Add `IntoAsyncIterator`
This introduces the `IntoAsyncIterator` trait and uses it in the desugaring of the unstable `for await` loop syntax. This is mostly added for symmetry with `Iterator` and `IntoIterator`.
r? `@compiler-errors`
cc `@rust-lang/libs-api,` `@rust-lang/wg-async`
Separate MIR lints from validation
Add a MIR lint pass, enabled with -Zlint-mir, which identifies undefined or
likely erroneous behaviour.
The initial implementation mostly migrates existing checks of this nature from
MIR validator, where they did not belong (those checks have false positives and
there is nothing inherently invalid about MIR with undefined behaviour).
Fixes#104736Fixes#104843Fixes#116079Fixes#116736Fixes#118990
tests: fix overaligned-constant to not over-specify getelementptr instr
On LLVM 18 we get slightly different arguments here, so it's easier to just regex those away. The important details are all still asserted as I understand things.
Fixes#119193.
`@rustbot` label: +llvm-main
Add support for `for await` loops
This adds support for `for await` loops. This includes parsing, desugaring in AST->HIR lowering, and adding some support functions to the library.
Given a loop like:
```rust
for await i in iter {
...
}
```
this is desugared to something like:
```rust
let mut iter = iter.into_async_iter();
while let Some(i) = loop {
match core::pin::Pin::new(&mut iter).poll_next(cx) {
Poll::Ready(i) => break i,
Poll::Pending => yield,
}
} {
...
}
```
This PR also adds a basic `IntoAsyncIterator` trait. This is partly for symmetry with the way `Iterator` and `IntoIterator` work. The other reason is that for async iterators it's helpful to have a place apart from the data structure being iterated over to store state. `IntoAsyncIterator` gives us a good place to do this.
I've gated this feature behind `async_for_loop` and opened #118898 as the feature tracking issue.
r? `@compiler-errors`
Exhaustiveness: reveal opaque types properly
Previously, exhaustiveness had no clear policy around opaque types. In this PR I propose the following policy: within the body of an item that defines the hidden type of some opaque type, exhaustiveness checking on a value of that opaque type is performed using the concrete hidden type inferred in this body.
I'm not sure how consistent this is with other operations allowed on opaque types; I believe this will require FCP.
From what I can tell, this doesn't change anything for non-empty types.
The observable changes are:
- when the real type is uninhabited, matches within the defining scopes can now rely on that for exhaustiveness, e.g.:
```rust
#[derive(Copy, Clone)]
enum Void {}
fn return_never_rpit(x: Void) -> impl Copy {
if false {
match return_never_rpit(x) {}
}
x
}
```
- this properly fixes ICEs like https://github.com/rust-lang/rust/issues/117100 that occurred because a same match could have some patterns where the type is revealed and some where it is not.
Bonus subtle point: if `x` is opaque, a match like `match x { ("", "") => {} ... }` will constrain its type ([playground](https://play.rust-lang.org/?version=nightly&mode=debug&edition=2021&gist=901d715330eac40339b4016ac566d6c3)). This is not the case for `match x {}`: this will not constain the type, and will only compile if something else constrains the type to be empty.
Fixes https://github.com/rust-lang/rust/issues/117100
r? `@oli-obk`
Edited for precision of the wording
[Included](https://github.com/rust-lang/rust/pull/116821#issuecomment-1813171764) in the FCP on this PR is this rule:
> Within the body of an item that defines the hidden type of some opaque type, exhaustiveness checking on a value of that opaque type is performed using the concrete hidden type inferred in this body.
Refactor AST trait bound modifiers
Instead of having two types to represent trait bound modifiers in the parser / the AST (`parser::ty::BoundModifiers` & `ast::TraitBoundModifier`), only to map one to the other later, just use `parser::ty::BoundModifiers` (moved & renamed to `ast::TraitBoundModifiers`).
The struct type is more extensible and easier to deal with (see [here](https://github.com/rust-lang/rust/pull/119099/files#r1430749981) and [here](https://github.com/rust-lang/rust/pull/119099/files#r1430752116) for context) since it more closely models what it represents: A compound of two kinds of modifiers, constness and polarity. Modeling this as an enum (the now removed `ast::TraitBoundModifier`) meant one had to add a new variant per *combination* of modifier kind, which simply isn't scalable and which lead to a lot of explicit non-DRY matches.
NB: `hir::TraitBoundModifier` being an enum is fine since HIR doesn't need to worry representing invalid modifier kind combinations as those get rejected during AST validation thereby immensely cutting down the number of possibilities.
On LLVM 18 we get slightly different arguments here, so it's easier to
just regex those away. The important details are all still asserted as I
understand things.
Fixes#119193.
@rustbot label: +llvm-main
Simple modification of `non_lifetime_binders`'s diagnostic information to adapt to type binders
fixes#119067
Replace diagnostic information "lifetime bounds cannot be used in this context" to "bounds cannot be used in this context".
```rust
#![allow(incomplete_features)]
#![feature(non_lifetime_binders)]
trait Trait {}
trait Trait2
where for <T: Trait> ():{}
//~^ ERROR bounds cannot be used in this context
```
- Make temporaries in if-let guards be the same variable in MIR when
the guard is duplicated due to or-patterns.
- Change the "destruction scope" for match arms to be the arm scope rather
than the arm body scope.
- Add tests.
coverage: Check for `async fn` explicitly, without needing a heuristic
The old code used a heuristic to detect async functions and adjust their coverage spans to produce better output. But there's no need to resort to a heuristic when we can just look back at the original definition and check whether the current function is actually an `async fn`.
In addition to being generally nicer, this also gets rid of the one piece of code that specifically cares about `CoverageSpan::is_closure` representing an actual closure. All remaining code that inspects that field just uses it as an indication that the span is a hole that should be carved out of other spans, and then discarded.
That opens up the possibility of introducing other kinds of “hole” spans, e.g. for nested functions/types/macros, and having them all behave uniformly.
---
`@rustbot` label +A-code-coverage
Add function ABI and type layout to StableMIR
This change introduces a new module to StableMIR named `abi` with information from `rustc_target::abi` and `rustc_abi`, that allow users to retrieve more low level information required to perform bit-precise analysis.
The layout of a type can be retrieved via `Ty::layout`, and the instance ABI can be retrieved via `Instance::fn_abi()`.
To properly handle errors while retrieve layout information, we had to implement a few layout related traits.
r? ```@compiler-errors```
-Znext-solver: adapt overflow rules to avoid breakage
Do not erase overflow constraints if they are from equating the impl header when normalizing[^1].
This should be the minimal change to not break crates depending on the old project behavior of "apply impl constraints while only lazily evaluating any nested goals".
Fixes https://github.com/rust-lang/trait-system-refactor-initiative/issues/70, see https://hackmd.io/ATf4hN0NRY-w2LIVgeFsVg for the reasoning behind this.
Only keeping constraints on overflow for `normalize-to` goals as that's the only thing needed for backcompat. It also allows us to not track the origin of root obligations. The issue with root goals would be something like the following:
```rust
trait Foo {}
trait Bar {}
trait FooBar {}
impl<T: Foo + Bar> FooBar for T {}
// These two should behave the same, rn we can drop constraints for both,
// but if we don't drop `Misc` goals we would only drop the constraints for
// `FooBar` unless we track origins of root obligations.
fn func1<T: Foo + Bar>() {}
fn func2<T: FooBaz>() {}
```
[^1]: mostly, the actual rules are slightly different
r? ``@compiler-errors``
rustc_codegen_ssa: Don't drop `IncorrectCguReuseType` , make `rustc_expected_cgu_reuse` attr work
In [100753], `IncorrectCguReuseType` accidentally stopped being emitted by removing `diag.span_err(...)`. Begin emitting it again rather than just blindly dropping it, and adjust tests accordingly.
We assume that there are no bugs and that the currently actual CGU reuse is correct. If there are bugs, they will be discovered and fixed eventually, and the tests will then be updated.
[100753]: 706452eba7 (diff-048389738ddcbe0f9765291a29db1fed9a5f03693d4781cfb5aaa97ffb3c7f84)Closes#118972
Add check for possible CStr literals in pre-2021
Fixes [#118654](https://github.com/rust-lang/rust/issues/118654)
Adds information to errors caused by possible CStr literals in pre-2021.
The lexer separates `c"str"` into two tokens if the edition is less than 2021, which later causes an error when parsing. This error now has a more helpful message that directs them to information about editions. However, the user might also have written `c "str"` in a later edition, so to not confuse people who _are_ using a recent edition, I also added a note about whitespace.
We could probably figure out exactly which scenario has been encountered by examining spans and editions, but I figured it would be better not to overcomplicate the creation of the error too much.
This is my first code PR and I tried to follow existing conventions as much as possible, but I probably missed something, so let me know!
add more niches to rawvec
Previously RawVec only had a single niche in its `NonNull` pointer. With this change it now has `isize::MAX` niches since half the value-space of the capacity field is never needed, we can't have a capacity larger than isize::MAX.
match lowering: Remove the `make_target_blocks` hack
This hack was introduced 4 years ago in [`a1d0266` (#60730)](a1d0266878) to improve LLVM optimization time, specifically noticed in the `encoding` benchmark. Measurements today indicate it is no longer needed.
r? `@matthewjasper`
The easter egg ICE on `break rust` is weird: it's the one ICE in the
entire compiler that doesn't immediately abort, which makes it
annoyingly inconsistent.
This commit changes it to abort. As part of this, the extra notes are
now appended onto the bug dignostic, rather than being printed as
individual note diagnostics, which changes the output format a bit.
These changes don't interferes with the joke, but they do help with my
ongoing cleanups to error handling.
Adjust the ignore-compare-mode-next-solver for hangs
Some new tests hang, some old tests don't hang.
r? lcnr or anyone in `@rust-lang/initiative-trait-system-refactor`
Use alias-eq in structural normalization
We don't need to register repeated normalizes-to goals in a loop in structural normalize, but instead we can piggyback on the fact that alias-eq will already normalize aliases until they are rigid.
This fixesrust-lang/trait-system-refactor-initiative#78.
r? lcnr
Desugar `yield` in `async gen` correctly, ensure `gen` always returns unit
1. Ensure `async gen` blocks desugar `yield $expr` to `task_context = yield async_gen_ready($expr)`. Previously we were not assigning the `task_context` correctly, meaning that `yield` expressions in async generators returned type `ResumeTy` instead of `()`, and that we were not storing the `task_context` (which is probably unsound if we were reading the old task-context which has an invalidated borrow or something...)
2. Ensure that all `(async?) gen` blocks and `(async?) gen` fns return unit. Previously we were only checking this for `gen fn`, meaning that `gen {}` and `async gen {}` and `async gen fn` were allowed to return values that weren't unit. This is why #119058 was an ICE rather than an E0308.
Fixes#119058.
And make all hand-written `IntoDiagnostic` impls generic, by using
`DiagnosticBuilder::new(dcx, level, ...)` instead of e.g.
`dcx.struct_err(...)`.
This means the `create_*` functions are the source of the error level.
This change will let us remove `struct_diagnostic`.
Note: `#[rustc_lint_diagnostics]` is added to `DiagnosticBuilder::new`,
it's necessary to pass diagnostics tests now that it's used in
`into_diagnostic` functions.
It doesn't look quite right, because the lines are too far apart,
and it's not going to be announced by screenreaders as a menu button,
since that's not what the symbol means.
This adds a real tooltip and uses a better drawing of the icon.
This change introduces a new module to StableMIR named `abi` with
information from `rustc_target::abi` and `rustc_abi`, that allow users
to retrieve more low level information required to perform
bit-precise analysis.
The layout of a type can be retrieved via `Ty::layout`, and the instance
ABI can be retrieved via `Instance::fn_abi()`.
To properly handle errors while retrieve layout information, we had
to implement a few layout related traits.
Fix ICE `ProjectionKinds Deref and Field were mismatched`
Fix#118144
Removed the check that ICEd if the sequence of projection kinds were different across captures. Instead we now sort based only on `Field` projection kinds.
Properly reject `default` on free const items
Fixes#117791.
Technically speaking, this is a breaking change but I doubt it will lead to any real-world regressions (maybe in some macro-trickery crates?). Doing a crater run probably isn't worth it.
coverage: Skip instrumenting a function if no spans were extracted from MIR
The immediate symptoms of #118643 were fixed by #118666, but some users reported that their builds now encounter another coverage-related ICE:
```
error: internal compiler error: compiler/rustc_codegen_llvm/src/coverageinfo/mapgen.rs:98:17: A used function should have had coverage mapping data but did not: (...)
```
I was able to reproduce at least one cause of this error: if no relevant spans could be extracted from a function, but the function contains `CoverageKind::SpanMarker` statements, then codegen still thinks the function is instrumented and complains about the fact that it has no coverage spans.
This PR prevents that from happening in two ways:
- If we didn't extract any relevant spans from MIR, skip instrumenting the entire function and don't create a `FunctionCoverateInfo` for it.
- If coverage codegen sees a `CoverageKind::SpanMarker` statement, skip it early and avoid creating `func_coverage`.
---
Fixes#118850.
This is a redesign of the feature, with parts pulled from
https://github.com/rust-lang/rust/pull/119049
but with a button that looks more like a button and matches the
one used on other sidebar pages.
adds a column number to `dbg!()`
this would be very nice to have for a few reasons:
1. the rfc, when deciding not to add column numbers to macro, failed to acknowledge any potential ambiguous cases -- such as the one provided in #114910 -- which do exist
2. would be able to consistently and easily jump directly to the `dbg!()` regardless of the sutation
3. takes up, at a maximum, 3 characters of _horizontal_ screen space
fixes#114910
fix: Overlapping spans in delimited meta-vars
Closes#118786
Delimited meta-vars inside of MBE's spans were set to have the same opening and closing position resulting in an ICE when debug assertions were enabled and an error was present in the templated code.
This ensures that the spans do not overlap, whilst still having the spans point at the usage of the meta-var inside the macro definition.
It includes a regression test.
🖤
More expressions correctly are marked to end with curly braces
Fixes#118859, and replaces the mentioned match statement with an exhaustive list, so that this code doesn't get overlooked in the future
skip rpit constraint checker if borrowck return type error
Fixes#117794Fixes#117886Fixes#119025
Prior to change #117418, the value of `concrete_opaque_types` for `mir_borrock(T:🅰️:opaque)` was `None`. However, due to modifications in `body.local_decls`, the return value had been changed.
The changed of `body.local_decls` has let to the addition of `ty:Error` to `infcx.opaque_type_storage.opaque_types` during `TypeChecker::equate_inputs_and_outputs`. This is due to it utilizing the output of a function signature that was appended during `construct_error`(which previously only appended a `ty::Error`) and then execute `TypeChecker::Related_types`.
Therefore, in this PR, I've implemented a condition to bypass the rpit check when an error is encountered.
r? `@compiler-errors`
rustdoc-search: remove parallel searchWords array
This might have made sense if the algorithm could use `searchWords` to skip having to look at `searchIndex`, but since it always does a substring check on both the stock word and the normalizedName, it doesn't seem to help performance anyway.
Profile: http://notriddle.com/rustdoc-html-demo-8/searchwords/index.html
This might have made sense if the algorithm could use `searchWords`
to skip having to look at `searchIndex`, but since it always
does a substring check on both the stock word and the normalizedName,
it doesn't seem to help performance anyway.
Collect lang items from AST, get rid of `GenericBound::LangItemTrait`
r? `@cjgillot`
cc #115178
Looking forward, the work to remove `QPath::LangItem` will also be significantly more difficult, but I plan on doing it as well. Specifically, we have to change:
1. A lot of `rustc_ast_lowering` for things like expr `..`
2. A lot of astconv, since we actually instantiate lang and non-lang paths quite differently.
3. A ton of diagnostics and clippy lints that are special-cased via `QPath::LangItem`
Meanwhile, it was pretty easy to remove `GenericBound::LangItemTrait`, so I just did that here.
Rollup of 7 pull requests
Successful merges:
- #117824 (Stabilize `ptr::{from_ref, from_mut}`)
- #118234 (Stabilize `type_name_of_val`)
- #118944 (Move type relations into submodule `relate` in rustc_infer, and notify when it has changed)
- #118977 (Simplify `src-script.js` code)
- #118985 (Remove `@JohnTitor` from diagnostics pings)
- #118986 (Simplify JS code a little bit)
- #118988 (rustdoc: add regression test for JS data file loading)
r? `@ghost`
`@rustbot` modify labels: rollup
Stabilize `type_name_of_val`
Make the following API stable:
```rust
// in core::any
pub fn type_name_of_val<T: ?Sized>(_val: &T) -> &'static str
```
This is a convenience method to get the type name of a value, as opposed to `type_name` that takes a type as a generic.
Const stability is not added because this relies on `type_name` which is also not const. That has a blocking issue https://github.com/rust-lang/rust/issues/97156.
Wording was also changed to direct most of the details to `type_name` so we don't have as much duplicated documentation.
Fixes tracking issue #66359.
There were two main concerns in the tracking issue:
1. Naming: `type_name_of` and `type_name_of_val` seem like the only mentioned options. Differences in opinion here come from `std::mem::{size_of, align_of, size_of_val, align_of_val}`. This PR leaves the name as `type_name_of_val`, but I can change if desired since it is pretty verbose.
2. What this displays for `&dyn`: I don't think that having `type_name_of_val` function resolve those is worth the headache it would be, see https://github.com/rust-lang/rust/issues/66359#issuecomment-1718480774 for some workarounds. I also amended the docs wording to leave it open-ended, in case we have means to change that behavior in the future.
``@rustbot`` label -T-libs +T-libs-api +needs-fcp
r? libs-api
Stabilize `ptr::{from_ref, from_mut}`
I propose to stabilize the following APIs:
```rust
// mod core::ptr
pub const fn from_ref<T: ?Sized>(r: &T) -> *const T;
pub const fn from_mut<T: ?Sized>(r: &mut T) -> *mut T;
```
Tracking issue: https://github.com/rust-lang/rust/issues/106116
---
``@RalfJung`` what do you think we should do with `from_mut`? Stabilize it as const, given that you can't call it anyway (no way to get `&mut` in `const fn`)? Defer stabilizing it as const leaving the same issue/feature? Change issue/feature? Change issue/feature to the "`&mut` in const fn" one?
codegen_llvm: set `DW_AT_accessibility`
Fixes#9228.
Based on #74778.
Sets the accessibility of types and fields in DWARF using `DW_AT_accessibility` attribute.
`DW_AT_accessibility` (public/protected/private) isn't exactly right for Rust, but neither is `DW_AT_visibility` (local/exported/qualified), and there's no way to set `DW_AT_visbility` in LLVM's API. Debuggers will special-case the handling of these per-language anyway.
r? `@wesleywiser` (visited in wg-debugging triage)
Currently, we assume that ScalarPair is always represented using
a two-element struct, both as an immediate value and when stored
in memory.
This currently works fairly well, but runs into problems with
https://github.com/rust-lang/rust/pull/116672, where a ScalarPair
involving an i128 type can no longer be represented as a two-element
struct in memory. For example, the tuple `(i32, i128)` needs to be
represented in-memory as `{ i32, [3 x i32], i128 }` to satisfy
alignment requirement. Using `{ i32, i128 }` instead will result in
the second element being stored at the wrong offset (prior to
LLVM 18).
Resolve this issue by no longer requiring that the immediate and
in-memory type for ScalarPair are the same. The in-memory type
will now look the same as for normal struct types (and will include
padding filler and similar), while the immediate type stays a
simple two-element struct type. This also means that booleans in
immediate ScalarPair are now represented as i1 rather than i8,
just like we do everywhere else.
The core change here is to llvm_type (which now treats ScalarPair
as a normal struct) and immediate_llvm_type (which returns the
two-element struct that llvm_type used to produce). The rest is
fixing things up to no longer assume these are the same. In
particular, this switches places that try to get pointers to the
ScalarPair elements to use byte-geps instead of struct-geps.
Sets the accessibility of types and fields in DWARF using
`DW_AT_accessibility` attribute.
`DW_AT_accessibility` (public/protected/private) isn't exactly right for
Rust, but neither is `DW_AT_visibility` (local/exported/qualified), and
there's no way to set `DW_AT_visbility` in LLVM's API.
Signed-off-by: David Wood <david@davidtw.co>
Some cleanup and improvement for invalid ref casting impl
This PR makes some cleanups and improvements to the `invalid_reference_casting` implementation in preparation for linting on new patterns, while reusing most of the logic.
r? `@est31` (feel free to re-assign)
rustdoc: allow resizing the sidebar / hiding the top bar
Fixes#97306
Preview: http://notriddle.com/rustdoc-html-demo-4/sidebar-resize/std/index.html

## Summary
This feature adds:
1. A checkbox to the Settings popover to hide the persistent navigation bar (the sidebar on large viewports and the top bar on small ones).
2. On large viewports, it adds a resize handle to the persistent sidebar. Resizing it into nothing is equivalent to turning off the persistent navigation bar checkbox in Settings.
3. If the navigation bar is hidden, a toolbar button to the left of the search appears. Clicking it brings the navigation bar back.
## Motivation
While "mobile mode" is definitely a good default, it's not the only reason people have wanted to hide the sidebar:
* Some people use tiling window managers, and don't like rustdoc's current breakpoints. Changing the breakpoints might help with that, but there's no perfect solution, because there's a gap between "huge screen" and "smartphone" where reasonable people can disagree about whether it makes sense for the sidebar to be on-screen. https://github.com/rust-lang/rust/issues/97306
* Some people ask for ways to reduce on-screen clutter because it makes it easier to focus. There's not a media query for that (and if there was, privacy-conscious users would turn it off). https://github.com/rust-lang/rust/issues/59829
This feature is designed to avoid these problems. Resizing the sidebar especially helps, because it provides a way to hide the sidebar without adding a new top-level button (which would add clutter), and it provides a way to make rustdoc play nicer in complex, custom screen layouts.
## Guide and Reference-level explanation
On a desktop or laptop with a mouse, resize the sidebar by dragging its right edge.
On any browser, including mobile phones, the sticky top bar or side bar can be hidden from the Settings area (the button with the cog wheel, next to the search bar). When it's hidden, a convenient button will appear on the search bar's left.
## Drawbacks
This adds more JavaScript code to the render blocking area.
## Rationale and alternatives
The most obvious way to allow people to hide the sidebar would have been to let them "manually enter mobile mode." The upside is that it's a feature we already have. The downside is that it's actually really hard to come up with a terse description. Is it:
* A Setting that forces desktop viewers to always have the mobile-style top bar? If so, how do we label it? Should it be visible on mobile, and, if so, does it just not do anything?
* A persistent hide/show sidebar button, present on desktop, just like on mobile? That's clutter that I'd like to avoid.
## Prior art
* The new file browser in GitHub uses a similar divider with a mouse-over indicator
* mdBook and macOS Finder both allow you to resize the sidebar to nothing as a gesture to hide it
* https://www.nngroup.com/articles/drag-drop/
## Future possibilities
https://rust-lang.zulipchat.com/#narrow/stream/266220-rustdoc/topic/Table.20of.20contents proposes a new, second sidebar (a table of contents). How should it fit in with this feature? Should it be resizeable? Hideable? Can it be accessed on mobile?
Don't merge cfg and doc(cfg) attributes for re-exports
Fixes#112881.
## Explanations
When re-exporting things with different `cfg`s there are two things that can happen:
* The re-export uses a subset of `cfg`s, this subset is sufficient so that the item will appear exactly with the subset
* The re-export uses a non-subset of `cfg`s (e.g. like the example I posted just above where the re-export is ungated), if the non-subset `cfg`s are active (e.g. compiling that example on windows) then this will be a compile error as the item doesn't exist to re-export, if the subset `cfg`s are active it behaves like 1.
### Glob re-exports?
**This only applies to non-glob inlined re-exports.** For glob re-exports the item may or may not exist to be re-exported (potentially the `cfg`s on the path up until the glob can be removed, and only `cfg`s on the globbed item itself matter), for non-inlined re-exports see https://github.com/rust-lang/rust/issues/85043.
cc `@Nemo157`
r? `@notriddle`
Opportunistically resolve region var in canonicalizer (instead of resolving root var)
See comment in `compiler/rustc_type_ir/src/infcx.rs`.
The **root** infer region for a given region vid may not actually be nameable from the universe of the original vid. That means that the assertion in the canonicalizer was too strict, since the `EagerResolver` that we use before canonicalizing is doing only as much resolving as it can.
This replaces `resolve_lt_var` and `probe_lt_var` in the `rustc_type_ir` API with `opportunistic_resolve_lt_var`, which acts as you expect it should. I left a FIXME that complains about the inconsistency.
This test is really gnarly, but I have no idea how to minimize it, since it seems to kind of just be coincidental that it triggered this issue. I hope the underlying root cause is easy enough to understand, though.
r? `@lcnr` or `@aliemjay`
Fixes#118950
Erase late bound regions from `Instance::fn_sig()` and add a few more details to StableMIR APIs
The Instance `fn_sig()` still included a late bound regions which needed a new compiler function in order to be erased. I've also bundled the following small fixes in this PR, let me know if you want me to isolate any of them.
- Add missing `CoroutineKind::AsyncGen`.
- Add optional spread argument to function body which is needed to properly analyze compiler shims.
- Add a utility method to iterate over all locals together with their declaration.
- Add a method to get the description of `AssertMessage`*.
* For the last one, we could consider eventually calling the internal `AssertKind::description()` to avoid code duplication. However, we still don't have ways to convert `AssertMessage`, `Operand`, `Place` and others, in order to use that. The other downside of using the internal method is that it will panic for some of the variants.
r ? `@ouz-a`
- Remove `fn_sig()` from Instance.
- Change return value of `AssertMessage::description` to `Cow<>`.
- Add assert to instance `ty()`.
- Generalize uint / int type creation.
Add all known `target_feature` configs to check-cfg
This PR adds all the known `target_feature` from ~~`rustc_codegen_ssa`~~ `rustc_target` to the well known list of check-cfg.
It does so by moving the list from `rustc_codegen_ssa` to `rustc_target` ~~`rustc_session` (I not sure about this, but some of the moved function take a `Session`)~~, then using it the `fill_well_known` function.
This already proved to be useful since portable-simd had a bad cfg.
cc `@nnethercote` (since we discussed it in https://github.com/rust-lang/rust/pull/118494)
Add -Zunpretty=stable-mir output test
As strongly suggested here https://github.com/rust-lang/rust/pull/118364#issuecomment-1827974148 this adds output test for `-Zunpretty=stable-mir`, added test shows almost all the functionality of the current printer.
r? `@compiler-errors`
Add inline const and other possible curly brace expressions to expr_trailing_brace
Add tests for `}` before `else` in `let...else` error
Change to explicit cases for expressions with optional values when being checked for trailing braces
Add tests for more complex cases of `}` before `else` in `let..else` statement
Move other possible `}` cases into separate arm and add FIXME for future reference
fix dynamic size/align computation logic for packed types with dyn trait tail
This logic was never updated to support `packed(N)` where `N > 1`, and it turns out to be wrong for that case.
Fixes https://github.com/rust-lang/rust/issues/80925
`@bjorn3` I have not looked at cranelift; I assume it basically copied the size-of-val logic and hence could use much the same patch.
Enable stack probes on aarch64 for LLVM 18
I tested this on `aarch64-unknown-linux-gnu` with LLVM main (~18).
cc #77071, to be closed once we upgrade our LLVM submodule.
Tweak `short_ty_string` to reduce number of files
When shortening types and writing them to disk, make `short_ty_string` capable of reusing the same file, instead of writing a file per shortened type.
rustdoc-search: use set ops for ranking and filtering
This commit adds ranking and quick filtering to type-based search, improving performance and having it order results based on their type signatures.
Preview
-------
Profiler output: https://notriddle.com/rustdoc-html-demo-6/profile-8/index.html
Preview: https://notriddle.com/rustdoc-html-demo-6/ranking-and-filtering-v2/std/index.html
Motivation
----------
If I write a query like `str -> String`, a lot of functions come up. That's to be expected, but `String::from` should come up on top, and it doesn't right now. This is because the sorting algorithm is based on the functions name, and doesn't consider the type signature at all. `slice::join` even comes up above it!
To fix this, the sorting should take into account the function's signature, and the closer match should come up on top.
Guide-level description
-----------------------
When searching by type signature, types with a "closer" match will show up above types that match less precisely.
Reference-level explanation
---------------------------
Functions signature search works in three major phases:
* A compact "fingerprint," based on the [bloom filter] technique, is used to check for matches and to estimate the distance. It sometimes has false positive matches, but it also operates on 128 bit contiguous memory and requires no backtracking, so it performs a lot better than real unification.
The fingerprint represents the set of items in the type signature, but it does not represent nesting, and it ignores when the same item appears more than once.
The result is rejected if any query bits are absent in the function, or if the distance is higher than the current maximum and 200 results have already been found.
* The second step performs unification. This is where nesting and true bag semantics are taken into account, and it has no false positives. It uses a recursive, backtracking algorithm.
The result is rejected if any query elements are absent in the function.
[bloom filter]: https://en.wikipedia.org/wiki/Bloom_filter
Drawbacks
---------
This makes the code bigger.
More than that, this design is a subtle trade-off. It makes the cases I've tested against measurably faster, but it's not clear how well this extends to other crates with potentially more functions and fewer types.
The more complex things get, the more important it is to gather a good set of data to test with (this is arguably more important than the actual benchmarking ifrastructure right now).
Rationale and alternatives
--------------------------
Throwing a bloom filter in front makes it faster.
More than that, it tries to take a tactic where the system can not only check for potential matches, but also gets an accurate distance function without needing to do unification. That way it can skip unification even on items that have the needed elems, as long as they have more items than the currently found maximum.
If I didn't want to be able to cheaply do set operations on the fingerprint, a [cuckoo filter] is supposed to have better performance. But the nice bit-banging set intersection doesn't work AFAIK.
I also looked into [minhashing], but since it's actually an unbiased estimate of the similarity coefficient, I'm not sure how it could be used to skip unification (I wouldn't know if the estimate was too low or too high).
This function actually uses the number of distinct items as its "distance function." This should give the same results that it would have gotten from a Jaccard Distance $1-\frac{|F\cap{}Q|}{|F\cup{}Q|}$, while being cheaper to compute. This is because:
* The function $F$ must be a superset of the query $Q$, so their union is just $F$ and the intersection is $Q$ and it can be reduced to $1-\frac{|Q|}{|F|}.
* There are no magic thresholds. These values are only being used to compare against each other while sorting (and, if 200 results are found, to compare with the maximum match). This means we only care if one value is bigger than the other, not what it's actual value is, and since $Q$ is the same for everything, it can be safely left out, reducing the formula to $1-\frac{1}{|F|} = \frac{|F|}{|F|}-\frac{1}{|F|} = |F|-1$. And, since the values are only being compared with each other, $|F|$ is fine.
Prior art
---------
This is significantly different from how Hoogle does it.
It doesn't account for order, and it has no special account for nesting, though `Box<t>` is still two items, while `t` is only one.
This should give the same results that it would have gotten from a Jaccard Distance $1-\frac{|A\cap{}B|}{|A\cup{}B|}$, while being cheaper to compute.
Unresolved questions
--------------------
`[]` and `()`, the slice/array and tuple/union operators, are ignored while building the signature for the query. This is because they match more than one thing, making them ambiguous. Unfortunately, this also makes them a performance cliff. Is this likely to be a problem?
Right now, the system just stashes the type distance into the same field that levenshtein distance normally goes in. This means exact query matches show up on top (for example, if you have a function like `fn nothing(a: Nothing, b: i32)`, then searching for `nothing` will show it on top even if there's another function with `fn bar(x: Nothing)` that's technically a closer match in type signature.
Future possibilities
--------------------
It should be possible to adopt more sorting criteria to act as a tie breaker, which could be determined during unification.
[cuckoo filter]: https://en.wikipedia.org/wiki/Cuckoo_filter
[minhashing]: https://en.wikipedia.org/wiki/MinHash
Add more suggestions to unexpected cfg names and values
This pull request adds more suggestion to unexpected cfg names and values diagnostics:
- it first adds a links to the [rustc unstable book](https://doc.rust-lang.org/nightly/unstable-book/compiler-flags/check-cfg.html) or the [Cargo reference](https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#check-cfg), depending if rustc is invoked by Cargo
- it secondly adds a suggestion on how to expect the cfg name or value:
*excluding well known names and values*
- for Cargo: it suggest using a feature or `cargo:rust-check-cfg` in build script
- for rustc: it suggest using `--check-cfg` (with the correct invocation)
Those diagnostics improvements are directed towards enabling users to fix the issue if the previous suggestions weren't good enough.
r? `@petrochenkov`
This commit adds ranking and quick filtering to type-based search,
improving performance and having it order results based on their
type signatures.
Motivation
----------
If I write a query like `str -> String`, a lot of functions come up.
That's to be expected, but `String::from_str` should come up on top, and
it doesn't right now. This is because the sorting algorithm is based
on the functions name, and doesn't consider the type signature at all.
`slice::join` even comes up above it!
To fix this, the sorting should take into account the function's
signature, and the closer match should come up on top.
Guide-level description
-----------------------
When searching by type signature, types with a "closer" match will
show up above types that match less precisely.
Reference-level explanation
---------------------------
Functions signature search works in three major phases:
* A compact "fingerprint," based on the [bloom filter] technique, is used to
check for matches and to estimate the distance. It sometimes has false
positive matches, but it also operates on 128 bit contiguous memory and
requires no backtracking, so it performs a lot better than real
unification.
The fingerprint represents the set of items in the type signature, but it
does not represent nesting, and it ignores when the same item appears more
than once.
The result is rejected if any query bits are absent in the function, or
if the distance is higher than the current maximum and 200
results have already been found.
* The second step performs unification. This is where nesting and true bag
semantics are taken into account, and it has no false positives. It uses a
recursive, backtracking algorithm.
The result is rejected if any query elements are absent in the function.
[bloom filter]: https://en.wikipedia.org/wiki/Bloom_filter
Drawbacks
---------
This makes the code bigger.
More than that, this design is a subtle trade-off. It makes the cases I've
tested against measurably faster, but it's not clear how well this extends
to other crates with potentially more functions and fewer types.
The more complex things get, the more important it is to gather a good set
of data to test with (this is arguably more important than the actual
benchmarking ifrastructure right now).
Rationale and alternatives
--------------------------
Throwing a bloom filter in front makes it faster.
More than that, it tries to take a tactic where the system can not only check
for potential matches, but also gets an accurate distance function without
needing to do unification. That way it can skip unification even on items
that have the needed elems, as long as they have more items than the
currently found maximum.
If I didn't want to be able to cheaply do set operations on the fingerprint,
a [cuckoo filter] is supposed to have better performance.
But the nice bit-banging set intersection doesn't work AFAIK.
I also looked into [minhashing], but since it's actually an unbiased
estimate of the similarity coefficient, I'm not sure how it could be used
to skip unification (I wouldn't know if the estimate was too low or
too high).
This function actually uses the number of distinct items as its
"distance function."
This should give the same results that it would have gotten from a Jaccard
Distance $1-\frac{|F\cap{}Q|}{|F\cup{}Q|}$, while being cheaper to compute.
This is because:
* The function $F$ must be a superset of the query $Q$, so their union is
just $F$ and the intersection is $Q$ and it can be reduced to
$1-\frac{|Q|}{|F|}.
* There are no magic thresholds. These values are only being used to
compare against each other while sorting (and, if 200 results are found,
to compare with the maximum match). This means we only care if one value
is bigger than the other, not what it's actual value is, and since $Q$ is
the same for everything, it can be safely left out, reducing the formula
to $1-\frac{1}{|F|} = \frac{|F|}{|F|}-\frac{1}{|F|} = |F|-1$. And, since
the values are only being compared with each other, $|F|$ is fine.
Prior art
---------
This is significantly different from how Hoogle does it.
It doesn't account for order, and it has no special account for nesting,
though `Box<t>` is still two items, while `t` is only one.
This should give the same results that it would have gotten from a Jaccard
Distance $1-\frac{|A\cap{}B|}{|A\cup{}B|}$, while being cheaper to compute.
Unresolved questions
--------------------
`[]` and `()`, the slice/array and tuple/union operators, are ignored while
building the signature for the query. This is because they match more than
one thing, making them ambiguous. Unfortunately, this also makes them
a performance cliff. Is this likely to be a problem?
Right now, the system just stashes the type distance into the
same field that levenshtein distance normally goes in. This means exact
query matches show up on top (for example, if you have a function like
`fn nothing(a: Nothing, b: i32)`, then searching for `nothing` will show it
on top even if there's another function with `fn bar(x: Nothing)` that's
technically a closer match in type signature.
Future possibilities
--------------------
It should be possible to adopt more sorting criteria to act as a tie breaker,
which could be determined during unification.
[cuckoo filter]: https://en.wikipedia.org/wiki/Cuckoo_filter
[minhashing]: https://en.wikipedia.org/wiki/MinHash
Coroutine variant fields can be uninitialized
Wrap coroutine variant fields in MaybeUninit to indicate that they might be uninitialized. Otherwise an uninhabited field will make the entire variant uninhabited and introduce undefined behaviour.
The analogous issue in the prefix of coroutine layout was addressed by 6fae7f8071.
Support bare unit structs in destructuring assignments
We should be allowed to use destructuring assignments on *bare* unit structs, not just unit structs that are located within other pattern constructors.
Fixes#118753
r? petrochenkov since you reviewed #95380, reassign if you're busy or don't want to review this.
codegen: panic when trying to compute size/align of extern type
The alignment is also computed when accessing a field of extern type at non-zero offset, so we also panic in that case.
Previously `size_of_val` worked because the code path there assumed that "thin pointer" means "sized". But that's not true any more with extern types. The returned size and align are just blatantly wrong, so it seems better to panic than returning wrong results. We use a non-unwinding panic since code probably does not expect size_of_val to panic.
[`RFC 3086`] Attempt to try to resolve blocking concerns
Implements what is described at https://github.com/rust-lang/rust/issues/83527#issuecomment-1744822345 to hopefully make some progress.
It is unknown if such approach is or isn't desired due to the lack of further feedback, as such, it is probably best to nominate this PR to the official entities.
`@rustbot` labels +I-compiler-nominated
Actually parse async gen blocks correctly
1. I got the control flow in `parse_expr_bottom` messed up, and obviously forgot a test for `async gen`, so we weren't actually ever parsing it correctly.
2. I forgot to gate the span for `async gen {}`, so even if we did parse it, we wouldn't have correctly denied it in `cfg(FALSE)`.
r? eholk
Add rustX check to codeblock attributes lint
We discovered this issue [here](https://github.com/rust-lang/rust/pull/118802#discussion_r1421815943).
I assume that the issue will be present in other places outside of the compiler so it's worth adding a check for it.
First commit is just a small cleanup about variables creation which was a bit strange (at least more than necessary).
r? ```@notriddle```
Fix alignment passed down to LLVM for simd_masked_load
Follow up to #117953
The alignment for a masked load operation should be that of the element/lane, not the vector as a whole
It can produce miscompilations after the LLVM optimizer notices the higher alignment and promotes this to an unmasked, aligned load followed up by blend/select - https://rust.godbolt.org/z/KEeGbevbb
tests: CGU tests require build-pass, not check-pass (remove FIXME)
CGU tests require CGU code to be exercised. We can't merely do "cargo check" on these tests.
Part of #62277
Correctly gate the parsing of match arms without body
https://github.com/rust-lang/rust/pull/118527 accidentally allowed the following to parse on stable:
```rust
match Some(0) {
None => { foo(); }
#[cfg(FALSE)]
Some(_)
}
```
This fixes that oversight. The way I choose which error to emit is the best I could think of, I'm open if you know a better way.
r? `@petrochenkov` since you're the one who noticed
Improve an error involving attribute values.
Attribute values must be literals. The error you get when that doesn't hold is pretty bad, e.g.:
```
unexpected expression: 1 + 1
```
You also get the same error if the attribute value is a literal, but an invalid literal, e.g.:
```
unexpected expression: "foo"suffix
```
This commit does two things.
- Changes the error message to "attribute value must be a literal", which gives a better idea of what the problem is and how to fix it. It also no longer prints the invalid expression, because the carets below highlight it anyway.
- Separates the "not a literal" case from the "invalid literal" case. Which means invalid literals now get the specific error at the literal level, rather than at the attribute level.
r? `@compiler-errors`
On borrow return type, suggest borrowing from arg or owned return type
When we encounter a function with a return type that has an anonymous lifetime with no argument to borrow from, besides suggesting the `'static` lifetime we now also suggest changing the arguments to be borrows or changing the return type to be an owned type.
```
error[E0106]: missing lifetime specifier
--> $DIR/variadic-ffi-6.rs:7:6
|
LL | ) -> &usize {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
LL | ) -> &'static usize {
| +++++++
help: instead, you are more likely to want to change one of the arguments to be borrowed...
|
LL | x: &usize,
| +
help: ...or alternatively, to want to return an owned value
|
LL - ) -> &usize {
LL + ) -> usize {
|
```
Fix#85843.
dont ICE when ConstKind::Expr for is_const_evaluatable
The problem is that we are not handling ConstKind::Expr inside report_not_const_evaluatable_error
Fixes [#114151]
End locals' live range before suspending coroutine
State transforms retains storage statements for locals that are not
stored inside a coroutine. It ensures those locals are live when
resuming by inserting StorageLive as appropriate. It forgot to end the
storage of those locals when suspending, which is fixed here.
While the end of live range is implicit when executing return, it is
nevertheless useful for inliner which would otherwise extend the live
range beyond return.
Fixes#117733
Attribute values must be literals. The error you get when that doesn't
hold is pretty bad, e.g.:
```
unexpected expression: 1 + 1
```
You also get the same error if the attribute value is a literal, but an
invalid literal, e.g.:
```
unexpected expression: "foo"suffix
```
This commit does two things.
- Changes the error message to "attribute value must be a literal",
which gives a better idea of what the problem is and how to fix it. It
also no longer prints the invalid expression, because the carets below
highlight it anyway.
- Separates the "not a literal" case from the "invalid literal" case.
Which means invalid literals now get the specific error at the literal
level, rather than at the attribute level.
Wrap coroutine variant fields in MaybeUninit to indicate that they
might be uninitialized. Otherwise an uninhabited field will make
the entire variant uninhabited and introduce undefined behaviour.
The analogous issue in the prefix of coroutine layout was addressed by
6fae7f8071.
State transforms retains storage statements for locals that are not
stored inside a coroutine. It ensures those locals are live when
resuming by inserting StorageLive as appropriate. It forgot to end the
storage of those locals when suspending, which is fixed here.
While the end of live range is implicit when executing return, it is
nevertheless useful for inliner which would otherwise extend the live
range beyond return.
`.debug_pubnames` and `.debug_pubtypes` are poorly designed and people
seldom use them. However, they take a considerable portion of size in
the final binary. This tells LLVM stop emitting those sections on
DWARFv4 or lower. DWARFv5 use `.debug_names` which is more concise
in size and performant for name lookup.
Do not parenthesize exterior struct lit inside match guards
Before this PR, the AST pretty-printer injects parentheses around expressions any time parens _could_ be needed depending on what else is in the code that surrounds that expression. But the pretty-printer did not pass around enough context to understand whether parentheses really _are_ needed on any particular expression. As a consequence, there are false positives where unneeded parentheses are being inserted.
Example:
```rust
#![feature(if_let_guard)]
macro_rules! pp {
($e:expr) => {
stringify!($e)
};
}
fn main() {
println!("{}", pp!(match () { () if let _ = Struct {} => {} }));
}
```
**Before:**
```console
match () { () if let _ = (Struct {}) => {} }
```
**After:**
```console
match () { () if let _ = Struct {} => {} }
```
This PR introduces a bit of state that is passed across various expression printing methods to help understand accurately whether particular situations require parentheses injected by the pretty printer, and it fixes one such false positive involving match guards as shown above.
There are other parenthesization false positive cases not fixed by this PR. I intend to address these in follow-up PRs. For example here is one: the expression `{ let _ = match x {} + 1; }` is pretty-printed as `{ let _ = (match x {}) + 1; }` despite there being no reason for parentheses to appear there.
Add lint against ambiguous wide pointer comparisons
This PR is the resolution of https://github.com/rust-lang/rust/issues/106447 decided in https://github.com/rust-lang/rust/issues/117717 by T-lang.
## `ambiguous_wide_pointer_comparisons`
*warn-by-default*
The `ambiguous_wide_pointer_comparisons` lint checks comparison of `*const/*mut ?Sized` as the operands.
### Example
```rust
let ab = (A, B);
let a = &ab.0 as *const dyn T;
let b = &ab.1 as *const dyn T;
let _ = a == b;
```
### Explanation
The comparison includes metadata which may not be expected.
-------
This PR also drops `clippy::vtable_address_comparisons` which is superseded by this one.
~~One thing: is the current naming right? `invalid` seems a bit too much.~~
Fixes https://github.com/rust-lang/rust/issues/117717
Remove edition umbrella features.
In the 2018 edition, there was an "umbrella" feature `#[feature(rust_2018_preview)]` which was used to enable several other features at once. This umbrella mechanism was not used in the 2021 edition and likely will not be used in 2024 either. During 2018 users reported that setting the feature was awkward, especially since they already needed to opt-in via the edition mechanism.
This PR removes this mechanism because I believe it will not be used (and will clean up and simplify the code). I believe that there are better ways to handle features and editions. In short:
- For highly experimental features, that may or may not be involved in an edition, they can implement regular feature gates like `tcx.features().my_feature`.
- For experimental features that *might* be involved in an edition, they should implement gates with `tcx.features().my_feature && span.at_least_rust_20xx()`. This requires the user to still specify `#![feature(my_feature)]`, to avoid disrupting testing of other edition features which are ready and have been accepted within the edition.
- For experimental features that have graduated to definitely be part of an edition, they should implement gates with `tcx.features().my_feature || span.at_least_rust_20xx()`, or just remove the feature check altogether and just check `span.at_least_rust_20xx()`.
- For relatively simple changes, they can skip the whole feature gating thing and just check `span.at_least_rust_20xx()`, and rely on the instability of the edition itself (which requires `-Zunstable-options`) to gate it.
I am working on documenting all of this in the rustc-dev-guide.
Implement repr(packed) for repr(simd)
This allows creating vectors with non-power-of-2 lengths that do not have padding. See rust-lang/portable-simd#319
Rearrange `default_configuration` and `CheckCfg::fill_well_known`.
There are comments saying these two functions should be kept in sync, but they have very different structures, process symbols in different orders, and there are some inconsistencies.
This commit reorders them so they're both mostly processing symbols in alphabetical order, which makes cross-checking them a lot easier. The commit also adds some macros to factor out repetitive code patterns.
The commit also moves the handling of `sym::test` out of `build_configuration` into `default_configuration`, where all the other symbols are handled.
r? `@bjorn3`
guarantee that char and u32 are ABI-compatible
In https://github.com/rust-lang/rust/pull/116894 we added a guarantee that `char` has the same alignment as `u32`, but there is still one axis where these types could differ: function call ABI. So let's nail that down as well: in a function signature, `char` and `u32` are completely equivalent.
This is a new stable guarantee, so it will need t-lang approval.
There are comments saying these two functions should be kept in sync,
but they have very different structures, process symbols in different
orders, and there are some inconsistencies.
This commit reorders them so they're both mostly processing symbols in
alphabetical order, which makes cross-checking them a lot easier. The
commit also adds some macros to factor out repetitive code patterns.
Plus it adds `sanitizer_cfi_normalize_{integers,pointers}` to
`fill_well_known`, which were missing.
The commit also moves the handling of `sym::test` out of
`build_configuration` into `default_configuration`, where all the other
symbols are handled.
This is an extension of the previous commit. It means the output of
something like this:
```
stringify!(let a: Vec<u32> = vec![];)
```
goes from this:
```
let a: Vec<u32> = vec![] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![];
```
`tokenstream::Spacing` appears on all `TokenTree::Token` instances,
both punct and non-punct. Its current usage:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `Alone` means "cannot join with the next token *or* can join with the
next token but that token is not a punct".
The fact that `Alone` is used for two different cases is awkward.
This commit augments `tokenstream::Spacing` with a new variant
`JointHidden`, resulting in:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `JointHidden` means "can join with the next token *and* that token is a
not a punct".
- `Alone` means "cannot join with the next token".
This *drastically* improves the output of `print_tts`. For example,
this:
```
stringify!(let a: Vec<u32> = vec![];)
```
currently produces this string:
```
let a : Vec < u32 > = vec! [] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![] ;
```
(The space after the `]` is because `TokenTree::Delimited` currently
doesn't have spacing information. The subsequent commit fixes this.)
The new `print_tts` doesn't replicate original code perfectly. E.g.
multiple space characters will be condensed into a single space
character. But it's much improved.
`print_tts` still produces the old, uglier output for code produced by
proc macros. Because we have to translate the generated code from
`proc_macro::Spacing` to the more expressive `token::Spacing`, which
results in too much `proc_macro::Along` usage and no
`proc_macro::JointHidden` usage. So `space_between` still exists and
is used by `print_tts` in conjunction with the `Spacing` field.
This change will also help with the removal of `Token::Interpolated`.
Currently interpolated tokens are pretty-printed nicely via AST pretty
printing. `Token::Interpolated` removal will mean they get printed with
`print_tts`. Without this change, that would result in much uglier
output for code produced by decl macro expansions. With this change, AST
pretty printing and `print_tts` produce similar results.
The commit also tweaks the comments on `proc_macro::Spacing`. In
particular, it refers to "compound tokens" rather than "multi-char
operators" because lifetimes aren't operators.
Implement `--env` compiler flag (without `tracked_env` support)
Part of https://github.com/rust-lang/rust/issues/80792.
Implementation of https://github.com/rust-lang/compiler-team/issues/653.
Not an implementation of https://github.com/rust-lang/rfcs/pull/2794.
It adds the `--env` compiler flag option which allows to set environment values used by `env!` and `option_env!`.
Important to note: When trying to retrieve an environment variable value, it will first look into the ones defined with `--env`, and if there isn't one, then only it will look into the environment variables. So if you use `--env PATH=a`, then `env!("PATH")` will return `"a"` and not the actual `PATH` value.
As mentioned in the title, `tracked_env` support is not added here. I'll do it in a follow-up PR.
r? rust-lang/compiler
remove redundant imports
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and removing redundant imports code into two PR.
r? `@petrochenkov`
Don't print host effect param in pretty `path_generic_args`
Make `own_args_no_defaults` pass back the `GenericParamDef`, so that we can pass both the args *and* param definitions into `path_generic_args`. That allows us to use the `GenericParamDef` to filter out effect params.
This allows us to filter out the host param regardless of whether it's `sym::host` or `true`/`false`.
This also renames a couple of `const_effect_param` -> `host_effect_param`, and restores `~const` pretty printing to `TraitPredPrintModifiersAndPath`.
cc #118785
r? `@fee1-dead` cc `@oli-obk`
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
Rollup of 5 pull requests
Successful merges:
- #117966 (add safe compilation options)
- #118747 (Remove extra check cfg handled by libc directly)
- #118774 (add test for inductive cycle hangs)
- #118775 (chore: add test case for type with generic)
- #118782 (use `&` instead of start-process in x.ps1)
r? `@ghost`
`@rustbot` modify labels: rollup
Don't warn an empty pattern unreachable if we're not sure the data is valid
Exhaustiveness checking used to be naive about the possibility of a place containing invalid data. This could cause it to emit an "unreachable pattern" lint on an arm that was in fact reachable, as in https://github.com/rust-lang/rust/issues/117119.
This PR fixes that. We now track whether a place that is matched on may hold invalid data. This also forced me to be extra precise about how exhaustiveness manages empty types.
Note that this now errs in the opposite direction: the following arm is truly unreachable (because the binding causes a read of the value) but not linted as such. I'd rather not recommend writing a `match ... {}` that has the implicit side-effect of loading the value. [Never patterns](https://github.com/rust-lang/rust/issues/118155) will solve this cleanly.
```rust
match union.value {
_x => unreachable!(),
}
```
I recommend reviewing commit by commit. I went all-in on the test suite because this went through a lot of iterations and I kept everything. The bit I'm least confident in is `is_known_valid_scrutinee` in `check_match.rs`.
Fixes https://github.com/rust-lang/rust/issues/117119.
add test for inductive cycle hangs
the same pattern is already tested for coinductive cycles, but I now understand the underlying issue and want to make sure we also test it for inductive ones
r? `@compiler-errors`
Strengthen well known check-cfg names and values test
https://github.com/rust-lang/rust/pull/118494 is changing the implementation of how we expect well known check-cfg names and values, but we currently don't have a test that checks every well known only some of them.
This PR therefore strengthen our well known names/values test to include all of the configs to at least avoid unintended regressions and validate new entry.
*this PR also contains some drive-by consolidation of unexpected `target_os`, `target_arch` into a single file*
r? `@nnethercote` (maybe? feel free to re-assign)
Add more SIMD platform-intrinsics
- [x] simd_masked_load
- [x] LLVM codegen - llvm.masked.load
- [x] cranelift codegen - implemented but untested
- [ ] simd_masked_store
- [x] LLVM codegen - llvm.masked.store
- [ ] cranelift codegen
Also added a run-pass test to test both intrinsics, and additional build-fail & check-fail to cover validation for both intrinsics
as they unnecessarily clutter the diagnostic output and make the
experience of adding a new target to the compiler more painful than
it should be.
target_os and target_arch are still being tested in the
well-known-values.rs test, but in one place.
Make async generators fused by default
I actually changed my mind about this since the implementation PR landed. I think it's beneficial for `async gen` blocks to be "fused" by default -- i.e., for them to repeatedly return `Poll::Ready(None)` -- rather than panic.
We have [`FusedStream`](https://docs.rs/futures/latest/futures/stream/trait.FusedStream.html) in futures-rs to represent streams with this capability already anyways.
r? eholk
cc ```@rust-lang/wg-async,``` would like to know if anyone else has opinions about this.
coverage: Simplify the heuristic for ignoring `async fn` return spans
The code for extracting coverage spans from MIR has a special heuristic for dealing with `async fn`, so that the function's closing brace does not have a confusing double count.
The code implementing that heuristic is currently mixed in with the code for flushing remaining spans after the main refinement loop, making the refinement code harder to understand.
We can solve that by hoisting the heuristic to an earlier stage, after the spans have been extracted and sorted but before they have been processed by the refinement loop.
The coverage tests verify that the heuristic is still effective, so coverage mappings/reports for `async fn` have not changed.
---
This PR also has the side-effect of fixing the `None some_prev` panic that started appearing after #118525.
The old code assumed that `prev` would always be present after the refinement loop. That was only true if the list of collected spans was non-empty, but prior to #118525 that didn't seem to come up in practice. After that change, the list of collected spans could be empty in some specific circumstances, leading to panics.
The new code uses an `if let` to inspect `prev`, which correctly does nothing if there is no span present.
update target feature following LLVM API change
LLVM commit e817966718 renamed* the `unaligned-scalar-mem` target feature to `fast-unaligned-access`.
(*) technically the commit folded two previous features into one, but there are no references to the other one in rust.
Add tests related to normalization in implied bounds
Getting ```@aliemjay's``` tests from #109763, so we can better track what's going on in every different example.
r? ```@jackh726```
coverage: Use `SpanMarker` to improve coverage spans for `if !` expressions
Coverage instrumentation works by extracting source code spans from MIR. However, some kinds of syntax are effectively erased during MIR building, so their spans don't necessarily exist anywhere in MIR, making them invisible to the coverage instrumentor (unless we resort to various heuristics and hacks to recover them).
This PR introduces `CoverageKind::SpanMarker`, which is a new variant of `StatementKind::Coverage`. Its sole purpose is to represent spans that would otherwise not appear in MIR, so that the coverage instrumentor can extract them.
When coverage is enabled, the MIR builder can insert these dummy statements as needed, to improve the accuracy of spans used by coverage mappings.
Fixes#115468.
---
```@rustbot``` label +A-code-coverage
temporarily revert "ice on ambguity in mir typeck"
Reverts #116530 as a temporary measure to fix#117577. That issue should be ultimately fixed by checking WF of type annotations prior to normalization, which is implemented in #104098 but this PR is intended to be backported to beta.
r? ``@compiler-errors`` (the reviewer of the reverted PR)
recurse into refs when comparing tys for diagnostics
before:

after:
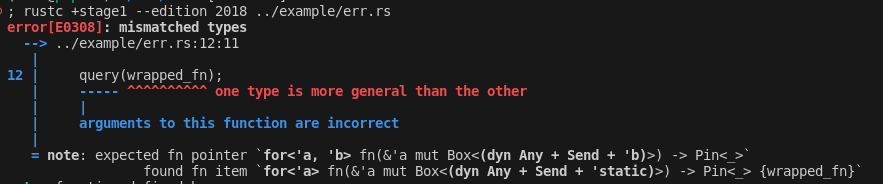
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
privacy: visit trait def id of projections
Fixes#117997.
A refactoring in #117076 changed the `DefIdVisitorSkeleton` to avoid calling `visit_projection_ty` for `ty::Projection` aliases, and instead just iterate over the args - this makes sense, as `visit_projection_ty` will indirectly visit all of the same args, but in doing so, will also create a `TraitRef` containing the trait's `DefId`, which also gets visited. The trait's `DefId` isn't visited when we only visit the arguments without separating them into `TraitRef` and own args first.
Eventually this influences the reachability set and whether a function is encoded into the metadata.
Add instance evaluation and methods to read an allocation in StableMIR
The instance evaluation is needed to handle intrinsics such as `type_id` and `type_name`.
Since we now use Allocation to represent all evaluated constants, provide a few methods to help process the data inside an allocation.
I've also started to add a structured way to get information about the compilation target machine. For now, I've only added information needed to process an allocation.
r? ``````@ouz-a``````
according to a poll of gay people in my phone, purple is the most popular color to use for highlighting
| color | percentage |
| ---------- | ---------- |
| bold white | 6% |
| blue | 14% |
| cyan | 26% |
| purple | 37% |
| magenta | 17% |
unfortunately, purple is not supported by 16-color terminals, which rustc apparently wants to support for some reason.
until we require support for full 256-color terms (e.g. by doing the same feature detection as we currently do for urls), we can't use it.
instead, i have collapsed the purple votes into magenta on the theory that they're close, and also because magenta is pretty.
Introduce support for `async gen` blocks
I'm delighted to demonstrate that `async gen` block are not very difficult to support. They're simply coroutines that yield `Poll<Option<T>>` and return `()`.
**This PR is WIP and in draft mode for now** -- I'm mostly putting it up to show folks that it's possible. This PR needs a lang-team experiment associated with it or possible an RFC, since I don't think it falls under the jurisdiction of the `gen` RFC that was recently authored by oli (https://github.com/rust-lang/rfcs/pull/3513, https://github.com/rust-lang/rust/issues/117078).
### Technical note on the pre-generator-transform yield type:
The reason that the underlying coroutines yield `Poll<Option<T>>` and not `Poll<T>` (which would make more sense, IMO, for the pre-transformed coroutine), is because the `TransformVisitor` that is used to turn coroutines into built-in state machine functions would have to destructure and reconstruct the latter into the former, which requires at least inserting a new basic block (for a `switchInt` terminator, to match on the `Poll` discriminant).
This does mean that the desugaring (at the `rustc_ast_lowering` level) of `async gen` blocks is a bit more involved. However, since we already need to intercept both `.await` and `yield` operators, I don't consider it much of a technical burden.
r? `@ghost`
never_patterns: Parse match arms with no body
Never patterns are meant to signal unreachable cases, and thus don't take bodies:
```rust
let ptr: *const Option<!> = ...;
match *ptr {
None => { foo(); }
Some(!),
}
```
This PR makes rustc accept the above, and enforces that an arm has a body xor is a never pattern. This affects parsing of match arms even with the feature off, so this is delicate. (Plus this is my first non-trivial change to the parser).
~~The last commit is optional; it introduces a bit of churn to allow the new suggestions to be machine-applicable. There may be a better solution? I'm not sure.~~ EDIT: I removed that commit
r? `@compiler-errors`
A refactoring in #117076 changed the `DefIdVisitorSkeleton` to avoid
calling `visit_projection_ty` for `ty::Projection` aliases, and instead
just iterate over the args - this makes sense, as `visit_projection_ty`
will indirectly visit all of the same args, but in doing so, will also
create a `TraitRef` containing the trait's `DefId`, which also gets
visited. The trait's `DefId` isn't visited when we only visit the
arguments without separating them into `TraitRef` and own args first.
Signed-off-by: David Wood <david@davidtw.co>
When MIR is built for an if-not expression, the `!` part of the condition
doesn't correspond to any MIR statement, so coverage instrumentation normally
can't see it.
We can fix that by deliberately injecting a dummy statement whose sole purpose
is to associate that span with its enclosing block.
Resolve associated item bindings by namespace
This is the 3rd commit split off from #118360 with tests reblessed (they no longer contain duplicated diags which were caused by 4c0addc80a) & slightly adapted (removed supertraits from a UI test, cc #118040).
> * Resolve all assoc item bindings (type, const, fn (feature `return_type_notation`)) by namespace instead of trying to resolve a type first (in the non-RTN case) and falling back to consts afterwards. This is consistent with RTN. E.g., for `Tr<K = {…}>` we now always try to look up assoc consts (this extends to supertrait bounds). This gets rid of assoc tys shadowing assoc consts in assoc item bindings which is undesirable & inconsistent (types and consts live in different namespaces after all)
> * Consolidate the resolution of assoc {ty, const} bindings and RTN (dedup, better diags for RTN)
> * Fix assoc consts being labeled as assoc *types* in several diagnostics
> * Make a bunch of diagnostics translatable
Fixes#112560 (error → pass).
As discussed
r? `@compiler-errors`
---
**Addendum**: What I call “associated item bindings” are commonly referred to as “type bindings” for historical reasons. Nowadays, “type bindings” include assoc type bindings, assoc const bindings and RTN (return type notation) which is why I prefer not to use this outdated term.
Rollup of 6 pull requests
Successful merges:
- #116420 (discard invalid spans in external blocks)
- #118686 (Only check principal trait ref for object safety)
- #118688 (Add method to get type of an Rvalue in StableMIR)
- #118707 (Ping GuillaumeGomez for changes in rustc_codegen_gcc)
- #118712 (targets: remove not-added {i386,i486}-unknown-linux-gnu)
- #118719 (CFI: Add char to CFI integer normalization)
Failed merges:
- #117586 (Uplift the (new solver) canonicalizer into `rustc_next_trait_solver`)
r? `@ghost`
`@rustbot` modify labels: rollup
discard invalid spans in external blocks
Fixes#116203
This PR has discarded the invalid `const_span`, thereby making the format more neat.
r? ``@Nilstrieb``
Avoid adding builtin functions to `symbols.o`
We found performance regressions in #113923. The problem seems to be that `--gc-sections` does not remove these symbols. I tested that lld removes these symbols, but ld and gold do not.
I found that `used` adds symbols to `symbols.o` at 3e202ead60/compiler/rustc_codegen_ssa/src/back/linker.rs (L1786-L1791).
The PR removes builtin functions.
Note that under LTO, ld still preserves these symbols. (lld will still remove them.)
The first commit also fixes#118559. But I think the second commit also makes sense.