Move the WorkerLocal type from the rustc-rayon fork into rustc_data_structures
This PR moves the definition of the `WorkerLocal` type from `rustc-rayon` into `rustc_data_structures`. This is enabled by the introduction of the `Registry` type which allows you to group up threads to be used by `WorkerLocal` which is basically just an array with an per thread index. The `Registry` type mirrors the one in Rayon and each Rayon worker thread is also registered with the new `Registry`. Safety for `WorkerLocal` is ensured by having it keep a reference to the registry and checking on each access that we're still on the group of threads associated with the registry used to construct it.
Accessing a `WorkerLocal` is micro-optimized due to it being hot since it's used for most arena allocations.
Performance is slightly improved for the parallel compiler:
<table><tr><td rowspan="2">Benchmark</td><td colspan="1"><b>Before</b></th><td colspan="2"><b>After</b></th></tr><tr><td align="right">Time</td><td align="right">Time</td><td align="right">%</th></tr><tr><td>🟣 <b>clap</b>:check</td><td align="right">1.9992s</td><td align="right">1.9949s</td><td align="right"> -0.21%</td></tr><tr><td>🟣 <b>hyper</b>:check</td><td align="right">0.2977s</td><td align="right">0.2970s</td><td align="right"> -0.22%</td></tr><tr><td>🟣 <b>regex</b>:check</td><td align="right">1.1335s</td><td align="right">1.1315s</td><td align="right"> -0.18%</td></tr><tr><td>🟣 <b>syn</b>:check</td><td align="right">1.8235s</td><td align="right">1.8171s</td><td align="right"> -0.35%</td></tr><tr><td>🟣 <b>syntex_syntax</b>:check</td><td align="right">6.9047s</td><td align="right">6.8930s</td><td align="right"> -0.17%</td></tr><tr><td>Total</td><td align="right">12.1586s</td><td align="right">12.1336s</td><td align="right"> -0.21%</td></tr><tr><td>Summary</td><td align="right">1.0000s</td><td align="right">0.9977s</td><td align="right"> -0.23%</td></tr></table>
cc `@SparrowLii`
Nicer ICE for #67981
Provides a slightly nicer ICE for #67981, documenting the problem. A proper fix will be necessary before `#![feature(unsized_fn_params)]` can be stabilized.
The problem is that the design of the `"rust-call"` ABI is fundamentally not compatible with `unsized_fn_params`. `"rust-call"` functions need to collect their arguments into a tuple, but if the arguments are not `Sized`, said tuple is potentially not even a valid type—and if it is, it requires `alloca` to create.
``@rustbot`` label +A-abi +A-codegen +F-unboxed_closures +F-unsized_fn_params
`IntoFuture::into_future` is no longer unstable
We don't need to gate the `IntoFuture::into_future` call in `.await` lowering anymore.
``@bors`` rollup
Sprinkle some `#[inline]` in `rustc_data_structures::tagged_ptr`
This is based on `nm --demangle (rustc +a --print sysroot)/lib/librustc_driver-*.so | rg CopyTaggedPtr` which shows many methods that should probably be inlined. May fix the regression in https://github.com/rust-lang/rust/pull/110795.
r? ```@Nilstrieb```
Fixes#35785 by converting non UTF-8 linker output to Unicode using the OEM code page.
Before:
```text
= note: Non-UTF-8 output: LINK : fatal error LNK1181: cannot open input file \'m\x84rchenhaft.obj\'\r\n
```
After:
```text
= note: LINK : fatal error LNK1181: cannot open input file 'märchenhaft.obj'
```
The difference is more dramatic if using a non-ascii language pack for Visual Studio.
Currently it creates an `Option` and then does `map`/`unwrap_or` and
`map_or_else` on it, which is hard to read.
This commit simplifies things by moving more code into the two arms of
the if/else.
Validation is neither necessary nor desirable.
The validation is already omitted at mir-opt-level >= 3, so there there
are not changes in MIR test output (the propagation of invalid constants
is covered by an existing test in tests/mir-opt/const_prop/invalid_constant.rs).
Rollup of 10 pull requests
Successful merges:
- #108760 (Add lint to deny diagnostics composed of static strings)
- #109444 (Change tidy error message for TODOs)
- #110419 (Spelling library)
- #110550 (Suggest deref on comparison binop RHS even if type is not Copy)
- #110641 (Add new rustdoc book chapter to describe in-doc settings)
- #110798 (pass `unused_extern_crates` in `librustdoc::doctest::make_test`)
- #110819 (simplify TrustedLen impls)
- #110825 (diagnostics: add test case for already-solved issue)
- #110835 (Make some region folders a little stricter.)
- #110847 (rustdoc-json: Time serialization.)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Add lint to deny diagnostics composed of static strings
r? ghost
I'm hoping to have a lint that semi-automatically converts simple diagnostics such as `struct_span_err(span, "msg").help("msg").span_note(span2, "msg").emit()` to typed session diagnostics. It's quite hacky and not entirely working because of problems with `x fix` but should hopefully help reduce some of the work.
I'm going to start trying to apply what I can from this, but opening this as a draft in case anyone wants to develop on it.
cc #100717
coverage: Don't underflow column number
I noticed this when running coverage on a debug build of rustc. There
may be other places that do this but I'm just fixing the one I hit.
r? `@wesleywiser` `@richkadel`
Rewrite MemDecoder around pointers not a slice
This is basically https://github.com/rust-lang/rust/pull/109910 but I'm being a lot more aggressive. The pointer-based structure means that it makes a lot more sense to absorb more complexity into `MemDecoder`, most of the diff is just complexity moving from one place to another.
The primary argument for this structure is that we only incur a single bounds check when doing multi-byte reads from a `MemDecoder`. With the slice-based implementation we need to do those with `data[position..position + len]` , which needs to account for `position + len` wrapping. It would be possible to dodge the first bounds check if we stored a slice that starts at `position`, but that would require updating the pointer and length on every read.
This PR also embeds the failure path in a separate function, which means that this PR should subsume all the perf wins observed in https://github.com/rust-lang/rust/pull/109867.
They're semantically the same, so this means the backends don't need to handle the intrinsic and means fewer MIR basic blocks in pointer arithmetic code.
Use `?0` notation for ty/ct/int/float/region vars
Aligns the notation for infer vars that T-types and friends most often uses for inference variables with the notation in the compiler (which is kinda a sigil nightmare IMO: `_#`) by adopting `?0` style infer vars.
This mostly affects debug output since verbose infer vars shouldn't show up in user-facing places.
Does this need an MCP? It's debug output, so I'm thinking no, but happy to open one. 🤔
r? types
Consider polarity in new solver
It's kinda ugly to have a polarity check in all of the builtin impls -- I guess I could consider the polarity at the top of assemble-builtin but that would require adding a polarity fn to `GoalKind`...
🤷 putting this up just so i dont forget, since it's needed to bootstrap core during coherence (this alone does not allow core to bootstrap though, additional work is needed!)
r? ``@lcnr``
Add `impl_tag!` macro to implement `Tag` for tagged pointer easily
r? `@Nilstrieb`
This should also lifts the need to think about safety from the callers (`impl_tag!` is robust (ish, see the macro issue)) and removes the possibility of making a "weird" `Tag` impl.
Switch to `EarlyBinder` for `explicit_item_bounds`
Part of the work to finish https://github.com/rust-lang/rust/issues/105779.
This PR adds `EarlyBinder` to the return type of the `explicit_item_bounds` query and removes `bound_explicit_item_bounds`.
r? `@compiler-errors` (hope it's okay to request you, since you reviewed #110299 and #110498😃)
[LLVM17] Adapt to `ExplicitEmulatedTLS` removal.
0d333bf0e3 removed the `ExplicitEmulatedTLS` field from `TargetOptions`.
Before that commit, `TargetMachine::useEmulatedTLS()` fell back to `TheTriple.hasDefaultEmulatedTLS()` if `ExplicitEmulatedTLS` was `false`/unset.
After that commit, `TargetMachine::useEmulatedTLS()` directly returns `Options.EmulatedTLS`, and the fallback to `TheTriple.hasDefaultEmulatedTLS()` was moved to `InitTargetOptionsFromCodeGenFlags`.
Since `rustc` does not use `InitTargetOptionsFromCodeGenFlags` (AFAICT) and instead manually builds `TargetOptions`, this PR initializes `EmulatedTLS` to `TheTriple.hasDefaultEmulatedTLS()`.
(I'm not really familiar with the details of what this option does, or if there are any tests that depend on `hasDefaultEmulatedTLS` being used correctly, so this PR is mostly untested (it does compile against LLVM17, though)).
`@rustbot` label: +llvm-main
Break up long function in trait selection error reporting + clean up nearby code
- Move blocks of code into their own functions
- Replace a few function argument types with their type aliases
- Create "AppendConstMessage" enum to replace a nested `Option`.
Add size asserts for MIR `SourceScopeData` & `VarDebugInfo`
There's vectors of both of these in `mir::Body`, so might as well track them.
(I was pondering adding something to one or the other, so wanted this to see the memory impact.)
Normalize types and consts in MIR opts.
Some passes were using a non-RevealAll param_env, which is needlessly restrictive in mir-opts.
As a drive-by, we normalize all constants, since just normalizing their types is not enough.
Add `intrinsics::transmute_unchecked`
This takes a whole 3 lines in `compiler/` since it lowers to `CastKind::Transmute` in MIR *exactly* the same as the existing `intrinsics::transmute` does, it just doesn't have the fancy checking in `hir_typeck`.
Added to enable experimenting with the request in <https://github.com/rust-lang/rust/pull/106281#issuecomment-1496648190> and because the portable-simd folks might be interested for dependently-sized array-vector conversions.
It also simplifies a couple places in `core`.
See also https://github.com/rust-lang/rust/pull/108442#issuecomment-1474777273, where `CastKind::Transmute` was added having exactly these semantics before the lang meeting (which I wasn't in) independently expressed interest.
Impl `Copy` for most HIR types
This simplifies the invocation of the `arena_types` macro and probably
makes working with HIR nicer in general.
Based on #109588
Fix printing native CPU on cross-compiled compiler.
If `rustc` is cross-compiled from a different host, then the "native" entry in `rustc --print=target-cpus` would not appear. There is a check in the printing code that will avoid printing the "native" entry if the user has passed `--target`. However, that check was comparing the `--target` value with the `LLVM_TARGET_TRIPLE` which is the triple of the host that `rustc` was built on (the "build" target in Rust lingo), not the target it was being built for (the "host" in Rust lingo). This fixes it to use the target that LLVM was built for (which I'm pretty sure this is the correct function to determine that).
This fixes the cpu listing for aarch64-apple-darwin which is built on CI using the x86_64-apple-darwin host.
Remove the size of locals heuristic in MIR inlining
This heuristic doesn't necessarily correlate to complexity of the MIR Body. In particular, a lot of straight-line code in MIR tends to never reuse a local, even though any optimizer would effectively reuse the storage or just put everything in registers. So it doesn't even necessarily make sense that this would be a stack size heuristic.
So... what happens if we just delete the heuristic? The benchmark suite improves significantly. Less heuristics better?
r? `@cjgillot`
Run various queries from other queries instead of explicitly in phases
These are just legacy leftovers from when rustc didn't have a query system. While there are more cleanups of this sort that can be done here, I want to land them in smaller steps.
This phased order of query invocations was already a lie, as any query that looks at types (e.g. the wf checks run before) can invoke e.g. const eval which invokes borrowck, which invokes typeck, ...
Turn on ConstDebugInfo pass.
Split from https://github.com/rust-lang/rust/pull/103657
Moving those constant into debuginfo allows to shrink the number of locals and the actual size of the MIR body.
This takes a whole 3 lines in `compiler/` since it lowers to `CastKind::Transmute` in MIR *exactly* the same as the existing `intrinsics::transmute` does, it just doesn't have the fancy checking in `hir_typeck`.
Added to enable experimenting with the request in <https://github.com/rust-lang/rust/pull/106281#issuecomment-1496648190> and because the portable-simd folks might be interested for dependently-sized array-vector conversions.
It also simplifies a couple places in `core`.
Expect that equating a projection term always succeeds in new solver
These should never fail. If they do, we have a problem with the logic that replaces a projection goal's term with an unconstrained infer var. Let's make sure we ICE in that case.
Clone region var origins instead of taking them in borrowck
Fixes an issue with the new solver where reporting a borrow-checker error ICEs because it calls `InferCtxt::evaluate_obligation`.
This also removes a handful of unnecessary `tcx.infer_ctxt().build()` calls that are only there to mitigate this same exact issue, but with the old solver.
Fixescompiler-errors/next-solver-hir-issues#12.
----
This implements `@aliemjay's` solution where we just don't *take* the region constraints, but clone them. This potentially makes it easier to write a bug about taking region constraints twice or never at all, but again, not many folks are touching this code.
Report allocation errors as panics
OOM is now reported as a panic but with a custom payload type (`AllocErrorPanicPayload`) which holds the layout that was passed to `handle_alloc_error`.
This should be review one commit at a time:
- The first commit adds `AllocErrorPanicPayload` and changes allocation errors to always be reported as panics.
- The second commit removes `#[alloc_error_handler]` and the `alloc_error_hook` API.
ACP: https://github.com/rust-lang/libs-team/issues/192Closes#51540Closes#51245
Evaluate place expression in `PlaceMention`
https://github.com/rust-lang/rust/pull/102256 introduces a `PlaceMention(place)` MIR statement which keep trace of `let _ = place` statements from surface rust, but without semantics.
This PR proposes to change the behaviour of `let _ =` patterns with respect to the borrow-checker to verify that the bound place is live.
Specifically, consider this code:
```rust
let _ = {
let a = 5;
&a
};
```
This passes borrowck without error on stable. Meanwhile, replacing `_` by `_: _` or `_p` errors with "error[E0597]: `a` does not live long enough", [see playground](https://play.rust-lang.org/?version=stable&mode=debug&edition=2021&gist=c448d25a7c205dc95a0967fe96bccce8).
This PR *does not* change how `_` patterns behave with respect to initializedness: it remains ok to bind a moved-from place to `_`.
The relevant test is `tests/ui/borrowck/let_underscore_temporary.rs`. Crater check found no regression.
For consistency, this PR changes miri to evaluate the place found in `PlaceMention`, and report eventual dangling pointers found within it.
r? `@RalfJung`
Remove some uses of dynamic dispatch during monomorphization/partitioning.
This removes a few uses of dynamic dispatch and instead uses generics, as well as an enum to allow for other partitioning methods to be added later.
Print ty placeholders pretty
Makes anon placeholders print like `!0` instead of `Placeholder { ... }`.
```
rustc_trait_selection::solve::compute_well_formed_goal goal=Goal{
predicate: !0,
param_env: ParamEnv{
caller_bounds: [
Binder(TraitPredicate(<!0 as std::marker::Copy>, polarity: Positive), []),
Binder(TraitPredicate(<!0 as std::clone::Clone>, polarity: Positive), []),
Binder(TraitPredicate(<!0 as std::marker::Sized>, polarity: Positive), []),
],
reveal: UserFacing,
constness: NotConst,
}
}
```
cc `@BoxyUwU` who might care about this formatting decision
Stable hash tag (discriminant) of `GenericArg`
This is a continuation of my quest of removing `transmute` if generic args and types (#110496, #110599).
r? `@compiler-errors`
Add offset_of! macro (RFC 3308)
Implements https://github.com/rust-lang/rfcs/pull/3308 (tracking issue #106655) by adding the built in macro `core::mem::offset_of`. Two of the future possibilities are also implemented:
* Nested field accesses (without array indexing)
* DST support (for `Sized` fields)
I wrote this a few months ago, before the RFC merged. Now that it's merged, I decided to rebase and finish it.
cc `@thomcc` (RFC author)
Rollup of 5 pull requests
Successful merges:
- #110333 (rustc_metadata: Split `children` into multiple tables)
- #110501 (rustdoc: fix ICE from rustc_resolve and librustdoc parse divergence)
- #110608 (Specialize some `io::Read` and `io::Write` methods for `VecDeque<u8>` and `&[u8]`)
- #110632 (Panic instead of truncating if the incremental on-disk cache is too big)
- #110633 (More `mem::take` in `library`)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Ensure mir_drops_elaborated_and_const_checked when requiring codegen.
mir_drops_elaborated_and_const_checked may emit errors while codegen has started, and the compiler would exit leaving object code files around.
Found by `@cuviper` in https://github.com/rust-lang/rust/issues/109731
Deduplicate unreachable blocks, for real this time
In https://github.com/rust-lang/rust/pull/106428 (in particular 41eda69516) we noticed that inlining `unreachable_unchecked` can produce duplicate unreachable blocks. So we improved two MIR optimizations: `SimplifyCfg` was given a simplify to deduplicate unreachable blocks, then `InstCombine` was given a combiner to deduplicate switch targets that point at the same block. The problem is that change doesn't actually work.
Our current pass order is
```
SimplifyCfg (does nothing relevant to this situation)
Inline (produces multiple unreachable blocks)
InstCombine (doesn't do anything here, oops)
SimplifyCfg (produces the duplicate SwitchTargets that InstCombine is looking for)
```
So in here, I have factored out the specific function from `InstCombine` and placed it inside the simplify that produces the case it is looking for. This should ensure that it runs in the scenario it was designed for.
Fixes https://github.com/rust-lang/rust/issues/110551
r? `@cjgillot`
Panic instead of truncating if the incremental on-disk cache is too big
It seems _unlikely_ that anyone would hit this truncation, but if this `as` does actually truncate, that seems incredibly bad.
rustc_metadata: Split `children` into multiple tables
instead of merging everything into a single bag.
If it's acceptable from performance point of view, then it's more clear to keep this stuff organized more in accordance with its use.
instead of merging everything into a single bag.
If it's acceptable from performance point of view, then it's more clear to keep this stuff organized more in accordance with its use.
Added byte position range for `proc_macro::Span`
Currently, the [`Debug`](https://doc.rust-lang.org/beta/proc_macro/struct.Span.html#impl-Debug-for-Span) implementation for [`proc_macro::Span`](https://doc.rust-lang.org/beta/proc_macro/struct.Span.html#) calls the debug function implemented in the trait implementation of `server::Span` for the type `Rustc` in the `rustc-expand` crate.
The current implementation, of the referenced function, looks something like this:
```rust
fn debug(&mut self, span: Self::Span) -> String {
if self.ecx.ecfg.span_debug {
format!("{:?}", span)
} else {
format!("{:?} bytes({}..{})", span.ctxt(), span.lo().0, span.hi().0)
}
}
```
It returns the byte position of the [`Span`](https://doc.rust-lang.org/beta/proc_macro/struct.Span.html#) as an interpolated string.
Because this is currently the only way to get a spans position in the file, I might lead someone, who is interested in this information, to parsing this interpolated string back into a range of bytes, which I think is a very non-rusty way.
The proposed `position()`, method implemented in this PR, gives the ability to directly get this info.
It returns a [`std::ops::Range`](https://doc.rust-lang.org/std/ops/struct.Range.html#) wrapping the lowest and highest byte of the [`Span`](https://doc.rust-lang.org/beta/proc_macro/struct.Span.html#).
I put it behind the `proc_macro_span` feature flag because many of the other functions that have a similar footprint also are annotated with it, I don't actually know if this is right.
It would be great if somebody could take a look at this, thank you very much in advanced.
Allow to feed a value in another query's cache and remove `WithOptConstParam`
I used it to remove `WithOptConstParam` queries, as an example.
The idea is that a query (here `typeck(function)`) can write into another query's cache (here `type_of(anon const)`). The dependency node for `type_of` would depend on all the current dependencies of `typeck`.
There is still an issue with cycles: if `type_of(anon const)` is accessed before `typeck(function)`, we will still have the usual cycle. The way around this issue is to `ensure` that `typeck(function)` is called before accessing `type_of(anon const)`.
When replayed, we may the following cases:
- `typeck` is green, in that case `type_of` is green too, and all is right;
- `type_of` is green, `typeck` may still be marked as red (it depends on strictly more things than `type_of`) -> we verify that the saved value and the re-computed value of `type_of` have the same hash;
- `type_of` is red, then `typeck` is red -> it's the caller responsibility to ensure `typeck` is recomputed *before* `type_of`.
As `anon consts` have their own `DefPathData`, it's not possible to have the def-id of the anon-const point to something outside the original function, but the general case may have to be resolved before using this device more broadly.
There is an open question about loading from the on-disk cache. If `typeck` is loaded from the on-disk cache, the side-effect does not happen. The regular `type_of` implementation can go and fetch the correct value from the decoded `typeck` results, and the dep-graph will check that the hashes match, but I'm not sure we want to rely on this behaviour.
I specifically allowed to feed the value to `type_of` from inside a call to `type_of`. In that case, the dep-graph will check that the fingerprints of both values match.
This implementation is still very sensitive to cycles, and requires that we call `typeck(function)` before `typeck(anon const)`. The reason is that `typeck(anon const)` calls `type_of(anon const)`, which calls `typeck(function)`, which feeds `type_of(anon const)`, and needs to build the MIR so needs `typeck(anon const)`. The latter call would not cycle, since `type_of(anon const)` has been set, but I'd rather not remove the cycle check.
Track if EvalCtxt has been tainted, make sure it can't be used to make query responses after
Just some additional protection against missing probes or strange candidate assembly behavior in the new solver.
For background, we don't ever want to call `evaluate_added_goals_and_make_canonical_response` if a previous call to `try_evaluate_added_goals` has bailed with `NoSolution`, since our nested goals are left in an undefined state at that point. This most commonly suggests a missing `EvalCtxt::probe`, but could also signify some other shenanigans like dropping a `QueryResult` on the floor without properly `?`'ing it.
r? `@lcnr`
remove unused ftl messages
r? `@davidtwco`
does it make sense to check via tidy that there exist no ftl message names which are never mentioned in `compiler/**.rs`
Substitute missing trait items suggestion correctly
Properly substitute missing item suggestions, so that when they reference generics from their parent trait they actually have the right time for the impl.
Also, some other minor tweaks like using `/* Type */` to signify a GAT's type is actually missing, and fixing generic arg suggestions for GATs in general.
Enable flatten-format-args by default.
Part of https://github.com/rust-lang/rust/issues/99012.
This enables the `flatten-format-args` feature that was added by https://github.com/rust-lang/rust/pull/106824:
> This change inlines string literals, integer literals and nested format_args!() into format_args!() during ast lowering, making all of the following pairs result in equivalent hir:
>
> ```rust
> println!("Hello, {}!", "World");
> println!("Hello, World!");
> ```
>
> ```rust
> println!("[info] {}", format_args!("error"));
> println!("[info] error");
> ```
>
> ```rust
> println!("[{}] {}", status, format_args!("error: {}", msg));
> println!("[{}] error: {}", status, msg);
> ```
>
> ```rust
> println!("{} + {} = {}", 1, 2, 1 + 2);
> println!("1 + 2 = {}", 1 + 2);
> ```
>
> And so on.
>
> This is useful for macros. E.g. a `log::info!()` macro could just pass the tokens from the user directly into a `format_args!()` that gets efficiently flattened/inlined into a `format_args!("info: {}")`.
>
> It also means that `dbg!(x)` will have its file, line, and expression name inlined:
>
> ```rust
> eprintln!("[{}:{}] {} = {:#?}", file!(), line!(), stringify!(x), x); // before
> eprintln!("[example.rs:1] x = {:#?}", x); // after
> ```
>
> Which can be nice in some cases, but also means a lot more unique static strings than before if dbg!() is used a lot.
This is mostly an optimization, except that it will be visible through [`fmt::Arguments::as_str()`](https://doc.rust-lang.org/nightly/std/fmt/struct.Arguments.html#method.as_str).
In https://github.com/rust-lang/rust/pull/106823, there was already a libs-api FCP about the documentation of `fmt::Arguments::as_str()` to allow it to give `Some` rather than `None` depending on optimizations like this. That was just a documentation update though. This PR is the one that actually makes the user visible change:
```rust
assert_eq!(format_args!("abc").as_str(), Some("abc")); // Unchanged.
assert_eq!(format_args!("ab{}", "c").as_str(), Some("abc")); // Was `None` before!
```
Remove public doc(hidden) core::fmt::rt::v1
All the types used by format_arg!() are now lang items, so they are no longer required as publicly exported items.
Part of #99012
After this change, the `rt` module is private, and contains only three lang items used by format_args (`Placeholder`, `Alignment`, and `Count`): 441682cca9/library/core/src/fmt/rt.rs
Add support for the x86_64h-apple-darwin target
See https://github.com/rust-lang/compiler-team/issues/599 for MCP.
r? compiler-team
CC `@BlackHoleFox` who recently overhauled the apple target code in `rustc-target`.
## Target Support Checklist
> - A tier 3 target must have a designated developer or developers (the "target
> maintainers") on record to be CCed when issues arise regarding the target.
> (The mechanism to track and CC such developers may evolve over time.)
I'm the designated developer.
> - Targets must use naming consistent with any existing targets; for instance, a
> target for the same CPU or OS as an existing Rust target should use the same
> name for that CPU or OS. Targets should normally use the same names and
> naming conventions as used elsewhere in the broader ecosystem beyond Rust
> (such as in other toolchains), unless they have a very good reason to
> diverge. Changing the name of a target can be highly disruptive, especially
> once the target reaches a higher tier, so getting the name right is important
> even for a tier 3 target.
This uses the same naming conventions used for the other macOS targets (`-apple-darwin`), combined with the convention used by LLVM for the `x86_64h` targets. LLVM's convention matches the architecture name used when invoking various tools such as `lipo`, `arch`, and (IMO) there's not really a compelling reason to depart from it.
> - Target names should not introduce undue confusion or ambiguity unless
> absolutely necessary to maintain ecosystem compatibility. For example, if
> the name of the target makes people extremely likely to form incorrect
> beliefs about what it targets, the name should be changed or augmented to
> disambiguate it.
I don't think this is especially likely, although I suppose someone could mistake it for `x86_64-apple-darwin`.
> - If possible, use only letters, numbers, dashes and underscores for the name.
> Periods (`.`) are known to cause issues in Cargo.
👍
> - Tier 3 targets may have unusual requirements to build or use, but must not
> create legal issues or impose onerous legal terms for the Rust project or for
> Rust developers or users.
> - The target must not introduce license incompatibilities.
It does not.
> - Anything added to the Rust repository must be under the standard Rust
> license (`MIT OR Apache-2.0`).
It is.
> - The target must not cause the Rust tools or libraries built for any other
> host (even when supporting cross-compilation to the target) to depend
> on any new dependency less permissive than the Rust licensing policy. This
> applies whether the dependency is a Rust crate that would require adding
> new license exceptions (as specified by the `tidy` tool in the
> rust-lang/rust repository), or whether the dependency is a native library
> or binary. In other words, the introduction of the target must not cause a
> user installing or running a version of Rust or the Rust tools to be
> subject to any new license requirements.
There are no new dependencies that don't also apply to `x86_64-apple-darwin`.
> - Compiling, linking, and emitting functional binaries, libraries, or other
> code for the target (whether hosted on the target itself or cross-compiling
> from another target) must not depend on proprietary (non-FOSS) libraries.
> Host tools built for the target itself may depend on the ordinary runtime
> libraries supplied by the platform and commonly used by other applications
> built for the target, but those libraries must not be required for code
> generation for the target; cross-compilation to the target must not require
> such libraries at all. For instance, `rustc` built for the target may
> depend on a common proprietary C runtime library or console output library,
> but must not depend on a proprietary code generation library or code
> optimization library. Rust's license permits such combinations, but the
> Rust project has no interest in maintaining such combinations within the
> scope of Rust itself, even at tier 3.
This has the same requirements as the other macOS targets (e.g. `x86_64-apple-darwin` and similar).
> - "onerous" here is an intentionally subjective term. At a minimum, "onerous"
> legal/licensing terms include but are *not* limited to: non-disclosure
> requirements, non-compete requirements, contributor license agreements
> (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms,
> requirements conditional on the employer or employment of any particular
> Rust developers, revocable terms, any requirements that create liability
> for the Rust project or its developers or users, or any requirements that
> adversely affect the livelihood or prospects of the Rust project or its
> developers or users.
No change here.
> - Neither this policy nor any decisions made regarding targets shall create any
> binding agreement or estoppel by any party. If any member of an approving
> Rust team serves as one of the maintainers of a target, or has any legal or
> employment requirement (explicit or implicit) that might affect their
> decisions regarding a target, they must recuse themselves from any approval
> decisions regarding the target's tier status, though they may otherwise
> participate in discussions.
👍
> - This requirement does not prevent part or all of this policy from being
> cited in an explicit contract or work agreement (e.g. to implement or
> maintain support for a target). This requirement exists to ensure that a
> developer or team responsible for reviewing and approving a target does not
> face any legal threats or obligations that would prevent them from freely
> exercising their judgment in such approval, even if such judgment involves
> subjective matters or goes beyond the letter of these requirements.
👍
> - Tier 3 targets should attempt to implement as much of the standard libraries
> as possible and appropriate (`core` for most targets, `alloc` for targets
> that can support dynamic memory allocation, `std` for targets with an
> operating system or equivalent layer of system-provided functionality), but
> may leave some code unimplemented (either unavailable or stubbed out as
> appropriate), whether because the target makes it impossible to implement or
> challenging to implement. The authors of pull requests are not obligated to
> avoid calling any portions of the standard library on the basis of a tier 3
> target not implementing those portions.
The standard library tests seem to pass.
> - The target must provide documentation for the Rust community explaining how
> to build for the target, using cross-compilation if possible. If the target
> supports running binaries, or running tests (even if they do not pass), the
> documentation must explain how to run such binaries or tests for the target,
> using emulation if possible or dedicated hardware if necessary.
Documentation is provided.
> - Tier 3 targets must not impose burden on the authors of pull requests, or
> other developers in the community, to maintain the target. In particular,
> do not post comments (automated or manual) on a PR that derail or suggest a
> block on the PR based on a tier 3 target. Do not send automated messages or
> notifications (via any medium, including via ``@`)` to a PR author or others
> involved with a PR regarding a tier 3 target, unless they have opted into
> such messages.
Noted. This target is nearly identical to `x86_64-apple-darwin`, so this is
unlikely to cause issues anyway.
> - Backlinks such as those generated by the issue/PR tracker when linking to
> an issue or PR are not considered a violation of this policy, within
> reason. However, such messages (even on a separate repository) must not
> generate notifications to anyone involved with a PR who has not requested
> such notifications.
👍
> - Patches adding or updating tier 3 targets must not break any existing tier 2
> or tier 1 target, and must not knowingly break another tier 3 target without
> approval of either the compiler team or the maintainers of the other tier 3
> target.
> - In particular, this may come up when working on closely related targets,
> such as variations of the same architecture with different features. Avoid
> introducing unconditional uses of features that another variation of the
> target may not have; use conditional compilation or runtime detection, as
> appropriate, to let each target run code supported by that target.
👍
fix lint regression in `non_upper_case_globals`
Fixes#110573
The issue also exists for inherent associated types (where I copied my impl from). `EarlyContext` is more involved to fix in this way, so I'll leave it be for now (note it's unstable so that's not urgent).
r? `@compiler-errors`
`deny(unsafe_op_in_unsafe_fn)` in `rustc_data_structures`
r? `@Nilstrieb`
I couldn't bring myself to document the safety in big `unsafe` functions but ehh
Make `impl Debug for Span` not panic on not having session globals.
I hit the panic that this patch avoids while messing with the early lints in `rustc_session::config::build_session_options()`. The rest of that project is not finished, but this seemed like a self-contained improvement.
(Should changes like this add tests? I don't see similar unit tests.)
Add suggestion to use closure argument instead of a capture on borrowck error
Fixes#109271
r? `@compiler-errors`
This should probably be refined a bit, but opening a PR so that I don't forget anything.
Support AIX-style archive type
Reading facility of AIX big archive has been supported by `object` since 0.30.0.
Writing facility of AIX big archive has already been supported by `ar_archive_writer`, but we need to bump the version to support the new archive type enum.
While it might *seem* that this does something, it actually doesn't.
`mut_borrow_of_mutable_ref` returns a `bool` that is ignored by the
let-else. This was basically
```rust
if !self.body.local_decls.get(local).is_some() {
return
}
```
Which is pretty useless
Don't transmute `&List<GenericArg>` <-> `&List<Ty>`
In #93505 we allowed safely transmuting between `&List<GenericArg<'_>>` and `&List<Ty<'_>>`. This was possible because `GenericArg` is a tagged pointer and the tag for types is `0b00`, such that a `GenericArg` with a type inside has the same layout as `Ty`.
While this was meant as an optimization, it doesn't look like it was actually any perf or max-rss win (see https://github.com/rust-lang/rust/pull/94799#issuecomment-1064340003, https://github.com/rust-lang/rust/pull/94841, https://github.com/rust-lang/rust/pull/110496#issuecomment-1513799140).
Additionally the way it was done is quite fragile — `unsafe` code was not properly documented or contained in a module, types were not marked as `repr(C)` (making the transmutes possibly unsound). All of this makes the code maintenance harder and blocks other possible optimizations (as an example I've found out about these `transmutes` when my change caused them to sigsegv compiler).
Thus, I think we can safely (pun intended) remove those transmutes, making maintenance easier, optimizations possible, code less cursed, etc.
r? `@compiler-errors`
Add `rustc_fluent_macro` to decouple fluent from `rustc_macros`
Fluent, with all the icu4x it brings in, takes quite some time to compile. `fluent_messages!` is only needed in further downstream rustc crates, but is blocking more upstream crates like `rustc_index`. By splitting it out, we allow `rustc_macros` to be compiled earlier, which speeds up `x check compiler` by about 5 seconds (and even more after the needless dependency on `serde_json` is removed from `rustc_data_structures`).
Rollup of 7 pull requests
Successful merges:
- #110432 (Report more detailed reason why `Index` impl is not satisfied)
- #110451 (Minor changes to `IndexVec::ensure_contains_elem` & related methods)
- #110476 (Delay a good path bug on drop for `TypeErrCtxt` (instead of a regular delayed bug))
- #110498 (Switch to `EarlyBinder` for `collect_return_position_impl_trait_in_trait_tys`)
- #110507 (boostrap: print output during building tools)
- #110510 (Fix ICE for transmutability in candidate assembly)
- #110513 (make `non_upper_case_globals` lint not report trait impls)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
make `non_upper_case_globals` lint not report trait impls
We should not lint on trait `impl`s for `non_upper_case_globals`; the user doesn't have control over the name. This brings `non_upper_case_globals` into consistency with other `nonstandard_style` lints.
Switch to `EarlyBinder` for `collect_return_position_impl_trait_in_trait_tys`
Part of the work to finish https://github.com/rust-lang/rust/issues/105779.
This PR adds `EarlyBinder` to the return type of the `collect_return_position_impl_trait_in_trait_tys` query and removes `bound_return_position_impl_trait_in_trait_tys`.
r? `@lcnr`
Delay a good path bug on drop for `TypeErrCtxt` (instead of a regular delayed bug)
r? `@lcnr`
Perhaps we should just delete the `Drop` impl altogether though?
Fixesrust-lang/rust-clippy#10645
`@matthiaskrgr:` I don't know how to make a clippy test for this. Any idea? Clippy's UI tests run with `-D warnings` and I have no idea how to switch it off to make a test that triggers this ICE in the clippy test suite 🤣
Don't allocate on SimplifyCfg/Locals/Const on every MIR pass
Hey! 👋🏾 This is a first PR attempt to see if I could speed up some rustc internals.
Thought process:
```rust
pub struct SimplifyCfg {
label: String,
}
```
in [compiler/src/rustc_mir_transform/simplify.rs](7908a1d654/compiler/rustc_mir_transform/src/simplify.rs (L39)) fires multiple times per MIR analysis. This means that a likely string allocation is happening in each of these runs, which may add up, as they are not being lazily allocated or cached in between the different passes.
...yes, I know that adding a global static array is probably not the future-proof solution, but I wanted to lob this now as a proof of concept to see if it's worth shaving off a few cycles and then making more robust.
Encode hashes as bytes, not varint
In a few places, we store hashes as `u64` or `u128` and then apply `derive(Decodable, Encodable)` to the enclosing struct/enum. It is more efficient to encode hashes directly than try to apply some varint encoding. This PR adds two new types `Hash64` and `Hash128` which are produced by `StableHasher` and replace every use of storing a `u64` or `u128` that represents a hash.
Distribution of the byte lengths of leb128 encodings, from `x build --stage 2` with `incremental = true`
Before:
```
( 1) 373418203 (53.7%, 53.7%): 1
( 2) 196240113 (28.2%, 81.9%): 3
( 3) 108157958 (15.6%, 97.5%): 2
( 4) 17213120 ( 2.5%, 99.9%): 4
( 5) 223614 ( 0.0%,100.0%): 9
( 6) 216262 ( 0.0%,100.0%): 10
( 7) 15447 ( 0.0%,100.0%): 5
( 8) 3633 ( 0.0%,100.0%): 19
( 9) 3030 ( 0.0%,100.0%): 8
( 10) 1167 ( 0.0%,100.0%): 18
( 11) 1032 ( 0.0%,100.0%): 7
( 12) 1003 ( 0.0%,100.0%): 6
( 13) 10 ( 0.0%,100.0%): 16
( 14) 10 ( 0.0%,100.0%): 17
( 15) 5 ( 0.0%,100.0%): 12
( 16) 4 ( 0.0%,100.0%): 14
```
After:
```
( 1) 372939136 (53.7%, 53.7%): 1
( 2) 196240140 (28.3%, 82.0%): 3
( 3) 108014969 (15.6%, 97.5%): 2
( 4) 17192375 ( 2.5%,100.0%): 4
( 5) 435 ( 0.0%,100.0%): 5
( 6) 83 ( 0.0%,100.0%): 18
( 7) 79 ( 0.0%,100.0%): 10
( 8) 50 ( 0.0%,100.0%): 9
( 9) 6 ( 0.0%,100.0%): 19
```
The remaining 9 or 10 and 18 or 19 are `u64` and `u128` respectively that have the high bits set. As far as I can tell these are coming primarily from `SwitchTargets`.
rustc_metadata: Remove `Span` from `ModChild`
It can be decoded on demand from regular `def_span` tables.
Partially mitigates perf regressions from https://github.com/rust-lang/rust/pull/109500.
Fluent, with all the icu4x it brings in, takes quite some time to
compile. `fluent_messages!` is only needed in further downstream rustc
crates, but is blocking more upstream crates like `rustc_index`. By
splitting it out, we allow `rustc_macros` to be compiled earlier, which
speeds up `x check compiler` by about 5 seconds (and even more after the
needless dependency on `serde_json` is removed from
`rustc_data_structures`).
Spelling compiler
This is per https://github.com/rust-lang/rust/pull/110392#issuecomment-1510193656
I'm going to delay performing a squash because I really don't expect people to be perfectly happy w/ my changes, I really am a human and I really do make mistakes.
r? Nilstrieb
I'm going to be flying this evening, but I should be able to squash / respond to reviews w/in a day or two.
I tried to be careful about dropping changes to `tests`, afaict only two files had changes that were likely related to the changes for a given commit (this is where not having eagerly squashed should have given me an advantage), but, that said, picking things apart can be error prone.
Rollup of 7 pull requests
Successful merges:
- #109981 (Set commit information environment variables when building tools)
- #110348 (Add list of supported disambiguators and suffixes for intra-doc links in the rustdoc book)
- #110409 (Don't use `serde_json` to serialize a simple JSON object)
- #110442 (Avoid including dry run steps in the build metrics)
- #110450 (rustdoc: Fix invalid handling of nested items with `--document-private-items`)
- #110461 (Use `Item::expect_*` and `ImplItem::expect_*` more)
- #110465 (Assure everyone that `has_type_flags` is fast)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Don't use `serde_json` to serialize a simple JSON object
This avoids `rustc_data_structures` depending on `serde_json` which allows it to be compiled much earlier, unlocking most of rustc.
This used to not matter, but after #110407 we're not blocked on fluent anymore, which means that it's now a blocking edge.
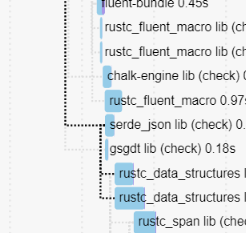
This saves a few more seconds.
cc ````@Zoxc```` who added it recently
Implement StableHasher::write_u128 via write_u64
In https://github.com/rust-lang/rust/pull/110367#issuecomment-1510114777 the cachegrind diffs indicate that nearly all the regression is from this:
```
22,892,558 ???:<rustc_data_structures::sip128::SipHasher128>::slice_write_process_buffer
-9,502,262 ???:<rustc_data_structures::sip128::SipHasher128>::short_write_process_buffer::<8>
```
Which happens because the diff for that perf run swaps a `Hash::hash` of a `u64` to a `u128`. But `slice_write_process_buffer` is a `#[cold]` function, and is for handling hashes of arbitrary-length byte arrays.
Using the much more optimizer-friendly `u64` path twice to hash a `u128` provides a nice perf boost in some benchmarks.
Tagged pointers, now with strict provenance!
This is a big refactor of tagged pointers in rustc, with three main goals:
1. Porting the code to the strict provenance
2. Cleanup the code
3. Document the code (and safety invariants) better
This PR has grown quite a bit (almost a complete rewrite at this point...), so I'm not sure what's the best way to review this, but reviewing commit-by-commit should be fine.
r? `@Nilstrieb`
Bypass the varint path when encoding InitMask
The data in a `InitMask` is stored as `u64` but it is a large bitmask (not numbers) so varint encoding doesn't make sense.
Check freeze with right param-env in `deduced_param_attrs`
We're checking if a trait (`Freeze`) holds in a polymorphic function, but not using that function's own (reveal-all) param-env. This causes us to try to eagerly normalize a specializable projection type that has no default value, which causes an ICE.
Fixes#110171
{kind=link}