Deprecate `intrinsics::drop_in_place` and `collections::Bound`, which accidentally weren't deprecated
Fixes#82080.
I've taken the liberty of updating the `since` values to 1.52, since an unobservable deprecation isn't much of a deprecation (even the detailed release notes never bothered to mention these deprecations).
As mentioned in the issue I'm *pretty* sure that using a type alias for `Bound` is semantically equivalent to the re-export; [the reference implies](https://doc.rust-lang.org/reference/items/type-aliases.html) that type aliases only observably differ from types when used on unit structs or tuple structs, whereas `Bound` is an enum.
Add a check for ASCII characters in to_upper and to_lower
This extra check has better performance. See discussion here:
https://internals.rust-lang.org/t/to-upper-speed/13896
Thanks to `@gilescope` for helping discover and test this.
Deprecate RustcEncodable and RustcDecodable.
We can't remove the `RustcEncodable` and `RustcDecodable` derive macros from the prelude, but we can deprecate them.
Add `reverse` search alias for Iterator::rev()
When searching for "reverse" in rustdoc you can't find the rev method on Iterator so here is a search alias for that.
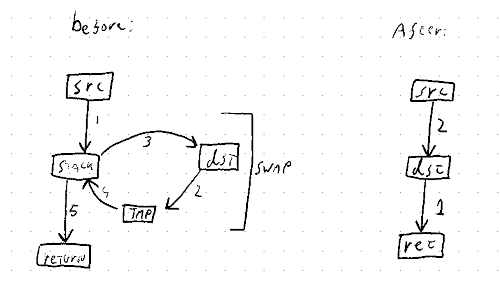
Don't implement mem::replace with mem::swap.
`swap` is a complicated operation, so this changes the implementation of `replace` to use `read` and `write` instead.
See https://github.com/rust-lang/rust/pull/83019.
I wrote there:
> Implementing the simpler operation (replace) with the much more complicated operation (swap) doesn't make a whole lot of sense. `replace` is just read+write, and the primitive for moving out of a `&mut`. `swap` is for doing that to *two* `&mut` at the same time, which is both more niche and more complicated (as shown by `swap_nonoverlapping_bytes`).
This could be especially interesting for `Option<VeryLargeStruct>::take()`, since swapping such a large structure with `swap_nonoverlapping_bytes` is going to be much less efficient than `ptr::write()`'ing a `None`.
But also for small values where `swap` just reads/writes using temporary variable, this makes a `replace` or `take` operation simpler:
convert slice doc link to intra-doc links
Continuing where #80189 stopped, with `core::slice`.
I had an issue with two dead links in my doc when implementing `Deref<Target = [T]>` for one of my type. This means that [`binary_search_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.binary_search_by_key) was available, but not [`sort_by_key`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.sort_by_key) even though it was linked in it's doc (same issue with [`as_ptr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_ptr) and [`as_mut_pbr`](https://doc.rust-lang.org/nightly/std/primitive.slice.html#method.as_mut_ptr)). It becomes available if I implement `DerefMut`, as it needs an `&mut self`.
<details>
<summary>Code that will have dead links in its doc</summary>
```rust
pub struct A;
pub struct B;
impl std::ops::Deref for B{
type Target = [A];
fn deref(&self) -> &Self::Target {
&A
}
}
```
</details>
I removed the link to `sort_by_key` from `binary_search_by_key` doc as I didn't find a nice way to have a live link:
- `binary_search_by_key` is in `core`
- `sort_by_key` is in `alloc`
- intra-doc link `slice::sort_by_key` doesn't work, as `alloc` is not available when `core` is being build (the warning can't be ignored: ```error[E0710]: an unknown tool name found in scoped lint: `rustdoc::broken_intra_doc_links` ```)
- keeping the link as an anchor `#method.sort_by_key` meant a dead link
- an absolute link would work but doesn't feel right...
Edition-specific preludes
This changes `{std,core}::prelude` to export edition-specific preludes under `rust_2015`, `rust_2018` and `rust_2021`. (As suggested in https://github.com/rust-lang/rust/issues/51418#issuecomment-395630382.) For now they all just re-export `v1::*`, but this allows us to add things to the 2021edition prelude soon.
This also changes the compiler to make the automatically injected prelude import dependent on the selected edition.
cc `@rust-lang/libs` `@djc`
Add Option::get_or_default
Tracking issue: #82901
The original issue is #55042, which was closed, but for an invalid reason (see discussion there). Opening this to reconsider (I hope that's okay). It seems like the only gap for `Option` being "entry-like".
I ran into a need for this method where I had a `Vec<Option<MyData>>` and wanted to do `vec[n].get_or_default().my_data_method()`. Using an `Option` as an inner component of a data structure is probably where the need for this will normally arise.
Stabilize `unsafe_op_in_unsafe_fn` lint
This makes it possible to override the level of the `unsafe_op_in_unsafe_fn`, as proposed in https://github.com/rust-lang/rust/issues/71668#issuecomment-729770896.
Tracking issue: #71668
r? ```@nikomatsakis``` cc ```@SimonSapin``` ```@RalfJung```
# Stabilization report
This is a stabilization report for `#![feature(unsafe_block_in_unsafe_fn)]`.
## Summary
Currently, the body of unsafe functions is an unsafe block, i.e. you can perform unsafe operations inside.
The `unsafe_op_in_unsafe_fn` lint, stabilized here, can be used to change this behavior, so performing unsafe operations in unsafe functions requires an unsafe block.
For now, the lint is allow-by-default, which means that this PR does not change anything without overriding the lint level.
For more information, see [RFC 2585](https://github.com/rust-lang/rfcs/blob/master/text/2585-unsafe-block-in-unsafe-fn.md)
### Example
```rust
// An `unsafe fn` for demonstration purposes.
// Calling this is an unsafe operation.
unsafe fn unsf() {}
// #[allow(unsafe_op_in_unsafe_fn)] by default,
// the behavior of `unsafe fn` is unchanged
unsafe fn allowed() {
// Here, no `unsafe` block is needed to
// perform unsafe operations...
unsf();
// ...and any `unsafe` block is considered
// unused and is warned on by the compiler.
unsafe {
unsf();
}
}
#[warn(unsafe_op_in_unsafe_fn)]
unsafe fn warned() {
// Removing this `unsafe` block will
// cause the compiler to emit a warning.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
#[deny(unsafe_op_in_unsafe_fn)]
unsafe fn denied() {
// Removing this `unsafe` block will
// cause a compilation error.
// (Also, no "unused unsafe" warning will be emitted here.)
unsafe {
unsf();
}
}
```
Added #[repr(transparent)] to core::cmp::Reverse
I found casting from an `&T` to an `&Reverse<T>` potentially useful, but found that `Reverse` was not `#[repr(transparent)]`, so after asking about it [on Reddit](https://www.reddit.com/r/rust/comments/le60uv/make_stdcmpreverse_reprtransparent_and_add_a/), I decided to go ahead and make a pull request which simply adds the attribute to the struct.
Implement built-in attribute macro `#[cfg_eval]` + some refactoring
This PR implements a built-in attribute macro `#[cfg_eval]` as it was suggested in https://github.com/rust-lang/rust/pull/79078 to avoid `#[derive()]` without arguments being abused as a way to configure input for other attributes.
The macro is used for eagerly expanding all `#[cfg]` and `#[cfg_attr]` attributes in its input ("fully configuring" the input).
The effect is identical to effect of `#[derive(Foo, Bar)]` which also fully configures its input before passing it to macros `Foo` and `Bar`, but unlike `#[derive]` `#[cfg_eval]` can be applied to any syntax nodes supporting macro attributes, not only certain items.
`cfg_eval` was the first name suggested in https://github.com/rust-lang/rust/pull/79078, but other alternatives are also possible, e.g. `cfg_expand`.
```rust
#[cfg_eval]
#[my_attr] // Receives `struct S {}` as input, the field is configured away by `#[cfg_eval]`
struct S {
#[cfg(FALSE)]
field: u8,
}
```
Tracking issue: https://github.com/rust-lang/rust/issues/82679
improve offset_from docs
`@thomcc` pointed out that the current docs leave it kind of unclear how one can satisfy the "no wrapping around `isize` or the address space" requirement of `offset_from`, so make the docs clearer about that.
FWIW, I don't think I entirely agree with that second paragraph about large objects (that I left mostly unchanged here). LLVM, to my knowledge, fundamentally assumes that all allocations fit into an `isize::MAX`. So in that sense creating a larger allocation is simply UB. I would expect a guarantee that Rust heap allocation methods will never return allocations larger than `isize::MAX` (or rather, Rust heap allocation methods should require that the `Layout` is no larger than `isize::MAX`). However, I cannot find any such requirement documented currently. Large allocations are not mentioned at all in the allocator docs, which is quite surprising -- even if we say that such allocations are not insta-UB (which I think is incompatible with LLVM), they are still extremely footgunny since `ptr::offset`/`ptr::add` do not support offsetting by more than `isize::MAX` bytes.
Furthermore, the allocator docs don't even say anything about allocations wrapping around the address space. But that is certainly something allocators must ensure never happens; we cannot expect clients to defend against this.
Cc `@rust-lang/wg-allocators`
Improve transmute docs with further clarifications
Closes#82493.
Please let me know if any of the new wording sounds off, English is not my mother tongue.
Prevent specialized ZipImpl from calling `__iterator_get_unchecked` twice with the same index
Fixes#82291
It's open for review, but conflicts with #82289, wait before merging. The conflict involves only the new test, so it should be rather trivial to fix.
Make some Option, Result methods unstably const
The following methods are now unstably const:
- Option::transpose
- Option::flatten
- Result::flatten
While some methods for could likely be made `const` in the future, nearly all of them require something to be dropped at compile-time, which isn't currently supported. The functions listed above should have a trivial path to stabilization.
Improve slice.binary_search_by()'s best-case performance to O(1)
This PR aimed to improve the [slice.binary_search_by()](https://doc.rust-lang.org/std/primitive.slice.html#method.binary_search_by)'s best-case performance to O(1).
# Noticed
I don't know why the docs of `binary_search_by` said `"If there are multiple matches, then any one of the matches could be returned."`, but the implementation isn't the same thing. Actually, it returns the **last one** if multiple matches found.
Then we got two options:
## If returns the last one is the correct or desired result
Then I can rectify the docs and revert my changes.
## If the docs are correct or desired result
Then my changes can be merged after fully reviewed.
However, if my PR gets merged, another issue raised: this could be a **breaking change** since if multiple matches found, the returning order no longer the last one instead of it could be any one.
For example:
```rust
let mut s = vec![0, 1, 1, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55];
let num = 1;
let idx = s.binary_search(&num);
s.insert(idx, 2);
// Old implementations
assert_eq!(s, [0, 1, 1, 1, 1, 2, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
// New implementations
assert_eq!(s, [0, 1, 1, 1, 2, 1, 2, 3, 5, 8, 13, 21, 34, 42, 55]);
```
# Benchmarking
**Old implementations**
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 4)
test slice::binary_search_l1_with_dups ... bench: 59 ns/iter (+/- 3)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 5)
test slice::binary_search_l2_with_dups ... bench: 77 ns/iter (+/- 17)
test slice::binary_search_l3 ... bench: 183 ns/iter (+/- 23)
test slice::binary_search_l3_with_dups ... bench: 185 ns/iter (+/- 19)
```
**New implementations (1)**
Implemented by this PR.
```rust
if cmp == Equal {
return Ok(mid);
} else if cmp == Less {
base = mid
}
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 58 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 4)
test slice::binary_search_l2 ... bench: 76 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 6)
test slice::binary_search_l3 ... bench: 200 ns/iter (+/- 30)
test slice::binary_search_l3_with_dups ... bench: 157 ns/iter (+/- 6)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 8)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 2)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l3 ... bench: 198 ns/iter (+/- 21)
test slice::binary_search_l3_with_dups ... bench: 158 ns/iter (+/- 11)
```
**New implementations (2)**
Suggested by `@nbdd0121` in [comment](https://github.com/rust-lang/rust/pull/74024#issuecomment-665430239).
```rust
base = if cmp == Greater { base } else { mid };
if cmp == Equal { break }
```
```sh
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 59 ns/iter (+/- 7)
test slice::binary_search_l1_with_dups ... bench: 37 ns/iter (+/- 5)
test slice::binary_search_l2 ... bench: 75 ns/iter (+/- 3)
test slice::binary_search_l2_with_dups ... bench: 56 ns/iter (+/- 3)
test slice::binary_search_l3 ... bench: 195 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 7)
$ ./x.py bench --stage 1 library/libcore
test slice::binary_search_l1 ... bench: 57 ns/iter (+/- 2)
test slice::binary_search_l1_with_dups ... bench: 38 ns/iter (+/- 2)
test slice::binary_search_l2 ... bench: 77 ns/iter (+/- 11)
test slice::binary_search_l2_with_dups ... bench: 57 ns/iter (+/- 4)
test slice::binary_search_l3 ... bench: 194 ns/iter (+/- 15)
test slice::binary_search_l3_with_dups ... bench: 151 ns/iter (+/- 18)
```
I run some benchmarking testings against on two implementations. The new implementation has a lot of improvement in duplicates cases, while in `binary_search_l3` case, it's a little bit slower than the old one.
Add diagnostic item to `Default` trait
This PR adds diagnostic item to `Default` trait to be used by rust-lang/rust-clippy#6562 issue.
Also fixes the obsolete path to the `symbols.rs` file in the comment.
{kind=link}