Store #[stable] attribute's `since` value in structured form
Followup to https://github.com/rust-lang/rust/pull/116773#pullrequestreview-1680913901.
Prior to this PR, if you wrote an improper `since` version in a `stable` attribute, such as `#[stable(feature = "foo", since = "wat.0")]`, rustc would emit a diagnostic saying **_'since' must be a Rust version number, such as "1.31.0"_** and then throw out the whole `stable` attribute as if it weren't there. This strategy had 2 problems, both fixed in this PR:
1. If there was also a `#[deprecated]` attribute on the same item, rustc would want to enforce that the stabilization version is older than the deprecation version. This involved reparsing the `stable` attribute's `since` version, with a diagnostic **_invalid stability version found_** if it failed to parse. Of course this diagnostic was unreachable because an invalid `since` version would have already caused the `stable` attribute to be thrown out. This PR deletes that unreachable diagnostic.
2. By throwing out the `stable` attribute when `since` is invalid, you'd end up with a second diagnostic saying **_function has missing stability attribute_** even though your function is not missing a stability attribute. This PR preserves the `stable` attribute even when `since` cannot be parsed, avoiding the misleading second diagnostic.
Followups I plan to try next:
- Do the same for the `since` value of `#[deprecated]`.
- See whether it makes sense to also preserve `stable` and/or `unstable` attributes when they contain an invalid `feature`. What redundant/misleading diagnostics can this eliminate? What problems arise from not having a usable feature name for some API, in the situation that we're already failing compilation, so not concerned about anything that happens in downstream code?
Mark .rmeta files as /SAFESEH on x86 Windows.
Chrome links .rlibs with /WHOLEARCHIVE or -Wl,--whole-archive to prevent the linker from discarding static initializers. This works well, except on Windows x86, where lld complains:
error: /safeseh: lib.rmeta is not compatible with SEH
The fix is simply to mark the .rmeta as SAFESEH aware. This is trivially true, since the metadata file does not contain any executable code.
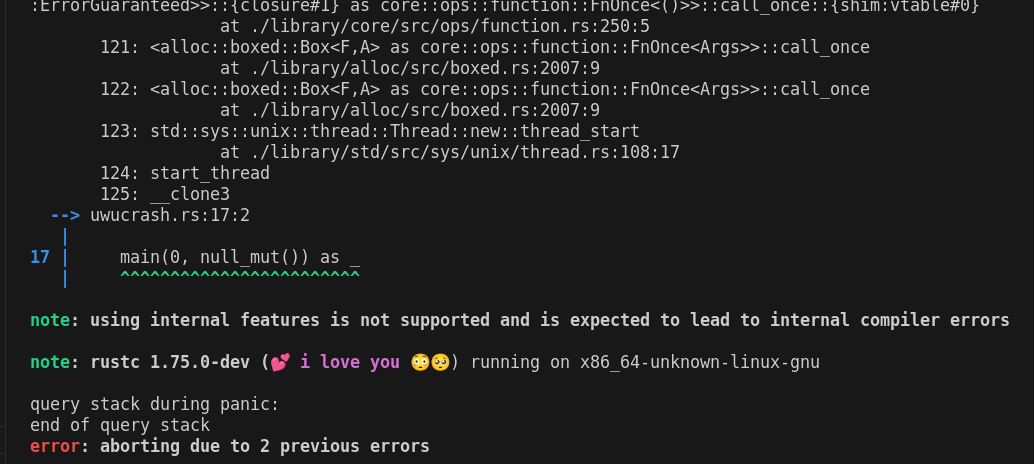
Stop telling people to submit bugs for internal feature ICEs
This keeps track of usage of internal features, and changes the message to instead tell them that using internal features is not supported.
I thought about several ways to do this but now used the explicit threading of an `Arc<AtomicBool>` through `Session`. This is not exactly incremental-safe, but this is fine, as this is set during macro expansion, which is pre-incremental, and also only affects the output of ICEs, at which point incremental correctness doesn't matter much anyways.
See [MCP 620.](https://github.com/rust-lang/compiler-team/issues/596)
The latest locals() method in stable MIR returns slices instead of vecs.
This commit also includes fixes to the existing tests that previously
referenced the private locals field.
The word internal has connotations about information that's not exposed.
It's more accurate to say that the remaining locals apply only to the
inner part of the function, so I'm renaming them to inner locals.
Rename AsyncCoroutineKind to CoroutineSource
pulled out of https://github.com/rust-lang/rust/pull/116447
Also refactors the printing infra of `CoroutineSource` to be ready for easily extending it with a `Gen` variant for `gen` blocks
Uplift `Canonical` to `rustc_type_ir`
I plan on moving the new trait solver's canonicalizer into either `rustc_type_ir` or a child crate. One dependency on this is lifting `Canonical<V>` to `rustc_type_ir` so we can actually name the canonicalized values.
I may also later lift `CanonicalVarInfo` into the new trait solver. I can't really tell what other changes need to be done, but I'm just putting this up sooner than later since I'm almost certain it'll need to be done regardless of other design choices.
There are a couple of warts introduced by this PR, since we no longer can define inherent `Canonical` impls in `rustc_middle` -- see the changes to:
* `compiler/rustc_trait_selection/src/traits/query/normalize.rs`
* `compiler/rustc_hir_typeck/src/fn_ctxt/_impl.rs`
r? lcnr
Improve the warning messages for the `#[diagnostic::on_unimplemented]`
This commit improves warnings emitted for malformed on unimplemented attributes by:
* Improving the span of the warnings
* Adding a label message to them
* Separating the messages for missing and unexpected options
* Adding a help message that says which options are supported
r? `@compiler-errors`
I'm happy to work on further improvements, so feel free to make suggestions.
Return multiple object-safety violation errors and code improvements to the object-safety check
See individual commits for more information. Split off of #114260, since it turned out that the main intent of that PR was wrong.
r? oli-obk
This keeps track of usage of internal features, and changes the message
to instead tell them that using internal features is not supported.
See MCP 620.
This is particularly helpful for the ui tests, but also could be helpful
for Stable MIR users who just want all the locals without needing to
concatenate responses
This commit hides the arg_count field in Body and instead exposes more
stable and user-friendly methods to get the return and argument locals.
As a result, Body instances must now be constructed using the `new`
function.
This field allows SMIR consumers to identify which locals correspond to
argument locals. It simply exposes the arg_count field from the MIR
representation.
HIR typeck tries to figure out which casts are trivial by doing them as
coercions and seeing whether this works. Since HIR typeck is oblivious
of lifetimes, this doesn't work for pointer casts that only change the
lifetime of the pointee, which are, as borrowck will tell you, not
trivial.
This change makes it so that raw pointer casts are never considered
trivial.
This also incidentally fixes the "trivial cast" lint false positive on
the same code. Unfortunately, "trivial cast" lints are now never emitted
on raw pointer casts, even if they truly are trivial. This could be
fixed by also doing the lint in borrowck for raw pointers specifically.
Rollup of 7 pull requests
Successful merges:
- #117111 (Remove support for alias `-Z instrument-coverage`)
- #117141 (Require target features to match exactly during inlining)
- #117152 (Fix unwrap suggestion for async fn)
- #117154 (implement C ABI lowering for CSKY)
- #117159 (Work around the fact that `check_mod_type_wf` may spuriously return `ErrorGuaranteed`)
- #117163 (compiletest: Display compilation errors in mir-opt tests)
- #117173 (Make `Iterator` a lang item)
r? `@ghost`
`@rustbot` modify labels: rollup
When encountering code like `f::<f::<f::<f::<f::<f::<f::<f::<...` with
unmatched closing angle brackets, add a linear check that avoids the
exponential behavior of the parse recovery mechanism.
Fix#117080.
Make `Iterator` a lang item
r? `@compiler-errors`
pulled out of https://github.com/rust-lang/rust/pull/116447
We're doing this change on its own, because iterator was the one diagnostic item that was load bearing on us correctly emitting errors about `diagnostic_item` mis-uses. It was used in some diagnostics as an early abort, before the actual checks of the diagnostic, so effectively the compiler was *unconditionally* checking for the iterator diagnostic item, even if it didn't emit any diagnostics. Changing those uses to use the lang item, caused us not to invoke the `all_diagnostic_items` query anymore, which then caused us to miss some issues around diagnostic items until they were actually used.
The reason we keep the diagnostic item around is that clippy uses it a lot and having `Iterator` be a lang item and a diagnostic item at the same time doesn't cost us anything, but makes clippy's internal code simpler
Work around the fact that `check_mod_type_wf` may spuriously return `ErrorGuaranteed`
Even if that error is only emitted by `check_mod_item_types`.
fixes https://github.com/rust-lang/rust/issues/117153
A cleaner refactoring would merge/chain these queries in ways that ensure we only actually get an `ErrorGuaranteed` if there was an error emitted.
Fix unwrap suggestion for async fn
Use `body_fn_sig` to get the expected return type of the function instead of `ret_coercion` in `FnCtxt`. This avoids accessing the `ret_coercion` when it's already mutably borrowed (e.g. when checking `return` expressions).
Fixes#117144
r? `@chenyukang`
Require target features to match exactly during inlining
In general it is not correct to inline a callee with a target features
that are subset of the callee. Require target features to match exactly
during inlining.
The exact match could be potentially relaxed, but this would require
identifying specific feature that are allowed to differ, those that need
to match, and those that can be present in caller but not in callee.
This resolves MIR part of #116573. For other concerns with respect to
the previous implementation also see areInlineCompatible in LLVM.
Remove support for alias `-Z instrument-coverage`
This flag was stabilized in rustc 1.60.0 (2022-04-07) as `-C instrument-coverage`, but the old unstable flag was kept around (with a warning) as an alias to ease migration.
It should now be reasonable to remove the somewhat tricky code that implemented that alias.
Fixes#116980.
Merge `impl_wf_inference` (`check_mod_impl_wf`) check into coherence checking
Problem here is that we call `collect_impl_trait_in_trait_types` when checking `check_mod_impl_wf` which is performed before coherence. Due to the `tcx.sess.track_errors`, since we end up reporting an error, we never actually proceed to coherence checking, where we would be emitting a more useful impl overlap error.
This change means that we may report more errors in some cases, but can at least proceed far enough to leave a useful message for overlapping traits with RPITITs in them.
Fixes#116982
r? types
This restricts instructions to those offered by Pentium,
to support e.g. AMD Geode.
There is already an entry for this target in the NetBSD
platform support page at
src/doc/rustc/src/platform-support/netbsd.md
...so this should forestall its removal.
Additional fixes are needed for some vendored modules, this
is the changes in the rust compiler core itself.
Remove fold code and add `Const::internal()` to StableMIR
We are not planning to support user generated constant in the foreseeable future, so we are cleaning up the fold logic and user created type for now. Users should use `Instance::resolve` in order to trigger monomorphization.
The Instance::resolve was however incomplete, since we weren't handling internalizing constants yet. Thus, I added that.
I decided to keep the `Const` fields private in case we decide to translate them lazily.
Modernize rustc_builtin_macros generics helpers
- Rustfmt-compatible formatting for the code snippets in comments
- Eliminate an _"Extra scope required"_ obsoleted by NLL
Uplift `ClauseKind` and `PredicateKind` into `rustc_type_ir`
Uplift `ClauseKind` and `PredicateKind` into `rustc_type_ir`.
Blocked on #116951
r? `@ghost`
Get rid of `'tcx` lifetime on `ConstVid`, `EffectVid`
These are simply newtyped numbers, so don't really have a reason (per se) to have a lifetime -- `TyVid` and `RegionVid` do not, for example.
The only consequence of this is that we need to use a new key type for `UnifyKey` that mentions `'tcx`. This is already done for `RegionVid`, with `RegionVidKey<'tcx>`, but this `UnifyKey` trait implementation may have been the original reason to give `ConstVid` a lifetime. See the changes to `compiler/rustc_middle/src/infer/unify_key.rs` specifically.
I consider the code cleaner this way, though -- we removed quite a few unnecessary `'tcx` in the process. This also makes it easier to uplift these two ids to `rustc_type_ir`, which I plan on doing in a follow-up PR.
r? `@BoxyUwU`
We are not planning to support user generated constant in the
foreseeable future, so we are removing the Fold logic for now in
favor of the Instance::resolve logic.
The Instance::resolve was however incomplete, since we weren't handling
internalizing constants yet. Thus, I added that.
I decided to keep the Const fields private in case we decide to
translate them lazily.
In general it is not correct to inline a callee with a target features
that are subset of the callee. Require target features to match exactly
during inlining.
The exact match could be potentially relaxed, but this would require
identifying specific feature that are allowed to differ, those that need
to match, and those that can be present in caller but not in callee.
This resolves MIR part of #116573. For other concerns with respect to
the previous implementation also see areInlineCompatible in LLVM.
Chrome links .rlibs with /WHOLEARCHIVE or -Wl,--whole-archive to prevent
the linker from discarding static initializers. This works well, except
on Windows x86, where lld complains:
error: /safeseh: lib.rmeta is not compatible with SEH
The fix is simply to mark the .rmeta as SAFESEH aware. This is trivially
true, since the metadata file does not contain any executable code.
Add method to convert internal to stable constructs
This is an alternative implementation to https://github.com/rust-lang/rust/pull/116999. I believe we can still improve the logic a bit here, but I wanted to see which direction we should go first.
In this implementation, the API is simpler and we keep Tables somewhat private. The definition is still public though, since we have to expose the Stable trait. However, there's a cost of keeping another thread-local and using `Rc`, but I'm hoping it will be a small cost.
r? ``@oli-obk``
r? ``@spastorino``
Suggest unwrap/expect for let binding type mismatch
Found it when investigating https://github.com/rust-lang/rust/issues/116738
I'm not sure whether it's a good style to suggest `unwrap`, seems it's may helpful for newcomers.
#116738 needs another fix to improve it.
Avoid unnecessary renumbering during borrowck
Currently, after renumbering there are always unused `RegionVid`s if the return type contains any regions, this is due to `visit_ty` being called twice on the same `Ty`: once with `TyContext::ReturnTy` and once with `TyContext::LocalDecl { local: _0 }`. This PR skips renumbering the first time around.
Introduce `-C instrument-coverage=branch` to gate branch coverage
This was extracted from https://github.com/rust-lang/rust/pull/115061 and can land independently from other coverage related work.
The flag is unused for now, but is added in advance of adding branch coverage support.
It is an unstable, nightly only flag that needs to be used in combination with `-Zunstable-options`, like so: `-Zunstable-options -C instrument-coverage=branch`.
The goal is to develop branch coverage as an unstable opt-in feature first, before it matures and can be turned on by default.
`OptWithInfcx` naming nits, trait bound simplifications
* Use an associated type `Interner` on `InferCtxtLike` to remove a redundant interner parameter (`I: Interner, Infcx: InferCtxtLike<I>` -> `Infcx: InferCtxtLike`).
* Remove double-`Option` between `infcx: Option<Infcx>` and `fn universe_of_ty(&self, ty: ty::InferTy) -> Option<ty::UniverseIndex>`. We don't need the infcx to be optional if we can provide a "noop" (`NoInfcx`) implementation that just always returns `None` for universe index.
* Also removes the `core::convert::Infallible` implementation which I found a bit weird...
* Some naming nits with params.
* I found `InferCtxt` + `InfCtx` and `Infcx` to be a lot of different ways to spell "inference context", so I got rid of the `InfCtx` type parameter name in favor of `Infcx` which is a more standard name.
* I found `OptWithInfcx` to be a bit redundant -> `WithInfcx`.
I'm making these changes because I intend to reuse the `InferCtxtLike` trait for uplifting the canonicalizer into a new trait -- conveniently, the information I need for uplifting the canonicalizer also is just the universe information of a type var, so it's super convenient 😸
r? `@BoxyUwU` or `@lcnr`
Validate `feature` and `since` values inside `#[stable(…)]`
Previously the string passed to `#[unstable(feature = "...")]` would be validated as an identifier, but not `#[stable(feature = "...")]`. In the standard library there were `stable` attributes containing the empty string, and kebab-case string, neither of which should be allowed.
Pre-existing validation of `unstable`:
```rust
// src/lib.rs
#![allow(internal_features)]
#![feature(staged_api)]
#![unstable(feature = "kebab-case", issue = "none")]
#[unstable(feature = "kebab-case", issue = "none")]
pub struct Struct;
```
```console
error[E0546]: 'feature' is not an identifier
--> src/lib.rs:5:1
|
5 | #![unstable(feature = "kebab-case", issue = "none")]
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
For an `unstable` attribute, the need for an identifier is obvious because the downstream code needs to write a `#![feature(...)]` attribute containing that identifier. `#![feature(kebab-case)]` is not valid syntax and `#![feature(kebab_case)]` would not work if that is not the name of the feature.
Having a valid identifier even in `stable` is less essential but still useful because it allows for informative diagnostic about the stabilization of a feature. Compare:
```rust
// src/lib.rs
#![allow(internal_features)]
#![feature(staged_api)]
#![stable(feature = "kebab-case", since = "1.0.0")]
#[stable(feature = "kebab-case", since = "1.0.0")]
pub struct Struct;
```
```rust
// src/main.rs
#![feature(kebab_case)]
use repro::Struct;
fn main() {}
```
```console
error[E0635]: unknown feature `kebab_case`
--> src/main.rs:3:12
|
3 | #![feature(kebab_case)]
| ^^^^^^^^^^
```
vs the situation if we correctly use `feature = "snake_case"` and `#![feature(snake_case)]`, as enforced by this PR:
```console
warning: the feature `snake_case` has been stable since 1.0.0 and no longer requires an attribute to enable
--> src/main.rs:3:12
|
3 | #![feature(snake_case)]
| ^^^^^^^^^^
|
= note: `#[warn(stable_features)]` on by default
```
Handle `ReErased` in responses in new solver
There are legitimate cases in the compiler where we return `ReErased` for lifetimes that are uncaptured in the hidden type of an opaque. For example, in the test committed below, we ignore ignore the bivariant lifetimes of an opaque when it's inferred as the hidden type of another opaque. This may result in a `type_of(Opaque)` call returning a type that references `ReErased`. Let's handle this gracefully in the new solver.
Also added a `rustc_hidden_type_of_opaques` attr to print hidden types. This seems useful for opaques.
r? lcnr
Separate move path tracking between borrowck and drop elaboration.
The primary goal of this PR is to skip creating a `MovePathIndex` for path that do not need dropping in drop elaboration.
The 2 first commits are cleanups.
The next 2 commits displace `move` errors from move-path builder to borrowck. Move-path builder keeps the same logic, but does not carry error information any more.
The remaining commits allow to filter `MovePathIndex` creation according to types. This is used in drop elaboration, to avoid computing dataflow for paths that do not need dropping.
Rollup of 6 pull requests
Successful merges:
- #107159 (rand use getrandom for freebsd (available since 12.x))
- #116859 (Make `ty::print::Printer` take `&mut self` instead of `self`)
- #117046 (return unfixed len if pat has reported error)
- #117070 (rustdoc: wrap Type with Box instead of Generics)
- #117074 (Remove smir from triage and add me to stablemir)
- #117086 (Update .mailmap to promote my livename)
r? `@ghost`
`@rustbot` modify labels: rollup
Detect if there is a potential typo where the `{` meant to open the
closure body was written before the body.
```
error[E0277]: expected a `FnOnce<({integer},)>` closure, found `Option<usize>`
--> $DIR/ruby_style_closure_successful_parse.rs:3:31
|
LL | let p = Some(45).and_then({|x|
| ______________________--------_^
| | |
| | required by a bound introduced by this call
LL | | 1 + 1;
LL | | Some(x * 2)
| | ----------- this tail expression is of type `Option<usize>`
LL | | });
| |_____^ expected an `FnOnce<({integer},)>` closure, found `Option<usize>`
|
= help: the trait `FnOnce<({integer},)>` is not implemented for `Option<usize>`
note: required by a bound in `Option::<T>::and_then`
--> $SRC_DIR/core/src/option.rs:LL:COL
help: you might have meant to open the closure body instead of placing a closure within a block
|
LL - let p = Some(45).and_then({|x|
LL + let p = Some(45).and_then(|x| {
|
```
Detect the potential typo where the closure header is missing.
```
error[E0277]: expected a `FnOnce<(&bool,)>` closure, found `bool`
--> $DIR/block_instead_of_closure_in_arg.rs:3:23
|
LL | Some(true).filter({
| _________________------_^
| | |
| | required by a bound introduced by this call
LL | |/ if number % 2 == 0 {
LL | || number == 0
LL | || } else {
LL | || number != 0
LL | || }
| ||_________- this tail expression is of type `bool`
LL | | });
| |______^ expected an `FnOnce<(&bool,)>` closure, found `bool`
|
= help: the trait `for<'a> FnOnce<(&'a bool,)>` is not implemented for `bool`
note: required by a bound in `Option::<T>::filter`
--> $SRC_DIR/core/src/option.rs:LL:COL
help: you might have meant to create the closure instead of a block
|
LL | Some(true).filter(|_| {
| +++
```
Partially address #27300.
return unfixed len if pat has reported error
- Fixes#116186
- Fixes#113021
This issue arises due to the creation of a fixed-length pattern, as a result of the mir body corruption. The corruption taints `tcx.eval_to_allocation_raw`, causing it to return `AlreadyReported`. Consequently, this prevents `len.try_eval_target_usize` from evaluating correctly and returns `None`. Lastly, it results in the return of `[usize; min_len]`.
To rectify this issue, my approach is that to return unfixed when encountering `ErrorHandled::Reported`. Additionally, in instances of `ErrorHandled::TooGeneric`, the previous logic has been reinstated.
Make `ty::print::Printer` take `&mut self` instead of `self`
based on #116815
This simplifies the code by removing all the `self` assignments and
makes the flow of data clearer - always into the printer.
Especially in v0 mangling, which already used `&mut self` in some
places, it gets a lot more uniform.
report `unused_import` for empty reexports even it is pub
Fixes#116032
An easy fix. r? `@petrochenkov`
(Discovered this issue while reviewing #115993.)
Note: We do not expect to provide internalizing methods for all
StableMIR constructs. They exist only to help migrating efforts to allow
users to mix StableMIR and internal constructs.
Implement jump threading MIR opt
This pass is an attempt to generalize `ConstGoto` and `SeparateConstSwitch` passes into a more complete jump threading pass.
This pass is rather heavy, as it performs a truncated backwards DFS on MIR starting from each `SwitchInt` terminator. This backwards DFS remains very limited, as it only walks through `Goto` terminators.
It is build to support constants and discriminants, and a propagating through a very limited set of operations.
The pass successfully manages to disentangle the `Some(x?)` use case and the DFA use case. It still needs a few tests before being ready.
Eliminate rustc_attrs::builtin::handle_errors in favor of emitting errors directly
Suggested in https://github.com/rust-lang/rust/pull/116773#pullrequestreview-1691411257.
This `handle_errors` function is originally from https://github.com/rust-lang/rust/pull/34531, in which it was useful because it allowed error messages and error codes (`E0542`) for multiple occurrences of the same error to be centralized in one place. For example rather than repeating this diagnostic in 2 places:
```rust
span_err!(diagnostic, attr.span, E0542, "missing 'since'");
```
one could repeat this instead:
```rust
handle_errors(diagnostic, attr.span, AttrError::MissingSince);
```
ensuring that all "missing 'since'" errors always remained consistent in message and error code.
Over time as error messages and error codes got factored to fluent diagnostics (https://github.com/rust-lang/rust/pull/100836), this rationale no longer applies. The new code has the same benefit while being less verbose (+73, -128).
```rust
sess.emit_err(session_diagnostics::MissingSince { span: attr.span });
```
r? `@cjgillot`
Location-insensitive polonius: consider a loan escaping if an SCC has member constraints applied only
The location-insensitive analysis considered loans to escape if there were member constraints, which makes *some* sense for scopes and matches the scopes that NLL computes on all the tests.
However, polonius and NLLs differ on the fuzzed case #116657, where an SCC has member constraints but no applied ones (and is kinda surprising). The existing UI tests with member constraints impacting scopes all have some constraint applied.
This PR changes the location-insensitive analysis to consider a loan to escape if there are applied member constraints, and for extra paranoia/insurance via fuzzing and crater: actually checks the constraint's min choice is indeed a universal region as we expect. (This could be turned into a `debug_assert` and early return as a slight optimization after these periods of verification)
The 4 UI tests where member constraints are meaningful for computing scopes still pass obviously, and this also fixes#116657.
r? `@matthewjasper`
Avoid having `rustc_smir` depend on `rustc_interface` or `rustc_driver`
This is done by moving all the logic into a macro that performs the entire "run" operation in one go.
This makes https://github.com/rust-lang/rust/pull/116806 obsolete
as a follow up we should make the macro usable without manually having to write
```rust
#[macro_use]
extern crate rustc_smir;
extern crate stable_mir;
extern crate rustc_driver;
extern crate rustc_interface;
use rustc_smir::rustc_internal;
```
in every crate that uses the macro.
r? `@spastorino`
Avoid a `track_errors` by bubbling up most errors from `check_well_formed`
I believe `track_errors` is mostly papering over issues that a sufficiently convoluted query graph can hit. I made this change, while the actual change I want to do is to stop bailing out early on errors, and instead use this new `ErrorGuaranteed` to invoke `check_well_formed` for individual items before doing all the `typeck` logic on them.
This works towards resolving https://github.com/rust-lang/rust/issues/97477 and various other ICEs, as well as allowing us to use parallel rustc more (which is currently rather limited/bottlenecked due to the very sequential nature in which we do `rustc_hir_analysis::check_crate`)
cc `@SparrowLii` `@Zoxc` for the new `try_par_for_each_in` function
add a `csky-unknown-linux-gnuabiv2hf` target
This is the rustc side changes to support csky based Linux target(`csky-unknown-linux-gnuabiv2`).
Tier 3 policy:
> A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
I pledge to do my best maintaining it.
> Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
This `csky` section is the arch name and the `unknown-linux` section is the same as other linux target, and `gnuabiv2` is from the cross-compile toolchain of `gcc`. the `hf`means hardfloat.
> Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
I think the explanation in platform support doc is enough to make this aspect clear.
> Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
It's using open source tools only.
> The target must not introduce license incompatibilities.
No new license
> Anything added to the Rust repository must be under the standard Rust license (MIT OR Apache-2.0).
Understood.
> The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the tidy tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
There are no new dependencies/features required.
> Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, rustc built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
As previously said it's using open source tools only.
> "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are not limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
There are no such terms present/
> Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
I'm not the reviewer here.
> This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
I'm not the reviewer here.
> Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
It supports for std
> The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
I have added the documentation, and I think it's clear.
> Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via ``@)`` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
Understood.
> Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
Understood.
> Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
I believe I didn't break any other target.
> In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
I think there are no such problems in this PR.
coverage: Emit the filenames section before encoding per-function mappings
When embedding coverage information in LLVM IR (and ultimately in the resulting binary), there are two main things that each CGU needs to emit:
- A single `__llvm_covmap` record containing a coverage header, which mostly consists of a list of filenames used by the CGU's coverage mappings.
- Several `__llvm_covfun` records, one for each instrumented function, each of which contains the hash of the list of filenames in the header.
There is a kind of loose cyclic dependency between the two: we need the hash of the file table before we can emit the covfun records, but we need to traverse all of the instrumented functions in order to build the file table.
The existing code works by processing the individual functions first. It lazily adds filenames to the file table, and stores the mostly-complete function records in a temporary list. After this it hashes the file table, emits the header (containing the file table), and then uses the hash to emit all of the function records.
This PR reverses that order: first we traverse all of the functions (without trying to prepare their function records) to build a *complete* file table, and then emit it immediately. At this point we have the file table hash, so we can then proceed to build and emit all of the function records, without needing to store them in an intermediate list.
---
Along the way, this PR makes some necessary changes that are also worthwhile in their own right:
- We split `FunctionCoverage` into distinct collector/finished phases, which neatly avoids some borrow-checker hassles when extracting a function's final expression/mapping data.
- We avoid having to re-sort a function's mappings when preparing the list of filenames that it uses.
Most coverage metadata is encoded into two sections in the final executable.
The `__llvm_covmap` section mostly just contains a list of filenames, while the
`__llvm_covfun` section contains encoded coverage maps for each instrumented
function.
The catch is that each per-function record also needs to contain a hash of the
filenames list that it refers to. Historically this was handled by assembling
most of the per-function data into a temporary list, then assembling the
filenames buffer, then using the filenames hash to emit the per-function data,
and then finally emitting the filenames table itself.
However, now that we build the filenames table up-front (via a separate
traversal of the per-function data), we can hash and emit that part first, and
then emit each of the per-function records immediately after building. This
removes the awkwardness of having to temporarily store nearly-complete
per-function records.
The main change here is that `VirtualFileMapping` now uses an internal hashmap
to de-duplicate incoming global file IDs. That removes the need for
`encode_mappings_for_function` to re-sort its mappings by filename in order to
de-duplicate them.
(We still de-duplicate runs of identical filenames to save work, but this is
not load-bearing for correctness, so a sort is not necessary.)
The combined `get_expressions_and_counter_regions` method was an artifact of
having to prepare the expressions and mappings at the same time, to avoid
ownership/lifetime problems with temporary data used by both.
Now that we have an explicit transition from `FunctionCoverageCollector` to the
final `FunctionCoverage`, we can prepare any shared data during that step and
store it in the final struct.
This gives us a clearly-defined place to run code after the instance's MIR has
been traversed by codegen, but before we emit its `__llvm_covfun` record.
Sync rustc_codegen_cranelift
The main highlights this time is new support for riscv64 linux enabled by a cranelift update. I have also updated some of the crates built as part of cg_clif's test suite which enabled removing several patches for them. And finally I have fixed a couple of tests in rustc's test suite with cg_clif.
r? `@ghost`
`@rustbot` label +A-codegen +A-cranelift +T-compiler +subtree-sync
Mention the syntax for `use` on `mod foo;` if `foo` doesn't exist
Newcomers might get confused that `mod` is the only way of defining scopes, and that it can be used as if it were `use`.
Fix#69492.
coverage: Emit mappings for unused functions without generating stubs
For a while I've been annoyed by the fact that generating coverage maps for unused functions involves generating a stub function at the LLVM level.
As I suspected, generating that stub function isn't actually necessary, as long as we specifically tell LLVM about the symbol names of all the functions that have coverage mappings but weren't codegenned (due to being unused).
---
There is some helper code that gets moved around in the follow-up patches, so look at the first patch to see the most important functional changes.
---
`@rustbot` label +A-code-coverage
fix spans for removing `.await` on `for` expressions
We need to use a span with the outer syntax context of a desugared `for` expression to join it with the `.await` span.
fixes https://github.com/rust-lang/rust/issues/117014
Lint `non_exhaustive_omitted_patterns` by columns
This is a rework of the `non_exhaustive_omitted_patterns` lint to make it more consistent. The intent of the lint is to help consumers of `non_exhaustive` enums ensure they stay up-to-date with all upstream variants. This rewrite fixes two cases we didn't handle well before:
First, because of details of exhaustiveness checking, the following wouldn't lint `Enum::C` as missing:
```rust
match Some(x) {
Some(Enum::A) => {}
Some(Enum::B) => {}
_ => {}
}
```
Second, because of the fundamental workings of exhaustiveness checking, the following would treat the `true` and `false` cases separately and thus lint about missing variants:
```rust
match (true, x) {
(true, Enum::A) => {}
(true, Enum::B) => {}
(false, Enum::C) => {}
_ => {}
}
```
Moreover, it would correctly not lint in the case where the pair is flipped, because of asymmetry in how exhaustiveness checking proceeds.
A drawback is that it no longer makes sense to set the lint level per-arm. This will silently break the lint for current users of it (but it's behind a feature gate so that's ok).
The new approach is now independent of the exhaustiveness algorithm; it's a separate pass that looks at patterns column by column. This is another of the motivations for this: I'm glad to move it out of the algorithm, it was akward there.
This PR is almost identical to https://github.com/rust-lang/rust/pull/111651. cc `@eholk` who reviewed it at the time. Compared to then, I'm more confident this is the right approach.
This simplifies the code by removing all the `self` assignments and
makes the flow of data clearer - always into the printer.
Especially in v0 mangling, which already used `&mut self` in some
places, it gets a lot more uniform.
Point at assoc fn definition on type param divergence
When the number of type parameters in the associated function of an impl and its trait differ, we now *always* point at the trait one, even if it comes from a foreign crate. When it is local, we point at the specific params, when it is foreign, we point at the whole associated item.
Fix#69944.
Mention `into_iter` on borrow errors suggestions when appropriate
If we encounter a borrow error on `vec![1, 2, 3].iter()`, suggest `into_iter`.
Fix#68445.
coverage: Fix inconsistent handling of function signature spans
While doing some more cleanup of `spans`, I noticed a strange inconsistency in how function signatures are handled. Normally the function signature span is treated as though it were executable as part of the start of the function, but in some cases the signature span disappears entirely from coverage, for no obvious reason.
This is caused by the fact that spans created by `CoverageSpan::for_fn_sig` don't add the span to their `merged_spans` field (unlike normal statement/terminator spans). In cases where the span-processing code looks at those merged spans, it thinks the signature span is no longer visible and deletes it.
Adding the signature span to `merged_spans` resolves the inconsistency.
(Prior to #116409 this wouldn't have been possible, because there was no case in the old `CoverageStatement` enum representing a signature. Now that `merged_spans` is just a list of spans, that's no longer an obstacle.)
Add stable Instance::body() and RustcInternal trait
The `Instance::body()` returns a monomorphized body.
For that, we had to implement visitor that monomorphize types and constants. We are also introducing the RustcInternal trait that will allow us to convert back from Stable to Internal.
Note that this trait is not yet visible for our users as it depends on Tables. We should probably add a new trait that can be exposed.
The tests here are very simple, and I'm planning on creating more exhaustive tests in the project-mir repo. But I was hoping to get some feedback here first.
r? ```@oli-obk```
Typo suggestion to change bindings with leading underscore
When encountering a binding that isn't found but has a typo suggestion for a binding with a leading underscore, suggest changing the binding definition instead of the use place.
Fix#60164.
coverage: Simplify the injection of coverage statements
This is a follow-up to #116046 that I left out of that PR because I didn't want to make it any larger.
After the various changes we've made to how coverage data is stored and transferred, the old code structure for injecting coverage statements into MIR is built around a lot of constraints that don't exist any more. We can simplify it by replacing it with a handful of loops over the BCB node/edge counters and the BCB spans.
---
`@rustbot` label +A-code-coverage
This query has a name that sounds general-purpose, but in fact it has
coverage-specific semantics, and (fortunately) is only used by coverage code.
Because it is only ever called once (from one designated CGU), it doesn't need
to be a query, and we can change it to a regular function instead.
When the number of type parameters in the associated function of an impl
and its trait differ, we now *always* point at the trait one, even if it
comes from a foreign crate. When it is local, we point at the specific
params, when it is foreign, we point at the whole associated item.
Fix#69944.
When encountering a binding that isn't found but has a typo suggestion
for a binding with a leading underscore, suggest changing the binding
definition instead of the use place.
Fix#60164.
Move where doc comment meant as comment check
The new place makes more sense and covers more cases beyond individual statements.
```
error: expected one of `.`, `;`, `?`, `else`, or an operator, found doc comment `//!foo
--> $DIR/doc-comment-in-stmt.rs:25:22
|
LL | let y = x.max(1) //!foo
| ^^^^^^ expected one of `.`, `;`, `?`, `else`, or an operator
|
help: add a space before `!` to write a regular comment
|
LL | let y = x.max(1) // !foo
| +
```
Fix#65329.
Uplift movability and mutability, the simple way
Just make type_ir a dependency of ast. This can be relaxed later if we want to make the dependency less heavy. Part of rust-lang/types-team#124.
r? `@lcnr` or `@jackh726`
The new place makes more sense and covers more cases beyond individual
statements.
```
error: expected one of `.`, `;`, `?`, `else`, or an operator, found doc comment `//!foo
--> $DIR/doc-comment-in-stmt.rs:25:22
|
LL | let y = x.max(1) //!foo
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected one of `.`, `;`, `?`, `else`, or an operator
|
help: add a space before `!` to write a regular comment
|
LL | let y = x.max(1) // !foo
| +
```
Fix#65329.
Fix duplicate labels emitted in `render_multispan_macro_backtrace()`
This PR replaces the `Vec` used to store labels with an `FxIndexSet` in order to eliminate duplicates
Fixes#116836
The `Instance::body()` returns a monomorphized body.
For that, we had to implement visitor that monomorphize types and
constants. We are also introducing the RustcInternal trait that will
allow us to convert back from Stable to Internal.
Note that this trait is not yet visible for our users as it depends on
Tables. We should probably add a new trait that can be exposed.
Implement rustc part of RFC 3127 trim-paths
This PR implements (or at least tries to) [RFC 3127 trim-paths](https://github.com/rust-lang/rust/issues/111540), the rustc part. That is `-Zremap-path-scope` with all of it's components/scopes.
`@rustbot` label: +F-trim-paths
This commit improves warnings emitted for malformed on unimplemented
attributes by:
* Improving the span of the warnings
* Adding a label message to them
* Separating the messages for missing and unexpected options
* Adding a help message that says which options are supported
Use v0.0.0 in compiler crates
I may be totally off base here, but my understanding is that it's conventional to use v0.0.0 to reflect the unversioned nature of the compiler crates. Fix that for some of the compiler crates that were created recently.
Don't ICE when encountering unresolved regions in `fully_resolve`
We can encounter unresolved regions due to unconstrained impl lifetime arguments because `collect_return_position_impl_trait_in_trait_tys` runs before WF actually checks that the impl is well-formed.
Fixes#116525
Bump `COINDUCTIVE_OVERLAP_IN_COHERENCE` to deny + warn in deps
1.73 is the first place this shows up in stable (recall that there was only 1 regression), so let's bump this to deny on nightly.
r? lcnr
coverage: Move most per-function coverage info into `mir::Body`
Currently, all of the coverage information collected by the `InstrumentCoverage` pass is smuggled through MIR in the form of individual `StatementKind::Coverage` statements, which must then be reassembled by coverage codegen.
That's awkward for a number of reasons:
- While some of the coverage statements do care about their specific position in the MIR control-flow graph, many of them don't, and are just tacked onto the function's first BB as metadata carriers.
- MIR inlining can result in coverage statements being duplicated, so coverage codegen has to jump through hoops to avoid emitting duplicate mappings.
- MIR optimizations that would delete coverage statements need to carefully copy them into the function's first BB so as not to omit them from coverage reports.
- The order in which coverage codegen sees coverage statements is dependent on MIR optimizations/inlining, which can cause unnecessary churn in the emitted coverage mappings.
- We don't have a good way to annotate MIR-level functions with extra coverage info that doesn't belong in a statement.
---
This PR therefore takes most of the per-function coverage info and stores it in a field in `mir::Body` as `Option<Box<FunctionCoverageInfo>>`.
(This adds one pointer to the size of `mir::Body`, even when coverage is not enabled.)
Coverage statements still need to be injected into MIR in some cases, but only when they actually affect codegen (counters) or are needed to detect code that has been optimized away as unreachable (counters/expressions).
---
By the end of this PR, the information stored in `FunctionCoverageInfo` is:
- A hash of the function's source code (needed by LLVM's coverage map format)
- The number of coverage counters added by coverage instrumentation
- A table of coverage expressions, associating each expression ID with its operator (add or subtract) and its two operands
- The list of mappings, associating each covered code region with a counter/expression/zero value
---
~~This is built on top of #115301, so I'll rebase and roll a reviewer once that lands.~~
r? `@ghost`
`@rustbot` label +A-code-coverage