We have several methods indicating the presence of errors, lint errors,
and delayed bugs. I find it frustrating that it's very unclear which one
you should use in any particular spot. This commit attempts to instill a
basic principle of "use the least general one possible", because that
reflects reality in practice -- `has_errors` is the least general one
and has by far the most uses (esp. via `abort_if_errors`).
Specifics:
- Add some comments giving some usage guidelines.
- Prefer `has_errors` to comparing `err_count` to zero.
- Remove `has_errors_or_span_delayed_bugs` because it's a weird one: in
the cases where we need to count delayed bugs, we should really be
counting lint errors as well.
- Rename `is_compilation_going_to_fail` as
`has_errors_or_lint_errors_or_span_delayed_bugs`, for consistency with
`has_errors` and `has_errors_or_lint_errors`.
- Change a few other `has_errors_or_lint_errors` calls to `has_errors`,
as per the "least general" principle.
This didn't turn out to be as neat as I hoped when I started, but I
think it's still an improvement.
`Diagnostic::code` has the type `DiagnosticId`, which has `Error` and
`Lint` variants. Plus `Diagnostic::is_lint` is a bool, which should be
redundant w.r.t. `Diagnostic::code`.
Seems simple. Except it's possible for a lint to have an error code, in
which case its `code` field is recorded as `Error`, and `is_lint` is
required to indicate that it's a lint. This is what happens with
`derive(LintDiagnostic)` lints. Which means those lints don't have a
lint name or a `has_future_breakage` field because those are stored in
the `DiagnosticId::Lint`.
It's all a bit messy and confused and seems unintentional.
This commit:
- removes `DiagnosticId`;
- changes `Diagnostic::code` to `Option<String>`, which means both
errors and lints can straightforwardly have an error code;
- changes `Diagnostic::is_lint` to `Option<IsLint>`, where `IsLint` is a
new type containing a lint name and a `has_future_breakage` bool, so
all lints can have those, error code or not.
In #119606 I added them and used a `_mv` suffix, but that wasn't great.
A `with_` prefix has three different existing uses.
- Constructors, e.g. `Vec::with_capacity`.
- Wrappers that provide an environment to execute some code, e.g.
`with_session_globals`.
- Consuming chaining methods, e.g. `Span::with_{lo,hi,ctxt}`.
The third case is exactly what we want, so this commit changes
`DiagnosticBuilder::foo_mv` to `DiagnosticBuilder::with_foo`.
Thanks to @compiler-errors for the suggestion.
We have `span_delayed_bug` and often pass it a `DUMMY_SP`. This commit
adds `delayed_bug`, which matches pairs like `err`/`span_err` and
`warn`/`span_warn`.
- `struct_foo` + `emit` -> `foo`
- `create_foo` + `emit` -> `emit_foo`
I have made recent commits in other PRs that have removed some of these
shortcuts for combinations with few uses, e.g.
`struct_span_err_with_code`. But for the remaining combinations that
have high levels of use, we might as well use them wherever possible.
This works for most of its call sites. This is nice, because `emit` very
much makes sense as a consuming operation -- indeed,
`DiagnosticBuilderState` exists to ensure no diagnostic is emitted
twice, but it uses runtime checks.
For the small number of call sites where a consuming emit doesn't work,
the commit adds `DiagnosticBuilder::emit_without_consuming`. (This will
be removed in subsequent commits.)
Likewise, `emit_unless` becomes consuming. And `delay_as_bug` becomes
consuming, while `delay_as_bug_without_consuming` is added (which will
also be removed in subsequent commits.)
All this requires significant changes to `DiagnosticBuilder`'s chaining
methods. Currently `DiagnosticBuilder` method chaining uses a
non-consuming `&mut self -> &mut Self` style, which allows chaining to
be used when the chain ends in `emit()`, like so:
```
struct_err(msg).span(span).emit();
```
But it doesn't work when producing a `DiagnosticBuilder` value,
requiring this:
```
let mut err = self.struct_err(msg);
err.span(span);
err
```
This style of chaining won't work with consuming `emit` though. For
that, we need to use to a `self -> Self` style. That also would allow
`DiagnosticBuilder` production to be chained, e.g.:
```
self.struct_err(msg).span(span)
```
However, removing the `&mut self -> &mut Self` style would require that
individual modifications of a `DiagnosticBuilder` go from this:
```
err.span(span);
```
to this:
```
err = err.span(span);
```
There are *many* such places. I have a high tolerance for tedious
refactorings, but even I gave up after a long time trying to convert
them all.
Instead, this commit has it both ways: the existing `&mut self -> Self`
chaining methods are kept, and new `self -> Self` chaining methods are
added, all of which have a `_mv` suffix (short for "move"). Changes to
the existing `forward!` macro lets this happen with very little
additional boilerplate code. I chose to add the suffix to the new
chaining methods rather than the existing ones, because the number of
changes required is much smaller that way.
This doubled chainging is a bit clumsy, but I think it is worthwhile
because it allows a *lot* of good things to subsequently happen. In this
commit, there are many `mut` qualifiers removed in places where
diagnostics are emitted without being modified. In subsequent commits:
- chaining can be used more, making the code more concise;
- more use of chaining also permits the removal of redundant diagnostic
APIs like `struct_err_with_code`, which can be replaced easily with
`struct_err` + `code_mv`;
- `emit_without_diagnostic` can be removed, which simplifies a lot of
machinery, removing the need for `DiagnosticBuilderState`.
rework `-Zverbose`
implements the changes described in https://github.com/rust-lang/compiler-team/issues/706
the first commit is only a name change from `-Zverbose` to `-Zverbose-internals` and does not change behavior. the second commit changes diagnostics.
possible follow up work:
- `ty::pretty` could print more info with `--verbose` than it does currently. `-Z verbose-internals` shows too much info in a way that's not helpful to users. michael had ideas about this i didn't fully understand: https://rust-lang.zulipchat.com/#narrow/stream/233931-t-compiler.2Fmajor-changes/topic/uplift.20some.20-Zverbose.20calls.20and.20rename.20to.E2.80.A6.20compiler-team.23706/near/408984200
- `--verbose` should imply `-Z write-long-types-to-disk=no`. the code in `ty_string_with_limit` should take `--verbose` into account (apparently this affects `Ty::sort_string`, i'm not familiar with this code). writing a file to disk should suggest passing `--verbose`.
r? `@compiler-errors` cc `@estebank`
`IntoDiagnostic` defaults to `ErrorGuaranteed`, because errors are the
most common diagnostic level. It makes sense to do likewise for the
closely-related (and much more widely used) `DiagnosticBuilder` type,
letting us write `DiagnosticBuilder<'a, ErrorGuaranteed>` as just
`DiagnosticBuilder<'a>`. This cuts over 200 lines of code due to many
multi-line things becoming single line things.
We can just get the error level in the `match` and then use
`DiagnosticBuilder::new`. This then means a number of `DiagCtxt`
functions are no longer needed, because this was the one place that used
them.
Note: the commit changes the treatment of spans for `Expect`, which was
different to all the other cases, but this has no apparent effect.
This lets different error levels share the same return type from
`emit_*`.
- A lot of inconsistencies in the `DiagCtxt` API are removed.
- `Noted` is removed.
- `FatalAbort` is introduced for fatal errors (abort via `raise`),
replacing the `EmissionGuarantee` impl for `!`.
- `Bug` is renamed `BugAbort` (to avoid clashing with `Level::Bug` and
to mirror `FatalAbort`), and modified to work in the new way with bug
errors (abort via panic).
- Various diagnostic creators and emitters updated to the new, better
signatures. Note that `DiagCtxt::bug` no longer needs to call
`panic_any`, because `emit` handles that.
Also shorten the obnoxiously long
`diagnostic_builder_emit_producing_guarantee` name.
`build_session` is passed an `EarlyErrorHandler` and then constructs a
`Handler`. But the `EarlyErrorHandler` is still used for some time after
that.
This commit changes `build_session` so it consumes the passed
`EarlyErrorHandler`, and also drops it as soon as the `Handler` is
built. As a result, `parse_cfg` and `parse_check_cfg` now take a
`Handler` instead of an `EarlyErrorHandler`.
Currently, `Handler::fatal` returns `FatalError`. But `Session::fatal`
returns `!`, because it calls `Handler::fatal` and then calls `raise` on
the result. This inconsistency is unfortunate.
This commit changes `Handler::fatal` to do the `raise` itself, changing
its return type to `!`. This is safe because there are only two calls to
`Handler::fatal`, one in `rustc_session` and one in
`rustc_codegen_cranelift`, and they both call `raise` on the result.
`HandlerInner::fatal` still returns `FatalError`, so I renamed it
`fatal_no_raise` to emphasise the return type difference.
Report errors in jobserver inherited through environment variables
This pr attempts to catch situations, when jobserver exists, but is not being inherited.
r? `@petrochenkov`
This is intended to be used for Linux kernel RETHUNK builds.
With this commit (optionally backported to Rust 1.73.0), plus a
patched Linux kernel to pass the flag, I get a RETHUNK build with
Rust enabled that is `objtool`-warning-free and is able to boot in
QEMU and load a sample Rust kernel module.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
This was made possible by the removal of plugin support, which
simplified lint store creation.
This simplifies the places in rustc and rustdoc that call
`describe_lints`, which are early on. The lint store is now built before
those places, so they don't have to create their own lint store for
temporary use, they can just use the main one.
The included measurements have varied over the years. At one point there
were quite a few more, but #49558 deleted a lot that were no longer
used. Today there's just four, and it's a motley collection that doesn't
seem particularly valuable.
I think it has been well and truly subsumed by self-profiling, which
collects way more data.
Most notably, this commit changes the `pub use crate::*;` in that file
to `use crate::*;`. This requires a lot of `use` items in other crates
to be adjusted, because everything defined within `rustc_span::*` was
also available via `rustc_span::source_map::*`, which is bizarre.
The commit also removes `SourceMap::span_to_relative_line_string`, which
is unused.
Stop telling people to submit bugs for internal feature ICEs
This keeps track of usage of internal features, and changes the message to instead tell them that using internal features is not supported.
I thought about several ways to do this but now used the explicit threading of an `Arc<AtomicBool>` through `Session`. This is not exactly incremental-safe, but this is fine, as this is set during macro expansion, which is pre-incremental, and also only affects the output of ICEs, at which point incremental correctness doesn't matter much anyways.
See [MCP 620.](https://github.com/rust-lang/compiler-team/issues/596)
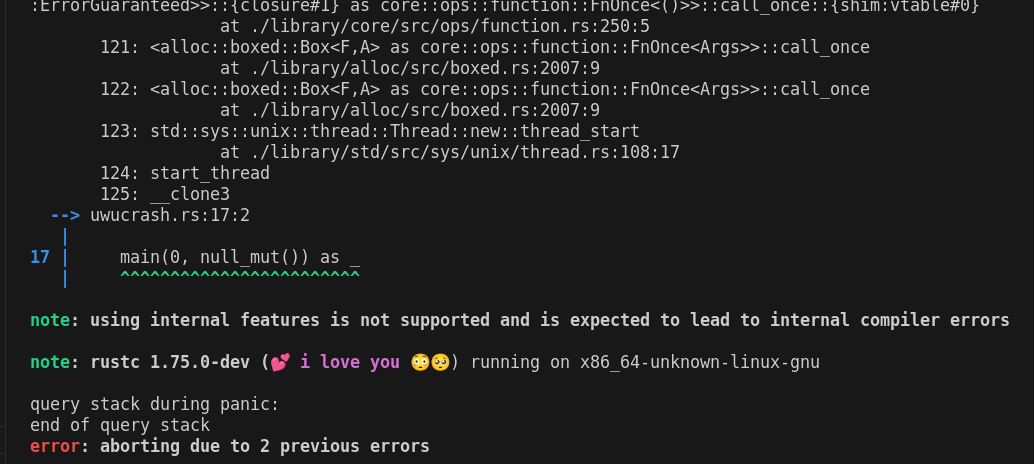
This keeps track of usage of internal features, and changes the message
to instead tell them that using internal features is not supported.
See MCP 620.
[breaking change] Validate crate name in `--extern` [MCP 650]
Reject non-ASCII-identifier crate names passed to the CLI option `--extern` (`rustc`, `rustdoc`).
Implements [MCP 650](https://github.com/rust-lang/compiler-team/issues/650) (except that we only allow ASCII identifiers not arbitrary Rust identifiers).
Fixes#113035.
[As mentioned on Zulip](https://rust-lang.zulipchat.com/#narrow/stream/233931-t-compiler.2Fmajor-changes/topic/Disallow.20non-identifier-valid.20--extern.20cr.E2.80.A6.20compiler-team.23650/near/376826988), doing a crater run probably doesn't make sense since it wouldn't yield anything. Most users don't interact with `rustc` directly but only ever through Cargo which always passes a valid crate name to `--extern` when it invokes `rustc` and `rustdoc`. In any case, the user wouldn't be able to use such a crate name in the source code anyway.
Note that I'm not using [`rustc_session::output::validate_crate_name`](https://doc.rust-lang.org/nightly/nightly-rustc/rustc_session/output/fn.validate_crate_name.html) (used for `--crate-name` and `#![crate_name]`) since the latter doesn't reject non-ASCII crate names and ones that start with a digit.
As an aside, I've also thought about getting rid of `validate_crate_name` entirely in a separate PR (with another MCP) in favor of `is_ascii_ident` to reject more weird `--crate-name`s, `#![crate_name]`s and file names but I think that would lead to a lot of actual breakage, namely because of file names starting with a digit. In `tests/ui` 9 tests would be impacted for example.
CC `@estebank`
r? `@est31`
CFI: Fix error compiling core with LLVM CFI enabled
Fix#90546 by filtering out global value function pointer types from the type tests, and adding the LowerTypeTests pass to the rustc LTO optimization pipelines.
Fix#90546 by filtering out global value function pointer types from the
type tests, and adding the LowerTypeTests pass to the rustc LTO
optimization pipelines.
Use SHA256 source file checksums by default when targeting MSVC
Currently, when targeting Windows (more specifically, the MSVC toolchain), Rust will use SHA1 source file checksums by default. SHA1 has been superseded by SHA256, and Microsoft recommends migrating to SHA256.
As of Visual Studio 2022, MSVC defaults to SHA256. This change aligns Rust and MSVC.
LLVM can already use SHA256 checksums, so this does not require any change to LLVM.
MSVC docs on source file checksums: https://learn.microsoft.com/en-us/cpp/build/reference/zh?view=msvc-170
Resurrect: rustc_llvm: Add a -Z `print-codegen-stats` option to expose LLVM statistics.
This resurrects PR https://github.com/rust-lang/rust/pull/104000, which has sat idle for a while. And I want to see the effect of stack-move optimizations on LLVM (like https://reviews.llvm.org/D153453) :).
I have applied the changes requested by `@oli-obk` and `@nagisa` https://github.com/rust-lang/rust/pull/104000#discussion_r1014625377 and https://github.com/rust-lang/rust/pull/104000#discussion_r1014642482 in the latest commits.
r? `@oli-obk`
-----
LLVM has a neat [statistics](https://llvm.org/docs/ProgrammersManual.html#the-statistic-class-stats-option) feature that tracks how often optimizations kick in. It's very handy for optimization work. Since we expose the LLVM pass timings, I thought it made sense to expose the LLVM statistics too.
-----
(Edit: fix broken link
(Edit2: fix segmentation fault and use malloc
If `rustc` is built with
```toml
[llvm]
assertions = true
```
Then you can see like
```
rustc +stage1 -Z print-codegen-stats -C opt-level=3 tmp.rs
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
3 aa - Number of MayAlias results
193 aa - Number of MustAlias results
531 aa - Number of NoAlias results
...
```
And the current default build emits only
```
$ rustc +stage1 -Z print-codegen-stats -C opt-level=3 tmp.rs
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
$
```
This might be better to emit the message to tell assertion flag necessity, but now I can't find how to do that...
On nightly, dump ICE backtraces to disk
Implement rust-lang/compiler-team#578.
When an ICE is encountered on nightly releases, the new rustc panic handler will also write the contents of the backtrace to disk. If any `delay_span_bug`s are encountered, their backtrace is also added to the file. The platform and rustc version will also be collected.
<img width="1032" alt="Screenshot 2023-03-03 at 2 13 25 PM" src="https://user-images.githubusercontent.com/1606434/222842420-8e039740-4042-4563-b31d-599677171acf.png">
The current behavior will *always* write to disk on nightly builds, regardless of whether the backtrace is printed to the terminal, unless the environment variable `RUSTC_ICE_DISK_DUMP` is set to `0`. This is a compromise and can be changed.
Implement rust-lang/compiler-team#578.
When an ICE is encountered on nightly releases, the new rustc panic
handler will also write the contents of the backtrace to disk. If any
`delay_span_bug`s are encountered, their backtrace is also added to the
file. The platform and rustc version will also be collected.
LLVM has a neat [statistics] feature that tracks how often optimizations kick
in. It's very handy for optimization work. Since we expose the LLVM pass
timings, I thought it made sense to expose the LLVM statistics too.
[statistics]: https://llvm.org/docs/ProgrammersManual.html#the-statistic-class-stats-option
Per the discussion in #106380 plt=no isn't a great default, and
rust-lang/compiler-team#581 decided that the default should be PLT=yes
for everything except x86_64. Not everyone agrees about the x86_64 part
of this change, but this at least is an improvement in the state of
things without changing the x86_64 situation, so I've attempted making
this change in the name of not letting the perfect be the enemy of the
good.
Because tiny CGUs make compilation less efficient *and* result in worse
generated code.
We don't do this when the number of CGUs is explicitly given, because
there are times when the requested number is very important, as
described in some comments within the commit. So the commit also
introduces a `CodegenUnits` type that distinguishes between default
values and user-specified values.
This change has a roughly neutral effect on walltimes across the
rustc-perf benchmarks; there are some speedups and some slowdowns. But
it has significant wins for most other metrics on numerous benchmarks,
including instruction counts, cycles, binary size, and max-rss. It also
reduces parallelism, which is good for reducing jobserver competition
when multiple rustc processes are running at the same time. It's smaller
benchmarks that benefit the most; larger benchmarks already have CGUs
that are all larger than the minimum size.
Here are some example before/after CGU sizes for opt builds.
- html5ever
- CGUs: 16, mean size: 1196.1, sizes: [3908, 2992, 1706, 1652, 1572,
1136, 1045, 948, 946, 938, 579, 471, 443, 327, 286, 189]
- CGUs: 4, mean size: 4396.0, sizes: [6706, 3908, 3490, 3480]
- libc
- CGUs: 12, mean size: 35.3, sizes: [163, 93, 58, 53, 37, 8, 2 (x6)]
- CGUs: 1, mean size: 424.0, sizes: [424]
- tt-muncher
- CGUs: 5, mean size: 1819.4, sizes: [8508, 350, 198, 34, 7]
- CGUs: 1, mean size: 9075.0, sizes: [9075]
Note that CGUs of size 100,000+ aren't unusual in larger programs.
Write to stdout if `-` is given as output file
With this PR, if `-o -` or `--emit KIND=-` is provided, output will be written to stdout instead. Binary output (those of type `obj`, `llvm-bc`, `link` and `metadata`) being written this way will result in an error unless stdout is not a tty. Multiple output types going to stdout will trigger an error too, as they will all be mixded together.
This implements https://github.com/rust-lang/compiler-team/issues/431
The idea behind the changes is to introduce an `OutFileName` enum that represents the output - be it a real path or stdout - and to use this enum along the code paths that handle different output types.
If `-o -` or `--emit KIND=-` is provided, output will be written
to stdout instead. Binary output (`obj`, `llvm-bc`, `link` and
`metadata`) being written this way will result in an error unless
stdout is not a tty. Multiple output types going to stdout will
trigger an error too, as they will all be mixded together.
Replace const eval limit by a lint and add an exponential backoff warning
The lint triggers at the first power of 2 that comes after 1 million function calls or traversed back-edges (takes less than a second on usual programs). After the first emission, an unsilenceable warning is repeated at every following power of 2 terminators, causing it to get reported less and less the longer the evaluation runs.
cc `@rust-lang/wg-const-eval`
fixes#93481closes#67217
{kind=link}