clarify that realloc refreshes pointer provenance even when the allocation remains in-place
This [matches what C does](https://en.cppreference.com/w/c/memory/realloc):
> The original pointer ptr is invalidated and any access to it is undefined behavior (even if reallocation was in-place).
Cc `@rust-lang/wg-allocators`
`VecDeque::resize` should re-use the buffer in the passed-in element
Today it always copies it for *every* appended element, but one of those clones is avoidable.
This adds `iter::repeat_n` (https://github.com/rust-lang/rust/issues/104434) as the primitive needed to do this. If this PR is acceptable, I'll also use this in `Vec` rather than its custom `ExtendElement` type & infrastructure that is harder to share between multiple different containers:
101e1822c3/library/alloc/src/vec/mod.rs (L2479-L2492)
* Fix doc examples for Platforms with underaligned integer primitives.
* Mutable pointer doc examples use mutable pointers.
* Fill out tracking issue.
* Minor formatting changes.
Rollup of 10 pull requests
Successful merges:
- #103117 (Use `IsTerminal` in place of `atty`)
- #103969 (Partial support for running UI tests with `download-rustc`)
- #103989 (Fix build of std for thumbv7a-pc-windows-msvc)
- #104076 (fix sysroot issue which appears for ci downloaded rustc)
- #104469 (Make "long type" printing type aware and trim types in E0275)
- #104497 (detect () to avoid redundant <> suggestion for type)
- #104577 (Don't focus on notable trait parent when hiding it)
- #104587 (Update cargo)
- #104593 (Improve spans for RPITIT object-safety errors)
- #104604 (Migrate top buttons style to CSS variables)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Fix build of std for thumbv7a-pc-windows-msvc
Attempting to build std for the tier-3 target `thumbv7a-pc-windows-msvc` fails with the following error:
```
Building stage1 std artifacts (x86_64-pc-windows-msvc -> thumbv7a-pc-windows-msvc)
..
LLVM ERROR: WinEH not implemented for this target
error: could not compile `panic_unwind`
```
EH (unwinding) is not supported by LLVM for 32 bit arm msvc targets. This changes panic unwind to use the dummy implementation for `thumbv7a-pc-windows-msvc`.
Revert Vec/Rc storage reuse opt
Remove the optimization for using storage added by #104205.
The perf wins were pretty small, and it relies on non-guarenteed behaviour. On platforms that don't implement shrinking in place, the performance will be significantly worse.
While it could be gated to platforms that do this (such as GNU), I don't think it's worth the overhead of maintaining it for very small gains. (#104565, #104563)
cc `@RalfJung` `@matthiaskrgr`
Fixes#104565Fixes#104563
Improve accuracy of asinh and acosh
This PR addresses the inaccuracy of `asinh` and `acosh` identified by the [Herbie](http://herbie.uwplse.org/) tool, `@pavpanchekha,` `@finnbear` in #104548. It also adds a couple tests that failed in the existing implementations and now pass.
Closes#104548
r? rust-lang/libs
Rollup of 8 pull requests
Successful merges:
- #102977 (remove HRTB from `[T]::is_sorted_by{,_key}`)
- #103378 (Fix mod_inv termination for the last iteration)
- #103456 (`unchecked_{shl|shr}` should use `u32` as the RHS)
- #103701 (Simplify some pointer method implementations)
- #104047 (Diagnostics `icu4x` based list formatting.)
- #104338 (Enforce that `dyn*` coercions are actually pointer-sized)
- #104498 (Edit docs for `rustc_errors::Handler::stash_diagnostic`)
- #104556 (rustdoc: use `code-header` class to format enum variants)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Enforce that `dyn*` coercions are actually pointer-sized
Implement a perma-unstable, rudimentary `PointerSized` trait to enforce `dyn*` casts are `usize`-sized for now, at least to prevent ICEs and weird codegen issues from cropping up after monomorphization since currently we enforce *nothing*.
This probably can/should be removed in favor of a more sophisticated trait for handling `dyn*` conversions when we decide on one, but I just want to get something up for discussion and experimentation for now.
r? ```@eholk``` cc ```@tmandry``` (though feel free to claim/reassign)
Fixes#102141Fixes#102173
Simplify some pointer method implementations
- Make `pointer::with_metadata_of` const (+simplify implementation) (cc #75091)
- Simplify implementation of various pointer methods
r? ```@scottmcm```
----
`from_raw_parts::<T>(this, metadata(self))` was annoying me for a while and I've finally figured out how it should _actually_ be done.
Fix mod_inv termination for the last iteration
On usize=u64 platforms, the 4th iteration would overflow the `mod_gate` back to 0. Similarly for usize=u32 platforms, the 3rd iteration would overflow much the same way.
I tested various approaches to resolving this, including approaches with `saturating_mul` and `widening_mul` to a double usize. Turns out LLVM likes `mul_with_overflow` the best. In fact now, that LLVM can see the iteration count is limited, it will happily unroll the loop into a nice linear sequence.
You will also notice that the code around the loop got simplified somewhat. Now that LLVM is handling the loop nicely, there isn’t any more reasons to manually unroll the first iteration out of the loop (though looking at the code today I’m not sure all that complexity was necessary in the first place).
Fixes#103361
Fix non-associativity of `Instant` math on `aarch64-apple-darwin` targets
This is a duplicate of #94100 (since the original author is unresponsive), which resolves#91417.
On `aarch64-apple-darwin` targets, the internal resolution of `Instant` is lower than that of `Duration`, so math between them becomes non-associative with small-enough durations.
This PR makes this target use the standard Unix implementation (where `Instant` has 1ns resolution), but with `CLOCK_UPTIME_RAW` so it still returns the same values as `mach_absolute_time`[^1].
(Edit: I need someone to confirm that this still works, I do not have access to an M1 device.)
[^1]: https://www.manpagez.com/man/3/clock_gettime/
Support `#[track_caller]` on async fns
Adds `#[track_caller]` to the generator that is created when we desugar the async fn.
Fixes#78840
Open questions:
- What is the performance impact of adding `#[track_caller]` to every `GenFuture`'s `poll(...)` function, even if it's unused (i.e., the parent span does not set `#[track_caller]`)? We might need to set it only conditionally, if the indirection causes overhead we don't want.
Attempt to reuse `Vec<T>` backing storage for `Rc/Arc<[T]>`
If a `Vec<T>` has sufficient capacity to store the inner `RcBox<[T]>`, we can just reuse the existing allocation and shift the elements up, instead of making a new allocation.
x86_64 SSE2 fast-path for str.contains(&str) and short needles
Based on Wojciech Muła's [SIMD-friendly algorithms for substring searching](http://0x80.pl/articles/simd-strfind.html#sse-avx2)
The two-way algorithm is Big-O efficient but it needs to preprocess the needle
to find a "critical factorization" of it. This additional work is significant
for short needles. Additionally it mostly advances needle.len() bytes at a time.
The SIMD-based approach used here on the other hand can advance based on its
vector width, which can exceed the needle length. Except for pathological cases,
but due to being limited to small needles the worst case blowup is also small.
benchmarks taken on a Zen2, compiled with `-Ccodegen-units=1`:
```
OLD:
test str::bench_contains_16b_in_long ... bench: 504 ns/iter (+/- 14) = 5061 MB/s
test str::bench_contains_2b_repeated_long ... bench: 948 ns/iter (+/- 175) = 2690 MB/s
test str::bench_contains_32b_in_long ... bench: 445 ns/iter (+/- 6) = 5732 MB/s
test str::bench_contains_bad_naive ... bench: 130 ns/iter (+/- 1) = 569 MB/s
test str::bench_contains_bad_simd ... bench: 84 ns/iter (+/- 8) = 880 MB/s
test str::bench_contains_equal ... bench: 142 ns/iter (+/- 7) = 394 MB/s
test str::bench_contains_short_long ... bench: 677 ns/iter (+/- 25) = 3768 MB/s
test str::bench_contains_short_short ... bench: 27 ns/iter (+/- 2) = 2074 MB/s
NEW:
test str::bench_contains_16b_in_long ... bench: 82 ns/iter (+/- 0) = 31109 MB/s
test str::bench_contains_2b_repeated_long ... bench: 73 ns/iter (+/- 0) = 34945 MB/s
test str::bench_contains_32b_in_long ... bench: 71 ns/iter (+/- 1) = 35929 MB/s
test str::bench_contains_bad_naive ... bench: 7 ns/iter (+/- 0) = 10571 MB/s
test str::bench_contains_bad_simd ... bench: 97 ns/iter (+/- 41) = 762 MB/s
test str::bench_contains_equal ... bench: 4 ns/iter (+/- 0) = 14000 MB/s
test str::bench_contains_short_long ... bench: 73 ns/iter (+/- 0) = 34945 MB/s
test str::bench_contains_short_short ... bench: 12 ns/iter (+/- 0) = 4666 MB/s
```
There seem to be some scenarios where `cpu.cfs_period_us` can contain `0`
This causes a panic when calling `std:🧵:available_parallelism()` as is done so
from binaries built by `cargo test`, which was how the issue was
discovered. I don't feel like `0` is a good value for `cpu.cfs_period_us`, but I
also don't think applications should panic if this value is seen.
This case is handled by other projects which read this information:
- num_cpus: e437b9d908/src/linux.rs (L207-L210)
- ninja: https://github.com/ninja-build/ninja/pull/2174/files
- dotnet: c4341d45ac/src/coreclr/pal/src/misc/cgroup.cpp (L481-L483)
Before this change, this panic could be seen in environments setup as described
above:
```
$ RUST_BACKTRACE=1 cargo test
Finished test [unoptimized + debuginfo] target(s) in 3.55s
Running unittests src/main.rs (target/debug/deps/x-9a42e145aca2934d)
thread 'main' panicked at 'attempt to divide by zero', library/std/src/sys/unix/thread.rs:546:70
stack backtrace:
0: rust_begin_unwind
1: core::panicking::panic_fmt
2: core::panicking::panic
3: std::sys::unix:🧵:cgroups::quota
4: std::sys::unix:🧵:available_parallelism
5: std:🧵:available_parallelism
6: test::helpers::concurrency::get_concurrency
7: test::console::run_tests_console
8: test::test_main
9: test::test_main_static
10: x::main
at ./src/main.rs:1:1
11: core::ops::function::FnOnce::call_once
at /tmp/rust-1.64-1.64.0-1/library/core/src/ops/function.rs:248:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
error: test failed, to rerun pass '--bin local-rabmq-amqpprox'
```
I've tested this change in an environment which has the bad setup and
rebuilding the test executable against a fixed std library fixes the
panic.
Make `pointer::byte_offset_from` more generic
As suggested by https://github.com/rust-lang/rust/issues/96283#issuecomment-1288792955 (cc ````@scottmcm),```` make `pointer::byte_offset_from` work on pointers of different types. `byte_offset_from` really doesn't care about pointer types, so this is totally fine and, for example, allows patterns like this:
```rust
ptr::addr_of!(x.b).byte_offset_from(ptr::addr_of!(x))
```
The only possible downside is that this removes the `T` == `U` hint to inference, but I don't think this matter much. I don't think there are a lot of cases where you'd want to use `byte_offset_from` with a pointer of unbounded type (and in such cases you can just specify the type).
````@rustbot```` label +T-libs-api
Fix inconsistent rounding of 0.5 when formatted to 0 decimal places
As described in #70336, when displaying values to zero decimal places the value of 0.5 is rounded to 1, which is inconsistent with the display of other half-integer values which round to even.
From testing the flt2dec implementation, it looks like this comes down to the condition in the fixed-width Dragon implementation where an empty buffer is treated as a case to apply rounding up. I believe the change below fixes it and updates only the relevant tests.
Nevertheless I am aware this is very much a core piece of functionality, so please take a very careful look to make sure I haven't missed anything. I hope this change does not break anything in the wider ecosystem as having a consistent rounding behaviour in floating point formatting is in my opinion a useful feature to have.
Resolves#70336
interpret: support for per-byte provenance
Also factors the provenance map into its own module.
The third commit does the same for the init mask. I can move it in a separate PR if you prefer.
Fixes https://github.com/rust-lang/miri/issues/2181
r? `@oli-obk`
- bump simd compare to 32bytes
- import small slice compare code from memmem crate
- try a few different probe bytes to avoid degenerate cases
- but special-case 2-byte needles
Add `rustc_deny_explicit_impl`
Also adjust `E0322` error message to be more general, since it's used for `DiscriminantKind` and `Pointee` as well.
Also add `rustc_deny_explicit_impl` on the `Tuple` and `Destruct` marker traits.
Move most of unwind's build script to lib.rs
Only the android libunwind detection remains in the build script
* Reduces dependence on build scripts for building the standard library
* Reduces dependence on exact target names in favor of using semantic cfg(target_*) usage.
* Keeps almost all code related to linking of the unwinder in one file
Remove unused symbols and diagnostic items
As the title suggests, this removes unused symbols from `sym::` and `#[rustc_diagnostic_item]` annotations that weren't mentioned anywhere.
Originally I tried to use grep, to find symbols and item names that are never mentioned via `sym::name`, however this produced a lot of false positives (?), for example clippy matching on `Symbol::as_str` or macros "implicitly" adding `sym::`. I ended up fixing all these false positives (?) by hand, but tbh I'm not sure if it was worth it...
Update compiler-builtins
This was originally a part of https://github.com/rust-lang/rust/pull/100316. However, extracting it to a seperate PR should help with any extra testing that might be needed.
Signed-off-by: Ayush Singh <ayushsingh1325@gmail.com>
Based on Wojciech Muła's "SIMD-friendly algorithms for substring searching"[0]
The two-way algorithm is Big-O efficient but it needs to preprocess the needle
to find a "criticla factorization" of it. This additional work is significant
for short needles. Additionally it mostly advances needle.len() bytes at a time.
The SIMD-based approach used here on the other hand can advance based on its
vector width, which can exceed the needle length. Except for pathological cases,
but due to being limited to small needles the worst case blowup is also small.
benchmarks taken on a Zen2:
```
16CGU, OLD:
test str::bench_contains_short_short ... bench: 27 ns/iter (+/- 1)
test str::bench_contains_short_long ... bench: 667 ns/iter (+/- 29)
test str::bench_contains_bad_naive ... bench: 131 ns/iter (+/- 2)
test str::bench_contains_bad_simd ... bench: 130 ns/iter (+/- 2)
test str::bench_contains_equal ... bench: 148 ns/iter (+/- 4)
16CGU, NEW:
test str::bench_contains_short_short ... bench: 8 ns/iter (+/- 0)
test str::bench_contains_short_long ... bench: 135 ns/iter (+/- 4)
test str::bench_contains_bad_naive ... bench: 130 ns/iter (+/- 2)
test str::bench_contains_bad_simd ... bench: 292 ns/iter (+/- 1)
test str::bench_contains_equal ... bench: 3 ns/iter (+/- 0)
1CGU, OLD:
test str::bench_contains_short_short ... bench: 30 ns/iter (+/- 0)
test str::bench_contains_short_long ... bench: 713 ns/iter (+/- 17)
test str::bench_contains_bad_naive ... bench: 131 ns/iter (+/- 3)
test str::bench_contains_bad_simd ... bench: 130 ns/iter (+/- 3)
test str::bench_contains_equal ... bench: 148 ns/iter (+/- 6)
1CGU, NEW:
test str::bench_contains_short_short ... bench: 10 ns/iter (+/- 0)
test str::bench_contains_short_long ... bench: 111 ns/iter (+/- 0)
test str::bench_contains_bad_naive ... bench: 135 ns/iter (+/- 3)
test str::bench_contains_bad_simd ... bench: 274 ns/iter (+/- 2)
test str::bench_contains_equal ... bench: 4 ns/iter (+/- 0)
```
[0] http://0x80.pl/articles/simd-strfind.html#sse-avx2
The `max` variable is unused. This change introduces the `min_plus`
variable, to make the example similar to the one from `saturating_abs`.
An alternative would be to remove the unused variable.
Fixed some `_i32` notation in `maybe_uninit`’s doc
This PR just changed two lines in the documentation for `MaybeUninit`:
```rs
let val = 0x12345678i32;
```
was changed to:
```rs
let val = 0x12345678_i32;
```
in two doctests, making the values a tad easier to read.
It does not seem like there are other literals needing this change in the file.
Stabilize const char convert
Split out `const_char_from_u32_unchecked` from `const_char_convert` and stabilize the rest, i.e. stabilize the following functions:
```Rust
impl char {
pub const fn from_u32(self, i: u32) -> Option<char>;
pub const fn from_digit(self, num: u32, radix: u32) -> Option<char>;
pub const fn to_digit(self, radix: u32) -> Option<u32>;
}
// Available through core::char and std::char
mod char {
pub const fn from_u32(i: u32) -> Option<char>;
pub const fn from_digit(num: u32, radix: u32) -> Option<char>;
}
```
And put the following under the `from_u32_unchecked` const stability gate as it needs `Option::unwrap` which isn't const-stable (yet):
```Rust
impl char {
pub const unsafe fn from_u32_unchecked(i: u32) -> char;
}
// Available through core::char and std::char
mod char {
pub const unsafe fn from_u32_unchecked(i: u32) -> char;
}
```
cc the tracking issue #89259 (which I'd like to keep open for `const_char_from_u32_unchecked`).
Move `unix_socket_abstract` feature API to `SocketAddrExt`.
The pre-stabilized API for abstract socket addresses exposes methods on `SocketAddr` that are only enabled for `cfg(any(target_os = "android", target_os = "linux"))`. Per discussion in <https://github.com/rust-lang/rust/issues/85410>, moving these methods to an OS-specific extension trait is required before stabilization can be considered.
This PR makes four changes:
1. The internal module `std::os::net` contains logic for the unstable feature `tcp_quickack` (https://github.com/rust-lang/rust/issues/96256). I moved that code into `linux_ext/tcp.rs` and tried to adjust the module tree so it could accommodate a second unstable feature there.
2. Moves the public API out of `impl SocketAddr`, into `impl SocketAddrExt for SocketAddr` (the headline change).
3. The existing function names and docs for `unix_socket_abstract` refer to addresses as being created from abstract namespaces, but a more accurate description is that they create sockets in *the* abstract namespace. I adjusted the function signatures correspondingly and tried to update the docs to be clearer.
4. I also tweaked `from_abstract_name` so it takes an `AsRef<[u8]>` instead of `&[u8]`, allowing `b""` literals to be passed directly.
Issues:
1. The public module `std::os::linux::net` is marked as part of `tcp_quickack`. I couldn't figure out how to mark a module as being part of two unstable features, so I just left the existing attributes in place. My hope is that this will be fixed as a side-effect of stabilizing either feature.
Only the android libunwind detection remains in the build script
* Reduces dependence on build scripts for building the standard library
* Reduces dependence on exact target names in favor of using semantic
cfg(target_*) usage.
* Keeps almost all code related to linking of the unwinder in one file
Rollup of 9 pull requests
Successful merges:
- #103709 (ci: Upgrade dist-x86_64-netbsd to NetBSD 9.0)
- #103744 (Upgrade cc for working is_flag_supported on cross-compiles)
- #104105 (llvm: dwo only emitted when object code emitted)
- #104158 (Return .efi extension for EFI executable)
- #104181 (Add a few known-bug tests)
- #104266 (Regression test for coercion of mut-ref to dyn-star)
- #104300 (Document `Path::parent` behavior around relative paths)
- #104304 (Enable profiler in dist-s390x-linux)
- #104362 (Add `delay_span_bug` to `AttrWrapper::take_for_recovery`)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Document `Path::parent` behavior around relative paths
A relative path with just one component will return `Some("")` as its parent, which wasn't clear to me from the documentation.
The parent of `""` is `None`, which was missing from the documentation as well.
Change the way libunwind is linked for *-windows-gnullvm targets
I have no idea why previous way works for `x86_64-fortanix-unknown-sgx` (assuming it actually works...) but not for `gnullvm`. It fails when linking libtest during Rust build (unless somebody adds `RUSTFLAGS='-Clinkarg=-lunwind'`).
Also fixes exception handling on AArch64.
This was originally a part of https://github.com/rust-lang/rust/pull/100316.
However, extracting it to a seperate PR should help with any extra
testing that might be needed.
Signed-off-by: Ayush Singh <ayushsingh1325@gmail.com>
Use `derive_const` and rm manual StructuralEq impl
This does not change any semantics of the impl except for the const stability. It should be fine because trait methods and const bounds can never be used in stable without enabling `const_trait_impl`.
cc `@oli-obk`
Add small clarification around using pointers derived from references
r? `@RalfJung`
One question about your example from https://github.com/rust-lang/libs-team/issues/122: at what point does UB arise? If writing 0 does not cause UB and the reference `x` is never read or written to (explicitly or implicitly by being wrapped in another data structure) after the call to `foo`, does UB only arise when dropping the value? I don't really get that since I thought references were always supposed to point to valid data?
```rust
fn foo(x: &mut NonZeroI32) {
let ptr = x as *mut NonZeroI32;
unsafe { ptr.cast::<i32>().write(0); } // no UB here
// What now? x is considered garbage when?
}
```
Merge crossbeam-channel into `std::sync::mpsc`
This PR imports the [`crossbeam-channel`](https://github.com/crossbeam-rs/crossbeam/tree/master/crossbeam-channel#crossbeam-channel) crate into the standard library as a private module, `sync::mpmc`. `sync::mpsc` is now implemented as a thin wrapper around `sync::mpmc`. The primary purpose of this PR is to resolve https://github.com/rust-lang/rust/issues/39364. The public API intentionally remains the same.
The reason https://github.com/rust-lang/rust/issues/39364 has not been fixed in over 5 years is that the current channel is *incredibly* complex. It was written many years ago and has sat mostly untouched since. `crossbeam-channel` has become the most popular alternative on crates.io, amassing over 30 million downloads. While crossbeam's channel is also complex, like all fast concurrent data structures, it avoids some of the major issues with the current implementation around dynamic flavor upgrades. The new implementation decides on the datastructure to be used when the channel is created, and the channel retains that structure until it is dropped.
Replacing `sync::mpsc` with a simpler, less performant implementation has been discussed as an alternative. However, Rust touts itself as enabling *fearless concurrency*, and having the standard library feature a subpar implementation of a core concurrency primitive doesn't feel right. The argument is that slower is better than broken, but this PR shows that we can do better.
As mentioned before, the primary purpose of this PR is to fix https://github.com/rust-lang/rust/issues/39364, and so the public API intentionally remains the same. *After* that problem is fixed, the fact that `sync::mpmc` now exists makes it easier to fix the primary limitation of `mpsc`, the fact that it only supports a single consumer. spmc and mpmc are two other common concurrency patterns, and this change enables a path to deprecating `mpsc` and exposing a general `sync::channel` module that supports multiple consumers. It also implements other useful methods such as `send_timeout`. That said, exposing MPMC and other new functionality is mostly out of scope for this PR, and it would be helpful if discussion stays on topic :)
For what it's worth, the new implementation has also been shown to be more performant in [some basic benchmarks](https://github.com/crossbeam-rs/crossbeam/tree/master/crossbeam-channel/benchmarks#results).
cc `@taiki-e`
r? rust-lang/libs
Improve performance of `rem_euclid()` for signed integers
such code is copy from
https://github.com/rust-lang/rust/blob/master/library/std/src/f32.rs and
https://github.com/rust-lang/rust/blob/master/library/std/src/f64.rs
using `r+rhs.abs()` is faster than calc it with an if clause. Bench result:
```
$ cargo bench
Compiling div-euclid v0.1.0 (/me/div-euclid)
Finished bench [optimized] target(s) in 1.01s
Running unittests src/lib.rs (target/release/deps/div_euclid-7a4530ca7817d1ef)
running 7 tests
test tests::it_works ... ignored
test tests::bench_aaabs ... bench: 10,498,793 ns/iter (+/- 104,360)
test tests::bench_aadefault ... bench: 11,061,862 ns/iter (+/- 94,107)
test tests::bench_abs ... bench: 10,477,193 ns/iter (+/- 81,942)
test tests::bench_default ... bench: 10,622,983 ns/iter (+/- 25,119)
test tests::bench_zzabs ... bench: 10,481,971 ns/iter (+/- 43,787)
test tests::bench_zzdefault ... bench: 11,074,976 ns/iter (+/- 29,633)
test result: ok. 0 passed; 0 failed; 1 ignored; 6 measured; 0 filtered out; finished in 19.35s
```
It seems that, default `rem_euclid` triggered a branch prediction, thus `bench_default` is faster than `bench_aadefault` and `bench_aadefault`, which shuffles the order of calculations. but all of them slower than what it was in `f64`'s and `f32`'s `rem_euclid`, thus I submit this PR.
bench code:
```rust
#![feature(test)]
extern crate test;
fn rem_euclid(a:i32,rhs:i32)->i32{
let r = a % rhs;
if r < 0 { r + rhs.abs() } else { r }
}
#[cfg(test)]
mod tests {
use super::*;
use test::Bencher;
use rand::prelude::*;
use rand::rngs::SmallRng;
const N:i32=1000;
#[test]
fn it_works() {
let a: i32 = 7; // or any other integer type
let b = 4;
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
for i in &d {
for j in &n {
assert_eq!(i.rem_euclid(*j),rem_euclid(*i,*j));
}
}
assert_eq!(rem_euclid(a,b), 3);
assert_eq!(rem_euclid(-a,b), 1);
assert_eq!(rem_euclid(a,-b), 3);
assert_eq!(rem_euclid(-a,-b), 1);
}
#[bench]
fn bench_aaabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_aadefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_abs(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_default(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_zzabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_zzdefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
}
```
Add the `#[derive_const]` attribute
Closes#102371. This is a minimal patchset for the attribute to work. There are no restrictions on what traits this attribute applies to.
r? `````@oli-obk`````
Remove lock wrappers in `sys_common`
This moves the lazy allocation to `sys` (SGX and UNIX). While this leads to a bit more verbosity, it will simplify future improvements by making room in `sys_common` for platform-independent implementations.
This also removes the condvar check on SGX as it is not necessary for soundness and will be removed anyway once mutex has been made movable.
For simplicity's sake, `libunwind` also uses lazy allocation now on SGX. This will require an update to the C definitions before merging this (CC `@raoulstrackx).`
r? `@m-ou-se`
A relative path with just one component will return `Some("")` as its
parent, which wasn't clear to me from the documentation.
The parent of `""` is `None`, which was missing from the documentation
as well.
Make `Hash`, `Hasher` and `BuildHasher` `#[const_trait]` and make `Sip` const `Hasher`
This PR enables using Hashes in const context.
r? ``@fee1-dead``
This patch allows the usage of the `track_caller` annotation on
generators, as well as sets them conditionally if the parent also has
`track_caller` set.
Also add this annotation on the `GenFuture`'s `poll()` function.
Add support for custom mir
This implements rust-lang/compiler-team#564 . Details about the design, motivation, etc. can be found in there.
r? ```@oli-obk```
Add context to compiler error message
Changed `creates a temporary which is freed while still in use` to `creates a temporary value which is freed while still in use`.
Const Compare for Tuples
Makes the impls for Tuples of ~const `PartialEq` types also `PartialEq`, impls for Tuples of ~const `PartialOrd` types also `PartialOrd`, for Tuples of ~const `Ord` types also `Ord`.
behind the `#![feature(const_cmp)]` gate.
~~Do not merge before #104113 is merged because I want to use this feature to clean up the new test that I added there.~~
r? ``@fee1-dead``
Added documentation for IPv6 Addresses `IN6ADDR_ANY_INIT` also known as
`in6addr_any` and `IN6ADDR_LOOPBACK_INIT` also known as
`in6addr_loopback` similar to `INADDR_ANY` for IPv4 Addresses.
Clarify licensing situation of MPSC and SPSC queue
Originally, these two files were licensed under the `BSD-2-Clause` license, as they were based off sample code on a blog licensing those snippets under that license:
* `library/std/src/sync/mpsc/mpsc_queue.rs`
* `library/std/src/sync/mpsc/spsc_queue.rs`
In 2017 though, the author of that blog agreed to relicense their code under the standard `MIT OR Apache-2.0` license in https://github.com/rust-lang/rust/pull/42149. This PR clarifies the situation in the files by expanding the comment at the top of the file.
r? ``@pnkfelix``
Fix `const_fn_trait_ref_impl`, add test for it
#99943 broke `#[feature(const_fn_trait_ref_impl)]`, this PR fixes this and adds a test for it.
r? ````@fee1-dead````
run alloc benchmarks in Miri and fix UB
Miri since recently has a "fake monotonic clock" that works even with isolation. Its measurements are not very meaningful but it means we can run these benches and check them for UB.
And that's a good thing since there was UB here: fixes https://github.com/rust-lang/rust/issues/104096.
r? ``@thomcc``
disable btree size tests on Miri
Seems fine not to run these in Miri, they can't have UB anyway. And this lets us do layout randomization in Miri.
r? ``@thomcc``
Specialize `iter::ArrayChunks::fold` for TrustedRandomAccess iterators
```
OLD:
test iter::bench_trusted_random_access_chunks ... bench: 368 ns/iter (+/- 4)
NEW:
test iter::bench_trusted_random_access_chunks ... bench: 30 ns/iter (+/- 0)
```
The resulting assembly is similar to #103166 but the specialization kicks in under different (partially overlapping) conditions compared to that PR. They're complementary.
In principle a TRA-based specialization could be applied to all `ArrayChunks` methods, including `next()` as we do for `Zip` but that would have all the same hazards as the Zip specialization. Only doing it for `fold` is far less hazardous. The downside is that it only helps with internal, exhaustive iteration. I.e. `for _ in` or `try_fold` will not benefit.
Note that the regular, `try_fold`-based and the specialized `fold()` impl have observably slightly different behavior. Namely the specialized variant does not fetch the remainder elements from the underlying iterator. We do have a few other places in the standard library where beyond-the-end-of-iteration side-effects are being elided under some circumstances but not others.
Inspired by https://old.reddit.com/r/rust/comments/yaft60/zerocost_iterator_abstractionsnot_so_zerocost/
The type is unsafe and now exposed to the whole crate.
Document it properly and add an unsafe method so the
caller can make it visible that something unsafe is happening.
Implement `std::marker::Tuple`, use it in `extern "rust-call"` and `Fn`-family traits
Implements rust-lang/compiler-team#537
I made a few opinionated decisions in this implementation, specifically:
1. Enforcing `extern "rust-call"` on fn items during wfcheck,
2. Enforcing this for all functions (not just ones that have bodies),
3. Gating this `Tuple` marker trait behind its own feature, instead of grouping it into (e.g.) `unboxed_closures`.
Still needing to be done:
1. Enforce that `extern "rust-call"` `fn`-ptrs are well-formed only if they have 1/2 args and the second one implements `Tuple`. (Doing this would fix ICE in #66696.)
2. Deny all explicit/user `impl`s of the `Tuple` trait, kinda like `Sized`.
3. Fixing `Tuple` trait built-in impl for chalk, so that chalkification tests are un-broken.
Open questions:
1. Does this need t-lang or t-libs signoff?
Fixes#99820
fix a comment in UnsafeCell::new
There are several safe methods that access the inner value: `into_inner` has existed since forever and `get_mut` also exists since recently. So this comment seems just wrong. But `&self` methods return raw pointers and thus require unsafe code (though the methods themselves are still safe).
libtest: run all tests in their own thread, if supported by the host
This reverts the threading changes of https://github.com/rust-lang/rust/pull/56243, which made it so that with `-j1`, the test harness does not spawn any threads. Those changes were done to enable Miri to run the test harness, but Miri supports threads nowadays, so this is no longer needed. Using a thread for each test is useful because the thread's name can be set to the test's name which makes panic messages consistent between `-j1` and `-j2` runs and also a bit more readable.
I did not revert the HashMap changes of https://github.com/rust-lang/rust/pull/56243; using a deterministic map seems fine for the test harness and the more deterministic testing is the better.
Fixes https://github.com/rust-lang/rust/issues/59122
Fixes https://github.com/rust-lang/rust/issues/70492
benchmark result:
```
$ cargo bench
Compiling div-euclid v0.1.0 (/me/div-euclid)
Finished bench [optimized] target(s) in 1.01s
Running unittests src/lib.rs (target/release/deps/div_euclid-7a4530ca7817d1ef)
running 7 tests
test tests::it_works ... ignored
test tests::bench_aaabs ... bench: 10,498,793 ns/iter (+/- 104,360)
test tests::bench_aadefault ... bench: 11,061,862 ns/iter (+/- 94,107)
test tests::bench_abs ... bench: 10,477,193 ns/iter (+/- 81,942)
test tests::bench_default ... bench: 10,622,983 ns/iter (+/- 25,119)
test tests::bench_zzabs ... bench: 10,481,971 ns/iter (+/- 43,787)
test tests::bench_zzdefault ... bench: 11,074,976 ns/iter (+/- 29,633)
test result: ok. 0 passed; 0 failed; 1 ignored; 6 measured; 0 filtered out; finished in 19.35s
```
benchmark code:
```rust
#![feature(test)]
extern crate test;
#[inline(always)]
fn rem_euclid(a:i32,rhs:i32)->i32{
let r = a % rhs;
if r < 0 {
// if rhs is `integer::MIN`, rhs.wrapping_abs() == rhs.wrapping_abs,
// thus r.wrapping_add(rhs.wrapping_abs()) == r.wrapping_add(rhs) == r - rhs,
// which suits our need.
// otherwise, rhs.wrapping_abs() == -rhs, which won't overflow since r is negative.
r.wrapping_add(rhs.wrapping_abs())
} else {
r
}
}
#[cfg(test)]
mod tests {
use super::*;
use test::Bencher;
use rand::prelude::*;
use rand::rngs::SmallRng;
const N:i32=1000;
#[test]
fn it_works() {
let a: i32 = 7; // or any other integer type
let b = 4;
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
for i in &d {
for j in &n {
assert_eq!(i.rem_euclid(*j),rem_euclid(*i,*j));
}
}
assert_eq!(rem_euclid(a,b), 3);
assert_eq!(rem_euclid(-a,b), 1);
assert_eq!(rem_euclid(a,-b), 3);
assert_eq!(rem_euclid(-a,-b), 1);
}
#[bench]
fn bench_aaabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_aadefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_abs(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_default(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_zzabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_zzdefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
}
```
such code is copy from
https://github.com/rust-lang/rust/blob/master/library/std/src/f32.rs
and
https://github.com/rust-lang/rust/blob/master/library/std/src/f64.rs
using r+rhs.abs() is faster than calc it directly.
Bench result:
```
$ cargo bench
Compiling div-euclid v0.1.0 (/me/div-euclid)
Finished bench [optimized] target(s) in 1.01s
Running unittests src/lib.rs (target/release/deps/div_euclid-7a4530ca7817d1ef)
running 7 tests
test tests::it_works ... ignored
test tests::bench_aaabs ... bench: 10,498,793 ns/iter (+/- 104,360)
test tests::bench_aadefault ... bench: 11,061,862 ns/iter (+/- 94,107)
test tests::bench_abs ... bench: 10,477,193 ns/iter (+/- 81,942)
test tests::bench_default ... bench: 10,622,983 ns/iter (+/- 25,119)
test tests::bench_zzabs ... bench: 10,481,971 ns/iter (+/- 43,787)
test tests::bench_zzdefault ... bench: 11,074,976 ns/iter (+/- 29,633)
test result: ok. 0 passed; 0 failed; 1 ignored; 6 measured; 0 filtered out; finished in 19.35s
```
bench code:
```
#![feature(test)]
extern crate test;
fn rem_euclid(a:i32,rhs:i32)->i32{
let r = a % rhs;
if r < 0 { r + rhs.abs() } else { r }
}
#[cfg(test)]
mod tests {
use super::*;
use test::Bencher;
use rand::prelude::*;
use rand::rngs::SmallRng;
const N:i32=1000;
#[test]
fn it_works() {
let a: i32 = 7; // or any other integer type
let b = 4;
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
for i in &d {
for j in &n {
assert_eq!(i.rem_euclid(*j),rem_euclid(*i,*j));
}
}
assert_eq!(rem_euclid(a,b), 3);
assert_eq!(rem_euclid(-a,b), 1);
assert_eq!(rem_euclid(a,-b), 3);
assert_eq!(rem_euclid(-a,-b), 1);
}
#[bench]
fn bench_aaabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_aadefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_abs(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_default(b: &mut Bencher) {
let d:Vec<i32>=(-N..=N).collect();
let n:Vec<i32>=(-N..0).chain(1..=N).collect();
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
#[bench]
fn bench_zzabs(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=rem_euclid(*i,*j);
}
}
res
});
}
#[bench]
fn bench_zzdefault(b: &mut Bencher) {
let mut d:Vec<i32>=(-N..=N).collect();
let mut n:Vec<i32>=(-N..0).chain(1..=N).collect();
let mut rng=SmallRng::from_seed([1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,21]);
d.shuffle(&mut rng);
n.shuffle(&mut rng);
d.shuffle(&mut rng);
b.iter(||{
let mut res=0;
for i in &d {
for j in &n {
res+=i.rem_euclid(*j);
}
}
res
});
}
}
```
After rust-lang/rust#101946 this completes the move to cfg-if 1.0 by:
* Updating getrandom 0.1.14->0.1.16
* Updating panic_abort, panic_unwind, and unwind to cfg-if 1.0
Rewrite implementation of `#[alloc_error_handler]`
The new implementation doesn't use weak lang items and instead changes `#[alloc_error_handler]` to an attribute macro just like `#[global_allocator]`.
The attribute will generate the `__rg_oom` function which is called by the compiler-generated `__rust_alloc_error_handler`. If no `__rg_oom` function is defined in any crate then the compiler shim will call `__rdl_oom` in the alloc crate which will simply panic.
This also fixes link errors with `-C link-dead-code` with `default_alloc_error_handler`: `__rg_oom` was previously defined in the alloc crate and would attempt to reference the `oom` lang item, even if it didn't exist. This worked as long as `__rg_oom` was excluded from linking since it was not called.
This is a prerequisite for the stabilization of `default_alloc_error_handler` (#102318).
Include both benchmarks and tests in the numbers given to `TeFiltered{,Out}`
Fixes#103794
`#[bench]` is broken on nightly without this, sadly. It apparently has no test coverage. In addition to manually testing, I've added a run-make smokecheck for this (which would have caught the issue), but it would be nice to have a better way to test, err, libtest. For now we should get this in ASAP IMO
The new implementation doesn't use weak lang items and instead changes
`#[alloc_error_handler]` to an attribute macro just like
`#[global_allocator]`.
The attribute will generate the `__rg_oom` function which is called by
the compiler-generated `__rust_alloc_error_handler`. If no `__rg_oom`
function is defined in any crate then the compiler shim will call
`__rdl_oom` in the alloc crate which will simply panic.
This also fixes link errors with `-C link-dead-code` with
`default_alloc_error_handler`: `__rg_oom` was previously defined in the
alloc crate and would attempt to reference the `oom` lang item, even if
it didn't exist. This worked as long as `__rg_oom` was excluded from
linking since it was not called.
This is a prerequisite for the stabilization of
`default_alloc_error_handler` (#102318).
Do fewer passes and generally be more efficient when filtering tests
Follow-on of the work I started with this PR: https://github.com/rust-lang/rust/pull/99939
Basically, the startup code for libtest is really inefficient, but that's not usually a problem because it is distributed in release and workloads are small. But under Miri which can be 100x slower than a debug build, these inefficiencies explode.
Most of the diff here is making test filtering single-pass. There are a few other small optimizations as well, but they are more straightforward.
With this PR, the startup time of the `iced` tests with `--features=code_asm,mvex` drops from 17 to 2 minutes (I think Miri has gotten slower under this workload since #99939). The easiest way to try this out is to set `MIRI_LIB_SRC` to a checkout of this branch when running `cargo +nightly miri test --features=code_asm,mvex`.
r? `@thomcc`
Prevent foreign Rust exceptions from being caught
Fix#102715
Use the address of a static variable (which is guaranteed to be unique per copy of std) to tell apart if a Rust exception comes from local or foreign Rust code, and abort for the latter.
The signature for new was
```
fn new<F>(f: F) -> Lazy<T, F>
```
Notably, with `F` unconstrained, `T` can be literally anything, and just
`let _ = Lazy::new(|| 92)` would not typecheck.
This historiacally was a necessity -- `new` is a `const` function, it
couldn't have any bounds. Today though, we can move `new` under the `F:
FnOnce() -> T` bound, which gives the compiler enough data to infer the
type of T from closure.
poll_fn and Unpin: fix pinning
See [IRLO](https://internals.rust-lang.org/t/surprising-soundness-trouble-around-pollfn/17484) for details: currently `poll_fn` is very subtle to use, since it does not pin the closure, so creating a `Pin::get_unchcked(&mut capture)` inside the closure is unsound. This leads to actual miscompilations with `futures::join!`.
IMO the proper fix is to pin the closure when the future is pinned, which is achieved by changing the `Unpin` implementation. This is a breaking change though. 1.64.0 was *just* released, so maybe this is still okay?
The alternative would be to add some strong comments to the docs saying that closure captures are *not pinned* and doing `Pin::get_unchecked` on them is unsound.
Clarify documentation about the memory layout of `UnsafeCell`
This PR addresses a [comment](https://github.com/rust-lang/rust/pull/101717#issuecomment-1279908390) by `@RalfJung` in PR #101717 to further clarify the documentation of `UnsafeCell<T>`. The previous PR was merged already before we had a chance to correct this, hence this second PR :)
To goal of this PR is:
1. Split the paragraph about the memory layout of `UnsafeCell<T>` and the usage of `UnsafeCell::(raw_)get()` into two paragraphs, so that it is easier to digest for the reader.
2. Slightly simplify the previously added examples in order to reduce redundancy between the new examples and the examples that already [existed](ddd119b2fe/library/core/src/cell.rs (L1858-L1908)) before these 2 PRs (which remained untouched by both PRs).
remove redundant Send impl for references
Also explain why the other instance is not redundant, move it next to the trait they are implementing, and out of the redundant module. This seems to go back all the way to 35ca50bd56, not sure why the module was added.
The instance for `&mut` is the default instance we get anyway, and we don't have anything similar for `Sync`, so IMO we should be consistent and not have the redundant instance here, either.
Try to say that memory outside the AM is always exposed
cc ``@Gankra`` ``@thomcc``
I want to confidently tell people that they can use `from_exposed_addr` to get a pointer for doing MMIO and/or other hardware interactions done with volatile reads/writes at particular addresses outside the Rust AM. Currently, the docs indicate that would be UB.
With this change, now the docs indicate that this is intended to be a valid use of `from_exposed_addr`.
r? ``@RalfJung``
Even nicer errors from assert_unsafe_precondition
For example, now running `cargo test` with this patch I get things like:
```
$ cargo +stage1 test
Finished test [unoptimized + debuginfo] target(s) in 0.01s
Running unittests src/lib.rs (target/debug/deps/malloc_buf-9d105ddf86862995)
running 5 tests
thread 'tests::test_null_buf' panicked at 'unsafe precondition violated: is_aligned_and_not_null(data) &&
crate::mem::size_of::<T>().saturating_mul(len) <= isize::MAX as usize', /home/ben/rust/library/core/src/slice/raw.rs:93:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread panicked while panicking. aborting.
error: test failed, to rerun pass `--lib`
Caused by:
process didn't exit successfully: `/tmp/malloc_buf-1.0.0/target/debug/deps/malloc_buf-9d105ddf86862995` (signal: 6, SIGABRT: process abort signal)
```
This is still not perfect, but these are better for another PR:
* `stringify!` is trying to do clever pretty-printing on the `expr` inside `assert_unsafe_precondition` and can even add a newline.
* It would be nice to print a bit more information about where the problem is. Perhaps this is `cfg_attr(debug_assertions, track_caller)`, or perhaps it the function name added to `Location`.
cc ``@RalfJung`` this is what I was thinking of for https://github.com/rust-lang/rust/pull/102732#discussion_r989068907
ptr::eq: clarify that comparing dyn Trait is fragile
Also remove the dyn trait example from `ptr::eq` since those tests are not actually guaranteed to pass due to how unstable vtable comparison is.
Cc ``@rust-lang/libs-api``
Cc discussion following https://github.com/rust-lang/rust/pull/80505
Use a faster allocation size check in slice::from_raw_parts
I've been perusing through the codegen changes that result from turning on the standard library debug assertions. The previous check in here uses saturating arithmetic, which in my experience sometimes makes LLVM just fail to optimize things around the saturating operation.
Here is a demo of the codegen difference: https://godbolt.org/z/WMEqrjajW
Before:
```asm
example::len_check_old:
mov rax, rdi
mov ecx, 3
mul rcx
setno cl
test rax, rax
setns al
and al, cl
ret
example::len_check_old:
mov rax, rdi
mov ecx, 8
mul rcx
setno cl
test rax, rax
setns al
and al, cl
ret
```
After:
```asm
example::len_check_new:
movabs rax, 3074457345618258603
cmp rdi, rax
setb al
ret
example::len_check_new:
shr rdi, 60
sete al
ret
```
Running rustc-perf locally, this looks like up to a 4.5% improvement when `debug-assertions-std = true`.
Thanks ```@LegionMammal978``` (I think that's you?) for turning my idea into a much cleaner implementation.
r? ```@thomcc```
Truncate thread names on Linux and Apple targets
These targets have system limits on the thread names, 16 and 64 bytes
respectively, and `pthread_setname_np` returns an error if the name is
longer. However, we're not in a context that can propagate errors when
we call this, and we used to implicitly truncate on Linux with `prctl`,
so now we manually truncate these names ahead of time.
r? ``````@thomcc``````
Fix grammar in docs for std::io::Read
Two independent clauses were incorrectly joined by a bare comma. The simplest fix would be to switch to a semicolon, but I think it's slightly better to keep the comma and use the coordinating conjunction "so".
Update libstd's libc to 0.2.135 (to make `libstd` no longer pull in `libiconv.dylib` on Darwin)
This is to pull in https://github.com/rust-lang/libc/pull/2944.
It's related to https://github.com/rust-lang/rust/pull/102766, in that they both remove unused dylibs from libstd on Darwin platforms. As a result, I'm marking this as relnotes since everybody agreed it was good to add it to the other as well. (The note should be about no longer linking against libiconv -- the libc update is irrelevant).
Might as well have the same reviewer too.
r? `@Mark-Simulacrum`
Don't link to `libresolv` in libstd on Darwin
Currently we link `libresolv` into every Rust program on apple targets despite never using it (as of https://github.com/rust-lang/rust/pull/44965). I had thought we needed this for `getaddrinfo` or something, but we do not / cannot safely use it.
I'd like to fix this for `libiconv` too (the other library we pull in. that's harder since it's coming in through `libc`, which is https://github.com/rust-lang/libc/pull/2944)).
---
This may warrant release notes. I'm not sure but I've added the flag regardless -- It's a change to the list of dylibs every Rust program pulls in, so it's worth mentioning.
It's pretty unlikely anybody was relying on this being pulled in, and `std` does not guarantee that it will link (and thus transitively provide access to) any particular system library -- anybody relying on that behavior would already be broken when dynamically linking std. That is, there's an outside chance something will fail to link on macOS and iOS because it was accidentally relying on our unnecessary dependency.
(If that *does* happen, that project could be easily fixed by linking libresolv explicitly on those platforms, probably via `#[link(name = "resolv")] extern {}`,` -Crustc-link-lib=resolv`, `println!("cargo:rustc-link-lib=resolv")`, or one of several places in `.config/cargo.toml`)
---
I'm also going to preemptively add the nomination for discussing this in the libs meeting. Basically: Do we care about programs that assume we will bring libraries in that we do not use. `libresolv` and `libiconv` on macOS/iOS are in this camp (`libresolv` because we used to use it, and `libiconv` because the `libc` crate was unintentionally(?) pulling it in to every Rust program).
I'd like to remove them both, but this may cause link issues programs that are relying on `std` to depend on them transitively. (Relying on std for this does not work in all build configurations, so this seems very fragile, and like a use case we should not support).
More generally, IMO we should not guarantee the specific set of system-provided libraries we use (beyond what is implied by an OS version requirement), which means we'd be free to remove this cruft.
Stabilize `duration_checked_float`
## Stabilization Report
This stabilization report is for a stabilization of `duration_checked_float`, tracking issue: https://github.com/rust-lang/rust/issues/83400.
### Implementation History
- https://github.com/rust-lang/rust/pull/82179
- https://github.com/rust-lang/rust/pull/90247
- https://github.com/rust-lang/rust/pull/96051
- Changed error type to `FromFloatSecsError` in https://github.com/rust-lang/rust/pull/90247
- https://github.com/rust-lang/rust/pull/96051 changes the rounding mode to round-to-nearest instead of truncate.
## API Summary
This stabilization report proposes the following API to be stabilized in `core`, along with their re-exports in `std`:
```rust
// core::time
impl Duration {
pub const fn try_from_secs_f32(secs: f32) -> Result<Duration, TryFromFloatSecsError>;
pub const fn try_from_secs_f64(secs: f64) -> Result<Duration, TryFromFloatSecsError>;
}
#[derive(Debug, Clone, PartialEq, Eq)]
pub struct TryFromFloatSecsError { ... }
impl core::fmt::Display for TryFromFloatSecsError { ... }
impl core::error::Error for TryFromFloatSecsError { ... }
```
These functions are made const unstable under `duration_consts_float`, tracking issue #72440.
There is an open question in the tracking issue around what the error type should be called which I was hoping to resolve in the context of an FCP.
In this stabilization PR, I have altered the name of the error type to `TryFromFloatSecsError`. In my opinion, the error type shares the name of the method (adjusted to accommodate both types of floats), which is consistent with other error types in `core`, `alloc` and `std` like `TryReserveError` and `TryFromIntError`.
## Experience Report
Code such as this is ready to be converted to a checked API to ensure it is panic free:
```rust
impl Time {
pub fn checked_add_f64(&self, seconds: f64) -> Result<Self, TimeError> {
// Fail safely during `f64` conversion to duration
if seconds.is_nan() || seconds.is_infinite() {
return Err(TzOutOfRangeError::new().into());
}
if seconds.is_sign_positive() {
self.checked_add(Duration::from_secs_f64(seconds))
} else {
self.checked_sub(Duration::from_secs_f64(-seconds))
}
}
}
```
See: https://github.com/artichoke/artichoke/issues/2194.
`@rustbot` label +T-libs-api -T-libs
cc `@mbartlett21`
Sort tests at compile time, not at startup
Recently, another Miri user was trying to run `cargo miri test` on the crate `iced-x86` with `--features=code_asm,mvex`. This configuration has a startup time of ~18 minutes. That's ~18 minutes before any tests even start to run. The fact that this crate has over 26,000 tests and Miri is slow makes a lot of code which is otherwise a bit sloppy but fine into a huge runtime issue.
Sorting the tests when the test harness is created instead of at startup time knocks just under 4 minutes out of those ~18 minutes. I have ways to remove most of the rest of the startup time, but this change requires coordinating changes of both the compiler and libtest, so I'm sending it separately.
(except for doctests, because there is no compile-time harness)
Remove redundant lifetime bound from `impl Borrow for Cow`
The lifetime bound `B::Owned: 'a` is redundant and doesn't make a difference,
because `Cow<'a, B>` comes with an implicit `B: 'a`, and associated types
will outlive lifetimes outlived by the `Self` type (and all the trait's
generic parameters, of which there are none in this case), so the implicit `B: 'a`
implies `B::Owned: 'a` anyway.
The explicit lifetime bound here does however [end up in documentation](https://doc.rust-lang.org/std/borrow/enum.Cow.html#impl-Borrow%3CB%3E),
and that's confusing in my opinion, so let's remove it ^^
_(Documentation right now, compare to `AsRef`, too:)_
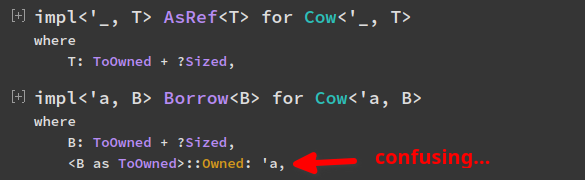
Use ptr::metadata in <[T]>::len implementation
This avoids duplication of ptr::metadata code.
I believe this is acceptable as the previous approach essentially duplicated `ptr::metadata` because back then `rustc_allow_const_fn_unstable` annotation did not exist.
I would like somebody to ping `@rust-lang/wg-const-eval` as the documentation says:
> Always ping `@rust-lang/wg-const-eval` if you are adding more rustc_allow_const_fn_unstable attributes to any const fn.
`MaybeUninit`: use `assume_init_drop()` in the partially initialized array example
The `assume_init_drop()` method does the same thing as the pointer conversion, and makes the example more straightforward.
kmc-solid: Handle errors returned by `SOLID_FS_ReadDir`
Fixes the issue where the `std::fs::ReadDir` implementaton of the [`*-kmc-solid_*`](https://doc.rust-lang.org/nightly/rustc/platform-support/kmc-solid.html) Tier 3 targets silently suppressed errors returned by the underlying `SOLID_FS_ReadDir` system function. The new implementation correctly handles all cases:
- `SOLID_ERR_NOTFOUND` indicates the end of directory stream.
- `SOLID_ERR_OK` + non-empty `d_name` indicates success.
- Some old filesystem drivers may return `SOLID_ERR_OK` + empty `d_name` to indicate the end of directory stream.
- Any other negative values (per ITRON convention) represent an error.
Document surprising and dangerous fs::Permissions behaviour on Unix
This documents the very surprising behaviour that `set_readonly(false)` will make a file *world writable* on Unix. I would go so far as to say that this function should be deprecated on Unix, or maybe even entirely. But documenting the bad behaviour is a good first step.
Fixes#74895
Clarify `array::from_fn` documentation
I've seen quite a few of people on social media confused of where the length of array is coming from in the newly stabilized `array::from_fn` example.
This PR tries to clarify the documentation on this.
Eliminate 280-byte memset from ReadDir iterator
This guy:
1536ab1b38/library/std/src/sys/unix/fs.rs (L589)
It turns out `libc::dirent64` is quite big—https://docs.rs/libc/0.2.135/libc/struct.dirent64.html. In #103135 this memset accounted for 0.9% of the runtime of iterating a big directory.
Almost none of the big zeroed value is ever used. We memcpy a tiny prefix (19 bytes) into it, and then read just 9 bytes (`d_ino` and `d_type`) back out. We can read exactly those 9 bytes we need directly from the original entry_ptr instead.
## History
This code got added in #93459 and tweaked in #94272 and #94750.
Prior to #93459, there was no memset but a full 280 bytes were being copied from the entry_ptr.
<table><tr><td>copy 280 bytes</td></tr></table>
This was not legal because not all of those bytes might be initialized, or even allocated, depending on the length of the directory entry's name, leading to a segfault. That PR fixed the segfault by creating a new zeroed dirent64 and copying just the guaranteed initialized prefix into it.
<table><tr><td>memset 280 bytes</td><td>copy 19 bytes</td></tr></table>
However this was still buggy because it used `addr_of!((*entry_ptr).d_name)`, which is considered UB by Miri in the case that the full extent of entry_ptr is not in bounds of the same allocation. (Arguably this shouldn't be a requirement, but here we are.)
The UB got fixed by #94272 by replacing `addr_of` with some pointer manipulation based on `offset_from`, but still fundamentally the same operation.
<table><tr><td>memset 280 bytes</td><td>copy 19 bytes</td></tr></table>
Then #94750 noticed that only 9 of those 19 bytes were even being used, so we could pick out only those 9 to put in the ReadDir value.
<table><tr><td>memset 280 bytes</td><td>copy 19 bytes</td><td>copy 9 bytes</td></tr></table>
After my PR we just grab the 9 needed bytes directly from entry_ptr.
<table><tr><td>copy 9 bytes</td></tr></table>
The resulting code is more complex but I believe still worthwhile to land for the following reason. This is an extremely straightforward thing to accomplish in C and clearly libc assumes that; literally just `entry_ptr->d_name`. The extra work in comparison to accomplish it in Rust is not an example of any actual safety being provided by Rust. I believe it's useful to have uncovered that and think about what could be done in the standard library or language to support this obvious operation better.
## References
- https://man7.org/linux/man-pages/man3/readdir.3.html
Reduce false positives in msys2 detection
Currently msys2 will be detected by getting the file path and looking to see if it contains the substrings "msys-" and "-ptr" (or "cygwin-" and "-pty"). This risks false positives, especially with filesystem files and if `GetFileInformationByHandleEx` returns a [full path](https://learn.microsoft.com/en-us/windows-hardware/drivers/ddi/ntifs/nf-ntifs-ntqueryinformationfile#remarks).
This PR adds a check to see if the handle is a pipe before doing the substring search. Additionally, for "msys2-" or "cygwin-" it only checks if the file name starts with the substring rather than looking at the whole path.
Adjust argument type for mutable with_metadata_of (#75091)
The method takes two pointer arguments: one `self` supplying the pointer value, and a second pointer supplying the metadata.
The new parameter type more clearly reflects the actual requirements. The provenance of the metadata parameter is disregarded completely. Using a mutable pointer in the call site can be coerced to a const pointer while the reverse is not true.
In some cases, the current parameter type can thus lead to a very slightly confusing additional cast. [Example](cad93775eb).
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = val as *const _ as *mut T;
let ptr = uninit.as_ptr().with_metadata_of(ptr);
```
This could then instead be simplified to:
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = uninit.as_ptr().with_metadata_of(&**val);
```
Tracking issue: https://github.com/rust-lang/rust/issues/75091
``@dtolnay`` you're reviewed #95249, would you mind chiming in?
On usize=u64 platforms, the 4th iteration would overflow the `mod_gate`
back to 0. Similarly for usize=u32 platforms, the 3rd iteration would
overflow much the same way.
I tested various approaches to resolving this, including approaches with
`saturating_mul` and `widening_mul` to a double usize. Turns out LLVM
likes `mul_with_overflow` the best. In fact now, that LLVM can see the
iteration count is limited, it will happily unroll the loop into a nice
linear sequence.
You will also notice that the code around the loop got simplified
somewhat. Now that LLVM is handling the loop nicely, there isn’t any
more reasons to manually unroll the first iteration out of the loop
(though looking at the code today I’m not sure all that complexity was
necessary in the first place).
Fixes#103361
These targets have system limits on the thread names, 16 and 64 bytes
respectively, and `pthread_setname_np` returns an error if the name is
longer. However, we're not in a context that can propagate errors when
we call this, and we used to implicitly truncate on Linux with `prctl`,
so now we manually truncate these names ahead of time.
Rollup of 9 pull requests
Successful merges:
- #102635 (make `order_dependent_trait_objects` show up in future-breakage reports)
- #103335 (Replaced wrong test with the correct mcve)
- #103339 (Fix some typos)
- #103340 (WinConsole::new is not actually fallible)
- #103341 (Add test for issue 97607)
- #103351 (Require Drop impls to have the same constness on its bounds as the bounds on the struct have)
- #103359 (Remove incorrect comment in `Vec::drain`)
- #103364 (rustdoc: clean up rustdoc-toggle CSS)
- #103370 (rustdoc: remove unused CSS `.out-of-band { font-weight: normal }`)
Failed merges:
r? `@ghost`
`@rustbot` modify labels: rollup
Remove incorrect comment in `Vec::drain`
r? ``@scottmcm``
Turns out this comment wasn't correct for 6 years, since #34951, which switched from using `slice::IterMut` into using `slice::Iter`.
Add default trait implementations for "c-unwind" ABI function pointers
Following up on #92964, only add default trait implementations for the `c-unwind` family of function pointers. The previous attempt in #92964 added trait implementations for many more ABIs and ran into concerns regarding the increase in size of the libcore rlib.
An attempt to abstract away function pointer types behind a unified trait to reduce the duplication of trait impls is being discussed in #99531 but this change looks to be blocked on a lang MCP.
Following `@RalfJung's` suggestion in https://github.com/rust-lang/rust/pull/99531#issuecomment-1233440142, this commit is another cut at #92964 but it _only_ adds the impls for `extern "C-unwind" fn` and `unsafe extern "C-unwind" fn`.
I am interested in landing this patch to unblock the stabilization of the `c_unwind` feature.
RFC: https://github.com/rust-lang/rfcs/pull/2945
Tracking Issue: https://github.com/rust-lang/rust/issues/74990
Change process spawning to inherit the parent's signal mask by default
Previously, the signal mask was always reset when a child process is
started. This breaks tools like `nohup` which expect `SIGHUP` to be
blocked for all transitive processes.
With this change, the default behavior changes to inherit the signal mask.
This also changes the signal disposition for `SIGPIPE` to only be changed if the `#[unix_sigpipe]` attribute isn't set.
The method takes two pointer arguments: one `self` supplying the pointer
value, and a second pointer supplying the metadata.
The new parameter type more clearly reflects the actual requirements.
The provenance of the metadata parameter is disregarded completely.
Using a mutable pointer in the call site can be coerced to a const
pointer while the reverse is not true.
An example of the current use:
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = val as *const _ as *mut T;
let ptr = uninit.as_ptr().with_metadata_of(ptr);
```
This could then instead be simplified to:
```rust
// Manually taking an unsized object from a `ManuallyDrop` into another allocation.
let val: &core::mem::ManuallyDrop<T> = …;
let ptr = uninit.as_ptr().with_metadata_of(&**val);
```
Mark `std::os::wasi::io::AsFd` etc. as stable.
io_safety was stabilized in Rust 1.63, so mark the io_safety exports in `std::os::wasi::io` as stable.
Fixes#103306.
Previously, the signal mask is always reset when a child process is
started. This breaks tools like `nohup` which expect `SIGHUP` to be
blocked.
With this change, the default behavior changes to inherit the signal mask.
This also changes the signal disposition for `SIGPIPE` to only be
changed if the `#[unix_sigpipe]` attribute isn't set.
Fixed docs typo in `library/std/src/time.rs`
* Changed comment from `Previous rust versions panicked when self was earlier than the current time.` to `Previous rust versions panicked when the current time was earlier than self.`
* Resolves#103282.
Adjust `transmute{,_copy}` to be clearer about which of `T` and `U` is input vs output
This is essentially a documentation-only change (although it does touch code in an irrelevant way).
Following up on #92964, only add default trait implementations for the
`c-unwind` family of function pointers. The previous attempt in #92964
added trait implementations for many more ABIs and ran into concerns
regarding the increase in size of the libcore rlib.
An attempt to abstract away function pointer types behind a unified
trait to reduce the duplication of trait impls is being discussed in #99531
but this change looks to be blocked on a lang MCP.
Following @RalfJung's suggestion in
https://github.com/rust-lang/rust/pull/99531#issuecomment-1233440142,
this commit is another cut at #92964 but it _only_ adds the impls for
`extern "C-unwind" fn` and `unsafe extern "C-unwind" fn`.
I am interested in landing this patch to unblock the stabilization of
the `c_unwind` feature.
RFC: https://github.com/rust-lang/rfcs/pull/2945
Tracking Issue: https://github.com/rust-lang/rust/issues/74990
Make transpose const and inline
r? `@scottmcm`
- These should have been const from the beginning since we're never going to do more than a transmute.
- Inline these always because that's what every other method in MaybeUninit which simply casts does. :) Ok, but a stronger justification is that because we're taking in arrays by `self`, not inlining would defeat the whole purpose of using `MaybeUninit` due to the copying.
{kind=link}