiler complains that &i doesn't live long enough. If `RwLockReadGuard` is covariant, then the above code is accepted because the lifetime can be shorter than `'a`.
In order for `RwLockReadGuard` to be covariant, it can't contain a full reference to the `RwLock`, which can never be covariant (because it exposes a mutable reference to the underlying data structure). By reducing the data structure to the required pieces of `RwLock`, the rest falls in place.
If there is a better way to do a test that tests successful compilation, please let me know.
Fixes#80392
Fix documentation for `with_capacity` and `reserve` families of methods
Fixes#95614
Documentation for the following methods
- `with_capacity`
- `with_capacity_in`
- `with_capacity_and_hasher`
- `reserve`
- `reserve_exact`
- `try_reserve`
- `try_reserve_exact`
was inconsistent and often not entirely correct where they existed on the following types
- `Vec`
- `VecDeque`
- `String`
- `OsString`
- `PathBuf`
- `BinaryHeap`
- `HashSet`
- `HashMap`
- `BufWriter`
- `LineWriter`
since the allocator is allowed to allocate more than the requested capacity in all such cases, and will frequently "allocate" much more in the case of zero-sized types (I also checked `BufReader`, but there the docs appear to be accurate as it appears to actually allocate the exact capacity).
Some effort was made to make the documentation more consistent between types as well.
Add a `is_known_utf8` flag to `Wtf8Buf`, which tracks whether the
string is known to contain UTF-8. This is efficiently computed in many
common situations, such as when a `Wtf8Buf` is constructed from a `String`
or `&str`, or with `Wtf8Buf::from_wide` which is already doing UTF-16
decoding and already checking for surrogates.
This makes `OsString::into_string` O(1) rather than O(N) on Windows in
common cases.
And, it eliminates the need to scan through the string for surrogates in
`Args::next` and `Vars::next`, because the strings are already being
translated with `Wtf8Buf::from_wide`.
Many things on Windows construct `OsString`s with `Wtf8Buf::from_wide`,
such as `DirEntry::file_name` and `fs::read_link`, so with this patch,
users of those functions can subsequently call `.into_string()` without
paying for an extra scan through the string for surrogates.
This allows implementing traits that require a raw FD on Arc and Box.
Previously, you'd have to add the function to the trait itself:
```rust
trait MyTrait {
fn as_raw_fd(&self) -> RawFd;
}
impl<T: MyTrait> MyTrait for Arc<T> {
fn as_raw_fd(&self) -> RawFd {
(**self).as_raw_fd()
}
}
```
Document Rust's stance on `/proc/self/mem`
Add documentation to `std::os::unix::io` describing Rust's stance on
`/proc/self/mem`, treating it as an external entity which is outside
the scope of Rust's safety guarantees.
`Stdio::makes_pipe`
Wrappers around `std::process::Command` may want to be able to override pipe creation. However, [`std::process::Stdio`](https://doc.rust-lang.org/std/process/struct.Stdio.html) is opaque so there's no way to tell if `Command` was told to create new pipes or not.
This is in some ways a more generic (and cross-platform) alternative to #97149. However, unlike that feature, this comes with the price of the user needing to actually create their own pipes rather than reusing the std one. So I think it stands (or not) on its own.
# Example
```rust
#![feature(stdio_makes_pipe)]
use std::process::Stdio;
let io = Stdio::piped();
assert_eq!(io.makes_pipe(), true);
```
Windows: `CommandExt::async_pipes`
Discussed in https://github.com/tokio-rs/tokio/issues/4670 was the need for third party crates to be able to force `process::Command::spawn` to create pipes as async.
This implements the suggestion for a `async_pipes` method that gives third party crates that option.
# Example:
```rust
use std::process::{Command, Stdio};
Command::new("cmd")
.async_pipes(true)
.stdin(Stdio::piped())
.stdout(Stdio::piped())
.stderr(Stdio::piped())
.spawn()
.unwrap();
```
Stabilize `Path::try_exists()` and improve doc
This stabilizes the `Path::try_exists()` method which returns
`Result<bool, io::Error>` instead of `bool` allowing handling of errors
unrelated to the file not existing. (e.g permission errors)
Along with the stabilization it also:
* Warns that the `exists()` method is error-prone and suggests to use
the newly stabilized one.
* Suggests it instead of `metadata()` to handle errors.
* Mentions TOCTOU bugs to avoid false assumption that `try_exists()` is
completely safe fixed version of `exists()`.
* Renames the feature of still-unstable `std::fs::try_exists()` to
`fs_try_exists` to avoid name conflict.
The tracking issue #83186 remains open to track `fs_try_exists`.
Documentation for the following methods
with_capacity
with_capacity_in
with_capacity_and_hasher
reserve
reserve_exact
try_reserve
try_reserve_exact
was inconsistent and often not entirely correct where they existed on the following types
Vec
VecDeque
String
OsString
PathBuf
BinaryHeap
HashSet
HashMap
BufWriter
LineWriter
since the allocator is allowed to allocate more than the requested capacity in all such cases, and will frequently "allocate" much more in the case of zero-sized types (I also checked BufReader, but there the docs appear to be accurate as it appears to actually allocate the exact capacity).
Some effort was made to make the documentation more consistent between types as well.
Fix with_capacity* methods for Vec
Fix *reserve* methods for Vec
Fix docs for *reserve* methods of VecDeque
Fix docs for String::with_capacity
Fix docs for *reserve* methods of String
Fix docs for OsString::with_capacity
Fix docs for *reserve* methods on OsString
Fix docs for with_capacity* methods on HashSet
Fix docs for *reserve methods of HashSet
Fix docs for with_capacity* methods of HashMap
Fix docs for *reserve methods on HashMap
Fix expect messages about OOM in doctests
Fix docs for BinaryHeap::with_capacity
Fix docs for *reserve* methods of BinaryHeap
Fix typos
Fix docs for with_capacity on BufWriter and LineWriter
Fix consistent use of `hasher` between `HashMap` and `HashSet`
Fix warning in doc test
Add test for capacity of vec with ZST
Fix doc test error
once cell renamings
This PR does the renamings proposed in https://github.com/rust-lang/rust/issues/74465#issuecomment-1153703128
- Move/rename `lazy::{OnceCell, Lazy}` to `cell::{OnceCell, LazyCell}`
- Move/rename `lazy::{SyncOnceCell, SyncLazy}` to `sync::{OnceLock, LazyLock}`
(I used `Lazy...` instead of `...Lazy` as it seems to be more consistent, easier to pronounce, etc)
```@rustbot``` label +T-libs-api -T-libs
Avoid `thread::panicking()` in non-poisoning methods of `Mutex` and `RwLock`
`Mutex::lock()` and `RwLock::write()` are poison-guarded against panics,
in that they set the poison flag if a panic occurs while they're locked.
But if we're already in a panic (`thread::panicking()`), they leave the
poison flag alone.
That check is a bit of a waste for methods that never set the poison
flag though, namely `get_mut()`, `into_inner()`, and `RwLock::read()`.
These use-cases are now split to avoid that unnecessary call.
Windows: No panic if function not (yet) available
In some situations (e.g. #97814) it is possible for required functions to be called before they've had a chance to be loaded. Therefore, we make it possible to recover from this situation simply by looking at error codes.
`@rustbot` label +O-windows
Add `#[inline]` to small fns of futex `RwLock`
The important methods like `read` and `write` were already inlined,
which can propagate all the way to inlining in user code, but these
small state functions were left behind as normal calls. They should
almost always be inlined as well, as they're just a few instructions.
Test NLL fix of bad lifetime inference for reference captured in closure.
This came up as a use-case for `thread::scope` API that only compiles successfully since `feature(nll)` got stabilized recently.
Closes#93203 which had been re-opened for tracking this very test case to be added.
Entry and_modify doc
This PR modifies the documentation for [HashMap](https://doc.rust-lang.org/std/collections/struct.HashMap.html#) and [BTreeMap](https://doc.rust-lang.org/std/collections/struct.BTreeMap.html#) by introducing examples for `and_modify`. `and_modify` is a function that tends to give more idiomatic rust code when dealing with these data structures -- yet it lacked examples and was hidden away. This PR adds that and addresses #98122.
I've made some choices which I tried to explain in my commits. This is my first time contributing to rust, so hopefully, I made the right choices.
os str capacity documentation
This is based on https://github.com/rust-lang/rust/pull/95394 , with expansion and consolidation
to address comments from `@dtolnay` and other `@rust-lang/libs-api` team members.
Add a `BorrowedFd::try_clone_to_owned` and accompanying documentation
Add a `BorrowedFd::try_clone_to_owned`, which returns a new `OwnedFd` sharing the underlying file description. And similar for `BorrowedHandle` and `BorrowedSocket` on WIndows.
This is similar to the existing `OwnedFd::try_clone`, but it's named differently to reflect that it doesn't return `Result<Self, ...>`. I'm open to suggestions for better names.
Also, extend the `unix::io` documentation to mention that `dup` is permitted on `BorrowedFd`.
This was originally requsted [here](https://github.com/rust-lang/rust/issues/88564#issuecomment-910786081). At the time I wasn't sure whether it was desirable, but it does have uses and it helps clarify the API. The documentation previously didn't rule out using `dup` on a `BorrowedFd`, but the API only offered convenient ways to do it from an `OwnedFd`. With this patch, the API allows one to do `try_clone` on any type where it's permitted.
The important methods like `read` and `write` were already inlined,
which can propagate all the way to inlining in user code, but these
small state functions were left behind as normal calls. They should
almost always be inlined as well, as they're just a few instructions.
STD support for the Nintendo 3DS
Rustc already supports compiling for the Nintendo 3DS using the `armv6k-nintendo-3ds` target (Tier 3). Until now though, only `core` and `alloc` were supported. This PR adds standard library support for the Nintendo 3DS. A notable exclusion is `std::thread` support, which will come in a follow-up PR as it requires more complicated changes.
This has been a joint effort by `@Meziu,` `@ian-h-chamberlain,` myself, and prior work by `@rust3ds` members.
### Background
The Nintendo 3DS (Horizon OS) is a mostly-UNIX looking system, with the caveat that it does not come with a full libc implementation out of the box. On the homebrew side (I'm not under NDA), the libc interface is partially implemented by the [devkitPro](https://devkitpro.org/wiki/devkitPro_pacman) toolchain and a user library like [`libctru`](https://github.com/devkitPro/libctru). This is important because there are [some possible legal barriers](https://github.com/rust-lang/rust/pull/88529#issuecomment-919938396) to linking directly to a library that uses the underlying platform APIs, since they might be considered a trade secret or under NDA.
To get around this, the standard library impl for the 3DS does not directly depend on any platform-level APIs. Instead, it expects standard libc functions to be linked in. The implementation of these libc functions is left to the user. Some functions are provided by the devkitPro toolchain, but in our testing, we used the following to fill in the other functions:
- [`libctru`] - provides more basic APIs, such as `nanosleep`. Linked in by way of [`ctru-sys`](https://github.com/Meziu/ctru-rs/tree/master/ctru-sys).
- [`pthread-3ds`](https://github.com/Meziu/pthread-3ds) - provides pthread APIs for `std::thread`. Implemented using [`libctru`].
- [`linker-fix-3ds`](https://github.com/Meziu/rust-linker-fix-3ds) - fulfills some other missing libc APIs. Implemented using [`libctru`].
For more details, see the `src/doc/rustc/src/platform-support/armv6k-nintendo-3ds.md` file added in this PR.
### Notes
We've already upstreamed changes to the [`libc`] crate to support this PR, as well as the upcoming threading PR. These changes have all been released as of 0.2.121, so we bump the crate version in this PR.
Edit: After some rebases, the version bump has already been merged so it doesn't appear in this PR.
A lot of the changes in this PR are straightforward, and follow in the footsteps of the ESP-IDF target: https://github.com/rust-lang/rust/pull/87666.
The 3DS does not support user space process spawning, so these APIs are unimplemented (similar to ESP-IDF).
[`libctru`]: https://github.com/devkitPro/libctru
[`libc`]: https://github.com/rust-lang/libc
Updated the HashMap's documentation to include two references to
add_modify.
The first is when the `Entry` API is mentioned at the beginning. I was
hesitant to change the "attack" example (although I believe that it is
perfect example of where `add_modify` should be used) because both uses
work equally, but one is more idiomatic (`add_modify`).
The second is with the `entry` function that is used for the `Entry`
API. The code example was a perfect use for `add_modify`, which is why
it was changed to reflect that.
This stabilizes the `Path::try_exists()` method which returns
`Result<bool, io::Error>` instead of `bool` allowing handling of errors
unrelated to the file not existing. (e.g permission errors)
Along with the stabilization it also:
* Warns that the `exists()` method is error-prone and suggests to use
the newly stabilized one.
* Suggests it instead of `metadata()` to handle errors.
* Mentions TOCTOU bugs to avoid false assumption that `try_exists()` is
completely safe fixed version of `exists()`.
* Renames the feature of still-unstable `std::fs::try_exists()` to
`fs_try_exists` to avoid name conflict.
The tracking issue #83186 remains open to track `fs_try_exists`.
Integrate measureme's hardware performance counter support.
*Note: this is a companion to https://github.com/rust-lang/measureme/pull/143, and duplicates some information with it for convenience*
**(much later) EDIT**: take any numbers with a grain of salt, they may have changed since initial PR open.
## Credits
I'd like to start by thanking `@alyssais,` `@cuviper,` `@edef1c,` `@glandium,` `@jix,` `@Mark-Simulacrum,` `@m-ou-se,` `@mystor,` `@nagisa,` `@puckipedia,` and `@yorickvP,` for all of their help with testing, and valuable insight and suggestions.
Getting here wouldn't have been possible without you!
(If I've forgotten anyone please let me know, I'm going off memory here, plus some discussion logs)
## Summary
This PR adds support to `-Z self-profile` for counting hardware events such as "instructions retired" (as opposed to being limited to time measurements), using the `rdpmc` instruction on `x86_64` Linux.
While other OSes may eventually be supported, preliminary research suggests some kind of kernel extension/driver is required to enable this, whereas on Linux any user can profile (at least) their own threads.
Supporting Linux on architectures other than x86_64 should be much easier (provided the hardware supports such performance counters), and was mostly not done due to a lack of readily available test hardware.
That said, 32-bit `x86` (aka `i686`) would be almost trivial to add and test once we land the initial `x86_64` version (as all the CPU detection code can be reused).
A new flag `-Z self-profile-counter` was added, to control which of the named `measureme` counters is used, and which defaults to `wall-time`, in order to keep `-Z self-profile`'s current functionality unchanged (at least for now).
The named counters so far are:
* `wall-time`: the existing time measurement
* name chosen for consistency with `perf.rust-lang.org`
* continues to use `std::time::Instant` for a nanosecond-precision "monotonic clock"
* `instructions:u`: the hardware performance counter usually referred to as "Instructions retired"
* here "retired" (roughly) means "fully executed"
* the `:u` suffix is from the Linux `perf` tool and indicates the counter only runs while userspace code is executing, and therefore counts no kernel instructions
* *see [Caveats/Subtracting IRQs](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Subtracting-IRQs) for why this isn't entirely true and why `instructions-minus-irqs:u` should be preferred instead*
* `instructions-minus-irqs:u`: same as `instructions:u`, except the count of hardware interrupts ("IRQs" here for brevity) is subtracted
* *see [Caveats/Subtracting IRQs](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Subtracting-IRQs) for why this should be preferred over `instructions:u`*
* `instructions-minus-r0420:u`: experimental counter, same as `instructions-minus-irqs:u` but subtracting an undocumented counter (`r0420:u`) instead of IRQs
* the `rXXXX` notation is again from Linux `perf`, and indicates a "raw" counter, with a hex representation of the low-level counter configuration - this was picked because we still don't *really* know what it is
* this only exists for (future) testing and isn't included/used in any comparisons/data we've put together so far
* *see [Challenges/Zen's undocumented 420 counter](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Epilogue-Zen’s-undocumented-420-counter) for details on how this counter was found and what it does*
---
There are also some additional commits:
* ~~see [Challenges/Rebasing *shouldn't* affect the results, right?](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Rebasing-*shouldn’t*-affect-the-results,-right) for details on the changes to `rustc_parse` and `rustc_trait_section` (the latter far more dubious, and probably shouldn't be merged, or not as-is)~~
* **EDIT**: the effects of these are no long quantifiable, the PR includes reverts for them
* ~~see [Challenges/`jemalloc`: purging will commence in ten seconds](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#jemalloc-purging-will-commence-in-ten-seconds) for details on the `jemalloc` change~~
* this is also separately found in #77162, and we probably want to avoid doing it by default, ideally we'd use the runtime control API `jemalloc` offers (assuming that can stop the timer that's already running, which I'm not sure about)
* **EDIT**: until we can do this based on `-Z` flags, this commit has also been reverted
* the `proc_macro` change was to avoid randomized hashing and therefore ASLR-like effects
---
**(much later) EDIT**: take any numbers with a grain of salt, they may have changed since initial PR open.
#### Write-up / report
Because of how extensive the full report ended up being, I've kept most of it [on `hackmd.io`](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view), but for convenient access, here are all the sections (with individual links):
<sup>(someone suggested I'd make a backup, so [here it is on the wayback machine](http://web.archive.org/web/20201127164748/https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view) - I'll need to remember to update that if I have to edit the write-up)</sup>
* [**Motivation**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Motivation)
* [**Results**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Results)
* [**Overhead**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Overhead)
*Preview (see the report itself for more details):*
|Counter|Total<br>`instructions-minus-irqs:u`|Overhead from "Baseline"<br>(for all 1903881<br>counter reads)|Overhead from "Baseline"<br>(per each counter read)|
|-|-|-|-|
|Baseline|63637621286 ±6||
|`instructions:u`|63658815885 ±2| +21194599 ±8| +11|
|`instructions-minus-irqs:u`|63680307361 ±13| +42686075 ±19| +22|
|`wall-time`|63951958376 ±10275|+314337090 ±10281|+165|
* [**"Macro" noise (self time)**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#“Macro”-noise-(self-time))
*Preview (see the report itself for more details):*
|| `wall-time` (ns) | `instructions:u` | `instructions-minus-irqs:u`
-: | -: | -: | -:
`typeck` | 5478261360 ±283933373 (±~5.2%) | 17350144522 ±6392 (±~0.00004%) | 17351035832.5 ±4.5 (±~0.00000003%)
`expand_crate` | 2342096719 ±110465856 (±~4.7%) | 8263777916 ±2937 (±~0.00004%) | 8263708389 ±0 (±~0%)
`mir_borrowck` | 2216149671 ±119458444 (±~5.4%) | 8340920100 ±2794 (±~0.00003%) | 8341613983.5 ±2.5 (±~0.00000003%)
`mir_built` | 1269059734 ±91514604 (±~7.2%) | 4454959122 ±1618 (±~0.00004%) | 4455303811 ±1 (±~0.00000002%)
`resolve_crate` | 942154987.5 ±53068423.5 (±~5.6%) | 3951197709 ±39 (±~0.000001%) | 3951196865 ±0 (±~0%)
* [**"Micro" noise (individual sampling intervals)**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#“Micro”-noise-(individual-sampling-intervals))
* [**Caveats**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Caveats)
* [**Disabling ASLR**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Disabling-ASLR)
* [**Non-deterministic proc macros**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Non-deterministic-proc-macros)
* [**Subtracting IRQs**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Subtracting-IRQs)
* [**Lack of support for multiple threads**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Lack-of-support-for-multiple-threads)
* [**Challenges**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Challenges)
* [**How do we even read hardware performance counters?**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#How-do-we-even-read-hardware-performance-counters)
* [**ASLR: it's free entropy**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#ASLR-it’s-free-entropy)
* [**The serializing instruction**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#The-serializing-instruction)
* [**Getting constantly interrupted**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Getting-constantly-interrupted)
* [**AMD patented time-travel and dubbed it `SpecLockMap`<br><sup> or: "how we accidentally unlocked `rr` on AMD Zen"</sup>**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#AMD-patented-time-travel-and-dubbed-it-SpecLockMapnbspnbspnbspnbspnbspnbspnbspnbspor-“how-we-accidentally-unlocked-rr-on-AMD-Zen”)
* [**`jemalloc`: purging will commence in ten seconds**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#jemalloc-purging-will-commence-in-ten-seconds)
* [**Rebasing *shouldn't* affect the results, right?**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Rebasing-*shouldn’t*-affect-the-results,-right)
* [**Epilogue: Zen's undocumented 420 counter**](https://hackmd.io/sH315lO2RuicY-SEt7ynGA?view#Epilogue-Zen’s-undocumented-420-counter)
Our condvar doesn't support setting attributes, like
pthread_condattr_setclock, which the current wait_timeout expects to
have configured.
Switch to a different implementation, following espidf.
Use `fcntl(fd, F_GETFD)` to detect if standard streams are open
In the previous implementation, if the standard streams were open,
but the RLIMIT_NOFILE value was below three, the poll would fail
with EINVAL:
> ERRORS: EINVAL The nfds value exceeds the RLIMIT_NOFILE value.
Switch to the existing fcntl based implementation to avoid the issue.
Fixes#96621.
std::io: Modify some ReadBuf method signatures to return `&mut Self`
This allows using `ReadBuf` in a builder-like style and to setup a `ReadBuf` and
pass it to `read_buf` in a single expression, e.g.,
```
// With this PR:
reader.read_buf(ReadBuf::uninit(buf).assume_init(init_len))?;
// Previously:
let mut buf = ReadBuf::uninit(buf);
buf.assume_init(init_len);
reader.read_buf(&mut buf)?;
```
r? `@sfackler`
cc https://github.com/rust-lang/rust/issues/78485, https://github.com/rust-lang/rust/issues/94741
`Mutex::lock()` and `RwLock::write()` are poison-guarded against panics,
in that they set the poison flag if a panic occurs while they're locked.
But if we're already in a panic (`thread::panicking()`), they leave the
poison flag alone.
That check is a bit of a waste for methods that never set the poison
flag though, namely `get_mut()`, `into_inner()`, and `RwLock::read()`.
These use-cases are now split to avoid that unnecessary call.
This allows to format into an `OsString` without unnecessary
allocations. E.g.
```
let mut temp_filename = path.into_os_string();
write!(&mut temp_filename, ".tmp.{}", process::id());
```
impl Read and Write for VecDeque<u8>
Implementing `Read` and `Write` for `VecDeque<u8>` fills in the VecDeque api surface where `Vec<u8>` and `Cursor<Vec<u8>>` already impl Read and Write. Not only for completeness, but VecDeque in particular is a very handy mock interface for a TCP echo service, if only it supported Read/Write.
Since this PR is just an impl trait, I don't think there is a way to limit it behind a feature flag, so it's "insta-stable". Please correct me if I'm wrong here, not trying to rush stability.
This commit adds a new unstable attribute, `#[doc(tuple_varadic)]`, that
shows a 1-tuple as `(T, ...)` instead of just `(T,)`, and links to a section
in the tuple primitive docs that talks about these.
In some situations it is possible for required functions to be called before they've had a chance to be loaded. Therefore, we make it possible to recover from this situation simply by looking at error codes.
Add documentation to `std::os::unix::io` describing Rust's stance on
`/proc/self/mem`, treating it as an external entity which is outside
the scope of Rust's safety guarantees.
Remove confusing sentence from `Mutex` docs
The docs were saying something about "statically initializing" the
mutex, and it's not clear what this means. Remove that part to avoid
confusion.
Remove migrate borrowck mode
Closes#58781Closes#43234
# Stabilization proposal
This PR proposes the stabilization of `#![feature(nll)]` and the removal of `-Z borrowck`. Current borrow checking behavior of item bodies is currently done by first infering regions *lexically* and reporting any errors during HIR type checking. If there *are* any errors, then MIR borrowck (NLL) never occurs. If there *aren't* any errors, then MIR borrowck happens and any errors there would be reported. This PR removes the lexical region check of item bodies entirely and only uses MIR borrowck. Because MIR borrowck could never *not* be run for a compiled program, this should not break any programs. It does, however, change diagnostics significantly and allows a slightly larger set of programs to compile.
Tracking issue: #43234
RFC: https://github.com/rust-lang/rfcs/blob/master/text/2094-nll.md
Version: 1.63 (2022-06-30 => beta, 2022-08-11 => stable).
## Motivation
Over time, the Rust borrow checker has become "smarter" and thus allowed more programs to compile. There have been three different implementations: AST borrowck, MIR borrowck, and polonius (well, in progress). Additionally, there is the "lexical region resolver", which (roughly) solves the constraints generated through HIR typeck. It is not a full borrow checker, but does emit some errors.
The AST borrowck was the original implementation of the borrow checker and was part of the initially stabilized Rust 1.0. In mid 2017, work began to implement the current MIR borrow checker and that effort ompleted by the end of 2017, for the most part. During 2018, efforts were made to migrate away from the AST borrow checker to the MIR borrow checker - eventually culminating into "migrate" mode - where HIR typeck with lexical region resolving following by MIR borrow checking - being active by default in the 2018 edition.
In early 2019, migrate mode was turned on by default in the 2015 edition as well, but with MIR borrowck errors emitted as warnings. By late 2019, these warnings were upgraded to full errors. This was followed by the complete removal of the AST borrow checker.
In the period since, various errors emitted by the MIR borrow checker have been improved to the point that they are mostly the same or better than those emitted by the lexical region resolver.
While there do remain some degradations in errors (tracked under the [NLL-diagnostics tag](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-diagnostics), those are sufficiently small and rare enough that increased flexibility of MIR borrow check-only is now a worthwhile tradeoff.
## What is stabilized
As said previously, this does not fundamentally change the landscape of accepted programs. However, there are a [few](https://github.com/rust-lang/rust/issues?q=is%3Aopen+is%3Aissue+label%3ANLL-fixed-by-NLL) cases where programs can compile under `feature(nll)`, but not otherwise.
There are two notable patterns that are "fixed" by this stabilization. First, the `scoped_threads` feature, which is a continutation of a pre-1.0 API, can sometimes emit a [weird lifetime error](https://github.com/rust-lang/rust/issues/95527) without NLL. Second, actually seen in the standard library. In the `Extend` impl for `HashMap`, there is an implied bound of `K: 'a` that is available with NLL on but not without - this is utilized in the impl.
As mentioned before, there are a large number of diagnostic differences. Most of them are better, but some are worse. None are serious or happen often enough to need to block this PR. The biggest change is the loss of error code for a number of lifetime errors in favor of more general "lifetime may not live long enough" error. While this may *seem* bad, the former error codes were just attempts to somewhat-arbitrarily bin together lifetime errors of the same type; however, on paper, they end up being roughly the same with roughly the same kinds of solutions.
## What isn't stabilized
This PR does not completely remove the lexical region resolver. In the future, it may be possible to remove that (while still keeping HIR typeck) or to remove it together with HIR typeck.
## Tests
Many test outputs get updated by this PR. However, there are number of tests specifically geared towards NLL under `src/test/ui/nll`
## History
* On 2017-07-14, [tracking issue opened](https://github.com/rust-lang/rust/issues/43234)
* On 2017-07-20, [initial empty MIR pass added](https://github.com/rust-lang/rust/pull/43271)
* On 2017-08-29, [RFC opened](https://github.com/rust-lang/rfcs/pull/2094)
* On 2017-11-16, [Integrate MIR type-checker with NLL](https://github.com/rust-lang/rust/pull/45825)
* On 2017-12-20, [NLL feature complete](https://github.com/rust-lang/rust/pull/46862)
* On 2018-07-07, [Don't run AST borrowck on mir mode](https://github.com/rust-lang/rust/pull/52083)
* On 2018-07-27, [Add migrate mode](https://github.com/rust-lang/rust/pull/52681)
* On 2019-04-22, [Enable migrate mode on 2015 edition](https://github.com/rust-lang/rust/pull/59114)
* On 2019-08-26, [Don't downgrade errors on 2015 edition](https://github.com/rust-lang/rust/pull/64221)
* On 2019-08-27, [Remove AST borrowck](https://github.com/rust-lang/rust/pull/64790)
Add note to documentation of HashSet::intersection
The functionality of the `std::collections::HashSet::intersection(...)` method was slightly surprising to me so I wanted to take a sec to contribute to the documentation for this method.
I've added a `Note:` section if that is appropriate.
Call the OS function to set the main thread's name on program init
Normally, `Thread::spawn` takes care of setting the thread's name, if
one was provided, but since the main thread wasn't created by calling
`Thread::spawn`, we need to call that function in `std::rt::init`.
This is mainly useful for system tools like debuggers and profilers
which might show the thread name to a user. Prior to these changes, gdb
and WinDbg would show all thread names except the main thread's name to
a user. I've validated that this patch resolves the issue for both
debuggers.
Lazily allocate and initialize pthread locks.
Lazily allocate and initialize pthread locks.
This allows {Mutex, Condvar, RwLock}::new() to be const, while still using the platform's native locks for features like priority inheritance and debug tooling. E.g. on macOS, we cannot directly use the (private) APIs that pthread's locks are implemented with, making it impossible for us to use anything other than pthread while still preserving priority inheritance, etc.
This PR doesn't yet make the public APIs const. That's for a separate PR with an FCP.
Tracking issue: https://github.com/rust-lang/rust/issues/93740
Tweak insert docs
For `{Hash, BTree}Map::insert`, I always have to take a few extra seconds to think about the slight weirdness about the fact that if we "did not" insert (which "sounds" false), we return true, and if we "did" insert, (which "sounds" true), we return false.
This tweaks the doc comments for the `insert` methods of those types (as well as what looks like a rustc internal data structure that I found just by searching the codebase for "If the set did") to first use the "Returns whether _something_" pattern used in e.g. `remove`, where we say that `remove` "returns whether the value was present".
Expose `get_many_mut` and `get_many_unchecked_mut` to HashMap
This pull-request expose the function [`get_many_mut`](https://docs.rs/hashbrown/0.12.0/hashbrown/struct.HashMap.html#method.get_many_mut) and [`get_many_unchecked_mut`](https://docs.rs/hashbrown/0.12.0/hashbrown/struct.HashMap.html#method.get_many_unchecked_mut) from `hashbrown` to the standard library `HashMap` type. They obviously keep the same API and are added under the (new) `map_many_mut` feature.
- `get_many_mut`: Attempts to get mutable references to `N` values in the map at once.
- `get_many_unchecked_mut`: Attempts to get mutable references to `N` values in the map at once, without validating that the values are unique.
Put a bound on collection misbehavior
As currently written, when a logic error occurs in a collection's trait parameters, this allows *completely arbitrary* misbehavior, so long as it does not cause undefined behavior in std. However, because the extent of misbehavior is not specified, it is allowed for *any* code in std to start misbehaving in arbitrary ways which are not formally UB; consider the theoretical example of a global which gets set on an observed logic error. Because the misbehavior is only bound by not resulting in UB from safe APIs and the crate-level encapsulation boundary of all of std, this makes writing user unsafe code that utilizes std theoretically impossible, as it now relies on undocumented QOI (quality of implementation) that unrelated parts of std cannot be caused to misbehave by a misuse of std::collections APIs.
In practice, this is a nonconcern, because std has reasonable QOI and an implementation that takes advantage of this freedom is essentially a malicious implementation and only compliant by the most langauage-lawyer reading of the documentation.
To close this hole, we just add a small clause to the existing logic error paragraph that ensures that any misbehavior is limited to the collection which observed the logic error, making it more plausible to prove the soundness of user unsafe code.
This is not meant to be formal; a formal refinement would likely need to mention that values derived from the collection can also misbehave after a logic error is observed, as well as define what it means to "observe" a logic error in the first place. This fix errs on the side of informality in order to close the hole without complicating a normal reading which can assume a reasonable nonmalicious QOI.
See also [discussion on IRLO][1].
[1]: https://internals.rust-lang.org/t/using-std-collections-and-unsafe-anything-can-happen/16640
r? rust-lang/libs-api ```@rustbot``` label +T-libs-api -T-libs
This technically adds a new guarantee to the documentation, though I argue as written it's one already implicitly provided.
Rollup of 6 pull requests
Successful merges:
- #97089 (Improve settings theme display)
- #97229 (Document the current aliasing rules for `Box<T>`.)
- #97371 (Suggest adding a semicolon to a closure without block)
- #97455 (Stabilize `toowned_clone_into`)
- #97565 (Add doc alias `memset` to `write_bytes`)
- #97569 (Remove `memset` alias from `fill_with`.)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Implement [OsStr]::join
Implements join for `OsStr` and `OsString` slices:
```Rust
let strings = [OsStr::new("hello"), OsStr::new("dear"), OsStr::new("world")];
assert_eq!("hello dear world", strings.join(OsStr::new(" ")));
````
This saves one from converting to strings and back, or from implementing it manually.
This PR has been re-filed after #96744 was first accidentally merged and then reverted.
The change is instantly stable and thus:
r? rust-lang/libs-api `@rustbot` label +T-libs-api -T-libs
cc `@thomcc` `@m-ou-se` `@faptc`
Remove "sys isn't exported yet" phrase
The oldest occurence is from 9e224c2bf1,
which is from the pre-1.0 days. In the years since then, std::sys still
hasn't been exported, and the last attempt was met with strong criticism:
https://github.com/rust-lang/rust/pull/97151
Thus, removing the "yet" part makes a lot of sense.
Use Box::new() instead of box syntax in library tests
The tests inside `library/*` have no reason to use `box` syntax as they have 0 performance relevance. Therefore, we can safely remove them (instead of having to use alternatives like the one in #97293).
The oldest occurence is from 9e224c2bf1,
which is from the pre-1.0 days. In the years since then, std::sys still
hasn't been exported, and the last attempt was met with strong criticism:
https://github.com/rust-lang/rust/pull/97151
Thus, removing the "yet" part makes a lot of sense.
Finish bumping stage0
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
This now brings us to cfg-clean, with the exception of check-cfg-features in bootstrap;
I'd prefer to leave that for a separate PR at this time since it's likely to be more tricky.
cc https://github.com/rust-lang/rust/pull/97147#issuecomment-1132845061
r? `@pietroalbini`
Normally, `Thread::spawn` takes care of setting the thread's name, if
one was provided, but since the main thread wasn't created by calling
`Thread::spawn`, we need to call that function in `std::rt::init`.
This is mainly useful for system tools like debuggers and profilers
which might show the thread name to a user. Prior to these changes, gdb
and WinDbg would show all thread names except the main thread's name to
a user. I've validated that this patch resolves the issue for both
debuggers.
It looks like the last time had left some remaining cfg's -- which made me think
that the stage0 bump was actually successful. This brings us to a released 1.62
beta though.
Add section on common message styles for Result::expect
Based on a question from https://github.com/rust-lang/project-error-handling/issues/50#issuecomment-1092339937
~~One thing I haven't decided on yet, should I duplicate this section on `Option::expect`, link to this section, or move it somewhere else and link to that location from both docs?~~: I ended up moving the section to `std::error` and referencing it from both `Result::expect` and `Option::expect`'s docs.
I think this section, when combined with the similar update I made on [`std::panic!`](https://doc.rust-lang.org/nightly/std/macro.panic.html#when-to-use-panic-vs-result) implies that we should possibly more aggressively encourage and support the "expect as precondition" style described in this section. The consensus among the libs team seems to be that panic should be used for bugs, not expected potential failure modes. The "expect as error message" style seems to align better with the panic for unrecoverable errors style where they're seen as normal errors where the only difference is a desire to kill the current execution unit (aka erlang style error handling). I'm wondering if we should be providing a panic hook similar to `human-panic` or more strongly recommending the "expect as precondition" style of expect message.
explain how to turn integers into fn ptrs
(with an intermediate raw ptr, not a direct transmute)
Direct int2ptr transmute, under the semantics I am imagining, will produce a ptr with "invalid" provenance that is invalid to deref or call. We cannot give it the same semantics as int2ptr casts since those do [something complicated](https://www.ralfj.de/blog/2022/04/11/provenance-exposed.html).
To my great surprise, that is already what the example in the `transmute` docs does. :) I still added a comment to say that that part is important, and I added a section explicitly talking about this to the `fn()` type docs.
With https://github.com/rust-lang/miri/pull/2151, Miri will start complaining about direct int-to-fnptr transmutes (in the sense that it is UB to call the resulting pointer).
As currently written, when a logic error occurs in a collection's trait
parameters, this allows *completely arbitrary* misbehavior, so long as
it does not cause undefined behavior in std. However, because the extent
of misbehavior is not specified, it is allowed for *any* code in std to
start misbehaving in arbitrary ways which are not formally UB; consider
the theoretical example of a global which gets set on an observed logic
error. Because the misbehavior is only bound by not resulting in UB from
safe APIs and the crate-level encapsulation boundary of all of std, this
makes writing user unsafe code that utilizes std theoretically
impossible, as it now relies on undocumented QOI that unrelated parts of
std cannot be caused to misbehave by a misuse of std::collections APIs.
In practice, this is a nonconcern, because std has reasonable QOI and an
implementation that takes advantage of this freedom is essentially a
malicious implementation and only compliant by the most langauage-lawyer
reading of the documentation.
To close this hole, we just add a small clause to the existing logic
error paragraph that ensures that any misbehavior is limited to the
collection which observed the logic error, making it more plausible to
prove the soundness of user unsafe code.
This is not meant to be formal; a formal refinement would likely need to
mention that values derived from the collection can also misbehave after a
logic error is observed, as well as define what it means to "observe" a
logic error in the first place. This fix errs on the side of informality
in order to close the hole without complicating a normal reading which
can assume a reasonable nonmalicious QOI.
See also [discussion on IRLO][1].
[1]: https://internals.rust-lang.org/t/using-std-collections-and-unsafe-anything-can-happen/16640
Document rounding for floating-point primitive operations and string parsing
The docs for floating point don't have much to say at present about either the precision of their results or rounding behaviour.
As I understand it[^1][^2], Rust doesn't support operating with non-default rounding directions, so we need only describe roundTiesToEven.
[^1]: https://github.com/rust-lang/rust/issues/41753#issuecomment-299322887
[^2]: https://github.com/llvm/llvm-project/issues/8472#issuecomment-980888781
This PR makes a start by documenting that for primitive operations and `from_str()`.
Use const initializer for LOCAL_PANIC_COUNT
This reduces the size of the __getit function for LOCAL_PANIC_COUNT and should speed up accesses of LOCAL_PANIC_COUNT a bit.
Make write/print macros eagerly drop temporaries
This PR fixes the 2 regressions in #96434 (`println` and `eprintln`) and changes all the other similar macros (`write`, `writeln`, `print`, `eprint`) to match the old pre-#94868 behavior of `println` and `eprintln`.
argument position | before #94868 | after #94868 | after this PR
--- |:---:|:---:|:---:
`write!($tmp, "…", …)` | 😡 | 😡 | 😺
`write!(…, "…", $tmp)` | 😡 | 😡 | 😺
`writeln!($tmp, "…", …)` | 😡 | 😡 | 😺
`writeln!(…, "…", $tmp)` | 😡 | 😡 | 😺
`print!("…", $tmp)` | 😡 | 😡 | 😺
`println!("…", $tmp)` | 😺 | 😡 | 😺
`eprint!("…", $tmp)` | 😡 | 😡 | 😺
`eprintln!("…", $tmp)` | 😺 | 😡 | 😺
`panic!("…", $tmp)` | 😺 | 😺 | 😺
Example of code that is affected by this change:
```rust
use std::sync::Mutex;
fn main() {
let mutex = Mutex::new(0);
print!("{}", mutex.lock().unwrap()) /* no semicolon */
}
```
You can see several real-world examples like this in the Crater links at the top of #96434. This code failed to compile prior to this PR as follows, but works after this PR.
```console
error[E0597]: `mutex` does not live long enough
--> src/main.rs:5:18
|
5 | print!("{}", mutex.lock().unwrap()) /* no semicolon */
| ^^^^^^^^^^^^---------
| |
| borrowed value does not live long enough
| a temporary with access to the borrow is created here ...
6 | }
| -
| |
| `mutex` dropped here while still borrowed
| ... and the borrow might be used here, when that temporary is dropped and runs the `Drop` code for type `MutexGuard`
```
Stabilize `Ipv6Addr::to_ipv4_mapped`
CC https://github.com/rust-lang/rust/issues/27709 (tracking issue for the `ip` feature which contains more
functions)
The function `Ipv6Addr::to_ipv4` is bad because it also returns an IPv4
address for the IPv6 loopback address `::1`. Stabilize
`Ipv6Addr::to_ipv4_mapped` so we can recommend that function instead.
Fix typo in futex RwLock::write_contended.
I wrote `state` where I should've used `s`.
This was spotted by `@Warrenren.`
This change removes the unnecessary `s` variable to prevent that mistake.
Fortunately, this typo didn't affect the correctness of the lock, as the
second half of the condition (!has_writers_waiting) is enough for
correctness, which explains why this mistake didn't show up during
testing.
Fixes https://github.com/rust-lang/rust/issues/97162
Fix rusty grammar in `std::error::Reporter` docs
### Commit
I initially saw "print's" instead of "prints" at the start of the doc comment for `std::error::Reporter`, while reading the docs for that type. Then I figured 'probably more where that came from', so, as well as correcting the foregoing to "prints", I've patched up these three minor solecisms (well, two [types](https://en.wikipedia.org/wiki/Type%E2%80%93token_distinction), three [tokens](https://en.wikipedia.org/wiki/Type%E2%80%93token_distinction)):
- One use of the indicative which should be subjunctive - indeed the sentence immediately following it, which mirrors its structure, _does_ use the subjunctive ([L871](https://github.com/rust-lang/rust/blob/master/library/std/src/error.rs?plain=1#L871)). Replaced with the subjunctive.
- Two separate clauses joined with commas ([L975](https://github.com/rust-lang/rust/blob/master/library/std/src/error.rs?plain=1#L975), [L1023](https://github.com/rust-lang/rust/blob/master/library/std/src/error.rs?plain=1#L1023)). Replaced the first with a semicolon and the second with a period. Admittedly those judgements are pretty much 100% subjective, based on my sense of how the sentences flowed into each other (though ofc the _replacement of the comma itself_ is not subjective or opinion-based).
I know this is silly and finicky, but I hope it helps tidy up the docs a bit for future readers!
### PR notes
**This is very much non-urgent (and, honestly, non-important).** I just figured it might be a nice quality-of-life improvement and bit of tidying up for the core contributors themselves not to have to do. 🙂
I'm tagging Steve, per the [contributing guidelines](https://rustc-dev-guide.rust-lang.org/contributing.html#r) ("Steve usually reviews documentation changes. So if you were to make a documentation change, add `r? `@steveklabnik`"):`
r? `@steveklabnik`
I wrote `state` where I should've used `s`.
This removes the unnecessary `s` variable to prevent that mistake.
Fortunately, this typo didn't affect the correctness of the lock, as the
second half of the condition (!has_writers_waiting) is enough for
correctness, which explains why this mistake didn't show up during
testing.
From reading the source code, it appears like the desired semantic of
std::unix::rand is to always provide some bytes and never block. For
that reason GRND_NONBLOCK is checked before calling getrandom(0), so
that getrandom(0) won't block. If it would block, then the function
falls back to using /dev/urandom, which for the time being doesn't
block. There are some drawbacks to using /dev/urandom, however, and so
getrandom(GRND_INSECURE) was created as a replacement for this exact
circumstance.
getrandom(GRND_INSECURE) is the same as /dev/urandom, except:
- It won't leave a warning in dmesg if used at early boot time, which is
a common occurance (and the reason why I found this issue);
- It won't introduce a tiny delay at early boot on newer kernels when
/dev/urandom tries to opportunistically create jitter entropy;
- It only requires 1 syscall, rather than 3.
Other than that, it returns the same "quality" of randomness as
/dev/urandom, and never blocks.
It's only available on kernels ≥5.6, so we try to use it, cache the
result of that attempt, and fall back to to the previous code if it
didn't work.
It is not obvious (at least for me) that complexity of iteration over hash tables depends on capacity and not length. Especially comparing with other containers like Vec or String. I think, this behaviour is worth mentioning.
I run benchmark which tests iteration time for maps with length 50 and different capacities and get this results:
```
capacity - time
64 - 203.87 ns
256 - 351.78 ns
1024 - 607.87 ns
4096 - 965.82 ns
16384 - 3.1188 us
```
If you want to dig why it behaves such way, you can look current implementation in [hashbrown code](f3a9f211d0/src/raw/mod.rs (L1933)).
Benchmarks code would be presented in PR related to this commit.
* For read and read_buf, only the front slice of a discontiguous
VecDeque is copied. The VecDeque is advanced after reading, making any
back slice available for reading with a second call to Read::read(_buf).
* For write, the VecDeque always appends the entire slice to the end,
growing its allocation when necessary.
Remove libstd's calls to `C-unwind` foreign functions
Remove all libstd and its dependencies' usage of `extern "C-unwind"`.
This is a prerequiste of a WIP PR which will forbid libraries calling `extern "C-unwind"` functions to be compiled in `-Cpanic=unwind` and linked against `panic_abort` (this restriction is necessary to address soundness bug #96926).
Cargo will ensure all crates are compiled with the same `-Cpanic` but the std is only compiled `-Cpanic=unwind` but needs the ability to be linked into `-Cpanic=abort`.
Currently there are two places where `C-unwind` is used in libstd:
* `__rust_start_panic` is used for interfacing to the panic runtime. This could be `extern "Rust"`
* `_{rdl,rg}_oom`: a shim `__rust_alloc_error_handler` will be generated by codegen to call into one of these; they can also be `extern "Rust"` (in fact, the generated shim is used as `extern "Rust"`, so I am not even sure why these are not, probably because they used to `extern "C"` and was changed to `extern "C-unwind"` when we allow alloc error hooks to unwind, but they really should just be using Rust ABI).
For dependencies, there is only one `extern "C-unwind"` function call, in `unwind` crate. This can be expressed as a re-export.
More dicussions can be seen in the Zulip thread: https://rust-lang.zulipchat.com/#narrow/stream/210922-project-ffi-unwind/topic/soundness.20in.20mixed.20panic.20mode
`@rustbot` label: T-libs F-c_unwind
Make HashMap fall back to RtlGenRandom if BCryptGenRandom fails
With PR #84096, Rust `std::collections::hash_map::RandomState` changed from using `RtlGenRandom()` ([msdn](https://docs.microsoft.com/en-us/windows/win32/api/ntsecapi/nf-ntsecapi-rtlgenrandom)) to `BCryptGenRandom()` ([msdn](https://docs.microsoft.com/en-us/windows/win32/api/bcrypt/nf-bcrypt-bcryptgenrandom)) as its source of secure randomness after much discussion ([here](https://github.com/rust-random/getrandom/issues/65#issuecomment-753634074), among other places).
Unfortunately, after that PR landed, Mozilla Firefox started experiencing fairly-rare crashes during startup while attempting to initialize the `env_logger` crate. ([docs for env_logger](https://docs.rs/env_logger/latest/env_logger/)) The root issue is that on some machines, `BCryptGenRandom()` will fail with an `Access is denied. (os error 5)` error message. ([Bugzilla issue 1754490](https://bugzilla.mozilla.org/show_bug.cgi?id=1754490)) (Discussion in issue #94098)
Note that this is happening upon startup of Firefox's unsandboxed Main Process, so this behavior is different and separate from previous issues ([like this](https://bugzilla.mozilla.org/show_bug.cgi?id=1746254)) where BCrypt DLLs were blocked by process sandboxing. In the case of sandboxing, we knew we were doing something abnormal and expected that we'd have to resort to abnormal measures to make it work.
However, in this case we are in a regular unsandboxed process just trying to initialize `env_logger` and getting a panic. We suspect that this may be caused by a virus scanner or some other security software blocking the loading of the BCrypt DLLs, but we're not completely sure as we haven't been able to replicate locally.
It is also possible that Firefox is not the only software affected by this; we just may be one of the pieces of Rust software that has the telemetry and crash reporting necessary to catch it.
I have read some of the historical discussion around using `BCryptGenRandom()` in Rust code, and I respect the decision that was made and agree that it was a good course of action, so I'm not trying to open a discussion about a return to `RtlGenRandom()`. Instead, I'd like to suggest that perhaps we use `RtlGenRandom()` as a "fallback RNG" in the case that BCrypt doesn't work.
This pull request implements this fallback behavior. I believe this would improve the robustness of this essential data structure within the standard library, and I see only 2 potential drawbacks:
1. Slight added overhead: It should be quite minimal though. The first call to `sys::rand::hashmap_random_keys()` will incur a bit of initialization overhead, and every call after will incur roughly 2 non-atomic global reads and 2 easily predictable branches. Both should be negligible compared to the actual cost of generating secure random numbers
2. `RtlGenRandom()` is deprecated by Microsoft: Technically true, but as mentioned in [this comment on GoLang](https://github.com/golang/go/issues/33542#issuecomment-626124873), this API is ubiquitous in Windows software and actually removing it would break lots of things. Also, Firefox uses it already in [our C++ code](https://searchfox.org/mozilla-central/rev/5f88c1d6977e03e22d3420d0cdf8ad0113c2eb31/mfbt/RandomNum.cpp#25), and [Chromium uses it in their code as well](https://source.chromium.org/chromium/chromium/src/+/main:base/rand_util_win.cc) (which transitively means that Microsoft uses it in their own web browser, Edge). If there did come a time when Microsoft truly removes this API, it should be easy enough for Rust to simply remove the fallback in the code I've added here
Fix use of SetHandleInformation on UWP
The use of `SetHandleInformation` (introduced in #96441 to make `HANDLE` inheritable) breaks UWP builds because it is not available for UWP targets.
Proposed workaround: duplicate the `HANDLE` with `inherit = true` and immediately close the old one. Traditional Windows Desktop programs are not affected.
cc `@ChrisDenton`
Add rustc_nonnull_optimization_guaranteed to Owned/Borrowed Fd/Socket
PR #94586 added support for using
`rustc_nonnull_optimization_guaranteed` on values where the "null" value
is the all-ones bitpattern.
Now that #94586 has made it to the stage0 compiler, add
`rustc_nonnull_optimization_guaranteed` to `OwnedFd`, `BorrowedFd`,
`OwnedSocket`, and `BorrowedSocket`, since these types all exclude
all-ones bitpatterns.
This allows `Option<OwnedFd>`, `Option<BorrowedFd>`, `Option<OwnedSocket>`,
and `Option<BorrowedSocket>` to be used in FFI declarations, as described
in the [I/O safety RFC].
[I/O safety RFC]: https://github.com/rust-lang/rfcs/blob/master/text/3128-io-safety.md#ownedfd-and-borrowedfdfd-1
ExitCode::exit_process() method
cc `@yaahc` / #93840
(eeek, hit ctrl-enter before I meant to and right after realizing the branch name was wrong. oh, well)
I feel like it makes sense to have the `exit(ExitCode)` function as a method or at least associated function on ExitCode, but maybe that would hurt discoverability? Probably not as much if it's at the top of the `process::exit()` documentation or something, but idk. Also very unsure about the name, I'd like something that communicates that you are exiting with *this* ExitCode, but with a method name being postfix it doesn't seem to flow. `code.exit_process_with()` ? `.exit_process_with_self()` ? Blech. Maybe it doesn't matter, since ideally just `code.exit()` or something would be clear simply by the name and single parameter but 🤷
Also I'd like to touch up the `ExitCode` docs (which I did a bit here), but that would probably be good in a separate PR, right? Since I think the beta deadline is coming up.
Clarify what values `BorrowedHandle`, `OwnedHandle` etc. can hold.
Reword the documentation to clarify that when `BorrowedHandle`, `OwnedHandle`, or `HandleOrNull` hold the value `-1`, it always means the current process handle, and not `INVALID_HANDLE_VALUE`.
`-1` should only mean `INVALID_HANDLE_VALUE` after a call to a function documented to return that to report errors, which should lead I/O functions to produce errors rather than succeeding and producing `OwnedHandle` or `BorrowedHandle` values. So if a consumer of an `OwnedHandle` or `BorrowedHandle` ever sees them holding a `-1`, it should always mean the current process handle.
PR #94586 added support for using
`rustc_nonnull_optimization_guaranteed` on values where the "null" value
is the all-ones bitpattern.
Now that #94586 has made it to the stage0 compiler, add
`rustc_nonnull_optimization_guaranteed` to `OwnedFd`, `BorrowedFd`,
`OwnedSocket`, and `BorrowedSocket`, since these types all exclude
all-ones bitpatterns.
This allows `Option<OwnedFd>`, `Option<BorrowedFd>`, `Option<OwnedSocket>`,
and `Option<BorrowedSocket>` to be used in FFI declarations, as described
in the [I/O safety RFC].
[I/O safety RFC]: https://github.com/rust-lang/rfcs/blob/master/text/3128-io-safety.md#ownedfd-and-borrowedfdfd-1
In the previous implementation, if the standard streams were open,
but the RLIMIT_NOFILE value was below three, the poll would fail
with EINVAL:
> ERRORS: EINVAL The nfds value exceeds the RLIMIT_NOFILE value.
Switch to the existing fcntl based implementation to avoid the issue.
Clarify that when `BorrowedHandle`, `OwnedHandle`, or `HandleOrNull`
hold the value `-1`, it always means the current process handle, and not
`INVALID_HANDLE_VALUE`.
Make `BorrowedFd::borrow_raw` a const fn.
Making `BorrowedFd::borrow_raw` a const fn allows it to be used to
create a constant `BorrowedFd<'static>` holding constants such as
`AT_FDCWD`. This will allow [`rustix::fs::cwd`] to become a const fn.
For consistency, make similar changes to `BorrowedHandle::borrow_raw`
and `BorrowedSocket::borrow_raw`.
[`rustix::fs::cwd`]: https://docs.rs/rustix/latest/rustix/fs/fn.cwd.html
r? `@joshtriplett`
CC #27709 (tracking issue for the `ip` feature which contains more
functions)
The function `Ipv6Addr::to_ipv4` is bad because it also returns an IPv4
address for the IPv6 loopback address `::1`. Stabilize
`Ipv6Addr::to_ipv4_mapped` so we can recommend that function instead.
Issue #84096 changed the hashmap RNG to use BCryptGenRandom instead of
RtlGenRandom on Windows.
Mozilla Firefox started experiencing random failures in
env_logger::Builder::new() (Issue #94098) during initialization of their
unsandboxed main process with an "Access Denied" error message from
BCryptGenRandom(), which is used by the HashMap contained in
env_logger::Builder
The root cause appears to be a virus scanner or other software interfering
with BCrypt DLLs loading.
This change adds a fallback option if BCryptGenRandom is unusable for
whatever reason. It will fallback to RtlGenRandom in this case.
Fixes#94098
Revert "Implement [OsStr]::join", which was merged without FCP.
This reverts commit 4fcbc53820, see https://github.com/rust-lang/rust/pull/96744. (I'm terribly sorry, and truly don't remember r+ing it, or even having seen it before yesterday, which is... genuinely very worrisome for me).
r? `@m-ou-se`
Improve floating point documentation
This is my attempt to improve/solve https://github.com/rust-lang/rust/issues/95468 and https://github.com/rust-lang/rust/issues/73328 .
Added/refined explanations:
- Refine the "NaN as a special value" top level explanation of f32
- Refine `const NAN` docstring: add an explanation about there being multitude of NaN bitpatterns and disclaimer about the portability/stability guarantees.
- Refine `fn is_sign_positive` and `fn is_sign_negative` docstrings: add disclaimer about the sign bit of NaNs.
- Refine `fn min` and `fn max` docstrings: explain the semantics and their relationship to the standard and libm better.
- Refine `fn trunc` docstrings: explain the semantics slightly more.
- Refine `fn powi` docstrings: add disclaimer that the rounding behaviour might be different from `powf`.
- Refine `fn copysign` docstrings: add disclaimer about payloads of NaNs.
- Refine `minimum` and `maximum`: add disclaimer that "propagating NaN" doesn't mean that propagating the NaN bit patterns is guaranteed.
- Refine `max` and `min` docstrings: add "ignoring NaN" to bring the one-row explanation to parity with `minimum` and `maximum`.
Cosmetic changes:
- Reword `NaN` and `NAN` as plain "NaN", unless they refer to the specific `const NAN`.
- Reword "a number" to `self` in function docstrings to clarify.
- Remove "Returns NAN if the number is NAN" from `abs`, as this is told to be the default behavior in the top explanation.
Remove `#[rustc_deprecated]`
This removes `#[rustc_deprecated]` and introduces diagnostics to help users to the right direction (that being `#[deprecated]`). All uses of `#[rustc_deprecated]` have been converted. CI is expected to fail initially; this requires #95958, which includes converting `stdarch`.
I plan on following up in a short while (maybe a bootstrap cycle?) removing the diagnostics, as they're only intended to be short-term.
Add more diagnostic items
This just adds a handful diagnostic items I noticed were missing.
Would it be worth doing this for all of the remaining types? I'm willing to do it if it'd be helpful.
Create clippy lint against unexpectedly late drop for temporaries in match scrutinee expressions
A new clippy lint for issue 93883 (https://github.com/rust-lang/rust/issues/93883). Relies on a new trait in `marker` (called `SignificantDrop` to enable linting), which is why this PR is for the rust-lang repo and not the clippy repo.
changelog: new lint [`significant_drop_in_scrutinee`]
Remove hard links from `env::current_exe` security example
The security example shows that `env::current_exe` will return the path used when the program was started. This is not really surprising considering how hard links work: after `ln foo bar`, the two files are _equivalent_. It is _not_ the case that `bar` is a “link” to `foo`, nor is `foo` a link to `bar`. They are simply two names for the same underlying data.
The security vulnerability linked to seems to be different: there an attacker would start a SUID binary from a directory under the control of the attacker. The binary would respawn itself by executing the program found at `/proc/self/exe` (which the attacker can control). This is a real problem. In my opinion, the example given here doesn’t really show the same problem, it just shows a misunderstanding of what hard links are.
I looked through the history a bit and found that the example was introduced in https://github.com/rust-lang/rust/pull/33526. That PR actually has two commits, and the first (8478d48dad) explains the race condition at the root of the linked security vulnerability. The second commit proceeds to replace the explanation with the example we have today.
This commit reverts most of the second commit from https://github.com/rust-lang/rust/pull/33526.
Add aliases for std::fs::canonicalize
The aliases are `realpath` and `GetFinalPathNameByHandle` which are explicitly mentioned in `canonicalize`'s documentation.
Use 64-bit time on 32-bit linux-gnu
The standard library suffered the [Year 2038 problem][Y2038] in two main places on targets with 32-bit `time_t`:
- In `std::time::SystemTime`, we stored a `timespec` that has `time_t` seconds. This is now changed to directly store 64-bit seconds and nanoseconds, and on 32-bit linux-gnu we try to use `__clock_gettime64` (glibc 2.34+) to get the larger timestamp.
- In `std::fs::Metadata`, we store a `stat64`, which has 64-bit `off_t` but still 32-bit `time_t`, and unfortunately that is baked in the API by the (deprecated) `MetadataExt::as_raw_stat()`. However, we can use `statx` for 64-bit `statx_timestamp` to store in addition to the `stat64`, as we already do to support creation time, and the rest of the `MetadataExt` methods can return those full values. Note that some filesystems may still be limited in their actual timestamp support, but that's not something Rust can change.
There remain a few places that need `timespec` for system call timeouts -- I leave that to future work.
[Y2038]: https://en.wikipedia.org/wiki/Year_2038_problem
Add a dedicated length-prefixing method to `Hasher`
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
Fixes#94026
r? rust-lang/libs
---
The core of this change is the following two new methods on `Hasher`:
```rust
pub trait Hasher {
/// Writes a length prefix into this hasher, as part of being prefix-free.
///
/// If you're implementing [`Hash`] for a custom collection, call this before
/// writing its contents to this `Hasher`. That way
/// `(collection![1, 2, 3], collection![4, 5])` and
/// `(collection![1, 2], collection![3, 4, 5])` will provide different
/// sequences of values to the `Hasher`
///
/// The `impl<T> Hash for [T]` includes a call to this method, so if you're
/// hashing a slice (or array or vector) via its `Hash::hash` method,
/// you should **not** call this yourself.
///
/// This method is only for providing domain separation. If you want to
/// hash a `usize` that represents part of the *data*, then it's important
/// that you pass it to [`Hasher::write_usize`] instead of to this method.
///
/// # Examples
///
/// ```
/// #![feature(hasher_prefixfree_extras)]
/// # // Stubs to make the `impl` below pass the compiler
/// # struct MyCollection<T>(Option<T>);
/// # impl<T> MyCollection<T> {
/// # fn len(&self) -> usize { todo!() }
/// # }
/// # impl<'a, T> IntoIterator for &'a MyCollection<T> {
/// # type Item = T;
/// # type IntoIter = std::iter::Empty<T>;
/// # fn into_iter(self) -> Self::IntoIter { todo!() }
/// # }
///
/// use std:#️⃣:{Hash, Hasher};
/// impl<T: Hash> Hash for MyCollection<T> {
/// fn hash<H: Hasher>(&self, state: &mut H) {
/// state.write_length_prefix(self.len());
/// for elt in self {
/// elt.hash(state);
/// }
/// }
/// }
/// ```
///
/// # Note to Implementers
///
/// If you've decided that your `Hasher` is willing to be susceptible to
/// Hash-DoS attacks, then you might consider skipping hashing some or all
/// of the `len` provided in the name of increased performance.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_length_prefix(&mut self, len: usize) {
self.write_usize(len);
}
/// Writes a single `str` into this hasher.
///
/// If you're implementing [`Hash`], you generally do not need to call this,
/// as the `impl Hash for str` does, so you can just use that.
///
/// This includes the domain separator for prefix-freedom, so you should
/// **not** call `Self::write_length_prefix` before calling this.
///
/// # Note to Implementers
///
/// The default implementation of this method includes a call to
/// [`Self::write_length_prefix`], so if your implementation of `Hasher`
/// doesn't care about prefix-freedom and you've thus overridden
/// that method to do nothing, there's no need to override this one.
///
/// This method is available to be overridden separately from the others
/// as `str` being UTF-8 means that it never contains `0xFF` bytes, which
/// can be used to provide prefix-freedom cheaper than hashing a length.
///
/// For example, if your `Hasher` works byte-by-byte (perhaps by accumulating
/// them into a buffer), then you can hash the bytes of the `str` followed
/// by a single `0xFF` byte.
///
/// If your `Hasher` works in chunks, you can also do this by being careful
/// about how you pad partial chunks. If the chunks are padded with `0x00`
/// bytes then just hashing an extra `0xFF` byte doesn't necessarily
/// provide prefix-freedom, as `"ab"` and `"ab\u{0}"` would likely hash
/// the same sequence of chunks. But if you pad with `0xFF` bytes instead,
/// ensuring at least one padding byte, then it can often provide
/// prefix-freedom cheaper than hashing the length would.
#[inline]
#[unstable(feature = "hasher_prefixfree_extras", issue = "88888888")]
fn write_str(&mut self, s: &str) {
self.write_length_prefix(s.len());
self.write(s.as_bytes());
}
}
```
With updates to the `Hash` implementations for slices and containers to call `write_length_prefix` instead of `write_usize`.
`write_str` defaults to using `write_length_prefix` since, as was pointed out in the issue, the `write_u8(0xFF)` approach is insufficient for hashers that work in chunks, as those would hash `"a\u{0}"` and `"a"` to the same thing. But since `SipHash` works byte-wise (there's an internal buffer to accumulate bytes until a full chunk is available) it overrides `write_str` to continue to use the add-non-UTF-8-byte approach.
---
Compatibility:
Because the default implementation of `write_length_prefix` calls `write_usize`, the changed hash implementation for slices will do the same thing the old one did on existing `Hasher`s.
Use futex-based locks and thread parker on {Free, Open, DragonFly}BSD.
This switches *BSD to our futex-based locks and thread parker.
Tracking issue: https://github.com/rust-lang/rust/issues/93740
This is a draft, because this still needs a new version of the `libc` crate to be published that includes https://github.com/rust-lang/libc/pull/2770.
r? `@Amanieu`
This accomplishes two main goals:
- Make it clear who is responsible for prefix-freedom, including how they should do it
- Make it feasible for a `Hasher` that *doesn't* care about Hash-DoS resistance to get better performance by not hashing lengths
This does not change rustc-hash, since that's in an external crate, but that could potentially use it in future.
Implement [OsStr]::join
Implements join for `OsStr` and `OsString` slices:
```Rust
let strings = [OsStr::new("hello"), OsStr::new("dear"), OsStr::new("world")];
assert_eq!("hello dear world", strings.join(OsStr::new(" ")));
````
This saves one from converting to strings and back, or from implementing it manually.
Relax memory ordering used in SameMutexCheck
`SameMutexCheck` only requires atomicity for `self.addr`, but does not need ordering of other memory accesses in either the success or failure case. Using `Relaxed`, the code still correctly handles the case when two threads race to store an address.
Relax memory ordering used in `min_stack`
`min_stack` does not provide any synchronization guarantees to its callers, and only requires atomicity for `MIN` itself, so relaxed memory ordering is sufficient.
This allows using `ReadBuf` in a builder-like style and to setup a `ReadBuf` and
pass it to `read_buf` in a single expression, e.g.,
```
// With this PR:
reader.read_buf(ReadBuf::uninit(buf).assume_init(init_len))?;
// Previously:
let mut buf = ReadBuf::uninit(buf);
buf.assume_init(init_len);
reader.read_buf(&mut buf)?;
```
Signed-off-by: Nick Cameron <nrc@ncameron.org>
The security example shows that `env::current_exe` will return the
path used when the program was started. This is not really surprising
considering how hard links work: after `ln foo bar`, the two files are
_equivalent_. It is _not_ the case that `bar` is a “link” to `foo`,
nor is `foo` a link to `bar`. They are simply two names for the same
underlying data.
The security vulnerability linked to seems to be different: there an
attacker would start a SUID binary from a directory under the control
of the attacker. The binary would respawn itself by executing the
program found at `/proc/self/exe` (which the attacker can control).
This is a real problem. In my opinion, the example given here doesn’t
really show the same problem, it just shows a misunderstanding of what
hard links are.
I looked through the history a bit and found that the example was
introduced in #33526. That PR actually has two commits, and the
first (8478d48dad) explains the race
condition at the root of the linked security vulnerability. The second
commit proceeds to replace the explanation with the example we have
today.
This commit reverts most of the second commit from #33526.
`SameMutexCheck` only requires atomicity for `self.addr`, but does not need ordering of other memory accesses in either the success or failure case. Using `Relaxed`, the code still correctly handles the case when two threads race to store an address.
`min_stack` does not provide any synchronization guarantees to its callers, and only requires atomicity for `MIN` itself, so relaxed memory ordering is sufficient.
rustdoc: Resolve doc links referring to `macro_rules` items
cc https://github.com/rust-lang/rust/issues/81633
UPD: the fallback to considering *all* `macro_rules` in the crate for unresolved names is not removed in this PR, it will be removed separately and will be run through crater.
Make [e]println macros eagerly drop temporaries (for backport)
This PR extracts the subset of #96455 which is only the parts necessary for fixing the 1.61-beta regressions in #96434.
My larger PR #96455 contains a few other changes relative to the pre-#94868 behavior; those are not necessary to backport into 1.61.
argument position | before #94868 | after #94868 | after this PR
--- |:---:|:---:|:---:
`write!($tmp, "…", …)` | 😡 | 😡 | 😡
`write!(…, "…", $tmp)` | 😡 | 😡 | 😡
`writeln!($tmp, "…", …)` | 😡 | 😡 | 😡
`writeln!(…, "…", $tmp)` | 😡 | 😡 | 😡
`print!("…", $tmp)` | 😡 | 😡 | 😡
`println!("…", $tmp)` | 😺 | 😡 | 😺
`eprint!("…", $tmp)` | 😡 | 😡 | 😡
`eprintln!("…", $tmp)` | 😺 | 😡 | 😺
`panic!("…", $tmp)` | 😺 | 😺 | 😺
Revert "Re-export core::ffi types from std::ffi"
This reverts commit 9aed829fe6.
Fixes https://github.com/rust-lang/rust/issues/96435 , a regression
in crates doing `use std::ffi::*;` and `use std::os::raw::*;`.
We can re-add this re-export once the `core::ffi` types
are stable, and thus the `std::os::raw` types can become re-exports as
well, which will avoid the conflict. (Type aliases to the same type
still conflict, but re-exports of the same type don't.)
Windows: Make stdin pipes synchronous
Stdin pipes do not need to be used asynchronously within the standard library. This is a first step in making pipes mostly synchronous.
r? `@m-ou-se`
std: directly use pthread in UNIX parker implementation
`Mutex` and `Condvar` are being replaced by more efficient implementations, which need thread parking themselves (see #93740). Therefore we should use the `pthread` synchronization primitives directly. Also, we can avoid allocating the mutex and condition variable because the `Parker` struct is being placed in an `Arc` anyways.
This basically is just a copy of the current `Mutex` and `Condvar` code, which will however be removed (again, see #93740). An alternative implementation could be to use dedicated private `OsMutex` and `OsCondvar` types, but all the other platforms supported by std actually have their own thread parking primitives.
I used `Pin` to guarantee a stable address for the `Parker` struct, while the current implementation does not, rather using extra unsafe declaration. Since the thread struct is shared anyways, I assumed this would not add too much clutter while being clearer.
Make EncodeWide implement FusedIterator
[`EncodeUtf16`](https://doc.rust-lang.org/std/str/struct.EncodeUtf16.html) and [`EncodeWide`](https://doc.rust-lang.org/std/os/windows/ffi/struct.EncodeWide.html) currently serve similar purposes: They convert from UTF-8 to UTF-16 and WTF-8 to WTF-16, respectively. `EncodeUtf16` wraps a &str, whereas `EncodeWide` wraps an &OsStr.
When Iteration has concluded, these iterators wrap an empty slice, which will forever yield `None` values. Hence, `EncodeUtf16` rightfully implements `FusedIterator`. However, `EncodeWide` in contrast does not, even though it serves an almost identical purpose.
This PR attempts to fix that issue. I consider this change minor and non-controversial, hence why I have not added a RFC/FCP. Please let me know if the stability attribute is wrong or contains a wrong version number. Thanks in advance.
Fixes https://github.com/rust-lang/rust/issues/96368
This reverts commit 9aed829fe6.
Fixes https://github.com/rust-lang/rust/issues/96435 , a regression
in crates doing `use std::ffi::*;` and `use std::os::raw::*;`.
We can re-add this re-export once the `core::ffi` types
are stable, and thus the `std::os::raw` types can become re-exports as
well, which will avoid the conflict. (Type aliases to the same type
still conflict, but re-exports of the same type don't.)
Define a dedicated error type for `HandleOrNull` and `HandleOrInvalid`.
Define `NullHandleError` and `InvalidHandleError` types, that implement std::error::Error, and use them as the error types in `HandleOrNull` and `HandleOrInvalid`,
This addresses [this concern](https://github.com/rust-lang/rust/issues/87074#issuecomment-1080031167).
This is the same as #95387.
r? `@joshtriplett`
Mutex and Condvar are being replaced by more efficient implementations, which need thread parking themselves (see #93740). Therefore use the pthread synchronization primitives directly. Also, avoid allocating because the Parker struct is being placed in an Arc anyways.
Windows Command: Don't run batch files using verbatim paths
Fixes#95178
Note that the first commit does some minor refactoring (moving command line argument building to args.rs). The actual changes are in the second.
Reduce allocations for path conversions on Windows
Previously, UTF-8 to UTF-16 Path conversions on Windows unnecessarily allocate twice, as described in #96297. This commit fixes that issue.
Improve Windows path prefix parsing
This PR fixes improves parsing of Windows path prefixes. `parse_prefix` now supports both types of separators on Windows (`/` and `\`).
[fuchsia] Add implementation for `current_exe`
This implementation returns a best attempt at the current exe path. On
fuchsia, fdio will always use `argv[0]` as the process name and if it is
not set then an error will be returned. Because this is not guaranteed
to be the case, this implementation returns an error if `argv` does not
contain any elements.
remove_dir_all_recursive: treat ELOOP the same as ENOTDIR
On older Linux kernels (I tested on 4.4, corresponding to Ubuntu 16.04), opening a symlink using `O_DIRECTORY | O_NOFOLLOW` returns `ELOOP` instead of `ENOTDIR`. We should handle it the same, since a symlink is still not a directory and needs to be `unlink`ed.
Use sys::unix::locks::futex* on wasm+atomics.
This removes the wasm-specific lock implementations and instead re-uses the implementations from sys::unix.
Tracking issue: https://github.com/rust-lang/rust/issues/93740
cc ``@alexcrichton``
Improve AddrParseError description
The existing description was incorrect for socket addresses, and misleading: users would see “invalid IP address syntax” and suppose they were supposed to provide an IP address rather than a socket address.
I contemplated making it two variants (IP, socket), but realised we can do still better for the IPv4 and IPv6 types, so here it is as six.
I contemplated more precise error descriptions (e.g. “invalid IPv6 socket address syntax: expected a decimal scope ID after %”), but that’s a more invasive change, and probably not worthwhile anyway.
Making `BorrowedFd::borrow_raw` a const fn allows it to be used to
create a constant `BorrowedFd<'static>` holding constants such as
`AT_FDCWD`. This will allow [`rustix::fs::cwd`] to become a const fn.
For consistency, make similar changes to `BorrowedHandle::borrow_raw`
and `BorrowedSocket::borrow_raw`.
[`rustix::fs::cwd`]: https://docs.rs/rustix/latest/rustix/fs/fn.cwd.html
This implementation returns a best attempt at the current exe path. On
fuchsia, fdio will always use `argv[0]` as the process name and if it is
not set then an error will be returned. Because this is not guaranteed
to be the case, this implementation returns an error if `argv` does not
contain any elements.
The existing description was incorrect for socket addresses, and
misleading: users would see “invalid IP address syntax” and suppose they
were supposed to provide an IP address rather than a socket address.
I contemplated making it two variants (IP, socket), but realised we can
do still better for the IPv4 and IPv6 types, so here it is as six.
I contemplated more precise error descriptions (e.g. “invalid IPv6
socket address syntax: expected a decimal scope ID after %”), but that’s
a more invasive change, and probably not worthwhile anyway.
Use a single ReentrantMutex implementation on all platforms.
This replaces all platform specific ReentrantMutex implementations by the one I added in #95727 for Linux, since that one does not depend on any platform specific details.
r? `@Amanieu`
fix error handling for pthread_sigmask(3)
Errors from `pthread_sigmask(3)` were handled using `cvt()`, which expects a return value of `-1` on error and uses `errno`.
However, `pthread_sigmask(3)` returns `0` on success and an error number otherwise.
Fix it by replacing `cvt()` with `cvt_nz()`.
Use u32 instead of i32 for futexes.
This changes futexes from i32 to u32. The [Linux man page](https://man7.org/linux/man-pages/man2/futex.2.html) uses `uint32_t` for them, so I'm not sure why I used i32 for them. Maybe because I first used them for thread parkers, where I used -1, 0, and 1 as the states.
(Wasm's `memory.atomic.wait32` does use `i32`, because wasm doesn't support `u32`.)
It doesn't matter much, but using the unsigned type probably results in fewer surprises when shifting bits around or using comparison operators.
r? ```@Amanieu```
Create (unstable) 2024 edition
[On Zulip](https://rust-lang.zulipchat.com/#narrow/stream/213817-t-lang/topic/Deprecating.20macro.20scoping.20shenanigans/near/272860652), there was a small aside regarding creating the 2024 edition now as opposed to later. There was a reasonable amount of support and no stated opposition.
This change creates the 2024 edition in the compiler and creates a prelude for the 2024 edition. There is no current difference between the 2021 and 2024 editions. Cargo and other tools will need to be updated separately, as it's not in the same repository. This change permits the vast majority of work towards the next edition to proceed _now_ instead of waiting until 2024.
For sanity purposes, I've merged the "hello" UI tests into a single file with multiple revisions. Otherwise we'd end up with a file per edition, despite them being essentially identical.
````@rustbot```` label +T-lang +S-waiting-on-review
Not sure on the relevant team, to be honest.
Windows: Use a pipe relay for chaining pipes
Fixes#95759
This fixes the issue by chaining pipes synchronously and manually pumping messages between them. It's not ideal but it has the advantage of not costing anything if pipes are not chained ("don't pay for what you don't use") and it also avoids breaking existing code that rely on our end of the pipe being asynchronous (which includes rustc's own testing framework).
Libraries can avoid needing this by using their own pipes to chain commands.
Document that DirEntry holds the directory open
I had a bug where holding onto DirEntry structs caused file descriptor exhaustion, and thought it would be good to document this.
Replace RwLock by a futex based one on Linux
This replaces the pthread-based RwLock on Linux by a futex based one.
This implementation is similar to [the algorithm](https://gist.github.com/kprotty/3042436aa55620d8ebcddf2bf25668bc) suggested by `@kprotty,` but modified to prefer writers and spin before sleeping. It uses two futexes: One for the readers to wait on, and one for the writers to wait on. The readers futex contains the state of the RwLock: The number of readers, a bit indicating whether writers are waiting, and a bit indicating whether readers are waiting. The writers futex is used as a simple condition variable and its contents are meaningless; it just needs to be changed on every notification.
Using two futexes rather than one has the obvious advantage of allowing a separate queue for readers and writers, but it also means we avoid the problem a single-futex RwLock would have of making it hard for a writer to go to sleep while the number of readers is rapidly changing up and down, as the writers futex is only changed when we actually want to wake up a writer.
It always prefers writers, as we decided [here](https://github.com/rust-lang/rust/issues/93740#issuecomment-1070696128).
To be able to prefer writers, it relies on futex_wake to return the number of awoken threads to be able to handle write-unlocking while both the readers-waiting and writers-waiting bits are set. Instead of waking both and letting them race, it first wakes writers and only continues to wake the readers too if futex_wake reported there were no writers to wake up.
r? `@Amanieu`
The current implementation uses a `hlt` instruction, which is the most
direct way to notify a connected debugger but is not the most flexible
way. This commit changes it to a call to the `abort` libc function,
making it possible for a system designer to override its behavior as
they see fit.
Remove ptr-int transmute in std::sync::mpsc
Since https://github.com/rust-lang/rust/pull/95340 landed, Miri with `-Zmiri-check-number-validity` produces an error on the test suites of some crates which implement concurrency tools<sup>*</sup>, because it seems like such crates tend to use `std::sync::mpsc` in their tests. This fixes the problem by storing pointer bytes in a pointer.
<sup>*</sup> I have so far seen errors in the test suites of `once_cell`, `parking_lot`, and `crossbeam-utils`.
(just updating the list for fun, idk)
Also `threadpool`, `async-lock`, `futures-timer`, `fragile`, `scoped_threadpool`, `procfs`, `slog-async`, `scheduled-thread-pool`, `tokio-threadpool`, `mac`, `futures-cpupool`, `ntest`, `actix`, `zbus`, `jsonrpc-client-transports`, `fail`, `libp2p-gossipsub`, `parity-send-wrapper`, `async-broadcast,` `libp2p-relay`, `http-client`, `mockito`, `simple-mutex`, `surf`, `pollster`, and `pulse`. Then I turned the bot off.
Since https://github.com/rust-lang/rust/pull/95340 landed, Miri with
-Zmiri-check-number-validity produces an error on the test suites of
some crates which implement concurrency tools, because it seems like
such crates tend to use std::sync::mpsc in their tests. This fixes the
problem by storing pointer bytes in a pointer.
Relevant commit messages from squashed history in order:
Add initial version of ThinBox
update test to actually capture failure
swap to middle ptr impl based on matthieu-m's design
Fix stack overflow in debug impl
The previous version would take a `&ThinBox<T>` and deref it once, which
resulted in a no-op and the same type, which it would then print causing
an endless recursion. I've switched to calling `deref` by name to let
method resolution handle deref the correct number of times.
I've also updated the Drop impl for good measure since it seemed like it
could be falling prey to the same bug, and I'll be adding some tests to
verify that the drop is happening correctly.
add test to verify drop is behaving
add doc examples and remove unnecessary Pointee bounds
ThinBox: use NonNull
ThinBox: tests for size
Apply suggestions from code review
Co-authored-by: Alphyr <47725341+a1phyr@users.noreply.github.com>
use handle_alloc_error and fix drop signature
update niche and size tests
add cfg for allocating APIs
check null before calculating offset
add test for zst and trial usage
prevent optimizer induced ub in drop and cleanup metadata gathering
account for arbitrary size and alignment metadata
Thank you nika and thomcc!
Update library/alloc/src/boxed/thin.rs
Co-authored-by: Josh Triplett <josh@joshtriplett.org>
Update library/alloc/src/boxed/thin.rs
Co-authored-by: Josh Triplett <josh@joshtriplett.org>
make windows compat_fn (crudely) work on Miri
With https://github.com/rust-lang/rust/pull/95469, Windows `compat_fn!` now has to be supported by Miri to even make stdout work. Unfortunately, it relies on some outside-of-Rust linker hacks (`#[link_section = ".CRT$XCU"]`) that are rather hard to make work in Miri. So I came up with this crude hack to make this stuff work in Miri regardless. It should come at no cost for regular executions, so I hope this is okay.
Cc https://github.com/rust-lang/rust/issues/95627 `@ChrisDenton`
Bump bootstrap compiler to 1.61.0 beta
This PR bumps the bootstrap compiler to the 1.61.0 beta. The first commit changes the stage0 compiler, the second commit applies the "mechanical" changes and the third and fourth commits apply changes explained in the relevant comments.
r? `@Mark-Simulacrum`
Update libc to 0.2.121
With the updated libc, UNIX stack overflow handling in libstd can now
use the common `si_addr` accessor function, rather than attempting to
use a field from that name in `siginfo_t`. This simplifies the
collection of the fault address, particularly on platforms where that
data resides within a union in `siginfo_t`.
Don't cast thread name to an integer for prctl
`libc::prctl` and the `prctl` definitions in glibc, musl, and the kernel headers are C variadic functions. Therefore, all the arguments (except for the first) are untyped. It is only the Linux man page which says that `prctl` takes 4 `unsigned long` arguments. I have no idea why it says this.
In any case, the upshot is that we don't need to cast the pointer to an integer and confuse Miri.
But in light of this... what are we doing with those three `0`s? We're passing 3 `i32`s to `prctl`, which doesn't fill me with confidence. The man page says `unsigned long` and all the constants in the linux kernel are macros for expressions of the form `1UL << N`. I'm mostly commenting on this because looks a whole lot like some UB that was found in SQLite a few years ago: <https://youtu.be/LbzbHWdLAI0?t=1925> that was related to accidentally passing a 32-bit value from a literal `0` instead of a pointer-sized value. This happens to work on x86 due to the size of pointers and happens to work on x86_64 due to the calling convention. But also, there is no good reason for an implementation to be looking at those arguments. Some other calls to `prctl` require that other arguments be zeroed, but not `PR_SET_NAME`... so why are we even passing them?
I would prefer to end such questions by either passing 3 `libc::c_ulong`, or not passing those at all, but I'm not sure which is better.
Fix unsound `File` methods
This is a draft attempt to fix#81357. *EDIT*: this PR now tackles `read()`, `write()`, `read_at()`, `write_at()` and `read_buf`. Still needs more testing though.
cc `@jstarks,` can you confirm the the Windows team is ok with the Rust stdlib using `NtReadFile` and `NtWriteFile`?
~Also, I'm provisionally using `CancelIo` in a last ditch attempt to recover but I'm not sure that this is actually a good idea. Especially as getting into this state would be a programmer error so aborting the process is justified in any case.~ *EDIT*: removed, see comments.
With the updated libc, UNIX stack overflow handling in libstd can now
use the common `si_addr` accessor function, rather than attempting to
use a field from that name in `siginfo_t`. This simplifies the
collection of the fault address, particularly on platforms where that
data resides within a union in `siginfo_t`.
Windows: Synchronize asynchronous pipe reads and writes
On Windows, the pipes used for spawned processes are opened for asynchronous access but `read` and `write` are done using the standard methods that assume synchronous access. This means that the buffer (and variables on the stack) may be read/written to after the function returns.
This PR ensures reads/writes complete before returning. Note that this only applies to pipes we create and does not affect the standard file read/write methods.
Fixes#95411
libc::prctl and the prctl definitions in glibc, musl, and the kernel
headers are C variadic functions. Therefore, all the arguments (except
for the first) are untyped. It is only the Linux man page which says
that prctl takes 4 unsigned long arguments. I have no idea why it says
this.
In any case, the upshot is that we don't need to cast the pointer to an
integer and confuse Miri.
Handle rustc_const_stable attribute in library feature collector
The library feature collector in [compiler/rustc_passes/src/lib_features.rs](551b4fa395/compiler/rustc_passes/src/lib_features.rs) has only been looking at `#[stable(…)]`, `#[unstable(…)]`, and `#[rustc_const_unstable(…)]` attributes, while ignoring `#[rustc_const_stable(…)]`. The consequences of this were:
- When any const feature got stabilized (changing one or more `rustc_const_unstable` to `rustc_const_stable`), users who had previously enabled that unstable feature using `#![feature(…)]` would get told "unknown feature", rather than rustc's nicer "the feature … has been stable since … and no longer requires an attribute to enable".
This can be seen in the way that https://github.com/rust-lang/rust/pull/93957#issuecomment-1079794660 failed after rebase:
```console
error[E0635]: unknown feature `const_ptr_offset`
--> $DIR/offset_from_ub.rs:1:35
|
LL | #![feature(const_ptr_offset_from, const_ptr_offset)]
| ^^^^^^^^^^^^^^^^
```
- We weren't enforcing that a particular feature is either stable everywhere or unstable everywhere, and that a feature that has been stabilized has the same stabilization version everywhere, both of which we enforce for the other stability attributes.
This PR updates the library feature collector to handle `rustc_const_stable`, and fixes places in the standard library and test suite where `rustc_const_stable` was being used in a way that does not meet the rules for a stability attribute.
- Refine the "NaN as a special value" top level explanation of f32
- Refine `const NAN` docstring.
- Refine `fn is_sign_positive` and `fn is_sign_negative` docstrings.
- Refine `fn min` and `fn max` docstrings.
- Refine `fn trunc` docstrings.
- Refine `fn powi` docstrings.
- Refine `fn copysign` docstrings.
- Reword `NaN` and `NAN` as plain "NaN", unless they refer to the specific `const NAN`.
- Reword "a number" to `self` in function docstrings to clarify.
- Remove "Returns NAN if the number is NAN" as this is told to be the default behavior in the top explanation.
- Remove "propagating NaNs", as full propagation (preservation of payloads) is not guaranteed.
allow arbitrary inherent impls for builtin types in core
Part of https://github.com/rust-lang/compiler-team/issues/487. Slightly adjusted after some talks with `@m-ou-se` about the requirements of `t-libs-api`.
This adds a crate attribute `#![rustc_coherence_is_core]` which allows arbitrary impls for builtin types in core.
For other library crates impls for builtin types should be avoided if possible. We do have to allow the existing stable impls however. To prevent us from accidentally adding more of these in the future, there is a second attribute `#[rustc_allow_incoherent_impl]` which has to be added to **all impl items**. This only supports impls for builtin types but can easily be extended to additional types in a future PR.
This implementation does not check for overlaps in these impls. Perfectly checking that requires us to check the coherence of these incoherent impls in every crate, as two distinct dependencies may add overlapping methods. It should be easy enough to detect if it goes wrong and the attribute is only intended for use inside of std.
The first two commits are mostly unrelated cleanups.
Strict Provenance MVP
This patch series examines the question: how bad would it be if we adopted
an extremely strict pointer provenance model that completely banished all
int<->ptr casts.
The key insight to making this approach even *vaguely* pallatable is the
ptr.with_addr(addr) -> ptr
function, which takes a pointer and an address and creates a new pointer
with that address and the provenance of the input pointer. In this way
the "chain of custody" is completely and dynamically restored, making the
model suitable even for dynamic checkers like CHERI and Miri.
This is not a formal model, but lots of the docs discussing the model
have been updated to try to the *concept* of this design in the hopes
that it can be iterated on.
See #95228
Ensure io::Error's bitpacked repr doesn't accidentally impl UnwindSafe
Sadly, I'm not sure how to easily test that we don't impl a trait, though (or can libstd use `where io::Error: !UnwindSafe` or something).
Fixes#95203
Stabilize Termination and ExitCode
From https://github.com/rust-lang/rust/issues/43301
This PR stabilizes the Termination trait and associated ExitCode type. It also adjusts the ExitCode feature flag to replace the placeholder flag with a more permanent name, as well as splitting off the `to_i32` method behind its own permanently unstable feature flag.
This PR stabilizes the termination trait with the following signature:
```rust
pub trait Termination {
fn report(self) -> ExitCode;
}
```
The existing impls of `Termination` are effectively already stable due to the prior stabilization of `?` in main.
This PR also stabilizes the following APIs on exit code
```rust
#[derive(Clone, Copy, Debug)]
pub struct ExitCode(_);
impl ExitCode {
pub const SUCCESS: ExitCode;
pub const FAILURE: ExitCode;
}
impl From<u8> for ExitCode { /* ... */ }
```
---
All of the previous blockers have been resolved. The main ones that were resolved recently are:
* The trait's name: We decided against changing this since none of the alternatives seemed particularly compelling. Instead we decided to end the bikeshedding and stick with the current name. ([link to the discussion](https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/Termination.2FExit.20Status.20Stabilization/near/269793887))
* Issues around platform specific representations: We resolved this issue by changing the return type of `report` from `i32` to the opaque type `ExitCode`. That way we can change the underlying representation without affecting the API, letting us offer full support for platform specific exit code APIs in the future.
* Custom exit codes: We resolved this by adding `From<u8> for ExitCode`. We choose to only support u8 initially because it is the least common denominator between the sets of exit codes supported by our current platforms. In the future we anticipate adding platform specific extension traits to ExitCode for constructors from larger or negative numbers, as needed.
Fix build on i686-apple-darwin systems
Replace `target_arch = "x86_64"` with `not(target_arch = "aarch64")` so that i686-apple-darwin systems dynamically choose implementation.
Move std::sys::{mutex, condvar, rwlock} to std::sys::locks.
This cleans up the the std::sys modules a bit by putting the locks in a single module called `locks` rather than spread over the three modules `mutex`, `condvar`, and `rwlock`. This makes it easier to organise lock implementations, which helps with https://github.com/rust-lang/rust/issues/93740.
Preserve the Windows `GetLastError` error in `HandleOrInvalid`.
In the `TryFrom<HandleOrInvalid> for OwnedHandle` and
`TryFrom<HandleOrNull> for OwnedHandle` implemenations, `forget` the
owned handle on the error path, to avoid calling `CloseHandle` on an
invalid handle. It's harmless, except that it may overwrite the
thread's `GetLastError` error.
r? `@joshtriplett`
In the `TryFrom<HandleOrInvalid> for OwnedHandle` and
`TryFrom<HandleOrNull> for OwnedHandle` implemenations, `forget` the
owned handle on the error path, to avoid calling `CloseHandle` on an
invalid handle. It's harmless, except that it may overwrite the
thread's `GetLastError` error.
Skip a test if symlink creation is not possible
If someone running tests on Windows does not have Developer Mode enabled then creating symlinks will fail which in turn would cause this test to fail. This can be a stumbling block for contributors.
remove_dir_all: use fallback implementation on Miri
Fixes https://github.com/rust-lang/miri/issues/1966
The new implementation requires `openat`, `unlinkat`, and `fdopendir`. These cannot easily be shimmed in Miri since libstd does not expose APIs corresponding to them. So for now it is probably easiest to just use the fallback code in Miri. Nobody should run Miri as root anyway...
Relax tests for Windows dos device names
Windows 11 no longer turn paths ending with dos device names into device paths.
E.g. `C:\path\to\COM1.txt` used to get turned into `\\.\COM1`. Whereas now this path is left as is.
Note though that if the given path is an exact (case-insensitive) match for the string `COM1` then it'll still be converted to `\\.\COM1`.
Add a `process_group` method to UNIX `CommandExt`
- Tracking issue: #93857
- RFC: https://github.com/rust-lang/rfcs/pull/3228
Add a `process_group` method to `std::os::unix::process::CommandExt` that
allows setting the process group id (i.e. calling `setpgid`) in the child, thus
enabling users to set process groups while leveraging the `posix_spawn` fast
path.
add `CStr` method that accepts any slice containing a nul-terminated string
I haven't created an issue (tracking or otherwise) for this yet; apologies if my approach isn't correct. This is my first code contribution.
This change adds a member fn that converts a slice into a `CStr`; it is intended to be safer than `from_ptr` (which is unsafe and may read out of bounds), and more useful than `from_bytes_with_nul` (which requires that the caller already know where the nul byte is).
The reason I find this useful is for situations like this:
```rust
let mut buffer = [0u8; 32];
unsafe {
some_c_function(buffer.as_mut_ptr(), buffer.len());
}
let result = CStr::from_bytes_with_nul(&buffer).unwrap();
```
This code above returns an error with `kind = InteriorNul`, because `from_bytes_with_nul` expects that the caller has passed in a slice with the NUL byte at the end of the slice. But if I just got back a nul-terminated string from some FFI function, I probably don't know where the NUL byte is.
I would wish for a `CStr` constructor with the following properties:
- Accept `&[u8]` as input
- Scan for the first NUL byte and return the `CStr` that spans the correct sub-slice (see [future note below](https://github.com/rust-lang/rust/pull/94984#issuecomment-1070754281)).
- Return an error if no NUL byte is found within the input slice
I asked on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/122651-general/topic/CStr.20from.20.26.5Bu8.5D.20without.20knowing.20the.20NUL.20location.3F) whether this sounded like a good idea, and got a couple of positive-sounding responses from ``@joshtriplett`` and ``@AzureMarker.``
This is my first draft, so feedback is welcome.
A few issues that definitely need feedback:
1. Naming. ``@joshtriplett`` called this `from_bytes_with_internal_nul` on Zulip, but after staring at all of the available methods, I believe that this function is probably what end users want (rather than the existing fn `from_bytes_with_nul`). Giving it a simpler name (**`from_bytes`**) implies that this should be their first choice.
2. Should I add a similar method on `CString` that accepts `Vec<u8>`? I'd assume the answer is probably yes, but I figured I'd try to get early feedback before making this change bigger.
3. What should the error type look like? I made a unit struct since `CStr::from_bytes` can only fail in one obvious way, but if I need to do this for `CString` as well then that one may want to return `FromVecWithNulError`. And maybe that should dictate the shape of the `CStr` error type also?
Also, cc ``@poliorcetics`` who wrote #73139 containing similar fns.
Consistently present absent stdio handles on Windows as NULL handles.
This addresses #90964 by making the std API consistent about presenting
absent stdio handles on Windows as NULL handles. Stdio handles may be
absent due to `#![windows_subsystem = "windows"]`, due to the console
being detached, or due to a child process having been launched from a
parent where stdio handles are absent.
Specifically, this fixes the case of child processes of parents with absent
stdio, which previously ended up with `stdin().as_raw_handle()` returning
`INVALID_HANDLE_VALUE`, which was surprising, and which overlapped with an
unrelated valid handle value. With this patch, `stdin().as_raw_handle()`
now returns null in these situation, which is consistent with what it
does in the parent process.
And, document this in the "Windows Portability Considerations" sections of
the relevant documentation.
Implement `Write for Cursor<[u8; N]>`, plus `A: Allocator` cursor support
This implements `Write for Cursor<[u8; N]>`, and also adds support for generic `A: Allocator` in `Box` and `Vec` cursors.
This was inspired by a user questioning why they couldn't write a `Cursor<[u8; N]>`:
https://users.rust-lang.org/t/why-vec-and-not-u8-makes-cursor-have-write/68210
Related history:
- #27197 switched `AsRef<[u8]>` for reading and seeking
- #67415 tried to use `AsMut<[u8]>` for writing, but did not specialize `Vec`.
Update stdlib for the l4re target
This PR contains the work by ``@humenda`` and myself to update standard library support for the x86_64-unknown-l4re-uclibc tier 3 target, split out from humenda/rust as requested in #85967. The changes have been rebased on current master and updated in follow up commits by myself. The publishing of the changes is authorized and preferred by the original author. To preserve attribution, when standard library changes were introduced as part of other changes to the compiler, I have kept the changes concerning the standard library and altered the commit messages as indicated. Any incompatibilities have been remedied in follow up commits, so that the PR as a whole should result in a clean update of the target.
Use verbatim paths for `process::Command` if necessary
In #89174, the standard library started using verbatim paths so longer paths are usable by default. However, `Command` was originally left out because of the way `CreateProcessW` was being called. This was changed as a side effect of #87704 so now `Command` paths can be converted to verbatim too (if necessary).
This adds a member fn that converts a slice into a CStr; it is intended
to be safer than from_ptr (which is unsafe and may read out of bounds),
and more useful than from_bytes_with_nul (which requires that the caller
already know where the nul byte is).
feature gate: cstr_from_bytes_until_nul
Also add an error type FromBytesUntilNulError for this fn.
Implement -Z oom=panic
This PR removes the `#[rustc_allocator_nounwind]` attribute on `alloc_error_handler` which allows it to unwind with a panic instead of always aborting. This is then used to implement `-Z oom=panic` as per RFC 2116 (tracking issue #43596).
Perf and binary size tests show negligible impact.
Fix for localized windows editions in testcase fn read_link() Issue#93211
This PR aims to fix the issue with localized windows versions that do not necessarily have the folder "Documents and settings" in English.
The idea was provided by `@the8472.` We check if the "CI" environment variable is set, then we always check for the "Documents and Settings"-folder, otherwise we check if the folder exists on the local machine, and if not we skip this assert.
Resoles #93211.
Improve doc wording for retain on some collections
I found the documentation wording on the various retain methods on many collections to be unusual.
I tried to invert the relation by switching `such that` with `for which` .
Use modern formatting for format! macros
This updates the standard library's documentation to use the new format_args syntax.
The documentation is worthwhile to update as it should be more idiomatic
(particularly for features like this, which are nice for users to get acquainted
with). The general codebase is likely more hassle than benefit to update: it'll
hurt git blame, and generally updates can be done by folks updating the code if
(and when) that makes things more readable with the new format.
A few places in the compiler and library code are updated (mostly just due to
already having been done when this commit was first authored).
`eprintln!("{}", e)` becomes `eprintln!("{e}")`, but `eprintln!("{}", e.kind())` remains untouched.
This updates the standard library's documentation to use the new syntax. The
documentation is worthwhile to update as it should be more idiomatic
(particularly for features like this, which are nice for users to get acquainted
with). The general codebase is likely more hassle than benefit to update: it'll
hurt git blame, and generally updates can be done by folks updating the code if
(and when) that makes things more readable with the new format.
A few places in the compiler and library code are updated (mostly just due to
already having been done when this commit was first authored).
Merge `#[deprecated]` and `#[rustc_deprecated]`
The first commit makes "reason" an alias for "note" in `#[rustc_deprecated]`, while still prohibiting it in `#[deprecated]`.
The second commit changes "suggestion" to not just be a feature of `#[rustc_deprecated]`. This is placed behind the new `deprecated_suggestion` feature. This needs a tracking issue; let me know if this PR will be approved and I can create one.
The third commit is what permits `#[deprecated]` to be used when `#![feature(staged_api)]` is enabled. This isn't yet used in stdlib (only tests), as it would require duplicating all deprecation attributes until a bootstrap occurs. I intend to submit a follow-up PR that replaces all uses and removes the remaining `#[rustc_deprecated]` code after the next bootstrap.
`@rustbot` label +T-libs-api +C-feature-request +A-attributes +S-waiting-on-review
Ignore `close_read_wakes_up` test on SGX platform
PR #94714 enabled the `close_read_wakes_up` test for all platforms. This is incorrect. This test should be ignored at least for the SGX platform.
cc: ``@mzohreva`` ``@jethrogb``
The initial stdlib modifications for L4Re just used the linux specifics
directly because they were reasonably close to L4Re's behavior.
However, this breaks when Linux-specific code relies on code that is
only available for the linux target, such as in #81825.
Put L4Re into its own platform to avoid such breakage in the future.
This uses the Linux-specific code as a starting point, which seems to be
in line with other OSes with a unix-y interface such as Fuchsia.
L4Re provides limited POSIX support which includes support for
standard I/O streams, and a limited implementation of the standard file
handling API. However, because as a capability based OS it strives to
only make a local view available to each application, there are
currently no standardized special files like /dev/null that could serve
to sanitize closed standard FDs.
For now, skip any attempts to sanitize standard streams until a more
complete POSIX runtime is available.
unix: reduce the size of DirEntry
On platforms where we call `readdir` instead of `readdir_r`, we store
the name as an allocated `CString` for variable length. There's no point
carrying around a full `dirent64` with its fixed-length `d_name` too.
Reverted atomic_mut_ptr feature removal causing compilation break
Fixes a regression introduced as part of https://github.com/rust-lang/rust/pull/94546
Std no longer compiles on nightly while using the following commnd:
export RUSTFLAGS='-C target-feature=+atomics,+bulk-memory'
cargo build --target wasm32-unknown-unknown -Z build-std=panic_abort,std
I can help add tests to avoid future breaks but i couldn't understand the test framework
unix: Avoid name conversions in `remove_dir_all_recursive`
Each recursive call was creating an `OsString` for a `&Path`, only for
it to be turned into a `CString` right away. Instead we can directly
pass `.name_cstr()`, saving two allocations each time.
Enable `close_read_wakes_up` test on Windows
I wonder if we could/should try enabling this again? It was closed by #38867 due to #31657. I've tried running this test (along with other tests) on my machine a number of times and haven't seen this fail yet,
Caveat: the worst that can happen is this succeeds initially but then causes random hangs in CI. This is not a great failure mode and would be a reason not to do this.
If this does work out, closes#39006
r? `@Mark-Simulacrum`
On platforms where we call `readdir` instead of `readdir_r`, we store
the name as an allocated `CString` for variable length. There's no point
carrying around a full `dirent64` with its fixed-length `d_name` too.
Remove argument from closure in thread::Scope::spawn.
This implements ```@danielhenrymantilla's``` [suggestion](https://github.com/rust-lang/rust/issues/93203#issuecomment-1040798286) for improving the scoped threads interface.
Summary:
The `Scope` type gets an extra lifetime argument, which represents basically its own lifetime that will be used in `&'scope Scope<'scope, 'env>`:
```diff
- pub struct Scope<'env> { .. };
+ pub struct Scope<'scope, 'env: 'scope> { .. }
pub fn scope<'env, F, T>(f: F) -> T
where
- F: FnOnce(&Scope<'env>) -> T;
+ F: for<'scope> FnOnce(&'scope Scope<'scope, 'env>) -> T;
```
This simplifies the `spawn` function, which now no longer passes an argument to the closure you give it, and now uses the `'scope` lifetime for everything:
```diff
- pub fn spawn<'scope, F, T>(&'scope self, f: F) -> ScopedJoinHandle<'scope, T>
+ pub fn spawn<F, T>(&'scope self, f: F) -> ScopedJoinHandle<'scope, T>
where
- F: FnOnce(&Scope<'env>) -> T + Send + 'env,
+ F: FnOnce() -> T + Send + 'scope,
- T: Send + 'env;
+ T: Send + 'scope;
```
The only difference the user will notice, is that their closure now takes no arguments anymore, even when spawning threads from spawned threads:
```diff
thread::scope(|s| {
- s.spawn(|_| {
+ s.spawn(|| {
...
});
- s.spawn(|s| {
+ s.spawn(|| {
...
- s.spawn(|_| ...);
+ s.spawn(|| ...);
});
});
```
<details><summary>And, as a bonus, errors get <em>slightly</em> better because now any lifetime issues point to the outermost <code>s</code> (since there is only one <code>s</code>), rather than the innermost <code>s</code>, making it clear that the lifetime lasts for the entire <code>thread::scope</code>.
</summary>
```diff
error[E0373]: closure may outlive the current function, but it borrows `a`, which is owned by the current function
--> src/main.rs:9:21
|
- 7 | s.spawn(|s| {
- | - has type `&Scope<'1>`
+ 6 | thread::scope(|s| {
+ | - lifetime `'1` appears in the type of `s`
9 | s.spawn(|| println!("{:?}", a)); // might run after `a` is dropped
| ^^ - `a` is borrowed here
| |
| may outlive borrowed value `a`
|
note: function requires argument type to outlive `'1`
--> src/main.rs:9:13
|
9 | s.spawn(|| println!("{:?}", a)); // might run after `a` is dropped
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
help: to force the closure to take ownership of `a` (and any other referenced variables), use the `move` keyword
|
9 | s.spawn(move || println!("{:?}", a)); // might run after `a` is dropped
| ++++
"
```
</details>
The downside is that the signature of `scope` and `Scope` gets slightly more complex, but in most cases the user wouldn't need to write those, as they just use the argument provided by `thread::scope` without having to name its type.
Another downside is that this does not work nicely in Rust 2015 and Rust 2018, since in those editions, `s` would be captured by reference and not by copy. In those editions, the user would need to use `move ||` to capture `s` by copy. (Which is what the compiler suggests in the error.)
Each recursive call was creating an `OsString` for a `&Path`, only for
it to be turned into a `CString` right away. Instead we can directly
pass `.name_cstr()`, saving two allocations each time.
Unix path::absolute: Fix leading "." component
Testing leading `.` and `..` components were missing from the unix tests.
This PR adds them and fixes the leading `.` case. It also fixes the test cases so that they do an exact comparison.
This problem reported by ``@axetroy``
Windows 11 no longer turn paths ending with dos device names into device paths.
E.g. `C:\path\to\COM1.txt` used to get turned into `\\.\COM1`. Whereas now the path is left as is.
UNIX `remove_dir_all()`: Try recursing first on the slow path
This only affects the _slow_ code path - if there is no `dirent.d_type` or if it is `DT_UNKNOWN`.
POSIX specifies that calling `unlink()` or `unlinkat(..., 0)` on a directory is allowed to succeed:
> The _path_ argument shall not name a directory unless the process has appropriate privileges and the implementation supports using _unlink()_ on directories.
This however can cause dangling inodes requiring an fsck e.g. on Illumos UFS, so we have to avoid that in the common case. We now just try to recurse into it first and unlink() if we can't open it as a directory.
The other two commits integrate the Macos x86-64 implementation reducing redundancy. Split into two commits for better reviewing.
Fixes#94335.
Rollup of 5 pull requests
Successful merges:
- #94362 (Add well known values to `--check-cfg` implementation)
- #94577 (only disable SIMD for doctests in Miri (not for the stdlib build itself))
- #94595 (Fix invalid `unresolved imports` errors for a single-segment import)
- #94596 (Delay bug in expr adjustment when check_expr is called multiple times)
- #94618 (Don't round stack size up for created threads in Windows)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Enable conditional compilation checking on the Rust codebase
This pull-request enable conditional compilation checking on every rust project build by the `bootstrap` tool.
To be more specific, this PR only enable well known names checking + extra names (bootstrap, parallel_compiler, ...).
r? `@Mark-Simulacrum`
Add #[track_caller] to track callers when initializing poisoned Once
This PR is for this Issue.
https://github.com/rust-lang/rust/issues/87707
With this fix, we expect to be able to track the caller when poisoned Once is initialized.
Before calling `CreateProcessW`, stdio handles are passed through
`stdio::get_handle`, which already converts NULL to
`INVALID_HANDLE_VALUE`, so we don't need extra checks for NULL after
that point.
This addresses #90964 by making the std API consistent about presenting
absent stdio handles on Windows as NULL handles. Stdio handles may be
absent due to `#![windows_subsystem = "windows"]`, due to the console
being detached, or due to a child process having been launched from a
parent where stdio handles are absent.
Specifically, this fixes the case of child processes of parents with absent
stdio, which previously ended up with `stdin().as_raw_handle()` returning
`INVALID_HANDLE_VALUE`, which was surprising, and which overlapped with an
unrelated valid handle value. With this patch, `stdin().as_raw_handle()`
now returns null in these situation, which is consistent with what it
does in the parent process.
And, document this in the "Windows Portability Considerations" sections of
the relevant documentation.
This only affects the `slow` code path, if there is no `dirent.d_type` or if
the type is `DT_UNKNOWN`.
POSIX specifies that calling `unlink()` or `unlinkat(..., 0)` on a directory can
succeed:
> "The _path_ argument shall not name a directory unless the process has
> appropriate privileges and the implementation supports using _unlink()_ on
> directories."
This however can cause orphaned directories requiring an fsck e.g. on Illumos
UFS, so we have to avoid that in the common case. We now just try to recurse
into it first and unlink() if we can't open it as a directory.
Use `HandleOrNull` and `HandleOrInvalid` in the Windows FFI bindings.
Use the new `HandleOrNull` and `HandleOrInvalid` types that were introduced
as part of [I/O safety] in a few functions in the Windows FFI bindings.
This factors out an `unsafe` block and two `unsafe` function calls in the
Windows implementation code.
And, it helps test `HandleOrNull` and `HandleOrInvalid`, and indeed, it
turned up a bug: `OwnedHandle` also needs to be `#[repr(transparent)]`,
as it's used inside of `HandleOrNull` and `HandleOrInvalid` which are also
`#[repr(transparent)]`.
r? ```@joshtriplett```
[I/O safety]: https://github.com/rust-lang/rust/issues/87074
Make regular stdio lock() return 'static handles
This also deletes the unstable API surface area previously added to expose this
functionality on new methods rather than built into the current set.
Closes#86845 (tracking issue for unstable API needed without this)
r? ``````@dtolnay`````` to kick off T-libs-api FCP
Clarification of default socket flags
This PR outlines the decision to disable inheritance of socket objects when possible to child processes in the documentation.
Use the new `HandleOrNull` and `HandleOrInvalid` types that were introduced
as part of [I/O safety] in a few functions in the Windows FFI bindings.
This factors out an `unsafe` block and two `unsafe` function calls in the
Windows implementation code.
And, it helps test `HandleOrNull` and `HandleOrInvalid`, which indeed turned
up a bug: `OwnedHandle` also needs to be `#[repr(transparent)]`, as it's
used inside of `HandleOrNull` and `HandleOrInvalid` which are also
`#[repr(transparent)]`.
[I/O safety]: https://github.com/rust-lang/rust/issues/87074
Update the documentation for `{As,Into,From}Raw{Fd,Handle,Socket}`.
This change weakens the descriptions of the
`{as,into,from}_raw_{fd,handle,socket}` descriptions from saying that
they *do* express ownership relations to say that they are *typically used*
in ways that express ownership relations. This is needed since, for
example, std's own [`RawFd`] implements `{As,From,Into}Fd` without any of
the ownership relationships.
This adds proper `# Safety` comments to `from_raw_{fd,handle,socket}`,
adds the requirement that raw handles be not opened with the
`FILE_FLAG_OVERLAPPED` flag, and merges the `OwnedHandle::from_raw_handle`
comment into the main `FromRawHandle::from_raw_handle` comment.
And, this changes `HandleOrNull` and `HandleOrInvalid` to not implement
`FromRawHandle`, since they are intended for limited use in FFI situations,
and not for generic use, and they have constraints that are stronger than
the those of `FromRawHandle`.
[`RawFd`]: https://doc.rust-lang.org/stable/std/os/unix/io/type.RawFd.html
There may eventually be something to say about `FILE_FLAG_OVERLAPPED` here,
however this appears to be independent of the other changes in this PR,
so remove them from this PR so that it can be discussed separately.
Rename `BorrowedFd::borrow_raw_fd` to `BorrowedFd::borrow_raw`.
Also, rename `BorrowedHandle::borrow_raw_handle` and
`BorrowedSocket::borrow_raw_socket` to `BorrowedHandle::borrow_raw` and
`BorrowedSocket::borrow_raw`.
This is just a minor rename to reduce redundancy in the user code calling
these functions, and to eliminate an inessential difference between
`BorrowedFd` code and `BorrowedHandle`/`BorrowedSocket` code.
While here, add a simple test exercising `BorrowedFd::borrow_raw_fd`.
r? ``````@joshtriplett``````
Add documentation about `BorrowedFd::to_owned`.
Following up on #88564, this adds documentation explaining why
`BorrowedFd::to_owned` returns another `BorrowedFd` rather than an
`OwnedFd`. And similar for `BorrowedHandle` and `BorrowedSocket`.
r? `````@joshtriplett`````
this avoids parsing mountinfo which can be huge on some systems and
something might be emulating cgroup fs for sandboxing reasons which means
it wouldn't show up as mountpoint
additionally the new implementation operates on a single pathbuffer, reducing allocations
Manually tested via
```
// spawn a new cgroup scope for the current user
$ sudo systemd-run -p CPUQuota="300%" --uid=$(id -u) -tdS
// quota.rs
#![feature(available_parallelism)]
fn main() {
println!("{:?}", std:🧵:available_parallelism()); // prints Ok(3)
}
```
Caveats
* cgroup v1 is ignored
* funky mountpoints (containing spaces, newlines or control chars) for cgroupfs will not be handled correctly since that would require unescaping /proc/self/mountinfo
The escaping behavior of procfs seems to be undocumented. systemd and docker default to `/sys/fs/cgroup` so it should be fine for most systems.
* quota will be ignored when `sched_getaffinity` doesn't work
* assumes procfs is mounted under `/proc` and cgroupfs mounted and readable somewhere in the directory tree
The ability to interoperate with C code via FFI is not limited to crates
using std; this allows using these types without std.
The existing types in `std::os::raw` become type aliases for the ones in
`core::ffi`. This uses type aliases rather than re-exports, to allow the
std types to remain stable while the core types are unstable.
This also moves the currently unstable `NonZero_` variants and
`c_size_t`/`c_ssize_t`/`c_ptrdiff_t` types to `core::ffi`, while leaving
them unstable.
use BOOL for TCP_NODELAY setsockopt value on Windows
This issue was found by the Wine project and mitigated there [^1].
Windows' setsockopt expects a BOOL (a typedef for int) for TCP_NODELAY
[^2]. Windows itself is forgiving and will accept any positive optlen and
interpret the first byte of *optval as the value, so this bug does not
affect Windows itself, but does affect systems implementing Windows'
interface more strictly, such as Wine. Wine was previously passing this
through to the host's setsockopt, where, e.g., Linux requires that
optlen be correct for the chosen option, and TCP_NODELAY expects an int.
[^1]: d6ea38f32d
[^2]: https://docs.microsoft.com/en-us/windows/win32/api/winsock/nf-winsock-setsockopt
Some improvements to the async docs
The goal here is to make the docs overall a little bit more comprehensive and add more links between the things.
One thing that's not working yet is the links to the keywords. Somehow I couldn't get them to work.
r? ````@GuillaumeGomez```` do you know how I could get the keyword links to work?
This issue was found by the Wine project and mitigated there [1].
Windows' documented interface for `setsockopt` expects a `BOOL` (a
`typedef` for `int`) for `TCP_NODELAY` [2]. Windows is forgiving and
will accept any positive length and interpret the first byte of
`*option_value` as the value, so this bug does not affect Windows
itself, but does affect systems implementing Windows' interface more
strictly, such as Wine. Wine was previously passing this through to the
host's `setsockopt`, where, e.g., Linux requires that `option_len` be
correct for the chosen option, and `TCP_NODELAY` expects an `int`.
[1]: d6ea38f32d
[2]: https://docs.microsoft.com/en-us/windows/win32/api/winsock/nf-winsock-setsockopt
POSIX allows `getsockopt` to set `*option_len` to a smaller value if
necessary. Windows will set `*option_len` to 1 for boolean options even
when the caller passes a `BOOL` (`int`) with `*option_len` as 4.
Previously `level` was named `opt` and `option_name` was named `val`,
then extra names of `payload` or `slot` were used for the option value.
This change aligns the wrapper parameters with their names in POSIX.
Winsock uses similar but more abbreviated names: `level`, `optname`,
`optval`, `optlen`.
Fix miniz_oxide types showing up in std docs
Fixes#90526.
Thanks to ```````@camelid,``````` I rediscovered `doc(masked)`, allowing us to prevent `miniz_oxide` type to show up in std docs.
r? ```````@notriddle```````
removing architecture requirements for RustyHermit
RustHermit and HermitCore is able to run on aarch64 and x86_64. In the future these operating systems will also support RISC-V. Consequently, the dependency to a specific target should be removed.
The build process of `hermit-abi` fails if the architecture isn't supported.
Add debug assertions to validate NUL terminator in c strings
The `unchecked` variants from the stdlib usually perform the check anyway if debug assertions are on (for example, `unwrap_unchecked`). This PR does the same thing for `CStr` and `CString`, validating the correctness for the NUL byte in debug mode.
Destabilise entry_insert
See: https://github.com/rust-lang/rust/pull/90345
I didn't revert the rename that was done in that PR, I left it as `entry_insert`.
Additionally, before that PR, `VacantEntry::insert_entry` seemingly had no stability attribute on it? I kept the attribute, just made it an unstable one, same as the one on `Entry`.
There didn't seem to be any mention of this in the RELEASES.md, so I don't think there's anything for me to do other than this?
kmc-solid: Use the filesystem thread-safety wrapper
Fixes the thread unsafety of the `std::fs` implementation used by the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets.
Neither the SOLID filesystem API nor built-in filesystem drivers guarantee thread safety by default. Although this may suffice in general embedded-system use cases, and in fact the API can be used from multiple threads without any problems in many cases, this has been a source of unsoundness in `std::sys::solid::fs`.
This commit updates the implementation to leverage the filesystem thread-safety wrapper (which uses a pluggable synchronization mechanism) to enforce thread safety. This is done by prefixing all paths passed to the filesystem API with `\TS`. (Note that relative paths aren't supported in this platform.)
Add MAIN_SEPARATOR_STR
Currently, if someone needs access to the path separator as a str, they need to go through this mess:
```rust
unsafe {
std::str::from_utf8_unchecked(slice::from_ref(&(MAIN_SEPARATOR as u8)))
}
```
This PR just re-exports an existing path separator str API.
Add documentation to more `From::from` implementations.
For users looking at documentation through IDE popups, this gives them relevant information rather than the generic trait documentation wording “Performs the conversion”. For users reading the documentation for a specific type for any reason, this informs them when the conversion may allocate or copy significant memory versus when it is always a move or cheap copy.
Notes on specific cases:
* The new documentation for `From<T> for T` explains that it is not a conversion at all.
* Also documented `impl<T, U> Into<U> for T where U: From<T>`, the other central blanket implementation of conversion.
* The new documentation for construction of maps and sets from arrays of keys mentions the handling of duplicates. Future work could be to do this for *all* code paths that convert an iterable to a map or set.
* I did not add documentation to conversions of a specific error type to a more general error type.
* I did not add documentation to unstable code.
This change was prepared by searching for the text "From<... for" and so may have missed some cases that for whatever reason did not match. I also looked for `Into` impls but did not find any worth documenting by the above criteria.
This removes all mutex/atomics based workarounds for non-monotonic clocks and makes the previously panicking methods saturating instead.
Effectively this moves the monotonization from `Instant` construction to the comparisons.
This has some observable effects, especially on platforms without monotonic clocks:
* Incorrectly ordered Instant comparisons no longer panic. This may hide some programming errors until someone actually looks at the resulting `Duration`
* `checked_duration_since` will now return `None` in more cases. Previously it only happened when one compared instants obtained in the wrong order or
manually created ones. Now it also does on backslides.
The upside is reduced complexity and lower overhead of `Instant::now`.
Fix hashing for windows paths containing a CurDir component
* the logic only checked for / but not for \
* verbatim paths shouldn't skip items at all since they don't get normalized
* the extra branches get optimized out on unix since is_sep_byte is a trivial comparison and is_verbatim is always-false
* tests lacked windows coverage for these cases
That lead to equal paths not having equal hashes and to unnecessary collisions.
Rollup of 10 pull requests
Successful merges:
- #90955 (Rename `FilenameTooLong` to `InvalidFilename` and also use it for Windows' `ERROR_INVALID_NAME`)
- #91607 (Make `span_extend_to_prev_str()` more robust)
- #92895 (Remove some unused functionality)
- #93635 (Add missing platform-specific information on current_dir and set_current_dir)
- #93660 (rustdoc-json: Add some tests for typealias item)
- #93782 (Split `pauth` target feature)
- #93868 (Fix incorrect register conflict detection in asm!)
- #93888 (Implement `AsFd` for `&T` and `&mut T`.)
- #93909 (Fix typo: explicitely -> explicitly)
- #93910 (fix mention of moved function in `rustc_hir` docs)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Implement `AsFd` for `&T` and `&mut T`.
Add implementations of `AsFd` for `&T` and `&mut T`, so that users can
write code like this:
```rust
pub fn fchown<F: AsFd>(fd: F, uid: Option<u32>, gid: Option<u32>) -> io::Result<()> {
```
with `fd: F` rather than `fd: &F`.
And similar for `AsHandle` and `AsSocket` on Windows.
Also, adjust the `fchown` example to pass the file by reference. The
code can work either way now, but passing by reference is more likely
to be what users will want to do.
This is an alternative to #93869, and is a simpler way to achieve the
same goals: users don't need to pass borrowed-`BorrowedFd` arguments,
and it prevents a pitfall in the case where users write `fd: F` instead
of `fd: &F`.
r? ```@joshtriplett```
Rename `FilenameTooLong` to `InvalidFilename` and also use it for Windows' `ERROR_INVALID_NAME`
Address https://github.com/rust-lang/rust/issues/90940#issuecomment-970157931
`ERROR_INVALID_NAME` (i.e. "The filename, directory name, or volume label syntax is incorrect") happens if we pass an invalid filename, directory name, or label syntax, so mapping as `InvalidInput` is reasonable to me.
Stabilise `is_aarch64_feature_detected!` under `simd_aarch64` feature
Initial implementation, looking for feedback on the approach here. https://github.com/rust-lang/rust/issues/86941
One point I noticed was that I haven't seen different "since" versions for the same feature - does this mean that other features can't be added to to the `simd_aarch64` feature once this is in stable? If so it might need a more specific name.
r? `@Amanieu`
Add implementations of `AsFd` for `&T` and `&mut T`, so that users can
write code like this:
```rust
pub fn fchown<F: AsFd>(fd: F, uid: Option<u32>, gid: Option<u32>) -> io::Result<()> {
```
with `fd: F` rather than `fd: &F`.
And similar for `AsHandle` and `AsSocket` on Windows.
Also, adjust the `fchown` example to pass the file by reference. The
code can work either way now, but passing by reference is more likely
to be what users will want to do.
This is an alternative to #93869, and is a simpler way to achieve the
same goals: users don't need to pass borrowed-`BorrowedFd` arguments,
and it prevents a pitfall in the case where users write `fd: F` instead
of `fd: &F`.
kmc-solid: Fix wait queue manipulation errors in the `Condvar` implementation
This PR fixes a number of bugs in the `Condvar` wait queue implementation used by the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets. These bugs can occur when there are multiple threads waiting on the same `Condvar` and sometimes manifest as an `unwrap` failure.
Neither the SOLID filesystem API nor built-in filesystems guarantee
thread safety by default. Although this may suffice in general embedded-
system use cases, and in fact the API can be used from multiple threads
without any problems in many cases, this has been a source of
unsoundness in `std::sys::solid::fs`.
This commit updates the `std` code to leverage the filesystem thread-
safety wrapper to enforce thread safety. This is done by prefixing all
paths passed to the filesystem API with `\TS`. (Note that relative paths
aren't supported in this platform.)
Use `NtCreateFile` instead of `NtOpenFile` to open a file
Generally the internal `Nt*` functions should be avoided but when we do need to use one we should stick to the most commonly used for the job. To that end, this PR replaces `NtOpenFile` with `NtCreateFile`.
NOTE: The initial version of this comment hypothesised that this may help with some recent false positives from malware scanners. This hypothesis proved wrong. Sorry for the distraction.
Make io::Error use 64 bits on targets with 64 bit pointers.
I've wanted this for a long time, but didn't see a good way to do it without having extra allocation. When looking at it yesterday, it was more clear what to do for some reason.
This approach avoids any additional allocations, and reduces the size by half (8 bytes, down from 16). AFAICT it doesn't come additional runtime cost, and the compiler seems to do a better job with code using it.
Additionally, this `io::Error` has a niche (still), so `io::Result<()>` is *also* 64 bits (8 bytes, down from 16), and `io::Result<usize>` (used for lots of io trait functions) is 2x64 bits (16 bytes, down from 24 — this means on x86_64 it can use the nice rax/rdx 2-reg struct return). More generally, it shaves a whole 64 bit integer register off of the size of basically any `io::Result<()>`.
(For clarity: Improving `io::Result` (rather than io::Error) was most of the motivation for this)
On 32 bit (or other non-64bit) targets we still use something equivalent the old repr — I don't think think there's improving it, since one of the fields it stores is a `i32`, so we can't get below that, and it's already about as close as we can get to it.
---
### Isn't Pointer Tagging Dodgy?
The details of the layout, and why its implemented the way it is, are explained in the header comment of library/std/src/io/error/repr_bitpacked.rs. There's probably more details than there need to be, but I didn't trim it down that much, since there's a lot of stuff I did deliberately, that might have not seemed that way.
There's actually only one variant holding a pointer which gets tagged. This one is the (holder for the) user-provided error.
I believe the scheme used to tag it is not UB, and that it preserves pointer provenance (even though often pointer tagging does not) because the tagging operation is just `core::ptr::add`, and untagging is `core::ptr::sub`. The result of both operations lands inside the original allocation, so it would follow the safety contract of `core::ptr::{add,sub}`.
The other pointer this had to encode is not tagged — or rather, the tagged repr is equivalent to untagged (it's tagged with 0b00, and has >=4b alignment, so we can reuse the bottom bits). And the other variants we encode are just integers, which (which can be untagged using bitwise operations without worry — they're integers).
CC `@RalfJung` for the stuff in repr_bitpacked.rs, as my comments are informed by a lot of the UCG work, but it's possible I missed something or got it wrong (even if the implementation is okay, there are parts of the header comment that says things like "We can't do $x" which could be false).
---
### Why So Many Changes?
The repr change was mostly internal, but changed one widely used API: I had to switch how `io::Error::new_const` works.
This required switching `io::Error::new_const` to take the full message data (including the kind) as a `&'static`, rather than just the string. This would have been really tedious, but I made a macro that made it much simpler, but it was a wide change since `io::Error::new_const` is used everywhere.
This included changing files for a lot of targets I don't have easy access to (SGX? Haiku? Windows? Who has heard of these things), so I expect there to be spottiness in CI initially, unless luck is on my side.
Anyway this large only tangentially-related change is all in the first commit (although that commit also pulls the previous repr out into its own file), whereas the packing stuff is all in commit 2.
---
P.S. I haven't looked at all of this since writing it, and will do a pass over it again later, sorry for any obvious typos or w/e. I also definitely repeat myself in comments and such.
(It probably could use more tests too. I did some basic testing, and made it so we `debug_assert!` in cases the decode isn't what we encoded, but I don't know the degree which I can assume libstd's testing of IO would exercise this. That is: it wouldn't be surprising to me if libstds IO testing were minimal, especially around error cases, although I have no idea).
* the logic only checked for / but not for \
* verbatim paths shouldn't skip items at all since they don't get normalized
* the extra branches get optimized out on unix since is_sep_byte is a trivial comparison and is_verbatim is always-false
* tests lacked windows coverage for these cases
That lead to equal paths not having equal hashes and to unnecessary collisions.
Also, rename `BorrowedHandle::borrow_raw_handle` and
`BorrowedSocket::borrow_raw_socket` to `BorrowedHandle::borrow_raw` and
`BorrowedSocket::borrow_raw`.
This is just a minor rename to reduce redundancy in the user code calling
these functions, and to eliminate an inessential difference between
`BorrowedFd` code and `BorrowedHandle`/`BorrowedSocket` code.
While here, add a simple test exercising `BorrowedFd::borrow_raw_fd`.
kmc-solid: Fix off-by-one error in `SystemTime::now`
Fixes a miscalculation of `SystemTime` on the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets.
Unlike the identically-named libc counterpart `tm::tm_mon`, `SOLID_RTC_TIME::tm_mon` contains a 1-based month number.
Link `try_exists` docs to `Path::exists`
Links to the existing `Path::exists` method from both `std::Path::try_exists` and `std::fs:try_exists`.
Tracking issue for `path_try_exists`: #83186
pub use std::simd::StdFloat;
Syncs portable-simd up to commit rust-lang/portable-simd@03f6fbb21e,
Diff: 533f0fc81a...03f6fbb21e
This sync requires a little bit more legwork because it also introduces a trait into `std::simd`, so that it is no longer simply a reexport of `core::simd`. Out of simple-minded consistency and to allow more options, I replicated the pattern for the way `core::simd` is integrated in the first place, however this is not necessary if it doesn't acquire any interdependencies inside `std`: it could be a simple crate reexport. I just don't know yet if that will happen or not.
To summarize other misc changes:
- Shifts no longer panic, now wrap on too-large shifts (like `Simd` integers usually do!)
- mask16x32 will now be many i16s, not many i32s... 🙃
- `#[must_use]` is spread around generously
- Adjusts division, float min/max, and `Mask::{from,to}_array` internally to be faster
- Adds the much-requested `Simd::cast::<U>` function (equivalent to `simd.to_array().map(|lane| lane as U)`)
Support configuring whether to capture backtraces at runtime
Tracking issue: https://github.com/rust-lang/rust/issues/93346
This adds a new API to the `std::panic` module which configures whether and how the default panic hook will emit a backtrace when a panic occurs.
After discussion with `@yaahc` on [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/219381-t-libs/topic/backtrace.20lib.20vs.2E.20panic), this PR chooses to avoid adjusting or seeking to provide a similar API for the (currently unstable) std::backtrace API. It seems likely that the users of that API may wish to expose more specific settings rather than just a global one (e.g., emulating the `env_logger`, `tracing` per-module configuration) to avoid the cost of capture in hot code. The API added here could plausibly be copied and/or re-exported directly from std::backtrace relatively easily, but I don't think that's the right call as of now.
```rust
mod panic {
#[derive(Copy, Clone, Debug, PartialEq, Eq)]
#[non_exhaustive]
pub enum BacktraceStyle {
Short,
Full,
Off,
}
fn set_backtrace_style(BacktraceStyle);
fn get_backtrace_style() -> Option<BacktraceStyle>;
}
```
Several unresolved questions:
* Do we need to move to a thread-local or otherwise more customizable strategy for whether to capture backtraces? See [this comment](https://github.com/rust-lang/rust/pull/79085#issuecomment-727845826) for some potential use cases for this.
* Proposed answer: no, leave this for third-party hooks.
* Bikeshed on naming of all the options, as usual.
* Should BacktraceStyle be moved into `std::backtrace`?
* It's already somewhat annoying to import and/or re-type the `std::panic::` prefix necessary to use these APIs, probably adding a second module to the mix isn't worth it.
Note that PR #79085 proposed a much simpler API, but particularly in light of the desire to fully replace setting environment variables via `env::set_var` to control the backtrace API, a more complete API seems preferable. This PR likely subsumes that one.
Fix incorrect panic message in example
The panic message when calling the `connect()` should probably be a message about connection failure, not a message about binding address failure.
Document valid values of the char type
As discussed at #93392, the current documentation on what constitutes a valid char isn't very detailed and is partly on the MAX constant rather than the type itself.
This PR expands on that information, stating the actual numerical range, giving examples of what won't work, and also mentions how a `char` might be a valid USV but still not be a defined character (terminology checked against [Unicode 14.0, table 2-3](https://www.unicode.org/versions/Unicode14.0.0/ch02.pdf#M9.61673.TableTitle.Table.22.Types.of.Code.Points)).
This change weakens the descriptions of the
`{as,into,from}_raw_{fd,handle,socket}` descriptions from saying that
they *do* express ownership relations to say that they are *typically used*
in ways that express ownership relations. This needed needed since, for
example, std's own [`RawFd`] implements `{As,From,Into}Fd` without any of
the ownership relationships.
This adds proper `# Safety` comments to `from_raw_{fd,handle,socket}`,
adds the requirement that raw handles be not opened with the
`FILE_FLAG_OVERLAPPED` flag, and merges the `OwnedHandle::from_raw_handle`
comment into the main `FromRawHandle::from_raw_handle` comment.
And, this changes `HandleOrNull` and `HandleOrInvalid` to not implement
`FromRawHandle`, since they are intended for limited use in FFI situations,
and not for generic use, and they have constraints that are stronger than
the those of `FromRawHandle`.
[`RawFd`]: https://doc.rust-lang.org/stable/std/os/unix/io/type.RawFd.html
Change Termination::report return type to ExitCode
Related to https://github.com/rust-lang/rust/issues/43301
The goal of this change is to minimize the forward compatibility risks in stabilizing Termination. By using the opaque type `ExitCode` instead of an `i32` we leave room for us to evolve the API over time to provide what cross-platform consistency we can / minimize footguns when working with exit codes, where as stabilizing on `i32` would limit what changes we could make in the future in how we represent and construct exit codes.
kmc-solid: Increase the default stack size
This PR increases the default minimum stack size on the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets to 64KiB (Arm) and 128KiB (AArch64).
This value was chosen as a middle ground between supporting a relatively complex program (e.g., an application using a full-fledged off-the-shelf web server framework) with no additional configuration and minimizing resource consumption for the embedded platform that doesn't support lazily-allocated pages nor over-commitment (i.e., wasted stack spaces are wasted physical memory). If the need arises, the users can always set the `RUST_MIN_STACK` environmental variable to override the default stack size or use the platform API directly.
Errors from pthread_sigmask(3) were handled using cvt(), which expects a
return value of -1 on error and uses errno.
However, pthread_sigmask(3) returns 0 on success and an error number
otherwise.
Fix it by replacing cvt() with cvt_nz().
kmc-solid: Inherit the calling task's base priority in `Thread::new`
This PR fixes the initial priority calculation of spawned threads on the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets.
Fixes a spawned task (an RTOS object on top of which threads are implemented for this target; unrelated to async tasks) getting an unexpectedly higher priority if it's spawned by a task whose priority is temporarily boosted by a priority-protection mutex.
unix: Use metadata for `DirEntry::file_type` fallback
When `DirEntry::file_type` fails to match a known `d_type`, we should
fall back to `DirEntry::metadata` instead of a bare `lstat`, because
this is faster and more reliable on targets with `fstatat`.
Fixes a spawned task getting an unexpectedly higher priority if it's
spawned by a task whose priority is temporarily boosted by a priority-
protection mutex.
When `DirEntry::file_type` fails to match a known `d_type`, we should
fall back to `DirEntry::metadata` instead of a bare `lstat`, because
this is faster and more reliable on targets with `fstatat`.
fs: Don't copy d_name from struct dirent
The dirent returned from readdir() is only guaranteed to be valid for
d_reclen bytes on common platforms. Since we copy the name separately
anyway, we can copy everything except d_name into DirEntry::entry.
Fixes#93384.
Move unstable is_{arch}_feature_detected! macros to std::arch
These macros are unstable, except for `is_x86_feature_detected` which is still exported from the crate root for backwards-compatibility.
This should unblock the stabilization of `is_aarch64_feature_detected`.
r? ```@m-ou-se```
The dirent returned from readdir() is only guaranteed to be valid for
d_reclen bytes on common platforms. Since we copy the name separately
anyway, we can copy everything except d_name into DirEntry::entry.
Fixes#93384.
kmc-solid: Implement `net::FileDesc::duplicate`
This PR implements `std::sys::solid::net::FileDesc::duplicate`, which was accidentally left out when this target was added by #86191.
Bump libc and fix remove_dir_all on Fuchsia after CVE fix
With the previous `is_dir` impl, we would attempt to unlink
a directory in the None branch, but Fuchsia supports returning
ENOTEMPTY from unlinkat() without the AT_REMOVEDIR flag because
we don't currently differentiate unlinking files and directories
by default.
On the Fuchsia side I've opened https://fxbug.dev/92273 to discuss
whether this is the correct behavior, but it doesn't seem like
addressing the error code is necessary to make our tests happy.
Depends on https://github.com/rust-lang/libc/pull/2654 since we
apparently haven't needed to reference DT_UNKNOWN before this.
With the previous `is_dir` impl, we would attempt to unlink
a directory in the None branch, but Fuchsia supports returning
ENOTEMPTY from unlinkat() without the AT_REMOVEDIR flag because
we don't currently differentiate unlinking files and directories
by default.
On the Fuchsia side I've opened https://fxbug.dev/92273 to discuss
whether this is the correct behavior, but it doesn't seem like
addressing the error code is necessary to make our tests happy.
Updates std's libc crate to include DT_UNKNOWN for Fuchsia.
Avoid double panics when using `TempDir` in tests
`TempDir` could panic on drop if `remove_dir_all` returns an error. If this happens while already panicking, the test process would abort and therefore not show the test results.
This PR tries to avoid such double panics.
Add os::unix::net::SocketAddr::from_path
Creates a new SocketAddr from a path, supports both regular paths and
abstract namespaces.
Note that `SocketAddr::from_abstract_namespace` could be removed after this as `SocketAddr::unix` also supports abstract namespaces.
Updates #65275
Unblocks https://github.com/tokio-rs/mio/issues/1527
r? `@m-ou-se`
With the addition of `sock_accept()` to snapshot1, simple networking via
a passed `TcpListener` is possible. This patch implements the basics to
make a simple server work.
Signed-off-by: Harald Hoyer <harald@profian.com>
Define c_char using cfg_if rather than repeating 40-line cfg
Libstd has a 40-line cfg that defines the targets on which `c_char` is unsigned, and then repeats the same cfg with `not(…)` for the targets on which `c_char` is signed.
This PR replaces it with a `cfg_if!` in which an `else` takes care of the signed case.
I confirmed that `x.py doc library/std` inlines the type alias because c_char_definition is not a publicly accessible path:
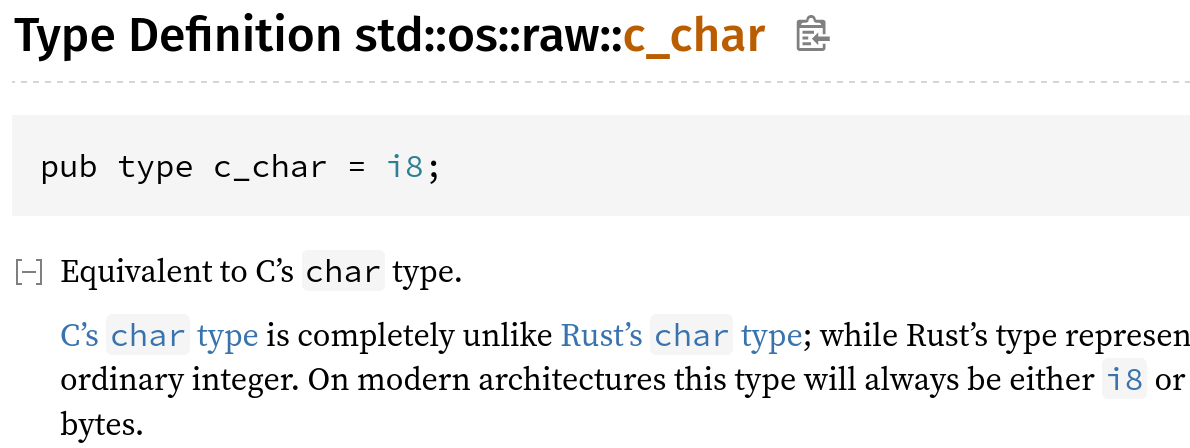
Make available the remaining float intrinsics that require runtime support
from a platform's libm, and thus cannot be included in a no-deps libcore,
by exposing them through a sealed trait, `std::simd::StdFloat`.
We might use the trait approach a bit more in the future, or maybe not.
Ideally, this trait doesn't stick around, even if so.
If we don't need to intermesh it with std, it can be used as a crate,
but currently that is somewhat uncertain.
The creation of libc::sockaddr_un is a safe operation, no need for it to
be unsafe.
This also uses the more performant copy_nonoverlapping instead of an
iterator.
Following up on #88564, this adds documentation explaining why
`BorrowedFd::to_owned` returns another `BorrowedFd` rather than an
`OwnedFd`. And similar for `BorrowedHandle` and `BorrowedSocket`.
Add a `try_clone()` function to `OwnedFd`.
As suggested in #88564. This adds a `try_clone()` to `OwnedFd` by
refactoring the code out of the existing `File`/`Socket` code.
r? ``@joshtriplett``
Fix STD compilation for the ESP-IDF target (regression from CVE-2022-21658)
Commit 54e22eb7db broke the compilation of STD for the ESP-IDF embedded "unix-like" Tier 3 target, because the fix for [CVE-2022-21658](https://blog.rust-lang.org/2022/01/20/Rust-1.58.1.html) uses [libc flags](https://github.com/esp-rs/esp-idf-svc/runs/4892221554?check_suite_focus=true) which are not supported on the ESP-IDF platform.
This PR simply redirects the ESP-IDF compilation to the "classic" implementation, similar to REDOX. This should be safe because:
* Neither of the two filesystems supported by ESP-IDF (spiffs and fatfs) support [symlinks](https://github.com/natevw/fatfs/blob/master/README.md) in the first place
* There is no notion of fs permissions at all, as the ESP-IDF is an embedded platform that does not have the notion of users, groups, etc.
* Similarly, ESP-IDF has just one "process" - the firmware itself - which contains the user code and the "OS" fused together and running with all permissions
Print a helpful message if unwinding aborts when it reaches a nounwind function
This is implemented by routing `TerminatorKind::Abort` back through the panic handler, but with a special flag in the `PanicInfo` which indicates that the panic handler should *not* attempt to unwind the stack and should instead abort immediately.
This is useful for the planned change in https://github.com/rust-lang/lang-team/issues/97 which would make `Drop` impls `nounwind` by default.
### Code
```rust
#![feature(c_unwind)]
fn panic() {
panic!()
}
extern "C" fn nounwind() {
panic();
}
fn main() {
nounwind();
}
```
### Before
```
$ ./test
thread 'main' panicked at 'explicit panic', test.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Illegal instruction (core dumped)
```
### After
```
$ ./test
thread 'main' panicked at 'explicit panic', test.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at 'panic in a function that cannot unwind', test.rs:7:1
stack backtrace:
0: 0x556f8f86ec9b - <std::sys_common::backtrace::_print::DisplayBacktrace as core::fmt::Display>::fmt::hdccefe11a6ac4396
1: 0x556f8f88ac6c - core::fmt::write::he152b28c41466ebb
2: 0x556f8f85d6e2 - std::io::Write::write_fmt::h0c261480ab86f3d3
3: 0x556f8f8654fa - std::panicking::default_hook::{{closure}}::h5d7346f3ff7f6c1b
4: 0x556f8f86512b - std::panicking::default_hook::hd85803a1376cac7f
5: 0x556f8f865a91 - std::panicking::rust_panic_with_hook::h4dc1c5a3036257ac
6: 0x556f8f86f079 - std::panicking::begin_panic_handler::{{closure}}::hdda1d83c7a9d34d2
7: 0x556f8f86edc4 - std::sys_common::backtrace::__rust_end_short_backtrace::h5b70ed0cce71e95f
8: 0x556f8f865592 - rust_begin_unwind
9: 0x556f8f85a764 - core::panicking::panic_no_unwind::h2606ab3d78c87899
10: 0x556f8f85b910 - test::nounwind::hade6c7ee65050347
11: 0x556f8f85b936 - test::main::hdc6e02cb36343525
12: 0x556f8f85b7e3 - core::ops::function::FnOnce::call_once::h4d02663acfc7597f
13: 0x556f8f85b739 - std::sys_common::backtrace::__rust_begin_short_backtrace::h071d40135adb0101
14: 0x556f8f85c149 - std::rt::lang_start::{{closure}}::h70dbfbf38b685e93
15: 0x556f8f85c791 - std::rt::lang_start_internal::h798f1c0268d525aa
16: 0x556f8f85c131 - std::rt::lang_start::h476a7ee0a0bb663f
17: 0x556f8f85b963 - main
18: 0x7f64c0822b25 - __libc_start_main
19: 0x556f8f85ae8e - _start
20: 0x0 - <unknown>
thread panicked while panicking. aborting.
Aborted (core dumped)
```
delete `Stdin::split` forwarder
Part of #87096. Delete the `Stdin::split` forwarder because it's seen as too niche to expose at this level.
`@rustbot` label T-libs-api A-io
Improve `Arc` and `Rc` documentation
This makes two changes (I can split the PR if necessary, but the changes are pretty small):
1. A bunch of trait implementations claimed to be zero cost; however, they use the `Arc<T>: From<Box<T>>` impl which is definitely not free, especially for large dynamically sized `T`.
2. The code in deferred initialization examples unnecessarily used excessive amounts of `unsafe`. This has been reduced.
readdir() is preferred over readdir_r() on Linux and many other
platforms because it more gracefully supports long file names. Both
glibc and musl (and presumably all other Linux libc implementations)
guarantee that readdir() is thread-safe as long as a single DIR* is not
accessed concurrently, which is enough to make a readdir()-based
implementation of ReadDir safe. This implementation is already used for
some other OSes including Fuchsia, Redox, and Solaris.
See #40021 for more details. Fixes#86649. Fixes#34668.
Help optimize out backtraces when disabled
The comment in `rust_backtrace_env` says:
> // If the `backtrace` feature of this crate isn't enabled quickly return
> // `None` so this can be constant propagated all over the place to turn
> // optimize away callers.
but this optimization has regressed, because the only caller of this function had an alternative path that unconditionally (and pointlessly) asked for a full backtrace, so the disabled state couldn't propagate.
I've added a getter for the full format that respects the feature flag, so that the caller will now be able to really optimize out the disabled backtrace path. I've also made `rust_backtrace_env` trivially inlineable when backtraces are disabled.
Little improves in CString `new` when creating from slice
Old code already contain optimization for cases with `&str` and `&[u8]` args. This commit adds a specialization for `&mut[u8]` too.
Also, I added usage of old slice in search for zero bytes instead of new buffer because it produce better code for constant inputs on Windows LTO builds. For other platforms, this wouldn't cause any difference because it calls `libc` anyway.
Inlined `_new` method into spec trait to reduce amount of code generated to `CString::new` callers.
Remove deprecated LLVM-style inline assembly
The `llvm_asm!` was deprecated back in #87590 1.56.0, with intention to remove
it once `asm!` was stabilized, which already happened in #91728 1.59.0. Now it
is time to remove `llvm_asm!` to avoid continued maintenance cost.
Closes#70173.
Closes#92794.
Closes#87612.
Closes#82065.
cc `@rust-lang/wg-inline-asm`
r? `@Amanieu`
Add diagnostic items for macros
For use in Clippy, it adds diagnostic items to all the stable public macros
Clippy has lints that look for almost all of these (currently by name or path), but there are a few that aren't currently part of any lint, I could remove those if it's preferred to add them as needed rather than ahead of time
Implement `panic::update_hook`
Add a new function `panic::update_hook` to allow creating panic hooks that forward the call to the previously set panic hook, without race conditions. It works by taking a closure that transforms the old panic hook into a new one, while ensuring that during the execution of the closure no other thread can modify the panic hook. This is a small function so I hope it can be discussed here without a formal RFC, however if you prefer I can write one.
Consider the following example:
```rust
let prev = panic::take_hook();
panic::set_hook(Box::new(move |info| {
println!("panic handler A");
prev(info);
}));
```
This is a common pattern in libraries that need to do something in case of panic: log panic to a file, record code coverage, send panic message to a monitoring service, print custom message with link to github to open a new issue, etc. However it is impossible to avoid race conditions with the current API, because two threads can execute in this order:
* Thread A calls `panic::take_hook()`
* Thread B calls `panic::take_hook()`
* Thread A calls `panic::set_hook()`
* Thread B calls `panic::set_hook()`
And the result is that the original panic hook has been lost, as well as the panic hook set by thread A. The resulting panic hook will be the one set by thread B, which forwards to the default panic hook. This is not considered a big issue because the panic handler setup is usually run during initialization code, probably before spawning any other threads.
Using the new `panic::update_hook` function, this race condition is impossible, and the result will be either `A, B, original` or `B, A, original`.
```rust
panic::update_hook(|prev| {
Box::new(move |info| {
println!("panic handler A");
prev(info);
})
});
```
I found one real world use case here: 988cf403e7/src/detection.rs (L32) the workaround is to detect the race condition and panic in that case.
The pattern of `take_hook` + `set_hook` is very common, you can see some examples in this pull request, so I think it's natural to have a function that combines them both. Also using `update_hook` instead of `take_hook` + `set_hook` reduces the number of calls to `HOOK_LOCK.write()` from 2 to 1, but I don't expect this to make any difference in performance.
### Unresolved questions:
* `panic::update_hook` takes a closure, if that closure panics the error message is "panicked while processing panic" which is not nice. This is a consequence of holding the `HOOK_LOCK` while executing the closure. Could be avoided using `catch_unwind`?
* Reimplement `panic::set_hook` as `panic::update_hook(|_prev| hook)`?
Remove `&mut` from `io::read_to_string` signature
``@m-ou-se`` [realized][1] that because `Read` is implemented for `&mut impl
Read`, there's no need to take `&mut` in `io::read_to_string`.
Removing the `&mut` from the signature allows users to remove the `&mut`
from their calls (and thus pass an owned reader) if they don't use the
reader later.
r? `@m-ou-se`
[1]: https://github.com/rust-lang/rust/issues/80218#issuecomment-874322129
Inline std::os::unix::ffi::OsStringExt methods
Those methods essentially do nothing at assembly level. On Unix systems, `OsString` is represented as a `Vec` without performing any transformations.
Partially stabilize `maybe_uninit_extra`
This covers:
```rust
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
```
It does not cover the const-ness of `write` under `const_maybe_uninit_write` nor the const-ness of `assume_init_read` (this commit adds `const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
`@m-ou-se` [realized][1] that because `Read` is implemented for `&mut impl
Read`, there's no need to take `&mut` in `io::read_to_string`.
Removing the `&mut` from the signature allows users to remove the `&mut`
from their calls (and thus pass an owned reader) if they don't use the
reader later.
[1]: https://github.com/rust-lang/rust/issues/80218#issuecomment-874322129
Add `std::error::Report` type
This is a continuation of https://github.com/rust-lang/rust/pull/90174, split into a separate PR since I cannot push to ```````@seanchen1991``````` 's fork
Simpilfy thread::JoinInner.
`JoinInner`'s `native` field was an `Option`, but that's unnecessary.
Also, thanks to `Arc::get_mut`, there's no unsafety needed in `JoinInner::join()`.
`WSADuplicateSocketW` returns 0 on success, which differs from
handle-oriented functions which return 0 on error. Use `sys::net::cvt`
to handle its return value, which handles the socket convention of
returning 0 on success, rather than `sys::cvt`, which handles the
handle-oriented convention of returning 0 on failure.
Eliminate "boxed" wording in `std::error::Error` documentation
In commit 29403ee, documentation for the methods on `std::any::Any` was
modified so that they referred to the concrete value behind the trait
object as the "inner" value. This is a more accurate wording than
"boxed": while putting trait objects inside boxes is arguably the most
common use, they can also be placed behind other pointer types like
`&mut` or `std::sync::Arc`.
This commit does the same documentation changes for `std::error::Error`.
Improve documentation for File::options to give a more likely example
`File::options().read(true).open(...)` is equivalent to just
`File::open`. Change the example to set the `append` flag instead, and
then change the filename to something more likely to be written in
append mode.
This covers:
impl<T> MaybeUninit<T> {
pub unsafe fn assume_init_read(&self) -> T { ... }
pub unsafe fn assume_init_drop(&mut self) { ... }
}
It does not cover the const-ness of `write` under
`const_maybe_uninit_write` nor the const-ness of
`assume_init_read` (this commit adds
`const_maybe_uninit_assume_init_read` for that).
FCP: https://github.com/rust-lang/rust/issues/63567#issuecomment-958590287.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Replace usages of vec![].into_iter with [].into_iter
`[].into_iter` is idiomatic over `vec![].into_iter` because its simpler and faster (unless the vec is optimized away in which case it would be the same)
So we should change all the implementation, documentation and tests to use it.
I skipped:
* `src/tools` - Those are copied in from upstream
* `src/test/ui` - Hard to tell if `vec![].into_iter` was used intentionally or not here and not much benefit to changing it.
* any case where `vec![].into_iter` was used because we specifically needed a `Vec::IntoIter<T>`
* any case where it looked like we were intentionally using `vec![].into_iter` to test it.
`File::options().read(true).open(...)` is equivalent to just
`File::open`. Change the example to set the `append` flag instead, and
then change the filename to something more likely to be written in
append mode.
In commit 29403ee, documentation for the methods on `std::any::Any` was
modified so that they referred to the concrete value behind the trait
object as the "inner" value. This is a more accurate wording than
"boxed": while putting trait objects inside boxes is arguably the most
common use, they can also be placed behind other pointer types like
`&mut` or `std::sync::Arc`.
This commit does the same documentation changes for `std::error::Error`.
Mak DefId to AccessLevel map in resolve for export
hir_id to accesslevel in resolve and applied in privacy
using local def id
removing tracing probes
making function not recursive and adding comments
Move most of Exported/Public res to rustc_resolve
moving public/export res to resolve
fix missing stability attributes in core, std and alloc
move code to access_levels.rs
return for some kinds instead of going through them
Export correctness, macro changes, comments
add comment for import binding
add comment for import binding
renmae to access level visitor, remove comments, move fn as closure, remove new_key
fmt
fix rebase
fix rebase
fmt
fmt
fix: move macro def to rustc_resolve
fix: reachable AccessLevel for enum variants
fmt
fix: missing stability attributes for other architectures
allow unreachable pub in rustfmt
fix: missing impl access level + renaming export to reexport
Missing impl access level was found thanks to a test in clippy
Previously suggested in https://github.com/rust-lang/rfcs/issues/2854.
It makes sense to have this since `char` implements `From<u8>`. Likewise
`u32`, `u64`, and `u128` (since #79502) implement `From<char>`.
Rollup of 7 pull requests
Successful merges:
- #92092 (Drop guards in slice sorting derive src pointers from &mut T, which is invalidated by interior mutation in comparison)
- #92388 (Fix a minor mistake in `String::try_reserve_exact` examples)
- #92442 (Add negative `impl` for `Ord`, `PartialOrd` on `LocalDefId`)
- #92483 (Stabilize `result_cloned` and `result_copied`)
- #92574 (Add RISC-V detection macro and more architecture instructions)
- #92575 (ast: Always keep a `NodeId` in `ast::Crate`)
- #92583 (⬆️ rust-analyzer)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
{kind=link}