This is an extension of the previous commit. It means the output of
something like this:
```
stringify!(let a: Vec<u32> = vec![];)
```
goes from this:
```
let a: Vec<u32> = vec![] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![];
```
`tokenstream::Spacing` appears on all `TokenTree::Token` instances,
both punct and non-punct. Its current usage:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `Alone` means "cannot join with the next token *or* can join with the
next token but that token is not a punct".
The fact that `Alone` is used for two different cases is awkward.
This commit augments `tokenstream::Spacing` with a new variant
`JointHidden`, resulting in:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `JointHidden` means "can join with the next token *and* that token is a
not a punct".
- `Alone` means "cannot join with the next token".
This *drastically* improves the output of `print_tts`. For example,
this:
```
stringify!(let a: Vec<u32> = vec![];)
```
currently produces this string:
```
let a : Vec < u32 > = vec! [] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![] ;
```
(The space after the `]` is because `TokenTree::Delimited` currently
doesn't have spacing information. The subsequent commit fixes this.)
The new `print_tts` doesn't replicate original code perfectly. E.g.
multiple space characters will be condensed into a single space
character. But it's much improved.
`print_tts` still produces the old, uglier output for code produced by
proc macros. Because we have to translate the generated code from
`proc_macro::Spacing` to the more expressive `token::Spacing`, which
results in too much `proc_macro::Along` usage and no
`proc_macro::JointHidden` usage. So `space_between` still exists and
is used by `print_tts` in conjunction with the `Spacing` field.
This change will also help with the removal of `Token::Interpolated`.
Currently interpolated tokens are pretty-printed nicely via AST pretty
printing. `Token::Interpolated` removal will mean they get printed with
`print_tts`. Without this change, that would result in much uglier
output for code produced by decl macro expansions. With this change, AST
pretty printing and `print_tts` produce similar results.
The commit also tweaks the comments on `proc_macro::Spacing`. In
particular, it refers to "compound tokens" rather than "multi-char
operators" because lifetimes aren't operators.
recurse into refs when comparing tys for diagnostics
before:

after:
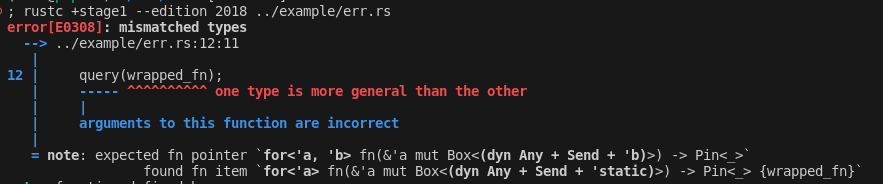
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
never_patterns: Parse match arms with no body
Never patterns are meant to signal unreachable cases, and thus don't take bodies:
```rust
let ptr: *const Option<!> = ...;
match *ptr {
None => { foo(); }
Some(!),
}
```
This PR makes rustc accept the above, and enforces that an arm has a body xor is a never pattern. This affects parsing of match arms even with the feature off, so this is delicate. (Plus this is my first non-trivial change to the parser).
~~The last commit is optional; it introduces a bit of churn to allow the new suggestions to be machine-applicable. There may be a better solution? I'm not sure.~~ EDIT: I removed that commit
r? `@compiler-errors`
Remove `#[rustc_host]`, use internal desugaring
Also removed a way for users to explicitly specify the host param since that isn't particularly useful. This should eliminate any pain with encoding attributes across crates and etc.
r? `@compiler-errors`
Pretty print `Fn<(..., ...)>` trait refs with parentheses (almost) always
It's almost always better, at least in diagnostics, to print `Fn(i32, u32)` instead of `Fn<(i32, u32)>`.
Related to but doesn't fix#118225. That needs a separate fix.
Stabilize C string literals
RFC: https://rust-lang.github.io/rfcs/3348-c-str-literal.html
Tracking issue: https://github.com/rust-lang/rust/issues/105723
Documentation PR (reference manual): https://github.com/rust-lang/reference/pull/1423
# Stabilization report
Stabilizes C string and raw C string literals (`c"..."` and `cr#"..."#`), which are expressions of type [`&CStr`](https://doc.rust-lang.org/stable/core/ffi/struct.CStr.html). Both new literals require Rust edition 2021 or later.
```rust
const HELLO: &core::ffi::CStr = c"Hello, world!";
```
C strings may contain any byte other than `NUL` (`b'\x00'`), and their in-memory representation is guaranteed to end with `NUL`.
## Implementation
Originally implemented by PR https://github.com/rust-lang/rust/pull/108801, which was reverted due to unintentional changes to lexer behavior in Rust editions < 2021.
The current implementation landed in PR https://github.com/rust-lang/rust/pull/113476, which restricts C string literals to Rust edition >= 2021.
## Resolutions to open questions from the RFC
* Adding C character literals (`c'.'`) of type `c_char` is not part of this feature.
* Support for `c"..."` literals does not prevent `c'.'` literals from being added in the future.
* C string literals should not be blocked on making `&CStr` a thin pointer.
* It's possible to declare constant expressions of type `&'static CStr` in stable Rust (as of v1.59), so C string literals are not adding additional coupling on the internal representation of `CStr`.
* The unstable `concat_bytes!` macro should not accept `c"..."` literals.
* C strings have two equally valid `&[u8]` representations (with or without terminal `NUL`), so allowing them to be used in `concat_bytes!` would be ambiguous.
* Adding a type to represent C strings containing valid UTF-8 is not part of this feature.
* Support for a hypothetical `&Utf8CStr` may be explored in the future, should such a type be added to Rust.
Fix `PartialEq` args when `#[const_trait]` is enabled
This is based off of your PR that enforces effects on all methods, so just see the last commits.
r? fee1-dead
Suggest `let` or `==` on typo'd let-chain
When encountering a bare assignment in a let-chain, suggest turning the
assignment into a `let` expression or an equality check.
```
error: expected expression, found `let` statement
--> $DIR/bad-if-let-suggestion.rs:5:8
|
LL | if let x = 1 && i = 2 {}
| ^^^^^^^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
help: you might have meant to continue the let-chain
|
LL | if let x = 1 && let i = 2 {}
| +++
help: you might have meant to compare for equality
|
LL | if let x = 1 && i == 2 {}
| +
```
When encountering a bare assignment in a let-chain, suggest turning the
assignment into a `let` expression or an equality check.
```
error: expected expression, found `let` statement
--> $DIR/bad-if-let-suggestion.rs:5:8
|
LL | if let x = 1 && i = 2 {}
| ^^^^^^^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
help: you might have meant to continue the let-chain
|
LL | if let x = 1 && let i = 2 {}
| +++
help: you might have meant to compare for equality
|
LL | if let x = 1 && i == 2 {}
| +
```
effects: Run `enforce_context_effects` for all method calls
So that we also perform checks when overloaded `PartialEq`s are called.
r? `@compiler-errors`
Rewrite exhaustiveness in one pass
This is at least my 4th attempt at this in as many years x) Previous attempts were all too complicated or too slow. But we're finally here!
The previous version of the exhaustiveness algorithm computed reachability for each arm then exhaustiveness of the whole match. Since each of these steps does roughly the same things, this rewrites the algorithm to do them all in one go. I also think this makes things much simpler.
I also rewrote the documentation of the algorithm in depth. Hopefully it's up-to-date and easier to follow now. Plz comment if anything's unclear.
r? `@oli-obk` I think you're one of the rare other people to understand the exhaustiveness algorithm?
cc `@varkor` I know you're not active anymore, but if you feel like having a look you might enjoy this :D
Fixes https://github.com/rust-lang/rust/issues/79307
Fixes error count display is different when there's only one error left
Supersedes #114759
### What did I do?
I did the small change in `rustc_errors` by hand. Then I did the other changes in `/compiler` by hand, those were just find replace on `*.rs` in the workspace. The changes in run-make are find replace for `run-make` in the workspace.
All other changes are blessed using `x test TEST --bless`. I blessed the tests that were blessed in #114759.
### how to review this nightmare
ping bors with an `r+`. You should check that my logic is sound and maybe quickly scroll through the diff, but fully verifying it seems fairly hard to impossible. I did my best to do this correctly.
Thank you `@adrianEffe` for bringing this up and your initial implementation.
cc `@flip1995,` you said you want to do a subtree sync asap
cc `@RalfJung` maybe you want to do a quick subtree sync afterwards as well for Miri
r? `@WaffleLapkin`
Deny more `~const` trait bounds
thereby fixing a family of ICEs (delayed bugs) for `feature(const_trait_impl, effects)` code.
As discussed
r? `@fee1-dead`
patterns: reject raw pointers that are not just integers
Matching against `0 as *const i32` is fine, matching against `&42 as *const i32` is not.
This extends the existing check against function pointers and wide pointers: we now uniformly reject all these pointer types during valtree construction, and then later lint because of that. See [here](https://github.com/rust-lang/rust/pull/116930#issuecomment-1784654073) for some more explanation and context.
Also fixes https://github.com/rust-lang/rust/issues/116929.
Cc `@oli-obk` `@lcnr`
Cleanup `rustc_mir_build/../check_match.rs`
The file had become pretty unwieldy, with a fair amount of duplication. As a bonus, I discovered that we weren't running some pattern checks in if-let chains.
I recommend looking commit-by-commit. The last commit is a whim, I think it makes more sense that way but I don't hold this opinion strongly.
Allows `#[diagnostic::on_unimplemented]` attributes to have multiple
notes
This commit extends the `#[diagnostic::on_unimplemented]` (and `#[rustc_on_unimplemented]`) attributes to allow multiple `note` options. This enables emitting multiple notes for custom error messages. For now I've opted to not change any of the existing usages of `#[rustc_on_unimplemented]` and just updated the relevant compile tests.
r? `@compiler-errors`
I'm happy to adjust any of the existing changed location to emit the old error message if that's desired.
Allow partially moved values in match
This PR attempts to unify the behaviour between `let _ = PLACE`, `let _: TY = PLACE;` and `match PLACE { _ => {} }`.
The logical conclusion is that the `match` version should not check for uninitialised places nor check that borrows are still live.
The `match PLACE {}` case is handled by keeping a `FakeRead` in the unreachable fallback case to verify that `PLACE` has a legal value.
Schematically, `match PLACE { arms }` in surface rust becomes in MIR:
```rust
PlaceMention(PLACE)
match PLACE {
// Decision tree for the explicit arms
arms,
// An extra fallback arm
_ => {
FakeRead(ForMatchedPlace, PLACE);
unreachable
}
}
```
`match *borrow { _ => {} }` continues to check that `*borrow` is live, but does not read the value.
`match *borrow {}` both checks that `*borrow` is live, and fake-reads the value.
Continuation of ~https://github.com/rust-lang/rust/pull/102256~ ~https://github.com/rust-lang/rust/pull/104844~
Fixes https://github.com/rust-lang/rust/issues/99180https://github.com/rust-lang/rust/issues/53114
notes
This commit extends the `#[diagnostic::on_unimplemented]` (and
`#[rustc_on_unimplemented]`) attributes to allow multiple `note`
options. This enables emitting multiple notes for custom error messages.
For now I've opted to not change any of the existing usages of
`#[rustc_on_unimplemented]` and just updated the relevant compile tests.
Mention the syntax for `use` on `mod foo;` if `foo` doesn't exist
Newcomers might get confused that `mod` is the only way of defining scopes, and that it can be used as if it were `use`.
Fix#69492.
Lint `non_exhaustive_omitted_patterns` by columns
This is a rework of the `non_exhaustive_omitted_patterns` lint to make it more consistent. The intent of the lint is to help consumers of `non_exhaustive` enums ensure they stay up-to-date with all upstream variants. This rewrite fixes two cases we didn't handle well before:
First, because of details of exhaustiveness checking, the following wouldn't lint `Enum::C` as missing:
```rust
match Some(x) {
Some(Enum::A) => {}
Some(Enum::B) => {}
_ => {}
}
```
Second, because of the fundamental workings of exhaustiveness checking, the following would treat the `true` and `false` cases separately and thus lint about missing variants:
```rust
match (true, x) {
(true, Enum::A) => {}
(true, Enum::B) => {}
(false, Enum::C) => {}
_ => {}
}
```
Moreover, it would correctly not lint in the case where the pair is flipped, because of asymmetry in how exhaustiveness checking proceeds.
A drawback is that it no longer makes sense to set the lint level per-arm. This will silently break the lint for current users of it (but it's behind a feature gate so that's ok).
The new approach is now independent of the exhaustiveness algorithm; it's a separate pass that looks at patterns column by column. This is another of the motivations for this: I'm glad to move it out of the algorithm, it was akward there.
This PR is almost identical to https://github.com/rust-lang/rust/pull/111651. cc `@eholk` who reviewed it at the time. Compared to then, I'm more confident this is the right approach.
Previously, any associated function could have `~const` trait bounds on
generic parameters, which could lead to ICEs when these bounds were used
on associated functions of non-`#[const_trait] trait` or
non-`impl const` blocks.
Includes changes as per @fee1-dead's comments in #116210.
Rollup of 6 pull requests
Successful merges:
- #115770 (Match on elem first while building move paths)
- #115999 (Capture scrutinee of if let guards correctly)
- #116056 (Make unsized casts illegal)
- #116061 (Remove TaKO8Ki from review rotation)
- #116062 (Change `start` to `#[start]` in some diagnosis)
- #116067 (Open the FileEncoder file for reading and writing)
r? `@ghost`
`@rustbot` modify labels: rollup
[breaking change] Validate crate name in `--extern` [MCP 650]
Reject non-ASCII-identifier crate names passed to the CLI option `--extern` (`rustc`, `rustdoc`).
Implements [MCP 650](https://github.com/rust-lang/compiler-team/issues/650) (except that we only allow ASCII identifiers not arbitrary Rust identifiers).
Fixes#113035.
[As mentioned on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/233931-t-compiler.2Fmajor-changes/topic/Disallow.20non-identifier-valid.20--extern.20cr.E2.80.A6.20compiler-team.23650/near/376826988), doing a crater run probably doesn't make sense since it wouldn't yield anything. Most users don't interact with `rustc` directly but only ever through Cargo which always passes a valid crate name to `--extern` when it invokes `rustc` and `rustdoc`. In any case, the user wouldn't be able to use such a crate name in the source code anyway.
Note that I'm not using [`rustc_session::output::validate_crate_name`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_session/output/fn.validate_crate_name.html) (used for `--crate-name` and `#![crate_name]`) since the latter doesn't reject non-ASCII crate names and ones that start with a digit.
As an aside, I've also thought about getting rid of `validate_crate_name` entirely in a separate PR (with another MCP) in favor of `is_ascii_ident` to reject more weird `--crate-name`s, `#![crate_name]`s and file names but I think that would lead to a lot of actual breakage, namely because of file names starting with a digit. In `tests/ui` 9 tests would be impacted for example.
CC `@estebank`
r? `@est31`
Fallback effects even if types also fallback
`||` is short circuiting, so if we do ty/int var fallback, we *don't* do effect fallback 😸
r? `@fee1-dead` or `@oli-obk`
Fixes#115791Fixes#115842
Improve invalid let expression handling
- Move all of the checks for valid let expression positions to parsing.
- Add a field to ExprKind::Let in AST/HIR to mark whether it's in a valid location.
- Suppress some later errors and MIR construction for invalid let expressions.
- Fix a (drop) scope issue that was also responsible for #104172.
Fixes#104172Fixes#104868
- Add doc comment to new type
- Restore "only supported directly in conditions of `if` and `while` expressions" note
- Rename variant with clearer name
Previously some invalid let expressions would result in both a feature
error and a parsing error. Avoid this and ensure that we only emit the
parsing error when this happens.
There was an incomplete version of the check in parsing and a second
version in AST validation. This meant that some, but not all, invalid
uses were allowed inside macros/disabled cfgs. It also means that later
passes have a hard time knowing when the let expression is in a valid
location, sometimes causing ICEs.
- Add a field to ExprKind::Let in AST/HIR to mark whether it's in a
valid location.
- Suppress later errors and MIR construction for invalid let
expressions.
Lower `Or` pattern without allocating place
cc `@azizghuloum` `@cjgillot`
Related to #111583 and #111644
While reviewing #111644, it occurs to me that while we directly lower conjunctive predicates, which are connected with `&&`, into the desirable control flow, today we don't directly lower the disjunctive predicates, which are connected with `||`, in the similar fashion. Instead, we allocate a place for the boolean temporary to hold the result of evaluating the `||` expression.
Usually I would expect optimization at later stages to "inline" the evaluation of boolean predicates into simple CFG, but #111583 is an example where `&&` is failing to be optimized away and the assembly shows that both the expensive operands are evaluated. Therefore, I would like to make a small change to make the CFG a bit more straight-forward without invoking the `as_temp` machinery, and plus avoid allocating the place to hold the boolean result as well.
On the following example, point at `String` instead of the whole type:
```
error[E0277]: the trait bound `String: Copy` is not satisfied
--> $DIR/own-bound-span.rs:14:24
|
LL | let _: <S as D>::P<String>;
| ^^^^^^ the trait `Copy` is not implemented for `String`
|
note: required by a bound in `D::P`
--> $DIR/own-bound-span.rs:4:15
|
LL | type P<T: Copy>;
| ^^^^ required by this bound in `D::P`
```
Fix #[inline(always)] on closures with target feature 1.1
Fixes#108655. I think this is the most obvious solution that isn't overly complicated. The comment includes more justification, but I think this is likely better than demoting the `#[inline(always)]` to `#[inline]`, since existing code is unaffected.
Better diagnostics for dlltool errors.
When dlltool fails, show the full command that was executed. In particular, llvm-dlltool is not very helpful, printing a generic usage message rather than what actually went wrong, so stdout and stderr aren't of much use when troubleshooting.
When dlltool fails, show the full command that was executed. In
particular, llvm-dlltool is not very helpful, printing a generic usage
message rather than what actually went wrong, so stdout and stderr
aren't of much use when troubleshooting.
(re-)tighten sourceinfo span of adjustments in MIR
Diagnostics rely on the spans of MIR statements being (approximately) correct in order to give suggestions relative to that span (i.e. `shrink_to_hi` and `shrink_to_lo`).
I discovered that we're *intentionally* lowering THIR exprs with their parent expr's span if they come from adjustments that are due to a parent expression. While I understand why that may be desirable to demonstrate the relationship of an adjustment and the expression that requires it, it leads to
1. very verbose borrowck output
2. incorrect spans for suggestions
Some diagnostics get around that by giving suggestions relative to other spans we've collected during MIR lowering, such as the span of the method's identifier (e.g. `name` in `.name()`), but this doesn't work too well when things come from desugaring.
I assume it also has lead to numerous tweaks and complications to diagnostics code down the road, which this PR doesn't necessarily aim to fix but may open the gates to fixing later... The last three commits are simplifications due to the fact that we can assume that the move span actually points to what is being moved (and a test).
This regressed in #89110, which was debated somewhat in #90286. cc `@Aaron1011` who originally made this change.
r? diagnostics
Fixes#113547Fixes#111016
Revert the lexing of `c"…"` string literals
Fixes \[after beta-backport\] #113235.
Further progress is tracked in #113333.
This PR *manually* reverts parts of #108801 (since a git-revert would've been too coarse-grained & messy)
and git-reverts #111647.
CC `@fee1-dead` (#108801) `@klensy` (#111647)
r? `@compiler-errors`
`@rustbot` label F-c_str_literals beta-nominated
Add `implement_via_object` to `rustc_deny_explicit_impl` to control object candidate assembly
Some built-in traits are special, since they are used to prove facts about the program that are important for later phases of compilation such as codegen and CTFE. For example, the `Unsize` trait is used to assert to the compiler that we are able to unsize a type into another type. It doesn't have any methods because it doesn't actually *instruct* the compiler how to do this unsizing, but this is later used (alongside an exhaustive match of combinations of unsizeable types) during codegen to generate unsize coercion code.
Due to this, these built-in traits are incompatible with the type erasure provided by object types. For example, the existence of `dyn Unsize<T>` does not mean that the compiler is able to unsize `Box<dyn Unsize<T>>` into `Box<T>`, since `Unsize` is a *witness* to the fact that a type can be unsized, and it doesn't actually encode that unsizing operation in its vtable as mentioned above.
The old trait solver gets around this fact by having complex control flow that never considers object bounds for certain built-in traits:
2f896da247/compiler/rustc_trait_selection/src/traits/select/candidate_assembly.rs (L61-L132)
However, candidate assembly in the new solver is much more lovely, and I'd hate to add this list of opt-out cases into the new solver. Instead of maintaining this complex and hard-coded control flow, instead we can make this a property of the trait via a built-in attribute. We already have such a build attribute that's applied to every single trait that we care about: `rustc_deny_explicit_impl`. This PR adds `implement_via_object` as a meta-item to that attribute that allows us to opt a trait out of object-bound candidate assembly as well.
r? `@lcnr`
- Either explicitly annotate `let x: () = expr;` where `x` has unit
type, or remove the unit binding to leave only `expr;` instead.
- Fix disjoint-capture-in-same-closure test
- On compiler-error's suggestion of moving this lower down the stack,
along the path of `report_mismatched_types()`, which is used
by `rustc_hir_analysis` and `rustc_hir_typeck`.
- update ui tests, add test
- add suggestions for references to fn pointers
- modify `TypeErrCtxt::same_type_modulo_infer` to take `T: relate::Relate` instead of `Ty`