fix dynamic size/align computation logic for packed types with dyn trait tail
This logic was never updated to support `packed(N)` where `N > 1`, and it turns out to be wrong for that case.
Fixes https://github.com/rust-lang/rust/issues/80925
`@bjorn3` I have not looked at cranelift; I assume it basically copied the size-of-val logic and hence could use much the same patch.
It's unclear why this is used here. All entries in the third column of
`UNICODE_ARRAY` are covered by `ASCII_ARRAY`, so if the lookup fails
it's a genuine compiler bug. It was added way back in #29837, for no
clear reason.
This commit changes it to `span_bug`, which is more typical.
It's necessary for `derive(Diagnostic)`, but is best avoided elsewhere
because there are clearer alternatives.
This required adding `Handler::struct_almost_fatal`.
cache param env canonicalization
Canonicalize ParamEnv only once and store it. Then whenever we try to canonicalize `ParamEnvAnd<'tcx, T>` we only have to canonicalize `T` and then merge the results.
Prelimiary results show ~3-4% savings in diesel and serde benchmarks.
Best to review commits individually. Some commits have a short description.
Initial implementation had a soundness bug (https://github.com/rust-lang/rust/pull/117749#issuecomment-1840453387) due to cache invalidation:
- When canonicalizing `Ty<'?0>` we first try to resolve region variables in the current InferCtxt which may have a constraint `?0 == 'static`. This means that we register `Ty<'?0> => Canonical<Ty<'static>>` in the cache, which is obviously incorrect in another inference context.
- This is fixed by not doing region resolution when canonicalizing the query *input* (vs. response), which is the only place where ParamEnv is used, and then in a later commit we *statically* guard against any form of inference variable resolution of the cached canonical ParamEnv's.
r? `@ghost`
This doesn't change behavior.
It should prevent unintentional resolution of inference variables
during canonicalization, which previously caused a soundness bug.
See PR description for more.
Enable stack probes on aarch64 for LLVM 18
I tested this on `aarch64-unknown-linux-gnu` with LLVM main (~18).
cc #77071, to be closed once we upgrade our LLVM submodule.
Add more suggestions to unexpected cfg names and values
This pull request adds more suggestion to unexpected cfg names and values diagnostics:
- it first adds a links to the [rustc unstable book](https://doc.rust-lang.org/nightly/unstable-book/compiler-flags/check-cfg.html) or the [Cargo reference](https://doc.rust-lang.org/nightly/cargo/reference/unstable.html#check-cfg), depending if rustc is invoked by Cargo
- it secondly adds a suggestion on how to expect the cfg name or value:
*excluding well known names and values*
- for Cargo: it suggest using a feature or `cargo:rust-check-cfg` in build script
- for rustc: it suggest using `--check-cfg` (with the correct invocation)
Those diagnostics improvements are directed towards enabling users to fix the issue if the previous suggestions weren't good enough.
r? `@petrochenkov`
Coroutine variant fields can be uninitialized
Wrap coroutine variant fields in MaybeUninit to indicate that they might be uninitialized. Otherwise an uninhabited field will make the entire variant uninhabited and introduce undefined behaviour.
The analogous issue in the prefix of coroutine layout was addressed by 6fae7f8071.
Support bare unit structs in destructuring assignments
We should be allowed to use destructuring assignments on *bare* unit structs, not just unit structs that are located within other pattern constructors.
Fixes#118753
r? petrochenkov since you reviewed #95380, reassign if you're busy or don't want to review this.
ParamEnv is canonicalized in *queries input* rather than query response.
In such case we don't "preserve universes" of canonical variable.
This means that `universe_map` always has the default value, which is
wasteful to store in the cache.
rustc_passes: Enforce `rustc::potential_query_instability` lint
Stop allowing `rustc::potential_query_instability` in all of `rustc_passes` and instead allow it on a case-by-case basis if it is safe. In this case, all instances of the lint are safe to allow.
Part of https://github.com/rust-lang/rust/issues/84447 which is E-help-wanted.
codegen: panic when trying to compute size/align of extern type
The alignment is also computed when accessing a field of extern type at non-zero offset, so we also panic in that case.
Previously `size_of_val` worked because the code path there assumed that "thin pointer" means "sized". But that's not true any more with extern types. The returned size and align are just blatantly wrong, so it seems better to panic than returning wrong results. We use a non-unwinding panic since code probably does not expect size_of_val to panic.
[`RFC 3086`] Attempt to try to resolve blocking concerns
Implements what is described at https://github.com/rust-lang/rust/issues/83527#issuecomment-1744822345 to hopefully make some progress.
It is unknown if such approach is or isn't desired due to the lack of further feedback, as such, it is probably best to nominate this PR to the official entities.
`@rustbot` labels +I-compiler-nominated
`unescape_raw_str_or_raw_byte_str` only does checking, no unescaping.
And it also now handles C string literals.
`unescape_raw_str` is used for all the non-raw strings.
Actually parse async gen blocks correctly
1. I got the control flow in `parse_expr_bottom` messed up, and obviously forgot a test for `async gen`, so we weren't actually ever parsing it correctly.
2. I forgot to gate the span for `async gen {}`, so even if we did parse it, we wouldn't have correctly denied it in `cfg(FALSE)`.
r? eholk
Fix alignment passed down to LLVM for simd_masked_load
Follow up to #117953
The alignment for a masked load operation should be that of the element/lane, not the vector as a whole
It can produce miscompilations after the LLVM optimizer notices the higher alignment and promotes this to an unmasked, aligned load followed up by blend/select - https://rust.godbolt.org/z/KEeGbevbb
The `span` arg is described in a comment as "interior span of the
literal, without quotes", which is incorrect. It's actually the span of
the error part of the literal, corresponding to `range`.
This commit renames `span` and `span_without_quotes` to make things
clearer, and fixes the erroneous comment.
Raw strings don't have escape sequences, so for them "unescaping" just
means checking for invalid chars like bare CR. Which means there is no
need to rebuild them one char or byte at a time while escaping, because
the unescaped version will be the same. This commit removes that
rebuilding.
Also, the commit changes things so that "unescaping" is unconditional for
raw strings and raw byte strings. That's simpler and they're rare enough
that the perf effect is negligible.
Correctly gate the parsing of match arms without body
https://github.com/rust-lang/rust/pull/118527 accidentally allowed the following to parse on stable:
```rust
match Some(0) {
None => { foo(); }
#[cfg(FALSE)]
Some(_)
}
```
This fixes that oversight. The way I choose which error to emit is the best I could think of, I'm open if you know a better way.
r? `@petrochenkov` since you're the one who noticed
rustc_codegen_llvm: Enforce `rustc::potential_query_instability` lint
Stop allowing `rustc::potential_query_instability` on all of `rustc_codegen_llvm` and instead allow it on a case-by-case basis if it is safe to do so. In this case, all 2 instances are safe to allow.
Part of https://github.com/rust-lang/rust/issues/84447 which is E-help-wanted.
Improve an error involving attribute values.
Attribute values must be literals. The error you get when that doesn't hold is pretty bad, e.g.:
```
unexpected expression: 1 + 1
```
You also get the same error if the attribute value is a literal, but an invalid literal, e.g.:
```
unexpected expression: "foo"suffix
```
This commit does two things.
- Changes the error message to "attribute value must be a literal", which gives a better idea of what the problem is and how to fix it. It also no longer prints the invalid expression, because the carets below highlight it anyway.
- Separates the "not a literal" case from the "invalid literal" case. Which means invalid literals now get the specific error at the literal level, rather than at the attribute level.
r? `@compiler-errors`
Clarify how to choose a FutureIncompatibilityReason variant.
There has been some confusion about how to choose these variants, or what the procedure is for handling future-incompatible errors. Hopefully this helps provide some more information on how these work.
On borrow return type, suggest borrowing from arg or owned return type
When we encounter a function with a return type that has an anonymous lifetime with no argument to borrow from, besides suggesting the `'static` lifetime we now also suggest changing the arguments to be borrows or changing the return type to be an owned type.
```
error[E0106]: missing lifetime specifier
--> $DIR/variadic-ffi-6.rs:7:6
|
LL | ) -> &usize {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
LL | ) -> &'static usize {
| +++++++
help: instead, you are more likely to want to change one of the arguments to be borrowed...
|
LL | x: &usize,
| +
help: ...or alternatively, to want to return an owned value
|
LL - ) -> &usize {
LL + ) -> usize {
|
```
Fix#85843.
dont ICE when ConstKind::Expr for is_const_evaluatable
The problem is that we are not handling ConstKind::Expr inside report_not_const_evaluatable_error
Fixes [#114151]
Renamings:
- find -> opt_hir_node
- get -> hir_node
- find_by_def_id -> opt_hir_node_by_def_id
- get_by_def_id -> hir_node_by_def_id
Fix rebase changes using removed methods
Use `tcx.hir_node_by_def_id()` whenever possible in compiler
Fix clippy errors
Fix compiler
Apply suggestions from code review
Co-authored-by: Vadim Petrochenkov <vadim.petrochenkov@gmail.com>
Add FIXME for `tcx.hir()` returned type about its removal
Simplify with with `tcx.hir_node_by_def_id`
Stop allowing `rustc::potential_query_instability` in all of
`rustc_passes` and instead allow it on a case-by-case basis if it is
safe. In this case, all instances of the lint are safe to allow.
Make most `rustc_type_ir` kinds `Copy` by default
1. There's no reason why `TyKind` and `ConstKind`/`ConstData` can't be `Copy`. This allows us to avoid needing a typed arena for the two types.
2. Simplify some impls into derives.
Stop allowing `rustc::potential_query_instability` on all of
`rustc_codegen_llvm` and instead allow it on a case-by-case basis. In
this case, both instances are safe to allow.
Fix BinOp `ty()` assertion and `fn_sig()` for closures
`BinOp::ty()` was asserting that the argument types were primitives. However, the primitive check doesn't include pointers, which can be used in a `BinaryOperation`. Thus extend the arguments to include them.
Since I had to add methods to check for pointers in TyKind, I just went ahead and added a bunch more utility checks that can be handy for our users and fixed the `fn_sig()` method to also include closures.
`@compiler-errors` just wanted to confirm that today no `BinaryOperation` accept SIMD types. Is that correct?
r? `@compiler-errors`
Monomorphize args while building Instance body in StableMIR
The function `Instance::body()` in StableMIR is supposed to return a monomorphic body by instantiating all possibly generic constructs. We were previously instantiating type and constants, but not generic arguments. This PR ensures that we also instantiate them.
r? ``@compiler-errors``
End locals' live range before suspending coroutine
State transforms retains storage statements for locals that are not
stored inside a coroutine. It ensures those locals are live when
resuming by inserting StorageLive as appropriate. It forgot to end the
storage of those locals when suspending, which is fixed here.
While the end of live range is implicit when executing return, it is
nevertheless useful for inliner which would otherwise extend the live
range beyond return.
Fixes#117733
Attribute values must be literals. The error you get when that doesn't
hold is pretty bad, e.g.:
```
unexpected expression: 1 + 1
```
You also get the same error if the attribute value is a literal, but an
invalid literal, e.g.:
```
unexpected expression: "foo"suffix
```
This commit does two things.
- Changes the error message to "attribute value must be a literal",
which gives a better idea of what the problem is and how to fix it. It
also no longer prints the invalid expression, because the carets below
highlight it anyway.
- Separates the "not a literal" case from the "invalid literal" case.
Which means invalid literals now get the specific error at the literal
level, rather than at the attribute level.
Wrap coroutine variant fields in MaybeUninit to indicate that they
might be uninitialized. Otherwise an uninhabited field will make
the entire variant uninhabited and introduce undefined behaviour.
The analogous issue in the prefix of coroutine layout was addressed by
6fae7f8071.
State transforms retains storage statements for locals that are not
stored inside a coroutine. It ensures those locals are live when
resuming by inserting StorageLive as appropriate. It forgot to end the
storage of those locals when suspending, which is fixed here.
While the end of live range is implicit when executing return, it is
nevertheless useful for inliner which would otherwise extend the live
range beyond return.
`.debug_pubnames` and `.debug_pubtypes` are poorly designed and people
seldom use them. However, they take a considerable portion of size in
the final binary. This tells LLVM stop emitting those sections on
DWARFv4 or lower. DWARFv5 use `.debug_names` which is more concise
in size and performant for name lookup.
Extract exhaustiveness into its own crate
It now makes sense to extract exhaustiveness into its own crate! This was much-requested by rust-analyzer (they currently maintain by hand a copy of the algorithm), and I hope this can serve other projects e.g. clippy.
This is the churny PR: it exclusively moves code around. It's not yet useable outside of rustc but I wanted the churny parts to be out of the way.
r? `@compiler-errors`
Do not parenthesize exterior struct lit inside match guards
Before this PR, the AST pretty-printer injects parentheses around expressions any time parens _could_ be needed depending on what else is in the code that surrounds that expression. But the pretty-printer did not pass around enough context to understand whether parentheses really _are_ needed on any particular expression. As a consequence, there are false positives where unneeded parentheses are being inserted.
Example:
```rust
#![feature(if_let_guard)]
macro_rules! pp {
($e:expr) => {
stringify!($e)
};
}
fn main() {
println!("{}", pp!(match () { () if let _ = Struct {} => {} }));
}
```
**Before:**
```console
match () { () if let _ = (Struct {}) => {} }
```
**After:**
```console
match () { () if let _ = Struct {} => {} }
```
This PR introduces a bit of state that is passed across various expression printing methods to help understand accurately whether particular situations require parentheses injected by the pretty printer, and it fixes one such false positive involving match guards as shown above.
There are other parenthesization false positive cases not fixed by this PR. I intend to address these in follow-up PRs. For example here is one: the expression `{ let _ = match x {} + 1; }` is pretty-printed as `{ let _ = (match x {}) + 1; }` despite there being no reason for parentheses to appear there.
resolve: Use `def_kind` query to cleanup some code
Follow up to https://github.com/rust-lang/rust/pull/118188.
Similar attempts to use queries in resolver resulted in perf regressions in the past, so this needs a perf run first.
Use a u64 for the rmeta root position
Waffle noticed this in https://github.com/rust-lang/rust/pull/117301#discussion_r1405410174
We've upgraded the other file offsets to u64, and this one only costs 4 bytes per file. Also the way the truncation was being done before was extremely easy to miss, I sure missed it! It's not clear to me if not having this change effectively made the other upgrades from u32 to u64 ineffective, but we can have it now.
r? `@WaffleLapkin`
Add lint against ambiguous wide pointer comparisons
This PR is the resolution of https://github.com/rust-lang/rust/issues/106447 decided in https://github.com/rust-lang/rust/issues/117717 by T-lang.
## `ambiguous_wide_pointer_comparisons`
*warn-by-default*
The `ambiguous_wide_pointer_comparisons` lint checks comparison of `*const/*mut ?Sized` as the operands.
### Example
```rust
let ab = (A, B);
let a = &ab.0 as *const dyn T;
let b = &ab.1 as *const dyn T;
let _ = a == b;
```
### Explanation
The comparison includes metadata which may not be expected.
-------
This PR also drops `clippy::vtable_address_comparisons` which is superseded by this one.
~~One thing: is the current naming right? `invalid` seems a bit too much.~~
Fixes https://github.com/rust-lang/rust/issues/117717
Remove edition umbrella features.
In the 2018 edition, there was an "umbrella" feature `#[feature(rust_2018_preview)]` which was used to enable several other features at once. This umbrella mechanism was not used in the 2021 edition and likely will not be used in 2024 either. During 2018 users reported that setting the feature was awkward, especially since they already needed to opt-in via the edition mechanism.
This PR removes this mechanism because I believe it will not be used (and will clean up and simplify the code). I believe that there are better ways to handle features and editions. In short:
- For highly experimental features, that may or may not be involved in an edition, they can implement regular feature gates like `tcx.features().my_feature`.
- For experimental features that *might* be involved in an edition, they should implement gates with `tcx.features().my_feature && span.at_least_rust_20xx()`. This requires the user to still specify `#![feature(my_feature)]`, to avoid disrupting testing of other edition features which are ready and have been accepted within the edition.
- For experimental features that have graduated to definitely be part of an edition, they should implement gates with `tcx.features().my_feature || span.at_least_rust_20xx()`, or just remove the feature check altogether and just check `span.at_least_rust_20xx()`.
- For relatively simple changes, they can skip the whole feature gating thing and just check `span.at_least_rust_20xx()`, and rely on the instability of the edition itself (which requires `-Zunstable-options`) to gate it.
I am working on documenting all of this in the rustc-dev-guide.
Implement repr(packed) for repr(simd)
This allows creating vectors with non-power-of-2 lengths that do not have padding. See rust-lang/portable-simd#319
Rearrange `default_configuration` and `CheckCfg::fill_well_known`.
There are comments saying these two functions should be kept in sync, but they have very different structures, process symbols in different orders, and there are some inconsistencies.
This commit reorders them so they're both mostly processing symbols in alphabetical order, which makes cross-checking them a lot easier. The commit also adds some macros to factor out repetitive code patterns.
The commit also moves the handling of `sym::test` out of `build_configuration` into `default_configuration`, where all the other symbols are handled.
r? `@bjorn3`
guarantee that char and u32 are ABI-compatible
In https://github.com/rust-lang/rust/pull/116894 we added a guarantee that `char` has the same alignment as `u32`, but there is still one axis where these types could differ: function call ABI. So let's nail that down as well: in a function signature, `char` and `u32` are completely equivalent.
This is a new stable guarantee, so it will need t-lang approval.
There are comments saying these two functions should be kept in sync,
but they have very different structures, process symbols in different
orders, and there are some inconsistencies.
This commit reorders them so they're both mostly processing symbols in
alphabetical order, which makes cross-checking them a lot easier. The
commit also adds some macros to factor out repetitive code patterns.
Plus it adds `sanitizer_cfi_normalize_{integers,pointers}` to
`fill_well_known`, which were missing.
The commit also moves the handling of `sym::test` out of
`build_configuration` into `default_configuration`, where all the other
symbols are handled.
This is an extension of the previous commit. It means the output of
something like this:
```
stringify!(let a: Vec<u32> = vec![];)
```
goes from this:
```
let a: Vec<u32> = vec![] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![];
```
`tokenstream::Spacing` appears on all `TokenTree::Token` instances,
both punct and non-punct. Its current usage:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `Alone` means "cannot join with the next token *or* can join with the
next token but that token is not a punct".
The fact that `Alone` is used for two different cases is awkward.
This commit augments `tokenstream::Spacing` with a new variant
`JointHidden`, resulting in:
- `Joint` means "can join with the next token *and* that token is a
punct".
- `JointHidden` means "can join with the next token *and* that token is a
not a punct".
- `Alone` means "cannot join with the next token".
This *drastically* improves the output of `print_tts`. For example,
this:
```
stringify!(let a: Vec<u32> = vec![];)
```
currently produces this string:
```
let a : Vec < u32 > = vec! [] ;
```
With this PR, it now produces this string:
```
let a: Vec<u32> = vec![] ;
```
(The space after the `]` is because `TokenTree::Delimited` currently
doesn't have spacing information. The subsequent commit fixes this.)
The new `print_tts` doesn't replicate original code perfectly. E.g.
multiple space characters will be condensed into a single space
character. But it's much improved.
`print_tts` still produces the old, uglier output for code produced by
proc macros. Because we have to translate the generated code from
`proc_macro::Spacing` to the more expressive `token::Spacing`, which
results in too much `proc_macro::Along` usage and no
`proc_macro::JointHidden` usage. So `space_between` still exists and
is used by `print_tts` in conjunction with the `Spacing` field.
This change will also help with the removal of `Token::Interpolated`.
Currently interpolated tokens are pretty-printed nicely via AST pretty
printing. `Token::Interpolated` removal will mean they get printed with
`print_tts`. Without this change, that would result in much uglier
output for code produced by decl macro expansions. With this change, AST
pretty printing and `print_tts` produce similar results.
The commit also tweaks the comments on `proc_macro::Spacing`. In
particular, it refers to "compound tokens" rather than "multi-char
operators" because lifetimes aren't operators.
Implement `--env` compiler flag (without `tracked_env` support)
Part of https://github.com/rust-lang/rust/issues/80792.
Implementation of https://github.com/rust-lang/compiler-team/issues/653.
Not an implementation of https://github.com/rust-lang/rfcs/pull/2794.
It adds the `--env` compiler flag option which allows to set environment values used by `env!` and `option_env!`.
Important to note: When trying to retrieve an environment variable value, it will first look into the ones defined with `--env`, and if there isn't one, then only it will look into the environment variables. So if you use `--env PATH=a`, then `env!("PATH")` will return `"a"` and not the actual `PATH` value.
As mentioned in the title, `tracked_env` support is not added here. I'll do it in a follow-up PR.
r? rust-lang/compiler
remove redundant imports
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and removing redundant imports code into two PR.
r? `@petrochenkov`
Don't print host effect param in pretty `path_generic_args`
Make `own_args_no_defaults` pass back the `GenericParamDef`, so that we can pass both the args *and* param definitions into `path_generic_args`. That allows us to use the `GenericParamDef` to filter out effect params.
This allows us to filter out the host param regardless of whether it's `sym::host` or `true`/`false`.
This also renames a couple of `const_effect_param` -> `host_effect_param`, and restores `~const` pretty printing to `TraitPredPrintModifiersAndPath`.
cc #118785
r? `@fee1-dead` cc `@oli-obk`
detects redundant imports that can be eliminated.
for #117772 :
In order to facilitate review and modification, split the checking code and
removing redundant imports code into two PR.
Don't warn an empty pattern unreachable if we're not sure the data is valid
Exhaustiveness checking used to be naive about the possibility of a place containing invalid data. This could cause it to emit an "unreachable pattern" lint on an arm that was in fact reachable, as in https://github.com/rust-lang/rust/issues/117119.
This PR fixes that. We now track whether a place that is matched on may hold invalid data. This also forced me to be extra precise about how exhaustiveness manages empty types.
Note that this now errs in the opposite direction: the following arm is truly unreachable (because the binding causes a read of the value) but not linted as such. I'd rather not recommend writing a `match ... {}` that has the implicit side-effect of loading the value. [Never patterns](https://github.com/rust-lang/rust/issues/118155) will solve this cleanly.
```rust
match union.value {
_x => unreachable!(),
}
```
I recommend reviewing commit by commit. I went all-in on the test suite because this went through a lot of iterations and I kept everything. The bit I'm least confident in is `is_known_valid_scrutinee` in `check_match.rs`.
Fixes https://github.com/rust-lang/rust/issues/117119.
Lower some forgotten spans
I wrote a HIR visitor that visited all of the spans in the HIR, and made it ICE when we have a unlowered span. That led me to discover these unlowered spans.
Strengthen well known check-cfg names and values test
https://github.com/rust-lang/rust/pull/118494 is changing the implementation of how we expect well known check-cfg names and values, but we currently don't have a test that checks every well known only some of them.
This PR therefore strengthen our well known names/values test to include all of the configs to at least avoid unintended regressions and validate new entry.
*this PR also contains some drive-by consolidation of unexpected `target_os`, `target_arch` into a single file*
r? `@nnethercote` (maybe? feel free to re-assign)
Add more SIMD platform-intrinsics
- [x] simd_masked_load
- [x] LLVM codegen - llvm.masked.load
- [x] cranelift codegen - implemented but untested
- [ ] simd_masked_store
- [x] LLVM codegen - llvm.masked.store
- [ ] cranelift codegen
Also added a run-pass test to test both intrinsics, and additional build-fail & check-fail to cover validation for both intrinsics
Make async generators fused by default
I actually changed my mind about this since the implementation PR landed. I think it's beneficial for `async gen` blocks to be "fused" by default -- i.e., for them to repeatedly return `Poll::Ready(None)` -- rather than panic.
We have [`FusedStream`](https://docs.rs/futures/latest/futures/stream/trait.FusedStream.html) in futures-rs to represent streams with this capability already anyways.
r? eholk
cc ```@rust-lang/wg-async,``` would like to know if anyone else has opinions about this.
coverage: Simplify the heuristic for ignoring `async fn` return spans
The code for extracting coverage spans from MIR has a special heuristic for dealing with `async fn`, so that the function's closing brace does not have a confusing double count.
The code implementing that heuristic is currently mixed in with the code for flushing remaining spans after the main refinement loop, making the refinement code harder to understand.
We can solve that by hoisting the heuristic to an earlier stage, after the spans have been extracted and sorted but before they have been processed by the refinement loop.
The coverage tests verify that the heuristic is still effective, so coverage mappings/reports for `async fn` have not changed.
---
This PR also has the side-effect of fixing the `None some_prev` panic that started appearing after #118525.
The old code assumed that `prev` would always be present after the refinement loop. That was only true if the list of collected spans was non-empty, but prior to #118525 that didn't seem to come up in practice. After that change, the list of collected spans could be empty in some specific circumstances, leading to panics.
The new code uses an `if let` to inspect `prev`, which correctly does nothing if there is no span present.
update target feature following LLVM API change
LLVM commit e817966718 renamed* the `unaligned-scalar-mem` target feature to `fast-unaligned-access`.
(*) technically the commit folded two previous features into one, but there are no references to the other one in rust.
coverage: Use `SpanMarker` to improve coverage spans for `if !` expressions
Coverage instrumentation works by extracting source code spans from MIR. However, some kinds of syntax are effectively erased during MIR building, so their spans don't necessarily exist anywhere in MIR, making them invisible to the coverage instrumentor (unless we resort to various heuristics and hacks to recover them).
This PR introduces `CoverageKind::SpanMarker`, which is a new variant of `StatementKind::Coverage`. Its sole purpose is to represent spans that would otherwise not appear in MIR, so that the coverage instrumentor can extract them.
When coverage is enabled, the MIR builder can insert these dummy statements as needed, to improve the accuracy of spans used by coverage mappings.
Fixes#115468.
---
```@rustbot``` label +A-code-coverage
Add new targets {x86_64,i686}-win7-windows-msvc
This PR adds two new Tier 3 targets, x86_64-win7-windows-msvc and i686-win7-windows-msvc, that aim to support targeting Windows 7 after the `*-pc-windows-msvc` target drops support for it (slated to happen in 1.76.0).
# Tier 3 target policy
> At this tier, the Rust project provides no official support for a target, so we place minimal requirements on the introduction of targets.
>
> A proposed new tier 3 target must be reviewed and approved by a member of the compiler team based on these requirements. The reviewer may choose to gauge broader compiler team consensus via a [Major Change Proposal (MCP)](https://forge.rust-lang.org/compiler/mcp.html).
>
> A proposed target or target-specific patch that substantially changes code shared with other targets (not just target-specific code) must be reviewed and approved by the appropriate team for that shared code before acceptance.
>
> - A tier 3 target must have a designated developer or developers (the "target maintainers") on record to be CCed when issues arise regarding the target. (The mechanism to track and CC such developers may evolve over time.)
This is me, `@roblabla` on github.
> - Targets must use naming consistent with any existing targets; for instance, a target for the same CPU or OS as an existing Rust target should use the same name for that CPU or OS. Targets should normally use the same names and naming conventions as used elsewhere in the broader ecosystem beyond Rust (such as in other toolchains), unless they have a very good reason to diverge. Changing the name of a target can be highly disruptive, especially once the target reaches a higher tier, so getting the name right is important even for a tier 3 target.
I went with naming the target `x86_64-win7-windows-msvc`, inserting the `win7` in the vendor field (usually set to to `pc`). This is done to avoid ecosystem churn, as quite a few crates have `cfg(target_os = "windows")` or `cfg(target_env = "msvc")`, but nearly no `cfg(target_vendor = "pc")`. Since my goal is to be able to seamlessly swap to the `win7` target, I figured it'd be easier this way.
> - Target names should not introduce undue confusion or ambiguity unless absolutely necessary to maintain ecosystem compatibility. For example, if the name of the target makes people extremely likely to form incorrect beliefs about what it targets, the name should be changed or augmented to disambiguate it.
I believe the naming is pretty explicit.
> - If possible, use only letters, numbers, dashes and underscores for the name. Periods (`.`) are known to cause issues in Cargo.
The name comforms to this requirement.
> - Tier 3 targets may have unusual requirements to build or use, but must not create legal issues or impose onerous legal terms for the Rust project or for Rust developers or users.
> - The target must not introduce license incompatibilities.
> - Anything added to the Rust repository must be under the standard Rust license (`MIT OR Apache-2.0`).
> - The target must not cause the Rust tools or libraries built for any other host (even when supporting cross-compilation to the target) to depend on any new dependency less permissive than the Rust licensing policy. This applies whether the dependency is a Rust crate that would require adding new license exceptions (as specified by the `tidy` tool in the rust-lang/rust repository), or whether the dependency is a native library or binary. In other words, the introduction of the target must not cause a user installing or running a version of Rust or the Rust tools to be subject to any new license requirements.
> - Compiling, linking, and emitting functional binaries, libraries, or other code for the target (whether hosted on the target itself or cross-compiling from another target) must not depend on proprietary (non-FOSS) libraries. Host tools built for the target itself may depend on the ordinary runtime libraries supplied by the platform and commonly used by other applications built for the target, but those libraries must not be required for code generation for the target; cross-compilation to the target must not require such libraries at all. For instance, `rustc` built for the target may depend on a common proprietary C runtime library or console output library, but must not depend on a proprietary code generation library or code optimization library. Rust's license permits such combinations, but the Rust project has no interest in maintaining such combinations within the scope of Rust itself, even at tier 3.
> - "onerous" here is an intentionally subjective term. At a minimum, "onerous" legal/licensing terms include but are *not* limited to: non-disclosure requirements, non-compete requirements, contributor license agreements (CLAs) or equivalent, "non-commercial"/"research-only"/etc terms, requirements conditional on the employer or employment of any particular Rust developers, revocable terms, any requirements that create liability for the Rust project or its developers or users, or any requirements that adversely affect the livelihood or prospects of the Rust project or its developers or users.
As far as I understand it, this target has exactly the same legal situation as the existing Tier 1 x86_64-pc-windows-msvc.
> - Neither this policy nor any decisions made regarding targets shall create any binding agreement or estoppel by any party. If any member of an approving Rust team serves as one of the maintainers of a target, or has any legal or employment requirement (explicit or implicit) that might affect their decisions regarding a target, they must recuse themselves from any approval decisions regarding the target's tier status, though they may otherwise participate in discussions.
> - This requirement does not prevent part or all of this policy from being cited in an explicit contract or work agreement (e.g. to implement or maintain support for a target). This requirement exists to ensure that a developer or team responsible for reviewing and approving a target does not face any legal threats or obligations that would prevent them from freely exercising their judgment in such approval, even if such judgment involves subjective matters or goes beyond the letter of these requirements.
Understood.
> - Tier 3 targets should attempt to implement as much of the standard libraries as possible and appropriate (core for most targets, alloc for targets that can support dynamic memory allocation, std for targets with an operating system or equivalent layer of system-provided functionality), but may leave some code unimplemented (either unavailable or stubbed out as appropriate), whether because the target makes it impossible to implement or challenging to implement. The authors of pull requests are not obligated to avoid calling any portions of the standard library on the basis of a tier 3 target not implementing those portions.
This target supports the whole libstd surface, since it's essentially reusing all of the x86_64-pc-windows-msvc target. Understood.
> - The target must provide documentation for the Rust community explaining how to build for the target, using cross-compilation if possible. If the target supports running binaries, or running tests (even if they do not pass), the documentation must explain how to run such binaries or tests for the target, using emulation if possible or dedicated hardware if necessary.
Wrote some documentation on how to build, test and cross-compile the target in the `platform-support` part. Hopefully it's enough to get started.
> - Tier 3 targets must not impose burden on the authors of pull requests, or other developers in the community, to maintain the target. In particular, do not post comments (automated or manual) on a PR that derail or suggest a block on the PR based on a tier 3 target. Do not send automated messages or notifications (via any medium, including via ``@`)` to a PR author or others involved with a PR regarding a tier 3 target, unless they have opted into such messages.
> - Backlinks such as those generated by the issue/PR tracker when linking to an issue or PR are not considered a violation of this policy, within reason. However, such messages (even on a separate repository) must not generate notifications to anyone involved with a PR who has not requested such notifications.
Understood.
> - Patches adding or updating tier 3 targets must not break any existing tier 2 or tier 1 target, and must not knowingly break another tier 3 target without approval of either the compiler team or the maintainers of the other tier 3 target.
> - In particular, this may come up when working on closely related targets, such as variations of the same architecture with different features. Avoid introducing unconditional uses of features that another variation of the target may not have; use conditional compilation or runtime detection, as appropriate, to let each target run code supported by that target.
Understood.
> If a tier 3 target stops meeting these requirements, or the target maintainers no longer have interest or time, or the target shows no signs of activity and has not built for some time, or removing the target would improve the quality of the Rust codebase, we may post a PR to remove it; any such PR will be CCed to the target maintainers (and potentially other people who have previously worked on the target), to check potential interest in improving the situation.
Understood.
Add emulated TLS support
This is a reopen of https://github.com/rust-lang/rust/pull/96317 . many android devices still only use 128 pthread keys, so using emutls can be helpful.
Currently LLVM uses emutls by default for some targets (such as android, openbsd), but rust does not use it, because `has_thread_local` is false.
This commit has some changes to allow users to enable emutls:
1. add `-Zhas-thread-local` flag to specify that std uses `#[thread_local]` instead of pthread key.
2. when using emutls, decorate symbol names to find thread local symbol correctly.
3. change `-Zforce-emulated-tls` to `-Ztls-model=emulated` to explicitly specify whether to generate emutls.
r? `@Amanieu`
Rollup of 6 pull requests
Successful merges:
- #117586 (Uplift the (new solver) canonicalizer into `rustc_next_trait_solver`)
- #118502 (fix: correct the arg for 'suggest to use associated function syntax' diagnostic)
- #118694 (Add instance evaluation and methods to read an allocation in StableMIR)
- #118715 (privacy: visit trait def id of projections)
- #118730 (recurse into refs when comparing tys for diagnostics)
- #118736 (temporarily revert "ice on ambguity in mir typeck")
r? `@ghost`
`@rustbot` modify labels: rollup
This is for post-monomorphization cycles. These are only caught later
(in drop elaboration for the example that I saw), so we need to handle
them here.
This issue wasn't noticed before because exhaustiveness only checked
inhabitedness when `exhaustive_patterns` was on. The preceding commit
now check inhabitedness always, which revealed the problem.
- `ConstructorSet` knows about both empty and nonempty constructors;
- If an empty constructor is present in the column, we output it in
`split().present`.
tidy error: /git/rust/compiler/rustc_ast_pretty/src/pprust/state.rs:1165: unexplained "```ignore" doctest; try one:
* make the test actually pass, by adding necessary imports and declarations, or
* use "```text", if the code is not Rust code, or
* use "```compile_fail,Ennnn", if the code is expected to fail at compile time, or
* use "```should_panic", if the code is expected to fail at run time, or
* use "```no_run", if the code should type-check but not necessary linkable/runnable, or
* explain it like "```ignore (cannot-test-this-because-xxxx)", if the annotation cannot be avoided.
tidy error: /git/rust/compiler/rustc_ast_pretty/src/pprust/state.rs:1176: unexplained "```ignore" doctest; try one:
* make the test actually pass, by adding necessary imports and declarations, or
* use "```text", if the code is not Rust code, or
* use "```compile_fail,Ennnn", if the code is expected to fail at compile time, or
* use "```should_panic", if the code is expected to fail at run time, or
* use "```no_run", if the code should type-check but not necessary linkable/runnable, or
* explain it like "```ignore (cannot-test-this-because-xxxx)", if the annotation cannot be avoided.
In all four of Break, Closure, Ret, Yeet, the needs_par_as_let_scrutinee
is guaranteed to return true because the .precedence().order() of those
expr kinds is <= AssocOp::LAnd.precedence().
The relevant functions in rustc_ast::util::parser are:
fn needs_par_as_let_scrutinee(order: i8) -> bool {
order <= prec_let_scrutinee_needs_par() as i8
}
fn prec_let_scrutinee_needs_par() -> usize {
AssocOp::LAnd.precedence()
}
The .precedence().order() of Closure is PREC_CLOSURE (-40) and of Break,
Ret, Yeet is PREC_JUMP (-30).
The value of AssocOp::LAnd.precedence() is 6.
So this commit causes no change in behavior, only potentially
performance by doing a redundant call to contains_exterior_struct_lit in
those four cases. This is fine because Break, Closure, Ret, Yeet should
be exceedingly rare in the position of a let scrutinee.
- Add `use Mode::*` to avoid all the qualifiers.
- Reorder the variants. The existing order makes no particular sense,
which has bugged me for some time. I've chosen an order that makes
sense to me.
These don't really make sense since C string literals were added. This
commit removes them in favour for `mode: Mode` args. `ascii_check` still
has a `characters_should_be_ascii: bool` arg.
Also, `characters_should_be_ascii` is renamed to be shorter.
temporarily revert "ice on ambguity in mir typeck"
Reverts #116530 as a temporary measure to fix#117577. That issue should be ultimately fixed by checking WF of type annotations prior to normalization, which is implemented in #104098 but this PR is intended to be backported to beta.
r? ``@compiler-errors`` (the reviewer of the reverted PR)
recurse into refs when comparing tys for diagnostics
before:

after:
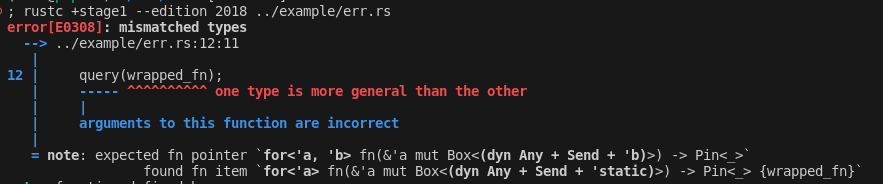
this diff from the test suite is also quite nice imo:
```diff
`@@` -4,8 +4,8 `@@` error[E0308]: mismatched types
LL | debug_assert_eq!(iter.next(), Some(value));
| ^^^^^^^^^^^ expected `Option<<I as Iterator>::Item>`, found `Option<&<I as Iterator>::Item>`
|
- = note: expected enum `Option<<I as Iterator>::Item>`
- found enum `Option<&<I as Iterator>::Item>`
+ = note: expected enum `Option<_>`
+ found enum `Option<&_>`
```
privacy: visit trait def id of projections
Fixes#117997.
A refactoring in #117076 changed the `DefIdVisitorSkeleton` to avoid calling `visit_projection_ty` for `ty::Projection` aliases, and instead just iterate over the args - this makes sense, as `visit_projection_ty` will indirectly visit all of the same args, but in doing so, will also create a `TraitRef` containing the trait's `DefId`, which also gets visited. The trait's `DefId` isn't visited when we only visit the arguments without separating them into `TraitRef` and own args first.
Eventually this influences the reachability set and whether a function is encoded into the metadata.
Add instance evaluation and methods to read an allocation in StableMIR
The instance evaluation is needed to handle intrinsics such as `type_id` and `type_name`.
Since we now use Allocation to represent all evaluated constants, provide a few methods to help process the data inside an allocation.
I've also started to add a structured way to get information about the compilation target machine. For now, I've only added information needed to process an allocation.
r? ``````@ouz-a``````
Uplift the (new solver) canonicalizer into `rustc_next_trait_solver`
Uplifts the new trait solver's canonicalizer into a new crate called `rustc_next_trait_solver`.
The crate name is literally a bikeshed-avoidance name, so let's not block this PR on that -- renames are welcome later.
There are a host of other changes that were required to make this possible:
* Expose a `ConstTy` trait to get the `Interner::Ty` from a `Interner::Const`.
* Expose some constructor methods to construct `Bound` variants. These are currently methods defined on the interner themselves, but they could be pulled into traits later.
* Expose a `IntoKind` trait to turn a `Ty`/`Const`/`Region` into their corresponding `*Kind`s.
* Some minor tweaks to other APIs in `rustc_type_ir`.
The canonicalizer code itself is best reviewed **with whitespace ignored.**
r? ``@lcnr``
Explicitly implement `DynSync` and `DynSend` for `TyCtxt`
This is an attempt to short circuit trait resolution. It should get a perf run for bootstrap impact.
according to a poll of gay people in my phone, purple is the most popular color to use for highlighting
| color | percentage |
| ---------- | ---------- |
| bold white | 6% |
| blue | 14% |
| cyan | 26% |
| purple | 37% |
| magenta | 17% |
unfortunately, purple is not supported by 16-color terminals, which rustc apparently wants to support for some reason.
until we require support for full 256-color terms (e.g. by doing the same feature detection as we currently do for urls), we can't use it.
instead, i have collapsed the purple votes into magenta on the theory that they're close, and also because magenta is pretty.
Introduce support for `async gen` blocks
I'm delighted to demonstrate that `async gen` block are not very difficult to support. They're simply coroutines that yield `Poll<Option<T>>` and return `()`.
**This PR is WIP and in draft mode for now** -- I'm mostly putting it up to show folks that it's possible. This PR needs a lang-team experiment associated with it or possible an RFC, since I don't think it falls under the jurisdiction of the `gen` RFC that was recently authored by oli (https://github.com/rust-lang/rfcs/pull/3513, https://github.com/rust-lang/rust/issues/117078).
### Technical note on the pre-generator-transform yield type:
The reason that the underlying coroutines yield `Poll<Option<T>>` and not `Poll<T>` (which would make more sense, IMO, for the pre-transformed coroutine), is because the `TransformVisitor` that is used to turn coroutines into built-in state machine functions would have to destructure and reconstruct the latter into the former, which requires at least inserting a new basic block (for a `switchInt` terminator, to match on the `Poll` discriminant).
This does mean that the desugaring (at the `rustc_ast_lowering` level) of `async gen` blocks is a bit more involved. However, since we already need to intercept both `.await` and `yield` operators, I don't consider it much of a technical burden.
r? `@ghost`