| experiments | ||
| ferret | ||
| figs | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| EVAL.md | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
 Ferret: Refer and Ground Anything Anywhere at Any Granularity
Ferret: Refer and Ground Anything Anywhere at Any Granularity
An End-to-End MLLM that Accept Any-Form Referring and Ground Anything in Response. [Paper]
Haoxuan You*, Haotian Zhang*, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, Yinfei Yang [*: equal contribution]
Overview

Diagram of Ferret Model.
Key Contributions:
- Ferret Model - Hybrid Region Representation + Spatial-aware Visual Sampler enable fine-grained and open-vocabulary referring and grounding in MLLM.
- GRIT Dataset (~1.1M) - A Large-scale, Hierarchical, Robust ground-and-refer instruction tuning dataset.
- Ferret-Bench - A multimodal evaluation benchmark that jointly requires Referring/Grounding, Semantics, Knowledge, and Reasoning.
Release
- [10/30] 🔥 We released the code of FERRET model.
Usage and License Notices: The data, and code is intended and licensed for research use only. They are also restricted to uses that follow the license agreement of LLaMA, Vicuna and GPT-4. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes.
Contents
Install
- Clone this repository and navigate to FERRET folder
git clone https://github.com/apple/ml-ferret
cd ml-ferret
- Install Package
conda create -n ferret python=3.10 -y
conda activate ferret
pip install --upgrade pip # enable PEP 660 support
pip install -e .
pip install pycocotools
pip install protobuf==3.20.0
- Install additional packages for training cases
pip install ninja
pip install flash-attn --no-build-isolation
Train
FERRET is trained on 8 A100 GPUs with 80GB memory. To train on fewer GPUs, you can reduce the per_device_train_batch_size and increase the gradient_accumulation_steps accordingly. Always keep the global batch size the same: per_device_train_batch_size x gradient_accumulation_steps x num_gpus.
Hyperparameters
We use a similar set of hyperparameters as LLaVA(Vicuna) in finetuning.
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|---|---|---|---|---|---|
| FERRET-7B | 128 | 2e-5 | 3 | 2048 | 0 |
| FERRET-13B | 128 | 2e-5 | 3 | 2048 | 0 |
Prepare Vicuna checkpoint and LLaVA's projector
Before you start, prepare our base model Vicuna, which is an instruction-tuned chatbot. Please download its weights following the instructions here. Vicuna v1.3 is used in FERRET.
Then download LLaVA's first-stage pre-trained projector weight (7B, 13B).
FERRET Training
The scripts are provided (7B, 13B).
Evaluation
Please see this doc for the details.
Demo
To run our demo, you need to train FERRET and use the checkpoints locally. Gradio web UI is used. Please run the following commands one by one.
Launch a controller
python -m ferret.serve.controller --host 0.0.0.0 --port 10000
Launch a gradio web server.
python -m ferret.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload --add_region_feature
Launch a model worker
This is the worker that load the ckpt and do the inference on the GPU. Each worker is responsible for a single model specified in --model-path.
CUDA_VISIBLE_DEVICES=0 python -m ferret.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path ./checkpoints/FERRET-13B-v0 --add_region_feature
Wait until the process finishes loading the model and you see "Uvicorn running on ...". Now, refresh your Gradio web UI, and you will see the model you just launched in the model list.
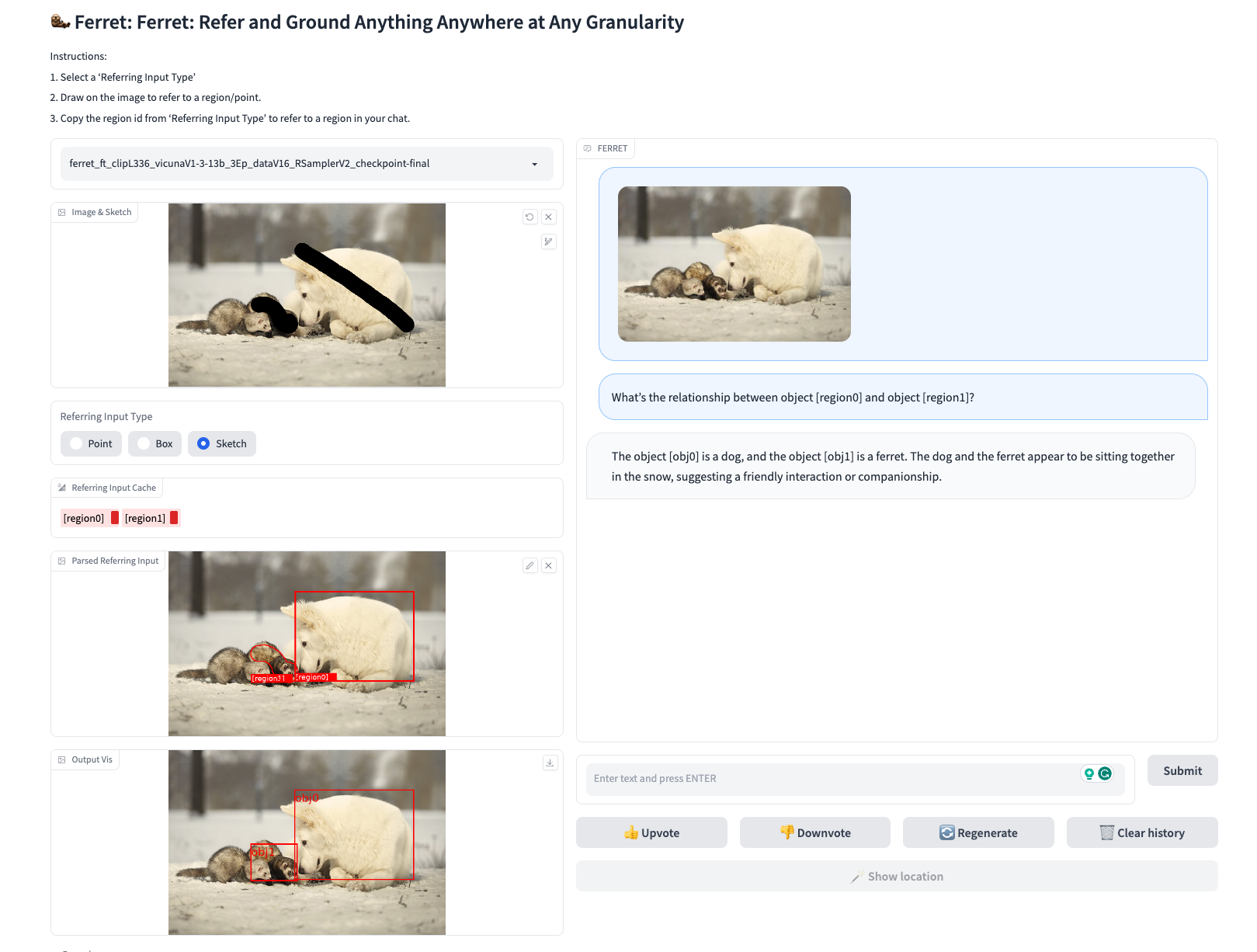
Example of Ferret Interactive Demo.
Citation
If you find Ferret useful, please cite using this BibTeX:
@article{you2023ferret,
title={Ferret: Refer and Ground Anything Anywhere at Any Granularity},
author={You, Haoxuan and Zhang, Haotian and Gan, Zhe and Du, Xianzhi and Zhang, Bowen and Wang, Zirui and Cao, Liangliang and Chang, Shih-Fu and Yang, Yinfei},
journal={arXiv preprint arXiv:2310.07704},
year={2023}
}