cache param env canonicalization
Canonicalize ParamEnv only once and store it. Then whenever we try to canonicalize `ParamEnvAnd<'tcx, T>` we only have to canonicalize `T` and then merge the results.
Prelimiary results show ~3-4% savings in diesel and serde benchmarks.
Best to review commits individually. Some commits have a short description.
Initial implementation had a soundness bug (https://github.com/rust-lang/rust/pull/117749#issuecomment-1840453387) due to cache invalidation:
- When canonicalizing `Ty<'?0>` we first try to resolve region variables in the current InferCtxt which may have a constraint `?0 == 'static`. This means that we register `Ty<'?0> => Canonical<Ty<'static>>` in the cache, which is obviously incorrect in another inference context.
- This is fixed by not doing region resolution when canonicalizing the query *input* (vs. response), which is the only place where ParamEnv is used, and then in a later commit we *statically* guard against any form of inference variable resolution of the cached canonical ParamEnv's.
r? `@ghost`
This doesn't change behavior.
It should prevent unintentional resolution of inference variables
during canonicalization, which previously caused a soundness bug.
See PR description for more.
ParamEnv is canonicalized in *queries input* rather than query response.
In such case we don't "preserve universes" of canonical variable.
This means that `universe_map` always has the default value, which is
wasteful to store in the cache.
Renamings:
- find -> opt_hir_node
- get -> hir_node
- find_by_def_id -> opt_hir_node_by_def_id
- get_by_def_id -> hir_node_by_def_id
Fix rebase changes using removed methods
Use `tcx.hir_node_by_def_id()` whenever possible in compiler
Fix clippy errors
Fix compiler
Apply suggestions from code review
Co-authored-by: Vadim Petrochenkov <vadim.petrochenkov@gmail.com>
Add FIXME for `tcx.hir()` returned type about its removal
Simplify with with `tcx.hir_node_by_def_id`
remove redundant imports
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and removing redundant imports code into two PR.
r? `@petrochenkov`
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
recurse into refs when comparing tys for diagnostics
before:

after:
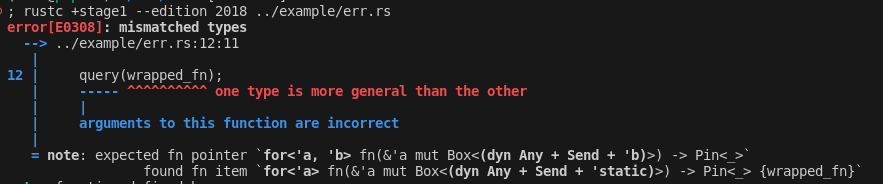
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
Unify `TraitRefs` and `PolyTraitRefs` in `ValuePairs`
I did this recently with `FnSigs` and `PolyFnSigs` but didn't think to do it with `TraitRefs` and `PolyTraitRefs`.
Currently we always do this:
```
use rustc_fluent_macro::fluent_messages;
...
fluent_messages! { "./example.ftl" }
```
But there is no need, we can just do this everywhere:
```
rustc_fluent_macro::fluent_messages! { "./example.ftl" }
```
which is shorter.
The `fluent_messages!` macro produces uses of
`crate::{D,Subd}iagnosticMessage`, which means that every crate using
the macro must have this import:
```
use rustc_errors::{DiagnosticMessage, SubdiagnosticMessage};
```
This commit changes the macro to instead use
`rustc_errors::{D,Subd}iagnosticMessage`, which avoids the need for the
imports.
Remove `HirId` from `QPath::LangItem`
Remove `HirId` from `QPath::LangItem`, since there was only *one* use-case (`ObligationCauseCode::AwaitableExpr`), which we can instead recover by walking the HIR tree.