This allows LLVM to optimize comparisons to zero before & after the
multiplication into one, saving on code size and eliminating an (always
true) branch from most Vec allocations.
Remove option_payload_ptr; redundant to offset_of
The `option_payload_ptr` intrinsic is no longer required as `offset_of` supports traversing enums (#114208). This PR removes it in order to dogfood offset_of (as suggested at https://github.com/rust-lang/rust/issues/106655#issuecomment-1790907626). However, it will not build until those changes reach beta (which I think is within the next 8 days?) so I've opened it as a draft.
Expose tests for {f32,f64}.total_cmp in docs
Expose tests for {f32,f64}.total_cmp in docs
Uncomment the helpful `assert_eq!` line, which is stripped out completely in docs, and leaves the reader to mentally play through the algorithm, or go to the playground and add a println!, to see what the result will be.
(If these tests are known to fail on some platforms, is there some mechanism to conditionalize this or escape the test so the `assert_eq!` source will be visible on the web? I am a newbie, which is why I was reading docs ;)
impl more traits for ptr::Alignment, add mask method
Changes:
* Adds `rustc_const_unstable` attributes where missing
* Makes `log2` method const
* Adds `mask` method
* Implements `Default`, which is equivalent to `Alignment::MIN`
No longer included in PR:
* Removes indirection of `AlignmentEnum` type alias (this was intentional)
* Implements `Display`, `Binary`, `Octal`, `LowerHex`, and `UpperHex` (should go through libs-api instead)
* Controversially implements `LowerExp` and `UpperExp` using `p` instead of `e` to indicate a power of 2 (also should go through libs-api)
Tracking issue for `ptr::Alignment`: #102070
Reenable effects in libcore
With #116670, #117531, and #117171, I think we would be comfortable with re-enabling the effects feature for more testing in libcore.
r? `@oli-obk`
cc `@fmease`
cc #110395
Remove asmjs
Fulfills [MCP 668](https://github.com/rust-lang/compiler-team/issues/668).
`asmjs-unknown-emscripten` does not work as-specified, and lacks essential upstream support for generating asm.js, so it should not exist at all.
feat: implement `DoubleEndedSearcher` for `CharArray[Ref]Searcher`
This PR implements `DoubleEndedSearcher` for both `CharArraySearcher` and `CharArrayRefSearcher`. I'm not sure whether this was just overlooked or if there is a reason for it, but since it behaves exactly like `CharSliceSearcher`, I think the implementations should be appropriate.
document ABI compatibility
I don't think we have any central place where we document our ABI compatibility rules, so let's create one. The `fn()` pointer type seems like a good place since ABI questions can only become relevant when invoking a function through a function pointer.
This will likely need T-lang FCP.
avoid exhaustive i16 test in Miri
https://github.com/rust-lang/rust/pull/116301 added a test that is way too slow to be running in Miri. So let's only test a few hopefully representative cases.
Custom MIR: Support cleanup blocks
Cleanup blocks are declared with `bb (cleanup) = { ... }`.
`Call` and `Drop` terminators take an additional argument describing the unwind action, which is one of the following:
* `UnwindContinue()`
* `UnwindUnreachable()`
* `UnwindTerminate(reason)`, where reason is `ReasonAbi` or `ReasonInCleanup`
* `UnwindCleanup(block)`
Also support unwind resume and unwind terminate terminators:
* `UnwindResume()`
* `UnwindTerminate(reason)`
Cleanup blocks are declared with `bb (cleanup) = { ... }`.
`Call` and `Drop` terminators take an additional argument describing the
unwind action, which is one of the following:
* `UnwindContinue()`
* `UnwindUnreachable()`
* `UnwindTerminate(reason)`, where reason is `ReasonAbi` or `ReasonInCleanup`
* `UnwindCleanup(block)`
Also support unwind resume and unwind terminate terminators:
* `UnwindResume()`
* `UnwindTerminate(reason)`
Add `std:#️⃣:{DefaultHasher, RandomState}` exports (needs FCP)
This implements rust-lang/libs-team#267 to move the libstd hasher types to `std::hash` where they belong, instead of `std::collections::hash_map`.
<details><summary>The below no longer applies, but is kept for clarity.</summary>
This is a small refactor for #27242, which moves the definitions of `RandomState` and `DefaultHasher` into `std::hash`, but in a way that won't be noticed in the public API.
I've opened rust-lang/libs-team#267 as a formal ACP to move these directly into the root of `std::hash`, but for now, they're at least separated out from the collections code in a way that will make moving that around easier.
I decided to simply copy the rustdoc for `std::hash` from `core::hash` since I think it would be ideal for the two to diverge longer-term, especially if the ACP is accepted. However, I would be willing to factor them out into a common markdown document if that's preferred.
</details>
Clarify UB in `get_unchecked(_mut)`
Inspired by #116915, it was unclear to me what exactly "out-of-bounds index" means in `get_unchecked`.
One could [potentially](https://rust.godbolt.org/z/hxM764orW) interpret it that `get_unchecked` is just another way to write `offset`, but I think `get_unchecked(len)` is supposed to be UB even though `.offet(len)` is well-defined (as is `.get_unchecked(..len)`), so write that more directly in the docs.
**libs-api folks**: Can you confirm whether this is what you expect this to mean? And is the situation any different for `<*const [T]>::get_unchecked`?
patterns: reject raw pointers that are not just integers
Matching against `0 as *const i32` is fine, matching against `&42 as *const i32` is not.
This extends the existing check against function pointers and wide pointers: we now uniformly reject all these pointer types during valtree construction, and then later lint because of that. See [here](https://github.com/rust-lang/rust/pull/116930#issuecomment-1784654073) for some more explanation and context.
Also fixes https://github.com/rust-lang/rust/issues/116929.
Cc `@oli-obk` `@lcnr`
Refactor the if/else checking on cmp::Ordering variants to a
"branchless" reassignment of left and right. This change results
in fewer branches and instructions.
Documentation cleanup for core::error::Request.
This part of the documentation currently render like this:

The new version renders like this:

Fixes:
* Add missing closing back tick.
* Remove spurious double back ticks.
* Add missing newline to render bullet point correctly.
* Fix grammar "there are methods calledrequest_ref and request_value are available" -> "there are methods calledrequest_ref and request_value".
* Change "methods" to "functions", which seems more appropriate for free functions.
document that the null pointer has the 0 address
Fixes https://github.com/rust-lang/rust/issues/116895
Will need t-lang FCP, but I think this is fairly uncontroversial -- there's probably already tons of code out there that relies on this.
Override `Waker::clone_from` to avoid cloning `Waker`s unnecessarily
This would be very useful for futures — I think it’s pretty much always what they want to do instead of `*waker = cx.waker().clone()`.
Tracking issue: https://github.com/rust-lang/rust/issues/98287
r? rust-lang/libs-api `@rustbot` label +T-libs-api -T-libs
Avoid unnecessary comparison in partition_equal
The branchy Hoare partition `partition_equal` as part of `slice::sort_unstable` has a bug that makes it perform a comparison of the last element twice.
Measuring inputs with a Zipfian distribution with characterizing exponent s == 1.0, yields a ~0.05% reduction in the total number of comparisons performed.
Add diagnostic items for a few of core's builtin macros
Specifically, `env`, `option_env`, and `include`. There are a number of reasons why people might want to look at these in lints (For example, to ensure that things behave consistently, detect things that might make builds less reproducible, etc).
Concretely, in PL/Rust (well, `plrustc`) we have lints that forbid these (which I'd like to [add to clippy as restriction lints](https://rust-lang.zulipchat.com/#narrow/stream/257328-clippy/topic/Landing.20a.20flotilla.20of.20lints.3F) eventually), and `dylint` also has [lints that look for `env!`/`option_env!`](109a07e9f2/examples/general/env_cargo_path/src/lib.rs) (although perhaps not `include`), which would benefit from this.
My experience is that it's pretty annoying to (robustly) check uses of builtin macros without these IME, although that's perhaps just my own fault (e.g. I could be doing it wrong).
At `@Nilstrieb's` suggestion, I've added a comment that explains why these are here, even though they are not used in the compiler. This is mostly to discourage removal, although it's not a big deal if it happens (I'm certainly not suggesting the presence of these be in any way stable).
---
In theory this is a library PR (in that it's in library/core), but I'm going to roll compiler because the existence of this or not is much more likely something they care about rather than libs. Hopefully nobody objects to this.
r? compiler
Stabilize `const_maybe_uninit_zeroed` and `const_mem_zeroed`
Make `MaybeUninit::zeroed` and `mem::zeroed` const stable. Newly stable API:
```rust
// core::mem
pub const unsafe fn zeroed<T>() ->;
impl<T> MaybeUninit<T> {
pub const fn zeroed() -> MaybeUninit<T>;
}
```
This relies on features based around `const_mut_refs`. Per `@RalfJung,` this should be OK since we do not leak any `&mut` to the user.
For this to be possible, intrinsics `assert_zero_valid` and `assert_mem_uninitialized_valid` were made const stable.
Tracking issue: #91850
Zulip discussion: https://rust-lang.zulipchat.com/#narrow/stream/146212-t-compiler.2Fconst-eval/topic/.60const_mut_refs.60.20dependents
r? libs-api
`@rustbot` label -T-libs +T-libs-api +A-const-eval
cc `@RalfJung` `@oli-obk` `@rust-lang/wg-const-eval`
Deref docs: expand and remove "smart pointer" qualifier
**Ready for review**
~~This is an unpolished draft to be sanity-checked~~
Fixes#91004
~~Comments on substance and content of this are welcome. This is deliberately unpolished until ready to review so please try to stay focused on the big-picture.~~
~~Once this has been sanity checked, I will similarly update `DerefMut` and polish for review.~~
Make `core::mem::zeroed` const stable. Newly stable API:
// core::mem
pub const unsafe fn zeroed<T>() -> T;
This is stabilized with `const_maybe_uninit_zeroed` since it is a simple
wrapper.
In order to make this possible, intrinsics `assert_zero_valid` was made
const stable under `const_assert_type2`.
`assert_mem_uninitialized_valid` was also made const stable since it is
under the same gate.
Make `MaybeUninit::zeroed` const stable. Newly stable API:
// core::mem
impl<T> MaybeUninit<T> {
pub const fn zeroed() -> MaybeUninit<T>;
}
Use of `const_mut_refs` should be acceptable since we do not leak the
mutability.
Tracking issue: #91850
Re-draft Deref docs
Make general advice more explicit and note the difference between
generic and specific implementations.
Re-draft DerefMut docs in-line with Deref
Fix Deref docs typos
Fix broken links
Clarify advice for specific-over-generic impls
Add comment addressing Issue #73682
x fmt
Copy faillibility warning to DerefMut
These methods currently return `(last_chunk, preceding_slice)`, which matches
the existing `split_x` methods that remove one item.
Change these to instead return `(preceding_slice, last_chunk)` which matches
string split methods, should be more intuitive, and will allow for consistency
with methods that split more items.
Remove support for compiler plugins.
They've been deprecated for four years.
This commit includes the following changes.
- It eliminates the `rustc_plugin_impl` crate.
- It changes the language used for lints in `compiler/rustc_driver_impl/src/lib.rs` and `compiler/rustc_lint/src/context.rs`. External lints are now called "loaded" lints, rather than "plugins" to avoid confusion with the old plugins. This only has a tiny effect on the output of `-W help`.
- E0457 and E0498 are no longer used.
- E0463 is narrowed, now only relating to unfound crates, not plugins.
- The `plugin` feature was moved from "active" to "removed".
- It removes the entire plugins chapter from the unstable book.
- It removes quite a few tests, mostly all of those in `tests/ui-fulldeps/plugin/`.
Closes#29597.
r? `@ghost`
They've been deprecated for four years.
This commit includes the following changes.
- It eliminates the `rustc_plugin_impl` crate.
- It changes the language used for lints in
`compiler/rustc_driver_impl/src/lib.rs` and
`compiler/rustc_lint/src/context.rs`. External lints are now called
"loaded" lints, rather than "plugins" to avoid confusion with the old
plugins. This only has a tiny effect on the output of `-W help`.
- E0457 and E0498 are no longer used.
- E0463 is narrowed, now only relating to unfound crates, not plugins.
- The `plugin` feature was moved from "active" to "removed".
- It removes the entire plugins chapter from the unstable book.
- It removes quite a few tests, mostly all of those in
`tests/ui-fulldeps/plugin/`.
Closes#29597.
Guarantee representation of None in NPO
This allows users to soundly transmute zeroes into `Option` types subject to the null pointer optimization (NPO). It unblocks https://github.com/google/zerocopy/issues/293.
Add track_caller to transmute_copy
Currently if `size_of::<Src>() < size_of::<Dst>()` you will see the following error:
```rust
thread 'test' panicked at /rustc/cc66ad468955717ab92600c770da8c1601a4ff33/library/core/src/mem/mod.rs:1056:5:
cannot transmute_copy if Dst is larger than Src
```
This fixes it so it will show the invocation location
Clarify `Unsize` documentation
The documentation erroneously says that:
```rust
/// - Types implementing a trait `Trait` also implement `Unsize<dyn Trait>`.
/// - Structs `Foo<..., T, ...>` implement `Unsize<Foo<..., U, ...>>` if all of these conditions
/// are met:
/// - `T: Unsize<U>`.
/// - Only the last field of `Foo` has a type involving `T`.
/// - `Bar<T>: Unsize<Bar<U>>`, where `Bar<T>` stands for the actual type of that last field.
```
Specifically, `T: Unsize<U>` is not required to hold -- only the final field must implement `FinalField<T>: Unsize<FinalField<U>>`. This can be demonstrated by the test I added.
---
Second commit fleshes out the documentation a lot more.
Support enum variants in offset_of!
This MR implements support for navigating through enum variants in `offset_of!`, placing the enum variant name in the second argument to `offset_of!`. The RFC placed it in the first argument, but I think it interacts better with nested field access in the second, as you can then write things like
```rust
offset_of!(Type, field.Variant.field)
```
Alternatively, a syntactic distinction could be made between variants and fields (e.g. `field::Variant.field`) but I'm not convinced this would be helpful.
[RFC 3308 # Enum Support](https://rust-lang.github.io/rfcs/3308-offset_of.html#enum-support-offset_ofsomeenumstructvariant-field_on_variant)
Tracking Issue #106655.
Clean up unchecked_math, separate out unchecked_shifts
Tracking issue: #85122
Changes:
1. Remove `const_inherent_unchecked_arith` flag and make const-stability flags the same as the method feature flags. Given the number of other unsafe const fns already stabilised, it makes sense to just stabilise these in const context when they're stabilised.
2. Move `unchecked_shl` and `unchecked_shr` into a separate `unchecked_shifts` flag, since the semantics for them are unclear and they'll likely be stabilised separately as a result.
3. Add an `unchecked_neg` method exclusively to signed integers, under the `unchecked_neg` flag. This is because it's a new API and probably needs some time to marinate before it's stabilised, and while it *would* make sense to have a similar version for unsigned integers since `checked_neg` also exists for those there is absolutely no case where that would be a good idea, IMQHO.
The longer-term goal here is to prepare the `unchecked_math` methods for an FCP and stabilisation since they've existed for a while, their semantics are clear, and people seem in favour of stabilising them.
Allows `#[diagnostic::on_unimplemented]` attributes to have multiple
notes
This commit extends the `#[diagnostic::on_unimplemented]` (and `#[rustc_on_unimplemented]`) attributes to allow multiple `note` options. This enables emitting multiple notes for custom error messages. For now I've opted to not change any of the existing usages of `#[rustc_on_unimplemented]` and just updated the relevant compile tests.
r? `@compiler-errors`
I'm happy to adjust any of the existing changed location to emit the old error message if that's desired.
Increase the reach of panic_immediate_abort
I wanted to use/abuse this recently as part of another project, and I was surprised how many panic-related things were left in my binaries if I built a large crate with the feature enabled along with LTO. These changes get all the panic-related symbols that I could find out of my set of locally installed Rust utilities.
memcpy assumptions: link to source showing that GCC makes the same assumption
I finally stumbled upon a source showing that GCC also generates overlapping `memcpy`. So if we're linking major C compilers making such assumptions here, let's have both clang and GCC.
notes
This commit extends the `#[diagnostic::on_unimplemented]` (and
`#[rustc_on_unimplemented]`) attributes to allow multiple `note`
options. This enables emitting multiple notes for custom error messages.
For now I've opted to not change any of the existing usages of
`#[rustc_on_unimplemented]` and just updated the relevant compile tests.
Rollup of 6 pull requests
Successful merges:
- #114998 (feat(docs): add cargo-pgo to PGO documentation 📝)
- #116868 (Tweak suggestion span for outer attr and point at item following invalid inner attr)
- #117240 (Fix documentation typo in std::iter::Iterator::collect_into)
- #117241 (Stash and cancel cycle errors for auto trait leakage in opaques)
- #117262 (Create a new ConstantKind variant (ZeroSized) for StableMIR)
- #117266 (replace transmute by raw pointer cast)
r? `@ghost`
`@rustbot` modify labels: rollup
Refactor some `char`, `u8` ASCII functions to be branchless
Extract conditions in singular `matches!` with or-patterns to individual `matches!` statements which enables branchless code output. The following functions were changed:
- `is_ascii_alphanumeric`
- `is_ascii_hexdigit`
- `is_ascii_punctuation`
Added codegen tests
---
Continued from https://github.com/rust-lang/rust/pull/103024.
Based on the comment from `@scottmcm` https://github.com/rust-lang/rust/pull/103024#pullrequestreview-1248697206.
The unmodified `is_ascii_*` functions didn't seem to benefit from extracting the conditions.
I've never written a codegen test before, but I tried to check that no branches were emitted.
Decompose singular `matches!` with or-patterns to individual `matches!`
statements to enable branchless code output. The following functions
were changed:
- `is_ascii_alphanumeric`
- `is_ascii_hexdigit`
- `is_ascii_punctuation`
Add codegen tests
Co-authored-by: George Bateman <george.bateman16@gmail.com>
Co-authored-by: scottmcm <scottmcm@users.noreply.github.com>
Explain implementation of mem::replace
This adds a comment to explain why `mem::replace` is not implemented in terms of `mem::swap` to prevent [naïfs like me](https://github.com/rust-lang/rust/pull/117189) from trying to "fix" it.
Rework negative coherence to properly consider impls that only partly overlap
This PR implements a modified negative coherence that handles impls that only have partial overlap.
It does this by:
1. taking both impl trait refs, instantiating them with infer vars
2. equating both trait refs
3. taking the equated trait ref (which represents the two impls' intersection), and resolving any vars
4. plugging all remaining infer vars with placeholder types
these placeholder-plugged trait refs can then be used normally with the new trait solver, since we no longer have to worry about the issue with infer vars in param-envs.
We use the **new trait solver** to reason correctly about unnormalized trait refs (due to deferred projection equality), since this avoid having to normalize anything under param-envs with infer vars in them.
This PR then additionally:
* removes the `FnPtr` knowable hack by implementing proper negative `FnPtr` trait bounds for rigid types.
---
An example:
Consider these two partially overlapping impls:
```
impl<T, U> PartialEq<&U> for &T where T: PartialEq<U> {}
impl<F> PartialEq<F> for F where F: FnPtr {}
```
Under the old algorithm, we would take one of these impls and replace it with infer vars, then try unifying it with the other impl under identity substitutions. This is not possible in either direction, since it either sets `T = U`, or tries to equate `F = &?0`.
Under the new algorithm, we try to unify `?0: PartialEq<?0>` with `&?1: PartialEq<&?2>`. This gives us `?0 = &?1 = &?2` and thus `?1 = ?2`. The intersection of these two trait refs therefore looks like: `&?1: PartialEq<&?1>`. After plugging this with placeholders, we get a trait ref that looks like `&!0: PartialEq<&!0>`, with the first impl having substs `?T = ?U = !0` and the second having substs `?F = &!0`[^1].
Then we can take the param-env from the first impl, and try to prove the negated where clause of the second.
We know that `&!0: !FnPtr` never holds, since it's a rigid type that is also not a fn ptr, we successfully detect that these impls may never overlap.
[^1]: For the purposes of this example, I just ignored lifetimes, since it doesn't really matter.
Rollup of 7 pull requests
Successful merges:
- #117111 (Remove support for alias `-Z instrument-coverage`)
- #117141 (Require target features to match exactly during inlining)
- #117152 (Fix unwrap suggestion for async fn)
- #117154 (implement C ABI lowering for CSKY)
- #117159 (Work around the fact that `check_mod_type_wf` may spuriously return `ErrorGuaranteed`)
- #117163 (compiletest: Display compilation errors in mir-opt tests)
- #117173 (Make `Iterator` a lang item)
r? `@ghost`
`@rustbot` modify labels: rollup
The branchy Hoare partition `partition_equal` as part of `slice::sort_unstable`
has a bug that makes it perform a comparison of the last element twice.
Measuring inputs with a Zipfian distribution with characterizing exponent s ==
1.0, yields a ~0.05% reduction in the total number of comparisons performed.
Derive `Ord`, `PartialOrd` and `Hash` for `SocketAddr*`
Fixes#116711
The main pain of this PR is to fix the buggy impl of `Ord` for `SocketAddrV6`, which ignored half of the fields (while `PartialEq` is derived):
4603f0b8af/library/core/src/net/socket_addr.rs (L99-L106)4603f0b8af/library/core/src/net/socket_addr.rs (L676)
For me it looks like a simple copy-paste error made in https://github.com/rust-lang/rust/pull/72239 (copy from v4 impl) (cc `@hch12907),` as I don't see this behavior being mentioned anywhere on the PR and it also does not respect `cmp` trait "rules". I also do not see any reasons for those impls to _not_ be derived.
It's a shame we did not notice this for 28 versions/3 years. I guess this is a bug fix, but I'm not sure what the process here should be.
r? libs
Validate `feature` and `since` values inside `#[stable(…)]`
Previously the string passed to `#[unstable(feature = "...")]` would be validated as an identifier, but not `#[stable(feature = "...")]`. In the standard library there were `stable` attributes containing the empty string, and kebab-case string, neither of which should be allowed.
Pre-existing validation of `unstable`:
```rust
// src/lib.rs
#![allow(internal_features)]
#![feature(staged_api)]
#![unstable(feature = "kebab-case", issue = "none")]
#[unstable(feature = "kebab-case", issue = "none")]
pub struct Struct;
```
```console
error[E0546]: 'feature' is not an identifier
--> src/lib.rs:5:1
|
5 | #![unstable(feature = "kebab-case", issue = "none")]
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
For an `unstable` attribute, the need for an identifier is obvious because the downstream code needs to write a `#![feature(...)]` attribute containing that identifier. `#![feature(kebab-case)]` is not valid syntax and `#![feature(kebab_case)]` would not work if that is not the name of the feature.
Having a valid identifier even in `stable` is less essential but still useful because it allows for informative diagnostic about the stabilization of a feature. Compare:
```rust
// src/lib.rs
#![allow(internal_features)]
#![feature(staged_api)]
#![stable(feature = "kebab-case", since = "1.0.0")]
#[stable(feature = "kebab-case", since = "1.0.0")]
pub struct Struct;
```
```rust
// src/main.rs
#![feature(kebab_case)]
use repro::Struct;
fn main() {}
```
```console
error[E0635]: unknown feature `kebab_case`
--> src/main.rs:3:12
|
3 | #![feature(kebab_case)]
| ^^^^^^^^^^
```
vs the situation if we correctly use `feature = "snake_case"` and `#![feature(snake_case)]`, as enforced by this PR:
```console
warning: the feature `snake_case` has been stable since 1.0.0 and no longer requires an attribute to enable
--> src/main.rs:3:12
|
3 | #![feature(snake_case)]
| ^^^^^^^^^^
|
= note: `#[warn(stable_features)]` on by default
```
document when atomic loads are guaranteed read-only
Based on this [discussion in Zulip](https://rust-lang.zulipchat.com/#narrow/stream/136281-t-opsem/topic/Can.20.60Atomic*.3A.3Aload.60.20perform.20a.20write).
The values for x86 and x86_64 are complete guesswork on my side, and I have no clue what the values might be for other architectures. I hope we can get the right people to chime in to gather the required information. :)
I'll update Miri to respect these rules once we have more data.
This makes it so that all the matchers that match against paths use the
definition path instead of the export path. This removes all duplication
around `std`/`alloc`/`core`.
This is not necessarily optimal because we now depend on internal
implementation details like `core::ops::control_flow::ControlFlow`,
which is not very nice and probably not acceptable for a stable
`on_unimplemented`.
An alternative would be to just string-replace normalize away
`alloc`/`core` to `std` as a special case, keeping the export paths but
making it so that we're still fully standard library flavor agnostic.
Stabilize `{IpAddr, Ipv6Addr}::to_canonical`
Make `IpAddr::to_canonical` and `IpV6Addr::to_canonical` stable (+const), as well as const stabilize `Ipv6Addr::to_ipv4_mapped`.
Newly stable API:
```rust
impl IpAddr {
// Newly stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
}
impl Ipv6Addr {
// Newly stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
// Already stable, this makes it const stable under
// `const_ipv6_to_ipv4_mapped`
const fn to_ipv4_mapped(&self) -> Option<Ipv4Addr>
}
```
These stabilize a subset of the following tracking issues:
- https://github.com/rust-lang/rust/issues/27709
- https://github.com/rust-lang/rust/issues/76205
Stabilization of all methods under the `ip` gate was attempted once at https://github.com/rust-lang/rust/pull/66584 then again at https://github.com/rust-lang/rust/pull/76098. These were not successful because there are still unknowns about `is_documentation` `is_benchmarking` and similar; `to_canonical` is much more straightforward.
I have looked and could not find any known issues with `to_canonical`. These were added in 2021 in https://github.com/rust-lang/rust/pull/87708
cc implementor ``@the8472``
r? libs-api
``@rustbot`` label +T-libs-api +needs-fcp
impl Not, Bit{And,Or}{,Assign} for IP addresses
ACP: rust-lang/libs-team#235
Note: since these are insta-stable, these require an FCP.
Implements, where `N` is either `4` or `6`:
```rust
impl Not for IpvNAddr
impl Not for &IpvNAddr
impl BitAnd<IpvNAddr> for IpvNAddr
impl BitAnd<&IpvNAddr> for IpvNAddr
impl BitAnd<IpvNAddr> for &IpvNAddr
impl BitAnd<&IpvNAddr> for &IpvNAddr
impl BitAndAssign<IpvNAddr> for IpvNAddr
impl BitAndAssign<&IpvNAddr> for IpvNAddr
impl BitOr<IpvNAddr> for IpvNAddr
impl BitOr<&IpvNAddr> for IpvNAddr
impl BitOr<IpvNAddr> for &IpvNAddr
impl BitOr<&IpvNAddr> for &IpvNAddr
impl BitOrAssign<IpvNAddr> for IpvNAddr
impl BitOrAssign<&IpvNAddr> for IpvNAddr
```
Implement FusedIterator for DecodeUtf16 when the inner iterator does
I have just implemented an iterator that wraps `DecodeUtf16` and wanted to implement `FusedIterator` for my iterator when I noticed that `DecodeUtf16` currently doesn't implement `FusedIterator` at all.
A quick look at the code of `DecodeUtf16` revealed that `DecodeUtf16::next` only returns `None` when its inner iterator returns `None`:
3462f79e94/library/core/src/char/decode.rs (L45)
As a result, we can implement `FusedIterator` for `DecodeUtf16` when the inner iterator does.
I'm following the example of #96397 here and consider this change minor and non-controversial, which is why I haven't added an RFC. I have also added the required feature name (`"decode_utf16_fused_iterator"`), however without adding a chapter to the Rust Unstable book (same as #96397).
optimize zipping over array iterators
Fixes#115339 (somewhat)
the new assembly:
```asm
zip_arrays:
.cfi_startproc
vmovups (%rdx), %ymm0
leaq 32(%rsi), %rcx
vxorps %xmm1, %xmm1, %xmm1
vmovups %xmm1, -24(%rsp)
movq $0, -8(%rsp)
movq %rsi, -88(%rsp)
movq %rdi, %rax
movq %rcx, -80(%rsp)
vmovups %ymm0, -72(%rsp)
movq $0, -40(%rsp)
movq $32, -32(%rsp)
movq -24(%rsp), %rcx
vmovups (%rsi,%rcx), %ymm0
vorps -72(%rsp,%rcx), %ymm0, %ymm0
vmovups %ymm0, (%rsi,%rcx)
vmovups (%rsi), %ymm0
vmovups %ymm0, (%rdi)
vzeroupper
retq
```
This is still longer than the slice version given in the issue but at least it eliminates the terrible `vpextrb`/`orb` chain. I guess this is due to excessive memcpys again (haven't looked at the llvmir)?
The `TrustedLen` specialization is a drive-by change since I had to do something for the default impl anyway to be able to specialize the `TrustedRandomAccessNoCoerce` impl.
* Remove duplicate alignment note that mentioned `AtomicBool` with other
types
* Update safety requirements about when non-atomic operations are
allowed
Implement `slice::split_once` and `slice::rsplit_once`
Feature gate is `slice_split_once` and tracking issue is #112811. These are equivalents to the existing `str::split_once` and `str::rsplit_once` methods.
Fix generic bound of `str::SplitInclusive`'s `DoubleEndedIterator` impl
`str::SplitInclusive`'s `DoubleEndedIterator` implementation currently uses a `ReverseSearcher` bound for the corresponding searcher. A `DoubleEndedSearcher` bound should have been used instead.
`DoubleEndedIterator` requires that repeated `next_back` calls produce the same items as repeated `next` calls, in opposite order. `ReverseSearcher` lets you search starting from the back of a string, but it makes no guarantees about how its matches correspond to the matches found by a forward search. `DoubleEndedSearcher` is a subtrait of `ReverseSearcher` and does require that the same matches are found in both directions.
This bug fix is a breaking change. Calling `next_back` on `"a+++b".split_inclusive("++")` is currently accepted with repeated calls producing `"b"` and `"a+++"`, while forward iteration yields `"a++"` and `"+b"`. Also see https://github.com/rust-lang/rust/issues/100756#issuecomment-1221307166 for more details.
I believe that this is the only iterator that uses this bound incorrectly — other related iterators such as `str::Split` do have a `DoubleEndedSearcher` bound for their `DoubleEndedIterator` implementation. And `slice::SplitInclusive` doesn't face this problem at all because it doesn't use patterns, only a predicate.
cc `@SkiFire13`
Reuse existing `Some`s in `Option::(x)or`
LLVM still has trouble re-using discriminants sometimes when rebuilding a two-variant enum, so when we have the correct variant already built, just use it.
That's shorter in the Rust code, as well as simpler in MIR and the optimized LLVM, so might as well: <https://rust.godbolt.org/z/KhdE8eToW>
Thanks to `@veber-alex` for pointing out this opportunity in https://github.com/rust-lang/rust/issues/101210#issuecomment-1732470941
Fix a comment in std::iter::successors
The `unfold` function have since #58062 been renamed to `from_fn`.
(I'm not sure if this whole comment is still useful—it's not like there are many iterators that *can't* be based on `from_fn`. Anyway, in its current form this comment is not correct, and it sent me into a half-hour research of what happened to `unfold` function, so I want to do *something* with it 🙃 deleting these three lines is a perfectly fine alternative, in my opinion.)
Clarify example in docs of str::char_slice
Just a one word improvement.
“Last” can be misread as meaning the last (third) instead of the previous (first).
LLVM still has trouble re-using discriminants sometimes when rebuilding a two-variant enum, so when we have the correct variant already built, just use it.
That's simpler in LLVM *and* in MIR, so might as well: <https://rust.godbolt.org/z/KhdE8eToW>
docs: Correct terminology in std::cmp
This PR is the result of some discussions on URLO:
* [Traits in `std::cmp` and mathematical terminology](https://users.rust-lang.org/t/traits-in-std-cmp-and-mathematical-terminology/69887)
* [Are poker hands `Ord` or `PartialOrd`?](https://users.rust-lang.org/t/are-poker-hands-ord-or-partialord/82644)
Arguably, the documentation currently isn't very precise regarding mathematical terminology. This can lead to misunderstandings of what `PartialEq`, `Eq`, `PartialOrd`, and `Ord` actually do.
While I believe this PR doesn't give any new API guarantees, it expliclitly mentions that `PartialEq::eq(a, b)` may return `true` for two distinct values `a` and `b` (i.e. where `a` and `b` are not equal in the mathematical sense). This leads to the consequence that `Ord` may describe a weak ordering instead of a total ordering.
In either case, I believe this PR should be thoroughly reviewed, ideally by someone with mathematical background to make sure the terminology is correct now, and also to ensure that no unwanted new API guarantees are made.
In particular, the following problems are addressed:
* Some clarifications regarding used (mathematical) terminology:
* Avoid using the terms "total equality" and "partial equality" in favor of "equivalence relation" and "partial equivalence relation", which are well-defined and unambiguous.
* Clarify that `Ordering` is an ordering between two values (and not an order in the mathematical sense).
* Avoid saying that `PartialEq` and `Eq` are "equality comparisons" because the terminology "equality comparison" could be misleading: it's possible to implement `PartialEq` and `Eq` for other (partial) equivalence relations, in particular for relations where `a == b` for some `a` and `b` even when `a` and `b` are not the same value.
* Added a section "Strict and non-strict partial orders" to document that the `<=` and `>=` operators do not correspond to non-strict partial orders.
* Corrected section "Corollaries" in documenation of `Ord` in regard to `<` only describing a strict total order in cases where `==` conforms to mathematical equality.
* ~~Added a section "Weak orders" to explain that `Ord` may also describe a weak order or total preorder, depending on how `PartialEq::eq` has been implemented.~~ (Removed, see [comment](https://github.com/rust-lang/rust/pull/103046#issuecomment-1279929676))
* Made documentation easier to understand:
* Explicitly state at the beginning of `PartialEq`'s documentation comment that implementing the trait will provide the `==` and `!=` operators.
* Added an easier to understand rule when to implement `Eq` in addition to `PartialEq`: "if it’s guaranteed that `PartialEq::eq(a, a)` always returns `true`."
* Explicitly mention in documentation of `Eq` that the properties "symmetric" and "transitive" are already required by `PartialEq`.
core library: Disable fpmath tests for i586 ...
This patch disables the floating-point epsilon test for i586 since x87 registers are too imprecise and can't produce the expected results.
Some clarifications regarding used (mathematical) terminology:
* Avoid using the terms "total equality" and "partial equality" in favor
of "equivalence relation" and "partial equivalence relation", which
are well-defined and unambiguous.
* Clarify that `Ordering` is an ordering between two values (and not an
order in the mathematical sense).
* Avoid saying that `PartialEq` and `Eq` are "equality comparisons"
because the terminology "equality comparison" could be misleading:
it's possible to implement `PartialEq` and `Eq` for other (partial)
equivalence relations, in particular for relations where `a == b` for
some `a` and `b` even when `a` and `b` are not the same value.
* Added a section "Strict and non-strict partial orders" to document
that the `<=` and `>=` operators do not correspond to non-strict
partial orders.
* Corrected section "Corollaries" in documenation of Ord in regard to
`<` only describing a strict total order in cases where `==` conforms
to mathematical equality.
Made documentation easier to understand:
* Explicitly state at the beginning of `PartialEq`'s documentation
comment that implementing the trait will provide the `==` and `!=`
operators.
* Added an easier to understand rule when to implement `Eq` in addition
to `PartialEq`: "if it’s guaranteed that `PartialEq::eq(a, a)` always
returns `true`."
* Explicitly mention in documentation of `Eq` that the properties
"symmetric" and "transitive" are already required by `PartialEq`.
Works around #115199 by temporarily disabling CFI for core and std CFI
violations to allow the user rebuild and use both core and std with CFI
enabled using the Cargo build-std feature.
Adapt `todo!` documentation to mention displaying custom values
Resolves#116130.
I copied from the [existing documentation](https://doc.rust-lang.org/std/macro.unimplemented.html) for `unimplemented!` more or less directly, down to the example trait used. I also took the liberty of fixing some formatting and typographical errors that I noticed.
Add `must_use` on pointer equality functions
`ptr == ptr` (like all use of `==`) has a similar warning, and these functions are simple convenience wrappers over that.
Correct misleading std::fmt::Binary example (#116165)
Nothing too crazy...
- Add two to the width specifier (so all 32 bits are correctly displayed)
- Pad out the compared string so the assert passes
- Add `// Note` comment highlighting the need for the extra width when using the `#` flag.
The exact contents (and placement?) of the note are, of course, highly bikesheddable.
Partially outline code inside the panic! macro
This outlines code inside the panic! macro in some cases. This is split out from https://github.com/rust-lang/rust/pull/115562 to exclude changes to rustc.
Add "integer square root" method to integer primitive types
For every suffix `N` among `8`, `16`, `32`, `64`, `128` and `size`, this PR adds the methods
```rust
const fn uN::isqrt() -> uN;
const fn iN::isqrt() -> iN;
const fn iN::checked_isqrt() -> Option<iN>;
```
to compute the [integer square root](https://en.wikipedia.org/wiki/Integer_square_root), addressing issue #89273.
The implementation is based on the [base 2 digit-by-digit algorithm](https://en.wikipedia.org/wiki/Methods_of_computing_square_roots#Binary_numeral_system_(base_2)) on Wikipedia, which after some benchmarking has proved to be faster than both binary search and Heron's/Newton's method. I haven't had the time to understand and port [this code](http://atoms.alife.co.uk/sqrt/SquareRoot.java) based on lookup tables instead, but I'm not sure whether it's worth complicating such a function this much for relatively little benefit.
fix a comment about assert_receiver_is_total_eq
"a type implements #[deriving]" doesn't make any sense, so I assume they meant "implement `Eq`"? Also the attribute is called `derive`.
error: unresolved link to `std::fmt::Error`
--> library/core/src/fmt/mod.rs:115:52
|
115 | /// This function will return an instance of [`std::fmt::Error`] on error.
|
|
= note: `-D rustdoc::broken-intra-doc-links` implied by `-D warnings`
ConstParamTy: require Eq as supertrait
As discussed with `@BoxyUwu` [on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/260443-project-const-generics/topic/.60ConstParamTy.60.20and.20.60Eq.60).
We want to say that valtree equality on const generic params agrees with `==`, but that only makes sense if `==` actually exists, hence we should have an appropriate bound. Valtree equality is an equivalence relation, so such a type can always be `Eq` and not just `PartialEq`.
Clarify example in `Pin::new_unchecked` docs
This example in the docs of `Pin::new_unchecked` puzzled me for a relatively long time. Now I understand that it comes down to the difference between dropping the `Pin` vs dropping the pinned value.
I have extended the explanation to highlight this difference. In my opinion it is clearer now, and I hope it helps others understand `Pin` better.
Document panics on unsigned wrapping_div/rem calls (#116063)
Add missing `# Panics` sections to the `uint_impl!` macro, documenting that the `wrapping_rem/div` calls will panic if passed zero.
Call panic_display directly in const_panic_fmt.
`panic_str` just directly calls `panic_display`. The only reason `panic_str` exists, is for a lint to detect an expansion of `panic_2015!(expr)` (which expands to `panic_str`).
It is `panic_display` that is hooked by const-eval, which is the reason we call it here.
Part of https://github.com/rust-lang/rust/issues/116005
r? ``@oli-obk``
Rename BoxMeUp to PanicPayload.
"BoxMeUp" is not very clear. Let's rename that to a description of what it actually represents: a panic payload.
This PR also renames the structs that implement this trait to have more descriptive names.
Part of https://github.com/rust-lang/rust/issues/116005
r? `@oli-obk`
Make `IpAddr::to_canonical` and `IpV6Addr::to_canonical` stable, as well as
const stabilize `Ipv6Addr::to_ipv4_mapped`.
Newly stable API:
impl IpAddr {
// Now stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
}
impl Ipv6Addr {
// Now stable under `ip_to_canonical`
const fn to_canonical(&self) -> IpAddr;
// Already stable, this makes it const stable under
// `const_ipv6_to_ipv4_mapped`
const fn to_ipv4_mapped(&self) -> Option<Ipv4Addr>
}
These stabilize a subset of the following tracking issues:
- https://github.com/rust-lang/rust/issues/27709
- https://github.com/rust-lang/rust/issues/76205
get rid of duplicate primitive_docs
Having this duplicate makes editing that file very annoying. And at least locally the generated docs still look perfectly fine...
Add `minmax{,_by,_by_key}` functions to `core::cmp`
This PR adds the following functions:
```rust
// mod core::cmp
#![unstable(feature = "cmp_minmax")]
pub fn minmax<T>(v1: T, v2: T) -> [T; 2]
where
T: Ord;
pub fn minmax_by<T, F>(v1: T, v2: T, compare: F) -> [T; 2]
where
F: FnOnce(&T, &T) -> Ordering;
pub fn minmax_by_key<T, F, K>(v1: T, v2: T, mut f: F) -> [T; 2]
where
F: FnMut(&T) -> K,
K: Ord;
```
(they are also `const` under `#[feature(const_cmp)]`, I've omitted `const` stuff for simplicity/readability)
----
Semantically these functions are equivalent to `{ let mut arr = [v1, v2]; arr.sort(); arr }`, but since they operate on 2 elements only, they are implemented as a single comparison.
Even though that's basically a sort, I think "sort 2 elements" operation is useful on it's own in many cases. Namely, it's a common pattern when you have 2 things, and need to know which one is smaller/bigger to operate on them differently.
I've wanted such functions countless times, most recently in #109402, so I thought I'd propose them.
----
r? libs-api
Small wins for formatting-related code
This PR does two small wins in fmt code:
- Override `write_char` for `PadAdapter` to use inner buffer's `write_char`
- Override some `write_fmt` implementations to avoid avoid the additional indirection and vtable generated by the default impl.
make `Debug` impl for `ascii::Char` match that of `char`
# Objective
use a more recognisable format for the `Debug` impl on `ascii::Char` than the derived one based off the enum variants. The alogorithm used is the following:
- escape `ascii::Char::{Null, CharacterTabulation, CarraigeReturn, LineFeed, ReverseSolidus, Apostrophe}` to `'\0'`, `'\t'`, `'\r'`, `'\n'`, `'\\'` and `'\''` respectively. these are the same escape codes as `<char as Debug>::fmt` uses.
- if `u8::is_ascii_control` is false, print the character wrapped in single quotes.
- otherwise, print in the format `'\xAB'` where `A` and `B` are the hex nibbles of the byte. (`char` uses unicode escapes and this seems like the corresponding ascii format).
Tracking issue: https://github.com/rust-lang/rust/issues/110998
impl Step for IP addresses
ACP: rust-lang/libs-team#235
Note: since this is insta-stable, it requires an FCP.
Separating out from the bit operations PR since it feels logically disjoint, and so their FCPs can be separate.
Update doc for `alloc::format!` and `core::concat!`
Closes#115551.
Used comments instead of `assert!`s as [`std::fmt`](https://doc.rust-lang.org/std/fmt/index.html#usage) uses comments.
Should all the str-related macros (`format!`, `format_args!`, `concat!`, `stringify!`, `println!`, `writeln!`, etc.) references each others? For instance, [`concat!`](https://doc.rust-lang.org/core/macro.concat.html) mentions that integers are stringified, but don't link to `stringify!`.
`@rustbot` label +A-docs +A-fmt
Specialize count for range iterators
Since `size_hint` is already specialized, it feels apt to specialize `count` as well. Without any specialized version of `ExactSizeIterator::len` or `Step::steps_between`, this feels like a more reliable way of accessing this without having to rely on knowing that `size_hint` is correct.
In my case, this is particularly useful to access the `steps_between` implementation for `char` from the standard library without having to compute it manually.
I didn't think it was worth modifying the `Step` trait to add a version of `steps_between` that used native overflow checks since this is just doing one subtraction in most cases anyway, and so I decided to make the inclusive version use `checked_add` so it didn't have this lopsided overflow-checks-but-only-sometimes logic.
clarify that unsafe code must not rely on our safe traits
This adds a disclaimer to PartialEq, Eq, PartialOrd, Ord, Hash, Deref, DerefMut.
We already have a similar disclaimer in ExactSizeIterator (worded a bit differently):
```
/// Note that this trait is a safe trait and as such does *not* and *cannot*
/// guarantee that the returned length is correct. This means that `unsafe`
/// code **must not** rely on the correctness of [`Iterator::size_hint`]. The
/// unstable and unsafe [`TrustedLen`](super::marker::TrustedLen) trait gives
/// this additional guarantee.
```
If there are any other traits that should carry such a disclaimer, please let me know.
Fixes https://github.com/rust-lang/rust/issues/73682
Make useless_ptr_null_checks smarter about some std functions
This teaches the `useless_ptr_null_checks` lint that some std functions can't ever return null pointers, because they need to point to valid data, get references as input, etc.
This is achieved by introducing an `#[rustc_never_returns_null_ptr]` attribute and adding it to these std functions (gated behind bootstrap `cfg_attr`).
Later on, the attribute could maybe be used to tell LLVM that the returned pointer is never null. I don't expect much impact of that though, as the functions are pretty shallow and usually the input data is already never null.
Follow-up of PR #113657Fixes#114442
Rework `no_coverage` to `coverage(off)`
As discussed at the tail of https://github.com/rust-lang/rust/issues/84605 this replaces the `no_coverage` attribute with a `coverage` attribute that takes sub-parameters (currently `off` and `on`) to control the coverage instrumentation.
Allows future-proofing for things like `coverage(off, reason="Tested live", issue="#12345")` or similar.
Clarify stability guarantee for lifetimes in enum discriminants
Since `std::mem::Discriminant` erases lifetimes, it should be clarified that changing the concrete value of a lifetime parameter does not change the value of an enum discriminant for a given variant. This is useful as it guarantees that it is safe to transmute `Discriminant<Foo<'a>>` to `Discriminant<Foo<'b>>` for any combination of `'a` and `'b`. This also holds for type-generics as long as the type parameters do not change, e.g. `Discriminant<Foo<T, 'a>>` can be transmuted to `Discriminant<Foo<T, 'b>>`.
Side note: Is what I've written actually enough to imply soundness (or rather codify it), or should it specifically be spelled out that it's OK to transmute in the above way?
Lint on invalid usage of `UnsafeCell::raw_get` in reference casting
This PR proposes to take into account `UnsafeCell::raw_get` method call for non-Freeze types for the `invalid_reference_casting` lint.
The goal of this is to catch those kind of invalid reference casting:
```rust
fn as_mut<T>(x: &T) -> &mut T {
unsafe { &mut *std::cell::UnsafeCell::raw_get(x as *const _ as *const _) }
//~^ ERROR casting `&T` to `&mut T` is undefined behavior
}
```
r? `@est31`
Outline panicking code for `RefCell::borrow` and `RefCell::borrow_mut`
This outlines panicking code for `RefCell::borrow` and `RefCell::borrow_mut` to reduce code size.
RangeFull: Remove parens around .. in documentation snippet
I’ve removed unnecessary parentheses in a documentation snippet documenting `RangeFull`. It could’ve lead people to believe the parentheses were necessary.
Also stabilizes saturating_int_assign_impl, gh-92354.
And also make pub fns const where the underlying saturating_*
fns became const in the meantime since the Saturating type was
created.
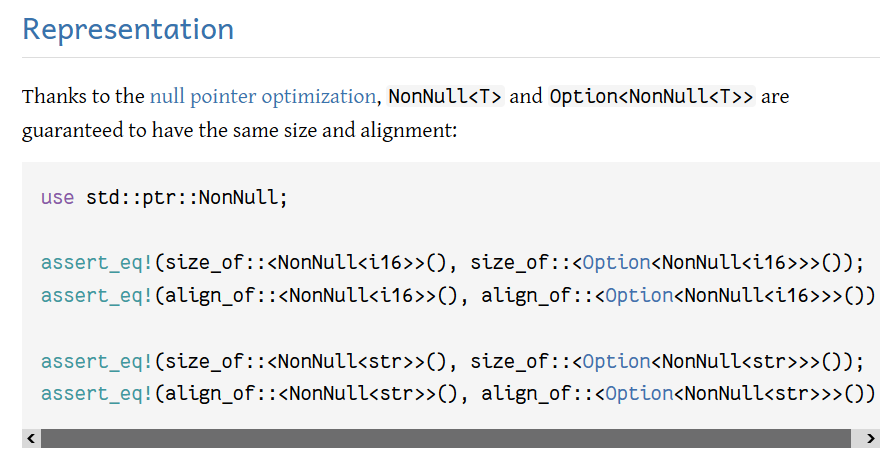
Add alignment to the NPO guarantee
This PR [changes](https://github.com/rust-lang/rust/pull/114845#discussion_r1294363357) "same size" to "same size and alignment" in the option module's null pointer optimization docs in <https://doc.rust-lang.org/std/option/#representation>.
As far as I know, this has been true for a long time in the actual rustc implementation, but it's not in the text of those docs, so I figured I'd bring this up to FCP it.
I also see no particular reason that we'd ever *want* to have higher alignment on these. In many of the cases it's impossible, as the minimum alignment is already the size of the type, but even if we *could* do things like on 32-bit we could say that `NonZeroU64` is 4-align but `Option<NonZeroU64>` is 8-align, I just don't see any value in doing that, so feel completely fine closing this door for the few things on which the NPO is already guaranteed. These are basically all primitives, and should end up with the same size & alignment as those primitives.
(There's no layout guarantee for something like `Option<[u8; 3]>`, where it'd be at least plausible to consider raising the alignment from 1 to 4 on, say, some hypothetical target that doesn't have efficient unaligned 4-byte load/stores. And even if we ever did start to offer some kind of guarantee around such a type, I doubt we'd put it under the "null pointer" optimization header.)
Screenshots for the new examples:

Implement Step for ascii::Char
This allows iterating over ranges of `ascii::Char`, similarly to ranges of `char`.
Note that `ascii::Char` is still unstable, tracked in #110998.
Currently, `CStr::from_ptr` contains its own implementation of `strlen`
that uses `const_eval_select` to either call libc's `strlen` or use a
naive Rust implementation. Refactor that into its own function so we can
use it elsewhere in the module.