Add vectored read and write support
This functionality has lived for a while in the tokio ecosystem, where
it can improve performance by minimizing copies.
r? @alexcrichton
There are two big categories of changes in here
- Removing lifetimes from common traits that can essentially never user a lifetime from an input (particularly `Drop` & `Debug`)
- Forwarding impls that are only possible because the lifetime doesn't matter (like `impl<R: Read + ?Sized> Read for &mut R`)
I omitted things that seemed like they could be more controversial, like the handful of iterators that have a `Item: 'static` despite the iterator having a lifetime or the `PartialEq` implementations where the flipped one cannot elide the lifetime.
Fixed the link to the ? operator
I'm working on updating all broken links, but figured I'd break up the pull requests so they are easier to review, versus just one big pull request.
Defactored Bytes::read
Removed unneeded refactoring of read_one_byte, which removed the unneeded dynamic dispatch (`dyn Read`) used by that function.
This function is only used in one place in the entire Rust codebase; there doesn't seem to be a reason for it to exist (and there especially doesn't seem to be a reason for it to use dynamic dispatch)
The std::io::read main documentation can lead to error because the
buffer is prefilled with 10 zeros that will pad the response.
Using an empty vector is better.
The `read_to_end` documentation is already correct though.
This is my first rust PR, don't hesitate to tell me if I did something
wrong.
Optimize `read_to_end`.
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
show in docs whether the return type of a function impls Iterator/Read/Write
Closes#25928
This PR makes it so that when rustdoc documents a function, it checks the return type to see whether it implements a handful of specific traits. If so, it will print the impl and any associated types. Rather than doing this via a whitelist within rustdoc, i chose to do this by a new `#[doc]` attribute parameter, so things like `Future` could tap into this if desired.
### Known shortcomings
~~The printing of impls currently uses the `where` class over the whole thing to shrink the font size relative to the function definition itself. Naturally, when the impl has a where clause of its own, it gets shrunken even further:~~ (This is no longer a problem because the design changed and rendered this concern moot.)
The lookup currently just looks at the top-level type, not looking inside things like Result or Option, which renders the spotlights on Read/Write a little less useful:
<details><summary>`File::{open, create}` don't have spotlight info (pic of old design)</summary>
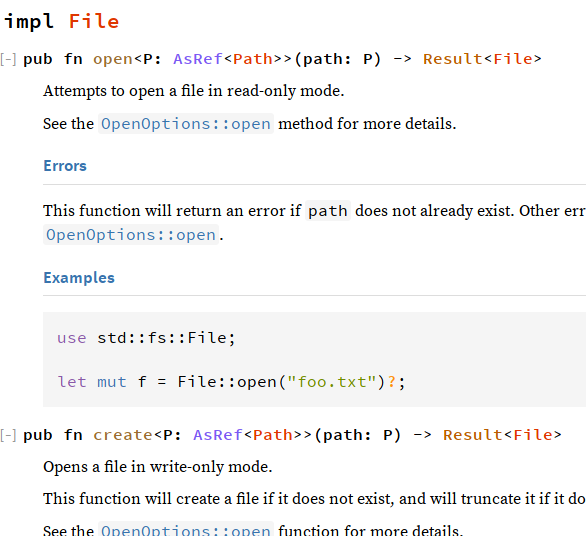
</details>
All three of the initially spotlighted traits are generically implemented on `&mut` references. Rustdoc currently treats a `&mut T` reference-to-a-generic as an impl on the reference primitive itself. `&mut Self` counts as a generic in the eyes of rustdoc. All this combines to create this lovely scene on `Iterator::by_ref`:
<details><summary>`Iterator::by_ref` spotlights Iterator, Read, and Write (pic of old design)</summary>
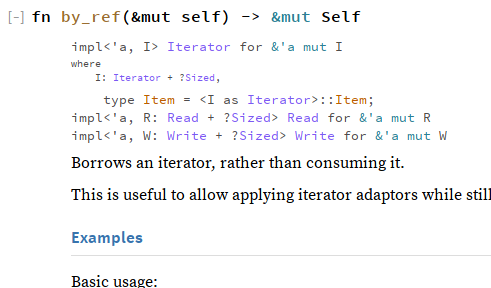
</details>
This patch makes `read_to_end` use Vec's memory-growth pattern rather
than using a custom pattern.
This has some interesting effects:
- If memory is reserved up front, `read_to_end` can be faster, as it
starts reading at the buffer size, rather than always starting at 32
bytes. This speeds up file reading by 2x in one of my use cases.
- It can reduce the number of syscalls when reading large files.
Previously, `read_to_end` would settle into a sequence of 8192-byte
reads. With this patch, the read size follows Vec's allocation
pattern. For example, on a 16MiB file, it can do 21 read syscalls
instead of 2057. In simple benchmarks of large files though, overall
speed is still dominated by the actual I/O.
- A downside is that Read implementations that don't implement
`initializer()` may see increased memory zeroing overhead.
I benchmarked this on a variety of data sizes, with and without
preallocated buffers. Most benchmarks see no difference, but reading
a small/medium file with a pre-allocated buffer is faster.
Remove sometimes in std::io::Read doc
We use it immediately in the next sentence, and the word is filler.
A different conversation to make is whether we want to call them Readers in the documentation at all. And whether it's actually called "Readers" elsewhere.
* Factor out the nigh-identical bodies of `_print` and `_eprint` to a helper
function `print_to` (I was sorely tempted to call it `_doprnt`).
* Update the issue number for the unstable `eprint` feature.
* Add entries to the "unstable book" for `eprint` and `eprint_internal`.
* Style corrections to the documentation.
* Since the switch to pulldown-cmark reference links need a blank line
before the URLs.
* Reference link references are not case sensitive.
* Doc comments need to be indented uniformly otherwise rustdoc gets
confused.
Add helpful hint in io docs about how ? is not allowed in main()
This is my effort to help alleviate the confusion caused by the error message:
```rust
error[E0277]: the trait bound `(): std::ops::Carrier` is not satisfied
--> hello_world.rs:72:5
|
72 | io::stdin().read_line(&mut d_input)?;
| ------------------------------------
| |
| the trait `std::ops::Carrier` is not implemented for `()`
| in this macro invocation
|
= note: required by `std::ops::Carrier::from_error`
error: aborting due to previous error
```
This has been discussed at length in https://github.com/rust-lang/rust/issues/35946, but I figured it would be helpful to mention in the docs.
Reading user input is one of the first things beginners will look up in the docs, so my thinking was they'd see this warning here and not have to deal with the [tricky error message](https://blog.rust-lang.org/2017/03/02/lang-ergonomics.html).
If you think this isn't the right place to put this in the docs, that's understandable, I'm open to suggestions for putting it elsewhere or removing it entirely.
Prior to this commit, most of the `BufRead` examples used `StdinLock` to
demonstrate how certain `BufRead` methods worked. Using `StdinLock` is
not ideal since:
* Relying on run-time data means we can't show concrete examples of how
these methods work up-front. The user is required to run them in order
to see how they behave.
* If the user tries to run an example in the playpen, it won't work
because the playpen doesn't support user input to stdin.
Working asmjs and wasm targets
This patch set results in a working standard library for the asmjs-unknown-emscripten and wasm32-unknown-emscripten targets. It is based on the work of @badboy and @rschulman.
It does a few things:
- Updates LLVM with the emscripten [fastcomp](https://github.com/rust-lang/llvm/pull/50) patches, which include the pnacl IR legalizer and the asm.js backend. This patch is thought not to have any significant effect on existing targets.
- Teaches rustbuild to correctly link C code with emscripten
- Updates gcc-rs to work correctly with emscripten
- Teaches rustbuild to run crate tests for emscripten with node
- Modifies Thread::new to return an error on emscripten, to facilitate debugging a common failure mode
- Modifies libtest to run in single-threaded mode for emscripten
- Ignores a host of tests that don't work yet, mostly dealing with threads and I/O
- Updates libc with wasm32 definitions (presently the same as asmjs)
- Adds a wasm32-unknown-emscripten target that feeds the output of LLVM's asmjs backend through emcc to generate wasm
Notes and caveats:
- This is only known to work with `--enable-rustbuild`.
- The wasm32 target can't be tested correctly yet because of issues in compiletest and limitations in node https://github.com/kripken/emscripten/issues/4542, but hello.rs does seem to work when run on node via the binaryen interpreter
- This requires an up to date installation of the emscripten sdk from its incoming branch
- Unwinding is very broken
- When enabling the emscripten targets jemalloc is disabled for all targets, which results in test failures for the host
Next steps are to fix the jemalloc issue, start building the two emscripten targets on the auto builders, then start producing nightlies.
https://github.com/rust-lang/rust/issues/36317 tracks work on this.
Fixes https://github.com/rust-lang/rust/issues/36515
Fixes https://github.com/rust-lang/rust/issues/36515
Fixes https://github.com/rust-lang/rust/issues/36356
{kind=link}
{kind=link}