Fix two ICEs in the parser
This pull request fixes#84104 and fixes#84148. The latter is caused by an invalid `assert_ne!()` in the parser, which I have simply removed because the error is then caught in another part of the parser.
#84104 is somewhat more subtle and has to do with a suggestion to remove extraneous `<` characters; for instance:
```rust
fn main() {
foo::<Ty<<<i32>();
}
```
currently leads to
```
error: unmatched angle brackets
--> unmatched-langle.rs:2:10
|
2 | foo::<Ty<<<i32>();
| ^^^ help: remove extra angle brackets
```
which is obviously wrong and stems from the fact that the code for issuing the above suggestion does not consider the possibility that there might be other tokens in between the opening angle brackets. In #84104, this has led to a span being generated that ends in the middle of a multi-byte character (because the code issuing the suggestion thought that it was only skipping over `<`, which are single-byte), causing an ICE.
Add variance-related information to lifetime error messages
This PR adds a basic framework for displaying variance-related information in error messages. For example:
```
error: lifetime may not live long enough
--> $DIR/type-check-pointer-comparisons.rs:12:5
|
LL | fn compare_mut<'a, 'b>(x: *mut &'a i32, y: *mut &'b i32) {
| -- -- lifetime `'b` defined here
| |
| lifetime `'a` defined here
LL | x == y;
| ^ requires that `'a` must outlive `'b`
|
= help: consider adding the following bound: `'a: 'b`
= note: requirement occurs because of a mutable pointer to &i32
= note: mutable pointers are invariant over their type parameter
= help: see <https://doc.rust-lang.org/nomicon/subtyping.html> for more information about variance
```
The last three lines are new.
This is accomplished by adding a new struct `VarianceDiagInfo`, and passing it along through the various relation methods. When relating types that change the variance (e.g. `&mut T` or `*mut T`), we pass a more specific `VarianceDiagInfo` storing information about the cause of the variance change. When an error, we use the `VarianceDiagInfo` to add additional information to the error message.
This PR doesn't change any variance-related computation or behavior - only diagnostic messages. Therefore, the implementation is quite incomplete - more detailed error messages can be filled in in subsequent PRs.
Limitations:
* We only attempt to deal with invariance - since it's at the bottom of the 'variance lattice', our variance will never change again after it becomes invariant. Handling contravariance would be trickier, since we can change between contravariance and covariance multiple times (e.g. `fn(fn(&'static u8))`). Since contravariance (AFAIK) is only used for function arguments, we can probably get away without a very fancy message for cases involving contravariance.
* `VarianceDiagInfo` currently only handles mutable pointers/references. However, user-defined types (structs, enums, and unions) have the variance of their type parameters inferred, so it would be good to eventually display information about that. We'll want to try to find a balance between displaying too much and too little information about how the variance was inferred.
* The improved error messages are only displayed when `#![feature(nll)]` / `-Z borrowck=mir` is enabled. If issue https://github.com/rust-lang/rust/issues/58781 is not resolved relatively soon, then we might want to duplicate some of this logic in the 'current' (non-NLL) region/outlives handling code.
linker: Reorder linker arguments
- Split arguments into order-independent and order-dependent, to define more precisely what (pre-,post-,late-,)link-args mean.
- Add some comments.
- Combine all native library arguments together, to simplify potential support for library deduplication and similar things
- Split arguments into order-independent and order-dependent, to define more precisely what (pre,post,late)-link-args mean
parser: Ensure that all nonterminals have tokens after parsing
`parse_nonterminal` should always result in something with tokens.
This requirement wasn't satisfied in two cases:
- `stmt` nonterminal with expression statements (e.g. `0`, or `{}`, or `path + 1`) because `fn parse_stmt_without_recovery` forgot to propagate `force_collect` in some cases.
- `expr` nonterminal with expressions with built-in attributes (e.g. `#[allow(warnings)] 0`) due to an incorrect optimization in `fn parse_expr_force_collect`, it assumed that all expressions starting with `#` have their tokens collected during parsing, but that's not true if all the attributes on that expression are built-in and inert.
(Discovered when trying to implement eager `cfg` expansion for all attributes https://github.com/rust-lang/rust/pull/83824#issuecomment-817317170.)
r? `@Aaron1011`
Drop an `if let` that will always succeed
We've already checked that `proj_base == []` in the line above and renaming
`place_local` to `local` doesn't gain us anything.
``@rustbot`` modify labels +C-cleanup +T-compiler
Tweak wasm_base target spec to indicate linker is not GNU and update linker inferring logic for wasm-ld.
Reported via [Zulip](https://rust-lang.zulipchat.com/#narrow/stream/131828-t-compiler/topic/wasi.20linker.20unknown.20argument.3A.20--as-needed): we try passing `--as-needed` to the linker if it's GNU ld which `wasm-ld` is not. Usually this isn't an issue for wasm as we would use the WasmLd linker driver but because the linker in question (`wasm32-unknown-wasi-wasm-ld`) ended with `-ld` our linker inferring [logic](f64503eb55/compiler/rustc_codegen_ssa/src/back/link.rs (L957-L1040)) used the `GccLinker` implementations. (UPD: The linker inferring logic actually didn't apply in this case because the linker is actually invoked through gcc in the reported issue. But it's still worth updating the logic I think.)
This change then has 2 parts:
1. Update wasm_base target spec to indicate `linker_is_gnu: false` plus a few additions of `target.is_like_wasm` to handle flags `wasm-ld` does in fact support.
2. Improve the linker detection logic to properly determine the correct flavor of wasm linker we're using when we can.
We need to add the new `target.is_like_wasm` branches to handle the case where the "linker" used could be something like clang which would then under the hood call wasm-ld.
Preserve metadata w/ Solaris-like linkers.
#84468 moved the `-zignore` linker flag from the `gc_sections` method to `add_as_needed` which is more accurate but Solaris-style linkers will also end up removing an unreferenced ELF sections [1]. This had the unfortunate side effect of causing the `.rustc` section (which has the metada) to be removed which could cause issues when trying to link against the resulting crates or use proc macros.
Since the `-zignore` is positional, we fix this by moving the metadata objects to before the flag.
[1] Specifically a section is considered unreferenced if:
* The section is allocatable
* No other sections bind to (relocate) to this section
* The section provides no global symbols
https://docs.oracle.com/cd/E19683-01/817-3677/6mj8mbtbs/index.html#chapter4-19
Show test type during prints
Test output can sometimes be confusing. For example doctest with the no_run argument are displayed the same way than test that are run.
During #83857 I got the feedback that test output can be confusing.
For the moment test output is
```
test $DIR/test-type.rs - f (line 12) ... ignored
test $DIR/test-type.rs - f (line 15) ... ok
test $DIR/test-type.rs - f (line 21) ... ok
test $DIR/test-type.rs - f (line 6) ... ok
```
I propose to change output by indicating the test type as
```
test $DIR/test-type.rs - f (line 12) ... ignored
test $DIR/test-type.rs - f (line 15) - compile ... ok
test $DIR/test-type.rs - f (line 21) - compile fail ... ok
test $DIR/test-type.rs - f (line 6) ... ok
```
by indicating the test type after the test name (and in the case of doctest after the function name and line) and before the "...".
------------
Note: this is a proof of concept, the implementation is probably not optimal as the properties added in `TestDesc` are only use in the display and does not represent actual change of behavior, maybe `TestType::DocTest` could have fields
Partial support for raw-dylib linkage
First cut of functionality for issue #58713: add support for `#[link(kind = "raw-dylib")]` on `extern` blocks in lib crates compiled to .rlib files. Does not yet support `#[link_name]` attributes on functions, or the `#[link_ordinal]` attribute, or `#[link(kind = "raw-dylib")]` on `extern` blocks in bin crates; I intend to publish subsequent PRs to fill those gaps. It's also not yet clear whether this works for functions in `extern "stdcall"` blocks; I also intend to investigate that shortly and make any necessary changes as a follow-on PR.
This implementation calls out to an LLVM function to construct the actual `.idata` sections as temporary `.lib` files on disk and then links those into the generated .rlib.
BPF target support
This adds `bpfel-unknown-none` and `bpfeb-unknown-none`, two new no_std targets that generate little and big endian BPF. The approach taken is very similar to the cuda target, where `TargetOptions::obj_is_bitcode` is enabled and code generation is done by the linker.
I added the targets to `dist-various-2`. There are [some tests](https://github.com/alessandrod/bpf-linker/tree/main/tests/assembly) in bpf-linker and I'm planning to add more. Those are currently not ran as part of rust CI.
Remove special handling of `box_free` from `LocalAnalyzer`
The special casing of `box_free` predates the use of dominators in
analyzer. It is no longer necessary now that analyzer verifies that
the first assignment dominates all uses.
This addresses a codegen-issue that needs to be fixed upstream in LLVM.
While we wait for the fix, we can disable it.
Verified manually that the outliner is no longer run when
`-Copt-level=z` is specified, and also that you can override this with
`-Cllvm-args=-enable-machine-outliner` if you need it anyway.
A regression test is not really feasible in this instance, given that we
do not have any minimal reproducers.
Fixes#85351
Allow raw pointers in SIMD types
Closes#85915 by loosening the strictness in typechecking and adding a test to guarantee it passes.
This still might be too strict, as references currently do pass monomorphization, but my understanding is that they are not guaranteed to be "scalar" in the same way.
Remove `doc(include)`
This nightly feature is redundant now that `extended_key_value_attributes` is stable (https://github.com/rust-lang/rust/pull/83366). `@rust-lang/rustdoc` not sure if you think this needs FCP; there was already an FCP in #82539, but technically it was for deprecating, not removing the feature altogether.
This should not be merged before #83366.
cc `@petrochenkov`
Implement DepTrackingHash for `Option` through blanket impls instead of macros
This avoids having to add a new macro call for both the `Option` and the type itself.
Noticed this while working on https://github.com/rust-lang/rust/pull/84233.
r? `@Aaron1011`
This does not yet support #[link_name] attributes on functions, the #[link_ordinal]
attribute, #[link(kind = "raw-dylib")] on extern blocks in bin crates, or
stdcall functions on 32-bit x86.
don't suggest unsized indirection in where-clauses
Skip where-clauses when suggesting using indirection in combination with
`?Sized` bounds on type parameters.
Fixes#85943.
`@estebank` I think this doesn't conflict with your work in #85947; please let me know if you'd like me to cherry pick it to a new branch based on yours instead.
wasm: Make simd types passed via indirection again
This commit updates wasm target specs to use `simd_types_indirect: true`
again. Long ago this was added since wasm simd types were always
translated to `v128` under-the-hood in LLVM, meaning that it didn't
matter whether that target feature was enabled or not. Now, however,
`v128` is conditionally used in codegen depending on target features
enabled, meaning that it's possible to get linker errors about different
signatures in code that correctly uses simd types. The fix is the same
as for all other platforms, which is to pass the type indirectly.
rustc: Store metadata-in-rlibs in object files
This commit updates how rustc compiler metadata is stored in rlibs.
Previously metadata was stored as a raw file that has the same format as
`--emit metadata`. After this commit, however, the metadata is encoded
into a small object file which has one section which is the contents of
the metadata.
The motivation for this commit is to fix a common case where #83730
arises. The problem is that when rustc crates a `dylib` crate type it
needs to include entire rlib files into the dylib, so it passes
`--whole-archive` (or the equivalent) to the linker. The problem with
this, though, is that the linker will attempt to read all files in the
archive. If the metadata file were left as-is (today) then the linker
would generate an error saying it can't read the file. The previous
solution was to alter the rlib just before linking, creating a new
archive in a temporary directory which has the metadata file removed.
This problem from before this commit is now removed if the metadata file
is stored in an object file that the linker can read. The only caveat we
have to take care of is to ensure that the linker never actually
includes the contents of the object file into the final output. We apply
similar tricks as the `.llvmbc` bytecode sections to do this.
This involved changing the metadata loading code a bit, namely updating
some of the LLVM C APIs used to use non-deprecated ones and fiddling
with the lifetimes a bit to get everything to work out. Otherwise though
this isn't intended to be a functional change really, only that metadata
is stored differently in archives now.
This should end up fixing #83730 because by default dylibs will no
longer have their rlib dependencies "altered" meaning that
split-debuginfo will continue to have valid paths pointing at the
original rlibs. (note that we still "alter" rlibs if LTO is enabled to
remove Rust object files and we also "alter" for the #[link(cfg)]
feature, but that's rarely used).
Closes#83730
This commit updates how rustc compiler metadata is stored in rlibs.
Previously metadata was stored as a raw file that has the same format as
`--emit metadata`. After this commit, however, the metadata is encoded
into a small object file which has one section which is the contents of
the metadata.
The motivation for this commit is to fix a common case where #83730
arises. The problem is that when rustc crates a `dylib` crate type it
needs to include entire rlib files into the dylib, so it passes
`--whole-archive` (or the equivalent) to the linker. The problem with
this, though, is that the linker will attempt to read all files in the
archive. If the metadata file were left as-is (today) then the linker
would generate an error saying it can't read the file. The previous
solution was to alter the rlib just before linking, creating a new
archive in a temporary directory which has the metadata file removed.
This problem from before this commit is now removed if the metadata file
is stored in an object file that the linker can read. The only caveat we
have to take care of is to ensure that the linker never actually
includes the contents of the object file into the final output. We apply
similar tricks as the `.llvmbc` bytecode sections to do this.
This involved changing the metadata loading code a bit, namely updating
some of the LLVM C APIs used to use non-deprecated ones and fiddling
with the lifetimes a bit to get everything to work out. Otherwise though
this isn't intended to be a functional change really, only that metadata
is stored differently in archives now.
This should end up fixing #83730 because by default dylibs will no
longer have their rlib dependencies "altered" meaning that
split-debuginfo will continue to have valid paths pointing at the
original rlibs. (note that we still "alter" rlibs if LTO is enabled to
remove Rust object files and we also "alter" for the #[link(cfg)]
feature, but that's rarely used).
Closes#83730
Support for force-warns
Implements https://github.com/rust-lang/rust/issues/85512.
This PR adds a new command line option `force-warns` which will force the provided lints to warn even if they are allowed by some other mechanism such as `#![allow(warnings)]`.
Some remaining issues:
* https://github.com/rust-lang/rust/issues/85512 mentions that `force-warns` should also be capable of taking lint groups instead of individual lints. This is not implemented.
* If a lint has a higher warning level than `warn`, this will cause that lint to warn instead. We probably want to allow the lint to error if it is set to a higher lint and is not allowed somewhere else.
* One test is currently ignored because it's not working - when a deny-by-default lint is allowed, it does not currently warn under `force-warns`. I'm not sure why, but I wanted to get this in before the weekend.
r? `@nikomatsakis`
For extern providers, both provide and provide_extern are called.
wasm_import_module_map is already provided in provide, so it doesn't
need to be provided in provide_extern.
Reland - Report coverage `0` of dead blocks
Fixes: #84018
With `-Z instrument-coverage`, coverage reporting of dead blocks
(for example, blocks dropped because a conditional branch is dropped,
based on const evaluation) is now supported.
Note, this PR relands an earlier, reverted PR that failed when compiling
generators. The prior issues with generators has been resolved and a new
test was added to prevent future regressions.
Check out the resulting changes to test coverage of dead blocks in the
test coverage reports in this PR.
r? `@tmandry`
fyi: `@wesleywiser`
Restoring the `num_def_ids` function in the CStore API
## The context
I am the maintainer of https://github.com/hacspec/hacspec, an embedded Rust DSL aimed at cryptographic specifications. As it is normal for an embedded DSL, Hacspec's compiler relies on being plugged to the internal API of the Rust compiler, which is unstable and subject to changes.
## The problem
The Hacspec compiler features its own typechecker, that performs an additional, more restrictive typechecking pass over the Rust code of a crate. To complete this typechecking, the Hacspec compiler needs to retrieve the signature of functions defined in non-local imported crates. Rather than retrieving these signatures on-demand, the Hacspec compiler pre-populates its typechecking context with all the Hacspec-compatible symbols defined in non-local crates first. This requires having a way to iterate over all the definitions in a non-local crate.
I used to do this with `CrateMetadata::all_def_path_hashes_and_def_ids`, but this function was deleted in 908bf5a310. Then, I fellback on `CStore::num_def_ids`, exploiting the fact that all the `DefIds` for a crate have the same `krate_num` and range from `0` to `num_def_ids(krate_num)`. But `num_def_ids` was deleted in b6120bfb35.
I looked to the `Cstore::item_children_untracked` function to replicate the feature of traversing through all the `DefId` for a crate, using `CRATE_DEF_INDEX` as the root, but this does not work as recursive `Cstore::item_children_untracked` calls do not reach all the symbols I was able to reach using the two previous methods.
## Description of this PR
This PR simply restores in the public API of `CStore` the `num_def_ids` function, giving the size of the definition table for a given crate.
Remove unused feature gates
The first commit removes a usage of a feature gate, but I don't expect it to be controversial as the feature gate was only used to workaround a limitation of rust in the past. (closures never being `Clone`)
The second commit uses `#[allow_internal_unstable]` to avoid leaking the `trusted_step` feature gate usage from inside the index newtype macro. It didn't work for the `min_specialization` feature gate though.
The third commit removes (almost) all feature gates from the compiler that weren't used anyway.
This commit updates wasm target specs to use `simd_types_indirect: true`
again. Long ago this was added since wasm simd types were always
translated to `v128` under-the-hood in LLVM, meaning that it didn't
matter whether that target feature was enabled or not. Now, however,
`v128` is conditionally used in codegen depending on target features
enabled, meaning that it's possible to get linker errors about different
signatures in code that correctly uses simd types. The fix is the same
as for all other platforms, which is to pass the type indirectly.
Improve debugging experience for enums on windows-msvc
This PR makes significant improvements over the status quo of debugging enums on the windows-msvc platform with either WinDbg or Visual Studio in three ways:
1. Improves the debugger experience for directly tagged enums.
2. Fixes a bug which caused the debugger to sometimes show the wrong debug info for niche layout enums. For example, `Option<&u32>` could sometimes use the debug info for `Option<&f64>` instead leading to nonsensical variable values in the debugger.
3. Significantly improves the debugger experience for niche-layout enums.
Let's look at a few examples:
```rust
pub enum CStyleEnum {
Base = 2,
Exponent = 16,
}
pub enum NicheLayoutEnum {
Tag1,
Data { my_data: CStyleEnum },
Tag2,
Tag3,
Tag4,
}
pub enum OtherEnum<T> {
Case1(T),
Case2(T),
}
fn main() {
let a = Some(CStyleEnum::Base);
let b = Option::<CStyleEnum>::None;
let c = NicheLayoutEnum::Tag1;
let d = NicheLayoutEnum::Data { my_data: CStyleEnum::Exponent };
let e = NicheLayoutEnum::Tag2;
let f = Some(&1u32);
let g = Option::<&'static u32>::None;
let h = Some(&2u64);
let i = Option::<&'static u64>::None;
let j = Some(12u32);
let k = Option::<u32>::None;
let l = Some(12.34f64);
let m = Option::<f64>::None;
let n = CStyleEnum::Base;
let o = CStyleEnum::Exponent;
let p = Some("IAMA optional string!".to_string());
let q = OtherEnum::Case1(42u32);
}
```
This is what WinDbg Preview shows using the latest rustc nightly:
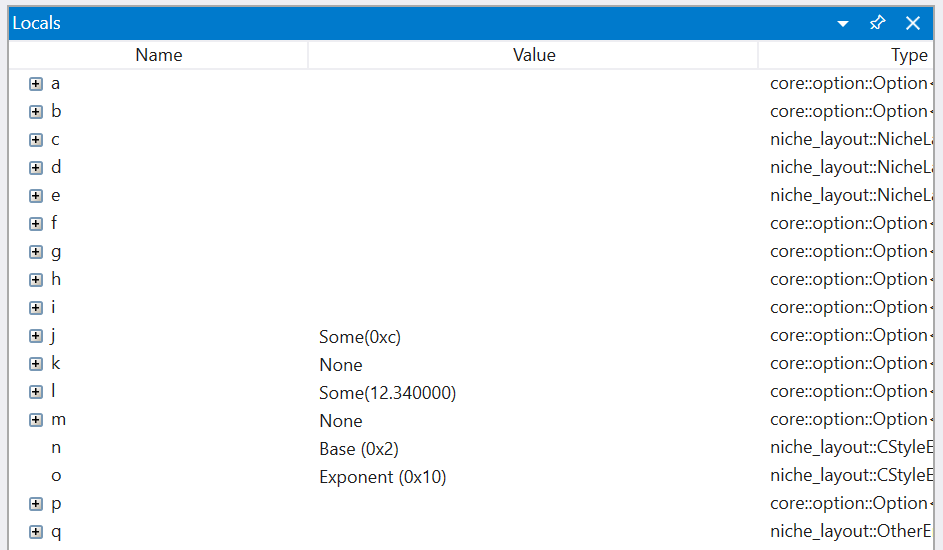
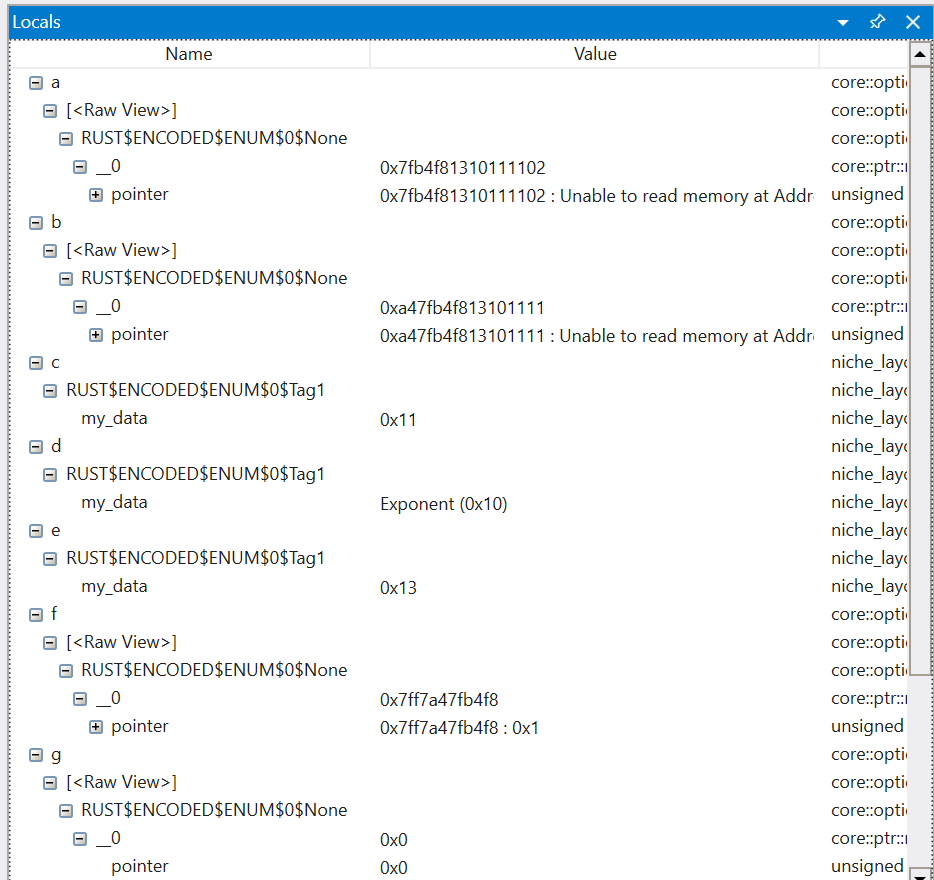
Most of the variables don't show a meaningful value expect for a few cases that we have targeted natvis definitions covering. Even worse, drilling into many of these variables shows information that can be difficult to interpret without an understanding of the layout of Rust types:
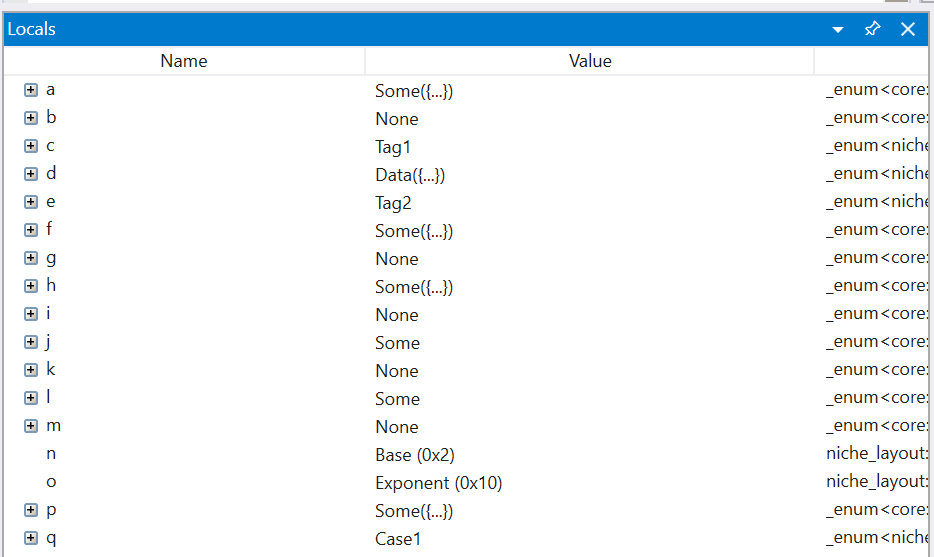
With the changes in this PR, we're able to write two natvis definitions that cover all enum cases generally. After building with these changes, WinDbg now shows this instead:
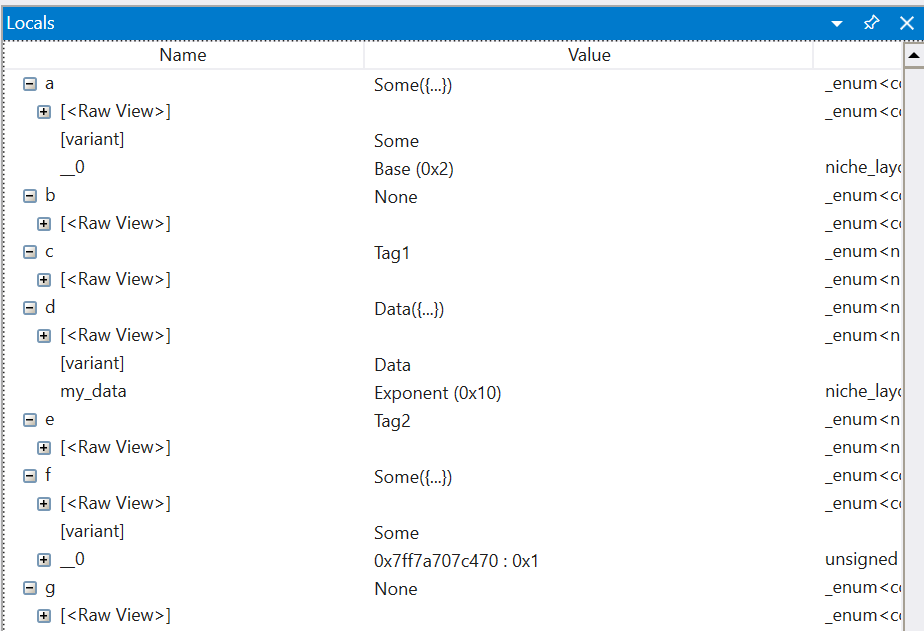
Drilling into the same variables, we can see much more useful information:
Fixes#84670Fixes#84671
Restored underlying num_def_ids_method
Update compiler/rustc_metadata/src/rmeta/decoder/cstore_impl.rs
Changed name to fit with naming convention
Co-authored-by: bjorn3 <bjorn3@users.noreply.github.com>
Update compiler/rustc_metadata/src/rmeta/decoder/cstore_impl.rs
Replace regular doc with Rustdoc comment
Co-authored-by: Joshua Nelson <jyn514@gmail.com>
Clarifies third-party use of num_def_ids_untracked
Use pattern matching instead of checking lengths explicitly
This piece of code checks that there are exaclty two variants, one having
exactly one field, the other having exactly zero fields. If any of these
conditions is violated, it returns `None`. Otherwise it assigns that one
field's ty to `field_ty`.
Instead of fiddling with indices and length checks explicitly, use pattern
matching to simplify this.
`@rustbot` modify labels +C-cleanup +T-compiler
Turn off frame pointer elimination on all Apple platforms.
This ends up disabling frame pointer elimination on aarch64_apple_darwin
which matches what clang does by default along with the
aarch64_apple_ios and x86_64_apple_darwin targets.
Further, the Apple docs "Writing ARM64 Code for Apple Platforms" has a section
called "Respect the Purpose of Specific CPU Registers" which
specifically calls out the frame pointer register (x29):
The frame pointer register (x29) must always address a valid frame
record. Some functions — such as leaf functions or tail calls — may
opt not to create an entry in this list As a result, stack traces
are always meaningful, even without debug information.
Other platforms are updated to not override the default.
rustc: Allow safe #[target_feature] on wasm
This commit updates the compiler's handling of the `#[target_feature]`
attribute when applied to functions on WebAssembly-based targets. The
compiler in general requires that any functions with `#[target_feature]`
are marked as `unsafe` as well, but this commit relaxes the restriction
for WebAssembly targets where the attribute can be applied to safe
functions as well.
The reason this is done is that the motivation for this feature of the
compiler is not applicable for WebAssembly targets. In general the
`#[target_feature]` attribute is used to enhance target CPU features
enabled beyond the basic level for the rest of the compilation. If done
improperly this means that your program could execute an instruction
that the CPU you happen to be running on does not understand. This is
considered undefined behavior where it is unknown what will happen (e.g.
it's not a deterministic `SIGILL`).
For WebAssembly, however, the target is different. It is not possible
for a running WebAssembly program to execute an instruction that the
engine does not understand. If this were the case then the program would
not have validated in the first place and would not run at all. Even if
this were allowed in some hypothetical future where engines have some
form of runtime feature detection (which they do not right now) any
implementation of such a feature would generate a trap if a module
attempts to execute an instruction the module does not understand. This
deterministic trap behavior would still not fall into the category of
undefined behavior because the trap is deterministic.
For these reasons the `#[target_feature]` attribute is now allowed on
safe functions, but only for WebAssembly targets. This notably enables
the wasm-SIMD intrinsics proposed for stabilization in #74372 to be
marked as safe generally instead of today where they're all `unsafe` due
to the historical implementation of `#[target_feature]` in the compiler.
This ends up disabling frame pointer elimination on aarch64_apple_darwin
which matches what clang does by default along with the
aarch64_apple_ios and x86_64_apple_darwin targets.
Further, the Apple docs "Writing ARM64 Code for Apple Platforms" has a section
called "Respect the Purpose of Specific CPU Registers" which
specifically calls out the frame pointer register (x29):
The frame pointer register (x29) must always address a valid frame
record. Some functions — such as leaf functions or tail calls — may
opt not to create an entry in this list As a result, stack traces
are always meaningful, even without debug information.
Other platforms are updated to not override the default.
Previously, we would generate a single struct with the layout of the
dataful variant plus an extra field whose name contained the value of
the niche (this would only really work for things like `Option<&_>`
where we can determine that the `None` case maps to `0` but for enums
that have multiple tag only variants, this doesn't work).
Now, we generate a union of two structs, one which is the layout of the
dataful variant and one which just has a way of reading the
discriminant. We also generate an enum which maps the discriminant value
to the tag only variants.
We also encode information about the range of values which correspond to
the dataful variant in the type name and then use natvis to determine
which union field we should display to the user.
As a result of this change, all niche-layout enums render correctly in
WinDbg and Visual Studio!
This wasn't necessary for msvc and caused issues where different types
with the same name such as different instantiations of `Option<T>` would
have colliding debuginfo. This confused the debugger which would pick
one of the type definitions and use for all types with that name even
though they had different layout.
Avoid creating anonymous nodes with zero or one dependency.
Anonymous nodes are only useful to encode dependencies, and cannot be replayed from one compilation session to another.
As such, anonymous nodes without dependency are always green.
Anonymous nodes with only one dependency are equivalent to this dependency.
cc #45408
cc `@michaelwoerister`
This piece of code checks that there are exaclty two variants, one having
exactly one field, the other having exactly zero fields. If any of these
conditions is violated, it returns `None`. Otherwise it assigns that one
field's ty to `field_ty`.
Instead of fiddling with indices and length checks explicitly, use pattern
matching to simplify this.
Fixes: #84018
With `-Z instrument-coverage`, coverage reporting of dead blocks
(for example, blocks dropped because a conditional branch is dropped,
based on const evaluation) is now supported.
Note, this PR relands an earlier, reverted PR that failed when compiling
generators. The prior issues with generators has been resolved and a new
test was added to prevent future regressions.
Check out the resulting changes to test coverage of dead blocks in the
test coverage reports in this PR.
Reduce the amount of untracked state in TyCtxt
Access to untracked global state may generate instances of #84970.
The GlobalCtxt contains the lowered HIR, the resolver outputs and interners.
By wrapping the resolver inside a query, we make sure those accesses are properly tracked.
As a no_hash query, all dependent queries essentially become `eval_always`,
what they should have been from the beginning.
Don't sort a `Vec` before computing its `DepTrackingHash`
Previously, we sorted the vec prior to hashing, making the hash
independent of the original (command-line argument) order. However, the
original vec was still always kept in the original order, so we were
relying on the rest of the compiler always working with it in an
'order-independent' way.
This assumption was not being upheld by the `native_libraries` query -
the order of the entires in its result depends on the order of entries
in `Options.libs`. This lead to an 'unstable fingerprint' ICE when the
`-l` arguments were re-ordered.
This PR removes the sorting logic entirely. Re-ordering command-line
arguments (without adding/removing/changing any arguments) seems like a
really niche use case, and correctly optimizing for it would require
additional work. By always hashing arguments in their original order, we
can entirely avoid a cause of 'unstable fingerprint' errors.
Emit a hard error when a panic occurs during const-eval
Previous, a panic during const evaluation would go through the
`const_err` lint. This PR ensures that such a panic always causes
compilation to fail.
Fix span of redundant generic arguments
Fixes#71563
Above issue is about lifetime arguments, but generic arguments also have same problem.
This PR fixes both help messages.
The special casing of `box_free` predates the use of dominators in
analyzer. It is no longer necessary now that analyzer verifies that
the first assignment dominates all uses.
Use correct edition when parsing `:pat` matchers
As described in issue #85708, we currently do not properly decode
`SyntaxContext::root()` and `ExpnId::root()` from foreign crates. As a
result, when we decode a span from a foreign crate with
`SyntaxContext::root()`, we end up up considering it to have the edition
of the *current* crate, instead of the foreign crate where it was
originally created.
A full fix for this issue will be a fairly significant undertaking.
Fortunately, it's possible to implement a partial fix, which gives us
the correct edition-dependent behavior for `:pat` matchers when the
macro is loaded from another crate. Since we have the edition of the
macro's defining crate available, we can 'recover' from seeing a
`SyntaxContext::root()` and use the edition of the macro's defining
crate.
Any solution to issue #85708 must reproduce the behavior of this
targeted fix - properly preserving a foreign `SyntaxContext::root()`
means (among other things) preserving its edition, which by definition
is the edition of the foreign crate itself. Therefore, this fix moves us
closer to the correct overall solution, and does not expose any new
incorrect behavior to macros.
Use command line metadata path if provided
If the command-line has `--emit metadata=some/path/libfoo.rmeta` then
use that.
Closes#85356
I couldn't find any existing tests for the `--emit TYPE=PATH` command line syntax, so I wasn't sure how to test this aside from ad-hoc manual testing. Is there a ui test type for "generated output file with expected name"?
Merge CrateDisambiguator into StableCrateId
This simplifies the code and potentially improves performance by reducing the amount of hashed data.
Fixes https://github.com/rust-lang/rust/issues/85795
Make `Step` trait safe to implement
This PR makes a few modifications to the `Step` trait that I believe better position it for stabilization in the short term. In particular,
1. `unsafe trait TrustedStep` is introduced, indicating that the implementation of `Step` for a given type upholds all stated invariants (which have remained unchanged). This is gated behind a new `trusted_step` feature, as stabilization is realistically blocked on min_specialization.
2. The `Step` trait is internally specialized on the `TrustedStep` trait, which avoids a serious performance regression.
3. `TrustedLen` is implemented for `T: TrustedStep` as the latter's invariants subsume the former's.
4. The `Step` trait is no longer `unsafe`, as the invariants must not be relied upon by unsafe code (unless the type implements `TrustedStep`).
5. `TrustedStep` is implemented for all types that implement `Step` in the standard library and compiler.
6. The `step_trait_ext` feature is merged into the `step_trait` feature. I was unable to find any reasoning for the features being split; the `_unchecked` methods need not necessarily be stabilized at the same time, but I think it is useful to have them under the same feature flag.
All existing implementations of `Step` will be broken, as it is not possible to `unsafe impl` a safe trait. Given this trait only exists on nightly, I feel this breakage is acceptable. The blanket `impl<T: Step> TrustedLen for T` will likely cause some minor breakage, but this should be covered by the equivalent impl for `TrustedStep`.
Hopefully these changes are sufficient to place `Step` in decent position for stabilization, which would allow user-defined types to be used with `a..b` syntax.
Don't panic when failing to initialize incremental directory.
This removes a panic when rustc fails to initialize the incremental directory. This can commonly happen on various filesystems that don't support locking (often various network filesystems). Panics can be confusing and scary, and there are already plenty of issues reporting this.
This has been panicking since 1.22 due to I think #44502 which was a major rework of how things work. Previously, things were simpler and the [`load_dep_graph`](https://github.com/rust-lang/rust/blob/1.21.0/src/librustc_incremental/persist/load.rs#L43-L65) function would emit an error and then continue on without panicking. With 1.22, [`load_dep_graph`](https://github.com/rust-lang/rust/blob/1.22.0/src/librustc_incremental/persist/load.rs#L44) was changed so that it assumes it can load the data without errors. Today, the problem is that it calls [`prepare_session_directory`](fbf1b1a719/compiler/rustc_interface/src/passes.rs (L175-L179)) and then immediately calls `garbage_collect_session_directories` which will panic since the session is `IncrCompSession::NotInitialized`.
The solution here is to have `prepare_session_directory` return an error that must be handled so that compilation stops if it fails.
Some other options:
* Ignore directory lock failures.
* Print a warning on directory lock failure, but otherwise continue with incremental enabled.
* Print a warning on directory lock failure, and disable incremental.
* Provide a different locking mechanism.
Cargo ignores lock errors if locking is not supported, so that would be a precedent for the first option. These options would require quite a bit more changes, but I'm happy to entertain any of them, as I think they all have valid justifications.
There is more discussion on the many issues where this is reported: #49773, #59224, #66513, #76251. I'm not sure if this can be considered closing any of those, though, since I think there is some value in discussing if there is a way to avoid the error altogether. But I think it would make sense to at least close all but one to consolidate them.
As described in issue #85708, we currently do not properly decode
`SyntaxContext::root()` and `ExpnId::root()` from foreign crates. As a
result, when we decode a span from a foreign crate with
`SyntaxContext::root()`, we end up up considering it to have the edition
of the *current* crate, instead of the foreign crate where it was
originally created.
A full fix for this issue will be a fairly significant undertaking.
Fortunately, it's possible to implement a partial fix, which gives us
the correct edition-dependent behavior for `:pat` matchers when the
macro is loaded from another crate. Since we have the edition of the
macro's defining crate available, we can 'recover' from seeing a
`SyntaxContext::root()` and use the edition of the macro's defining
crate.
Any solution to issue #85708 must reproduce the behavior of this
targeted fix - properly preserving a foreign `SyntaxContext::root()`
means (among other things) preserving its edition, which by definition
is the edition of the foreign crate itself. Therefore, this fix moves us
closer to the correct overall solution, and does not expose any new
incorrect behavior to macros.
A bit more polish on const eval errors
This PR adds a bit more polish to the const eval errors:
- a slight improvement to the PME messages from #85633: I mentioned there that the erroneous item's paths were dependent on the environment, and could be displayed fully qualified or not. This can obscure the items when they come from a dependency. This PR uses the pretty-printing code ensuring the items' paths are not trimmed.
- whenever there are generics involved in an item where const evaluation errors out, the error message now displays the instance and its const arguments, so that we can see which instantiated item and compile-time values lead to the error.
So we get this slight improvement for our beloved `stdarch` example, on nightly:
```
error[E0080]: evaluation of constant value failed
--> ./stdarch/crates/core_arch/src/macros.rs:8:9
|
8 | assert!(IMM >= MIN && IMM <= MAX, "IMM value not in expected range");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the evaluated program panicked at 'IMM value not in expected range', /rustc/9111b8ae9793f18179a1336417618fc07a9cac85/library/core/src/../../stdarch/crates/core_arch/src/macros.rs:8:9
|
```
to this PR's:
```
error[E0080]: evaluation of `core::core_arch::macros::ValidateConstImm::<51_i32, 0_i32, 15_i32>::VALID` failed
--> ./stdarch/crates/core_arch/src/macros.rs:8:9
|
8 | assert!(IMM >= MIN && IMM <= MAX, "IMM value not in expected range");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the evaluated program panicked at 'IMM value not in expected range', ./stdarch/crates/core_arch/src/macros.rs:8:9
|
```
with this PR.
Of course this is an idea from Oli, so maybe r? `@oli-obk` if they have the time.
This commit updates the compiler's handling of the `#[target_feature]`
attribute when applied to functions on WebAssembly-based targets. The
compiler in general requires that any functions with `#[target_feature]`
are marked as `unsafe` as well, but this commit relaxes the restriction
for WebAssembly targets where the attribute can be applied to safe
functions as well.
The reason this is done is that the motivation for this feature of the
compiler is not applicable for WebAssembly targets. In general the
`#[target_feature]` attribute is used to enhance target CPU features
enabled beyond the basic level for the rest of the compilation. If done
improperly this means that your program could execute an instruction
that the CPU you happen to be running on does not understand. This is
considered undefined behavior where it is unknown what will happen (e.g.
it's not a deterministic `SIGILL`).
For WebAssembly, however, the target is different. It is not possible
for a running WebAssembly program to execute an instruction that the
engine does not understand. If this were the case then the program would
not have validated in the first place and would not run at all. Even if
this were allowed in some hypothetical future where engines have some
form of runtime feature detection (which they do not right now) any
implementation of such a feature would generate a trap if a module
attempts to execute an instruction the module does not understand. This
deterministic trap behavior would still not fall into the category of
undefined behavior because the trap is deterministic.
For these reasons the `#[target_feature]` attribute is now allowed on
safe functions, but only for WebAssembly targets. This notably enables
the wasm-SIMD intrinsics proposed for stabilization in #74372 to be
marked as safe generally instead of today where they're all `unsafe` due
to the historical implementation of `#[target_feature]` in the compiler.
const-eval: disallow unwinding across functions that `!fn_can_unwind()`
Following https://github.com/rust-lang/miri/pull/1776#discussion_r633074343, so r? `@RalfJung`
This PR turns `unwind` in `StackPopCleanup::Goto` into a new enum `StackPopUnwind`, with a `NotAllowed` variant to indicate that unwinding is not allowed. This variant is chosen based on `rustc_middle::ty::layout::fn_can_unwind()` in `eval_fn_call()` when pushing the frame. A check is added in `unwind_to_block()` to report UB if unwinding happens across a `StackPopUnwind::NotAllowed` frame.
Tested with Miri `HEAD` with [minor changes](https://github.com/rust-lang/miri/compare/HEAD..9cf3c7f0d86325a586fbcbf2acdc9232b861f1d8) and the rust-lang/miri#1776 branch with [these changes](d866c1c52f..626638fbfe).
Fix incorrect suggestions for E0605
Fixes#84598. Here is a simplified version of the problem presented in issue #84598:
```Rust
#![allow(unused_variables)]
#![allow(dead_code)]
trait T { fn t(&self) -> i32; }
unsafe fn foo(t: *mut dyn T) {
(t as &dyn T).t();
}
fn main() {}
```
The current output is:
```
error[E0605]: non-primitive cast: `*mut (dyn T + 'static)` as `&dyn T`
--> src/main.rs:7:5
|
7 | (t as &dyn T).t();
| ^^^^^^^^^^^^^ invalid cast
|
help: borrow the value for the cast to be valid
|
7 | (&t as &dyn T).t();
| ^
```
This is incorrect, though: The cast will _not_ be valid when writing `&t` instead of `t`:
```
error[E0277]: the trait bound `*mut (dyn T + 'static): T` is not satisfied
--> t4.rs:7:6
|
7 | (&t as &dyn T).t();
| ^^ the trait `T` is not implemented for `*mut (dyn T + 'static)`
|
= note: required for the cast to the object type `dyn T`
```
The correct suggestion is `&*t`, which I have implemented in this pull request. Of course, this suggestion will always require an unsafe block, but arguably, that's what the user really wants if they're trying to cast a pointer to a reference.
In any case, claiming that the cast will be valid after implementing the suggestion is overly optimistic, as the coercion logic doesn't seem to resolve all nested obligations, i.e. the cast may still be invalid after implementing the suggestion. I have therefore rephrased the suggestion slightly ("consider borrowing the value" instead of "borrow the value for the cast to be valid").
Additionally, I have fixed another incorrect suggestion not mentioned in #84598, which relates to casting immutable references to mutable ones:
```rust
fn main() {
let mut x = 0;
let m = &x as &mut i32;
}
```
currently leads to
```
error[E0605]: non-primitive cast: `&i32` as `&mut i32`
--> t5.rs:3:13
|
3 | let m = &x as &mut i32;
| ^^^^^^^^^^^^^^ invalid cast
|
help: borrow the value for the cast to be valid
|
3 | let m = &mut &x as &mut i32;
| ^^^^
```
which is obviously incorrect:
```
error[E0596]: cannot borrow data in a `&` reference as mutable
--> t5.rs:3:13
|
3 | let m = &mut &x as &mut i32;
| ^^^^^^^ cannot borrow as mutable
```
I've changed the suggestion to a note explaining the problem:
```
error[E0605]: non-primitive cast: `&i32` as `&mut i32`
--> t5.rs:3:13
|
3 | let m = &x as &mut i32;
| ^^^^^^^^^^^^^^ invalid cast
|
note: this reference is immutable
--> t5.rs:3:13
|
3 | let m = &x as &mut i32;
| ^^
note: trying to cast to a mutable reference type
--> t5.rs:3:19
|
3 | let m = &x as &mut i32;
| ^^^^^^^^
```
In this example, it would have been even nicer to suggest replacing `&x` with `&mut x`, but this would be much more complex because we would have to take apart the expression to be cast (currently, we only look at its type), and `&x` could be stored in a variable, where such a suggestion would not even be directly applicable:
```rust
fn main() {
let mut x = 0;
let r = &x;
let m = r as &mut i32;
}
```
My solution covers this case, too.
Sync rustc_codegen_cranelift
The main highlight this sync is the removal of several dependencies, making compilation of cg_clif itself faster. There have also been a couple of new features like `#[link_section]` now supporting different segments for Mach-O binaries (thanks `@eggyal!)` and the `imported_main` feature, which is currently unstable.
r? `@ghost`
`@rustbot` label +A-codegen +A-cranelift +T-compiler
Update cc
Recent commits have improved `cc`'s finding of MSVC tools on Windows. In particular it should help to address these issues: #83043 and #43468
readd capture disjoint fields gate
This readds a feature gate guard that was added in PR #83521. (Basically, there were unintended consequences to the code exposed by removing the feature gate guard.)
The root bug still remains to be resolved, as discussed in issue #85561. This is just a band-aid suitable for a beta backport.
Cc issue #85435
Note that the latter issue is unfixed until we backport this (or another fix) to 1.53 beta
stabilize member constraints
Stabilizes the use of "member constraints" in solving `impl Trait` bindings. This is a step towards stabilizing a "MVP" of "named impl Trait".
# Member constraint stabilization report
| Info | |
| --- | --- |
| Tracking issue | [rust-lang/rust#61997](https://github.com/rust-lang/rust/issues/61997) |
| Implementation history | [rust-lang/rust#61775] |
| rustc-dev-guide coverage | [link](https://rustc-dev-guide.rust-lang.org/borrow_check/region_inference/member_constraints.html) |
| Complications | [rust-lang/rust#61773] |
[rust-lang/rust#61775]: https://github.com/rust-lang/rust/pull/61775
[rust-lang/rust#61773]: https://github.com/rust-lang/rust/issues/61773
## Background
Member constraints are an extension to our region solver that was introduced to make async fn region solving tractable. There are used in situations like the following:
```rust
fn foo<'a, 'b>(...) -> impl Trait<'a, 'b> { .. }
```
The problem here is that every region R in the hidden type must be equal to *either* `'a` *or* `'b` (or `'static`). This cannot be expressed simply via 'outlives constriants' like `R: 'a`. Therefore, we introduce a 'member constraint' `R member of ['a, 'b]`.
These constraints were introduced in [rust-lang/rust#61775]. At the time, we kept them feature gated and used them only for `impl Trait` return types that are derived from `async fn`. The intention, however, was always to support them in other contexts once we had time to gain more experience with them.
**In the time since their introduction, we have encountered no surprises or bugs due to these member constraints.** They are tested extensively as part of every async function that involves multiple unrelated lifetimes in its arguments.
## Tests
The behavior of member constraints is covered by the following tests:
* [`src/test/ui/async-await/multiple-lifetimes`](20e032e650/src/test/ui/async-await/multiple-lifetimes) -- tests using the async await, which are mostly already stabilized
* [`src/test/ui/impl-trait/multiple-lifetimes.rs`](20e032e650/src/test/ui/impl-trait/multiple-lifetimes.rs)
* [`src/test/ui/impl-trait/multiple-lifetimes/ordinary-bounds-unsuited.rs`](20e032e650/src/test/ui/impl-trait/multiple-lifetimes/ordinary-bounds-unsuited.rs)
* [`src/test/ui/async-await/multiple-lifetimes/ret-impl-trait-fg.rs`](20e032e650/src/test/ui/async-await/multiple-lifetimes/ret-impl-trait-fg.rs)
* [`src/test/ui/async-await/multiple-lifetimes/ret-impl-trait-one.rs`](20e032e650/src/test/ui/async-await/multiple-lifetimes/ret-impl-trait-one.rs)
These tests cover a number of scenarios:
* `-> implTrait<'a, 'b>` with unrelated lifetimes `'a` and `'b`, as described above
* `async fn` that returns an `impl Trait` like the previous case, which desugars to a kind of "nested" impl trait like `impl Future<Output = impl Trait<'a, 'b>>`
## Potential concerns
There is a potential interaction with `impl Trait` on local variables, described in [rust-lang/rust#61773]. The challenge is that if you have a program like:
```rust=
trait Foo<'_> { }
impl Foo<'_> for &u32 { }
fn bar() {
let x: impl Foo<'_> = &44; // let's call the region variable for `'_` `'1`
}
```
then we would wind up with `'0 member of ['1, 'static]`, where `'0` is the region variable in the hidden type (`&'0 u32`) and `'1` is the region variable in the bounds `Foo<'1>`. This is tricky because both `'0` and `'1` are being inferred -- so making them equal may have other repercussions.
That said, `impl Trait` in bindings are not stable, and the implementation is pretty far from stabilization. Moreover, the difficulty highlighted here is not due to the presence of member constraints -- it's inherent to the design of the language. In other words, stabilizing member constraints does not actually cause us to accept anything that would make this problem any harder.
So I don't see this as a blocker to stabilization of member constraints; it is potentially a blocker to stablization of `impl trait` in let bindings.
E0599 suggestions and elision of generic argument if no canditate is found
fixes#81576
changes: In error E0599 (method not found) generic argument are eluded if the method was not found anywhere. If the method was found in another inherent implementation suggest that it was found elsewhere.
Example
```rust
struct Wrapper<T>(T);
struct Wrapper2<T> {
x: T,
}
impl Wrapper2<i8> {
fn method(&self) {}
}
fn main() {
let wrapper = Wrapper(i32);
wrapper.method();
let wrapper2 = Wrapper2{x: i32};
wrapper2.method();
}
```
```
Error[E0599]: no method named `method` found for struct `Wrapper<_>` in the current scope
....
error[E0599]: no method named `method` found for struct `Wrapper2<i32>` in the current scope
...
= note: The method was found for Wrapper2<i8>.
```
I am not very happy with the ```no method named `test` found for struct `Vec<_, _>` in the current scope```. I think it might be better to show only one generic argument `Vec<_>` if there is a default one. But I haven't yet found a way to do that,
While stdlib implementations of the unchecked methods require unchecked
math, there is no reason to gate it behind this for external users. The
reasoning for a separate `step_trait_ext` feature is unclear, and as
such has been merged as well.
Post-monomorphization errors traces MVP
This PR works towards better diagnostics for the errors encountered in #85155 and similar.
We can encounter post-monomorphization errors (PMEs) when collecting mono items. The current diagnostics are confusing for these cases when they happen in a dependency (but are acceptable when they happen in the local crate).
These kinds of errors will be more likely now that `stdarch` uses const generics for its intrinsics' immediate arguments, and validates these const arguments with a mechanism that triggers such PMEs.
(Not to mention that the errors happen during codegen, so only when building code that actually uses these code paths. Check builds don't trigger them, neither does unused code)
So in this PR, we detect these kinds of errors during the mono item graph walk: if any error happens while collecting a node or its neighbors, we print a diagnostic about the current collection step, so that the user has at least some context of which erroneous code and dependency triggered the error.
The diagnostics for issue #85155 now have this note showing the source of the erroneous const argument:
```
note: the above error was encountered while instantiating `fn std::arch::x86_64::_mm_blend_ps::<51_i32>`
--> issue-85155.rs:11:24
|
11 | let _blended = _mm_blend_ps(a, b, 0x33);
| ^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
```
Note that #85155 is a reduced version of a case happening in the wild, to indirect users of the `rustfft` crate, as seen in https://github.com/ejmahler/RustFFT/issues/74. The crate had a few of these out-of-range immediates. Here's how the diagnostics in this PR would have looked on one of its examples before it was fixed:
<details>
```
error[E0080]: evaluation of constant value failed
--> ./stdarch/crates/core_arch/src/macros.rs:8:9
|
8 | assert!(IMM >= MIN && IMM <= MAX, "IMM value not in expected range");
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the evaluated program panicked at 'IMM value not in expected range', ./stdarch/crates/core_arch/src/macros.rs:8:9
|
= note: this error originates in the macro `$crate::panic::panic_2015` (in Nightly builds, run with -Z macro-backtrace for more info)
note: the above error was encountered while instantiating `fn _mm_blend_ps::<51_i32>`
--> /tmp/RustFFT/src/avx/avx_vector.rs:1314:23
|
1314 | let blended = _mm_blend_ps(rows[0], rows[2], 0x33);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
note: the above error was encountered while instantiating `fn _mm_permute_pd::<5_i32>`
--> /tmp/RustFFT/src/avx/avx_vector.rs:1859:9
|
1859 | _mm_permute_pd(self, 0x05)
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
note: the above error was encountered while instantiating `fn _mm_permute_pd::<15_i32>`
--> /tmp/RustFFT/src/avx/avx_vector.rs:1863:32
|
1863 | (_mm_movedup_pd(self), _mm_permute_pd(self, 0x0F))
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0080`.
error: could not compile `rustfft`
To learn more, run the command again with --verbose.
```
</details>
I've developed and discussed this with them, so maybe r? `@oli-obk` -- but feel free to redirect to someone else of course.
(I'm not sure we can say that this PR definitely closes issue 85155, as it's still unclear exactly which diagnostics and information would be interesting to report in such cases -- and we've discussed printing backtraces before. I have prototypes of some complete and therefore noisy backtraces I showed Oli, but we decided to not include them in this PR for now)
Disallow shadowing const parameters
This pull request fixes#85348. Trying to shadow a `const` parameter as follows:
```rust
fn foo<const N: i32>() {
let N @ _ = 0;
}
```
currently causes an ICE. With my changes, I get:
```
error[E0530]: let bindings cannot shadow const parameters
--> test.rs:2:9
|
1 | fn foo<const N: i32>() {
| - the const parameter `N` is defined here
2 | let N @ _ = 0;
| ^ cannot be named the same as a const parameter
error: aborting due to previous error
```
This is the same error you get when trying to shadow a constant:
```rust
const N: i32 = 0;
let N @ _ = 0;
```
```
error[E0530]: let bindings cannot shadow constants
--> src/lib.rs:3:5
|
2 | const N: i32 = 0;
| ----------------- the constant `N` is defined here
3 | let N @ _ = 0;
| ^ cannot be named the same as a constant
error: aborting due to previous error
```
The reason for disallowing shadowing in both cases is described [here](https://github.com/rust-lang/rust/issues/33118#issuecomment-233962221) (the comment there only talks about constants, but the same reasoning applies to `const` parameters).
Previously, we sorted the vec prior to hashing, making the hash
independent of the original (command-line argument) order. However, the
original vec was still always kept in the original order, so we were
relying on the rest of the compiler always working with it in an
'order-independent' way.
This assumption was not being upheld by the `native_libraries` query -
the order of the entires in its result depends on the order of entries
in `Options.libs`. This lead to an 'unstable fingerprint' ICE when the
`-l` arguments were re-ordered.
This PR removes the sorting logic entirely. Re-ordering command-line
arguments (without adding/removing/changing any arguments) seems like a
really niche use case, and correctly optimizing for it would require
additional work. By always hashing arguments in their original order, we
can entirely avoid a cause of 'unstable fingerprint' errors.
Emit a diagnostic when the monomorphized item collector
encounters errors during a step of the recursive item collection.
These post-monomorphization errors otherwise only show the
erroneous expression without a trace, making them very obscure
and hard to pinpoint whenever they happen in dependencies.
deal with `const_evaluatable_checked` in `ConstEquate`
Failing to evaluate two constants which do not contain inference variables should not result in ambiguity.
Use TargetTriple::from_path in rustdoc
This fixes the problem reported in https://github.com/Rust-for-Linux/linux/pull/272 where rustdoc requires the absolute path of a target spec json instead of accepting a relative path like rustc.
Bump bootstrap compiler to beta 1.53.0
This PR bumps the bootstrap compiler to version 1.53.0 beta, as part of our usual release process (this was supposed to be Wednesday's step, but creating the beta release took longer than expected).
The PR also includes the "Bootstrap: skip rustdoc fingerprint for building docs" commit, see the reasoning [on Zulip](https://zulip-archive.rust-lang.org/241545trelease/88450153betabootstrap.html).
r? `@Mark-Simulacrum`
Make building THIR a stealable query
This PR creates a stealable `thir_body` query so that we can build the THIR only once for THIR unsafeck and MIR build.
Blocked on #83842.
r? `@nikomatsakis`
Extend `rustc_on_implemented` to improve more `?` error messages
`_Self` could match the generic definition; this adds that functionality for matching the generic definition of type parameters too.
Your advice welcome on the wording of all these messages, and which things belong in the message/label/note.
r? `@estebank`
CTFE get_alloc_extra_mut: also provide ref to MemoryExtra
This would let me use mutable references in more places in Stacked Borrows, avoiding some `RefCell` overhead. :)
r? `@oli-obk`
{kind=link}
{kind=link}
{kind=link}
{kind=link}