Stabilize refcell_take
Tracking Issue: #71395
``@KodrAus`` nominated this for FCP, so here's a PR!
I've never made a stabilization PR, so please mention if there's anything I can improve, thanks.
Stabilize alloc::Layout const functions
Stabilizes #67521. In particular the following stable methods are stabilized as `const fn`:
* `size`
* `align`
* `from_size_align`
Stabilizing `size` and `align` should not be controversial as they are simple (usize and NonZeroUsize) fields and I don't think there's any reason to make them not const compatible in the future. That being true, the other methods are trivially `const`. The only other issue being returning a `Result` from a `const fn` but this has been made more usable by recent stabilizations.
Split each iterator adapter and source into individual modules
This PR creates individual modules for each iterator adapter and iterator source.
This is done to enhance the readability of corresponding modules (`adapters/mod.rs` and `sources.rs`) which were hard to navigate and read because of lots of repeated lines (e.g.: `adapters/mod.rs` was 3k lines long). This is also in line with some adapters which already had their own modules (`Flatten`, `FlatMap`, `Chain`, `Zip`, `Fuse`).
This PR also makes `Take`s adapter fields private (I have no idea why they were `pub(super)` before).
r? ``@LukasKalbertodt``
Add f{32,64}::is_subnormal
The docs recommend that you use dedicated methods instead of calling `classify` directly, although there isn't actually a way of checking if a number is subnormal without calling classify. There are dedicated methods for all other forms, excluding `is_zero` (which is just `== 0.0` anyway).
Stabilize clamp
Tracking issue: https://github.com/rust-lang/rust/issues/44095
Clamp has been merged and unstable for about a year and a half now. How do we feel about stabilizing this?
More consistently use spaces after commas in lists in docs
This PR changes instances of lists that didn't use spaces after commas, like `vec![1,2,3]`, to `vec![1, 2, 3]` to be more consistent with idiomatic Rust style (the way these were looks strange to me, especially because there are often lists that *do* use spaces after the commas later in the same code block 😬).
I noticed one of these in an example in the stdlib docs and went looking for more, but as far as I can see, I'm only changing those spots in user-facing documentation or rustc output, and the changes make no semantic difference.
clarify rules for ZST Boxes
LLVM's rules around `getelementptr inbounds` with offset 0 are a bit annoying, and as a consequence we have no choice but say that a `Box<()>` pointing to previously allocated memory that has since been freed is UB. Clarify the docs to reflect this.
This is based on conversations on the LLVM mailing list.
* Here's my initial mail: https://lists.llvm.org/pipermail/llvm-dev/2019-February/130452.html
* The first email of the March part of that thread: https://lists.llvm.org/pipermail/llvm-dev/2019-March/130831.html
* First email of the April part: https://lists.llvm.org/pipermail/llvm-dev/2019-April/131693.html
The conclusion for me at least was that `getelementptr inbounds` with offset 0 is *not* the identity function, but can sometimes return `poison` even when the input is a regular pointer -- specifically, it returns `poison` when this pointer points into something that LLVM "knows has been deallocated", i.e., a former LLVM-managed allocation. It is however the identity function on pointers obtained by casting integers.
Note that there [are formal proposals](https://people.mpi-sws.org/~jung/twinsem/twinsem.pdf) for LLVM semantics where `getelementptr inbounds` with offset 0 isn't quite the identity function but never returns `poison` (it affects the provenance of the pointer but in a way that doesn't matter if this pointer is never used for memory accesses), and indeed this is likely necessary to consistently describe LLVM semantics. But with the informal LLVM LangRef that we have right now, and with LLVM devs insisting otherwise, it seems unwise to rely on this.
Add lint for panic!("{}")
This adds a lint that warns about `panic!("{}")`.
`panic!(msg)` invocations with a single argument use their argument as panic payload literally, without using it as a format string. The same holds for `assert!(expr, msg)`.
This lints checks if `msg` is a string literal (after expansion), and warns in case it contained braces. It suggests to insert `"{}", ` to use the message literally, or to add arguments to use it as a format string.
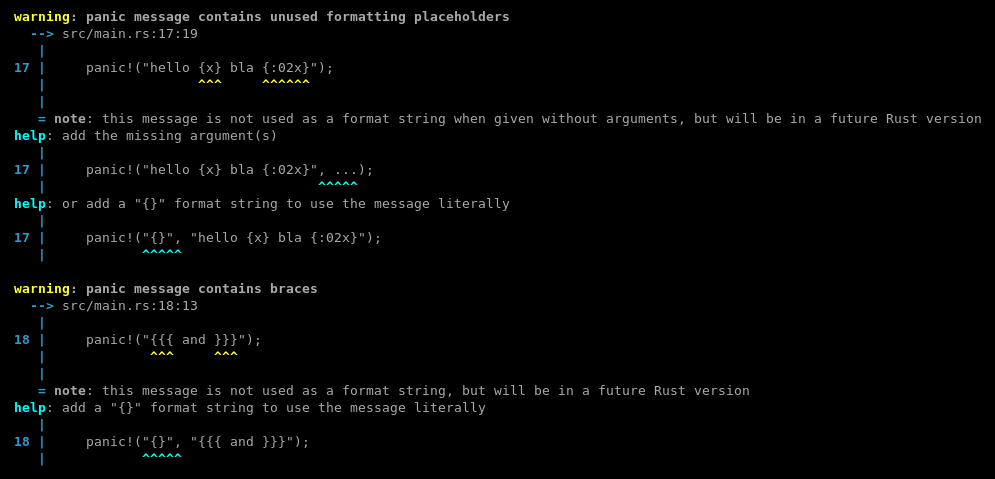
This lint is also a good starting point for adding warnings about `panic!(not_a_string)` later, once [`panic_any()`](https://github.com/rust-lang/rust/pull/74622) becomes a stable alternative.
Make as{_mut,}_slice on array::IntoIter public
The functions are useful in cases where you want to move data out of the IntoIter in bulk, by transmute_copy'ing the slice and then forgetting the IntoIter.
In the compiler, this is useful for providing a sped up IntoIter implementation. One can alternatively provide a separate allocate_array function but one can avoid duplicating some logic by passing everything through the generic iterator using interface.
As per suggestion in https://github.com/rust-lang/rust/pull/78569/files#r526506964
Clarify availability of atomic operations
This was noticed while we were updating the embedded rust book: https://github.com/rust-embedded/book/pull/273/files
These targets do natively have atomic load/stores, but do not support CAS operations.
This macro is used in expression position (a match arm), and only
compiles because of #33953
Regardless of what happens with that issue, this makes the
usage of the macro less confusing at the call site.
add trailing_zeros and leading_zeros to non zero types
as a way towards being able to use the optimized intrinsics ctlz_nonzero and cttz_nonzero from stable.
have not crated any tracking issue if this is not a solution that is wanted
Rename/Deprecate LayoutErr in favor of LayoutError
Implements rust-lang/wg-allocators#73.
This patch renames LayoutErr to LayoutError, and uses a type alias to support users using the old name.
The new name will be instantly stable in release 1.49 (current nightly), the type alias will become deprecated in release 1.51 (so that when the current nightly is 1.51, 1.49 will be stable).
This is the only error type in `std` that ends in `Err` rather than `Error`, if this PR lands all stdlib error types will end in `Error` 🥰
Test structural matching for all range types
As of #70166 all range types (`core::ops::Range` etc.) can be structurally matched upon, and by extension used in const generics. In reference to the fact that this is a publicly observable property of these types, and thus falls under the Rust stability guarantees of the standard library, a regression test was added in #70283.
This regression test was implemented by me by testing for the ability to use the range types within const generics, but that is not the actual property the std guarantees now (const generics is still unstable). This PR addresses that situation by adding extra tests for the range types that directly test whether they can be structurally matched upon.
Note: also adds the otherwise unrelated test `test_range_to_inclusive` for completeness with the other range unit tests
Duration::zero() -> Duration::ZERO
In review for #72790, whether or not a constant or a function should be favored for `#![feature(duration_zero)]` was seen as an open question. In https://github.com/rust-lang/rust/issues/73544#issuecomment-691701670 an invitation was opened to either stabilize the methods or propose a switch to the constant value, supplemented with reasoning. Followup comments suggested community preference leans towards the const ZERO, which would be reason enough.
ZERO also "makes sense" beside existing associated consts for Duration. It is ever so slightly awkward to have a series of constants specifying 1 of various units but leave 0 as a method, especially when they are side-by-side in code. It seems unintuitive for the one non-dynamic value (that isn't from Default) to be not-a-const, which could hurt discoverability of the associated constants overall. Elsewhere in `std`, methods for obtaining a constant value were even deprecated, as seen with [std::u32::min_value](https://doc.rust-lang.org/std/primitive.u32.html#method.min_value).
Most importantly, ZERO costs less to use. A match supports a const pattern, but const fn can only be used if evaluated through a const context such as an inline `const { const_fn() }` or a `const NAME: T = const_fn()` declaration elsewhere. Likewise, while https://github.com/rust-lang/rust/issues/73544#issuecomment-691949373 notes `Duration::zero()` can optimize to a constant value, "can" is not "will". Only const contexts have a strong promise of such. Even without that in mind, the comment in question still leans in favor of the constant for simplicity. As it costs less for a developer to use, may cost less to optimize, and seems to have more of a community consensus for it, the associated const seems best.
r? ```@LukasKalbertodt```
Refactor IntErrorKind to avoid "underflow" terminology
This PR is a continuation of #76455
# Changes
- `Overflow` renamed to `PosOverflow` and `Underflow` renamed to `NegOverflow` after discussion in #76455
- Changed some of the parsing code to return `InvalidDigit` rather than `Empty` for strings "+" and "-". https://users.rust-lang.org/t/misleading-error-in-str-parse-for-int-types/49178
- Carry the problem `char` with the `InvalidDigit` variant.
- Necessary changes were made to the compiler as it depends on `int_error_matching`.
- Redid tests to match on specific errors.
r? ```@KodrAus```
Stabilize `Poll::is_ready` and `is_pending` as const
Insta-stabilize the methods `is_ready` and `is_pending` of `std::task::Poll` as const, in the same way as [PR#76198](https://github.com/rust-lang/rust/pull/76198).
Possible because of the recent stabilization of const control flow.
Part of #76225.
Partially fix#55002, deprecate in another release
Co-authored-by: Ashley Mannix <kodraus@hey.com>
Update stable version for stabilize_spin_loop
Co-authored-by: Joshua Nelson <joshua@yottadb.com>
Use better example for spinlock
As suggested by KodrAus
Remove renamed_spin_loop already available in master
Fix spin loop example
`crate::` -> `core::`
It looks weird to have `crate::` in the link text and we use the actual
crate name everywhere else.
If anyone is curious, I used this Vim command to update all the links:
%s/\(\s\)\[`crate::\(.*\)`\]/\1[`core::\2`](crate::\2)/g
Add fetch_update methods to AtomicBool and AtomicPtr
These methods were stabilized for the integer atomics in #71843, but the methods were not added for the non-integer atomics `AtomicBool` and `AtomicPtr`.
Point out that total_cmp is no strict superset of partial comparison
Partial comparison and total_cmp are not equal. This helps
preventing the mistake of creating float wrappers that
base their Ord impl on total_cmp and their PartialOrd impl on
the PartialOrd impl of the float type. PartialOrd and Ord
[are required to agree with each other](https://doc.rust-lang.org/std/cmp/trait.Ord.html#how-can-i-implement-ord).
Trivial fixes to bitwise operator documentation
Added fixes to documentation of `BitAnd`, `BitOr`, `BitXor` and
`BitAndAssign`, where the documentation for implementation on
`Vector<bool>` was using logical operators in place of the bitwise
operators.
r? @steveklabnik
Closes#78619
Clarify handling of final line ending in str::lines()
I found the description as it stands a bit confusing. I've added a bit more explanation to make it clear that a trailing line ending does not produce a final empty line.
These methods were stabilized for the integer atomics in #71843, but the methods
were not added for the non-integer atomics `AtomicBool` and `AtomicPtr`.
Partial comparison and total_cmp are not equal. This helps
preventing the mistake of creating float wrappers that
base their Ord impl on total_cmp and their PartialOrd impl on
the PartialOrd impl of the float type. PartialOrd and Ord
are required to agree with each other.
fix various aliasing issues in the standard library
This fixes various cases where the standard library either used raw pointers after they were already invalidated by using the original reference again, or created raw pointers for one element of a slice and used it to access neighboring elements.
Fix doc links to std::fmt
`std::format` and `core::write` macros' docs linked to `core::fmt` for format string reference, even though only `std::fmt` has format string documentation (and the link titles were `std::fmt`)
Added fixes to documentation of `BitAnd`, `BitOr`, `BitXor` and
`BitAndAssign`, where the documentation for implementation on
`Vector<bool>` was using logical operators in place of the bitwise
operators.
r? @steveklabnik
cc #78619
I found the description as it stands a bit confusing. I've added a bit more explanation to make it clear that a trailing line ending does not produce a final empty line.
std::format and core::write macros' docs linked to core::fmt for format string reference, even though only std::fmt has format string documentation and the link titles were std::fmt.
Improve documentation for slice strip_* functions
Prompted by the stabilisation tracking issue #73413 I looked at the docs for `strip_prefix` and `strip_suffix` for both `str` and `slice`, and I felt they could be slightly improved.
Thanks for your attention.
Separate unsized locals
Closes#71694
Takes over again #72029 and #74971
cc @RalfJung @oli-obk @pnkfelix @eddyb as they've participated in previous reviews of this PR.
The lint checks arguments in calls to `transmute` or functions that have
`Pointer` as a trait bound and displays a warning if the argument is a function
reference. Also checks for `std::fmt::Pointer::fmt` to handle formatting macros
although it doesn't depend on the exact expansion of the macro or formatting
internals. `std::fmt::Pointer` and `std::fmt::Pointer::fmt` were also added as
diagnostic items and symbols.
Add [T]::as_chunks(_mut)
Allows getting the slices directly, rather than just through an iterator as in `array_chunks(_mut)`. The constructors for those iterators are then written in terms of these methods, so the iterator constructors no longer have any `unsafe` of their own.
Unstable, of course. #74985
Optimise align_offset for stride=1 further
`stride == 1` case can be computed more efficiently through `-p (mod
a)`. That, then translates to a nice and short sequence of LLVM
instructions:
%address = ptrtoint i8* %p to i64
%negptr = sub i64 0, %address
%offset = and i64 %negptr, %a_minus_one
And produces pretty much ideal code-gen when this function is used in
isolation.
Typical use of this function will, however, involve use of
the result to offset a pointer, i.e.
%aligned = getelementptr inbounds i8, i8* %p, i64 %offset
This still looks very good, but LLVM does not really translate that to
what would be considered ideal machine code (on any target). For example
that's the codegen we obtain for an unknown alignment:
; x86_64
dec rsi
mov rax, rdi
neg rax
and rax, rsi
add rax, rdi
In particular negating a pointer is not something that’s going to be
optimised for in the design of CISC architectures like x86_64. They
are much better at offsetting pointers. And so we’d love to utilize this
ability and produce code that's more like this:
; x86_64
lea rax, [rsi + rdi - 1]
neg rsi
and rax, rsi
To achieve this we need to give LLVM an opportunity to apply its
various peep-hole optimisations that it does during DAG selection. In
particular, the `and` instruction appears to be a major inhibitor here.
We cannot, sadly, get rid of this load-bearing operation, but we can
reorder operations such that LLVM has more to work with around this
instruction.
One such ordering is proposed in #75579 and results in LLVM IR that
looks broadly like this:
; using add enables `lea` and similar CISCisms
%offset_ptr = add i64 %address, %a_minus_one
%mask = sub i64 0, %a
%masked = and i64 %offset_ptr, %mask
; can be folded with `gepi` that may follow
%offset = sub i64 %masked, %address
…and generates the intended x86_64 machine code.
One might also wonder how the increased amount of code would impact a
RISC target. Turns out not much:
; aarch64 previous ; aarch64 new
sub x8, x1, #1 add x8, x1, x0
neg x9, x0 sub x8, x8, #1
and x8, x9, x8 neg x9, x1
add x0, x0, x8 and x0, x8, x9
(and similarly for ppc, sparc, mips, riscv, etc)
The only target that seems to do worse is… wasm32.
Onto actual measurements – the best way to evaluate snipets like these
is to use llvm-mca. Much like Aarch64 assembly would allow to suspect,
there isn’t any performance difference to be found. Both snippets
execute in same number of cycles for the CPUs I tried. On x86_64,
we get throughput improvement of >50%!
Fixes#75579
Properly define va_arg and va_list for aarch64-apple-darwin
From [Apple][]:
> Because of these changes, the type `va_list` is an alias for `char*`,
> and not for the struct type in the generic procedure call standard.
With this change `/x.py test --stage 1 src/test/ui/abi/variadic-ffi`
passes.
Fixes#78092
[Apple]: https://developer.apple.com/documentation/xcode/writing_arm64_code_for_apple_platforms
transmute_copy: explain that alignment is handled correctly
The doc comment currently is somewhat misleading because if it actually transmuted `&T` to `&U`, a higher-aligned `U` would be problematic.
replace `#[allow_internal_unstable]` with `#[rustc_allow_const_fn_unstable]` for `const fn`s
`#[allow_internal_unstable]` is currently used to side-step feature gate and stability checks.
While it was originally only meant to be used only on macros, its use was expanded to `const fn`s.
This pr adds stricter checks for the usage of `#[allow_internal_unstable]` (only on macros) and introduces the `#[rustc_allow_const_fn_unstable]` attribute for usage on `const fn`s.
This pr does not change any of the functionality associated with the use of `#[allow_internal_unstable]` on macros or the usage of `#[rustc_allow_const_fn_unstable]` (instead of `#[allow_internal_unstable]`) on `const fn`s (see https://github.com/rust-lang/rust/issues/69399#issuecomment-712911540).
Note: The check for `#[rustc_allow_const_fn_unstable]` currently only validates that the attribute is used on a function, because I don't know how I would check if the function is a `const fn` at the place of the check. I therefore openend this as a 'draft pull request'.
Closesrust-lang/rust#69399
r? @oli-obk
Fix const core::panic!(non_literal_str).
Invocations of `core::panic!(x)` where `x` is not a string literal expand to `panic!("{}", x)`, which is not understood by the const panic logic right now. This adds `panic_str` as a lang item, and modifies the const eval implementation to hook into this item as well.
This fixes the issue mentioned here: https://github.com/rust-lang/rust/issues/51999#issuecomment-687604248
r? `@RalfJung`
`@rustbot` modify labels: +A-const-eval
change the order of type arguments on ControlFlow
This allows ControlFlow<BreakType> which is much more ergonomic for common iterator combinator use cases.
Addresses one component of #75744
Check for exhaustion in RangeInclusive::contains and slicing
When a range has finished iteration, `is_empty` returns true, so it
should also be the case that `contains` returns false.
Fixes#77941.
add `insert` to `Option`
This removes a cause of `unwrap` and code complexity.
This allows replacing
```
option_value = Some(build());
option_value.as_mut().unwrap()
```
with
```
option_value.insert(build())
```
It's also useful in contexts not requiring the mutability of the reference.
Here's a typical cache example:
```
let checked_cache = cache.as_ref().filter(|e| e.is_valid());
let content = match checked_cache {
Some(e) => &e.content,
None => {
cache = Some(compute_cache_entry());
// unwrap is OK because we just filled the option
&cache.as_ref().unwrap().content
}
};
```
It can be changed into
```
let checked_cache = cache.as_ref().filter(|e| e.is_valid());
let content = match checked_cache {
Some(e) => &e.content,
None => &cache.insert(compute_cache_entry()).content,
};
```
*(edited: I removed `insert_with`)*
This removes a cause of `unwrap` and code complexity.
This allows replacing
```
option_value = Some(build());
option_value.as_mut().unwrap()
```
with
```
option_value.insert(build())
```
or
```
option_value.insert_with(build)
```
It's also useful in contexts not requiring the mutability of the reference.
Here's a typical cache example:
```
let checked_cache = cache.as_ref().filter(|e| e.is_valid());
let content = match checked_cache {
Some(e) => &e.content,
None => {
cache = Some(compute_cache_entry());
// unwrap is OK because we just filled the option
&cache.as_ref().unwrap().content
}
};
```
It can be changed into
```
let checked_cache = cache.as_ref().filter(|e| e.is_valid());
let content = match checked_cache {
Some(e) => &e.content,
None => &cache.insert_with(compute_cache_entry).content,
};
```
Doc formating consistency between slice sort and sort_unstable, and big O notation consistency
Updated documentation for slice sorting methods to be consistent between stable and unstable versions, which just ended up being minor formatting differences.
I also went through and updated any doc comments with big O notation to be consistent with #74010 by italicizing them rather than having them in a code block.
Implement TryFrom between NonZero types.
This will instantly be stable, as trait implementations for stable types and traits can not be `#[unstable]`.
Closes#77258.
@rustbot modify labels: +T-libs
Duration::ZERO composes better with match and various other things,
at the cost of an occasional parens, and results in less work for the
optimizer, so let's use that instead.
This expands time's test suite to use more and in more places the
range of methods and constants added to Duration in recent
proposals for the sake of testing more API surface area and
improving legibility.
Improve wording of "cannot multiply" type error
For example, if you had this code:
fn foo(x: i32, y: f32) -> f32 {
x * y
}
You would get this error:
error[E0277]: cannot multiply `f32` to `i32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
However, that's not usually how people describe multiplication. People
usually describe multiplication like how the division error words it:
error[E0277]: cannot divide `i32` by `f32`
--> src/lib.rs:2:7
|
2 | x / y
| ^ no implementation for `i32 / f32`
|
= help: the trait `Div<f32>` is not implemented for `i32`
So that's what this change does. It changes this:
error[E0277]: cannot multiply `f32` to `i32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
To this:
error[E0277]: cannot multiply `i32` by `f32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
Add Pin::static_ref, static_mut.
This adds `Pin::static_ref` and `Pin::static_mut`, which convert a static reference to a pinned static reference.
Static references are effectively already pinned, as what they refer to has to live forever and can never be moved.
---
Context: I want to update the `sys` and `sys_common` mutexes/rwlocks/condvars to use `Pin<&self>` in their functions, instead of only warning in the unsafety comments that they may not be moved. That should make them a little bit less dangerous to use. Putting such an object in a `static` (e.g. through `sys_common::StaticMutex`) fulfills the requirements about never moving it, but right now there's no safe way to get a `Pin<&T>` to a `static`. This solves that.
Writing any fmt::Arguments would trigger the inclusion of usize
formatting and padding code in the resulting binary, because indexing
used in fmt::write would generate code using panic_bounds_check, which
prints the index and length.
These bounds checks are not necessary, as fmt::Arguments never contains
any out-of-bounds indexes.
This change replaces them with unsafe get_unchecked, to reduce the
amount of generated code, which is especially important for embedded
targets.
Move `slice::check_range` to `RangeBounds`
Since this method doesn't take a slice anymore (#76662), it makes more sense to define it on `RangeBounds`.
Questions:
- Should the new method be `assert_len` or `assert_length`?
For example, if you had this code:
fn foo(x: i32, y: f32) -> f32 {
x * y
}
You would get this error:
error[E0277]: cannot multiply `f32` to `i32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
However, that's not usually how people describe multiplication. People
usually describe multiplication like how the division error words it:
error[E0277]: cannot divide `i32` by `f32`
--> src/lib.rs:2:7
|
2 | x / y
| ^ no implementation for `i32 / f32`
|
= help: the trait `Div<f32>` is not implemented for `i32`
So that's what this change does. It changes this:
error[E0277]: cannot multiply `f32` to `i32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
To this:
error[E0277]: cannot multiply `i32` by `f32`
--> src/lib.rs:2:7
|
2 | x * y
| ^ no implementation for `i32 * f32`
|
= help: the trait `Mul<f32>` is not implemented for `i32`
Deny broken intra-doc links in linkchecker
Since rustdoc isn't warning about these links, check for them manually.
This also fixes the broken links that popped up from the lint.
Add `str::{Split,RSplit,SplitN,RSplitN,SplitTerminator,RSplitTerminator,SplitInclusive}::as_str` methods
tl;dr this allows viewing unyelded part of str-split-iterators, like so:
```rust
let mut split = "Mary had a little lamb".split(' ');
assert_eq!(split.as_str(), "Mary had a little lamb");
split.next();
assert_eq!(split.as_str(), "had a little lamb");
split.by_ref().for_each(drop);
assert_eq!(split.as_str(), "");
```
--------------
This PR adds semi-identical `as_str` methods to most str-split-iterators with signatures like `&'_ Split<'a, P: Pattern<'a>> -> &'a str` (Note: output `&str` lifetime is bound to the `'a`, not the `'_`). The methods are similar to [`Chars::as_str`]
`SplitInclusive::as_str` is under `"str_split_inclusive_as_str"` feature gate, all other methods are under `"str_split_as_str"` feature gate.
Before this PR you had to sum `len`s of all yielded parts or collect into `String` to emulate `as_str`.
[`Chars::as_str`]: https://doc.rust-lang.org/core/str/struct.Chars.html#method.as_str
Replace absolute paths with relative ones
Modern compilers allow reaching external crates
like std or core via relative paths in modules
outside of lib.rs and main.rs.
Stabilize slice_partition_at_index
This stabilizes slice_partition_at_index, including renaming `partition_at_index*` -> `select_nth_unstable*`.
Closes#55300
r? `@Amanieu`
{kind=link}
{kind=link}