`-Z debug-macros` is "stabilized" by enabling it by default and removing.
`-Z collapse-macro-debuginfo` is stabilized as `-C collapse-macro-debuginfo`.
It now supports all typical boolean values (`parse_opt_bool`) in addition to just yes/no.
Default value of `collapse_debuginfo` was changed from `false` to `external` (i.e. collapsed if external, not collapsed if local).
`#[collapse_debuginfo]` attribute without a value is no longer supported to avoid guessing the default.
Implement Modified Condition/Decision Coverage
This is an implementation based on llvm backend support (>= 18) by `@evodius96` and branch coverage support by `@Zalathar.`
### Major changes:
* Add -Zcoverage-options=mcdc as switch. Now coverage options accept either `no-branch`, `branch`, or `mcdc`. `mcdc` also enables `branch` because it is essential to work.
* Add coverage mapping for MCDCBranch and MCDCDecision. Note that MCDCParameter evolves from llvm 18 to llvm 19. The mapping in rust side mainly references to 19 and is casted to 18 types in llvm wrapper.
* Add wrapper for mcdc instrinc functions from llvm. And inject associated statements to mir.
* Add BcbMappingKind::Decision, I'm not sure is it proper but can't find a better way temporarily.
* Let coverage-dump support parsing MCDCBranch and MCDCDecision from llvm ir.
* Add simple tests to check whether mcdc works.
* Same as clang, currently rustc does not generate instrument for decision with more than 6 condtions or only 1 condition due to considerations of resource.
### Implementation Details
1. To get information about conditions and decisions, `MCDCState` in `BranchInfoBuilder` is used during hir lowering to mir. For expressions with logical op we call `Builder::visit_coverage_branch_operation` to record its sub conditions, generate condition ids for them and save their spans (to construct the span of whole decision). This process mainly references to the implementation in clang and is described in comments over `MCDCState::record_conditions`. Also true marks and false marks introduced by branch coverage are used to detect where the decision evaluation ends: the next id of the condition == 0.
2. Once the `MCDCState::decision_stack` popped all recorded conditions, we can ensure that the decision is checked over and push it into `decision_spans`. We do not manually insert decision span to avoid complexity from then_else_break in nested if scopes.
3. When constructing CoverageSpans, add condition info to BcbMappingKind::Branch and decision info to BcbMappingKind::Decision. If the branch mapping has non-zero condition id it will be transformed to MCDCBranch mapping and insert `CondBitmapUpdate` statements to its evaluated blocks. While decision bcb mapping will insert `TestVectorBitmapUpdate` in all its end blocks.
### Usage
```bash
echo "[build]\nprofiler=true" >> config.toml
./x build --stage 1
./x test tests/coverage/mcdc_if.rs
```
to build the compiler and run tests.
```shell
export PATH=path/to/llvm-build:$PATH
rustup toolchain link mcdc build/host/stage1
cargo +mcdc rustc --bin foo -- -Cinstrument-coverage -Zcoverage-options=mcdc
cd target/debug
LLVM_PROFILE_FILE="foo.profraw" ./foo
llvm-profdata merge -sparse foo.profraw -o foo.profdata
llvm-cov show ./foo -instr-profile=foo.profdata --show-mcdc
```
to check "foo" code.
### Problems to solve
For now decision mapping will insert statements to its all end blocks, which may be optimized by inserting a final block of the decision. To do this we must also trace the evaluated value at each end of the decision and join them separately.
This implementation is not heavily tested so there should be some unrevealed issues. We are going to check our rust products in the next. Please let me know if you had any suggestions or comments.
Introduce perma-unstable `wasm-c-abi` flag
Now that `wasm-bindgen` v0.2.88 supports the spec-compliant C ABI, the idea is to switch to that in a future version of Rust. In the meantime it would be good to let people test and play around with it.
This PR introduces a new perma-unstable `-Zwasm-c-abi` compiler flag, which switches to the new spec-compliant C ABI when targeting `wasm32-unknown-unknown`.
Alternatively, we could also stabilize this and then deprecate it when we switch. I will leave this to the Rust maintainers to decide.
This is a companion PR to #117918, but they could be merged independently.
MCP: https://github.com/rust-lang/compiler-team/issues/703
Tracking issue: https://github.com/rust-lang/rust/issues/122532
Currently it's a method on `EarlyDiagCtxt`, which is not the right place
for it at all -- `EarlyDiagCtxt` is used to issue diagnostics, but
shouldn't be doing any of the actual checking.
This commit moves it into a standalone function that takes an
`EarlyDiagCtxt` as an argument, which is more sensible. This does
require adding `EarlyDiagCtxt::early_struct_warn`, so a warning can be
returned and then modified with a note. (And that likely explains why
somebody put `initialize_checked_jobserver` into `EarlyDiagCtxt` in the
first place.)
Currently `SourceMap` is constructed slightly later than
`SessionGlobals`, and inserted. This commit changes things so they are
done at the same time.
Benefits:
- `SessionGlobals::source_map` changes from
`Lock<Option<Lrc<SourceMap>>>` to `Option<Lrc<SourceMap>>`. It's still
optional, but mutability isn't required because it's initialized at
construction.
- `set_source_map` is removed, simplifying `run_compiler`, which is
good because that's a critical function and it's nice to make it
simpler.
This requires moving things around a bit, so the necessary inputs are
available when `SessionGlobals` is created, in particular the `loader`
and `hash_kind`, which are no longer computed by `build_session`. These
inputs are captured by the new `SourceMapInputs` type, which is threaded
through various places.
Backend and target selection is a mess: the target can override the
backend (via `Target::default_codegen_backend`), *and* the backend can
override the target (via `CodegenBackend::target_override`).
The code that handles this is ugly. It calls `build_target_config`
twice, once before getting the backend and once again afterward. It also
must check that both overrides aren't triggering at the same time.
This commit removes the latter override. It's used in rust-gpu but
@eddyb said via Zulip that removing it would be ok. This simplifies the
code greatly, and will allow some nice follow-up refactorings.
This new nightly-only flag can be used to toggle fine-grained flags that
control the details of coverage instrumentation.
Currently the only supported flag value is `branch` (or `no-branch`), which is
a placeholder for upcoming support for branch coverage. Other flag values can
be added in the future, to prototype proposed new behaviour, or to enable
special non-default behaviour.
Adds initial support for DataFlowSanitizer to the Rust compiler. It
currently supports `-Zsanitizer-dataflow-abilist`. Additional options
for it can be passed to LLVM command line argument processor via LLVM
arguments using `llvm-args` codegen option (e.g.,
`-Cllvm-args=-dfsan-combine-pointer-labels-on-load=false`).
bjorn3 says:
> On errors we don't finalize the incr comp cache, but non-fatal diagnostics are cached afaik.
Otherwise we would have to replay the query in question, which we may not be able to do if the query
key is not reconstructible from the dep node fingerprint.
So we must track these flags to avoid replaying incorrect diagnostics.
It was added in #54232. It seems like it was aimed at NLL development,
which is well in the past. Also, it looks like `-Ztreat-err-as-bug` can
be used to achieve the same effect. So it doesn't seem necessary.
Remove `-Zreport-delayed-bugs`.
It's not used within the repository in any way (e.g. in tests), and doesn't seem useful.
It was added in #52568.
r? ````@oli-obk````
Remove `-Zdump-mir-spanview`
The `-Zdump-mir-spanview` flag was added back in #76074, as a development/debugging aid for the initial work on what would eventually become `-Cinstrument-coverage`. It causes the compiler to emit an HTML file containing a function's source code, with various spans highlighted based on the contents of MIR.
When the suggestion was made to [triage and remove unnecessary `-Z` flags (Zulip)](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/.60-Z.60.20option.20triage), I noted that this flag could potentially be worth removing, but I wanted to keep it around to see whether I found it useful for my own coverage work.
But when I actually tried to use it, I ran into various issues (e.g. it crashes on `tests/coverage/closure.rs`). If I can't trust it to work properly without a full overhaul, then instead of diving down a rabbit hole of trying to fix arcane span-handling bugs, it seems better to just remove this obscure old code entirely.
---
````@rustbot```` label +A-code-coverage
`build_session` is passed an `EarlyErrorHandler` and then constructs a
`Handler`. But the `EarlyErrorHandler` is still used for some time after
that.
This commit changes `build_session` so it consumes the passed
`EarlyErrorHandler`, and also drops it as soon as the `Handler` is
built. As a result, `parse_cfg` and `parse_check_cfg` now take a
`Handler` instead of an `EarlyErrorHandler`.
This is intended to be used for Linux kernel RETHUNK builds.
With this commit (optionally backported to Rust 1.73.0), plus a
patched Linux kernel to pass the flag, I get a RETHUNK build with
Rust enabled that is `objtool`-warning-free and is able to boot in
QEMU and load a sample Rust kernel module.
Signed-off-by: Miguel Ojeda <ojeda@kernel.org>
Add -Z llvm_module_flag
Allow adding values to the `!llvm.module.flags` metadata for a generated module. The syntax is
`-Z llvm_module_flag=<name>:<type>:<value>:<behavior>`
Currently only u32 values are supported but the type is required to be specified for forward compatibility. The `behavior` element must match one of the named LLVM metadata behaviors.viors.
This flag is expected to be perma-unstable.
Remove `-Zperf-stats`.
The included measurements have varied over the years. At one point there were quite a few more, but #49558 deleted a lot that were no longer used. Today there's just four, and it's a motley collection that doesn't seem particularly valuable.
I think it has been well and truly subsumed by self-profiling, which collects way more data.
r? `@wesleywiser`
The included measurements have varied over the years. At one point there
were quite a few more, but #49558 deleted a lot that were no longer
used. Today there's just four, and it's a motley collection that doesn't
seem particularly valuable.
I think it has been well and truly subsumed by self-profiling, which
collects way more data.
Allow adding values to the `!llvm.module.flags` metadata for a generated
module. The syntax is
`-Z llvm_module_flag=<name>:<type>:<value>:<behavior>`
Currently only u32 values are supported but the type is required to be
specified for forward compatibility. The `behavior` element must match
one of the named LLVM metadata behaviors.viors.
This flag is expected to be perma-unstable.
It was added way back in #28585 under the name `-Zkeep-mtwt-tables`. The
justification was:
> This is so that the resolution results can be used after analysis,
> potentially for tool support.
There are no uses of significance in the code base, and various Google
searches for both option names (and variants) found nothing of interest.
@petrochenkov says removing this part (and it's only part) of the
hygiene data is dubious. It doesn't seem that big, so let's just keep it
around.
`parse_cfgspecs` and `parse_check_cfg` run very early, before the main
interner is running. They each use a short-lived interner and convert
all interned symbols to strings in their output data structures. Once
the main interner starts up, these data structures get converted into
new data structures that are identical except with the strings converted
to symbols.
All is not obvious from the current code, which is a mess, particularly
with inconsistent naming that obscures the parallel string/symbol data
structures. This commit clean things up a lot.
- The existing `CheckCfg` type is generic, allowing both
`CheckCfg<String>` and `CheckCfg<Symbol>` forms. This is really
useful, but it defaults to `String`. The commit removes the default so
we have to use `CheckCfg<String>` and `CheckCfg<Symbol>` explicitly,
which makes things clearer.
- Introduces `Cfg`, which is generic over `String` and `Symbol`, similar
to `CheckCfg`.
- Renames some things.
- `parse_cfgspecs` -> `parse_cfg`
- `CfgSpecs` -> `Cfg<String>`, plus it's used in more places, rather
than the underlying `FxHashSet` type.
- `CrateConfig` -> `Cfg<Symbol>`.
- `CrateCheckConfig` -> `CheckCfg<Symbol>`
- Adds some comments explaining the string-to-symbol conversions.
- `to_crate_check_config`, which converts `CheckCfg<String>` to
`CheckCfg<Symbol>`, is inlined and removed and combined with the
overly-general `CheckCfg::map_data` to produce
`CheckCfg::<String>::intern`.
- `build_configuration` now does the `Cfg<String>`-to-`Cfg<Symbol>`
conversion, so callers don't need to, which removes the need for
`to_crate_config`.
The diff for two of the fields in `Config` is a good example of the
improved clarity:
```
- pub crate_cfg: FxHashSet<(String, Option<String>)>,
- pub crate_check_cfg: CheckCfg,
+ pub crate_cfg: Cfg<String>,
+ pub crate_check_cfg: CheckCfg<String>,
```
Compare that with the diff for the corresponding fields in `ParseSess`,
and the relationship to `Config` is much clearer than before:
```
- pub config: CrateConfig,
- pub check_config: CrateCheckConfig,
+ pub config: Cfg<Symbol>,
+ pub check_config: CheckCfg<Symbol>,
```
In `test_edition_parsing`, change the
`build_session_options_and_crate_config` call to
`build_session_options`, because the config isn't used.
That leaves a single call site for
`build_session_options_and_crate_config`, so just inline and remove it.
The value of `-Cinstrument-coverage=` doesn't need to be `Option`
(Extracted from #117199, since this is a purely internal cleanup that can land independently.)
Not using this flag is identical to passing `-Cinstrument-coverage=off`, so there's no need to distinguish between `None` and `Some(Off)`.
Stop telling people to submit bugs for internal feature ICEs
This keeps track of usage of internal features, and changes the message to instead tell them that using internal features is not supported.
I thought about several ways to do this but now used the explicit threading of an `Arc<AtomicBool>` through `Session`. This is not exactly incremental-safe, but this is fine, as this is set during macro expansion, which is pre-incremental, and also only affects the output of ICEs, at which point incremental correctness doesn't matter much anyways.
See [MCP 620.](https://github.com/rust-lang/compiler-team/issues/596)
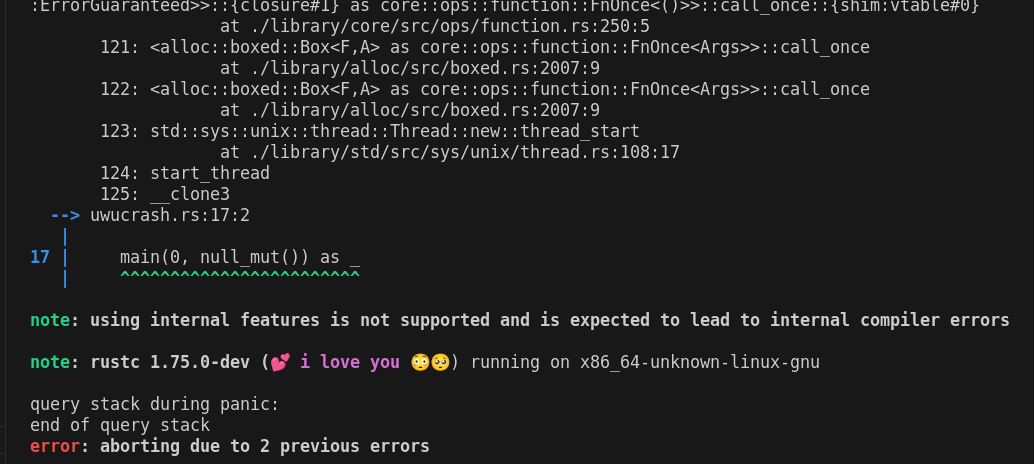
This keeps track of usage of internal features, and changes the message
to instead tell them that using internal features is not supported.
See MCP 620.
Add an (perma-)unstable option to disable vtable vptr
This flag is intended for evaluation of trait upcasting space cost for embedded use cases.
Compared to the approach in #112355, this option provides a way to evaluate end-to-end cost of trait upcasting. Rationale: https://github.com/rust-lang/rust/issues/112355#issuecomment-1658207769
## How this flag should be used (after merge)
Build your project with and without `-Zno-trait-vptr` flag. If you are using cargo, set `RUSTFLAGS="-Zno-trait-vptr"` in the environment variable. You probably also want to use `-Zbuild-std` or the binary built may be broken. Save both binaries somewhere.
### Evaluate the space cost
The option has a direct and indirect impact on vtable space usage. Directly, it gets rid of the trait vptr entry needed to store a pointer to a vtable of a supertrait. (IMO) this is a small saving usually. The larger saving usually comes with the indirect saving by eliminating the vtable of the supertrait (and its parent).
Both impacts only affects vtables (notably the number of functions monomorphized should , however where vtable reside can depend on your relocation model. If the relocation model is static, then vtable is rodata (usually stored in Flash/ROM together with text in embedded scenario). If the binary is relocatable, however, the vtable will live in `.data` (more specifically, `.data.rel.ro`), and this will need to reside in RAM (which may be a more scarce resource in some cases), together with dynamic relocation info living in readonly segment.
For evaluation, you should run `size` on both binaries, with and without the flag. `size` would output three columns, `text`, `data`, `bss` and the sum `dec` (and it's hex version). As explained above, both `text` and `data` may change. `bss` shouldn't usually change. It'll be useful to see:
* Percentage change in text + data (indicating required flash/ROM size)
* Percentage change in data + bss (indicating required RAM size)
This reverts commit 4410868798, reversing
changes made to 249595b752.
This causes linker failures with the binutils version used by
cross (#115239), as well as miscompilations when using the mold
linker.
This option tells LLVM to emit relaxable relocation types
R_X86_64_GOTPCRELX/R_X86_64_REX_GOTPCRELX/R_386_GOT32X in applicable cases. True
matches Clang's CMake default since 2020-08 [1] and latest LLVM default[2].
This also works around a GNU ld<2.41 issue[3] when using
general-dynamic/local-dynamic TLS models in `-Z plt=no` mode with latest LLVM.
[1]: c41a18cf61
[2]: 2aedfdd9b8
[3]: https://sourceware.org/bugzilla/show_bug.cgi?id=24784
new unstable option: -Zwrite-long-types-to-disk
This option guards the logic of writing long type names in files and instead using short forms in error messages in rustc_middle/ty/error behind a flag. The main motivation for this change is to disable this behaviour when running ui tests.
This logic can be triggered by running tests in a directory that has a long enough path, e.g. /my/very-long-path/where/rust-codebase/exists/
This means ui tests can fail depending on how long the path to their file is.
Some ui tests actually rely on this behaviour for their assertions, so for those we enable the flag manually.
This option guards the logic of writing long type names in files and
instead using short forms in error messages in rustc_middle/ty/error
behind a flag. The main motivation for this change is to disable this
behaviour when running ui tests.
This logic can be triggered by running tests in a directory that has a
long enough path, e.g. /my/very-long-path/where/rust-codebase/exists/
This means ui tests can fail depending on how long the path to their
file is.
Some ui tests actually rely on this behaviour for their assertions,
so for those we enable the flag manually.
Prototype: Add unstable `-Z reference-niches` option
MCP: rust-lang/compiler-team#641
Relevant RFC: rust-lang/rfcs#3204
This prototype adds a new `-Z reference-niches` option, controlling the range of valid bit-patterns for reference types (`&T` and `&mut T`), thereby enabling new enum niching opportunities. Like `-Z randomize-layout`, this setting is crate-local; as such, references to built-in types (primitives, tuples, ...) are not affected.
The possible settings are (here, `MAX` denotes the all-1 bit-pattern):
| `-Z reference-niches=` | Valid range |
|:---:|:---:|
| `null` (the default) | `1..=MAX` |
| `size` | `1..=(MAX- size)` |
| `align` | `align..=MAX.align_down_to(align)` |
| `size,align` | `align..=(MAX-size).align_down_to(align)` |
------
This is very WIP, and I'm not sure the approach I've taken here is the best one, but stage 1 tests pass locally; I believe this is in a good enough state to unleash this upon unsuspecting 3rd-party code, and see what breaks.
Resurrect: rustc_llvm: Add a -Z `print-codegen-stats` option to expose LLVM statistics.
This resurrects PR https://github.com/rust-lang/rust/pull/104000, which has sat idle for a while. And I want to see the effect of stack-move optimizations on LLVM (like https://reviews.llvm.org/D153453) :).
I have applied the changes requested by `@oli-obk` and `@nagisa` https://github.com/rust-lang/rust/pull/104000#discussion_r1014625377 and https://github.com/rust-lang/rust/pull/104000#discussion_r1014642482 in the latest commits.
r? `@oli-obk`
-----
LLVM has a neat [statistics](https://llvm.org/docs/ProgrammersManual.html#the-statistic-class-stats-option) feature that tracks how often optimizations kick in. It's very handy for optimization work. Since we expose the LLVM pass timings, I thought it made sense to expose the LLVM statistics too.
-----
(Edit: fix broken link
(Edit2: fix segmentation fault and use malloc
If `rustc` is built with
```toml
[llvm]
assertions = true
```
Then you can see like
```
rustc +stage1 -Z print-codegen-stats -C opt-level=3 tmp.rs
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
3 aa - Number of MayAlias results
193 aa - Number of MustAlias results
531 aa - Number of NoAlias results
...
```
And the current default build emits only
```
$ rustc +stage1 -Z print-codegen-stats -C opt-level=3 tmp.rs
===-------------------------------------------------------------------------===
... Statistics Collected ...
===-------------------------------------------------------------------------===
$
```
This might be better to emit the message to tell assertion flag necessity, but now I can't find how to do that...
Implement rust-lang/compiler-team#578.
When an ICE is encountered on nightly releases, the new rustc panic
handler will also write the contents of the backtrace to disk. If any
`delay_span_bug`s are encountered, their backtrace is also added to the
file. The platform and rustc version will also be collected.
LLVM has a neat [statistics] feature that tracks how often optimizations kick
in. It's very handy for optimization work. Since we expose the LLVM pass
timings, I thought it made sense to expose the LLVM statistics too.
[statistics]: https://llvm.org/docs/ProgrammersManual.html#the-statistic-class-stats-option
If `-o -` or `--emit KIND=-` is provided, output will be written
to stdout instead. Binary output (`obj`, `llvm-bc`, `link` and
`metadata`) being written this way will result in an error unless
stdout is not a tty. Multiple output types going to stdout will
trigger an error too, as they will all be mixded together.
Add `force` option for `--extern` flag
When `--extern force:foo=libfoo.so` is passed to `rustc` and `foo` is not actually used in the crate, ~inject an `extern crate foo;` statement into the AST~ force it to be resolved anyway in `CrateLoader::postprocess()`. This allows you to, for instance, inject a `#[panic_handler]` implementation into a `#![no_std]` crate without modifying its source so that it can be built as a `dylib`. It may also be useful for `#![panic_runtime]` or `#[global_allocator]`/`#![default_lib_allocator]` implementations.
My work previously involved integrating Rust into an existing C/C++ codebase which was built with Buck and shipped on, among other platforms, Android. When targeting Android, Buck builds all "native" code with shared linkage* so it can be loaded from Java/Kotlin. My project was not itself `#![no_std]`, but many of our dependencies were, and they would fail to build with shared linkage due to a lack of a panic handler. With this change, that project can add the new `force` option to the `std` dependency it already explicitly provides to every crate to solve this problem.
*This is an oversimplification - Buck has a couple features for aggregating dependencies into larger shared libraries, but none that I think sustainably solve this problem.
~The AST injection happens after macro expansion around where we similarly inject a test harness and proc-macro harness. The resolver's list of actually-used extern flags is populated during macro expansion, and if any of our `--extern` arguments have the `force` option and weren't already used, we inject an `extern crate` statement for them. The injection logic was added in `rustc_builtin_macros` as that's where similar injections for tests, proc-macros, and std/core already live.~
(New contributor - grateful for feedback and guidance!)
Stabilize raw-dylib, link_ordinal, import_name_type and -Cdlltool
This stabilizes the `raw-dylib` feature (#58713) for all architectures (i.e., `x86` as it is already stable for all other architectures).
Changes:
* Permit the use of the `raw-dylib` link kind for x86, the `link_ordinal` attribute and the `import_name_type` key for the `link` attribute.
* Mark the `raw_dylib` feature as stable.
* Stabilized the `-Zdlltool` argument as `-Cdlltool`.
* Note the path to `dlltool` if invoking it failed (we don't need to do this if `dlltool` returns an error since it prints its path in the error message).
* Adds tests for `-Cdlltool`.
* Adds tests for being unable to find the dlltool executable, and dlltool failing.
* Fixes a bug where we were checking the exit code of dlltool to see if it failed, but dlltool always returns 0 (indicating success), so instead we need to check if anything was written to `stderr`.
NOTE: As previously noted (https://github.com/rust-lang/rust/pull/104218#issuecomment-1315895618) using dlltool within rustc is temporary, but this is not the first time that Rust has added a temporary tool use and argument: https://github.com/rust-lang/rust/pull/104218#issuecomment-1318720482
Big thanks to ``````@tbu-`````` for the first version of this PR (#104218)
Add cross-language LLVM CFI support to the Rust compiler
This PR adds cross-language LLVM Control Flow Integrity (CFI) support to the Rust compiler by adding the `-Zsanitizer-cfi-normalize-integers` option to be used with Clang `-fsanitize-cfi-icall-normalize-integers` for normalizing integer types (see https://reviews.llvm.org/D139395).
It provides forward-edge control flow protection for C or C++ and Rust -compiled code "mixed binaries" (i.e., for when C or C++ and Rust -compiled code share the same virtual address space). For more information about LLVM CFI and cross-language LLVM CFI support for the Rust compiler, see design document in the tracking issue #89653.
Cross-language LLVM CFI can be enabled with -Zsanitizer=cfi and -Zsanitizer-cfi-normalize-integers, and requires proper (i.e., non-rustc) LTO (i.e., -Clinker-plugin-lto).
Thank you again, ``@bjorn3,`` ``@nikic,`` ``@samitolvanen,`` and the Rust community for all the help!